Программирование основы Программирование Технологии программирования Разработка программ Работа с данными Методы программирования Программирование интерфейсов Программирование - IDE интерфейс Программирование - графический интерфейс Программирование - Power Strip Программирование и тестирование Программирование - отладка Программирование - тестирование |

|
Стили и методы программирования
Модификации традиционной архитектуры
После того, как выяснилось, что традиционная архитектура препятствует повышению производительности, она стала изменяться. Ниже приведены самые распространенные ее модификации:
Вводятся ячейки внутри процессора со специальной адресацией, не требующие обращения к памяти. С их помощью можно уменьшать адресность команд машины, передавать промежуточные результаты вычислений от команды к команде, выполнять иные локальные действия. Они называются быстрыми регистрами процессора.
Появляются команды, кодирующие довольно сложные действия над операндами.
Процессор снабжается памятью для команд (кэш команд) и для данных (кэш данных). Кэш команд заполняется одновременно с выполнением текущей команды теми командами, которые, как кажется процессору, будут выполняться после текущей. В кэш данных дублируются значения, которые, как кажется процессору, будут операндами следующих команд.
Память разбивается по уровням доступа: регистры процессора; область быстрого доступа с непосредственной адресацией; область, адресация которой требует предварительного указания некоторого сегмента, ячейки которого адресуются непосредственно, и т. д.
Полезность подобных модификаций очевидна. Но кэширование, прочие изменения классической канонической модели, и даже многопроцессорность, - это лишь полумеры, позволяющие расширить, но никак не ликвидировать узкое место.
Внимание!
Важным следствием традиционной структуры компьютера является следующее: в машинной программе все действия и условия локальны.
Для повышения эффективности в оборудовании порой отказываются от принципа однородности памяти. Упомянем две архитектурные модификации традиционной машины.
В некоторых (в первую очередь специализированных) машинах предусмотрено явное выделение в памяти областей данных и областей команд. В обычном режиме выполнения программ процессору не разрешается записывать что-либо в область команд, в результате повышается надежность программ. Для записи чего-либо в область команд нужно аппаратно включить соответствующий режим4).
Но разделение между командами и данными достаточно грубое. Полезно рассмотреть архитектуру, в которой предлагается так называемое тегирование. Смысл его заключается в том, что в ячейках (основной памяти) выделены специальные разряды, именуемые тегом, которые указывают тип хранимого в остальной части значения (см. рис. 2.2).

Рис. 2.2. Структура ячейки при тегировании
Тегирование, реализованное аппаратно, дает следующие преимущества.
В языковых терминах тегирование выражается как динамическая (определяемая при выполнении программы) типизация данных. В этом отношении тегирование в аппаратуре лет на десять опередило первые экспериментальные попытки динамической типизации в языках программирования. Сейчас динамическая типизация, с логической точки зрения полностью аналогичная тегированию, является одним из инструментов объектно-ориентированного программирования.
В языке C тегированное данное соответствует описанию структуры, подобному этому:
struct tagged { int type_tag; union { int x; float y; } }
В языке Pascal тегированная ячейка может быть представлена следующей вариантной структурой:
record case tag : Boolean of true: (i :integer); false: (r :real) end;
Тегирование великолепно сочетается со структурным программированием, и поэтому практически всегда используется вместе с модификацией адресации и структуры памяти, называемой стековой архитектурой. При реализации языков высокого уровня на современных системах программирования практически всегда создается структура контекстов.
В стековой архитектуре машины уже физическая память организована как структурированный стек контекстов (см.
рис. 2.3).
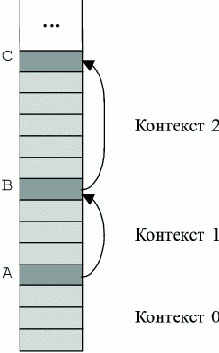
Рис. 2.3. Стек и контексты
Стек растет вниз. Нынешний контекст назван Контекст 0. Самая нижняя единица в стеке - текущий результат. Стек структурирован как стек стеков. Каждый подстек включает данные для блока программы. Таким образом, каждый из подстеков задает контекст для вычислений в соответствующем блоке. В начале каждого подстека находится его маркер, который содержит всю необходимую служебную информацию о подстеке, в частности ссылку на предыдущий маркер.
Для абстрактного вычислителя со стеком в начале обработки каждой конструкции нужно запомнить в стеке текущий экземпляр состояния контекста. Далее можно выполнять обычные действия по вычислению конструкции.
Стековая архитектура была воплощена в системах команд машин серий Barroughs и Эльбрус. Они прекрасно зарекомендовали себя как машины для сложных ответственных вычислений, но не выдержали конкуренции с армадой PC, задавивших их числом и дешевизной.
Есть и противоположное направление развития аппаратуры. В машинах с так называемой RISC-архитектурой машинные команды исключительно просты, но в полупостоянной части оперативной памяти заложены подпрограммы для команд `нормального' или даже `высокого' уровня, так что в принципе RISC-процессор может в зависимости от режима эмулировать5) машины разной архитектуры. Например, такая система была использована в машинах знаменитой серии Power PC - Power Mac, которые могли выступать для пользователя и программиста и как PC, и как Macintosh. Эта серия потерпела коммерческую неудачу скорее из-за ошибок в продвижении на рынок, чем из-за отсутствия реальных достоинств.
Нетрадиционные архитектуры
Крутой подумал. Ему понравилось. Он решил когда-нибудь на досуге подумать еще раз. Русский анекдот
Исторический экскурс
Во время Великой французской революции в связи с введением метрической системы мер, да и для улучшения качества артиллерии и флота, возникла необходимость быстро и качественно пересчитать множество таблиц: артиллерийские, навигационные, астрономические, геодезические и т. п.
Решение этой задачи (вдохновителем и организатором работ был выдающийся математик и администратор Л. Карно) было гениально с точки зрения концептуальной и организационной проработки. Вначале с помощью методов интерполяции все функции были заменены их кусочно-полиномиальными приближениями, не имеющими разрывов (современный термин - сплайн). Полиномы могут вычисляться методом конечных разностей, поэтому алгоритм вычисления полинома был распределен на сложения, вычитания и небольшое число умножений на константы. Для организации таких вычислений было использовано две параллельно работающие роты грамотных солдат под руководством математиков. Одни и те же расчеты проводились ротами независимо. Каждый солдат получал аргументы от двух указанных ему товарищей, складывал либо вычитал их (действие было предопределено заранее и не менялось). Самые грамотные солдаты получали аргумент от одного товарища и умножали его на заданную константу. По команде результаты действий передавались далее. Математики-надзиратели проверяли полученные результаты на правдоподобие и пересчитывали их выборочно. В случаях расхождения результатов рот счет производился заново. Таким образом таблицы были пересчитаны практически без ошибок, с минимальными затратами, высокой точностью и в кратчайшее время. В результате артиллерийские таблицы французской армии оставались лучшими более пяти лет, до тех пор, пока русские артиллеристы под руководством гр. Аракчеева не посчитали их еще лучше6).
Так что в том первом историческом случае, когда значительный объем вычислений был индустриализирован, была весьма квалифицированно выбрана модель вычислений.
Именно этим примером руководствовался при создании первой программно-управляемой механической вычислительной машины Чарльз Бэббидж, поскольку на механических элементах невозможно было добиться приемлемой скорости без распараллеливания вычислений. Быстродействующие, но ненадежные элементы первых ЭВМ практически вынудили отказаться от параллельной модели вычислений и перейти к более примитивной последовательной модели. Все преподавание и математическое обеспечение стало развиваться с ориентацией на последовательные вычисления. И когда появилась возможность электронной реализации параллельных вычислений, к ней оказались не готовы ни математики, ни программисты.
Прежде всего, можно просто иметь несколько процессоров. Многопроцессорность может быть использована несколькими способами.
Можно увеличить надежность вычислений. В некоторых бортовых машинах, рассчитанных на длительную работу без обслуживания, три процессора считают каждую очередную команду. Тем самым сбой одного из них не страшен.
Можно вычислять одновременно несколько программ. В принципе, наибольшая производительность машины с несколькими процессорами достигается именно тогда, когда каждый из них работает со своей программой, расположенной в своей области памяти. В современных машинах по сути дела именно так совмещается работа центрального процессора и устройств управления вводом, выводом и отображением информации. Но переносу этого принципа на саму архитектуру машины мешает привычка к рассмотрению ее как устройства для выполнения непосредственно нужной в данный момент задачи.
В связи с этим имеется, насколько известно автору, ни разу не использованное решение (предложенное автором еще в начале 70-х гг., но тогда отвергнутое). Поскольку каналы связи с памятью являются неустранимым узким местом, можно было бы снабдить процессор несколькими каналами и одновременно выполнять на одном процессоре несколько независимых программ. Вследствие этого можно было бы обойтись маленьким кэшем, состоящим из действительно нужных команд и данных (следующих команд и данных каждого из процессов).
И, наконец, можно попытаться использовать несколько процессоров для одного и того же процесса над общей памятью. В этом случае нужны изощренные алгоритмы кэширования и распределения программ между процессорами, а производительность растет всего лишь пропорционально корню квадратному от числа процессоров (и то в лучшем случае!) Получается, как зачастую бывает в современной информатике, круто, но весьма нерационально.
Прямое развитие данной идеи наталкивается также на массу тонких вопросов синхронизации. Простейший и наиболее очевидный из конфликтов синхронизации - попытка одновременной записи результатов нескольких команд в одну ячейку памяти, поэтому присваивания становятся тормозом на пути программирования.
Рассмотрим теперь те архитектуры, где до известной степени ликвидируется централизованное управление и появляется возможность глубокого распараллеливания вычислений.
Здесь стоит обратить внимание на два взаимосвязанных момента. Во-первых, часто нет нужды в хранении промежуточных результатов счета и, как следствие, потребность в пассивной памяти существенно снижается. Во-вторых, ликвидируется примитивное устройство управления, а его роль принимают на себя элементы оборудования, отвечающие за выяснение готовности команд к выполнению. Это - одна из схем, которая подчиняет управление потокам данных (data flow). Такие схемы противопоставляются управляющим потокам (control flow) традиционных вычислений.
Рассмотрим гипотетическую схему машины, управляемой потоком данных. Каждая команда имеет ссылку на те команды, от которых она зависит (предпосылки команды). Если выполнены все предпосылки, команда имеет право выполниться. Например, рассмотрим следующую схему.
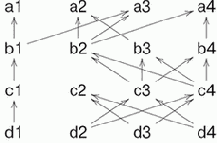
Рис. 2.4. Поток данных
На схеме вершины означают команды. Каждая команда зависит не более чем от двух, но зависеть от нее может сколько угодно других.
Представленная идея неоднократно воплощалась в оборудовании (так называемые машины потоков данных). Но каждый раз узким местом для подобных машин оказывалось несоответствие стиля программ, требуемого для них, тем стилям, к которым привыкли программисты.
Как следствие, в каждом из таких процессоров делались грубые системные ошибки, приводившие к затруднениям в программировании, а также к понижению скорости и гибкости вычислений. Тем не менее поскольку скорость света очень скоро поставит предел механическому увеличению пропускной способности каналов, к подобным схемам придется вернуться на другом уровне.
Конечно же, при реализации идеи возникают сложности. Пару из них демонстрирует следующий поток.
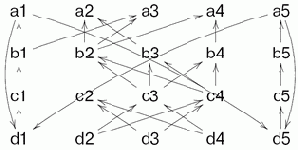
Рис. 2.5. Поток данных с взаимодействующими циклами
В потоке имеются два цикла, подготавливающие данные друг для друга. Возникает вопрос, а если один из циклов вторично подошел к точке, где требуются данные из другого, не устарели ли уже имеющиеся данные и не нужно ли подождать, пока они обновятся? Далее, здесь видно, что инициализацию потока данных часто необходимо выделять в самостоятельный блок, поскольку формально вычисление обоих циклов просто не сможет начаться.
Машины потоков данных уже несколько десятилетий используются на практике, так называемые суперЭВМ считают вычислительные задачи колоссальной трудоемкости (например, метеорологические). В подобных задачах, как правило, вычисление может быть записано в матричной алгебре, и новые матрицы строка за строкой вычисляются по старым. Таким образом, можно организовать конвейер, когда элементы целого вектора данных параллельно считаются по элементам предшествующего вектора, а переход к следующему происходит, когда все новые элементы посчитаны (так что вопрос о старении данных решается радикально: все, что использовалось для предыдущего вектора, по умолчанию считается устаревшим для следующего). Особенно хорошо конвейер работает, когда подпрограммы вычисления для каждого из элементов массива практически не изменяются (конечно же, для разных элементов они могут быть разные), поскольку инициализация процесса занимает много времени и сил. Конвейер с 1024 процессорами увеличивает производительность вычислений для некоторых реальных задач примерно в 300 раз, и для многих приблизительно в 100 раз.
Первой серийной суперЭВМ, успешно применившей конвейерную организацию, стала система машин Cray.
Одной из особенностей машин потоков данных является повышение активности памяти, в которой размещаются команды и их операнды. По этому пути можно пойти еще дальше, сделав всю память активной. Во избежание полной анархии, память обычно имеет общее устройство управления, задающее одну команду (или несколько команд, в зависимости от какого-то быстро проверяемого условия), которую выполняют все ячейки (ассоциативная память). История реализации этой идеи аналогична истории машин потоков данных: аппаратные предпосылки есть, но эффективных способов программирования нет.
Несмотря на очевидные преимущества для отдельных классов задач других моделей вычислений и на очевидную неэффективность классической модели вычислений, не происходит переход к другим, более перспективным с точки зрения ускорения счета, моделям. Почему? Это очень непростой вопрос, связанный как со сложившимися традициями, так и с огромным грузом накопленного программного обеспечения. В частности, другие модели вычислений, очевидно, не универсальны, ориентированы на некоторые классы задач, а иллюзия универсальности, основанная на примитивно истолкованной теореме об универсальном алгоритме, сопутствует традиционной модели вычислений. Но, пожалуй, более всего консерватизм обусловлен тем, что сегодняшняя армия программистов воспитана на традиционной модели, и она уже не в состоянии перестроиться.
Уже в машине потоков данных мы видим, что приказ выполнить следующую команду может быть заменен на разрешение ее выполнить. Таким образом, в программировании имеется возможность перехода от повелительного наклонения к изъявительному. Реализация идеи внедрения изъявительного наклонения в языки программирования возможна по следующим направлениям:
Соответствие данных шаблону трактуется как разрешение применить данное правило. Применение правила состоит в замене выделенного при сопоставлении фрагмента данных на что-то другое. Однократное выполнение такой замены трактуется как атомарный акт вычисления.
Способ передачи данных и активизации вычислений в коммутационной системе может рассматриваться как одна из реализаций потока данных в системе функций. В частности, если граф не имеет циклов, то коммутационная система становится формой представления нерекурсивной системы функций. Если граф коммутационной системы содержит циклы, то он может быть интерпретирован как рекурсивная система функций. Такая система может быть теоретически представлена как бесконечный ациклический граф.
Алгоритм действия может быть задан в любом стиле (например, в рамках традиционного программирования), его результатом для системы является набор пар, порождаемых в ходе локального действия, а исходные аргументы при этом уничтожаются. Легко заметить, что ассоциативная система может рассматриваться как иная форма коммутационной системы, и с точки зрения возможностей, предоставляемых для программирования, они теоретически эквивалентны. Однако эта форма соответствует иному взгляду на описываемые вычисления, который лучше подходит, в частности, для работы с базами знаний7).
В случае наиболее распространенной классической логики и языка исчисления предикатов либо некоторого его расширения на систему аксиом можно смотреть как на описание предметной области (либо, что то же самое, на задание соотношений между данными). Вычислительные действия в подобной системе активизируются по запросам, целью которых является вывод некоторой формулы (что для классической логики и элементарных формул соответствует выводу истинности либо ложности некоторого факта; такой вывод уже не назовешь проверкой, поскольку он не является элементарной операцией). Программиста в такой системе обычно интересует не способ вывода, а лишь его осуществимость.
Все описанное выше если и может быть сегодня реализовано в оборудовании, то крайне ущербным и частным способом. Но еще в 60-е гг. ХХ века стало видно, что программное обеспечение настолько сильно экранирует физическую структуру компьютера, что для всех пользователей и большинства программистов компьютер вместе с базовым программным обеспечением является единой системой.
В связи с этим все чаще говорят о системе программирования как о машине. Например, реализация языка Java определяется через Java-машину, в терминах которой понимаются все вычисления. Достаточно часто такая программная машина, реализующая некоторую модель вычислений, служила основой для аппаратной реализации ключевых особенностей данной модели. Например, Алгол-машина легла в основу компьютеров со стековой архитектурой и тегированием.
 |
|
|
В подавляющем большинстве книг она называется по имени фон Неймана, опубликовавшего под своим именем результаты английских коллег-союзников, а также результаты фон Цузе, находившегося тогда в США в фактическом рабстве как военнопленный.
2)
Такой взгляд полезен программисту при разработке интерпретирующих программ, когда ему нужно промоделировать передачи управления.
3)
Схема выполнения команды на рис. 2.1 иллюстрирует интенсивность работы канала машины фон Цузе. Для выполнения двухадресной команды КО1О2 требуется шесть обращений к каналу. Интересно, что первоклассный программист, посмотрев на рисунок, увидел лишь четыре обращения. Дело в том, что на физическом уровне при чтении ячейки происходит ее стирание, и поэтому требуется восстановление ее содержимого. Для прочтения трех ячеек нужно шесть операций, а факт перезаписи некоторых из них не увеличивает числа обращений к памяти в том случае, если сама команда запрограммирована корректно на аппаратном уровне.
4)
Частичным аналогом этого может служить BIOS в общераспространенных персональных компьютерах.
5)
Эмуляция - программное моделирование некоторых особенностей вычислительной системы, реализованное таким образом, что оно невидимо не только для пользователя, но и для обычного программиста.
6)
Никто не знает, каким способом!
7)
Теоретическая эквивалентность понятий означает для программиста выбор между двумя формами представления, которые практически неэквивалентны!
8)
Говорить о цепочке преобразований здесь слишком скромно, поскольку в развитых аксиоматических системах вывод является сложной иерархической структурой, а алгоритмы поиска вывода сразу планируют эту структуру.
Традиционная модель
Из материалов предыдущего раздела видно, что подходы к решению программистских задач при использовании различных языков отличаются друг от друга. Иногда эти различия непринципиальны и сводятся лишь к текстовому представлению программы, а иногда они довольно существенны. Если различия непринципиальны, то мы говорим, что языки имеют сходную модель вычислений.
Модель вычислений языка не обязательно совпадает с моделью вычислений, заложенной в оборудование. Эти модели расходятся, если сама машина имеет традиционную архитектуру. Более того, даже машины другой архитектуры программно моделируются на машинах традиционной архитектуры. В дальнейшем мы будем пользоваться термином традиционные языки, понимая под этим языки, модель вычислений которых унаследована от традиционной архитектуры машин. Архитектура, впервые использованная Конрадом фон Цузе1) еще на рубеже 30-40-х гг. XX в., в несколько модифицированной форме до сих пор принята почти для всех вычислительных машин.
В этой архитектуре вычислительной системы имеются следующие три элемента:
Эти элементы обладают следующими особенностями.
Значение в ячейке, с точки зрения процессора, является последовательностью битов фиксированной длины без каких бы то ни было ограничений.
Адреса служат указателями для процессора, откуда следует извлекать или куда помещать значение.
Из однородности памяти следует, что команды и данные (перерабатываемые значения) располагаются в единой общей памяти и одинаково адресуются.
Для передачи данных или команд между памятью и процессором используется специальное оборудование, называемое каналом связи. Работа канала осуществляется в случаях, когда требуется:
Такую архитектуру будем называть традиционной.
Традиционная архитектура машины конкретизируется для соответствующей среды применения. В частности, она всегда дополняется устройствами ввода и вывода данных.
На рис. 2.1 показано взаимодействие устройств традиционной машины.
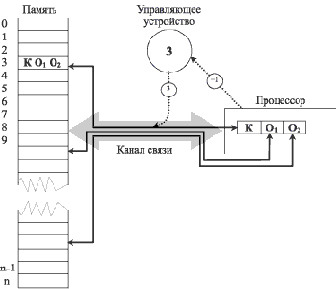
Рис. 2.1. Схема выполнения двухадресной команды на машине традиционной архитектуры
В команде КО1О2 К — код операции, O1 и O2 — адреса операндов. Команда размещена по адресу 3. Сплошными стрелками отмечена передача информации по каналу. Пунктирные стрелки обозначают действия, которые осуществляются непосредственно до исполнения команды (запрос кода команды по адресу 3) и после нее (указание на необходимость запроса команды, следующей в памяти за исполняемой).
Традиционная архитектура ЭВМ сформировалась в условиях ненадежности физических элементов. В частности, по этой причине выбран довольно примитивный способ управления: переход к следующей команде или к команде по принудительно задаваемому адресу. А в дальнейшем, несмотря на появление качественно новой элементной базы, стремительный рост производства машин такого типа препятствовал смене архитектуры.
Есть причина, из-за которой увеличение эффективности традиционных машин принципиально ограничено. Повышение быстродействия процессора как активного элемента оборудования приводит к росту скорости счета лишь в пределах, определяемых скоростью канала связи между процессором и памятью: если она невысока, то процессор будет простаивать, ожидая очередной команды, операндов или окончания выполнения присваивания3).
Темпы роста скорости процессора выше, чем у канала связи.
На эти принципиально непреодолимые ограничения классической модели вычислений указал Бэкус еще в середине семидесятых годов (Тьюринговская лекция Бэкуса [35]), назвав канал связи памяти с процессором узким местом (буквально bottleneck) традиционной модели.
Традиционная архитектура машин менее всего связана с конкретным классом решаемых задач. Она скорее связана с двумя наиболее распространенными и наиболее низкоуровневыми стилями программирования: структурным и автоматным программированием.
Под стилем программирования мы понимаем внутренне концептуально согласованную совокупность средств, базирующуюся на некоторой логике построения программ. Теоретические исследования последних десятилетий показали, что различным классам задач и методов соответствуют различные логики построения программ, и эти логики несовместимы друг с другом. Логики (и, соответственно, стили программирования) дают самую общую оболочку, не зависящую от конкретных предметных областей и даже от конкретных методов. Как только мы уясняем себе особенности методов, стили начинают конкретизироваться далее. Так, известный Вам (поскольку именно он преподается в качестве единственно существующего во всех современных учебных пособиях по началам программирования) структурный стиль конкретизируется в циклический либо рекурсивный варианты (ипостаси).
Для разных стилей логики построения несовместимы, поэтому прежде чем обсуждать стили в системе, мы познакомимся с примерами реализации различных стилей. Но еще до этого целесообразно рассмотреть другие архитектуры машин.
Конструкции традиционных языков
Рассмотрим традиционные языки, ключевые средства которых "выросли" из традиционной архитектуры машин. Ниже перечислены те средства языков, которые унаследованы от этой архитектуры.
Оператор. Основной конструкцией, выражающей действия, является оператор. Выполнение одного оператора зависит от выполнения другого только в том смысле, что более ранние вычисления могут менять память.
Присваивание значений — наиболее часто встречающийся вид операторов. В большинстве языков программирования понятие переменной рассматривается как аналог ячейки (или группы ячеек) памяти. Присваивание предназначено для локального запоминания результата вычислений. Оно прямой потомок передачи значения по каналу связи от процессора к памяти.
Структура управления. Если явно не предписано иначе, то операторы выполняются текстуально друг за другом. Это соответствует последовательному выполнению команд процессором. Оператор перехода трактуется как явное указание того оператора, который должен выполняться следующим. Он соответствует машинной команде безусловной передачи управления по адресу. То же можно сказать и о ситуациях, когда вычисления определяют, какой оператор будет выполняться следующим (условные операторы, циклы и т. п.). Прообразом этих операторов явились часто используемые приемы программирования на языке команд.
Приведение. В традиционных языках обычным является употребление значения одного типа, которое присваивается переменной другого типа. Автоматические приведения вырабатываемых значений к типам, определяемым контекстом использования, — прямое следствие соглашения об однородности памяти. В развитых языках программирования (кроме семейства C) стремятся избегать неконтролируемых приведений1).
Подпрограмма — группа операторов, имеющая собственное имя. К такой последовательности можно обращаться неоднократно. Подпрограммы появились еще на машинных языках, поскольку они необходимы для накопления программистских знаний и облегчения работы со сложными программами. Особенность подпрограмм в том, что их описание отделено от оператора вызова подпрограммы, а после исполнения оператора вызова управление возвращается в тот же контекст, который был до вызова, а управление передается оператору, непосредственно следующему за вызовом.
Заметим, что в достаточно развитых языках программист строит тексты программ в соответствии с особенностями решаемой задачи, отходя от тех правил, которые явно поддерживаются языком (писать в другом стиле). Но если в языке не хватает возможностей, адекватных для такого построения (а это, вообще говоря, обычная ситуация), то приходится прибегать к хакерскому2) моделированию нужных возможностей. Когда при этом требуется высокая эффективность (а это опять-таки обычно) необходимо учитывать реалии конкретного компьютера. Как следствие, весьма вероятны нарушение адекватности моделирования и потеря наглядности решения.
Примеры традиционных языков
Приведем с небольшими комментариями далеко не полный перечень традиционных языков.
1. FORTRAN. Патриарх среди языков программирования, постепенно вбирающий в себя новые веяния, но полностью сохраняющий преемственность в ее лучшем и худшем смысле. Сегодня FORTRAN — это эклектическое собрание как полезных, так и архаичных средств. Упоминая FORTRAN, мы имеем в виду язык, сформировавшийся в середине семидесятых, так называемый FORTRAN-77 (дальнейшие модификации уже не столь принципиальны). Модель вычислений языка FORTRAN в точности соответствует представлению о том, что нужно для реализации вычислительных алгоритмов и что можно реализовать на компьютерах традиционного типа, сложившемуся в 50-х гг. XX века. Таким образом, это наиболее последовательный пример традиционного языка.
Разработчики ранних версий языка FORTRAN не принимали в расчет полезности определения языка, независимого от системы программирования. И формальное определение языка, по существу, задавалось транслятором. В результате случайные решения, принятые в ранних трансляторах, последующие разработчики вынуждены сохранять на многие годы. Для этого языка такое положение дел объяснимо и простительно3).
FORTRAN служит классическим примером языка со статическим определением памяти: еще на стадии трансляции точно устанавливается, где что лежит.
2. Algol 60. Язык, сформировавшийся как реализация идеи представления алгоритмов, одновременно понятного и для компьютеров, и для человека. Очень скоро утопичность идеи выяснилась, и Algol 604) стал в глазах программистов-практиков5) лишь более строгим, но зато более многословным, менее привычным и эффективным аналогом языка FORTRAN. На самом деле в Алголе появились принципиальные новшества, выгодно отличающие его от предшественника. Это, прежде всего, определение языка, не зависящее от транслятора, далее, структурность описания языка и определение действий абстрактного вычислителя на базе понятий из строгого описания языка.
В Алголе впервые предложена структурная организация контекстов выполнения конструкций, которая выводит вычислитель языка за рамки канона однородности и прямой произвольной индексной адресации памяти, — так называемая блочная структура программы.
Тем самым была изобретена стековая дисциплина распределения памяти в рабочих программах. При таком распределении памяти место для понятий, описанных в некотором блоке, выделяется при входе в данный блок и освобождается после его завершения.
Стековая дисциплина с тех пор повсеместно используется при реализации языков программирования.
Хотя понятие структурного программирования еще не было осознано, в Algol 60 появилась вся необходимая база для него.
Не случайно именно Алгол стал отправной точкой развития большинства языков программирования, а также основой многих теоретических разработок, прояснивших языковые и программистские понятия. Появились и до эры персональных компьютеров были популярны вычислительные архитектуры, явно поддерживающие алголовскую организацию памяти. Наиболее известными из них являются машины фирмы Burroughs (США) и линия многопроцессорных вычислительных комплексов Эльбрус (СССР).
Таким образом, Algol 60 стал существенным шагом вперед, а в отношении концептуального единства он до сих пор остается непревзойденным среди традиционных языков.
3. Симула 67 характеризуется разработчиками как универсальный язык моделирования. Это, как и его предшественник Симула 1, — правильное расширение Algol 60, а потому сохраняет его достоинства и недостатки. Впрочем, именно недостатки этой базы стали главной причиной того, что данные языки оказались недооценены практиками. Разработчики Симулы 67 показали, как нужно выражать программистский опыт в языковых формах: воплощать не конкретные решения, а содержательные сущности, их обобщающие. В результате новые для того времени конструкции, отражающие объектный взгляд на обрабатываемые данные, стали основой для перспективных методологий программирования, в частности для методологии объектно-ориентированного программирования.
4. PL/1. Этот язык разрабатывался как попытка объединения всего, что в принципе может потребоваться программисту. Неизвестно, так это или нет, но вполне правдоподобно, что число "1" в названии языка есть амбициозное "единственный", т.
е. способный сделать бессмысленными любые другие языки программирования. Совсем не заботясь о чистоте объединения всех известных программистских средств, разработчики языка предложили изначально эклектичную коллекцию, которая лишь с натяжкой может быть названа системой. Непознаваемость языка отмечается многими критиками. По выражению Э. Дейкстры, PL/1 — это "рождественская елка", а не инструмент, который можно эффективно использовать. Разрозненность и несводимость к единым концепциям создает большие трудности и для реализации: системы программирования для PL/1 всегда выделяли некоторый диалект, по существу, определяя соответствующее подмножество средств, зависящее от транслятора.
5. Алгол 68 — язык программирования, который, как и PL/1, претендовал на всеобщность, но уже на базе математического обобщения разрозненных средств программирования в традиционной модели вычислений. Можно сказать, что это PL/1 с элементами научности (С. Костер). Попытка распространения средств, хорошо себя зарекомендовавших в одной сфере, на уровень максимального обобщения в целом удалась, но разработчики зафиксировали в языковых формах лишь то, что уже было известно на момент появления проекта языка. По этой причине в Алголе 68 нет хороших средств поддержки модульного построения программ, в точном соответствии с традиционной архитектурой перерабатываемые данные не являются активными. К недостаткам языка следует отнести тяжеловесное формальное описание, совершенно недоступное для практического применения в качестве руководства для программиста6). Основная заслуга разработчиков Алгола 68 в том, что они сумели реализовать на практике принцип обобщения без потерь, продемонстрировали продуктивность этого принципа. Наличие в данном курсе ссылок на фактически не используемый сейчас язык Алгол 68 объясняется тем, что в этом языке, несмотря на явные недостатки в форме описания языка, одновременно имелся ряд блестящих концептуально важных находок, таких, в частности, как система понятий, остающаяся до сего дня наиболее последовательной и строгой.
Некоторые из концепций Алгола 68 были восприняты в языках C и Ada, но сама система была при этом утеряна. До сих пор в журнале "Communications of the ACM" периодически появляются комментарии к опубликованным статьям, озаглавленные приблизительно в следующем стиле: "Algol 68 ignorance considered harmful", сводящиеся к тому, что очередные "новые" предложения являются лишь ухудшенной версией того, что уже давно было реализовано в Алголе 68.
Одной из побудительных причин создания языка стало осознание стройной концепции системы типов, вычисляемых статически, т. е. во время трансляции программы.
Базовая машина допускает произвольную трактовку смысла хранимых значений (принцип однородности памяти), но для человека смысл значений первичен, поэтому в программе нужно фиксировать не только вычисления, но и типы значений. Появляется возможность смыслового контроля программы, отделенного от обработки данных. Для этого нужно строго определить типы и дать точные механизмы построения одних типов через другие. Такое определение позволяет, не зная конкретных значений переменных, входящих в выражение, определять тип выражения. В результате целый ряд содержательных потенциальных ошибок в программе может быть выявлен уже при трансляции. Но в Алголе 68 эта концепция была недостаточно хорошо реализована.
6. Pascal — один из самых распространенных языков программирования. По этой причине он представлен множеством диалектов и версий. Первый Pascal был предложен Н. Виртом (N.Wirth) в ответ на принципиальное несогласие с позицией руководства рабочей группы по созданию Алгола 68, в частности с ван Вейнгаарденом. Главное в критике Вирта — чрезмерная сложность языка и особенно метода его формального описания.
В частности, Pascal дал более изящную и приемлемую для программистов реализацию идеи статической системы типов, возникшей еще в то время, когда первоначальная рабочая группа по Алголу 68 не распалась7).
Есть и другие особенности языка Pascal, которые делают этот язык строгим, есть и естественные ограничения возможностей, которые упрощают понимание языковых средств программистом.
Язык создан так, чтобы поддержать написание хороших программ (в понимании, которое сложилось к концу шестидесятых годов). Все это позволило утверждать Вирту, что он разработал язык для обучения студентов программированию. Это утверждение не лишено основания, особенно если иметь в виду, что существует методика обучения с его помощью, которую разработал сам Вирт. В учебных заведениях, где имеются серьезные курсы информатики, Pascal остается самым распространенным языком обучения.
Вскоре после своего появления Pascal становится популярным языком программирования. Но программирование продолжало развиваться, появлялись новые концепции. Сам Вирт разрабатывает на базе языка Pascal языки-наследники, которые в большей степени поддерживают составление программ с независимыми модулями: Modula и Modula-2.
Заслуживают внимания и более близкие родственники стандартного языка Pascal, последовательно версией за версией предлагавшиеся коллективом фирмы Borland: языки и системы программирования линии Turbo Pascal. В них новые, весьма развитые возможности органично укладываются в строй родительского языка, не нарушая концепций. К сожалению, в разработанной этой же фирмой системе Delphi язык Object Pascal выпадает из этого ряда: концептуальной целостности сохранить не удалось.
7. Язык С и другие машинно-ориентированные языки. Осознание того, что программирование с использованием универсального языка, не отражающего особенности конкретного вычислительного оборудования, не дает возможности достичь предельной эффективности программ на этом оборудовании, привело к появлению так называемых машинно-ориентированных языков. Популярность таких языков зависит не только от распространенности оборудования, для которого они рассчитаны, но и от успешности выполненных с их помощью проектов.
В этом отношении показателен язык С, успех которого был во многом обеспечен удачным решением операционной системы Unix. Для разработки этой системы на машины серии PDP и был построен язык C, с помощью которого, в частности, предложен технологичный метод переноса программного обеспечения.
Справедливости ради следует сказать, что хотя вклад системы Unix в успех С очень велик, но не менее важно и то, что этот язык предоставляет достаточно удобную для составления эффективных программ оболочку, закрывающую невыразительные средства машинного уровня. Растущая популярность этого языка повлияла на то, что компьютеры стали конструировать так, чтобы их архитектура соответствовала модели вычислений языка C. В результате популярность таких архитектур выросла. В этом процессе наиболее преуспела фирма Intel, процессоры которой становятся стандартом де-факто в сфере разработки персональных компьютеров. Сегодня уже нельзя представить массовый компьютер, который не поддерживал бы программное обеспечение, разработанное под эти процессоры8).
Язык С если не первый, то один из первых языков программирования, в которых с самого начала существования провозглашалась идея рассматривать в качестве вычислителя не уровень команд конкретного компьютера, а уровень операционной системы. Иными словами, в данном языке присутствуют конструкции, выполнение которых не может осуществляться без соответствующего обращения к средствам операционной системы. Конечно же, это не новшество. Во всех практически используемых языках программирования такие средства есть, и всегда они расширяют программистский взгляд на среду функционирования программы. Но чаще всего они представлены в языке как подчиненные средства, вынесенные на уровень библиотек, и далеко не всегда точно специфицированы. В С ситуация иная. В частности, наряду с автоматическим распределением памяти, в языке определены механизмы предоставления участков памяти по запросам и возврата их, когда они перестают быть нужными.
На фоне заслуженной популярности С уместно упомянуть менее распространенный язык Bliss. Этот машинно-ориентированный язык программирования мог бы быть концептуально более выверенной альтернативой С, но отсутствие разработанного с его помощью проекта, сравнимого по значимости с Unix, не позволило ему выделиться. И хотя в идейном плане Bliss повлиял на языкотворчество, интерес к нему не вышел за рамки академических исследований.
Отечественный опыт разработки машинно- ориентированных языков демонстрирует поддержку архитектуры, отличную от Intel-подобной. Укажем на два проекта этого рода. Первый — язык ЯРМО (аббревиатура: язык реализации машинно-ориентированный), построенный для ЭВМ БЭСМ-6 и отражающий все тогдашние веяния в информатике. О качестве и востребованности этого языка можно судить хотя бы по тому, что было реализовано несколько его версий. Второй пример — Эль-76, разработанный в качестве аналога ассемблерного языка для многопроцессорного вычислительного комплекса Эльбрус. Оставаясь в целом традиционной машиной, архитектура этого комплекса достаточно далеко отходит от канонических принципов. В частности, в ней предусмотрена аппаратная поддержка вызова процедур, стековая организация памяти, тегирование и другие высокоуровневые средства программирования.
Все архитектурные особенности Эльбруса отражены в Эль-76, что позволило рассматривать данный язык в качестве единственного инструмента программирования системных программ. Конечно, нельзя говорить о механическом переносе этого языка в архитектурную среду другого типа, а потому время использования его, как и любого машинно-ориентированного языка, ограничено временем жизни данной архитектуры9).
8. Язык Ada. Он разрабатывался по заказу Министерства обороны США на конкурсной основе с предварительным сбором и анализом требований, с обширной международной экспертизой. По существу, в нем воплощена попытка определить язык программирования как экспертно обоснованный комплекс средств программирования. На завершающем этапе конкурса приняли участие около ста коллективов. В результате проверки на соответствие представленных разработок сформулированным требованиям для обсуждения общественности было отобрано четыре языка, зашифрованных как Red, Green, Blue и Yellow. В разной степени критике подверглись все четыре кандидата. Особенно острым критиком оказался Э. Дейкстра, который камня на камне не оставил от Red, Blue и Yellow, но чуть-чуть "пожалел" Green, доказывая, что все недостатки языка связаны с несвободой в выборе решений, обусловленных жестко фиксированными требованиями: там, где авторы могли бы решать какие-либо проблемы по-своему, они были вынуждены идти на поводу у априорных предписаний.
Тем не менее Green стал приемлемым вариантом и получил одобрение. Как оказалось, это был единственный из финалистов язык, предложенный не американцами. Конкурсная комиссия утвердила его в качестве единого официального языка Министерства обороны США для разработки программ для встроенных систем и дала ему имя Ada — в честь Ады Августы Лавлейс, дочери Байрона и ученицы Бэббиджа — первой в истории программистки.
Отметим, что успеха разработчики языка добились благодаря акценту на концептуальную целостность — именно это выделяло Green среди конкурентов. Заметим, что в ходе последующего развития в язык Ada стали включать новые средства в угоду появившимся пользователям. В результате к концу девяностых годов Ada по стилю построения стала подобна PL/1: в ней есть средства поддержки всего, что можно найти в работе программистов в конце XX века. Как отмечал известный советский программист В. Ш. Кауфман, язык Ada 9х можно рассматривать как добротную энциклопедию программистского знания и опыта, но никак не в качестве инструмента, ориентированного на пользователя.
9. Объектно-ориентированные языки. Последним достижением в области программистского языкотворчества считается поддержка объектно-ориентированной методологии. Эта сфера интересует многих разработчиков языков начиная с восьмидесятых годов. Первым проектом, провозгласившим принцип перехода от пассивных данных к активным объектам, стал Smalltalk. В этом языке объектам предоставляется возможность действовать в ответ на получаемые ими сообщения без каких бы то ни было иных способов активизации действий. Эта возможность реализована в рамках идеи динамической типизации (в отличие от статической типизации, тип выражения может в определенных пределах вычисляться наряду с его значением). В качестве наглядной демонстрации мощи идеи была предложена система программирования Smalltalk-80 с очень богатой библиотечной поддержкой конструирования графических интерфейсов.
Smalltalk — последний крупный проект, который был представлен на всестороннее обсуждение программистской общественностью.
В результате таких обсуждений выяснилось, что нужно для поддержки объектной ориентированности в языках промышленного производства программ. Такие языки появились достаточно скоро.
Заметными объектными языками стали Turbo Pascal версий с 5.5 до 7.0 и Object Pascal системы Delphi.
Общим для промышленного развития линии языка Smalltalk является возврат к статическим типам данных, повышенное внимание к вопросам защиты. Появились системы программирования, приемлемые по эффективности объектного кода и удовлетворяющие требованиям технологичного программирования. Однако, как это обычно бывает с производственными системами, на смену аналитическим исследованиям границ применимости и роли языка пришли реклама достоинств и замалчивание недостатков.
10. Язык C++. Наибольшее распространение из объектно-ориентированных языков получил С++, по-видимому, из-за огромной популярности С.
C++ был создан в конце 80-х гг., он практически являлся расширением C. В отличие от языков семейства Simula, в С++ воплощались не столько концепции, сколько конкретные, полезные для его создателей, приемы. Язык С++ по конструкции намного сложнее С, а определение его производит впечатление еще большей эклектичности. Но С++, усугубив недостатки С с точки зрения человека, сохранил при колоссальном расширении возможностей языка все достоинства С, касающиеся машинной ориентированности и эффективности.
С++ отличается прежде всего значительным усилением системы описаний (объектно-ориентированные возможности являются одним из наиболее применяемых расширений)10).
Еще более укрепляют позиции языка С++ многие современные инструментальные системы, создававшиеся на нем без учета потребностей других языковых средств. В частности, системы работы с динамически подключаемыми программами (middleware) CORBA и COM практически требуют, чтобы программа, к ним обращающаяся, была написана на С++, поскольку вся система интерфейсов ориентирована на типы данных этого языка и порою даже на конкретные их представления.
11. Язык Java.
Заметным этапом в развитии объектно- ориентированного подхода стало появление языка Java, который был предложен как средство программирования не для отдельного компьютера, а сразу для всех машин, имеющих реализацию так называемой Java-машины — исполнителя программ на промежуточном языке более высокого уровня, нежели командный язык обычных машин. Иными словами, реализуется система программирования с явно определенным промежуточным языком. Другая особенность Java-проекта — его ориентация на Интернет-программирование: поддерживается возможность построения приложений, работающих сразу на нескольких машинах.
Схема трансляции с выделенным промежуточным языком, не зависящим от исходного языка, не нова. В шестидесятые годы ее пытались применять для сокращения расходов на разработку трансляторов (например, в США в качестве промежуточного языка был разработан язык Uncol, в Советском Союзе для тех же целей предлагался язык АЛМО).
Пусть требуется реализация m языков на n машинах. В схеме без промежуточного языка в этом случае нужно запрограммировать m ? n трансляторов, тогда как использование такого языка позволяет сократить это число до m + n: для каждого языка пишется транслятор в промежуточный язык (m) и для каждой машины создается транслятор или интерпретатор промежуточного языка (n). Можно предположить, что затраты на 'половинки' трансляторов сократятся. Схема может быть реализована, если удается построить промежуточный язык, удовлетворяющий следующим условиям:
Выполнить эти условия весьма сложно даже для близких языков и машин, близких по архитектуре. Затраты на решение этих задач часто неизмеримо и неоправданно превышают стоимость пресловутых m ? n трансляторов, поэтому после серии экспериментальных проектов идея промежуточного языка была предана забвению.
В проекте Java она возродилась (правда, в урезанном до одного языка варианте) благодаря почти унифицированной архитектуре массовых компьютеров и значительному росту технических возможностей машин.
Именно эти дополнительные условия, а также квалифицированное сужение исходного языка С++, позволили воплотить старую идею в промышленной разработке11).
В контексте обсуждения традиционности языков необходимо рассмотреть вопрос о том, насколько далеко язык Java и Java-машина отходят от традиционной модели вычислений. Совместная разработка этих двух компонентов системы программирования для нового языка позволила прийти к достаточно практичным компромиссам, удовлетворить условиям выбранной схемы реализации, о которых шла речь выше.
Условие (1) выполняется почти автоматически, и можно сосредоточить внимание на том, чтобы обеспечить наиболее рациональное вложение модели вычислений языка в модель машины. Что касается условия (2), то здесь ставка делалась на фактическое сходство архитектуры конкретных вычислителей, для которой уже накоплен опыт программистских решений во многих типовых ситуациях. В результате отход от традиционной модели вычислений в Java-системе хотя и заметен, но не столь значителен. Достаточно сказать, что Java-машина построена на принципах, предложенных еще в 1963 году для организации вычислений в рабочей программе Ветстоунского компилятора для Algol 6012) [24].
Важным новым качеством Java-машины является поддержка работы программиста с потенциально неограниченной памятью. При выполнении конкретной программы на языке Java можно не заботиться о том, что какая-то часть памяти перестает быть нужной. Система программирования сама сделает так, что та память, которая оказалась недоступной, а значит, ненужной, возвращается для использования в новых запросах. Такие ситуации выявляются в процессе вычислений, когда фактические ресурсы, предоставляемые для размещения данных, требуется пополнить для переиспользования. В угоду этому соглашению отказались от ряда приемов организации ручного переиспользования памяти, необходимых, например, при программировании на С.
Модель вычислений Java в точности соответствует тому, что требуется от объектно-ориентированного программирования: активность памяти на уровне методов объектов, совместное описание данных и программ методов, отделение предоставляемых средств от их реализации. Все это сочетается с традиционной схемой управления вычислениями при описании алгоритмов обработки.
Следует отметить, что разработчики языка не стали включать в него средства, с трудом укладывающиеся в концептуальную схему Java-машины и обычно предоставляемые через довольно произвольные реализационные соглашения (как, например, в С++). Ориентация Java-машины на классическую со времен Algol 60 схему организации вычислений, повлияла на язык в том отношении, что все, выходящее за рамки принятой модели, представлено таким образом, чтобы это можно было вычислить в период трансляции. К примеру, проблемы статической типизации в данном языке решены радикально: в нем просто нет средств конструирования структурных типов, отличных от классов объектов. В результате язык стал лаконичнее, например, по сравнению с С++.
Для первого опыта Java достаточно гармонично соединила ряд нововведений, которые в разрозненном виде появлялись в различных языках, и которые в совокупности повышают уровень исходных понятий примерно до второго типа в иерархии типов. Программирование на Java принципиально отходит от ориентации на особенности конкретных вычислителей. Остается лишь предположить (далеко не всегда оправданно!), что используемые машины выполняют требуемые действия с приемлемым уровнем эффективности.
В значительной степени для того, чтобы перехватить инициативу у языка Java, и был создан C#, эффективно работающий прежде всего с системами middleware, и стремящийся сохранить в новой области эффективность C/C++. Для наших целей в большинстве случаев различия между С++ и С# несущественны.
Как видим, традиционные языки прошли путь серьезной эволюции. Посмотрим, как трансформируются традиционные принципы вычислений при использовании объектной модели.
Очевидно, что отход от однородности памяти для этой модели более радикален, нежели, к примеру, в языке Pascal. Если рассматривать объекты как хранимые в памяти данные, то за счет связанности этих данных с программами (методами объектов) память в объектной модели приобретает активность. На концептуальном уровне рассмотрения можно увидеть, что модернизируется управление: объект сам знает, какую программу-метод нужно активизировать, чтобы выполнить то или иное действие. Несомненно, все это повышает гибкость программирования, способствует расширению возможности отхода от традиционного взгляда на программу как на автомат, выполняющий предписания-команды. Однако на уровне реализации программ-методов все остается по-старому: то же последовательное выполнение операторов, те же подходы к разветвлениям вычислений и к организации циклической обработки.
Более того, последовательный характер вычислений остается и при задании взаимодействия объектов. Следовательно, объектный подход, хотя и способствует взгляду на вычислительные процессы, отличающемуся от традиционного стиля, сам по себе не приводит к смене базовой модели вычислений.
Объектно-ориентированный подход применяется в настоящее время для организации вычислений на основе моделей, отличных от традиционных. При этом совершенно не принимается во внимание концептуальная совместимость объектно-ориентированного подхода с новым базисом и относительный уровень базиса и надстройки. Пример рассматривается в главе, посвященной функциональному программированию.
|
|
|
1)
Даже в семействе С слишком необычные приведения рассматриваются всеми нынешними трансляторами как события, требующие выдачи предупреждений программисту.
2)
Хакерство — неестественное применение конструкций, а также использование недокументированных возможностей либо явных недоработок языка.
3)
Удивительно, что и сегодня, в XXI веке, появляются языки, зависимые от реализации, которые претендуют на универсальное применение (например, Delphi Object Pascal, C#, Java).
4)
До него был еще Algol 58, но лишь Algol 60 был утвержден в качестве стандарта и получил широкое распространение. Его часто называют в литературе просто Алгол.
5)
Прежде всего, физиков и американцев; европейцы, не являвшиеся физиками, приняли его хорошо.
6)
Такова цена, которую пришлось заплатить за полную формальную точность описания.
7)
Одно из центральных понятий программирования — это призрак: то, что нужно для понимания программы, но в программу не входит. Pascal и Алгол 68 позволили многим призракам стать реальными программными сущностями.
8)
Безусловно, это тормозит развитие машинных архитектур.
9)
Это утверждение не противоречит долголетию С. Как уже отмечалось, данный язык сегодня фактически навязывает архитектуру машин, которая не противоречит его эффективной реализации. Например, использование С в качестве базового языка для Эльбруса явно ограничивало бы доступ ко многим развитым машинным возможностям.
10)
В качестве анекдота заметим, что система описаний С++ настолько мощна, что на стадии трансляции в принципе можно вычислить любую программу, например, выдавая результат в качестве сообщения об ошибке.
11)
Про новые условия данного проекта говорят обычно с неохотой или же вовсе замалчивают их. К примеру, в книге "Java-технология" успех старой идеи в новом проекте объясняется тем, что в прежние времена эту идею изучали в университетах, тогда как сегодня за нее взялись промышленники.
12)
В этой связи уместно следующее замечание. Если бы книга [24] не была бы сегодня библиографической редкостью, то ее главу 2 "Рабочая программа" можно было бы рекомендовать в качестве пособия для тех, кто желает изучить устройство Java-машины. После прочтения понимание Java-машины окажется более глубоким.
Абстрактный и конкретный синтаксис
При рассмотрении приемов программирования и примеров на разных языках необходимо как можно больше отвлекаться от частных особенностей и учиться видеть за ними общее с тем, чтобы оставшиеся различия были бы уже принципиальными. Отделить существенное от несущественного помогает, в частности, соотношение между синтаксисом и семантикой. Например, оказывается, что некоторые синтаксические особенности КС-грамматики языка не нужны для описания его семантики.
Обычное синтаксическое определение языка задает конкретные синтаксические правила построения программы как строки символов. При этом определяется, какие структурные элементы могут быть выделены в тексте программы (конкретное представление программы).
Действия абстрактного вычислителя определяются на структурном представлении программы и не зависят от многих особенностей конкретного синтаксиса. Например, для присваивания важно лишь то, что в нем есть получатель и источник, сам по себе знак присваивания (=, := или, скажем, LET) совершенно не важен. Более того, неважно, в каком порядке расположены составные части присваивания в тексте программы. Например, конструкция языка COBOL
MOVE X+Y TO Z
выражающая присваивание получателю Z значения выражения X+Y, совершенно аналогична обычному оператору присваивания.
Для того, чтобы четко отличать конкретное представление от существенной структуры, стоит рассматривать конкретный и абстрактный синтаксис. Скажем, абстрактный синтаксис всех перечисленных форм операции присваивания один и тот же.
Аналогично, три оператора
X = a * b + c * d; X = (a * b) + (c * d); (4.1) X = ((a * b) + (c * d));
и подобные им полностью эквивалентны с точки зрения абстрактного синтаксиса, тогда как с точки зрения текстового представления — различны.
Таким образом, нужна структура синтаксических понятий, которая соответствует некоторому алгоритмически разрешимому8) (см., напр. [20]) понятию эквивалентности программ. Но это понятие эквивалентности должно быть исключительно простым, поскольку теоретические результаты показывают, что нетривиальные понятия эквивалентности программ неразрешимы.
Выбранное понятие эквивалентности определяет структурное представление синтаксиса, используемого для задания абстрактного вычислителя (абстрактно-синтаксическое представление).
Фрагментом абстрактно-синтаксического представления является чаще всего применяемый на практике ход. Задают понятие синтаксической эквивалентности, которое очевидным образом согласуется с функциональной эквивалентностью. Так, например, предложения, перечисленные в примере 4.1, могут описываться следующим понятием синтаксической эквивалентности: скобки вокруг подвыражений, связанных операцией более высокого приоритета, чем операция, примененная к их результату, могут опускаться. В данном смысле присваивание рассматривается как операция, имеющая более низкий приоритет, чем любая из арифметических операций. Таким образом, например, определяется эквивалентность выражений в языке Prolog. Подвыражение X + 3, скажем, является в нем всего лишь другим вариантом записи для +(X,3), и при вычислении характеристик выражения оно прежде всего преобразуется в форму без знаков операций.
Еще одну возможность, открываемую переходом к абстрактно-синтаксическим определениям, можно увидеть, если определить эквивалентность подвыражений для сложения и умножения
A + B - B + A.
Здесь абстрактная эквивалентность выражает свойство самой операции. Опыт показывает, что дальше учета ассоциативности и коммутативности в абстрактном синтаксисе двигаться весьма опасно.
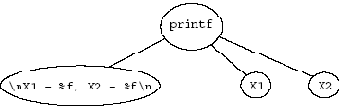
Рис. 4.1. Оператор печати
Пример на рис. 4.1 иллюстрирует вызов функции:
printf ("\nX1 = %f, X2 = %f\n", X1, X2);
Показанная на рисунке структура абстрактного синтаксиса данного оператора показывает, как можно ликвидировать привязку конструкции языка к конкретному синтаксису: остались только имя функции, строка и два параметра.
Рассмотрим более сложный пример, показывающий родство абстрактного синтаксиса традиционных языков. На рис. 4.2 показано абстрактное представление фрагмента текста следующей программы:
. . . if ( D > 0 ) { D = sqrt ( D );
Пример 4.5.1.
Текст некоторой программы
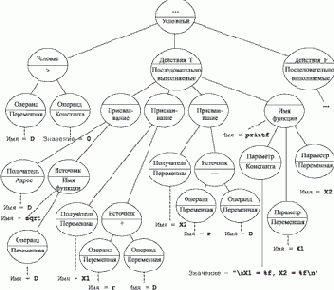
Рис. 4.2. Представление фрагмента текста программы
|
|
|
Язык программирования и алгоритмический язык почти всегда являются синонимами. В данном пособии они синонимичны.
2)
Нельзя абсолютизировать это требование. Совместные вычисления могут производиться в неизвестном программисту порядке. Более того, автору известен случай, когда прагматика (системы Common Lisp) четко отмечает, что в некотором случае нельзя пользоваться конкретным линейным порядком, который система порождает, пополняя заданный пользователем частичный порядок зависимостей, поскольку алгоритм упорядочивания может быть в любой момент и без предупреждения заменен. На самом деле такая прагматика часто полностью соответствует содержательному смыслу создаваемых программ: если два действия независимы, нельзя предполагать, что одно из них происходит раньше другого (хотя обычно программист вынужден это предполагать ввиду идиотизма "современных" систем). Если бы такие прагматические замечания встречались почаще!
3)
Поскольку синтаксис порою (особенно раньше) отождествлялся с контекстно-свободной его частью, в литературе иногда можно встретить термин "статическая семантика" для описания контекстных зависимостей. Вспоминая определение семантики, мы видим, что такой термин вводит в заблуждение.
4)
Даже возможная противоречивость библиотек друг другу соответствует стилю содержательного мышления (И.Н. Скопин).
5)
Вообще говоря, данная подсказка избыточна для современных трансляторов, поскольку распознать шаблон вида <переменная> ":=" <переменная /* та же самая */> "+" 1 и им подобные не представляет труда не только в тех случаях, когда <переменная> указана явно, но и тогда, когда она вычисляется (индексирование, косвенная адресация и т. д.).
6)
Сегодня с помощью семантической прагматики выражают также расширения модели вычислений, выводящие за рамки исходного абстрактного исполнителя. К примеру, — системы параллельного программирования над C++ и FORTRAN MPI и OPEN MP (И. Н. Скопин).
7)
Модель вычислений препроцессора можно охарактеризовать следующими свойствами. Исходные перерабатываемые данные — это текст (любой структуры, не обязательно на языке С), в котором имеются строки, начинающиеся с символа '#'. Такие строки представляют команды, управляющие работой препроцессора. Например, #include . . . заставляет препроцессор вставить некоторый файл в перерабатываемый текст (не следует понимать это буквально — нужно просто обеспечить соответствующий эффект). Другой пример: #define two 2 дает указание препроцессору на то, что в оставшейся части текста идентификатор two должен заменяться числом 2. Результат вычислений препроцессора — текст, который не содержит его команд.
8)
Как принято в современной теории, "алгоритмически разрешимое" далее называется просто "разрешимое".
Прагматика
До сих пор речь шла об определении языка его абстрактным вычислителем. Прагматика задает конкретизацию абстрактного вычислителя для данной вычислительной системы. Большая часть прагматики размазана по тексту документации о реализации языка (эту часть прагматики программист варьировать не может). Например, прагматическим является замечание, что тип Longint в системе Visual C++ определяется как 32-разрядное двоичное число с фиксированной точкой, занимающее слово памяти.
Та часть прагматики, которую может варьировать программист, требует отдельного синтаксического оформления. В языке Pascal есть так называемые прагматические комментарии, например, {$I+}, {$I-} (включение/выключение контроля ввода-вывода). Многие из таких комментариев практически во всех версиях одни и те же. В самом стандарте языка явно предписана лишь их внешняя форма: {$...}.
Даже если язык ориентирован на реализацию в единственной операционной обстановке (например, это какой-нибудь язык скриптов для микропроцессора, встроенного в собачий ошейник), для понимания сути того, что относится к действиям, а что — к их оптимизации, прагматику нужно выделить хотя бы в документации для программистов.
Принципиально различаются два вида прагматики языка программирования: синтаксическая и семантическая.
Синтаксическая прагматика — это правила сокращения записи, можно сказать, скоропись для данного языка. Пример, который можно рассматривать как синтаксическую прагматику — команды увеличения и уменьшения на единицу. В С/С++ они представлены операторами
<переменная>++; или ++<переменная>;
и
<переменная>--; или --<переменная>;
В С/С++ команды такого рода следует относить к модели вычислений языка, так как для нее постулируется, что язык является машинно-ориентированным и отражает особенности архитектуры вычислительного оборудования, а команды увеличения и уменьшения на единицу предоставляются программисту на уровне оборудования достаточно часто.
В Turbo Pascal и Object Pascal эти команды выражены следующим образом:
Inc (<переменная>)
и
Dec (<переменная>)
соответственно. Если рассматривать Turbo Pascal как правильное расширение стандартного языка Pascal, не содержащего обсуждаемые команды, то эти команды — просто подсказка транслятору, как надо программировать данное вычисление. Следовательно, указанные операторы для данного языка можно относить к прагматике 5).
Другой пример — возможность записи в языке Prolog вместо вызова +(X,Y) выражения X+Y.
Семантическая прагматика — это определение того, что в описании языка оставлено на усмотрение реализации или предписывается в качестве вариантов вычислений.
Например, стандарт языка Pascal утверждает, что при использовании переменной с индексом на уровне вычислений контролируется выход индекса за диапазон допустимых значений. Однако в объектном коде постоянные проверки этого свойства могут показаться накладными и избыточными (например, когда программа написана настолько хорошо, что можно гарантировать соответствующие значения индексов). Стандарт языка для таких случаев предусматривает сокращенный, т. е. без проверок, режим вычислений. Выбор режимов управляется пользователем с помощью прагматических указаний для транслятора, выражаемых в конкретном синтаксисе как прагматические комментарии {$R+} и {$R-}6).
Разработчики системы программирования должны прилагать специальные усилия, чтобы обеспечить явное выделение прагматического уровня. Без этого может сложиться превратное представление как о предлагаемой модели вычислений, так и о ее реализации. Вдобавок, резко ограничиваются возможности программиста в применении методов абстрагирования. Проиллюстрируем это.
Пример 4.4.1. Стандарт языка С предписывает, что системы программирования на нем должны предусматривать специальный инструмент для обработки программных текстов, который называется препроцессором. Препроцессор делает массу полезных преобразований. Как уже упоминалось, он берет на себя решение задачи подключения к программе внешних (библиотечных) файлов, с его помощью можно скрывать утомительные детали программирования, достигать ряда нужных эффектов, не предусмотренных в основных средствах языка (например, именованные константы).
Постулируется, что программа на языке С есть то, что получается после работы препроцессора с текстом (разумеется, если результат такой работы окажется корректным). Следовательно, использование препроцессора — синтаксическая прагматика языка. Но это противоречит практике работы программиста: он просто не в состоянии написать содержательную программу, которая может быть оттранслирована без использования препроцессора. Работа препроцессора не очень затрудняет понимание получившейся программы, если при программировании на С ограничиваются употреблением препроцессорных команд подключения файлов определений и определения констант. Но когда применяются, к примеру, условные препроцессорные конструкции, возможно появление программ-химер, зрительно воспринимаемый текст которых дезинформирует относительно их реальной структуры.
Пусть написано
if (x > 0) Firstmacro else PerformAction;
Кажется, что действие выполняется, если x
 0, но первый макрос раскрывается как
0, но первый макрос раскрывается какPrepareAction; if (x <= 0) CancelAction
Даже автор данной программы через некоторое время не поймет, почему же она так себя ведет.
Как это ни странно, подобные построения используются в практике программирования на С: они применяются, чтобы в одном тексте задать несколько вариантов выполняемых программ, которые разграничиваются при работе препроцессора, т. е. до выполнения.
Наложение команд препроцессора на текст программы — это смешение двух моделей вычислений: одна из них — модель базового языка С, другая — модель препроцессора7). В результате программист при составлении и изучении программ вынужден думать на двух уровнях сразу, а это трудно и провоцирует ошибки.
Разработчики С и С++ с самого начала не задумывались о соблюдении концептуальной целостности. Это приводило к тому, что при развитии языка он становился все более эклектичным.
Во многих языках, в частности в Object Pascal, для подобных целей используется более концептуально подходящее средство, так называемая условная компиляция. Суть его в том, что программисту дана возможность указать, что некоторый фрагмент компилируется, если при компиляции задан соответствующий параметр, и не компилируется в противном случае.
При этом оказывается исключенной ситуация, приведенная в предыдущем примере, поскольку чаще всего способ задания фрагмента привязан к синтаксическим конструкциям языка (т. е. условную компиляцию можно задавать не для произвольных фрагментов, а лишь для тех, которые являются языковыми конструкциями). При условной компиляции проверяется корректность синтаксиса и, что не менее существенно, зримый образ программы явно отражает ее вариантность (именно это свойство нарушено в примере 4.4.1).
Даже концептуально целостные системы в результате развития часто сползают к эклектичности. В этой связи поучительно обсудить развитие языка Pascal линии Turbo.
Модель вычислений стандартного языка Pascal изначально была довольно целостна, поскольку в ней четко проводились несколько хорошо согласованных базовых идей и не было ничего лишнего. Но она не во всем удовлетворяла практических программистов. В языке Pascal, в частности, не было модульности, и требовалась значительно более глубокая проработка прагматики, что стало стимулом для развития языка, на которое повлияла конкретная реализация: последовательность версий Turbo Pascal. Разработчики данной линии смогли сохранить стиль исходного языка вплоть до версии 7, несмотря на значительные расширения. В этом им помогло появление нового языка Modula, построенного как развитие языка Pascal в направлении модульности. Идея модульности и многие конкретные черты ее реализации, созданные в Modula, были добавлены к языку Pascal.
Далее пришел черед модных средств ООП, которые также были интегрированы в язык с минимальным ущербом для его концептуальной целостности.
Таким образом, создатели линии Turbo Pascal успешно решили трудную задачу расширения языка при сохранении концептуального единства и отделения прагматики от развивающейся модели вычислений.
Однако со столь трудной проблемой не удалось справиться тем же разработчикам, когда они взялись за конструирование принципиально новой системы программирования Delphi и ее языка Object Pascal. Одним из многих отрицательных следствий явилась принципиальная неотделимость языка от системы программирования.А далее история Delphi с точностью до деталей повторяет то, что было с языком С/С++. В последовавших версиях системы, вынужденных поддерживать преемственность, все более переплетаются модель вычислений и прагматика. Заметим, что "прагматизм" не принес никакого прагматического выигрыша: все равно Delphi плохо поддерживает современные системы middleware, ориентированные на C++ и Java.
Внимание!
Есть большая опасность, связанная с добавлением новых возможностей к хорошей системе без глубокой концептуальной проработки. Сплошь и рядом то, что хорошо работало раньше, после таких модификаций перестает устойчиво работать.
Текст некоторой
| . . . if ( D > 0 ) { D = sqrt ( D ); |
| Пример 4.5.1. Текст некоторой программы |
| Закрыть окно |
Различные стороны определения языка
Для создания, проверки и преобразования программ, построения систем программирования, а также для многих других нужд нам необходимо если не определение, то хотя бы описание алгоритмического языка. При этом требуются точные описания как текстов, так и их интерпретации. Рассмотрим существующие варианты.
Именно так пытались поступать на заре программирования, когда, скажем, легендарный язык FORTRAN создавался одновременно с первым транслятором с данного языка.
Первый вариант — совершенно неудовлетворительный путь, поскольку всякое изменение в программе-трансляторе может полностью изменить смысл некоторых конструкций языка со всеми вытекающими отсюда последствиями.
Второй вариант соответствует взгляду на язык как на множество правильно построенных последовательностей символов. Если последовательность символов принадлежит языку, то она считается синтаксически правильной. Для программы это означает, что транслятор на ней не выдает ошибки. Но синтаксическая правильность не гарантирует даже осмысленности программы. Таким образом, здесь определяется лишь одна сторона языка.
Третий вариант работает только вместе со вторым, поскольку структурные единицы должны соединиться в синтаксически правильную систему. Он раскрывает еще одну сторону языка.
Таким образом, мы видим, что каждый язык имеет три стороны: синтаксис (второй вариант), семантика (третий вариант), прагматика (первый вариант).
Синтаксис алгоритмического языка — совокупность правил, позволяющая:
Семантика алгоритмического языка — соответствие между синтаксически правильными программами и действиями абстрактного исполнителя, позволяющее определить, какие последовательности действий абстрактного исполнителя будут правильны в случае, если мы имеем данную программу и данное ее внешнее окружение.
Под внешним окружением понимаются характеристики машины, на которой исполняется программа (точность представления данных, объем памяти, другие программы, которые можно использовать при выполнении данной, и т. д.), и потоки входных данных, поступающие в программу в ходе ее исполнения.
Прагматика алгоритмического языка — то, что связывает программу с ее конкретной реализацией. При этом, в частности, происходит следующее.
Прагматика иногда предписывается стандартом языка, иногда нет. Это зависит от того, для каких целей предназначены язык и его реализация.
Описание языка требует точного задания синтаксиса и семантики. На практике, однако, чем точнее и чем лучше для построения транслятора описан язык, тем, как правило, такое описание более громоздко и менее понятно для обычного человека, и поэтому точные описания существуют не для всех реальных языков программирования. Даже если они имеются, то в виде стандартов, к которым обращаются лишь в крайних случаях.
Семантика
Мы определили семантику как соответствие между синтаксически правильными программами и действиями абстрактного исполнителя. Но остается вопрос, как задавать это соответствие. Семантика чаще всего определяется индукцией (рекурсией) по синтаксическим определениям.
Цель программиста - получить нужный ему эффект в результате исполнения программы на конкретном оборудовании. Но, составляя программу, он думает о программе как об абстрактной сущности и чаще всего совсем не хочет знать о регистрах, процессоре и других объектах конкретного оборудования. В соответствии с позицией программиста моделью вычислений языка программирования естественно считать то, какой абстрактный вычислитель задается описанием языка. Эта позиция подкрепляется также тем, что трансляция и исполнение может осуществляться на разных конкретных вычислителях. Следуя этой точке зрения, мы, говоря о модели программы, всегда имеем в виду ее образ в виде команд абстрактного, а не конкретного вычислителя.
Понятие модели вычислений языка естественно распространяется на случаи, когда используются библиотеки программ. Библиотеки, стандартизованные описанием языка, можно считать частью реализации языка независимо от того, как реализуются библиотечные средства: на самом языке или нет. Иными словами, библиотечные средства - дополнительные команды абстрактного вычислителя языка. Не зависящие от определения языка библиотеки можно рассматривать как расширения языка, т. е. как появление новых языков, включающих в себя исходный язык. И хотя таких расширений может быть много, рассмотрение модели вычислений для языка вместе с его библиотеками хорошо соответствует стилю мышления человека, конструирующего программу4).
Задаваемое семантикой соответствие между входными данными, программой и действиями, вообще говоря, определяется лишь полным текстом программы, включающим, в частности, все тексты используемых библиотечных модулей, но для понимания программы и работы над ней необходимо, чтобы синтаксически законченные фрагменты программы могли интерпретироваться автономно от окружающего их текста. Надо заметить, что современные системы практически никогда этому требованию не удовлетворяют. Слишком часто для понимания ошибки в программе нужно анализировать необъятные тексты библиотек.
Реализованный язык всегда является прагматическим компромиссом между абстрактной моделью вычислений и возможностями ее воплощения.
и самая разработанная часть описания
Синтаксис — самая простая и самая разработанная часть описания алгоритмического языка.
Грамматика определяется системой синтаксических правил (чаще всего в описаниях языков называемых просто правилами). На уровне грамматики определяются понятия, последовательное раскрытие которых, называемое выводом, в конце концов дает их представление в виде последовательностей символов. Символы называются также терминальными понятиями, а все остальные понятия нетерминальными. Понятия бывают смысловые, т. е. языковые конструкции, для которых определено то или иное действие абстрактного вычислителя, и вспомогательные, нужные лишь для построения текста, но самостоятельного смысла не имеющие. Минимальные смысловые понятия соответствуют лексемам. Некоторые понятия вводятся лишь для того, чтобы сделать текст читаемым для человека. Минимальные из них (они подобны знакам пунктуации) естественно считать вспомогательными лексемами.
Но даже задача полного описания синтаксиса достаточно сложна и требует выделения подзадач.
Синтаксис принято разделять на две части:
Понятие контекстно-свободной грамматики стало первым строгим понятием в описаниях практических алгоритмических языков. За понятием КС-грамматики при внешней его простоте стоит достаточно серьезная теория. Эта грамматика представляется во многих формах (синтаксические диаграммы, металингвистические формулы Бэкуса-Наура либо расширенные металингвистические формулы) и, как правило, сопровождает систематизированное изложение конкретного языка. Каждое такое конкретное представление КС-грамматики достаточно просто, и может быть изучено по любому учебнику программирования.
Содержательно можно охарактеризовать КС-грамматику языка как ту часть его синтаксиса, которая игнорирует вопросы, связанные с зависимостью интерпретации лексем от описаний имен в программе.
Контекстные зависимости сужают множество правильных программ.
Например, правило " все идентификаторы должны иметь описания в программе" указывает на то, что программа с неописанными именами не принадлежит данному языку (хотя она и допустима с точки зрения контекстно-свободного синтаксиса).
Неоднократные попытки формально описывать контекстные зависимости при определении языков показали, что эта задача гораздо более сложная, чем задание контекстно-свободного синтаксиса. Вдобавок ко всему, даже такие естественные правила, как только что представленное, при формальном описании становятся громоздкими и весьма трудными для понимания человека. По этой причине в руководствах редко прибегают к формализации описаний контекстных зависимостей (одним из немногих исключений является Алгол 68).
Пример 4.2.1. Требование о том, что каждое имя должно быть описано (в частности, в языках Pascal и C), конкретизируется в следующей форме.
Такая совокупность требований достаточна для того, чтобы человек мог проверить по тексту программы, как в данном месте понимается данное имя3).
В практических описаниях языков и в курсах программирования обычно довольствуются неформальным, но достаточно точным описанием контекстных зависимостей. Приведем пример такого описания.
Алгоритм для сопоставления объектного выражения E с образцом P в Рефал-5.
Вхождения атомов, скобок и переменных будут называться элементами выражений. Пропуски между элементами будут называться узлами. Сопоставление E : P определяется как процесс отображения, или проектирования, элементов и узлов образца P на элементы и узлы объектного выражения E. Графическое представление успешного сопоставления приведено на рис. 5.2. Здесь узлы представлены знаками o.
Следующие требования являются инвариантом алгоритма сопоставления и их выполнение обеспечивается на каждой его стадии.
Дополнительные возможности
В нашей программе 5.3.1 алфавит определен статически. Было бы хорошо иметь возможность заменять эту глобальную информацию. Для хранения динамической глобальной информации (чаще всего числовых характеристик либо словарей) в языке Рефал имеются стандартные функции работы со стеками закопанных данных. Функция
выкапывает верхушку стека. Если стек пуст, то ошибки нет, просто выдается пустое выражение. Несколько других функций дополняют возможности работы с глобальной информацией. Cp копирует верхушку стека без ее удаления, Rp замещает верхушку стека на свой аргумент, DgAll выкапывает сразу весь стек.
Ввод-вывод организован в Рефале довольно лаконично, без излишеств. Имеется функция открытия канала ввода, которая открывает файл либо для ввода, либо для вывода (в этом случае первым аргументом служит 'r' и присваивает ему номер. Одна строка символов из файла читается с помощью функции Get, заменяющей свой вызов на прочитанную строку, одна строка пишется в файл путем функций
либо
Вторая функция стирает свое поле зрения, а первая оставляет в качестве результата напечатанное выражение.
Следует заметить, что эти функции читают и пишут именно последовательности символов. При их использовании программист должен сам преобразовать последовательности цифр в числа, а скобки-символы в структурные скобки. Более того, при выводе часть информации теряется: невозможно различить последовательность букв и идентификатор, последовательность цифр и число, структурные скобки и скобки-символы. Поэтому имеется еще одна совокупность функций, автоматизирующих преобразование. Каждая из этих функций обрабатывает сбалансированное по скобкам выражение. При вводе это выражение заканчивается пустой строкой.
или
Первая из функций предназначена для ввода файлов, подготовленных вручную. Вторая и третья — для обмена промежуточной информацией с диском.
Только что перечисленные функции вместе с функцией Go требуют объяснения инструментов модульности в Рефале. Рефал-модуль — просто Рефал-программа, не обязательно включающая Go. Функции, предоставляемые в пользование другим модулям, описываются спецификатором $ENTRY как входы. В свою очередь, использующий модуль должен описать внешние функции:
$EXTRN F1,F2,F3;
Вызов программы, состоящей из нескольких модулей, производится оператором примерно следующего вида:
refgo prog1+functions+reflib
Модуль основной программы должен идти первым. Никаких средств включить требование вызова модуля в текст другого модуля нет, модули сопрягаются внешним образом. При конфликтах имен берется определение функции из первого в порядке подключения модуля.
В частности, только что описанные расширенные функции ввода-вывода определяются в стандартном модуле reflib.
Важнейшими средствами современного Рефала является работа с метавыражениями. Базовое ее средство — встроенная функция Mu, которая заключает свой аргумент в функциональные скобки и тем самым дает возможность вычислить динамически построенное выражение. По словам Турчина, Mu работает так, как работало бы определение
Mu { s.F e.X =
если бы оно было синтаксически допустимо.
В частности, через Mu работает стандартный модуль Рефала e (Evaluation), дающий возможность вычислить динамически введенное выражение. Он обрабатывает это выражение через функцию Upd, которая должна быть добавлена к модулю, где осуществляется динамическое вычисление выражений. Например, если добавить описание
$ENTRY Upd {e.X =
то командная строка refgo e+prog1 приведет к требованию написать выражение. Это выражение будет сделано полем памяти программы prog1 и вычислено, а результат выведен.
Например, написав для программы 5.3.1
мы получим в качестве результата
'abcdefghijklmnopqrstuvwxyz'
Естественно возникает вопрос об обработке внутри языка не только объектных, но и произвольных выражений. Для этого имеются стандартные функции Up и Dn. Первая из них превращает объектное выражение в выражение произвольного вида, вторая кодирует свою область зрения (ею, по семантике языка, может быть лишь объектное выражение) в форме, годящейся для общих выражений и даже метавыражений. В стандартном комплекте Рефала есть даже модуль прогонки, который позволяет подать на вход программы метавыражение и вычислить его настолько, насколько это возможно без знания значений переменных.
При решении сложных задач на Рефале естественно возникла задача представления мультииерархической структуры. Для частного случая двух независимых иерархий, одна из которых считается главной, а вторая начнет работать после исчерпания главной, в Рефале разработано мультискобочное представление выражений.Оно поддерживается библиотечными функциями кодирования и декодирования выражений и программ, переводящих мультискобочное выражение в его стандартный код и наоборот. Для частного случая, когда вторичная иерархия — наши обычные скобки, а первичная иерархия — ссылка глубоко внутрь скобочного выражения, неявно задающая одноуровневую скобочную структуру, независимую от стандартной, алгоритм кодирования исключительно прост. Выражение разбито на две несбалансированные по скобкам части: левую и правую. В обеих частях непарные скобки заменяем на пары )(. Открывающую скобку высшего уровня представляем как ((, место, куда ведет ссылка — как ))(, закрывающую скобку высшего уровня как )).
И в заключение рассмотрим достаточно сложный алгоритм на Рефале, иллюстрирующий многие приемы программирования: хранение промежуточной информации, обработку ошибок, ввод-вывод.
Пусть у нас дано выражение с различными парными скобками (в конкретном случае мы используем пары '()[]{}<>', но программа составлена так, чтобы эти пары можно было заменить в любой момент).
Для эффективной работы на Рефале это выражение нужно закодировать, используя структурные скобки. Кодом пары скобок Левая Правая будут скобки (Левая и Правая). Ниже дан алгоритм кодировки.
При записи данного алгоритма используется еще одна возможность Рефала-5. После образца через запятую может идти произвольное выражение, включающее свободные переменные образца, а затем другой образец. Во втором образце мы отождествляем вспомогательное выражение, не изменяя значений переменных, унаследованных из предыдущего образца. Если после второго образца идут фигурные скобки, то мы задаем безымянную функцию внутри функции. Если же их нет, то это отождествление рассматривается как дополнительное условие успешности первого отождествления. Эта иерархия вложенности может продолжиться на несколько уровней, причем переменные внешних уровней на внутренних уровнях остаются связанными, уже не изменяя значений.
Иерархически вложенные функции и условия в принципе не нужны для Рефала, но их использование позволяет сократить и, главное, лучше структурировать текст программы.
$ENTRY Go{=
Листинг 5.4.1. Мультискобочное выражение: Рефал
Для того, чтобы нагляднее увидеть влияние стиля на программные решения, сравните эту программу с развитием программы в традиционном стиле, приведенным в § 11.5 книги [22]. Данная программа намного выразительнее, короче, легче модифицируема и не менее эффективна, чем программа 11.5.3 из указанного параграфа.
В практике работы со студентами автору приходилось сталкиваться с ситуацией, когда программа для одной и той же задачи, написанная на традиционном языке, была более чем в пять раз длиннее программы на Рефале. Так что использование специализированных инструментов окупается (естественно, когда они применены в подходящих случаях).
Из литературы по языку Рефал можно рекомендовать учебные пособия [38], первое из которых имеется в общедоступном русском переводе, в частности на сайте http://www.refal.ru/diaspora.html.
|
|
|
Здесь слово 'структура' понимается не в узко программистском, а в научном и математическом смысле.
2)
Здесь у языка Рефал общая особенность с языками Prolog и LISP!
3)
Заметьте тонкую разницу между словами 'формироваться' и 'задаваться'! Имена функций заданы статически, но конкретное имя из заданного конечного множества функций может быть сформировано динамически.
4)
При реализации языка Рефал В. Ф. Турчин задумался, как избежать слишком частых обращений к каким-то суррогатам возможностей традиционных языков. Он решил заранее описать алгоритм преобразования выражений и подобрать для него подходящую структуру данных. Описанный им алгоритм хорошо работает с целым классом случаев, включая те, которые заранее не предусматривались, — отличительный признак концептуально продуманного решения. В лекции, относящийся к языку PROLOG можно увидеть, что происходит, если структуру данных хорошо не продумать на ранних этапах, а тем более зафиксировать случайные промежуточные результаты как стандарт.
Более того, описанные Турчиным алгоритм и структуры данных являются отличной базой для точного определения семантики на базе абстрактного синтаксиса языка Рефал.
5)
Изменение, введенное в ныне работающую реализацию Refal-PZ. В учебнике Турчина двойные кавычки являются альтернативным вариантом ограничителя строк.
6)
К этой концептуальной конфетке еще бы красивую обертку!
Конкретизация
Язык Рефал был создан В. Ф. Турчиным для программирования символьных преобразований. Исходный толчок он получил от идеи алгорифмов Маркова (см., например, теоретическое приложение к книге [21]), но эта идея была полностью пересмотрена в ходе работы по созданию языка. Идейный и математический уровень проработки языка исключительно высокий, но вопросы дизайна почти проигнорированы.
В основе языка лежит (другой по сравнению с языком PROLOG) частный случай операции отождествления: конкретизация метавыражения.
Под конкретизацией понимается такой частный случай отождествления, при котором переменные встречаются лишь в метавыражении и поиск их значений происходит путем подбора без рекурсии.
Язык Рефал определен через три компонента: структуру данных, Рефал-машину, обрабатывающую эти данные, и собственно конкретный синтаксис языка.
Модель вычислений и Рефал-программа
Основные два шага в Рефал-вычислениях — конкретизация переменных в образце в соответствии с областью зрения и подстановка полученных значений в другое метавыражение. В языке рассматривается лишь частный случай конкретизации.
Конкретизация образца Me в объектное выражение E называется такая подстановка значений вместо переменных Me, что после применения данной подстановки Me совпадет с E.
Заметим, что одно и то же метавыражение может иметь много конкретизаций в одно и то же объектное выражение. Например, рассмотрим метавыражение
e.Begin s.Middle e.End (5.3)
и объектное выражение
AhAhAh 'OhOhOh' (Ugu','Udgu) '(((' Basta'!' (5.4)
Имеется 11 вариантов конкретизации (5.3) в (5.4) (проверьте!).
Если у метавыражения Me есть много вариантов конкретизации в E, то они упорядочиваются по предпочтительности в следующем порядке.
Пусть Env1 и Env2 — два варианта конкретизации Me в P. Рассмотрим все вхождения переменных в Me. Если Env1 и Env2 не совпадают, они приписывают некоторым переменным различные значения. Найдем в P самое первое слева вхождение переменной, которому Env1 и Env2 приписывают разные значения и сравним длину этих значений. Та из конкретизаций, в которой значение, приписываемое данному вхождению переменной, короче, предшествует другой и имеет приоритет перед ней.
Например, сопоставим объектное выражение (A1 A2 A3)(B1 B2) с образцом e.1 (e.X s.A e.Y) e.2. В результате получится следующее множество вариантов сопоставления:
{e.1 = , eX = , sA = A1, eY = A2 A3, e.2 = (B1 B2) } {e.1 = , eX = A1, sA = A2, eY = A3, e.2 = (B1 B2) } {e.1 = , eX = A1 A2, sA = A3, eY = , e.2 = (B1 B2) } {e.1 = (A1 A2 A3), eX = , sA = B1, eY = B2, e.2 = } {e.1 = (A1 A2 A3), eX = B1, sA = B2, eY = , e.2 = }
Пример 5.1. Множество вариантов сопоставления
Варианты сопоставления перечислены в соответствии с их приоритетами, т. е. самый первый вариант находится на первом месте и т. д. Описанный способ упорядочения вариантов сопоставления называется сопоставлением слева направо.
Тот алгоритм конкретизации, который используется в Рефале, называется проецированием и согласован с введенным нами отношением порядка. Опишем его (описание взято из учебника Турчина [38]). Обратите внимание, как в данном случае общая и не всегда эффективно реализуемая операция 'проецируется' на свою частную реализацию, одновременно повышающую эффективность, сохраняющую общность и предписывающую методику программирования.
Общие требования к отображению P на E (сопоставлению E : P)
Рис. 5.2. Сопоставление E : P является отображением P на E. Здесь объектным выражением E является 'A'((2'B'))'B', а образцом P является 'A'(e.1 t.2)s.3
Предполагается, что в начале сопоставления граничные узлы P отображаются в граничные узлы E. Процесс отображения описывается при помощи следующих шести правил. На каждом шаге отображения правила 1–4 определяют следующий элемент, подлежащий отображению; таким образом, каждый элемент из P получает при отображении уникальный номер.
Правила отображения
На рис. 5. 2 сопоставление производится следующим образом. Вначале имеется два жестких элемента с одним отображенным концом: 'A' и s.3. В соответствии с Правилом 3 отображается 'A', и этот элемент получает при отображении номер 1.Номера 2 и 3 будут назначены левой и правой скобкам согласно Правилам 3 и 1. Внутри скобок начинается перемещение справа налево, так как t.2 является жестким элементом, который может быть отображен, в то время как значение e.1 еще не может быть определено. На следующем шаге обнаруживается, что e.1 является закрытой переменной, чью проекцию не требуется обозревать для того, чтобы присвоить ей значение; что бы ни было между двумя узлами, это годится для присвоения (на самом деле, значение e.1 оказывается пустым). Отображение s.3 завершает сопоставление. Расположение отображающих номеров над элементами образца дает наглядное представление описанного алгоритма:
1 2 5 4 3 6 'A' ( e.1 t.2 ) s.3
Этот сложный алгоритм упрятан в простые программные конструкции.
Программа на Рефале является последовательностью определений функций. Каждое описание функции в Рефале имеет вид
Имя функции {Последовательность сопоставлений}
Каждое сопоставление имеет вид
Образец = Метавыражение;
Относительное расположение членов последовательности определений никакой роли не играет, и функции можно группировать из логических или технологических соображений. Относительное расположение сопоставлений внутри определения функции существенно.
Пример 5.3.2. Рассмотрим пример Рефал-программы.
Pre_alph { *1. Отношение рефлексивно s.1 s.1 = T; *2. Если буквы различны, проверить, входит ли * первая из них в алфавит до второй s.1 s.2 =
Листинг 5.3.1. Программа вычисления предиката предшествования одного символа другому в заданном алфавите
Строки, начинающиеся с *, служат комментариями. Последняя из функций Alphabet введена для технологичности, чтобы определение алфавита было в одном месте и его легко было изменять.
A1 A2, sA
| {e.1 = , eX = , sA = A1, eY = A2 A3, e.2 = (B1 B2) } {e.1 = , eX = A1, sA = A2, eY = A3, e.2 = (B1 B2) } {e.1 = , eX = A1 A2, sA = A3, eY = , e.2 = (B1 B2) } {e.1 = (A1 A2 A3), eX = , sA = B1, eY = B2, e.2 = } {e.1 = (A1 A2 A3), eX = B1, sA = B2, eY = , e.2 = } |
| Пример 5.1. Множество вариантов сопоставления |
| Закрыть окно |
Структура данных
Данные, обрабатываемые языком Рефал, представляют собой последовательности атомов, структурированные несколькими согласованными между собою видами скобок. Например, в некотором конкретном синтаксисе такое выражение могло бы иметь вид {a+[b-(c+d)**2]/3}*(a+d). В поле памяти Рефал-машины задействованы два вида скобок: структурные и функциональные.
Выражения языка Рефал.
В конкретном синтаксисе Рефала функциональные скобки обозначаются < >, структурные -- ( ). Атомы делятся на:
В поле памяти выделяется основная часть, а также стеки глобальных данных - закопанные данные. Перед каждым шагом исполнения в основной части поля памяти выделяется активная часть - поле зрения. Данные в поле зрения и закопанные данные имеют общую структуру1), которая является подструктурой структуры поля памяти. Поскольку и программа имеет практически ту же самую структуру2), в ходе развития языка появилась третья структура данных (метаданные), расширяющая поле памяти.
Дадим точные определения.
Объектное выражение — выражение, не содержащее функциональных скобок.
Минимальное функциональное выражение — выражение, имеющее вид
поле памяти Рефал-машины представляет собой набор выражений, одно из которых называется основной частью. В основной части в любой момент, за исключением момента выдачи окончательного результата и остановки программы, есть функциональные скобки.
Поле зрения (активная часть) поле памяти — первое из встречающихся в основной части поля памяти минимальных функциональных выражений.
Детерминатив — первый символ в функциональной скобке.
Детерминатив интерпретируется как имя функции, обрабатывающей содержимое функциональных скобок. Эта функция должна определяться статически, поэтому в ходе вычислений не могут образовываться выражения вида <
Пример 5.2.3. Рассмотрим пример памяти Рефал-машины в ходе вычислений.
Поле памяти:
'aaxzACDE'
Поле зрения выделено в поле памяти жирным шрифтом. Заметим, что в поле памяти можно выделить данные, обработка которых уже завершена и которые не изменятся до конца исполнения программы (те, которые находятся вне программных скобок; в нашем случае 'aaxzACDE' и 'XZ<('). У символов, представляющих скобки, есть 'обычные' двойники, не обязательно имеющие парные и не влияющие на структурирование выражения. Первый атом Perm стоит в позиции функции, а последний из атомов Perm стоит в позиции данных, так что имена функций могут формироваться3) динамически. При записи программы пробелы, если они не находятся внутри символьных констант, игнорируются, за исключением тех, которые отделяют один символ от другого (эти пробелы просто опускаются после того, как на этапе лексического анализа сыграли роль разделителей). И, наконец, еще одна тонкость. 123 — это один атом, '123' — три атома, -123.0 — опять один атом, -123 — два атома: символ '-', после которого стоит число.
Кроме основной части поля памяти, в ходе исполнения может появиться несколько стеков закопанных выражений, например:
Stack1 '=' 15 Stack2 '=' Perm B A 21 Perm C2 C1 -45 Perm 'X' 20 60
В принципе, несколько стеков — избыточная конструкция.
Но, поскольку здесь стеки рассматриваются как общие области памяти, лучше в каждом модуле иметь свой стек. К сожалению, явной связи между стеками и модулями в Рефал-программах нет.
Допустим, есть строка < AB(CD)(E)F>. Она во всех известных нам Рефал-системах представляется двунаправленным списком, изображенным на рис. 5.1. Этот формат представления стал общераспространенным для Рефал-систем, начиная с реализации, описанной в [25]. Однако
Рис. 5.1. Реализация структуры данных Рефала
он не является обязательным4). Преобразование выражений в формат для обработки делается один раз, при вводе информации либо при трансляции программы.
Рассмотрим конкретный синтаксис выражений.
Идентификатор — любая последовательность цифр и букв, начинающаяся с большой буквы. Идентификатор является символьным литералом и представляет составной символ. Символы, заключенные в одинарные ' ' кавычки, являются символьными литералами, представляют сами себя. Дважды повторенная кавычка представляет кавычку. Двойные кавычки " " используются для ограничения имени составного символа, не обязательно являющегося идентификатором5). Если вне кавычек встречается символ, не являющийся скобкой, частью идентификатора или числа, это трактуется как ошибка.
Определение метавыражения Рефала получается из определения выражения добавлением еще одного базисного случая: переменная является метавыражением.Переменные не могут быть детерминативами.
Метавыражение называется образцом, если оно не содержит функциональных скобок.
В конкретном синтаксисе обозначение переменной включает тип и символ переменной, записываемые как тип.атом. В стандартном Рефале имеются переменные трех типов: символьные (s.First), термовые (t.Inner) и общие (e.Last).
Значением символьной переменной служит атом, термовой — терм (символ или выражение в скобках), общей — произвольное (может быть, пустое) объектное выражение.
Рефал развивался как язык символьных преобразований в самом широком смысле этого слова, и поэтому в него была заложена возможность обрабатывать собственные программы.Он предоставляет стандартные функции метакодирования, взаимно-однозначно и взаимнообратно преобразующие произвольное метавыражение в объектное и наоборот. Таким образом, появляется возможность создавать программы в ходе выполнения других программ и затем выполнять их "на лету". Такая возможность, просто гибельная для программ в большинстве систем и стилей программирования, в данном случае не приводит ни к каким отрицательным последствиям из-за уникального концептуального единства и продуманности языка6).
Динамическое пополнение и порождение программы
Поскольку структура программы и структура Поля зрения практически изоморфны, естественно ставить вопрос о динамическом порождении PROLOG-программ. Кроме этого высокоуровневого соображения, есть и прагматическое, которое можно извлечь из нашей программы 6.3.2. В нашу программу мы были вынуждены записать и определение лабиринта.Конечно же, можно было бы прочитать с помощью встроенной функции read определение лабиринта и записать его в список, но тогда мы почти утратили бы все преимущества языка PROLOG, не избавившись при этом ни от одного его недостатка. Гораздо естественнее иметь возможность прочитать базу данных из файла.
Для этой цели в PROLOG был введен встроенный предикат consult(file[.pl]). Он читает предложения и факты из файла и помещает их в конец программы, тем самым оставляя в неприкосновенности ранее данные определения предикатов. С его использованием наша программа может быть переписана в следующем виде.
way0(X,Y,Z):-consult(labyr),way(X,Y,Z). way(X,X,[X]). way(X,Y,[Y|Z]):-connect(U,Y), not member(Y,Z),way(X,U,Z). way(X,Y,[Y|Z]):-connect(U,Y), way(X,U,Z).
Листинг 6.4.1. Вводимый лабиринт
Пример файла labyr.pl:
connect(begin,1). connect(1,begin). connect(1,2). connect(2,3). connect(3,1). connect(3,4). connect(4,end).
Программа 6.4.1 представляет лишь идею решения, но эту идею она представляет исключительно выразительно. PROLOG приспособлен для нахождения решения, но не для его оптимизации. Например, если стремиться найти в некотором отношении оптимальный путь, то предыдущая программа окажется затемнена частностями языка PROLOG, которые испортят выразительность, и тем не менее не дадут возможность решить задачу столь же эффективно, как это делается на традиционном языке.
Есть еще один класс встроенных отношений, которые действуют как встроенные функции, но не требуют явной активизации операцией is. К ним, в частности, относятся многие действия над списками. Рассмотрим, например, предикат append(E1,E2,E3). Он корректно унифицируется, когда объединение первых двух списков является третьим.
Соответственно, он может использоваться для вычисления любого из своих трех аргументов, если два других заданы. Например,
append(X,Y,Z)
при Z=[a,b,c,d], Y=[c,d] унифицируется как X=[a,b].
Очень жаль, что в PROLOG таким же образом не реализованы арифметические функции!
Для динамического порождения фактов и предложений имеются функции, разбирающие предложения и синтезирующие их. Функторы могут быть объявлены метапредикатами, и тогда некоторые из их аргументов могут быть предложениями. Из метапредикатов важнее всего два, перечисленных ниже.
Метапредикат assert(P:-P1,. . . ,Pn) помещает свой аргумент в PROLOG- программу. Имеются несколько его вариантов, располагающие новое предложение или факт в начало или в конец программы. Метапредикат retract(P:-P1,. . . ,Pn), наоборот, удаляет из программы предложение или факт, унифицируемый с его аргументом.
С их помощью можно, в частности, имитировать различные более эффективные алгоритмы перебора для работы с лабиринтом, но при этом программа до некоторой степени теряет ясность структуры и становится крайне трудно ее отладить и модифицировать. А эффективности, сравнимой с традиционными методами, достичь все равно не удастся.
Но, например, если Вы анализируете сложную систему правил и ищете вывод, то результат анализа часто можно записать как файл динамически порожденных предложений, и это, наоборот, делает программу красивее, а ее отладку легче. Так что есть смысл использовать динамическое порождение в том случае, когда программа сначала коллекционирует и анализирует информацию, а лишь затем начинает действовать. А порождение, перемешанное с действиями, — кратчайший путь к провалу программы, и должно рассматриваться как хакерство.
Далее, после того, как использованы динамически порожденные факты или предложения, их можно удалить из программы при помощи предиката
retractall(Name / Arity)
Этот предикат удаляет все предложения и факты, говорящие о предикате Name арности Arity. Естественно, при этом удаляется лишь определение. Если Вы его использовали, то нужно потрудиться удалить также использующие предложения.
Поэтому предикаты лучше удалять целыми содержательно связанными группами, и концентрировать все такие удаления в одном предложении для каждой группы.
Динамическое порождение программ — метод, исключительно сильный, когда применен в подходящей обстановке и корректно, и исключительно опасный, когда применен в неподходящем окружении либо хоть чуть-чуть некорректно. В традиционных языках ему всячески препятствуют. Там он (по причине очень многих практических провалов) имеет одиозную репутацию. Но эта репутация связана прежде всего с тем, что такой рискованный и красивый метод требует высокой проработки идей, а в традиционном программировании мы, пытаясь его применить, вынуждены прорабатывать глупейшие технические проблемы (строить множество подпорок, см. словарь).
Внимание!
В новых версиях языка PROLOG предикаты, которые Вы намерены динамически видоизменять, нужно объявить. Например, dynamic(connect).
Для проверки типов термов имеются, в частности, следующие встроенные предикаты.
Для анализа и построения термов имеются, в частности, следующие предикаты.
Примеры.
?- send(hello, X) =.. List. List = [send, hello, X] ?- Term=.. [send, hello, X] Term = send(hello,X)
free_variables(Term, List) List унифицируется как список новых переменных, каждая из которых равна свободной терма Term.
atom_codes(Atom, String) Преобразование атома в строку и наоборот.
Многие из реализаций языка PROLOG включают пакет прогонки, позволяющий осуществлять частичное вычисление PROLOG-программы.
Общие концепции
Язык логического программирования PROLOG представляет собой одну из моделей сентенциального программирования. Мы используем лишь те возможности языка PROLOG, которые согласуются с принятым в 1996 г. стандартом [36]. Как руководство по программированиюна языке PROLOG можно использовать, скажем, книгу [6]. В ней содержится наименьшее число недочетов и откровенных ошибок, а также наибольшее число практических советов по сравнениюс другими известными автору пособиями.
Первой находкой создателей языка PROLOG явилось понятие унификации, изобретенное в методе резолюций для доказательства формул классической логики предикатов.
Два выражения называются унифицируемыми, если они могут быть приведены к одному и тому же виду подстановкой значений вместо свободных переменных. Унификация—вид конкретизации, при котором границы всех синтаксических единиц фиксированы, структура выражения однозначно определена и подстановка, приводящая два выражения к одному и тому же виду, вычисляется рекурсивно.
Второй находкой, перенесенной авторами языка PROLOG из специализированных программ (для логики и искусственного интеллекта) в языки программирования, стала система обработки неудач. Успешно произведенная унификация является лишь разрешением выполнить некоторое действие. После проверки других условий, возможно, мы будем вынуждены вернуться и выбрать другой вариант.
Третья находка языка PROLOG, перенесенная в программирование из метода резолюций, — это стандартизация цели. Целью доказательства в методе резолюций всегда является получение пустого дизъюнкта, то есть стирание доказываемого выражения (с логической точки зрения, приведение его к абсурду). Точно так же и в языке PROLOG: успешное исполнение программы означает стирание поля зрения.
Четвертая находка создателей языка PROLOG взята из ограничения классической логики. Хорновские формулы
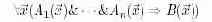
обладают важным свойством. Для нахождения вывода в системе хорновских формул достаточно производить так называемую линейную резолюцию, когда на каждом шаге делается вывод из исходной формулы и наследника цели. Никаких сочетаний исходных формул между собой либо различных вариантов раскрытия цели между собой делать, в принципе, не нужно.
Организация вычислений и ввода-вывода
Во многих случаях даже в поисковой программе необходимо производить вычисления. В языке PROLOG имеется способ вычисления значения по аргументам. Это так называемые встроенные функции, которые могут быть заменены на свое значение, если их аргумент известен. Такими функциями служат, в частности, числовые арифметические операции. Заметим, что даже встроенная функция не вычисляется, пока не будет дан явный сигнал. У Вас в программе может, скажем, накопиться в качестве значения переменной выражение 1 + 1 + 1, но оно не будет равно 3.
Для организации вычисления имеется специальное отношение X is E. В этом отношении Е является таким выражением, которое после подстановки текущих значений переменных конкретизируется7) в композицию встроенных функций от константных аргументов. Эта композиция вычисляется, и переменная Х унифицируется как ее значение.
Таким образом, можно постепенно накапливать вычисления, а затем в подходящий момент их произвести. Смотрите пример.
?- assert(a(1+1)). Yes ?- assert(b(2 * 2)). Yes ?- a(X), b(Y), Z is X + Y. X = 1+1 Y = 2*2 Z = 6
Внимание!
is не является присваиванием! Для того, чтобы убедиться в этом, исполните простейшее предложение языка PROLOG:
?- X is 1, X is X + 1.
Лучше всего и естественней всего вводятся в PROLOG-программу данные, полностью соответствующие синтаксису предложений и фактов языка. Если файл данных не очень велик, то для ввода достаточно воспользоваться уже описанным нами предикатом consult.
Конечно же, имеется и более традиционная система ввода-вывода. Опишем ее базовые возможности.
open(SrcDest, Mode, Stream, Options)
Открытие файла. SrcDes является атомом, содержащим имя файла в обозначениях системы Unix. Mode может быть read, write, append или update. Два последних способа открытия используются, соответственно, для дописывания в существующий файл и для частичного переписывания его. Stream либо переменная, и тогда ей присваивается целое число, которое служит для идентификации файла, либо атом, и тогда он служит внутри программы именем файла.
Options могут быть опущены, среди них нам важна одна опция: type(binary), которая позволяет записать коды в двоичный файл. Опции образуют список.
Конечно же, имеется возможность вручную установить текущую позицию внутри файла:
seek(Stream, Offset, Method, NewLocation)
Method — это метод отсчета относительной позиции. bof отсчитывает ее с начала файла, current от нынешней точки, eof от конца. Переменная NewLocation унифицируется с новой позицией, отсчитываемой обязательно с начала.
Предикат close(Stream) комментариев не требует.
read(Stream, Term)
Переменная Term унифицируется с термом, прочитанным из потока Stream.
read_clause(Stream, Term)
Читается предложение. По умолчанию пользователя предупреждают о переменных, которые отсутствуют в голове и лишь однажды присутствуют в хвосте.
read_term(Stream, Term, Options)
Аналогично read, но позволяет установить целый ряд возможностей, регулирующих представление терма. Смотрите подробнее в документации конкретной PROLOG-системы.
writeq(Stream, Term)
Term пишется в Stream, вставляются кавычки и скобки, где нужно.
write_canonical(Stream, Term)
Term пишется в Stream таким способом, чтобы его однозначно прочитала любая PROLOG-программа, а не только Вы и Ваша программа на Вашей системе.
Есть способ читать и писать символы, а через них строки и прочее, но это настолько примитивно и уродливо, что можно дать практический совет:
Внимание!
Если Вам нужно ввести в PROLOG файл иноязычного или просто обычного формата либо вывести из него в предписанном Вам не укладывающемся в систему термов формате, напишите переходник на Рефале или на Perl.
Тем не менее вот минимальный (и практически полный) список предикатов символьного и двоичного ввода и вывода.
get_byte(Stream, Byte)
Byte рассматривается как целое число и унифицируется со следующим байтом входного потока. Конец файла читается как -1.
get_char(Stream, Char)
Аналогично, но следующий байт рассматривается как имя атома, состоящее из одного символа. Конец файла унифицируется с атомом end_of_file.
Русские буквы, пробелы и прочие нестандартные символы могут вызвать неприятности.
get(Stream, Char)
Аналогично, но пропускаются невидимые символы.
skip(Stream, Char)
Пропускает все, пока не встретится символ Char либо конец файла. Само первое вхождение Char также будет пропущено.
put(Stream, Char)
Вывод одного символа либо байта. Char унифицируется либо как целое число из диапазона [0, 255], либо как атом с именем из одного символа.
nl(+Stream)
Вывести перевод строки.
|
|
|
В отличие от клауз, посылки логических формул ни в каком смысле не могут считаться последовательно достигаемыми.
2)
Внутри языка они называются атомами.
3)
В части реализаций эти ограничения могут распространяться и на функции, определенные программистом.
4)
Мысознательно отказались от сопоставления двух видов целей в PROLOG с конъюнкцией и дизъюнкцией, поскольку их семантика принципиально отличается от семантики этих логических связок.
5)
Более того, можно было бы унифицировать любые соответственные друг другу внутренние подвыражения в произвольном порядке, лишь бы объемлющие унифицировались после подчиненных. Автору неизвестно ни одно использование этого естественного и многообещающего обобщения алгоритма унификации.
В первой реализации языка PROLOG, основные особенности которой стали в дальнейшем фактическим стандартом, создатели допустили ошибку в понимании и, соответственно, в реализации алгоритма унификации, которая, к примеру, разрушает свойство частичного исполнения и может привести к излишней конкретизации, в то время как можно было бы найти более общую конкретизирующую подстановку. Эта ошибка несущественна, она не влияет на подавляющее большинство программ, но иногда она приводит к появлению бесконечных термов, и некоторые реализаторы языка PROLOG с гордостью пишут, что они умеют печатать и показывать на экране даже такие термы.
Желающие в качестве упражнения выловить ошибку самостоятельно, сравните алгоритмы унификации, описанные в книге [30] и [12].
6)
Здесь мы не оговорились: в данном случае предложения лучше трактовать как операторы, поскольку как утверждения их в данном случае рассматривать невозможно.
7)
Здесь мы употребили термин конкретизация, поскольку используются именно текущие значения переменных, согласования не происходит.
В любой момент исполнения программы
В любой момент исполнения программы база данных и база знаний могут быть модифицированы.
Теперь перейдем к конкретному представлению данных.
В конкретном синтаксисе переменные языка представлены именами, состоящими из букв и начинающимися с большой буквы либо с символа подчеркивания _. Переменная _ называется анонимной переменной и считается различной во всех своих вхождениях.
Константы языка PROLOG2) в конкретном синтаксисе делятся на имена (идентификаторы, начинающиеся с маленькой буквы либо совокупность нескольких специальных символов типа <, =, $), символы и числа (символы отождествляются с целыми числами, являющимися их кодами). Произвольная последовательность символов может быть сделана единой константой, например:
'C:\"SICS Prolog"\program.pl'.
Любое константное имя может служить функтором. Функторы различаются арностью (т. е. количеством аргументов), таким образом, может быть сразу несколько функторов с одним и тем же именем. Например, write(a(1)) и write(a(1),file1) используют различные функторы. Некоторые функции могут быть описаны как операции (инфиксные, префиксные либо постфиксные). В отличие от почти всех остальных языков, операции рассматриваются лишь как сокращение для выразительности. Например, x+y означает в точности то же, что и +(x,y).
Для некоторых из предопределенных в системе функций и предикатов имеются дополнительные ограничения на аргументы3). Например, в функции load(f) f должно быть именем файла.
Поле зрения (цель), содержащее непосредственно обрабатываемые программой данные, состоит из последовательности термов, разделенных либо запятыми (в этом случае они понимаются как "последовательно достигаемые подцели"), либо символами |, в этом случае подцели "альтернативны".Наиболее важным и классическим является случай последовательно достигаемых подцелей, через который определяется и семантика альтернативных подцелей4).
В конкретном представлении предложение, например,
grandfather(X,Z) :- parent(X,Y), father(Y,Z).
также рассматривается как терм, поскольку имена , (здесь символ запятой — имя операции) и :- рассматриваются как инфиксные операции, причем запятая связывает сильнее.
Как правило, предложения, относящиеся к одному и тому же предикату, группируются вместе, например:
parent(X,Y) :- mother(X,Y). parent(X,Y) :- father(X,Y).
Порядок предложений существенен.
База данных состоит из фактов. Факты могут выражаться в одном из двух видов. Во-первых, факт может рассматриваться как предложение, немедленно приводящее к успеху (успех— это стирание целей). Поэтому он может быть записан:
father(ivan,vasilij):-true.
Здесь мы встретились с одной из двух стандартных целей: true обозначает очевидную удачу, а fail — очевидную неудачу.
Во-вторых, специально для фактов имеется скоропись, означающая то же самое:
father(ivan,vasilij).
В принципе, все остальные структуры языка PROLOG выражаются через элементарные, определенные выше. Но некоторые из структур прагматически настолько важны, что получили отдельное оформление и более эффективную реализацию. Это, прежде всего, списки и строки. Список, в принципе, определяется как терм, построенный из других термов и пустого списка [] применением двухместного функтора .(head,tail). Выстроенная в стандартном порядке композиция
.(a,.(b,. . . , .(z,[]). . . ))
понимается как линейный список и обозначается [a,b,. . . ,z].
Для обозначения присоединения нескольких данных термов к началу списка имеется стандартная операция
[t,u|L].
Строки рассматриваются как линейные списки кодов символов и обозначаются последовательностью символов, взятой в двойные кавычки:
"Ну, получили то, что искали? Ответьте y или n."
Заслуживает упоминания механизм введения новых операций в язык PROLOG. Каждый пользователь может определить свои собственные унарные или бинарные операции или переопределить стандартные. Приведем в качестве примера описания некоторых стандартных операторов языка PROLOG:
:- op(1200,xfx, ':-'). :- op(1200,fx, [':-','?-']). :- op(1000,xfy, ','). :- op(700, xfx, [=,is,<,=<,==]). :- op(500, yfx, [+,-]). :- op(500, fx, [+,-,not]). :- op(400, yfx,[*,/,div]).
Первый аргумент в этих описаниях — приоритет операции. Он может быть от 1 до 1500. Второй аргумент — шаблон операции; x обозначает выражение с приоритетом, строго меньшим приоритета операции; y — выражение с приоритетом, который меньше или равен приоритету операции, f — положение самого символа операции относительно аргументов. Таким образом, шаблон yfx для операции - означает, что выражение X-Y-Z понимается как (X-Y)-Z, шаблон xfy для запятой означает, что t,u,r понимается как t,(u,r),шаблон xfx для :- означает невозможность использования нескольких таких операций подряд без дополнительных скобок. Операции с меньшими приоритетами связывают свои аргументы сильнее. Один и тот же атом может быть определен и как унарная, и как бинарная операция.
Пример описаний операций показывает, что даже локальное использование различения конкретно- и абстрактно-синтаксических представлений программы дает возможность получить большие преимущества. В PROLOG не пришлось отдельно заниматься семантикой операций, поскольку в абстрактном синтаксисе их нет. Автоматически устраняются многие тонкие вопросы, связанные, в частности, с возможностью PROLOG-программы преобразовывать саму себя (см. упр. 7).
Поле зрения, поле памяти и PROLOG-программа
Когда рассматривается исполнение программы в нетрадиционном языке (например, PROLOG-программы), то естественно воспринимать конкретную реализацию языка как новую машину нетрадиционной архитектуры с высокоуровневыми командами (в данном случае как PROLOG-машину).
Данные, используемые PROLOG-машиной, размещаются во всех частях поля памяти и имеют общую структуру.
Рассмотрим на уровне абстрактного синтаксиса структуру данных, обрабатываемых языком PROLOG. Все данные языка PROLOG являются термами. Термы построены из атомов при помощи функциональных символов. Атомами могут быть переменные и константы, в свою очередь, делящиеся на имена и числа. Функциональные символы являются именами и называются функторами. Среди функторов выделяются детерминативы, которые в реализации делятся на предикаты и встроенные функции (функции обычно используются внутри выражений, а предикаты являются основными единицами управления и обычно используются вне скобок как основной функциональный символ выражения). Детерминативы должны быть описаны в программе, а остальные функторы рассматриваются просто как структурные единицы и могут оставаться неописанными.
В поле памяти выделяется поле зрения, содержащее непосредственно обрабатываемые программой данные. Оно называется также целью и состоит из последовательности термов.
Поле памяти имеет скрытую (при использовании стандартных возможностей языка) часть, в которой прослеживается история выполнения программы с тем, чтобы в случае необходимости произвести обработку неудачи.
И, наконец, в поле памяти помещается сама PROLOG-программа, которая естественно структурируется на две части, нередко перемешанные в тексте самой программы, но обычно разделяемые при использовании внешней памяти: база данных и база знаний.
База данных состоит из фактов, представляющих собой предикат, примененный к термам.
База знаний состоит из предложений (клауз). Каждое предложение имеет вид, подобный хорновской формуле
grandfather(X,Z) :- parent(X,Y), father(Y,Z).
Предложение состоит из головного выражения (соответствующего заключению хорновской формулы) и его раскрытия: нескольких выражений, соединенных как последовательно достигаемые подцели (они соответствуют посылкам хорновской формулы)1).
Пример greater(X,Y):-greater1(X,Y).
| greater(X,Y):-greater1(X,Y). greater(X,Y):-greater1(Z,Y),greater(X,Z). greater1(X,f(X)). estimation(X,Y):-greater(X,Y),known(Y). known(f(f(f(f(a))))). unknown(a). unknown(b). |
| Пример 6.3.1. |
| Закрыть окно |
Управление исполнением программы
Джулией Робинсон доказано (см., напр. [30]), что для выражений первого порядка имеется эффективный алгоритм унификации, находящий для двух выражений унифицирующую подстановку либо обосновывающий, что такой подстановки нет.
Пример 6.3.1. Две последовательности выражений
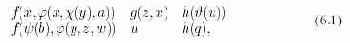
где a, b — константы, а латинские буквы из конца алфавита — переменные, унифицируются в
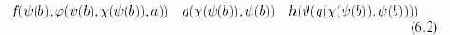
подстановкой
А в двух последовательностях
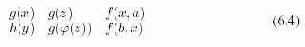
никакие два соответственных выражения унифицированы быть не могут.
Уже в приведенном примере видно, что унификация — глобальная операция.
Заметим, что логический алгоритм унификации обладает свойством частичного исполнения: если унифицировать две подструктуры, то после исполнения унифицирующей подстановки можно продолжить унификацию остальных подструктур, и результат унификации не изменится. Так что выражения могут унифицироваться одно за другим5).
Рассмотрим, как исполняется программа на языке PROLOG. В программе может быть одно целевое предложение, не имеющее головной части. Оно начинается с функтора :- или ?-. В программе, транслируемой и исполняемой в пакетном режиме, обычно используется первый функтор, а при задании цели с терминала в режиме диалога—второй. Разница между ними проявляется лишь в режиме диалога. Второй вариант цели позволяет пользователю после нахождения одного из решений продолжить выполнение программы для поиска следующего решения. Первый такой возможности ему не представляет, программа находит какое-нибудь решение и останавливается.
Исходная цель называется запросом. Переменные, входящие в запрос, носят особый статус. Их значения в ходе последовательных унификаций накапливаются в скрытой части поля памяти программы и при успешном исполнении выдаются в качестве ответа на запрос.
В каждый момент рассматривается первый из термов цели. Если его детерминатив не является встроенной функцией или встроенным оператором с особым определением, то ищется предложение, голова которого унифицируется с этим термом. При этом прежде всего проверяется наличие предложений, детерминатив которых совпадает с детерминативом первого терма.
Если таких предложений несколько, то создается точка возврата, в которой запоминается состояние программы для отработки возможных неудач.
Предложения испытываются, начиная с первого. Полученная унифицирующая подстановка применяется ко всем термам в поле зрения и к хвосту успешно унифицированного предложения. После этого хвост заменяет унифицированную голову, и выполнение возобновляется. Исполнение считается успешным, если на некотором шаге цель исчезает. Исполнение считается неудачным, если в некоторый момент для первого из термов не найдется унифицируемого с ним предложения.
Заметим, что переменные предыдущих унификаций отождествляются с переменными следующих унификаций лишь в том случае, если эти переменные дожили в поле зрения до соответствующей унификации. Если переменная уже получила постоянное значение либо значение, в котором она не встречается, то в последующем переменные с тем же именем трактуются как новые. Таким образом, конкретные имена переменных имеют значение лишь внутри одного предложения.
Если исполнение оказалось неудачным, то программа возвращается к последней из точек возврата (происходит откат) и испытывается следующее по порядку предложение с тем же детерминативом. Если таких предложений больше не осталось, то происходит откат к следующей точке возврата, и так далее. Если исполнение откатилось до запроса и больше кандидатов на унификацию не осталось, программа заканчивается общей неудачей.
Стандартным ответом программы на запрос служит Yes, если программа закончилась удачно, и No, если она закончилась неудачно. При удаче выводятся значения всех переменных исходного запроса.
Так, например, если программа и ее база данных имеют вид
greater(X,Y):-greater1(X,Y). greater(X,Y):-greater1(Z,Y),greater(X,Z). greater1(X,f(X)). estimation(X,Y):-greater(X,Y),known(Y). known(f(f(f(f(a))))). unknown(a). unknown(b).
Пример 6.3.1.
то ответом на запрос
?-unknown(Y),estimation(Y,X).
будет
Y=a X=(f(f(f(f(a)))) Yes
а при попытке ответа на запрос
?-estimation(b,X).
программа зациклится.
Насколько каверзны вроде бы невинные предположения (например, условие, что подцели достигаются строго одна за другой и варианты перебираются в том же порядке), сделанные в языке PROLOG, видно из того, что при логически эквивалентной переформулировке одного из предложений программы
estimation(X,Y):-known(Y),greater(X,Y).
программа успешно ответит на второй запрос
No
Еще более впечатляющий пример рассмотрен в упражнении 5.
Есть еще одна особенность языка PROLOG, которая кажется явным ляпсусом, но на самом деле является отражением результата Косовского и др. (неизвестного реализаторам и пользователям языка PROLOG, но лучшими из них ощущаемого интуитивно) о несовместимости моделей отождествления PROLOG и Рефала. Вся работа системы PROLOG основана на предположении, что значения унифицируемых переменных набираются однозначно, и следующий вариант может получиться лишь в результате унификации с другим фактом либо предложением. Поэтому когда (как в случае со списками или строками) PROLOG встречается с неоднозначным отождествлением, он никогда не будет перебирать разные его варианты. Он либо выберет первый из них (например, при унификации неизвестных [X|Y] с уже известным списком Z X будет пустым списком), либо зациклится на бесконечном повторении одного и того же варианта (смотри предыдущую скобку, которая иллюстрирует сразу две неприятности: если к такой унификации вернутся, будет выбран 'новый' пустой список в качестве X).
Для того, чтобы вычислить выражение, имеется предопределенная бинарная операция is. Она должна иметь вторым аргументом выражение, составленное из атомов при помощи функций. После применения X is 1+2 вместо X подставится 3. Даже выражение 1+2 остается в таком же виде, пока оно не попадет во второй аргумент is.
Внимание!
То, что некоторый функтор определен как операция, не значит, что он вычисляется. Это просто изменение конкретно-синтаксического представления. Для того чтобы иметь возможность вычислить выражение, нужно определить функтор как внутреннюю или внешнюю функцию.
При этом необязательно делать его операцией.
Рассмотренные до сих пор средства языка PROLOG не дают возможности сформулировать отрицание. Впрочем, отрицание и не может присутствовать в хорновых формулах, его наличие разрушает свойства, которые послужили основой для модели вычислений языка PROLOG. Но на практике оно нужно, и поэтому в языке PROLOG введен его суррогат. Этот суррогат дает возможность программисту минимально управлять точками возврата. Если в цели встал на первое место атом ! (называемый предикатом отсечения), то он успешно унифицируется и уничтожает последнюю точку возврата. Предикат ! используется прежде всего для определения отрицания как явного неуспеха подцели.
Пример 6.3.2. Рассмотрим, как с помощью ! и списков программируется поиск пути в лабиринте (и даже в произвольном ориентированном графе).
way(X,X,[X]). way(X,Y,[Y|Z]):-connect(U,Y), nomember(Y,Z),way(X,U,Z). way(X,Y,[Y|Z]):-connect(U,Y), way(X,U,Z). nomember(Y,Z):-member(Y,Z),!,fail. nomember(Y,Z). connect(begin,1). connect(1,begin). connect(1,2). connect(2,3). connect(3,1). connect(3,4). connect(4,end).
Листинг 6.3.2. Статический лабиринт
В ответ на запрос
?-way(begin,end,X).
программа выдаст
X = [end, 4, 3, 2, 1, begin] Yes
Вместо определения nomember можно написать предложение
way(X,Y,[Y|Z]):-connect(U,Y),not (member(Y,Z)),way(X,U,Z).
Предикат отсечения можно использовать для того, чтобы превратить PROLOG-программу в программу с традиционным управлением, оставив из специфики языка лишь операцию унификации. На практике и при обучении часто бывают случаи, когда кому-нибудь никак не удается совладать с PROLOG и отладить свою программу, поскольку он зациклен на императивном стиле программирования. Узнав о !, он облегченно вздыхает и переписывает свою программу таким образом, что она становится изоморфной программе в обычном языке программирования. Как правило, при такой трансформации теряются главные преимущества языка PROLOG, но зато сохраняются все его недостатки.
Внимание!
Некоторые из русскоязычных учебных пособий по языку PROLOG написаны людьми, не понимающими сути других стилей программирования. Видимым признаком такого пособия может служить постоянное использование отсечений.
Прагматические соглашения о порядке выполнения действий в программе привели к тому, что если мы запишем в форме языка PROLOG тривиальную тавтологию
A:-A.
и этот оператор6) выполнится, то программа зациклится. И по этой причине, и по причине ошибки в унификации предложения языка PROLOG, сохранив внешнюю форму логических, по существу отношения к логике уже не имеют.
Конечно же, несообразности были использованы и для получения новых эффектов. Рассмотрим следующее определение.
repeat. repeat:-repeat.
Если вставить теперь цель repeat в раскрытие другой цели и позаботиться о том, чтобы последующие подцели в большинстве случаев заканчивались неудачей, а после удачи поставить !, то эти подцели будут повторяться вплоть до удачи и их побочные эффекты будут исполняться в цикле.
Приведенное выше определение repeat писать в программах не нужно. В стандарте PROLOG задан встроенный предикат repeat, потенциально бесконечное число раз успешно унифицируемый. Реализованный в языке PROLOG перебор вариантов при всех своих недостатках довольно удачно моделирует недетерминированные алгоритмы в программе.
Недетерминированную модель вычислений, соответствующую PROLOG, можно определить в общем виде следующим образом:
е. ни одно из выбранных продолжений не является тупиком).
Недетерминированным достижением цели называется успешное вычисление. Таким образом, если какая-то из последовательностей продолжений приводит к цели, то цель процесса считается достигнутой. Недетерминированная модель вычислений может применяться и как средство декомпозиции решаемой задачи, когда программист просто откладывает 'на потом' вопрос, как будет организован перебор вариантов.
Есть теорема, доказывающая, что в принципе недетерминированный конечный автомат всегда можно преобразовать в детерминированный. Идея преобразования — склейка состояний, как показано на рис. 6.1. При этом, содержательно говоря, мы создаем линейный порядок на множестве альтернатив и выбираем альтернативы в строгом соответствии с этим порядком. Именно так с самого начала поступили в языке PROLOG. Беды в этом нет. В то время, когда создавался язык PROLOG, идея совместности (т. е. безразличия некоторых последовательностей предложений к порядку их исполнения) и недетерминированности (т. е. ситуации, когда один и тот же оператор в одном и том же контексте может давать разные результаты) как положительного фактора была только что осознана. А те, кто делают что-либо принципиально новое, почти всегда забывают согласовать свою находку с другими принципиальными достижениями того же времени, предпочитая локализовать новизну и в остальных пунктах работать как можно более традиционно. Беды начались, когда особенности конкретного упорядочивания стали беспощадно использоваться в хакерском духе, да еще и выставляться как принципиальные новации.
Рис. 6.1. Преобразование недетерминированного поиска в детерминированный
Теорема детерминирования конечного автомата обосновывает существование успешного вычисления. Но она не дает никаких хороших оценок изменения сложности вычислений при переходе к детерминированному поиску. И даже если успешное вычисление существует, это не означает, что трансформировать ассоциированные с переходами действия легко и что после трансформации они будут хоть сколько-нибудь понимаемы.По этой причине часто обработку удобнее описывать как недетерминированную, поручая решение задачи организации перебора вариантов системе программирования.
Развитие языка Prolog
Британско-канадская группа, создававшая Prolog, первоначально ориентировалась на задачи математической лингвистики, где сложные преобразования данных сопряжены с проверкой гипотез.
Это естественно навело их на ортогональный Рефалу подход1), формально мотивированный математической логикой. Наличие именно формальной мотивировки оказало медвежью услугу языку Prolog и всему направлению. Его сущность оказалась замаскирована примитивным методологически-теоретическим анализом и неадекватным названием: логическое программирование.
Prolog вдохновлялся ограничением классического исчисления предикатов, предложенным Хорном. Как известно (см., например, книгу [20]), в классической логике в любой достаточно богатой теории появляются чистые теоремы существования, когда из доказательства невозможно выделить построение требуемого объекта. Если ограничиться конъюнкциями импликаций вида
 x1, . . . , xn
x1, . . . , xn y1, . . . , yk . . . (A1&· · ·&An
y1, . . . , yk . . . (A1&· · ·&An  B),
B),где каждая составляющая является элементарной формулой и само доказанное утверждение имеет такой же вид, то получить построение из доказательства возможно, поскольку у нас не остается даже косвенных способов сформулировать и нетривиально использовать что-либо похожее на A
 ¬A. Такие формулы называются хорновыми.
¬A. Такие формулы называются хорновыми.От лишних кванторов можно избавиться при помощи сколемизации, когда кванторы существования заменяются на функцию, аргументами которой являются все переменные, связанные ранее стоящими кванторами всеобщности2). Таким образом, мы приходим к простейшему виду хорновых формул (хорновы импликации):
x1, . . . , xn (A1&· · ·&An B).Применив к последней формуле преобразование, выполненное лишь в классической логике, мы приходим к хорновым дизъюнктам:
x1, . . . , xn (¬A1 · · · ¬An B).Именно от последней формы представления хорновых утверждений получила имя основная структура данных языка Prolog. Но тот факт, что импликация преобразована в дизъюнкцию, на самом деле нигде в этом языке не используется, он послужил лишь для установления взаимосвязей с алгоритмом метода резолюций [30], который в тот момент был последним криком моды в автоматическом доказательстве теорем (и действительно громадным концептуальным продвижением).
Метод резолюций до сих пор остается одним из нескольких наиболее часто применяемых методов автоматического доказательства, и единственным, известным широкой публике. Этот метод поставил три идеи (унификация, стандартизация цели, стандартизация порядка вывода), красивой программистской реализацией которых явился Prolog. Но находки языка Prolog не исчерпываются реализацией идей, взятых из теории. Они внесли существенный вклад в теорию и методологию программирования3).
Именно на примере языка Prolog западное программистское сообщество четко осознало, что могут быть совсем другие модели исполнения программы, не являющиеся ни традиционными, ни их расширением. Был реабилитирован и стал порою успешно использоваться метод динамического порождения программы. Стала актуальной идея косвенного управления вычислениями. Этих достоинств с лихвой хватит для того, чтобы Prolog мог считаться важным принципиальным достижением.
Развитию языка Prolog мешает, прежде всего, слишком большая привязка к конкретной модели вычислений, которая в погоне за мнимой эффективностью была зафиксирована слишком рано. Совершенно извращено понимание его места и роли. На самом деле Prolog представляет собой великолепную заготовку для языка моделирования идей, а никакое не логическое программирование.
Рассмотрим, что именно этой заготовке мешает в реальности стать таким языком. Как мы уже неоднократно видели, главное препятствие — потеря целостности, вызванная лишними возможностями. В первую очередь, это эклектичные добавки операционных средств, которые провоцируют программиста к операционному мышлению и хакерскому стилю. Так, в задаче о лабиринте было бы естественно не зацикливание исполнения, когда не предусмотрены ограничивающие условия, заставляющие программу продвигаться вперед, а указание того, что в процессе выполнения не хватает условий, что возможны определенные варианты ограничений, делающие программу корректной. В результате разработчикам языка пришлось искать дополнительные средства выражения требуемых, а не предлагаемых, действий.
Ничего лучшего по сравнению с известными операционными методами они не нашли и включили соответствующие средства в язык, полностью потеряв первоначальную концепцию.
Одним из классических примеров применения первоуровневых моделей и плоских, неадекватных практике, но привлекательно звучащих и просто объясняемых, выводов, которые делаются на их основе, является утверждение: "Логика Хорна достаточна для спецификации вычислений, поскольку, как было доказано, она эквивалентна машине Тьюринга4)". С этим утверждением можно было бы согласиться, если бы решения реальных задач, которые апеллируют к базам данных-фактов и должны решаться с использованием баз знаний-утверждений, являющихся следствиями из имеющихся фактов, всегда можно было бы формулировать в такой разделенной манере: сначала задаются факты, затем предложения-соотношения и далее идет манипулирование информацией. На самом деле таким образом формулируемые решения пригодны только для узкого класса задач, которые характеризуются стабильностью фактов, и только в том случае, когда не принимается в расчет эффективность.
Развитие языка Рефал и его диалекты
Язык Рефал был создан В. Ф. Турчиным для аналитических вычислений в физике. Первоначально Турчин продумал саму идею конкретизации и представил ее в виде языка, демонстративно записанного в не слишком прямо представимой форме. Например, не было понятия детерминатива, предложения имели вид, подобный
§1.1.2 E1 + (E2 * E3)= (K E1 + E2 .)* (K E1 + E3 .)
Конкретно-синтаксическая форма языка, данная в теоретической работе Турчина (см., напр. [27]) сразу же была изменена для удобства представления и работы5). Уже при первой реализации был продуман и проверен приведенный выше алгоритм отождествления, были выброшены иерархические комментарии в начале предложений, а вместо них появились понятия детерминатива и функции.
Дальнейшая доработка потребовала процедур ввода-вывода и механизма хранения глобальных данных, что было реализовано через стеки закопанных данных. Получившийся язык Рефал-2 длительное время был практическим стандартом Рефал-систем.
В языке Рефал-4 были сделаны две попытки расширения языка. Во-первых, как и во множестве других систем, к Рефалу были достаточно механически добавлены нарождавшиеся модные объектно-ориентированные средства. Эта попытка быстро зашла в тупик и была оставлена. Во-вторых, были определены метаоперации. Это нововведение доказало свою жизнеспособность и выжило. В языке Рефал-5 [38], который сейчас является фактическим стандартом6), объекты были отброшены, зато последовательно была проведена как стандартная надстройка над языком идея метакодирования. В нем получили свое окончательное оформление вложенные процедуры и дополнительные условия.
Из других существующих версий языка стоит отметить Рефал-6 и Рефал+ [10], которые развивают одну и ту же линию. В реализации Рефал+ отошли от представления, принятого в [25], с тем чтобы воспользоваться современными алгоритмами сборки мусора. Вместо стеков закопанных значений в этих языках предлагаются объекты, которые имеют лишь одно значение. В частности, такие объекты используются для описания графического ввода и вывода, что полностью игнорируется в стандартном Рефале.
В этих версиях позволяется объявить функцию откатной и пытаться при невозможности отождествлений обработать неудачу. Но автор этих версий проигнорировал концептуальную несовместимость неудач с общей структурой управления в языке Рефал. Из находок Рефал+, помимо новой структуры данных, стоит отметить концепцию упорядочения возможных отождествлений и возможность до некоторой степени управлять этим упорядочением (правда, в языке предусмотрен лишь переход от прямого порядка к его обращению, но уже это дает в некоторых случаях большой выигрыш в выразительности).
Наиболее заметным недостатком новых версий языка Рефал7) явилось отсутствие различения абстрактного и конкретного синтаксиса. Можно было бы просто отказаться от фиксации оформления в определении языка и дать возможность определять синтаксические расширения и представления самим разработчикам.
Стоит заметить, что нынешний язык Рефал находится в мягком концептуальном противоречии со столь блестяще реализованной в нем же идеей динамического вычисления программ. Решение исполнять ту функциональную скобку, внутри которой нет других таких скобок, было оправдано и логично при создании Рефала, а теперь оно уже мешает эффективно использовать аппарат метапреобразований. Необходимо заметить, что Рефал созрел для настоящего представления мультииерархической структуры, что позволит языку выйти на новые классы приложений. Таким образом, в ближайшее время можно ожидать появления нового сентенциального языка, реализующего идею конкретизации. Будет просто беда, если под красивой оберткой кто-нибудь подсунет в эту область концептуально непродуманное 'прагматическое' решение. Выигрыш от прагматизма будет минимальным, временным и локальным, а потери — длительными, на порядок превосходящими аналогичные для традиционных языков, и к тому же глобальными.
Именно в языке Рефал было четко показано, как выбирать структуры данных и алгоритм работы абстрактной машины для нетрадиционных вычислений и насколько это важно. В нем впервые избавились от жесткой привязки к конкретному синтаксису.Он продемонстрировал советскому программистcкому сообществу возможность альтернативных моделей вычислений, выполнив на востоке ту же роль, что Prolog на западе. В нем впервые была реализована концепция встроенных частичных вычислений программ. Он не поддался давлению моды, и этим способствовал осознанию наличия альтернатив даже в том случае, когда подходы в принципе близки. Всего этого достаточно для признания пионерской роли этого языка.
Сравнение версий сентенциального программирования
Прежде всего, методы управления языка Prolog и языка Рефал принципиально отличаются. В Prolog'е неудача глобальна, но исправима, а в Рефале — локальна, но фатальна.
Унификация в Prolog и конкретизация в Рефале являются операциями примерно одного и того же уровня общности. Но направления унификации и конкретизации ортогональны.
Внимание!
Модели унификации и конкретизации формально несовместимы, поскольку, соединив их, мы получаем алгоритмически неразрешимое понятие отождествления (Н. К. Косовский и др., 1990).
Это — глубочайший теоретический результат и одно из редких прямых предупреждений, сделанных теорией практике8). Поэтому при сходстве многих идей, положенных в их основу, эти модели развиваются и должны дальше развиваться независимо (что не исключает творческого заимствования идей из одной ипостаси подхода в другую). Обратите внимание, что мы столкнулись с той же самой ситуацией, которая имеет место для циклической и рекурсивной ипостасей структурного программирования.
Точно так же, как циклическая ипостась структурного программирования, Рефал приспособлен для работы с данными, развернутыми в основном вширь и для развертывания процесса в ширину. Точно так же, как рекурсивная ипостась, Prolog приспособлен для развертывания процесса в глубину и для работы с данными, имеющими ограниченную ширину, но зато большую глубину.
Даже машинная реализация этих языков сродни двум ипостасям структурного программирования. В Рефале вызовы, которые выглядят как рекурсивные, на самом деле рекурсией не являются9), поскольку мы заканчиваем породивший вызов, и лишь после этого переходим к отработке порожденных. Prolog больше похож на рекурсию, поскольку после вызова внутреннего предиката мы можем возвратиться к внешнему и продолжить попытки его унификации. В Рефале достаточно общего поля памяти, а в Prolog вынуждены запоминать также управляющие данные ( точки возврата10)).
Стоит заметить, что сентенциальное программирование, и особенно его разновидность, базирующаяся на модели отождествления-замены, великолепно сочетается с идеей ассоциативной памяти (см. стр. 31), и здесь возможен прорыв одновременно на аппаратном и программном уровнях.
Вариант сентенциального программирования, базирующийся на возвратах и унификации, отлично сочетается с идеей машины потоков данных. Японцы попытались использовать его в своем проекте ЭВМ пятого поколения. Провал данного проекта надолго дискредитировал направление соединения сентенциального программирования с потоками данных, но к нему придется вернуться в будущем на другой технической и, видимо, на гораздо более концептуально выверенной программистской основе.
Концепция унификации и возвратов после неудач исключительно хорошо подходит для выражения
-параллелизма (см. § 15.2). Более того, уже имеются системы (в частности, Muse), реализующие этот вариант параллелизма в языке Prolog.Рефал, в свою очередь, великолепно подходит для &-параллелизма. Подстановки значений переменных в результирующее выражение можно осуществлять независимо друг от друга.
Более того, в принципе можно было бы даже в нынешнем варианте Рефала вычислять различные функциональные скобки в параллель, помешать этому могут лишь значения, передаваемые через аппарат закапывания-выкапывания. Но это — стандартная проблема синхронизации для параллельных вычислений, с которой можно справляться хорошо разработанными средствами, тем более что аппарат для соответствующей разметки программы еще в ходе ее составления концептуально подготовлен в языке.
Таким образом, две ветви сентенциального программирования ориентированы даже на разные классы параллельных вычислений. Именно на примере сентенциального программирования нами был сделан вывод о том, что и для других стилей должны быть альтернативные реализации. Их выявлению мешал прежде всего закон экологической ниши.
При создании и развитии языков PROLOG и Рефал ярко проявились сильные и слабые стороны русской и англо-американской школ науки.
В. Ф. Турчин проделал адекватный анализ, не устаревший за 40 лет, но он не стремился к общепонятности и слишком большой популяризации (может быть, потому, что ему не нужно было выбивать гранты). Его последователи четко восприняли идею и развивали ее, практически полностью избегая концептуально противоречащих ей возможностей. Но популяризация языка и внешняя сторона работы с ним (удобные системы, интерфейсы и т. п.) оказались практически полностью проигнорированными, и поэтому язык остается достоянием узкой группы приверженцев11).
Создатели Prolog с самого начала в значительной мере использовали теорию и методологию как заклинания либо молитвы, не имеющие отношения к сути дела и произносимые для его освящения. Тем самым теоретическая база сразу же оказалась неадекватной, что и привело к быстрому расползанию системы и потере концептуального единства. Язык в значительно большей мере, чем Рефал, оказался загрязнен чужеродными элементами12).
Неадекватность теории практике помешала осознанию реальных достижений подхода, основанного на унификации, поскольку они часто противоречили мифам и саморекламе.
Зато развитие внешнего оформления и удобных ( с точки зрения дизайна) средств работы с языком шло адекватными темпами, а реклама его действительных и мнимых достижений далеко опережающими. Язык вошел в практику обучения многих университетов мира и попал даже в стандарты программ обучения специалистов IFAC.
Если говорить о практических задачах, то Prolog значительно лучше подходит для поиска, а Рефал — для синтаксических преобразований. Стоит также помнить, что в нынешнем состоянии Prolog не может служить даже для прототипирования, это язык лишь для моделирования решений и логики поведения программы.Но это — особенность нынешних конкретных реализаций идеи унификации и возвратов, она связана с тем, что примитивный концептуальный механизм пришел в противоречие с выявившимися богатейшими потенциальными возможностями подхода.
Рефал делает символьные преобразования столь же эффективно, как и программа на традиционном языке, и поэтому может быть использован на всех уровнях: и для создания прототипа программы, и для написания надпрограммы, и для написания подпрограммы.
Таким образом, Рефал по эффективности и ясности представления уже сейчас может служить языком прототипирования, и, если бы его снабдить удовлетворительными интерфейсами, вполне мог бы служить и для окончательных решений, работающих в многоязыковой среде. В момент написания книги существует единственный имеющийся надежно работающий интерфейс Рефала: с языком PHP преобразования HTML-текстов.
В особенности Рефал хорош в тех случаях, когда нужно произвести нетривиальное преобразование символьных входных либо выходных файлов. Его использование, как показала практика автора и студентов в многоязыковом программировании, зачастую оправдывается даже тогда, когда ведется передача данных через файл.
У Prolog ныне интерфейсы имеются, но они, как правило, ориентированы лишь на C++ и LISP13) и совершенно не стандартизованы. Каждая реализация имеет свой интерфейс.
Мы затронули общий недостаток нынешних систем сентенциального программирования.
Это — плохая проработка связей с другими языками. При создании средств высших уровней необходимо с самого начала продумать вопросы связи с другими языками и использования языка в многоязыковой и многостилевой методологии программирования.
|
|
|
Они не имели никаких сведений о Рефале и работали совершенно независимо. Просто потребность сентенциального программирования назрела. К счастью для информатики, обе группы инициаторов не были осведомлены о работах друг друга, иначе, скорее всего, одна из двух ортогональных концепций осталась бы неразвитой. Это подтверждает история других стилей: тот, кто первым добился успеха, захватывает экологическую нишу и видоизменяет условия в ней таким образом, чтобы ничто другое не могло в ней выжить (причем часто нет никакого злого умысла, просто работают законы развития науки и вообще эволюционирующих систем).
2)
Как именно это делается, сейчас неважно.
3)
Одновременно данное направление нанесло и существенный вред этой теории и методологии, который был бы еще глубже, если бы у Prolog'а с самого начала не было бы друга-соперника Рефала.
4)
Слишком прямое применение теории, особенно когда получается привлекательное на вид следствие — бич современной науки. Именно оно приводит к тому, что многие серьезные практики попросту игнорируют теорию, из-за этого делают другие, не менее глупые и вредные, и не менее привлекательные на вид, ошибки. Пример такой глобальной ошибки — С++, лишь обостривший все проблемы традиционного программирования. Он создавался практиками, по их же собственному признанию, принципиально игнорировавшими теории.
5)
Если человек не привязан к конкретным словам, то обычно это доказывает, что он ясно осознал идеи, которые отстаивает.
6)
Внимание! В самых последних реализациях, называемых PZ SciTE, язык без огласки чуть-чуть пересмотрен, и отражено это лишь в файлах news.txt.
7)
Подавляющее большинство систем программирования имеют этот недостаток, но в данном случае он ощущается наиболее остро.
8)
Даже прямые предупреждения, как правило, игнорируются практиками, многие из которых не понимают самого понятия алгоритмической неразрешимости; в качестве примера можно взять безвременно скончавшийся Рефал-6.
9)
Примером того, насколько многие привыкли судить о явлениях по внешнему виду, а не по сущности, является кочующее из книги в книгу утверждение о том, что Рефал — язык функционального рекурсивного программирования.
10)
После этой аналогии становится более ясно, почему программисты трактуют использование отсечения ! в языке PROLOG как хакерство. Представьте себе, что было бы, если бы Вам в C++ предоставили явный доступ к отложенным из-за рекурсии вызовам процедур и разрешили по своему произволу их убирать!
11)
Сами представители Рефал-сообщества объясняли свою позицию относительно интерфейсов примерно следующим образом.
— Чайники и ламеры все равно Рефалом не пользуются, а квалифицированный человек сам легко напишет переходник, тем более, что код системы открыт.
Автор в свое время вынужден был писать переходник между Рефалом-2 и Алголом 68, но, конечно же, такое решение и приведенная выше аргументация неудовлетворительны.
12)
История отказа от введения объектов в Рефал является практически исключительным в мире современной информатики примером понимания вреда концептуальных противоречий. В конце концов, разум должен стоять выше моды!
13)
Некоторые коммерческие системы Prolog имеют интерфейсы еще и с Java.
Модель вычислений LISP
Для LISP (как и для любого другого функционального языка) не обязательно2) говорить, где и как размещаются структуры данных (списки).
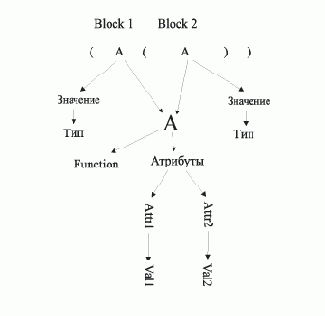
Рис. 8.1. Структура информации, сопоставленной атому языка LISP
Их стоит рассматривать как сугубо математические объекты со сложной структурой, которая всегда точно указывает на текущие вычислительные элементы:
Общую структуру данных и программы функционального языка можно рассматривать как связный нагруженный граф, динамически изменяющийся в ходе вычислений, у которого имеются активные вершины, т. е. функции, вычисляемые в данный момент, потенциально активные вершины, соответствующие функциям, которым назначено вычисление или продолжение вычисления (отложенного, приостановленного и т. п.), и пассивные вершины, участие которых в вычислениях в данный момент не запланировано. Дуги графа отмечают связи по управлению или по данным между функциями. Такой граф далее называется абстрактным графом функциональных вычислений.
Конкретизировать такой граф и стратегию отработки активных вершин можно разными способами.
При этом могут появляться разные ипостаси функционального программирования.
Для абстрактного вычислителя граф функциональных зависимостей естественно считать полем памяти функциональной программы, в котором выделено поле зрения: активные (либо активные и потенциально активные) вершины-функции со своими аргументами.
В практике реализации функциональных систем программирования имеется три варианта конкретизации представления графа:
Коммутационные и ассоциативные схемы рассмотрены при обсуждении неимперативных моделей вычислений (см. § 1.2 и 3.1). Выбор последовательно просматриваемой структуры для первого функционального языка обусловлен единственной для того времени возможностью реализации функциональности путем моделирования ее операционными средствами традиционной модели вычислений. Списочная структура также строится посредством более или менее стандартного для традиционной модели адресного представления. С языковой точки зрения именно этот выбор обеспечивает однородность структуры программы и данных, на базе которой Дж. Маккарти удалось построить систему средств, достаточную для практического функционального программирования.
Программа на языке LISP задается как список применений функций, часть из которых может вычисляться во время исполнения самой программы.
Как правило, заданные в программе списки интерпретируются как применения функций и вычисляются, если другое не определяют ранее активированные функции (вы видели, что функция quote запрещает вычисление своего аргумента, функция setq запрещает вычисление лишь первого из двух аргументов, а функция setf заставляет вычислить первый аргумент лишь до стадии, когда получена ссылка на его значение). Любое выражение выдает значение, что используется, в частности, при диалоговой работе с LISP (на примере которой иллюстрируются понятия).
Основные управляющие функции концептуально едины и позволяют динамически строить блочную структуру программы. В частности, функция
(block name e1 . . . en) (8.1)
вычисляет свои аргументы, начиная со второго, один за другим, тем самым задавая последовательность команд. Первый ее аргумент, name, служит именем блока. В любой момент из любого объемлющего блока можно выйти и выдать значение с помощью функции
(return-from name value) (8.2)
Этим LISP выгодно отличается от большинства языков, где такие структурные переходы либо неполны, либо некорректно реализованы.
Далее, блоком считается любое описание функции. Описание функции производится при помощи функции defun, которая, в свою очередь, определяется через примитивы function и lambda. Первый из них задает, что имя, являющееся его аргументом, рассматривается как функция (он часто сокращается в конкретном синтаксисе до #’), второй образует значение функционального типа. Имя функции является и именем функционального блока.
Пример 8.4.1. В данном примере иллюстрируются определение факториала, вызов анонимной функции и возможность вычисления произвольного функционального выражения, созданного в программе.
[1]> (defun fact (n) (if (= n 0) 1 (* (fact (- n 1)) n))) FACT [2]> (fact 40) 815915283247897734345611269596115894272000000000 [3]> ((lambda (x) (fact (* x x))) 5) 15511210043330985984000000 [4]> (setq g ’(lambda (x) (fact (* x x)))) (LAMBDA (X) (FACT (* X X))) [5]> (eval (list g 3)) 362880
Нужно заметить, что определение функции с данным именем и значение имени могут задаваться независимо. Например, мы можем в этом же контексте задать (setq fact 7), хотя, конечно же, это отвратительный способ программирования.
Все формальные параметры функций являются локальными переменными. Никакие изменения их значений не выходят наружу. Но все другие свойства остаются глобальными! Приведем пример.
[23]> (defun f (x) (progn (setf (get ’x ’weight) ’(25 kg)) (+ x 3))) F [24]> (setf (get ’x ’weight) ’(30 kg)) (30 KG) [25]> (get ’x ’weight) (30 KG) [26]> (setq x 5) 5 [27]> (f 3) 6 [28]> x 5 [29]> (get ’x ’weight) (25 KG)
В LISP имеется возможность создать анонимный блок со своими локальными переменными, не объявляя его функцией. Создание такого блока называется связыванием переменных и производится функцией let.
Значение имени, унаследованного извне, все равно будет внешним! Смотрите пример ниже.
[32]>(setq a ’(b c d)) (B C D) [33]>(setq b 5) 5 [34]> (list (let ((b 6)) (eval (car a))) (eval (car a))) (5 5) [35]> (list (let ((b 6)) b) (eval (car a))) (6 5) [36]> (list (let ((b 6)) (list b a)) (eval (car a))) ((6 (B C D)) 5) [37]> (list (let ((b 6)) (eval (car (list ’b a)))) (eval (car a))) (5 5)
Важнейшей особенностью функционального программирования как стиля, впервые использованной в языке LISP, являются функционалы с аргументами-функциями. Рассмотрим пример возведения всех членов кортежа в квадрат.
[57]> (setq a (list 1 5 7 9 11 13 15 19 22 28)) (1 5 7 9 11 13 15 19 22 28) [58]> (mapcar (function (lambda (x) (* x x))) a) (1 25 49 81 121 169 225 361 484 784)
Функционал mapcar применяет свой первый аргумент ко всем членам второго.
Такие функционалы, в частности, делают циклы практически ненужными. Тем не менее в языке LISP есть конструкции циклов как дань программистской традиции. Чужеродность циклов подчеркивается тем, что они всегда выдают значение NIL.
И, наконец, приведем пример3).
Пример 8.4.2. Данная программа строит автомат для нахождения всех вхождений некоторой системы слов во входной поток.
Позже она анализируется с точки зрения автоматного программирования.
;================================================== ; ; свертка/развертка системы текстов ; текст представлен списком ;((Имя Вариант ...)...) ; первое имя в свертке - обозначение системы текстов ; (Элемент ...) ; (Имя Лексема (Варианты)) ; ((пример (ма (ш н) ; (ш а) ) ; ( ш н ) ) ; ((н ина)) ) ;================================================== ; реализация свертки: unic, ass-all, swin, gram, bnf
(defun unic (vac) (remove-duplicates (mapcar ’car vac) )) ;; список уникальных начал
(defun ass-all (Key Vac) ;; список всех вариантов продолжения ( что может идти за ключом) (cond ((Null Vac) Nil) ((eq (caar Vac) Key) (cons (cdar Vac) (ass-all Key (cdr Vac)) )) (T (ass-all Key (cdr Vac)) ) ) )
(defun swin (key varl) (cond ;; очередной шаг свертки или снять скобки при отсутствии вариантов ((null (cdr varl))(cons key (car varl))) (T (list key (gram varl)) ) ))
(defun gram (ltext) ;; левая свертка, если нашлись общие начала ( (lambda (lt) (cond ((eq (length lt)(length ltext)) ltext) (T (mapcar #’(lambda (k) (swin k (ass-all k ltext ) )) lt ) ) ) ) (unic ltext) ) )
(defun bnf (main ltext binds) (cons (cons main (gram ltext)) binds)) ;; приведение к виду БНФ
;=================================================== ; реализация развертки: names, words, lexs, d-lex, d-names, ; h-all, all-t, pred, sb-nm, chain, level1, lang
(defun names (vac) (mapcar ’car vac)) ;; определяемые символы
(defun words (vac) (cond ;; используемые символы ((null vac) NIL) ((atom vac) (cons vac NIL )) (T (union (words(car vac)) (words (cdr vac)))) ))
(defun lexs (vac) (set-difference (words vac) (names vac))) ;; неопределяемые лексемы
(defun d-lex ( llex) ;; самоопределение терминалов (mapcar #’(lambda (x) (set x x) ) llex) ) (defun ( llex)
;; определение нетерминалов (mapcar #’(lambda (x) (set (car x )(cdr x )) ) llex) )
(defun h-all (h lt) ;; подстановка голов (mapcar #’(lambda (a) (cond ((atom h) (cons h a)) (T (append h a)) ) ) lt) )
(defun all-t (lt tl) ;; подстановка хвостов (mapcar #’(lambda (d) (cond ((atom d) (cons d tl)) (T(append d tl)) ) ) lt) )
(defun pred (bnf tl) ;; присоединение предшественников (level1 (mapcar #’(lambda (z) (chain z tl )) bnf) ))
(defun sb-nm (elm tl) ;; постановка определений имен (cond ((atom (eval elm)) (h-all (eval elm) tl)) (T (chain (eval elm) tl)) ) )
(defun chain (chl tl) ;; сборка цепочек (cond ((null chl) tl) ((atom chl) (sb-nm chl tl))
((atom (car chl)) (sb-nm (car chl) (chain (cdr chl) tl) ))
(T (pred (all-t (car chl) (cdr chl)) tl)) ))
(defun level1 (ll) ;; выравнивание (cond ((null ll)NIL) (T (append (car ll) (level1 (cdr ll)) )) ))
(defun lang ( frm ) ;; вывод заданной системы текстов (d-lex (lexs frm)) (d-names frm) (pred (eval (caar frm)) ’(()) ) )
Листинг 8.4.1. Автомат для нахождения всех вхождений некоторой системы слов во входной поток
Объекты и LISP
Стандартная надстройка над Common Lisp, имитирующая объектно-ориентированный стиль, это модуль CLOS — Common Lisp Object System. Сама по себе объектность не дает никакого выигрыша по сравнению с языком LISP, поскольку возможности динамического вычисления функций в LISP даже шире. Видимо, именно поэтому в CLOS имеются две интересных модификации, делающие его не совсем похожим на стандартное ООП.
Начнем с понятия структуры данных в языке Common Lisp. Структура определяется функцией defstruct вида
(defstruct pet name (species ’cat) age weight sex)
Задание структуры автоматически задает функцию-конструктор структуры make-pet, которая может принимать ключевые аргументы для каждого из полей:
(make-pet :nick ’Viola :age ’(3 years) :sex ’femina))
и функцию доступа для каждого из полей, например pet-nick, использующуюся для получения значения поля или ссылки на него. Если поле не инициализировано (ни по умолчанию, ни конструктором), оно получает начальное значение NIL. Никакой дальнейшей спецификации полей структур нет6).
В объекте для каждого поля могут явно указываться функции доступа и имена ключевых параметров для инициализации аргументов. Приведем пример класса, определенного на базе другого класса.
(defclass pet (animal possession) ( (species :initform ’cat) (nick :accessor nickof :inintform ’Pussy :initarg namepet) )
Этот класс наследует поля, функции доступа и прочее от классов animal и possession. Например, поле cost имеется в значении класса, если оно имеется в одном из этих классов. Поскольку статических типов у полей нет, нет и конфликтов.
Основная функция наследования в CLOS — определение упорядочения на классах. С каждым классом связано свое упорядочение. Наследник меньше своих предков, из предков меньшим считается тот, который раньше перечислен в списке наследования при определении класса. CLOS достраивает этот частичный порядок до линейного. Способ пополнения порядка может быть в любой момент и без оповещения изменен, и хакерское использование особенностей конкретного пополнения считается грубой стилистической ошибкой.
Если система находит несовместимость в определении порядка, то она выдает ошибку, как в следующем примере:
[6]> (defclass init () ()) #
В CLOS могут задаваться методы, отличающиеся от функций тем, что их аргументы специфицированы, например
(defmethod inspectpet ((x pet) (y float)) (setf weightofanimal 3.5))
Как видно из этого примера, методы не обязательно связаны с классами. Они могут быть связаны с любыми типами. Методы в CLOS могут иметь дополнительные спецификации. Для того, чтобы разобраться, как эти спецификации взаимодействуют с упорядочением типов классов, рассмотрим следующую программу и генерируемый при ее исполнении результат.
(defclass thing () ((weight :initform ’(0 kg) :accessor weightof :initarg :weight))) (defclass animal (thing) ((specie :accessor specieof :initarg :spec) (sex :accessor sexof :initform ’m :initarg :sex))) (defclass possession (thing) ((owner :accessor ownerof :initform ’nnn) (cost :accessor costof :initform ’(0 bucks) :initarg :cost)) ) (defclass person (animal) ((specie :initform ’human) (name :initarg :thename :accessor nameof))) (defclass pet (animal possession) ((nick :initarg :thenick :accessor nickof) (specie :initform ’cat)))
(defmethod act :before ((p pet)) (print "Cat mews")) (defmethod act :after ((p pet)) (print "Cat turns")) (defmethod act :around ((p pet)) (progn (print "You have a cat") (call-next-method)))
(defmethod act ((p animal)) (progn (print "Animal is close to you") (call-next-method))) (defmethod act :before ((p animal)) (print "You see an animal")) (defmethod act :after ((p animal)) (print "You send the animal off")) (defmethod act :around ((p animal)) (progn (print "You don’t like wild animals") (call-next-method)))
(defmethod act ((p possession)) (progn (print "You test your property") (call-next-method))) (defmethod act :before ((p possession)) (print "You see your property")) (defmethod act :after ((p possession)) (print " You are pleased by your property")) (defmethod act :around ((p possession)) (progn (print "You admire your property if it is in good state") (call-next-method)))
(defmethod act ((p thing)) (print "You take the thing")) (defmethod act :before ((p thing)) (print "You see something")) (defmethod act :after ((p thing)) (print "You identified this thing")) (defmethod act :around ((p thing)) (progn (print "You are not interested in strange things") (call-next-method)))
(act (make-instance ’pet :thenick "Viola" :cost ’(25 kop)))
Листинг 8.6.1. Взаимодействие дополнительных спецификаций методов в CLOS с упорядочением типов классов
При загрузке этого файла происходит следующее:
[1]> (load ’myclasses) ;; Loading file E:\clisp-2000-03-06\myclasses.lsp ... "You have a cat" "You don’t like wild animals" "You admire your property if it is in good state" "You are not interested in strange things" "Cat mews" "You see an animal" "You see your property" "You see something" "Cat purrs" "Animal is close to you" "You test your property" "You take the thing" "You identified this thing" "You are pleased by your property" "You send the animal off" "Cat turns" ;; Loading of file E:\clisp-2000-03-06\myclasses.lsp is finished. T
Пример 8.6.2. Результат загрузки программы 8.6.1
Видно, что упорядоченность классов по отношению наследования позволяет выстраивать целые последовательности действий при вызове одного метода.
Поскольку в CLOS нет ни механизмов скрытия конкретных представлений, ни механизмов замены прямого доступа к данным на функции, ни других характерных особенностей ООП, мы видим еще один пример того, как модным словом (в данном случае ООП) прикрывается другая, не менее интересная сущность: начатки планирования действий по структуре типов данных.
В связи с этим стоит напомнить блестящий эксперимент планирования вычислений по структуре данных, в настоящий момент (судя по всему, временно) забытый: эстонскую систему PRIZ [28].
Неадекватное теоретизирование мешает увидеть и развить реальные достоинства системы и закрепляет слабые места.
|
|
|
И уж точно первый из выживших, поскольку Plankalkul Цузе умер вместе с его машинами.
2)
А для предотвращения хакерских трюков и нежелательно!
3)
Любезно предоставленный Л. Городней (ИСИСО РАН и НГУ)
4)
Как сделано в системе TEX-LATEX.
5)
Примером, иллюстрирующим ситуацию, может служить XML, линейность конкретного синтаксиса которого является лишь следствием стихийных стандартов.
6)
Имеется редко используемая возможность указать, какого типа должно быть поле.
Поле зрения и поле памяти
Если не применены специальные операции блокирования вычислений, первый аргумент списка интерпретируется как функция, аргументами которой являются оставшиеся элементы списка. Это позволяет программу также задавать списком.
Таким образом, в LISP, так же, как в сентенциальных языках, структура данных программы и поля памяти, обрабатываемого программой, совпадают. Видимо, это одна из удачнейших форм поддержания концептуального единства для высокоуровневых систем.
В поле памяти с каждым атомом-именем могут быть связаны атрибуты. Стандартный атрибут — значение атома. Для установки этого атрибута есть функция (setq atom value), аналогичная присваиванию. Эта функция не вычисляет свой первый аргумент, она рассматривает его как имя, которому нужно приписать значение.
Значение в языке LISP может быть локальным. Если мы изменили значение атома внутри некоторого блока, то такое ‘присваивание’ действует лишь внутри минимальных объемлющих его скобок и исчезает снаружи блока. Кроме значения, имена могут иметь сколько угодно других атрибутов, которые обязательно глобальны. Они принадлежат самому имени, а не блоку. Способ установки значений этих атрибутов несколько искусственный. Имеется еще одна функция setf, вычисляющая свой первый аргумент, дающий ссылку на место, которому можно приписать значение (например, на атрибут). Функция получения значения атрибута get, даже если атрибута еще нет, указывает на его место. Следующий пример демонстрирует, как это работает.
[38]> (setf (get ’b ’weight) ’(125 kg)) (125 KG) [39]> (get ’b ’weight) (125 KG)
Рассмотрим подробнее структуру данных языка LISP. Она является двухуровневой. На верхнем уровне имеется структура списков. На нижнем находится структура информации, сопоставленной атому. Она изображена на рис. 8.1. Оба этих уровня рекурсивно ссылаются друг на друга, например, атрибуты атома являются списками.
Типы данных (в смысле программирования) в LISP есть, но они определяются динамически. В частности, если действительное число придано атому как значение, то тип атома становится float.
Прагматические добавления и динамическое порождение программ
Разберем возможности языка LISP в комплексе.
Выразительные средства конкретно-синтаксического представления общей структуры данных и программ языка LISP крайне скупы. Но это представление позволяет практически однозначно связать синтаксис и реализационную структуру.
Реализационное представление как нельзя лучше соответствует соглашению об общности функциональной структуры и структуры данных: в каждом списке голова рассматривается как указание (имя, ссылка или что-то подобное) на функцию, а хвост — как последовательность указаний на аргументы. Задание свойства списка не быть функцией, т. е. отмена выделенного статуса головы, обозначающей функцию, достигается с помощью блокировок. Это удачное решение в условиях принятого соглашения, позволяющее трактовать нефункциональный список как константную функцию, "вычисляющую" свое изображение (представление). Еще более важно то, что оно обеспечивает гибкость представления: функцию eval, заставляющую список принудительно вычисляться, естественно трактовать просто как снятие блокировок. Заметим, что на уровне абстрактного синтаксиса функция eval обязана быть универсально применимой к любому списку.
К сожалению, такой универсализм провоцирует крайне ненадежное и неэффективное программирование, поэтому это решение нельзя считать удачным. Справедливости ради заметим, что в те времена, когда разрабатывался язык, задача надежности еще не была поставлена, но плохо то, что сформировался стихийный стандарт, не способствующий качеству программирования.
Для обеспечения практической пользы функции eval следовало бы предусмотреть компенсирующие регламенты ее корректного применения на уровне конкретного синтаксиса, режимов вычислений и системных механизмов.
Внимание!
На уровне абстрактного и конкретного синтаксиса разные семантические возможности имеют разный статус, поэтому в конкретном представлении необходимо предусматривать механизм скрытия и даже полного запрета тех возможностей, которые концептуально разумны лишь на уровне абстрактного синтаксиса4).
Структура списков LISP идеальна для представления абстрактного синтаксиса языка. И хотя злые языки называют этот синтаксис "утомительным нагромождением скобок", он в точности соответствует абстрактному синтаксису. Если даже не учитывать преимущества указанного соответствия, то остается простота представления программ и данных в виде линейной текстовой последовательности символов.
Другие гипотетические кандидаты на роль конкретного синтаксиса по этому критерию явно проигрывают. Традиционные математические формы задания функций и их применений являются текстуально избыточными (как префиксная, так и постфиксная записи требуют обязательного обрамления параметров скобками), а бесскобочная нотация Лукасевича (и прямая, и обратная) еще более запутывали бы тексты по сравнению с "утомительным нагромождением скобок". Но за счет внеязыковых прагматических соглашений о том, как располагать на двумерном носителе (на бумаге или на экране) скобочную структуру, можно существенно облегчить. Если же система программирования будет поддерживать (и проверять!) прагматические соглашения (что характерно для развитых систем), то вид программ станет вполне читаемым. Таким образом преодолеваются неудобства линейного представления.
Сегодня можно было бы говорить о других форматах конкретного синтаксиса LISP, в том числе и не связанных с линейным представлением. Использование развитых средств графики при экранном наборе программ позволяет на полную мощь подключить двумерную работу. Однако традиции и стихийно сформировавшиеся стандарты не оставляют возможности для внедрения таких форматов. Здесь в очередной раз и в полной мере проявились вредные эффекты ранней стандартизации, мешающие развитию направления, остающегося одним из самых концептуально богатых и перспективных.
Диктат линейности укоренился настолько глубоко, что даже в тех случаях, когда он мог бы быть преодолен безболезненно, языковая система чаще всего все равно строится как линейная. Это касается не только функционального стиля5).
что может идти за ключом)
|
;================================================== ; ; свертка/развертка системы текстов ; текст представлен списком ;((Имя Вариант ...)...) ; первое имя в свертке - обозначение системы текстов ; (Элемент ...) ; (Имя Лексема (Варианты)) ; ((пример (ма (ш н) ; (ш а) ) ; ( ш н ) ) ; ((н ина)) ) ;================================================== ; реализация свертки: unic, ass-all, swin, gram, bnf (defun unic (vac) (remove-duplicates (mapcar ’car vac) )) ;; список уникальных начал (defun ass-all (Key Vac) ;; список всех вариантов продолжения ( что может идти за ключом) (cond ((Null Vac) Nil) ((eq (caar Vac) Key) (cons (cdar Vac) (ass-all Key (cdr Vac)) )) (T (ass-all Key (cdr Vac)) ) ) ) (defun swin (key varl) (cond ;; очередной шаг свертки или снять скобки при отсутствии вариантов ((null (cdr varl))(cons key (car varl))) (T (list key (gram varl)) ) )) (defun gram (ltext) ;; левая свертка, если нашлись общие начала ( (lambda (lt) (cond ((eq (length lt)(length ltext)) ltext) (T (mapcar #’(lambda (k) (swin k (ass-all k ltext ) )) lt ) ) ) ) (unic ltext) ) ) (defun bnf (main ltext binds) (cons (cons main (gram ltext)) binds)) ;; приведение к виду БНФ ;=================================================== ; реализация развертки: names, words, lexs, d-lex, d-names, ; h-all, all-t, pred, sb-nm, chain, level1, lang (defun names (vac) (mapcar ’car vac)) ;; определяемые символы (defun words (vac) (cond ;; используемые символы ((null vac) NIL) ((atom vac) (cons vac NIL )) (T (union (words(car vac)) (words (cdr vac)))) )) (defun lexs (vac) (set-difference (words vac) (names vac))) ;; неопределяемые лексемы (defun d-lex ( llex) ;; самоопределение терминалов (mapcar #’(lambda (x) (set x x) ) llex) ) (defun ( llex) ;; определение нетерминалов (mapcar #’(lambda (x) (set (car x )(cdr x )) ) llex) ) (defun h-all (h lt) ;; подстановка голов (mapcar #’(lambda (a) (cond ((atom h) (cons h a)) (T (append h a)) ) ) lt) ) (defun all-t (lt tl) ;; подстановка хвостов (mapcar #’(lambda (d) (cond ((atom d) (cons d tl)) (T(append d tl)) ) ) lt) ) (defun pred (bnf tl) ;; присоединение предшественников (level1 (mapcar #’(lambda (z) (chain z tl )) bnf) )) (defun sb-nm (elm tl) ;; постановка определений имен (cond ((atom (eval elm)) (h-all (eval elm) tl)) (T (chain (eval elm) tl)) ) ) (defun chain (chl tl) ;; сборка цепочек (cond ((null chl) tl) ((atom chl) (sb-nm chl tl)) ((atom (car chl)) (sb-nm (car chl) (chain (cdr chl) tl) )) (T (pred (all-t (car chl) (cdr chl)) tl)) )) (defun level1 (ll) ;; выравнивание (cond ((null ll)NIL) (T (append (car ll) (level1 (cdr ll)) )) )) (defun lang ( frm ) ;; вывод заданной системы текстов (d-lex (lexs frm)) (d-names frm) (pred (eval (caar frm)) ’(()) ) ) |
| Листинг 8.4.1. Автомат для нахождения всех вхождений некоторой системы слов во входной поток |
| Закрыть окно |
Списки и функциональные выражения
Основной единицей данных для LISP-системы является список.
Списки задаются следующим индуктивным определением.
 1 — атомы либо списки, то (l1, . . . , ln) — также список.
1 — атомы либо списки, то (l1, . . . , ln) — также список.Элементами списка (l1, . . . , ln) называются l1, . . . , ln. Равенство списков задается следующим индуктивным определением.
Пример 8.2.2. Все списки (), (()), ((())) и т. д. различны. Различны также и списки nil, (nil, nil), (nil, nil, nil) и так далее. Попарно различны и списки ((A,B), C), (A, (B,C)), (A,B,C), где A, B, C — различные атомы.
Поскольку понятие, задаваемое индуктивным определением, должно строиться в результате конечного числа шагов применения определения, мы исключаем списки, ссылающиеся сами на себя. Списки в нашем рассмотрении изоморфны упорядоченным конечным деревьям, листьями которых являются nil либо атомы.
Вершины списка L задаются следующим индуктивным определением.
Длиной списка называется количество элементов в нем. Глубиной списка называется максимальное количество вложенных пар скобок в нем. Соединением списков (l1, . . . , ln) и (k1, . . . , km) называется список
(l1, . . . , ln, k1, . . . , km).
Замена вершины a списка L на атом либо список M получается заменой поддерева L, соответствующего a, на дерево для M. Замена обозначается L[a | M]. Через L[a || M] будем обозначать результат замены нескольких вхождений вершины a на M.
Атомами в языке LISP являются числа, имена, истина T. Ложью служит пустой список NIL, который в принципе атомом не является, но в языке LISP при проверке на то, является ли он атомом, выдается истина. Точно так же выдается истина и при проверке, является ли он списком. Однако все списковые операции применимы к NIL, а те, которые работают с атомами, часто к нему неприменимы.
Например, попытка присваивания значения выдает ошибку.
Основная операция для задания списков (list a b . . . z). Она вычисляет свои аргументы и собирает их в список. Для этой операции без вычисления аргументов есть скоропись ’(a b . . . z). Она является частным случаем функции quote (сокращенно обозначаемой ’), которая запрещает всякие вычисления в своем аргументе и копирует его в результат так, как он есть.
По традиции, элементарные операции разбора списков обозначаются именами, которые начинаются с c и кончаются на r, а в середине идет некоторая последовательность букв a и d; (car s) выделяет голову (первый член списка), (cdr s) — хвост (подсписок всех членов, начиная со второго). Буквы a и d применяются, начиная с конца. Общее число символов в получающемся атоме должно быть не больше шести. Рассмотрим фрагмент диалога, иллюстрирующий эти операции. Как только в диалоге вводится законченное выражение, оно вычисляется либо выдается ошибка.
[13]>(setq a ’(b c (d e) f g)) (B C (D E) F G) [14]> (cddr a) ((D E) F G) [15]> (cddar a) *** - CDDAR: B is not a list 1. Break [16]> ^Z [17]> (caaddr a) D [18]> (cdaddr a) (E)
?-абстракции
В некоторых случаях осознанное усвоение концепций даже на самом низком уровне нереально без базовых теоретических сведений. А знакомство с таким базисом, в свою очередь, стимулирует значительно более глубокий интерес к теории и способствует пониманию того, что на высшие уровни знаний и умений не подняться без овладения теорией.
Теоретической основой языка LISP является логика функциональности: комбинаторная логика или (по наименованию одного из основных понятий в наиболее популярной из нынешних ее формализаций) ?-исчисление.
В ?-исчислении выразительные средства, на первый взгляд, крайне скупы. Имеются две базисные операции: применение функции к аргументу (?x) и квантор образования функции по выражению ?x t[x]. В терминах ?-исчисления функция возведения числа в квадрат записывается как ?x (sqrx) или, если быть ближе к обычным математическим обозначениям, ?x x2.
Основная операция — символьное вычисление применения функции к аргументу: (?x t[x] u) преобразуется в t[u]. Но эта операция может применяться в любом месте выражения, так что никакая конкретная дисциплина вычислений не фиксируется. Более того, функции могут вычисляться точно так же, как аргументы. Уже эта маленькая тонкость приводит к принципиальному расширению возможностей ?-исчисления по сравнению с обычными вызовами процедур. Если мы желаем ограничиться лишь ею, рассматривается типизированное ?-исчисление, в котором, как принято в большинстве современных систем программирования, значения строго разделены по типам. В типизированном ?-исчислении есть только типы функций, но этого хватает, поскольку функции могут принимать в качестве параметров и выдавать функции.
Но в исходной своей форме ?-исчисление является нетипизированным, любой объект может быть и функцией, и аргументом, и, более того, функция может применяться к самой себе. Конечно же, при этом появляется возможность зацикливания, но без нее не обойдется ни одна "универсальная" алгоритмическая система. Например, выражение
(?x (xx) ?x (xx))
вычисляется бесконечно, а чуть более сложное выражение
((?x ?y x a) (?x (xx) ?x (xx)))
может либо дать a, либо зациклиться, в зависимости от выбора порядка его вычисления. Но все равно, если мы приходим к результату, то он определяется однозначно. Так что совместность вычислений не портит однозначности, если язык хорошо сконструирован.
Дж. Маккарти перенес идеи ?-исчисления в программирование, не потеряв практически ничего из исходных концепций. Далее, он заметил, что в рудиментарном виде в ?-исчислении появилось понятие списка, и перенес списки в качестве основных структур данных в свой язык. ?-исчислением было навеяно и соглашение языка LISP о том, что первый член списка трактуется как функция, применяемая к остальным.
Автоматные задачи
Многие программистские задачи удобно решать с помощью методов, формализацией которых могут служить таблицы состояний и переходов (напр., их собрание см. в [32] и на сайте http://is.ifmo.ru).
Пример 9.1.1. Модель изменяющейся системы.
Пусть мы моделируем динамическую либо экологическую систему, у которой в различных областях принципиально разное поведение. Вместо того, чтобы совмещать внутри одного и того же программного модуля анализ, какой области принадлежит точка, и вычисление следующего состояния системы, мы можем написать несколько простых модулей моделирования поведения системы в каждой из областей (единственная проверка, которая при этом может понадобиться, вышли мы при очередном шаге моделирования за границы области или нет). Как отдельный модуль строится глобальная управляющая программа, которая проверяет, в каком состоянии находится система, и вызывает соответствующий вычислительный модуль.
В данном случае выигрыш не столько в длине программы, сколько в ее обозримости и модифицируемости (хотя именно эти важнейшие качества программы начинающие программисты чаще всего недооценивают). Но если при входе в новую область нужно проделать ряд организационных действий (в каждой области различных), а уже в зависимости от их результата выбрать дальнейшую траекторию системы, то описание в виде автомата становится все более выигрышным.
Если при анализе задачи удается выявить набор состояний описываемого процесса, условия перехода между состояниями и действия, ассоциированные с состояниями, то задачу уместно решать методами таблиц состояний. При анализе таких методов можно применять конечные автоматы Мура.
Теоретически автомат Мура представляется как матрица переходов, строками которой служат состояния автомата, а столбцами - входные символы1). В качестве входных символов на практике можно рассматривать результаты проверки некоторых условий. Неявное в теории, но важнейшее на практике содержимое каждого состояния автомата - процедура, приводящая к глобальному изменению состояния вычислительной системы.
Такие процедуры назовем действиями.
Таблицы автоматов часто также представляются в виде графов, что особенно удобно, когда не все возможные переходы между состояниями реализуемы. См., напр., рис. 9.1, где представлены и таблица, и граф.
Рис. 9.1. Таблица состояний. Граф переходов.
Здесь состояния идентифицируются порядковыми номерами, а воздействия - буквами.
На таблице состояний или на ее графовом аналоге все действия предполагаются по умолчанию глобальными, и каждое действие соединено с распознаванием, какое из перечисленных на выходящих из него ребрах условий выполнено. В зависимости от того, какое из них выполнено, автомат переходит в соответствующее состояние, которому опять-таки, если оно не заключительное, сопоставлено действие и распознавание.
Имеется вариация понятия автоматов, порождающая другой метод автоматного программирования. В теории автомат Мили отличается тем, что результат, записываемый на выходную ленту автомата, может зависеть от выбранного перехода. На практике действия в таблице состояний и переходов могут ассоциироваться либо с состояниями (с вершинами графа, автомат Мура), либо с переходами (с дугами графа, автомат Мили). Ниже Вы увидите примеры, когда при программировании естественно возникают оба этих варианта2). Модель вычислений автомата Мили лучше использовать, если проверки в каждом состоянии по существу различны, а модель автоматов Мура - если проверки по существу однородны, как в примере 9.1.1.Метод программирования, когда действия сопоставляются переходам, назовем преобразованиями на переходах (сокращенно просто "на переходах"), метод, когда действия производятся в состояниях, назовем преобразованиями в состояниях (сокращенно просто "в состояниях").
Заметим, что естественно рассматривать таблицы состояний и переходов как недетерминированные, поскольку после выполнения действия вполне может оказаться истинно сразу несколько условий, соответствующих выходящим ребрам.
Внимание!
В данном случае мы видим один из неистощимых источников ошибок в программах, который впервые заметил Д.
Грис. Если по сути задачи нам все равно, какое из действий будет выполнено, а язык (как те стандартные языки, на которых обычно работают) заставляет детерминировать переходы, либо ранжировав их по порядку, либо принудительно сделав их условия логически противоречивыми, то при изменении программы часто возникают трудности. Они связаны с тем, что после изменения детерминировать-то надо было по-другому, но уже нельзя различить, какие из условий существенны, а какие вставлены лишь для детерминации.
Как было показано в нашем примере, таблицы переходов и состояний являются естественным способом программирования для модуля, имеющего дело с глобальными операциями над некоторой средой (эти глобальные операции сами, как правило, программируются в другом стиле). Для автоматного программирования характерно go to, и здесь оно на месте.
Есть много конкретных методик автоматного программирования, укладывающихся в рамки двух главных методов. Автоматное программирование хорошо демонстрирует то, как варьируются практические методы решения логически и математически, вроде бы, однородных задач. Небольшое изменение в ресурсных ограничениях - и, хотя старые методы, как правило, остаются уместными, но лучше перейти к другим.
Методы действий в состояниях и на переходах: анализ состояний и построение таблицы
В данном разделе начинается детальный показ двух методов автоматного программирования, основанных на модели Мура и Мили. Методика работы в них почти одна и та же, но, как чаще всего бывает, маленькое и вроде бы техническое различие (чему сопоставляются действия: состояниям или переходам?) порождает два несовместимых метода. Их несовместимость не столь грубая, как во многих других случаях (два таких случая - несовместимость между автоматами и присваиваниями и между циклами и рекурсиями - рассмотрены ниже). Если это и противоречие, то противоречие технологическое. Произвольно перемешивая эти два метода, мы в дальнейшем затрудняем модификацию программы, а в настоящем вынуждены множить число подпорок.
Человек даже грубые противоречия игнорирует или обходит 4). Для применения правила важно знать не только его, но и когда можно его нарушать. Общеметодологический принцип здесь такой: если уж нарушать, то на полную катушку (проехав перекресток на красный свет, глупо останавливаться сразу за ним)! Второй принцип: если нельзя, но очень нужно, то надо! А. А. Шалыто указал, что в теории 5) есть и такое смешанное понятие, как автоматы Мили-Мура. Одной из моделей таких автоматов является автомат с двумя выходными лентами: на одну пишется результат в состояниях, на другую - на переходах. Программной интерпретацией такой теоретической модели является, например, модуль, который в состояниях ведет диалог с окружающей средой, в результате чего получает данные для определения очередного перехода, а на переходах производит внутренние вычисления.
Для отработки методики используется простая задача, не затемняющая ее суть частными тонкостями и пригодная для реализации любым из двух методов. Полученная методика переносится на широкий класс задач и не отказывает вплоть до тысяч состояний.
Основные структуры автоматного программирования
Информационное пространство всех блоков и процедур при автоматном программировании в первом приближении одно и то же: состояния системы, моделируемой совокупностью программных действий. Но на самом деле многие блоки либо процедуры работают с подсистемами. Подсистемы, ввиду их автономности, могут иметь характеристики, прямо недоступные для общей системы, и ограниченный доступ к общему системному пространству данных. Более того, подсистемы могут общаться прямо, в обход иерархически вышестоящей системы (см. рис. 9.2). Таким образом, структура информационного пространства при автоматном программировании в общих чертах соответствует той, которая навязывается современными системами с развитой модульностью3). В системах модульности есть понятия, предоставляемые для пользования другими модулями, есть модули, которые автоматически получают доступ ко всем понятиям дружественного модуля, и есть интерфейсы между модулями.
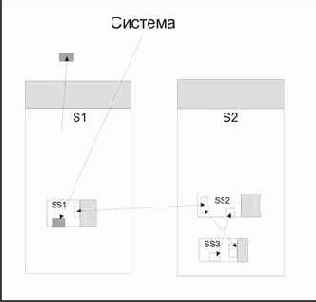
Рис. 9.2. Информационное пространство систем
Светло-серые области - традиционный общий контекст системы и подсистемы. Темно-серые иллюстрируют, что доступность может быть односторонней, и не только по иерархии. Одна из систем может влиять на часть информационного пространства другой, а та может лишь пассивно следить, что натворил коллега. Области, связанные двусторонними стрелками, иллюстрируют прямое общение в обход иерархии.
Исторически первой моделью автоматного программирования, использованной как на практике, так и для теоретических исследований, было представление программы в виде блок-схемы (см., напр., рис. 9.3), узлы которой являлись состояниями. Узлы блок-схемы делятся на пять типов:
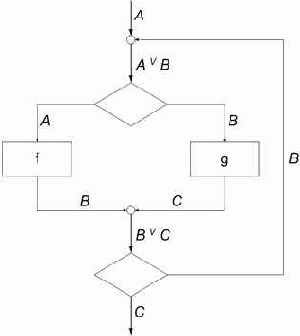
Рис. 9.3. Блок-схема
Представление программ в виде блок- схем было целесообразно для многих классов программ, писавшихся в машинных кодах без средств автоматизации программирования. Блок-схемы тогда были основным средством планирования разработки программ и их документирования. Традиционные блок-схемы - предмет изучения, в частности, теоретического программирования (см. книги Котова [16], [17]).
Таблицы переходов концептуально противоречат такому фундаментальному понятию программирования, как присваивание. В блок-схеме произвольной формы исключительно трудно проследить, как будет изменяться значение переменной, какие существуют зависимости между данными переменными, и т. п.
Действия в автоматном программировании глобальны, а условия локальны. Проверка условия не изменяет состояния всей системы (ни одного из ее параметров или характеристик), она лишь переводит саму программу в то или иное состояние.
Это подтверждает и анализ практических систем, для моделирования которых удобно применять автоматное программирование. Например, открытие или закрытие одного вентиля в трубопроводной системе изменяет все потоки в системе, а проверка - открыт ли вентиль - локальная операция. Изменение температуры рабочего вещества в системе опять-таки влияет на все ее характеристики, а измерить эту температуру можно, сняв показания всего одного датчика.
Здесь мы сталкиваемся с необходимостью четко различать внешние понятия, описывающие систему, которая связана с решаемой программой задачей, и внутренние понятия самой программы. Для системы в целом безразличны состояния автомата, который ее моделирует либо взаимодействует с ней. Для нее важно, какие изменения в ней самой происходят. Таким образом, состояние памяти вычислительной системы вполне может рассматриваться как внешняя характеристика по отношению к программе, которая в ней работает.
Необходимость одновременного и согласованного рассмотрения внешних и внутренних характеристик приводит к тому, что, когда внутренние характеристики раздробляются и детализируются (например, при соединении стиля автоматного программирования с присваиваниями), программист начинает путаться, согласованность понятий исчезает и возникают ошибки.
Внимание!
Если пользоваться произвольными таблицами переходов, то надо позаботиться о том, чтобы присваивания встречались как можно реже, в идеале обойтись без них совсем либо присваивать лишь значения переменным, которые немедленно после этого используются в качестве основания для выбора в операторе типа case.
Граф состояний и переходов, называемый также таблицей переходов — нагруженный ориентированный граф G. Каждой вершине графа G сопоставлено наименование состояния, а каждой дуге — условие.
Условие AB, сопоставленное дуге, ведущей из a в b, содержательно интерпретируется следующим образом. При выполнении AB в состоянии a управление передается состоянию b (или же в другом смысле осуществляется переход по данной дуге).
Когда граф состояний и переходов используется для документирования программы, наименования состояний, как правило, совпадают с именами процедур, выполняющихся в данном состоянии.
Постановка задачи и первичный анализ
Пусть требуется решить следующую задачу. Словом называется любая непустая последовательность букв латинского алфавита (для простоты - только строчных букв). Перепечатать из входной последовательности символов все максимальные входящие в нее слова в следующем виде:
<слово> - <длина слова><конец строки печати>
Ввод заканчивается пустой строкой.
Например, по строкам
попугай бегемот 1мот2крот1мот
нужно выдать что-либо вроде
попугай 7 бегемот 7 мот 3 крот 4 мот 3
Для решения задачи входную последовательность символов естественно считать потоком, читаемым слева направо, пока не будет прочитана пустая строка. При чтении букв, других символов и конца строки действия, которые необходимо выполнять, различны. Кроме того, различаются действия для первой буквы и для последующих букв слова.
Построение графа состояний
Прежде всего, определим набор состояний, исходя из различных реакций на прочитанный символ.
Вот полный перечень вариантов реакций:
Есть еще одно действие, не отраженное в этом списке, но подразумеваемое: стандартное действие, происходящее перед началом отработки нового состояния. В данном случае это чтение очередного символа, которое должно выполняться, когда переход срабатывает. В других случаях автоматных моделей роль чтения очередного символа может играть, скажем, последующий шаг моделирования. Для данного и для большинства других автоматных примеров стандартное действие не нужно указывать явно, поскольку оно автоматически сопоставляется каждому переходу и полностью соответствует математической модели.
Из перечня действий для рассматриваемой задачи следует, что должно быть, как минимум, два класса состояний, имеющие разные действия-реакции.
Следующий методический прием - это определение начального состояния, т. е. того, в котором вычислительный процесс активизируется. Нужно указать, какие действия возможны в данном состоянии и какие условия перехода в нем должны быть.
Для рассматриваемого случая в начальном состоянии (St1), возможны переходы:
Рис. 9.4. Начало построения графа состояний по Муру
Результат только что проведенного анализа можно представить в виде графа, изображенного на рис. 9.4. С каждой дугой графа связано условие перехода. С каждым состоянием может быть связано действие.
В состояниях St1 и St3 действием является пропуск очередного символа и чтение следующего, но соединить их сейчас нельзя, поскольку в первом из них переход на завершение работы невозможен, так что перевод строки анализируется по-разному. Это позволяет предположить, что в данной задаче действия стоит ассоциировать с переходами, а не с состояниями. Правильный выбор того, с чем ассоциировать действия, может сильно оптимизировать программу. Для показа двух возможных вариантов, которые в данном случае почти эквивалентны по сложности, мы будем действовать как на переходах, так и в состояниях. В частности, предварительный анализ состояний при методе преобразований на переходах дан на рис. 9.5.
Рис. 9.5. Начало построения графа состояний при использовании метода на переходах
Внимание!
Если у Вас есть две близкие, но концептуально противоречивые, модели, в начале развития программы нужно сделать выбор в пользу одной из них. Небольшие эксперименты и отступления в начале оборачиваются большой экономией сил в конце.
На схемах вход и выход обозначаются черными прямоугольными блоками. При желании их можно считать специальными состояниями, с которыми ассоциированы действия инициализации и завершения процесса. Состояние St2 изображено штриховой линией, поскольку анализ его еще не проведен. Для каждого из еще не проанализированных состояний (в данном случае для St2) следует определить условия перехода (и соответствующие им действия, если выбрали работу на переходах).
В рассматриваем случае в состоянии St2 возможны переходы:
После этого построения проверяется, не является ли новое состояние копией уже имеющихся как по действиям, так и по переходам. Если это так, то новое состояние можно отождествить (склеить) с одним из ранее построенных.
Вновь появляющиеся состояния анализируются аналогично.
Для решаемой задачи легко выяснить, что состояние St3 требует тех же действий и переходов, что и St5, а St4 изоморфно St1. Следовательно, возможна склейка этих двух состояний со старыми и построение графа завершается, так как новых состояний нет (см. рис. 9.6). С тем, чтобы не дублировать действия <Завершить процесс>, можно определить еще одно, заключительное состояние, с выходом из которого будет ассоциировано это действие (один раз!).
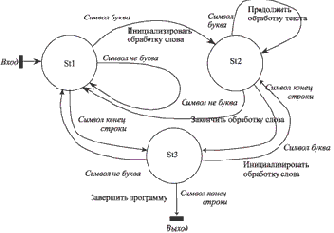
Рис. 9.6. Полученный граф состояний при действиях на переходах
Аналогично можно поступить и когда мы работаем в состояниях. Здесь процесс удлиняется на один шаг, поскольку необходимо выделить завершение обработки слова в отдельное действие (причем в двух вариантах: после перевода строки и после других небуквенных символов). Полученный результат показан на рис. 9.7.
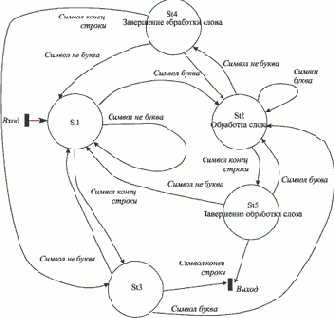
Рис. 9.7. Полученный граф состояний при действиях в состояниях
Программные представления графа состояний
Отметим, что программные представления графа состояний сильно зависят от динамики данного графа. Стоит выделить четыре подслучая.
Табличное представление графа состояний
Графическое или иное представление графа состояний конечного автомата, явно отражающее наименования состояний, условия переходов между состояниями и ассоциированные с ними действия, называют таблицей переходов. Такое представление является одним из центральных компонентов широко используемого в индустриальном программировании языка объектно-ориентированного дизайна UML (в частности, в форме, реализованной в системе Rational Rose) - state transition diagrams (диаграммы состояний и переходов).
Различают визуальные представления таблиц переходов, которые предназначены для человека, и их программные представления. Требования к визуальным представлениям - понятность для человека, статическая проверяемость свойств; требования к программным представлениям - выполнимость при посредстве какой-либо системы программирования; общее требование к представлениям обоих видов - однозначное соответствие между ними, позволяющее обоснованно утверждать вычислительную эквивалентность.
Ответ на вопрос, какое представление графа состояний лучше всего использовать, зависит от сложности графа, статичности либо динамичности его и того, для каких целей требуется спецификация в виде графа состояний. Понятно, что важнейшей для нас промежуточной целью является программа на алгоритмическом языке. Но подходы к построению такой программы могут быть различны. Существует две принципиально различные методики применения спецификаций:
Как при трансляционной, так и интерпретационной позиции возможен целый спектр реализаций. Ближайшая же цель в том, чтобы научиться удобно для человека представлять граф состояний и переходов. Наиболее естественно описывать его в виде таблицы. Для методов на переходах и в состояниях таблицы несколько различаются. На табл. 9.1 представлен случай Мили.
Опишем значение колонок таблицы.
Кроме того, определяется специальная (первая) строка, в которой помещаются операторы, инициирующие процесс, и адрес перехода начального состояния.
В табличном представлении графа переходов в состояниях (таблица 9.2) действия помещаются во втором столбце, сразу после обозначения состояния, а уже затем идут переходы. Анализируя таблицу 9.2, можно заметить ряд повторяющихся действий. Конечно же, если бы эти действия были более сложными, их просто описали бы как процедуры. Но такие повторения заставляют задуматься, а нельзя ли сократить число состояний? Введя дополнительную булевскую переменную, отметившую, что последним символом был перевод строки, мы могли бы избавиться от пары состояний. Но такой переменной нужно присваивать новое значение в процессе проверки условий, и при этом в строго определенный момент: сначала проверить, не является ли символ концом строки, а уже затем переприсваивать данную переменную. Это решение сильно отдает хакерством, и, если Вы хотите писать качественные, легко перестраиваемые программы, то таких решений нужно избегать.
Еще раз показать тонкую грань между хакерством и естественностью можно, рассмотрев один из моментов, возникающих в наших программах. При работе в состояниях нам приходится обнулять счетчик букв слова в тот момент, когда кончается очередное слово, поскольку иначе пришлось бы выделять еще одно состояние, соответствующее середине обработки слова. Но это гораздо менее искусственное решение: неплохо восстанавливать начальные значения и делать другие действия по приведению в порядок информации в тот момент, когда заканчивается очередной этап работы; неплохо делать это всегда в начале нового этапа; плохо лишь произвольно перемешивать эти две дисциплины.
|
char symbol; // Чтение потока символов неявное // Чтение происходит перед выполнением проверок и действий int Cnt; . . . // Инициализация | St1|
| 'a'<=symbol && symbol <= 'z' | printf ("%c", symbol); Cnt = 1; | St2
/*(symbol<'a'|| 'z'| /* Действий нет */ | St1 |
| symbol='\n' | /* Действий нет */ | St3
| 'a'<=symbol && symbol <= 'z' | printf ("%c", symbol);cnt++; | St2
/*(symbol<'a'|| 'z'| printf ("- %i\n", Cnt); | St1 |
| symbol='\n' | printf ("- %i\n", Cnt); | St3
| 'a'<=symbol && symbol <= 'z' | printf ("%c", symbol); Cnt = 1; | St2
/*(symbol<'a'|| 'z'| /* Действий нет */ | St1 |
| symbol='\n' | Второй '\n' дальше не нужно читать | exit
| /* Нет неявного чтения потока */ | return 0; // Считать данную секцию таблицы состоянием или нет - дело вкуса |
|
char symbol; // Чтение потока символов неявное // Чтение происходит после выполнения действия, перед проверками int Cnt; ...Cnt=0; // Инициализация | St1|
| /* Действий нет */ | 'a'<=symbol && symbol <= 'z' | St2
| /*(symbol<'a'|| 'z' | |
| symbol='\n' | St3|
| printf ("%c", symbol); Cnt++; | 'a'<=symbol && symbol <= 'z' | St2
| /*(symbol<'a'|| 'z' | |
| symbol='\n' | St5|
| /* Действий нет */ | 'a'<=symbol && symbol <= 'z' | St2
| /*(symbol<'a'|| 'z' | |
| Второй '\n' дальше не нужно читать symbol='\n' | exit|
| printf ("- %i\n", Cnt); Cnt=0; | 'a'<=symbol && symbol <= 'z' | St2
| /*(symbol<'a'|| 'z' | |
| symbol='\n' | St3|
| printf ("- %i\n", Cnt); Cnt=0; | 'a'<=symbol && symbol <= 'z' | St2
| /*(symbol<'a'|| 'z' | |
| Второй '\n' дальше не нужно читать symbol='\n' | exit|
| /* Нет неявного чтения потока */ | return 0; // Считать данную секцию таблицы состоянием или нет - дело вкуса |
|
|
|
Если Вы посмотрите точное определение, то есть еще один компонент: преобразование состояний в выходные символы. Аналогом этого компонента в программировании может служить массив процедур, вызовы которых сопоставлены состояниям, но для принципиальных рассмотрений у нас он не важен.
2)
Конечно же, в каждом конкретном модуле нужно использовать лишь одну из структур, концептуально несовместимых, хотя формально эквивалентных.
3)
Интересно, что необходимость развитых средств поддержки модуляризации программ первоначально провозглашалась для структурного программирования, но оказалась прекрасно приспособлена совсем к другому стилю. Впрочем, в современных программах самый верхний (часто полуавтоматически генерируемый системами визуального программирования и поэтому обычно мало интересный для программистов) этаж структуры программ, как правило, записан именно в стиле автоматного программирования.
4)
Данный абзац добавлен после обсуждения с проф. А.А. Шалыто.
5)
Сделаем общее замечание насчет доказательной силы аргумента: "Это исследовано в теории". При применении теории необходимо всегда помнить, что вовсю исследуются не только разумные понятия, но и извращения.
Анализ состояния дел
Построение таблиц заканчивает этап спецификации нашей программы. Таблицы 9.1 и 9.2-другое формализованное представление рисунков 9.6 и 9.7. Как всегда, разные формализмы отличаются по практической направленности. Граф в некоторых случаях может быть автоматизированно преобразован в прототип программы (попытайтесь сами проделать это со спецификацией на языке UML), но получающиеся программы всегда требуют ручной доработки. Табличное же представление допустимо рассматривать как мини-язык программирования. Для него возможно построение транслятора или интерпретатора, которые в частных типах таблиц давно уже используются (их широкому применению мешает привязка к конкретным предметным областям и приложениям, поскольку профессиональные системные программисты свысока смотрели на столь простые задачи).
Обратимся к семантике вычислений на языке таблиц. Рассматривается контекст некоторой программы на языке C++ (или на другом языке традиционного типа). В этом контексте определяется значение переменной Entry (множество ее значений совпадает с множеством наименований состояний), далее выполняются следующие действия:
Для рассматриваемого сейчас примера указанной семантики вычислений недостаточно. Во многих случаях полезно расширение выразительных возможностей таблиц за счет добавления действий, которые выполняются в начале и в конце обработки текущего состояния.
Это достигается, например, с помощью специальных служебных слов:
Можно также определять локальные данные для состояний (в примере такие данные определены только для начального состояния), но это должно быть согласовано с правилами локализации имен языка программирования и с общим стилем, в котором написана программа. Заметим, что локальные данные всех состояний конечного автомата должны быть помещены в общий контекст, а приписывание их к конкретным состояниям является ограничением видимости, подобным тому, которое используется в модульном программировании (если Вы уже программировали на Object Pascal Delphi, Java либо Oberon, то знакомы с модульностью). Это прагматически следует из того положения, что работа теоретического конечного автомата не требует привлечения памяти2).
Озаботимся теперь тем, как запрограммировать требуемые действия, когда нет возможности воспользоваться языком таблиц непосредственно. С таблицами, представляющими таблицу переходов, можно сделать следующее.
Рассмотрим последовательно эти три возможности.
Автоматизированное преобразование таблиц переходов
Если автоматизировать работу с табличным представлением, то прежде всего требуется строго определить структуру данных, представляющих таблицу переходов. Способ задания таблицы зависит от стратегии дальнейшей обработки. В частности, если вручную строится текстовое представление таблицы, которое в дальнейшем преобразуется к исполняемому виду, то приемлемо, например, такое представление.
_1 char symbol; // Чтение потока символов неявное int cnt; . . . // Инициализация _4 St1 _5 _1 St1 _2 'a'<=symbol && symbol <= 'z' _3 printf ("%c", symbol); cnt = 1; _4 St2 _5 _1 _2 //symbol <'a' && 'z'< symbol && symbol != '\n' _3 //Так как нужно печатать только слова, //действий нет _4 St1 _5 _1 _2 failure _3 // symbol == '\n' не нужно читать _4 St3 _5 _1 St2 _2 'a'<=symbol && symbol <= 'z' _3 printf ("%c", symbol); cnt++; _4 St2 _5 _1 _2 //(symbol <'a'||'z'< symbol)&&*/ symbol!='\n' _3 printf (" - %i\n", Cnt); _4 St1 _5 _1 _2 failure _3 printf (" - %i\n", Cnt); _4 St3 _5 _1 St3 _2 'a'<=symbol && symbol <= 'z' _3 printf ("%c", symbol); cnt = 1; _4 St2 _5 _1 _2 //symbol <'a' && 'z'< symbol && symbol != '\n' _3 //Так как нужно печатать только слова, //действий нет _4 St1 _5 _1 _2 failure _3 // symbol == '\n' не нужно читать _4 exit_5 _1 exit_2 // условие истина, но без неявного чтения потока _3 return 0; _4 _5
Листинг 10.3.1. Программа в виде размеченного текста.
Здесь <_i>, i = 1, . . . , 5 обозначают позиции таблицы. Эти сочетания символов, нигде в обычной программе не встречающиеся, легко могут распознаваться препроцессором. Размещаемые между ними последовательности символов разносятся по соответствующим полям нужной структуры, которая, в зависимости от выбранной стратегии, интерпретируется либо транслируется. С помощью этих сочетаний осуществляется разметка текста, которая дает возможность распознавать и осмысливать его фрагменты.
Стоит обратить внимание на то, что за счет специального взаимного расположения символов в данном тексте представляемая им таблица автомата вполне обозрима. Если нет более подходящего представления, то данную структуру можно рекомендовать для ввода.
Однако непосредственная интерпретация универсального текстового размеченного представления довольно затруднительна. Предпочтительнее, чтобы единицами интерпретации были бы сами поля таблицы. Вообще, этому противоречит наличие в таблице полей, значения которых - фрагменты исполняемого кода на языке программирования (такая запись удобна для человека, так как для заполнения таблицы не приходится прибегать ни к каким дополнительным соглашениям). На самом деле противоречие возникает только для поля действий, поскольку последовательности символов между <_2> и <_3> имеют ясно выраженную семантику: это проверка условия. Если всегда рассматривать условия как проверку того, чему равен входной символ, то вполне понятны, легко задаются, распознаются и интерпретируются специальные обозначения: перечисления значений, их диапазоны и т.д. Трактовка этих обозначений не вызывает осложнений, а потому подобные приемы кодирования применяются довольно часто.
Если говорить о полях действий, то их представление для большинства языков программирования плохо разработано. Данное обстоятельство препятствует использованию автоматного программирования: кодирование действий усложняет обработку. Но если в языке можно задавать подпрограммы как данные, то описание структуры таблицы, которое будет согласовано с дальнейшей трансляцией или интерпретацией, возможно, в частности, в языках функционального программирования (семейство LISP и ML) и в языке Prolog. Но функциональное и сентенциальное программирование хорошо интерпретируют лишь частные случаи таблиц.
Пусть тип T_StructTableLine описывает структуру одной строки таблицы, а вся таблица представлена в виде массива Table таких структур. Пусть далее iSt - переменная, используемая для индексирования массива Table, некоторые из ее значений представляют состояния конечного автомата (но не все, а только те, к которым определен переход!).
Наконец, пусть
int handler ( int );
-обработчик строки (ее интерпретатор или транслятор), <понимающий> структуру T_StructTableLine, специфицируемый как функция, при выполнении которой должно быть определено очередное значение iSt. Значение iSt, не указывающее ни на какую строку таблицы, служит сигналом для завершения обработки (при желании можно заняться кодированием того, как завершилась обработка с помощью задания различных таких значений).
Тогда схема программы, которая оперирует с таблицей с помощью функции handler, может быть задана следующим циклом:
iSt = 0; do { iSt = handler ( iSt ); } while ( OUTSIDE ( iSt ) );
Понятно, что выбор массива в качестве представления автомата непринципиален. Допустимо, а иногда и предпочтительнее, работать со списком строк. Также непринципиален способ вычисления предиката OUTSIDE, проверяющего условие окончания цикла, хотя он и зависит от выбранного представления автомата. Возможность не рассматривать явно имена состояний, напротив, принципиальна: тот факт, что строки таблицы сгруппированы вокруг (поименованных) состояний, ничего не значит ни для обработки, ни для интерпретации, поскольку у конечного автомата следующее состояние всегда определяется явно.
Логика функции handler, интерпретирующей таблицу, проста. Для правильной таблицы, не содержащей состояний, в которых возможны неопределенные переходы, она строится следующим образом:
Осталось предусмотреть детали для заключительных состояний, но это сделать уже легко.
Таким образом, нужно научиться описывать структуру строки таблицы. На языке C++/С# эта задача может решаться довольно просто:
struct T_StructTableLine { // поле для имени состояния избыточно int (*condition)(); // поле условия void (*action)(); // поле действия int ref; // поле перехода: индекс строки таблицы, // которая будет обрабатываться следующей, // или признак завершения процесса }
Сама таблица описывается следующим образом:
T_StructTableLine Table[]
или
T_StructTableLine Table [Размер таблицы]
если значения строк задаются вне этого описания.
Однако сразу же видно ограничивающее соглашение, которое пришлось принять в связи с особенностями языка реализации: все условия и все действия оформлены как функции, тогда как задача, по своей сути, этого не требует. Более того, отделенное от таблицы описание функций, предписываемое языком С++/C#, резко снижает выразительность представления:
int Cond_St1_1() - условие в Table[1]
и
void Act_St1_1() - действие в Table[1] (строка 1 состояния St1);
int Cond_St1_2() - условие в Table[2]
и
void Act_St1_2() - действие в Table[2] (строка 2 состояния St1);
и т. д.
Еще один неприятный момент данного представления - невозможность единообразно с действиями представить их общий контекст (нулевая строка таблицы), а поскольку инициализацию естественно рассматривать как задание предварительных действий, готовящих собственно обработку, то ее предпочтительнее соединять с контекстом, а не с функциями, реализующими проверки и действия.
Последний недостаток неустраним ни в каком языке, если проверки и действия трактовать как процедуры, которые работают в общем контексте, задаваемом в заголовке таблицы. Так что лучше сразу отказаться от описания этого контекста в рамках таблицы (задание инициализации в ней возможно). Что касается первого недостатка, то он носит почти синтаксический характер, и если бы можно было задавать тела процедур как значения полей структур, то наглядность представления можно было бы сохранить. В языковом оформлении, похожем на С/С++/C#, это выглядело бы как следующее присваивание значения Table в качестве инициализации.
Table[]= { {{return true;}, /* инициализация */, 1}, /*St1*/{{return 'a'<=symbol && symbol <= 'z';}, {printf ("%c", symbol); cnt = 1;}, 4}, {{return symbol != '\n';}, /* Так как нужно печатать только слова, действия не заполняются */, 1}, {{return true}, /* Переход не требует чтения, symbol == '\n' не нужно читать */, 0}, /*St2*/{{return 'a'<=symbol && symbol <= 'z';}, {printf ("%c", symbol); cnt++;}, 4}, {{return symbol!='\n';}, {printf ("-%i\n",cnt);}, 1}, {{return true }, {printf ("- %i\n",cnt);}, 0} };
Листинг 10.3.2.
Но для С/С++/C#, а также для других языков, не ориентированных на работу с таблицами, говорить о естественности представления не приходится. По-видимому, наиболее разумно строить автоматический преобразователь (типа препроцессора, но не путать этот термин с С!), который составляет текст программы по таблице. В этом случае снимается много проблем:
Это решение часто является приемлемым, однако и у него есть свои недостатки. Прежде всего, поиск ошибок, допущенных в текстах условий и действий, затруднен, возникает проблема двойной интерпретации (приходится понимать как исходное представление, так и внутреннее). Так что ручной перевод остается важным методом преобразования таблиц.
Проанализировав исходную таблицу, легко заметить, что используется фактически два варианта функций-условий и три - функций-действий. Из-за нестандартности работы с инициализацией (нулевая строка таблицы) удобно пополнить этот набор еще двумя функциями: <условием> и <действием>, выполняемыми при переходе к этой строке, которая интерпретируется как завершение работы автомата (таким образом, предикат OUTSIDE (iSt) можно представить как равенство аргумента нулю).
Теперь почти все готово для составления программы 10.3.3, реализующей интерпретатор таблицы переходов. Осталось решить вопрос о неявном для таблицы, но с необходимостью явно м для программы способе чтения потока символов. Этот вопрос имеет три аспекта:
Следовательно, читать очередной символ целесообразно после отработки действия.
Отметим, что данные соглашения не являются абсолютными, и поставленные вопросы нуждаются в решении всякий раз, когда реализуется переход от табличного представления к программе. В предыдущем параграфе Вы уже видели, как практически в каждой реализации метод чтения слегка изменялся.
С учетом сделанных замечаний программа, решающая задачу подсчета длин строк методом интерпретации таблицы, может быть записана следующим образом.
#include
int c0(), c1(), c2(); // функции-условия void a0(), a1(), a2(), a3(); // функции-действия int handler ( int i ); // обработчик строк таблицы struct T_StructTableLine { // поле для имени состояния избыточно int (*condition)(); // поле условия void (*action)(); // поле действия int ref; // поле перехода: индекс строки таблицы, // которая будет обрабатываться следующей, // или признак завершения процесса } T_StructTableLine Table[]={ {c0,a0,1}, // таблица инициализируется статически, {c1,a1,2}, // альтернативное решение - специальная {c2,a0,1}, // функция задания начальных значений. {c0,a0,3}, // Оно более гибкое, но менее {c1,a2,2}, // эффективно. {c2,a3,1}, // О наглядности см.комментарий {c0,a3,3}; // в тексте. {c1,a2,2}, {c2,a3,1}, {c0,a3,0}}; void main() { int iSt=0; do { iSt = handler ( iSt ); } while ( iSt); }
int handler ( int i ) { if (Table[i].condition()) { Table[i].action(); if (Table[i].ref) { symbol = getchar (); return Table[i].ref; } } else return ++i; }
// Описания используемых функций: int c0(){return symbol == '\n';} int c1(){return 'a'<=symbol && symbol <= 'z';} int c2(){return 'a'>symbol ||symbol > 'z';}
void a0(){} void a1(){printf ("%c", symbol);cnt = 1;} void a2(){printf ("%c", symbol);cnt++;} void a3(){printf ("- %i\n", cnt);}
Листинг 10.3.3. Длины слов: интерпретатор конечного автомата.
Обсуждение решения
Как уже отмечалось, фрагменты, описывающие условия и действия в таблице переходов и реализованные как процедурные вставки, с точки зрения препроцессора (не препроцессора системы программирования, а специального преобразователя, генерирующего представление таблицы для интерпретации), являются нераспознаваемыми данными, которые он просто пропускает без изменений для обработки компилятором. Интерпретатор же, наоборот, не в силах сам исполнять процедуры, а потому трактует ссылки на них (в соответствующих полях) как данные. Таким образом, условия и действия в таблице двойственны: они являются одновременно и данными, и программными фрагментами. Автоматический преобразователь таблицы, не понимая языка таких двойственных данных, пытается, тем не менее, их объединить с обычными данными (в рассматриваемом случае это индексы строк переходов) в одной структуре.
На первый взгляд кажется, что ситуация существенно упростилась бы в языке, в котором есть возможность воспринимать данные как выполнимые фрагменты. Пример такого рода - команда <Вычислить строку>. Эта команда давала бы возможность интерпретатору понимать программы-данные, не оставляя их нераспознанными. Подобная команда порою встречается в языках скриптов, ориентированных на интерпретацию. А в языке LISP, в котором структуры данных и программы просто совпадают, указанная двойственность не возникает. Но по опыту известно, что столь общее решение чревато столь же общими и вездесущими неприятностями, и нужно искать частный его вариант, адекватный данной задаче.
Метод решения задач с помощью построения таблиц и графов состояний и переходов часто удобен для обработки потоков данных. В книгах [32], [33], а особенно в задачнике [2] и на сайте http://is.ifmo.ru, имеется ряд задач такого рода. Решения стоит оценить количественно и качественно: сколько требуется состояний и действий, как лучше получается в данном случае (в состояниях или на переходах). Может оказаться, что понадобятся средства, выходящие за рамки описанных методов.
Это допустимо, следует только осознавать грань между использованием конечного автомата и применением другого подходящего метода, а также четко разделять внутри программы возможности, относящиеся к разным стилям программирования.
Подведем итоги
Таблица и граф - два теоретически эквивалентных (но практически разных) представления. Каждое из них имеет свои достоинства и недостатки (на графе информация беднее, но обозримость может быть лучше). Одна из этих спецификаций чаще всего делает ненужной другую.
Таблицы и графы гораздо лучше самой программы с точки зрения модифицируемости и преобразований.
Таким образом, табличное и графовое представления автомата являются спецификациями №1, о которых нужно думать в первую очередь, когда составляется автоматная программа.
Главный недостаток табличных и графовых методов представления автоматов в том, что их приходится дополнительно преобразовывать в программу. А в дальнейшем возникает соблазн модифицировать непосредственно программу, и спецификация перестает быть адекватной программе.
В связи с этим возникает вопрос об улучшении поддержки методов табличного и графового представления автоматных программ.
|
|
|
В этом пункте заложено недетерминированное поведение получаемой программы. Как правило, при применении метода таблиц переходов возможность недетерминированного поведения игнорируется. Вместо этого задается какое-либо произвольное детерминированное правило, например, выбирается текстуально первое из действий, для которого условие истинно. Это похоже на то, как определяются условные выражения и оператор переключения в традиционных языках.
2)
Памятью можно считать номер текущего состояния (замечание проф. А. А.Шалыто).
3)
Это верно и для унификационного варианта.
4)
Этот вариант сознательно запрограммирован на Object Pascal, поскольку разница между языками традиционного типа несущественна, а изменение языка заодно выделяет и тот факт, что данный вариант ориентирован на другую модель автоматного программирования.
Вторая программа, чуть дальше от
|
ENTRY Go{= |
| Листинг 10.2.1. Длины слов: рефал |
| Закрыть окно |
|
// Реализация автомата с табл. 9.1 #include char symbol; int cnt; enum States { St1, St2, St3 } State; void main( void ) {fstream a,b; a.open("input.txt",ios::in); b.open("output.txt",ios::out); State = St1; while (true ) {symbol=a.get(); switch ( State ) { case St1: if ('a'<=symbol && symbol <= 'z') { b< |
| Листинг 10.2.2. Длины слов: явный цикл обработки потока |
| Закрыть окно |
|
#include char symbol; int cnt; enum States { St1, St2, St3, Exit } State; inline States f_St1 () { if ('a'<=symbol && symbol <= 'z') printf ("%c", symbol); cnt = 1; symbol = getchar (); return St2; } else if (symbol != '\n') { symbol = getchar (); return } else {symbol = getchar (); return } inline States f_St2 () { if ('a'<=symbol && symbol <= 'z') printf ("%c", symbol); cnt++; symbol = getchar (); return St2; } else if (symbol != '\n') { printf (" -%i\n", cnt); symbol = getchar (); return St1; } else { printf (" - %i\n", cnt); symbol = getchar (); return St3; } } inline States f_St3 () { if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); return St2; } else if (symbol != '\n') { symbol = getchar (); return St1; } else return Exit; } void main( void ) { symbol = getchar (); State = St1; for (;;) { switch ( State ) { case St1: State = f_St1 (); break; case St2: State = f_St2 (); break; case St3: State = f_St3 (); break; default: return; } } } |
| Листинг 10.2.3. Длины слов: использование процедур для описания состояний. |
| Закрыть окно |
|
program funcgoto; {$APPTYPE CONSOLE} {$T+} uses SysUtils; type P=procedure; type Pp= ^P; const maxstate = 7; const maxcond = 3; type states = 1.. maxstate; conds = 1.. maxcond; type table = array [states, conds] of states; type act = array [states] of P; const gotos: table = ((2,2,2),(3,2,4),(3,5,6),(3,2,7),(3,2,4),(3,2,7),(1,1,1)); var Symbol: char; var Cnt: integer; var Inf, Outf: text; var state: states; procedure Start; begin Cnt:=0; AssignFile(Inf, 'input.txt'); Reset(Inf); AssignFile(Outf, 'output.txt'); Rewrite(Outf); end; procedure Finish; begin Closefile(Inf); Closefile(Outf); Abort; end; procedure St1; begin {No actions} end; procedure St2; begin write(outf,Symbol); Inc(Cnt); end; procedure St4; begin writeln(outf,' - ',Cnt); Cnt:=0; end; const actions: act = (Start, St1,St2,St1,St4,St4,Finish); begin state:=1; while true do begin actions[state]; if (state <>1) and (state<>7) then begin read(inf,Symbol); if Ord(Symbol)=10 then read(inf,Symbol) end; if Symbol in ['a'..'z'] then state:= gotos[state,1]; if not(Symbol in ['a'..'z']) and (Ord(Symbol)<>13) then state:=gotos[state,2]; if Ord(Symbol)=13 then state:=gotos[state,3]; end; end. |
| Листинг 10.2.4. Длины слов: массив функций и переходов |
| Закрыть окно |
|
#include char symbol; int cnt; void main( void ) { symbol = getchar (); St1: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); goto St2; } else if (symbol != '\n') { symbol = getchar (); goto St1; } else /* (symbol == '\n') */ {symbol = getchar (); goto St3;}; St2: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt++; symbol = getchar (); goto St2; } else if (symbol != '\n') { printf (" -%i\n", cnt); symbol = getchar (); goto St1; } else { printf (" -%i\n", cnt); symbol = getchar (); goto St3; }; St3: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); goto St2; } else if (symbol != '\n') { symbol = getchar (); goto St1; } else /* (symbol == '\n') */ return; } |
| Листинг 10.2.5. Длины слов: состояния - метки в программе. |
| Закрыть окно |
Ручная трансляция таблиц переходов
В решениях 1 и 2 возникает следующий вопрос: во что транслировать таблицу переходов? Вариантов множество, ниже рассматриваются лишь некоторые из них.
Вариант 1.Можно считать St1 и St2 функциями, реализующими все действия состояний.При использовании верно подобранных стиля и инструментальных средств этот подход дает отличный результат. Рассмотрим, в частности, как может быть реализована наша задача (еще точнее, автомат таблицы 9.1) на языке Рефал.
ENTRY Go{=
Листинг 10.2.1. Длины слов: рефал
Эти программы настолько коротки и естественны, что практически не требуют комментариев. Единственная новая возможность, использованная здесь, в принципе излишняя, но делает программу красивее. Конструкции
Стандартная функция
Таким образом, структура управления на переходах хорошо согласуется со структурой управления в конкретизационном варианте сентенциального программирования3). Вновь отметим, что, хотя некоторые описания функций кажутся рекурсивными, рекурсий нет, так как исходный вызов завершается до активизации порожденных им вызовов. Каждый шаг конкретизации начинается с проверки условий, поэтому действия естественно сопоставить именно переходам.
В данном случае удалось добиться столь красивого результата потому, что действия также полностью соответствовали той области, где применение языка Рефал наиболее выигрышно. Но даже в таком простом случае после минимальной ручной доработки программа стала еще лучше.
Формально функциональное представление состояний возможно как на языке традиционного типа, так и на LISP и Prolog. Но в этом случае мы проигрываем в выразительности и естественности программы, а также еще по одному важному критерию. Во всех этих случаях то, что выглядит как рекурсия, действительно ею является, а рекурсия в данном случае лишь мешает.
Вариант 2. Считать St1, St2, St3 значениями некоторого перечислимого типа State.
// Реализация автомата с табл. 9.1 #include
char symbol; int cnt;
enum States { St1, St2, St3 } State; void main( void ) {fstream a,b; a.open("input.txt",ios::in); b.open("output.txt",ios::out); State = St1; while (true ) {symbol=a.get(); switch ( State ) { case St1: if ('a'<=symbol && symbol <= 'z') { b<
Листинг 10.2.2. Длины слов: явный цикл обработки потока
Программа 10.2.2 хороша только в том случае, если ограничиться автоматными моделями в достаточно узком смысле. Программа точно соответствует табличному представлению автомата, почти все дублирования действий, связанные с таким представлением, остались. Возникает некоторая неудовлетворенность тем, что появилось лишнее действие: выбор выполняемого фрагмента по значению переменной State. Если ограничиться управляющими средствами методологии структурного программирования, то это - наилучший выход. Попытки применить циклы внутри фрагментов, помеченных как case St1: и case St2:, приводят лишь к уменьшению наглядности по сравнению с табличным представлением.
Есть еще один вопрос, который требуется решить при таком подходе, - выбор типа результата функций-состояний и способа возвращения результата. Естественный результат такой функции - это новое состояние, в которое попадает автомат при переходе. Он может быть представлен, например, глобальной переменной (такой как State в программе 10.2.2, которой присваивается новое значение при выполнении функции-состояния). Но предпочтительнее не трогать State в каждой из функций, а предоставить задачу фактического изменения состояния общему их контексту. Наиболее правильной реализацией состояний при таком подходе являются функции, которые вырабатывают в качестве результата значение типа, перечисляющего все состояния.
Следующая программа 10.2.3 почти буквально реализует данную идею. В отличие от программы 10.2.2, тип States содержит четыре значения: St1, St2, St3 и Exit. Последнему из них не соответствует ни одна функция из-за тривиальности переходов и действий в данном состоянии.
#include
char symbol; int cnt; enum States { St1, St2, St3, Exit } State;
inline States f_St1 () { if ('a'<=symbol && symbol <= 'z') printf ("%c", symbol); cnt = 1; symbol = getchar (); return St2; } else if (symbol != '\n') { symbol = getchar (); return } else {symbol = getchar (); return }
inline States f_St2 () { if ('a'<=symbol && symbol <= 'z') printf ("%c", symbol); cnt++; symbol = getchar (); return St2; } else if (symbol != '\n') { printf (" -%i\n", cnt); symbol = getchar (); return St1; } else { printf (" - %i\n", cnt); symbol = getchar (); return St3; } }
inline States f_St3 () { if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); return St2; } else if (symbol != '\n') { symbol = getchar (); return St1; } else return Exit; }
void main( void ) { symbol = getchar (); State = St1; for (;;) { switch ( State ) { case St1: State = f_St1 (); break; case St2: State = f_St2 (); break; case St3: State = f_St3 (); break; default: return; } } }
Листинг 10.2.3. Длины слов: использование процедур для описания состояний.
Следует обратить внимание на то, что программа наглядна, строго соответствует таблице автомата. Можно сказать, что граф автомата определяет распределенную по состояниям схему потоковой обработки. На самом деле она гораздо лучше подходит модели вычислений в состояниях, а не на переходах. Более того, эта программа при небольшом увеличении числа состояний быстро теряет наглядность, если программировать на переходах, поскольку следующие состояния упрятаны внутри соответствующих процедур, но сохранит ее, если программировать в состояниях.
Таким образом, мы пришли к тому, что в рамках стандартной методики программирования все решения имеют некоторые недостатки. Надо искать другое, и здесь стоит вспомнить пословицу (на самом деле отражающую один из приемов творческого мышления): "Новое - хорошо забытое старое". Поищем решение среди того, что забраковано стандартными методиками.
Проанализировав граф автомата или таблицу, можно заметить, что в данном примере, наряду с циклом потоковой обработки, имеется еще один цикл: передача управления между состояниями. Это причина, из-за которой в двух предыдущих вариантах появились присваивание переменной State значения и выбор выполняемого фрагмента по этому значению.
Особенность последовательностей действий
State = <значение>;
switch ( State )
которая выполняется всякий раз в конце действий, ассоциированных с состояниями (точнее - реализаций действий в программах), в том, что в каждой точке программы, где встречается данное присваивание, можно точно указать результат динамически следующего оператора переключения, причем эта информация не зависит от обрабатываемого потока и может быть определена до вычислений статически.
А нельзя ли использовать это явно для организации управления конечным автоматом? Можно, это демонстрирует четвертый вариант решения обсуждаемой задачи.
Вариант 4. Матрица переходов и вектор-функций, соответствующих состояниям4)
program funcgoto; {$APPTYPE CONSOLE} {$T+} uses SysUtils;
type P=procedure; type Pp= ^P; const maxstate = 7; const maxcond = 3; type states = 1.. maxstate; conds = 1.. maxcond; type table = array [states, conds] of states; type act = array [states] of P; const gotos: table = ((2,2,2),(3,2,4),(3,5,6),(3,2,7),(3,2,4),(3,2,7),(1,1,1)); var Symbol: char; var Cnt: integer; var Inf, Outf: text; var state: states;
procedure Start; begin Cnt:=0; AssignFile(Inf, 'input.txt'); Reset(Inf); AssignFile(Outf, 'output.txt'); Rewrite(Outf); end;
procedure Finish; begin Closefile(Inf); Closefile(Outf); Abort; end;
procedure St1; begin {No actions} end;
procedure St2; begin write(outf,Symbol); Inc(Cnt); end;
procedure St4; begin writeln(outf,' - ',Cnt); Cnt:=0; end;
const actions: act = (Start, St1,St2,St1,St4,St4,Finish);
begin state:=1; while true do begin actions[state]; if (state <>1) and (state<>7) then begin read(inf,Symbol); if Ord(Symbol)=10 then read(inf,Symbol) end; if Symbol in ['a'..'z'] then state:= gotos[state,1]; if not(Symbol in ['a'..'z']) and (Ord(Symbol)<>13) then state:=gotos[state,2]; if Ord(Symbol)=13 then state:=gotos[state,3]; end; end.
Листинг 10.2.4. Длины слов: массив функций и переходов
Это решение неплохое, но оно годится лишь для вычислений в состояниях.
Фактически оно резко расходится с канонами структурного программирования, где даже не предполагалось переключение между функциями внутри массива функций. Оно несколько утяжелено деталями, связанными с отработкой особых состояний ввода входного потока. Зато повторяющиеся действия не дублируются.
Рассмотрим последний вариант.
Вариант 5. Использование статической информации о разветвлениях вычислений.
#include
char symbol; int cnt; void main( void ) { symbol = getchar (); St1: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); goto St2; } else if (symbol != '\n') { symbol = getchar (); goto St1; } else /* (symbol == '\n') */ {symbol = getchar (); goto St3;}; St2: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt++; symbol = getchar (); goto St2; } else if (symbol != '\n') { printf (" -%i\n", cnt); symbol = getchar (); goto St1; } else { printf (" -%i\n", cnt); symbol = getchar (); goto St3; }; St3: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); goto St2; } else if (symbol != '\n') { symbol = getchar (); goto St1; } else /* (symbol == '\n') */ return; }
Листинг 10.2.5. Длины слов: состояния - метки в программе.
В данном варианте исчезает необходимость вычисляемого перехода (результат внедрения статической информации в текст программы), и, как следствие, становятся избыточными описания типа States и переменной State этого типа. В программе появляются операторы безусловного перехода, из-за этого структура управления программы полностью расходится с канонами структурного программирования, что дает повод догматически мыслящим программистам и теоретикам подвергать критике такой вариант программы. Но в данном случае отступление от канонов структурного программирования полностью оправдано, поскольку за счет специального расположения фрагментов текста вся программа оказалась похожа на таблицу конечного автомата, а структура передач управления копирует граф конечного автомата.Более того, такое представление нейтрально по отношению к моделям Мура и Мили. Таким образом, лишь после полного отхода от канонов структурности программа стала адекватна своей спецификации.
Стили и методы программирования
Пример 10.2.1
Анализ состояния дел
Ручная трансляция таблиц переходов
Автоматизированное преобразование таблиц переходов
Обсуждение решения
Опционы
История опционов начинается в XVIII веке в Голландии, где впервые их стали использовать на рынке живых цветов. C тех пор опционы обращаются на многих мировых рынках: продуктов питания, ценных бумаг и, конечно, валютном рынке. Бум опционов, равно как и всех остальных производных инструментов, пришелся на 80-90-е годы.Анализ опционов
Бинарные опционы
Виды опционов
Закон об опционах
Учебник по опционам
Опционы на Форекс
Контракт на опционы
Математика опционов
Оценка опционов
Реальные опционы
Классический подход к опционам
А-опционы
Опционный риск
Опционы в России
Спрэд на опционах
Опционные стратегии
Торговля опционами
Цена опциона