
|
Введение в DOM
Базовое приложение
Начнем с создания базового приложения, класса с именем OrderProcessor.import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import java.io.File; import org.w3c.dom.Document; public class OrderProcessor { public static void main (String args[]) { File docFile = new File("orders.xml"); Document doc = null; try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); doc = db.parse(docFile);
} catch (Exception e) { System.out.print("Problem parsing the file: "+e.getMessage()); } } }
Сначала Java-код импортирует необходимые классы, а затем создает приложение OrderProcessor. Примеры в этом учебнике рассматривают один файл, так что для краткости приложение содержит прямую ссылку на него.
Так как объект Document может быть использован позже, приложение определяет его вне блока try-catch.
В блоке try-catch приложение создает объект DocumentBuilderFactory, который затем используется для создания DocumentBuilder. Наконец, DocumentBuilder разбирает файл для создания Document.
Базовые типы узлов: документ, элемент, атрибут и текст
Наиболее распространенными типами узлов в XML являются:Базовый XML-файл
Примеры во всем этом учебнике используют XML-файл, который содержит приведенный ниже пример кода, представляющий заказы, проходящие через торговую систему. Кратко, основными частями XML-файла являются:В DOM работа с XML-информацией означает разбиение ее сначала по узлам.
Что такое DOM?
Основой Расширяемого Языка Разметки, Extensible Markup Language или XML является DOM. XML-документы содержат иерархию информационных единиц, называемых узлами; DOM является способом описания этих узлов и отношений между ними.Вдобавок к ее роли концептуального описания XML-данных, DOM является серией Рекомендаций, вырабатываемых Консорциумом World Wide Web (W3C). DOM начиналась как способ для Web-браузеров для идентификации и манипулирования элементами на странице - функциональности, которая еще предшествовала вовлечению в нее W3C и известна, как "DOM, Уровень 0".
Действующая Рекомендация DOM, сейчас она находится на Уровне 2 (на момент написания учебника Уровень 3 находится на последнем этапе разработки), является API, который определяет объекты, представляемые в XML-документе, а также методы и свойства, которые используются для доступа к ним и манипулирования ими.
Этот учебник демонстрирует API Ядра DOM (DOM Core) как средство чтения и манипулирования XML-данными на примере серии заказов в системе торговли. Он также обучает вас, как создавать объекты DOM в вашем собственном проекте для хранения данных и работы с ними.
Что такое пространство имен?
Одно из главных усовершенствований между DOM Уровня 1 и DOM Уровня 2 является добавление поддержки пространств имен. Поддержка пространств имен позволяет разработчикам использовать информацию из разных источников или в разных целях без конфликтов.Концептуально пространства имен являются зонами, в которых все имена должны быть уникальны.
Например, я работаю в офисе и у меня то же имя, что и у клиента. Если я где-то в офисе, и секретарь говорит: "Ник, возьми трубку на 1-й линии", - каждый понимает, что она имеет в виду меня, потому что я нахожусь в "пространстве имен офиса". Аналогично, если она говорит "Ник звонит по 1-й линии", - каждый знает, что она говорит о клиенте, потому что звонящий находится вне пространства имен офиса.
С другой стороны, если я нахожусь вне офиса, и она делает такое же заявление, возможно недоразумение, поскольку существуют две возможности.
Те же проблемы возникают, когда XML-данные из разных источников комбинируются (как в информации о кредитоспособности в файле-примере, подробно рассматриваемом в этом учебнике позже).
Для обучения
Для получения продуктов и технологий
Добавление узлов: добавление узлов в документ
Вы можете создать новый Node многими способами, и этот пример применяет несколько из них. Во-первых, объект Document может создавать новый текстовый узел со значением totalString. Новый Node теперь существует, но еще никуда не присоединен к Document. Новый элемент total создается аналогично, и он также поначалу свободный.Другой способ добавление узла - применение appendChild(), как показано здесь для нового элемента total.
Наконец, приложение может использовать insertBefore() для добавления нового элемента Document, указывая новый Node и предшествующий Node.
Прохождение через документ проверяет изменения.
... changeOrder(root, "status", "processing"); NodeList orders = root.getElementsByTagName("order"); for (int orderNum = 0; orderNum < orders.getLength(); orderNum++) { ... String totalString = new Double(total).toString(); Node totalNode = doc.createTextNode(totalString); Element totalElement = doc.createElement("total"); totalElement.appendChild(totalNode); thisOrder.insertBefore(totalElement, thisOrder.getFirstChild());
} stepThrough(root);
...
Добавление узлов: подготовка данных
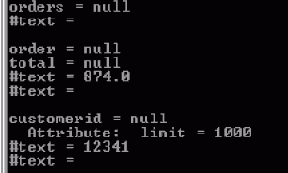
Иногда необходимо не изменить существующий узел, а добавить узел, и у вас есть несколько способов сделать это. В нашем примере приложение вычисляет общую стоимость каждого заказа и добавляет в order элемент total. Оно получает общую стоимость, выбирая каждый заказ и проходя через все его составляющие, чтобы получить стоимость составляющей, а затем итоговую стоимость их всех. Затем приложение добавляет новый элемент в заказ (см. код ниже).Сначала приложение выбирает элементы order так же, как оно выбирало элементы status. Затем перебирает каждый из этих элементов.
Для каждого из этих order приложению нужен NodeList из его составляющих item, так что приложение должно сначала преобразовать узел (Node) order в Element, чтобы использовать getElementsByTagName().
Приложение затем может перебрать составляющие item для выбранного order. Каждая из них преобразуется в Element, так что из него можно выбрать по имени price и qty. Приложение делает это при помощи метода getElementsByTagName(), и поскольку их всего по одному в каждом item, оно может прямо брать item(0), первую составляющую результирующего NodeList. Этот первый элемент представляет элемент price (или qty). Из него извлекается значение текстового узла.
Значение текстового узла имеет тип String, приложение затем преобразует его в double, чтобы сделать возможным вычисление.
Когда приложение заканчивает проверку всех составляющих для каждого заказа, total типа double представляет итоговое значение. Затем total преобразуется в String, так что оно может использоваться как содержимое нового элемента,
... changeOrder(root, "status", "processing"); NodeList orders = root.getElementsByTagName(" order "); for (int orderNum = 0; orderNum < orders.getLength(); orderNum++) { Element thisOrder = (Element)orders.item(orderNum); NodeList orderItems = thisOrder.getElementsByTagName("item"); double total = 0; for (int itemNum = 0; itemNum < orderItems.getLength(); itemNum++) { // Total up cost for each item and // add to the order total //Get this item as an Element Element thisOrderItem = (Element)orderItems.item(itemNum); //Get pricing information for this Item String thisPrice = thisOrderItem.getElementsByTagName("price").item(0) .getFirstChild().getNodeValue(); double thisPriceDbl = new Double(thisPrice).doubleValue(); //Get quantity information for this Item String thisQty = thisOrderItem.getElementsByTagName("qty").item(0) .getFirstChild().getNodeValue(); double thisQtyDbl = new Double(thisQty).doubleValue(); double thisItemTotal = thisPriceDbl*thisQtyDbl; total = total + thisItemTotal; } String totalString = new Double(total).toString();
} ...
DOM как API
Начиная с DOM Уровня 1, DOM API содержит интерфейсы, которые представляют всевозможные типы информации, которые могут быть найдены в XML-документе, такие, как элементы и текст. Он также включает в себя методы и свойства, необходимые для работы с этими объектами.Уровень 1 включает в себя поддержку XML 1.0 и HTML, в которой каждый элемент HTML представляется как интерфейс. Он включает в себя методы для добавления, редактирования, перемещения и чтения информации, содержащейся в узлах и т.д. Он, однако, не включает в себя поддержку пространств имен XML, которые обеспечивают возможность сегментировать информацию внутри документа.
Поддержка пространств была добавлена в DOM Уровня 2. Уровень 2 расширяет Уровень 1, позволяя разработчикам обнаруживать и использовать информацию пространств имен, которая может быть применима к узлу. Уровень 2 добавляет также несколько модулей поддержки Каскадируемых Таблиц Стилей, Cascading Style Sheets (CSS), событий и расширенных манипуляций с деревом.
DOM Уровня 3, в настоящее время находящийся на последнем этапе разработки, включает в себя улучшенную поддержку объекта Document (предыдущие версии оставляли это на усмотрение приложений, что делало затруднительным создание родовых приложений), расширенную поддержку пространств имен, и новые модули для загрузки и сохранения документов, проверки правильности и XPath, средства для выбора узлов, используемые в XSL Transformations и других технологиях XML.
Модуляризация DOM означает для разработчиков, что вы должны знать, поддерживаются ли те возможности, которые вы хотите использовать, той реализацией DOM, с которой вы работаете.
DOM как структура
Прежде, чем начинать работу с DOM, стоит получить представление о том, что она на самом деле представляет. Объект DOM Document является коллекцией узлов или порций информации, организованных в иерархию. Эта иерархия позволяет разработчику двигаться по дереву в поисках нужной информации. Анализ структуры обычно требует, чтобы был загружен полный документ, и иерархия была построена до начала работы. Поскольку DOM основывается на иерархии информации, про нее говорят, что она древовидно-базированная или объектно-базированная.Для исключительно больших документов разбор и загрузка полного документа может быть медленной и ресурсоемкой, так что для работы с такими данными могут оказаться лучшими другие средства. Событийно-базированные модели, такие, как Simple API for XML (SAX), работают на потоке данных, обрабатывая его по мере поступления. (SAX является темой другого учебника и других статей в XML-зоне developerWorks. Дополнительную информацию см. в .) Событийно-базированный API обходит необходимость построения дерева в памяти, но фактически не позволяет разработчику изменять данные в исходном документе.
С другой стороны, DOM также обеспечивает API, который позволяет разработчику добавлять или удалять узлы в любой точке дерева в надлежащим образом созданном приложении.
Инструменты
Примеры в этом учебнике, если вы решите их выполнить, требуют установки и правильной работы следующего инструментария. Выполнение примеров не является обязательным требованием для понимания.Исключения парсера
При всех разнообразных возможностях в создании парсера многие вещи могут быть неправильно сделаны. Как показано в примере, приложение сводит все это в единственное родовое Exception, которое не может быть достаточно полезным в смысле отладки.Чтобы лучше диагностировать проблемы, вы можете вылавливать специфические исключения, относящиеся к различным аспектам создания и использования парсера:
... try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); doc = db.parse(docFile); } catch (javax.xml.parsers.ParserConfigurationException pce) { System.out.println("The parser was not configured correctly."); System.exit(1); } catch (java.io.IOException ie) { System.out.println("Cannot read input file."); System.exit(1); } catch (org.xml.sax.SAXException se) { System.out.println("Problem parsing the file."); System.exit(1); } catch (java.lang.IllegalArgumentException ae) { System.out.println("Please specify an XML source."); System.exit(1);
} ...
Когда парсер создал документ, приложение может проходить через него для обработки данных.
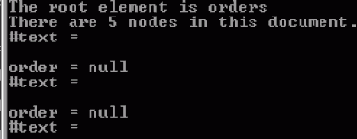
Использование getFirstChild() и getNextSibling()
Отношения предок-потомок и братские отношения предлагают альтернативный способ для перебора всех потомков данного узла, который может быть более подходящим в некоторых ситуациях, например, когда для понимания данных важны отношения и порядок, в котором появляются потомки.На Шаге 3, цикл for начинается с первого потомка корня. Приложение перебирает "братьев" первого потомка, пока все они не будут обработаны. При выполнении каждой итерации цикла приложение выбирает объект Node, выводит его имя и значение. Заметьте, что в число пяти потомков orders входят элементы order и три текстовых узла. Заметьте также, что элементы имеют значение null, а не текст, как ожидалось. Эти текстовые узлы являются потомками элементов, которые имеют в качестве своих значений реальное содержимое.
... import org.w3c.dom.Node;
... //STEP 3: Step through the children for (Node child = root.getFirstChild(); child != null; child = child.getNextSibling()) { System.out.println(start.getNodeName()+" = " +start.getNodeValue()); }
} } ...
Изменение значения в узле
Просмотр содержимого XML-документ полезен, но когда вы имеете дело с полнофункциональным приложением, вам может понадобиться изменять данные, добавляя, перемещая или удаляя информацию. Возможность редактирования данных также важна при создании новых XML-документов. Простейшим из таких изменений является изменение текстового содержания элемента.Нашей целью является изменить значение текстового узла элемента, в данном случае установкой status для каждого order в "processed", а затем вывести новые значения на экран.
Метод changeOrder() вызывается с передачей ему начального узла (root) в качестве параметра, а также имени изменяемого элемента и измененного значения.
changeOrder() сначала проверяет имя узла, чтобы увидеть, тот ли элемент, который редактируется. Если это так, приложению нужно изменить значение не этого узла, а его первого потомка, поскольку этот первый потомок является текстовым узлом, который на самом деле содержит содержимое элемента.
В противном случае приложение проверяет каждый потомок так же, как это делалось при прохождении по документу в первый раз.
Когда изменения выполнены, значение проверяются при помощи getElementsByTagName(). Этот метод возвращает список всех дочерних элементов с заданным именем, таким, как status. Приложение может затем проверить значения в списке, чтобы убедиться, что метод changeOrder() работает.
... public class OrderProcessor { private static void changeOrder (Node start, String elemName, String elemValue) { if (start.getNodeName().equals(elemName)) { start.getFirstChild().setNodeValue(elemValue); } for (Node child = start.getFirstChild(); child != null; child = child.getNextSibling()) { changeOrder(child, elemName, elemValue); } }
... public static void main (String args[]) { ... // Change text content changeOrder(root, "status", "processing"); NodeList orders = root.getElementsByTagName("status"); for (int orderNum = 0; orderNum < orders.getLength(); orderNum++) { System.out.println(orders.item(orderNum) .getFirstChild().getNodeValue()); }
} }

Заметьте, что приложение выбирает узлы status даже, несмотря на то, что они являются "внуками" корневого элемента, а не непосредственными его "детьми". getElementsByTagName() проходит через документ и находит все элементы с определенным именем.