
|
XML - статьи
Анализ производительности
В этом разделе представлены результаты тестирования производительности системы BizQuery. Насколько известно авторам, в открытом доступе сегодня не существует средств тестирования производительности систем, подобных BizQuery. Поэтому пришлось воспользоваться средством для тестирования XML СУБД - пакетом XMark [18] и адаптировать его для BizQuery.Документ, соответствующий DTD XMark auctions, был разбит на части, которые были распределены по трем источникам - одному XML-источнику и двум реляционным. В качестве XML-источника выступала программа QuiP [19] компании Software AG, представляющая собой XQuery-процессор над файловой системой. В качестве реляционного источника использовалась СУБД Oracle 8i. Следует заметить, что QuiP не является полноценной СУБД, а также является прототипом. Поэтому производительность этого программного средства была невысокой, что повлияло на распределение данных. Кроме того, чтобы представить определенные части исходного документа в виде реляционных таблиц, пришлось упростить эти части (например, путем избавления от вложенности элементов).
В результате первый реляционный источник содержал 5 таблиц, суммарное количество картежей которых превышало 1,8 миллиона. Второй реляционный источник содержал 3 таблицы с более чем 4,2 миллионами кортежей. Суммарный объем XML-файлов, по которым строились реляционные таблицы, превышает 700Mb. XML-источник содержал 4 файла, общим объемом 5,8Mb.
В табл. 2 показаны запросы, для которых приводятся результаты измерения.
| Q1 | for $x in document("real:sql1/item")/ table/tuplewhere $x/QUANTITY="5" and $x/location="Germany"return $x |
| Q2 | for $y in document("real:sql2/interest") /table/tuplefor $z in document("real:sql2/people") /table/tuple[business="yes" and city="Moscow"] for $x in document("real:sql1/categories") /table/tuple [name="all"]where $y/ref_category=$x/ id_category and $y/ref_person= $z/id_personreturn ($x, $z) |
| Q3 | document("virtual:closed_auction.xml") |
| Q4 | for $v in document("virtual:item.xml") /item[location= "United States"]for $z in document("real:sql1/mailbox") /table/tuple[mail_date="12/11/99"] where $v/id=$z/ref_itemreturn element {name($v)} {$v/*[not empty(./text())]} |
Табл. 2. XQuery-запросы, использованные при тестировании
Для измерения производительности использовалась следующая конфигурация. BizQuery Integration Server работал на Pentium-IV 1500Mhz c 512Mb RAM. Для XML-источника данных (QuiP) использовалась такая же машина. Оба сервера реляционных СУБД (Oracle) работали на машинах одинаковой конфигурации - Pentium-III 733Mhz с 256Mb RAM. Все машины работали под управлением Windows 2000.
Запрос Q1 адресуется реальному документу item (таблице реляционного источника 1) и просто налагает условие на данные. Запрос Q2 содержит два соединения, одно из которых выполняется между документами одного источника, а второе соединение - кроссдоменное - между разными реляционными источниками. Запрос Q3 показывает возможность построения виртуального документа closed_auctions.xml целиком. И, наконец, запрос Q4 выполняет соединение между виртуальным документом item.xml и реальным документом mailbox из второго реляционного источника. Результаты выполнения представлены в табл. 3.
| Номер запроса | Размер результата (в Kb) | Общее время работы источников | Время работы BizQuery | Общее время выполнения запроса |
| Q1 | 23 | 5,984 | 0,078 | 6,062 |
| Q2 | 12 | 82,485 | 1,796 | 84,281 |
| Q3 | 3673 | 67,907 | 3,093 | 71,000 |
| Q4 | 27 | 52,766 | 0,938 | 53,704 |
Во всех четырех запросах, вне зависимости от общего времени выполнения, чистое время работы BizQuery (включающее оптимизацию и, если необходимо, выполнение кроссдоменных операций) относительно невелико. Это обеспе-чивается посредством перезаписи запросов (особенно в случае запроса Q4, где производится соединение виртуального документа с реальным) и декомпозиции запросов, которая приводит к выделению наиболее дорого-стоящей части запроса и передачи ее для выполнения источнику. Заметим, что общее время выполнения запроса можно было бы снизить, введя дополни-тельные индексы в источниках, однако рассмотрение данного вопроса выходит за рамки статьи. Ограниченный объем статьи не позволяет также привести примеры работы логического оптимизатора по существенному упрощению запросов, содержащих сложные трансформации (особенно те запросы, которые генерируются автоматически). Эти примеры чрезвычайно объемны.
Аннотация.
При возрастающем интересе к решению проблемы интеграции распределенных и разнородных источников данных виртуальный подход представляется перспективным и многообещающим. В своей общей постановке эта проблема исключительно сложна, и до сих пор ее решению уделялось недостаточное внимание. Однако быстрое развитие XML - многофункционального формата представления данных - и языков запросов к XML-данным, таких как XQuery, позволяет по-новому взглянуть на старую проблему. В статье содержится описание общей архитектуры BizQuery - системы виртуальной интеграции, основанной на модели данных XML. В системе локальные источники единообразно отображаются на глобальную схему как ее представления в терминах XML и UML на основе использования декларативных языков XQuery и UQL. Обсуждаются вопросы отображения схем, оптимизации, декомпозиции и выполнения запросов в системе виртуальной интеграции.Ключевые слова: виртуальная интеграция данных, XML, XQuery, UML, оптимизация запросов, декомпозиция запросов, обработка запросов, трансформация схем
Архитектура и структура системы
В этом разделе рассматривается архитектура системы BizQuery и поясняется назначение основных компонентов. Прежде всего, выделяются две фазы использования системы: подготовительная фаза (Рис. 1(a)) и рабочая фаза, на которой система обрабатывает запросы к интегрируемым данным (Рис. 1(b)). Прежде чем адресовать запросы интеграционной системе, необходимо выпол-нить ряд подготовительных действий, таких как создание глобальной схемы инте-грируемых данных в терминах UML и XML, сбор информации о схемах инте-грируемых источников и построение отображения схем источников на глобальную схему. Эти подготовительные действия происходят при выпол-нении подготовительной фазы. Метаданные, созданные на этом этапе, помещается в BizQuery Repository, и затем они используется во время выполнения запросов. Необходимо заметить, что во время развертывания системы происходит работа только с метаданными, то есть со схемами источников и глобальной схемой, а не с данными.Архитектура времени выполнения
Подсистема BizQuery времени выполнения содержит два основных компонента: BizQuery Integration Server (BQIS) and User Interface Management Server (UIMS). BQIS отвечает за обработку запросов, сформулированных на языках UQL или XQuery. Однако все UQL-запросы транслируются в XQuery-запросы, и реальное выполнение запроса производится в терминах XML. Эта трансляция возможна благодаря наличию метаданных, поскольку, с одной стороны, эти метаданные описывают исходную модель, а с другой стороны, сами представляются в формате XML.В прямо сформулированный или полученный из UQL-запроса XQuery-запрос подставляются представления локальных источников, хранимые в BizQuery Repository (заметим, что в результате этой подстановки запрос переформулируется в терминах схем локальных источников, и структура запроса существенно усложняется). После этого запрос оптимизируется логическим оптимизатором путем применения правил перезаписи, что приводит к значительному упрощению и "улучшению" структуры переформулированного запроса. Это один из наиболее важных шагов обработки запроса. Обсуждение применяемых методов содержится в разд. 4.
Далее, оптимизированный запрос декомпозируется в набор частичных запросов (по прежнему на XQuery), каждый из которых формулируется в терминах локальной схемы соответствующего локального источника данных (по одному частичному запросу на один локальный источник). Каждый частичный запрос транслируется соответствующей "оберткой" (wrapper) на язык запросов, понимаемый локальным источником (в настоящее время поддерживаются обертки для SQL и XQuery). Трансляция на XQuery тривиальна, но пере-формулировка произвольного XQuery-запроса к реляционным данным в SQL-запрос не очень проста. Этот вопрос обсуждается в статье позже.
После декомпозиции запрос разбивается на набор частичных запросов к локальным источникам и так называемую "межисточниковую часть" (т.е. часть запроса, для выполнения которой нужны данные одновременно от нескольких локальных источников), которая должна выполняться самой системой интеграции, в случае BizQuery за это отвечает компонент, называемый XQuery Execution Engine. Выше мы привели лишь краткую характеристику основных компонентов BQIS и шагов обработки запросов, адресованных к системе интеграции. Детали приводятся в разд. 4.
BQIS реализует API для взаимодействия клиентских приложений с интеграционным сервером посредством адресации XQuery и UQL запросов, то есть реализует низкоуровневый интерфейс доступа к данным, который, вообще говоря, не пригоден для конечных пользователей. Компонент UIMS призван сгладить разрыв между пользователем и BQIS. Он предоставляет три графических интерфейса пользователя доступа к данным в терминах UML. Catalogs обеспечивает навигационный интерфейс доступа к данным, предоставляя пользователю возможность просматривать существующие экземпляры классов UML-модели и переходить по ссылкам от одного экземпляра к другому. Два других интерфейса - Forms и Graphic Map - декларативные. Они позволяют перемещаться по UML-модели и накладывать условия на атрибуты экземпляров класса. В обоих случаях в результате действия пользователя генерируется UQL-запрос, который адресуется BQIS, а полученный результат отображается на экране. Поскольку пользователь оперирует только понятиями UML-модели, выразительных средств UQL достаточно для формулирования запроса.
UIMS реализован в виде Web-приложения и обладает развитыми возможностями настройки, благодаря использованию XSLT. Графический интерфейс пользователя генерируется автоматически по UML-модели, хранящейся в BizQuery Repository.
BizQuery Integration Server
В этом разделе обсуждается компонент BizQuery, отвечающий за выполнение XQuery- и UQL-запросов. Он состоит из следующих частей: синтаксический анализатор языков UQL и XQuery, транслятор UQL-запросов в запросы на языке XQuery, оптимизатор, подсистема выделения подзапросов, подсистема выполнения XQuery-запросов и подсистема оберток для связи с источниками данных.Не секрет, что при построении систем виртуальной интеграции приходится сталкиваться с существенными ограничениями производительности таких систем, и как следствие, время ожидания ответа пользователем может быть неудовлетворительным. В качестве основных причин можно указать отсутствие актуальной статистики распределения данных и отсутствие структур данных, позволяющих оптимизировать доступ к данным (то есть индексов). Определенные проблемы связаны также с задержкой передачи данных по сети и их последующим преобразованием во внутренний формат для обработки. Эти проблемы возникают из-за того, что виртуальная интеграционная система не материализует интегрируемые данные.
По всей видимости, системы виртуальной интеграции никогда не смогут достигнуть производительности систем, основанных на хранилищах данных, однако они вполне могут быть пригодны в тех случаях, когда действительно необходимы актуальные данные.
В ходе работы над ядром BizQuery Integration Server были выделены три составляющие ядра, которые, вероятно, являются ключевыми для эффективной обработки запросов (перечислены в порядке убывания важности).
Далее эти составляющие рассматриваются подробнее, и поясняется, почему они являются ключевыми.
BizQuery Mapper
Как отмечалось выше, основная задача фазы развертывания состоит в построении отображения локальных источников данных на глобальную XML схему. Понятно, что глобальная схема данных может быть, вообще говоря, произвольной, и отображение локальных источников на нее является нетривиальным: документы могут подвергаться сложным трансформациям, на их основе могут строиться новые документы, которые затем вновь подвергаются трансформациям и т.д.Прежде, чем рассказывать про BizQuery Mapper - компонент системы, который занимается решением поставленной задачи, обсудим возможные способы построения отображения между схемами. В общем смысле эта задача может быть переформулирована следующим образом. Пусть имеются некоторые данные, соответствующие схеме A. Как преобразовать эти данные, чтобы они соответствовали схеме B? Имеется несколько методов решения этой проблемы:
В соответствии с приведенной классификацией BizQuery Mapper базируется преимущественно на методе 3 и, частично, на методе 4. Основным сообра-жением при выборе подхода было то, что у пользователя не должно быть принципиальных ограничений при построении отображения одной схемы на другой. При этом он должен иметь относительно удобный интерфейс и манипулировать высокоуровневыми терминами. Алгоритмы сопоставления схем являются приятным, но не обязательным дополнением. От пользователя не должны требоваться такие дополнительные сведения, как описание семантики данных или статистика.
Итак, схема B получается из схемы A итеративным путем, посредством после-довательного применения функций трансформации. Операции трансформации замкнуты относительно множества схем, то есть представляют собой алгебру. Единственным ограничением является то, что результирующая схема должна быть принципиально выводимой из исходной. На практике это означает, что в трансформациях не должно быть зависимости по данным; например, ситуация, где содержимое элемента становится именем нового элемента, недопустима. Ниже приведен список функций трансформации (в основу была положена не минимальность набора, а удобство использования):
С помощью приведенных операций, которые манипулируют поддеревьями, а не узлами или последовательностями узлов XML-документа, многие запросы, такие, как получить исходный документ, в котором атрибут по определенному пути удваивается, выражаются проще, чем на XQuery. Тем не менее, отображение, построенное в высокоуровневых терминах, переводится в XQuery - целевой язык системы интеграции, микрооперации которого проще оптимизировать и выполнять.
BizQuery Mapper, обеспечивающий описанную выше функциональность, реализован в виде отдельного компонента, который предоставляет удобный графический интерфейс в стиле drag-and-drop для проведения трансформаций.
Декларативные языки запросов системы BizQuery
В соответствии с двумя уровнями интеграции данных (XML и UML), поддерживаются два языка запросов интегрированных данных, а именно XQuery и UQL. Язык XQuery, развиваемый консорциумом W3C, был выбран как будущий стандарт языков запросов XML-данных.В системе BizQuery пользователь с помощью XQuery может оперировать двумя типами сущностей: виртуальными документами, которые стоят за глобальной XML схемой (посредством указания ключевого слова virtual в функции document, например document("virtual:foo.xml")), и реальными документами, которые представляют собой действительно существующие документы XML-источников или таблицы реляционной базы данных (посредством указания ключевого слова real, например document("real:sql/foo")). В первом случае пользователь оперирует виртуальным документом или представлением, за которым стоят запросы к реальным документам. Во втором случае пользователь работает с сущностями интегрируемых источников (поскольку вся обработка данных производится в терминах XML, реляционные таблицы путем тривиального отображения представляются в виде XML документов).
В ходе работы над средствами манипулирования данными была осознана потребность в создании языка запросов, который бы оперировал в терминах UML-модели. Этим языком стал UQL. Он служит для выборки экземпляров класса (т.е. объектов, которые соответствуют структуре, определенной на UML) построенной диаграммы классов (глобальной UML-схемы в случае BizQuery).
В основу UQL был положен язык OCL [12], который является частью спецификации UML, с несколько измененным и синтаксисом и семантикой. Основное назначение OCL состоит в определении ограничений данных, соответствующих модели (диаграмме классов), в терминах этой UML-модели.
Коротко говоря, UQL позволяет запрашивать экземпляры классов посредством накладывания условий на атрибуты, перемещения по связям между экземплярами классов и использования кванторов всеобщности и существования. Более подробное описание UQL см. в [4].
Вот пример UQL-запроса: "Найти все открытые аукционы (экземпляры класса open_auction), в которых цена больше 40, и покупатель имеет годовой доход не меньше 50000".
context model-id("1803"): extent(closed_auction)=>
select(c|c.price>"40" and c!buyer@person=>exist(p|p.income>="50000"))
Декомпозиция запросов
Задача декомпозиции запроса состоит в том, что требуется разбить запрос на части таким образом, что определенные части будут выполняться на стороне источников данных, а оставшаяся часть - на стороне интеграционной системы. В зависимости от типов интегрируемых источников существуют две диаметрально противоположные позиции по этому вопросу. Одна позиция связана с рассмотрением источников, которые предоставляют крайне ограниченные выразительные средства для формулирования запросов, например, имеют в качестве интерфейса HTML-формы [16]. Другая позиция подразумевает, что в источниках поддерживаются развитые, декларативные языки запросов. Система BizQuery ориентирована на второй случай. Более точно, как отмечалось ранее, BizQuery ориентируется на два типа источников - реляционные системы с интерфейсом SQL и системы, поддерживающие язык XQuery. Тогда задача декомпозиции запроса сводится к выделению "максимального" частичного запроса к источнику. Другими словами, источникам адресуются максимально возможные компоненты исходного запроса, которые они в состоянии выполнить. Например, если в исходном запросе имеются такие потребляющие много ресурсов операции, как соединение или сортировка, относящиеся к одному источнику, то они отдаются в источник при условии, конечно, что источник в состоянии их выполнить. Преимущества выделения максимального подзапроса состоят в следующем:Параллельное выполнение максимальных частей исходного запроса (части исходного запроса, адресуемые различным источникам, могут выполняться параллельно).
Развитые источники данных зачастую способны выполнять запросы быстрее, чем интеграционная система, поскольку в них имеется более полная информация о хранимых данных (например, развитая структура индексов).
В типичных случаях размер передаваемого по сети результата частичного запроса намного меньше общего размера документа, хранимого в соответствующем источнике данных (в частности, по причине наличия в частичном запросе условий выборки).
Итак, в случае BizQuery задача разбивается на нахождение в дереве запроса максимальных поддеревьев, относящихся к одному источнику, и перевод их на язык запросов, поддерживаемый источником. Оставшаяся часть дерева запроса содержит операции, для выполнения которых требуются данные из разных ис-точников (для краткости будем называть такие операции "кроссдоменными"), и эти операции должны быть выполнены на стороне интеграционной системы (рис. 2b).
Необходимо заметить, что для полноценного выделения частичных запросов крайне важно, чтобы запрос находился в нормальной форме, о которой говорилось выше (рис. 2a). Поскольку листья дерева запроса представляют собой выражения XPath, можно гарантировать возможность их выполнения в источниках данных, поддерживающих соответствующий язык запросов. Выше по дереву находятся операции соединения и полусоединения, которые тоже могут быть переданы для выполнения источникам данных, если их операнды черпаются только из одного источника данных. Таким образом, на стороне интеграционной системы приходится выполнять только те операции соединения и полусоединения, которые являются кроссдоменными (в том числе, если они прямо или косвенно опираются на результаты других кроссдоменных операций). Если в дереве запроса существует хотя бы одна кроссдоменная операция, которая должна быть выполнена до уровня трансформации, то трансформация тоже выполняется на стороне интеграционной системы.
Приведем пример декомпозиции запроса. Предположим, что имеется запрос, содержащий обращения к двум документам одного реляционного источника (схемы документов представлены в табл. 1 в виде DTD); запрос выдает данные об отделах, в которых имеются сотрудники моложе 20 лет.
for $d in document("real:sql1/deps")/table/tuple
where some $e in document("real:sql1/emps")/table/tuple[age < 20] satisfies $d/id = $e/dep_id
return element dep {$d/name, element additional {$d/address}}

Запрос содержит полусоединение (определяется разделами for и where) двух документов одного источника, которое может быть выполнена на стороне источника, а также трансформацию, не поддерживаемую реляционным источником. Ниже показан подзапрос к источнику sql1.
select * from deps where (exists (select * from emps where deps.id = emps.dep_id and emps.age < 20))
Заметим, что представленную ранее нормальную форму XQuery-запроса можно подвергнуть определенной критике. Очевидно, что существует ряд простых трансформаций, которые могут быть выполнены ранее операций соединения (например, вертикальная проекция на стороне реляционного источника). Однако для выполнения таких трансформаций не требуется слишком много ресурсов, и их выполнение на стороне интеграционной системы не сильно сказывается на производительности. Значительно важнее выделить именно "тяжелые" операции, такие как соединения и сортировки.
Фаза развертывания системы
BizQuery предоставляет два интерфейса доступа к данным: в терминах глобальной UML-схемы и в терминах глобальной XML-схемы. Процесс внедрения начинается с конструирования глобальной UML-схемы, которая служит для моделирования предметной области и представляет собой диаграмму классов UML. При конструировании этой схемы во внимание должны приниматься одновременно два фактора. Во-первых, схема должна соответствовать требованиям будущих пользователей. Во-вторых, схема должна быть адекватной доступным или предполагаемым источникам данных, которые требуется интегрировать. За отслеживание этих факторов отвечает специалист, выполняющий подготовительную фазу. Затем эта схема автоматически преобразуется в XML-документ в формате XMI [13], который представляет собой глобальную XML-схему. Необходимо отметить, что глобальная XML-схема является ключом для функционирования системы, не важно, каким образом эта схема была произведена. Иначе говоря, для интеграции данных в терминах XML совершенно не обязательно создавать UML-схему, если есть возможность сразу предоставить XML-схему. От интегрируемых источников на этом этапе требуется только схема хранимых данных. Поскольку для системы интеграции нужна, прежде всего, структурная информация об источниках, для хранения схемы использовался формат DTD. В настоящее время происходит миграция на Relax NG[14]. Для XML-источников схема данных должна быть предоставлена вручную, для реляционных источников схема получается автоматически средствами системы.Завершающий и наименее тривиальный этап фазы развертывания состоит в построении отображения схем локальных источников на глобальную XML-схему. Выполнение этого процесса поддерживается компонентом системы BizQuery Mapper, который обсуждается в разд. 3.
Литература
*Проект выполнялся исследовательской группой MODIS Института системного программирования РАН (http://www.ispras.ru/groups/modis/modis.html ) в сотрудничестве с международной компанией ATS (www.atssoft.com) при поддержке РФФИ (гранты 02-01-01088-а и 02-07-90300-в).
Логическая оптимизация
Значимость оптимизатора запросов для СУБД трудно переоценить: разница во времени выполнения исходного запроса и оптимизированного запроса может различаться на порядки. В настоящее время во многих промышленных СУБД используется так называемая оценочная оптимизация (cost-based optimization), то есть выбор оптимального плана выполнения запроса из множества возможных планов производится на основе оценки стоимости выполнения операции. Оптимальным считается тот план, совокупная стоимость операций которого является наименьшей. Другой метод оптимизации основан на правилах эквивалентного преобразования запросов на основе эвристик с целью получения нового запроса, который является эффективнее первого. Такой вид оптимизации носит название оптимизации на основе правил (rule-based optimization), или перезаписи запросов (query rewriting). Именно этот подход применяется для оптимизации в BizQuery. Это связано со следующими основными причинами:в виртуальной интеграционной системе отсутствует статистика, на основе которой можно было бы оценить стоимость операций (данные в источниках могут изменяться без ведома системы интеграции);
обычно пользовательский запрос адресуется к виртуальному документу (т.е. к представлению), после выполнения подстановки тела представления содержит много лишней информации и, таким образом, поддается существенному упрощению.
Особенно важен последний пункт, так как в зависимости от сложности виртуального документа размер запроса может отличаться на порядки.
Перечислим список целей, достигаемых посредством перезаписи запросов в системе BizQuery:
сокращение объема запроса после подстановки тела представления;
"выталкивание" (push down) предикатов (как можно более раннее применение предикатов) и устранение избыточных вычислений (например, конструирования элементов до обработки путевых выражений);
повышение уровня декларативности запроса (например, путем нахождения конструкций, эквивалентных соединениям);
частичная перезапись запроса, содержащего вызовы рекурсивных функций, в запрос без рекурсии (с использованием схемы данных) с последующей оптимизацией;
преобразование запроса в более "целенаправленную" форму на основе информации из схемы с возможным устранением избыточных просмотров данных (например, замена метасимвола в путевом выражении именем некоторого XML-элемента).
Необходимо заметить, что поскольку в XQuery отсутствует явное понятие соединения, потребовалось ввести такую логическую (и физическую) операцию, что привело к созданию расширенной модели данных XQuery. Обычно соединение выражается через FLWR-выражение (что навязывает конкретный алгоритм выполнения - соединение путем использования вложенных циклов), и поэтому выделение соединения в виде отдельной операции повышает декларативность запроса, так как становится возможным использовать другие, зачастую более эффективные алгоритмы. Тем не менее, наличие упорядоченности в XQuery понижает уровень значимости этой декларативности (например, из-за того, что нельзя произвольным образом изменять порядок выполнения соединений).
Этап логической оптимизации на основе перепизаписи крайне важен еще и по следующей причине. Результатом переписывания запроса является запрос вполне определенного ("нормализованного") вида. Условно, дерево запроса можно поделить на три части: в листьях дерева расположены операции выборки данных с накладываемыми на данные условиями; в центре дерева находятся операции соединения; верхняя часть запроса состоит преимущественно из трансформаций данных (рис. 2a). Подобная нормализация запроса играет важнейшую роль на этапе декомпозиции запросов, который будет рассматриваться ниже.

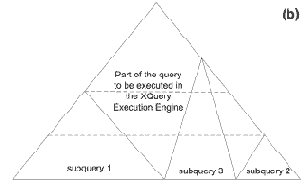
Рис. 2. Схема XQuery-запроса: (a) - после нормализации; (b) - после декомпозиции запроса
Подробнее правила перезаписи XQuery-запросов обсуждаются в [15].
Оперативная интеграция данных на основе XML: системная архитектура BizQuery
К.В. Антипин, А.В. Фомичев, М.Н. Гринев, С.Д. Кузнецов, Л.Г. Новак, П.О. Плешачков, М.П. Рекуц, Д.Р. ШиряевТруды
Интеграция разнородных гетерогенных данных является
Интеграция разнородных гетерогенных данных является одной из старейших задач в области разработки баз данных и информационных систем. Кратко, проблема может быть сформулирована следующим образом.Предположим, имеются несколько гетерогенных источников данных, которые каким-то образом связаны на логическом уровне. Имеется задача предоставить программное обеспечение, которое обеспечивало бы возможность унифициро-ванного доступа к этим данным, как будто бы они имели единое логическое и физическое представление. Мы не будем обосновывать очевидную важность этой проблемы.
Существуют два фундаментальных подхода к решению этой проблемы. Первый подход связан с построением хранилищ данных, когда интегрируемые данные из разных источников трансформируются в соответствии с целевой моделью данных и помещаются в одну локальную базу данных. По поводу этого подхода имеется обширная литература, современное состояние дел описывается, например, в [1].
Второй подход связан с понятием виртуальной интеграции гетерогенных источников данных, когда данные не материализуются в локальной базе данных, а используется промежуточное программное обеспечение, которое транслирует пользовательские запросы в подзапросы к источникам и формирует окончательный результат. Краткий обзор эволюции систем, исполь-зующий виртуальный подход, включая мультибазы данных [2] и федеративные базы данных [3], может быть найден в [4]. Подход этих систем был связан, прежде всего, с интеграцией данных с четкой структурой (хотя структура могла быть разная). Следующим этапом было возникновение систем интеграции на базе медиаторов [5], которые создавались на основе полуструктурированных данных [6]. Возникновение XML [7] и сопутствующих технологий (XSLT [8], XQuery [9]) вызвало всплеск новых разработок по тематике виртуальной интеграции [10], [11] и т.д.
Система виртуальной интеграции BizQuery на основе технологий XML [7] и UML [12], обсуждаемая в этой статье, является результатом работы исследова-тельской группы, которая на протяжении последних четырех лет занимается вопросами исследования и разработки методов управления XML-данными. Основные возможности BizQuery заключаются в следующем:
интегрированный доступ к нескольким источникам данных, которые могут быть реляционными или содержать XML-данные;
использование XML как для внутреннего представления данных, так и для представления результата;
представление глобальной схемы интегрированных данных как в терминах UML, так и в терминах XML;
возможность формулировки запросов к интегрированным данным с использованием декларативных языков запросов UQL (разработка группы [4]) и XQuery в терминах UML и XML соответственно;
развитая обработка запросов, включая оптимизацию запросов; декомпозицию запросов на частичные запросы, адресуемые к индивидуальным источникам данных; формирование окончательного результата с потенциальным выполнением соединений и трансформаций данных.
Основная цель проекта BizQuery состояла в проведении исследований по проблематике подхода виртуальной интеграции и реализации "приближенной к жизни" системы виртуальной интеграции на основе XML-технологий. Участники проекта пытались показать, что создание практической системы на основе XML технологий с учитом прошлого опыта разработки систем виртуальной интеграции вполне возможно. В статье рассматривается общая архитектура системы и концепции, которые были заложены в ее основу, объясняется, почему были выбраны именно такие подходы к решению задачи.
Основная часть статьи организована следующим образом. В разделе 2 описывается общая архитектура системы BizQuery. В разделах 3 и 4 обсуждаются детали двух основных компонентов системы - BizQuery Mapper и BizQuery Integration Server. В разделе 5 приводятся некоторые результаты, демонстрирующие производительность системы при ее испытаниях на тестовых наборах данных и запросов. Раздел 6 является заключением статьи.
XQuery-процессор
После стадии декомпозиции исходное дерево запроса преобразуется в физический план выполнения запроса, листья которого представляют собой подзапросы в терминах источников. При этом физический план, вообще говоря, может быть достаточно сложным для выполнения. Это связано преимущественно со следующими причинами:исходный запрос содержит кроссдоменные операции (например, соединение);
запрос содержит трансформации, не поддерживаемые источником (например, реляционные источники способны выполнять крайне ограниченный набор трансформаций).
По этим причинам в состав BizQuery входит полнофункциональный процессор подмножества языка XQuery. Введенная разработчиками явная операция соединения реализована в виде физической операции, что позволило повысить производительность системы.
Была адаптирована итераторная модель (называемая также моделью "top-down") выполнения запросов [17], которая широко применяется в реляционных СУБД. Это позволяет не материализовывать промежуточные результаты после вычисления каждой операции. На самом деле, такой подход к организации обработки запросов имеет далеко идущие последствия.
Для многих пользовательских запросах в результате получается не единичный документ, а последовательность из нескольких (часто однотипных) XML элементов. Особенно это характерно для UQL-запросов, в результате которых получается последовательность элементов - экземпляров класса. Часто, особенно при использовании графического интерфейса, пользователю доста-точно получить в качестве ответа на запрос первые n XML-элементов и иметь возможность в дальнейшем просмотреть оставшиеся элементы. Это подход соответствует понятию курсора, широко применяемому в реляционных СУБД, и позволяет существенно сократить время отклика системы на запрос пользователя.
Строго говоря, в XQuery-процессоре был реализован так называемый потоковый или конвейерный подход к организации вычислений. В контексте того, что XQuery является функциональным языком (по крайней мере, его подмножество, поддерживаемое в BizQuery), это выразилось в реализации "ленивой" семантики (lazy semantics) XQuery. Вообще говоря, это является расхождением со спецификацией, так как по стандарту XQuery является языком со строгой семантикой (strict semantics). Однако применение ленивой семантики ни в коей мере не сокращает класс вычислимых запросов: если запрос вычислим в системе, использующей строгую семантику, то он вычислим и в системе с ленивой семантикой. Обратное утверждение неверно: некоторые запросы, не вычислимые в соответствии со спецификацией, могут быть вычислены системой BizQuery.
В статье представлена архитектура системы
В статье представлена архитектура системы виртуальной интеграции данных BizQuery, основанной на модели данных XML/XQuery, которая позволяет обращаться к данным как в терминах XML, так и в терминах UML. Обсуждены разработанные средства построения отображения глобальной схемы на лока-льные схемы источников. Рассмотрена роль декларативных языков запросов UQL и XQuery в системе BizQuery.Представлены средства автоматического построения пользовательского интерфейса по описанию модели интегри-руемых данных в виде диаграммы классов UML. Обсуждена проблема производительности систем виртуальной интег-рации, и были выделены три ключевых задачи, от решения которых зависит пригодность системы для пользователя с точки зрения времени ожидания ответа на запрос. Эти задачи были детально проработаны, и предложены решения. Правильность подхода подтверждена экспериментальными результатами. Проблема виртуальной интеграции данных была и остается исключительно сложной проблемой в области управления данными. Развитие технологии XML обеспечивает простую возможность унифицированного представления всех видов данных, но в то же время порождает ряд новых проблем, включающих более сложные методы оптимизации и выполнения запросов. При работе над проектом BizQuery авторы стремились обозначить эти проблемы и предложить их решения. Это позволило создать эффективную систему виртуальной интеграции данных и доказать практическую применимость подхода.
XML - статьи
Что такое язык BPML
Язык BPML дополняет язык реализации бизнес-процессов (Business Process Execution Language, сокр. BPEL). BPML может использоваться для определения детальных бизнес-процессов, исполняемых при вызове каждого web-сервиса. BPML преобразует ("мэппирует") бизнес-операции в обменные сообщения. Этот язык может использоваться для определения корпоративных бизнес-процессов, комплексных web-сервисов и многостороннего сотрудничества. В разработке BPML-спецификаций участвует целый ряд организаций: CSC, Intalio, SAP, Sun, SeeBeyond, Versata и др.Как следует из BPML-спецификаций, назначение BPML заключается в следующем: "BPML - это язык XML, предназначенный для определения формальной модели, выражающей выполнимые процессы, которые описывают все аспекты корпоративных бизнес-процессов. BPML определяет операции разного уровня сложности, транзакции и компенсации, управление данными, параллелизм, обработку исключений и операционную семантику. Грамматика BPML оформляется в виде XML-схемы, что обеспечивает постоянство определений и их обмен между гетерогенными системами и инструментами моделирования".
BPML - это богатый и зрелый язык, с помощью которого можно описывать как простые, так и сложные бизнес-процессы. Поскольку BPML и BPEL - это языки с блочной структурой, то у них одинаковый набор выражений и похожий синтаксис. По сравнению с операциями, которые поддерживает BPEL, возможности BPML шире. Синтаксис BPML поддерживает операции и их типы, процессы, свойства, сигналы, расписания и нестандартные ситуации.
Корпорация: языки управления бизнес-процессамиBPML
Подготовлено: по материалам зарубежных сайтовПеревод: Intersoft Lab
Мы уже писали о языке реализации бизнес-процессов для Web-сервисов (Бизнес-процессы и XML). Предлагаемая вниманию читателей статья посвящена другому языку - языку моделирования бизнес-процессов.
В 2000 г. в Калифорнии была основана некоммерческая организация Business Process Management Initiative (Инициатива по управлению бизнес-процессами, сокр. BPMI). Она поставила своей целью разработку и продвижение открытых, полных и бесплатных стандартов на основе языка XML для поддержки и развития систем BPM в бизнесе (Business Process Management - управление бизнес-процессами).
В марте 2001 г. эта организация опубликовала язык моделирования бизнес-процессов (Business Process Modeling Language, сокр. BPML), в ноябре 2002 г. - спецификацию для графического представления моделирования бизнес-процессов (Business Process Modeling Notation,
сокр. BPMN). Последняя версия BPMN-спецификации была выпущена в мае 2004 г. Все это доступно для загрузки на сайте BPMI (http://www.bpmi.org/). Вскоре ожидается появление еще одного продукта - языка запросов для бизнес-процессов (Business Process Query Language, сокр. BPQL).
Простые типы операций BPML
Публикации
Сложные типы операций BPML
All: выполняет операции параллельно.Choice: выполняет операции из одного из составных комплектов, выбранного в ответ на событие.
Foreach: однократно выполняет операции для каждого пункта из списка.
Sequence: выполняет операции в последовательном порядке.
Switch: выполняет операции из одного из составных комплектов, выбранного на основе истинного значения условия.
Until: выполняет операции один или более раз на основе истинного значения условия.
While: не выполняет операции или выполняет их один или более раз на основе истинного значения условия.
Сложная операция - это операция, включающая в себя одну или более дочерних операций. Она устанавливает контекст для выполнения действий и направляет это выполнение. Сложные операции определяют иерархическую организацию. Она может быть простой - например, повторяющееся выполнение одной и той же операции, или более сложной - например, установление вложенного контекста для выполнения множественных операций. BPML также поддерживает и другие формы организации, в том числе циклические графы и рекурсивные операции. Сложные операции используются в тех случаях, когда требуется иерархическая организация, в частности, для установления нового контекста, необходимого при выполнении дочерних операций.
Простые операции - это операции, которые могут привести к выполнению множественных операций, в частности такие, как action, call, compensate и spawn. Но сама простая операция не определяет контекст для выполнения других операций. Приведенный ниже краткий обзор языка дает более детальный анализ разницы между сложными и простыми операциями и показывает, что BPML включает все логические конструкции строгого языка программирования.
Сложная операция, включающая комплекты множественных операций, должна выбирать, какой из них использовать. Для этого применяется несколько стандартных логических конструкций. Операция choice ждет события, которое должно быть инициировано, а затем выбирает комплект операций, связанный с обработчиком этого события. Операция switch оценивает условия и выбирает комплект операций, связанный с тем условием, значение которого является истинным. Все остальные сложные операции, определенные в спецификации BPML, включают только один комплект операций, поэтому им не приходится принимать подобные решения.
Сложная операция также определяет, сколько раз должны быть выполнены операции из общего набора операций. Для этого используются следующие стандартные логические конструкции: операция until - повторяет выполнение операций, пока значение условия не станет истинным; операция while - повторяет выполнение операций, пока значение условия остается истинным; и операция foreach - выполняет операции однократно для каждого пункта списка. Все остальные названные выше сложные операции выполняют действия из комплекта операций однократно.
Помимо этого, сложная операция определяет порядок выполнения других операций. Операция sequence обеспечивает выполнение всех действий из комплекта операций в последовательном порядке. Операция
all обеспечивает выполнение всех действий из комплекта операций одновременно. Остальные сложные операции языка BPML обеспечивают выполнение операций в последовательном порядке.
Сложная операция считается завершенной, когда закончено выполнение всех действий из комплекта операций. Это включает все действия, перечисленные в списке операций, и все процессы, запускаемые из определения, сделанного в контексте комплекта операций. Вложенные процессы и процессы обработки нестандартных ситуаций рассматриваются как действия из комплекта операций.
Простые операции прерывают выполнение (abort) или выдают сообщение об ошибке (fault), если их завершению препятствует неожиданная ошибка. Сложные операции прерываются и разрываются, если одно из действий, входящих в их состав, разрывается таким образом, что его восстановление невозможно.
Обладая средствами дополнительной поддержки вложенных процессов и другого синтаксиса, BPML может считаться расширенным вариантом языка BPEL. В тех случаях, когда эти языки используются совместно, сквозной обзор показывает роль каждого бизнес-процесса в общей картине и то, какие бизнес-операции он выполняет.
BPEL и BPML - это похожие подходы к решению одной и той же проблемы: определение логики процессов в языке XML таким образом, чтобы результат мог использоваться как исполняемый код программными продуктами на основе BPM. Это развивающиеся языки. Все эти продукты являются решениями одной и той же проблемы, их спецификации и языки концептуально похожи, поэтому со временем они, возможно, будут объединены в единую спецификацию.
XML - статьи
Еще несколько советов тем, кто работает с XML
XML устроен сравнительно просто, поэтому использование его для работы со слишком сложными структурами не является оптимальным. Этим проблемам посвящен достаточно подробный материал Симона Сенлорена (Simon St. Laurent) ""Монастырский" XML" (Monastic XML) (см. раздел ). Автор этого материала обсуждает фундаментальную роль символьных данных и разметки (элементов и атрибутов). Кроме того, он объясняет, почему родовой идентификатор (generic identifier), также называемый именем типа элемента, является важной концепцией и каким образом он может быть сделан единственным основным ключевым элементом структуры размеченной информации. В реальности при использовании пространств имен XML основным ключевым элементом является универсальное имя (пространство имени URI плюс локальное имя). Такая сложность - это одна из причин, по которой Сенлорен призывает к осторожности в использовании пространств имен. Еще одна проблема XML - это работа с деревьями. Хотя на первый взгляд кажется, что иерархическая структура XML может быть легко распространена на графические структуры, на практике моделирование графов в XML оказывается непростым делом. Наконец, еще один важный совет относится к области оптимизации разметки для обработки документов XML. XML - это декларативная технология, и данный факт составляет как его главную силу, так и источник разочарований для многих разработчиков. Те разработчики, кто старается слишком приблизить дизайн XML к деталям обработки, в конечном итоге обнаруживают, что обработка становится более сложной. Ключ к успешной работе с XML - это обращение основного внимания на сущность информации, которая должна быть представлена в абстрактном виде. При этом необходимо дистанцироваться от технического дизайна систем, которые будут заниматься обработкой этой информации.Как не выглядеть некомпетентным в области XML
Хенри Сивонен (Henri Sivonen) написал весьма полезную статью - "Как избежать обвинений в некомпетентности при работе с XML" (HOWTO Avoid Being Called a Bozo When Producing XML) (см. раздел ). В ней он обсуждает, как корректно работать с XML, используя пространства имен и возможности форматов загрузки Интернета на основе XML - RSS и Atom. Во введении к своей статье он отмечает, что существуют разработчики, которые считают, что очень трудно или даже практически невозможно добиться корректности при создании документов XML путем программирования. Но в то же время есть разработчики, которые легко справляются с этой задачей и не могут понять, почему другие столь некомпетентны. Никто не хочет считать себя некомпетентным. Советы, приведенные ниже, помогут избежать этого неприятного ощущения.Первый совет Хенри Сивонена заключался в том, что не надо рассматривать XML как текстовый формат. Автор настоящей статьи полагает, что это весьма опасный совет. Его основная идея верна: при создании или редактировании документа XML следует быть более осторожным, чем при работе с обычным текстовым документом. Но это относится ко всем текстовым форматам любой структуры. Однако утверждение, что документ XML не является текстом, - это отрицание одной из базовых характеристик XML, обозначенной в определении XML, которое дается в его спецификации ("Текстовый объект является корректно оформленным документом XML [если он соответствует настоящей спецификации]"). Помимо этого, в XML существует техническое определение текста как последовательности символов, интерпретируемых как XML. Текст - это не просто символы, ограниченные элементами дерева или атрибутами. Такая структура технически называется символьными данными. Текст - основа всех сущностей XML, поэтому утверждение, что XML - это не текст, является противоречивым. Гораздо полезнее подчеркнуть специфические особенности, которые отличают XML от текстовых форматов, уже известных разработчикам.
Хенри Сивонен, безусловно, прав, предупреждая о том, что нельзя бездумно объединять все в одно понятие и надеяться, что документ XML будет корректно оформлен. При создании документов XML лучше использовать хорошо разработанные комплекты инструментов XML, а не простые текстовые инструменты (см. статью автора в разделе ). Общий совет может быть таким: не использовать механизмы, если нет уверенности в том, что они приведут к созданию корректно оформленного документа XML. Одни из подходов к безопасному созданию документов XML - пересылка событий SAX с использованием для этого дерева, стека или парсера XML. Но при этом нужно помнить, что инструменты SAX могут не обеспечивать все необходимые операции по проверке корректности. Например, в XML не допускаются некоторые символы Unicode. Для выявления таких моментов могут понадобиться дополнительные проверки.
Разумным также выглядит предложение о том, что пользователи не должны вручную управлять пространствами имен. С пространствами имен XML необходимо обращаться очень осторожно. Обычно разработчики оперируют универсальными именами (пространство имени универсального указателя ресурса (Uniform Resource Identifier, сокр. URI) плюс локальное имя (local name)), но иногда им приходится иметь дело с префиксами или декларациями XML. В спецификациях, подобных XSLT (Extensible Stylesheet Transformation Language - расширяемый язык преобразования таблиц стилей), внутри значений атрибутов может использоваться класс QName (комбинация префикса и локального имени). При этом предполагается, что префикс интерпретируется в соответствии с внутренними декларациями пространств имен. Такой вариант использования называется контекстным оператором QName (QName in context). В данном случае разработчик должен контролировать заявленный префикс, в противном случае результирующая обработка XML не будет осуществлена. Но когда разработчики действительно полностью управляют собственными декларациями пространств имен, то результат часто оказывается непредсказуемым из-за сложности пространств имен XML.
Одни из способов корректировки синтаксиса пространств имен, который может нарушиться в процессе обработки XML, - это вставка так называемого канонического шага (canonicalization step), т.е. шага, независимого от конечной реализации, в конце обработки. Канонизация XML исключает ту синтаксическую вариабельность, которая разрешается XML 1.0 и пространствами имен XML, в том числе различные особенности деклараций пространств имен. Но при этом следует помнить, что канонизация не может исключить абсолютно всех проблем, которые делают декларации пространств имен ненадежными для разработчиков. Канонизация не помогает в решении вопросов, связанных с QNames в контекстных проблемах, поскольку она не меняет префиксы, используемые в документе. Но она все же существенно сокращает беспорядок деклараций пространств имен - до такой степени, когда разработчик может легко распознать проблемы или даже написать программу для их автоматического устранения. Библиотека GenX автоматически генерирует канонический документ XML, многие другие комплекты инструментов предоставляют возможности канонизации как опцию.
По мнению автора, совет Хенри Сивонена относительно недопустимости включения пробелов структурной распечатки программы в символьные данные является несколько натянутым. По мнению Хенри Сивонена, если документ XML представлен в виде, показанном в листинге 1, то, как правило, представление его в виде, показном в листинге 2, не является безопасным.
Листинг 1. Пример XML
Листинг 2. Пример XML с пробелами, добавленными к символьным данным
Но если структурно распечатать документ XML, представленный в листинге 3, то эта операция будет безопасной (листинг 4).
Листинг 3. Еще один пример XML
Листинг 4. Пример XML из листинга 3 с пробелами, добавленными к символьным данным
Многие инструменты сериализации распознают эту разницу между сравнительно безопасной и относительно небезопасной структурной распечаткой. Важно понимать, что формы структурных распечаток, показанные в листингах 3 и 4, могут вызывать искажения, если пробелы добавлены к смешанному содержанию. Этих проблем можно избежать, если преобразование будет управляться схемой. Но на практике большинство словарей, использующих смешанное содержание, не столь чувствительны к нормализации пробелов, поэтому не стоит уделять много внимания структурной распечатке. Просто необходимо помнить об этой потенциальной проблеме и быть уверенным, что существует возможность отключения структурной распечатки (предпочтительно, чтобы эта опция по умолчанию была отключена). Хенри Сивонен рекомендует тип структурной распечатки, представленный в листинге 5, но автор настоящей статьи не согласен с ним, поскольку такая разметка выгляди плохо и неудобна для работы.
Листинг 5. Структурная распечатка, предложенная Хенри Сивоненом, но не поддерживаемая автором настоящей статьи
Полезные советы для работы с XML
,Оригинальный текст статьи:
Перевод:
Язык XML уже используется очень широко, но способы и методы его применения еще находятся в процессе развития. Кроме того, даже уже оформившиеся подходы часто имеют некачественный дизайн, что весьма затрудняет обработку данных и поддержку языка. Существенную часть этих проблем составляют сложности, связанные с инфраструктурой обслуживания XML. С целью решения данных проблем был организован ряд общественных обсуждений передового опыта в области XML. Предлагаем вниманию читателей мнение одного из известных экспертов XML Юча Огбуджи (Uche Ogbuji), статьи которого неоднократно появлялись на страницах нашего Журнала. На этот раз он дает практические советы в области дизайна XML и рассуждает о наиболее передовых подходах к использованию XML.
Ресурсы
ОбразовательныеДетали работы с Python и Unicode:
Продукты и технологии
.
Дискуссии
в области XML мнения всегда
При анализе передового опыта в области XML мнения всегда будут отличаться, особенно на современных, ранних стадиях развития этого языка, но это является положительным моментом. Помимо перечисленных выше, существуют и другие актуальные темы для обсуждения, поэтому не стоит останавливаться на достигнутом.XML - статьи
Аннотация
Проект GraphML был начат комитетом "Graph Drawing Steering Committee" до начала симпозиума в Вильямсбурге. Рабочая была проведена накануне симпозиума, и на ней было согласовано создание группы, которая определила новый, основанный на языке XML, формат файла, который должен в конечном счете лечь в основу стандарта описания графов.С тех пор, язык был расширен в части поддержки основных типов атрибутов и в части включения информации для использования синтаксическими анализаторами. Следующим важным шагом в расширении языка будет включение абстрактной информации для описания топологии графа и шаблонов с помощью которых эту информацию можно было бы преобразовать в различные графические форматы. Программное обеспечение для поддержки работы с GraphML находится в стадии разработки.
Один из главных предшественников GraphML - . GML появился в результате работы, начатой на в Пассау и завершенной на Graph Drawing 1996 в Беркли. GML был (и все еще остается) основным файловым форматом для , а также поддерживается рядом других систем обработки графов.
Data-extension.type
Механизм расширения содержимого элементов иData.type
Комплексный тип, определяющий элемент . data.type является смешанным типом, поэтому элемент может содержать #PCDATA. Тип содержимого: расширение типа data-extension.type, который по умолчанию пуст. Описание типа конечно.Атрибуты:
Назначение: в GraphML возможно определение данных привязанных к графам, узлам, портам, ребрам, гиперребрам, конечной точке, а также ко всей совокупности графов, описанных в
Область применения:
Тип: data.type - комплексный тип, содержащий описание элемента . Тип data.type - смешанный, поэтому элемент может содержать данные типа #PCDATA. Допустимое содержание - расширения типа data-extension.type, которое по умолчанию задает пустое значение. Определение типа конечно.
Атрибуты:
Ограничения целостности: data_data_key_unique. Это ограничение гарантирует уникальность атрибутов 'key' у элементов , являющихся потомками данного элемента .
Default.type
Комплексный тип, определяющий элементАтрибуты:
default.extra.attrib - описание дополнительных, определяемых пользователем, атрибутов .
Область применения:
Тип: default.type - комплексный тип, содержащий описание элемента
Атрибуты: default.extra.attrib - ссылка на описание дополнительных, определяемых пользователем, атрибутов.
Область применения:
Тип - xs:string.
Добавление комплексных типов
Структурированное содержимое может быть добавлено с помощью элемента data. Например, пользователь может хранить для узлов их изображения в формате .Элемент node и его графическое представление
... xmlns:svg="http://www.w3.org/2000/svg" ...
Для добавления структурированных данных в GraphML-элементы используется механизм расширения GraphML. Это расширение должно быть задано с помощью XML-схемы. Документ демонстрирует как элементы могут быть добавлены в содержимое data:
Расширение GraphML структурированными данными
Вышеприведенная схема похожа на схему в примере с . Во первых присутсвуют объявления именного пространтсва. Во вторых, импортировано именное пространство SVG. Наконец расширен комплексный тип data-extension.type, который является базовым для описания содержимого элемента data, путем добавления элемента svg из именного пространства SVG.
В файле приведен документ, соответствующий схеме :
GraphML - документ с данными типа SVG
Заметим, что узел с идентификатором n1 допускает графическое изображение по умолчанию, заданное элементом key с идентификатором k0. Вышеприведенный пример также демонстрирует использование именных пространств XML: задано два различных элемента desc - один в именном пространстве GraphML, а второй в именном пространстве SVG . Возможный конфликт, связанный с одинаковыми именами элементов в различных XML-языках, разрешен с помощью использования различных именных пространств.
Добавление XML-атрибутов в GraphML-элементы
В большинстве случаев, дополнительная информация может (и должна) быть связана с GraphML-элементами с помощью , что гарантируется совместимостью GraphML-парсеров. Однако, в ряде случаев более удобно использовать XML-атрибуты. Предположим у вас имеется парсер, который умеет обрабатывать -атрибут href и корректно интерпретировать его как URL. Предположим вы хотите хранить в GraphML граф, узлы которого представляют собой WWW-страницы. Для ассоциации узла со страницей его модель должна позволять вам в теге node присваивать атрибуту xlink:href URL-ссылку на соответсвующую страницу:Элемент node, содержащий URL-ссылку
...
Для добавления XML-атрибутов в GraphML-элементы используется механизм расширение GraphML. Это расширение должно быть определено в XML-схеме. В документе показан атрибут href добавленный к элементу node:
Расширение GraphML: атрибуты
Приведенный выше документ имеет следующие функциональные составляющие: в качестве корневого элемента документ имеет элемент schema. Значение атрибута targetNamespace ="http://graphml.graphdrawing.org/xmlns" говорит о том, что данный документ соответствует спецификации языка GraphML. Три следующих строки задают именное пространство документа, используемое по умолчанию и префикс именного пространства для XLink и XMLSchema . Атрибуты elementFormDefault и attributeFormDefault в данном примере неважны.
Кроме node.extra.attrib, имеются соответствующие группы атрибутов для всех основных GraphML-элементов.
В документе приведен пример документа который соответствует схеме .
GraphML-документ с дополнительными XML-атрибутами
Дополнительные данные
GraphML обеспечивают механизм добавление данных к структурным элементам (например, таким какДополнительные понятия I: вложенные графы, гиперребра и порты
Для некоторых приложений модель графа, описанная в предыдущем разделе слишком ограничена и не моделирует адекватно данные прикладной программы.В данном разделе мы рассмотрим расширенную модель, которая позволяет описать вложенную иерархию графов, гиперребра и порты.
Дополнительные понятия II: расширение GraphML
Язык GraphML может быть легко расширен. В GraphML легко описывать топологию графа с помощью элементов имеющих простые атрибуты. Для хранения комплексных данных GraphML может быть расширен. В данном разделе мы рассмотрим различные возможности расширения GraphML.Расширения GraphML должны быть заданы в XML-схеме. Схема, в которой определены расширения, может быть порождена из схемы GraphML-документа с помощью стандартного механизма похожего на механизм, применяемый в XHTML.
Edge.type
Комплексный тип, определяющий элементАтрибуты:
Содержимое: ?, *, ?
Область применения:
Тип: edge.type - комплексный тип, содержащий описание элемента
Атрибуты:
Содержимое: ?, *, ?
Ограничения целостности: edge_data_key_unique - обеспечивает уникальность атрибутов 'key' элементов , являющихся потомками данного элемента
Endpoint.type.type
Простой тип, задающий допустимые значения атрибута 'type' элементаEndpoint.type
Комплексный тип, определяющий элементАтрибуты:
Содержимое: ?
Область применения:
Тип: endpoint.type - комплексный тип, содержащий описание элемента
Атрибуты:
Содержимое: ?
Гиперребра
Гиперребра это смысловое объединение ребер которое не не только связывает две конечные точки, но и выражает зависимость между произвольным числом конечных точек (например, описание кратчайшего пути - примечание переводчика). Гиперребра объявляются с помощью элемента hyperedge. Каждой конечной точке входящей в данное гиперребро соответствует элемент endpoint. Элемент endpoint должен иметь XML-атрибут node, который содержит идентификатор узла в документе. Следующий пример содержит гиперребра и два ребра. Гиперребра изображены в виде дуг, а ребра в виде прямых линий. Заметим, что ребра задаются с помощью элемента edge или с помощью элемента hyperedge содержащего два элемента endpoint.Граф с гиперребрами.
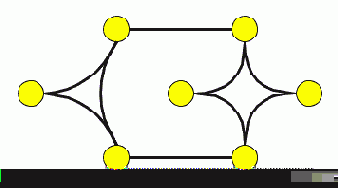
Файл содержит соответствующий GraphML-документ:
GraphML-документ с гиперграфами
Как и ребра, гиперребра и конечные точки могут иметь XML-атрибут id, который является уникальным идентификатором для соответствующих элементов.
XML - статьи
Простой тип, задающий допустимые значения атрибута 'edgedefault' элементаXML - статьи
Комплексный тип, определяющий элементАтрибуты:
Содержимое: ?, ( ( | | | ) * | )
Область применения:
Тип: graph.type - комплексный тип, содержащий описание элемента
Атрибуты:
Содержимое: ?, ( ( | | | ) * | )
Ограничения целостности:
XML - статьи
В предыдущем разделе мы обсудили порядок описания топологии графа на языке GraphML. Поскольку для различных приложений может потребоваться различная информация о топологии графа, необходимо иметь механизм для включения такой информации в описание графа.С помощью механизма расширения, который называется GraphML-атрибуты для элементов графа может быть задана дополнительная информация простого типа. Простой тип подразумевает, что данные ограничены скалярными величинами. Например, числами и строками.
Если в элементы графа вам необходимо добавить структурированные данные, то вы должны использовать механизм расширения GraphM L под названием ключ/данные (data/key). Более подробно этот механизм рассмотрен в . GraphML-атрибуты специализированное расширение механизма ключ/данные (data/key).
GraphML-атрибуты не следует путать с XML-атрибутами, это разные понятия.
XML - статьи
Описание синтаксиса GraphML с помощью DTD представлено в файле .XML - статьи
GraphML-схема представлена следующими файлами:XML - статьи
Комплексный тип, определяющий элементАтрибуты: graphml.extra.attrib - описание дополнительных, определяемых пользователем, атрибутов.
Содержимое: ?, *, ( | ) *
Область применения: root.
Тип: graphml.type - комплексный тип, содержащий описание элемента
Атрибуты: graphml.extra.attrib - ссылка на описание дополнительных, определяемых пользователем, атрибутов.
Содержимое: ?, *, ( | ) *
Ограничения целостности:
Hyperedge.type
Комплексный тип, определяющий элементАтрибуты:
Содержимое: ?, ( | ) *, ?
Область применения:
Тип: hyperedge.type - комплексный тип, содержащий описание элемента
Атрибуты:
Содержимое: ?, ( | ) *, ?
Ограничение целостности: hyperedge_data_key_unique - обеспечивает уникальность атрибутов 'key' элементов , являющихся потомками данного элемента
Информация для парсера
Для оптимизации синтаксического разбора документа с помощью парсера используются специальные метаданные, которые могут быть добавлены к некоторым GraphML-элементам с помощью XML-атрибутов. Все XML-атрибуты, задающие метаданные имеют префикс parse . Имеется два вида метаданных: информация о количестве элементов и информация о способе кодирования данных.Во первых рассмотрим информацию о количестве элементов. Для элемента graph определены следующие XML-атрибуты: XML-атрибут parse.nodes задает количество узлов в графе, XML-атрибут parse.edges - количество ребер. XML-атрибут parse.maxindegree определяет максимальное количество входящих в вершину ребер, а XML-атрибут parse.maxoutdegree - максимальное количество исходящих из вершины ребер. Для элемента node XML-атрибут parse.indegree определяет максимальное количество входящих ребер для данной вершины, а XML-атрибут parse.outdegree - максимальное количество исходящих ребер для данной вершины.
Во вторых рассмотрим информацию, связанную с кодированием. Для элемента graph определены следующие XML-атрибуты: если XML-атрибут parse.nodeids имеет значение canonical , все узлы имеют идентификатор вида nX, где X обозначает количество элементов node предшествующих данному элементу. Второе значение XML-атрибута - free . Аналогично этому, XML-атрибут parse.edgeids задает вид идентификатора для узлов. Отличие состоит только в том, что идентификатор имеет вид eX. XML-атрибут parse.order определяет порядок в котором узлы и ребра располагаются в документе. При значении равном nodesfirst все элементы node располагаются раньше элементов edge. При значении равном adjacencylist, объявление узла предшествует объявлению его смежных вершин. Для значения free порядок следования не устанавливается.
Следующий пример иллюстрирует использование информации для парсера: Граф с дополнительной информацией для парсера.
Информация для синтаксических анализаторов
Расширение базового языка в части описания информации для синтаксического анализа добавляет несколько дополнительных атрибутов к элементамKey.for.type
Простой тип, задающий допустимые значения атрибута 'for' элементаKey.type
Комплексный тип, определяющий элементАтрибуты:
Содержимое: ?, ?
Область применения:
Тип: key.type - комплексный тип, содержащий описание элемента
Атрибуты:
Содержимое: ?, ?
Locator.type
Комплексный тип, определяющий элементАтрибуты:
xlink:href (обязателен) ссылка на ресурс данного локатора.
xlink:type (необязателен) тип гиперссылки (может быть только типа 'simple').
locator.extra.attrib - описание дополнительных, определяемых пользователем, атрибутов.
Область применения:
Тип: locator.type - комплексный тип, содержащий описание элемента
Атрибуты:
Node.type
Комплексный тип, определяющий элементАтрибуты:
Содержимое: ?, ( ( | ) *, ? | )
Область применения:
Тип: node.type - комплексный тип, содержащий описание элемента
Атрибуты:
Содержимое: ?, ( ( | ) *, ? | )
Ограничения целостности:
О сайте GraphML
Сайт GraphML перепроектирован и перезапущен 22 июня 2002 года. С этого времени страницы генерируются с помощью XML publishing framework . Мы благодарим Джона Риттера (университет Konstanz) за эту работу.Объявление графа
Граф в GraphML - смешанный, другими словами он может содержать направленные и ненаправленные ребра одновременно. Если при объявлении ребра его направленность не определена, то применяется направленность заданная по умолчанию. Направленность ребер, присваиваемая по умолчанию, задается XML-атрибутом edgedefault элемента graph. Этот XML-атрибут может принимать одно из двух значений: directed и undirected. Значение по умолчанию должно быть задано обязательно.Дополнительно, с помощью атрибута id, графу может быть присвоен идентификатор. Идентификатор присваивают тогда, когда на данный граф требуется организовать ссылку.
Объявление GraphML-атрибутов
GraphML-атрибут объявляется с помощью элемента key который задает идентификатор, имя, тип, и домен атрибута.Идентификатор задается XML-атрибутом id и используется для ссылки на данный GraphML-атрибут внутри документа.
Имя GraphML-атрибута определяется с помощью XML-атрибута attr.name и должно быть уникальным среди всех объявленных в документе GraphML-атрибутах. Имя нужно для того, чтобы приложения могли идентифицировать данный атрибут. Обратите внимание, что имя GraphML-атрибута не используется для ссылок внутри документа, для этого используется идентификатор.
Тип GraphML-атрибута может быть boolean, int, long, float, double, или string . Эти типы определены в соответствии с аналогичными типами в языке Java(TM) .
Домен GraphML-атрибута определяет перечень элементов в которых GraphML-атрибут может быть объявлен. Возможные значения: graph, node, edge, и all .
Объявление GraphML-атрибута
...
Для GraphML-атрибутов можно определить значение по умолчанию. Содержимое элемента default определяет текстовое значение по умолчанию.
Объявление GraphML-атрибута со значением по умолчанию
...
Объявление ребра
Ребро в графе объявляется с помощью элемента edge. Каждое ребро имеет две конечные точки, задаваемые с помощью XML-атрибутов source и target. Значения атрибутов source и target должны содержать идентификаторы узлов, определенных в том же документе что и ребро.Ребра с одной конечной точкой, называемые петлями, циклами, или замкнутыми ребрами, определяются с помощью одинаковых значений, заданных в атрибутах source и target.
Дополнительный XML-атрибут directed определяет направленность ребра, заданную в явном виде. Значение true задает направленное ребро, а false - ненаправленное. Если направленность в явном виде не задана, то применяется направленность заданная по умолчанию при объявлении графа.
Дополнительно, с помощью XML-атрибута id, может быть задан идентификатор ребра. XML-атрибут id задается когда необходимо организовать ссылку на данное ребро.
Ребро со всеми XML-атрибутами
...
Объявление узла
Уз е л в графе объявляется с помощью элемента node. Каждый узел имеет уникальный (в пределах данного документа) идентификатор. Идентификатор узла задается с помощью XML-атрибута id.Общие сведения
Спецификация языка GraphML определяет его синтаксис, правила правила обработки базового языка (структурный уровень) и двух его расширений, связанных с описанием атрибутов базовых типов и описанием информации для синтаксического анализа. Хотя достаточно подробное введение в описание языка можно найти , дополнительную информацию, связанную с GraphML можно найти по адресу: U. Brandes, M. Eiglsperger, I. Herman, M. Himsolt, and M.S. Marshall: . Proc. 9th Intl. Symp. Graph Drawing (GD '01), LNCS 2265, pp. 501-512. © Springer-Verlag, 2002.Определение значений GraphML-атрибутов
Значение GraphML-атрибута в элементе графа задается с помощью элемента data вложенного в данный элемент. Элемент data имеет XML-атрибут key, который ссылается на идентификатор GraphML-атрибута. Значение GraphML-атрибута задается текстовым содержимым элемента data. Это значение должно иметь тип, объявленный в соответствующем элементе key.Значения GraphML-атрибута
...
Могут быть такие GraphML-атрибуты, которые определены, но не объявлены с помощью элемента data. Если значение по умолчанию определено для данного GraphML-атрибута, то тогда это значение применяется к соответствующему (входящему в домен GraphML-атрибута) элементу графа. В вышеприведенном примере значение не определено для узла с идентификатором n1 и GraphML-атрибута с именем color . Однако по для данного GraphML-атрибута определено значение по умолчанию yellow , которое будет присвоено данному узлу. Если значение по умолчанию не задано, как для GraphML-атрибута weight в вышеприведенном примере, то значение GraphML-атрибута для элемента графа не определено. В вышеприведенном примере не определено значение GraphML-атрибута, задающего вес ребра с идентификатором e3.
Основные понятия
Назначение GraphML-документа - определение графа. Для начала рассмотрим граф показанный на приведенном ниже рисунке. Он содержит 11 узлов и 12 ребер.Простой граф

Пользовательские расширения
GraphML может быть расширен двумя способами:Как это можно сделать, будет разъяснено в более подробном описании, которое в настоящее время готовится.
Port.type
Комплексный тип, определяющий элементАтрибуты:
Содержимое: ?, ( | ) *
Область применения:
Тип: port.type - комплексный тип, содержащий описание элемента
Атрибуты:
Содержимое: ?, ( | ) *
Ограничения целостности: port_data_key_unique - обеспечивает уникальность атрибутов 'key' элементов , являющихся потомками данного элемента
Порты
Узлы могут содержать различные логические точки подключения ребер и гиперребер. Такие точки подключения называются портами.Порты узла объявляются с помощью элементов port, которые являются дочерними по отношению к соответствующему элементу node. Обратите внимание, что порты могут быть вложенными, т.е., они могут содержать внутри себя другие элементы port. Каждый элемент port должен иметь XML-атрибут name, который идентифицирует этот порт. Элемент edge имеет необязательные XML-атрибуты sourceport и targetport которые задают для ребра исходящий и входящий порты узла, соответственно. Аналогично элемент endpoint имеет необязательный XML-атрибут port.
Документ - пример документа с портами:
GraphML-документ с портами
Правила обработки
Элементы, которые приложение не может обработать, игнорируются. То есть GraphML-документ интерпретируется так, как будто он состоит только из тех элементов, которые известны и понятны приложению. В частности:Проект GraphML имеет целью создание
Проект GraphML имеет целью создание стандартизованного языка описания графов являющегося подмножеством языка XML. Данный документ представляет собой перевод материалов сайта , содержащего информацию о проекте GraphML на русский язык, и объединяет в одном файле материалы из нескольких разделов указанного выше сайта. При этом нормативными документами считаются оригинальные тексты на английском языке, которые можно найти в соответствующих разделах сайта . Представленный документ может содержать ошибки перевода. Перевод выполнил Шокоров В. П. ().Данный документ представляет собой перевод документа “ GraphML Primer ” на русский язык. При этом нормативным документом считается оригинальный текст на английском языке, который можно найти по адресу . Представленный документ может содержать ошибки перевода. Перевод выполнил Шокоров В. П. ().
Пример GraphML-атрибутов
В качестве примера в данном разделе рассматривается граф с раскрашенными узлами и оцифрованными ребрами.Граф с раскрашенными узлами и оцифрованными ребрами.

Мы будем использовать GraphML-атрибуты для хранения данных в узлах и ребрах. Результат показан в файле :
Example of a GraphML Document with GraphML-Attributes
Простой граф
Простой граф описан в файлеПростой граф
GraphML-документ состоит из элемента graphml и ряда подэлементов: graph, node, edge. В конце раздела рассмотрим перечисленные элементы подробнее , и покажем, как они определяют граф.
Рабочая группа
GraphML создается многими людьми, находящимися в различных местах. Наравне с другими текущую работу координируют: Ulrik Brandes (University of Konstanz); Markus Eiglsperger; Michael Kaufmann (University of Tübingen); Jürgen Lerner (University of Konstanz); Christian Pich (University of Konstanz).В консультативную группу входят: Ivan Herman (CWI); Stephen North (AT&T Research); Roberto Tamassia (Brown University).
На этапе формирования структуры активно работали, или были подписаны на полуоткрытый список обсуждения GraphML: Michael Himsolt (DaimlerChrysler); M. Scott Marshall (then CWI); Vladimir Batagelj (University of Ljubljana); Anne-Lise Gros (LIRMM); Carsten Gutwenger (Caesar); David Jensen (University of Massachusetts); Serban Jora (AT&T Research); Sascha Meinert (University of Tübingen); Guy Melancon (LIRMM); Petra Mutzel (Technical University of Vienna); Maurizio Patrignani (University of Rome III); Tim Pattison (DSTO); Matthew Phillips (DSTO); John Punin (Rensselaer Polytechnic Institute); Susan Sim (University of Toronto); Adrian Vasiliu (Ilog); Vance Waddle (IBM Research); Andreas Winter (University of Koblenz).
С чего начать
Для быстрого ознакомления с GraphML рекомендуется ознакомится с . Оно не является нормативным документом, а предназначен для облегчения понимания возможностей GraphML. Нормативное описание языка содержится в нижеприведённой спецификации GraphML.Не смотря на то, что
Синтаксис GraphML определяется GraphML-схемой. Не смотря на то, что схема является более информативным документом, также обеспечено менее строгое описание синтаксиса с помощью Document Type Definition (DTD), в котором, например, не описаны ссылочные типы вроде идентификаторов ребер и узлов графа. Однако, для нормальной работы некоторых приложений, возможно, требуется DTD.Типизация данных
позволяет специфицировать диапазон значений вышеупомянутых типов данных. Это делает с помощью дополнительного атрибута 'attr.type' элементаС помощью атрибута 'attr.name' элемента
Топология графа
Граф обозначается с помощью элемента graph. Элементы расположенные внутри элемента graph обеспечивают объявление узлов и ребер. Узел объявляется с помощью элемента node, а ребро с помощью элемента edge.Определение графа
В GraphML не установлен порядок появления элементов node и edge. Поэтому следующий пример является синтаксически правильным GraphML-фрагментом:
Определение графа
Вложенные графы
GraphML поддерживает вложенные графы, т.е., графы в которых узлы иерархически упорядочены. Иерархия выражается через структуру GraphML-документа. Узел в GraphML-документе может иметь элемент graph, который содержит узлы иерархически вложенные в данный узел. Ниже приводится пример вложенного графа и соответствующий ему GraphML-документ. Обратите внимание, что на рисунке графа иерархия выражена с помощью оболочки, т.е., узел а находится в иерархии ниже узла b если графическое представление узла a расположено внутри графического представления узла b.Вложенный граф.
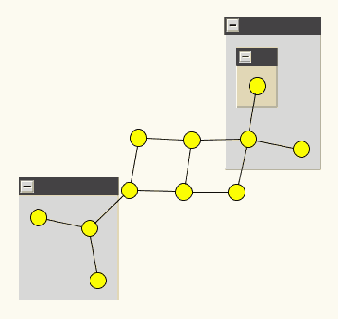
В файле содержится соответствующий GraphML-документ:
GraphML-документ с вложенными графами
Ребра соединяющие два узла, находящиеся во вложенном графе, должны быть объявлены в графе, который является предком обоих узлов в иерархии. Обратите внимание, что в нашем примере именно так и сделано. Объявление ребра между узлом n6::n1 и узлом n4::n0:: n0 в графе n6::n0 было бы неправильно, а объявление их в графе G - правильно. Хорошая практика состоит в том, чтобы размещать объявление ребра в наиболее общем предке или на самом верхнем уровне иерархии.
Для приложений, которые не поддерживают вложенность графов, рекомендуется игнорировать узлы, которые не принадлежат графу верхнего уровня, и игнорировать ребра у которых обе конечные точки не принадлежат графу верхнего уровня.
Заголовок
Рассмотрим фрагмент , общий для всех GraphML-документов, основанный на элементе graphml.Заголовок со ссылкой на XML-схему
...
Первая строка документа это инструкция обработки, которая определяет что документ является подмножеством стандарта XML 1.0, и что документ выполнен в кодировке UTF-8. Конечно, для GraphML-документов могут быть выбраны и другие кодировки.
Вторая строка содержит корневой элемент GraphML-документа: graphml. Элемент graphml, также как и все остальные элементы языка GraphML, принадлежит именному пространству http://graphml.graphdrawing.org/xmlns . По этой причине, с помощью XML-атрибута xmlns="http://graphml.graphdrawing.org/xmlns",мы определяем это именное пространство как именное пространство документа заданное по умолчанию. Следующие два XML-атрибута определяют XML-схему данного документа. В нашем примере мы используем стандартную схему GraphML-документа, расположенную на сервере graphdrawing.org. Первый атрибут, xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" - определяет, xsi в качестве префикса именного пространства XML-схемы. Второй атрибут, xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd" - определяет местонахождение XML-схемы для элементов именного пространства GraphML.
Ссылка на XML-схему не обязательна, но она обеспечивает механизм для синтаксической проверки документа и поэтому строго рекомендуется. Заголовок без ссылки на XML-схему
...
XML - статьи
Язык MDDL - "освободитель" данных о рынках
Подготовлено: по материалам зарубежных сайтовПеревод: Intersoft Lab
Возможно, наши читатели уже слышали о формате обмена информацией на основе XML, который называется Market Data Definition Language (язык определения данных о рынках, сокр. MDDL). Предлагаем вам ознакомиться с этим форматом подробнее.
MDDL был в основном разработан подразделением Financial Information Services Division (Отдел информационных финансовых услуг,
сокр. FISD) организации Software & Information Industry Association (Ассоциация компаний, работающих в области программного обеспечения и информационных технологий, сокр. SIIA). Версия 1.0 этого языка была выпущена в ноябре 2001 г., версия 2. 2 - в апреле 2004 г. и, наконец, последняя, самая свежая версия 2.3 - в августе 2004 г. Сейчас в разработке находится следующая (2.4) спецификация языка.
MDDL - это новая, находящаяся в свободном доступе отраслевая спецификация, которая стандартизирует схемы обмена данными на финансовом рынке. MDDL обеспечивает типовой формат обмена на основе XML для тех элементов, которые описывают различные динамические (меняющиеся/текущие) и статические (исторические) показатели финансовых инструментов и корпоративных событий, влияющие на статус, коммерческую реализуемость и оценку этих инструментов в определенный момент времени. Разнообразные частные показатели, связанные с рынком (в том числе различные экономические и отраслевые индикаторы), также включены в MDDL-спецификации.
Глоссарий MDDL состоит из стандартного семантического набора, который можно получить из общего словаря данных, четко определяющего и описывающего элементы данных о рынках - финансовые инструменты (собственный и заемный капитал), рыночные и корпоративные события и отраслевые показатели в рамках событий контекстных временных рядов (например, изменения цен открытия и закрытия торгов) - а также динамические связи этих элементов друг с другом. MDDL является открытым и легко расширяемым языком, поэтому в него можно вносить дополнения и расширения корпоративных моделей информационного обмена или моделей отдельных поставщиков. Полная версия языка MDDL, обладающая высокой степенью связности и основанная на проверенных моделях XML, включает XML-схему языка MDDL, описание типа (шаблона) XML-документа в формате MDDL (Document Type Definition, сокр. DTD), глоссарий/словарь данных MDDL и образец таблицы стилей для глоссария. MDDL-документ может быть приспособлен для того, чтобы включить широкий спектр данных о рынках и их классификацию. Это помогает компаниям лучше учитывать, анализировать и вести торговлю финансовыми инструментами на мировых рынках.
MDDL сможет учесть все показатели, включенные в первичный массив финансовых данных (индексы Dow Jones, Telekurs, Bloomberg и т.д.), и проверит каждый элемент данных о рынках в соответствии с корректно оформленным, основанном на языке XML форматом обмена, который включает глобальные данные о ценных бумагах, индексах и коллективных механизмах инвестирования. По мере того как поставщики данных будут продвигать и публиковать свои продукты в соответствии с рекомендациями MDDL, бизнесмены смогут тратить меньше времени и ресурсов на интеграцию различных внешних специализированных форматов с внутренними базами данных и приложениями. А это, в свою очередь, приведет к уменьшению количества сбоев при консолидации и преобразовании данных и процессах их очистки в различных средах Хранилищ данных. В рамках общего стандарта, который включает наиболее важную информацию о рынках, необходимую потребителям данных, также упрощаются сложные задачи поддержки и проблемы изменения менеджмента. С разработкой MDDL у компаний появился язык, который устанавливает форматы и определения элементов финансовых данных, что позволяет осуществлять обмен информацией, имеющей отношение к финансовым рынкам, более эффективным и целостным образом. Хранение, получение и поиск информации о рынках с использованием общего признанного формата с нормализованными связями элементов данных существенно улучшает работу финансовых систем организации. Точки интеграции данных из множественных источников, которые служат "входами" в системы стратегических транзакций или поддержки принятия решений, могут быть упорядочены за счет общего понимания и согласованности содержания данных о рынках. MDDL обеспечивает фундамент для создания такой платформы, общей для множества классов активов и временных/календарных измерений.
Запуск глобальных финансовых систем, использующих язык MDDL, созданный на основе XML, в качестве формата для представления данных, дает возможность улучшить автоматизацию и консолидацию всех видов торговых механизмов и процессов. MDDL устанавливает регламентированный финансовый лексикон для независимого от платформ протокола обмена (XML), который легко интегрируется с наиболее распространенными современными средами разработки приложений (J2EE и .NET) и может поддерживать самые востребованные информационные модели: сервис-ориентированную архитектуру (service oriented architecture, сокр. SOA) или типа "публикация и подписка" (publish and subscribe). Корпоративные запросы к Web-сервисам, а также процедуры и запросы ETL (extraction, transformation, loading - технология извлечения, преобразования и загрузки данных), которые передают и ищут финансовую информацию, становятся менее специфичными и гетерогенными. Критически важные системные процессы, которые выполняются в условиях несопоставимых структур ввода и передачи данных, теперь могут преобразовывать данные о рынках в соответствии с одной XML-спецификацией. Работая со стандартизированными данными о рынках, разработчики и системные инженеры могут составлять совместимые с MDDL прикладные программы и программы по извлечению данных, пригодные для многократного использования. Интерфейсы для извлечения и доставки данных о рынках могут использовать общий формат запроса. Улучшаются качество данных и управление ими, что сопровождается существенной экономией средств на всех уровнях корпоративного потока данных. Это улучшение, в свою очередь, ведет к сокращению торговых циклов и созданию возможностей для реализации надежных портальных подходов в области сбора и распространения данных.
Наличие нормализованной семантики MDDL позволяет использовать общепринятую таксономию точных значений понятий и контролируемых словарей. Расширение организационных моделей данных, направленное на использование новых классов финансовых инструментов, может оказаться чрезвычайно сложной и малоуправляемой задачей без эффективного и централизованного управления семантикой и иерархией справочных данных о рынках. Корпорации нанимают специалистов по моделям данных и программам для обработки данных, которые стали "экспертами" во всех соответствующих областях, для того, чтобы они затрачивали огромное количество времени на изменение форматов данных о рынках и исследование автономных блоков справочных данных. Теперь появилась возможность лучше консолидировать и поддерживать (как логически, так и физически) многочисленные и часто избыточные защищенные справочные файлы, число которых быстро увеличивается в каждой корпорации. Это облегчает их федерализацию и объединение во внутренние системы данных. Также эти файлы могут быть легче организованы для передачи внешним потребителям.
MDDL уже занял определенное место в IT-мире и будет укреплять позиции по мере развития своих сильных сторон и расширения сферы применения. Развитие этого языка продолжается (последняя версия имеет номер 2.0), он прочно связан со стандартами, которые облегчают генерирование данных о рынках и их понимание производителями и потребителями. Он находит применение при решении все большего числа бизнес-задач благодаря созданию строгой иерархии производителей и рынков, лучшей классификации действий на уровне отрасли, региона и корпорации, а также оптимизированной характеристике и представлению менее традиционных активов, таких как фьючеры и опционы. Версия MDDL 1.0 определяет свойства обыкновенных акций, открытых паевых инвестиционных фондов и индексов валютных курсов. Версия 2.0 добавляет к этому лексическую информацию, необходимую для характеристики обязательств. Благодаря выдающимся характеристикам MDDL в области эффективного моделирования финансового мира, а также тому, что он основан на всеми признанном языке XML, риск внедрения проектов, основанных на MDDL, сводится к минимуму. MDDL уже является стандартом для представления объектов финансовых рынков, помогая определять, как компании управляют и манипулируют данными этих рынков. Те поставщики данных о рынках, которые раньше других станут использовать основы MDDL в своих продуктах, смогут занимать все больший сегмент этого рынка по мере того, как их клиенты начнут получать значительные прибыли от проектов и инфраструктуры, основанных на языке MDDL.
Пример кода MDDL
Данный пример взят из спецификации языка MDDL и представляет собой информацию гипотетического поставщика данных ypd.net о неком открытом паевом инвестиционном фонде Spanish Mutual Fund MF128, представленном на бирже Барселоны. Этот фонд создан на базе обыкновенных акций компаний French Common Equity XY12 и United States Common Equity PQ39, представленных в разных долях. BSE-MF128 ../../name BSE PSE-XY12 ../../name NYSE-PQ39 ../../name XML - статьи
Миф: спецификация XQuery никогда
Казалось, что этому не будет конца, но на момент написания статьи рабочие группы по XML Query и XSL находятся на завершающей стадии работы над языками XQuery, XPath и XSLT. Помимо этого, уже существует целый набор готовых предложений XQuery.Миф: XQuery не подходит для работы
Во многих отношениях сфера разработки XQuery-стандартов рассматривает интернет как одну большую распределенную базу данных на основе XML. С этой точки зрения язык запросов обеспечивает возможности поиска, при котором пользователи могут получать данные из одного или более найденных документов. С позиций баз данных XQuery - это инструмент для структурного и контентного формирования запросов к большому набору данных, который является мировой базой данных на основе XML. Такой взгляд показывает, что XQuery способен работать с очень большими объемами данных.Масштабируемость и производительность решений XQuery зависят от цели внедрения этого языка. Например, в ряде случаев XQuery используется преимущественно для управления контентом и интеграционных сервисов. Такие решения лучше всего подходят для создания и поддержки Web-сайтов и порталов для ограниченной аудитории. Решения XQuery для функций баз данных на основе XML очень полезны для эффективной обработки больших массивов данных.
Для того, чтобы понять направленность того или иного XQuery-решения, нужно обратиться к его происхождению. Например, в рабочей группе, занимающейся этим языком, четко выделяются два круга специалистов: те, кто пришел к XQuery от работы с XML-документами, и те, кто привык работать с XML-данными. Эксперты, работавшие с документами, в прошлом имели дело с языком SGML, когда существенным моментом был быстрый доступ к сравнительно небольшому количеству XML-данных. Специалисты по базам данных имеют за плечами опыт работы с иерархическими, реляционными и XML-базами и осознают важность возможностей индексирования, расширений для текстового поиска, транзакций и двухфазного завершения, внешних индексов, а также набора средств разработки программного обеспечения и интерфейсов прикладного программирования для разработчиков.
Миф: XQuery поддерживает текстовый поиск по маркерам
Хотя спецификация полнотекстового поиска для XQuery и определяет текстовый поиск по маркерам, рабочая группа по XQuery умышленно оставила некоторые области не до конца разработанными. Например, в XQuery нет стандартного механизма загрузки документа или просмотра списка доступных документов. С точки зрения автора, отсутствие тотальной спецификации обеспечивает плавное развитие XQuery. Существующие реализации XQuery варьируют по своей направленности, а также по средствам управления данными, лежащими в их основе. Такая гибкость делает XQuery таким же удобным механизмом, как и система поиска в базе данных для организации фильтрации. А это усиливает его позиции.Миф: XQuery труднее использовать
На самом деле, XQuery легче использовать с XML-данными, чем интерфейсы прикладного программирования, осуществляющие разбор XML-документов. JDOM, JAXP и другие интерфейсы предоставляют код на языке Java и методы работы с XML-данными. Многие стандартные подходы объектно-ориентированного программирования предполагают создание объектов, которые будут работать со сложными XML-документами. Создание объектов Java требует времени, усилий и опыта. Любое, даже небольшое изменение базового XML-формата данных требует поддержки этого объекта. Энтузиасты XQuery считают, что XQuery-скрипт быстрее найдет XML-данные, которые должно вывести приложение, чем объект Java, созданный с использованием JDOM. Помимо этого, многие библиотеки XQuery предоставляют Java-интерфейс, так что код на XQuery появляется в классах Java и выдает результат в таком виде, как будто для его получения был вызван метод. А класс Java затем обрабатывает результат.Миф: XQuery трудно освоить
Разработчики программного обеспечения, пользующиеся языками Java, .NET и другими, не испытывают проблем с освоением XQuery. Напротив, в XML есть множество компонентов, которые никак нельзя назвать элегантными, в том числе те его части, которые сохранились от более раннего SGML-стандарта. XQuery использует краткий набор команд для облегчения работы с XML-данными. Хотя обычный разработчик и может испытывать определенные проблемы в освоении XQuery, это не потребует каких-то чрезвычайных усилий или затрат времени.Миф: XQuery заменит SQL
XQuery лучше всего приспособлен для XML, также как SQL лучше всего приспособлен для реляционных данных. XQuery обеспечивает похожие на SQL возможности выполнения запросов в тех приложениях, где требуются доступ, выбор, интеграция и трансформация из одного или более XML-наборов. В то время как энтузиасты XML желают видеть все данные записанными с помощью XML-тэгов, модель реляционной базы данных уже прочно укоренилась, а большинство цифровых данных в мире хранятся в виде таблиц, состоящих из строк и полей. SQL вряд ли перестанет использоваться в ближайшее время. Что касается XQuery, то уже появились расширения, позволяющие запросам обрабатывать результаты SQL-вызовов как часть набора XML-документов.Как уже было сказано, XQuery имеет такое же значение для XML, как и SQL для реляционных данных. Но иногда XQuery легче использовать, причем даже для работы с реляционными данными. Например, для обычного разработчика гораздо сложнее использовать SQL для создания outer join, которое выводит результаты в новый XML-документ, чем сделать это на языке XQuery.
Популярность XML заставила рабочие группы, занимающиеся стандартами, расширить SQL-спецификацию и включить в нее функции обработки XML.
Миф: XQuery заменит XSLT
За XQuery и XSLT стоят достаточно мощные движущие силы разработчиков, поэтому они будут сосуществовать. На самом деле, последние спецификации, описывающие XQuery 1.0 и XSLT 2.0, разрабатываются в тандеме.Область пересечения XQuery и XSLT - это те проблемы, для решения которых они созданы: трансформация данных в формате XML, федерализация XML-наборов и расширенные запросы к XML-данным. Разработчикам придется наблюдать и дальнейшие дискуссии о возможностях каждого из этих языков, в которых будет немало мифов и заблуждений. Например, бытует утверждение, что способность XQuery осуществлять запросы к многочисленным несовместимым источникам за один проход дает ему очевидное преимущество над XSLT. На самом деле, процессоры, работающие с XSLT версии 2.0, могут представлять кратные узлы как входную последовательность. В версии XSLT 1.0 есть функция document() для доступа к нескольким источникам за одну операцию трансформации, а версия 2.0 поддерживает функцию
new collection() (новый набор). Также существует мнение, что, хотя синтаксис XQuery выглядит лучше, в нем отсутствует возможность поддержки шаблонов стилей, характерная для XSLT. Возможно, это и так, но, вероятно, в XQuery скоро появится такая функция. В конце концов, разработчики могут ожидать как новых улучшений, так и проблем в обеих технологиях, поэтому их функции и возможности будут оставаться достаточно близкими.
Кроме того, есть еще проблема некоторой "заторможенности" разработчиков. Иногда после посещения презентаций, посвященных XSLT, так и не появляется ощущение реального понимания этого языка. XSLT - это синтаксис для операций трансформации, у которого нет функции main() или метода запуска, в отличие от программ на Java и Jython. Поэтому иногда XSLT-скрипт может выглядеть недетерминированным.
Разоблачение мифов и заблуждений о XQuery
Фрэнк Кохен (Frank Cohen).Перевод: Intersoft Lab
Перспективная технология облегчает создание сервисов, работающих с XML
Язык XQuery выглядит очень перспективным для архитекторов и разработчиков программного обеспечения, поскольку он позволяет существенно сократить написание программного кода, необходимого для создания сервисов, работающих с XML. Некоторые думают, что XQuery способен на все и хорошо понимаем, но среди разработчиков программного обеспечения все еще существует немало неправильных представлений и заблуждений относительно этого языка. Автор предлагаемой статьи детально рассматривает и объясняет многие мифы и заблуждения, окружающие XQuery.
Те, кто работает с XML, Web-сервисами или сервис-ориентированной архитектурой (СОА), вероятно, смогут получить преимущества от использования вновь появившегося стандарта XQuery. Он еще даже не является формально принятым, но уже широко внедрен в практику, облегчая жизнь архитекторам и разработчикам программного обеспечения. Язык, начинавшийся как стандарт для запросов к XML-документам, сегодня включает стандарты следующего поколения для осуществления выбора фрагментов XML-документа (XPath 2), преобразований XML-документа в поток байтов, полнотекстового поиска и функционального моделирования XML-данных. Вокруг такого значительного проекта неизбежно возникает множество мифов и заблуждений, которые нуждаются в разоблачении. Ниже рассматриваются некоторые из наиболее распространенных мифов, связанных с XQuery.
Ресурсы
JSR 225 - интерфейс прикладного программирования XQuery для Java.
XQuery.
The INCITS H2 group;
ISO/IEC JTC1/SC32/WG2.
XQEngine - компонент Java с открытым исходным кодом для запросов к XML-документам.
XQuery Normalizer и Static Analyzer (XQNSTA) - интерфейс прикладного программирования и графический интерфейс пользователя на основе Java для нормализации и расчетов выражений XQuery статичного типа.
PushToTest.com, где можно найти TestMaker - свободный тестовый инструмент с открытым исходным кодом, включающий средства XQuery для разбора ответов Web-сервиса.
Xperanto, который объединяет XML, XQuery, возможности текстового поиска и технологию Web-сервисов для того, чтобы предоставить пользователю инструменты поиска в XML-документах, плоских файлах, электронных таблицах и других источниках информации, содержащихся в отдельной базе данных.
developerWorks XML zone - дополнительные XML-ресурсы.
Developer Bookstore, в т.ч. книга автора статьи "Тестирование и проектирование на Java: от тестов элементов до автоматических Web-тестов" (Java Testing and Design: From Unit Tests to Automated Web Tests).
Примечания:
1Серия документов IETF (Internet Engineering Task Force - проблемная группа проектирования Internet), начатая в 1969 году и содержащая описания набора протоколов Internet и связанную с ними информацию (прим. переводчика).
Заблуждение: для того, чтобы работать
XQuery одинаково работает как в процедурных языках для написания скриптов, так и в языках объектно-ориентированного программирования. Если, например, человека устраивает написание PHP-скриптов, то он может продолжать пользоваться ими. Для большинства существующих языков программирования уже есть XQuery-приложения.XQuery полезен для разработчиков тем, что позволяет существенно сократить размер программы, необходимой для выполнения запросов. Например, разработчик имеет реляционные данные, находящиеся в двух или более базах, и ему требуется выдать отчет, показывающий объединение этих баз. Разработчик, использующий процедурный язык программирования, например, такой, как Python, может написать программу в 100 или более строк для извлечения, разбора и обработки данных. Или же он может написать всего несколько строк на языке XQuery.
Заблуждение: компании, создающие
На самом деле компании, занимающиеся базами данных, рассматривают XQuery как возможность расширить свои решения.Для архитекторов и разработчиков программного обеспечения XQuery - это увеличение производительности и скорости выполнения операций. Поэтому объяснимо желание поставщиков инструментов (см. раздел ) воспользоваться возможностями этого языка.
С точки зрения разработчиков, XQuery очень похож на SQL, поэтому их часто сравнивают. Помимо этого, все больше данных записываются в формате XML, что вынуждает компании, разрабатывающие базы данных, добавлять в свои продукты возможности кратко- и долгосрочного хранения данных в этом формате, а также средства выполнения -запросов к XML-документам. XQuery оказался столь полезным для разработчиков. что даже такие извечные конкуренты, как IBM и Oracle, отвлеклись на время от своего соперничества, чтобы включить возможности XQuery в основные продукты, связанные с базами данных.
Компании - разработчики баз данных также видят возможность стать первыми поставщиками баз, использующих все возможности формата XML, и в дальнейшем занять лидирующее положение на этом рынке. На сегодняшний день данные, хранящиеся в реляционных базах, нормализуются по полям и строкам. В системе XML каждая строка содержит неограниченное число полей, а каждое поле является частью иерархии родительских и дочерних элементов. Тот поставщик баз данных, который первым обеспечит быстрое выполнение запросов и гибкие возможности языка XQuery, получит преимущество на значительном новом рынке.
Доказательством этой возможности является тот факт, что XQuery сплотил жестких конкурентов - компании IBM и Oracle - для совместной разработки спецификации JSR 225 (см. раздел ) - интерфейса прикладного программирования на языке XQuery для Java (XQJ). А Microsoft и IBM объединились для того, чтобы представить тестовый комплект XQuery в Консорциум всемирной сети (World Wide Web Consortium W3C).
Заблуждение: не являются ли XPath и XQuery фактически одним и тем же языком?
На самом деле, XQuery создан на основе XPath и XSLT. Архитекторы и разработчики программного обеспечения используют XPath как язык запросов для нахождения элементов в XML-документе и преобразовании их в XHTML или другой XML-формат с помощью XSLT. Например, разработчик может использовать XPath для нахождения в XML-файле информации о посещении зубного врача пациентом и XSLT - для преобразования этой информации в HTML-формат, удобный для ее просмотра в браузере. Такая схема хорошо работает, если данные уже находятся в XML-формате, но надо иметь в виду, что XPath и XSLT работают только с XML-файлами.Язык XPath ориентирован на операции выбора, а язык XSLT - на преобразование данных; при этом обе технологии все еще нуждаются в разработке эффективного способа выбора, объединения и преобразования данных в необходимую форму. XQuery способен удовлетворять потребности в данных того или иного приложения за счет того, что он обеспечивает доступ к многочисленным источникам, выбор информации из них и объединение данных. Это относится не только к данным в XML-формате: источники, с которыми способен работать XQuery, включают формы документов, Web-страницы и другие слабо структурированные данные.
Заблуждение: в XQuery нет механизма обновления
Это действительно правда: в спецификации XQuery нет механизма обновления. Но на момент написания этой статьи рабочая группа по XQuery готовилась к выпуску основной спецификации XQuery, и несколько ее членов собирались заняться спецификацией для обновлений. Автор статьи предсказывает, что в спецификации XQuery будет использован подход, характерный для SQL. Механизмы обновлений скорее всего будут реализованы в виде набора автономных операций, отражающих и поддерживающих уже существующие команды реляционных баз данных. Но некоторые специалисты по внедрению, а также существующие XQuery-решения предлагают более свободный способ осуществления обновлений с помощью XQuery.Важно отметить, что большинство реализаций XQuery предоставляют собственный механизм осуществления обновлений. Например, одно из популярных решений XQuery включает расширение, в которое входят операции CRUD: Create (создать), Read (читать), Update (обновить), and Delete (уничтожить) - для работы как с данными в формате XML, так и с другими.
Заблуждение: XQuery бесполезен для OLAP и приложений Хранилищ данных
На самом деле XQuery обеспечивает необходимые возможности для связи с OLAP и приложениями Хранилищ данных. Например, обычно корпорация имеет более одного Хранилища для отслеживания и анализа данных о своей деятельности. Эти Хранилища играют роль изолированных структур, и извлечение бизнес-информации из них требует определенных усилий, средств и опыта. Установление связи между ними обычно является трудоемкой и дорогой задачей. XQuery предлагает решение, облегчающее использование средств OLAP за счет установления связи между многочисленными Хранилищами данных на основе запросов. Например, в одном Хранилище содержатся данные о продукции, поставляемой в цепь розничных поставок внутри страны, а в другом - записи о запросах на продукцию, предлагаемую в розничных поставках. XQuery связывает эти Хранилища, показывая, запросы на какую продукцию удовлетворяются хуже всего. Этот пример иллюстрирует преимущества XQuery в логических операциях в Хранилищах данных, аналитике, ETL-операциях и интеграции корпоративных приложений.Заблуждение: XQuery - это не продукт, а слой в стеке
Во всех случаях, когда требуется осуществить управление данными в формате XML или какие-либо манипуляции с ними, XQuery является подходящей спецификацией для функций, которые могут обеспечить библиотека, прикладная программа или сервисный стек. Но механизм, лежащий в основе хранения, извлечения и индексирования XML-данных, вносит существенные отличия в функции, выполнение и масштабируемость XQuery-приложений. Например, первые попытки хранения XML-данных в полях varchar2 реляционной базы данных сопровождались низкой производительностью выполнения запросов в тех случаях, когда инструменты XQuery просто помещались сверху. Это привело к разработке специализированных решений XQuery для целого ряда разнообразных задач. Данные задачи включают управление контентом, обеспечение сохранности данных, работу Web-сервисов и сервис-ориентированной архитектуры, создание Хранилищ данных, оперативную аналитическую обработку (OLAP), процедуры извлечения, преобразования и загрузки (ETL), интеграцию корпоративных приложений (EAI), а также управление питанием.Заблуждение: XQuery не играет роли в преобразовании данных
На самом деле XQuery играет все более существенную роль в преобразованиях данных по мере того, как возникают новые схемы и эволюционируют старые. Для компаний, которым необходимо создать приложение для цепи поставок, преобразование несовместимых форматов сообщений является самой дорогостоящей процедурой. Например, покупатель проводит стандартизацию на основе определенного стандарта (например, RosettaNet), но не располагает оригинальной внутрифирменной схемой. В таком случае поставщик вынужден совмещать свое приложение для цепи поставок со стандартом покупателя, но хочет избежать затрат и риска, связанных с перестройкой своей системы на чужой стандарт. XQuery - это решение, которое позволит бизнесу перейти на новый стандарт без приостановки текущих операций продаж.XQuery позволяет преобразовать ("мэппировать") существующую схему в другой формат без необходимости создавать большую библиотеку нового кода. Вместо этого пишется XQuery-программа, позволяющая преобразовать ответные данные в новый формат.
Заблуждение: XQuery не имеет значения
Архитекторы и разработчики программного обеспечения обращаются к XQuery для решения проблем, связанных с производительностью и сложностью, поскольку системы, которые они создают, содержат большое количество данных в XML-формате. Ниже, в качестве примера, перечислено несколько сценариев и XQuery-решений:Помимо этого, при разработке приложений для цепи поставок средства XQuery для хранения и извлечения XML-данных могут играть важную роль в улучшении общей производительности системы. Средства XQuery для хранения XML-данных и выполнения функций запросов могут оказаться очень полезными для обработки транзакций цепи поставок, поскольку каждый продукт можно будет отслеживать в контексте бизнес-связей, описанных в XML-документе.
XQuery является очень перспективным средством,
Итак, XQuery является очень перспективным средством, поскольку сокращает написание программ, необходимых для создания сервисов, работающих с XML. В более широком плане XQuery обеспечивает единый способ организации запросов к XML-документам, в том числе XML-операции выбора, преобразования к потоку байтов, полнотекстового поиска и функционального моделирования данных. Рабочая группа по созданию спецификаций XQuery продолжает свою деятельность, и это означает, что разработчики программного обеспечения, связанные с XML, могут ожидать появления новых удобных инструментов.XML - статьи
История создания и краткая информация об организационной структуре
Organization for Structured Information Standards (OASIS, Организация по стандартизации структурированной информации) - международный, некоммерческий консорциум, объединяющий в своих рядах более 600 корпоративных и индивидуальных членов из различных стран мира. Вместе с ООН OASIS финансирует проект ebXML, спецификацию обмена данными электронного бизнеса. Кроме того, консорциум осуществляет управление XML.org, центром анализа и синтеза XML-схем, а также поддерживает Cover Pages, интерактивную коллекцию совместимых стандартов языков разметки.Корни организации уходят в 1993 год, когда был основан консорциум SGML Open, цель которого состояла в разработке принципов согласованности продуктов, поддерживающих язык SGML. Чтобы соответствовать изменившимся реалиям: росту объема технических разработок, включая работу над языком XML и другими связанными стандартами, в 1998 году консорциум сменил название на нынешнее.
Общее руководство консорциумом осуществляет Совет директоров (Board of Directors), избираемый членами OASIS. Совет директоров состоит из восьми директоров, срок полномочий которых составляет два года.
Как и в международном консорциуме W3C, большая часть работы по созданию стандартов ведется в Технических комитетах (Technical Committee, TC). В состав комитетов может войти любое лицо, являющееся либо индивидуальным членом OASIS, либо служащим компании-члена OASIS, либо членом другой организации, которая располагает правами объединенного членства, или другим физическим лицом, в случае принятия Советом директоров соответствующего решения. Кроме того, в работе над спецификациями могут принимать участие лица, не являющиеся членами OASIS - несмотря на то, что они не располагают правом голоса, они могут выражать свое мнению по рассматриваемому вопросу, направляя отзывы в комитет (comment list).
Международная организация OASIS: сообщество рабочих групп
Дата: 09-04-2003Подготовлено: по материалам организации
Перевод: Intersoft Lab
От спецификации технических комитетов до открытого стандарта OASIS
Первым шагом на пути становления стандарта является формирование списка обсуждения (discussion list), цель которого - обоснование необходимости создания технического комитета и обсуждение его задач, устава и т. п. Для этого не менее трех членов консорциума должны направить в Правление технических комитетов OASIS (OASIS TC Administration) соответствующую просьбу, указав потенциальные задачи будущего комитета, название списка обсуждения, имена лиц, участвующих в его формировании, контактную информацию, а также имя руководителя этого проекта.Не позднее 15 дней после направления указанной просьбы Правление технических комитетов OASIS обязано обнародовать эти материалы, призвав членов организации к участию в обсуждении. Упомянутый выше список обсуждения представляет собой реестр электронных адресов, который может находится на сайте OASIS не более трех месяцев.
Следующий шаг - обращение в Правление технических комитетов OASIS с предложением об образования Технического комитета. Такая заявка должна включать следующую информацию:
Не позднее 15 дней после получения данного предложения Правление технических комитетов OASIS обязано обнародовать данную информацию, призвав членов организации к участию в работе данного комитета, либо отклонить заявку, указав причину отказа. В случае положительного решения Правление также формирует для данного комитета общедоступный и закрытый списки рассылки.
Призыв к участию в работе нового комитета - это фактически предложение присоединиться к комитету - для этого необходимо направить на имя председателя комитета не позднее чем за 15 дней до первого заседания комитета соответствующее письмо, а также подписаться на общедоступный список рассылки.
Согласно Регламенту технических комитетов OASIS (OASIS Technical Committee Process) консорциум принимает и публикует два типа технических материалов: Спецификации комитетов (Committee Specification) и Стандарт OASIS (OASIS Standard).
Спецификация комитета
Спецификация комитета - это окончательная и утвержденная членами комитета версия документа. Наличие этого статуса является достаточным условием для того, чтобы организации и компании могли начать использовать данную спецификацию, хотя переход спецификации на следующий уровень - Стандарт OASIS - придает ей дополнительный "вес". Необходимо иметь в виду, что Технический комитет вправе не выдвигать свою спецификацию на получение статуса Стандарта.Для того, чтобы разработанная Техническим комитетом спецификация была признана Стандартом, необходимо не менее двух третий голосов членов этого комитета. При этом, против должно высказаться не более четверти его членов.
Как и в случае других решений, принимаемых комитетом, данное "постановление" должно быть занесено в протокол и опубликовано на Web-странице и в списке рассылки. Кроме того, председатель комитета должен поставить об этом в известность Управляющего техническими комитетами (TC Administrator), чтобы спецификация появилась на Web-странице, на которой перечислены Спецификации комитетов.
XML - статьи
CSaxHandler – класс обработчиков SAX-анализатора
Пока мы будем использовать только три обработчика SAX-анализатора – обработчики начала и конца элементов, а также обработчик символьных данных. Это минимум, который необходим для разбора документа. Дополнительно могут потребоваться обработчики ошибок fatalError() и команд обработки processingInstruction(). Последний, в частности, может использоваться для определения кодировки документа, задаваемый в декларации XML атрибутом encoding.Класс CSaxHandler порожден от класса Qt QxmlDefaultHandler, содержащего весь необходимый набор обработчиков парсера, которые по умолчанию ничего не делают. Для того чтобы расширить функциональность нашего класса, достаточно добавить в него объявление и реализацию соответствующих методов. Очень удобно.
// csaxhandler.h
#ifndef CSAXHANDLER_H #define CSAXHANDLER_H
#include
//---------------------------------------------------------------------- // обработчики для SAX-парсера //----------------------------------------------------------------------
class CNode;
class CSaxHandler : public QXmlDefaultHandler { private: CNode* doc; // указатель на объект QStack
// связывание объекта с обработчиками void setDocument(CNode* node); void reset(); // очистить стек и буферы
// обработчики bool startElement(const QString &namespaceURI, const QString &localName, const QString &qName, const QXmlAttributes &attributes); bool characters(const QString &str); bool endElement(const QString &namespaceURI, const QString &localName, const QString &qName); }; //----------------------------------------------------------------------
#endif // CSAXHANDLER_H
Объект, с которым взаимодействует SAX-анализатор при разборе XML-документа, передается в обработчики в виде указателя doc. Это выполняется либо в конструкторе, либо в явном виде методом setDocument().
В определении класса (ниже) видно, что этот указатель помещается в стек nodeStack. В дальнейшем, по мере продвижения по содержимому документа, в этот стек помещаются и удаляются указатели на узлы объекта. Это обеспечивает работу с вложенными объектами узловых классов синхронно с разбором документа.
// csaxhandler.cpp
#include "csaxhandler.h" #include "cnode.h"
//----------------------------------------------------------------------
CSaxHandler::CSaxHandler(){ reset(); }
CSaxHandler::CSaxHandler(CNode* node){ setDocument(node); }
CSaxHandler::~CSaxHandler(){ // doc не удаляем (владелец - внешняя программа)! textElement.clear(); nodeStack.clear(); }
void CSaxHandler::reset(){ doc=0; textElement.clear(); nodeStack.clear(); }
void CSaxHandler::setDocument(CNode* node){ reset(); doc=node;
// корневой элемент nodeStack.push(doc); } //----------------------------------------------------------------------
bool CSaxHandler::startElement(const QString &namespaceURI, const QString &localName, const QString &qName, const QXmlAttributes &attributes){
if(nodeStack.isEmpty()) return false;
// текущий элемент CNode* node=nodeStack.top();
// обрабатываемый элемент if(node) node=node->getNode(localName);
// инициализация реквизитов if(node) node->setRequisites(localName,attributes);
// сделаем его текущим nodeStack.push(node); textElement.clear(); return true; } //----------------------------------------------------------------------
bool CSaxHandler::characters(const QString &str){ textElement+=str; return true; } //----------------------------------------------------------------------
bool CSaxHandler::endElement(const QString &namespaceURI, const QString &localName, const QString &qName){ if(nodeStack.isEmpty()) return false;
CNode* node=nodeStack.top();
// инициализация текстовых элементов if(node && node->isTextElement(localName)){ QXmlAttributes textAttr; textAttr.append(localName,"","",textElement); node->setRequisites(localName,textAttr); }
// элемент обработан nodeStack.pop(); return true; } //----------------------------------------------------------------------
Реквизиты объекта, соответствующие атрибутам исходного документа, инициализируются в обработчике startElement(), реквизиты, соответствующие символьным данным, – в endElement(). Для инициализации используется один и тот же метод интерфейсного класса setRequisites(). Для этого значение текстового элемента записывается в объект класса QXmlAttributes, используемого для передачи атрибутов.
Это искусственный прием, позволяющий сэкономить один метод в интерфейсе CNode. Правда, при этом немного усложняется реализация setRequisites() в узловых классах, поскольку в нем появляется дополнительный условный оператор. Альтернатива – добавление в интерфейс метода инициализации только текстовых реквизитов. Что лучше – судите сами. Автору представляется, что его вариант более экономный.
Собственно, этими двумя классами и ограничивается реализация общего подхода для разбора произвольных XML-документов. Как ими пользоваться – в следующем разделе на примере конкретного документа.
Достоинства и ограничения подхода
Главное достоинство предлагаемого способа заключается в чрезвычайной простоте работы с XML-документом. В качестве примера приведем элементарный пример работы со следующим исходным текстом:Фрагмент программного кода, показывающего работу с атрибутами документа:
// объект CED ed;
// 1. чтение документа (инициализация реквизитов объекта) ed.readDocument(fileName);
// 2. изменение реквизитов ed.EDNo = "1"; ed.EDDate = "2010-03-22"; ed.EDAuthor = "4552000001";
// 3. запись измененного XML-документа ed.writeDocument(fileName);
Выходной документ:
Этот пример хорошо иллюстрирует цепочку преобразований «XML –> объект –> XML», обеспечивающую последовательное чтение, изменение и запись XML-документа. Объект в середине этой цепочки является представлением документа в виде, удобном для использования в прикладных программах.
Естественно, за любое удобство надо платить. В данном случае платой является то, что с помощью таких объектов можно работать только с документами заранее известной структуры. При изменении структуры документов необходимо, кроме участков кода, где используются реквизиты объекта, менять и само объявление класса, описывающего представление документа.
Здесь мы намеренно не касаемся вопросов эффективного использования оперативной памяти – это отдельная задача, которая должна решаться для каждого конкретного случая. Во всяком случае, автору представляется, что предложенное решение в этом отношении ничуть не хуже, чем использование DOM, но обладает большей гибкостью и удобством использования.
Интерфейсный класс CNode
Класс CNode является предком всех узловых классов объектного представления, включая корневой узел. Объявление этого класса следующее:// cnode.h
#ifndef CNODE_H #define CNODE_H
#include
//---------------------------------------------------------------------- // CNode - узел объекта // Интерфейсный класс, обеспечивающий взаимодействие объекта и XML //----------------------------------------------------------------------
// Forward Decls class QXmlAttributes; class QXmlStreamWriter; class QIODevice;
class CNode { private: // вспомогательные методы работы с устройствами записи/чтения bool writeToDevice(QIODevice* device); bool readFromDevice(QIODevice* device); protected: // пространство имен и префикс элемента QString nodeNamespace; QString nodePrefix;
// методы для записи в XML необязательных реквизитов void writeAttribute(QXmlStreamWriter& writer,const QString& name, const QString& value); void writeTextElement(QXmlStreamWriter& writer,const QString& nsUri,const QString& name,const QString& text);
// интерфейсные методы - используются для чтения из XML SAX-парсером friend class CSaxHandler; virtual void setRequisites(const QString &name,const QXmlAttributes &attributes); virtual CNode* getNode(const QString &name); virtual bool isTextElement(const QString &name);
// интерфейсный метод - запись объекта в XML virtual bool writeNode(QXmlStreamWriter& writer,const QString& nsUri); public: CNode();
// наименование узла QString nodeName;
// чтение объекта из XML - из файла или символьного массива bool readDocument(const QString &fileName); bool readDocument(QByteArray* array);
// запись объекта в XML - в файл или символьный массив bool writeDocument(const QString &fileName); bool writeDocument(QByteArray* array);
// флаги, используемые при записи static QString encoding; // кодировка, используемая при записи static bool autoFormatting; // флаг форматирования XML при записи }; //----------------------------------------------------------------------
#endif // CNODE_H
Класс обработчиков парсера CSaxHandler объявлен дружественным, чтобы скрыть интерфейсные методы в защищенной области. Как ранее говорилось, интерфейс должен включать четыре метода:
Интерфейсный класс обеспечивает методами readDocument() и writeDocument() чтение и запись XML-документа в файл или символьный массив QByteArray, которые подключаются в качестве устройств ввода/вывода. Символьный массив играет роль строки, но с более широкими возможностями работы с различными кодировками XML-документов.
Обратите внимание на реквизит nodeName: его необходимо инициализировать в конструкторах прикладных классов именем элементов XML-документов, отображением которых эти классы являются.
Определение класса CNode также не отличается чрезмерной сложностью. Как уговаривались, для базового класса все интерфейсные методы имеют реализации по умолчанию, позволяющие не определять их в наследниках, если в этом нет необходимости:
// cnode.cpp
#include "cnode.h"
#include "cnode.h" #include "csaxhandler.h" #include
QString CNode::encoding = "WINDOWS-1251"; bool CNode::autoFormatting = true; //----------------------------------------------------------------------
CNode::CNode(){ } //---------------------------------------------------------------------- // интерфейсные методы //----------------------------------------------------------------------
void CNode::setRequisites(const QString &name,const QXmlAttributes &attributes){ // ничего не делается - для классов, не содержащих реквизиты }
// указатель на узел элемент CNode* CNode::getNode(const QString &name){ if(name==nodeName) return this; else return 0; }
// проверка, является ли элемент текстовым bool CNode::isTextElement(const QString &name){ return false; }
bool CNode::writeNode(QXmlStreamWriter& writer,const QString& nsUri){ return true; } //---------------------------------------------------------------------- // запись необязательных реквизитов ЭС //----------------------------------------------------------------------
void CNode::writeAttribute(QXmlStreamWriter& writer,const QString& name, const QString& value){ if(!value.isEmpty()) writer.writeAttribute(name, value); }
void CNode::writeTextElement(QXmlStreamWriter& writer,const QString& nsUri,const QString& name,const QString& text){ if(!text.isEmpty()) writer.writeTextElement(nsUri,name,text); } //---------------------------------------------------------------------- // чтение из XML (при совпадении типов документа и объекта) //----------------------------------------------------------------------
bool CNode::readDocument(const QString &fileName){ QFile device(fileName); return readFromDevice(&device); }
bool CNode::readDocument(QByteArray* array){ QBuffer device(array); return readFromDevice(&device); }
bool CNode::readFromDevice(QIODevice* device){ if(!device->open(QIODevice::ReadOnly | QIODevice::Text)) return false;
QXmlInputSource xmlInputSource(device); CSaxHandler handler(this);
QXmlSimpleReader reader; reader.setContentHandler(&handler); bool ok=reader.parse(xmlInputSource);
device->close(); return true; } //---------------------------------------------------------------------- // запись в XML //----------------------------------------------------------------------
bool CNode::writeDocument(const QString &fileName){ QFile device(fileName); return writeToDevice(&device); }
bool CNode::writeDocument(QByteArray* array){ array->clear(); QBuffer device(array); return writeToDevice(&device); }
bool CNode::writeToDevice(QIODevice* device){ QXmlStreamWriter writer(device);
if(!device->open(QIODevice::WriteOnly)) return false;
writer.setAutoFormatting(autoFormatting);
// формирование xml-документа writer.setCodec(encoding.toAscii().data()); writer.writeStartDocument(); if(!nodeNamespace.isEmpty()) writer.writeNamespace(nodeNamespace, nodePrefix); // вызов виртуального метода writeNode(writer,nodeNamespace); writer.writeEndDocument();
device->close(); return true; } //----------------------------------------------------------------------
В качестве SAX-анализатора в приведенном коде используется класс Qt QXmlSimpleReader. Для его работы нужны обработчики, которые реализованы в виде класса CSaxHandler и помещены в отдельный модуль. Для записи документа используется, как уже упоминалось, класс Qt QXmlStreamWriter .
Для методов, обеспечивающих чтение и запись XML-документов, необходимо дать некоторые пояснения.
Во-первых, понятно, что метод чтения readDocument() вызывается для уже созданного объекта конкретного типа, и исходный XML-документ должен соответствовать этому типу. Поэтому в общем случае при чтении не известного заранее документа необходимо сначала определить его тип по имени корневого элемента и создать нужный объект. Это несложно, а то, как это сделать – смотрите в библиотеке QLibUfebs по приведенному выше адресу. Здесь же этот случай не рассматривается.
Что касается записи XML-документа, то в нашем случае для записи атрибутов и текстовых элементов в методах прикладного класса используются, соответственно, методы QXmlStreamWriter::writeAttribute() и QXmlStreamWriter::writeTextElement(). Чтобы облегчить реализацию записи необязательных реквизитов, предусмотрены методы CNode::writeAttribute() и CNode::writeTextElement() с очень похожим синтаксисом, которые формируют атрибут или элемент только для непустых значений.
Исходный XML-документ
В качестве исходного документа, для которого будем реализовывать объектное представление, возьмем слегка упрощенный документ специализированного формата ED201 (по сравнению с оригинальным форматом, в нашем документе отсутствуют один атрибут и пара текстовых элементов). Это сделано с целью упрощения иерархии объекта:Использование в прикладной программе
Здесь приведен пример использования сконструированных классов в прикладной программе.Входной документ:
Слот xmlSlot() выполняет чтение XML-документа text, содержащегося в текстовом редакторе textEdit, в объект ed. Затем с использованием этого объекта выполняется изменение реквизитов и запись объекта в выходной XML-документ out, который добавляется в текстовый редактор для отображения на экране: void MainWindow::xmlSlot(){ QByteArray in; QString text=textEdit->toPlainText(); in.append(text);
// 1. чтение XML-документа CED201 ed; ed.readDocument(&in);
// 2. работа с реквизитами ed.EDNo = "1"; ed.EDDate = "2010-03-01"; ed.EDAuthor = "4552000001";
// 3. запись XML-документа QByteArray out; ed.writeDocument(&out);
textEdit->append(""); textEdit->append(out); }
В результате получаем XML-документ:
Объявления узловых классов
Узловые (прикладные) классы конструируются очень просто:Часто бывает, что нет необходимости объявлять некоторые из методов. Например, в CEDRefID нет текстовых элементов, вложенных объектов, поэтому отсутствуют isTextElement() и getNode(): // cbr_ed201.h
#ifndef cbr_ed201H #define cbr_ed201H
#include "cnode.h"
//----------------------------------------------------------------------
// EDRefID
class CEDRefID : public CNode { protected: virtual void setRequisites(const QString &name,const QXmlAttributes &attributes); public: virtual bool writeNode(QXmlStreamWriter& writer,const QString& nsUri); CEDRefID();
// Methods & Properties QString EDNo; QString EDDate; QString EDAuthor; }; //----------------------------------------------------------------------
// ED201
class CED201 : public CEDRefID { private: virtual void setRequisites(const QString &name,const QXmlAttributes &attributes); virtual CNode* getNode(const QString &name); virtual bool isTextElement(const QString &name); virtual bool writeNode(QXmlStreamWriter& writer,const QString& nsUri); public: CED201();
// Methods & Properties QString CtrlCode; QString CtrlTime; QString Annotation; CEDRefID EDRefID; }; //----------------------------------------------------------------------
#endif
Имена реквизитов в классах объявлены с нарушением принятого в C++ стиля именования (с прописной буквы). Это не небрежность автора. Дело в том, что в описании форматов XML-документов, для которых реализованы эти классы, принята именно такая нотация. А в объявление класса они попали методом «copy/paste». И вообще, весь подход объектного представления направлен на то, чтобы процесс конструирования сводился к простым формальным приемам.
Пример для документа с повторяющимися элементами
Случай, когда в XML-документе имеется множественное включение одноименных элементов, встречается достаточно часто, и поэтому стоит рассмотреть реализацию объектного представления для таких документов. В качестве примера возьмем документ ED232 (тоже немного упрощенный):Объявление класса для этого документа может выглядеть так (опускаем объявление класса CPLAN): class CPLAN; typedef QVector
class CED232 : public CED { private: virtual CNode* getNode(const QString &name); virtual bool writeNode(QXmlStreamWriter& writer,const QString& nsUri); public: CED232(); ~CED232();
CEDRefID InitialED; CPLANList PLAN; };
Как видно, повторяющаяся часть документа реализована в виде списка с использованием шаблона QVector, аналогичного вектору стандартной библиотеки. В список содержатся указатели на объекты, созданные в памяти. Поэтому для класса CED232 нужен деструктор, который освобождает память, занятую объектами CPLAN: CED232::~CED232(){ for(int i=0; i
bool CED232::writeNode(QXmlStreamWriter& writer,const QString& nsUri){ writer.writeStartElement(nsUri,nodeName); writer.writeAttribute("EDNo", EDNo); writer.writeAttribute("EDDate", EDDate); writer.writeAttribute("EDAuthor", EDAuthor);
for(int i=0; i
writer.writeEndElement(); return true; }
Пример иерархии прикладных классов
На рисунке представлена статическая UML-диаграмма класса, являющегося объектным представлением нашего XML-документа:
Намеренно выбран пример, где один из узловых классов (CEDRefID), объект которого включен в качестве члена класса CED201, используется также и как предок этого класса. Такие структурные решения являются обычным делом в объектном проектировании, и позволяют значительно сэкономить затраты за счет повторного использования кода. И, как можно будет убедиться далее, это оказывает влияние на метод записи данных при формировании XML-документа.
Реализация классов
Для наглядности в данном подразделе текст модуля cbr_ed201.cpp разделен на части, с комментариями перед каждой его частью.В конструкторе узлового класса CEDRefID задаются пространство имен nodeNamespace и его префикс nodePrefix. Это не обязательно. Можно опустить либо оба присвоения (тогда действует ранее объявленное или пространство имен по-умолчанию), либо опустить префикс. Если не задавать префикс, тогда он будет формироваться в соответствии с областью действия пространства имен в форме «n1», «n2» и т.д.: // cbr_ed201.cpp
#include "cbr_ed201.h" #include
// EDRefID CEDRefID::CEDRefID(){ // пространство имен nodeNamespace = "urn:cbr-ru:ed:v2.0"; nodePrefix = "ed"; }
Так выполняется присвоение реквизитов объекта, являющихся аналогом атрибутов XML-документа (для текстовых элементов будет показано ниже): // инициализация реквизитов документа при чтении ЭД void CEDRefID::setRequisites(const QString &,const QXmlAttributes &attributes){ EDNo=attributes.value("EDNo"); EDDate=attributes.value("EDDate"); EDAuthor=attributes.value("EDAuthor"); }
Поскольку EDRefID является элементом исходного документа (узлом), для него определен метод writeNode(), начинающийся с записи открывающего тега writeStartElement() и заканчивающийся записью закрывающего тега writeEndElement(): bool CEDRefID::writeNode(QXmlStreamWriter& writer,const QString& nsUri){ writer.writeStartElement(nsUri,nodeName); writer.writeAttribute("EDNo", EDNo); writer.writeAttribute("EDDate", EDDate); writer.writeAttribute("EDAuthor", EDAuthor); writer.writeEndElement(); return true; }
Для узловых классов задаем имя nodeName, совпадающее с именем открывающего тега элемента исходного документа. Для вложенных элементов надо придерживаться правила – если элементы одинакового типа встречаются в документах с разными именами, то nodeName задается в конструкторе класса-владельца, если везде имена одинаковые – то в своем конструкторе. Однако, чтобы избежать ошибок, предпочтителен первый способ: // ED201 CED201::CED201(){ nodeName="ED201"; EDRefID.nodeName="EDRefID"; }
В методе setRequisites() приведен пример инициализации текстового реквизита Annotation, об этой особенности уже упоминалось выше. Если опустить первое условие, то после инициализации текстового реквизита произойдет очистка остальных реквизитов, т.к. аргумент attributes их не содержит.
Инициализацию реквизитов класса-родителя CEDRefID можно выполнить либо явным образом, как и остальные реквизиты (что может привести к проблемам при изменении формата документа), либо вызовом метода с явным разыменованием (предпочтительно): // инициализация реквизитов документа при чтении ЭД void CED201::setRequisites(const QString &name,const QXmlAttributes &attributes){ if(name=="Annotation") Annotation=attributes.value(name); else{ // инициализация реквизитов базового класса CEDRefID::setRequisites(name,attributes);
CtrlCode=attributes.value("CtrlCode"); CtrlTime=attributes.value("CtrlTime"); } }
Этот метод должен быть определен в двух случаях – если класс содержит вложенные объекты (в нашем случае – EDRefID), либо если в классе есть реквизиты, являющиеся аналогом текстовых элементов (Annotation): CNode* CED201::getNode(const QString &name){ if(name==nodeName name=="Annotation") return this; else if(name=="EDRefID") return &EDRefID; else return 0; }
Для класса, содержащего реквизиты – аналог текстовых элементов, нужно определить этот метод: bool CED201::isTextElement(const QString &name){ return (name=="Annotation"); }
В данном примере есть небольшая особенность. Реквизиты EDNo, EDDate, EDAuthor наследуются от класса СEDRefID, но использовать метод СEDRefID::writeNode() мы не можем, т.к. в этом случае сформируются открывающий и закрывающий теги элемента. Поэтому запись этих реквизитов выполняется так, как если бы они были объявлены в CED201: bool CED201::writeNode(QXmlStreamWriter& writer,const QString& nsUri){ writer.writeStartElement(nsUri,nodeName); writer.writeAttribute("EDNo", EDNo); writer.writeAttribute("EDDate", EDDate); writer.writeAttribute("EDAuthor", EDAuthor); writer.writeAttribute("CtrlCode", CtrlCode); writer.writeAttribute("CtrlTime", CtrlTime); writer.writeTextElement(nsUri,"Annotation", Annotation); EDRefID.writeNode(writer,nsUri); writer.writeEndElement(); return true; }
В заключение несколько слов о записи необязательных реквизитов. Если какой-либо атрибут может отсутствовать в XML-документе, то его запись нужно выполнять, используя альтернативные методы интерфейсного класса CNode::writeAttribute(),CNode::writeTextElement(). Например, запись writer.writeAttribute("EDNo", EDNo);
надо заменить на следующую: writeAttribute(writer, "EDNo", EDNo);
Реализация подхода
Объем кода, который обеспечивает реализацию предложенного подхода, не очень большой, поэтому он приведен в этом разделе почти полностью. Из классов удалены лишь некоторые несущественные детали (например, флаги, специфичные для конкретной реализации, обработчик ошибок).Исходные тексты, приведенные ниже, разбиты на два модуля – cnode.cpp и csaxhandler.cpp.
Список использованной литературы
Структура класса повторяет структуру XML-документа
Само по себе использование объекта для представления XML-документа никакого выигрыша не дает, все дело в том, как инициализировать реквизиты объекта. Те примеры, которые приведены в [1] или в составе Qt SDK, оптимизма не вселяли – организация работы по использованию данных документа в этих примерах возлагалось на обработчики SAX-анализатора: startElement(),endElement() и characters(). Естественно, такое решение для работы с большим набором различных форматов XML-документов не подходило.Поэтому сразу появилась мысль всю работу по чтению (инициализации) и записи объектов возложить на сами объекты, а обработчики парсера сделать независимыми от формата исходного документа. Сделать это достаточно просто, используя такие замечательные свойства C++, как наследование и полиморфизм. А третий «кит» объектно-ориентированного языка (инкапсуляция) позволяет так реализовать классы объектного представления, что будущее (неизбежное!) изменение формата документов уже не будет представляться такой уж сложной задачей.
Итак, вспомним, как SAX-анализатор выполняет разбор XML-документа – он начинает с верхнего (корневого) узла и проходит по дереву, в узлах которого находятся элементы XML-документа. Когда встречается открывающий тег элемента, происходит вызов обработчика startElement(), куда передается список значений атрибутов этого элемента; когда парсер достигает закрывающего тега – вызывается endElement(). Обработка символьных данных выполняется иначе, но, как будет показано ниже, эти отличия не играют существенной роли.
Для выполнения инициализации реквизитов объекта необходимо, чтобы каждому структурному элементу XML-документа был поставлен в соответствие структурный элемент класса, описывающего представление. Иными словами, необходимо, чтобы структура класса повторяла структуру XML-документа. Это легко выполнить, если потребовать, чтобы при конструировании классов каждый элемент (узел) исходного документа отображался в свой класс, который назовем узловым классом.
Атрибуты или текстовые элементы исходного документа реализуются в классе в виде членов-данных, вложенные элементы исходного документа – в виде объектов других узловых классов. Как правило, если XML-документ был спроектирован правильно, каждый узловой класс представляет собой некую сущность предметной области, поэтому узловые классы еще называют прикладными.
И, наконец, если у каждого узлового класса будет общий предок, на которого возложим интерфейсные функции, то нетрудно обеспечить, чтобы из обработчиков вызывались соответствующие методы этого интерфейсного класса. Для этого обработчики должны оперировать указателем на интерфейсный класс (да здравствует полиморфизм!).
Узловые классы имеют общего предка
Интерфейс между парсером и объектным представлением XML-документа обеспечивается специальным классом, который, как уже было указано выше, должен быть предком всех узловых (прикладных) классов. Требования к интерфейсному классу (назовем его CNode, префикс «C» от англ. class) диктуются спецификацией SAX-анализатора.Во-первых, самое очевидное:
Атрибуты и текстовые элементы (символьные данные) отображаются в объектном представлении одинаково – в виде реквизитов (членов-данных) класса. Однако обрабатываются они по-разному: атрибуты – в обработчике startElement(), символьные данные – в обработчике endElement(). Дело в том, что парсер передает программе символьные данные посредством обработчика characters(), однако уверенность в том, что данные были переданы полностью, появляется только при достижении парсером конца элемента, содержащего эти данные. Для того чтобы вызвать интерфейсный метод инициализации для текстового элемента, необходимо знать, что тип этого элемента – текстовый. Таким образом, можно сформулировать второе требование к интерфейсу:
Получив в обработчике endElement() информацию о том, что текущий элемент был символьным, можно смело вызывать метод инициализации реквизитов.
И, наконец, обработчики должны обращаться к методам конкретного объекта (или его структурной части). Начинается разбор всегда с корневого узла, но по мере продвижения по дереву документа, должен меняться указатель на текущий узел объекта. Таким образом:
Если текущий узел объекта не содержит других объектов, то метод просто возвращает this. В противном случае указатель инициализируется на нужный вложенный узел. Последнее требование должно сопровождаться организацией в обработчиках парсера стека указателей таким образом, чтобы обработчики всегда работали с текущим узлом объекта.
Сформулированные выше требования относятся к взаимодействию объектного представления с SAX-анализатором в процессе чтения (разбора) XML-документа.
Запись документа может выполняться с использованием любых средств, предоставляемых выбранным средством программирования. В Qt такие достаточно удобные средства предоставляет класс QXmlStreamWriter. Реализация записи, учитывая древовидную природу XML, должна быть распределена по иерархии объектного представления, поэтому в интерфейсе выделяем еще один метод, а именно:
Итак, для обеспечения интерфейса с парсером и классом записи документа в интерфейсе CNode должны быть предусмотрены четыре виртуальных метода. Все эти методы должны иметь реализацию по умолчанию, чтобы в порожденных классах можно было выполнять определение только тех методов, какие действительно необходимы. Взаимодействие объектов с парсером осуществляется через средства, представляемые CNode. Обработчики парсера в данном случае выполнены в виде класса CSaxHandler.
Это, так сказать, обеспечение заявленного универсального подхода. О реализации этих двух классов – в следующем разделе.
то может показаться, что объем
Кому- то может показаться, что объем кода, который нужно определить при использовании предложенного объектного представления XML-документа, больше, чем хотелось бы. Однако это не так. Например, для того чтобы использовать так называемые «свойства» классов (property, расширение C++Builder), в реализации аналогичной библиотеки с использованием DOM приходится определять довольно много кода. К примеру, определение класса CED101 в упомянутой библиотеке занимает около 300 строк, когда как при использовании предлагаемого подхода – всего 120. И это притом, что в DOM не надо заботиться о записи XML-документов в файл.Правда, справедливости ради надо отметить, что большая часть кода в C++Builder генерируется автоматически по XSD-схемам специальным инструментом XML Data Binding wizard. Но и ручной работы после этого остается достаточно.
XML - статьи
PMML и главенство Хранилищ данных
Есть и еще одно различие во взглядах (а также подспудно существующая причина непонимания) в области data mining.Всегда существует различие во мнениях между аналитиками, разрабатывающими модели, и SQL-программистами, обслуживающими Хранилище данных. Оно возникает из-за не очень изящного (с точки зрения аналитиков) традиционного способа осуществления data mining.
Хранилище данных всегда было важной составляющей анализа, поскольку это то место, где данные согласованы и объединены. Но во многих случаях data mining не производится в самом Хранилище. Вместо этого данные выгружаются из Хранилища и помещаются во внешний репозиторий.
Такой подход, однако, является не самым эффективным в смысле производительности и оперативности. Эти проблемы могут быть решены с помощью SQL-моделей. Компании, использующие уже существующие стандарты, вложили в это большие инвестиции, и в том числе в оплату недешевых услуг аналитиков. Поэтому они хотят окупить свои вложения в программное обеспечение и ресурсы, но они также хотят использовать и возможности осуществления data mining в самом Хранилище.
И PMML позволяет им это сделать. PMML устраняет необходимость перемещения данных на другой сервер, сокращая, таким образом, время на доставку данных и запуск модели. Теперь аналитики, разрабатывающие модели, могут просто предложить клиенту свою продукцию, которая работает в самой базе данных, а необходимость создания запросов на языке SQL отпадает.
PMML: возможности data mining для всех?
Подготовлено: по материалам зарубежных сайтовПеревод: Intersoft Lab
Мы продолжаем знакомить читателей с различными XML-форматами. В предыдущем номере журнала мы подробно рассказывали о стандарте обмена статистическими данными и метаданными (Инициатива SDMX: новые подходы к обмену статистическими данными и ), в этом вы можете найти статью о - языке определения данных о рынках. Предлагаемый материал посвящен важному событию - появлению на рынке еще одного нового формата - языка разметки для прогнозного моделирования (predictive modeling mark-up language, сокр. PMML), который наконец-то начинает широко использоваться после восьми лет, потраченных на его создание и усовершенствование.
PMML - это XML-диалект, который используется для описания статистических моделей и моделей data mining. Его главное преимущество заключается в том, что PMML-совместимые приложения позволяют легко обмениваться моделями данных с другими PMML-инструментами. Разработка и внедрение PMML осуществляется IT-консорциумом Data Mining Group.
Одно из существенных достоинств PMML, по словам его сторонников, - это то, что PMML делает data mining более демократичным, т.е. превращает его из занятия, доступного лишь избранным, искушенным в тонкостях уже существующих программных продуктов, в средство, которым могут воспользоваться многие. В результате пользователи, не знакомые с тонкостями ранее разработанных программ, могут эффективно работать с уже созданными моделями данных PMML. Пользователям необходимо часто использовать модели - ежедневно или даже несколько раз в день, и это именно то, для чего существует PMML, - для практической работы с моделями данных.
Как и другой долго разрабатывавшийся стандарт, XML-язык запросов (XML Query language, сокр. XQuery), PMML также потребовал немало времени для своего создания. Но в отличие от Xquery, PMML развивался с течением времени. Пять лет назад появилась его первая версия - 1.1. Сегодня существует уже третья версия этого диалекта (3.0), а многие компании предлагают различные виды поддержки для использования этой технологии.
Практическое использование PMML
По мнению Дэна Фридмэна (Dan Friedman), директора консалтинговой фирмы по маркетингу программного обеспечения DHF Consulting, существует несколько причин, заставляющих поставщиков программного обеспечения включать PMML-поддержку в свои продукты. Но основной из них является необходимость удовлетворения разнообразных требований к разработке и практическому использованию моделей данных.Фридмэн считает, что для прогнозных статистических моделей важны два элемента: время разработки и продолжительность рабочего цикла. Разработка осуществляется независимо, обычно с использованием уже существующих статистических пакетов. Она может занять несколько недель или месяцев и обычно выполняется высоко квалифицированными аналитиками.
Преимущество PMML, по его мнению, заключается в том, что этот диалект может способствовать сокращению рабочего цикла модели. Продолжительность рабочего цикла зависит от того, как модель встраивается в операционную систему, такую как CRM (Customer Relationship Management - системы управления отношениями с клиентами) или финансовую систему. Обычно модель запускается и используется для получения неких показателей, с которыми потом работают в соответствии с определенными бизнес-правилами или иной бизнес-логикой. Такая оценка проводится в режиме реального времени и занимает менее секунды.
Фридмэн также указывает на различия во взглядах между статистиками и специалистами в той или иной сфере бизнеса. PMML может помочь и здесь. Проблема заключается в том, что практическое использование модели и ее создание требуют совершенно разных навыков. На практике использование модели осуществляется "предметниками", которые глубоко понимают бизнес-процесс, но не являются экспертами компьютерного обучения или статистиками. Статистики же хорошо знают математику, но не знакомы с бизнес-процессом. Поэтому те, кто на практике работает с моделями, хотят иметь доступ к инструментам моделирования и других компаний, а также быть уверенными в том, что они могут максимально эффективно использовать эти инструменты. Поскольку практические пользователи моделей не являются специалистами в области моделирования, они стараются применять уже существующие стандарты для того, чтобы быть уверенными: они смогут работать с большинством моделей, которые будут созданы сегодня или в будущем.
По мнению Тоби Данна (Toby Dunn), IT-специалиста отдела образования одного из известных штатов Юго-Запада, в этом случае PMML может оказаться наиболее практичным выбором для решения многих неприятных проблем бизнеса. Ему можно верить: ранее он работал в фирме, которая разрабатывала модели данных для банков и компаний, выпускающих кредитные карты. Эти модели включали оценки кредитоспособности, прогноз доходов и формирование очередей в центре обработки запросов. Они разрабатывались с помощью SAS и устанавливались на сайте клиента с использованием соответствующей программы, написанной на языке Java.
Одна из проблем, связанных с таким подходом, заключается в том, что программа на Java, созданная в компании клиента, должна быть способна работать с моделями данных, разработанными в другой организации, а также с уже существующими и будущими моделями самих клиентов.
Как утверждает Данн, диалект PMML способен решить эту проблему. PMML стал использоваться по двум причинам. Во-первых, это известный и стабильный стандартный набор тэгов, который каждый может найти в интернете. Таким образом, независимо от того, кто разрабатывал модель, ее авторам необходимо было всего лишь представить эту модель клиенту в определенной версии PMML. Клиент, в свою очередь, мог быстро и легко внедрить ее в свою систему. Во-вторых, с помощью PMML можно было производить вычисления, необходимые для того, чтобы соответствующая программа Java работала надлежащим образом и выдавала отчет пользователю.
XML - статьи
Часто используемые конструкции (встречаются, по крайней мере, в трети из рассмотренных схем)
Наиболее часто используемые конструкции XML-схем. Здесь также доминирует упрощение. Лучше всего начать проектирование схемы с этого набора.Чем занимаются проектировщики схем?
Следующим этапом исследования предполагалось сделать шаг вперед по сравнению с работой Костелло и попытаться выяснить, какие из элементов xml-схемы нашли реальное практическое применение. Есть ли согласие во мнениях касательно наиболее часто используемых конструкций? Существуют ли особенности, которых проектировщики стараются избегать?Для этого были собраны данных из 1400 схем, полученных от множества консорциумов. Цель состояла в том, чтобы выяснить, существует ли единый профиль xml-схемы, отражающий согласие практиков.
Предполагалось, что именно схемы консорциумов, стандартные и внедряющиеся в каждой предметной области множество раз, не только имеют различное влияние на рынке, но и должны показать групповое согласие по критериям разработки. Кроме того, они находятся в свободном доступе.
Достоинства и недостатки
Первый шаг на пути изучения профиля – анализ схемы как таковой. Плюсы и минусы многих методов разработки схем нам, фактически, уже известны. Они описаны на вебсайте Роджера Костелло (Roger Costello), который проделал огромную работу по сбору комментариев и мнений разработчиков, а также по объединению и анализу преимуществ и недостатков многих критериев проектирования. Разработчики схем уже несколько лет обращаются к его сайту.На практике при создании схем также может быть интересен вопрос влияния каждой из конструкций на дальнейшее внедрение. Некоторые возможности используются повсеместно и хорошо поддерживаются в интегрированных средах разработки (IDEs) и других инструментах, как, например, кодогенерирующее ПО. Однако среди них есть и малоиспользуемые, которые могут вызвать определенные проблемы из-за отсутствия достаточной инструментальной поддержки.
Инструментальная поддержка
Во многих зарекомендовавших себя инструментах поддержка XML-схемы обеспечивается на высоком уровне. В частности, интегрированные среды разработки (IDE) для редактирования схем предлагают достаточно средств поддержки даже для проблемных конструкций, таких как xsd:union. Проблема инструментальной поддержки может проявляться в двух формах:Источники
Рассматривались схемы следующих организаций:Есть еще множество других консорциумов, информация от которых могла бы использоваться и, скорее всего, будет добавлена к данному анализу.
История вопроса
Профиль – это набор согласованных методик, отражающих наиболее приемлемые практические способы применения данной технологии. Профиль использования XML-схемы отражает ряд конструкций, которые обычно реализуются и поддерживаются инструментами.Концепция профиля XML-схемы обсуждалась уже несколько лет. В 2004-м году консорциум Web Services Interoperability сформировал для исследования идеи формального профиля XML-схемы. В результате консорциум W3C вынужден был провести (XML Schema 1.0 User Experiences), где данные из множества источников были объединены в один план действий. Недавно появился проект документа , где представлены .
Кроме того, многие отраслевые консорциумы разработали руководства или шаблоны для разработки библиотек схем, согласно своему профилю. Изучив как формально, так и неформально многие из них, можно сделать вывод о допустимости или недопустимости тех или иных возможностей XML-схемы. Появились и инструменты, помогающие в разработке профилей схем.
Schematron используется для добавления дополнительных ограничений, помимо тех, что уже есть в схеме. Mindreef's SOAPScope Server
содержит подробно разработанную поддержку для создания настраиваемых профилей схем, предлагая стандартный список ограничений, которые налагаются в различных тестовых случаях. Однако сложно сказать, является ли этот профиль пригодным для межотраслевого использования.
данные
Данные в представленных ниже таблицах отражают результаты исследования. Они взяты с соответствующих сайтов (большинство из которых перечислено здесь). Рис. 1 – это итоговые результаты. На рис. 2 показано, какое количество схем содержит ту или иную конструкцию, а на рис. 3 – число раз, когда эта функция была встречена в той или иной схеме.Рис. 1. Итоговые показатели
Рис. 2. Количество схем, где используются перечисленные конструкции
Рис. 3. Как часто встречаются данные конструкции
Проблемы с инструментальной поддержкой
Эти возможности XML-схем используются часто, но инструментальная поддержка для них не развита. Прежде чем добавить тот или иной элемент в схему, стоит выяснить, поддерживается ли он конкретным программным средством.Эта конструкция встречалась в тестируемых схемах чаще, чем используется на практике. Во-первых, одна организация использовала ее очень часто, а многие другие – избегали. Во-вторых, в анализе учитывался xsd:attributeGroup как для объявлений, так и для повторного использования конструкции @ref. Поэтому, фактически, частота примененияattributeGroups может быть существенно меньше. В большинстве инструментов поддержка этой конструкции не слишком осложнена, но просто не имеет высокого приоритета;
Замечание по поводу групповых символов (wildcards)
По результатам анализа они находятся в середине списка по частоте использования, однако, вероятнее, их применяют чаще. Некоторые из консорциумов создают единый элемент расширения группового символа, на который в дальнейшем ссылаются (с помощью конструкции "@ref") по мере необходимости. Поэтому фактическое количество встретившихся в анализе групповых символов ниже, чем в реальности.
Профилирование XML-схемы
Пол Киль (Paul Kiel)Перевод:
Оригинал:
XML-схеме уже пять лет, из «новорожденного младенца» эта спецификация превратилась в довольно энергичного «юношу». Что же нам известно о нем? С самого начала было ясно, что явление это сложное. И действительно, исходные дебаты том, стоит ли сделать эту спецификацию Рекомендации, уже выявили проблему. (См. материалы «Последнее слово» и «Опрос разработчиков XML-схем»). Этот богатый инструментарий поставил перед разработчиками задачу выбора тех функций, которые им нужно (или не нужно) использовать. Если проанализировать, что фактически было реализовано, то можно дать какие-то рекомендации.
Автор попытался провести исследование, которое позволит скомпилировать некий профиль XML-схемы, основанный на известном на сегодняшний день опыте.
Редко используемые конструкции (встречающиеся в схемах реже, чем в 10% случаев)
Перечисленные ниже функции либо не встречались вообще, либо использовались крайне редко.Разработчики схем четко разделили эти концепции на определенные типы;
Возможно, в дальнейшем это ограничение войдет в силу. Однако в проанализированных схемах такие области имен применялись повсеместно;
Результаты: Профиль XML-схемы
1414 рассмотренных схем показали очевидное стремление к упрощению. По крайней мере, где-то треть из них имела всего шесть структурных средств. И лишь в десяти и менее процентов случаев можно было наблюдать 17 средств. Многие из неиспользуемых конструкций применяются только в очень специфических случаях.Кроме упрощения, характерна эксплицитность схем. Она выражается в очень четком и ясном задании имен в отсутствии моделей со смешанным содержимым и абстрактными типами, в предпочтении конструкции xsd:sequence перед xsd:all.
схем можно сформировать, рассматривая существующие
Четкий профиль использования XML- схем можно сформировать, рассматривая существующие на сегодняшний день наработки. Именно в нем отражены основные черты пятилетнего развития технологии. Основная тенденция - упрощение. В большинстве своем, конструкции содержат простые используемые типы, которые комбинируются в последовательности элементов, и дополняются перечислениями. Многие сложные функции оказались неиспользуемыми. Кроме того, тестирование показало эксплицитность схем. Редко комбинируется или абстрагируется содержимое, элементы отделяются от значений по умолчанию. Для проектировщиков использование основных шаблонов, предложенных в профиле XML-схемы, может оказаться очень полезным.Замечания к рисункам
Несколько дублированных схемы не использовались в анализе, такие как схемы схем (XMLSchema.xsd), которые обычно распространяются со многими библиотеками. Ассоциация ACORD предлагает для своих схем отмену пространства имен. В данном исследовании использовались только именованные версии. В тестовых файлах организаций HR-XML и OAGi анализировались версии разработчиков или неавтономные версии. И хотя в OAGi-схемах не применялись substitutionGroups, но проектирование глобальных элементов все-таки предполагает использование подстановок в качестве возможности расширения. Набор схем W3C включает mathML.XML - статьи
Использование RDF
Выше были введены базовые понятия RDF и объяснено устройство модели данных. Фактически, содержательная часть технологии этим и исчерпывается, поскольку в задачу RDF входило лишь предоставление простой базовой модели для описания отношения ресурсов в терминах именованных свойств и их значений, а также некоторого синтаксиса, который мог бы использоваться различными сторонами для обмена данными. В рекомендации ничего не говорится о том, какие свойства могут быть у конкретных объектов и каковы их допустимые значения, подобно тому, как в спецификации XML определяются лишь правила разметки данных, но не конкретный язык для выделенной предметной области. Исключением здесь являются лишь несколько универсальных характеристик, таких как упомянутое выше свойство “type”, принадлежащих непосредственно пространству имен RDF.Модель данных сама по себе всего лишь скелет. Для того чтобы описание обрело некий смысл, необходимо воспользоваться словарями, которые задаются при помощи дополнительной технологии – RDF Schema, играющей для RDF такую же роль, что и схема для XML (причем выражения схемы RDF также являются корректными выражениями RDF, как и выражения схемы XML – корректные выражения XML).
Под словарем следует понимать совокупность ресурсов, использующихся для описания свойств других ресурсов; классов ресурсов, которые могут быть описаны при помощи заданных свойств; и ограничения, налагаемые на их значения или наборы допустимых значений. При этом классы могут состоять в отношении “подкласс” и аналогично свойства могут быть связаны отношением “подсвойство” [2, 8].
Модель данных, построенная при использовании надлежащих словарей, предлагает осмысленное описание ресурсов, но этого еще не достаточно для понимания Web машинами. Подобно тому, как один человек не имеет возможности передать знание другому, если они оба умеют говорить на одном языке, но используют для этого различную лексику, цель не будет достигнута, пока не будут разработаны единые словари для описания каких-то фактов, и программы не смогут пользоваться ими.
Реальное значение RDF невозможно оценить, пока он используется для внутренних целей отдельно взятого приложения. Польза от внедрения RDF будет тогда, когда он станет средством межпрограммного взаимодействия, обмена данными, когда машины получат способность комбинировать информацию, полученную из различных источников, тем самым, получая какую-то новую информацию. Чем больше приложений в Интернете смогут работать с данными, тем выше станет их ценность [1, 7].
Одним из наиболее ярких примеров существующего общеизвестного словаря является Dublin Core – набор атрибутов для метаописания ресурсов с целью каталогизации. Dublin Core предоставляет пятнадцать характеристик, семантика которых была согласована интернациональной междисциплинарной группой, состоящей из специалистов в области библиотечного дела, информатики, представителей музейного сообщества и других сторон [9].
Эти характеристики, описывающие содержимое документов (или других объектов, например, рисунков), версию, формат, язык и так далее, а также права на интеллектуальную собственность, были разработаны независимо от RDF. Тем не менее, одной из целей создания технологии описания ресурсов было получение средства для указания метаданных, и информационная модель RDF прекрасно подходит для описания ресурсов при помощи атрибутов Dublin Core. Более того, авторы ряда статей рассматривают RDF исключительно в этом качестве, даже не упоминая о других возможностях применения данной технологии.
В то же время RDF прекрасно подходит и для представления самих данных, их структуры и связей. Таким образом, при применении специально разработанных RDF-схем (в качестве средства описания онтологии предметной области) технология может быть использована для выражения информации, относящейся к некоторым разделам знаний, понятным для различных приложений Интернета образом.
Модель данных RDF и вопросы сериализации
Основополагающим для RDF является понятие модели данных. Это есть набор фактов и семантических связей между ними, задаваемый конкретным RDF-документом.В настоящее время RDF допускает две различные нотации, основанные на XML. Также существует несколько других способов сериализации, не связанных с последним, но поддержанных производителями. Базирование на XML с самого начала разработки считалась необходимым, поскольку давало разработчикам возможность воспользоваться всеми его преимуществами, включая сопутствующие технологии и стандартные средства для работы с ними.
После того как программа-парсер прочитала RDF-описание и построила по нему внутренне представление, до определенной степени напоминающее объектную модель документа для XML, вся дальнейшая программная работа с описанием ведется на уровне модели данных и абсолютно не зависит от изначально используемого языка сериализации. Два документа считаются эквивалентными, если совпадают их представления в виде модели, поэтому в случае использования RDF не может возникнуть проблема неоднозначного описания одного и того же факта, как это могло случиться при работе с XML [6, 7].
Для более точного понимания связи RDF с XML и другими языками сериализации можно привести следующую аналогию. Знание, присутствующее в голове человека, ни коим образом не зависит от способа его передачи другим людям. Например, его можно было бы выразить при помощи английского языка, а можно и по-русски. В этой абстракции RDF-модель данных эквивалентна знанию, а XML – английскому языку, который, хотя и является всего лишь одним из возможных способов представления, но имеет статус международного средства общения. Две существующие XML-нотации в этом случае можно сравнить с различными диалектами одного языка.
Принципы построения модели
Базовый строительный блок модели данных – утверждение, представляющее собой тройку: ресурс, именованное свойство и его значение. В терминологии RDF эти три части утверждения называются соответственно: субъект, предикат и объект [6].Ресурсом называют все, что описывается средствами RDF. Это может быть обыкновенная Web-страница или какая-то ее часть, например, отдельный элемент HTML или XML разметки, являющийся частью описываемого документа. Также ресурсом может быть целая коллекция страниц, такая как отдельно взятый Web-сайт. И, наконец, в качестве ресурса может выступать нечто, не являющееся доступным непосредственно через Интернет, например, произвольный предмет из мира вещей. Одним словом, все, чему можно приписать некоторый URI (универсальный идентификатор) или URI с добавлением внутреннего имени объекта (имени якоря в HTML) может стать ресурсом и быть описано при помощи RDF.
Под свойством следует понимать некий аспект, характеристику, атрибут или отношение, используемое для описания ресурса. Каждое свойство имеет свой специфический смысл, допустимые значения, тип ресурсов, к которым оно может быть применено, а также отношения с другими свойствами.
Для обеспечения уникальности имен свойства подобно названиям элементов в XML придерживаются концепции пространства имен. Это означает, что не существует атрибута “цвет” как такового, а существует “цвет” в каком-то уникальном пространстве. В другом пространстве может существовать свое одноименное свойство. Таким образом, имя характеристики представляет собой URI, что делает ее потенциальным объектом для описания при помощи RDF отдельно от характеризуемого ресурса и имеющегося значения. То есть каждое свойство в RDF само является ресурсом и может иметь свои собственные атрибуты.
Одним из общезначимых свойств является “type”, относящееся к пространству имен, задаваемому непосредственно спецификацией RDF. Оно позволяет указать класс описываемого ресурса. Это может быть автомобиль, человек, книга и так далее, а может быть некоторая последовательность объектов (для выражения данного факта существует специальное значение “Seq”, также принадлежащее к пространству имен RDF).
Согласно спецификации, значение свойства может иметь один из двух типов. Первый – это ресурс, задаваемый некоторым URI. Второй тип – литерал – есть некоторое текстовое значение характеристики. Впрочем, литерал может выражать собой значение любого примитивного типа данных, присутствующего в XML. Его тест также может содержать в себе некую разметку, например, XML, но отличительной особенностью такой разметки является то, что она не обрабатывается RDF-процессором и воспринимается как обычная строка.
Тот факт, что значением свойства может быть некоторый ресурс, превращает модель данных из дерева, которым является XML-разметка, в ориентированный граф. Вершинами этого графа являются субъекты и объекты, а дугами – именованные свойства. Поскольку свойство в свою очередь может быть субъектом некоторого утверждения, графы могут быть как линейными, так и вложенными, например, мы можем выражать сомнение или согласие с каким-либо утверждением или указывать источник получения сведений [2, 6].
В качестве простой иллюстрации RDF-документа можно привести описание парка, состоящего из двух автомобилей, для каждого из которых указан год выпуска:
Этому описанию соответствует модель данных, которая представляется следующим графом (при графическом изображении RDF ресурсы принято рисовать овалами, а литералы – прямоугольниками):
Проблема описания семантики и границы XML
Несколько лет назад World Wide Web Консорциумом был разработан язык XML, предоставляющий стандарт структурирования и разметки произвольной информации. По мнению многих специалистов появление XML стало своего рода революцией в сфере Web-программирования. Разработчики получили простое средство для хранения данных в понятном для человека и легко читаемом формате, где разметка говорит сама за себя. Появилась возможность отделить информационное наполнение Интернет-страниц от их визуального представления.Наиболее важной заслугой XML видится то, что программы различных производителей получили возможность “разговаривать” на одном языке. Взамен многочисленных разрозненных способов представления данных появился один универсальный синтаксис, который лег в основу передачи информации между программами, работающими в различных точках Интернета.
Универсальный синтаксис открыл дорогу появлению ряда важных сопутствующих XML технологий. Это языки XSL и XPath, предназначенные для работы с древовидной структурой документов; XML Schema – стандарт описания конкретных языков разметки, использующий синтаксис XML; XLink и XPointer – средства связи распределенных блоков информации в один общий документ; XQuery – язык запросов к размеченным данным и другие технологии.
Важным качеством всех указанных стандартов является их открытость и независимость от конкретных сфер применения и разделов знания. Их задача состоит в том, чтобы предоставить возможность пользователям и программам общаться между собой и друг с другом, не ограничиваясь какой-то конкретной предметной областью.
В свою очередь указанный универсализм привел к созданию стандартных средств поддержки XML и дополнительных технологий, а также к появлению стандартных программных интерфейсов для взаимодействия с ними. Таким образом, программисты получили не только удобные языки для работы с данными, но универсальные библиотеки для осуществления этой работы.
Однако постепенно с течением времени мировое сообщество приходит к пониманию того, что при всех своих достоинствах XML не в состоянии стать подходящим средством выражения семантики размеченных данных. Позволяя закодировать любую информацию и давая разработчику возможность без особого труда получить синтаксический анализатор и средства манипулирования данными, XML удовлетворяет потребностям программистов иметь универсальное средство разметки, обладающее синтаксической интероперабельностью (способностью быть средством взаимодействия между различными программами). Но при этом он не в состоянии адекватно справиться с задачей семантической интероперабельности.
Данное утверждение требует более детального объяснения.
Практически параллельно с работами по стандартизации XML основатель WWW Консорциума Тим Бернерс-Ли сформулировал новое понятие – Semantic Web – то, каким он видит будущее глобальной сети, и инициировал исследования в этом направлении. В основе предполагаемого им будущего лежит способность машин не только читать, но и понимать содержание Интернет-ресурсов, причем достигнуть этого, по мнению Бернерса-Ли, мы должны не через создание программ искусственного интеллекта, моделирующих деятельность человека, а через использование средств выражения семантики данных и их связей [1].
На пути к осуществлению поставленной задачи можно выделить несколько трудностей. С одной стороны программы должны понимать язык соответствующей предметной области, с другой – должны уметь сопоставлять связанные термины различных предметных областей. Это требование является существенным, поскольку в противном случае программы смогли бы работать лишь с отдельными сферами знаний, описанными, например, специализированными XML-языками. Целью же Интернета будущего является создание непрерывного информационного поля.
Здесь можно привести следующий пример. Предположим, что в одной точке глобальной сети размещены данные о какой-то компании и ее сотрудниках, в другой точке – информация о людях, в третьей – об адресах. Очевидно, что компании, люди и адреса принадлежат к отдельным, относительно независимым областям знаний. С другой стороны в непрерывном информационном поле программа должна без особого труда суметь сопоставить сотрудников и людей, адреса этих людей и предметную область адресов как таковых.
Итак, если синтаксическая интероперабельность неразрывно связана с синтаксическим анализом данных, то семантическая требует анализа самой информации, связи ее с мировым информационным полем, установления соответствия терминов и словарей одной предметной области элементам другой [2].
XML не может стать средством, обеспечивающим связь различных данных по ряду причин.
Основное его ограничение состоит в том, что XML лишь описывает грамматику. Выделить семантическую единицу в конкретной предметной области попросту нельзя, поскольку этот язык ориентирован на структуру документа и не предполагает общей интерпретации данных, содержащихся в нем.
XML оказывается слишком гибким средством описания данных и позволяет одну и ту же информацию разметить совершенно различными способами. В качестве иллюстрации сказанного можно представить несколько различных записей утверждения о том, что автомобиль имеет красный цвет:
Данный факт может быть выражен и другими способами, а в том случае, когда имеется уже несколько упорядоченных отношений, вариантов кодирования еще больше [3].
С указанной проблемой можно было бы попытаться справиться одним из двух способов: либо всем заинтересованным сторонам договориться об используемом формате описания, либо прибегать к преобразованию одной грамматики в другую [2]. Однако, очевидно, что первый из этих способов не реален, поскольку заинтересованных сторон, как правило, много и состав их регулярно меняется, а второй способ крайне громоздок, и оба они по-прежнему не решают проблему выделения семантической единицы предметной области. Поэтому приходится признавать, что для эффективного представления фактов необходимо вводить некие ограничения на уровне самого языка.
Следующая сложность, которую следует отметить, несколько забегая вперед, связана с неудобством использования XML для задания метаданных по причине значимого порядка элементов. Вряд ли правильно и вообще возможно заботиться, например, чтобы при поиске книги автор был указан первым, а название вторым. Факты в информационном поле должны быть упорядочены только тогда, когда этот порядок важен с точки зрения самих данных, а не их записи.
И последняя причина заключается в том, что разметка, допускающая смесь из текста и вложенных элементов, сложна для вычленения данных и установления связи между ними. Эта сложность возникает, если необходимо отразить, что объект имеет некоторое свойство, а его значение в свою очередь представлено не значением простого типа и не вложенным поддеревом, а смешанной разметкой (“mixed content” в терминологии XML Schema) [4].
Подводя итог сказанному, следует отметить, что для Интернета будущего, в котором программы смогут автоматически анализировать содержание ресурсов, необходимо новое средство выражения семантики данных, а не только их записи.
Resource Description Framework
Технология описания ресурсов – Resource Description Framework (RDF) – является тем самым средством, на которое WWW Консорциум возлагает надежды на решение указанных задач, связанных с описанием семантики.Несмотря на то, что RDF получил статус рекомендации еще в феврале 1999 года, он по-прежнему не обрел широкого распространения. Причин этому несколько. С одной стороны в отличие от языка XML RDF не сразу получил широкую программную поддержку. С другой – RDF не имел такой первоочередной нацеленности на электронную коммерцию и до сих пор остается преимущественно в области интересов исследователей. Третья причина видится в том, что текущий синтаксис RDF вызывает многочисленные споры и нарекания со стороны потенциальных пользователей данной технологии. По их мнению предложенные формы записи сложны и громозди, что делает описание ресурсов не слишком удобным для применения [3, 5].
Тем не менее, RDF представляется весьма интересной технологией и является важным шагом к созданию Semantic Web. Он продолжает привлекать внимание исследователей и, по мнению многих из них, несет в себе большой потенциал. Можно сказать, что это средство еще не известно широким массам разработчиков или только осознается ими, и есть надежда, что в будущем RDF займет предназначенное ему место.
Выражение семантики данныхRDF против XML
Владимир Шрайбман,При всевозрастающем объеме электронной информации давно и остро стоит задача ее представления в формате, понятном не только человеку, но и интеллектуальной программе. Этот текст является обзорной частью более общей работы, возникшей в результате моего интереса к технологии RDF. Возможно, он будет интересен и полезен кому-нибудь еще.
XML - статьи
Что такое RSS?
Mark Pilgrim, сайт www.xml.comОригинал: What is RSS? (2002 г.)
Перевод: , сайт Webmascon (2003 г.)
RSS это формат, предназначенный для публикации новостей на новостных и подобных им сайтах, начиная от таких ведущих новостных сайтов, как Wired, Slashdot, и кончая личными сетевыми дневниками (weblog-ами). Но по сути, публиковать можно не только новости. Практически любой материал, который можно разделить на отдельные части, можно публиковать с помощью RSS: например, объявления о последних публикациях в "wiki", информация об обновлениях в CVS, история изменений, внесенных в книгу. После того, как информация преобразована в формат RSS, программа, понимающая этот формат, может вытягивать сведения о внесенных изменениях и в зависимости от результата, например, автоматически предпринимать какие-либо действия.
Программы, умеющие работать с RSS, называются агрегаторами, и они очень популярны среди людей, ведущих сетевые дневники (weblog-и). Некоторые программы-дневники даже позволяют другим делать комментарии к записям. И многие дневники умеют публиковать записи в формате RSS. Программа-агрегатор позволяет вам собирать все эти публикации вместе, и вы получаете возможность одновременно следить за появлением новых новостей на всех сайтах сразу и читать их краткое содержание, не посещая каждый сайт в отдельности.
Как выглядит RSS?
Скажем, вы захотели написать программу, которая считывает новости в формате RSS, чтобы, например, публиковать заголовки новостей на своем сайте, или чтобы создать портал новостей и так далее. Как выглядит RSS-файл? Все зависит от того, о какой версии RSS идет речь. Вот пример файла в формате RSS 0.91 (урезанная версия новостей с http://www.xml.com/):http://www.xml.com/
http://www.xml.com/pub/a/2002/12/04/normalizing.html
http://www.xml.com/pub/a/2002/12/04/som.html
http://www.xml.com/pub/a/2002/12/04/svg.html
Все просто, правда? Блок новостей (channel) состоит из заголовка, ссылки, данных о языке новостей и описания. После этого идет список самих новостей, где в каждом пункте указывается заголовок, ссылка и краткое описание новости.
Теперь давайте взглянем, как та же самая информация выглядит в формате RSS 1.0:
xmlns="http://purl.org/rss/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
>
http://www.xml.com/
http://www.xml.com/pub/a/2002/12/04/normalizing.html
http://www.xml.com/pub/a/2002/12/04/som.html
http://www.xml.com/pub/a/2002/12/04/svg.html
Довольно многословно, не так ли? Те, кто знаком с RDF, сразу узнают, что этот файл - RDF-документ, сохраненный в XML. Остальные, разберутся, что в файле представлена вся та же информация, что и в первом примере. Мы только добавили еще некоторую дополнительную информацию, как, например, авторство каждой новости, и дату публикации, которых нет в RSS 0.91.
Несмотря на то, что RSS 1.0 является смесью RDF и XML, структурно он схож с предыдущими версиями RSS - схож достаточно, чтобы мы рассматривали его как обычный XML-файл. Следовательно мы можем написать одну программу, которая умеет извлекать информацию из обоих форматов: и из RSS 0.91 и из RSS 1.0. Однако есть все-таки некоторые различия, о которых ваша программа должна знать:
В RSS 1.0 используются пространства имен (namespaces). Пространство имен для RSS 1.0 выглядит так http://purl.org/rss/1.0/. И это пространство имен принимается по умолчанию. Кроме того в файле используются пространства имен http://www.w3.org/1999/02/22-rdf-syntax-ns# для элементов, специфичных для RDF (мы их тоже можем игнорировать), и http://purl.org/dc/elements/1.1/ (Dublin Core) для дополнительных метаданных об авторах статей и датах публикаций.
Вы можете пойти двумя путями: если ваш XML-парсер не понимает пространства имен, вы можете просто считать, что в файле используются элементы с префиксами и слепо искать в них элементы items и dc:creator. Такой способ сработает в большинстве случаев, так как в новостях формата RSS 1.0 чаще всего используется только пространство имен, принятое по умолчанию, и пространство имён Dublin Core. Конечно, данный способ - не элегантен, ведь нет никаких гарантий, что в каких-нибудь новостях не будет использовано какое-либо другое пространство имен (что вполне легально с точки зрения RDF и XML). И ваш парсер пропустит все новости.
Если же ваш XML- парсер понимает пространства имен, вы можете построить более изящное решение, которое сумеет разобрать новости и формате 0.91 и в формате 1.0.
А как выглядит формат RSS 2.0? К счастью, для программ, понимающих форматы RSS 0.91 и 1.0, формат RSS 2.0 будет проще пареной репы.
http://www.xml.com/
http://www.xml.com/pub/a/2002/12/04/normalizing.html
http://www.xml.com/pub/a/2002/12/04/som.html
http://www.xml.com/pub/a/2002/12/04/svg.html
Как показывает данный пример, в RSS 2. 0 тоже используются пространства имен, как и в RSS 1.0. Но это не RDF. Как и в RSS 0.91, нет пространства имен, принятого по умолчанию, а новости (в элементах item) размещены опять в элементе channel.
document.write('');

Архив новостей
(66)
2 Август, 17:53
(19)
2 Август, 17:51
(34)
2 Август, 15:40
(42)
2 Август, 15:35
(1)
2 Август, 14:54
(3)
2 Август, 14:34
(3)
2 Август, 14:15
(2)
2 Август, 13:34
(7)
2 Август, 13:04
(3)
2 Август, 12:28
BrainBoard.ru
Море работы для программистов, сисадминов, вебмастеров.
Иди и выбирай!
google.load('search', '1', {language : 'ru'}); google.setOnLoadCallback(function() { var customSearchControl = new google.search.CustomSearchControl('018117224161927867877:xbac02ystjy'); customSearchControl.setResultSetSize(google.search.Search.FILTERED_CSE_RESULTSET); customSearchControl.draw('cse'); }, true);
|
|
| IT-консалтинг | Software Engineering | Программирование | СУБД | Безопасность | Internet | Сети | Операционные системы | Hardware |
| PR-акции, размещение рекламы — , тел. +7 495 6608306, ICQ 232284597 | Пресс-релизы — |
|
|
|
| This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 |
|
|
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. |
|
Советуем обратить внимание: доступная. |
Краткая история
Программисты, будьте бдительны! Под термином "RSS" скрывается формат, который распался на несколько различных версий как минимум двух различных (но существующих одновременно) форматов. Исходный RSS, версию 0.90, разработали в компании Netscape. Это был формат, предназначенный для создания новостных порталов ведущих новостных компаний. Так как многие посчитали его слишком сложным, компания Netscape разработала более простую версию - 0.91, которую, впрочем, забросила, потеряв всякий интерес к бизнесу порталов. Но версия 0.91 была передана на поруки компании UserLand Software, которая собирается использовать этот формат как основу для своих weblog-продуктов и других web-приложений.Тем временем, третья, уже некоммерческая организация, отколовшись от общего течения, создала новый формат, который, как полагалось, соответствует духу и принципам исходного формата RSS 0.90 (т.е. до того, как он был упрощен до 0.91). Этот формат, основанный на языке RDF, назвали RSS 1.0. К сожалению, компания UserLand не принимала участия в разработке этого нового формата, и как защитник упрощенной версии 0.90 она не была счастлива, когда появился формат RSS 1.0. Вместо принятия этого формата UserLand решила развить ветку 0.9х и создала версии 0.92, потом 0.93, 0.94 и наконец 2.0.
Вот такой винегрет.
Так каким же форматом мне пользоваться?
Итак, существует 7 - только подумайте "7!" - различных форматов, и все они называются RSS. Как программисту, пишущему программу-агрегатор, вам придется сражаться со всеми этими форматами. Ну а какой формат выбрать пользователю, публикующему свои новости в формате RSS?| Версии RSS и рекомендации | ||||
| Версия | Владелец | За | Статус | Советы |
| 0.90 | Netscape | Отменен версией 1.0 | Не пользуйтесь | |
| 0.91 | UserLand | Очень-очень простой | Официально отменен выходом версии 2.0. Но все еще популярен | Пользуйтесь для простых публикаций. Если вам понадобится большее, вы легко сможете перейти на 2.0 |
| 0.92, 0.93, 0.94 | UserLand | Больше возможностей, чем у 0.91 | Отменен с выходом версии 2.0 | Пользуйтесь версией 2.0 |
| 1.0 | RSS-DEV Working Group | Основан на языке RDF. Расширяется с помощью модулей. Не зависит от какой-либо одной компании | Стабилен. Ведется активная разработка модулей | Используйте для приложений, где используется RDF, либо в том случае, если вам нужен какой-то определенный модуль |
| 2.0 | UserLand | Расширяется с помощью модулей. Прост при миграции с ветки форматов 0.9х | Стабилен. Ведется активная разработка модулей | Используйте для публикации новостей общего назначения |
RSS - новости с доставкой на дом
aka StraNNickС каждым днём всё больше людей используют RSS для чтения новостей и, соответственно, всё больше сайтов применяют эту технологию для распространения контента. Что же такое RSS? Рассмотрим этот вопрос с точки зрения посетителя и владельца сайта.
Для простоты я приведу пример.
В нашем небольшом городе (Улан-Удэ) шесть кинотеатров. Я люблю кино. Вероятность того, что если я своевременно узнаю о фильме, то схожу на него достаточно велика, благо время и деньги вполне позволяют...
Однако, когда я проезжаю мимо кинотетра и вижу афишу - это еще не повод для решения о проведении досуга (а ведь я могу и не проехать...), поэтому хотелось бы более подробной информации - жанр, кто снимался, рецензии...
Для этого существуют сайты. И они таки есть. Но что толку? Во-первых - мне откровенно лень запоминать их адреса или искать их в поисковике. Я могу это сделать один раз. Я могу забить их в закладки. Но заходить каждый день для того, чтобы взглянуть - не появилось ли чего нового? Увольте, у меня масса более интересных дел.
Добавьте к этому тот факт, что каждый из этих сайтов стремится выделиться дизайнерскими изысками, и хотя всё это довольно симпатично, но искать на каждом сайте куда дизайнер засунул информацию о текущих сеансах, рецензиях и ценах на билеты... Оно мне надо?
Теперь предположим, что создатели и владельцы сайтов побеспокоились не только о производимом впечатлении (у нас есть офигительно крутой сайт!), но и об удобстве посетителей, а также о том, чтобы сайт выполнял свою непосредственную функцию - вовремя доносил информацию до потенциально заинтересованных клиентов и, тем самым, привлекал их.
Можно завести старую-добрую почтовую рассылку. Но, во-первых, она требует дополнительных действий от посетителя (например, надо подтвердить подписку), а во-вторых эти письма будут теряться среди моря спама, заполонившего почтовые ящики. Теперь рассмотрим RSS. Потенциальный зритель зашел на сайт. Для подписки требуется буквально пара кликов мышкой. После этого, все обновления, произошедшие на сайте, будут доставлены ему автомагически. Причем в удобной для чтения форме. Я надеюсь, понятно, что в данном случае имеет смысл включить в новость такие вещи как название фильма, цену билетов и время сеансов, а также рецензии, либо ссылки на них (что, в рунете нет ни одного сайта, обозревающего фильмы? Не смешите меня...). Но всего этого нет. И я хожу в кино редко, хотя мог бы чаще...
Я привел вполне жизненный пример. На сегодняшний день в 48 сайтов. Представляете, сколько времени занял бы "обход" их всех? Еще один плюс - экономится время и траффик, так как я вижу только свежие статьи.
Итак, как же можно просматривать RSS-ленты?
Во-первых, в нормальные браузеры (читай, не IE) уже вставлена поддержка этой технологии. В IE пока только ожидается. Так что используйте, например, .
Во-вторых, существует множество онлайн-аггрегаторов, т.е. сайтов, которые собирают RSS-новости, на которые Вы подписались, на одной страничке. Это например или, используемый мной .
В третьих, существует множество удобных программ. Могу посоветовать - вполне приятная кроссплатформенная программа.
Напоследок - пара ссылок, где более подробно рассказывается, что же такое RSS:
Теперь рассмотрим, чем RSS полезен владельцу сайта?
Собственно, всё просто.
Если Ваш сайт раз и навсегда наполнен одним и тем же содержимым, например справочной информацией о Вашей компанией, RSS Вам не нужен.
Если же Вы регулярно обновляете сайт, выкладывая на него всё новые и новые порции информации - Вы заинтересованы, чтобы эту информацию увидело как можно большее количество людей (а иначе зачем Вам сайт?).
Разово привлечь людей не так уж сложно. Ссылка на Ваш сайт на странице известного сетевого обозревателя или новостного ресурса обеспечивает должный приток посетителей. Вся штука в том, что это разовый приток. Ваша цель, заставить посетителя вернуться. А в идеале, возвращаться к Вам снова и снова...
Добиться этого можно разными способами. Однажды я делал онлайновую версию оффлайновой газеты (скажу сразу - мы не сработались). Их метод для достижения этой цели был чрезвычайно прост, цитирую: "...вставь на сайт информер погодный, курс доллара... Анекдоты, там..."
Честно говоря, подобные методы кажутся мне сомнительными. Подобного г... (пардон, добра) на просторах рунета - великое множество. Скорее следует сосредоточиться на том, что делает Ваш ресурс уникальным. И это отнюдь не оформление, как думают слишком многие. Оно тоже играет свою роль, но первой скрипкой всегда был и будет контент. Наполнение. То, зачем к Вам на ресурс идут посетители (а Вы думали, на оформление любоваться?).
Так вот. Как только окно браузера закрыто - адрес забыт. Проверено (в первую очередь на себе). А захочет ли пользователь снова искать его - это еще большой вопрос.
Другое дело, если пользователь, придя к Вам, обнаруживает кроме искомой статьи, множество других интересных материалов. Возможно он задержится на какое-то время, но в конечном итоге уйдёт. При этом он либо занесёт понравившийся адрес в закладки, либо забьёт в аггрегатор RSS.
В чём разница?
В первом случае, заходить он будет только когда вспомнит (читай - нечасто), а вот во втором, новости к нему будут приходить сразу после публикации. Чувствуете разницу?
Возникает вопрос - как учитывать тех посетителей, которые читают RSS, не заходя на сайт? Первое решение, которое приходит в голову - публиковать через RSS только заголовки в корне неправильное. Оно просто-напросто сводит всю затею на нет, хотя и практикуется. Исходя из личных предпочтений - не рекомендую. Не факт, что пользователь зайдёт. Не жадничайте, публикуйте полный текст.
Для учета RSS-пользователей можно либо считать обращения к RSS-файлу (если Вы используете свой сервер и свой счетчик), либо использовать сервис (именно так я и делаю). Этот сервис позволяет делать feed не зависящий от того, какую версию RSS поддерживает аггрегатор пользователя, ведёт статистику (сколько подписчиков и каким софтом они пользуются), а также делает многое другое.
Следующий вопрос - чем генерировать ленту (RSS-feed)?
Если Вы не используете никакого движка для своего сайта, т.е. просто выкладываете статические странички - наилучшим выходом будет расширение для браузера Firefox - , в случае использования самостоятельно написанного движка лучше всего попросить программиста дописать модуль, отвечающий за RSS (как это делать - не мне ему советовать... Хотя Atom API порекомендую, но это чисто субъективный выбор), в других случаях, когда используются сторонние движки, уточните, в подавляющем большинстве уже есть необходимая функциональность.
В общем, надеюсь, я убедил Вас в том, что RSS - крайне полезная технология, позволяющая упростить жизнь как владельцам сайтов, так и их посетителям. Эта штука здорово экономит мне время, так что я заинтересован в том, чтобы появлялось как можно больше сайтов с её поддержкой.
Спецификации актуальных версий RSS:
Несколько полезных ссылок:
XML - статьи
Принципы проектирования XML-схем: нужны ли производные сложные типы
Дата: 14-10-2003Автор: Фахеем Кан (Faheem Khan)
Перевод: Intersoft Lab
Несмотря на то, что в спецификации консорциума W3C XML Schema содержится ряд конструкций, напоминающих понятия объектно-ориентированного программирования - в том числе определение производных типов и полиморфизм, реальная практика показывает, что они скорее усложняют схемы, обладая трудно уловимой взаимосвязью, которая чревата возникновением серьезных проблем, и зачастую могут быть заменены другими конструкциями XML Schema. В этой статье рассмотрены определение производных сложных типов посредством наложения ограничений и расширений, показаны достоинства и недостатки обоих подходов, предложены альтернативные решения.
Проблемы, возникающие при определении производных сложных типов посредством ограничений
В предыдущей статье "Как избежать запутанности" (Avoiding Complexity) из серии "Принципы проектирования XML-схем" автор объяснил почему необходимо быть осторожным при использовании определения сложных типов посредством ограничения: "Правила определения сложных типов посредством наложения ограничений описаны в Разделах 3.4.6 и 3.9.6 Рекомендации W3C "XML Schema". Большинство багов в реализациях тесно связаны с этой функциональностью, и довольно часто при обсуждении различных нюансов получения таких производных типов разработчики высказывают самое серьезное недовольство. Более того, этот способ определения производных типов не полностью соответствует понятиям ни предметно-ориентированного программирования, ни теории реляционных баз данных, которые являются основными потребителями и создателями XML-данных".Для того класса пользователей, которым важен контракт, основанный на проверке допустимости, получение производных типов посредством ограничения мало привлекательно, если вообще привлекательно, по сравнению с определением моделей содержания без задания ограничений. Приведенная ниже схема является эквивалентом рассмотренной выше с тем условием, что все, что от нее требуется, это гарантия того, что элемент XML-Deviant (или DareObasanjo) соответствует указанной модели данных.
Кажется, что для пользователей, которые хотят использовать XML-схему для проверки XML-документа на соответствие контракту, определение производных сложных типов посредством расширений является отличным способом разложить на компоненты аспекты схемы и повторно воспользоваться ими. Однако, первое впечатление обманчиво - взаимодействие с другими конструкциями XML-схемы W3C, как, например, группами подстановки (substitution groups) и xsi:type, превращает использование определения производных сложных типов посредством расширений в разряд трудно контролируемых задач. Рассмотрим, например, следующее объявление элемента:
в котором объявляется элемент xml-deviant, тип которого, XML-Deviant, является сложным типом, описанным в приведенной выше схеме. Оба XML-элемента, приведенные в следующем фрагменте, являются допустимыми в соответствии с этим объявлением элемента xml-deviant:
Несмотря на то, что в объявлении этого элемента явно указано, что типом элемента xml-deviant является сложный тип XML-Deviant, экземпляр может замещать это объявление в схеме, используя атрибут xsi:type, при условии, что этот новый тип является подтипом первоначального типа. Это означает, что по умолчанию даже если элемент успешно прошел проверку на допустимость, он необязательно соответствует модели содержания, по которой, как полагает получатель, он проверяется. Схожая проблема возникает, когда рассматриваемое объявление элемента назначается заголовком (head) групп подстановок.
Существует два способа обойти эту потенциальную проблему, возникающую при определении производных сложных типов посредством расширений. Первый заключается в блокировании подстановки или определении производного типа посредством размещения атрибута block или final в объявлении элемента или в описании сложного типа. Аналогично, атрибут blockDefault или finalDefault может быть добавлен в элемент xs:schema для указания, какой вид подстановок или определения производных типов неразрешен в этой схеме. Второй способ состоит в использовании поименованных групп моделей (xs:group) и групп атрибутов для разбиения схемы на модули - как альтернатива определению производных сложных типов посредством расширений. Ниже приведена схема, которая была рассмотрена в предыдущем раздела и в которую были добавлены поименованные группы моделей.
Стоит заметить, что эта схема не обеспечивает отношения между типами XML-Deviant и DareObasanjo. Этот альтернативный подход неудовлетворителен для тех случаев, когда нужно поддерживать отношение подтипов.
Для сценариев использования, в которых схема применяется для создания строго типизированного XML, получение производных типов посредством ограничения чревато возникновением проблем. В реляционной модели и традиционных положениях об определении производных типов в объектно-ориентированных языках программирования отсутствует возможность накладывать ограничения на факультативные элементы и атрибуты. Приведенный выше пример, в котором элемент email является факультативным в базовом типе, а в производном не может появляться, несовместим с нотацией получения производного типа с позиции объектно-ориентированного подхода; его также трудно смоделировать, используя таблицы реляционной базы данных. Аналогично, изменение признака, указывающего, что модель содержания типа является пустой, не является характеристикой, которая соответствует реляционной или объектно-ориентированной моделям. С другой стороны, пример, в котором не используется получение производного типа посредством ограничения, более просто моделировать в виде классов на языке объектно-ориентированного программирования или в виде реляционных таблиц. Это важно, если учесть, что это уменьшает рассогласование, возникающее при попытке отобразить содержание XML-документа в реляционную базу данных или преобразовать его в экземпляр объектно-ориентированного класса.
Несмотря на то, что некоторые аспекты получения производных типов посредством ограничения плохо преобразуются, их все же можно реализовать напрямую, например, генерируя исключение при попытке обратиться к свойству или полю в производном типе, который был удален при наложении ограничения. Однако такое прямое задание ограничений XML-схемы W3C является неестественным для разработчиков, привыкших писать на объектно-ориентированных языках программирования, и маловероятно, чтобы эти правила стали общепринятыми у всех разработчиков инструментов преобразования XML-схемы W3C.
Для сценариев использования, которые применяют строго типизированные XML-документы, определение производных сложных типов посредством расширений представляет хотя и отличный, но родственный ряд проблем. В случае, если XML-схема используется в качестве основы преобразования между XML и объектно-ориентированной или реляционной моделями, такое определение производных сложных типов не оказывается проблематичным. Однако, при обработки таких строго типизированных XML-документов с помощью языков программирования, поддерживающих схему, как, например, XQuery или XSLT 2.0, возникают определенные сложности. XQuery - это статически типизированный язык, а это значит, что ожидается, что он обнаружит ошибки, связанные с типом, во время компиляции, а не во воремя исполнения. Следующий запрос, заданный к приведенному выше примеру, чреват возникновением проблем:
for $x in //xml-deviant return $x/signature
С одной стороны, это выражение должно привести к статической ошибке, поскольку элемент xml-deviant объявлен как элемент типа XML-Deviant, который не содержит элемент signature. С другой стороны, поскольку у XML-Deviant существует подтип, у которого в модели содержания есть элемент signature и который, следовательно, мог бы быть адресатом директивы xsi:type, это ошибка не должна расцениваться как статическая. Обе позиции являются допустимыми, но независимо от того, что выберет XQuery, всегда найдутся люди, которые будут ожидать противоположенное. Разработчики, знакомые с XPath, могут решить, что этот запрос будет работать, в то время как, те, кто освоился со статически типизированными языками, посчитает его эквивалентом следующего выражения и, таким образом, ошибкой:
foreach(xmldeviant b in list) { yield b.signature; // static type error. }
Чтобы предотвратить эту и другие родственные проблемы, самое лучше - это постараться не использовать определение производных сложных типов посредством расширений, если XML-документ будет обрабатываться с помощью языка обработки, поддерживающего XML-схему, как, например, XQuery.
Рассмотрение определения производных сложных типов посредством ограничений
При наложении ограничений на сложные типы получается производный сложный тип, моделью содержания которого является подмножество модели содержания его базового типа. Это означает, что экземпляр производного типа также должен быть допустимым экземпляром этого базового сложного типа. Ниже приведены некоторые ограничения, которые можно накладывать на модель содержания:Определение производного типа посредством ограничений в основном удобно в сочетании с абстрактными элементами или типами. Так, можно создать абстрактный тип, который содержит все характеристики ряда связанных моделей содержания, а затем ограничить его для создания каждой из требуемых моделей содержания. Этот прием был рассмотрен в сообщении Роджера Костелло (Roger Costello), направленного в адрес XML-DEV, в котором он свел PublicationType к MagazineType.
В приведенной ниже схеме, которая была позаимствована из предыдущих статей, используется ограничение сложного типа для получения из типа, характеризующего подписчика списка рассылки XML-DEV, типа, описывающего автора. В результате, можно проверить допустимость любого элемента, соответствующего типу DareObasanjo, как экземпляра типа XML-Deviant.
При расширении сложных типов получается производный сложный тип, модель содержания которого является расширенным множеством модели содержания его базового типа. Другими словами, к модели содержания базового типа в составе производного типа добавляются дополнительные атрибуты или элементы. При этом добавленные элементы трактуются так, как будто бы они были последовательно присоединены к модели содержания базового типа (конструкция sequence). Этот подход удобен для извлечения общих свойств из набора сложных типов с последующим использованием этих общностей посредством расширения определения базового типа.
В приведенной ниже схеме используется расширение сложного типа для получения из сложного типа, характеризующего подписчика списка рассылки XML-DEV, типа, описывающего автора. Таким образом, экземпляр типа DareObasanjo необязательно является допустимым экземпляром типа XML-Deviant.
Заметим, что когда заданный сложный тип должен быть получен из другого сложного типа посредством ограничения, его модель содержания должна быть продублирована и переопределена.
Зачем проверять XML-документы на допустимость
Рекомендация консорциума W3C "XML Schema" - это всего лишь одна из множества спецификаций языков XML-схем: DTD, RELAX NG и XML Data-Reduced. Для описания структуры XML-документа в XML-схеме определяются допустимые элементы, которые могут находится в документе, порядок их следования, а также ограничения, накладываемые на определенные характеристики этих элементов. Все более широкое распространение языка XML и языков XML-схем выявило два основных сценария использования XML-схем для проверки допустимости XML- документа.Это описание контракта охватывает широкий спектр сценариев использования языка XML, начиная бизнес-субъектами, обменивающимися XML-документами, и заканчивая приложениями, в которых используются конфигурационные XML-файлы.
В рекомендации консорциума W3C "XML Schema" описывается создание аннотированного информационного набора типов, появляющегося в результате проверки допустимости документа по схеме. При проверке документа по XML-схеме W3C входной информационный набор XML преобразуется в постверификационный информационный набор (post schema validation infoset (PSVI)), в котором помимо всего прочего содержатся аннотации типов. Однако, практический опыт показывает, что для создания аннотированных информационных наборов типов не требуется проведения полной проверки допустимости документа; как правило, большинство приложений, в которых используются XML-схемы для формирования строго типизированных XML-документов, например, для преобразования XML<->объект, не выполняет полной проверку допустимости документов, поскольку ряд конструкций XML-схемы W3C не соответствует понятиям предметной области.
В этой статье рассматриваются достоинства и недостатки определения производных сложных типов с точки зрения их влияния на указанные случаи использования XML-схемы.
С учетом нынешнего уровня развития
С учетом нынешнего уровня развития технологий возможность определения производных сложных типов в соответствии с положениями XML-схемы W3C скорее добавит сложности, а не упростит ситуацию в двух наиболее общих случаях использования схемы. Для сценариев проверки допустимости документов получение производных типов посредством ограничений имеет минимальную ценность, но получение производных типов посредством расширений - это удобный способ применить модульный подход и воспользоваться принципом повторного использования. Однако, следует внимательно изучить последствия использования подстановок различных типов (xsi:type и группы подстановок) при определении производных типов посредством расширения в сценариях, задействованных в проверке допустимости документа.В настоящий момент обработка и хранение строго типизированных XML-данных - это удел традиционных объектно-ориентированных языков программирования и реляционных баз данных. Это означает, что определенные возможности XML-схемы W3C, такие как получение производного типа посредством ограничения (и в меньшей степени определение производного типа посредством расширения) являются причиной возникновения несоответствия между системой типов, используемых для описания строго типизированного XML-документа, и механизма, применяемого для обработки и хранения вышеупомянутого XML. В конечном счете, когда такие технологии, как XQuery, получат широкое распространение как средство обработки и поддержки типизированных XML-документов, а XML-схема W3C будет интегрирована в основные продукты баз данных, это несоответствии перестанет быть существенным. Но до этого момента необходимо тщательно продумывать, применять ли определение производных сложных типов в ситуациях, в которых XML-схема W3C используется главным образом как механизм создания аннотированных информационных наборов типов XML.
XML - статьи
Абстрактные элементы и типы
Язык XML-схемы обеспечивает возможность принудительной замены специфических элементов или типов. Если элемент или тип объявлены "абстрактными", то они не могут использоваться в документе. Когда абстрактным объявляется элемент, то в документе должны использоваться элементы, входящие в его группу замены. Если элемент соответствующего типа объявлен абстрактным, то все экземпляры этого элемента должны использовать xsi:type для указания производного типа, который не является абстрактным.В примере группы замены, описанном в подразделе 4.6, запретим использование элемента comment так, чтобы в документах можно было использовать только элементы customerComment и shipComment. Для этого объявим элемент comment абстрактным, и изменим его первоначальное объявление в схеме международного заказа на покупку, ipo.xsd, следующим образом:
< element name="comment" type="string" abstract="true"/>
С элементом comment объявленным абстрактным, документы международных заказов на покупку будут синтаксически правильными, если они содержат комментарии в элементах customerComment и shipComment.
Объявление абстрактного элемента требует использования группы замены. Объявление абстрактного типа требует использования в документе производного (идентифицированного атрибутом xsi:type) от него типа. Рассмотрим приведенный ниже пример. Схема описания транспортных средств:
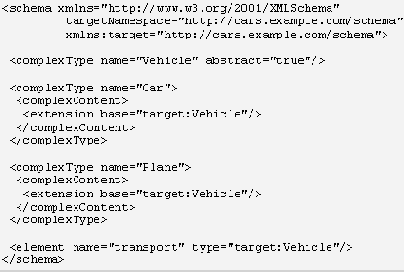
Элемент transport не абстрактен, поэтому может появиться в документах. Однако его определение типа абстрактно, и поэтому элемент transport не может появляться в документе без атрибута xsi:type, который ссылается на производный тип. Это означает, что следующий фрагмент не соответствует схеме (так как элемент transport имеет абстрактный тип):
< transport xmlns="http://cars.example.com/schema"/>
Однако следующий фрагмент синтаксически правилен, поскольку элемент transport имеет не абстрактный тип Car, замещающий абстрактный тип Vehicle.

Аннотации
Язык XML-схемы обеспечивает три элемента предназначенные для аннотации схемы. Содержимое этих элементов предназначено как для чтения человеком, так и для чтения приложением. В схеме заказа на покупку, мы размещаем описание схемы и информацию об авторском праве в элементе documentation, в котором рекомендуется размещать информацию для чтения документа человеком. Мы рекомендуем для указания языка комментариев использовать атрибут xml:lang со всеми элементами documentation. Вместо этого можно указать язык всей схемы, помещая атрибут xml:lang в элементе schema.Элемент appInfo, который мы не применяли в схеме заказа закупки, может использоваться, чтобы предоставить информацию для инструментальных средств, таблиц стилей и других приложений. Интересный пример, использования appInfo приводится в схеме (http://www.w3.org/TR/2001/REC-xmlschema-2-20010502/#schema), которая в документе "XML-схема. Часть 2: Типы данных" описывает простые типы. Например, внутри элемента appInfo представлена информация о том, какие фасеты могут быть применены к каждому из простых типов. Впоследствии эта информация была использована специальным приложением для автоматической генерации текста документа "XML-схема. Часть 2: Типы данных".
И documentation, и appInfo являются подэлементами annotation. Элемент annotation обычно размещают в начале большинства схем. В приведенном ниже примере элементы annotation располагаются вначале объявления элемента и вначале определения комплексного типа. Элементы annotation в объявлении элемента и определении типа:
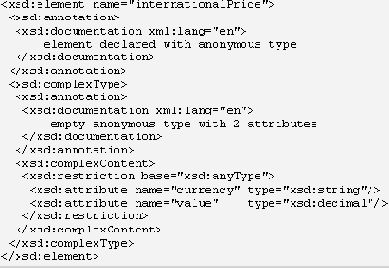
Элемент annotation также может располагаться в начале других операторов языка XML-схемы, например, таких как schema, simpleType, и attribute.
AnyType
anyType представляет абстракцию, называемую оur-typ (), которая является базовым типом прародителем всех простых и комплексных типов. Тип anyType не ограничивает как-либо свое содержимое. Тип anyType используется подобно другим типам, например:
Содержание элемента, объявленного этим способом никак не ограничивается. Элемент может принимать значение 423.46, но это может быть и любая другая последовательность символов, или смесь символов и элементов. Фактически, anyType - это тип, задаваемый по умолчанию. Так что вышеуказанное объявление может выглядеть следующим образом:

Элементы с произвольным содержанием могут применяться, например, в случае элементов содержащих литературный текст с символами национальной разметки. В этом случае заданное по умолчанию объявление или немного ограниченный вид этого объявления могут быть вполне подходящими. Тип text, описанный в подразделе 5.5 - пример такого типа.
Библиотеки типов
Поскольку XML-схемы становятся широко распространенным, то авторам схем понадобится возможность создания простых и комплексных типов, которые могут быть повторно использованы как стандартные блоки для создания новых схем. XML-схема обеспечивает типы, которые играют эту роль, в частности типы, описанные в приложении "Простые типы" и во ведении в библиотеку типов ().Собственные библиотеки типов могут создаваться, например, для того, чтобы описать денежные форматы, единицы измерения, адреса, и так далее. Каждая библиотека могла бы состоять из схемы, содержащей одно или более определений. Ниже приводится пример схемы, содержащей определение валют.
Пример определения типов валют в библиотеке типов:

Пример элемента, появляющегося в документе и имеющего указанный выше тип:
< convertFrom name="AFA">199.37< /convertFrom>
Как только тип валют определен, то он становится доступным для многократного использования в других схемах через только что описанный механизм импорта.
Целевые именные пространства и не квалифицируемые локальные объекты
В новом варианте схемы заказа на закупку (po1.xsd) мы явно объявляем целевое именное пространство, и определяем, что локально определенные элементы и локально определенные атрибуты должны быть не квалифицированы. Целевое именное пространство в po1.xsd задается значением атрибута targetNamespace и равно "http://www.example.com/PO1".Квалификация локальных элементов и атрибутов может быть глобально определена парой атрибутов, elementFormDefault и attributeFormDefault, элемента schema, или может быть определена отдельно для каждого локального объявления с помощью атрибута form. Значение каждого из этих атрибутов может быть установлено в unqualified или в qualified, что указывает на признак квалифицируемости локально объявленных элементов и атрибутов.
В po1.xsd глобально определен параметр квалифицированности элементов и атрибутов путем присвоения атрибутам elementFormDefault и attributeFormDefault значения равного unqualified. Строго говоря, эти атрибуты с таким значением можно не задавать, потому что это значение является для обоих атрибутов значением по умолчанию. Мы задаем их здесь в явном виде для того, чтобы показать разницу между этим вариантом и другими вариантами, которые мы опишем позже.
Схема заказа на закупку с целевым именным пространством, po1.xsd:
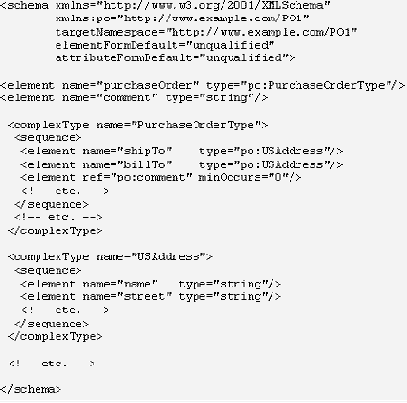
Чтобы увидеть, как пополняется целевое именное пространство приведенной выше схемы, рассмотрим каждое из объявлений элементов и определений типов. Начнем с конца схемы. Здесь мы определяем тип с названием USAddress, который состоит из элементов name, street, и т.д. В результате определения, тип USAddress включается в состав именного пространства схемы. Затем мы определяем тип с названием PurchaseOrderType, который состоит из элементов shipTo, billTo, comment, и т.д. PurchaseOrderType также включается в состав именного пространства схемы. Обратите внимание, что ссылки на тип в объявлениях трех элементов имеют префикс: po:USAddress, po:USAddress и po:comment, и этот префикс связан с именным пространством http://www.example.com/PO1. Это то же самое именное пространство, что и целевое именное пространство схемы. Поэтому обработчик этой схемы будет знать, что определение типа USAddress и объявление элемента comment находятся в пределах данной схемы. Вы также можете сослаться на определение типов находящееся в другой схеме с другим целевым именным пространством. Следовательно, допускается повторное переопределение типов и переобъявление элементов от схемы к схеме.
В начале схемы po1. xsd мы объявляем элементы purchaseOrder и comment. Они включаются в целевое именное пространство схемы. Тип элемента purchaseOrder имеет префикс также как и тип элемента USAddress. Напротив, префикс типа у элемента comment имеющего тип string не установлен.
Ниже приводится пример того, как целевое именное пространство схемы затрагивает соответствующий документ. Заказ на закупку с неквалифицированными локальными объектами, po1.xml:

В документе объявлено одно именное пространство http://www.example.com/PO1, которое связано с префиксом apo:. Этот префикс используется для того, чтобы квалифицировать два элемента в документе: purchaseOrder и comment. Именное пространство документа то же, что и целевое именное пространство схемы в файле po1.xsd. Поэтому при анализе документа обработчик будет знать, в какой схеме искать объявления purchaseOrder и comment. Целевым именное пространство названо в том смысле, что оно является именным пространством, в котором находятся элементы purchaseOrder и comment. Поэтому целевые именные пространства схемы управляют верификацией соответствующих именных пространств документа.
Префикс apo: применен к глобальным элементам purchaseOrder и comment. Кроме того, elementFormDefault и attributeFormDefault требуют, чтобы префикс не применялся ни к одному из локальных элементов вроде shipTo, billTo, name и street, и ни к одному из атрибутов (которые все объявлены локально). Элементы purchaseOrder и comment являются глобальными, так как объявлены в контексте схемы в целом, а не в пределах контекста какого-либо типа. Например, объявление элемента purchaseOrder в po1.xsd является дочерним по отношению к элементу schema, тогда как объявление shipTo является дочерним по отношению к элементу complexType, который определяет тип PurchaseOrderType.
Если локальные элементы и атрибуты не квалифицированы, то автору для создания корректных документов могут в той или иной степени потребоваться знания о подробностях схем этих документов. Ситуация несколько проясняется если автор знает что только корневой элемент (типа purchaseOrder) является глобальным. Тогда квалифицировать нужно только корневой элемент. Если автор знает, что все элементы объявлены глобально, то все элементы в документе могут иметь префикс, который возможно связан с именным пространством, объявленным по умолчанию (мы исследуем этот подход в подразделе 3.3). С другой стороны, если нет какого-либо однородного правила для глобальных и локальных объявлений, то автор документов будет нуждаться в детальном знании схемы для правильного применения префиксов к глобальным элементам и атрибутам.
Дополнительные понятия I: именные пространства, схемы & квалификация
Схема может рассматриваться как коллекция (словарь) определений типов и объявлений элементов, имена которых принадлежат определенному именному пространству, называемому целевым именным пространством. Целевые именные пространства дают возможность различать определения и объявления, принадлежащие различным словарям. Например, целевое именное пространство позволяет отличить элемент объявленный в словаре языка XML-схемы от элемента, объявленного в гипотетическом словаре языка описания химических элементов. Первый элемент принадлежит целевому именному пространству , а последний - часть некого другого целевого именного пространства.Когда мы хотим убедиться, что документ соответствует одной или более схемам (с помощью процесса, называемого верификацией схемы), то мы должны идентифицировать объявления элементов и атрибутов, а также определения типов в схемах которые будут использоваться для проверки соответствующих элементов и атрибутов в документе. Целевое именное пространство играет важную роль в процессе идентификации. Роль целевого именного пространства будет рассмотрена в следующем разделе.
Автору схемы предоставляется ряд опций, которые влияют на то, как будут отождествляться элементы и атрибуты, представленные в документе. Автор может решить, действительно ли появление локально объявленных элементов и атрибутов в документе должно быть квалифицировано явным или неявным (заданным по умолчанию) префиксом именного пространства. Выбор автора схемы относительно квалифицирования локальных элементов и атрибутов может зависеть от множества факторов касающихся структуры схемы и документов. Некоторые из этих факторов мы рассмотрим в следующих разделах.
Дополнительные понятия II: международный заказ на покупку
Схема заказа на покупку, описанная в разделе 2 размещалась в одном файле, и большинство конструкций схемы, типа объявлений элементов и определений типов, были созданы вновь. В действительности, у авторов схем возникает потребность составлять схемы из конструкций, расположенных в нескольких файлах, и создавать новые типы, основанные на существующих типах. В этом разделе, мы исследуем механизмы, которые допускают такие композиции схем и методы создания типов.Дополнительные понятия III: квартальный отчет
Программы формирования заказов и выписки счетов обычно могут генерировать отчеты, в которых указывается, сколько и каких изделий было реализовано в заданном временном диапазоне. Пример такого отчета, за четвертый квартал 1999 года, приведен в 4Q99.xml.Обратите внимание, что в этом разделе (где возможно), в схеме мы используем квалифицированные элементы, а в документах именное пространство, заданное по умолчанию.
Квартальный отчет 4Q99.xml:

Отчет содержит раздел с данными об изделиях (номер изделия и наименование) и раздел с описанием партий изделий, отгруженных по различным почтовым адресам. Для каждого такого раздела, в отчете имеется соответствующее описание. В разделе отгруженных партий товаров отсутствуют итоговые данные по почтовым адресам. Это связано с действующими ограничениями на оформление отчета. Например, каждый почтовый индекс может появиться только однажды (ограничение уникальности). Точно так же описание каждого отгруженного в данный адрес изделия появляется только однажды, хотя отдельные изделия могут входить в различные партии товара, имеющие разные почтовые индексы (ссылочное ограничение). Например, изделие с номером 455-BX. В последующих разделах мы рассмотрим, как, используя XML-схему задать указанные выше ограничения.
XML-схема отчета, report.xsd:

Глобальные элементы и атрибуты
Глобальные элементы, и глобальные атрибуты, создаются с помощью объявлений, которые являются дочерними элементами элемента schema. Как было указано выше, на глобальный элемент или глобальный атрибут можно сослаться с помощью параметра ref в одном или более объявлениях.Объявление, которое использует ссылку на глобальный элемент, позволяет элементу, на который указывает ссылка, появиться в документе в качестве содержимого данного объявления. Так, например, элемент comment появляется в po.xml на том же самом уровне, что и shipTo, billTo и элементы items, что связано с тем, что объявление comment находится в комплексном определении типа на том же самом уровне, что и объявления других трех элементов.
Объявление глобального элемента дает возможность элементу появиться в документе в качестве элемента верхнего уровня. Следовательно, purchaseOrder, который объявлен как глобальный элемент в po.xsd, может появиться как элемент верхнего уровня в po.xml. Обратите внимание, что объявление элемента comment как глобального позволяет ему появиться в документе po.xml как элементу верхнего уровня, а не только в качестве подэлемента элемента purchaseOrder.
Есть множество особенностей относительно использования глобальных элементов и атрибутов. Одна из них состоит в том, что глобальные объявления, не могут содержать ссылки: такие объявления должны задавать простые или сложные типы непосредственно. Говоря конкретно, глобальные объявления не могут содержать атрибута ref, они должны использовать атрибут type. Вторая особенность состоит в том, что в глобальных объявлениях нельзя использовать ограничение на количество вхождений элементов, хотя оно может быть помещено в локальные объявления, которые на них ссылаются. Другими словами, глобальные объявления не могут содержать атрибуты minOccurs, maxOccurs, или use.
Глобальные объявления в сравнении с локальными объявлениями
Другой стиль применяется тогда, когда наименования всех элементов в пределах именного пространства уникальны. При этом автор создает схемы, в которых все элементы являются глобальными. Это напоминает использование оператора < !ELEMENT> в DTD. В нижеприведенном примере, мы изменили оригинал po1.xsd так, что все элементы объявлены глобально. Обратите внимание, что в этом примере мы опустили атрибуты elementFormDefault и attributeFormDefault. Это сделано для того, чтобы подчеркнуть, что когда объявлены только глобальные элементы и атрибуты, значения этих атрибутов являются несущественными. Модифицированная версия po1.xsd, использующая только глобальные объявления элементов:
С помощью этого "глобального" варианта po1.xsd можно проверить правильность ранее рассмотренного документа po2.xml, который также соответствует "квалифицированному" варианту схемы po1.xsd. Другими словами, оба варианта схемы могут проверить правильность одного и того же документа, чье именное пространство задано по умолчанию. Таким образом, с одной стороны оба варианта схемы подобны, хотя с другой стороны различны. Когда все элементы объявлены глобально, преимущества локального объявления теряются. Например, Вы можете объявить только один глобальный элемент с именем "title". В противоположность к глобальному объявлению, Вы можете объявить несколько локальных элементов с одинаковым именем. Например, можно объявить локальный элемент с именем "title", который будет подэлементом элемента "book", и иметь строковый тип. В пределах той же самой схемы (целевого именного пространства) Вы можете объявить второй элемент с именем "title", который является перечислением значений "Mr Mrs Ms".
Группы атрибутов
Предположим, что мы хотим обеспечить подробную информацию о каждом продукте в заказе на закупку. Например, вес каждого продукта и предпочтительный вариант отгрузки. Мы можем достигнуть этого, добавив к определению типа item (анонимному) объявления атрибутов weightKg и shipBy .Включение атрибутов непосредственно в определение типа:

Вместо этого, мы можем создать поименованную группу атрибутов, содержащую все желательные атрибуты элемента item, и в объявлении item сделать ссылку на эту группу.
Добавление атрибутов с использованием группы атрибутов:

Применение группы атрибутов улучшает читаемость и облегчает модификацию схемы, так как группа атрибутов может быть определена и отредактирована в одном месте, а ссылки на нее могут использоваться в нескольких определениях и объявлениях. Эта характеристика групп атрибутов делает их похожими на сущность параметра в XML 1.0. Обратите внимание, что группа атрибутов может содержать другие группы атрибутов. Обратите также внимание, что и объявления атрибутов и ссылка на группу атрибутов, должны находиться в конце определений комплексных типов.
Группы замены
XML-схема обеспечивает механизм, называемый группами замены, который позволяет заменять одни элементы другими. Более точно, элементы могут быть объединены в специальную группу элементов, которые, как говорят, являются замещающими для элемента, называемого головным. Обратите внимание, что головной элемент должен быть объявлен как глобальный. Для иллюстрации, мы объявим два элемента customerComment и shipComment, и объединим их в группу замены, главный элемент которой - comment. В результате customerComment и shipComment можно использоваться везде, где мы можем использовать comment. Элементы в группе замены должны иметь тот же самый тип, что и головной элемент, или они могут иметь тип, который был порожден из типа головного элемента. Ниже приводится пример, в котором два новых элемента заменяют элемент comment. Объявление заменяющих элементов для элемента comment:
Когда эти объявления будут добавлены к схеме международного заказа на покупку, тогда в документе элемент comment можно заменить элементами shipComment и customerComment.
Отрывок ipo.xml с замещающими элементами:

Обратите внимание, что когда документ содержит элементы замены, типы которых получены из их главных элементов, то нет необходимости идентифицировать производные типы с помощью конструкции xsi:type, которую мы описали в подразделе 4.3. Существование группы замены не требует обязательного использования какого-либо из элементов этой группы, и при этом не препятствует использованию главного элемента. Это просто позволяет элементам быть взаимозаменяемыми.
Импортирование типов
Схема, report.xsd, использует простой тип xipo:SKU, который определен в другой схеме, и в другом целевом именном пространстве. Механизм повторного вызова, который мы задействовали с помощью элемента include в схеме ipo.xsd, позволяет использовать определения и объявления из address.xsd. В данном случае мы не можем использовать элемент include в report.xsd, потому что он может размещаться в определениях и объявлениях схемы, целевое именное пространство которой то же самое что и целевое именное пространство включаемой подсхемы. Следовательно, элемент include не идентифицирует именное пространство (хотя требует schemaLocation). Механизм импорта, который мы описываем в этом разделе - важный механизм, который дает возможность элементам схемы из различного целевого именного пространства использоваться совместно, и, следовательно, допускает проверку правильности схемы документа, определенной в нескольких именных пространствах. Чтобы импортировать тип SKU и использовать его в схеме отчета, необходимо идентифицировать именное пространство, в котором SKU определен, и ассоциировать это именное пространство с префиксом который будет использован в схеме отчета. Для этого мы используем элемент import, который идентифицирует целевое именное пространство http://www.example.com/IPO элемента SKU, и стандартным способом в элементе schema ассоциируем это именное пространство с префиксом xipo. При этом в определении или объявлении схемы отчета на простой тип SKU, определенный в именном пространстве , можно сослаться как xipo:SKU.В нашем примере, мы импортировали один простой тип из одного внешнего именного пространства, и использовали его для объявления атрибутов. Фактически XML-схема разрешает импортировать множество элементов из множества именных пространств, при этом они могут быть упомянуты и в определениях и в объявлениях. Например, в report.xsd мы можем повторно использовать элемент comment, объявленный в ipo.xsd, ссылаясь на тот элемент в объявлении:
< element ref="xipo:comment"/>
Обратите внимание, что мы не можем многократно использовать элемент shipTo из po.xsd, и приведенный ниже пример является ошибочным, так как только глобальные элементы схемы могут быть импортированы:
< element ref="xipo:shipTo"/>
В ipo.xsd, comment объявлен как глобальный элемент, другими словами он объявлен как элемент схемы. Напротив, shipTo объявлен локально, другими словами - это элемент, объявленный в комплексном определении типа, а именно PurchaseOrderType. Комплексные типы также могут быть импортированы, и использованы как исходные для образования новых типов. Только поименованные комплексные типы могут быть импортированы; локальные и непоименованные - нет. Предположим, что мы хотим включить в наш отчет наряду с информацией о контракте имя аналитика. Мы можем повторно использовать (глобально определенный), комплексный тип USAddress из address.xsd, и методом расширения получить из него новый тип с именем Analyst. Для этого добавим новые элементы phone и email.
Определение Analyst расширением USAddress:
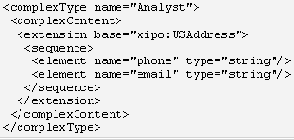
Используя этот новый тип, объявляем элемент analyst как часть объявления элемента purchaseReport (объявление не показано) в схеме отчета. Тогда, приведенный ниже документ будет соответствовать измененной схеме сообщения. Документ, соответствующий схеме отчета с типом Analyst:
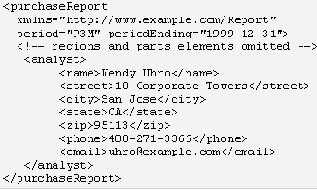
Когда элементы схемы импортированы из нескольких именных пространств, то каждое именное пространство должно быть идентифицировано отдельным элементом import. Элементы import должны быть подэлементами элемента schema. Кроме того, с помощью стандартного объявления именного пространства каждое именное пространство должно быть ассоциировано с префиксом, и префикс должен использоваться для квалификации ссылок к любым элементам схемы, принадлежащим этому именному пространству. Наконец, элементы import содержат необязательный атрибут schemaLocation, который подсказываем местоположение ресурса, связанного с именным пространством. Более подробно атрибут schemaLocation обсудим позднее.
Использование производных типов в документах
В сценарии нашего примера заказы на покупку генерируются в ответ на запросы клиентов, которые могут находиться в различных странах. Значит, реквизиты отгрузки товаров и счетов могут зависеть от национальных особенностей. Ниже приводится пример международного заказа на покупку, ipo.xml, в котором товар отгружается в Великобританию, а счет отсылается в США. Очевидно, что нецелесообразно определять в схеме все возможные комбинации международных адресов, целесообразнее определить новые типы адресов, порождая их из типа Address.В XML-схеме определены billTo и shipTo как элементы типа Address (см. ipo.xsd) которые использованы в документе для указания международного адреса в том месте, где должны находится элементы типа Address. Другими словами документ, содержащий данные типа UKAddress будет синтаксически правильным, если это содержимое находится в документе на том месте, где ожидается элемент типа Address (подразумевается, что содержимое UKAddress синтаксически правильно). Для того чтобы эта функция XML-схемы работала, и для указания того, какой именно производный тип применяется, производный тип должен быть идентифицирован в документе-образце. Тип идентифицируется с помощью атрибута xsi:type, который принадлежит именному пространству языка XML-схемы. В примере ipo.xml использование производных типов UKAddress и USAddress идентифицируется с помощью значения заданного атрибутом xsi:type.
Международный заказ на покупку, ipo.xml:

Как управлять использованием производных типов описывается в подразделе 4.8.
Комплексные типы из простых типов
Вначале рассмотрим, как объявить элемент, который имеет атрибут и содержит значение простого типа. В документе такой элемент мог бы выглядеть как:
XML-схема заказа содержит объявление элемента USPrice, которое является отправной точкой:

Добавим к элементу атрибут. Поскольку, как мы прежде выяснили, простые типы не могут иметь атрибут, а decimal - простой тип, то чтобы добавить объявление атрибута, мы должны определить комплексный тип. Поскольку мы хотим, чтобы содержание элемента было простым числом типа decimal, то требуется ответить на вопрос: как задать определение комплексного типа, который основан на простом типе decimal? Ответ - мы должны получить новый комплексный тип из простого типа decimal.
Получение комплексного типа из простого типа:

Для того чтобы начать описание нового анонимного типа, мы используем элемент complexType. Чтобы указать, что новый тип содержит только символьные данные и не содержит подэлементов, мы используем элемент simpleContent. Наконец, мы получаем новый тип, расширяя простой тип decimal. Расширение типа decimal заключается в добавлении (путем использования стандартного объявления) атрибута currency. Более детально образование типов будет рассмотрено в разделе 4. Пример использования в документе элемента internationalPrice, описанного в приведенном выше примере XML-схемы, располагается в начале данного пункта.
Конфликты имен
Теперь разберем, как определить новые комплексные типы (см., PurchaseOrderType), объявить элементы (см., purchaseOrder) и объявить атрибуты (см., orderDate). Все эти действия манипулируют с именами, поэтому обычно возникает вопрос, что будет, если объявить два объекта с одинаковыми именами?Рассмотрим несколько примеров. Если объявить два объекта с одинаковыми именами, но разными типами, то такое объявление создаст конфликтную ситуацию. Например, конфликт имен вызовут комплексный тип с именем USStates и простой тип с именем USStates. Однако если мы определяем комплексный тип с именем USAddress, и объявляем элемент или атрибут с именем USAddress, то конфликт не возникает. Конфликт также не возникает, если элементы с одинаковыми именами объявлены внутри определения различных типов. Например, если мы объявим один элемент как часть типа USAddress, а второй элемент с тем же именем как часть типа Item, то конфликт имен не возникнет. Такие объявления называют локальными. Наконец, если имеется два типа, один из которых определен вами (например, decimal), а второй встроен в язык XML-схемы, то конфликт имен также не возникает. Отсутствие конфликта связано с тем, что эти два типа принадлежат различным именным пространствам. Более подробно использование именных пространств в XML-схемах будет рассмотрено позже.
Квалифицируемые локальные объекты
Квалификация элементов и квалификация атрибутов может быть произведена независимо. Начнем с рассмотрения квалифицирования локальных элементов. Для указания того, что все локально объявленные элементы в схеме должны быть квалифицированы, мы устанавливаем значение elementFormDefault равным qualified.Модификация po1.xsd с квалифицируемыми локальными объектами:

Ниже приводится приспособленный к измененной схеме документ, в котором все элементы квалифицированы явно. Заказ на закупку с явно квалифицированными локальными элементами:

Попробуем заменить явную квалификацию каждого элемента неявной. Неявная квалификация обеспечивается именным пространством, назначенным по умолчанию (пример в po2.xml).
Заказ на покупку с квалификаций локальных объектов по умолчанию. po2.xml:
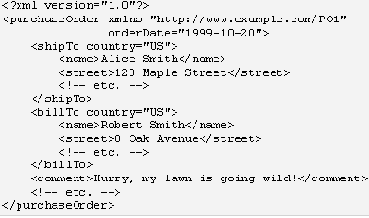
В po2.xml все элементы в документе принадлежат тому же именному пространству, которое объявлено по умолчанию с помощью атрибута xmlns. Следовательно, явное добавление префикса к элементам становится ненужным.
Другой пример использования квалифицированных элементов - схемы в разделе 5. Все указанные схемы требуют квалифицированных элементов.
Квалификация атрибутов очень похожа на квалификацию элементов. Атрибуты, которые должны быть квалифицированы (либо потому что объявлены глобально, либо потому что признак attributeFormDefault, установлен в qualified), в документах появляются с префиксом. Один из примеров квалифицированного атрибута - атрибут xsi:nil, который был рассмотрен в подразделе 2.9. Фактически, атрибуты, которые должны быть квалифицированы, должны иметь явно заданные префиксы. Это связано с тем, что спецификация XML-Namespaces () не обеспечивает механизм задания именного пространства для атрибутов по умолчанию. Атрибуты, которые не обязаны быть квалифицированны, появляются в документах без префиксов, что является типичным случаем.
Механизм квалификации, который мы до сих пор описывали, управлял всеми локальными объявлениями элементов и атрибутов в пределах конкретного целевого именного пространства. С помощью атрибута form, возможно управлять квалификацией отдельного объявления. Например, если требуется, чтобы локально объявленный атрибут publicKey в документах был квалифицирован, мы объявляем его нижеследующим способом.
Квалификация одного атрибута:
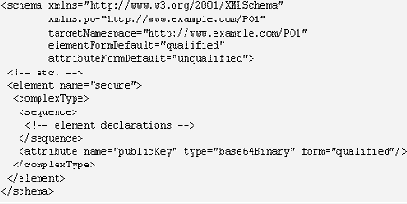
Заметьте, что для publicKey, значение атрибута form отменяет значение атрибута attributeFormDefault. Таким же образом атрибут form может быть применен к объявлению элемента. Ниже приводится документ, который соответствует приведенной схеме.
Документ с квалифицированным атрибутом:
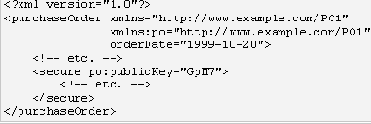
Любой элемент, любой атрибут
В предыдущих разделах мы рассмотрели несколько механизмов для расширения модели содержимого комплексных типов. Например, смешанная модель содержимого может включать в дополнение к элементам произвольные символьные данные, а также элементы, типы которых импортированы из внешнего именного пространства. Однако эти механизмы обеспечивают, соответственно, либо очень широкие, либо очень узкие возможности контроля. Цель этого раздела состоит в том, чтобы описать гибкий механизм, который дает возможность моделям содержимого быть расширенными любыми элементами и атрибутами, принадлежащими указанному именному пространству.Например, рассмотрим вариант ежеквартального отчета, 4Q99html.xml, в который мы внедрили HTML-представление раздела с данными об отгруженных изделиях. HTML-текст появляется как содержание элемента htmlExample. Для того чтобы все HTML-элементы принадлежали именному пространству HTML (), изменено значение по умолчанию именного пространства у самого внешнего HTML-элементе (table).
Квартальный отчет с HTML, 4Q99html.xml:
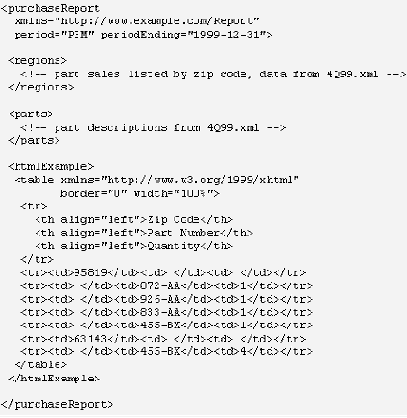
Чтобы разрешать появление HTML-элементов в документе, мы изменяем схему отчета, объявляя новый элемент htmlExample, чье содержание определено оператором any. Элемент any определяет, что любой элемент, удовлетворяющий правилам языка XML, допустим в модели содержимого данного типа. В нижеприведенном примере, мы определяем, что XML-элементы принадлежат именному пространству http://www.w3.org/1999/xhtml, другими словами, эти XML-элементы должны быть HTML-элементами. В примере также задано, что в документе может быть не менее одного такого элемента, на что указывают значения minOccurs и maxOccurs.
Модификация объявления purchaseReport для включения в документ HTML-фрагмента:
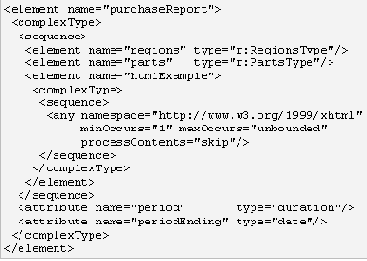
В результате указанного выше изменения, любому XML-элементу, принадлежащему именному пространству , разрешено появляться в элементе htmlExample. В связи с этим 4Q99html.xml допустим, так как в нем есть один элемент table (с дочерними элементами), который является допустимым, и этот элемент появляется в элементе htmlExample, и в документе указано, что элемент table и его содержимое принадлежат требуемому именному пространству. Однако фактически HTML-фрагмент может содержать неверные данные, потому что в 4Q99html.xml ничто не гарантирует их достоверность. Если такая гарантия требуется, то значение атрибута processContents должно быть установлено в strict (значение по умолчанию). В этом случае XML-процессор должен получить схему, связанную с требуемым именным пространством, и проверить правильность HTML-фрагмента, появляющегося внутри элемента htmlExample.
В другом примере, мы определяем тип text, который подобен текстовому типу, определенному во введении в библиотеку типов XML-схемы () (см., также подраздел 5.4.1), и подходящий для работы с интернационализированным текстом. Текстовый тип с дополнительным атрибутом xml:lang разрешает произвольную смесь символов и элементов из любого именного пространства, например текст в нотации Ruby (). Значение lax атрибута processContents предписывает XML-процессору проверить правильность содержимого элемента. Процессор проверит правильность элементов и атрибутов, для которых он может получить информацию схемы, но процессор не будет сообщать об ошибках для тех компонент, для которых отсутствует информация схемы.
Тип Text:

Именное пространство может использоваться различными способами, в зависимости от значения атрибута namespace (см. таблицу 4) для того чтобы разрешить или запретить содержимое элемента:
Таблица 4. Атрибут namespace элемента any
| Значения атрибута Namespace | Допустимое содержимое элемента |
| ##any | Любой XML-элемент из любого именного пространства (значение по умолчанию) |
| ##local | Любой XML-элемент, который не квалифицирован, то есть, не объявлен в именном пространстве |
| ##other | Любой XML-элемент не из целевого именного пространства определяемого типа |
| "http://www.w3.org/1999/xhtml ##targetNamespace" | Любой XML-элемент, принадлежащий любому именному пространству в (разделитель - пробел) списке; ##targetNamespace - псевдоним для обозначения целевого именного пространства определяемого типа |

Это объявление разрешает HTML-атрибуту, скажем href, появляться в htmlExample элементе.
Пример HTML-атрибута у элемента htmlExample:
Атрибуту namespace в элементе anyAttribute может быть присвоено любое из значений, перечисленных в таблице 4 для элемента any. У anyAttribute может быть задан атрибут processContents. В отличие от элемента any, элемент anyAttribute не содержит ограничение на число атрибутов, которые могут появиться у элемента.
Необъявленные целевые именные пространства
В разделе 2 мы объяснили основы языка XML-схем, используя схему, в которой не объявлялось целевое именное пространство, и документ, в котором не объявлялось именное пространство. Возникает вопрос: каково целевое именное пространство в этих примерах, и как на него ссылаются?В схеме заказа на закупку po.xsd мы не объявляли ни ее целевое именное пространство, ни префикса (наподобие po:) связанного целевым именным пространством схемы в котором содержатся определения типов и объявления элементов и атрибутов. Вследствие того, что в схеме отсутствует объявление целевого именного пространства, на определения и объявления находящиеся внутри схемы, типа USAddress и purchaseOrder, ссылаются без квалификационного префикса. Другими словами в схеме нет ни явного префикса, используемого в ссылках ни определения именного пространства используемого в ссылках по умолчанию. Пример - элемент purchaseOrder объявленный с использованием ссылки на тип PurchaseOrderType. Напротив, все элементы и типы, принадлежащие словарю языка XML-схемы, используемые в po.xsd явно квалифицированы префиксом xsd:, который связан с именным пространством языка XML-схемы.
В случаях, когда схема разработана без целевого именного пространства, строго рекомендуется, чтобы все элементы, принадлежащие словарю языка XML-схемы, были явно квалифицированы префиксом xsd:, который связан с именным пространством языка XML-схемы (как в po.xsd). Такая рекомендация объясняется тем, что если элементы и типы языка XML-схем связываются с именным пространством языка XML-схем по умолчанию, то есть без префиксов, то ссылки на типы определенные в языке XML-схемы будет невозможно отличить от ссылок на типы определенные пользователем.
Объявления элементов в схеме без целевого именного пространства используется для верификации неквалифицированных элементов в документе. То есть они определяют правильность элементов, для которых не заданы никакие префиксы именного пространства: ни явные, ни заданные по умолчанию (xmlns:).
Ограничение вхождений
Значение параметра minOccurs равное 0 у элемента comment говорит о том, что он не обязательно будет присутствовать в составе элемента PurchaseOrderType. Вообще, элемент является обязательным, если значение minOccurs больше или равно 1. Максимальное число появлений элемента определяется значением, задаваемым параметром maxOccurs. Это значение может быть положительным целым числом типа 41, или термом unbounded, что означает отсутствие ограничения максимального числа появлений. Значение по умолчанию для minOccurs и для maxOccurs равно 1. Таким образом, когда элемент типа comment объявлен без maxOccurs , то это означает, что элемент может появиться не более одного раза. Если Вы определяете значение только для minOccurs, то убедитесь что это значение меньше или равно значению по умолчанию maxOccurs. То есть это значение должно быть 0 или 1. Точно так же, если Вы определяете значение только для maxOccurs, то это значение должно быть больше или равно значению по умолчанию minOccurs, то есть 1 или больше. Если оба значения опущены, элемент должен появиться в документе точно один раз.Атрибуты, в отличие от элементов, могут появиться только однажды или ни разу. Поэтому и синтаксис для определения появления атрибутов отличается от синтаксиса для определения числа появлений элементов. В частности атрибуты могут быть объявлены с параметром use. В зависимости от значения этого параметра атрибут обязателен (use="required"), необязателен (use="optional"), или запрещен (use="prohibited"). Например, объявление атрибута partNum в po.xsd.
Значения по умолчанию и атрибутов и элементов могут быть объявлены с использованием параметра default, хотя этот параметр в том или ином случае работает по разному. Атрибут со значением, определенным по умолчанию, может появляться или не появляться в документе. Если атрибут не появляется в документе, то обработчик схемы обеспечивает, атрибут со значением равным значению default. Обратите внимание, что значения по умолчанию для атрибутов имеют смысл, только если сами атрибуты являются необязательными, поэтому будет ошибкой определить значение по умолчанию вместе с параметром use отличным от use="optional".
Значение по умолчанию для элементов обрабатывается немного по-другому. Если элемент появляется в документе, но не содержит какого либо значения, то в качестве его значения подставляется значение по умолчанию. Однако если элемент не появляется в документе, то обработчик схемы не обеспечивает его значения вообще. В общем, различия между значениями по умолчанию элемента и атрибута в следующем: заданное по умолчанию значение атрибута применяется тогда, когда атрибут отсутствует, а заданное по умолчанию значение элемента применяются тогда, когда элемент присутствует в документе, но не имеет значения (пуст).
Атрибут fixed используется в объявлениях и атрибутов и элементов. Он используется, чтобы указать, что атрибут или элемент могут принимать фиксированные значения. Например, в po.xsd объявлен атрибут country, со значением равным US. Приведенное в примере объявление означает, что атрибут country является необязательным (по умолчанию значение параметра use равно optional), хотя, если атрибут появляется в документе, то его значением должно быть US. Если атрибут country, не появляется в документе, обработчик схемы обеспечит атрибут country со значением US. Обратите внимание, что понятия фиксированного значения и значения по умолчанию являются взаимоисключающими, поэтому объявление не может одновременно содержать атрибуты fixed и default.
Примеры использования указанных выше параметров в объявлениях элементов и атрибутов приведены в таблице 1.
Таблица 1 . Ограничения на появление элементов и атрибутов в документе
| Элементы (minOccurs, maxOccurs) fixed, default |
Атрибуты use, fixed, default |
Примечание |
| (1, 1) -, - | required, -, - | элемент/атрибут должен появиться однажды, может иметь любое значение |
| (1, 1) 37, - | required, 37, - | элемент/атрибут должен появиться однажды, его значение должно быть 37 |
| (2, unbounded) 37, - | n/a | элемент должен появиться не менее 2 раз, его значение должно быть 37; minOccurs и maxOccurs могут быть положительными целыми числами. maxOccurs равный unbounded задает неограниченное появление элемента |
| (0, 1) -, - | optional, -, - | элемент/атрибут может появиться однажды, и может иметь любое значение |
| (0, 1) 37, - | optional, 37, - | элемент/атрибут может появиться однажды. Если он появится, то его значение должно быть 37. Если он не появится, то его значение будет 37. |
| (0, 1) -, 37 | optional, -, 37 | элемент/атрибут может появиться однажды. Если элемент не задан, то его значение по умолчанию равно 37, иначе его допустимое значение равно заданному |
| (0, 2) -, 37 | n/a | элемент может появиться однажды, или дважды, или ни разу. Если элемент не появится, то его значение не обеспечено; если появится, и его значение не задано, то по умолчанию его значение будет равно 37; иначе его допустимое значение равно заданному в документе. Вообще значениями, minOccurs и maxOccurs могут быть положительные целые числа. При этом значение maxOccurs может также принимать значение unbounded (не ограничено) |
| (0, 0) -, - | prohibited, -, - | элемент/атрибут не должен появиться в документе |
| Обратите внимание, что ни minOccurs, maxOccurs, ни use не может появиться в объявлениях глобальных элементов и атрибутов. |
Для обеспечения механизма уникальности XML
Для обеспечения механизма уникальности XML 1.0 (), использует атрибут типа ID и связанные c ним атрибуты типа IDREF и IDREFS. Этот механизм поддержан языком XML-схемы через простые типы ID, IDREF, и IDREFS, которые могут использоваться для того, чтобы объявить атрибуты в стиле XML 1.0. Кроме того, язык XML-схемы вводит новые механизмы, которые более гибки и мощны. Например, они могут быть применены к содержимому любого элемента и атрибута, независимо от его типа. Напротив, ID задает тип атрибута и поэтому не может быть применен к атрибутам, элементам или их содержимому. Кроме того, язык XML-схемы дает возможность определить область, в пределах которой обеспечивается уникальность, тогда как действие ID распространяется на весь документ. Наконец, XML-схема дает возможность создать ключи (key) и ссылки (keyref) из комбинаций содержимого элементов и атрибутов, тогда как ID не имеет такого средства.Определение анонимных типов
При создании схем применяется два стиля. Схемы могут создаваться путем определения поименованных типов (например, PurchaseOrderType) с последующим объявлением элементов этого типа (например, purchaseOrder). При этом объявленные элементы ссылаются на поименованный тип с помощью конструкции type= . Этот стиль является достаточно простым, но может стать неуправляемым, особенно если Вы определяете много типов, на которые ссылаетесь только один раз, и которые содержат немного ограничений. В этих случаях, тип может быть более кратко определен как анонимный. Анонимный тип нет необходимости именовать и, следовательно, задавать на него ссылки. Определение типа Items в po.xsd содержит два объявления item и quantity, использующие анонимный тип. Наличие в схеме анонимного типа можно идентифицировать за счет отсутствия в объявлении элементов или атрибутов параметра type=, и присутствия непоименованного определения простого или комплексного типа.Объявление двух анонимных типов:

Элемент item представляет собой анонимный комплексный тип, состоящий из элементов productName, quantity, USPrice, comment, и shipDate, и имеющий атрибут partNum. Элемент quantity представляет собой анонимный простой тип, полученный из integer. При этом элемент типа quantity может принимать значение между 1 и 99.
Определение ключей и ссылок на них
В ежеквартальном отчете за 1999 год, описание каждой отгруженной партии товара появляется только однажды. Мы могли бы установить это ограничение, используя элемент unique. Однако мы также хотим гарантировать, что каждый элемент, задающий количество изделий, включенных в партию с данным почтовым индексом, имеет соответствующий раздел с описанием изделия. Для установки этого ограничения, используем элементы key и keyref. В схеме отчета, report.xsd, показано применение механизма key и keyref, использующего почти тот же самый синтаксис, что и механизм unique. Элемент key применен к значению атрибута number элемента part, который является подэлементом элемента parts. Объявление атрибута number в качестве ключа означает, что его значение должно быть уникально и не может быть пустым (nil). Имя pNumKey, используется для ссылки на ключ из других мест схемы.Чтобы гарантировать, что элементы, задающие количество изделий будут иметь соответствующие разделы описания, устанавливаем, что атрибут number (
< field xpath="@number" ) этих элементов (
< selector> zip/part < /selector>
) должен быть объявлен как ссылка (keyref) на ключ с именем pNumKey. Объявление атрибута number как keyref не подразумевает, что его значение должно быть уникально. Это только означает, что он должен иметь то же самое значение, что и ключ с именем pNumKey.
Возможно, вы уже догадались, что по аналогии с unique можно определить комбинации значений keyref и key. Используя этот механизм, мы можем не просто обеспечить эквивалентность идентификаторов изделий в различных разделах отчета, но и определить комбинацию значений, которые должны быть эквивалентны. Такие значения могут включать комбинации значений нескольких типов (string, integer, date, и т.д.), при условии, что порядок и тип ссылок в элементах field одинаков в определениях key и keyref.
Определение комплексных типов, объявление элементов и атрибутов
В XML-схеме есть различие между комплексными типами элементов, которые могут иметь вложенные элементы и атрибуты, и простыми типами, которые не могут иметь вложенных элементов или атрибутов. Также имеется различие между определениями и объявлениями. Определения создают новые типы элементов (простые и комплексные). Объявления задают имена и содержимое элементов и атрибутов (простых и комплексных), которые могут использоваться в документах, соответствующих данной схеме. В этом разделе, мы сосредоточимся на определении комплексных типов и объявлении элементов и атрибутов, которые могут появиться внутри них.Новые комплексные типы определяются с помощью оператора complexType. Такие определения обычно содержат набор из объявлений элементов, ссылок на элементы, и объявлений атрибутов. Объявления не задают самостоятельно типы. Скорее они создают ассоциации между именем элемента и ограничениями, которые управляют появлением этого имени в документах, соответствующих данной схеме. Элементы объявляются, с помощью оператора element. Атрибуты объявляются, с помощью оператора attribute. В качестве примера рассмотрим определение комплексного типа USAddress. Внутри определения USAddress мы видим пять объявлений элемента и одно объявление атрибута.
Определение типа USAddress:
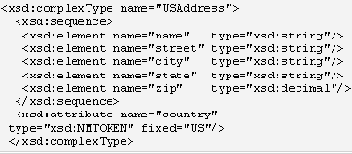
В результате этого определения любой элемент типа USAddress, появляющийся в документе (например, элемент shipTo в файле po.xml), должен состоять из пяти элементов и одного атрибута. Имена этих пяти элементов (name, street, city, state и zip) объявляются с помощью атрибута name оператора element, причем элементы должны появиться в той же самой последовательности, в которой они объявлены. Первые четыре из этих элементов будут содержать строковое значение, а пятый - десятичное число. Элемент, тип которого объявляют как USAddress, может появиться с атрибутом country, который должен содержать строковую константу US.
Определение USAddress содержит объявления, включающие только простые типы: string, decimal и NMTOKEN. Напротив, определение PurchaseOrderType содержит объявления элементов, имеющих комплексные типы. Например, USAddress. Хотя оба вида объявлений (простые и комплексные) используют тот же самый атрибут type.
Определение типа PurchaseOrderType:
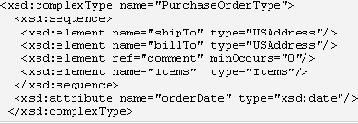
В определении PurchaseOrderType, объявления элементов shipTo и billTo, связывают различные имена элементов с одним и тем же комплексным типом, а именно с USAddress. Вследствие этого определения любой элемент типа PurchaseOrderType, появляющийся в документе (например, в po.xml), должен состоять из элементов shipTo и billTo. Каждый из этих элементов должен содержать пять подэлементов (name, street, city, state и zip), которые были объявлены в определении USAddress. Элементы shipTo и billTo могут иметь атрибут country, который был объявлен как часть определения USAddress.
Определение PurchaseOrderType содержит объявление атрибута orderDate, который, подобно объявлению атрибута country, задается с помощью простого типа. Фактически, все объявления атрибутов должны выполняться с помощью простых типов, потому что, в отличие от элементов, атрибуты не могут содержать другие элементы или другие атрибуты.
Объявления элементов, которые мы ранее описывали, представляют собой имя, связанное с заданным нами типом элемента. Иногда предпочтительно использовать ссылку на существующий тип элемента, а не объявлять новый, например:
< xsd:element ref="comment" minOccurs="0"/>
В этом объявлении приводится ссылка на существующий элемент comment, который объявлен где-то в другом месте схемы заказа на закупку. Значение атрибута ref должно рассматриваться, как ссылаться на глобальный элемент, который был объявлен в элементе schema, а не как часть определения комплексного типа. Вследствие этого элемент comment может появиться в документе внутри элемента PurchaseOrderType, причем его содержание должно быть совместимо с типом string.
Определение уникальности
XML-схема дает нам возможность указать, что значение атрибута или элемента в пределах некоторой области должны быть уникальны. Для определения уникальности используют элемент unique: во первых, для того чтобы выбрать ("select") набор элементов в пределах которого должна быть обеспечена уникальность, и во вторых чтобы идентифицировать поле ("field") (атрибут или элемент), которое должно быть уникально в пределах выбранного набора элементов. В схеме report.xsd атрибут xpath элемента selector содержит Xpath-выражение равное regions/zip, которое задает список всех элементов zip в отчете. Аналогично, атрибут xpath элемента field содержит второе Xpath-выражение равное @code, которое определяет, что значения атрибута code элементов zip должны быть уникальны. Обратите внимание, что Xpath-выражения ограничивают область того, что должно быть уникально. Отчет мог бы содержать другой атрибут code, но его значение не обязательно должно быть уникальным, если он находится вне области, определенной Xpath-выражениеми. Также обратите внимание, что Xpath-выражения, которые Вы можете использовать в атрибуте xpath, ограничены подмножеством () полной версии языка Xpath, определенного в XML Path Language 1.0 ().Мы также можем указать комбинации полей, которые должны быть уникальны. Например, предположим, что мы хотим ослабить ограничение установленное для почтовых индексов. Ранее ограничение состояло в том, что почтовые индексы могли быть указаны только однажды, хотя мы все еще хотим оставить ограничение, состоящее в том, что любое изделие может быть в пределах данного почтового индекса перечислено только однажды. Мы можем достигнуть такого ограничения, определяя, что комбинация почтового индекса и номера изделия должна быть уникальна. В отчете 4Q99.xml, имеются следующие комбинации значений почтового индекса и номеров изделий: {95819 872-AA}, {95819 926-AA}, {95819 833-AA}, {95819 455-BX}, и {63143 455-BX}. Конечно, эти комбинации могут встретиться как в пределах одного списка рассылки, так и в пределах нескольких. Но использование этих комбинаций позволяет однозначно определить изделие, встречающееся в пределах данного почтового индекса более одного раза. Другими словами обработчик схемы сможет обнаружить нарушение уникальности.
Чтобы определить комбинации значений, мы просто добавляем элементы field, которые идентифицируют все возможные значения полей. Чтобы добавить номер изделия к существующему определению, мы включаем еще один элемент field, чей атрибут xpath со значением равным part/@number идентифицирует атрибут number элементов part, которые являются дочерними подэлементами элементов zip. При этом набор уникальных элементов включает элементы zip, отбор которых задан Xpath-выражением regions/zip.
Уникальное составное значение:

Основные понятия: документ "Заказ на покупку"
Назначение XML-схемы состоит в том, чтобы определить класс XML-документов. В связи с этим термин "документ" часто используется для того, чтобы обозначить XML-документ, который соответствует определенной схеме. В действительности схемы документов не существуют сами по себе. Обычно они представляют собой потоки данных, которыми обмениваются между собой приложения, набор тегов в XML-файлах или поля в записях баз данных. Но для упрощения мы будем рассматривать примеры документов и их схемы как просто документы и файлы.Для начала рассмотрим документ "Заказ на покупку", представленный в файле po.xml. Этот XML-документ описывает заказ, сгенерированный с помощью программ, обеспечивающих формирование заказа на покупку.
Заказ на покупку. Файл po.xml:

Заказ состоит из основного элемента, purchaseOrder, и подэлементов shipTo, billTo, comment и items. Эти подэлементы (кроме comment) в свою очередь содержат другие подэлементы, и так далее, пока не встретится подэлемент типа USPrice. Элемент USPrice содержит число, а не другие подэлементы. Элементы, которые содержат подэлементы или имеют атрибуты, называют элементами комплексного типа, тогда как элементы, которые содержат числа (строки, даты, и т.д.), но не содержат подэлементов или атрибутов, называются элементами простого типа. Как видно из примера, некоторые элементы имеют атрибуты. Атрибуты всегда представляют собой элементы простого типа.
В приведенном примере документа, комплексные типы, и некоторые простые типы, определены в его XML-схеме. Вместе с тем в документе имеются простые типы, которые представляют собой типы, встроенные в язык XML-схем.
Прежде чем продолжить исследование заказ на покупку, сделаем небольшое отступление, чтобы рассмотреть связь между ним и его схемой. Как вы можете заметить, в приведенном выше тексте заказа нет упоминания о его схеме. Это связано с тем, документ не обязан иметь ссылку на свою схему, хотя очень часто такая ссылка может присутствовать. Для начала мы упростим задачу, и не будем рассматривать то, каким образом обработчик документа получает ссылку на его схему. Позднее мы рассмотрим, каким образом устанавливается связь документа с его схемой.
Переопределение типов и групп
В подразделе 4.1 мы описали, как включить определения и объявления, полученные из внешних подсхем, имеющих одинаковое целевое именное пространство. Механизм include дает возможность использовать созданные вовне компоненты схемы "как есть", без какой либо модификации.Мы описали, как получить новые типы расширением и ограничением. Здесь мы рассмотрим механизм переопределения (redefine), который дает возможность переопределить простые и комплексные типы, группы, и группы атрибутов, полученные из внешних файлов схемы. Подобно механизму включения, механизм переопределения, требует, чтобы внешние компоненты находились в том же самом целевом именном пространстве, что и переопределяемая схема, хотя внешние компоненты схем, которые не имеют никакого именного пространства, также могут быть переопределены. В последнем случае, переопределенные компоненты становятся частью адресного пространства переопределяемой схемы.
Чтобы проиллюстрировать механизм переопределения, мы используем его вместо механизма включения в схеме международного заказа на покупку, ipo.xsd. Используем механизм переопределения для изменения комплексного типа Address, находящегося в address.xsd.
Использование переопределения в международном заказе на покупку:

Элемент redefine действует подобно элементу include, поскольку включает все объявления и определения из файла address.xsd. Определение комплексного типа Address использует знакомый синтаксис расширения для того, чтобы добавить элемент country к определению Address. Обратите внимание, что исходный тип - также Address.
Теперь, когда тип Address переопределен, расширение применяется ко всем элементам схемы, которые используют Address. Например, address.xsd содержит определения типов международных адресов, которые образованы из Address. Эти образования отражают переопределенный тип Address, как показано в приведенном ниже фрагменте.
Фрагмент ipo.xml использующий переопределенный тип Address:

Приведенный пример был тщательно продуман на предмет того, чтобы переопределенный тип Address не конфликтовал с производными типами, полученными из первоначального определения типа Address. Но заметим, что такой конфликт создать очень просто. Например, если тип международных адресов является расширением типа Address, полученным добавлением элемента country, то переопределение типа Address будет прибавлять к модели содержимого Address элемент с тем же самым именем. Наличие двух элементов с одинаковыми именами (в одном и том же целевом именном пространстве) но различными моделями содержимого - недопустимо. Поэтому попытка переопределить Address вызвала бы ошибку. Вообще, переопределение не защищает от таких ошибок, поэтому этот механизм должен использоваться осторожно.
Получение производных типов расширением
Создание адресных конструкций начинаем с определения комплексного типа Address (см. address.xsd). Тип Address содержит основные элементы адреса: имя, улицу и город (такое определение адреса используется не во всех странах, но вполне подойдет для нашего примера). От этой отправной точки мы получаем два новых комплексных типа, которые содержат все элементы первоначального типа плюс дополнительные элементы, необходимые для указания адресов принятых в США и Великобритании. Методика, которую мы здесь используем, чтобы получить новые (комплексные) адресные типы, расширяя существующий тип - та же самая методика, которую мы использовали в пункте 2.5.1. Отличие заключается в том, что наш исходный тип, это комплексный тип, тогда как исходным типом в предыдущем разделе был простой тип.С помощью элемента complexType определяем два новых комплексных типа, USAddress и UKAddress. Используя элемент complexContent, мы указываем, что модели содержимого новых типов комплексны, то есть содержат элементы. Кроме того, с помощью атрибута base элемента extension указываем, что новый тип создается путем расширения базового типа Address. Когда комплексный тип получен расширением, его модель содержимого включает модель содержимого исходного типа плюс модель содержимого заданная в описании создаваемого типа. Кроме того, обе модели содержимого оформлены как две дочерних записи групповой последовательности. В случае UKAddress, модель содержимого UKAddress состоит из модели содержимого Address плюс объявления элемента postcode и атрибута exportCode. Такое объявление аналогично объявлению типа UKAddress с нуля, пример которого приводится ниже.
Пример альтернативного объявления UKAddress:

Данный документ представляет собой перевод
Данный документ представляет собой перевод спецификации "XML Schema Part 0: Primer" на русский язык. При этом нормативным документом считается оригинальная спецификация на английском языке, которую можно найти по адресу . Представленный документ может содержать ошибки перевода.Производные сложные типы, полученные путем ограничений
Существует два метода создания новых комплексных типов. Первый метод основан на расширении модели содержимого базового типа, а второй - на ограничении модели содержимого базового типа. Ограничение сложных типов концептуально аналогично ограничению простых типов, за исключением того, что ограничение сложных типов затрагивает объявления типа, а не диапазон допустимых значений как в случае простого типа. Сложный тип, полученный ограничением очень похож на свой базовый тип, за исключением того, что его объявления более ограничены, чем соответствующие объявления в базовом типе. Фактически, значения, представленные новым типом являются подмножеством значений, представленных в базовом типе (как это имеет место с ограничением простых типов). Другими словами, приложение, подготовленное к работе со значениям базового типа будет готово к работе со значениями ограниченного типа.Например, предположим, что мы хотим модифицировать определение списка продукции в международном заказе на покупку так, чтобы он содержал не менее одного товара в заказе. Схема, приведенная в ipo.xsd, позволяет элементу items появляться без каких-либо дочерних элементов. Чтобы создавать новый тип ConfirmedItems, мы обычным путем определяем новый тип и указываем, что он получен ограничением базового типа Items. При этом задаем новое (более ограниченное) значение минимального числа элементов item. Обратите внимание, что типы, полученные ограничением должны повторить все компоненты определения базового типа, которые должны быть включены в производный тип.
Тип ConfirmedItems полученный ограничением типа Items:

В соответствии с приведенными выше изменениями, требуется, чтобы список состоял не менее чем из одного дочернего элемента вместо того, чтобы как раньше разрешать нуль или больше дочерних элементов. Это сужает диапазон допустимого числа дочерних элементов от минимума равного 0 к минимуму равному 1. Заметим, что все элементы типа ConfirmedItems также будут допустимы как элементы типа Item.
Для иллюстрации ограничений в таблице 3 приводится несколько примеров того, как в пределах определений типов могут быть ограничены объявления элементов и атрибутов.
Таблица 3 Примеры ограничений
| Базовые значения | Ограничения | Примечания |
| default="1" | Установка значения по умолчанию | |
| fixed="100" | Установка фиксированного значения | |
| type="string" | Спецификация типа | |
| (minOccurs, maxOccurs) | (minOccurs, maxOccurs) | |
| (0, 1) | (0, 0) | Исключение необязательного компонента; этого также можно достигнуть, опуская объявление компонента в определении производного типа |
| (0, unbounded) | (0, 0) (0, 37) | |
| (1, 9) | (1, 8) (2, 9) (4, 7) (3, 3) | |
| (1, unbounded) | (1, 12) (3, unbounded) (6, 6) | |
| (1, 1) | - | Ограничение с помощью minOccurs или maxOccurs невозможно |
Простые типы
XML-схема заказа на покупку содержит объявления нескольких элементов и атрибутов простого типа. Некоторые из этих простых типов, например string и decimal встроены в язык XML-схемы, в то время как другие определены специально для данного типа документа. Например, атрибут partNum имеет тип по имени SKU (Stock Keeping Unit), который получен из встроенного простого типа string. Встроенные простые типы, и их вариации могут использоваться в объявлениях элементов и атрибутов. В таблице 2 приводится список простых встроенных в язык XML-схемы типов.Таблица 2. Список простых типов
| Простой тип | Примеры (разграничены запятыми) | Примечания |
| string | Confirm this is electric | |
| normalizedString | Confirm this is electric | см., 3) |
| token | Confirm this is electric | см., 4) |
| byte | -1, 126 | см., 2) |
| unsignedByte | 0, 126 | см., 2) |
| base64Binary | GpM7 | |
| hexBinary | 0FB7 | |
| integer | -126789, -1, 0, 1, 126789 | см., 2) |
| positiveInteger | 1, 126789 | см., 2) |
| negativeInteger | -126789, -1 | см., 2) |
| nonNegativeInteger | 0, 1, 126789 | см., 2) |
| nonPositiveInteger | -126789, -1, 0 | см., 2) |
| int | -1, 126789675 | см., 2) |
| unsignedInt | 0, 1267896754 | см., 2) |
| long | -1, 12678967543233 | см., 2) |
| unsignedLong | 0, 12678967543233 | см., 2) |
| short | -1, 12678 | см., 2) |
| unsignedShort | 0, 12678 | см., 2) |
| decimal | -1.23, 0, 123.4, 1000.00 | см., 2) |
| float | -INF, -1E4, -0, 0, 12.78E-2, 12, INF, NaN | 32-х битовое число однократной точности с плавающей запятой. NaN - число не задано, прим. (2) |
| double | -INF, -1E4, -0, 0, 12.78E-2, 12, INF, NaN | 64-х битовое число двойной точности с плавающей запятой, см., 2) |
| boolean | true, false 1, 0 | |
| time | 13:20:00.000, 13:20:00.000-05:00 | см., 2) |
| dateTime | 1999-05-31T13:20:00.000-05:00 | 31 мая 1999 года 13 часов 20 минут Восточноевропейского стандартного времени, которое на 5 часов отстает от Универсального времени. См.,2) |
| duration | P1Y2M3DT10H30M12.3S | 1 год, 2 месяца, 3 дня, 10 часов, 30 минут, и 12.3 секунды |
| date | 1999-05-31 | см., 2) |
| gMonth | --05-- | Май, см., 2) и 5) |
| gYear | 1999 | 1999, см., 2) и 5) |
| gYearMonth | 1999-02 | Февраль 1999 года, не зависимо от номера дня, см., 2) и 5) |
| gDay | ---31 | 31 день, см., 2) и 5) |
| gMonthDay | --05-31 | 31 мая, см., 2) и 5) |
| Name | shipTo | XML 1.0 тип Name |
| QName | po:USAddress | XML Namespace QName |
| NCName | USAddress | XML Namespace NCName, то есть QName без префикса и двоеточия |
| anyURI | , | |
| language | en-GB, en-US, fr | Значения допустимые для xml:lang как определено в XML 1.0 |
| ID | XML 1.0 атрибут типа ID, см., 1) | |
| IDREF | XML 1.0 атрибут типа IDREF, см., 1) | |
| IDREFS | XML 1.0 атрибут типа IDREFS, см., 1) | |
| ENTITY | XML 1.0 атрибут типа ENTITY, см., 1) | |
| ENTITIES | XML 1.0 атрибут типа ENTITIES, см., 1) | |
| NOTATION | XML 1.0 атрибут типа NOTATION, см., 1) | |
| NMTOKEN | US, Bresil | XML 1.0 атрибут типа NMTOKEN, см., 1) |
| NMTOKENS | US UK, Bresil Canada Mexique | XML 1.0 атрибут типа NMTOKENS, то есть список NMTOKEN разделенных пробелами, см., 1) |
| Примечания: 1) Для обеспечения совместимости XML-схем и XML 1.0 DTD, простые идентификаторы типов ( IDREF, IDREFS, ENTITY, ENTITIES, NOTATION, NMTOKEN, NMTOKENS), должны использоваться только в атрибутах. 2) Значение этого типа может быть представлено больше чем одним лексическим форматом. Например, 100 и 1.0E2 - оба значения представлены в формате с плавающей точкой, и значением равным "сто". Однако, для этого типа были установлены правила, которые определяют канонический лексический формат (см., "XML-схема. Часть 2: Типы данных"). 3) Символы перевода строки, табуляции, и перевода каретки в типе normalizedString перед обработкой схемы преобразуются в пробелы. 4) Как и в normalizedString, смежные пробелы сокращены до единственного пробела, предшествующие и завершающие пробелы удаляются. 5) Префикс "g", задает время по Григорианскому календарю. |
Новые простые типы можно определить, получая их от существующих простых типов (встроенных или ранее определенных). В частности мы можем получить новый простой тип, ограничивая существующий простой тип. Другими словами, для нового типа мы можем установить собственный диапазон значений как подмножество диапазона значений существующего типа. Для определения имени и типа собственного простого типа используют оператор simpleType. При этом c помощью оператора restriction указывают прототип, и идентифицируют фасеты (параметры), которые ограничивают диапазон значений базового типа. Список фасетов приводится в приложении B.
Предположим, что мы хотим создать новый тип целого числа, названного myInteger, чей диапазон значений должен находиться между 10000 и 99999 (включительно). Мы базируем наше определение на встроенном простом типе integer, чей диапазон значений включает так же и целые числа как меньше чем 10000, так и больше чем 99999. Чтобы определить тип myInteger, мы ограничиваем диапазон базового типа integer, используя два фасета, названные minInclusive и maxInclusive.
Определение myInteger. Диапазон 10000-99999:
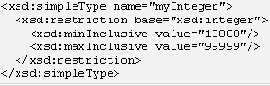
Приведенный пример показывает использование одной из возможных комбинаций базового типа, и двух фасетов, которые были применены для определения myInteger. Но возможно использование и других комбинаций встроенных простых типов и фасетов (см., приложение B). Рассмотрим более сложный пример определения простого типа. Тип по имени SKU получен из простого типа string. Мы ограничиваем значения SKU путем использования фасета pattern, который содержит регулярное выражение, определяющее допустимый формат строки "\d{3}-[A-Z]{2}". Это выражение читается следующим образом: "строка начинается с трех цифр, за которыми следует дефис, за дефисом следует два ASCII-символами верхнего регистра".
Определение простого типа SKU:
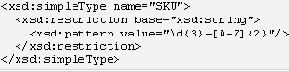
Более полно язык регулярных выражений описан в приложении D.
Язык XML-схем определяет пятнадцать фасетов, которые перечислены в приложении B. Среди них особенно полезен фасет enumeration. Его можно использовать для ограничения значения почти каждого простого типа, кроме boolean. Фасет enumeration ограничивает простой тип набором явных значений. Например, мы можем использовать enumeration, чтобы определить новый простой тип по имени USState, полученный из типа string, значение которого должно быть одним из стандартных сокращений наименования штатов США.
Использование фасета enumeration:
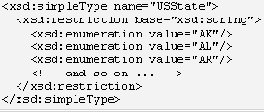
Использование типа USState является хорошей заменой типа string, при использовании в элементе state (содержит наименование штата). За счет такой замены мы можем ограничить значения элемента state в подэлементах billTo и shipTo. При этом эти значения ограничены следующим перечнем: AK, АL, AR, и т.д. Обратите внимание, что перечисляемые значения, указанные для данного типа должны быть уникальны.
Пустое содержимое
Теперь предположим, что элемент internationalPrice будет задавать наименование валюты и цену как значения атрибутов, а не как значение атрибута и содержимого элемента. Например: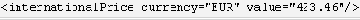
Такой элемент вообще не имеет никакого содержания. Чтобы определить тип, содержание которого пусто, мы по существу, определяем тип, который позволяет включать в его состав только подэлементы, но при этом не объявляем никаких элементов.
Пустой комплексный тип:
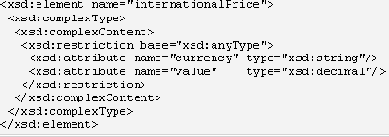
В этом примере, мы определяем анонимный тип с помощью оператора complexContent, то есть предполагается, что он будет содержать только элементы. Оператор complexContent говорит о том, что мы намереваемся ограничивать или расширять модель комплексного типа, а элемент restriction с параметром anyType объявляет два атрибута, но не задает никакого содержания элемента (более подробно ограничения рассматриваются в подразделе 4.4). В вышеприведенном примере показано как элемент internationalPrice, объявленный этим способом, может появиться в документе.
Предыдущий синтаксис для объявления пустого элемента является относительно подробным. Элемент internationalPrice можно объявить короче.
Упрощенное объявление пустого комплексного типа:
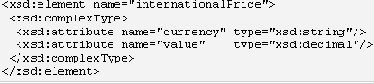
Этот компактный синтаксис работает потому, что комплексный тип, определенный без simpleContent или complexContent интерпретируется как упрощенное описание комплексного типа, который по умолчанию ограничивается параметром anyType.
Часть 0: Пример" является ненормативным
Документ "XML-схема. Часть 0: Пример" является ненормативным и представляет собой учебник для начинающих. Описание особенностей языка дается через многочисленные примеры, которые дополнены ссылками к нормативным документам.Нормативное описание языка XML-схем содержат документы "XML-схема. Часть 1: Структуры" () и "XML-схема. Часть 2: Типы данных" ().
SchemaLocation
XML-схема использует атрибуты schemaLocation и xsi:schemaLocation в трех случаях.1. В документе атрибут xsi:schemaLocation обеспечивает подсказку автора обработчику документа относительно размещения схемы документов. Автор гарантирует, что схема документов являются уместной для проверки документа на предмет его соответствия данной схеме. Например, мы можем указать для обработчика документа "Квартальный отчет" размещение его схемы. Атрибут schemaLocation содержит пару значений: первая часть пары - задает именное пространство; вторая часть пары - подсказка к первой части, описывающая, где находится схема, соответствующая данному документу. Присутствие этой подсказки не требует от обработчика документа обязательного использования указанной схемы. Обработчик документа свободен в своем выборе: он может использовать другие схемы, полученные любыми подходящими средствами, или не использовать никакой схемы вообще. Схема не обязана иметь именного пространства (см. подраздел 3.4), поэтому имеется атрибут noNamespaceSchemaLocation, который используется, чтобы обеспечить подсказку для указания местонахождения схемы документов, которая не имеет целевого именного пространства.
Применение schemaLocation в документе "Квартальный отчете", 4Q99html.xml:
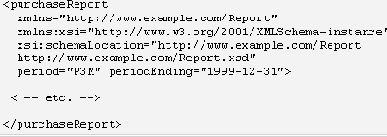
2. Элемент include языка XML-схемы имеет обязательный атрибут schemaLocation, который содержит URI-ссылку, идентифицирующую схему документа. В результате формируется конечная схема, объединяющая объявления и определения исходной схемы и включенных схем. Например, в разделе 4 для создания единой схемы документа были объединены определения типов Address, USAddress, UKAddress, USState (наряду с объявлениями их атрибутов и локальных элементов) из address.xsd с объявлениям элементов purchaseOrder, comment и определениям типов PurchaseOrderType, Items, SKU (наряду с объявлениями их атрибутов и локальных элементов) из ipo.xsd.
3. Элемент import языка XML-схемы имеет необязательные атрибуты namespace и schemaLocation. Если атрибут schemaLocation задан, то его интерпретируют также как xsi:schemaLocation (см., пункт 1). А именно, он обеспечивает подсказку автора схемы обработчику документа относительно размещения схемы документа, в которой автор гарантирует компоненты именного пространства идентифицированного атрибутом namespace. Чтобы импортировать элементы, которые не находятся ни в каком целевом именном пространстве, элемент import, используются без атрибута namespace (или без атрибута schemaLocation). Ссылки к элементам, импортированным этим способом неквалифицированны. Обратите внимание, что schemaLocation - это только подсказка и некоторые обработчики документов или приложения могут не использовать эти данные. Например, HTML-редактор для работы с HTML-документами может иметь встроенную HTML-схему.
Схема в нескольких файлах
Поскольку схемы становятся большими, то в целях упрощения сопровождения, управления доступом, и читабельности, желательно делить их содержимое на части. По этим причинам, мы взяли конструкции связанные с определением адресов из схемы po.xsd, и поместили их в новый файл с именем address.xsd. Измененную схему заказа сохраним в файле с именем ipo.xsd.Международная схема заказа на покупку, ipo.xsd:

Ниже приводится файл с конструкциями описания адресов.
Адреса для схемы международного заказа на покупку, address.xsd:

Схема заказа на покупку и адресные конструкции теперь содержатся в двух различных файлах: ipo.xsd и address.xsd. Чтобы включать описание адресов в схему международного заказа на покупку, другими словами, чтобы включить их в именное пространство схемы международного заказа на покупку, в схеме ipo.xsd используется элемент include:
< include schemaLocation="http://www.example.com/schemas/address.xsd"/>
Элемент include добавляет определения и объявления, содержащиеся в address.xsd, и делать их доступными как часть целевого именного пространства схемы международного заказа на покупку. Использование include имеет одно важное ограничение: целевое именное пространство включенных элементов должно быть то же самое что и целевое именное пространство схемы, в которую производится включение. В приведенном выше примере это http://www.example.com/IPO. Включение определений и объявлений с использованием механизма include добавляет элементы к существующему целевому именному пространству. В подразделе 4.5, мы опишем механизм, который дает возможность переопределить некоторые включенные элементы после того, когда они добавлены.
В нашем примере, мы показали только одну включающую схему и одну включенную подсхему. Практически возможно включить больше чем одну подсхему, используя несколько элементов include, при этом включаемые подсхемы могут включать другие подсхемы. Однако, вложение подсхем этим способом допустимо, только если все включенные части схемы объявлены с одним и тем же целевым именным пространством.
Документы, которые соответствуют схеме сформированной из нескольких частей (подсхем), нуждаются в ссылке только на "самую верхнюю" схему и общее для всех подсхем именное пространство. Ответственность за сборку схемы из подсхем ложится на программу обработки схемы. В нашем примере, документ ipo.xml (см. подраздел 4.3) ссылается только на одно общее целевое именное пространство, , и (косвенно) на один файл со схемой, http://www.example.com/schemas/ipo.xsd. Подключение файла address.xsd обеспечивает программа обработки схемы. В подразделе 5.4 мы опишем, как схемы могут использоваться для проверки правильности содержимого документа, зависящего от нескольких именных пространств.
Схема заказа на покупку
Схема документа "Заказ на покупку" содержится в файле po.xsd.Схема заказа на покупку. Файл po.xsd:

Схема заказа на покупку состоит из элемента schema и множества подэлементов, среди которых наиболее часто упоминаются element, complexType и simpleType. Элементы схемы определяют порядок следования элементов и их содержание в документах типа "Заказ на покупку".
Каждый из элементов в схеме имеет префикс xsd:. Этот префикс связан с именным пространством XML-схемы через объявление xmlns:xsd=http://www.w3.org/2001/XMLSchema, которое задано в элементе schema. Префикс xsd: используется в соответствии с соглашением об использовании этого именного пространства для обозначения элементов XML-схемы, хотя можно использовать любой префикс. Тот же самый префикс, и следовательно, та же самая ассоциация с именным пространством, используется и в названиях встроенных простых типов. Например, xsd:string. Цель ассоциации состоит в том, чтобы идентифицировать принадлежность элементов и простых типов словарю языка XML-схем, а не словарю автора схемы. Для упрощения, мы будем упоминать только названия элементов и простых типов, опуская префикс. Например, simpleType вместо xsd:simpleType.
Смешанное содержимое
Схема заказа может быть охарактеризована как конструкция из элементов, содержащих подэлементы. При этом наиболее глубоко вложенные подэлементы содержат символьные данные. XML-схема также предусматривает конструкцию, где символьные данные могут появиться вместе с подэлементами. Это значит, что символьные данные могут располагаться в любых элементах.Для иллюстрации рассмотрим следующий отрывок документа "письмо клиенту", который содержит теже элементы, что и заказ на покупку. Отрывок письма клиенту:
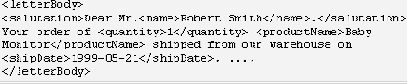
Обратите внимание на текст, появляющийся между элементами и их дочерними подэлементами. Текст появляется между элементами salutation, quantity, productName и shipDate, которые являются дочерними элементами letterBody. Ниже приводится отрывок схемы содержащий объявление letterBody.
Отрывок XML-схемы документа "письмо клиенту" c объявлением letterBody:

Элементы, появляющиеся в письме клиенту объявлены, и их типы определены, с помощью операторов element и complexType которые мы уже рассматривали. Чтобы разрешить символьным данным появиться между дочерними элементами letterBody, атрибут mixed в операторе определения типа равен true.
Обратите внимание, что смешанная модель, задаваемая XML-схемой, существенно отличается от смешанной модели принятой XML 1.0 (). В смешанной модели задаваемой XML-схемой порядок и число дочерних элементов, появляющихся в документе-образце должны согласовываться с порядком и номером дочерних элементов, указанных в XML-схеме. Напротив, в смешанной модели XML 1.0, порядок и число дочерних элементов, появляющихся в документе не ограничивается. В общем, применение XML-схемы, позволяет полностью контролировать применение смешанной модели содержимого элемента в отличие от смешанной модели XML 1.0, которая обеспечивает частичную проверку содержимого элемента.
Содержимое элемента
Схема заказа имеет много примеров элементов, содержащих другие элементы (например, items); элементов, имеющих атрибуты и содержащих другие элементы (например, shipTo); и элементов, содержащих только значения простого типа (например, USPrice). Однако мы еще не рассматривали элементы, которые имеют атрибуты, но содержат значения простого типа; элементы, которые содержат другие элементы, смешанные с символьными выражениями; элементы, которые вообще не имеют никакого содержания. В этом разделе мы исследуем эти разновидности элементов.Соответствие
Документ может быть обработан в соответствии с его схемой для того, чтобы проверить, соответствует ли он правилам, указанным в его схеме. Обычно такая обработка делает две вещи: 1) проверяет документ на соответствие правилам. Это называется этапом верификации схемы; 2) добавляет дополнительную информацию, вроде типов и значений по умолчанию, явно не присутствующую в документе. Это называется этапом создания информационной среды (XML-Infoset).Автор документа, такого как "Заказ на покупку", может объявить в самом документе, что он соответствует правилам данной схемы. Автор может сделать это с помощью рассмотренного выше атрибута schemaLocation. Но независимо от того, присутствует ли атрибут schemaLocation, приложение свободно в обработке документа в независимости от какой либо схемы. Например, программное приложение покупателя может иметь алгоритм, который всегда использует определенную схему заказа на закупку, независимо от значений schemaLocation.
Верификацию можно представить как пошаговую операцию. Сначала проверяется, что корневой элемент документа имеет допустимое содержание. Затем проверяется каждый подэлемент на соответствие его описанию в схеме, и так далее пока весь документ не будет проверен. Обработчик обязан сообщать, какая проверка была выполнена.
Чтобы проверить элемент на соответствие, обработчик сначала определяет местоположение объявления элемента в схеме, затем проверяет, что атрибут targetNamespace в схеме задает действительный URI целевого именного пространства элемента. В противном случае он может решить, что схема не имеет атрибута targetNamespace и элемент в документе неквалифицирован. Предположим, что именное пространство задано, тогда обработчик проверяет тип элемента на соответствие объявлению в схеме или на соответствие значению атрибута xsi:type в документе. В последнем случае, тип, указанный в документе должен быть допустимой заменой для типа, заданного в схеме, что контролируется атрибутом block в объявлении элемента.
Затем обработчик проверяет атрибуты и содержимое элемента, сравнивая их с разрешенными для данного типа элемента атрибутами и содержимым. Например, рассматривая элемент shipTo (см., подраздел 2.1), обработчик проверяет, что он соответствует типу Address (элемент shipTo имеет тип Address).
Если элемент имеет простой тип, обработчик проверяет, что элемент не имеет никаких атрибутов или вложенных элементов, и что его символьное содержание соответствует правилам установленным для простого типа. Иногда может выполняться проверка символьной последовательности на наличие регулярных выражений или перечислений, а иногда проверка того, что символьная последовательность представляет значение в разрешенном диапазоне.
Если элемент имеет комплексный тип, то обработчик проверяет, что требуемые атрибуты присутствуют, и что их значения соответствуют требованиям соответствующих им простых типов. Также проверяется, что все требуемые подэлементы присутствуют, и что последовательность подэлементов (и любой смешанный текст) соответствует модели содержимого, объявленной для данного комплексного типа.
Создание моделей содержимого
Все определения комплексных типов в схеме заказа на закупку представляют собой последовательность объявлений элементов, которые должны появиться в документе-образце. Вхождение в документ каждого элемента, объявленного в так называемой модели содержимого данного типа, является необязательным, если атрибут minOccurs равен нулю или может быть ограничено в зависимости от значений атрибутов minOccurs и maxOccurs. XML-схема также может обеспечить ограничения вхождения группы элементов в данную модель содержимого. Эти ограничения отражают правила, применяемые в XML 1.0 и плюс некоторые дополнительные ограничения. Заметим, что ограничения не применимы к атрибутам.XML-схема позволяет определить поименованную группу элементов, которые могут использоваться в моделях содержимого комплексного типа. Также может быть определена непоименованная группа элементов, которые вместе с элементами из поименованной группы будут появляться в документе в той же самой последовательности, в которой были объявлены. Вместе с тем, группы также могут быть спроектированы таким образом, что только один из элементов группы может появиться в документе-образце.
Для иллюстрации вышесказанного в определение PurchaseOrderType из схемы заказа на покупку введем две группы, так что заказ сможет содержать либо специальные элементы для указания адреса отправителя и продавца, либо адрес и отправителя и продавца будут задаваться одним и тем же элементом.
Группы выбора и последовательности:
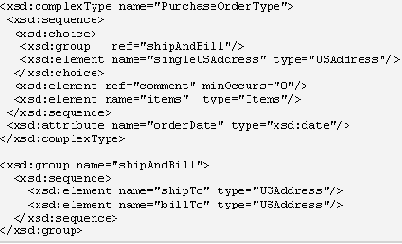
Элемент выбора в группе choice обеспечивает правило, по которому в документе-образце может появиться только один из его дочерних элементов. Элемент choice имеет двух потомков. Один из его потомков - элемент group, который ссылается на поименованную группу shipAndBill, и состоит из последовательности элементов shipTo, billTo. Второй потомок - singleUSAddress. Следовательно, в документе, элемент purchaseOrder должен содержать или элемент shipTo, за которым следует элемент billTo, или элемент singleUSAddress. За элементом группового выбора choice следуют объявления элементов comment и items. В свою очередь и элемент группового выбора и объявления элементов являются дочерними элементами групповой последовательности sequence. Применение двух последовательностей позволяет описать правило, по которому за адресом должны следовать комментарии, а за ними спецификация товаров.
Для ограничения появления элементов в группе существует еще одна возможность. Все элементы группы должны появиться один раз или не должны появиться ни разу, причем появляться они могут в произвольном порядке. Групповой элемент all ограничивает модель содержимого сверху. Кроме того, все дочерние элементы группы должны быть индивидуальными элементами (не группами), и все элементы должны появиться не более одного раза. То есть это соответствует значениям minOccurs = 0 и maxOccurs = 1. Например, чтобы позволить дочерним элементам purchaseOrder, появиться в любом порядке, переопределим PurchaseOrderType указанным ниже образом. Группа 'All':
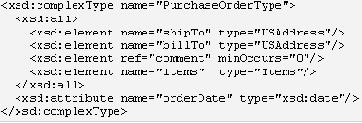
В соответствии с этим определением элемент comment может появиться в любом месте purchaseOrder, причем как до, так и после элементов shipTo, billTo или Items. Но при этом он может появиться только однажды. Кроме того соглашения группы all не позволяют нам объявлять элементы вроде comment вне группы, что ограничивает возможность его использования для многократного появления. Язык XML-схемы предполагает, что группа all будет использоваться как единственный потомок в начале модели содержимого. Другими словами следующее объявление неверно.
Пример неверного использования группы 'All':

Поименованные и непоименованные группы, которые используются в моделях содержимого (group, choice, sequence, all) могут иметь атрибуты minOccurs и maxOccurs. Комбинируя и вкладывая различные группы, обеспечиваемые языком XML-схемы, и устанавливая значения minOccurs и maxOccurs, возможно представить любую модель содержимого, которая может быть выражена с помощью XML 1.0 DTD. Кроме того, группа all обеспечивает дополнительную выразительность языка XML-схемы по сравнению с XML 1.0 DTD.
Статус данного документа
Этот раздел описывает статус документа "XML-схема. Часть 0: Пример" на момент его публикации. Другие документы могут заменить этот документ. Текущий статус этого документа можно уточнить в W3C.Данный документ был рассмотрен членами W3C, другими заинтересованными сторонами и утвержден Директором в качестве Рекомендации W3C. Документ является окончательным и может использоваться как материал для ссылки и цитирования в других документах. Участие W3C в продвижении представленной Рекомендации заключается в привлечении к ней внимания и способствовании ее широкому распространению. Тем самым наращиваются функциональные возможности, и повышается степень универсальности Сети.
Документ разработан W3C рабочей группой по XML-схеме как часть XML-направления. Назначение языка XML-схемы рассмотрено в документе "Требования к XML-схеме" (). Авторы этого документа - члены рабочей группы по XML-схеме. Различные части документа редактировались разными людьми.
Версия данной редакции документа включает в себя изменения, относившиеся к более ранним редакциям.
Пожалуйста, сообщите об ошибках обнаруженных вами в этом документе по email (архив сообщений находится по адресу ). Список известных ошибок доступен по адресу .
Только английская версия этой спецификации является нормативной. Информация о переводах этого документа на другие языки доступна по адресу .
Список W3C рекомендаций и другие технические документы можно найти по адресу .
Тип List
В дополнение к так называемым атомарным типам, которые составляют большинство, XML-схема имеет понятие списка. Перечень атомарных типов перечислен в таблице 2. Атомарные типы, списочные типы, и типы объединения, описанные в следующем разделе, все вместе называются простыми типами. Использование атомарных типов индивидуализирует используемые значения. Например, NMTOKEN индивидуализирует значение US, делая его неделимым в том смысле, что никакая часть US, типа символа "S", не имеет значения отдельно от целого. Списочные типы состоят из последовательностей атомарных типов, и, следовательно, допустимыми значениями могут быть только "атомы" из этой последовательности. Например, списочный тип NMTOKENS состоит из значений типа NMTOKEN, разделенных пробелами. Например, "US UK FR". Язык XML-схем имеет три встроенных списочных типа: NMTOKENS, IDREFS и ENTITIES.В дополнение к встроенным списочным типам Вы можете создать новые списочные типы из существующих атомарных типов. Невозможно создать списочные типы из существующих списочных типов или из комплексных типов. Например, рассмотрим списочный тип listOfMyIntType, состоящий из значений myInteger:
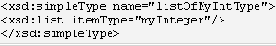
Элемент в документе, содержимое которого соответствует типу listOfMyIntType, может выглядеть следующим образом:

Для создания списочного типа могут быть применены следующие фасеты: length, minLength, maxLength, и enumeration. Например, чтобы определить список точно из шести штатов США (SixUSStates), мы сначала определяем новый списочный тип (полученный из типа USState) с именем USStateList, а затем создаем тип SixUSStates, ограничивая USStateList только шестью элементами. Списочный тип SixUSStates:
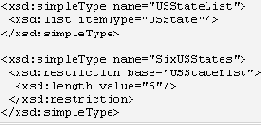
Элементы, тип которых - SixUSStates, должны содержать шесть элементов, и каждый из этих шести элементов должен быть одним из атомарных значений перечислимого типа USState, например:

Обратите внимание, что мы получили списочный тип из элементов атомарного типа string. Однако, тип string может содержать пробелы, а пробелы разграничивают элементы в списочном типе. Поэтому Вы должны быть внимательным, используя списочные типы, исходный тип которых - string. Например, мы определили новый списочный тип на основе базового типа string и фасета length равным 3. Тогда следующие три элемента списка являются законными:
Asie Europe Afrique.
Но следующие три элемента списка незаконны:
Asie Europe Amerique Latine.
Даже учитывая что "Amerique Latine" может существовать вне списка как отдельная строка, когда это значение включено в список, то пробел между Amerique и Latine фактически создает четвертый элемент списка. Поэтому последний пример не будет соответствовать списочному типу с тремя элементами.
Тип Union
Атомарные типы и списочные типы дают возможность элементу или атрибуту принимать значение (одно или более) экземпляра одного атомарного типа. Тип Union дает возможность элементу или атрибуту принимать значение (одно или более) одного типа, образованного путем объединения множества атомарных и списочных типов. Например, создадим union-тип для идентификации штатов США как односимвольного сокращения названия или списка числовых кодов. Рассмотрим тип zipUnion. Он сформирован из одного атомарного типа, и одного списка:
Когда мы определяем union-тип, то атрибут memberTypes оператора union задает список всех типов в объединении. Предположим, что мы объявили элемент с названием zips типа zipUnion, тогда он может принимать следующие значения:

К типу union могут быть применены два фасета: pattern и enumeration.
Управление созданием и использованием производных типов
До этого мы порождали новые типы и использовали их в документах, без каких либо ограничений. В действительности авторы схем могут захотеть управлять порождением новых типов и использованием их в документах.Язык XML-схемы обеспечивает несколько механизмов, которые управляют образованием типов. Один из этих механизмов позволяет автору схемы ограничить получение новых типов из данного комплексного типа: (a) - новые типы не могут быть получены с использованием ограничений, (b) - новые типы не могут быть получены с использованием расширений, (c) - новые типы не могут быть получены вообще. Чтобы проиллюстрировать сказанное, предположим, что мы хотим предотвратить любое образование новых типов из типа Address методом ограничения. Будем считать, что мы намереваемся использовать этот тип только как базовый для расширенных типов типа USAddress и UKAddress. Чтобы предотвратить любые такие образования немного изменим первоначальное определение Address так, как показано ниже.
Предотвращение образования типов методом ограничения типа Address:
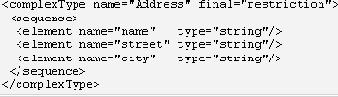
Значение restriction атрибута final предотвращает образования новых типов методом ограничения. Значение #all предотвращает образование новых типов вообще. Значение extension предотвращает образования новых типов методом расширения. Кроме того, у элемента schema существует необязательный атрибут finalDefault, который может принимать одно из значений указанных для атрибута final. Появление атрибута finalDefault эквивалентно определению атрибута final для каждого определения типа и объявления элемента в схеме.
Другой механизм контроля над образованием типов, заключается в указании того, какие фасеты могут быть применены при образовании нового простого типа. При определении простого типа к любому из его фасетов может быть применен атрибут fixed. Этот атрибут предотвращает порождение нового типа путем изменения значения фиксированного фасета. Например, определим простой тип Postcode.
Защита изменений фасетов для простого типа:
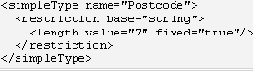
Как только тип Postcode определен, мы можем получить из него новый тип почтового кода. Новый тип получим путем применения фасета, неограниченного в базовом типе Postcode (см., пример ниже).
Корректное образование нового типа из Postcode:
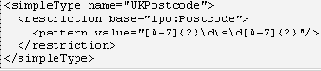
Однако мы не можем получить новый почтовый код, в котором мы повторно переопределяем какой-либо фасет, зафиксированный в базовом определении.
Некорректное образование нового типа из Postcode:
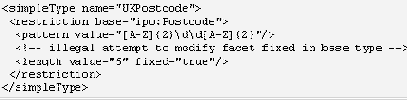
В дополнение к механизмам, которые управляют порождением новых типов, язык XML-схемы обеспечивают механизм, который управляет тем, какие образования и группы замены могут использоваться в документах. В подразделе 4.3, мы описали, как производные типы USAddress и UKAddress, могли использоваться в документах через элементы shipTo и billTo. Поскольку эти производные типы получены из типа Address, то они могут заменить модель содержимого, обеспеченную типом Address. Однако замену производными типами можно контролировать с помощью атрибута block, задаваемого в определении базового типа. Например, если мы хотим блокировать использование любого, образованного методом ограничения типа, вместо Address (возможно, поэтому мы определили Address с final="restriction"), то мы можем изменить первоначальное определение Address указанным ниже образом.
Защита от использования в документах типа Address, полученного методом ограничения:
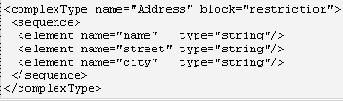
Атрибут block="restriction" препятствует замене в документах типа Address всеми порожденным из него, в соответствии с методом ограничения, типами. Однако это не препятствовало бы UKAddress и USAddress заменять Address, поскольку они были получены методом расширения. Предотвращение замены модели содержимого базового типа порожденными типами вообще, или типами, образованными методом расширения, обозначено значениями #all и extension соответственно. Как и в случае с final, у элемента schema существует дополнительный атрибут blockDefault, значение которого может быть одним из значений, которые может принимать атрибут block. Эффект от определения атрибута blockDefault эквивалентен определению атрибута block в каждом определении типа и объявлении элемента в схеме.
XML-СХЕМАЧАСТЬ 0: ПРИМЕР
Перевод выполнилРекомендации W3C, 2 мая 2001 года.
Значения Nil
Один из объектов в заказе на закупку, перечисленных в po.xml, Lawnmower, не имеет элемента shipDate. Автор схемы, возможно, предусмотрел такую возможность, чтобы указать еще не отгруженные изделия. Но вообще, отсутствие элемента не дает какой-либо определенной информации. Это может указывать на то, что информация отсутствует, или не соответствует действительности, или элемент может отсутствовать по другой причине. Иногда желательно представить не отгруженное изделие, неизвестную или неподходящую информацию явно с помощью элемента, а не отсутствующим элементом. Например, это может быть полезным при работе с пустыми значениями ("Null") реляционной базы данных. Для этих целей в языке XML-схемы имеется Nil-механизм. Этот механизм позволяет элементу появляться c или без нулевого значения.Для индикации возможности пустого значения элемента Nil-механизм XML-схемы использует специальный признак. Другими словами, возможное пустое значение элемента обозначается не с помощью какого-либо специального Nil-значения содержимого, а с помощью специального атрибута, индицирующего возможность пустого значение элемента. Для иллюстрации вышесказанного, объявление элемента shipDate изменим так, чтобы можно было идентифицировать его пустое значение:
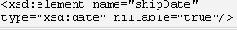
Для того чтобы явно указать в документе, что shipDate имеет пустое значение, устанавливаем атрибут nil равным true. Для идентификации того, что атрибут xsi:nil принадлежит языку XML-схемы, а не схеме данного типа документа в имени атрибута используем именное пространство языка XML-схем:
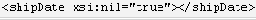
Атрибут nil определен в именном пространстве языка XML-схемы, http://www.w3.org/2001/XMLSchema-instance, и поэтому в документе-образце используется с префиксом (таким как xsi:), связанным с этим именным пространством. Как и xsd:, префикс xsi: используется в соответствии со стандартным соглашением. Заметим, что nil-механизм применим только к значениям элементов, а не к значениям атрибутов. Элемент с xsi:nil="true" не может иметь никакого содержания, но может иметь атрибуты.
XML - статьи
Инициатива SDMX: новые подходы к обмену статистическими данными
Подготовлено: по материалам зарубежных сайтовПеревод: Intersoft Lab
В сентябре 2001 г. в г. Вашингтоне состоялся международный семинар, организованный крупнейшими мировыми финансовыми и статистическими организациями: Банком международных расчетов (Bank for International Settlements - BIS), Европейским Центральным Банком (European Central Bank - ECB), Статистическим бюро европейского сообщества (Statistical Office of the European Communities - EUROSTAT), Международным валютным фондом (International Monetary Fund - IMF), Организацией экономического сотрудничества и развития (Organization for Economic Co-operation and Development - OECD) и Статистическим департаментом ООН (United Nations Statistical Division). Семинар был посвящен проблеме обмена статистическими данными и метаданными. Участники семинара признали необходимым начать работу по созданию международных стандартов в этой области. В результате возникла так называемая инициатива SDMX - Statistical Data and Metadata Exchange Initiative, которая и поставила своей целью выработку таких стандартов. В настоящее время, помимо вышеназванных организаций, в состав SDMX входит также Мировой банк (World Bank).
История вопроса
Считается, что история мировой стандартизации статистических данных началась в 1928 г. на Международной конференции по экономической статистике (International Conference Relating to Economic Statistics), организованной Лигой Наций (League of Nations). После Второй мировой войны история создания международных стандартов продолжилась выпуском в 1947 г. документа "Система мер для оценки национального дохода и составления социальных счетов" (Measurement of National Income and the Construction of Social Accounts), созданного под эгидой ООН, и "Руководства по составлению платежного баланса" (Balance of Payments Manual) от Мирового банка в 1948 г.Всплеск активности в области стандартизации данных начался с появлением компьютеров в 1953 г. Вначале эта деятельность ограничивалась созданием внутренних стандартов кодирования статистических данных, а в конце 20-го века, с развитием недорогих электронных средств коммуникации, на первый план вышла задача разработки стандартов для электронного обмена информацией. Первыми здесь оказались коммерческие корпорации - авиакомпании и банки, за ними последовали и организации государственного сектора. К началу 21-го века электронный обмен статистическими данными стал стандартной практикой для таких организаций, как EUROSTAT, IMF, BIS, ECB и стран - членов этих организаций.
Наряду с разработкой правил синтаксиса развивалось и другое направление обмена данными - создание стандартного языка для описания документов. Первым стал стандартный обобщенный язык описания документов (Standard Generalized Markup Language - SGML), одобренный Международной организацией по стандартизации (International Standard Organization) в 1986 г. Без его производной - языка разметки гипертекста (Hypertext Markup Language - HTML) сейчас невозможно представить существование интернета.
Следующим шагом стало создание так называемого расширяемого языка разметки (Extensible Markup Language - XML), с помощью которого можно описать формат для передачи данных. Первая версия этого языка была опубликована в 1998 г.
Разработка стандартов для обмена информацией совпала с появлением потребности в новых экономических данных на международном уровне. Развитие экономики привело к тому, что возникла необходимость в макроэкономических данных, а великая депрессия 1930-х годов продемонстрировала, что для достижения более стабильной экономики в мировом масштабе государства должны сотрудничать. Стало ясно, что макроэкономические данные различных стран должны быть легко сравнимы между собой. Помимо этого, появилась потребность в новом типе стандартизованной информации, описывающей, откуда берутся данные национальных экономик, т.е. источники этих данных и способы их распространения.
В результате актуальной стала проблема так называемых метаданных, т.е. данных, описывающих другие данные. В документе "Руководство по размещению статистических метаданных в интернете" (Guidelines for Statistical Metadata on the Internet), выпущенном Европейской экономической комиссией ООН (Economic Commission for Europe - ЕСЕ), статистические метаданные определяются как "данные, необходимые для правильного получения и использования тех данных, которые они описывают". То есть это данные, дающие информацию о статистических данных и, до некоторой степени, о процессах и средствах, вовлеченных в получение и использование статистических данных.
Как и в случае с обычными данными, вновь появляющиеся наборы метаданных также вовлекаются в обмен между государствами, региональными и международными организациями и общественностью. Из этого логически вытекает необходимость разработки стандартов обмена метаданными.
Возвращаясь к инициативе SDMX, необходимо отметить, что в рамки ее деятельности входит обмен данными и метаданными в пределах совместной работы финансовых и экономических организаций, входящих в это сообщество. Таким образом, ее деятельность направлена на выработку стандартов преимущественно в области социально-экономической статистики.
Важно подчеркнуть, что одним из основных принципов деятельности организации SDMX является открытость в разработке стандартов и обеспечение доступа всех государств - членов организации и заинтересованных потребителей данных к участию в этой работе. При этом стоимость участия в процессе должна быть минимальной, чтобы не создавать препятствий для желающих присоединиться к данной деятельности. Интеллектуальная собственность, которая появится в результате работы организации, должна быть доступна бесплатно и без ограничений.
Практическое применение стандарта SDMX
Федеральный резервный банк Нью-Йорка (Federal Reserve Bank of New York) разместил на своем сайте данные об обменных курсах, используя стандарты SDMX, разработанные в ходе практического исследования новых электронных стандартов обмена данными в 2003 г. (http://www.newyorkfed.org/xml/fx.html).Данные, оформленные таким образом, доступны для автоматизированного использования. Структуры, схемы и списки кодов, поддерживающие эти файлы, также совместимы со стандартами SDMX.
Это первый известный случай применения SDMX-стандартов для публикации данных в интернете.
Помимо этого, Федеральный резервный банк Нью-Йорка информировал организации, входящие в SDMX-инициативу, о том, что банком также рассматривается вопрос о размещении в интернете и других статистических рядов данных на основе тех же стандартов.
рубрики будет посвящена техническому описанию стандарта SDMX.
Проекты SDMX
Наряду с разработкой первого стандарта SDMX в рамках этой инициативы выполняется и ряд других проектов, направленных на поддержку и развитие новых электронных стандартов обмена данными. Проекты SDMX нацелены на использование новых интернет-технологий и опыта тех, кто занимается бизнес-требованиями и IT поддержкой для сбора, компиляции и распространения статистической информации.В настоящее время в рамках организации SDMX выполняется четыре проекта:
Практическое исследование новых электронных стандартов обмена данными
В фокусе данного проекта было изучение способов, с помощью которых новые интернет-технологии, такие как XML, web-сервисы и другие, могут быть использованы для упрощения сбора, компиляции и распространения статистической информации.
К настоящему времени подготовлен набор технических проектов, устанавливающих стандарты. Эти проекты доступны для комментариев на сайте SDMX-инициативы (http://www.sdmx.org/). В них содержится детальная информация о результатах проекта.
Если говорить коротко, то в рамках этого проекта новые и экспериментальные стандарты, основанные на web-технологиях, были использованы для обработки статистики внешнего долга, предоставленной BIS, IMF, OECD и Мировым банком.
Данные этих организаций доступны на web-узле, который они поддерживают совместно. Основной результат проекта - это то, что, используя интернет, можно получать данные с такого "виртуального" узла без использования центральной базы данных (т.е. с помощью ссылок на данные, которые хранятся на разных сайтах). Этот результат дает дополнительные основания считать, что распространение статистической информации через интернет с помощью новых стандартов и технологий может стать основанием для создания web-сервисов, посредством которых можно будет напрямую обмениваться данными, минуя промежуточную стадию пересылки данных в централизованные базы. Если расширить рамки этой концепции, то данные, находящиеся в интернете, могут рассматриваться как библиотека статистической информации с широким доступом, способная удовлетворять самые разнообразные требования пользователей.
Более подробную информацию об этом проекте можно найти по адресу
http://www.registrysolutions.co.uk/sdmxDemo/notes/index.htm.
Пакетный обмен данными
Generic Statistical Message - это синтаксис, разработанный для стандарта EDIFACT в начале 1990-х годов. В 1998-99 годах BIS, ЕСВ и EUROSTAT представили новый вариант этого синтаксиса, названный GESMES/СВ. Все участники SDMX-инициативы договорились поддерживать и использовать именного его как стандарт для пакетного обмена данными временных рядов.
К настоящему времени в рамках проекта разработана модель синтаксиса GESMES для временных рядов, названная GESMES/TS. На сайте SDMX-инициативы (http://www.sdmx.org/) сейчас доступна третья, последняя версия этого синтаксиса, а также руководство для пользователей. Последнее описывает модель данных, которая используется в этой версии, синтаксис EDIFACT и дает указания по разработке приложений, необходимых для использования GESMES/TS при пакетном обмене данных.
Создание общего словаря метаданных
Задачей этого проекта является создание и поддержка ключевого набора элементов метаданных и связанных с ними определений с целью улучшения стандартизации содержимого метаданных и стимулирования работы по совместимости данных на международном уровне.
Обновленная версия этого словаря была выпущена в апреле 2004 г. Она содержит полный набор определений, описывающих статистические данные и процессы, которые используются для их компиляции государственными агентствами и международными организациями. Эта версия также доступна на сайте SDMX-инициативы.
Репозитории метаданных
Целью проекта является содействие и расширение обмена метаданными среди международных агентств и между странами с помощью стандартизации процедуры организации репозиториев метаданных.
Проект имеет две краткосрочных цели: 1) идентификация общих моментов в структурах метаданных, входящих в состав наборов макроэкономических данных, которые собираются и хранятся в репозиториях; 2) использование этих общностей для развития стандартизации. В работе должен учитываться уже накопленный опыт создания репозиториев метаданных, который есть у IMF и EUROSTAT.
Долгосрочной целью проекта является создание web-сайтов государственных и международных структур и организаций частного сектора с использованием одного и того же словаря поиска. Такие сайты должны предоставлять возможности поиска по ним. При этом один запрос может быть одновременно отправлен по разным адресам, что сделает возможной компиляцию агрегированных результатов. Выполнение этого проекта также будет связано как с деятельностью по практическому исследованию новых электронных стандартов обмена данными, так и с работами по другим проектам, связанным с моделями и словарями данных и метаданных.
Текущее состояние дел по этому проекту также отражено на сайте SDMX-инициативы.
Стандарт SDMX
Стандарт SDMX определяет форматы для обмена агрегированных статистических данных и метаданных, необходимых для понимания того, как эти данные структурированы. Основное внимание обращается на данные, представленные в виде временных рядов, но также поддерживаются и так называемые перекрестные XML-форматы3. Первая версия стандарта SDMX содержит технические спецификации форматов данных на основе общей информационной модели. Эти форматы используют синтаксис языка XML и технологии EDIFACT4.Первая версия стандарта SDMX была выпущена в сентябре 2004 г. В декабре того же года, перед представлением стандарта на утверждение в Международную организацию по стандартизации (International Standard Organization - ISO), в некоторые секции первоначальной версии были внесены незначительные изменения. Первая версия стандарта SDMX была представлена в ISO в декабре 2004 г.
XML - статьи
Форматы данных SDMX
В отличие от формата SDMX-EDI, который разработан для поддержки преимущественно пакетного обмена, формат SDMX-ML должен удовлетворять более широкому спектру требований. Действительно, XML-форматы используются для множества различных видов автоматизированной обработки данных и, следовательно, должны поддерживать более разнообразные сценарии обработки. Вот почему язык SDMX-ML включает несколько типов сообщений. Каждый из них приспособлен для поддержки определенного набора требований к обработке данных:Поскольку все форматы SDMX-ML являются практическим воплощением одной и той же информационной модели, а все сообщения о данных могут быть получены из сообщения об определении структуры, которое описывает набор данных, то между всеми форматами данных возможно осуществление стандартных операций преобразования. Эти операции могут проводиться с помощью родовых инструментов трансформации, полезных для всех пользователей SDMX-ML. Помимо того, эти инструменты не относятся только к отдельным ключевым понятиям наборов данных, а являются общеупотребительными (даже если форматы, с которыми они имеют дело, являются таковыми).
Модули XML-схемы
В рассматриваемой архитектуре XML-схемы существует так называемая "схема упаковки" (packaging scheme). В основе этой схемы лежит идея, что пространства имен XML могут быть использованы как модули для того, чтобы любой пользователь или приложение могли иметь доступ ко всей библиотеке, даже зная только часть ее.Каждый модуль - это отдельный экземпляр элемента схемы W3C XML (W3C XML Schema Language), связанный со своим собственным пространством имен XML. В тех случаях, когда эти модули взаимозависимы, они используют механизм импортирования XML-схемы для использования конструкций, описанных в других модулях. Ниже приведено краткое описание этих модулей:
Пример электронного документа в формате SDMX-ML
В заключение кратко рассмотрим основных конструкций языка SDMX-ML, для чего воспользуемся небольшим примером, входящим в состав пакета спецификаций языка SDMX-ML.Статистические данные, приведенные в этом примере, это величины внешнего долга, подлежащие погашению, в млн. долларов США. Данные приводятся на каждый месяц на начало отчетного периода:
| Отчетный период | Данные |
| 2000-01 | 3.14 |
| 2000-02 | 3.14 |
| 2000-03 | 4.29 |
| 2000-04 | 6.04 |
| 2000-05 | 5.18 |
| 2000-06 | 5.07 |
| 2000-07 | 3.13 |
| 2008-08 | 1.17 |
| 2000-09 | 1.14 |
| 2000-10 | 3.04 |
| 2000-11 | 1.14 |
| 2000-12 | 3.24 |
XML-код этого примера представлен в
Листинге 1.
Прежде всего стоит обратить внимание на объявления пространств имен, реализующее принцип модульности, о котором шла речь выше.
Корневой элемент
Элемент первого уровня
Элемент второго уровня
Элемент
Элемент