Программирование основы Программирование Технологии программирования Разработка программ Работа с данными Методы программирования Программирование интерфейсов Программирование - IDE интерфейс Программирование - графический интерфейс Программирование - Power Strip Программирование и тестирование Программирование - отладка Программирование - тестирование |

|
Телекоммуникационные технологии. Том 1
Ipx_
4.2.1.1 IPX-протоколСеменов Ю.А. (ГНЦ ИТЭФ)
Протокол IPX предназначен для передачи дейтограмм в системах, неориентированных на соединение (также как и IP или NETBIOS, разработанный IBM и эмулируемый в Novell), он обеспечивает связь между NetWare серверами и конечными станциями. Максимальный размер IPX-дейтограммы составляет 576 байт, из них 30 байта занимает заголовок. Предполагается, что сеть, через которую транспортируются эти дейтограммы, способна пересылать пакеты соответствующей длины. IPX-пакеты могут рассылаться широковещательно, для этого поле типа должно принять значение 0x14, адрес сети назначения должен соответствовать локальной сети, адрес узла назначения при этом принимает значение 0xFFFFFF.
Оригинальный транспортный протокол Novell, на мой взгляд, не способствует успеху этой сети. Не успев своевременно переориентироваться на транспортные и маршрутные протоколы стека TCP/IP этот крайне популярный совсем недавно вид сетей в настоящее время имеет шансы исчезнуть.
IPX-пакеты, передаваемые по сети Ethernet, могут иметь несколько разных форматов. Старейший из них носит в Novell название “802.3” (информацию об интеграции сетей Novell и Интернет можно найти в документах: RFC-1234, -1420, -1553, -1634, -1792) и используется по умолчанию в версиях вплоть до 3.11. В последующих версиях форматом по умолчанию является “802.2”. Применим также и формат, называемый Ethernet II, который наиболее близок идеологии TCP/IP. Сеть в Netware - это логический канал, который используется совместно рядом узлов так, что они могут взаимодействовать друг с другом непосредственно. Так процессы, реализуемые на одном сервере, считаются подключенными к внутренней IPX-сети. Все пользователи сети типа Ethernet II образуют логическую сеть IPX. Все пользователи одной сети типа 802.3 рассматриваются как узлы различных сетей IPX. Сопоставление форматов пакетов для различных сетевых стандартов представлено на рис. 4.2.1.1.

Рис. 4.2.1.1. Форматы сетевых пакетов
Из рисунка видно, что различия непринципиальны и не препятствуют сосуществованию всех перечисленных форматов в пределах одной локальной сети.
IPX- заголовок начинается сразу после поля Тип или Длина в зависимости от используемого протокола.
Серверы Netware можно сконфигурировать так, чтобы они воспринимали пакеты разных типов, и поэтому могли иметь непосредственные связи с разными сетями. IPX-сервер может выполнять и функции маршрутизатора. Формат заголовка пакета IPX показан на рис. 4.2.1.2. За заголовком следуют данные, их объем определяется кодом поля Длина пакета (минус 30) и лежит в диапазоне от 0 до 546 байт.

Рис. 4.2.1.2. Формат заголовка IPX-пакета
Поле Контрольная сумма (2 байта) устанавливается ipx-драйвером равным 0xffff, это означает, что контрольного суммирования не производилось. Приложениям разрешено использовать поле контрольной суммы при работе с кадрами Ethernet II, ieee 802.2 и Ethernet SNAP и запрещено для работы с кадрами ieee 802.3. Данное ограничение можно легко понять, обратившись к рис. 4.2.1.1. Контрольная сумма служит лишь для контроля правильности IPX-заголовка и не имеет никакого отношения к полю данных IPX-дейтограммы. Для того чтобы работать с контрольными суммами на NetWare-сервере, следует выдать команду set enable IPX checksum=n, где n указывает на то, что контрольная сумма использована. Возможные значения n и их смысл приведены ниже в таблице 4.2.1.1.
Таблица 4.2.1.1
| Код n | Назначение в сервере |
| 0 | Контрольная сумма не используется |
| 1 | Контрольная сумма используется, если доступна клиенту |
| 2 | Контрольная сумма должна использоваться |
| То же для клиента | |
| 0 | Контрольная сумма не используется (по умолчанию) |
| 1 | Контрольная сумма используется, но лишена приоритета |
| 2 | Контрольная сумма используется и имеет приоритет |
| 3 | Контрольная сумма должна использоваться |
Следует также иметь в виду, что согласно регламентациям Novell длина пакета может принимать только четные значения. Программист не должен беспокоиться о содержании этого поля, это за него сделает сам протокол IPX. Поле управление пересылкой (1 байт) устанавливается IPX-драйвером равным нулю перед посылкой пакета. Каждый маршрутизатор увеличивает значение этого поля на 1. Если пакет прошел через 15 маршрутизаторов, очередной - удалит пакет из сети (в некотором смысле это аналог поля время жизни - TTL в протоколах TCP/IP). Поле управление пересылкой можно использовать для оптимизации маршрутов в локальной сети. Если станция общается только с серверами соседней субсети, ее следует переключить туда и снизить тем самым нагрузку маршрутизатора. Контроль за содержимым этого поля выполняется протоколом IPX. Поле тип пакета (1 байт) устанавливается прикладной программой. При использовании протокола ipx это поле должно содержать нуль (или 4), в случае использования протокола SPX - 5, а для протокола NCP(Netware core protocol) -17. Поля адрес узла назначения и адрес узла отправителя содержат 12-байтовые структуры ipxaddr_1. Эта структура включает в себя 4 байта адреса сети (присваивается администратором сети при установке сети Novell), 6 байт адреса узла (физический адрес, задается изготовителем сетевого интерфейса) и 2 байта дескриптора соединителя (socket, необходим для адресации программы, принимающей пакеты, заполняется приложением). Пакеты, адресованные серверу в NetWare 3.x или 4.x содержат в поле адреса узла получателя код 0x00 00 00 00 00 01 (аналогичный код будет записан в поле адрес отправителя, если им является сервер). Адрес же узла получателя на уровне Ethernet или Token Ring будет равен физическому сетевому адресу интерфейса или локального маршрутизатора, если сервер размещен в другой субсети. Соединители (socket) служат для управления обработкой пакетов. Широковещательный пакет будет получен ЭВМ, если она имеет открытый соединитель для процесса, которому он адресован.
По этой причине должны приниматься специальные меры, чтобы предотвратить возможность посылки двумя программами пакетов различного типа на один и тот же соединитель. Ряд номеров соединителей зарезервировано IPX-протоколом для определенных целей:
2 - соединитель протокольных откликов; 3 - обработчик ошибок.
Некоторые номера заняты под нужды Netware:
Приложение должно устанавливать поля тип пакета и адрес узла назначения, а IPX-драйвер заполняет остальные поля. Возможные значения кода поля тип пакета представлены в таблице 4.2.1.2.
Таблица 4.2.1.2 Коды типа IPX-пакета.
| Тип пакета | Значение |
| 0 | Обычный IPX-пакет |
| 1 | Пакет с маршрутной информацией (RIP - routing information protocol) |
| 2 | Отклик |
| 3 | Ошибка |
| 4 | Информационный пакетный обмен (pep - packet exchange protocol) |
| 5 | Последовательный пакетный обмен (SPX - sequence packet exchange) |
| 17 | Протоколы ядра NetWare (NCP) |
| 20 | Именной пакет netbios (широковещательный) |
Маршрутная информация передается между серверами и маршрутизаторами. Динамический маршрутный протокол RIP (routing information protocol, базируется на стандарте Xerox IP; cм. также RFC-1058) обеспечивает конечные станции информацией, которая необходима для динамического управления оптимизацией маршрутов.
Рассылка маршрутной информации производится с помощью широковещательных пакетов. Как видим, сети Novell являются источником значительных потоков широковещательных пакетов. Аналогичным образом объекты сети оповещаются о других изменениях в сетевой среде, например, рассылка информации о доступных услугах (SAP - service advertisement protocol). Протокол SAP позволяет узлам, которые предлагают определенные услуги (например, файл-серверы или принт-серверы), сообщать о своих адресах и видах доступных услуг. Администратор может регулировать поток таких пакетов, задавая постоянные времени для таймеров обновления информации. Маршрутизаторы рассылают маршрутную информацию в пяти случаях:
Маршрутизация пакетов в сети достаточно проста. Каждому сетевому сегменту маршрутизатор присваивает номер в пределах от 1 до fffffffe. Каждой группе устройств присваивается “сетевой номер”, который представляет эту группу во всех маршрутизаторах сети. Пакеты, посылаемые от одного члена группы другому, посылаются непосредственно. Пакеты от одного члена группы к объекту из другой группы будут пересланы через маршрутизаторы. Для выбора маршрута в пределах локальной сети используется маршрутный протокол RIP. Формат пакета NetWare RIP показан на рис. 4.2.1.3.

Рис. 4.2.1.3. Формат RIP-пакета в NetWare
Поле тип пакета содержит код 0x0001, если это запрос, и 0x0002, если отклик. В поле адреса сети записывается адрес сети места назначения, если пакет является запросом. Если в поле записан код 0xff ff ff ff, это означает, что запрос относится ко всем известным сетям. Поле число шагов до цели имеет смысл лишь в случае пакетов-откликов. В этом случае сюда заносится число маршрутизаторов, которые должен пройти пакет по дороге к сети назначения.
Поле время в тиках имеет смысл для пакетов-откликов и указывает на время, необходимое для достижения сети адресата. Один тик равен 1/18 секунды. Сходный протокол маршрутизации используется в сетях appletalk (RTMP).
Для межсетевой маршрутизации в Novell разработан протокол NLSP (NetWare link services protocol). NLSP базируется на той же идеологии, что и протокол IS-IS (intermediate system-to-intermediate system), созданный для сетей OSI и IP. В NLSP значение метрики маршрута задается вручную. nlsp-маршрутизаторы хранят полную карту сети, по которой принимаются решения о наилучших возможных маршрутах.
На рис. 4.2.1.4 представлена схема соответствия протоколов Novell и 7-уровневой модели osi.

Рис. 4.2.1.4. Схема соответствия протоколов Novell и модели osi
Протокол SAP (service advertising protocol) служит для получения информации обо всех серверах, имеющихся в сети, и поддерживает следующие виды запросов и функции:
Каждому серверу NetWare присваивает номер, а некоторые сервера могут иметь и имя. Номер сервера и его имя хранятся в базе данных объектов bindary каждого сервера. Пакет запроса SAP-сервиса содержит 2 байта типа пакета и два байта типа сервера. Поле тип пакета определяет, является ли данный пакет общим запросом сервиса (код=0x0003), или запросом ближайших услуг (код=0x0001). Таблица кодов поля тип сервера приведена ниже (4.2.1.3).
Таблица 4.2.1.3 Коды тип сервера (cм. также )
| Тип сервера | Описание |
| 0x0001 | Пользователь |
| 0x0004 | Файл-сервер |
| 0x0005 | Сервер заданий |
| 0x0006 | Внешний сетевой порт (gateway) |
| 0x0007 | Принт-сервер |
| 0x0009 | Сервер архива |
| 0x000a | Очередь задач |
| 0x0017 | Диагностика |
| 0x0020 | NetBios |
| 0x0021 | NAS SNA порт |
| 0x0027 | TCP/IP сервер порта |
| 0x0028 | Сервер моста x.25 точка-точка |
| 0x02e | Динамический SAP |
| 0x0047 | Оповещающий принт-сервер |
| 0x004b | vap 5.0 |
| 0x004c | SQL VAP |
| 0x007a | TES-NetWare VMS |
| 0x0098 | Сервер доступа к NetWare |
| 0x009a | Сервер именованных труб |
| 0x009e | Портативный NetWare-Unix |
| 0x0107 | NetWare 386 |
| 0x0111 | Тест-сервер |
| 0x0166 | Управление NetWare |
| 0x026a | Управление NetWare |
| 0x026b | Временная синхронизация |
| 0x0278 | Сервер каталогов NetWare |
br>
SAP-пакеты-отклики ( периодически рассылаемые пакеты) имеют следующий формат (рис. 4.2.1.5).

Рис. 4.2.1.5. Формат пакета SAP
Поле тип пакета принимает значение 0x0002 для SAP-откликов общего обслуживания (General Service Response) и 0x0004 для отклика ближайшего сервера. Запросы о ближайшем сервере используются для поиска в сети сервера конкретной разновидности (пакет запроса содержит лишь первые два поля). Реально отклик будет получен от всех серверов данного типа, а не только от ближайшего. Насколько данный сервер близок, определяется по числу маршрутизаторов до него. Эти запросы/отклики служат для составления списка доступных серверов. Поле тип сервера содержит код доступного вида услуг, а в поле наименование сервиса записывается имя услуги уникальное для данного сервера (длина поля на рис. 4.2.1.5 равна N). Поле адрес сети представляет собой 4-байтовое число, которое идентифицирует адрес сервера. Поле адрес узла характеризует адрес сервера в сети. Службы NetWare указывают адрес 0x00.00.00.00.00.01. Поле дескриптор соединителя характеризует код соединителя, который будет использовать сервер. Последнее поле - число шагов до сервера (число транзитных сетей) характеризует число маршрутизаторов между сервером и клиентом. При отключении сервера от сети он должен широковещательно разослать SAP-уведомление “Останов сервера”. Уведомление содержит код сервера и его полный адрес.
Для поля флаги имени характерна
| 1_ _ _ | _ _ _ _ | Отклик |
| _ 000 | 0 _ _ _ | Запрос |
| _ _ _ _ | _ _ 0 _ | Не укорочено |
| _ _ _ _ | _ 1 _ _ | Официальный ответ |
| 0_ _ _ | _ _ _ _ | Уникальное имя NetBIOS |
| _ 10 _ | _ _ _ _ | Узел М-типа |
| _ _ _ _ | _ 1 _ _ _ | Активное имя |
| _ _ _ _ | _ _ 0_ | Временное имя |
| 1 _ _ _ | _ _ _ _ | Имя группы NetBIOS |
| _ 10 _ | _ _ _ _ | Узел М-типа |
| _ _ _ _ | _ 1 _ _ | Активное имя |
| _ _ _ _ | _ _ 0_ | Временное имя |
Локальные сети персональных компьютеров. Использование
4.2.1 Протоколы Novell (IPX/SPX)Семенов Ю.А. (ГНЦ ИТЭФ)
| Номер раздела | Название раздела | Объем в страницах | Объем в кбайт |
| 4.2.1.1 | 4 | 60 | |
| 4.2.1.2 | 2 | 26 | |
| 4.2.1.3 | 3 | 18 | |
| 4.2.1.4 | 3 | 24 | |
| 4.2.1.5 | 4 | 52 |
Первоначально пакеты Novell инкапсулировались в кадры IEEE 802.3. В настоящее время схема инкапсуляции поддерживает 802.2 и протокол SNAP (Sub-Network Access Protocol).
Телекоммуникационные технологии. Том 1
Канал связи с изменяющимися состояниями
Как было указано выше, канал характеризуется условными распределениями З2, задающими вероятности тех или иных искажений посылаемого сигнала х1. Несколько изменим схему канала связи, считая, что имеется некоторое множество Z возможных состояний z канала связи, причем если канал находится в некотором состоянии z и на входе возникает сигнал x1, то независимо от других предшествующих обстоятельств канал переходит в другое состояние z1. Этот переход подвержен случайностям и описывается условными распределениями P(C|x1, z) (P(C|x1, z) - вероятность того, что новое состояние z1 будет входить в множество C М Z). При этом уже считается, что выходной сигнал х2 однозначно определяется состоянием канала z1, т.е. существует некоторая функция j = j (z) на пространстве z возможных состояний канала такая, что х2= j (z1). Эта более общая схема позволяет учитывать те изменения, которые в принципе могут возникать в канале по мере его работы.Рассмотрим стационарный режим работы канала связи. Предположим, что последовательно передаваемые сигналы
…., x 1(-1), x 1(0), x 1(1),…, соответствующие состояниям канала …, z (-1), z (0), z (1),…, и определяемые ими сигналы
…, x 2(-1), x 2(0), x 2(1),…, на выходе образуют стационарные и стационарно связанные случайные последовательности. Величина С=supI(x 1,x 2), где I(x 1,x 2), означает скорость передачи информации о стационарной последовательности {x1(n)} последовательностью {x 2(n)} и верхняя грань берется по всем допустимым распределениям вероятностей входной последовательности {x1(n)}, называется пропускной способностью канала связи.
Предположим, что поступающие на вход канала связи сообщения {x 0(n)}, n =…, -1, 0, 1 ,…, образуют случайную последовательность. Будем считать правило кодирования заданным, если при всех k, m и k1,…, km і k определены условные вероятности
P{x 1(k1) О B1,…, x 1 (km)О Bm|x 0(-Ґ ,k)}
Того, что при поступлении последовательности сообщений
x 0(-Ґ ,k) = …, x 0(k-1), x 0(k)
на соответствующих местах будут переданы сигналы x 1(k1),…, x 1(km), входящие в указанные множества B1, …, Bm.
Эти вероятности считаются стационарными в том смысле, что они не меняются при одновременной замене индексов k и k1,…,km на k+l и k1+l,…,km+l при любом целом l. Аналогичными вероятностями p{ x 3(k1) О D1,…, x 3(km) О Dm|x 2(-Ґ ,k)} задается правило декодирования.
Определим величину H формулой H = inf I( x 0,x 3), где I(x 0, x 3) - скорость передачи информации о стационарной последовательности {x0(n)} последовательностью {x3(n)}, n = …, -1, 0, 1,… (эти последовательности предполагаются стационарно связанными), и нижняя грань берется по всем допустимым распределениям вероятностей, удовлетворяющим требованиям точности передачи {x0(n)} ® { x3(n)}.
Неравенство H Ј C является необходимым условием возможности передачи
{x 0(n)} ® {x 1(n)} ® {x 2(n)} ® {x 3(n)}.
Напомним, что каждое сообщение x0(n) представляет собой некоторый элемент х0 из совокупности Х0. Можно интерпретировать Х0 как некоторый алфавит, состоящий из символов х0. Предположим, что этот алфавит Х0 является конечным и требование точности передачи состоит в безошибочном воспроизведении передаваемых символов:
P{x 3(k) = x 3(k)} =1 для любого целого k.
Предположим также, что имеется лишь конечное число входных сигналов х1 и состояний канала z. Обозначим состояния канала целыми числами 1, 2, …, N, и пусть p(k, x1,j) - соответствующие вероятности перехода из состояния k в состояние j при входном сигнале x1:
p(k,x1,j) = P{z (x+1) = j|z (n)=k, x 1(n+1)=x1}.
Дополнительно предположим, что любые произведения вида
p(k0,x1(1),k1)p(k1,x1(2),k2)… p(kn-1,x1(n),kn)
являются стохастическими матрицами, задающими эргодические цепи Маркова. Это условие будет выполнено, если, например, каждая из переходных матриц {p(k,x1,j)} имеет положительный коэффициент эргодичности. Тогда при выполнении неравенства H
Пусть x 1 = {x (t), t О T1} и x 2= {x (t), t О T2} - два семейства случайных величин, имеющих совместное гауссово распределение вероятностей, и пусть H1 и H2 - замкнутые линейные оболочки величин x (t), t О T1, и x (t), t О T2, в гильбертовом пространстве L2 (W). Обозначим буквами P1 и P2 операторы проектирования на пространства H1 и H2 и положим P(1) = P1P2P1, P(2) = P2P1P2. Количество информации I(x1,x 2) о семействе величин x1, содержащееся в семействе x2, конечно тогда и только тогда, когда один из операторов P(1) или P(2) представляет собой ядерный оператор, т.е. последовательность l 1, l 2,… его собственных значений (все они неотрицательны) удовлетворяет условию
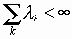 . При этом
. При этом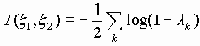 .
.В случае, когда x 1 и x 2 образованы конечным числом гауссовых величин:
x1={x (1),…, x (m)}, x 2 = {x (m+1),…, x (m+n)}, причем корреляционная матрица B общей совокупности x (1),…, x (m+n) является невырожденной, количество информации I(x 1, x 2) может быть выражено следующей формулой:
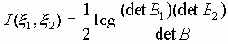 ,
,где B1 и B2 - корреляционные матрицы соответствующих совокупностей x 1 и x 2.
Гауссовы распределения обладают следующим экстремальным свойством. Для произвольных распределений вероятностей величин
x 1 = {x (1), …, x (m)} и x 2 = {x (m+1), …, x (m+n)}
с соответствующими корреляционными матрицами B1, B2 и B количество информации I(x 1, x 2) удовлетворяет неравенству

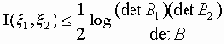
Пусть x = (x 1,…,x n) и h = (h 1,…,hn) - векторные случайные величины в n-мерном евклидовом пространстве X и r(x,y) - некоторая неотрицательная функция, определяющая условие близости величин x и h, которое выражается следующим соотношением:
Mr(x ,h ) Ј e .
Величину H=He, определенную как He = inf I(x, h), обычно называют e-энтропией случайной величины x (нижняя грань берется по всем случайным величинам h, удовлетворяющим указанному условию e-близости случайной величине x).
Пусть r(x,y) = r(|x-y|) и существует производная r’(0), 0< r’(0)<Ґ. Тогда при e ® 0 имеет место асимптотическая формула, в которой логарифмы берутся по основанию e:
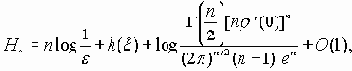
где g() - гамма функция и h(x) - дифференциальная энтропия случайной величины x:
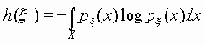
(px(x) - плотность распределения вероятностей, удовлетворяющая весьма широким условиям, которые выполняются, например, если плотность px(x) ограничена и h(x ) > -Ґ ).
Пусть
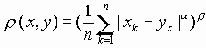 (a, b > 0)
(a, b > 0)Тогда

В частности, при a =2, b =1 имеет место асимптотическая формула
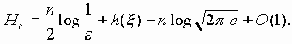
Пусть пара случайных процессов (x 1(t), x 2(t)) образует стационарный в узком смысле процесс, x [u,v] - совокупность значений x (t), u Ј t Ј v, и пусть
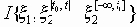 - условное количество информации о процессе x1=
- условное количество информации о процессе x1=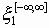 , содержащееся в отрезке
, содержащееся в отрезке 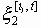 процесса x2. Среднее количество указанной информации представляет собой линейно растущую функцию от t:
процесса x2. Среднее количество указанной информации представляет собой линейно растущую функцию от t: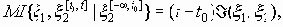
Фигурирующая здесь величина I(x1, x2) называется средней скоростью передачи информации стационарным процессом x2 о стационарном процессе x1 или просто - скоростью передачи информации.
Скорость передачи информации I(x1,x2) обладает рядом свойств, аналогичных свойствам количества информации. Но она имеет и специфические свойства. Так для всякого сингулярного случайного процесса x 2, т.е. такого процесса, все значения x 2(t) которого являются функциями от совокупности величин
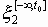 (t0 может быть выбрано любым), имеет место равенство I(x 1, x 2)=0.
(t0 может быть выбрано любым), имеет место равенство I(x 1, x 2)=0.Для всякого регулярного случайного процесса x 2 равенство I(x1,x2)=0 справедливо лишь тогда, когда случайный процесс x 1 не зависит от процесса x2 (это говорит о том, что в некоторых случаях I(x1,x2) № I(x 2,x 1) ).
При дополнительных условиях типа регулярности скорость передачи информации I(x 1,x 2) совпадает с пределом
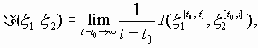 ,
,где
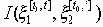 - количество информации об отрезке процесса
- количество информации об отрезке процесса 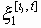 , заключенное в
, заключенное в 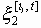 . Так будет, например тогда, когда время меняется дискретно, а отдельные величины x1(t) и x2(t) могут принимать лишь конечное число различных значений или когда распределение вероятностей процессов x1 и x2 является гауссовым. В случае непрерывного времени t так будет для гауссовых процессов, когда спектральная плотность f(l) процесса x2(t) удовлетворяет условию
. Так будет, например тогда, когда время меняется дискретно, а отдельные величины x1(t) и x2(t) могут принимать лишь конечное число различных значений или когда распределение вероятностей процессов x1 и x2 является гауссовым. В случае непрерывного времени t так будет для гауссовых процессов, когда спектральная плотность f(l) процесса x2(t) удовлетворяет условию0< c Ј l 2nf(l ) Ј c < Ґ
Пусть стационарный процесс x = x (t) представляет собой последовательность величин, каждая из которых принимает значения из некоторого алфавита x, состоящего из конечного числа символов x1, x2,…,xn. Предположим, что вероятность появления на фиксированном месте определенного символа xi есть pi, а вероятность появиться за ним символу xj не зависит от предшествующих xi значений и есть pij:
P{x (t) = xi} = pi, P{x(t+1) = xi xi|x(t) = xi, x(t-1),…, } = pij
Другими словами x = x (t) - стационарная цепь Маркова с переходными вероятностями {pij} и стационарным распределением {pi}. Тогда скорость передачи информации стационарным процессом x(t) будет
I(x,x) = -
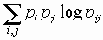
В частности, если x = x(t) - последовательность независимых величин (в случае pij = pj), то
I(x,x) = -
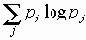
Пусть x1 = x1(t) и x2 = x2(t) - стационарные гауссовы процессы со спектральными плотностями f11(l), f22(l) и взаимной спектральной плотностью f12(l) причем процесс x2 = x2(t) является регулярным. Тогда
I(x1, x2) = -
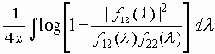
Рассмотрим следующее условие близости гауссовых стационарных процессов x1(t) и x2(t):
M|x1(t) - x2(t)|2 Јd2
Наименьшая скорость передачи информации
H = infI(x1,x2), совместимая с указанным условием “d-точности”, выражается следующей формулой:
 где
где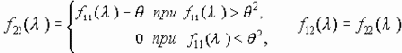 ,
,а параметр q2 определяется из равенства
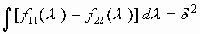 .
.Эта формула показывает, какого типа спектральная плотность f22(l) должна быть у регулярного стационарного процесса x 2(t), который несет минимальную информацию I (x1,x 2) » H о процессе x1(t). В случае дискретного времени, когда f11(l ) і q 2 при всех l , -p Ј l Ј p, нижняя грань H скорости передачи достигается для такого процесса x 2 (t) (со спектральной плотностью f22(l), задаваемой приведенной выше формулой), который связан с процессом x 1(t) формулой
x 2(t) = x 1(t) + z(t), где z(t) - стационарный гауссов шум, не зависящий от процесса x 2(t); в общем случае формула f22(l) задает предельный вид соответствующей спектральной плотности регулярного процесса x 2(t).
В случае, когда спектральная плотность f11(l) приближенно выражается формулой
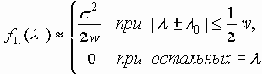
соответствующая минимальная скорость передачи информации H может быть вычислена по приближенной формуле
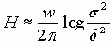 , s2 = M[x(t)]2.
, s2 = M[x(t)]2.2.10.3. Симметричный канал без памяти
Рассмотрим симметричный канал передачи данных без памяти c конечным числом входных сигналов х1, когда передаваемый сигнал х1 с вероятностью 1-p правильно принимается на выходе канала связи, а с вероятностью p искажается, причем все возможные искажения равновероятны: вероятность того, что на выходе будет сигнал х2, равна
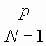 для любого х2 № x1, где N - общее число сигналов. Для такого канала связи пропускная способность
для любого х2 № x1, где N - общее число сигналов. Для такого канала связи пропускная способность c = supI( x1,x2) достигается в случае, когда на вход поступает последовательность независимых и равномерно распределенных сигналов …, x 1(-1), x 1(0), x 1(1),…; эта пропускная способность выражается формулой
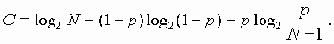
Рассмотрим канал связи, на входе которого сигналы образуют стационарный процесс x 1 = x1(t), M[x 1(t)]2 < Ґ.
Пусть при прохождении сигнала x 1 = x 1(t) он подвергается линейному преобразованию Aj со спектральной характеристикой j (l) и, кроме того, на него накладывается аддитивный стационарный гауссов шум z =z (t), так что на выходе канала имеется случайный процесс x 2(t) вида x 2(t) = aj x 1(t) + z (t).
Предположим также, что ограничения на входной процесс состоит в том, что M[x 1(t)]2 Ј D 2 (постоянная D2 ограничивает среднюю энергию входного сигнала). Пропускная способность такого канала может быть вычислена по формуле

(в последнем выражении интегрирование ведется в пределах -p Ј l Ј p для дискретного времени t и в пределах -Ґ
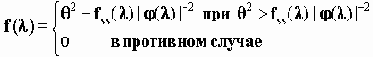
а параметр q2 определяется из равенства
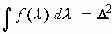
Нужно сказать, что если функция f(l) представляет собой спектральную плотность регулярного стационарного гауссова процесса x 1(t), то этот процесс, рассматриваемый как входной сигнал, обеспечивает максимальную скорость передачи информации: I(x 1,x 2) = C. Однако в наиболее интересных случаях, когда время t меняется непрерывно, функция f(l) обращается в нуль на тех интервалах частот l, где уровень шума сравнительно высок (отличные от нуля значения f(l) сосредоточены в основном на тех интервалах частот l, где уровень шума сравнительно мал), и поэтому не может служить спектральной плотностью регулярного процесса.
Более того, если в качестве входного сигнала выбрать процесс x 1(t) с спектральной плотностью f(l), то этот сигнал будет сингулярным и соответствующая скорость передачи информации I(x 1,x2) будет равна нулю, а не максимально возможному значению C, указанному выше.
Тем не менее, приведенные выражения полезны, так как позволяют приблизительно представить вид спектральной плотности f(l) регулярного входного сигнала x 1(t), обеспечивающей скорость передачи I(x1, x2), близкую к максимальному значению C. С практической точки зрения наиболее интересен случай, когда канал связи имеет ограниченную полосу w пропускаемых частот, т.е. когда спектральная характеристика выражается формулой
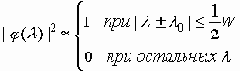
а проходящий через канал шум имеет равномерный спектр:
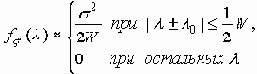
В этом случае пропускная способность может быть вычислена по приближенной формуле
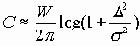 .
.При этом входной сигнал x1(t), обеспечивающий скорость передачи информации I(x1, x2), близкую к максимальной, является гауссовым стационарным процессом со спектральной плотностью f(l) вида
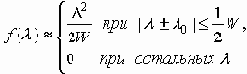
так что параметры D2 и s2 имеют следующий физический смысл:
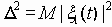 - энергетический уровень входного сигнала,
- энергетический уровень входного сигнала,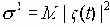 - энергетический уровень шума.
- энергетический уровень шума.Преобразование, кодировка и передача информации
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ruДля передачи информации на большие расстояния в настоящее время используются исключительно электромагнитные волны (акустические волны пригодны лишь для ограниченных расстояний). При этом пересылка может осуществляться по медным проводам, оптоволоконному кабелю или непосредственно, по схеме передатчик-приемник. В последнем случае используются антенны. Для того чтобы антенна была эффективна, ее размеры должны быть сравнимы с длиной передаваемой волны. Чем шире динамический диапазон передаваемых частот, тем труднее сделать антенну, пригодную для решения этой задачи. Именно по этой причине для передачи используются частоты, начиная с многих сотен килогерц и выше (длина волн сотни метров и меньше). Передача сигнала непосредственно по лучу лазера ограничена расстояниями 100-3000м и становится неустойчивой при наличии осадков даже для инфракрасных длин волн. Между тем человек воспринимает акустические колебания в диапазоне 20-12000 Гц и для целей пересылки звука (например, телефония) требуется именно этот диапазон частот. Динамический диапазон частот в этом случае равен 600, а для высококачественного воспроизведения звука он в два раза шире. При решении этой проблемы используется преобразование частот и различные методы модуляции. Так тот же частотный диапазон, лежащий в пределах (100 - 100,012) Мгц, соответствует динамическому диапазону 0,012%, что позволяет сделать компактную антенну и упростить частотное выделение сигнала.
Для преобразования частот используется перемножение сигналов. Пусть мы имеем два синусоидальных сигнала: A1*sin(w1 t) и A2*sin( w2t). Из тригонометрии известно, что:
A1*sin( w1t)*A2*sin( w2 t)=1/2*A1*A2*[sin( w1+w2)t + sin( w1-w2)t]. [1.1]
Это означает, что в результате перемножения вместо двух частот f1=w1/2p и f2= w2/2p мы имеем две новые частоты (w1+w2)/2p и (w1-w2)/2p с амплитудой 1/2*A1*A2. Если входной сигнал имеет полосу 0 - fм, то после перемножения с сигналом, имеющим частоту fн (несущая частота), получим сигнал с полосой в интервале от (fн - fм) до (fн+ fм).
Это преобразование проиллюстрировано на рис. 2.1. (по вертикальной оси отложена спектральная плотность сигнала f(jw )). На практике это преобразование выполняется с помощью смесителей или гетеродинов, частота fн называется сигналом гетеродина или несущей.
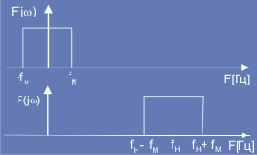
Рис. 2.1. Частотное преобразование
Получение исходного сигнала из преобразованного достигается путем обратного преобразования, которое сводится к умножению полученного сигнала на sin(wнt), где wн = 2 p*fн. При таком обратном преобразовании мы получим сигнал с исходным частотным диапазоном. Помимо этого будет получен сигнал с полосой от (2fн - fм) до (2fн+ fм). Так как fн обычно много больше fм, серьезных проблем это не вызывает - достаточно воспользоваться соответствующим фильтром. Этому методу обратного преобразования присущи некоторые недостатки. Если сигнал fн имеет фазовый сдвиг q по отношению к тому, что имел сигнал, использованный при прямом преобразовании, то амплитуда выходного сигнала будет пропорциональна cosq. Понятно, что при вариации фазы амплитуда будет меняться, а при q=p/2 станет нулевой. По этой причине должны быть предприняты специальные меры для синхронизации этих сигналов (fн. передатчика и fн приемника).
Соотношение [1.1] используется при реализации амплитудной, частотной или фазовой модуляции. Так в случае амплитудной модуляции при временной вариации A1 (=Авх) будет изменяться и амплитуда выходного сигнала (А2=Aн - амплитуда несущей частоты при этом остается постоянной; w1=w н при этом может также варьироваться). Форма сигнала на выходе такого преобразователя имеет вид: Авых = Ан[1+Авх(t)] sin wнt. Для получения формы исходного сигнала на принимающей стороне используется схема детектора (например, диодного), на выходе которого получается сигнал, пропорциональный модулю огибающей функции входного сигнала. Существуют и другие методы демодуляции амплитудно-модулированного сигнала. Главным недостатком метода амплитудной модуляции является возможность нелинейных искажений из-за перемодуляции (когда амплитуда модулирующего сигнала слишком велика).
При частотной и фазовой модуляции амплитуда передаваемого сигнала остается почти постоянной, что исключает нелинейные искажения, связанные с широким динамическим амплитудным диапазоном. Выходной сигнал для этого вида модуляции имеет вид: Авых = Ан sin[wнt + q(t)], где q(t) зависит от формы преобразуемого входного сигнала. Часто используется комбинация амплитудной и фазовой модуляции, которая носит название квадратурной модуляции.
Системы передачи данных с амплитудной или частотной модуляцией являются аналоговыми системами и по этой причине весьма чувствительны к шумам на входе приемника. Применение цифровых методов пересылки информации увеличивает вероятность корректной доставки. Если для аналоговой передачи требуется отношение сигнал/шум на уровне 40-60 дБ, то при цифровой передаче достаточно 10-12 дБ. Выбор типа модуляции зависит от стоящей задачи и от характеристик канала (полосы пропускания, ослабления сигнала и т.д.). Частотная модуляция менее чувствительна к амплитудным флуктуациям сигнала. Ослабление сигнала может варьироваться во времени из-за изменений в транспортной среде, это довольно типично для коммутируемых телефонных сетей. В сетях, использующих выделенные каналы, это также возможно благодаря применению динамических протоколов маршрутизации, когда длина пути может изменяться в пределах одного сеанса связи. В любом случае на передающей стороне необходим модулятор, а на принимающей демодулятор. Так как обмен обычно двунаправлен, эти устройства объединяются в одном приборе, который называется модемом (см. также раздел “4.3.7. ").
В модемах применимы несколько видов модуляции:
| FSK | (Frequency Shift Keying) - ступенчатое переключение частоты синусоидального сигнала от f1 к f2 при неизменной амплитуде, частоте f1 ставится в соответствие логический нуль, а f2 - логическая единица. |
| BPSK | (Binary Phase-Shift Keying) - скачкообразное переключение фазы синусоидального сигнала на p при неизменной амплитуде, при этом фазе 0 ставится в соответствие логический нуль, а p- логическая единица. |
| DPSK | (Differential Phase Shift Keying) - метод, при котором изменяется фаза несущей частоты при постоянной амплитуде и частоте. Разновидность PSK, при которой кодируется лишь изменение сигнала. |
| QAM | (Quadrature Amplitude Modulation) - комбинация амплитудной и фазовой модуляции, позволяет осуществить кодирование 8 бит на бод. |
| QPSK | (Quadrature Phase-Shift Keying) - квадратурная фазовая модуляция. Использует 4 фиксированных значения фазы 0, p/2, p и 3p/2. Требует в два раза более узкую полосу, чем PSK, и по этой причине весьма популярна. |
TCM | (Trellis Coded Modulation) - метод предполагает использование избыточности, каждый бод несет дополнительный бит, который позволяет более точно восстановить информационную битовую последовательность. При кодировании сигнала используется метод QAM. Метод реализован в современных высокоскоростных модемах и позволяет снизить требования к отношению сигнал/шум на 4-5 дБ. |

Рис. 2.2. QAM-модуляция с 3 битами на бод (слева) и 4 битами на бод (справа)
Статистическая теория каналов связи
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ruДанная статья имеет целью познакомить с терминологией и математическими основами статистической теории передачи данных. Именно на этой математической основе зиждятся приведенные выше теоремы Шеннона и Найквиста. Статья является компиляцией из нескольких источников (Ю.В.Прохоров, Ю.А.Розанов "Теория вероятностей. Основные понятия, предельные теоремы, случайные процессы" Наука, М. 1967; Л.Ф. Куликовский, В.В.Мотов, "Теоретические основы информационных процессов", Высшая школа, 1987; Р. Галлагер "Теория информации и надежная связь" Советское радио, 1974 и др.). Материалы, предлагаемые здесь не могут считаться исчерпывающими и призваны быть поводом для более углубленного изучения по существующим монографиям.
Канал связи предназначен для транспортировки сообщений. Математическая модель канала связи описывается некоторой совокупностью Х1 элементов х1 (X1 = {x11, x12,, …x1j}), называемых сигналами на входе канала, совокупностью Х2 элементов х2 (x2 = {x21, x22,, …x2k}), называемых выходными сигналами, и условными распределениями вероятностей p2=p2(a2 |x1) в пространстве x2 выходных сигналов x2. Если посланный сигнал (сигнал на входе) есть х1, то с вероятностью P2=P2(A2|x1) на выходе канала будет принят сигнал х2 из некоторого множества A2 М Х2 (распределения задают вероятности того или иного искажения посланного сигнала х1). Совокупность всех возможных сообщений обозначим символом x0. Предполагается, что каждое из сообщений x0О X0 может поступать с определенной вероятностью. То есть, в пространстве X0 имеется определенное распределение вероятностей P0=P0(A0 ).
Сообщения х0 не могут быть переданы по каналу связи непосредственно, для их пересылки используются сигналы x1О X1. Кодирование сообщений х0 в сигналы х1 описывается при помощи условного распределения вероятностей P1=P1(A1 |x0). Если поступает сообщение х0, то с вероятностью P1=P1(A1|x0) будет послан один из сигналов х1, входящих в множество A1 М Х1 (условные распределения P1(A1|x0) учитывают возможные искажения при кодировании сообщений).
Аналогичным образом описывается декодирование принимаемых сигналов х2 в сообщения x3. Оно задается условным распределением вероятностей P3=P3(A3|x2) на пространстве Х3 сообщений х3, принимаемых на выходе канала связи.
На вход канала связи поступает случайное сообщение x0 с заданным распределением вероятностей P0=P0(A0). При его поступлении передается сигнал x1, распределение вероятностей которого задается правилом кодирования P1=P1(A1|x0):
P{x2 О A2|x0, x1} = P2(A2|x1)
Принятый сигнал x2 декодируется, в результате чего получается сообщение x3:
P{x3 О A3|x0, x1, x2} = P3(A3| x2)
Последовательность x0 ® x1 ® x 2 ® x3 является марковской. При любых правилах кодирования и декодирования описанного типа имеет место неравенство:
I(x0,x3) Ј I(x1, x2),
где I(x0, x3) - количество информации о x0 в принятом сообщении x3, I(x1, x2) - количество информации о x1 в принятом сигнале x2.
Предположим, что распределение вероятности входного сигнала x1 не может быть произвольным и ограничено определенными требованиями, например, оно должно принадлежать классу W. Величина C = sup I(( x1 , x2) , где верхняя грань берется по всем возможным распределениям P1 О W, называется емкостью канала и характеризует максимальное количество информации, которое может быть передано по данному каналу связи (теорема Шеннона).
Предположим далее, что передача сообщений x0 ® x3 должна удовлетворять определенным требованиям точности, например, совместное распределение вероятностей Px0 x1 передаваемого и принимаемого сообщений x0 и x3 должно принадлежать некоторому классу V. Величина H= inf I( x0 x3), где нижняя грань берется по всем возможным распределениям Px0 x3 О V, характеризует минимальное количество информации, которое должно заключать в себе принимаемое сообщение x3 о x0, чтобы было выполнено условие точности передачи. Величина H называется энтропией источника сообщений.
Если возможна передача x0 ® x1 ® x2 ® x3 с соблюдением требований V и W, то есть существуют соответствующие способы кодирования и декодирования (существуют условные распределения P1, P2 и P3), то H Ј С.
Для выполнения этого неравенства передача является возможной, т.е. возможна передача последовательно поступающих сообщений
Предположим, что совокупность Х0 всех возможных сообщений х0 является дискретной (имеется не более чем счетное число различных сообщений x0, поступающих с соответствующими вероятностями P0(x0), x0 О X0) и условие точности передачи v состоит в том, что принимаемое сообщение x3 должно просто совпадать с переданным сообщением x3 = x0 с вероятностью 1. Тогда
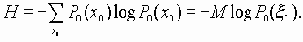
Предположим далее, что имеется лишь конечное число N различных входных сигналов х1 и нет никаких ограничений на вероятности P{ x1 = x1}, x1 О X1. Кроме того, предположим, что передаваемые сигналы принимаются без искажений, то есть с вероятностью 1 x2= x1. Тогда емкость канала выражается формулой C = log2N, т.е. передаваемое количество информации I(x1, x 2 ) будет максимальным в том случае, когда сигналы x1 О X1 равновероятны.
Если сообщения
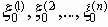 поступают независимо друг от друга, то количество информации, которое несет группа сообщений
поступают независимо друг от друга, то количество информации, которое несет группа сообщений 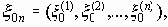 есть
есть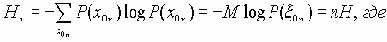
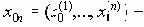 группа сообщений, поступающая на кодирование с вероятностью
группа сообщений, поступающая на кодирование с вероятностью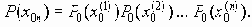
Пусть H
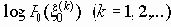
с математическим ожиданием
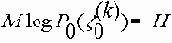
для любого e >0 найдется такое n(e), что при всех n і n(e )
P{-H-d Ј (1/n)logP( x 0n) Ј H+d } і 1-e, где

Полученное неравенство говорит о том, что все группы сообщений х0n можно разбить на два класса. К первому классу
 относятся высоковероятные сообщения х0n, для которых P(x0n) і 2-n(H+d ) и количество которых Mn не больше чем 2n(H+d ):
относятся высоковероятные сообщения х0n, для которых P(x0n) і 2-n(H+d ) и количество которых Mn не больше чем 2n(H+d ):Mn Ј 2n(H+d )
Ко второму классу
 относятся все остальные маловероятные сообщения х0n:
относятся все остальные маловероятные сообщения х0n: 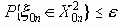 .
.Каждую группу высоковероятных сообщений х0n можно в принципе передать, закодировав ее соответствующей комбинацией сигналов
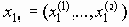 . Число всевозможных комбинаций такого вида есть Nn=2nC, и видно, что Mn
. Число всевозможных комбинаций такого вида есть Nn=2nC, и видно, что Mn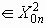 передавать некоторый один и тот же сигнал
передавать некоторый один и тот же сигнал  (отличный от сигналов, при помощи которых передаются высоковероятные сообщения x0n
(отличный от сигналов, при помощи которых передаются высоковероятные сообщения x0n 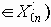 , то с вероятностью, не меньшей чем 1-e, на выходе канала связи будет приниматься последовательность
, то с вероятностью, не меньшей чем 1-e, на выходе канала связи будет приниматься последовательность 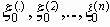 :
: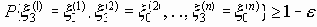 .
.При выполнении неравенства H < C оказывается возможной передача достаточно длинных сообщений
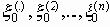 с той оговоркой, что с вероятностью e (e - наперед заданное сколь угодно малое положительное число) может быть допущена ошибка. Имеется целое семейство каналов связи и источников сообщений, зависящих от параметра n.
с той оговоркой, что с вероятностью e (e - наперед заданное сколь угодно малое положительное число) может быть допущена ошибка. Имеется целое семейство каналов связи и источников сообщений, зависящих от параметра n.Количество информации I(x0, x3) для абстрактных случайных величин x0 и x3 со значениями в пространствах Х0 и Х3 может быть записано в виде:
I(x0, x 3) = Mi(x0, x3), где
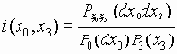
- информационная плотность. Последовательность пар (x0n, x3n) называется информационно устойчивой, если при n ® Ґ
I(x0, x3) ® Ґ и
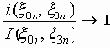
(по вероятности)
Рассмотренная выше последовательность (x0n, x3n), x3n= x0n поступающих сообщений x 0n =(
) обладает свойством информационной устойчивости, что в конечном счете и определило возможность передачи сообщений x 0n с точностью до e. Этот факт допускает широкое обобщение. Например, если Сn - пропускная способность канала x1n® x 2n, Hn - минимальное количество информации, необходимое для соблюдения требуемой точности передачи x0n ® x 3n, причем
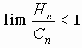
(при n ® Ґ ),
и существуют информационно устойчивые последовательности пар (x0n, x3n) и (x1n, x2n), для которых одновременно
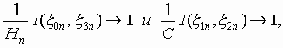
то при весьма широких предположениях для любого наперед заданного e >0 существует такое n(e), что по всем каналам связи с параметром n і n(e) возможна передача с точностью до e.
Телекоммуникационные технологии. Том 1
Адрес обратной связи
Уникастный адрес 0:0:0:0:0:0:0:1 называется адресом обратной связи. Он может использоваться для посылки IPv6 дейтограмм самому себе. Его нельзя использовать в качестве идентификатора интерфейса.Адрес обратной связи не должен применяться в качестве адреса отправителя в IPv6 дейтограммах, которые посылаются за пределы узла. IPv6 дейтограмма с адресом обратной связи в качестве адреса места назначения не может быть послана за пределы узла.
Алгоритм кластеризации
В исходном алгоритме DTS процедура выбора часов прерывается в данной точке с выбором кандидатов из центра области пересечения. Однако это ведет к заметной потере точности и стабильности, так как не учитываются индивидуальные статистические свойства партнеров. Следовательно, в NTP только кандидаты, которые остаются в результате описанного выше отбора, могут участвовать в последующей обработке. Список кандидатов преобразуется к форме [расстояние, индекс], где расстояние вычисляется на основе кода слоя и расстояния синхронизации l партнера. Масштабный коэффициент позволяет реализовать механизм весового учета вкладов от кодов слоя и расстояния. Обычно, код слоя доминирует, если только один или более кандидатов имеют слишком большие расстояния. Список упорядочивается согласно величине расстояния.m
| for (each peer) begin | /* обращение ко всем партнерам */ |
if (low ? q ? high) begin
| l | /* сформировать запись в списке */ |
dist l}
add [dist, peer] to candidate list;
m
endif;
endfor;
sort candidate list by increasing dist;
Последующие шаги служат для того, чтобы отсеять кандидатов со слишком большими дисперсиями. Практика показывает, что число кандидатов здесь может быть достаточно велико. Это может привести к большому числу циклов повторения процедуры отбора, которые не дадут какого-либо улучшения результатов. Длина списка кандидатов ограничивается переменной ntp.maxclock.
Заметим, что exi представляет собой дисперсию относительно i-го партнера из списка кандидатов, которая может быть вычислена методом дисперсии фильтра, описанным выше. ej - дисперсия j-ого партнера из списка, включающая в себя вклады от ошибок измерения, от накопления дрейфа и из-за дисперсии фильтра. Если максимальное значение exi больше чем минимальное значение ej, а число кандидатов больше чем ntp.minclock, i-ый партнер удаляется из списка и процедура повторяется. Если текущий источник синхронизации является одним из членов списка и нет других кандидатов из более низкого слоя, процедура прерывается, и никакие другие последующие шаги не предпринимаются.
В противном случае в качестве источника синхронизации берется первый кандидат из списка. В ниже приведенном тексте i, j, k, l - индексы партнеров, k - индекс текущего источника синхронизации (нуль, если такой источник отсутствует), l - индекс первого кандидата в списке.
while begin
| for (each survivor [distance, index]) begin | /* вычисление дисперсии */ |
find index j for min ej;
endfor
if (e{xi} ? ej or m ? NTP.MINCLOCK) break;
| peer.survivor [i] | /* отбрасывание i-го партнера */ |
delete the ith peer from the candidate list;
m
endwhile
if (peer.survivor [k] = 0 or peer.stratum [k] >> peer.stratum [l]) begin
sys.peer
call poll-update;
endif
end clock-select procedure;
Алгоритм сконструирован так, чтобы отдавать предпочтение партнерам из головной части списка, которые размещены в более низком слое, имеют наименьшее расстояние и могут обеспечить наибольшую точность и стабильность. С помощью правильного выбора весового коэффициента v (называемого ntp.select), можно удалить некоторые записи из финальной части списка.
Алгоритм пересечения
begin clock-selection procedureКаждый из партнеров просматривается последовательно и добавляется в конец списка, если он прошел ряд тестов. Для каждого из m кандидатов в список заносятся 3 записи в форме [указатель, тип]: [q - l, - 1], [q, 0] и [q + l, 1]. В результате в списке будет 3m записей, которые будут позднее упорядочены.
m
| for (each peer) | /*обращение ко всем партнерам */ |
if ({peer.reach ? 0 and peer.dispersion < ntp.maxdisperse} and not (peer.stratum > 1 И peer.refid = peer.hostaddr)) begin
l
| andistance (peer); | /* запись в список */ |
add [q - l, -1] to endpoint list;
add [q, 0] to endpoint list;
add [q + l, 1] to endpoint list;
m
endif
endfor
| if (m = 0) begin | /* уход, если кандидаты отсутствуют */ |
sys.peer
sys.stratum
exit;
endif
sort endpoint list by increasing endpointtype;
Ниже приведенный алгоритм представляет собой адаптированную версию DTS [DEC89] и сконструирован так, чтобы отбирать только истинных кандидатов. Алгоритм начинается с инициализации значения f и занесения нуля в счетчики i и c. Затем, начиная с конца упорядоченного, для каждой записи [указатель, тип] значение типа вычитается из кода счетчика i, который содержит число пересечений. Если код типа равен нулю, инкрементируется значение c, которое регистрирует число ложных кандидатов. Если для некоторых записей i і ? m - f, конец записи становится нижней границей пересечения; в противном случае, f увеличивается на 1 и процедура повторяется. Без сброса значений f или c, аналогичная процедура используется для нахождения верхней границы, за исключением того, что значение кода тип добавляется к счетчику. Если после того как обе границы определены c Ј f, процедура продолжается для найденных m - f кандидатов, в противном случае, f увеличивается на 1 и вся процедура повторяется.
| for (f from 0 to f ? m/2) begin | /* обращение ко всем кандидатам */ |
c
i
| for (each [endpoint, type] from lowest) begin | /* нахождение нижней границы */ |
i
low
if (i ? m - f) break;
if (type = 0) c
endfor;
i
| for (each [endpoint, type] from highest) begin | /* нахождение верхней границы */ |
high
if (i ? m - f) break;
if (type = 0 ) c
endfor;
| if (c ? f) break; | /* продолжить, пока не будут найдены все ложные кандидаты */ |
| if (low > high) begin | /* завершить, если не найдено ни одного пересечения */ |
exit;
endif;
Заметим, что работа продолжается далее данной точки, только если имеется более m/2 пересечений. Однако возможно, но не слишком вероятно, что в области пересечения окажется менее m/2 кандидатов.
Алгоритмы фильтрации и селекции
Наиболее важным фактором, влияющим на точность и надежность синхронизации, является набор алгоритмов, используемых для уменьшения статистических ошибок и искажений при сбоях в различных компонентах субсети. Алгоритмы, описанные в этой статье, не являются частью стандарта NTP, по этой причине допускается использование любых других алгоритмов.Для того чтобы NTP алгоритмы фильтрации и отбора работали эффективно, полезно иметь меру вариации для каждого из партнеров. Принятая мера вариации базируется на разностях первого порядка, которые легко вычислить. Существует две меры, одна называемая дисперсией фильтра es, и другая дисперсия выбора (select dispersion) ez. Обе меры вычисляются как взвешенные суммы смещений из списка, сформированного на основе расстояний синхронизации. Если qi (0Ј i < n) смещение i-ой записи, тогда разность eij i-ой записи по отношению к j-ой записи определяется как |qi - q j|. Дисперсия относительно j-ой записи определяется как
ej =
 ,
,где w - весовой коэффициент, который служит для учета влияния расстояния синхронизации на дисперсию. В алгоритмах NTP w выбирается меньше 1/2: w = ntp.filter для дисперсии фильтра (filter dispersion) и w = NTP.SELECT для дисперсии выбора (select dispersion).
Дисперсия es и ex определены относительно 0-ой записи e0.
Существует две процедуры, описанные ниже, процедура "часовой-фильтр" (clock-filter), которая используется для выбора лучших записей смещения для данных часов, и процедура "выбора часов" (clock-selection), которая используется, чтобы выбрать наилучшие часы среди иерархического набора часов.
Аннулирование (Teardown)
Сообщения RSVP "аннулирование" удаляет проход или состояние резервирования. Хотя прямое уничтожение старого резервирования не является обязательным, оно настоятельно рекомендуется, так как ускоряет переходные процессы в сети.Существует два типа RSVP сообщений аннулирования: PathTear и ResvTear. Сообщение PathTear направляется всем получателям и ликвидирует состояние прохода, а также все зависящие от него состояния резервирования. Сообщение ResvTear уничтожает состояние резервирования и направляется всем отправителям.
Запрос аннулирование (teardown) может посылаться приложением оконечной системы (получатель или отправитель), или маршрутизатором в результате таймаута или при появлении привилегированной задачи. После инициализации запрос-аннулирование должен переадресовываться от узла к узлу без задержки. Сообщение аннулирование уничтожает специфицированное состояние в узле-получателе.
Подобно другим сообщениям RSVP, запросы-аннулирования доставляются без гарантии надежности. Потеря такого запроса не вызовет катастрофы, так как не используемое состояние будет рано или поздно ликвидировано по таймауту. Если маршрутизатор не получил сообщения аннулирования, он ликвидирует соответствующее состояние по таймауту и формирует сообщение аннулирование, рассылаемое последующим узлам. Предполагая, что вероятность потери сообщения RSVP мала, наибольшее среднее время ликвидации ненужного состояния не превышает периода обновления.
Необходимо иметь возможность ликвидировать любой субнабор установленных состояний. Для состояний прохода минимально это может быть один отправитель. Для состояний резервирования таким объектом является спецификация фильтра. Например, в случае, показанном на рис. 4.4.9.6.7, получатель R1 может послать сообщение ResvTear только отправителю S2 (или любому субнабору из списка спецификаций фильтрации), оставляя S1 без изменений.
Сообщение ResvTear специфицирует стиль и фильтры, любая спецификация flowspec игнорируется. Любая рабочая спецификация flowspec будет убрана, если все ее спецификации фильтров будут ликвидированы.
Одной из наиболее сложных систем
4.4.13.2 Нотация ASN.1Семенов Ю.А. (ГНЦ ИТЭФ)
Одной из наиболее сложных систем сегодня являются открытые системы связи OSI (Open System Interconnection). OSI представляет собой достаточно формализованную стандартную архитектуру управления межкомпьютерными коммуникациями. Для описания этой системы была разработана абстрактный синтаксис нотаций ASN.1 (Abstract Syntax Notation; cм. A Layman’s Guide to a Subset of ASN.1, BER, and DER. Burton S. Kaliski Jr., RSA Data Security, Inc. Redwood City, CA, 1991). ASN.1 является формальным языком, который обладает двумя основными чертами.
ASN.1 представляет собой язык описания типов данных и их значений. В общем виде такое описание имеет вид:
data type value name | data type identifier ::= data value или {data type identifier (data value)}
Коме того, ASN.1 является языком программирования. Этот язык служит для описания MIB и может использоваться для модификации существующей или создания новой базы данных MIB для SNMP. Список наиболее распространенных ключевых слов ASN.1 для описания MIB SNMP включает в себя: BEGIN, IDENTIFIER, END, OCTETS, STRING, SEQUENCE, INTEGER, STRING, OBJECT,OF, NULL, DEFINITIONS DESCRIPTION
Объекты MIB создаются макросами ASN.1. Макрос OBJECT-TYPE имеет формат:
data type value name OBJECT-TYPE
SYNTAX data type identifier
UNITS
ACCESS
STATUS
DESCRIPTION
REFERENCE
INDEX
DEFVAL
::= {data value}
Используемая в документах нотация легко читаема и понимаема, а в компактном кодовом представлении информация может использоваться коммуникационными протоколами.
Неотъемлемой частью ASN. 1 являются базовые правила кодирования BER (Basic Encoding Rules), которые позволяют определить большое разнообразие типов данных. BER описывает то, как представить или закодировать любую величину в рамках стандарта ASN.1. чки вс е величины здесь представляются в виде последовательности 8-битных октетов. Восьмой бит октета всегда считается самым старшим. BER позволяет закодировать величину более чем одним способом. Имеется также поднабор правил кодирования DER (Distinguished Encoding Rules, описаны в документе Х.509), которые определяют однозначные способы кодирования величин ASN.1.
Ниже приведены базовые правила обозначений метасинтаксиса ASN.1.
| n | (полужирный курсив) обозначает переменную |
| [ ] | (квадратные скобки, напечатанные полужирным шрифтом) указывают на то, что терм является опционным. |
| { } | (фигурные скобки, напечатанные полужирным шрифтом) группируют родственные термы. |
| | | (вертикальная черта, напечатанная полужирным шрифтом) выделяет альтернативные значения. |
| … | (многоточие, напечатанное полужирным шрифтом) обозначает повторения. |
| = | (знак равенства, напечатанный полужирным шрифтом) описывает терм как субтерм. |
Все типы ASN.1 кроме CHOICE и ANY имеют метки, которые состоят из класса и неотрицательного кода метки. Типы ASN.1 тождественны, если их числовые метки совпадают. Существует четыре класса меток.
| universal | для типов, значения которых является неизменным для всех приложений. Эти типы определены в документе Х.208. |
| application | для типов со значением, специфическим для приложений, таких как служба каталогов Х.500. Типы двух разных приложений могут иметь одну и ту же метку и разные значения. |
| private | для типов, которые являются специфическими для данного предприятия. |
| content-specific | для типов со значением, специфическим для данного структурного типа. |
Ниже приведена таблица 4.4.13.2.1 типов и их меток универсального класса.
Таблица 4.4.13.2.1. Типы и их метки
| Тип | Комментарий | Цифровая метка (шестнадцатеричное) |
| INTEGER | Любое целое число | 02 |
| BIT STRING | Произвольная строка бит | 03 |
| OCTET STRING | Произвольная последовательность октетов | 04 |
| NULL | 0 | 05 |
| OBJECT IDENTIFIER | Последовательность целых компонент, идентифицирующих объект | 06 |
| SEQUENCE and SEQUENCE OF | 10 | |
| SET and SET OF | 11 | |
| PrintableString | Последовательность печатных символов | 13 |
| IA5String | Произвольная строка символов IA5 (ASCII) | 16 |
| UTCTime | Универсальное время (по Гринвичу; GMT) | 17 |
В SMI (Structure of Management Information) не используется полный набор типов объектов, предусмотренный в ASN.1, разрешены только следующие типы примитивов: INTEGER, OCTET STRING, OBJECT IDENTIFIER и NULL.
Стандарт ASN.1 определяет форму представления информации и имен. Для строчных типов может быть введено ограничение на максимальный размер. В ASN.1 определено четыре структурированных типов:
| SEQUENCE | упорядоченный набор из одного или более типов. |
| SEQUENCE OF | упорядоченный набор из нуля или более представителей данного типа. |
| SET | неупорядоченный набор из одного или более типов. |
| SET OF | неупорядоченный набор из нуля или более представителей данного типа. |
Существуют типы помеченные явно и неявно. Неявно помеченные типы получаются из других типов путем изменения метки. Для неявной пометки используется ключевое слово IMPLICIT.
Явно помеченные типы получаются из других типов путем добавления внешней метки. Помеченный явно тип - это структурированный тип, состоящий из одного компонента основного типа. Для явной пометки используется ключевое слово EXPLICIT. Пометка (тэгирование) весьма удобна для различия типов в пределах одного приложения.
Тип CHOICE обозначает объединение одного или более альтернатив. Тип ANY служит для обозначения произвольной величины для произвольного типа.
Правила BER определяют один или более способов представить любую величину в виде строки октетов. Существует три метода кодирования величин (в рамках BER): примитивный с известной длиной; конструктивный при известной длине и конструктивный при неизвестной длине. Выбор метода зависит от типа величины и от того, известна ли длина преобразуемой величины. Для простых не строчных типов используется примитивный метод кодирования. В каждом методе BER-кодирование имеет три или четыре части:
| Identifier octets | Определяет класс и числовую метку значения, а также указывает, является ли метод примитивным или конструктивным. |
| Length octets | Для методов кодирования с известной длиной определяет число октетов содержимого. |
| Contents octets | Для примитивных методов с заданной длиной дает конкретное выражение значения. |
| End-of-contents octets | Для конструктивных методов с неопределенной длиной указывает на конец содержимого. |
Этот метод применим для простых типов и типов полученных из простых типов путем неявной пометки. Здесь необходимо, чтобы длина величины была известна заранее. Октеты идентификатора имеют два формата: для числовых меток от 0 до 31, и для числовых меток более 31. В первом случае биты 7 и 8 определяют класс (см. таблицу 4.4.13.2.2), бит 6 равен нулю, указывая на то, что метод кодирования primitive. Остальные биты используются для записи кода числовой метки. Во втором случае используется два или более октетов. В первом октете кодировка аналогична первому варианту за исключением того, что биты 1-5 содержат единицы.
Таблица 4.4.13.2.2. Коды классов
| Класс | Бит 8 | Бит 7 |
| Универсальный | 0 | 0 |
| Прикладной | 0 | 1 |
| Контекстно-ориентированный | 1 | 0 |
| Частный | 1 | 1 |
Конструктивный метод с заданной длиной
Этот метод используется для простых строчных и структурированных типов, типов, производных от простых строчных типов, и некоторых других. Здесь октеты идентификатора и октеты длины имеют формат, идентичный используемому примитивным методом, за исключением того, что бит 6 первого октета идентификатора равен 1.
Конструктивный метод кодирования с незаданной длиной
Метод используется для простых строчных типов, структурированных типов и типов, полученных из простых и структурированных типов с помощью неявной пометки. Октеты идентификатора идентичны предшествующему. Октет длины содержит код 80. Два октета конца содержательной части содержат 00 00.
Нотация типов, помеченных неявно, имеет вид:
[[class] number] IMPLICIT Type
class = UNIVERSAL | APPLICATION | PRIVITE
где Type - тип, class - опционное имя класса и number - цифровая метка (неотрицательное целое число).
Если имя класса отсутствует, тогда метка является контекстно-ориентированной. Такие метки могут появляться только в структурных компонентах или в типе CHOICE. Например:
PrivateKeyInfo ::= SEQUENCE {
version Version,
privateKeyAlgorithm PrivateKeyAlgorithmIdentifier,
privateKey PrivateKey,
attributes [0] IMPLICIT Attributes OPTIONAL }
Здесь исходным (порождающим) типом является Attributes, класс отсутствует (т.е. контекстно-ориентированный), а числовая метка равна нулю. Кодирование компоненты attributes величины PrivateKeyInfo осуществляется следующим образом.
Октеты идентификатора равны 80, если значение порождающей величины Attributes имеет конструктивное BER-кодирование.
Октеты длины и содержимого строго соответствуют октетам порождающей величины Attributes.
Непосредственная (явная) пометка используется для опционных компонент SEQUENCE c порождающим типом ANY и для компонент version типа Certificate
(X.509 и RFC-1114). Нотация типов, помеченных явно, имеет формат.
[ [class] number] EXPLICIT Type
class = UNIVERSAL | APPLICATION | PRIVATE
где Type - тип, class - опционное имя класса, а number - числовая метка в пределах класса (неотрицательное целое число). Пример:
ContentInfo ::= SEQUENCE {
ContebtType ContentType,
Content [0] EXPLICIT ANY DEFINED BY contentType OPTIONAL }
Тип ContentInfo имеет опционную компоненту content с явной контекстно-ориентированной меткой. Здесь порождающим типом является ANY DEFINED BY contentType, класс отсутствует, а числовая метка в пределах класса равна 0.
Другим примером может являться тип Certificate [X.509], имеющий компоненту с явной контекстно-ориентированной меткой (ключевое слово EXPLICIT опущено).
Certificate ::= …
Version [0] Version DEFAULT v1988,
…
BER-кодирование величин, помеченных явно, является всегда конструктивным. Октеты содержимого идентичны соответствующим октетам порождающей величины. Например, BER-кодирование компоненты content величины ContentInfo имеет следующий вид.
Октеты идентификатора равны нулю, Октеты длины представляют длину BER-кодирования порождающей величины ANY DEFINED BY contentType.
Тип ANY
Тип ANY обозначает произвольную величину произвольного типа, где произвольный тип возможно определен при регистрации идентификатора объекта или является целочисленным индексом. Нотация типа ANY имеет формат:
ANY [DEINED BY identifier]
где identifier - опционный идентификатор. Форма ANY DEINED BY identifier может появиться только в компоненте типа SEQUNCE или SET, для которой identifier определяет какую-то другую компоненту и эта компонента имеет тип INTEGER или OBJECT IDENTIFIER. В этой форме истинный тип задается величиной этой другой компоненты. Например, тип AlgorithmIdentifier [X.509] имеет компоненту типа ANY:
AlgorithmIdentifier ::= SEQUENCE {
algorithm OBJECT IDENTIFIER,
parameter ANY DEFINED BY algorithm OPTIONAL }
Здесь истинный тип компоненты parameter зависит от величины компоненты algorithm. Истинный тип будет определен при регистрации объекта величины идентификатора длякомпоненты algorithm.
Битовые строки
Тип BIT STRING обозначает произвольные битовые последовательности произвольной длины (включая ноль). Тип BIT STRING используется для цифровых сигнатур типа ExtendedCertificate или Certificate [X.509]. Нотация BIT STRING имеет формат.
BIT STRING
Например, тип SubjectPublicKeyInfo имеет компоненту типа BIT STRING:
SubjectPublicKeyInfo ::= SEQUENCE {
Algorithm AlgorithmIdentifier,
PublicKey BIT STRING }
BER-кодирование величины BIT STRING может быть примитивным или конструктивным. При примитивном кодировании первый октет содержимого несет в себе длину битовой строки в октетах. В последующих октетах записывается сама битовая последовательность. Процедура кодирования может включать в себя дополнение битовой строки до целого числа октетов нулями (если это необходимо). Строка делится на октеты.
При конструктивном кодировании октеты содержимого представляют собой соединение последовательности субстрок, только последняя из которых содержит код длины, выраженный в октетах. Например, при BER-кодировании значения BIT STRING “0111 1101 1001 1111 11” может быть представлена в одном из следующих видов, в зависимости от выбора схемы дополнения до целого числа октетов, от формата октетов длины и от метода кодирования примитивный/конструктивный).
| 03 04 06 7D 9F C0 | DER-кодирование |
| 03 04 06 7D 9F E0 | Дополнение кодом “100000” |
| 03 81 04 06 7D 9F C0 | Длинная форма представления октетов длины |
| 23 09 03 03 00 7D 9F 03 02 06 C0 |
Конструктивное кодирование “01111101 1001 1111” +”11” |
Во втором байте третей строки записана 8, что указывает на длинную форму представления октетов длины. Последующая 1 говорит о том, что использован один дополнительный октет длины. Код длины в четвертом примере записан также во втором октете (далее следует 9 октетов). В этом варианте битовая строка разбита на две субстроки, первая из которых имеет длину в два октета. DER-кодирование предполагает всегда примитивный метод представления с дополнением строки нулями до длины, кратной целому числу октетов.
Тип CHOICE
Этот тип служит для объединения одной или более альтернатив. Нотация типа CHOICE имеет формат.
CHOICE {
[identifier1] Type1,
…,
[identifiern] Typen }
где identifier1, …, identifiern являются опционными идентификаторами альтернатив, а типы Type1, …, Typen - альтернативы. Идентификаторы нужны для документирования и не играют какой-либо роли при кодировании. Типы должны иметь определенные метки. Рассмотрим пример типа ExtendedCertificateOrCertificate, который относится к типу CHOICE.
ExtendedCertificateOrCertificate ::= CHOICE {
certificate Certificate, -- X.509 certificate
extendedCertificate [0] IMPLICIT ExtendedCertificate }
Здесь идентификаторами для альтернатив являются certificate и extendedCertificate, а сами альтернативы представлены типами Certificate и [0] IMPLICIT ExtendedCertificate. BER-кодирование для типа CHOICE сводится к кодированию альтернатив. При этом октеты идентификатора для рассмотренного примера содержат код 30, если выбранная альтернатива certificate, и A0 - в случае ExtendedCertificate.
Строки IA5
Тип IA5String представляет любые последовательности IA5-символов (международный алфавит 5 - эквивалентно ASCII). Длина строки может быть любой, включая нуль. Этот тип используется для адресов электронной почты и неструктурированных имен. Нотация типа IA5String имеет простой формат.
IA5String
BER-кодирование величины IA5String может быть примитивным или структурированным. При примитивном кодировании октеты содержимого представляют собой символы IA5 в ASCII-кодов.
При конструктивном кодировании октеты содержимого представляют собой соединение ряда IA5-субстрок. Рассмотрим примеры представления значения IA5-строки “test1@rsa.com”.
| 12 0D 74 65 73 74 31 40 72 73 61 2E 63 6F 6D | DER-кодирование |
| Длинная форма октетов длины | |
| 32 13 12 05 74 65 73 74 31 12 01 40 12 07 72 73 61 2E 63 6F 6D |
Конструктивное кодирование: “test1” + “@” + “rsa.com” |
Целое
Тип INTEGER представляет любые целые числа (положительные, отрицательные или 0). Тип INTEGER используется для номеров версий, криптографических параметров (показателей, модулей) и типов RSAPublicKey, RSAPrivatKey, DHParameter PBEParameter. Нотация типа INTEGER имеет формат:
INTEGER [{identifier1(value1) … identifiern(valuen) }]
где identifier1 … identifiern являются опционными идентификаторами, а value1… valuen опционные целые значения. Например, Version RFC-1114 относится к целому типу со значением:
Version ::= INTEGER { 1988(0) }
Идентификатору v1988 поставлено в соответствие значение 0. Тип Certificate RFC-1114 использует идентификатор v1988для присвоения значения по умолчанию компоненту version:
Certificate
version Version DEFAULT v1988,
…
BER-кодирование значения INTEGER является всегда примитивным. Октеты содержимого представляют значение целого по модулю 256 в форме дополнения по модулю 2. Старшая цифра является первой. Значение нуль кодируется одним октетом 00. Примеры BER-кодирования (совпадающего в данном случае с DER-кодированием) представлены в таблице 4.4.13.2.3.
Таблица 4.4.13.2.3. Примеры BER-кодирования
| Значение целого | BER-код |
| 0 | 02 01 00 |
| 127 | 02 02 00 7F |
| 128 | 02 02 00 80 |
| 256 | 02 02 01 00 |
| -128 | 02 01 80 |
| -129 | 02 02 FF 7F |
Тип NULL обозначает нулевую величину и предназначен для использования в качестве параметра алгоритмов. Нотация для типа NULL имеет формат:
NULL
Кодирование для типа NULL является всегда примитивным, октеты содержимого пусты.
Например, BER- представление значения NULL может иметь одну из приведенных ниже форм (зависит от используемого представления октетов длины).
05 00
05 81 00
DER-кодирование типа NULL является также примитивным и совпадает с первой строкой приведенного выше примера.
Объектные идентификаторы
Тип OBJECT IDENTIFIER служит для обозначения дентификаторов, которые представляют собой последовательность целочисленных компонент, которые идентифицируют такие объекты, как алгоритм или атрибут имени каталога. Значение OBJECT IDENTIFIER может содержать любое число неотрицательных компонент. Этот тип не относится в числу строчных. Значения OBJECT IDENTIFIER присваиваются при регистрации.
Тип OBJECT IDENTIFIER используется для идентификации содержимого ContentInfo, алгоритмов в X.509 (AlgorithmIdentifier) и атрибутов Attribute и AttributeValueAssertion (X.501). Нотация OBJECT IDENTIFIER имеет формат.
OBJECT IDENTIFIER
Нотация величины OBJECT IDENTIFIER имеет вид:
{ [identifier] component1… componentn}
componenti = identifieri | identifieri (valuei) | valuei
где identifier, identifier1, … identifiern являются идентификаторами, а value1 …, valuen - опционные целые числа. Идентификаторы без целых значений могут встретиться только для объектов, описанных в Х.208.
Например, нижеприведенные величины объектных идентификаторов присвоены RSA DATA Security, Inc.
{ iso(1) member-body(2) 840 113549 }
{ 1 2 840 113549 }
В таблице 4.4.13.2.4 представлены некоторые объектные идентификаторы и их значения.
Таблица 4.4.13.2.4. Некоторые объектные идентификаторы и их значения
| Величина объектного идентификатора | Назначение |
| { 1 2 } | Члены ISO |
| { 1 2 840 } | US (ANSI) |
| { 1 2 840 113549} | RSA Data Security, Inc. |
| { 1 2 840 113549 } | RSA Data Security, Inc. PKCS (Public Key Cryptography Standard) |
| { 2 5 } | Служба каталогов (X.500) |
| { 2 5 8 } | Служба каталогов - алгоритмы |
Каждая октетная строка несет в себе целое число по модулю 128 (старшая часть первая). 8-ой бит каждого октета, кроме последнего, равен 1. Пусть value1, …, valuen целые значения компонентов объектного идентификатора. Тогда n-1 субидентификаторов, из которых формируется октетная строка, будут иметь следующий вид.
+ value2. (значение value1 лежит в пределах 0-2 включительно, а value2 в интервале 0-39, когда value1 равна 0 или 1.
Например, субидентификаторы объектного идентификатора RSA Data Security, Inc. равны 42 = 40ґ 1 + 2, 840, 113549 и 1. В шестнадцатеричном представлении BER-код этого объектного идентификатора имеет вид:
06 07 2A 86 48 86 F7 0D 01
DER-кодирование в данном случае совпадает с BER.
Строки октетов
Тип OCTET STRING служит для представления произвольных последовательностей октетов. Значение OCTET STRING может иметь любую длину, включая нуль. OCTET STRING используется для представления сообщений, включая зашифрованные, а также для типа PBEParameter. Нотация типа OCTET STRING имеет формат.
OCTET STRING [SIZE ({size | size1..size2})]
где size, size1 и size2 опционные ограничения размера. В форме OCTET STRING SIZE(size) строка октетов должна иметь октеты size. В формате OCTET STRING SIZE(size1 .. size2) строка должна содержать число октетов между size1 и size2. Например, тип PBEParameter имеет компоненту типа OCTET STRING:
PBEParameter ::= SEQUENCE {
salt OCTET STRING SIZE (8),
iterationCount INTEGER }
Здесь размер компоненты salt всегда равен 8 октетам. BER-кодирование типа OCTET STRING может быть примитивным или конструктивным. При примитивном кодировании октеты содержимого несут в себе октеты строки с первого по последний. При конструктивном кодировании содержимое октетов представляет собой последовательное объединение субстрок значения OCTET STRING. Например, BER-код значения OCTET STRING 01 23 45 67 89 AB CD EF может иметь один из следующих видов, в зависимости от формата октетов длины и вида кодирования (примитивное/конструктивное).
| 04 08 01 23 45 67 89 AB CD EF | DER-кодирование |
| 04 81 08 01 23 45 67 89 AB CD EF | Длинный формат октетов длины |
| 24 0С | Конструктивное кодирование |
| 04 04 01 23 45 67 | “01 23 45 67” + “89 AB CD EF” |
| 04 04 89 AB CD EF |
| 13 0B 54 65 73 74 20 55 73 65 72 20 31 | DER-кодирование |
| 13 81 0B 54 65 73 74 20 55 73 65 72 20 31 | Длинная форма октетов длины |
| 33 0F | Конструктивная форма, |
| 13 05 54 65 73 74 20 | “Test” + “User 1” |
| 13 06 55 73 65 72 20 31 |
end UTCTime }
Здесь start и end являются идентификаторами компонент, а типом компонент служит UTCTime. BER-кодирование значения SEQUENCE является всегда конструктивным. Октеты содержимого представляют последовательное объединение BER-кодов значений компонентов последовательности.
Тип SEQUENCE OF
Тип SEQUENCE OF обозначает упорядоченную последовательность из нуля или более компонентов данного типа, используется для имен в X.501. Нотация SEQUENCE OF имеет вид:
SEQUENCE OF Type
Так например, тип RNDSequence состоит из нуля или более компонент типа RelativeDistinguishedName.
RNDSequence ::= SEQUENCE OF RelativeDistinguishedName
BER-кодирование SEQUENCE OF является всегда конструктивным. Октеты содержимого представляют собой объединение BER-кодов значений элементов последовательности в порядке их расположения. DER-кодирование имеет тот же формат.
Тип SET
Тип SET представляет собой неупорядоченное объединение из одного или более типов. Нотация типа SET имеет вид.
SET {
[identifier1] Type1 Type1
[{OPTIONAL | DEFAULT value1}],
…,
[identifiern] Typen [{OPTIONAL | DEFAULT valuen}],
где identifier1 , …, identifiern
являются опционными идентификаторами компонентов, Type1
, …, Typen - типы компонентов, а value1 ,…, valuen
опционные значения компонентов по умолчанию. Квалификатор OPTIONAL указывает на то, что значения компонентов являются опционными. Квалификатор DEFAULT говорит о том, что величина компонента является опционной и ей присваивается определенное значение, если компонент отсутствует.
BER-кодирование для типа SET является всегда конструктивным. Октеты содержимого представляют последовательное объединение BER-кодов значений компонентов набора.
Тип SET OF
Тип SET OF представляет неупорядоченный набор, состоящий из нуля или более компонентов заданного типа и предназначенный для атрибутов PKCS (Public-Key Cryptography Standard) и имен X.501. Нотация типа SET OF имеет вид:
SET OF Type
где Type - тип. Так тип RelativeDistinguishedName состоит из нуля или более компонентов типа AttributeValueAssertion.
RelativeDistinguishedName ::= SET OF AttributeValueAssertion
BER- кодирование типа SET OF является всегда конструктивным. Октеты содержимого представляют собой объединение BER-кодов величин компонентов в порядке их исходного расположения. DER-кодирование также является всегда конструктивным, октеты содержимого представляются как и в случае BER-кодировки. Но компоненты лексикографически упорядочиваются.
Тип UTCTime
Тип UTCTime служит для обозначения универсального местного времени с привязкой по Гринвичу (GMT). Значение UTCTime характеризует местное время с точностью минут или секунд и временной сдвиг по отношению к GMT. Оно может иметь следующие формы:
YYMMDDhhmm-hh`mm`
YYMMDDhhmmssZ
YYMMDDhhmmss+ hh`mm`
YYMMDDhhmmss- hh`mm`
где
| YY | младшие две цифры года |
| ММ | код месяца (01 - 12) |
| DD | код дня (01 - 31) |
| hh | код часа (00 - 23) |
| mm | код минут (00 - 59) |
| ss | код секунд (00 - 59) |
| Z | означает местное время по Гринвичу, + указывает на то, что местное время отстает от GMT, а - указывает на то, что местное время опережает GMT. |
| hh` | абсолютное значение смещения по отношению к GMT в часах |
| mm` | абсолютное смещение по отношению к GMT в минутах. |
UTCTime
BER-кодирование значения UTCTime может быть примитивным или конструктивным. При примитивном кодировании октеты представляют собой символы строки в виде ASCII-кодов. При конструктивном кодировании октеты образуют объединение BER-кодов последовательных субстрок. В качестве примера рассмотрим варианты представления времени 4:45:40 после полудня 6 мая 1991 года (Pacific Daylight Time) в виде величины UTCTime.
“910506164540-0700”
“910506234540Z”
Это представление эквивалентно следующим BER-кодам:
17 0D 39 31 30 35 30 36 32 33 34 35 34 30 5A
17 11 39 31 30 35 30 36 31 36 34 35 34 30 2D 30 37 30 30
DER-кодирование типа UTCTime всегда является примитивным.
Ниже приводится пример ASN.1 нотации имен типа X.501.
Name ::= CHOICE { RNDSequence }
RNDSequence ::= SEQUENCE OF RelativeDistinguishedName
RelativeDistinguishedName ::= SET OF AttributeValueAssertion
AttributeValueAssertion ::= SEQUENCE { AttributeType, AttributeValue }
AttributeType ::= OBJECT IDENTIFIER
AttributeValue ::= ANY
Тип Name идентифицирует объект в каталоге X.500. Name имеет тип CHOICE с одной альтернативой RNDSequence. Тип RNDSequence указывает проход по дереву каталогов X.500, начиная с корневой части. RNDSequence имеет тип SEQUENCE OF, состоящий из нуля или более компонентов RelativeDistinguishedName. Тип RelativeDistinguishedName присваивает уникальное имя объекту на дереве каталога. RelativeDistinguishedName имеет тип SET OF, состоящий из нуля или более компонентов AttributeValueAssertion. Тип AttributeValueAssertion присваивает значение атрибуту имени (например, определяющее принадлежность к стране). AttributeValueAssertion имеет тип SEQUENCE, состоящий из двух компонентов AttributeType и AttributeValue. AttributeType идентифицирует атрибут с помощью объектного идентификатора. AttributeValue присваивает значение атрибуту. Ниже предлагается пример DER-кодирования типа Name. В качестве имени использовано RSA Data Security, Inc. NOTARY (отдел Internet Privacy Enhanced Mail).
(root)
|
countryName = ”US”
|
organizationName = ”RSA Data Security, Inc.”
|
organizationalUnitName = ”NOTARY”
Каждый уровень соответствует одному значению RelativeDistinguishedName, в выбранном случае они имеют только одно значение AttributeValueAssertion. Значение AttributeType помещается до знака равенства, а AttributeValue (строка печатных символов с заданным типом атрибута) - после знака равенства.
Тип атрибута
DER-кодирование трех значений AttributeType согласно примитивному методу с заданной длиной дает следующие строки октетов.
| 06 03 55 04 06 | countryName |
| 06 03 55 04 0A | organizationName |
| 06 03 55 04 0B | organizationalUnitName |
AttributeType OBJECT IDENTIFIER ::= { joint-iso-ccitt(2) ds(5) 4 }
countryName OBJECT IDENTIFIER ::= { AttributeType 6 }
organizationName OBJECT IDENTIFIER ::= { AttributeType 10 }
organizationalUnitName OBJECT IDENTIFIER ::= { AttributeType 11 }
Октеты идентификатора имеют формат с меткой, так как метка равна 6 для OBJECT IDENTIFIER. Биты 8 и 7 равны 0, указывая на универсальный класс, бит 6 также равен 0, что говорит о примитивном методе кодирования. Октеты длины ориентированы на короткую форму представления. Октеты содержимого представляют собой объединения трех-октетных строк, полученных из субидентификаторов: 85 = 40x2 + 5; 4 и 6, 10 или 11.
Значение атрибута
DER-кодирование трех значений AttributeValue в соответствии с примитивным методом при заданной длине дает следующие строки:
| 13 02 55 53 | “US” |
| 13 17 52 53 41 20 | “RSA |
| 44 61 74 61 20 | Data |
| 53 65 63 75 72 69 74 79 2C 20 | Security, |
| 49 6E 63 2E | Inc.” |
Атрибут ValueAssertion
DER-кодирование трех значений AttributeValueAssertion в соответствии с конструктивным методом дает следующие строки октетов.
| 30 09 06 03 55 04 06 13 02 55 53 |
countryName = “US” |
| 30 1E 06 03 55 04 0A 13 17 52 53 41 20 44 61 74 61 20 53 65 63 75 72 69 74 79 2C 20 49 6E 63 2E |
organizationName = “RSA Data Security, Inc.” |
| 30 0D 06 03 55 04 0B 13 06 4E 4F 54 41 52 59 |
organizationalUnitName = “NOTARY” |
RelativeDistinguishedName/p>
DER- кодирование трех значений RelativeDistinguishedName, выполняемое согласно конструктивному методу, дает следующие строки октетов.
31 0B
| 30 09 … 55 53 |
| 30 1E … 63 2E |
| 30 0D … 52 59 |
RDNSequence
DER-кодирование значений RDNSequence, выполняемое согласно конструктивному методу при заданной длине, дает следующие строки октетов.
30 40
31 0B … 55 53
31 20 … 63 2E
31 0F … 52 59
Октеты идентификатора используют короткий формат (low-octet form), так как для SEQUENCE OF метка равна 16. Биты 8 и 7 равны 0 (универсальный класс), а бит 6 равен 1 (конструктивное кодирование). Октеты длины следуют “короткому” формату, а октеты содержимого представляют собой объединение DER-кодов трех компонент RelativeDistinguishedName в порядке их следования.
Name
DER-кодирование значений Name выполняется аналогично значениям RDNSequence и выдает следующие результаты.
30 40 31 0B 30 09 06 03 55 04 06
13 02 55 53
31 20 30 1E 06 03 55 04 0A
13 17 52 53 41 20 44 61 74 61 20 53 65 63 75 72 69 74 79 2C 20 49 6E 63 2E
31 0F 30 0D 06 03 55 04 0B
13 06 4E 4F 54 41 52 59
Атрибут флагов сообщения
Этот атрибут представляет собой список из нуля или более именованных лексем, соотнесенный данному сообщению. Флаг устанавливается путем его добавления к этому списку и обнуляется путем его удаления. Существует два типа флагов в IMAP 4.1. Флаг может быть постоянным или действующим только на время данной сессии.Системным флагом является флаг, чье имя определено в данной спецификации. Все системные флаги начинаются с символа "\". Некоторые системные флаги (\deleted и \seen) имеют специальную семантику, заданную вне рамок данного документа. В настоящее время определены следующие системные флаги:
| \seen | Сообщение прочитано |
| \answered | На сообщение послан ответ |
| \flagged | Сообщение "помечено" как срочное, требующее особого внимания |
| \deleted | Сообщение помечено как стертое для последующего удаления посредством expunge |
| \draft | Сообщения не является законченным (помечено, как проект). |
| \recent | Сообщение только что положено в почтовый ящик. Эта сессия является первой, где фигурирует данное сообщение; для последующих сессий это сообщение не будет иметь флага \recent. Флаг не может быть изменен клиентом. |
Если невозможно определить, является ли эта сессия первой для данного сообщения, его следует считать относящимся к текущей сессии. Ключевое слово определяется реализацией сервера. Ключевые слова не начинаются с символа "\". Серверы могут позволять клиенту создавать новые ключевые слова в почтовом ящике. Постоянные флаги клиент может устанавливать для данного сообщения или удалять на постоянной основе; таким образом, последующая сессия может воспользоваться новыми значениями флагов.
Замечание: Системный флаг \recent имеет статус флага сессии. Флаг \recent не может использоваться в качестве аргумента команды store, и по этой причине не может быть изменен вообще.
Внутренняя дата и время сообщения на сервере. Это не та дата и время, которые указаны в заголовке [RFC-822], а время и дата получения сообщения. В случае доставки сообщения посредством протокола , это должна быть дата и время доставки конечному адресату. В случае сообщений, доставленных командой IMAP 4.1 copy, это должны быть внутренняя дата и время отправителя сообщения. В случае доставки сообщения командой IMAP 4.1 append, это должна быть дата и время, заданные в описании команды append.
Атрибут размера сообщения определяет число октетов в сообщении (рассмотрен в документе [RFC-822]). Атрибут структуры конверта сообщения соответствует требованиям документа [RFC-822]. Атрибут структуры тела сообщения несет в себе информацию о структуре сообщения в соответствии с регламентациями [MIME-IMB]. Кроме доставки текстового сообщения, как это описано в RFC-822, IMAP 4.1 позволяет осуществлять передачу части текста. Можно отдельно доставить заголовок и тело сообщения или даже часть тела сообщения.
Атрибут сообщения UID
Каждому сообщению ставится в соответствие 32-битовый код, который при использовании совместно с уникальным идентификатором образует 64-битовую последовательность, гарантирующую однозначную идентификацию сообщения в почтовом ящике. Сообщения, приходящие позднее имеют больший код UID, чем полученные ранее.В отличие от порядкового номера сообщения, уникальные идентификаторы не образуют упорядоченной последовательности, но они работают и за пределами текущей сессии. Это позволяет осуществлять ссылки на сообщение в случае обрыва сессии [IMAP-DISC].
UID ассоциируется с почтовым ящиком и посылается в виде кода uidvalidity отклика (ok) на фазе выбора почтового ящика. Если UID из предыдущей сессии по какой-то причине не может быть использован, UID должен быть инкрементирован.
Замечание: UID для данного почтового ящика должен всегда изменяться монотонно. Если порядок записей изменен вне рамок IMAP, необходимо перегенерировать UID для данного почтового ящика, так как порядок старых значений UID в этом случае уже не будет монотонным.
Еще одной причиной не сохранения UID может служить стирание старого и создание нового почтового ящика с тем же именем. Так как имя почтового ящика не изменилось, клиент может не знать об этом и пытаться использовать старые UID. Хорошим значением UID можно считать 32-битное представление даты и времени создания почтового ящика. Вполне приемлемо и значение 1, если имеется гарантия, что это значение никогда не будет использовано повторно, даже в случае стирания и создания нового почтового ящика с тем же именем.
UID сообщения не должно изменяться в пределах сессии, его не следует изменять и от сессии к сессии. Однако если невозможно сохранить UID сообщения в последующей сессии, каждая следующая сессия должна иметь новый уникальный код идентификатора, который больше чем любой UID использованный ранее.
Атрибут порядкового номера сообщения
Этот атрибут определяет порядковый номер сообщения в почтовом ящике, начиная с 1. Последующее сообщение всегда имеет значение этого атрибута на 1 большее, чем у предшествующего.
Допускается изменение порядкового номера сообщения на протяжении сессии. Например, когда сообщение удаляется из почтового ящика, номера всех последующих сообщений изменяются. Аналогично, новому сообщению может быть присвоен номер удаленного сообщения.
Номера сообщений могут использоваться при вычислениях, касающихся указателей. Например, если сообщение 287 в почтовом ящике, содержащем 523 сообщения, имеет UID 12345, имеется 286 сообщений, имеющих меньшее значение UID и 236 сообщений с большими UID.
Атрибуты AVP
Как это определено в разделе 4.1, AVP содержат поля ID производителя, атрибута и значения. Для ID производителя значение 0 IANA поддерживает регистр присвоенных атрибутов, а в некоторых случаях и значений. Атрибуты 0-39 присвоены согласно тому, как это описано в разделе 4.4. Остальные значения доступны для присвоения при согласовании с IETF [RFC 2434].Аутентификация прокси PPP
L2TP определяет AVP, которые могут пересылаться в процессе установления сессии с целью передачи PPP аутентификационной информации, полученной в LAC, для перепроверки в LNS (смотри раздел 4.4.5). Это предполагает полное доверие между LAC и LNS. Если LNS решит использовать прокси аутентификацию, она должна быть конфигурируема, требуя нового цикла PPP-аутентификации по инициативе LNS (который может включать или нет новый раунд согласования параметров с LCP).Аутентификация туннеля
L2TP включает в себя простую, опционную, CHAP-подобную [RFC1994] систему аутентификации туннеля в процессе установления \управляющего соединения. Если LAC или LNS хочет идентифицировать партнера, с которым контактирует или контактировал посредством AVP приглашения, включенного в SCCRQ или SCCRP-сообщения. Если в SCCRQ или SCCRP получена AVP приглашения, AVP отклика приглашения должна быть послана в следующем SCCRP или SCCCN, соответственно. Если ожидаемый отклик партнера не соответствует полученному, установление туннеля должно быть запрещено.При участии в аутентификации туннеля LAC и LNS должны обладать общим секретным кодом. Это тот же секретный код, который использовался для AVP-сокрытия (смотри раздел 4.3).
AVP, применимые для всех управляющих сообщений
Тип сообщения (все сообщения)Тип сообщения AVP, тип атрибута 0, идентифицируют управляющее сообщение и определяет контекст, в котором будет определено точное значение последующих AVP. Поле значения атрибута для этой AVP имеет следующий формат:
| 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
| Тип сообщения |
Рис. 6
Тип сообщения характеризуется целым 2-октетным числом без знака.
Тип сообщения AVP должен быть первым AVP в сообщении, который следует непосредственно сразу за заголовком управляющего cообщения (определено в разделе 3.1). Список типов управляющих сообщений и их идентификаторов смотри в разделе 3.2.
Обязательный бит (M) в типе сообщения AVP имеет специальное назначение. Этот бит служит скорее не для указания того, следует ли игнорировать саму AVP, если бы она не распознана, а указанием того, что при не распознании следует игнорировать управляющее сообщение. Таким образом, если M-бит равен 1 в типе сообщения AVP, а тип сообщения неизвестен программе, туннель должен быть ликвидирован. Если бит M=0, тогда программа может игнорировать сообщения неизвестных типов. M-бит должен быть сделан равным 1 для всех типов сообщений определенных в данном документе. Эта AVP не может быть скрытой (H-бит должен быть равен нулю 0). Длина этого AVP равна 8.
Случайный вектор (все сообщения)
Случайный вектор AVP, тип атрибута 36, используются для разрешения сокрытия значения атрибута AVP.
Случайная последовательность октетов может иметь произвольную длину, хотя для случайного вектора рекомендуется длина, по крайней мере, 16 октетов. Строка содержит случайный вектор для использования при вычислении хэша MD5 чтобы извлечь или скрыть значение атрибута скрытого AVP (смотри раздел 4.2).
В сообщении может быть более одного случайного вектора AVP. Эта AVP должна предшествовать первому AVP с битом H =1.
M-бит для этого AVP должно быть равно 1. Это AVP не должно быть скрыто (H-бит должен быть равен 0). Длина этого AVP равно 6 плюс длина случайной строки октетов.
AVP прокси LCP и аутентификации
LAC может откликнуться на вызов и согласовать LCP с удаленной системой, возможно для того чтобы установить идентичность системы. В этом случае, эти AVP могут быть включены для индикации свойств канала, которые запросила удаленная система в исходном состоянии, свойства, согласованные удаленной системой и LAC после согласования, а также аутентификационная информация PPP, полученная LAC. Эта информация может быть использована, чтобы инициировать PPP LCP и аутентификационные системы в LNS, позволяя PPP продолжить работу без повторного согласования параметров с LCP.LCP CONFREQ, полученный в исходном состоянии (ICCN)
В AVP, полученного в исходном состоянии LCP CONFREQ, тип атрибута 26, предоставляет LNS исходное сообщение CONFREQ, полученное LAC от партнера PPP.
LCP CONFREQ является копией тела полученного исходного CONFREQ, начиная с первой опции тела сообщения LCP. Длина поля значения атрибута LCP CONFREQ имеет произвольную длину. Эта AVP может быть скрытой (H-бит может быть 0 или 1). M-бит для этой AVP должен быть равен 0. Длина (до сокрытия) этой AVP равна 6 плюс длина CONFREQ.
Последний посланный LCP CONFREQ (ICCN)
В AVP последнего посланного LCP CONFREQ, тип атрибута 27, предоставляет LNS последнего CONFREQ, посланного LAC партнеру PPP.
LCP CONFREQ является копией тела финального CONFREQ, посланного клиенту с целью завершения LCP-согласования, начиная с первой опции тела LCP-сообщения. Длина поля значения атрибута LCP CONFREQ имеет произвольную длину. Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит этой AVP должен быть равен 0. Длина (до сокрытия) этой AVP равна 6 плюс длина CONFREQ.
Последний полученный LCP CONFREQ (ICCN)
AVP последнего полученного LCP CONFREQ, тип атрибута 28, предоставляет LNS последнего CONFREQ, полученного концентратором LAC от PPP-партнера.
LCP CONFREQ является копией тела последнего CONFREQ, полученного от клиента с целью завершения процедуры согласования LCP, начиная с первой опции тела LCP-сообщения.
Эта AVP может быть скрытой (бит H может быть 0 или 1).
M- бит для этой AVP должен быть равен 0. Длина (до сокрытия) этой AVP равна 6 плюс длина CONFREQ.
Тип прокси Authen (ICCN)
AVP типа прокси Authen, тип атрибута 29, определяет, должна ли использоваться прокси аутентификация. Тип Authen представляет собой 2-октетное целое число без знака.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 0. Длина (до сокрытия) этой AVP равна 8. Определенные значения типа Authen:
0 - Зарезервировано
1 - Текстовой обмен имя пользователя/пароль
2 - PPP CHAP
3 - PPP PAP
4 - Никакой аутентификации
5 - Microsoft CHAP версия 1 (MSCHAPv1)
Эта AVP должна присутствовать, если должна использоваться прокси аутентификация. Если она отсутствует, тогда предполагается, что этот партнер не может выполнить прокси аутентификацию, необходимую для повторного запуска фазы аутентификации в LNS, если клиент уже вошел в эту фазу с LAC (который может быть определен AVP Proxy LCP, если имеется). Далее описаны соответствующие AVP для каждого типа аутентификации.
Имя прокси Authen (ICCN)
AVP имени прокси Authen, тип атрибута 30, специфицирует имя аутентифицируемого клиента при использовании прокси аутентификации.
Имя Authen является строкой октетов произвольной длины. Оно содержит имя, специфицированное в отклике аутентификации клиента.
Эта AVP должна присутствовать в сообщениях, содержащих AVP типа Proxy Authen с типом Authen 1, 2, 3 или 5. Может быть, желательно применить AVP-сокрытие для защиты имени, представленного открытым текстом. Эта AVP может быть скрытой (H-бит может быть 0 или 1). M-бит для этой AVP должен быть равен 0. Длина (до сокрытия) равна 6 плюс длина имени.
Приглашение прокси Authen (ICCN)
AVP приглашения прокси Authen, тип атрибута 31, специфицирует приглашение, посланное LAC партнеру PPP при использовании прокси аутентификации. Приглашение представляет собой строку из одного или более октетов.
Эта AVP должна присутствовать для типов прокси Authen 2 и 5. Поле приглашения содержит приглашение CHAP, предлагаемое LAC клиенту.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 0. Длина (до сокрытия) этой AVP равна 6, плюс длина приглашения.
ID прокси Authen (ICCN)
AVP ID прокси Authen, тип атрибута 32, специфицирует код ID PPP-аутентификации, которая реализуется между LAC и PPP-партнером, когда используется прокси аутентификация. Поле значения атрибута для этого AVP имеет следующий формат:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Зарезервировано | ID |
ID представляет собой 2-октетное целое число без знака, старший октет которого должен быть равен нулю.
AVP прокси Authen ID должна присутствовать для типов Proxy authen 2, 3 и 5. Для 2 и 5, поле ID содержит значение ID-байта переданное LAC клиенту в его приглашении (Challenge). Для 3 - это значение идентификатора Authenticate-Request. Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 0.
Отклик прокси Authen Response (ICCN)
AVP отклика прокси Authen, тип атрибута 33, специфицирует отклик аутентификации PPP, полученный LAC от PPP-партнера, когда используется прокси аутентификация. Отклик представляет собой строку октетов произвольной длины.
Эта AVP должна присутствовать для типов прокси authen 1, 2, 3 и 5. Поле отклика содержит отклик клиента на приглашение. Для типов прокси authen 2 и 5, это поле содержит значение отклика, полученное LAC. Для типов 1 или 3, оно несет в себе открытый текст пароля, полученного LAC от клиента. В случае паролей с открытым текстом рекомендуется AVP-сокрытие.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 0. Длина (до сокрытия) этой AVP равна 6 плюс длина отклика.
AVP статуса вызова
Ошибки вызова (WEN)AVP ошибок вызова, тип атрибута 34, используется LAC для посылки LNS информации об ошибке. Поле значения атрибута для этого AVP имеет следующий формат:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Зарезервировано | Ошибка CRC (H) | ||||||||||||||||||||||||||||||
| Ошибка CRC (L) | Ошибка в формате кадра (H) | ||||||||||||||||||||||||||||||
| Ошибка в формате кадра (L) | Аппаратное переполнение (H) | ||||||||||||||||||||||||||||||
| Аппаратное переполнение (L) | Переполнение буфера (H) | ||||||||||||||||||||||||||||||
| Переполнение буфера (L) | Ошибка таймаута (H) | ||||||||||||||||||||||||||||||
| Ошибка таймаута (L) | Ошибка выравнивания (H) | ||||||||||||||||||||||||||||||
| Ошибка выравнивания (L) |
Рис. 16. Поле значения атрибута для AVP ошибок вызова
Определены следующие поля:
| Зарезервировано | Не используется, должно равняться нулю 0 |
| Ошибки CRC | Число PPP-кадров, полученных с CRC-ошибками с момента реализации вызова |
| Ошибки формата кадров | Число полученных PPP-пакетов с неверным форматом |
| Аппаратное переполнение | Число переполнений аппаратного буфера с момента реализации вызова |
| Число переполнений буфера | Число зарегистрированных переполнений буфера с момента реализации вызова |
| Число ошибок таймаутов | Число таймаутов с момента реализации вызова |
| Ошибки выравнивания | Число ошибок выравнивания с момента реализации вызова |
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 32.
ACCM (SLI)
AVP ACCM, тип атрибута 35, используется LNS, чтобы проинформировать LAC о ACCM, согласуемом LNS с PPP-партнером. Поле значения атрибута для этого AVP имеет следующий формат:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Зарезервировано | Послать ACCM (H) | ||||||||||||||||||||||||||||||
| Послать ACCM (L) | Получить ACCM (H) | ||||||||||||||||||||||||||||||
| Получить ACCM (L) |
Рис. 17. Поле значения атрибута для AVP ACCM
Посланное ACCM и полученное ACCM имеют по 4 октета, перед которыми размещаются 2 октета зарезервированного количества. Значение посланного ACCM должно использоваться LAC для обработки пакетов, которые он отправляет через канал. Значение полученного ACCM должно использоваться LAC для обработки пакетов, которые он получает через канал. Значения по умолчанию, используемые LAC для обоих этих полей равны 0xFFFFFFFF. LAC должен учитывать значения этих полей, если только нет конфигурационной информации, которая указывает, что запрошенная маска должна быть модифицирована, чтобы разрешить операцию.
Эта AVP может быть скрытой (бит H может быть 1 или 0). M-бит для этой AVP должен быть равен 1. Длина этой AVP равна 16.
AVP управления контрольным соединением
Версия протокола (SCCRP, SCCRQ)Версия протокола AVP, тип атрибута - 2, указывает на версию протокола L2TP отправителя. Поле значения атрибута для данной AVP имеет следующий формат:
| 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
| Ver | Rev |
Рис. 8. Поле значения атрибута для AVP управления контрольным соединением
Поле Ver характеризуется целым числом без знака длиной в один октет и содержит код 1. Поле Rev характеризуется целым числом без знака длиной в один октет и содержит код 0. Так характеризуется версия протокола L2TP 1, и модификация версии 0. Заметим, что это не тот же код версии, что включается в заголовок каждого сообщения.
Эта AVP не должна быть скрытой (бит H должен быть равен 0). Бит M для данной AVP должен быть равен 1. Длина этой AVP равна 8.
Возможность работы с кадрами (SCCRP, SCCRQ)
Возможность работы с кадрами AVP, тип атрибута - 3, предоставляет партнеру указание на типы кадров, которые будут приняты или запрошены отправителем. Поле значения атрибута для этого AVP имеет следующий формат:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Зарезервировано для будущих определений типа кадрового обмена | A | S |
Рис. 9. Поле значения атрибута для AVP возможности работы с кадрами
Поле значения атрибута представляет собой 32-битовую маску, с двумя определенными битами. Если бит A=1, поддерживается асинхронный обмен кадрами. Если бит S=1, поддерживается синхронный обмен кадрами.
Партнер не должен запрашивать входящий или исходящий вызов с кадровым типом AVP, специфицирующим значение, не указанное в AVP, которые были получены при установлении управляющего соединения. Такая попытка приведет к тому, что вызов будет отвергнут.
Эта AVP может быть скрытой (H-бит может быть 0 или 1). M-бит для этого AVP должен быть равен 1. Длина (до сокрытия) равна 10.
Возможности носителя (SCCRP, SCCRQ)
AVP возможностей носителя, тип атрибута - 4, предоставляют партнеру указание на типы носителя, поддерживаемые аппаратным интерфейсом отправителя для исходящих вызовов.
Поле значения атрибута для этого AVP имеет следующий формат:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Зарезервировано для будущих определений типа несущей среды | A | D |
Это 32-битная маска, с двумя определенными битами. Если бит A =1, поддерживается аналоговый доступ. Если бит D =1, поддерживается цифровой доступ.
LNS не должен запрашивать исходящих вызовов, специфицирующих значение в AVP типа носителя для приборов, неуказанных в AVP типа носителя, полученных от LAC при установлении управляющего соединения. Такая попытка приведет к тому, что вызов будет отвергнут. Эти AVP должны присутствовать, если отправитель может осуществлять исходящие вызовы, когда это требуется.
Заметим, что LNS, который не может работать как LAC, а также не поддерживает оборудование для обработки входящих и исходящих вызовов, должен установить биты A и D этого AVP равными 0, или не должен вообще посылать AVP. LNS, который может работать в качестве LAC, и направлять исходящие вызовы, должен устанавливать биты A или D так, как это нужно. Присутствие этого сообщения не гарантирует того, что данный исходящий вызов будет направлен отправителем, если это потребуется, хотя такая возможность и существует.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) равна 10.
Арбитр конфликта (Tie Breaker (SCCRQ))
AVP арбитра конфликта, тип атрибута - 5, указывает, что отправитель желает иметь один туннель между заданной парой LAC-LNS.
Значение Tie Breaker характеризуется 8-октетным кодом, который используется для выбора одного туннеля, когда LAC и LNS требуют формирования туннеля одновременно. Получатель SCCRQ должен проверить, был ли послано партнеру SCCRQ и, если это так, должен сравнить свое значение Tie Breaker с полученным. Более низкое значение "wins" и "loser" должно вызвать молчаливую ликвидацию туннеля.
В случае, когда код арбитра присутствует на обеих сторонах и значения равны, обе стороны должны ликвидировать туннели. Если получен tie breaker, а невыполненный просроченный SCCRQ не имеет значения tie breaker, инициатор, который включает AVP Tie Breaker "выигрывает". Если ни одна из сторон не посылает Tie Breaker, тогда открываются два туннеля.
Эта AVP не должна быть скрытой (H-бит должен быть равен 0). M-бит для этого AVP должен быть равен 0. Длина этой AVP равна 14.
Фирменная версия (Firmware Revision) (SCCRP, SCCRQ)
Фирменная версия AVP, тип атрибута 6, указывает на фирменную версию прибора, пославшего сообщение.
Поле фирменная версия имеет 2 октета и представляется целым числом без знака, закодированным в формате, который определяется фирмой.
Для приборов, которые не имеют кода фирменной версии (универсальные ЭВМ, где, например, работают программные модули L2TP), вместо этого может быть сообщена модификация программных модулей L2TP.
Эта AVP может быть скрыта (H-бит может быть равен 0 или 1). M-бит для этой AVP должен быть равен 0. Длина (до сокрытия) равна 8.
Имя ЭВМ (SCCRP, SCCRQ)
AVP имени ЭВМ, тип атрибута 7, указывает на имя ЭВМ, реализующей функцию LAC или LNS.
Имя ЭВМ имеет переменную длину, но должно иметь, по крайней мере, один октет. Это имя должно быть максимально уникальным; для ЭВМ, участвующих в DNS [RFC1034], следует выбирать полное имя домена.
Эта AVP не должна быть скрыта (H-бит должен быть 0). M-бит для этой AVP должен быть равен 1. Длина этой AVP равна 6 плюс длина имени ЭВМ.
Имя производителя (SCCRP, SCCRQ)
AVP имени производителя, тип атрибута 8, содержит специфическую для производителя строку, которая характеризует тип используемого LAC или LNS.
Имя производителя представляет собой строку октетов произвольной длины. Для обеспечения читаемости текст этой AVP должен быть представлен с помощью символьного набора UTF-8 на языке, выбранном по умолчанию [RFC2277].
Эта AVP может быть скрытой (H-бит может быть 0 или 1). M-бит для данной AVP должен быть равен 0.
Длина ( до сокрытия) этой AVP равна 6 плюс длина имени производителя.
ID, присвоенное туннелю (SCCRP, SCCRQ, StopCCN)
AVP ID, присвоенного туннелю, тип атрибута 9, несет в себе ID, присвоенное туннелю отправителем. ID, присвоенное туннелю, содержит в себе 2-октетное целое неравное нулю число без знака.
AVP ID, присвоенное туннелю, определяет код, используемый при мультиплексировании и демультиплексировании в случае работы с несколькими туннелями между LNS и LAC. Партнер L2TP должен помещать этот код в поле заголовка ID-туннеля всех управляющих и информационных сообщений, пересылаемых через туннель. Пока от партнера не получена AVP с присвоенным ID-туннеля, управляющие сообщения должны посылаться этому партнеру со значением ID-туннеля = 0.
В управляющем сообщении StopCCN, AVP ID, присвоенного туннелю, должно быть тождественно AVP ID, присвоенного туннелю, посланному первым, позволяя партнеру идентифицировать соответствующий туннель, даже если сообщение StopCCN послано до получения AVP ID.
Эта AVP может быть скрытой (H-бит может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 8.
Размер приемного окна (Receive Window Size (SCCRQ, SCCRP))
Размер приемного окна AVP, тип атрибута 10, специфицирует размер приемного окна, которое предлагает удаленный партнер. Размер окна характеризуется 2-октетным целым числом без знака.
Если размер окна отсутствует, партнер должен предполагать этот код равным 4. Удаленный партнер может послать специфицированный номер управляющего сообщения, прежде чем ожидать отклика.
Эта AVP не должна быть скрытой (H-бит должен быть равен 0). M-бит для этой AVP должен быть равен 1. Длина этой AVP равна 8.
Приглашение (Challenge (SCCRP, SCCRQ))
AVP приглашения, тип атрибута 11, указывает, что отправивший его партнер хочет аутентифицировать концы туннеля, используя CHAP-стиль аутентификационного механизма. Вызов содержит один или более октетов произвольной информации.
Эта AVP может быть скрытой (бит H может быть 0 или 1).M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 6 плюс длина приглашения (challenge).
Отклик на приглашение (Challenge Response (SCCCN, SCCRP))
AVP отклика, тип атрибута 13, направляет ответ на полученное сообщение.
Поле отклик содержит 16 октетов, соответствуя CHAP-стилю [RFC1994] отклика на вызов.
Эта AVP должна присутствовать в SCCRP или SCCCN, если приглашение было получено в предыдущем SCCRQ или SCCRP. Для целей вычисления значения ID в CHAP-отклике используется код типа сообщения AVP для этого кадра (например, 2 для SCCRP, и 3 для SCCCN).
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 22.
AVP управления вызовом
Q.931 код причины (CDN)AVP, тип атрибута 12, используется, чтобы предоставить дополнительную информацию в случае непреднамеренного разрыва соединения. Поле значения атрибута для этого AVP имеет следующий формат:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Код причины | Сообщение причины | Сообщение-рекомендация |
Рис. 11. Поле значения атрибута для AVP кода причины Q.931
В качестве кода причины присылается код Q.931, а в качестве сообщения причины - сообщение Q.931 (например, DISCONNECT), ассоциированное с кодом причины. Оба кода присылаются в их исходных кодировках ITU [DSS1]. Дополнительный ASCI-текст сообщения-рекомендации может быть включен (присутствие определяется с помощью кода длины AVP) для дальнейшего уточнения причины отсоединения.
Эта AVP не должна быть скрытой (H-бит должен быть равен 0). M-бит для этой AVP должен быть равен 1. Длина этой AVP равна 9, плюс размер сообщения Advisory.
ID, присвоенное сессии (CDN, ICRP, ICRQ, OCRP, OCRQ)
AVP ID, присвоенного сессии, тип атрибута 14, содержит ID, присвоенное сессии отправителем сообщения. ID, присвоенное сессии, представляет собой 2-октетное целое, ненулевое число без знака.
AVP ID, присвоенного сессии, определяет код, который используется для мультиплексирования и демультиплексирования данных, посылаемых через туннель между LNS и LAC. Партнер L2TP должен поместить этот код в поле заголовка ID-сессии всех управляющих и информационных сообщений, которые пересылаются по туннелю в рамках данной сессии. До того как от партнера придет AVP ID, присвоенного сессии, управляющие сообщения должны посылаться партнеру с ID-сессии, равным нулю.
В управляющем сообщении CDN, используется первое AVP ID-сессии, полученное партнером, позволяя партнеру идентифицировать соответствующий туннель, даже если CDN послано до получения ID, присвоенное сессии.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 8.
Порядковый номер вызова (ICRQ, OCRQ)
AVP порядкового номера вызова, тип атрибута 15, несет в себе идентификатор, присвоенный данному вызову LAC или LNS. Порядковый номер вызова представляет собой 32-битовый код.
Порядковый номер вызова предназначен для удобного административного указателя для обоих концов туннеля, когда необходимо проанализировать причину отказа. Порядковые номера вызова должны быть монотонно возрастающими числами, которые должны быть уникальными для достаточно большого периода времени для всех соединенных LNS и LAC.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 10.
Максимальный BPS (OCRQ)
AVP максимального BPS, тип атрибута 16, характеризует минимальную приемлемую скорость передачи канала для данного вызова.
Максимальный BPS представляет собой 32-битовый код, характеризующий скорость передачи в битах в секунду.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 10.
Максимальный BPS (OCRQ)
AVP максимального BPS, тип атрибута 17, характеризует максимальную приемлемую скорость канала для данного вызова.
Максимальный BPS представляет собой 32-битный код, характеризующий скорость передачи в битах в секунду.
Эта AVP может быть скрытым (H-бит может быть 0 или 1). M-бит для этого AVP должен быть равен 1. Длина (до сокрытия) этого AVP равна 10.
Тип носителя (ICRQ, OCRQ)
AVP типа носителя, тип атрибута 18, характеризует тип носителя для входящего или исходящего вызовов. Поле значения атрибута для этого AVP имеет следующий формат:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Зарезервировано для будущих определений типа несущей среды | A | D |
Тип носителя представляет собой 32-битовую маску, которая характеризует возможности несущей среды для вызова (ICRQ) или требования к среде для данного вызова (OCRQ).
Если бит A=1, то вызов относится к аналоговому каналу. Если бит D=1, то вызов относится к цифровому каналу. Могут быть установлены оба бита, что может означать, что тип канала не определен, или допустима работа, как с аналоговым, так и цифровым каналами.
Биты в поле значение данной AVP должны устанавливаться LNS для OCRQ, если они были установлены в AVP возможностей носителя, полученной от LAC в период установления управляющего соединения.
Можно не устанавливать ни A, ни D-биты в ICRQ. Такая установка может означать, что вызов не был получен по физическому каналу (например, если LAC и PPP находятся в той же подсистеме).
Эта AVP может быть скрыта (H-бит может быть 0 или 1). M-бит этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 10.
Тип кадрового обмена (ICCN, OCCN, OCRQ)
AVP типа кадрового обмена, тип атрибута 19, характеризует тип кадров для входящих и исходящих вызовов. Поле значения
атрибута для этого AVP имеет следующий формат:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Зарезервировано для будущих определений типа кадрового обмена | A | S |
Тип кадрового обмена представляет собой 32-битовую маску, которая указывает тип кадрового обмена PPP, запрошенный для OCRQ, или тип кадрового обмена PPP, согласованный для OCCN или ICCN. Тип кадрового обмена может быть использован как указание PPP на LNS, какую из канальных опций использовать для согласования с LCP [RFC1662].
Бит A указывает на асинхронный обмен кадрами. Бит S указывает на синхронный обмен кадрами. Для OCRQ могут быть установлены оба бита, что будет означать допустимость обоих типов кадрового обмена.
Биты в поле значение этой AVP должны устанавливаться только LNS для OCRQ, если они были установлены в AVP возможностей кадрового обмена, полученной от LAC в процессе установления управляющего соединения. Эта AVP может быть скрытой (H-бит может быть 0 или 1). M-бит для этой AVP должен быть равен 1.
Длина ( до сокрытия) этой AVP равна 10.
Вызванный номер (Called Number (ICRQ, OCRQ))
AVP вызванного номера, тип атрибута 21, характеризует телефонный номер, куда посылается вызов для OCRQ.
Вызванный номер представляет собой ASCII-строку произвольной длины. Может быть необходим контакт между администратором LAC и LNS для координации интерпретации значения, необходимого данной AVP.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 6 плюс длина телефонного номера.
Вызывающий номер (Calling Number (ICRQ))
AVP вызывающего номера, тип атрибута 22, содержит телефонный номер входящего вызова.
Вызывающий номер представляет собой ASCII-строку произвольной длины. Может быть необходим контакт между администратором LAC и LNS для координации интерпретации значения, необходимого данной AVP.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 6 плюс длина телефонного номера.
Субадрес (ICRQ, OCRQ)
AVP субадреса, тип атрибута 23, несет в себе дополнительную информацию по вызову.
Субадрес является ASCII-строкой. Может быть, необходим контакт между администратором LAC и LNS для координации интерпретации значения, необходимого данной AVP.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 6 плюс длина субадреса.
Скорость канала (Tx) (Connect Speed (ICCN, OCCN))
AVP скорости канала (Tx) BPS, тип атрибута 24, характеризует быстродействие устройства, выбранного для попытки установления соединения. Скорость канала (Tx) BPS содержит 4 октета и характеризует скорость обмена в битах в секунду.
Когда присутствует опционная AVP скорости соединения Rx, значение этой AVP представляет быстродействие канала с точки зрения LAC (например, скорость передачи данных, передаваемых от LAC в удаленную систему). Когда опционная AVP скорости соединения Rx отсутствует, быстродействие канала между удаленной системой и LAC предполагается симметричным и представляется одной величиной этой AVP.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит для этой AVP должен быть равен 1. Длина (до сокрытия) этой AVP равна 10.
Скорость соединения Rx (Connect Speed (ICCN, OCCN))
AVP скорости соединения Rx, тип атрибута 38, представляет скорость канала с точки зрения LAC (например, информация, передаваемая от удаленной системы в LAC). Поле значения атрибута для этого AVP имеет следующий формат:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| BPS (H) | BPS (L) |
BPS имеет 4 октета, характеризующие скорость обмена в битах в секунду. Присутствие этой AVP означает, что быстродействие канала может быть асимметричным с учетом скорости передачи, заданной в AVP скорости соединения Rx.
Эта AVP может быть скрытой (бит H может быть 1 или 0). M-бит для этой AVP должен быть равен 0. Длина (до сокрытия) этой AVP равна 10.
ID физического канала (ICRQ, OCRP)
AVP ID физического канала, тип атрибута 25, представляет код физического канала, присвоенный ему производителем, и используемый при вызове. ID физического канала имеет 4 октета и служит только для целей регистрации.
Эта AVP может быть скрытой (бит H может быть 0 или 1). M-бит этой AVP должен быть равен 0. Длина (до сокрытия) этой AVP равна 10.
ID частной группы (ICCN)
AVP ID частной группы, тип атрибута 37, используется LAC для индикации того, что этот вызов ассоциируется с определенной группой клиентов. ID частной группы представляет собой строку октетов произвольной длины.
LNS может воспринимать PPP-сессию, а также сетевой трафик в рамках сессии специальным образом, определенным партнером. Например, если LNS соединен с несколькими частными сетями, использующими незарегистрированные адреса, эта AVP может быть включена LAC, чтобы индицировать, что данный вызов должен быть ассоциирован с одной из частных сетей.
ID частной группы представляет собой строку, соответствующую таблице в LNS, которая определяет конкретные характеристики выбранной группы.LAC может определить ID частной группы из отклика RADIUS, локальной конфигурации, или некоторых других источников.
Эта AVP может быть скрытой (H-бит может быть 1 или 0). M-бит для этой AVP должен быть равен 0. Длина (до сокрытия) этой AVP равна 6 плюс длина ID частной группы.
Необходима нумерация (Sequencing Required (ICCN, OCCN))
AVP Sequencing Required, тип атрибута 39, сообщает LNS, что порядковые номера должны всегда присутствовать в информационном канале. Эта AVP не имеет поля значения атрибута.
Эта AVP не должна быть скрытой (H-бит должен быть 0). M-бит этой AVP должен быть равен 1. Длина этой AVP равна 6.
B Потеря пакета и повторная передача
Существующий туннель имеет новую сессию, запрошенную LAC. Пакет ICRP потерян и должен быть послан LNS повторно. Заметим, что потеря ICRP несет в себе две проблемы: это не только блокирует машину состояний высокого уровня, но и лишает LAC своевременного прихода подтверждения его ICRQ на нижнем уровне.LAC LNS
ICRQ ->
Nr: 1, Ns: 2
| (пакет потерян) | |
| Nr: 3, Ns: 1 |
(пауза; таймер LAC запускается первым, поэтому первым и срабатывает)
ICRQ ->
Nr: 1, Ns: 2
(Понимая, что он уже видел этот пакет, LNS отбрасывает его и посылает ZLB)
| Nr: 3, Ns: 2 |
(срабатывает таймер повторной передачи LNS)
| Nr: 3, Ns: 1 |
ICCN ->
Nr: 2, Ns: 3
| Nr: 4, Ns: 2 |
Безопасность на конце туннеля
Концы туннеля могут опционно выполнять процедуру аутентификации друг друга при установлении туннеля. Эта аутентификация имеет те же атрибуты безопасности, что и CHAP, и обладает разумной защитой против атак воспроизведения и искажения в процессе установления туннеля. Этот механизм не реализует аутентификации при формировании туннеля; так как достаточно просто для злонамеренного пользователя, который наблюдает обмен в туннеле, ввести свои пакеты, когда аутентификация полностью завершена.Для реализации аутентификации LAC и LNS должны использовать общий секретный ключ. Каждая из сторон использует один и тот же ключ, когда выполняет роль аутентификатора и аутентифицируемого. Так как используется только один ключ, AVP аутентификации туннеля несут в себе разные значения полей в CHAP ID для вычисления дайджеста каждого сообщения, чтобы противостоять атакам воспроизведения.
Assigned Tunnel ID и Assigned Session ID (смотри раздел 4.4.3) должны быть выбраны непредсказуемым образом. Такая методика препятствует деятельности хакеров, которые не имеют доступа к пакетам, которыми обмениваются LAC и LNS.
Безопасность от начала до конца
Защищая поток L2TP-пакетов, так как это делает безопасный транспорт, мы защищаем данные, передаваемые по PPP-туннелю от LAC к LNS. Такая защита не должна рассматриваться как замена для безопасности точка-точка при передаче данных между ЭВМ или приложениями.Безопасность пакетного уровня
Обеспечение безопасности L2TP требует, чтобы транспортная среда могла обеспечить шифрование передаваемых данных, целостность сообщений и аутентификацию услуг для всего L2TP-трафика. Этот безопасный транспорт работает с пакетом L2TP в целом и функционально независим от PPP и протокола, вложенного в PPP. Как таковой, L2TP ответственен за конфиденциальность, целостность и аутентифицированность L2TP-пакетов внутри туннеля (LAC и LNS).Безопасность
При использовании протокола RSVP возникают определенные проблемы безопасности.Повреждение или фальсификация запросов резервирования может привести к получению услуг неавторизованными пользователями или к отказам в услугах. RSVP осуществляет защиту против таких атак с помощью механизма аутентификации, действующего в каждом из узлов и использующего шифрование с применением хэш-функций. Механизм поддерживается объектами INTEGRITY, которые могут быть включены в любое сообщение RSVP. Эти объекты используют технику криптографических дайджестов, которая предполагает, что соседи RSVP совместно владеют секретом шифрования (см. [Baker96]).
Управление политикой будет зависеть от положительного результата аутентификации для каждого из запросов резервирования. Информация, характеризующая политику, может быть включена в сообщение в виде криптографически защищенного сертификата пользователя.
Первые два пункта касались выполнения операций RSVP. Третий пункт касается резервирования для безопасных потоков данных. В частности, использование IPSEC (IP Security) в потоке данных создает проблему для RSVP: если транспортный и вышележащие заголовки зашифрованы, общие номера порта RSVP не могут использоваться для определения сессии или отправителя.
Для решения этой проблемы определено расширение RSVP, в котором идентификатор секретности (IPSEC SPI) играет ту же роль что и номер порта [RFC 2207].
и CISCO. Главная цель BGP
4.4.11.4 Внешний протокол BGPСеменов Ю.А. (ГНЦ ИТЭФ)
Протокол BGP (RFC-1267, BGP-3; RFC-1268; RFC-1467, BGP-4; -1265-66, 1655) разработан компаниями IBM и CISCO. Главная цель BGP - сократить транзитный трафик. Местный трафик либо начинается, либо завершается в автономной системе (AS); в противном случае - это транзитный трафик. Системы без транзитного трафика не нуждаются в BGP (им достаточно EGP для общения с транзитными узлами). Но не всякая ЭВМ, использующая протокол BGP, является маршрутизатором, даже если она обменивается маршрутной информацией с пограничным маршрутизатором соседней автономной системы. AS передает информацию только о маршрутах, которыми она сама пользуется. BGP-маршрутизаторы обмениваются сообщениями об изменении маршрутов (UPDATE-сообщения, рис. 4.4.11.4.1). Максимальная длина таких сообщений составляет 4096 октетов, а минимальная 19 октетов. Каждое сообщение имеет заголовок фиксированного размера. Объем информационных полей зависит от типа сообщения.

Рис. 4.4.11.4.1. Формат BGP-сообщений об изменениях маршрутов
Поле маркер содержит 16 октетов и его содержимое может легко интерпретироваться получателем. Если тип сообщения "OPEN", или если код идентификации в сообщении open равен нулю, то поле маркер должно быть заполнено единицами. Маркер может использоваться для обнаружения потери синхронизации в работе BGP-партнеров. Поле длина имеет два октета и определяет общую длину сообщения в октетах, включая заголовок. Значение этого поля должно лежать в пределах 19-4096. Поле тип представляет собой код разновидности сообщения и может принимать следующие значения:
| 1 | OPEN | (открыть) |
| 2 | UPDATE | (изменить) |
| 3 | NOTIFICATION | (внимание) |
| 4 | KEEPALIVE | (еще жив) |
Кроме заголовка сообщение open содержит следующие поля (рис. 4.4.11.4.2):

Рис. 4.4.11.4.2 Формат сообщения open
Поле версия описывает код версии используемого протокола, на сегодня для BGP он равен 4. Двух-октетное поле моя автономная система определяет код AS отправителя. Поле время сохранения характеризует время в секундах, которое отправитель предлагает занести в таймер сохранения. После получения сообщения OPEN BGP-маршрутизатор должен выбрать значение времени сохранения. Обычно выбирается меньшее из полученного в сообщении open и значения, определенного при конфигурации системы (0-3сек). Время сохранения определяет максимальное время в секундах между сообщениями KEEPALIVE и UPDATE или между двумя UPDATE-сообщениями. Каждому узлу в рамках BGP приписывается 4-октетный идентификатор (BGP-identifier, задается при инсталляции и идентичен для всех интерфейсов локальной сети). Если два узла установили два канала связи друг с другом, то согласно правилам должен будет сохранен канал, начинающийся в узле, BGP-идентификатор которого больше. Предусмотрен механизм разрешения проблемы при равных идентификаторах.
Одно-октетный код идентификации позволяет организовать систему доступа, если он равен нулю, маркер всех сообщений заполняется единицами, а поле идентификационных данных должно иметь нулевую длину. При неравном нулю коде идентификации должна быть определена процедура доступа и алгоритм вычисления кодов поля маркера. Длина поля идентификационных данных определяется по формуле:
Длина сообщения = 29 + длина поля идентификационных данных.
Минимальная длина сообщения open составляет 29 октетов, включая заголовок.
Сообщения типа UPDATE (изменения) используются для передачи маршрутной информации между BGP-партнерами. Этот тип сообщения позволяет сообщить об одном новом маршруте или объявить о закрытии группы маршрутов, причем объявление об открытии нового и закрытии старых маршрутов возможно в пределах одного сообщения. Сообщение UPDATE всегда содержит стандартный заголовок и может содержать другие поля в соответствии со схемой:

Рис. 4.4.11.4.3 Формат update-сообщения
Если длина списка отмененных маршрутов равна нулю, ни один маршрут не отменен, а поле отмененные маршруты в сообщении отсутствует. Поле отмененные маршруты имеет переменную длину и содержит список IP-адресных префиксов маршрутов, которые стали недоступны. Каждая такая запись имеет формат:

Длина префикса (в битах), равная нулю означает, что префикс соответствует всем IP-адресам, а сам имеет нулевой размер. Поле префикс содержит IP-адресные префиксы, за которыми следуют разряды, дополняющие их до полного числа октетов. Значения этих двоичных разрядов смысла не имеют.
Нулевое значение полной длины списка атрибутов пути говорит о том, что информация о доступности сетевого уровня в UPDATE-сообщении отсутствует. Список атрибутов пути присутствует в любом UPDATE-сообщении. Этот список имеет переменную длину, а каждый атрибут содержит три составные части: тип атрибута, длину атрибута и значение атрибута. Тип атрибута представляет собой двух-октетное поле со структурой:

Старший бит (бит0) поля флаги атрибута определяет, является ли атрибут опционным (бит0=1) или стандартным (well-known, бит0=0). Бит 1 этого поля определяет, является ли атрибут переходным (бит1=1) или непереходным (бит1=0). Для обычных атрибутов этот бит должен быть равен 1. Третий бит (бит 2) поля Флагов атрибута определяет, является ли информация в опционном переходном атрибуте полной (бит2=0) или частичной (бит2=1). Для обычных и для опционных непереходных атрибутов этот бит должен быть равен нулю. Бит 3 поля флагов атрибута информирует о том, имеет ли длина атрибута один (бит3=0) октет или два октета (бит3=1). Бит3 может быть равен 1 только в случае, когда длина атрибута более 255 октетов. Младшие 4 бита октета флагов атрибута не используются (и должны обнуляться). Если бит3=0, то третий октет атрибута пути содержит длину поля данных атрибута в октетах. Если же бит3=1, то третий и четвертый октеты атрибута пути хранят длину поля данных атрибута. Остальные октеты поля атрибут пути характеризуют значение атрибута и интерпретируются согласно флагам атрибута.
Атрибуты пути бывают "стандартные обязательные" (well-known mandatory), "стандартные на усмотрение оператора", "опционные переходные" и "опционные непереходные". Стандартные атрибуты должны распознаваться любыми BGP-приложениями. Опционные атрибуты могут не распознаваться некоторыми приложениями. Обработка нераспознанных атрибутов задается битом 1 поля флагов. Пути с нераспознанными переходными опционными атрибутами должны восприниматься, как рабочие. Один и тот же атрибут может появляться в списке атрибутов пути только один раз.
Предусмотрены следующие разновидности кодов типа атрибута:
ORIGIN (код типа = 1) - стандартный обязательный атрибут, который определяет происхождение путевой информации. Генерируется автономной системой, которая является источником маршрутной информации. Значение атрибута в этом случае может принимать следующие значения:
| Код атрибута | Описание |
| 0 | IGP - информация достижимости сетевого уровня является внутренней по отношению к исходной автономной системе; |
| 1 | EGP - информация достижимости сетевого уровня получена с помощью внешнего протокола маршрутизации; |
| 2 | Incomplete - информация достижимости сетевого уровня получена каким-то иным способом. |
| Код типа сегмента | Описание |
| 1 | AS_set: неупорядоченный набор маршрутов в update сообщении; |
| 2 | AS_sequence: упорядоченный набор маршрутов автономной системы в UPDATE-сообщении. |
br>
Длина сегмента пути представляет собой одно-октетное поле, содержащее число as, записанных в поле оценка сегмента пути. Последнее поле хранит один или более кодов автономной системы, по два октета каждый.
NEXT_HOP (код типа = 3) - стандартный обязательный атрибут, определяющий IP-адрес пограничного маршрутизатора, который должен рассматриваться как цель следующего шага на пути к точке назначения.
MULTI_EXIT_DISC (код типа = 4) представляет собой опционный непереходной атрибут, который занимает 4 октета и является положительным целым числом. Величина этого атрибута может использоваться при выборе одного из нескольких путей к соседней автономной системе.
LOCAL_PREF (код типа = 5) является опционным атрибутом, занимающим 4 октета. Он используется BGP-маршрутизатором, чтобы сообщить своим BGP-партнерам в своей собственной автономной системе степень предпочтения объявленного маршрута.
ATOMIC_AGGREGATE (код типа = 6) представляет собой стандартный атрибут, который используется для информирования партнеров о выборе маршрута, обеспечивающего доступ к более широкому списку адресов.
aggregator (код типа = 7) - опционный переходной атрибут с длиной в 6 октетов. Атрибут содержит последний код автономной системы, который определяет агрегатный маршрут (занимает два октета), и IP-адрес BGP-маршрутизатора, который сформировал этот маршрут (4 октета). Объем информации о достижимости сетевого уровня равен (в октетах):
Длина сообщения UPDATE - 23 - полная длина атрибутов пути - длина списка отмененных маршрутов. Информация о достижимости кодируется в следующей форме:

Поле длина определяет длину IP-адресного префикса в битах. Если длина равна нулю, префикс соответствует всем IP-адресам. Префикс содержит IP-адресные префиксы и двоичные разряды, дополняющие код до целого числа октетов.
Информация о работоспособности соседних маршрутизаторов получается из KEEPALIVE-сообщений, которые должны посылаться настолько часто, чтобы уложиться во время, отведенное таймером сохранения (hold).
Обычно это время не должно превышать одной трети от времени сохранения, но не должно быть и меньше 1 секунды. Если выбранное значение времени сохранения равно нулю, периодическая посылка KEEPALIVE-сообщений не обязательна.
NOTIFICATION-сообщения посылаются, когда обнаружена ошибка. BGP-связь при этом немедленно прерывается. Помимо заголовка NOTIFICATION-сообщение имеет следующие поля:

Код ошибки представляет собой одно-октетное поле и указывает на тип данного сообщения. Возможны следующие коды ошибки:
Таблица 4.4.11.4.1. Коды ошибок
| Код ошибки | Описание |
| 1 | Ошибка в заголовке сообщения. |
| 2 | Ошибка в сообщении open |
| 3 | Ошибка в сообщении update |
| 4 | Истекло время сохранения |
| 5 | Ошибка машины конечных состояний |
| 6 | Прерывание |
Одно-октетное поле cубкод ошибки предоставляет дополнительную информацию об ошибке. Каждый код ошибки может иметь один или более субкодов. Если поле содержит нуль, это означает, что никаких субкодов не определено.
Таблица 4.4.11.4.2 Субкоды ошибок
| Ошибка | Субкод | Описание |
| Заголовок | 1 2 3 |
Соединение не синхронизовано Неверная длина сообщения Неверный тип сообщения |
| Сообщения OPEN | 1 2 3 4 5 6 |
Неверный код версии Ошибочный код as-партнера Ошибочный идентификатор BGP Ошибка в коде идентификации Ошибка при идентификации Неприемлемое время сохранения |
| Сообщения UPDATE | 1 2 3 4 5 6 7 8 9 10 11 |
Ошибка в списке атрибутов Не узнан стандартный атрибут Отсутствует стандартный атрибут Ошибка в флагах атрибута Ошибка в длине атрибута Неправильный атрибут origin Циклический маршрут Ошибка в атрибуте next_hop Ошибка в опционном атрибуте Ошибка в сетевом поле Ошибка в as_path |
| 1. | ADJ-RIBS-IN: | Запоминает маршрутную информацию, которая получена из update-сообщений. Это список маршрутов, из которого можно выбирать. (policy information base - PIB). |
| 2. | LOC-RIB: | Содержит локальную маршрутную информацию, которую BGP-маршрутизатор отобрал, руководствуясь маршрутной политикой, из ADJ-RIBS-IN. |
| 3. | ADJ-RIBS-OUT: | Содержит информацию, которую локальный BGP-маршрутизатор отобрал для рассылки соседям с помощью UPDATE-сообщений. |
br>
Так как разные BGP- партнеры могут иметь разную политику маршрутизации, возможны осцилляции маршрутов. Для исключения этого необходимо выполнять следующее правило: если используемый маршрут объявлен не рабочим (в процессе корректировки получено сообщение с соответствующим атрибутом), до переключения на новый маршрут необходимо ретранслировать сообщение о недоступности старого всем соседним узлам.
Протокол BGP позволяет реализовать маршрутную политику, определяемую администратором AS (см. раздел ""). Политика отражается в конфигурационных файлах BGP. Маршрутная политика это не часть протокола, она определяет решения, когда место назначения достижимо несколькими путями, политика отражает соображения безопасности, экономические интересы и пр. Количество сетей в пределах одной AS не лимитировано. Один маршрутизатор на много сетей позволяет минимизировать таблицу маршрутов.
BGP использует три таймера:
Connectretry (сбрасывается при инициализации и коррекции; 120 сек),
Holdtime (запускается при получении команд Update или Keepalive; 90сек) и
keepalive (запускается при посылке сообщения Keepalive; 30сек).
BGP отличается от RIP и OSPF тем, что использует TCP в качестве транспортного протокола. Две системы, использующие BGP, связываются друг с другом и пересылают посредством TCP полные таблицы маршрутизации. В дальнейшем обмен идет только в случае каких-то изменений. ЭВМ, использующая BGP, не обязательно является маршрутизатором. Сообщения обрабатываются только после того, как они полностью получены.
BGP является протоколом, ориентирующимся на вектор расстояния. Вектор описывается списком AS по 16 бит на AS. BGP регулярно (каждые 30сек) посылает соседям TCP-сообщения, подтверждающие, что узел жив (это не тоже самое что "Keepalive" функция в TCP). Если два BGP-маршрутизатора попытаются установить связь друг с другом одновременно, такие две связи могут быть установлены. Такая ситуация называется столкновением, одна из связей должна быть ликвидирована.
При установлении связи маршрутизаторов сначала делается попытка реализовать высший из протоколов (например, BGP-4), если один из них не поддерживает эту версию, номер версии понижается.
Протокол BGP-4 является усовершенствованной версией (по сравнению с BGP-3). Эта версия позволяет пересылать информацию о маршруте в рамках одного IP-пакета. Концепция классов сетей и субсети находятся вне рамок этой версии. Для того чтобы приспособиться к этому, изменена семантика и кодирование атрибута AS_PASS. Введен новый атрибут LOCAL_PREF (степень предпочтительности маршрута для собственной AS), который упрощает процедуру выбора маршрута. Атрибут INTER_AS_METRICSпереименован в MULTI_EXIT_DISC (4 октета; служит для выбора пути к одному из соседей). Введены новые атрибуты ATOMIC_AGGREGATE и AGGREGATOR, которые позволяют группировать маршруты. Структура данных отражается и на схеме принятия решения, которая имеет три фазы:
Бесклассовая интердоменная маршрутизация (CIDR- classless interdomain routing, RFC-1520, -1519) - способ избежать того, чтобы каждая С-сеть требовала свою таблицу маршрутизации. Основополагающий принцип CIDR заключается в группировке (агрегатировании) IP-адресов таким образом, чтобы сократить число входов в таблицах маршрутизации (RFC-1519, RFC-1518, RFC-1467, RFC-1466). Протокол совместим с RIP-2, OSPF и BGP-4. Основу протокола составляет идея бесклассовых адресов, где нет деления между полем сети и полем ЭВМ. Дополнительная информация, например 32-разрядная маска, выделяющая поле адреса сети, передается в рамках протокола маршрутизации. При этом выдерживается строгая иерархия адресов: провайдер > предприятие > отдел/здание > сегмент локальной сети.
Групповой (агрегатный) адрес воспринимается маршрутизатором как один адрес. Группу может образовывать только непрерывная последовательность IP-адресов. Такой бесклассовый интернетовский адрес часто называется IP-префиксом. Так адрес 192.1.1.0/24 означает диапазон адресов 192.1.1.0 - 192.1.1.255, а адрес 192.1.128.0/17 описывает диапазон 192.1.128.0 - 192.1.255.255, таким образом, число, следующее после косой черты, задает количество двоичных разрядов префикса. Это представление используется при описании политики маршрутизации и самих маршрутов (см. разд.4.4.11.4 - ). Для приведенных примеров это в терминах масок выглядит следующим образом:

24 и 17 длины префикса сети.
Следует помнить, что маски с разрывами здесь недопустимы. Ниже приведена таблица метрик маршрутизации для различных протоколов.
| Протокол | Метрика | Диапазон | Код "маршрут недостижим" |
| RIP hello BGP |
Число скачков Задержка в ms Не определена |
0-15 0-29999 0-65534 |
16 30000 65535 |

Рис. 4.4.11.4.4. Пример разных маршрутов для пути "туда" и "обратно".
Предполагается, что оператор находится в ЭВМ-отправителе. Команда traceroute 192.148.166.33 в этом случае выдаст:
| 1 GW-1 | (192.148.166.35) |
| 2 Место назначения | (192.148.166.33) |
| 1 GW-1 | (192.148.166.35) |
| 2 GW-2 | (192.148.166.7) |
| 3 Место назначения | (192.148.165.80) |
| 1 GW-1 | (192.148.166.35) |
| 2 ***** | ; В этом режиме маршрутизатор не откликается |
| 3 Место назначения | (192.148.165.80) |
| 4 GW-1 | (192.148.166.35) |
| 5 ЭВМ-отправитель | (192.148.166.32) |
Из приведенных примеров видна также полезность команды traceroute для понимания того, как движутся пакеты в сети. В некоторых случаях это может помочь оптимизировать маршрутизацию и улучшить пропускную способность сети.
Другой полезной командой является Netstat, которая позволяет получить разнообразную информацию о состоянии сети. Существует четыре модификации этой команды:
-a отображает состояния всех соединений;
-i отображает значения конфигурационных параметров;
-r отображает таблицу маршрутов;
-v отображает статистику обмена локального Ethernet-интерфейса.
Например, команда netstat -r может выдать:
Routing tables (таблицы маршрутизации)
| Destination | Gateway | Flags | Refcnt | Use | Interface |
| Stavropol-GW.ITEP.RU | nb | UGHD | 0 | 109 | le0 |
| ihep.su | itepgw | UGHD | 0 | 103 | le0 |
| m10.ihep.su | itepgw | UGHD | 0 | 16 | le0 |
| 194.85.66.50 | itepgw | UGHD | 0 | 455 | le0 |
| Kharkov.ITEP-Kharkov | nb | UGHD | 0 | 105 | le0 |
| Bryansk-GW.ITEP.Ru | nb | UGHD | 1 | 8113 | le0 |
| 193.124.225.67 | nb | UGHD | 0 | 0 | le0 |
| ixwin.ihep.su | itepgw | UGHD | 1 | 6450 | le0 |
| ihep.su | itepgw | UGHD | 0 | 14 | le0 |
| 192.148.166.21 | nb | UGHD | 0 | 109 | le0 |
| ihep.su | itepgw | UGHD | 0 | 224 | le0 |
| 193.124.225.71 | nb | UGHD | 0 | 10 | le0 |
| 194.85.112.0 | ITEP-FDDI-BBone.ITEP | UGD | 0 | 253 | le0 |
| default | itepgw | UG | 10 | 102497 | le0 |
Базовая команда netstat может обеспечить следующую информацию:
Active Internet connections (активные Интернет связи)
| Proto | Recv-Q | Send-Q | Local Address | Foreign Address | (state) |
| tcp | 0 | 0 | 127.0.0.1.1313 | 127.0.0.1.sunrpc | TIME_WAIT |
| tcp | 0 | 0 | ns.1312 | 193.124.18.65.smtp | SYN_SENT |
| tcp | 0 | 0 | 127.0.0.1.1311 | 127.0.0.1.sunrpc | TIME_WAIT |
| tcp | 0 | 0 | ns.1310 | ns.domain | TIME_WAIT |
| tcp | 0 | 0 | 127.0.0.1.1309 | 127.0.0.1.sunrpc | TIME_WAIT |
| tcp | 39 | 24576 | ns.nntp | Bryansk-GW.ITEP.1697 | ESTABLISHED |
| tcp | 0 | 0 | ns.telnet | semenov.1802 | ESTABLISHED |
| tcp | 0 | 188 | ns.1033 | xmart.desy.de.6000 | ESTABLISHED |
| udp | 0 | 0 | 127.0.0.1.domain | *.* | |
| udp | 0 | 0 | ns.domain | *.* |
| Address | Type | Recv-Q | Send-Q | Vnode | Conn | Refs | Nextref Addr |
| ff64b38c | stream | 0 | 0 | ff13187c | 0 | 0 | 0 /dev/printer |
| ff64b28c | dgram | 0 | 0 | 0 | 0 | 0 | 0 |
| ff64698c | dgram | 0 | 0 | <>ff137fa8 | 0 | 0 | 0 /dev/log |
Битовые и двоичные строки
8-битовая текстовая и двоичная почта поддерживается посредством шифрования [MIME-IMB]. Реализации IMAP 4.1 могут передавать 8-битные или многооктетные символы в литералах, но должны это делать, только когда определен [CHARSET]. Если даже определена кодировка BINARY, незакодированные двоичные строки не могут быть разрешены. "Двоичная строка" - это любая строка из NUL символов. Реализации программ должны перекодировать двоичные данные в текстовую форму, такую как BASE64, прежде чем их пересылать. Строка с большим числом символов CTL может рассматриваться как двоичная.Биты заголовка AVP
Имеется 4 резервных бита в заголовке AVP. Дополнительные биты должны присваиваться через стандартную процедуру [RFC 2434].Будущая совместимость
В будущем для существующих классов могут быть описаны новые объекты C-Типа, а могут быть определены и новые классы объектов. Крайне желательно использовать такие объекты Интернет в рамках старых приложений, которые их не распознают. К сожалению, это возможно с заметными ограничениями. Здесь нужно придерживаться следующих правил (`b' означает бит).1. Неизвестный класс
Существует три возможных способа, чтобы приложение RSVP могло работать с объектом неизвестного класса. Этот выбор определяется двумя старшими битами октета Class-Num.
Ниже приведены более детализированные правила для работы с нераспознанными классами объектов для Class-Num вида 11bbbbbb:
Хотя объекты с неизвестным классом не могут объединяться, эти правила позволяют передать их вплоть до узла, который сможет их распознать и объединить.
2. Неизвестный C-Тип для известного класса
Появление объекта с неизвестным C-типом приведет к выбрасыванию всего сообщения и генерации сообщения об ошибке (ResvErr или PathErr). Сообщение об ошибке будет включать Class-Num и C-тип, который был не распознан. Оконечная система, которая отправила нераспознанное сообщение может использовать эту информацию, чтобы попытаться повторить попытку с объектом другого C-типа.
Объекты определенных классов (FLOWSPEC, ADSPEC и POLICY_DATA) не прозрачны для RSVP, который просто передает их системе управления трафиком или другим модулям управления. В зависимости от внутренних правил любой из упомянутых модулей может отвергнуть C-Тип и информировать об этом RSVP-процесс; RSVP должен тогда отвергнуть такое сообщение и проинформировать об ошибке.
Call-Disconnect-Notify (CDN)
Сообщение Call-Disconnect-Notify (CDN) является L2TP управляющим сообщением, посылаемым LAC или LNS с целью запроса разрыва соединения для определенного вызова в пределах туннеля. Его целью является информирование партнера о рассоединении и причине разрыва соединения. Партнер должен освободить все ресурсы, и не посылать сообщений о причине данной операции.Следующие AVP должны присутствовать в CDN:Message Type
Код результата (Result Code)
Assigned Session ID
| Следующие AVP могут присутствовать в CDN: | Код причины Q.931 |
Dns_
4.4.12 DNS (структура, обработка запросов, ресурсные записи)Семенов Ю.А. (ГНЦ ИТЭФ)
| Номер раздела | Название раздела | Объем в страницах | Объем в кбайт |
| 4.4.12.1 | 53 | 235 |
Главной ЭВМ любой системы является та, на которой работаете вы. Но помимо этой машины и маршрутизатора локальной сети не последнюю роль играет сервер имен (DNS-система, RFC-4032, -4034, -4035, -2137, -2052, -2136, -1996, -1918, -1793, -1712-13, -1706, -1664, -1611-12, -1536-37, -1401, -1383, -1183, -1101, -1034-35). Сервер имен это программа управления распределенной базой данных, в которой хранятся символьные имена сетей и ЭВМ вместе с их IP-адресами. Наиболее распространенным программным продуктом, решающим данную задачу является BIND (Berkrley Internet Name Domain). Иногда для этой цели выделяют специальную машину. Задача DNS - преобразование символьного имени в IP-адрес и наоборот в условиях, когда число узлов Internet растет экспоненциально, совсем не проста. Сама иерархическая система имен (DNS) настроена на упрощение решения этой проблемы. Схема взаимодействия программы пользователя с локальным и удаленными DNS-серверами показана ниже на рисунке 4.4.12.1.

Рис. 4.4.12.1. Структура взаимодействия с серверами имен
База имен является распределенной, так как нет такой ЭВМ, где бы хранилась вся эта информация. Как уже отмечалось имя содержит несколько полей (длиной не более 63 символов), разделенных точками. Имя может содержать не более 255 октетов, включая байт длины. Анализ имени производится справа налево. Самая правая секция имени характеризует страну (двухсимвольные национальные коды смотри в приложении), или характер организации образовательная, коммерческая, правительственная и т.д.).
Следующие 3-х символьные коды в конце Internet-адреса означают функциональную принадлежность узла:
Таблица 4.4.12.1. Стандартизованные суффиксы имен
| Поле адреса | Тип сети |
| .aero | Фирма или организация, относящаяся к сфере авиации; |
| .biz | Организация, относящаяся к сфере бизнеса; |
| .com | Коммерческая организация; |
| .coop | Кооперативная организация; |
| .gov | Государственное учреждение (США); |
| .info | Открытая TLD-структура (регистрация имен доменов) |
| .org | Бесприбыльная организация; |
| .edu | Учебное заведение; |
| .mil | Военное предприятие или организация (США); |
| .museum | Имя домена музея |
| .name | Имя домена частного лица |
| .net | Большая сеть; |
| .pro | Профессионал, достойный доверия. Управляется RegistryPro (); |
| .int | Международная организация; |
| .arpa | Специальный домен, используемый для преобразования ip-адреса в имя |
Секции .mil и . gov принадлежат исключительно американским сетям (хотя и многие другие трех-символьные секции адреса, например .edu, чаще, но не всегда, принадлежат американским университетам и другим учебным организациям). Структура имен обычно отражает структуру организации, которой принадлежат сети или ЭВМ, но не архитектуру сети в этой организации. Так имя itep.ru - это имя домена itepnet (Институт Теоретической и Экспериментальной физики, Москва). cl.itep.ru - имя mvax-кластера в ИТЭФ, vxitep.itep.ru - имя vax-кластера, а suncom.itep.ru - имя одной из ЭВМ SUN в той же сети. По имени, как правило, нельзя определить является ли оно именем сети, маршрутизатора или конкретной ЭВМ. Для записи символьных имен используется исключительно латинский алфавит.
Маленький фрагмент интернетовской иерархии имен показан на рис. 4.4.12.2. Число уровней реально больше, но обычно не превышает 5.

Рис. 4.4.12.2. Иерархия имен в Интернет-DNS (I - домен первого уровня; II - второго уровня)
Каждому узлу (прямоугольнику на рисунке) соответствует имя, которое может содержать до 63 символов. Только самый верхний, корневой узел не имеет имени. При написании имени узла строчные и прописные символы эквивалентны. Имя домена, завершающееся точкой называется абсолютным или полным именем домена (например, itep.ru.). В некоторых странах создана структура имен сходная с com/edu/org. Так в Англии можно встретить адреса .ac.uk для академических учреждений и .co.uk - для коммерческих. Если имя домена не завершено символом точки, DNS может попытаться его дополнить, например имя ns может быть преобразовано в ns.itep.ru. На приведенной схеме каждому объекту трех верхних уровней соответствуют серверы имен, которые могут взаимодействовать друг с другом при решении задачи преобразования имени в IP-адрес. Можно было бы построить схему, при которой в любом сервере имен имелись адреса серверов .com, .edu, .ru и т.д. и при необходимости он мог бы послать туда запрос. Реальная схема серверов не столь идеальна и стройна - существуют серверы nsf.gov, oakland.edu и т.д., которые непосредственно связаны с базовым сервером имен.
Каждый сервер содержит лишь часть дерева имен. Эта часть называется зоной ответственности сервера. DNS-сервер может делегировать ответственность за часть зоны другим серверам, создавая субзоны. Когда в зоне появляется новая ЭВМ или субдомен, администратор зоны записывает ее имя и IP-адреса в базу данных сервера. Администратор зоны определяет, какой из DNS-серверов имен является для данной зоны первичным. Число вторичных серверов не лимитировано. Первичный и вторичный серверы должны быть независимыми и работать на разных ЭВМ, так чтобы отказ одного из серверов не выводил из строя систему в целом. Отличие первичного сервера имен от вторичного заключается в том, что первичный загружает информацию о зоне из файлов на диске, а вторичный получает ее от первичного. Администратор вносит любые изменения в соответствующие файлы первичного сервера, а вторичные серверы получают эту информацию, периодически (раз в 3 часа) запрашивая первичный сервер. Пересылка информации из первичного во вторичные серверы имен называется зонным обменом. Как будет вести себя сервер, если он не имеет запрашиваемой информации? Он должен взаимодействовать с корневыми серверами. Таких серверов насчитывается около десяти и их IP-адреса должны содержаться в конфигурационных файлах.
Список корневых серверов вы можете получить с помощью анонимного FTP по адресам: или . Корневые серверы хранят информацию об именах и адресах всех серверов доменов второго уровня. Существует два вида запросов: рекурсивные и итеративные. Первый вид предполагает получение клиентом IP-адреса, а второй - адреса сервера, который может сообщить адрес. Первый вид медленнее, но дает сразу IP-адрес, второй эффективнее - в вашем сервере копится информация об адресах серверов имен. Одним из способов повышения эффективности трансляции имен в адреса является кэширование, то есть хранение в оперативной памяти имен-адресов, которые использовались последнее время особенно часто. Рассмотрение процесса обмена между ЭВМ-клиентом и сервером имен может прояснить работу системы в целом.
Прежде чем использовать протоколы UDP или TCP прикладная программа должна узнать IP-адрес объекта, куда она хочет послать дейтограмму. Для решения этой проблемы программа посылает запрос в локальный сервер имен. В Unix-системах имеются специальные библиотечные процедуры gethostbyname и gethostbyaddr, которые позволяют определить IP-адрес по имени ЭВМ и наоборот. В одном запросе может содержаться несколько вопросов. Если сервер не сможет ответить на вопросы, он пришлет отклик, где содержатся адреса других серверов, способных решить эту задачу. Ниже на рисунке 4.4.12.3 представлен формат таких сообщений (в качестве транспорта используется UDP или TCP, порт 53).

Рис. 4.4.12.3. Формат DNS-сообщений
Каждое сообщение начинается с заголовка, который содержит поле идентификация, позволяющее связать в пару запрос и отклик. Поле флаги определяет характер запрашиваемой процедуры, а также кодировку отклика. Поля число... определяют число записей соответствующего типа, содержащихся в сообщении. Так число запросов задает число записей в секции запросов, где записаны запросы, требующие ответов. Каждый вопрос состоит из символьного имени домена, за которым следует тип запроса и класс запроса. Значения битов поля флаги в сообщении сервера имен отображены в таблице 4.4.12.2. Разряды пронумерованы слева направо, начиная с нуля рис. 4.4.12.4.

Рис. 4.4.12.4. Назначение битов поля флаги.
Таблица 4.4.12.2. Коды поля флаги
| Код поля флаги | Описание | |
| 0 (QR) | Операция: | 0 Запрос 1 Отклик |
| 1…4 | Тип запроса (opcode): | 0 стандартный 1 инверсный 2 запрос состояния сервера |
| 5 (AA) | Равен 1 при отклике от сервера (RR), в ведении которого находится домен, упомянутый в запросе. | |
| 6 (TC) | Равен 1 при укорочении сообщения. Для UDP это означает, что ответ содержал более 512 октетов, но прислано только первые 512. | |
| 7 (RD) | Равен 1, если для получения ответа желательна рекурсия. | |
| 8 (RA) | Равен 1, если рекурсия для запрашиваемого сервера доступна. | |
| 9…11 | Зарезервировано на будущее. Должны равняться нулю. | |
| 12…15 | Тип отклика (rcode): | 0 нет ошибки 1 ошибка в формате запроса 2 сбой в сервере 3 имени не существует |
Ниже описан формат секции запросов в DNS-сообщении.

Рис. . 4.4.12.5. Формат секции вопросов DNS-запроса.

Поле символьное имя домена имеет переменную длину, содержит одно или более субполей, начинающихся с байта длины (0-63). Поле завершается 0. Например, для ns.itep.ru (цифры представляют собой октеты длины):
В реальной нотации байты длины субполя могут иметь два старших бита равные 1, что преобразует интервал значений из 0-63 в 192-255. Такой байт в поле означает, что это не мера длины секции, а 16-битный указатель, 14 бит которого являются смещением от начала DNS-сообщения, указывающим на место продолжения секции. Смещение для первого байта поля идентификации равно нулю. Эти ухищрения придуманы для сокращения длины сообщений, так как одно и то же имя домена в отклике может повторяться много раз. Поле тип запроса характеризует разновидность запроса:
Таблица 4.4.12.3.. Разновидности полей тип запроса и их коды
| Тип запроса | Код запроса | Описание |
| A | 1 | IP-адрес |
| NS | 2 | Сервер имен. |
| CNAME | 5 | Каноническое имя. |
| SOA | 6 | Начало списка серверов. Большое число полей, определяющих часть иерархии имен, которую использует сервер. |
| MB | 7 | Имя домена почтового ящика. |
| WKS | 11 | well-known service - стандартная услуга. |
| PTR | 12 | Запись указателя. |
| HINFO | 13 | Информация об ЭВМ. |
| MINFO | 14 | Информация о почтовом ящике или списке почтовых адресов. |
| MX | 15 | Запись о почтовом сервере. |
| TXT | 16 | Не интерпретируемая строка ASCII символов. |
| AXFR | 252 | Запрос зонного обмена |
| * или ANY | 255 | Запрос всех записей. |
Последние две строки в таблице 4.4.12.3 относятся только к запросам. Поле класс запроса позволяет использовать имена доменов для произвольных объектов (все официальные имена Интернет относятся к одному классу [IN] - 1). В сообщении DNS-сервера каждая из секций (дополнительной информации, ответов или узловых серверов имен) состоит из набора ресурсных записей, которые описывают имена доменов и некоторую другую информацию (например, их адреса).
Появление ресурсных полей в DNS базе данных придают ей новые качества. Каждая запись описывает только одно имя, формат этих записей отображен на рис. 4.4.12.6.

Рис. 4.4.12.6. Формат ресурсных записей в DNS (RR)
Всего существует 20 различных типов RR-записей. Имя домена в такой записи может иметь произвольную длину. Поля тип и класс характеризуют тип и класс данных, включенных в запись (аналогичны используемым в запросах). Поле время жизни (TTL) содержит время (в секундах), в течение которого запись о ресурсах может храниться в буферной памяти (в кэше). Обычно это время соответствует двум дням. Формат информации о ресурсах зависит от кода в поле тип, так для тип=1 - это 4 байта IP-адреса. Сервер имен может обслуживать и другие запросы, например, по IP-адресу определять символьное имя домена или преобразовать имя домена в адрес почтового сервера. Когда организация присоединяется к Интернет, она получает в свое распоряжение не только определенную DNS-область, но и часть пространства в in-addr.arpa, соответствующую ее IP-адресам. Домен in-addr.arpa предназначен для определения имен по их IP-адресам. Такая схема исключает процесс перебора серверов при подобном преобразовании.
Имена в домене IN-ADDR.ARPA могут иметь до четырех субполей помимо суффикса IN-ADDR.ARPA. Каждое субполе представляет собой октет IP-адреса, и содержит последовательность символов, отображающую коды в диапазоне 0-255. Так имя для IP-адреса 192.148.166.137 (если оно существует) содержится в домене с именем 137.166.148.192.IN-ADDR.ARPA. Запись адреса задом наперед диктуется общими принципами записи имен доменов (корневая часть имени находится справа). Направив несколько запросов в домен IN-ADDR.ARPA относительно имен объектов с интересующими вас IP-адресами, можно получить следующий результат:
| IP_address | Hard-addr | Delay | Date | Host_name |
| 128.141.202.101 | 00.00.0c.02.69.7d | 440 | 10/10/95 | na48-1.cern.ch |
| 192.148.166.102 | 00.00.a7.14.41.c2 | 5 | 10/10/95 | |
| 192.148.166.237 | 00.00.0c.02.69.7d | 5 | 10/10/95 | ITEP-M9.Relcom.ITEP.RU |
где в левой колонке записаны IP-адреса, имена которых ищутся, во второй - записаны аппаратные адреса интерфейсов, через которые доступны искомые объекты. Поскольку первая и третья строки относятся к внешним по отношению к узлу ITEP объектам, здесь записан адрес интерфейса пограничного маршрутизатора. В третьей колонке содержится значение RTT в мсек, а в оследней - имена объектов. IP-адресу 192.148.166.102 не соответствует никакого имени.
Задержка при выполнении команды telnet между выдачей команды и появлением на экране IP-адреса связана с доступом и работой DNS-сервера. Пауза между появлением надписи Trying и Connected to определяется временем установления TCP-связи между клиентом и сервером. База данных имен может содержать и другую информацию. Типы такой информации представлены в таблице 4.4.12.3. Для извлечения информации из этой распределенной базы данных можно воспользоваться программой host (SUN или другая ЭВМ, работающая под UNIX). Рассмотрим несколько примеров (курсивом выделены команды, выданные с терминала).
host -t cname cernvm.cern.ch
cernvm.cern.ch is a nickname for crnvma.cern.ch
Напомним, что CNAME - каноническое имя узла или ЭВМ, иногда называемое также псевдонимом (alias).
host -t hinfo ns.itep.ru
ns.itep.ru HINFO SparcStation-1 SunOS-4.1.3
HINFO - информация об ЭВМ. Это обычно две последовательности символов, которые характеризуют ЭВМ и ее операционную систему. Много полезной информации можно узнать о почтовом сервере узла посредством команды:
host -t mx cl.itep.ru
cl.itep.ru is a nickname for r02vax.itep.ru
r02vax.itep.ru mail is handled by relay1.kiae.su
r02vax.itep.ru mail is handled by relay2.kiae.su
r02vax.itep.ru mail is handled by mx.itep.ru
r02vax.itep.ru mail is handled by x4u2.desy.de
host -v info.cern.ch
Trying domain "itep.ru"
rcode = 3 (Non-existent domain), ancount=0
Trying null domain
rcode = 0 (Success), ancount=2
| info.cern.ch | 86400 | IN | CNAME | www6.cern.ch |
| www6.cern.ch | 86400 | IN | A | 128.141.202.119 |
Trying domain "itep.ru"
rcode = 3 (Non-existent domain), ancount=0
Trying null domain
rcode = 0 (Success), ancount=1
The following answer is not authoritative:
| www6.cern.ch | 86400 | IN | A | 128.141.202.119 |
| CERN.CH | 52256 | IN | NS | dxmon.cern.ch |
| CERN.CH | 52256 | IN | NS | ns.eu.net |
| CERN.CH | 52256 | IN | NS | sunic.sunet.se |
| CERN.CH | 52256 | IN | NS | scsnms.switch.ch |
dxmon.cern.ch 79157 IN A 192.65.185.10
ns.eu.net 56281 IN A 192.16.202.11
sunic.sunet.se 85087 IN A 192.36.125.2
sunic.sunet.se 85087 IN A 192.36.148.18
scsnms.switch.ch 72545 IN A 130.59.1.30
scsnms.switch.ch 72545 IN A 130.59.10.30
Опция -v, используемая совместно с командой host позволяет получить более полную информацию об узле. Во второй колонке данной выдачи указано время жизни (TTL) в секундах. Значение TTL в первых строках соответствует суткам (24x60x60=86400). IN в следующей колонке указывает на принадлежность к классу Интернет. В четвертой колонке проставлены указатели типов запроса (см. табл. 4.4.12.3). В пятой колонке идут названия серверов имен и IP-адреса ЭВМ. Далее следуют коды предпочтения. MX-записи активно используются почтовыми серверами. Обмен MX-записями производится в следующих случаях:
MX-записи снабжены 16-битными кодами предпочтения. Если для адреса имеется несколько MX-записей, они используются в порядке нарастания этого кода. Если вы хотите узнать список доступных услуг на той или иной ЭВМ, вы можете напечатать команду (WKS - Well Known Services, сюда не входят услуги прикладного уровня, например, услуги NEWS-сервера и пр.):
host -tv wks ns.itep.ru
ns.itep.ru WKS 193.124.224.35 udp domain tftp
ns.itep.ru WKS 193.124.224.35 tcp echo ftp telnet smtp time finger
Если вам нужно узнать IP- адреса того или иного узла можно также воспользоваться командой host:
host vxdesy.desy.de
vxdesy.desy.de has address 131.169.35.78
vxdesy.desy.de has address 131.169.35.79
vxdesy.desy.de has address 131.169.35.76
vxdesy.desy.de has address 131.169.35.77
Большая часть данных относится к типу "А".
Выше уже говорилось, что для транспортировки DNS-запросов применяются протоколы UDP и TCP. Когда же следует использовать эти протоколы? Обычно используется UDP. Когда в ответ на запрос программа получает отклик с битом флагов TC=1 (сообщение укорочено), программа повторяет запрос, но уже с использованием протокола TCP. Этот протокол применяется также для зонных обменов между первичным и вторичным DNS-серверами.
Обычно реализация сервера имен (версия BIND - Berkeley Internet Name Domain) предполагает наличие трех конфигурационных файлов:
named.boot - файл начальной загрузки сервера имен;
named.local - стартовый файл клиента DNS;
named.ca - исходный буфер имен и адресов.
Это текстовые файлы, строки и фрагменты, начинающиеся с точки с запятой, представляют собой комментарии. В первом из перечисленных файлов строка, начинающаяся со слова sortlist, указывает на порядок присылки адресов при условии, что отклик на запрос содержит несколько адресов. Строка, начинающаяся со слова directory, содержит название каталога, где хранятся конфигурационные файлы (по умолчанию /etc). Строка cache сообщает имя файла-буфера имен и адресов (по умолчанию named.ca). Далее обычно следует несколько строк, начинающихся со слова primary. Эти строки указывают имена файлов (например, named.hosts или named.local), где содержится информация о соответствии имен и адресов для определенных субдоменов. Вместо имени файла может быть указан IP-адрес. Укладка данных в файле соответствует требованиям документа RFC-1033. Для вторичного (secondary) DNS файл named.boot имеет схожую структуру. Вместо строк со словом primary в этом файле присутствуют строки secondary.
Эти строки содержат помимо имен субдоменов и файлов IP-адрес первичного DNS. Последний выполняет и функцию переадресации запросов вышестоящим серверам. Вторичный DNS-сервер при невозможности выполнить запрос переадресует его первичному серверу, а не вышестоящему. Первичный сервер может создавать большой кэш-буфер для локального обслуживания часто поступающих запросов.
Файл named.local служит для спецификации интерфейса сервера имен и содержит в себе запись SOA (Start of Authority) и две ресурсных записи. Запись SOA определяет начало зоны. Символ @ в начале первой строки файла определяет имя зоны. Здесь же указываются опционные параметры:
Запись может выглядеть как (RFC-1033):
@ IN SOA SRI-NIC.ARPA. HOSTMASTER.SRI-NIC.ARPA. (
45 ;serial
3600 ;refresh
600 ;retry
3600000 ;expire
86400 ) ;minimum
В файле приводится имя первичного сервера имен для данного субдомена (флаг NS) и имя администратора с указанием адреса его электронной почты. Последняя запись в файле содержит указатель на местную ЭВМ. Первая цифра в строке этой записи содержит суффикс IP-адреса этой машины.
Файл named.ca используется для заполнения кэша при первичной загрузке DNS. Примером, иллюстрирующим возможное содержимое файла можно считать следующее (взято из RFC-1033):
;list of possible root servers
. 1 IN NS SRI-NIC.ARPA.
NS C.ISI.EDU.
NS BRL-AOS.ARPA.
NS C.ISI.EDU.
;and their addresses
SRI-NIC.ARPA. A 10.0.0.51
A 26.0.0.73
C.ISI.EDU. A 10.0.0.52
BRL-AOS.ARPA. A 192.5.25.82
A 192.5.22.82
A 128.20.1.2
A.ISI.EDU.
A 26.3.0.103
Первое поле представляет собой имя домена или субдомена, второе поле - значение TTL, третье - поле класс (Internet), четвертое - тип записи (NS для сервера имен или A для адреса), и последнее поле характеризует имя ЭВМ или IP-адрес. Если какие-то поля пусты, это означает, что они тождественны приведенным выше. Точка в начале первой строки указывает на корневой домен.
Для администраторов, обслуживающих DNS, весьма полезно ознакомиться с документом RFC-1536 (“Common DNS Implementation Errors and Suggested Fixes”). Ошибки при конфигурации DNS-сервера могут привести к досадным ошибкам и отказам системы. Обычно, при получении запроса DNS сначала определяется его зона и просматривается кэш. Если запрос не может быть выполнен, просматривается список вышестоящих DNS-серверов, которые могут содержать необходимую информацию, и запрос пересылается одному из них. Если клиент прислал рекурсивный запрос и сервер поддерживает рекурсию, запрос пересылается соответствующим серверам. Если рекурсия не поддерживается, сервер возвращает клиенту список DNS-серверов, предоставляя ему решать свои проблемы самостоятельно. Однако в некоторых случаях DNS-сервер по ошибке может включить себя в такой список серверов. Если программное обеспечение клиента не проверяет список, запрос может быть послан этому серверу повторно, что вызовет бесконечный цикл запросов.
Возможна и другая схема возникновения циклов запросов. Предположим, что сервер содержит в своем списке внешних DNS сервер , а последний в свою очередь содержит в своем списке сервер . Такого рода перекрестные ссылки трудно обнаружить особенно, если в перечне фигурирует большое число серверов. Иногда возникает ситуация, когда клиент, получив список DNS-серверов, не знает, что с ним делать и посылает запрос повторно тому же серверу. Идентифицировать такого рода ошибки весьма трудно, особенно когда в это вовлечены внешние серверы, содержимое конфигурационных файлов которых недоступно.
Иногда DNS-сервер в ответ на запрос не присылает сообщений об ошибке и никаких-либо данных клиенту.
Это случается когда запрашиваемое имя вполне корректно, но записей нужного типа не найдено. Например, запрошен адрес почтового сервера домена xxx.com. Домен этот существует, но рекорда типа MX не обнаружено. Дальнейшие события зависят от характера программного обеспечения клиента. Если клиент считает такого рода “отклик” некорректным, он может послать запрос повторно и т.д. и т.д. По этой причине в случае, если программное обеспечение это позволяет, рекомендуется ограничить число повторных запросов клиента. Приведенные примеры показывают, насколько актуальна корректная конфигурация DNS клиента и сервера.
В системах Windows часто используется своя служба имен WINS (Windows Internet Naming Service, см. RFC-2136 и RFC-2137). Эта служба совместима с системой динамического конфигурирования сети DHCP (Dynamic Host Configuration Protocol, использует динамическое распределение IP-адресов). В WINS, также как и в DHCP, имеются части, работающие у клиента и на сервере. WINS автоматически устанавливается и конфигурируется при установке системы DHCP. Эта система имеет удобную встроенную диагностику, позволяющую контролировать процесс обработки запросов к службе имен. WINS осуществляет преобразование NETBIOS-имен в IP-адреса. Эта техника предполагает использование протокола NetBIOS поверх TCP/IP (NetBT). В ОС WINDOWS 2000 технология WINS заменена DDNS (Dynamic Domain Name Service).
WINS-запросы обычно транспортируются в UDP-дейтограммах. При этом используется порт отправителя=137. В поле данных размешается 2-октетное поле идентификатора, позволяющего связать запрос с откликом. Далее следует 2 байта флагов, в случае запроса туда записывается 0. За ним размещается два октета, содержащие число вопросов, 2 октета числа ответов и еще 4 нулевых октетов. Завершается кадр запроса двумя октетами поля типа (00 21 -> статус узла NetBIOS) и полем класса (для Интернет 00 01 -> (IN,1)). Такие запросы позволяют получить дополнительные данные (имя узла, его MAC-адрес, NetBIOS-имя, имя группы) об ЭВМ с заданным IP-адресом.
Причем эта ЭВМ может находиться где угодно в Интернет, но непременно работать в OS Windows. Формат поля данных UDP-дейтограммы запроса показан на рис. 4.4.12.7.

Рис. 4.4.12.7. Формат запроса WINS
В поле данных UDP-дейтограммы отклика располагается 2-байтовое поле идентификатора, идентичного содержащемуся в пакете запроса. Далее следует поле флагов с длиной в два октета. Формат поля данных UDP-дейтограммы отклика показан на рис. 4.4.12.8.

Рис. 4.4.12.8. Формат отклика на WINS-запрос
Поле флаги имеет следующую структуру:
| 0 _ _ _ | _ _ _ _ | Команда |
| _ 000 | 0 _ _ _ | Запрос |
| _ _ _ _ | _ _ 0 _ | Не укорочено |
| _ _ _ _ | _ _ _ 0 | Рекурсия нежелательна |
| 1 _ _ _ | _ _ _ _ | Отклик |
| _ 000 | 0 _ _ _ | Запрос |
| _ _ _ _ | _ _ 0 _ | Не укорочено |
| _ _ _ _ | _ 1 _ _ | Официальный ответ |
| 0 _ _ _ | _ _ _ _ | Уникальное имя NetBIOS |
| _ 10 _ | _ _ _ _ | Узел М-типа |
| _ _ _ _ | _ 1 _ _ | Активное имя |
| _ _ _ _ | _ _ 0 _ | Временное имя |
| 1 _ _ _ | _ _ _ _ | Имя группы NetBIOS |
| _ 10 _ | _ _ _ _ | Узел М-типа |
| _ _ _ _ | _ 1 _ _ | Активное имя |
| _ _ _ _ | _ _ 0 _ | Временное имя |
Еще одной проблемой, связанной со службой имен, являются атаки, которые сопряжены с имитацией DNS. Для преодоления таких атак разработан метод транзакционных подписей TSIG (Transaction SIGnarure).
Формальный синтаксис
Последующая синтаксическая спецификация использует нотацию Бакуса-Наура (BNF - Backus-Naur Form), как это описано в [RFC-822] с одним исключением, разделителем, используемым в конструкции "#", служит одиночный пробел (SPACE), а не одна или более запятых.В случае альтернативных или опционных правил, в которых последующее правило перекрывается с более ранним, более приоритетным считается правило, встретившееся первым. Некоторые, но не все случаи таких правил представлены ниже. Если не указано обратного, все буквенные символы не зависят от использования строчных или прописных букв. Конкретные программные реализации должны воспринимать такие строки при любом написании.
address ::= "(" addr_name SPACE addr_adl SPACE addr_mailbox SPACE addr_host ")"
addr_adl ::= nstring
;; Хранит маршрут из route-addr [RFC-822], если не равно нулю
addr_host ::= nstring
;; NIL указывает на синтаксис группы [RFC-822].
;; В противном случае, содержит имя домена [RFC-822]
addr_mailbox ::= nstring
;; NIL индицирует конец группы [RFC-822]; если не NIL, а addr_host равно NIL,
;; содержит имя группы ;; [RFC-822].
;; В противном случае, содержит локальную часть [RFC-822]
addr_name ::= nstring
;; Содержит фразу из почтового ящика [RFC-822], если не NIL
alpha ::= "A" / "B" / "C" / "D" / "E" / "F" / "G" / "H" /
"I" / "J" / "K" / "L" / "M" / "N" / "O" / "P" /
"Q" / "R" / "S" / "T" / "U" / "V" / "W" / "X" /
"Y" / "Z" /
"a" / "b" / "c" / "d" / "e" / "f" / "g" / "h" /
"i" / "j" / "k" / "l" / "m" / "n" / "o" / "p" /
"q" / "r" / "s" / "t" / "u" / "v" / "w" / "x" /
"y" / "z"
;; Чувствительно к набору строчными или прописными буквами
append ::= "APPEND" SPACE mailbox [SPACE flag_list]
[SPACE date_time] SPACE literal
astring ::= atom / string
atom ::= 1*ATOM_CHAR
ATOM_CHAR ::=
atom_specials ::= "(" / ")" / "{" / SPACE / CTL / list_wildcards /
quoted_specials
authenticate ::= "AUTHENTICATE" SPACE auth_type *(CRLF base64)
auth_type ::= atom
;; Определено в [IMAP-AUTH]
base64 ::= *(4base64_char) [base64_terminal]
base64_char ::= alpha / digit / "+" / "/"
base64_terminal ::= (2base64_char "==") / (3base64_char "=")
body ::= "(" body_type_1part / body_type_mpart ")"
body_extension ::= nstring / number / "(" 1#body_extension ")"
;; Будущее расширение. Реализации клиента должны воспринимать поля
;; body_extension. Реализации сервера не должны генерировать
;; поля body_extension, за исключением случаев, закрепленных в будущих
;; стандартах или зарегистрированных модификациях уже существующих норм.
body_ext_1part ::= body_fld_md5 [SPACE body_fld_dsp
[SPACE body_fld_lang
[SPACE 1#body_extension]]]
;; не должны присылаться при non-extensible доставке "BODY"
body_ext_mpart ::= body_fld_param
[SPACE body_fld_dsp SPACE body_fld_lang
[SPACE 1#body_extension]]
;; MUST NOT be returned on non-extensible "BODY" fetch
body_fields ::= body_fld_param SPACE body_fld_id SPACE
body_fld_desc SPACE body_fld_enc SPACE
body_fld_octets
body_fld_desc ::= nstring
body_fld_dsp ::= "(" string SPACE body_fld_param ")" / nil
body_fld_enc ::= ( ("7BIT" / "8BIT" / "BINARY" / "BASE64"/
"QUOTED-PRINTABLE") ) / string
body_fld_id ::= nstring
body_fld_lang ::= nstring / "(" 1#string ")"
body_fld_lines ::= number
body_fld_md5 ::= nstring
body_fld_octets ::= number
body_fld_param ::= "(" 1#(string SPACE string) ")" / nil
body_type_1part ::= (body_type_basic / body_type_msg / body_type_text)
[SPACE body_ext_1part]
body_type_basic ::= media_basic SPACE body_fields
;; субтип MESSAGE не должен следовать "RFC822"
body_type_mpart ::= 1*body SPACE media_subtype
[SPACE body_ext_mpart]
body_type_msg ::= media_message SPACE body_fields SPACE envelope
SPACE body SPACE body_fld_lines
body_type_text ::= media_text SPACE body_fields SPACE body_fld_lines
capability ::= "AUTH=" auth_type / atom
;; Новая возможность должна начинаться с "X" или быть зарегистрирована
;; IANA в качестве стандарта или являться усовершенствованием
;; существующего стандарта
capability_data ::= "CAPABILITY" SPACE [1#capability SPACE] "IMAP4rev1"
[SPACE 1#capability]
;; серверы IMAP 4.1, которые предлагают совместимость с RFC 1730
;; должны включать "IMAP4" в список возможностей этой реализации
CHAR ::=
0x01 - 0x7f>
CHAR8 ::=
command ::= tag SPACE (command_any / command_auth /
command_nonauth / command_select) CRLF
;; Modal based on state
command_any ::= "CAPABILITY" / "LOGOUT" / "NOOP" / x_command
;; Справедливо для всех состояний
command_auth ::= append / create / delete / examine / list / lsub /
rename / select / status / subscribe / unsubscribe
;; Работает только в состояниях Authenticated или Selected
command_nonauth ::= login / authenticate
;; Работает только в состоянии Non-Authenticated
command_select ::= "CHECK" / "CLOSE" / "EXPUNGE" /
copy / fetch / store / uid / search
;; Работает только в состоянии Selected
continue_req ::= "+" SPACE (resp_text / base64)
copy ::= "COPY" SPACE set SPACE mailbox
CR ::=
create ::= "CREATE" SPACE mailbox
;; Использование INBOX не приводит к ошибке
CRLF ::= CR LF
CTL ::=
0x00 - 0x1f, 0x7f>
date ::= date_text / date_text
date_day ::= 1*2digit
;; День месяца
date_day_fixed ::= (SPACE digit) / 2digit
;; Версия с фиксированным форматом date_day
date_month ::= "Jan" / "Feb" / "Mar" / "Apr" / "May" / "Jun" /
"Jul" / "Aug" / "Sep" / "Oct" / "Nov" / "Dec"
date_text ::= date_day "-" date_month "-" date_year
date_year ::= 4digit
date_time ::= date_day_fixed "-" date_month "-" date_year
SPACE time SPACE zone
delete ::= "DELETE" SPACE mailbox
;; Использование INBOX не приводит к ошибке
digit ::= "0" / digit_nz
digit_nz ::= "1" / "2" / "3" / "4" / "5" / "6" / "7" / "8" / "9"
envelope ::= "(" env_date SPACE env_subject SPACE env_from
SPACE env_sender SPACE env_reply_to SPACE env_to
SPACE env_cc SPACE env_bcc SPACE env_in_reply_to
SPACE env_message_id ")"
env_bcc ::= "(" 1*address ")" / nil
env_cc ::= "(" 1*address ")" / nil
env_date ::= nstring
env_from ::= "(" 1*address ")" / nil
env_in_reply_to ::= nstring
env_message_id ::= nstring
env_reply_to ::= "(" 1*address ")" / nil
env_sender ::= "(" 1*address ")" / nil
env_subject ::= nstring
env_to ::= "(" 1*address ")" / nil
examine ::= "EXAMINE" SPACE mailbox
fetch ::= "FETCH" SPACE set SPACE ("ALL" / "FULL" /
"FAST" / fetch_att / "(" 1#fetch_att ")")
fetch_att ::= "ENVELOPE" / "FLAGS" / "INTERNALDATE" /
"RFC822" [".HEADER" / ".SIZE" / ".TEXT"] /
"BODY" ["STRUCTURE"] / "UID" /
"BODY" [".PEEK"] section
[""]
flag ::= "\Answered" / "\Flagged" / "\Deleted" /
"\Seen" / "\Draft" / flag_keyword / flag_extension
flag_extension ::= "\" atom
;; Будущее расширение. Реализации клиента должны воспринимать
;; флаги flag_extension. Реализации сервера не должны генерировать
;; флаги flag_extension, за исключением случаев, определенных в
;; будущих стандартах или зарегистрированных модификациях
;; данной спецификации.
flag_keyword ::= atom
flag_list ::= "(" #flag ")"
greeting ::= "*" SPACE (resp_cond_auth / resp_cond_bye) CRLF
header_fld_name ::= astring
header_list ::= "(" 1#header_fld_name ")"
LF ::=
list ::= "LIST" SPACE mailbox SPACE list_mailbox
list_mailbox ::= 1*(ATOM_CHAR / list_wildcards) / string
list_wildcards ::= "%" / "*"
literal ::= "{" number "}" CRLF *CHAR8
;; Число характеризует количество октетов CHAR8
login ::= "LOGIN" SPACE userid SPACE password
lsub ::= "LSUB" SPACE mailbox SPACE list_mailbox
mailbox ::= "INBOX" / astring
;; INBOX не чувствителен к использованию строчных или прописных букв.
;; все версии написания INBOX (напр., "iNbOx") должны
;; интерпретироваться как INBOX, а не как строку.
mailbox_data ::= "FLAGS" SPACE flag_list /
"LIST" SPACE mailbox_list /
"LSUB" SPACE mailbox_list /
"MAILBOX" SPACE text /
"SEARCH" [SPACE 1#nz_number] /
"STATUS" SPACE mailbox SPACE
"(" #
number SPACE "EXISTS" / number SPACE "RECENT"
mailbox_list ::= "(" #("\Marked" / "\Noinferiors" /
"\Noselect" / "\Unmarked" / flag_extension) ")"
SPACE ( QUOTED_CHAR / nil) SPACE mailbox
media_basic ::= ( ("APPLICATION" / "AUDIO" / "IMAGE" /
"MESSAGE" / "VIDEO") ) / string)
SPACE media_subtype
;; Определено в [MIME-IMT]
media_message ::= "MESSAGE" SPACE
"RFC822"
;; Определено в [MIME-IMT]
media_subtype ::= string
;; Определено в [MIME-IMT]
media_text ::= "TEXT" SPACE media_subtype
;; Определено в [MIME-IMT]
message_data ::= nz_number SPACE ("EXPUNGE" /
("FETCH" SPACE msg_att))
msg_att ::= "(" 1#("ENVELOPE" SPACE envelope /
"FLAGS" SPACE "(" #(flag / "\Recent") ")" /
"INTERNALDATE" SPACE date_time /
"RFC822" [".HEADER" / ".TEXT"] SPACE nstring /
"RFC822.SIZE" SPACE number /
"BODY" ["STRUCTURE"] SPACE body /
"BODY" section [""] SPACE nstring /
"UID" SPACE uniqueid) ")"
nil ::= "NIL"
nstring ::= string / nil
number ::= 1*digit
;; 32- битное целое число без знака
;; (0
nz_number ::= digit_nz *digit
;; 32-битное не равное нулю целое число без знака
;; (0 < n < 4,294,967,296)
password ::= astring
quoted ::= *QUOTED_CHAR
QUOTED_CHAR ::= /
"\" quoted_specials
quoted_specials ::= / "\"
rename ::= "RENAME" SPACE mailbox SPACE mailbox
;; Использование INBOX в качестве места назначения не дает ошибки
response ::= *(continue_req / response_data) response_done
response_data ::= "*" SPACE (resp_cond_state / resp_cond_bye /
mailbox_data / message_data / capability_data)
CRLF
response_done ::= response_tagged / response_fatal
response_fatal ::= "*" SPACE resp_cond_bye CRLF
;; Сервер закрывает соединение немедленно
response_tagged ::= tag SPACE resp_cond_state CRLF
resp_cond_auth ::= ("OK" / "PREAUTH") SPACE resp_text
;; Условие аутентификации
resp_cond_bye ::= "BYE" SPACE resp_text
resp_cond_state ::= ("OK" / "NO" / "BAD") SPACE resp_text
;; Условие состояния
resp_text ::= ["[" resp_text_code "]" SPACE] (text_mime2 / text)
;; текст не должен начинаться с "[" или "="
resp_text_code ::= "ALERT" / "PARSE" /
"PERMANENTFLAGS" SPACE "(" #(flag / "\*") ")" /
"READ-ONLY" / "READ-WRITE" / "TRYCREATE" /
"UIDVALIDITY" SPACE nz_number /
"UNSEEN" SPACE nz_number /
atom [SPACE 1*]
search ::= "SEARCH" SPACE ["CHARSET" SPACE astring SPACE]
1#search_key
;; Символьный набор [CHARSET] должен быть зарегистрирован IANA
search_key ::= "ALL" / "ANSWERED" / "BCC" SPACE astring /
"BEFORE" SPACE date / "BODY" SPACE astring /
"CC" SPACE astring / "DELETED" / "FLAGGED" /
"FROM" SPACE astring /
"KEYWORD" SPACE flag_keyword / "NEW" / "OLD" /
"ON" SPACE date / "RECENT" / "SEEN" /
"SINCE" SPACE date / "SUBJECT" SPACE astring /
"TEXT" SPACE astring / "TO" SPACE astring /
"UNANSWERED" / "UNDELETED" / "UNFLAGGED" /
"UNKEYWORD" SPACE flag_keyword / "UNSEEN" /
;; Выше этой строки все в [IMAP2]
"DRAFT" /
"HEADER" SPACE header_fld_name SPACE astring /
"LARGER" SPACE number / "NOT" SPACE search_key /
"OR" SPACE search_key SPACE search_key /
"SENTBEFORE" SPACE date / "SENTON" SPACE date /
"SENTSINCE" SPACE date / "SMALLER" SPACE number /
"UID" SPACE set / "UNDRAFT" / set /
"(" 1#search_key ")"
section ::= "[" [section_text / (nz_number *["." nz_number]
["." (section_text / "MIME")])] "]"
section_text ::= "HEADER" / "HEADER.FIELDS" [".NOT"]
SPACE header_list / "TEXT"
select ::= "SELECT" SPACE mailbox
sequence_num ::= nz_number / "*"
;; * является наибольшим используемым числом.
Для порядковых номеров
;; сообщений оно равно количеству сообщений в почтовом ящике.
;; Для уникальных идентификаторов оно равно уникальному
;; идентификатору последнего сообщения в почтовом ящике./p>
set ::= sequence_num / (sequence_num ":" sequence_num) /
(set "," set)
;; Идентифицирует набор сообщений. Для порядковых номеров
;; сообщений это последовательность чисел с 1 до числа
;; сообщений в почтовом ящике.
;; Запятая разграничивает индивидуальные номера, двоеточие
;; указывает на диапазон чисел включительно.
;; Пример для почтового ящика с 15 сообщениями: 2,4:7,9,12:*
;; эквивалентно 2,4,5,6,7,9,12,13,14,15.
SPACE ::=
status ::= "STATUS" SPACE mailbox SPACE "(" 1#status_att ")"
status_att ::= "MESSAGES" / "RECENT" / "UIDNEXT" / "UIDVALIDITY" /
"UNSEEN"
store ::= "STORE" SPACE set SPACE store_att_flags
store_att_flags ::= (["+" / "-"] "FLAGS" [".SILENT"]) SPACE
(flag_list / #flag)
string ::= quoted / literal
subscribe ::= "SUBSCRIBE" SPACE mailbox
tag ::= 1*
text ::= 1*TEXT_CHAR
text_mime2 ::= "=?" "?" "?"
"?="
;; Синтаксис определен в [MIME-HDRS]
TEXT_CHAR ::=
time ::= 2digit ":" 2digit ":" 2digit
;; Часы, минуты, секунды
uid ::= "UID" SPACE (copy / fetch / search / store)
;; Уникальные идентификаторы используются вместо
;; последовательных номеров сообщения.
uniqueid ::= nz_number
;; В возрастающем порядке
unsubscribe ::= "UNSUBSCRIBE" SPACE mailbox
userid ::= astring
x_command ::= "X" atom
zone ::= ("+" / "-") 4digit
;; Число из 4 цифр со знаком hhmm, представляющее часы и минуты к западу от Гринвича
;; (Это число отличается от Universal Time). Вычитая временную зону из данного времени, можно получить
;; форму UT. Зона Universal Time равна "+0000".
Формат данных
IMAP 4.1 использует текстовые команды и отклики. Данные в IMAP 4.1 могут иметь одну из следующих форм: атом, число, строка, список, заключенный в скобки или NIL.Атом состоит из одного или более неспециализированных символов.
Число состоит из одной или более цифр и характеризует некоторое числовое значение.
Строка может иметь одну из двух форм: литерал или строка в кавычках. Литеральная форма является основной формой строки. Строка в кавычках является альтернативной формой, исключающей избыточность литеральной формы за счет ограничений, налагаемых на символы, используемые в строке.
Литерал представляет собой нуль или более октетов (включая CR и LF). Литерал начинается с октета, где хранится число символов. Этот октет заключается в фигурные скобки, за которыми следует последовательность CRLF. В случае передачи литералов от сервера к клиенту за CRLF следуют непосредственно данные. При передаче литералов от клиента серверу клиент должен подождать прихода команды продолжения, прежде чем начать пересылку данных.
Строка в кавычках представляет собой последовательность из нуля или более 7-битовых символов за исключением CR и LF, начинающуюся и завершающуюся двойной кавычкой (). Пустая строка представляется как "" или как литерал {0}, за которым следует последовательность CRLF.
Замечание: Даже если число октетов равно нулю, клиент, передающий литерал должен подождать прихода команды продолжения.
Формат сообщений управления NTP
Формат заголовков управляющих NTP-сообщений показан на рис. 4.4.15.2. Этот заголовок располагается непосредственно вслед за UDP-заголовком.
Рис. 4.4.15.2. Формат управляющего сообщения ntp
Первые два бита, обозначенные ZZ, должны всегда содержать 0.
Номер версии (VN - version number) - трехбитовое поле, указывающее на номер версии протокола NTP, в настоящее время (3).
Режим (Mode) - трехбитовое поле, определяющее режим, значение кода режима для управляющих сообщений равно 6.
Бит отклика (R) - равен нулю для команд и 1 для откликов.
Бит ошибки (E) - равен нулю для нормального отклика и 1 в случае ошибки.
Бит продолжения (M - more) - равен нулю для последнего фрагмента и 1 - для всех остальных.
Код операции (OP) - 5-битовое поле, определяющее код команды. Значения кодов и их функции представлены в таблице 4.4.15.5.
Таблица 4.4.15.5. Коду операции управляющего сообщения
| Код | Функция |
| 0 | Зарезервировано |
| 1 | чтение статуса команда/отклик |
| 2 | чтение переменной команда/отклик |
| 3 | запись переменной команда/отклик |
| 4 | чтение переменных часов команда/отклик |
| 5 | запись переменных часов команда/отклик |
| 6 | установка адреса/порта trap команда/отклик |
| 7 | отклик на Trap |
| 8-31 | Зарезервировано на будущее |
Порядковый номер (Sequence) - 16-битовое поле, определяющее номер запроса или отклика, и облегчающее определения их соответствия.
Статус - 16-битовое поле, содержащее код статуса системы, партнера или часов.
Идентификатор ассоциации (Association ID) - 16-битовое поле, несущее в себе идентификатор ассоциации.
Смещение (Offset) - 16-битовое поле, определяющее положение первого октета поля данных в сообщении, передаваемом в нескольких дейтограммах (позиция задается в октетах).
Длина (Count) - 16-битовое поле, определяющее длину поля данных в октетах.
Данные - это поле содержит информацию сообщения, как для команды, так и для отклика. Максимальное число октетов в поле данных равно 468.
Аутентификатор (опционно). Поле, содержащие аутентификационную информацию. Используется лишь в случае реализации NTP-аутентификации.
Форматы объектов
Каждый объект состоит из одного или более 32-битных слов с 4-байтовым заголовком. Формат объекта показан на рис. 4.4.9.6.9:
Рис. 4.4.9.6.9. Формат объекта
Заголовок объекта имеет следующие поля:
Длина в байтах
16-битовое поле, содержащее полную длину объекта в байтах. Длина должна быть кратна 4 октетам, минимальное значение равно 4.
Class-Num
Идентифицирует класс объекта. Каждый класс объекта имеет свое имя, которое в данном документе записывается прописными буквами. Приложения RSVP должны распознавать следующие классы:
NULL
Объект NULL имеет код Class-Num равный нулю, а его C-тип игнорируется. Его длина должна быть, по крайней мере, равна 4, но может быть любой кратной 4. Объект NULL может появиться где угодно в последовательности объектов. Его содержимое получателем игнорируется.
SESSION
Содержит IP-адрес места назначения (DestAddress), идентификатор протокола IP, и обобщенный номер порта назначения, для того чтобы специфицировать сессию для других объектов, которые следуют далее. Этот класс должен присутствовать в любом сообщении RSVP.
RSVP_HOP
Несет в себе IP-адрес узла, поддерживающего протокол RSVP, который послал это сообщение, и дескриптор логического выходного интерфейса (LIH). Этот класс характеризует предшествующий узел (previous hop).
TIME_VALUES
Содержит значение периода обновления R, используемого отправителем сообщения. Необходим в каждом сообщении Path и Resv.
STYLE
Определяет стиль резервирования, а также зависящую от стиля информацию, которая не включена в объекты FLOWSPEC или FILTER_SPEC. Необходим в каждом сообщении Resv.
FLOWSPEC
Определяет желательный уровень QoS, в сообщениях Resv.
FILTER_SPEC
Определяет субнабор информационных пакетов сессии, которые должны получить желательный уровень QoS (специфицированный объектом FLOWSPEC), в сообщениях Resv.
SENDER_TEMPLATE
Содержит IP-адрес отправителя и, может быть, некоторые дополнительную информацию, идентифицирующую отправителя. Необходим в сообщениях Path.
SENDER_TSPEC
Определяет характеристики информационного трафика отправителя.
Необходим в сообщениях Path.
ADSPEC
Несет в себе данные OPWA, в сообщении Path.
ERROR_SPEC
Специфицирует ошибку в сообщениях PathErr, ResvErr, или подтверждение в сообщении ResvConf.
POLICY_DATA
Несет в себе информацию, которая позволит локальному модулю, определяющему политику, принять решение, допустимо ли административно соответствующее резервирование. Может присутствовать в сообщениях Path, Resv, PathErr или ResvErr.
INTEGRITY
Несет в себе криптографические данные для аутентификации исходного узла и для верификации содержимого сообщения RSVP. Использование объекта INTEGRITY описано в ссылке [Baker96] в конце данного документа.
SCOPE
Несет в себе список ЭВМ-отправителей, к которым должно быть переадресовано данное сообщение. Может присутствовать в сообщениях Resv, ResvErr или ResvTear.
RESV_CONFIRM
Несет в себе IP-адрес получателя, который запросил подтверждение. Может присутствовать в сообщениях Resv или ResvConf.
C-Type
Тип объекта, уникален в пределах класса Class-Num.
Максимальная длина объекта равна 65528 байт. Поля Class-Num и C-Тип могут использоваться совместно, как 16-битовое число, для определения уникального типа для каждого из объектов.
Старшие два бита Class-Num используются для определения того, какие действия должен предпринять узел, если он не распознает Class-Num объекта.
Framing Capabilities & Bearer Capabilities
AVP Framing Capabilities и Bearer Capabilities (определенные в разделе 4.4.3) содержат 32-битовые маски. Дополнительные биты могут быть определены через стандартную процедуру [RFC 2434].Функциональная спецификация RSVP Формат сообщений RSVP
Сообщение RSVP состоит из общего заголовка, за которым следует тело сообщения, состоящее из переменного числа объектов переменной длины. Для каждого типа сообщения RSVP, существует набор правил допустимого выбора типов объектов. Эти правила специфицированы с использованием стандартных форм Бакуса-Наура (BNF), дополняемых опционными субпоследовательностями, которые помещаются в квадратные скобки. Объекты следуют в определенном порядке. Однако, во многих случаях (но не во всех), порядок объектов не играет роли. Приложение должно создавать сообщения с порядком объектов, предлагаемом в данном документе. Но оно должно быть способно воспринимать объекты в любом порядке.Генерирование псевдослучайных -битовых идентификаторов
Ниже приведенная подпрограмма (заимствована из RFC-1889) генерирует псевдослучайные 32-битовые идентификаторы, используя программы MD5, опубликованные в RFC-1321 [11]. Системные программы могут и не присутствовать во всех операционных системах, но они помогают понять, какого рода информация может использоваться.o getdomainname() ,
o getwd() , или
o getrusage()
"Живые" видео или аудио сигналы могут быть также не плохим источником случайных числе, при этом только следует позаботиться о том, чтобы микрофон не был отключен, а объектив камеры не был закрыт [7].
Использование этой или другой подобной программы предполагает определенную процедуру инициализации, которая нужна для получения первых псевдослучайных чисел. Так как эта программа заметно загружает процессор, ее непосредственное использование для генерации RTCP-периодов нельзя считать приемлемым. Следует заметить, что данная программа выдает один и тот же результат при последовательных вызовах до тех пор, пока не изменится показание системных часов или не будет задано другое значение аргумента type.
/*
* Генерация псевдослучайного 32-битового числа.
*/
#include
#include
#include
#include
#include
#include
#include "global.h" /* from RFC 1321 */
#include "md5.h" /* from RFC 1321 */
#define MD_CTX MD5_CTX
#define MDInit MD5Init
#define MDUpdate MD5Update
#define MDFinal MD5Final
static u_long md_32(char *string, int length)
{
MD_CTX context;
union {
char c[16];
u_long x[4];
} digest;
u_long r;
int i;
MDInit (&context);
MDUpdate (&context, string, length);
MDFinal ((unsigned char *)&digest, &context);
r = 0;
for (i = 0; i < 3; i++) {
r ^= digest.x[i];
}
return r;
} /* md_32 */
/*
* Полученный результат - 32-битовое число без знака. Используйте аргумент 'type' если вам
* нужно получить несколько разных величин подряд.
*/
u_int32 random32(int type)
{
struct {
int type;
struct timeval tv;
clock_t cpu;
pid_t pid;
u_long hid;
uid_t uid;
gid_t gid;
struct utsname name;
} s;
gettimeofday(&s.tv, 0);
uname(&s.name);
s.type = type;
s.cpu = clock();
s.pid = getpid();
s.hid = gethostid();
s.uid = getuid();
s.gid = getgid();
return md_32((char *)&s, sizeof(s));
} /* random32 */
Характеристики BI-TCP
При аналезе характеристик протокола предполагается, что потери пакетов происходят с вероятностью 1/р. Авторы определяют эпоху перегрузки как время между двумы последовательными потерями пакетов.Пусть Wmax обозначает размер окна непосредственно перед потерей пакета. После потери размер окна уменьшается до Wmax(1 - b). BI-TCP переключается от аддитивного увеличения к двоичному поисковому увеличению окна, когда различие между текущим значением ширины окна и конечным значением (target) меньше Smax. Так как конечное (target)значение ширины окна является средней точкой между Wmax и текущим значением ширины окна, можно сказать, что BI-TCP переключается между этими двумя приращениями, когда разница между текщией шириной окна и Wmax меньше 2Smax. Ниже в таблицах 2 и 3 представлены расчетные характеристики протоколов AIMD, BI-TCP, HSTCP и STCP для каналов с быстродействием 100 и 2500 Мбит/c.
Таблица 2. Отношения пропускной способности протоколов при 100Мбит/c
| Отношение RTT | 1 | 3 | 6 |
| AIMD | 0,99 | 7,31 | 26,12 |
| BI-TCP | 0,94 | 13,06 | 33,81 |
| HSTCP | 1,13 | 10,42 | 51,09 |
| STCP | 1,12 | 27,84 | 72,74 |
Таблица 3. Отношения пропускной способности протоколов при 2,5Гбит/c
| Отношение RTT | 1 | 3 | 6 |
| AIMD | 1,05 | 6,56 | 22,55 |
| BI-TCP | 0,96 | 9,18 | 35,76 |
| HSTCP | 0,99 | 47,42 | 131,03 |
| STCP | 0,92 | 140,52 | 300,32 |
На рис. 6 приведены расчетные данные для откликов при использовании разных модификаций протокола ТСР.

Рис. 6. Сравнение функций отклика для разных протоколов
ICMPv(ICMP для IPv
ICMPv6 используется узлами IPv6 для сообщений об ошибках при обработке пакетов, и для выполнения других функций уровня Интернет, таких как диагностика (ICMPv6 "ping") и сообщение об участии в мультикастинг группах. Протокол ICMPv6 является интегрированной частью IPv6 и должен реализовываться каждым узлом, поддерживающим IPv6.Incoming-Call-Connected (ICCN)
Incoming-Call-Connected (ICCN) является управляющим сообщением, посылаемым от LAC к LNS в ответ на полученное сообщение ICRP. Оно является третьим сообщением из трех сообщений обмена, используемых для установления сессий в пределах L2TP-туннеля.ICCN используется для индикации того, что ICRP принято, на вызов получен ответ, а L2TP-сессия должна перейти в состояние “установлена”. Оно также предоставляет дополнительную информацию LNS о параметрах, используемых для вызова, на который получен ответ (параметры, которые не всегда быть доступны в момент посылки ICRQ).
Следующие AVP должны присутствовать в ICCN:
Тип сообщения (Message Type)
Скорость обмена в канале ((Tx) Connect Speed)
Тип кадрового обмена (Framing Type)
Следующие AVP могут присутствовать в ICCN:
Initial Received LCP CONFREQ
Последнее посланное LCP CONFREQ
Последнее полученное LCP CONFREQ
Тип Proxy Authen
Имя Proxy Authen
Приглашение Proxy Authen
Прокси Authen ID
Отклик прокси Authen
ID частной группы
Скорость обмена соединения (Rx Connect Speed)
Необходима нумерация (Sequencing Required)
с другом связать запрос эхо

Рис. 4.4.1.1.37. Сообщение запрос эхо
Поля IPv6:
Адрес места назначения - любой легальный IPv6-адрес
Поля ICMPv6:
Тип 128
Код 0
Идентификатор. Идентификатор, который помогает друг с другом связать запрос эхо и эхо-отклик. Может равняться нулю.
Номер по порядку
Номер по порядку имеет целью связать друг с другом запрос эхо и эхо-отклик. Может равняться нулю.
Информация. Нуль или более октетов произвольных данных.
Описание
Каждый узел должен реализовать функцию эхо-отклика ICMPv6 при получении запроса эхо. Узлу следует также предоставить пользовательский интерфейс для посылки запросов эхо и получения эхо-откликов для целей диагностики.
Формат сообщения эхо-отклик идентичен формату запроса эхо (рис. 20.5).
Поля IPv6:
Адрес места назначения копируется из поля адрес отправителя пакета запрос эхо.
Поля ICMPv6:
Тип 129
Код 0
Идентификатор. Идентификатор из исходного запроса эхо (echo request).
Номер по порядку. Номер по порядку из исходного запроса эхо.
Информация. Данные из исходного запроса эхо.
Описание
Каждый узел должен иметь встроенную функцию отклика ICMPv6, которая получает запросы эхо и посылает соответствующие эхо-отклики. Узел должен также реализовать интерфейс прикладного уровня для посылки запросов эхо и получения эхо-откликов для диагностических целей.
Адрес отправителя эхо-отклика, посылаемого в ответ на уникастный запрос эхо должен быть тем же самым, что и адрес места назначения в запросе эхо.
Эхо-отклик должен быть послан в ответ на запрос эхо, посланный по мультикастному адресу. Адрес отправителя в отклике должен быть уникастным адресом, принадлежащим интерфейсу, через который был получен мультикастный запрос эхо.
Информация, полученная в ICMPv6 сообщении запроса эхо, должна быть полостью возвращена без модификации в ICMPv6 эхо-отклике, если эхо-отклик не превысит MTU обратного прохода, в противном случае пакет укорачивается.
Оповещение верхнего уровня
Сообщения эхо-отклик должны передаваться пользовательскому интерфейсу ICMPv6, если соответствующий запрос эхо исходит не из IP-уровня.
Сообщение о членстве в группе имеет следующий формат:

Рис. 4.4.1.1.38. Сообщения участия в группе
Поля IPv6:
Адрес места назначения
В сообщении-запросе о членстве в группе запрашивается мультикаст-адрес группы.
В отчете о членстве в группе или в сообщении о сокращении членства в группе сообщается мультикаст-адрес группы.
Поле Hop Limit = 1 (предельное число шагов)
Поля ICMPv6:
Тип 130 - Запрос членства в группе
131 - Отчет о членстве в группе
132 - Сокращение членства в группе
Код 0
Максимальное время отклика
В сообщениях запросах - это максимальное время в миллисекундах, на которое может задержаться сообщение-отчет. В сообщениях-отчетах и сообщениях о сокращении в это поле отправитель записывает нуль, а получатель его игнорирует.
Не используется. Отправитель записывает нуль, получатель игнорирует.
Мультикаст-адрес
Адрес мультикаст-группы, сообщение о которой послано. В сообщениях-запросах поле мультикаст-адреса может равняться нулю, что означает запрос ко всем группам.
Описание
Сообщения ICMPv6 о членстве в группе используются для передачи информации о членстве в мультикаст-группе от узлов к их ближайшим маршрутизаторам. Подробности их использования можно найти в [RFC-1112].
Интерфейс маршрутизации RSVP
Реализация RSVP нуждается в следующей поддержке со стороны механизма маршрутизации узла.Для пересылки сообщений Path и PathTear процесс RSVP должен быть способен запрашивать процесс маршрутизации с целью получения маршрутных данных.
Ucast_Route_Query( [ SrcAddress, ] DestAddress,
Notify_flag ) -> OutInterface
Mcast_Route_Query( [ SrcAddress, ] DestAddress,
Notify_flag )
-> [ IncInterface, ] OutInterface_list
В зависимости от протокола маршрутизации запрос может зависеть или нет от SrcAddress, т.е., от IP-адреса ЭВМ-отправителя, который является также IP-адресом источника сообщения. IncInterface характеризует интерфейс, через который ожидается прибытие пакета. Некоторые мультикастные протоколы маршрутизации могут не выдавать этот адрес. Если флаг Notify_flag = True, блок маршрутизации отправит сообщение о непреднамеренном изменении маршрута, если такое изменение произойдет.
Мультикастный маршрутный запрос может вернуть пустой список OutInterface_list, если за оговоренным маршрутизатором нет ни одного получателя. Запрос маршрутной информации может вернуть сообщение `No such route' (такой маршрут отсутствует) возможно, в результате временной рассогласованности (например, сообщение Path или PathTear для запрошенного маршрута не дошло). В любом случае локальное состояние должно быть актуализовано так, как это требуется в запросе, который не может быть переслан далее.
При маршрутном запросе с флагом Notify_flag = True, процесс маршрутизации может послать асинхронное сообщение процессу RSVP, который уведомляет об изменении определенного маршрута.
Ucast_Route_Change( ) -> [ SrcAddress, ] DestAddress,
OutInterface
Mcast_Route_Change( ) -> [ SrcAddress, ] DestAddress,
[ IncInterface, ] OutInterface_list
RSVP должен быть способен запоминать, какой реальный и виртуальный интерфейсы являются активными, а также их IP-адреса.
Должна быть предусмотрена возможность логической дезактивации интерфейса для RSVP. Когда интерфейс дезактивирован, сообщения Path не должны проходить через данный интерфейс, если сообщение RSVP получено, оно должно быть отброшено (возможно, с соответствующей записью в журнале операций).
Интерфейс приложения RSVP
Структура реального интерфейса может зависеть от операционной системы. Некоторые из вызовов предполагают асинхронную присылку информации.Вызов: SESSION( DestAddress , ProtocolId, DstPort
[ , SESSION_object ]
[ , Upcall_Proc_addr ] ) -> Session-id
Этот вызов инициирует RSVP обработку сессии, заданной DestAddress, ProtocolId и, возможно, номером порта DstPort. В случае успеха вызов SESSION возвращает локальный идентификатор сессии Session-id, который может использоваться при последующих вызовах.
Параметр Upcall_Proc_addr определяет адрес вызова процедуры получения кода ошибки или информации о событии. Параметр SESSION_object включен для организации механизма поддержки более общего описания сессии ("обобщенный порт назначения"). Обычно SESSION_object опускается.
Вызов: SENDER( Session-id
[ , Source_Address ] [ , Source_Port ]
[ , Sender_Template ]
[ , Sender_Tspec ] [ , Adspec ]
[ , Data_TTL ] [ , Policy_data ] )
Отправитель использует этот вызов, чтобы определить или модифицировать атрибуты информационного потока. Первое обращение к SENDER для регистрации сессии как `Session-id' заставит RSVP начать рассылку сообщений Path для данной сессии; последующие вызовы будут модифицировать информацию о проходе.
Параметры SENDER интерпретируются следующим образом:
Вызов: RESERVE( session-id, [ receiver_address , ]
[ CONF_flag, ] [ Policy_data, ]
style, style-dependent-parms )
Получатель использует этот вызов, для того чтобы осуществить или модифицировать резервирование для сессии `session-id'. Первое обращение RESERVE инициирует периодическую передачу сообщений Resv. Последующие вызовы RESERVE могут служить для модификации параметров предыдущих обращений.
Опционный параметр `receiver_address' может использоваться получателем в маршрутизаторе или ЭВМ с несколькими сетевыми интерфейсами; это IP-адрес одного из интерфейсов узла. Флаг CONF_flag должен быть установлен, если желательно подтверждение резервирования. Параметр `Policy_data' специфицирует управляющие данные получателя, в то время как параметр `style' указывает на стиль резервирования. Остальные параметры зависят от стиля; обычно они соответствуют спецификациям фильтра и flowspecs.
Вызов: RELEASE( session-id )
Этот вызов удаляет состояние RSVP для сессии, указанной в session-id. Узел затем шлет соответствующие сообщения отмены (teardown) и прекращает рассылку сообщений обновления для session-id.
Общая форма вызова имеет вид:
Обращение:
information_parameters
"Upcall_Proc" представляет собой процедуру, чей адрес был дан при вызове SESSION. Это обращение может произойти асинхронно в любое время после вызова SESSION до вызова RELEASE и служит для индикации ошибки или события.
В настоящее время имеется пять типов обращений, отличающихся параметром Info_type. Выбор информационных параметров зависит от типа.
1. Info_type = PATH_EVENT
Обращение Path Event приводит к тому, что получение первого сообщения Path для данной сессии, указывает приложению получателя на наличие, по крайней мере, одного отправителя или на изменение состояние прохода.
Обращение (отклик):
Info_type = PATH_EVENT,
Sender_Tspec, Sender_Template
[ , Adspec ] [ , Policy_data ]
Это обращение выдает спецификации Sender_Tspec, Sender_Template, Adspec и управляющую информацию из запроса Path.
2. Info_type = RESV_EVENT
Обращение Resv Event запускается в результате получения первого сообщения RESV, или как следствие модификации предшествующего состояния резервирования для данной сессии.
Обращение (отклик):
Info_type = RESV_EVENT,
Style, Flowspec, Filter_Spec_list
[ , Policy_data ]
`Flowspec' - эффективное значение QoS, которое получено. Заметим, что сообщение Resv (стиль FF) может вызвать несколько обращений RESV_EVENT, по одному для каждого дескриптора потока.
3. Info_type = PATH_ERROR
Событие Path Error индицирует ошибку в информации отправителя, которая была специфицирована в запросе SENDER.
Обращение (отклик):
Info_type=PATH_ERROR,
Error_code , Error_value ,
Error_Node , Sender_Template
[ , Policy_data_list ]
Параметр Error_code определяет ошибку, а Error_value может нести в себе некоторую дополнительную (возможно системно-зависимую) информацию об ошибке. Параметр Error_Node специфицирует IP-адрес узла, который обнаружил ошибку. Параметр Policy_data_list, если он присутствует, содержит любые объекты POLICY_DATA из неудачного сообщения Path.
4. Info_type = RESV_ERR
Событие Resv Error указывает на ошибку в сообщении резервирования, в формирование которого приняло участие данное приложение.
Обращение (отклик):
Info_type = RESV_ERROR,
Error_code , Error_value ,
Error_Node , Error_flags ,
Flowspec, Filter_spec_list
[ , Policy_data_list ]
Параметр Error_Node специфицирует IP- адрес узла, который обнаружил данное событие.
Имеется два флага Error_flags:
- InPlace
Этот флаг может быть равен 1 при ошибке контроля доступа для индикации наличия резервирования в узле, где произошла ошибка. Этот флаг устанавливается при ошибке и транспортируется сообщениями ResvErr.
- NotGuilty
Этот флаг может быть равен 1 при ошибке контроля доступа для индикации того, что запрошенная получателем спецификация flowspec оказалась меньше той, которая вызвала ошибку. Этот флаг устанавливается API получателя.
Filter_spec_list и Flowspec содержат соответствующие объекты из ошибки дескриптора потока. List_count специфицирует число FILTER_SPECS в списке Filter_spec_list. Параметр Policy_data_list содержит любые объекты POLICY_DATA из сообщения ResvErr.
5. Info_type = RESV_CONFIRM
Событие Подтверждение указывает, что получено сообщение ResvConf.
Обращение (отклик):
Info_type = RESV_CONFIRM,
Style, List_count,
Flowspec, Filter_spec_list
[ , Policy_data ]
Параметры интерпретируются также как и для отклика Resv Error.
Хотя сообщения RSVP, указывающие на события path или resv могут приходить периодически, API должно послать соответствующие асинхронные отклики приложению только на первое из них или при изменении полученной информации. Все события, сопряженные с ошибками или подтверждениями должны доводиться до сведения приложения.
Интерфейс управления трафиком RSVP
Трудно представить общий интерфейс для управления трафиком, так как детали установления резервирования сильно зависят от технологии реализации канального уровня в интерфейсе.Объединение RSVP-резервирований необходимо из-за мультикастной доставки данных, при которой информационные пакеты размножаются для отправки последующим узлам. В каждой такой точке размножения, RSVP должен объединять запросы резервирования от последующих узлов путем выбора “максимума” их спецификаций flowspecs. В данном маршрутизаторе или ЭВМ может присутствовать несколько таких точек объединения/размножения.
1. IP-уровень
Мультикастная IP рассылка выполняет разветвление потока на IP-уровне. В этом случае RSVP должен объединять резервирования, соответствующих выходных интерфейсов для последующей отправки запроса резервирования далее.
2. Сеть
Размножение пакетов может иметь место и после узла, например, в широковещательных сетях, в переключателях канального уровня или системе маршрутизаторов, не поддерживающих RSVP. В этих случаях RSVP должен объединять запросы резервирования от ряда предыдущих узлов, для того чтобы выполнить резервирование для одного выходного интерфейса
3. Драйвер канального уровня
В технологиях со множественным доступом размножение пакетов может осуществляться на уровне канального драйвера или сетевого интерфейса.
В общем, эти сложности не влияют на реализацию протокола RSVP, нужно только четко определить какие запросы резервирования следует объединить. Может оказаться желательным организовать реализацию RSVP из двух блоков: ядро, которое выполняет канально-независимую обработку и адаптационный уровень, учитывающий канальную специфику.
Вызов: TC_AddFlowspec( Interface, TC_Flowspec,
TC_Tspec, TC_Adspec, Police_Flags )
-> RHandle [, Fwd_Flowspec]
Параметр TC_Flowspec определяет желательное значение QoS для управления доступом;. Его значение вычисляется как максимум совокупности спецификаций flowspecs для последующих узлов (см. ниже описание вызова Compare_Flowspecs).
Параметр TC_Tspec определяет эффективное значение спецификации отправителя Tspec Path_Te. Параметр TC_Adspec задает спецификацию Adspec. Параметр Police_Flags несет в себе три флага E_Police_Flag, M_Police_Flag и B_Police_Flag.
Если данный вызов оказался успешным, он устанавливает новый канал резервирования, соответствующий RHandle; в противном случае, он возвращает код ошибки. Код RHandle используется вызывающей программой для будущих ссылок на это резервирование. Если служба управления трафиком модифицирует flowspec, вызов вернет модифицированный объект Fwd_Flowspec.
Вызов: TC_ModFlowspec( Interface, RHandle, TC_Flowspec,
TC_Tspec, TC_Adspec, Police_flags )
[ -> Fwd_Flowspec ]
Этот вызов используется для модификации существующего резервирования. TC_Flowspec передается блоку контроля разрешения. Если разрешения нет, текущая спецификация flowspec остается в силе. Соответствующие спецификации фильтров, если таковые имеются, остаются не затронутыми. Другие параметры определены также как и в TC_AddFlowspec. Если система модифицирует flowspec, вызов вернет также модифицированный объект Fwd_Flowspec.
Вызов: TC_DelFlowspec( Interface, RHandle )
Этот вызов ликвидирует существующее резервирование, включая спецификацию flowspec и все сопряженные спецификации фильтров.
Вызов: TC_AddFilter( Interface, RHandle,
Session , FilterSpec ) -> FHandle
Этот вызов добавляет новую спецификацию фильтра для резервирования, заданного RHandle. Запрос посылается после успешного вызова TC_AddFlowspec. Этот вызов возвращает дескриптор фильтра FHandle.
Вызов: TC_DelFilter( Interface, FHandle )
Этот вызов используется для удаления какого-либо фильтра, идентифицируемого FHandle.
Вызов: TC_Advertise( Interface, Adspec,
Non_RSVP_Hop_flag ) -> New_Adspec
Этот вызов используется при OPWA и служит для вычисления выходной спецификации New_Adspec для заданного интерфейса.Битовый флаг Non_RSVP_Hop_flag должен устанавливаться в случае, когда демон RSVP обнаруживает, что предшествующий узел содержит один или более маршрутизаторов, не поддерживающих RSVP. TC_Advertise вставит эту информацию в New_Adspec для оповещениястить обнаружения такого узла.
Обращение (отклик): TC_Preempt() -> RHandle, Reason_code
Для того чтобы выдать новый запрос резервирования, модули контроля разрешения и управления могут осуществить выделение квот для одного или двух существующих резервирований. Это вызовет отклик TC_Preempt() на каждое привилегированное RSVP резервирование, отправляя дескриптор резервирования RHandle и субкод причины.
Интерфейсы RSVP
RSVP в маршрутизаторе имеет интерфейсы для управления трафиком, а в ЭВМ - интерфейсы для приложений (т.е., API), а также для управления трафиком (если такой контроль предусмотрен).В Интернет используется много различных
4.4.1 IP-протоколСеменов Ю.А. (ГНЦ ИТЭФ)
| Номер раздела | Название раздела | Объем в страницах | Объем в кбайт |
| 4.4.1.1 | 45 | 45 | |
| 4.4.1.2 | 1 | 87 | |
| 4.4.1.3 | 48 | 48 |

Рис. 4.4.1.1. Формат дейтограммы Интернет
Поле версия характеризует версию IP-протокола (например, 4 или 6). Формат пакета определяется программой и, вообще говоря, может быть разным для разных значений поля версия. Только размер и положение этого поля незыблемы. Поэтому в случае изменений длины IP-адреса слишком тяжелых последствий это не вызовет. Понятно также, что значение поля версия во избежании непредсказуемых последствий должно контролироваться программой. HLEN - длина заголовка, измеряемая в 32-разрядных словах, обычно заголовок содержит 20 октетов (HLEN=5, без опций и заполнителя). Поле полная длина определяет полную длину IP-дейтограммы (до 65535 октетов), включая заголовок и данные. Одно-октетное поле тип сервиса (TOS - type of service) характеризует то, как должна обрабатываться дейтограмма. Это поле делится на 6 субполей:

Субполе Приоритет предоставляет возможность присвоить код приоритета каждой дейтограмме. Значения приоритетов приведены в таблице (в настоящее время это поле не используется).
0 Обычный уровень
1 Приоритетный
2 Немедленный
3 Срочный
4 Экстренный
5 ceitic/ecp
6 Межсетевое управление
7 Сетевое управление
Формат поля TOS определен в документе RFC-1349.
Биты C, D, T и R характеризуют пожелание относительно способа доставки дейтограммы. Так D=1 требует минимальной задержки, T=1 - высокую пропускную способность, R=1 - высокую надежность, а C=1 - низкую стоимость. TOS играет важную роль в маршрутизации пакетов. Интернет не гарантирует запрашиваемый TOS, но многие маршрутизаторы учитывают эти запросы при выборе маршрута (протоколы OSPF и IGRP). В таблице 4.4.1.1 приведены рекомендуемые значения TOS.
Таблица 4.4.1.1. Значения TOS для разных протоколов
| Процедура | Минимал. задержка | Максим. пропускная способность | Максим. надежность | Минимал. стоимость | Код TOS |
| FTP управление, FTP данные | |||||
| 1 | 0 | 0 | 0 | 0x10 | |
| 0 | 1 | 0 | 0 | 0x08 | |
| TFTP | 1 | 0 | 0 | 0 | 0x10 |
| DNS, UDP TCP |
1 | 0 | 0 | 0 | 0x00 |
| 0 | 0 | 0 | 0 | 0x10 | |
| 0 | 0 | 0 | 0 | 0x00 | |
| telnet | 1 | 0 | 0 | 0 | 0x10 |
| ICMP | 0 | 0 | 0 | 0 | 0x00 |
| IGP | 0 | 0 | 1 | 0 | 0x04 |
| SMTP управление SMTP данные |
|||||
| 1 | 0 | 0 | 0 | 0x10 | |
| 0 | 1 | 0 | 0 | 0x08 | |
| SNMP | 0 | 0 | 1 | 0 | 0x04 |
| NNTP | 0 | 0 | 0 | 1 | 0x02 |
До середины 90-х годов поле TOS в большинстве реализаций игнорировалось. Но после начала разработок средств обеспечения качества обслуживания (QoS) внимание к этому возрасло. Появилось предложение замены поля TOS на поле DSCP (Differenciated Services Code Point), которое также имеет 8 бит (см. RFC-2474). Смотри рис. 4.4.1.1a. Биты CU пока не определены. Иногда это поле называется байтом DS (Differentiated Services).

Рис. 4.4.1.1a. Формат поля DSCP.
Биты DS0-DS5 определяют селектор класса. Значения этого кода представлены в таблице ниже. Стандартным значением DSCP по умолчанию является 000000.
| Селектор класса | DSCP |
| Приоритет 1 | 001000 |
| Приоритет 2 | 010000 |
| Приоритет 3 | 011000 |
| Приоритет 4 | 100000 |
| Приоритет 5 | 101000 |
| Приоритет 6 | 110000 |
| Приоритет 7 | 111000 |
В рамках этой политики определяются коды DSCP внутри классов. Например, для политики немедленной переадресации EF рекомендуемое значение DSCP=101110. Эта политика соответствует наиболее высокому уровню обслуживания.
Маршрут транспортировки IP-дейтограммы нельзя знать заранее, это связано с поэтапным (по-шаговом) принятием решения о пути каждого пакета. Это свойство маршрутизации обусловлено тем, что IP является протоколом передачи данных без установления соединения.
Поля идентификатор, флаги (3 бита) и указатель фрагмента (fragment offset) управляют процессом фрагментации и последующей "сборки" дейтограммы. Идентификатор представляет собой уникальный код дейтограммы, позволяющий идентифицировать принадлежность фрагментов и исключить ошибки при "сборке" дейтограмм. Бит 0 поля флаги является резервным, бит 1 служит для управления фрагментацией пакетов (0 - фрагментация разрешена; 1 - запрещена), бит 2 определяет, является ли данный фрагмент последним (0 - последний фрагмент; 1 - следует ожидать продолжения). Поле время жизни (TTL - time to live) задает время жизни дейтограммы в секундах, т.е. предельно допустимое время пребывания дейтограммы в системе. При каждой обработке дейтограммы, например в маршрутизаторе, это время уменьшается в соответствии со временем пребывания в данном устройстве или согласно протоколу обработки. Если TTL=0, дейтограмма из системы удаляется. Во многих реализациях TTL измеряется в числе шагов, в этом случае каждый маршрутизатор выполняет операцию TTL=TTL-1. TTL помогает предотвратить зацикливание пакетов. Поле протокол аналогично полю тип в Ethernet-кадре и определяет структуру поля данные (см. табл. 4.4.1.2).
Поле контрольная сумма заголовка вычисляется с использованием операций сложения 16-разрядных слов заголовка по модулю 1. Сама контрольная сумма является дополнением по модулю один полученного результата сложения. Обратите внимание, здесь осуществляется контрольное суммирование заголовка, а не всей дейтограммы.
Поле опции не обязательно присутствует в каждой дейтограмме. Размер поля опции зависит от того, какие опции применены. Если используется несколько опций, они записываются подряд без каких-либо разделителей. Каждая опция содержит один октет кода опции, за которым может следовать октет длины и серия октетов данных. Если место, занятое опциями, не кратно 4 октетам, используется заполнитель. Структура октета кода опции отражена на рис. 4.4.1.2.
Таблица 4.4.1.2. Коды протоколов Интернет
| Код протокола Интернет | Сокращенное название протокола | Описание |
| 0 | - | Зарезервировано |
| 1 | ICMP | Протокол контрольных сообщений [rfc792] |
| 2 | IGMP | Групповой протокол управления [rfc1112] |
| 3 | GGP | Протокол маршрутизатор-маршрутизатор [RFC-823] |
| 4 | IP | IP поверх IP (инкапсуляция/туннели) |
| 5 | ST | Поток [rfc1190] |
| 6 | TCP | Протокол управления передачей [RFC-793] |
| 7 | UCL | UCL |
| 8 | EGP | Протокол внешней маршрутизации [RFC-888] |
| 9 | IGP | Протокол внутренней маршрутизации |
| 10 | BBN-MON | BBN-RCC мониторирование |
| 11 | NVP-II | Сетевой протокол для голосовой связи [RFC-741] |
| 12 | PUP | PUP |
| 13 | ARGUS | argus |
| 14 | Emcon | emcon |
| 15 | Xnet | Перекрестный сетевой отладчик [IEN158] |
| 16 | Chaos | Chaos |
| 17 | UDP | Протокол дейтограмм пользователя [RFC-768] |
| 18 | MUX | Мультиплексирование [IEN90] |
| 19 | DCN-MEAS | DCN измерительные субсистемы |
| 20 | HMP | Протокол мониторирования ЭВМ (host [RFC-869]) |
| 21 | PRM | Мониторирование при передаче пакетов по радио |
| 22 | XNS-IDP | Xerox NS IDP |
| 23 | Trunk-1 | Trunk-1 |
| 24 | Trank-2 | Trunk-2 |
| 25 | Leaf-1 | Leaf-1 |
| 26 | Leaf-2 | Leaf-2 |
| 27 | RDP | Протокол для надежной передачи данных [RFC-908] |
| 28 | IRTP | Надежный TP для Интернет [RFC-938] |
| 29 | ISO-TP4 | ISO транспортный класс 4 [RFC-905] |
| 30 | Netblt | Массовая передача данных [RFC-969] |
| 31 | MFE-NSP | Сетевая служба MFE |
| 32 | Merit-INP | Межузловой протокол Merit |
| 33 | SEP | Последовательный обмен |
| 34 | не определен | |
| 35 | IDRP | Междоменный протокол маршрутизации |
| 36 | XTP | Xpress транспортный протокол |
| 37 | DDP | Протокол доставки дейтограмм |
| 38 | IDPR-CMTP | IDPR передача управляющих сообщений |
| 39 | TP++ | TP++ транспортный протокол |
| 40 | IL | IL-транспортный протокол |
| 41 | SIP | Простой Интернет-протокол |
| 42 | SDRP | Протокол маршрутных запросов для отправителя |
| 43 | SIP-SR | SIP исходный маршрут |
| 44 | SIP-Frag | SIP-фрагмент |
| 45 | IDRP | Интер-доменный маршрутный протокол |
| 46 | RSVP | Протокол резервирования ресурсов канала |
| 47 | GRE | Общая инкапсуляция маршрутов |
| 49 | BNA | BNA |
| 50 | SIPP-ESP | SIPP ESЗ |
| 52 | I-NLSP | Интегрированная система безопасности сетевого уровня |
| 53 | Swipe | IP с кодированием |
| 54 | NHRP | nbma протокол определения следующего шага |
| 55-60 | не определены | |
| 61 | Любой внутренний протокол ЭВМ | |
| 62 | CFTP | CFTP |
| 63 | Любая локальная сеть | |
| 64 | Sat-Expak | Satnet и Expak |
| 65 | MIT-Subn | Поддержка субсетей MIT |
| 66 | RVD | Удаленный виртуальный диск MIT |
| 67 | IPPC | IPPC |
| 68 | Любая распределенная файловая система | |
| 69 | Sat-Mon | Мониторирование Satnet |
| 70 | не определен | |
| 71 | IPCV | Базовая пакетная утилита |
| 75 | PVP | Пакетный видео-протокол |
| 76 | BRsat-Mon | Резервное мониторирование Satnet |
| 78 | Wb-mon | Мониторирование Expak |
| 79 | Wb-expak | Широкополосная версия Expak |
| 80 | ISO-IP | ISO Интернет протокол |
| 88 | IGRP | IGRP (Cisco) - внутренний протокол маршрутизации |
| 89 | OSPFIGP | OSPFIGP - внутренний протокол маршрутизации |
| 92 | MTP | Транспортный протокол мультикастинга |
| 101-254 | не определены | |
| 255 | зарезервировано |

Рис. 4.4.1.2. Формат описания опций
Флаг копия равный 1 говорит о том, что опция должна быть скопирована во все фрагменты дейтограммы. При равенстве этого флага 0 опция копируется только в первый фрагмент. Ниже приведены значения разрядов 2-битового поля класс опции:
| Значение поля класс опции | Описание |
| 0 | Дейтограмма пользователя или сетевое управление |
| 1 | Зарезервировано для будущего использования |
| 2 | Отладка и измерения (диагностика) |
| 3 | Зарезервировано для будущего использования |
| Класс опции | Номер опции | Длина описания | Назначение |
| 0 | 0 | - | Конец списка опций. Используется, если опции не укладываются в поле заголовка (смотри также поле "заполнитель") |
| 0 | 1 | - | Никаких операций (используется для выравнивания октетов в списке опций) |
| 0 | 2 | 11 | Ограничения, связанные с секретностью (для военных приложений) |
| 0 | 3 | * | Свободная маршрутизация. Используется для того, чтобы направить дейтограмму по заданному маршруту |
| 0 | 7 | * | Запись маршрута. Используется для трассировки |
| 0 | 8 | 4 | Идентификатор потока. Устарело. |
| 0 | 9 | * | Жесткая маршрутизация. Используется, чтобы направить дейтограмму по заданному маршруту |
| 2 | 4 | * | Временная метка Интернет |
Наибольший интерес представляют собой опции временные метки и маршрутизация. Опция записать маршрут (RR) создает дейтограмму, где зарезервировано место, куда каждый маршрутизатор по дороге должен записать свой IP-адрес (например, утилита traceroute). Формат опции записать маршрут в дейтограмме представлен ниже на рис. 4.4.1.3 (предусмотрено место для записи 9 IP-адресов, к сожаления, реализация RR не является обязательной):

Рис. 4.4.1.3 Формат опций записать маршрут
Поле код содержит номер опции (7 в данном случае). Поле длина определяет размер записи для опций, включая первые 3 октета. Указатель отмечает первую свободную позицию в списке IP-адресов (куда можно произвести запись очередного адреса).
Интересную возможность представляет опция маршрут отправителя, которая открывает возможность посылать дейтограммы по заданному отправителем маршруту. Это позволяет исследовать различные маршруты, в том числе те, которые недоступны через узловые маршрутизаторы. Существует две формы такой маршрутизации: Свободная маршрутизация и Жесткая маршрутизация (маршрутизация отправителя). Форматы для этих опций показаны ниже:

Рис. 4.4.1.3а. Формат опций маршрутизации
Жесткая маршрутизация означает, что адреса определяют точный маршрут дейтограммы. Проход от одного адреса к другому может включать только одну сеть. Свободная маршрутизация отличается от предшествующей возможностью прохода между двумя адресами списка более чем через одну сеть. Поле длина задает размер списка адресов, а указатель отмечает адрес очередного маршрутизатора на пути дейтограммы.
IP-слой имеет маршрутные таблицы, которые просматриваются каждый раз, когда IP получает дейтограмму для отправки. Когда дейтограмма получается от сетевого интерфейса, IP первым делом проверяет, принадлежит ли IP-адрес места назначения к списку локальных адресов, или является широковещательным адресом. Если имеет место один из этих вариантов, дейтограмма передается программному модулю в соответствии с кодом в поле протокола. IP-процессор может быть сконфигурирован как маршрутизатор, в этом случае дейтограмма может быть переадресована в другой узел сети. Маршрутизация на IP-уровне носит пошаговый характер. IP не знает всего пути, он владеет лишь информацией - какому маршрутизатору послать дейтограмму с конкретным адресом места назначения.
Просмотр маршрутной таблицы происходит в три этапа:
Для того чтобы посмотреть, как выглядит простая маршрутная таблица, воспользуемся командой netstat -rn (ЭВМ Sun. Флаг -r выводит на экран маршрутную таблицу, а -n отображает IP-адреса в цифровой форме. С целью экономии места таблица в несколько раз сокращена).
| routing tables destination | gateway | flags | refcnt | use | interface |
| 193.124.225.72 | 193.124.224.60 | ughd | 0 | 61 | le0 |
| 192.148.166.1 | 193.124.224.60 | ughd | 0 | 409 | le0 |
| 193.124.226.81 | 193.124.224.37 | ughd | 0 | 464 | le0 |
| 192.160.233.201 | 193.124.224.33 | ughd | 0 | 222 | le0 |
| 192.148.166.234 | 193.124.224.60 | ughd | 1 | 3248 | le0 |
| 193.124.225.66 | 193.124.224.60 | ughd | 0 | 774 | le0 |
| 192.148.166.10 | 193.124.224.60 | ughd | 0 | 621 | le0 |
| 192.148.166.250 | 193.124.224.60 | ughd | 0 | 371 | le0 |
| 192.148.166.4 | 193.124.224.60 | ughd | 0 | 119 | le0 |
| 145.249.16.20 | 193.124.224.60 | ughd | 0 | 130478 | le0 |
| 192.102.229.14 | 193.124.224.33 | ughd | 0 | 13206 | le0 |
| default | 193.124.224.33 | ug | 9 | 5802624 | le0 |
| 193.124.224.32 | 193.124.224.35 | u | 6 | 1920046 | le0 |
| 193.124.134.0 | 193.124.224.50 | ugd | 1 | 291672 | le0 |
| u | Маршрут работает (up). |
| g | Путь к маршрутизатору (gateway), если этот флаг отсутствует, адресат доступен непосредственно. |
| h | Маршрут к ЭВМ (host), адрес места назначения является полным адресом этой ЭВМ (адрес сети + адрес ЭВМ). Если флаг отсутствует, маршрут ведет к сети, а адрес места назначения является адресом сети. |
| d | Маршрут возник в результате переадресации. |
| m | Маршрут был модифицирован с помощью переадресации. |
Каждый маршрутизатор на пути дейтограммы делает запись в одном из полей дейтограммы (два слова по 32 разряда; смотри раздел ). Формат этой опции отображен на рисунке 4.4.1.4.

Рис. 4.4.1.4 Формат опции "временные метки"
Смысл полей длина и указатель идентичен тому, что сказано о предыдущих опциях. 4-битовое поле переполнение содержит число маршрутизаторов, которые не смогли записать временные метки из-за ограничений выделенного места в дейтограмме. Значения поля флаги задают порядок записи временных меток маршрутизаторами:
Таблица 4.4.1.3.
| Значение флага | Назначение |
| 0 | Записать только временные метки; опустить IP-адреса. |
| 1 | Записать перед каждой временной меткой IP-адрес (как в формате на предыдущем рисунке). |
| 3 | IP-адреса задаются отправителем; маршрутизатор записывает только временные метки, если очередной IP-адрес совпадает с адресом маршрутизатора |
Взаимодействие других протоколов с IP можно представить из схемы на рис. 4.4.1.5. В основании лежат протоколы, обеспечивающие обмен информацией на физическом уровне, далее следуют протоколы IP, ICMP, ARP, RARP, IGMP и протоколы маршрутизаторов. Чем выше расположен протокол, тем более высокому уровню он соответствует. Протоколы, имена которых записаны в одной и той же строке, соответствуют одному и тому же уровню. Но все разложить аккуратно по слоям невозможно - некоторые протоколы занимают промежуточное положение, что и отражено на схеме, (области таких протоколов захватывают два уровня. Здесь протоколы IP, ICMP и IGMP помещены на один уровень, для чего имеется не мало причин. Но иногда последние два протокола помещают над IP, так как их пакеты вкладываются в IP-дейтограммы. Так что деление протоколов по уровням довольно условно. На самом верху пирамиды находятся прикладные программы, хотя пользователю доступны и более низкие уровни (например, ICMP), что также отражено на приведенном рисунке (4.4.1.5).

Рис. 4.4.1.5. Распределение протоколов Интернет по уровням
Интернет - это инструмент общения, средство доступа к информации и как всякий инструмент требует практики. Из вашего собственного опыта вы знаете, что можно прочесть ворох инструкций о том, как забивать гвозди, но научиться этому можно лишь на практике. Поэтому рекомендую с самого начала, читая данные тексты, чаще садитесь за терминал.
IP
При работе в IP-среде протокол L2TP должен обеспечить UDP-инкапсуляцию, описанную в 8.1. Другие конфигурации (возможно соответствующие формату со сжатием заголовков) могут быть определены и доступны в качестве конфигурируемой опции.IPvадреса с вложенными IPvадресами
Алгоритмы IPv6 включают в себя механизм (для ЭВМ и маршрутизаторов) организации туннелей для IPv6 пакетов через маршрутную инфраструктуру IPv4. Узлам IPv6, которые используют этот метод, присваиваются специальные IPv6 уникастные адреса, которые в младших 32 битах содержат адрес IPv4. Этот тип адреса называется "IPv4-compatible IPv6 address" и имеет формат, изображенный на рис. 4.4.1.1.5:
Рис. 4.4.1.1.5
Определен и второй тип IPv6 адреса, который содержит внутри IPv4 адрес. Этот адрес используется для представления IPv6 адресов узлам IPv4 (тем, что не поддерживают IPv6). Этот тип адреса называется "IPv4-mapped IPv6 address" и имеет формат показанный на рис. 4.4.1.1.6:

Рис. 4.4.1.1.6
IPX Адреса
Соответствие IPX и IPv6 адресов показано ниже на рис. 4.4.1.1.8:
Рис. 4.4.1.1.8
Исходящие вызовы
Исходящие вызовы инициируются LNS и заставляют LAC реализовать вызов. Для исходящих вызовов используется три сообщения: Outgoing-Call-Request, Outgoing-Call-Reply, и Outgoing-Call-Connected. LNS посылает Outgoing-Call-Request, специфицирующий телефонный номер партнера, субадрес и другие параметры. LAC должен реагировать на сообщение Outgoing-Call-Request откликом Outgoing-Call-Reply, так как LAC определяет, что имеется возможность реализовать вызов, который должен быть административно авторизован. Например, разрешено ли LNS осуществлять международные телефонные вызовы? Если для исходящего вызова осуществлено соединение, LAC посылает LNS сообщение Outgoing-Call-Connected, характеризующее окончательный результат попытки вызова.Если топология не содержит петель, зацикливания сообщений Resv и ResvErr при произвольном выборе отправителя можно избежать, следуя приведенному выше правилу: состояние, которое получено через определенный интерфейс, никогда не должно переадресовываться через этот же интерфейс. Однако, когда топология содержит петли, необходимы дополнительные усилия для предотвращения циклов автоматического обновления для сообщений Resv и ResvErr с произвольным выбором отправителя. Решением этой проблемы может быть включение списка адресов получателей в объект SCOPE.
Когда сообщение Resv с стилем WF должно быть переадресовано определенному предыдущему узлу, следует определить новый список адресов для объекта SCOPE на основе аналогичного объекта, полученного с соответствующими сообщениями Resv. Если новый объект SCOPE пуст, сообщение не направляется предыдущему узлу. Правила для вычисления нового объекта SCOPE/ для сообщения Resv приведены ниже:
На рис. 4.4.9.6.10 показан пример Resv сообщений (стиль WF). Адресный список объекта SCOPE показан в квадратных скобках.

| Интерфейс IА | Интерфейс IБ | Интерфейс IВ | |||
| Получает | Отправляет | Получает | Отправляет | Получает | Отправляет |
| WF([S1,S2,S3]) | WF([S4]) | WF([S2,S3,S4]) | WF([S1]) | WF([S4,S1]) | WF([S2,S3]) |
Объекты SCOPE не являются необходимыми, если мультикастинг-маршрутизация использует совместные деревья или если стиль резервирования предполагает явный выбор отправителей. При использовании объектов SCOPE в сообщениях ResvErr стиля WF следует придерживаться следующих правил:
Исключение циклов сообщений RSVP
Переадресация сообщений RSVP должна исключать возможность образования петель. В спокойном состоянии сообщения Path и Resv направляются каждому узлу только раз за период обновления. Это исключает зацикливание пакетов, но имеется еще возможность петель "автоматического обновления". Такие петли автоматического обновления сохраняют состояние "вечно", даже если оконечные узлы прекращают их обновление до тех пор, пока получатели не покинут мультикастинг-группу и/или отправители прекратят посылку сообщения Path. С другой стороны сообщения об ошибке и об аннулировании (teardown) посылаются немедленно и могут служить причиной возникновения циклов.Рассмотрим каждый тип сообщения.
Использование порядковых номеров в канале данных
Порядковые номера определены в заголовке L2TP для управляющих сообщений и опционно для информационных (смотри раздел 3.1). Они используются для организации надежной транспортировки управляющих сообщений (смотри раздел 5.8) и опционно информационных сообщений. Каждый партнер поддерживает отдельную нумерацию для управляющего соединения и для каждой информационной сессии в пределах туннеля.В отличие от канала управления L2TP, информационный канал L2TP не использует нумерацию сообщений для повторной пересылки. Скорее информационные сообщения могут использовать порядковые номера для детектирования потерь пакетов и/или восстановления исходной последовательности пакетов, которые могут быть перемешаны при транспортировке. LAC может потребовать, чтобы порядковые номера присутствовали в информационных сообщениях, посредством AVP необходимого упорядочения (смотри раздел 4.4.6). Если эта AVP присутствует при установлении сессии, порядковые номера должны присутствовать всегда. Если эта AVP отсутствует, упорядочивание сообщений находится под управлением LNS. Сервер LNS управляет разрешением и запрещением использования порядковых номеров путем посылки информационных сообщений с или без порядковых номеров на протяжении всей сессии. Таким образом, если LAC получает информационное сообщение без порядкового номера, он должен прекратить посылку сообщений с порядковыми номерами. Если LAC получает информационное сообщение с порядковым номером, он должен начать посылку информационных сообщений с порядковыми номерами. Если LNS разрешает нумерацию сообщений после предыдущего запрещения в ходе сессии, порядковые номера устанавливаются в соответствии с состоянием их последнего применения.
LNS может инициировать запрет нумерации сообщений в любое время в ходе сессии (включая первое информационное сообщение). Рекомендуется, чтобы для соединений, где возможна потеря или изменение порядка пакетов, нумерация сообщений была всегда разрешена. Запрещение нумерации возможно, только когда риск ошибки считается приемлемым. Например, если PPP-сессия при туннелировании не использует каких-либо посторонних протоколов или сжатия данных и работает только с IP (как это определено в ходе процедуры инициализации), тогда LNS может запретить нумерацию пакетов так как IP сам следит за их порядком.
Использование портов
Сессия RSVP определяется в норме тремя параметрами: DestAddress, ProtocolId, DstPort. Здесь DstPort является полем порта назначения UDP/TCP. DstPort может быть опущен (сделан равным нулю), если ProtocolId специфицирует протокол, который не имеет поля порта места назначения.RSVP допускает любое значение для ProtocolId. Однако, реализации оконечных систем RSVP могут знать об определенных значениях для этого поля и в частности значения для UDP и TCP (17 и 6 соответственно). Оконечная система может выдать сигнал ошибки приложению, которая:
Спецификации фильтра и шаблоны отправителя определяют пару: SrcAddress, SrcPort, где SrcPort поле UDP/TCP порта. В некоторых случаях SrcPort может быть опущен (установлен равным нулю). Существуют следующие правила использования нулевого значения полей DstPort и/или SrcPort в RSVP.
1. Порты назначения должны быть взаимосогласованными.
Состояния прохода и резервирования для одного и того же DestAddress и ProtocolId должны иметь свои значения DstPort, которые все равны нулю или все не равны нулю. Нарушение этого условия в узле является ошибкой "конфликт портов назначения (Conflicting Dest Ports)".
2. Правило портов назначения.
Если DstPort в описании сессии равен нулю, все поля SrcPort, используемые для этой сессии, также должны быть равны нулю. При этом предполагается, что протокол не имеет портов типа UDP/TCP. Нарушение этого условия в узле вызовет ошибку "Bad Src Ports".
3. Порты источников должны быть взаимосогласованы.
ЭВМ-отправитель не должна посылать состояния прохода со значением SrcPort равным так и неравным нулю. Нарушение этого условия вызовет ошибку "Conflicting Sender Port". Заметим, что протокол не допускает произвольного назначения номеров портов (wildcard), т.е., нулевой порт не может соответствовать ненулевому порту.
Эникаст-адреса
Эникаст-адрес IPv6 является адресом, который приписан нескольким интерфейсам (обычно принадлежащим разным узлам), при этом пакет, посланный по эникастному адресу, будет доставлен ближайшему интерфейсу в соответствии с метрикой протокола маршрутизации.Эникастные адреса выделяются из уникастного адресного пространства, и используют один из известных уникастных форматов. Таким образом эникастные адреса синтаксически неотличимы от уникастных адресов. Когда уникастный адрес приписан более чем одному интерфейсу, он превращается в эникастный адрес и узлы, которым он приписан, должны быть сконфигурированы так, чтобы распознавать этот адрес.
Для любого эникастного адреса существует адресный префикс P, который определяет топологическую область, где находятся все соответствующие ему интерфейсы. В пределах области, заданной P, каждый член эникастной (anycast) группы должен быть объявлен, как отдельный вход в маршрутной системе; вне области, заданной P, эникастный адрес может быть занесен в маршрутную запись для префикса p.
Заметим, что в худшем случае префикс P эникастной группы (anycast set) может быть нулевым, т.e., члены группы могут не иметь никакой топологической локальности. В этом случае эникастный адрес должен объявляться как отдельная маршрутная единица (separate routing entry) по всему Интернет, что представляет собой серьезное ограничение, так как число таких "глобальных" эникастных адресов не может быть большим.
Одним ожидаемым приложением эникастных адресов является идентификация набора маршрутизаторов, принадлежащих Интернет сервис провайдеру. Такие адреса в маршрутном заголовке IPv6 могут использоваться в качестве промежуточных, чтобы обеспечить доставку пакета через определенного провайдера или последовательность провайдеров. Другим возможным приложением может стать идентификация набора маршрутизаторов, связанных с определенной субсетью, или набора маршрутизаторов, обеспечивающих доступ в определенный домен.
Существует ограниченный опыт широкого применения эникастных Интернет адресов, некоторые возможные осложнения и трудности рассмотрены в [anycst]. Имеются следующие ограничения при использовании эникастных IPv6 адресов:
ЭВМ с несколькими сетевыми интерфейсами
При работе с ЭВМ, имеющими несколько сетевых интерфейсов, требуется выполнение ряда специальных правил. К такого рода устройствам относятся и маршрутизаторы, которые поддерживают локальные прикладные программы.Приложение, исполняемое на такой машине, должно явно указывать через какой интерфейс осуществляется передача данного информационного потока, для того чтобы заменить интерфейс, заданный по умолчанию системой.
Приложение отправителя использует API вызов для декларации характеристик его информационного потока для RSVP. Этот вызов может опционно включать локальный IP-адрес отправителя. Если он установлен приложением, этот параметр должен быть адресом интерфейса для отправки информационных пакетов, в противном случае, используется системный интерфейс по умолчанию.
Процесс RSVP ЭВМ посылает затем приложению сообщения Path только через специфицированный интерфейс.
Keepalive (Hello)
Механизм keepalive используется L2TP, для того чтобы разделять простои туннеля от длительных периодов отсутствия управления или информационной активности в туннеле. Это выполняется путем введения управляющих сообщений Hello (смотри раздел 6.5) после специфицированного периода времени, истекшего с момента последнего получения управляющего сообщения через туннель. Как для любого другого управляющего сообщения, при недоставке сообщения Hello туннель объявляется нерабочим, и система возвращается в исходное состояние. Механизм перевода транспортной среды в исходное состояние путем введения сообщений Hello гарантирует, что разрыв соединения между LNS и LAC будет детектирован на обоих концах туннеля.Коды результата и ошибки
Результирующий код (CDN, StopCCN)Результирующий код AVP, тип атрибута - 1, индицируют причину завершения работы управляющего канала или сессии. Поле значения атрибута AVP имеет следующий формат:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Код результата | Код ошибки (опц.) | ||||||||||||||||||||||||||||||
| Сообщение об ошибке (опц.) |
Рис. 7. Формат поля значения атрибута AVP
Результирующий код представляет собой целое число без знака длиной в 2 октета. Опционный код ошибки представляет собой 2-октетное целое число без знака. Опционное сообщение об ошибке поясняет код ошибки. Присутствие кода ошибки и сообщения определяется полем длины AVP. Сообщение об ошибке содержит произвольную строку текста, пригодного для чтения, характеризующего ситуацию. Читабельный текст во всех сообщений об ошибке должен быть представлен в кодировке UTF-8, для языка по умолчанию [RFC2277].
Эта AVP не должна быть скрытой (H-бит должен быть равен 0). M-бит для этой AVP должен быть равен 1. Длина равна 8, если в сообщении нет кода ошибки и нет сообщения об ошибке, 10, если имеется код ошибки, но нет сообщения об ошибке, или 10 + длина сообщения об ошибке, если имеется код и сообщение об ошибке. Определенные значения кодов результата для сообщения StopCCN перечислены ниже:
Определены следующие значения кодов результата для сообщений CDN:
0 - Зарезервировано
1 - Вызов прерван из-за потери несущей.
2 - Вызов прерван по причине, указанной в коде ошибки
3 - Вызов прерван по административным причинам
4 - Вызов не прошел из-за отсутствия необходимых условий (временная причина)
5 - Вызов не прошел из-за отсутствия необходимых условий (постоянная причина)
6 - Неверное место назначения
7 - Вызов не прошел из-за невозможности детектировать несущую
8 - Вызов не прошел из-за регистрации сигнала “занято”
9 - Вызов не прошел из-за отсутствия постоянного гудка (разрешение набора номера)
10 - Вызов не состоялся в пределах временного интервала, выделенного LAC
11 - Вызов реализовал соединение, но не обнаружено соответствующих кадров
Коды ошибок, определенные ниже, относятся к типам ошибок, которые не являются специфическими для любого конкретного L2TP-запроса, и относятся скорее к ошибкам протокола или формата сообщения. Если L2TP-отклик указывает в своем коде результата, что произошла общая ошибка, для выяснения причины должен быть проанализирован общий код ошибки. В настоящее время определены общие коды ошибки и их значение:
Когда используется код общей ошибки = 6, дополнительная информация об ошибке должна быть помещена в поле сообщения об ошибке.
Команда APPEND
Аргументы: имя почтового ящика,опционно - флаг списка со скобками,
опционно - строка даты и времени,
литерал сообщения
Отклики: команда не требует какого-либо специального отклика
| Результат: | OK | команда успешно исполнена |
| NO | команда не прошла: добавление в почтовый ящик не удалось, ошибка во флагах или дате/времени, или в тексте сообщения | |
| BAD | команда неизвестна или неверен аргумент |
Команда APPEND добавляет литеральный аргумент в качестве нового сообщения в почтовый ящик. Этот аргумент должен следовать формату сообщений [RFC-822]. Допускается использование в сообщениях 8-битовых символов. Реализация сервера, которая не может работать с 8-битовыми данными, должна быть способна преобразовывать 8-битовую информацию APPEND в 7-битовую, используя транспортное кодирование [MIME-IMB]. Если специфицирован флаг списка со скобками, в результирующих сообщениях должны быть установлены флаги, в противном случае список флагов будет установлен по умолчанию пустым.
Если специфицировано date_time, в результирующем сообщении должна быть установлена внутренняя дата, в противном случае, внутренняя дата и время результирующего сообщения будут установлены по умолчанию равными текущим значениям. Если команда append по какой-то причине не прошла, почтовый ящик должен быть возвращен в состояние, которое он имел до команды APPEND.
Если почтовый ящик места назначения не существует, сервер должен сообщить об ошибке, а не должен автоматически создавать новый почтовый ящик. Если не ясно, может или нет быть создан почтовый ящик, сервер должен послать код отклика "[TRYCREATE]" в качестве префикса текста маркированного отклика NO. Это указывает клиенту на возможность попытки исполнения команды CREATE, после чего, в случае успеха, повторить команду APPEND.
Если в настоящее время почтовый ящик и выбран, то немедленно должны начаться почтовые операции. Сервер должен уведомить клиента об этом, послав немаркированный отклик EXISTS. Если сервер не делает этого, клиент после одной или более команд APPEND может выдать команду NOOP (или при неудаче команду CHECK).
Пример: C: A003 APPEND saved-messages (\Seen) {310}
C: Date: Mon, 7 Feb 1994 21:52:25 -0800 (PST)
C: From: Fred Foobar
C: Subject: afternoon meeting
C: To: mooch@owatagu.siam.edu
C: Message-Id:
C: MIME-Version: 1.0
C: Content-Type: TEXT/PLAIN; CHARSET=US-ASCII
C:
C: Hello Joe, do you think we can meet at 3:30 tomorrow?
C:
S: A003 OK APPEND completed
Замечание: команда APPEND не используется для доставки сообщений, так как она не содержит в себе механизма передачи служебной информации [SMTP].
Команда AUTHENTICATE
Аргументы: имя механизма аутентификации.Отклики: может быть запрошена дополнительная информация.
| Результат | OK | Аутентификация завершена, осуществлен переход в состояние "аутентификация выполнена"; |
| NO | Ошибка аутентификации: неподдерживаемый механизм аутентификации, параметры аутентификации отвергнуты; | |
| BAD | Неизвестная команда или неверный аргумент, механизм аутентификации прерван. |
Команда AUTHENTICATE указывает серверу на механизм аутентификации, как это описано в [IMAP-AUTH]. Если сервер поддерживает запрошенный механизм аутентификации, он выполняет обмен согласно аутентификационному протоколу и идентифицирует клиента. Он может также согласовать опционный механизм защиты для последующих протоколов взаимодействия. Если запрошенный механизм аутентификации не поддерживается, сервер должен отвергнуть команду AUTHENTICATE путем посылки маркированного отклика NO.
Протокол аутентификационного обмена состоит из последовательности запросов сервера и соответствующих ответов клиента. Запрос сервера состоит из отклика-запроса продолжения с символом "+", за которым следует строка кодов BASE64. Ответ клиента состоит из строки, содержащей коды BASE64. Если клиент хочет аннулировать аутентификационный обмен, он выдает строку, содержащую только "*". Если сервер получает такой ответ, он должен отклонить команду AUTHENTICATE, послав маркированный отклик BAD.
Механизм защиты обеспечивает целостность и конфиденциальность соединения. Если механизм защиты согласовыван, то в дальнейшем он используется для всех сообщений, проходящих через данное соединение. Механизм защиты начинает действовать сразу после ввода последовательности CRLF, которая завершает аутентификационный обмен для клиента, и прихода CRLF маркированного отклика OK сервера. Раз механизм защиты вступил в силу, поток октетов команд и откликов заносится в буферы шифрованного текста. Каждый буфер передается через соединение в виде потока октетов, который начинается с четырех октетов, содержащих длину последующих данных.
Максимальный размер буфера для текста-шифра определяется выбранным механизмом защиты.
Аутентификационные механизмы являются опционными. Механизмы защиты также опционны; аутентификационный механизм может реализоваться в отсутствии какого-либо механизма защиты. Если команда AUTHENTICATE не прошла и получен отклик NO, клиент может совершить повторную попытку, послав еще одну команду AUTHENTICATE, или может попытаться выполнить аутентификацию с помощью команды LOGIN. Другими словами, клиент может затребовать тип аутентификации в порядке понижения уровня предпочтения, команда LOGIN используется как последний вариант.
Пример: S: * OK KerberosV4 IMAP4rev1 Server
C: A001 AUTHENTICATE KERBEROS_V4
S: + AmFYig==
C: BAcAQU5EUkVXLkNNVS5FRFUAOCAsho84kLN3/IJmrMG+25a4DT
+nZImJjnTNHJUtxAA+o0KPKfHEcAFs9a3CL5Oebe/ydHJUwYFd
WwuQ1MWiy6IesKvjL5rL9WjXUb9MwT9bpObYLGOKi1Qh
S: + or//EoAADZI=
C: DiAF5A4gA+oOIALuBkAAmw==
S: A001 OK Kerberos V4 authentication successful
Команда CAPABILITY
Аргументы: отсутствуют.Отклики: Необходим немаркированный отклик: CAPABILITY.
Результат: OK - успешное завершение команды;
BAD - команда неизвестна или неверный аргумент
Команда CAPABILITY запрашивает перечень возможностей, поддерживаемых сервером. Сервер должен послать один немаркированный отклик CAPABILITY с "IMAP 4.1" в списке возможностей, прежде чем отправлять маркированный отклик OK. Этот список не зависит от состояния соединения или пользователя. Следовательно, нет необходимости направлять команду CAPABILITY более одного раза на соединение. Название возможности, которая начинается с "AUTH=" указывает, что сервер поддерживает определенный механизм аутентификации. Все такие имена по определению являются частью данной спецификации. Например, аутентификационные возможности для экспериментального аутентификатора "blurdybloop" могут быть описаны как "AUTH=XBLURDYBLOOP", а не "XAUTH=BLURDYBLOOP" или "XAUTH=XBLURDYBLOOP".
Другие имена возможностей относятся к расширениям, новым версиям или коррекциям данной спецификации.
Пример: C: abcd CAPABILITY
S: * CAPABILITY IMAP 4.1 AUTH=KERBEROS_V4
S: abcd OK CAPABILITY completed
Команда CHECK
Аргументы: отсутствуют.Отклики: команда не требует какого-либо специального отклика;
Результат: OK - проверка завершена;
BAD - команда неизвестна или неверен аргумент.
Команда CHECK осуществляет проверку выбранного почтового ящика. Проверка относится к любым характеристикам, зависящим от реализации (например, выявление положения почтового ящика в памяти сервера и на диске). Если сервер не поддерживает таких возможностей, команда эквивалентна NOOP.
Не существует гарантии, что в результате CHECK будет прислан немаркированный отклик. Для проверки поступления новой почты следует использовать команду NOOP, а не CHECK.
Пример: C: FXXZ CHECK
S: FXXZ OK CHECK Completed
Команда CLOSE
Аргументы: отсутствуют.Отклики: команда не требует какого-либо специального отклика.
Результат: OK - команда выполнена, система в состоянии "аутентификация выполнена";
NO - команда не прошла, никакого ящика не выбрано;
BAD - команда неизвестна или неверен аргумент.
Команда CLOSE навечно удаляет из выбранного почтового ящика все сообщения, помеченные флагом \Deleted, и возвращает систему в состояние "аутентификация выполнена". Никакого немаркированного отклика EXPUNGE не посылается.
Никаких сообщений не удаляется и никаких флагов ошибки не возвращается, если почтовый ящик был выбран командой EXAMINE или находился в режиме "только для чтения".
Даже если почтовый ящик выбран, команды SELECT, EXAMINE или LOGOUT могут быть использованы без предварительного исполнения команды CLOSE. Команды SELECT, EXAMINE и LOGOUT безоговорочно закрывают выбранный в данный момент почтовый ящик без удаления сообщений. Однако когда удалено много сообщений, последовательность CLOSE-LOGOUT или CLOSE-SELECT значительно быстрее, чем EXPUNGE-LOGOUT или EXPUNGE-SELECT, так как здесь не посылается никаких немаркированных откликов EXPUNGE (которые клиент вероятно проигнорирует).
Пример: C: A341 CLOSE
S: A341 OK CLOSE completed
Команда COPY
Аргументы: набор сообщений,имя почтового ящика.
Отклики: команда не требует какого-либо специального отклика.
| Результат: | OK | команда успешно завершена; |
| NO | команда не прошла: не могут быть скопированы эти сообщения вообще или в данный почтовый ящик; | |
| BAD | команда неизвестна или неверен аргумент. |
Команда COPY копирует специфицированное сообщение в конец указанного почтового ящика. Флаги и внутренняя дата сообщения должны быть сохранены в копии.
Если указанный почтовый ящик отсутствует, сервер должен прислать сообщение об ошибке. Он не должен автоматически создавать почтовый ящик. Если заведомо не известно, что ящик не может быть создан, сервер должен послать код отклика "[TRYCREATE]" в качестве префикса текста маркированного отклика NO. Это предлагает клиенту возможность исполнить команду CREATE, после чего в случае успешного завершения повторно исполнить COPY.
Если команда COPY не прошла по какой-то причине, сервер должен восстановить почтовый ящик назначения в состояние, которое он имел до выполнения COPY.
Пример: C: A003 COPY 2:4 MEETING
S: A003 OK COPY completed
Команда CREATE
Аргументы: имя почтового ящика.Отклики: на эту команду не посылается каких-либо откликов.
| Результат | OK | Команда выполнена; |
| NO | команда не выполнена: почтовый ящик с таким именем не может быть создан; | |
| BAD | команда неизвестна или неверен аргумент. |
Команда CREATE создает почтовый ящик с заданным именем. Отклик OK присылается в случае, когда новый почтовый ящик с указанным именем создан. Попытка создания INBOX или почтового ящика с именем, существующего почтового ящика, является ошибкой . Любая ошибка при попытке создания почтового ящика вызовет маркированный отклик NO.
Если имя почтового ящика имеет суффикс с символом сепаратора иерархии сервера (в соответствии с тем, что получено при выполнении команды LIST), то это является декларацией клиента о намерении создать почтовый ящик с именем в рамках указанной иерархии. Реализации сервера, которые не требуют этой декларации, должны ее игнорировать.
Если символ-сепаратор иерархии сервера появляется где-либо еще в имени, сервер должен создать любые имена более высокого уровня иерархии, которые необходимы для успешного завершения выполнения команды CREATE. Другими словами, попытка создания "foo/bar/zap" на сервере, для которого символ "/" является иерархическим сепаратором, должна привести к созданию foo/ и foo/bar/, если они до этого не существовали.
Если новый почтовый ящик создан с именем стертого почтового ящика, то его идентификатор должен быть больше, использованного его предшественником, если только новая версия ящика не имеет другого значения UID.
Пример: C: A003 CREATE owatagusiam/
S: A003 OK CREATE completed
C: A004 CREATE owatagusiam/blurdybloop
S: A004 OK CREATE completed
Замечание: интерпретация этого примера зависит от того, является ли символ "/" иерархическим сепаратором. Если "/" иерархический сепаратор, создается новый иерархический уровень с "owatagusiam" с новым членом иерархии этого уровня "blurdybloop". В противном случае создаются два почтовых ящика на одном и том же уровне иерархии.
Команда DELETE
Аргументы: имя почтового ящика.Отклики: команда не требует каких-либо откликов.
Результат: OK - команда завершена;
NO - ошибка при выполнении команды: не удается стереть ящик с этим именем;
BAD - команда неизвестна или неверен аргумент.
Команда DELETE навечно удаляет почтовый ящик с указанным именем. При этом присылается маркированный отклик OK только в том случае, когда ящик уничтожен. Ошибкой считается попытка стереть INBOX или ящик с несуществующим именем.
Команда DELETE не должна удалять ящики с более низкой иерархией, чем текущая. Например, если почтовый ящик "foo" имеет иерархическую структуру "foo.bar" (предполагается, что "." является иерархическим сепаратором), удаление "foo" не должно удалять "foo.bar". Считается ошибкой попытка удаления имени, которому соответствуют нижележащие иерархические уровни, имеющие атрибут \Noselect.
Разрешено удалять имена, которым соответствуют нижележащие иерархические уровни, но не имеющие атрибута имени \Noselect. В этом случае все сообщения из этого почтового ящика также будут удалены, а имя получит атрибут \Noselect.
Значение наибольшего используемого уникального идентификатора удаленных почтовых ящиков должно сохраняться, так чтобы новые созданные ящики с тем же именем не использовали идентификаторы своих предшественников, если только новый ящик не имеет другое значение UID.
Примеры: C: A682 LIST "" *
S: * LIST () "/" blurdybloop
S: * LIST (\Noselect) "/" foo
S: * LIST () "/" foo/bar
S: A682 OK LIST completed
C: A683 DELETE blurdybloop
S: A683 OK DELETE completed
C: A684 DELETE foo
S: A684 NO Name "foo" has inferior hierarchical names
C: A685 DELETE foo/bar
S: A685 OK DELETE Completed
C: A686 LIST "" *
S: * LIST (\Noselect) "/" foo
S: A686 OK LIST completed
C: A687 DELETE foo
S: A687 OK DELETE Completed
C: A82 LIST "" *
S: * LIST () "." blurdybloop
S: * LIST () "." foo
S: * LIST () "." foo.bar
S: A82 OK LIST completed
C: A83 DELETE blurdybloop
S: A83 OK DELETE completed
C: A84 DELETE foo
S: A84 OK DELETE Completed
C: A85 LIST "" *
S: * LIST () "." foo.bar
S: A85 OK LIST completed
C: A86 LIST "" %
S: * LIST (\Noselect) "." foo
S: A86 OK LIST completed
Команда EXAMINE
Аргументы: имя почтового ящика.Отклики: необходимы немаркированные отклики: FLAGS, EXISTS, RECENT;
опционны немаркированные отклики OK: UNSEEN, PERMANENTFLAGS.
| Результат: | OK | Осмотр закончен, система в состоянии "выбор сделан" ; |
| NO | Осмотр не прошел, система в состоянии "аутентификация выполнена"; нет такого почтового ящика; доступ к почтовому ящику невозможен; | |
| BAD | Команда неизвестна или неверен аргумент. |
Команда EXAMINE идентична команде SELECT и дает тот же результат, однако, выбранный почтовый ящик идентифицируется как "только для чтения". Никакие изменения постоянного состояния почтового ящика в этом случае не разрешены. Текст маркированного отклика OK на команду EXAMINE должен начинаться с кода отклика "[READ-ONLY]".
Пример: C: A932 EXAMINE blurdybloop
S: * 17 EXISTS
S: * 2 RECENT
S: * OK [UNSEEN 8] Message 8 is first unseen
S: * OK [UIDVALIDITY 3857529045] UIDs valid
S: * FLAGS (\Answered \Flagged \Deleted \Seen \Draft)
S: * OK [PERMANENTFLAGS ()] No permanent flags permitted
S: A932 OK [READ-ONLY] EXAMINE completed
Команда EXPUNGE
Аргументы: отсутствуют.Отклики: немаркированные отклики: EXPUNGE.
Результат: OK - команда успешно завершена;
NO - команда не прошла: стирание не выполнено (например, запрещено);
BAD - команда неизвестна или неверен аргумент.
Команда EXPUNGE навечно удаляет из выбранного почтового ящика все сообщения, которые помечены флагами \Deleted. Прежде чем выдать клиенту сигнал OK, посылается немаркированный отклик EXPUNGE для каждого из удаляемых сообщений.
Пример: C: A202 EXPUNGE
S: * 3 EXPUNGE
S: * 3 EXPUNGE
S: * 5 EXPUNGE
S: * 8 EXPUNGE
S: A202 OK EXPUNGE completed
Замечание: в этом примере, сообщения 3, 4, 7 и 11 имеют установленный флаг \Deleted. Следует учитывать, что после каждого удаления сообщения перенумеруются.
Команда FETCH
Аргументы: набор сообщений,имена информационных сообщений.
Отклики: немаркированные отклики: FETCH
Результат: OK - операция успешно завершена;
NO - команда не прошла: не удалось доставить эти данные;
BAD - команда неизвестна или неверен аргумент.
Команда FETCH извлекает данные, соответствующие сообщению в почтовом ящике. В качестве доставляемых данных может выступать отдельный атом или список элементов, помещенных в скобками. В настоящее время определены следующие типы данных, которые могут быть доставлены:
ALL Эквивалентно: (FLAGS INTERNALDATE RFC822.SIZE ENVELOPE)
BODY Нерасширяемая форма BODYSTRUCTURE.
BODY[]>
Текст определенной части тела сообщения. Спецификация секции представляет собой нуль или более спецификаторов, разделенных точками. Спецификатором части является либо число, либо одно из имен:
HEADER, HEADER.FIELDS, HEADER.FIELDS.NOT, MIME и TEXT. Пустая спецификация относится ко всему сообщению, включая заголовок.
Каждое сообщение имеет номер, по крайней мере, одной части.
Сообщения не-[MIME-IMB] и несоставные сообщения [MIME-IMB] без инкапсуляции имеют только часть 1.
Частям составных сообщений присваиваются последовательные номера в порядке появления. Если конкретная часть является составным сообщением, то его части должны быть выделены точкой, за которой следует номер части.
Спецификаторы частей HEADER, HEADER.FIELDS, HEADER.FIELDS.NOT и TEXT являются базовыми. Перед ними могут размещаться один или более числовых спецификаторов частей сообщения, которые указывают на принадлежность типу MESSAGE/RFC822. Перед спецификатором части MIME должны размещаться один или более числовых спецификаторов. Спецификаторы частей HEADER, HEADER.FIELDS, HEADER.FIELDS.NOT относятся к заголовку сообщения [RFC-822] или инкапсулированному сообщению [MIME-IMT] MESSAGE/RFC822. За HEADER.FIELDS и HEADER.FIELDS.NOT следует список имен полей (как это определено в [RFC-822]). Субнабор, возвращаемый HEADER.FIELDS, содержит только те поля заголовка, имена которых соответствуют одному из имен списка.
Аналогично, субнабор, возвращаемый HEADER.FIELDS.NOT, содержит только поля заголовка с несоответствующими именами полей. Соответствие является точным, но нечувствительным к использованию строчных и прописных букв. Во всех случаях, вставляется разграничивающая пустая строка между заголовком и телом сообщения.
Спецификатор MIME части относится к заголовку [MIME-IMB] этой части. Спецификатор текстовой части относится к телу сообщения, без заголовка [RFC-822]. Ниже приведен пример составного сообщения с некоторыми спецификаторами его частей:
HEADER ([RFC-822] заголовок сообщения)
TEXT MULTIPART/MIXED
1 TEXT/PLAIN
2 APPLICATION/OCTET-STREAM
3 MESSAGE/RFC822
3.HEADER ([RFC-822] заголовок сообщения)
3.TEXT ([RFC-822] текстовое тело сообщения)
3.1 TEXT/PLAIN
3.2 APPLICATION/OCTET-STREAM
4 MULTIPART/MIXED
4.1 IMAGE/GIF
4.1.MIME ([MIME-IMB] заголовок для IMAGE/GIF)
4.2 MESSAGE/RFC822
4.2.HEADER ([RFC-822] заголовок сообщения)
4.2.TEXT ([RFC-822] текстовое тело сообщения)
4.2.1 TEXT/PLAIN
4.2.2 MULTIPART/ALTERNATIVE
4.2.2.1 TEXT/PLAIN
4.2.2.2 TEXT/RICHTEXT
Имеется возможность доставить субстроку определенного текста. Это делается путем присоединения к спецификатору части открытой угловой скобки ("
При любой частичной доставке, при которой производится попытка чтения за пределами текста, фрагмент соответствующим образом обрезается.
Замечание: это означает, что запрос BODY[] сообщения длиной 1500 октетов пришлет BODY[] с литералом размера 1500, а не BODY[].
| BODY.PEEK[] > | Альтернативная форма BODY[], которая не устанавливает флаг \Seen. |
| BODYSTRUCTURE | Структура тела сообщения [MIME-IMB]. Она вычисляется сервером путем разбора полей заголовка [MIME-IMB] [RFC-822] и заголовков [MIME-IMB]. |
| ENVELOPE | Структура заголовка сообщения. Она вычисляется сервером в результате разбора заголовка [RFC-822] на части, присваивая им значения по умолчания, если это необходимо. |
| FAST | Макро эквивалент (FLAGS INTERNALDATE RFC822.SIZE) |
| FLAGS | Флаги, присвоенные сообщению. |
| FULL | Макро эквивалент (FLAGS INTERNALDATE RFC822.SIZE ENVELOPE BODY) |
| INTERNALDATE | Внутренняя дата сообщения. |
| RFC822 | Функционально эквивалентно BODY[], отличается по синтаксису результирующих немаркированных данных FETCH (возвращается RFC822). |
| RFC822.HEADER | Функционально эквивалентно BODY.PEEK[HEADER], отличается по синтаксису результирующих немаркированных данных FETCH (возвращает данные в формате RFC822.HEADER). |
| RFC822.SIZE | Размер сообщения [RFC-822]. |
| RFC822.TEXT | Функционально эквивалентно BODY[TEXT], отличается по синтаксису результирующих немаркированных данных FETCH (возвращается RFC822.TEXT). |
| UID | Уникальный идентификатор сообщения. |
S: * 2 FETCH ....
S: * 3 FETCH ....
S: * 4 FETCH ....
S: A654 OK FETCH completed
Команда LIST
Аргументы: имя,имя почтового ящика может содержать символы подмены (wildcard).
Отклики: немаркированные отклики LIST.
| Результат: | OK | команда list выполнена; |
| NO | команда не прошла: не возможно выполнение list для данного образца или имени; | |
| BAD | команда неизвестна или неверен аргумент. |
Команда LIST возвращает субнабор имен из полного набора, доступного клиенту. Присылается нуль или более немаркированных откликов LIST, содержащих атрибуты имен, иерархические разделители и имена.
Команда LIST должна возвращать данные быстро без существенных задержек. Например, она не должна тратить время на выяснение статуса (\Marked или \Unmarked) или на выполнение другой трудоемкой обработки, ведь если каждое имя требует одной секунды, то обработка списка из 1200 имен займет 20 минут.
Аргумент, содержащий пустую строку образца имени (""), указывает, что имя почтового ящика интерпретируется также, как это делает команда SELECT. Присланные имена почтовых ящиков должны соответствовать полученному шаблону имени. Непустой аргумент является шаблоном имени почтового ящика или уровеня иерархии и указывает на контекст, в котором интерпретируется имя. Пустой аргумент имени ("") представляет собой специальный запрос, требующий присылки иерархического разделителя и корневого имени. Значение, возвращаемое в качестве корневого имени, может быть нулем, если шаблону не соответствует никакая иерархия. Иерархический разделитель присылается во всех случаях. Это позволяет клиенту получить иерархический разделитель даже в случае, когда нет почтовых ящиков, соответствующих данному имени.
Шаблон и имя почтового ящика интерпретируются по-разному в зависимости от реализации. В каноническом варианте анализ происходит слева направо.
Любая часть аргумента шаблона, которая включена в интерпретированную форму, должна предшествовать интерпретированной форме. Она должна иметь тот же формат, что и аргумент шаблона имени. Это правило позволяет клиенту определить, соответствует ли присланное имя почтового ящика контексту шаблона.
Без этого правила, клиент должен был бы знать семантику имен сервера.
Ниже приведены некоторые примеры того, как могут интерпретироваться образцы и имена почтовых ящиков на серверах базирующихся на UNIX:
| Шаблон | Имя почтового ящика | Интерпретация |
| ~smith/Mail/ | foo.* | ~smith/Mail/foo.* |
| Archive/ | % | archive/% |
| #news. | comp.mail.* | #news.comp.mail.* |
| ~smith/Mail/ | /usr/doc/foo | /usr/doc/foo |
| archive/ | ~fred/Mail/* | ~fred/Mail/* |
Символ "*" представляет собой подмену (wildcard), и соответствует нулю или более символов в данной позиции. Символ "%" подобен "*", но он не соответствует иерархическому разделителю. Если символ "%" является последним символом имени почтового ящика, то в отклике будут присланы и соответствующие уровни иерархии. Если эти уровни не являются почтовыми ящиками, которые можно выбрать, то их имена снабжаются атрибутом \Noselect. Реализациям сервера таким образом позволено спрятать некоторые почтовые ящики, имена которых могли бы быть раскрыты с использованием шаблонов с символами подмены (wildcard). Например, сервер на основе UNIX может ограничить интерпретацию "*" так, что начальный символ "/" будет приводить к несоответствию имени шаблону.
Специальное имя INBOX включается в выдачу команды LIST, если INBOX поддерживается данным сервером для данного пользователя и, если строка "INBOX", напечатанная прописными буквами, соответствует интерпретированному шаблону.
Пример: C: A101 LIST "" ""
S: * LIST (\Noselect) "/" ""
S: A101 OK LIST Completed
C: A102 LIST #news.comp.mail.misc ""
S: * LIST (\Noselect) "." #news.
S: A102 OK LIST Completed
C: A103 LIST /usr/staff/jones ""
S: * LIST (\Noselect) "/" /
S: A103 OK LIST Completed
C: A202 LIST ~/Mail/ %
S: * LIST (\Noselect) "/" ~/Mail/foo
S: * LIST () "/" ~/Mail/meetings
S: A202 OK LIST completed
Команда LOGIN
Аргументы: имя пользователя, пароль.Отклики: команда не требует какого-либо специального отклика.
Результат: OK - login завершено, система в состоянии с аутентификацией;
NO - login не прошла: имя пользователя или пароль отвергнуты;
BAD - команда неизвестна или неверный аргумент.
Команда LOGIN идентифицирует клиента серверу и передает пароль пользователя открытым текстом.
Пример: C: a001 LOGIN SMITH SESAME
S: a001 OK LOGIN completed
Команда LOGOUT
Аргументы: отсутствуют.Отклики: необходим немаркированный отклик BYE.
Результат: OK - прерывание сессии завершено;
BAD - неизвестная команда или неверный аргумент.
Команда LOGOUT информирует сервер о том, что клиент прерывает соединение. Сервер должен послать немаркированный отклик BYE, прежде чем отсылать маркированный отклик OK, после чего завершить разрыв соединения.
Пример: C: A023 LOGOUT
S: * BYE IMAP 4.1 Server logging out
S: A023 OK LOGOUT completed
(Сервер и клиент разорвали соединение)
Команда LSUB
Аргументы: имя-шаблон,имя почтового ящика может содержать символы подмены (wildcards).
Отклики: немаркированный отклик: LSUB
| Результат: | OK | команда успешно исполнена; |
| NO | команда не прошла: не возможна выдача списка для предлагаемого шаблона или имени; | |
| BAD | команда неизвестна или неверен аргумент. |
Команда LSUB возвращает субнабор имен из списка пользователя, который декларирован как "активный" или "подписной". При этом отправляется нуль или более немаркированных откликов LSUB. Аргументы LSUB имеют тот же формат, что и для команды LIST.
Сервер может проверить имена из подписного листа с тем, чтобы проверить, существуют ли они еще. Если имени не существует, оно должно быть помечено в отклике LSUB атрибутом \Noselect. Сервер не должен по своему усмотрению удалять имена почтовых ящиков из подписного листа даже, если такого ящика более не существует.
Пример: C: A002 LSUB "#news." "comp.mail.*"
S: * LSUB () "." #news.comp.mail.mime
S: * LSUB () "." #news.comp.mail.misc
S: A002 OK LSUB completed
Команда NOOP
Аргументы: отсутствуют.Отклики: никакого специального отклика на эту команду не требуется.
Результат: OK - команда успешно завершена;
BAD - команда неизвестна или неверен аргумент;
Команда NOOP ничего не делает и всегда успешно завершается.
Так как любая команда может прислать немаркированные данные об изменении состояния, команда NOOP может использоваться, как периодический запрос нового сообщения или информации об изменении статуса в периоды неактивности. Команда NOOP может также использоваться для сброса таймера прерывания сессии сервером из-за отсутствия активности.
Пример: C: a002 NOOP
S: a002 OK NOOP completed
. . .
C: a047 NOOP
S: * 22 EXPUNGE
S: * 23 EXISTS
S: * 3 RECENT
S: * 14 FETCH (FLAGS (\Seen \Deleted))
S: a047 OK NOOP completed
Команда RENAME
Аргументы: имя существующего почтового ящика, имя нового почтового ящика.Отклики: эта команда не требует каких-либо специфических откликов.
| Результат: | OK | переименование успешно осуществилось; |
| NO | переименование не прошло: не удалось переименовать ящик с данным именем, не удалось присвоить новое имя; | |
| BAD | команда неизвестна или неверен аргумент. |
Команда RENAME изменяет имя почтового ящика. Маркированный отклик OK присылается лишь в случае, когда почтовый ящик переименован. Считается ошибкой попытка переименовать не существующий почтовый ящик или присвоить ящику уже имеющееся имя. Любая ошибка при переименовании вызовет маркированный отклик NO.
Если ящик содержит в себе иерархическую структуру, имена этой структуры не должны меняться. Например, переименование "foo" в "zap" переименует "foo/bar" (предполагая, что "/" является иерархическим разделителем) в "zap/bar".
Значение наибольшего использованного уникального идентификатора имени старого почтового ящика должно быть сохранено, так чтобы новый создаваемый с тем же именем почтовый ящик не использовал идентификатора своего предшественника, если только он не имеет другого значения UID.
Переименование INBOX разрешено, но имеет свою специфику. Оно перемещает все сообщения в почтовый ящик с новым именем, оставляя INBOX пустым. Если реализация сервера поддерживает иерархические системы имен INBOX, это никак не сказывается на переименовании INBOX.
Примеры: C: A682 LIST "" *
S: * LIST () "/" blurdybloop
S: * LIST (\Noselect) "/" foo
S: * LIST () "/" foo/bar
S: A682 OK LIST completed
C: A683 RENAME blurdybloop sarasoop
S: A683 OK RENAME completed
C: A684 RENAME foo zowie
S: A684 OK RENAME Completed
C: A685 LIST "" *
S: * LIST () "/" sarasoop
S: * LIST (\Noselect) "/" zowie
S: * LIST () "/" zowie/bar
S: A685 OK LIST completed
C: Z432 LIST "" *
S: * LIST () "." INBOX
S: * LIST () "." INBOX.bar
S: Z432 OK LIST completed
C: Z433 RENAME INBOX old-mail
S: Z433 OK RENAME completed
C: Z434 LIST "" *
S: * LIST () "." INBOX
S: * LIST () "." INBOX.bar
S: * LIST () "." old-mail
S: Z434 OK LIST completed
Команда SEARCH
Аргументы: опционны, [CHARSET]-спецификация.Критерии поиска (один или более).
Отклики: необходим немаркированный отклик: SEARCH.
Результат: OK - поиск завершен;
NO - ошибка: поиск для данного набора символов или критериев не возможен;
BAD - команда неизвестна или неверен аргумент
Команда SEARCH ищет почтовый ящик, который отвечает выбранным критериям отбора. Критерий отбора состоит из одного или более ключей поиска. Немаркированный отклик SEARCH от сервера содержит список номеров сообщений, которые соответствуют критериям отбора.
Когда специфицировано несколько ключей, результатом является (функция AND) совокупность всех сообщений, отвечающим заданным критериям. Например, критерий DELETED FROM "SMITH" SINCE 1-Feb-1994 относится ко всем стертым сообщениям от Смита, которые были положены в почтовый ящик после 1-го февраля 1994. (например, для объединения этих ключей с помощью функций OR и NOT).
Опционная спецификация [CHARSET] состоит из слова "CHARSET", за которым следует зарегистрированное наименование символьного набора [CHARSET]. Он включает в себя [CHARSET] строк, которые используются в качестве критерия отбора. Транспортное кодирование содержимого [MIME-IMB] и строки [MIME-HDRS] в [RFC-822]/[MIME-IMB] заголовках, должны декодироваться перед сравнением текста в представлении [CHARSET], отличном от US-ASCII. US-ASCII должно поддерживаться всегда, но могут использоваться и другие символьные наборы. Если сервер не поддерживает специфицированный набор символов [CHARSET], он должен вернуть маркированный отклик NO (но не BAD).
Для всех ключей поиска, которые используют строки, сообщение соответствует ключу, если строка является частью строки поля в сообщении. Соответствие не должно зависеть от использования строчных или прописных символов. Стандартными ключами поиска являются следующие слова и выражения.
| Сообщения с номерами, соответствующими специфицированному набору номеров | |
| ALL | Все сообщения в почтовом ящике. Ключ отбора по умолчанию для применения команд AND |
| ANSWERED | Сообщения с установленным флагом \Answered. |
| BCC | Сообщения, которые содержат специфицированную строку в поле BCC структуры заголовка сообщения. |
| BEFORE | Сообщения, чьи внутренние даты раньше указанной. |
| BODY | Сообщения, которые содержат специфицированную строку в теле сообщения. |
| CC | Сообщения, которые содержат специфицированную строку в CC поле заголовка. |
| DELETED | Сообщения с установленным флагом \Deleted. |
| DRAFT | Сообщения с установленным флагом \Draft. |
| FLAGGED | Сообщения c установленным флагом \Flagged. |
| FROM | Сообщения, которые содержат специфицированную строку в поле FROM заголовка. |
| HEADER | Сообщения, которые содержат заголовок со специфицированным именем поля (в соответствии с [RFC-822]) и специфицированную строку в теле данного поля. |
| KEYWORD | Сообщения со специфицированным ключевыми словами. |
| LARGER | Сообщения с размером [RFC-822] больше чем специфицированное число октетов. |
| NEW | Сообщения, которые имеют установленный флаг \Recent, но не имеют флага \Seen. Это функционально эквивалентно "(RECENT UNSEEN)". |
| NOT | Сообщения, которые не содержат специфицированного ключевого слова. |
| OLD | Сообщения, которые не имеют флага \Recent. "NOT RECENT" (противоположно "NOT NEW"). |
| ON | Сообщения, чья внутренняя дата соответствует специфицированному значению даты. |
| OR | Сообщения, которые соответствуют любому из ключевых слов поиска. |
| RECENT | Сообщения, которые имеют установленный флаг \Recent. |
| SEEN | Сообщения, которые имеют установленный флаг \Seen. |
| SENTBEFORE | Сообщения, чье содержимое заголовка, соответствует дате ранее специфицированного значения [RFC-822]. |
| SENTON | Сообщения, чье содержимое заголовка, соответствует специфицированной дате [RFC-822] |
| SENTSINCE | Сообщения, чье содержимое заголовка, соответствует [RFC-822]: специфицированному значению даты или позже. |
| SINCE | Сообщения, чья внутренняя дата соответствует или позже специфицированного значения. |
| SMALLER | Сообщения с размером [RFC-822] меньше чем специфицированное число октетов. |
| SUBJECT | Сообщения, которое содержит специфицированную строку в поле SUBJECT заголовка. |
| TEXT | Сообщения, которые содержат специфицированную строку в заголовке или теле сообщения |
| TO | Сообщения, которые содержат специфицированную строку в поле заголовка TO. |
| UID | Сообщения с уникальными идентификаторами, соответствующими заданному значению идентификатора. |
| UNANSWERED | <>Сообщения, которые не имеют флага \Answered. |
| UNDELETED | Сообщения, которые не имеют флага \Deleted. |
| UNDRAFT | Сообщения, которые не имеют флага \Draft. |
| UNFLAGGED | Сообщения, которые не имеют флага \Flagged. |
| UNKEYWORD | Сообщения, которые не содержат заданных ключевых слов. |
| UNSEEN | Сообщения, которые не имеют флага \Seen. |
Пример: C: A282 SEARCH FLAGGED SINCE 1-Feb-1994 NOT FROM "Smith"
S: * SEARCH 2 84 882
S: A282 OK SEARCH completed
Команда SELECT
Аргументы: имя почтового ящика.Отклики: необходимы немаркированные отклики: FLAGS, EXISTS, RECENT;
опционны немаркированные отклики OK: UNSEEN, PERMANENTFLAGS.
Результат: OK - процедура выбора закончена, система находится в состоянии "выбрано";
NO - выбор неудачен: нет такого ящика, доступ к почтовому ящику невозможен;
BAD - команда неизвестна или неверен аргумент.
Команда SELECT осуществляет выбор почтового ящика, так чтобы обеспечить доступ к сообщениям, находящимся там. Прежде чем присылать клиенту OK, сервер должен послать клиенту следующие немаркированные данные:
FLAGS - флаги, определенные для почтового ящика.
EXISTS Число сообщений в почтовом ящике.
RECENT Число сообщений с набором флагов \Recent.
OK [UIDVALIDITY ] Уникальный идентификатор корректности.
Сервер должен также послать "невидимый" код отклика внутри немаркированного сообщения OK, который представляет собой порядковый номер первого невидимого сообщения в почтовом ящике.
Если клиент не может изменить состояние одного или нескольких флагов, перечисленных в немаркированном отклике FLAGS, сервер должен в немаркированном отклике OK послать код PERMANENTFLAGS, перечислив флаги, которые клиент может изменить.
Единовременно для одного соединения может быть выбран только один почтовый ящик. Одновременный доступ к нескольким почтовым ящикам требует установления соответствующего числа соединений. Команда SELECT автоматически аннулирует выбор почтового ящика при повторной попытке его выбора. Следовательно, если почтовый ящик был выбран, а команда SELECT не прошла, предшествующий выбор ящика аннулирован. Если клиенту разрешено модифицировать почтовый ящик, сервер должен снабжать маркированный текст отклика OK префиксом "[READ-WRITE]".
Если клиенту не позволено модифицировать почтовый ящик, но разрешен доступ для чтения, почтовый ящик выбирается в режиме "только для чтения" и сервер должен перед посылкой текста передать маркированный отклик OK в ответ на команду SELECT с кодом отклика "[READ-ONLY]". Доступ "только для чтения" тем не менее, отличается от команды EXAMINE, при нем некоторые почтовые ящики позволяют изменять постоянное состояние некоторых флагов пользователя. Сетевые новости из файла .newsrc являются примером того, как некоторые состояния могут изменяться для почтовых ящиков типа "только для чтения".
Пример: C: A142 SELECT INBOX
S: * 172 EXISTS
S: * 1 RECENT
S: * OK [UNSEEN 12] Message 12 is first unseen
S: * OK [UIDVALIDITY 3857529045] UIDs valid
S: * FLAGS (\Answered \Flagged \Deleted \Seen \Draft)
S: * OK [PERMANENTFLAGS (\Deleted \Seen \*)] Limited
S: A142 OK [READ-WRITE] SELECT completed
Команда STATUS
Аргументы: имя почтового ящика, статусная информация имен.Отклики: немаркированные отклики: STATUS.
Результат: OK - команда успешно выполнена;
NO - команда не прошла: нет статусной информации для данного имени;
BAD - команда неизвестна или неверен аргумент.
Команда STATUS запрашивает статусные данные для указанного почтового ящика. Она не изменяет выбор почтового ящика и не вносит каких-либо изменений в состояние сообщений для запрошенного ящика (в частности команда STATUS не должна вызывать потерю флага \Recent).
Команда STATUS предоставляет альтернативу открытию дополнительного IMAP 4.1 соединения и реализует команду EXAMINE для запрашиваемого почтового ящика, не изменяя выбора, выполненного при первичном соединении.
В отличии от команды LIST, команда STATUS не гарантирует быстрого отклика. В некоторых реализациях сервер обязан открыть почтовый ящик в режиме "только чтение", чтобы получить нужные статусные данные. Кроме того, команда STATUS не допускает символов подмены в шаблоне имени. В настоящее время определены следующие статусные данные, которые могут быть запрошены:
| MESSAGES | Число сообщений в почтовом ящике |
| RECENT | Число сообщений с установленным флагом \Recent |
| UIDNEXT | Следующее значение, которое будет предписано новому сообщению в почтовом ящике. Гарантируется, что это значение не изменится, если только в ящик не будет положено новое сообщение. UID будет изменен при укладке нового сообщения, даже если оно после этого стерто. |
| UIDVALIDITY | Уникальный валидатор почтового ящика |
| UNSEEN | Число сообщений, не имеющих установленного флага \Seen |
Пример: C: A042 STATUS blurdybloop (UIDNEXT MESSAGES)
S: * STATUS blurdybloop (MESSAGES 231 UIDNEXT 44292)
S: A042 OK STATUS completed
Команда STORE
Аргументы: набор сообщений,имя элемента сообщения,
значение элемента сообщения.
Отклики: немаркированные отклики: FETCH.
Результат: OK - операция успешно завершена;
NO - команда не прошла: данные не могут быть запомнены;
BAD - команда неизвестна или неверен аргумент.
Команда STORE заносит данные в почтовый ящик. В норме команда STORE возвращает обновленную версию данных с немаркированным откликом FETCH. ".SILENT" в имени элемента данных блокирует немаркированный отклик FETCH, и сервер должен предполагать, что клиент определил обновленное значение сам или ему обновленное значение не нужно.
Замечание: вне зависимости от того используется или нет суффикс ".SILENT", сервер должен послать немаркированный отклик FETCH, если внешние причины вызвали изменение флагов сообщения.
В настоящее время определены следующие элементы данных:
| FLAGS | Заменить флаги для сообщения, приведенного в аргументе. Новое значение флагов присылается, как если бы выполнялась команда FETCH для этих флагов. |
| FLAGS.SILENT | Эквивалентно FLAGS, но без возвращения нового значения. |
| +FLAGS | Добавить аргумент к флагам сообщения. Новое значение флагов возвращается, как при исполнении команды FETCH. |
| +FLAGS.SILENT | Эквивалентно +FLAGS, но без возвращения нового значения. |
| -FLAGS | Удаляет аргумент из флагов сообщения. Новое значение флагов возвращается, как при исполнении команды FETCH. |
| -FLAGS.SILENT | Эквивалентно -FLAGS, но без возвращения нового значения. |
Пример: C: A003 STORE 2:4 +FLAGS (\Deleted)
S: * 2 FETCH FLAGS (\Deleted \Seen)
S: * 3 FETCH FLAGS (\Deleted)
S: * 4 FETCH FLAGS (\Deleted \Flagged \Seen)
S: A003 OK STORE completed
Команда SUBSCRIBE
Аргументы: имя почтового ящика.Отклики: эта команда не требует каких-либо специфических откликов.
Результат: OK - процедура подписки завершена;
NO - подписка не прошла: подписка для данного имени невозможна;
BAD - команда неизвестна или неверен аргумент.
Команда SUBSCRIBE добавляет специфицированное имя почтового ящика к списку "активных" или "подписных" ящиков сервера, как это реализуется командой LSUB. Эта команда присылает маркированный отклик OK только в случае успешного осуществления подписки.
Сервер может проверить аргумент команды SUBSCRIBE, чтобы проконтролировать его корректность для данного почтового ящика. Однако он не должен в одностороннем порядке удалять существующее имя почтового ящика из подписного листа, даже если ящика с таким именем более не существует.
Замечание: это требование возникает потому, что некоторые серверы могут удалить почтовый ящик с известным именем, например, "system-alerts") после того как срок годности его содержимого истек с тем, чтобы создать его вновь при появлении новых сообщений.
Пример: C: A002 SUBSCRIBE #news.comp.mail.mime
S: A002 OK SUBSCRIBE completed
Команда UID
Аргументы: имя команды,аргументы команды.
Отклики: немаркированные отклики: FETCH, SEARCH.
Результат: OK - команда UID завершена;
NO - команда UID не прошла;
BAD - команда неизвестна или неверен аргумент.
Команда UID имеет две формы. В первой форме она использует в качестве аргумента имена команд COPY, FETCH или STORE (с их аргументами). Однако числа в списке аргументов в этом случае представляют собой уникальные идентификаторы, а не порядковые номера сообщений.
Во второй форме команда UID использует команду SEARCH с ее аргументами. Интерпретация аргументов та же, что и в случае SEARCH; однако, числа, возвращаемые в отклике на команду UID SEARCH, представляют собой уникальные идентификаторы, а не порядковые номера сообщений. Например, команда UID SEARCH 1:100 UID 443:557 возвратит уникальный идентификатор, соответствующий пересечению порядкового номера сообщения 1:100 и UID 443:557.
Допускаются диапазоны номеров сообщений, однако, нет гарантии, что уникальные идентификаторы образуют монотонную последовательность без пропусков. Не существующие уникальные идентификаторы в списке сообщений игнорируются без генерации сообщения об ошибке.
Число после "*" в немаркированном отклике FETCH всегда является порядковым номером сообщения, а не уникальным идентификатором, даже для отклика на команду UID. Однако реализации сервера должны безоговорочно включать значения UID в качестве части любого отклика FETCH, вызванного командой UID, вне зависимости от того, был ли UID специфицирован в качестве элемента сообщения для FETCH.
Пример: C: A999 UID FETCH 4827313:4828442 FLAGS
S: * 23 FETCH (FLAGS (\Seen) UID 4827313)
S: * 24 FETCH (FLAGS (\Seen) UID 4827943)
S: * 25 FETCH (FLAGS (\Seen) UID 4828442)
S: A999 UID FETCH completed
Команда UNSUBSCRIBE
Аргументы: имя почтового ящика.Отклики: эта команда не требует каких-либо специфических откликов.
Результат: OK - ликвидация подписки прошла успешно;
NO - ликвидация подписки не прошла: это невозможно для данного имени;
BAD - команда неизвестна или неверен аргумент.
Команда UNSUBSCRIBE удаляет специфицированный почтовый ящик из списка "активных" или "подписных" почтовых ящиков данного сервера, как это определяется командой LSUB. Эта команда возвращает маркированный отклик OK только в случае, если ликвидация подписки прошла успешно.
Пример: C: A002 UNSUBSCRIBE #news.comp.mail.mime
S: A002 OK UNSUBSCRIBE completed
Команды и отклики
Соединение IMAP 4.1 подразумевает установление связи между клиентом и сервером. Клиент посылает серверу команды, сервер клиенту данные и уведомления о статусе выполнения запроса. Все сообщения, как клиента, так и сервера имеют форму строк, которые завершаются последовательностью CRLF. Получатель (клиент или сервер) воспринимает такую строку или последовательность октетов известной длины, за которой следует строка.Команды клиента - экспериментальные и расширения Команда X
Аргументы: определяется приложением.Отклики: определяется приложением.
Результат: OK - команда выполнена;
NO - отказ;
BAD - команда неизвестна или неверен аргумент.
Любая команда с префиксом X является экспериментальной командой. Команды, которые не являются частью этой спецификации стандарта, модификации стандарта или одобренного IESG экспериментального протокола, должны использовать префикс X.
Любой добавленный немаркированный отклик, посланный экспериментальной командой также должен иметь префикс X. Реализации сервера не должны посылать такие немаркированные отклики, если только клиент не запрашивает их посредством какой-либо экспериментальной команды.
Пример: C: a441 CAPABILITY
S: * CAPABILITY IMAP4rev1 AUTH=KERBEROS_V4 XPIG-LATIN
S: a441 OK CAPABILITY completed
C: A442 XPIG-LATIN
S: * XPIG-LATIN ow-nay eaking-spay ig-pay atin-lay
S: A442 OK XPIG-LATIN completed-cay
Команды клиента - любое состояние
Следующие команды могут использоваться в любом состоянии: CAPABILITY, NOOP и LOGOUT.Команды клиента в состоянии "аутентификация осуществлена"
В состоянии "аутентификация осуществлена" разрешены команды манипуляции почтовыми ящиками, как объектами-атомами. Команды SELECT и EXAMINE реализует выбор почтового ящика и переход в состояние "выбрано" .В добавление к стандартным командам (CAPABILITY, NOOP и LOGOUT), в состоянии "аутентификация осуществлена" допустимы следующие команды: SELECT, EXAMINE, CREATE, DELETE, RENAME, SUBSCRIBE, UNSUBSCRIBE, LIST, LSUB, STATUS и APPEND.
Команды клиента - в состоянии без аутентификации
В состоянии без аутентификации, команды AUTHENTICATE или LOGIN организуют аутентификацию и переводят систему в состояние с аутентификацией. Об аутентификации в IMAP можно прочесть в документе RFC-1731. Команда AUTHENTICATE предоставляет общий механизм для целого ряда методов аутентификации, среди которых команда LOGIN используется для традиционного ввода имени и пароля в текстовом виде.Различные реализации сервера могут позволять доступ без аутентификации к некоторым почтовым ящикам. По договоренности в этом случае команда LOGIN предполагает ввод имени "anonymous". Ввод пароля всегда обязателен. Требования на пароль определяются конкретной версией программной реализации.
По завершении аутентификации невозможно вернуться непосредственно в состояние “без аутентификации”. В дополнение к универсальным командам (CAPABILITY, NOOP и LOGOUT), в состоянии “без аутентификации” возможны команды: AUTHENTICATE и LOGIN.
Команды клиента в состоянии "выбор сделан"
В состоянии "выбор сделан", разрешены команды, которые манипулируют сообщениями в почтовом ящике. Помимо универсальных команд (CAPABILITY, NOOP и LOGOUT), а также команд режима аутентификации (SELECT, EXAMINE, CREATE, DELETE, RENAME, SUBSCRIBE, UNSUBSCRIBE, LIST, LSUB, STATUS и APPEND), в данном режиме доступны следующие команды: CHECK, CLOSE, EXPUNGE, SEARCH, FETCH, STORE, COPY и UID.Команды клиента
Ниже описаны команды IMAP 4.1. Команды рассматриваются с учетом состояния, в котором они допустимы.Команды
Команды состоят из заголовка и опционного поля данных. Если поле данных присутствует, оно включает в себя список идентификаторов и, возможно, их значений.где представляет собой имя переменной системы или партнера в форме ASCII-последовательности, а является десятичным или шестнадцатеричным числом, или строкой, соответствующей синтаксису языка C. Для большей читаемости допускается применение пробелов (Whitespace). IP-адреса представляются в формате [n.n.n.n], где n - десятичное число. Скобки являются опционными.
Команды интерпретируются следующим образом:
Чтение статуса (1). Поле данных команды пусто или содержит список идентификаторов, разделенных запятыми. Команда работает по-разному в зависимости от значения идентификатора. Если идентификатор не равен нулю, отклик содержит идентификатор партнера и статусное слово. Если идентификатор ассоциации равен нулю, отклик содержит системный идентификатор (0) и статусное слово, в то время как поле данных содержит список пар двоичных кодов:
,
по одному на каждую, определенную в данный момент ассоциацию.
Чтение переменных (2). Поле данных команды пусто или содержит список идентификаторов, разделенных запятыми. Если идентификатор ассоциации не равен нулю, отклик включает в себя идентификатор запрашиваемого партнера и его статусное слово, в то время как в поле данных записывается список переменных партнера и их значения. Если идентификатор ассоциации равен нулю, поле данных содержит список системных переменных и их значения. Если партнер выбран в качестве источника синхронизации, отклик включает в себя идентификатор партнера и его статусное слово.
Запись переменных (3). Поле данных команды содержит список присвоений, описанный выше. Отклик идентичен отклику на команду чтения переменных.
Чтение переменных часов (4). Поле данных команды пусто или содержит список идентификаторов, разделенных запятыми. Идентификатор ассоциации выбирает переменные системных часов или партнера точно также, как в случае команды чтения переменных.
Отклик включает в себя запрошенные идентификатор часов и статусное слово, а поле данных несет в себе список переменных часов и их значений, включая последний временной код, полученный от часов.
Запись переменных часов (5). Поле данных команды содержит список присвоений, как это описано выше. Отклик имеет формат, как в случае команду чтения переменных часов.
Установка адреса/порта Trap (6). Идентификатор ассоциации команды, статус и поле данных игнорируются. Адрес и номер порта для последующих TRAP-сообщений берутся из самого управляющего сообщения. Исходное значение счетчика TRAP для сообщений откликов заимствуется из поля номера по порядку. Идентификатор ассоциации, статус и поле данных в отклике несущественны.
Отклик на TRAP (7). Это сообщение посылается, когда происходит событие (exception) в систему, у партнера или для данных часов. Код команды равен 7, а бит R=1. Содержимое trap-счетчика увеличивается на 1 для каждого сообщения данного типа. Поле номер по порядку сообщения равно содержимому этого счетчика. При посылке сообщения TRAP используется IP-адрес и номер порта, заданные командой установки адреса и порта TRAP. В случае системного TRAP идентификатор ассоциации устанавливается равным нулю, а поле статус содержит статусное слово системы. В случае TRAP партнера поле идентификатора ассоциации соответствует партнеру, а поле статус несет в себе его статусное слово. В поле данных опционно может быть включено любое символьное сообщение (ASCII).
Конфигурация и управление
Исходная конфигурация SNTP серверов и клиентов может быть произведена на основе конфигурационного файла, если такой файл имеется, или через последовательный порт. Предполагается, что SNTP серверы и клиенты практически не требуют какого-то конфигурирования, специфического для данного узла (помимо IP-адреса, маски субсети или адреса OSI NSAP).Уникастные клиенты должны быть снабжены именем сервера или его адресом. Если используется имя сервера, то необходим один или несколько адресов ближайших DNS-серверов. Мультикастные серверы и эникастные клиенты должны снабжаться значением TTL, а также местным широковещательным или групповым мультикастным адресом. Эникастные серверы и мультикастные клиенты могут конфигурироваться с привлечением списков пар адрес-маска. Это обеспечивает контроль доступа, так что операции будут производиться только с известными клиентами или серверами. Эти серверы и клиенты должны поддерживать протокол IGMP, а также знать местный широковещательный или групповой мультикастный адрес.
Существует несколько сценариев, которые помогают обнаружить и выбрать сервер для SNTP клиента без предварительной конфигурации (IP-адрес и маска субсети предполагается известной). Для IP-субсети или сегмента LAN, содержащих работающий NTP-сервер клиент может быть сконфигурирован для мультикастного режима, используя местный широковещательный адрес. Тот же подход может быть применен для других серверов, используя групповой мультикастинг-адрес. В обоих случаях предоставление списка адресов-масок серверов является желательным.
В другом сценарии, удобном для протяженных сетей с большими задержками распространения клиенты могут конфигурироваться для эникастного режима, как на начальной фазе, так и в случае, когда выбранный уникастный источник становится недоступным. Следуя протоколу, клиент устанавливает связь с первым откликнувшимся сервером и далее продолжает обмен в уникастном режиме. В этом режиме локальные часы могут автоматически корректироваться с учетом задержки распространения.
В еще одном сценарии, удобном для любой сети, где мультикастные услуги недоступны, DNS может быть сконфигурирована с одним CNAME, аналогично time.domain.net, и списком адресных записей для серверов NTP в домене. Используя адрес time.domain.net и получив список, клиент выбирает сервер и начинает с ним работу в уникастном режиме.
Ликвидация туннеля
Разрыв туннеля происходит в случае посылки партнером сообщения Stop-Control-Connection-Notification. Отправитель этого уведомления должен ждать определенное время отклика на это сообщение, прежде чем ликвидировать управляющую информацию, имеющую отношение к туннелю. Получатель этого уведомления должен послать подтверждение получения этого сообщения и затем ликвидировать управляющую информацию.Конкретная программная реализация может использовать определенный алгоритм принятия решения о разрыве управляющего соединения. Некоторые реализации могут оставить туннель открытым на некоторое время. Другие могут решить закрыть туннель немедленно после разрыва последнего соединения пользователей.
Локальное восстановление
Когда маршрут изменяется, следующее сообщение обновления Path или Resv установит проход или состояние резервирования (соответственно) вдоль нового маршрута. Чтобы обеспечить быструю адаптацию к изменениям маршрута, не вводя чрезмерно коротких периодов обновления, местный модуль протокола маршрутизации может сообщить процессу RSVP об изменении маршрута до определенных мест назначения. Процесс RSVP должен использовать эту информацию для запуска обновления в соответствующих областях с учетом изменения маршрута.При этом используются следующие правила спецификации:
Локальные часы
Для того чтобы иметь точные локальные часы, ЭВМ должна быть оборудована аппаратными часами, состоящими из задающего генератора и интерфейса, обеспечивающего необходимые операции установки и коррекции. Логические часы конструируются, используя эти компоненты и программы, которые осуществляют подстройку частоты и абсолютного показания локальных часов. Такая система позволяет достичь точности времени до 15 нс и стабильности частоты на уровне 0.3 мс в день. Предлагаемая модель удобна для применения как для компенсируемых, так и для некомпенсируемых кварцевых генераторов, пригодна она и для часов, использующих для создания временной шкалы частоту сети переменного тока.Важно заметить, что конкретная описанная реализация является лишь одной из многих возможных.
Существует два типа уникастных адресов локального использования. Имеется локальные адреса сети и канала. Локальный адрес канала предназначен для работы с одним каналом, а локальный адрес сети - с одной локальной сетью (site). Локальный IPv6 уникаст-адрес канала имеет формат, отображенный ниже на рис. 4.4.1.1.10:

Рис. 4.4.1.1.10. Локальный адрес канала
Локальные адреса канала предназначены для обращения через определенный канал, например, для целей авто-конфигурации адресов, поиска соседей или в случае отсутствия маршрутизатора. Маршрутизаторы не должны переадресовывать пакеты с локальными адресами отправителя. Локальный адрес сети имеет формат, показанный на рис. 4.4.1.1.11:

Рис. 4.4.1.1.11. Локальный адрес сети
Локальные адреса сети могут использоваться для локальных сетей или организаций, которые (пока еще) не подключены к глобальному Интернет. Им не нужно запрашивать или “красть” префикс адреса из глобального адресного пространства Интернет. Вместо этого можно использовать локальный адрес сети IPv6. Когда организация соединяется с глобальным Интернет, она может сформировать глобальные адреса путем замещения локального префикса сети префиксом подписчика.
Маршрутизаторы не должны переадресовывать пакеты с локальными адресами сети отправителя.
LP через UDP/IP
L2TP использует зарегистрированный UDP-порт 1701 [RFC1700]. Весь L2TP-пакет, включая поле данных и L2TP-заголовок, пересылается внутри UDP-дейтограммы. Создатель L2TP-туннеля выбирает доступный UDP-порт (который может быть или не быть 1701), и посылает пакет по нужному адресу места назначения с номером порта 1701. Получатель выбирает свободный номер порта в своей системе (который может быть или не быть 1701), и посылает отклик инициатору по его номеру порта и адресу. Раз номера портов отправителя и получателя определены, они должны оставаться неизменными в течение всей жизни туннеля.Может происходить IP-фрагментация, так как L2TP-пакет путешествует через Интернет. Протокол L2TP не предпринимает каких-то специальных усилий, чтобы оптимизировать этот процесс.
По умолчанию для любых реализаций L2TP должно быть активизировано контрольное суммирование UDP как для управляющих, так и информационных сообщений. Реализация L2TP может предоставить опцию, способную блокировать контрольное суммирование UDP-дейтограмм для информационных сообщений. Рекомендуется, чтобы контрольные суммы UDP были всегда активированы для управляющих сообщений.
Порт 1701 используется как пакетами L2F [RFC2341], так и L2TP. Поле версия в каждом из заголовков может использоваться, чтобы отличить пакеты этих двух типов (L2F использует значение 1, а версия L2TP, описанная в этом документе, использует 2). Реализация L2TP, работающая в системе, которая не поддерживает L2F, должна отбрасывать все L2F-пакеты.
Для PPP-клиентов, использующих туннель L2TP-поверх-UDP/IP, PPP-связь имеет возможность менять порядок или отбрасывать пакеты. В первом случае могут нарушаться протоколы, отличные от IP и использующие для транспортировки PPP. Во втором - могут нарушаться протоколы, в которых предполагается по пакетный контроль ошибок, такой как TCP со сжатием заголовков. Контроль порядка можно осуществить, используя номера информационных L2TP-сообщений, если какой-то протокол, транспортируемый через PPP-туннель, не способен справиться с изменением порядка пакетов.
Молчаливое отбрасывание пакетов может оказаться проблематичным для некоторых протоколов. Если в PPP разрешена надежная доставка [RFC1663], никакой выше расположенный протокол не может столкнуться с потерей пакетов. Если в L2TP разрешена нумерация пакетов, L2TP может контролировать потерю пакетов. В случае LNS, PPP и L2TP стеки присутствуют в LNS, и потеря пакета может регистрироваться, как если бы пакет получен с неверной CRC. Когда клиенты LAC и PPP физически различны, возможна аналоговая сигнализация, реализуемая путем посылки PPP-клиенту пакета с неверной контрольной суммой. Заметим, что это сильно усложнит отладку канальных программ клиента, так как статистика клиента не сможет отличить истинные ошибки транспортной среды от ошибок, инициированных LAC. Эта техника нереализуема на аппаратном уровне.
Если используется VJ-сжатие, и не разрешена ни надежная доставка в PPP, ни нумерация пакетов, каждый потерянный пакет будет приводить к вероятности 2-16 того, что сегмент TCP будет переадресован с неверным содержимым [RFC1144]. Там где вероятность потери велика, не следует использовать сжатие заголовков TCP-сегментов.
LP и IPsec
При работе поверх IP, IPsec (безопасный IP) предоставляет безопасность на пакетном уровне за счет ESP и/или AH. Все управляющие и информационные пакеты L2TP в конкретном туннеле выглядят для системы Ipsec, как обычные информационные UDP/IP-пакеты.Помимо транспортной безопасности IP, IPsec определяет режим работы, который позволяет туннелировать IP-пакеты. Шифрование и аутентификация на пакетном уровне, выполняемые режимом туннеля IPsec и средства L2TP, поддержанные IPsec предоставляют эквивалентные уровни безопасности.
IPsec определяет также средства контроля доступа, которые необходимы для приложений, поддерживающих IPsec. Эти средства позволяют фильтровать пакеты, на основе характеристик сетевого и транспортного уровней, таких как IP-адрес, порт, и т.д.. В модели L2TP-туннеля, аналогичная фильтрация выполняется на PPP-уровне или сетевом уровне поверх L2TP. Эти средства управления доступом на сетевом уровне могут быть реализованы в LNS за счет механизма авторизации, специфицированного производителем, или на сетевом уровне, используя транспортный режим IPsec точка-точка между взаимодействующими ЭВМ.
Максимальное время жизни пакета
В отличие от IPv4, узлы IPv6 не требуют установки максимального времени жизни пакетов. По этой причине поле IPv4 "time to live" (TTL) переименовано в "hop limit" (предельное число шагов) для IPv6. На практике очень немногие IPv4 приложения, используют ограничения по TTL, так что фактически это не принципиальное изменение.Максимальный размер поля данных для протоколов высокого уровня
При вычислении максимального размера поля данных, доступного для протокола верхнего уровня, должен приниматься во внимание большой размер заголовка IPv6 относительно IPv4. Например, в IPv4, mss опция TCP вычисляется как максимальный размер пакета (значение по умолчанию или величина полученная из MTU) минус 40 октетов (20 октетов для минимальной длины IPv4 заголовка и 20 октетов для минимальной длины TCP заголовка). При использовании TCP поверх IPv6, MSS должно быть вычислено как максимальная длина пакета минус 60 октетов, так как минимальная длина заголовка IPv6 (т.e., IPv6 заголовок без заголовков расширения) на 20 октетов больше, чем для IPv4.Манипуляции, зависящие от вида услуг
Flowspecs, Tspecs и Adspecs являются объектами, совершенно недоступными для RSVP; их содержимое определено в документах спецификации услуг. Для того чтобы манипулировать этими объектами процесс RSVP должен иметь в своем распоряжении следующие программы, зависящие от типа услуг.Compare_Flowspecs( Flowspec_1, Flowspec_2 ) ->
result_code
Возможный результат операции result_codes указывает: flowspecs равны, Flowspec_1 меньше, Flowspec_2 больше, flowspecs совместимы и можно вычислить LUB, или flowspecs не совместимы. Заметим, что, сравнивая две спецификации, мы косвенно сопоставляем Tspecs, которые они содержат. Хотя процесс RSVP не может сам осуществить разбор flowspec с целью извлечения Tspec, он может использовать вызов процедуры Compare_Flowspecs для косвенного вычисления Resv_Te.
LUB_of_Flowspecs( Flowspec_1, Flowspec_2 ) ->
Flowspec_LUB
GLB_of_Flowspecs( Flowspec_1, Flowspec_2 ) ->
Flowspec_GLB
Compare_Tspecs( Tspec_1, Tspec_2 ) -> result_code
Возможным результатом процедуры result_codes может быть: Tspecs равны или Tspecs не равны.
Sum_Tspecs( Tspec_1, Tspec_2 ) -> Tspec_sum
Этот вызов используется для вычисления Path_Te.
Маршрутный заголовок
Заголовок маршрутизации используется отправителем, чтобы заставить пакет посетить один или более промежуточных узлов на пути к месту назначения. Эта функция схожа с опцией принудительной маршрутизации в протоколе IPv4. Заголовок маршрутизации идентифицируется кодом 43 поля следующий заголовок предыдущего заголовка и имеет формат:| Следующий заголовок | 8-битовый селектор. Определяет тип заголовка, который следует непосредственно за заголовком маршрутизации. Использует те же коды протоколов, что и IPv4 [RFC-1700]. |
| hdr ext len | 8-битовое целое без знака. Длина заголовка маршрутизации выражается в 8-октетных блоках, и не включает в себя первые 8 октетов. |
| Тип маршрутизации | 8-битовый идентификатор конкретного варианта маршрутизации |
| Оставшиеся сегменты | 8-битовое число без знака. Число остающихся сегментов пути, т.e. число промежуточных узлов, которые должны быть посещены пакетом по пути к месту назначения. |
| Данные, зависящие от типа | Поле переменной длины, формат зависит от кода поля тип маршрутизации, а длина определяется заголовком маршрутизации и кратна 8 октетам. |
Если в процессе обработки входного пакета встретится заголовок маршрутизации с не узнанным полем тип маршрутизации, то поведение узла зависит от содержимого поля число оставшихся сегментов пути.

Рис. 4.4.1.1.20. Формат заголовка маршрутизации типа 0
| Следующий заголовок | 8-битовый селектор. Идентифицирует тип заголовка, следующего непосредственно за заголовком маршрутизации. Использует те же коды протоколов, что и IPv4 [RFC-1700]. |
| hdr ext len | 8-битовое целое без знака. Длина заголовка маршрутизации в 8-октетных блоках, исключая первые 8 октетов. Для заголовков маршрутизации типа 0 hdr ext len равна удвоенному числу адресов в заголовке, должно быть четным числом меньше или равным 46. |
| Тип маршрутизации | 0. |
| Оставшиеся сегменты | 8-битовое целое без знака. Число оставшихся сегментов пути, т.e., число узлов, которые следует посетить на пути к месту назначения. Максимально допустимое число = 23 |
| Резерв | 8-битовое поле резерва. Инициализируется нулем при передаче и игнорируется при приеме. |
| strict/loose bit map | 24-битовый код-маска, биты пронумерованы, начиная с 0 до 23, слева направо. Для каждого из сегментов пути указывает должен ли следующий узел быть соседом: 1 означает strict (должен быть соседом), 0 означает пропустить (не должен быть соседом). |
| Адрес[1..n] | Вектор 128-битовых адресов, пронумерованных с 1 до n. |
Мультикастинг-адреса не должны встречаться в заголовке маршрутизации типа 0, или в поле места назначения IPv6 пакета, несущего в себе заголовок маршрутизации типа 0.
Если бит 0 поля Strict/loose bit map имеет значение 1, поле адреса места назначения IPv6 заголовка в исходном пакете должно идентифицировать соседа. Если бит 0 имеет значение 0, отправитель может использовать любой легальный не мультикастинговый адрес в качестве адреса места назначения.
Биты с номерами более n, где n - число адресов в заголовке маршрутизации, должны быть обнуляться отправителем и игнорироваться получателем.
Заголовок маршрутизации не рассматривается и не анализируется до тех пор, пока пакет не достигнет места назначения, указанного в поле IPv6 заголовка. Узел, указанный в поле следующий заголовок заголовка, которому принадлежит модуль заголовка маршрутизации, реализует следующий алгоритм:
Если оставшееся число сегментов = 0
{ продолжить обработку следующего заголовка пакета, чей тип задан полем следующий заголовок заголовка маршрутизации }
else если HDR ext len является нечетным или больше 46,
{посылается сообщение ICMP (parameter problem, код 0) с указателем на поле HDR #EXT LEN, пакет выбрасывается}
else
{ вычислить n, число адресов в заголовке маршрутизации, для этого код HRD EXT LEN делится на 2
Если число оставшихся сегментов пути больше n,
{послать сообщение ICMP (parameter problem, код 0) с указанием на поле числа оставшихся сегментов пути }
else
{ уменьшить число оставшихся сегментов пути на 1;
Вычислить i, индекс следующего адреса, который следует посетить, для этого вычесть число оставшихся сегментов пути из n
Если адрес [i] или адрес места назначения IPv6 являются мультикастинговыми
{ выбросить пакет }
else { поменять местами адрес места назначения IPv6 и адрес[i]
если бит i поля strict/loose bit map имеет значение 1 и новый адрес места назначения не является адресом узла соседа
{ послать сообщение ICMP destination unreachable -- not a neighbor
и выбросить пакет }
else если код IPv6 hop limit меньше или равен 1
{послать сообщение icmp time exceeded -- hop limit exceeded in transit message и выбросить пакет }
else { уменьшить hop limit на 1
повторно направить пакет модулю IPv6 для отправки новому адресату }
}
}
}
В качестве примера работы приведенного выше алгоритма, рассмотрим случай, когда узел отправителя s посылает пакет получателю D, используя заголовок маршрутизации, чтобы заставить пакет пройти через промежуточные узлы I1, I2 и I3. Значения кодов полей заголовка IPv6 и заголовка маршрутизации для каждого из сегментов пути принимают следующие значения:
При движении пакетов от S к I1:
| Адрес отправителя = S | Hdr Ext Len = 6 |
| Адрес получателя = I1 | Число оставшихся сегментов пути = 3 |
| Адрес[1] = I2 | |
| Если бит 0 bit map равен 1, s и i1 должны быть соседями; это проверяется узлом S |
Адрес[2] = I3 Адрес[3] = d |
| Адрес отправителя = s | Hdr Ext Len = 6 |
| Адрес получателя = I2 | Число оставшихся сегментов пути = 2 |
| Адрес[1] = I1 | |
| Если бит 1 bit map равен 1, I1 и I2 должны быть соседями; это проверяется узлом I1 |
Адрес[2] = i3 Адрес[3] = D |
| Адрес отправителя = S | Hdr Ext Len = 6 |
| Адрес получателя = I3 | Число оставшихся сегментов пути = 1 Адрес[1] = I1 |
| Если бит 2 bit map равен 1, I2 и I3 должны быть соседями; это проверяется узлом I2 |
Адрес[2] = I2 |
| Адрес[3] = D |
| Адрес отправителя = S | Hdr Ext Len = 6 |
| Адрес получателя = D | Число оставшихся сегментов пути = 0 Адрес[1] = I1 |
| Если бит 3 bit map равен 1, I3 и D должны быть соседями; это проверяется узлом I3 | Адрес[2] = I2 Адрес[3] = i3 |
Машины состояний управляющего соединения
Управляющие сообщения, определенные в разделе 6 пересылаются в соответствии с таблицами состояний, описанными в данном разделе. Таблицы определены для входящих вызовов, исходящих вызовов, а также для инициации самого туннеля. Таблицы состояний не задают таймауты и поведение при повторной передаче, так как это определяется механизмами, рассмотренными в секции 5.8.Mbn_
4.4.9.1 Мультикастинг и MBONEСеменов Ю.А. (ГНЦ ИТЭФ)
MBONE - это виртуальная сеть, базирующаяся на мультикастинг-протоколах, которые были одобрены IETF летом 1992 года. В основу легли разработки, выполненные в компании Ксерокс. Данный режим работы поддерживается не всеми маршрутизаторами. Сеть представляет собой систему Ethernet-сетей, объединенных друг с другом соединениями точка-точка, которые называются "туннелями". Конечными точками таких туннелей обычно являются машины класса рабочих станций, снабженные соответствующим программным обеспечением. Впервые мультикастинг-туннель был реализован в Стэнфордском университете в 1988 году.
IP-мультикастинг-пакеты инкапсулируются при передаче через туннели так, что они выглядят как обычные IP-уникаст-пакеты.
Мультикастинг-маршрутизатор при посылке пакета через туннель подготавливает IP-пакет с заголовком, который содержит адрес маршрутизатора-партнера на другом конце туннеля, при этом поле IP-протокола содержит код 4 (IP). Маршрутизатор-приемник извлекает вложенный мультикастинг-пакет и направляет далее, если это требуется.
MBONE требует пропускной способности магистральных каналов не ниже 500Kбит/с.
Каждый туннель имеет определенный порог для переменной времени жизни пакета (time-to-live - TTL). Согласно договоренности (IETF) широкополосная видео-информация передается с малыми начальными значениями TTL. Малые значения TTL не позволяет видео-пакетам загружать слишком большие участки сети. Мультикастинг-дейтограмма с TTL=0 может быть доступна только процессу, существующему в ЭВМ, породившей эту дейтограмму. По умолчанию мультикастинг-дейтограммы имеют TTL=1, такая дейтограмма не может покинуть пределов субсети, и только дейтограммы с TTL>1 могут переадресовываться маршрутизаторами. Следует помнить, что маршрутизатор не откликнется ICMP-сообщением "время истекло", когда TTL достигнет нуля, так как вообще дейтограммы с мультикастинг-адресами не вызывают ICMP-откликов. Увеличивая TTL, прикладной процесс может расширять "зону взаимодействия".
Сначала дейтограмма может посылаться с TTL=1, если отклика не получено, c TTL=2 и так далее. Эта схема позволяет найти ближайший сервер (с точки зрения числа шагов до него). Для приложений, которые ограничивают свою активность в пределах одного шага, предусмотрен специальный интервал адресов 224.0.0.0 - 224.0.0.255. Мультикастинг-маршрутизатор не должен переадресовывать дейтограммы с такими адресами вне зависимости от значения TTL. Адрес 224.0.0.1 является адресом группы "все ЭВМ" и относится ко всем ЭВМ и маршрутизаторам, способным работать в режиме мультикастинга. Каждая ЭВМ автоматически включается в эту группу при инициализации интерфейса. О членстве в этой группе ЭВМ не сообщает.
Конфигурация системы в режиме мультикастинга производится автоматически. Для того чтобы изменить конфигурацию системы, или добавить еще один туннель используются специальные конфигурационные команды, которые записываются в /etc/mrouted.conf. Существует два типа таких команд:
phyint
tunnel
Первая команда может отменить мультикастинг-маршрутизацию для конкретного физического интерфейса, идентифицируемого по его IP-адресу (
Специфика мультикастинг-туннелей требует принципиально новых решений задачи маршрутизации, первой попыткой разрешить эту проблему был протокол DVMRP. Следует иметь в виду, что DVMRP может решить лишь часть задачи, хотя бы потому, что это внутренний протокол. Главной особенностью мультикастинг-маршрутизации является то, что нужно проложить маршруты от источника к совокупности адресатов, от которых пришли запросы участия в процессе.Режим мультикастинга поддерживается не всеми маршрутизаторами Интернет. Возможны конфликты при решении задачи маршрутизации, когда транзитный маршрутизатор не имеет "своих" участников группы (а должен выделить заметный ресурс каналов для удовлетворения внешних запросов).
Медленный старт в управляющем канале и подавление перегрузки |
Хотя каждая из сторон указала максимальный размер окна приема, рекомендуется, чтобы при передаче управляющих пакетов использовался медленный старт и метод подавления перегрузки. Методы, описанные здесь, базируются на TCP-алгоритме подавления перегрузки, как это описано в разделе 21.6 книги “TCP/IP Illustrated”, том I, написанной W. Richard Stevens [STEVENS].
Медленный старт и подавление перегрузки используют несколько переменных. Окно перегрузки (CWND) определяет число пакетов, которые отправитель может послать, не дожидаясь подтверждения. Размер CWND расширяется и сокращается так, как это описано ниже. Заметим, однако, что CWND никогда не должно превышать размера окна, полученного из AVP приемного окна (далее предполагается, что любое увеличение ограничивается размером приемного окна). Переменная SSTHRESH определяет, когда отправитель переходит от медленного старта к подавлению перегрузки. Медленный старт используется, когда CWND меньше SSHTRESH.
Отправитель начинает работу с фазы медленного старта. Начальный размер CWND равен одному пакету, а уровень SSHTRESH в начальный момент определяется размером окна (полученным из AVP приемного окна). Отправитель передает один пакет и ждет подтверждения получения. Когда подтверждение получено, окно перегрузки увеличивается на единицу и становится равным двум. Во время медленного старта, размер CWND увеличивается на единицу при получении каждого ACK. Увеличение CWND на 1 при получении ACK приводит к удвоению CWND за время RTT, что эквивалентно экспоненциальному росту. Когда значение CWND достигает SSHTRESH, фаза медленного старта завершается и начинается подавление перегрузки.
При подавлении перегрузки, CWND расширяется более медленно. В частности, оно увеличивается на 1/CWND для каждого полученного подтверждения ACK. Расширение окна на фазе подавления перегрузки является линейным, с увеличением CWND на 1 за время RTT.
Когда происходит перегрузка (индицируемая повторной передачей пакета) половина CWND записывается в SSTHRESH, а CWND делается равным 1. Отправитель после этого возвращается в режим медленного старта.
Механизм аутентификации NTP
Когда предполагается использовать аутентификацию, инициализируется ряд переменных, определяющих выбор сертификата, алгоритма шифрования и крипто-ключ и, возможно, другие параметры. Процедуры инициализации и выбора этих переменных не регламентируются протоколом NTP. Набор переменных партнера и пакетов может включать в себя следующие компоненты:Бит разрешения аутентификации (peer.authenable). Этот бит указывает, что ассоциация работает в режиме аутентификации. Для сконфигурированных партнеров этот бит определяется на фазе инициализации. Для неконфигурированных - этот бит делается равным 1, если приходящее сообщение содержит аутентификатор, в противном случае =0.
Бит аутентификации (peer.authentic). Этот бит указывает, что последнее сообщение, полученное от партнера, было корректно аутентифицировано.
Идентификатор ключа (peer.hostkeyid, peer.peerkeyid, pkt.keyid). Это целое число идентифицирует криптографический ключ, используемый для генерации кода аутентификации сообщения. Системная переменная peer.hostkeyid используется для активной ассоциации. Переменная peer.peerkeyid инициализируется нулем, когда ассоциация сформирована.
Криптографические ключи (sys.key). Это набор 64-битовых ключей DES, где 7 младших бит каждого октета соответствуют битам 1-7 DES, а старший бит соответствует биту четности 8 (сумма нечетна).
Контрольная крипто-сумма (pkt.check). Крипто-сумма вычисляется процедурой шифрования.
Поле аутентификатора состоит из двух субполей, одно содержит переменную pkt.keyid, а другое переменную pkt.check, вычисленную программой шифрования, вызываемой процедурой передачи протокола NTP, а также программой дешифровки, которая вызывается процедурой приема NTP. Ее присутствия определяется по общей длине UDP-дейтограммы. Для целей аутентификации NTP-сообщение дополняется нулями, для того чтобы сделать ее длину кратной 64 битам. Аутентификатор содержит 96 бит, куда входят 32-битовый идентификатор ключа и 64-битовая крипто-сумма. Дополнительная информация (например, о сертификате и алгоритме шифрования), если необходимо, может быть вставлена между NTP-сообщением и идентификатором ключа. Подобно аутентификатору эта информация не включается в контрольное крипто-суммирование.
Метки потоков
24-битовое поле метки потока в заголовке IPv6 может использоваться отправителем для выделения пакетов, для которых требуется специальная обработка в маршрутизаторе, такая например, как нестандартная QoS или "real-time " сервис. Этот аспект IPv6 является пока экспериментальным и может быть изменен позднее. Для ЭВМ или маршрутизаторов, которые не поддерживают функцию пометки потоков, это поле должно быть обнулено при формировании пакета, сохраняться без изменения при переадресации и игнорироваться при получении.Поток это последовательность пакетов, посылаемых отправителем определенному адресату, при этом предполагается, что все пакеты данного потока должны быть подвергнуты определенной обработке. Характер этой специальной обработки может быть передан маршрутизатору посредством протокола управления или внутри самих пакетов, например, в опции hop-by-hop.
Допускается несколько потоков между отправителем и получателем, а также обмен, не ассоциированный ни с одним из потоков. Поток однозначно описывается комбинацией адреса отправителя и ненулевой меткой потока. Пакеты, не принадлежащие ни одному из потоков, имеют метку равную нулю.
Метка потока присваивается потоку узлом отправителя. Новые метки потоков должны выбираться псевдослучайным образом из диапазона чисел 1 - FFFFFF. Целью псевдослучайного выбора метки является возможность использования любого набора бит поля метки потока в качестве хэш ключа маршрутизаторами для контроля состояния соответствующего потоку.
Все пакеты, принадлежащие одному потоку, должны быть посланы одним отправителем, иметь один и тот же адрес места назначения, приоритет и метку потока. Если какой-либо из этих пакетов включает в себя заголовок опций hop-by-hop, тогда все они должны начинаться с одного и того же содержания заголовка опций hop-by-hop (исключая поле следующий заголовок заголовка опций hop-by-hop). Если любой из этих пакетов включает заголовок маршрутизации, тогда все они должны иметь идентичные заголовки расширения, включая заголовок маршрутизации но исключая поле следующий заголовок заголовка маршрутизации.
Маршрутизаторы и узлы- адресаты могут проверять эти требования (хотя это и необязательно). Если обнаружено нарушение, должно быть послано ICMP сообщение отправителю (problem message, код 0) с указателем на старший октет поля метка потока (т.e., смещение 1 в IPv6 пакете).
Маршрутизаторы могут произвольно варьировать способ обработки потоков данных, даже когда имеется какая-либо информация о потоке со стороны протокола управления, опции hop-by-hop или другого источника. Например, при получении пакетов от какого-то источника с неизвестной ненулевой меткой, маршрутизатор может обрабатывать их IPv6-заголовок и любой необходимый заголовок расширения так, как если бы метка равнялась нулю. Такая обработка может включать выявление интерфейса следующего шага и другие действия, такие как актуализация опции hop-by-hop, перемещение указателя и адресов в заголовке маршрутизации и т.д.. Маршрутизатор может запомнить результаты такой обработки, занеся их в кэш (адрес отправителя и метка образуют ключ кэша). Последующие пакеты с тем же адресом отправителя и меткой потока могут обрабатываться с использованием информации из кэша без детального просмотра всех полей, которые, согласно уже описанному, должны быть идентичными.
Режим обработки пакетов с использованием кэш должен быть аннулирован не позднее 6 секунд после своей установки вне зависимости от того, продолжают ли поступать пакеты данного потока. Если приходит другой пакет от того же отправителя с той же меткой после того как кэш режим отменен, он подвергается обычной обработке (как если бы имел нулевую метку), такая ситуация может быть причиной повторного формирования кэш режима.
Время жизни режима обработки потока задается явно в процессе конфигурации, например, через протокол управления или опцию hop-by-hop, и может превышать 6 секунд.
Отправитель не должен использовать старую метку для нового потока в пределах времени жизни любого потока. Так как режим обработки потока на 6 секунд может быть установлен для любого потока, минимальный интервал между последним пакетом одного потока и первым пакетом нового, использующего ту же метку, должно быть равно 6 секундам.Метки потока, которые используются для потоков, существующих более продолжительное время не должны использоваться соответственно дольше.
Когда узел останавливает или перезапускает процесс (например, в случае сбоя), он должен позаботиться о том, чтобы метка потока была уникальной и не совпадала с другой еще действующей меткой. Это может быть сделано путем записи используемых меток в стабильную память, так чтобы ею можно было воспользоваться даже после серьезного сбоя в системе. Если известно минимальное время перезагрузки системы (time for rebooting, обычно более 6 секунд), это время можно использовать для задания времени жизни меток потоков.
Не требуется, чтобы все или даже большинство пакетов принадлежали потокам с ненулевыми метками. Например, было бы неумно сконструировать маршрутизатор так, чтобы он работал только с пакетами, принадлежащими к тому или иному потоку, или создать схему сжатия заголовков, которая работает только с помеченными потоками.
Международное соглашение об именах почтовых ящиков
Согласно договоренности имена международных почтовых ящиков специфицированы в соответствии модифицированной версией кодировки UTF-7, описанной в [UTF-7]. Целью этих модификаций было устранение следующих проблем, связанных с UTF-7:В модифицированном UTF-7, печатные символы US-ASCII за исключением "&" представляются в исходном виде; то есть, символами со значениями октетов 0x20-0x25 и 0x27-0x7e. Символ "&" (0x26) представляется в виде двух октетной последовательности "&-". Все другие символы (значения октетов 0x00-0x1f, 0x7f-0xff, и все уникодные 16-битовые октеты) представляются в модифицированной кодировке BASE64, с дополнительными видоизменениями из [UTF-7]. Модифицированная BASE64 не должна использоваться для представления любых печатных символов US-ASCII, которые должны представлять самих себя.
Символ "&" используется для перехода к модифицированной кодировке BASE64 а "-" для возврата назад к US-ASCII. Все имена начинаются с US-ASCII, и должны завершаться US-ASCII (то есть, имя, которое заканчивается уникодным 16-битовым октетом, должно быть завершено символом "-"). Примером может служить имя почтового ящика, в котором смешаны фрагменты текста на английском, японском и китайском языках: ~peter/mail/&ZeVnLIqe-/&U,BTFw-
Вся управляющая информация для контроля
4.4.13.1 Управляющая база данных MIBСеменов Ю.А. (ГНЦ ИТЭФ)
Вся управляющая информация для контроля ЭВМ и маршрутизаторами Интернет концентрируется в базе данных MIB (Management Information Base, RFC-1213 или STD0017). Именно эти данные используются протоколом SNMP. Система SNMP состоит из трех частей: менеджера SNMP, агента SNMP и базы данных MIB. Агент SNMP должен находиться резидентно в памяти объекта управления. SNMP-менеджер может быть частью системы управления сетью NMS (Network Management System), что реализуется, например, в маршрутизаторах компании CISCO (CiscoWorks).
MIB определяет, например, что IP программное обеспечение должно хранить число всех октетов, которые приняты любым из сетевых интерфейсов, управляющие программы могут только читать эту информацию.
Согласно нормативам MIB управляющая информация делится на восемь категорий (см. также рис. 4.4.13.1.1):
MIB-категория включает в себя информацию о
| MIB-категория | Описание | Код |
| system | Операционная система ЭВМ или маршрутизатора. | 1 |
| Interfaces | Сетевой интерфейс. | 2 |
| addr.trans | Преобразование адреса (напр., с помощью ARP). | 3 |
| IP | Программная поддержка протоколов Интернет. | 4 |
| ICMP | Программное обеспечение ICMP-протокола. | 5 |
| TCP | Программное обеспечение TCP-протокола. | 6 |
| UDP | Программное обеспечение UDP-протокола. | 7 |
| EGP | Программное обеспечение EGP-протокола. | 8 |
| SNMP | Программное обеспечение SNMP-протокола. | 11 |
| Системная переменная | Описание | Код |
| Sysdescr | Текстовое описание объекта; | 1 |
| Sysobjectid | Идентификатор производителя в рамках дерева 1.3.6.1.4.1 | 2 |
| Sysuptime | Время с момента последней загрузки системы (timeticks); | 3 |
| Syscontact | Имя системного менеджера и способы связи с ним; | 4 |
| Sysname | Полное имя домена; | 5 |
| Syslocation | Физическое местоположение системы; | 6 |
| Sysservice | Величина, которая характеризует услуги, предоставляемые узлом (сумма номеров уровней модели OSI); | 7 |
| Переменная описания интерфейсов (iftable) | Тип данных | Описание | ifEntry |
| IFindex | integer | Список интерфейсов от 1 до ifnumber. | 1 |
| IfDescr | displaystring | Текстовое описание интерфейса. | 2 |
| IfType | integer | Тип интерфейса, например, 6 - ethernet; 9 - 802.5 маркерное кольцо; 23 - PPP; 28 - SLIP. | 3 |
| IfNumber | integer | Число сетевых интерфейсов. | |
| IfMTU | integer | mtu для конкретного интерфейса; | 4 |
| IfSpeed | gauge | Скорость в бит/с. | 5 |
| IfPhysaddress | physaddress | Физический адрес или строка нулевой длины для интерфейсов без физического адреса (напр. последовательный). | 6 |
| IfAdminStatus | [1...3] | Требуемое состояние интерфейса: 1 - включен; 2 - выключен; 3 - тестируется. | 7 |
| IfOperStatus | [1...3] | Текущее состояние интерфейса: 1 - включен; 2 - выключен; 3 - тестируется. | 8 |
| IfLastchange | timeticks | Sysuptime, когда интерфейс оказался в данном состоянии. | 9 |
| IfInOctets | counter | Полное число полученных байтов. | 10 |
| IfInUcastpkts | counter | Число пакетов, доставленных на верхний системный уровень (unicast). | 11 |
| IfInNUcastpkts | counter | Число пакетов, доставленных на верхний системный уровень (unicast). | 12 |
| IfInDiscads | counter | Число полученных но отвергнутых пакетов. | 13 |
| IfInErrors | counter | Число пакетов, полученных с ошибкой; | 14 |
| IfInUnknownProtos | counter | Число пакетов, полученных с ошибочным кодом протокола; | 15 |
| IfOutOctets | counter | Число отправленных байтов; | 16 |
| IfOutUcastPkts | counter | Число unicast- пакетов, полученных с верхнего системного уровня; | 17 |
| IfOutNucastPkts | counter | Число мультикастинг- и широковещательных пакетов, полученных с верхнего системного уровня; | 18 |
| IfOutDiscads | counter | Количество отвергнутых пакетов из числа отправленных; | 19 |
| IfOutErrors | counter | Число отправленных пакетов, содержащих ошибки; | 20 |
| IfOutQlen | gauge | Число пакетов в очереди на отправку; | 21 |
| Название объекта | Цифра-точечное представление |
| org | 1.3 |
| dod | 1.3.6 |
| internet | 1.3.6.1 |
| directory | 1.3.6.1.1 |
| mgmt | 1.3.6.1.2 |
| experimental | 1.3.6.1.3 |
| private | 1.3.6.1.4 |
| enterprises | 1.3.6.1.4.1 |
| security | 1.3.6.1.5 |
| snmpV2 | 1.3.6.1.6 |
| snmpDomains | 1.3.6.1.6.1 |
| snmpProxys | 1.3.6.1.6.2 |
| snmpModules | 1.3.6.1.6.3 |
| snmpMIB | 1.3.6.1.6.3.1 |
| snmpMIBObjects | 1.3.6.1.6.3.1.1 |
| snmpTraps | 1.3.6.1.6.3.1.1.5 |
| mib-2 | 1.3.6.1.2.1 |
| ifMIB | 1.3.6.1.2.1.31 |
| interfaces | 1.3.6.1.2.1.2 |
| ifMIBObjects | 1.3.6.1.2.1.31.1 |
| ifConformance | 1.3.6.1.2.1.31.2 |
| ifTableLastChange | 1.3.6.1.2.1.31.1.5 |
| ifXTable | 1.3.6.1.2.1.31.1.1 |
| ifStackTable | 1.3.6.1.2.1.31.1.2 |
| ifStackLastChange | 1.3.6.1.2.1.31.1.6 |
| ifRcvAddressTable | 1.3.6.1.2.1.31.1.4 |
| ifTestTable | 1.3.6.1.2.1.31.1.3 |
| ifXEntry | 1.3.6.1.2.1.31.1.1.1 |
| ifName | 1.3.6.1.2.1.31.1.1.1.1 |
| ifInMulticastPkts | 1.3.6.1.2.1.31.1.1.1.2 |
| ifInBroadcastPkts | 1.3.6.1.2.1.31.1.1.1.3 |
| ifOutMulticastPkts | 1.3.6.1.2.1.31.1.1.1.4 |
| ifOutBroadcastPkts | 1.3.6.1.2.1.31.1.1.1.5 |
| ifLinkUpDownTrapEnable | 1.3.6.1.2.1.31.1.1.1.14 |
| ifHighSpeed | 1.3.6.1.2.1.31.1.1.1.15 |
| ifPromiscuousMode | 1.3.6.1.2.1.31.1.1.1.16 |
| ifConnectorPresent | 1.3.6.1.2.1.31.1.1.1.17 |
| ifAlias | 1.3.6.1.2.1.31.1.1.1.18 |
| ifCounterDiscontinuityTime | 1.3.6.1.2.1.31.1.1.1.19 |
| ifStackEntry | 1.3.6.1.2.1.31.1.2.1 |
| ifStackHigherLayer | 1.3.6.1.2.1.31.1.2.1.1 |
| ifStackLowerLayer | 1.3.6.1.2.1.31.1.2.1.2 |
| ifStackStatus | 1.3.6.1.2.1.31.1.2.1.3 |
| ifRcvAddressEntry | 1.3.6.1.2.1.31.1.4.1 |
| ifRcvAddressAddress | 1.3.6.1.2.1.31.1.4.1.1 |
| ifRcvAddressStatus | 1.3.6.1.2.1.31.1.4.1.2 |
| ifRcvAddressType | 1.3.6.1.2.1.31.1.4.1.3 |
| ifTestEntry | 1.3.6.1.2.1.31.1.3.1 |
| ifTestId | 1.3.6.1.2.1.31.1.3.1.1 |
| ifTestStatus | 1.3.6.1.2.1.31.1.3.1.2 |
| ifTestType | 1.3.6.1.2.1.31.1.3.1.3 |
| ifTestResult | 1.3.6.1.2.1.31.1.3.1.4 |
| ifTestCode | 1.3.6.1.2.1.31.1.3.1.5 |
| ifTestOwner | 1.3.6.1.2.1.31.1.3.1.6 |
| ifGroups | 1.3.6.1.2.1.31.2.1 |
| ifCompliances | 1.3.6.1.2.1.31.2.2 |
| ifGeneralInformationGroup | 1.3.6.1.2.1.31.2.1.10 |
| ifFixedLengthGroup | 1.3.6.1.2.1.31.2.1.2 |
| ifHCFixedLengthGroup | 1.3.6.1.2.1.31.2.1.3 |
| ifPacketGroup | 1.3.6.1.2.1.31.2.1.4 |
| ifHCPacketGroup | 1.3.6.1.2.1.31.2.1.5 |
| ifVHCPacketGroup | 1.3.6.1.2.1.31.2.1.6 |
| ifRcvAddressGroup | 1.3.6.1.2.1.31.2.1.7 |
| ifStackGroup2 | 1.3.6.1.2.1.31.2.1.11 |
| ifCounterDiscontinuityGroup | 1.3.6.1.2.1.31.2.1.13 |
| ifGeneralGroup | 1.3.6.1.2.1.31.2.1.1 |
| ifTestGroup | 1.3.6.1.2.1.31.2.1.8 |
| ifStackGroup | 1.3.6.1.2.1.31.2.1.9 |
| ifOldObjectsGroup | 1.3.6.1.2.1.31.2.1.12 |
| ifCompliance2 | 1.3.6.1.2.1.31.2.2.2 |
| ifCompliance | 1.3.6.1.2.1.31.2.2.1 |
| ifNumber | 1.3.6.1.2.1.2.1 |
| ifTable | 1.3.6.1.2.1.2.2 |
| ifEntry | 1.3.6.1.2.1.2.2.1 |
| ifIndex | 1.3.6.1.2.1.2.2.1.1 |
| ifDescr | 1.3.6.1.2.1.2.2.1.2 |
| ifType | 1.3.6.1.2.1.2.2.1.3 |
| ifMtu | 1.3.6.1.2.1.2.2.1.4 |
| ifSpeed | 1.3.6.1.2.1.2.2.1.5 |
| ifPhysAddress | 1.3.6.1.2.1.2.2.1.6 |
| ifAdminStatus | 1.3.6.1.2.1.2.2.1.7 |
| ifOperStatus | 1.3.6.1.2.1.2.2.1.8 |
| ifLastChange | 1.3.6.1.2.1.2.2.1.9 |
| ifInOctets | 1.3.6.1.2.1.2.2.1.10 |
| ifInUcastPkts | 1.3.6.1.2.1.2.2.1.11 |
| ifInNUcastPkts | 1.3.6.1.2.1.2.2.1.12 |
| ifInDiscards | 1.3.6.1.2.1.2.2.1.13 |
| ifInErrors | 1.3.6.1.2.1.2.2.1.14 |
| ifInUnknownProtos | 1.3.6.1.2.1.2.2.1.15 |
| ifOutOctets | 1.3.6.1.2.1.2.2.1.16 |
| ifOutUcastPkts | 1.3.6.1.2.1.2.2.1.17 |
| ifOutNUcastPkts | 1.3.6.1.2.1.2.2.1.18 |
| ifOutDiscards | 1.3.6.1.2.1.2.2.1.19 |
| ifOutErrors | 1.3.6.1.2.1.2.2.1.20 |
| ifOutQLen | 1.3.6.1.2.1.2.2.1.21 |
| ifSpecific | 1.3.6.1.2.1.2.2.1.22 |
br>
Таблица 4.4.13.1.3. Переменные IP-группы
| Переменная IP-группы | Тип данных | Описание | Код |
| ipForwarding | integer | Указание на то, что данный объект осуществляет переадресацию (работает как маршрутизатор). | 1 |
| IPdefaultTTL | integer | Значение, которое использует IP в поле TTL. | 2 |
| IPinreceives | counter | Число полученных дейтограмм. | 3 |
| ipInHdrErrors | counter | Число дейтограмм, отвергнутых из-за ошибок формата или неверных адресов или опций, из-за истекшего TTL. | 4 |
| ipInHdrErrors | counter | Число дейтограмм, отвергнутых из-за неверного IP-адреса, например, 0.0.0.0, или неподдерживаемого класса, например Е. | 5 |
| ipForwDatagrams | counter | Число дейтограмм, для которых данный объект не является местом назначения (маршрутизация отправителя). | 6 |
| ipInUnknownProtos | counter | Число дейтограмм с неподдерживаемым кодом протокола. | 7 |
| ipInDiscards | counter | Число дейтограмм, отвергнутых из-за переполнения буфера. | 8 |
| ipInDelivers | counter | Полное число входных дейтограмм, успешно обработанных на IP-уровне. | 9 |
| ipOutRequests | counter | Полное число IP и ICMP дейтограмм, переданных для отправки. | 10 |
| ipOutRequests | counter | Полное число IP и ICMP дейтограмм, переданных для отправки. | 11 |
| IPoutNoroutes | counter | Число неудач при маршрутизации. | 12 |
| ipReasmTimeout | counter | Максимальное число секунд ожидания сборки фрагментов. | 13 |
| ipReasmReqds | counter | Число полученных фрагментов | 14 |
| ipReasmOKs | counter | Число полученных и успешно собранных IP-дейтограмм | 15 |
| ipReasmFails | counter | Число полученных IP-дейтограмм, которые по тем или иным причинам не удалось собрать | 16 |
| IPFragOKs | counter | Число успешно фрагментированных IP- дейтограмм. | 17 |
| ipFragFails | counter | Число IP- дейтограмм, которые нужно фрагментировать, но сделать это нельзя (например, из-за флага). | 18 |
| ipFragCreates | counter | Число IP-дейтограмм фрагментов, сформированных данным объектом. | 19 |
| ipAddrTable | counter | Таблица адресной информации данного объекта. | 20 |
| ipRouteTable | Последовательность записей маршрутной таблицы | Запись в маршрутной таблице | 21 |
| ipAddrEntry | |||
| IPAdEntAddr | IPaddress | IP-адрес для данного ряда | 1 |
| IPadentifindex | integer | Число интерфейсов. | 2 |
| IPadentnetmask | IPaddress | Маска субсети для данного IP-адреса; | 3 |
| IPAdEntBcastAddr | [0...1] | Значение младшего бита широковещательного адреса (обычно 1); | 4 |
| IPAdEntReasmMaxsize | [0...65535] | Размер наибольшей IP-дейтограммы, полученной интерфейсом, которая может быть собрана. | 5 |
br>
Помимо простых переменных объектами MIB могут быть таблицы. Для каждой таблицы имеется один или несколько индексов.
Таблица 4.4.13.1.4. Переменные TCP-группы
| Переменные TCP-группы | Тип данных | Описание | Код |
| tcpRtoAlgorithm | integer | Алгоритм выявления таймаута для повторной передачи TCP-пакетов: 1 - ни один из следующих; 2 - постоянное RTO; 3 - стандарт MIL-std-1778; 4 - алгоритм Ван Джакобсона | 1 |
| tcpRtoMin | integer | Минимальное допустимое время повторной передачи tcp- пакетов. | 2 |
| tcpRtoMax | integer | Максимальное значение тайм-аута в миллисек. | 3 |
| tcpMaxConn | integer | Максимальное допустимое число tcp-соединений. | 4 |
| tcpActiveOpens | integer | Число TCP-соединений Active-Open | 5 |
| tcpPassiveOpens | integer | Число TCP-соединений Passive-Open (из состояния LISTEN) | 6 |
| tcpAttemptFails | integer | Число неудачных TCP-соединений | 7 |
| tcpEstabResets | integer | Число разрывов TCP-соединений из состояний ESTABLISHED или CLOSE-WAIT | 8 |
| tcpCurrEstab | Gauge | Число TCP-соединений, для которых текущее состояние ESTABLISHED или CLOSE-WAIT | 9 |
| tcpInSegs | counter | Полное число полученных tcp-сегментов. | 10 |
| tcpOutSegs | counter | Полное число посланных сегментов, исключая повторно пересылаемые. | 11 |
| tcpRetransSegs | counter | Полное число повторно пересланных сегментов. | 12 |
| tcpConnTable | counter | Таблица данных специфичных для соединения | 13 |
| tcpInErrs | counter | Полное число сегментов, полученных с ошибкой. | 14 |
| tcpOutRsts | counter | Полное число посланных сегментов с флагом rst=1. | 15 |
| tcpconntable. tcp-таблица связей | |||
| tcpconnstate | [1...12] | Состояние соединения: 1 - closed; 2 - listen; 3 - syn_sent; 4 - syn_rcvd; 5 - established, 6 - fin_wait_1; 7 - fin_wait_2; 8 - close_wait; 9 - last_ack; 10 - closing; 11 - time_wait;, 12 - delete TCB. Только последняя переменная может устанавливаться менеджером, немедленно прерывая связь. | |
| tcpconnlocal address |
ipaddress | Местный IP-адрес. 0.0.0.0 означает, что приемник готов установить связь через любой из интерфейсов. | |
| tcpconnlocal port |
[0...65535] | Местный номер порта. | |
| tcpconnlocal address |
ipaddress | Удаленный ip-адрес. | |
| tcpconnrem port |
[0...65535] | Удаленный номер порта. |
br>
Таблица 4.4.13.1.5. Переменные ICMP-группы (тип данных - counter)
| Переменная icmp-группы | Описание | Код |
| icmpInMsgs | Полное число полученных ICMP-сообщений. | 1 |
| icmpInErrors | Число ICMP-сообщений, полученных с ошибками. | 2 |
| icmpInDestUnreach | Число ICMP-сообщений о недостижимости адресата. | 3 |
| icmpintimeexcds | Число ICMP-сообщений об истечении времени. | 4 |
| icmpInParmProbs | Число полученных ICMP-сообщений о проблемах с параметрами. | 5 |
| icmpInSrcQuench | Число ICMP-сообщений с требованием сократить или прервать посылку пакетов из-за перегрузки. | 6 |
| icmpInRedirects | Число ICMP-сообщений о переадресации. | 7 |
| icmpInEchos | Число полученных ICMP-запросов отклика. | 8 |
| icmpInEchoReps | Число полученных ICMP-эхо- откликов. | 9 |
| icmpInTimestamps | Число ICMP-запросов временных меток. | 10 |
| icmpInTimestampReps | Число ICMP-откликов временных меток. | 11 |
| icmpInAddrMasks | Число ICMP-запросов адресных масок. | 12 |
| icmpInAddrMaskReps | Число ICMP-откликов на запросы адресных масок. | 13 |
| icmpOutMsgs | Число отправленных ICMP- сообщений. | 14 |
| icmpOutErrors | Число не отправленных ICMP- сообщений из-за проблем в ICMP (напр. нехватка буферов). | 15 |
| icmpOutDestUnreachs | Число ICMP-сообщений о недоступности адресата. | 16 |
| icmpOutTimesExcds | Число посланных ICMP-сообщений об истечении времени. | 17 |
| icmpOutParmProbs | Число посланных ICMP-сообщений о проблемах с параметрами. | 18 |
| icmpOutSrcQuench | Число посланных ICMP-сообщений об уменьшении потока пакетов. | 19 |
| icmpOutRedirects | Число посланных ICMP-сообщений о переадресации. | 20 |
| icmpOutEchos | Число посланных ICMP-эхо-запросов. | 21 |
| icmpOutEchoReps | Число посланных ICMP-эхо-откликов. | 22 |
| icmpOutTimestamps | Число посланных ICMP-запросов временных меток. | 23 |
| icmpOutTimestampReps | Число посланных ICMP-откликов на запросы временных меток. | 24 |
| icmpOutAddrMasks | Число посланных ICMP-запросов адресных масок. | 25 |
| Переменные at-группы | Тип данных | Описание | atEntry |
| atIfIndex | integer | Число интерфейсов. | 1 |
| atPhysAddress | physaddress | Физический адрес. Если эта переменная равна строке нулевой длины, физический адрес отсутствует. | 2 |
| atNetAddress | networkaddress | IP-адрес. | 3 |
br>
Каждый протокол ( например IP) имеет свою таблицу преобразования адресов. Для IP это ipnettomediatable. Способ пропечатать эту таблицу с помощью программы SNMPI описан ниже.
MIB II содержит управляемые объекты, принадлежащие к группе snmp. SNMP-группа предоставляет информацию о SNMP-объектах, информационных потоках, о статистике ошибок:
| Название объекта | Описание | Код |
| snmpInPkts | Число пакетов, полученных от слоя, расположенного ниже SNMP. | 1 |
| snmpOutPkts | Число пакетов доставленных от SNMP к нижележащему слою. | 2 |
| snmpInBadVersions | Индицирует число PDU, полученных с ошибкой в поле версия. | 3 |
| snmpInBadCommunityNames | Индицирует число PDU, полученных с нечитаемым или нелегальным именем community. | 4 |
| snmpInBadCommunityUses | Полное число SNMP-пакетов, полученных с нечитаемым или нелегальным значение операции для данного имени community. | 5 |
| snmpInAsnParsErrs | Указывает полное число ошибок ASN.1 или BER, которые не могут быть обработаны во входных SNMP-сообщениях | 6 |
| snmpInTooBigs | Указывает число полученных PDU со слишком большим значением поля статус ошибки. | 8 |
| snmpInNoSuchNames | Указывает число PDU, полученных с индикацией ошибки в поле nosuchname. | 9 |
| snmpInBadValues | Указывает число PDU, полученных с индикацией ошибки в поле badvalue. | 10 |
| snmpInReadOnlys | Указывает число PDU, полученных с индикацией ошибки в поле readonly. | 11 |
| snmpNnGenErrs | Указывает число PDU, полученных с generr-полем. | 12 |
| snmpInTotalReqVar | Указывает число объектов MIB, которые были восстановлены. | 13 |
| snmpInTotalSetVars | Указывает число объектов MIB, которые были изменены. | 14 |
| snmpInGetRequests | Указывает число соответствующих pdu, которые были получены. | 15 |
| snmpInGetNexts | Указывает полное число pdu с запросами GetNext | 16 |
| snmpInSetRequests | Указывает полное число pdu, полученных с запросами SET | 17 |
| snmpInGetResponses | Указывает полное число pdu, полученных c откликами на запросы | 18 |
| snmpInTraps | Указывает полное число, полученных и успешно обработанныз TRAP | 19 |
| snmpOutTooBig | Указывает число посланных PDU с полем toobig. | 20 |
| snmpOutNoSuchNames | Указывает число посланных PDU с полем nosuchname. | 21 |
| snmpOutBadValues | Указывает число посланных PDU с полем badvalue. | 22 |
| snmpOutGenErrs | Указывает число посланных PDU с полем genErrs. | 24 |
| snmpOutGetRequests | Указывает число посланных PDU Get-Request | 25 |
| snmpOutGetNexts | Указывает число посланных PDU Get-NEXT | 26 |
| snmpOutSetRequests | Указывает число посланных PDU SET | 27 |
| snmpOutGetResponses | Указывает число посланных PDU откликов | 28 |
| snmpOutTraps | Указывает число посланных PDU TRAPs | 29 |
| snmpEnableAuthTraps | Говорит о том, разрешены или нет ловушки (TRAPS). | 30 |
br>
Стандарт на структуру управляющей информации (SMI) требует, чтобы все MIB-переменные были описаны и имели имена в соответствии с ASN.1 (abstract syntax notation 1, формализованный синтаксис). ASN.1 является формальным языком, который обладает двумя основными чертами:
используемая в документах нотация легко читаема и понимаема, а в компактном кодовом представлении информация может использоваться коммуникационными протоколами. В SMI не используется полный набор типов объектов, предусмотренный в ASN.1, разрешены только следующие типы примитивов: integer, octet string, object identifier и null. Практически в протоколе SNMP фигурируют следующие виды данных:
integer. Некоторые переменные объявляются целыми (integer) с указанием начального значения или с заданным допустимым диапазоном значений (в качестве примера можно привести номера UDP- или TCP-портов).
octet string (последовательность байтов). В соответствии с требованиями BER (basic encoding rules, ASN.1) последовательность октетов должна начинаться с числа байт в этой последовательности (от 0 до n).
object identifier (идентификатор объекта). Имя объекта, представляющее собой последовательность целых чисел, разделенных точками. Например, 192.148.167.129 или 1.3.6.1.2.1.5.
null. Указывает, что соответствующая переменная не имеет значения.
displaystring. Строка из 0 или более байт (но не более 255), которые представляют собой ASCII-символы. Представляет собой частный случай octet string.
physaddress. Последовательность октетов, характеризующая физический адрес объекта (6 байт для Ethernet). Частный случай object identifier.
Сетевой адрес. Допускается выбор семейства сетевых протоколов. В рамках ASN.1 этот тип описан как choice, он позволяет выбрать протокол из семейства протоколов. В настоящее время идентифицировано только семейство протоколов Интернет.
IP-адрес. Этот адрес используется для определения 32-разрядного Интернет-адреса. В нотации ASN.1 - это octet string.
time ticks (такты часов). Положительное целое число, которое используется для записи, например, времени последнего изменения параметров управляемого объекта, или времени последней актуализации базы данных.
Время измеряется в сотых долях секунды.
gauge (масштаб). Положительное целое число в диапазоне 0 - (232-1), которое может увеличиваться или уменьшаться. Если эта переменная достигнет величины 232-1, она будет оставаться неизменной до тех пор пока не будет обнулена командой сброс. Примером такой переменной может служить tcpcurresta, которая характеризует число TCP соединений, находящихся в состоянии established или close_wait.
counter (счетчик). Положительное целое число в диапазоне 0 - (232-1), которое может только увеличиваться, допуская переполнение.
sequence. Этот объект аналогичен структуре в языке Си.
Например, MIB определяет sequence с именем udpentry, содержащую информацию об активных UDP-узлах. В этой структуре содержится две записи:
1. UDPlocaladdress типа ipaddress, содержит местные IP-адреса.
2. UDPlocalport типа integer, содержит номера местных портов.
SEQUENCE OF. Описание вектора, все элементы которого имеют один и тот же тип. Элементы могут представлять собой простые объекты, например, типа целое. В этом случае мы имеем одномерный список. Но элементами вектора могут быть объекты типа SEQUENCE, тогда этот вектор описывает двумерный массив.
В Интернет MIB каждый объект должен иметь имя (object identifier), синтаксис и метод кодировки.
Стандарт ASN.1 определяет форму представления информации и имен. Имена переменных MIB соответствуют в свою очередь стандартам ISO и CCITT. Структура имен носит иерархический характер, отображенный на рис. 4.4.13.1.1.

Рис. 4.4.13.1.1 Структура идентификаторов переменных в MIB
В приведенной ниже таблице охарактеризованы четыре простые переменные, идентификаторы которых помещены в нижней части рис. 4.4.13.1.1. Все эти переменные допускают только чтение.
| Имя переменной | Тип данных | Описание | Код |
| udpInDatagrams | counter | Число UDP-дейтограмм, присланных процессам пользователя. | 1 |
| udpNoPorts | counter | Число полученных UDP-дейтограмм, для которых отсутствует прикладной процесс в порте назначения. | 2 |
| udpInErrors | counter | Число не доставленных UDP-дейтограмм по причинам, отличающимся от отсутствия процесса со стороны порта назначения (напр., ошибка контрольной суммы). | 3 |
| udpOutDatagrams | counter | Число посланных UDP-дейтограмм. | 4 |
| udpTable | counter | Таблица, содержащая данные о принимающей стороне | 5 |
br>
Ниже приведено описание таблицы (udptable; index =
| Имя переменной | Тип данных | Описание |
| udplocaladdress | ipaddress | Местный IP-адрес для данного приемника; |
| udplocalport | (0 - 65535) | Местный номер порта приемника. |
Помимо стандартного набора переменных и таблиц MIB возможно использование индивидуальных расширений этой базы данных. Это можно продемонстрировать на примере MIB маршрутизаторов Cisco (рис. 4.4.13.1.2).

Рис. 4.4.13.1.2. Расширение базы данных mib маршрутизаторов Cisco
Префикс 1.3.6.1.4.1. является стандартным, далее следует расширение, индивидуальное для маршрутизаторов компании Cisco. Например, группа IPcheckpoint accounting позволяет контролировать поток байтов с определенных адресов локальной сети, что бывает важно при работе с коммерческими провайдерами услуг.
Коды-префиксы для различных производителей телекоммуникационного оборудования приведены в таблице 4.4.13.1.7.
Таблица 4.4.13.1.7 Коды-префиксы производителей
| Код префикса | Название фирмы |
| 0 | Зарезервировано |
| 1 | Proteon |
| 2 | IBM |
| 3 | CMU |
| 4 | UNIX |
| 5 | ACC |
| 6 | TWG |
| 7 | Cayman |
| 8 | PSI |
| 9 | Cisco |
| 10 | NSC |
| 11 | HP |
| 12 | Epilogue |
| 13 | U of Tennessee |
| 14 | BBN |
| 15 | Xylogics, inc. |
| 16 | Unisys |
| 17 | Canstar |
| 18 | Wellfleet |
| 19 | TRW |
| 20 | MIT |
Маршрутизаторы Cisco поддерживают две базы данных: active accounting и checkpoint accounting. В первую заносятся текущие результаты измерения входящего и исходящего трафика. Эти результаты копируются в базу данных checkpoint accounting и, если там уже имеются предыдущие данные, они объединяются. Для очистки базы данных checkpointed database выдается команда clear IP accounting, а для базы checkpoint - clear IP accounting checkpoint (для использования этих команд необходимы системные привилегии). Объем памяти, выделяемой для этих баз данных задается командой IP accounting-threshold , по умолчанию максимальное число записей в базе данных равно 512.
Лучшим способом закрепить в памяти все вышесказанное является использование программы SNMPI (SNMP initiator) или ее аналога. Если в вашем распоряжении имеется ЭВМ, работающая под unix, например SUN, вы можете попутно узнать много полезного о вашей локальной сети. Ниже описан синтаксис обращения к SNMPI.
snmpi [-a agent] [-c community] [-f file] [-p portno] [-d] [-v] [-w]
SNMPI - крайне простая программа, используемая для тестирования SNMPD. Для того чтобы проверить, работает ли она, выдайте команду:
% SNMPI dump
Следует отметить, что в ответ на эту операцию будет произведена весьма объемная выдача.
Опция -a предлагает возможность ввести адрес SNMP-объекта - имя ЭВМ, IP-адрес или транспортный адрес. По умолчанию это местная ЭВМ. Аналогично опция -p позволяет задать номер UDP-порта. По умолчанию это порт 161.
Опция -c позволяет задать групповой пароль (community) для snmp-запроса. По умолчанию - это public, т.е. свободный доступ.
Опция -f позволяет выбрать файл, содержащий откомпилированные описания mib-модулей. По умолчанию - это objects.defs.
Опция -w включает режим наблюдения, осуществляя выдачу на терминал всех служебных сообщений. Уход из программы по команде quit (q).
Если вы работаете на IBM/PC, и ваша машина подключена к локальной сети, получите допуск к одной из UNIX-машин в сети (если вы его не имели) и приступайте. Можно начать с обращения типа:
SNMPI -a 193.124.224.33 (адрес или символьное имя надо взять из вашей локальной сети)
Машина откликнется, отобразив на экране SNMPI>, это означает, что программа имеется и вы можете вводить любые команды.
Начать можно со знакомства с системными переменными системы (в дальнейшем курсивом выделены команды, введенные с клавиатуры):
SNMPI> get sysdescr.0
snmpi> sysdescr.0="GS software (gs3-k), version 9.1(4) [fc1], software copyright (c) 1986-1993 by cisco systems, inc. compiled thu 25-mar-93 09:49 by daveu"
snmpi> get sysobjectid.0
snmpi> sysobjectid.0=1.3.6.1.4.1.9.1.1
snmpi> get sysuptime.0
snmpi> sysuptime.0=14 days, 7 hours, 0 minutes, 15.27 seconds (123481527 timeticks)
snmpi> get sysservices.0
snmpi> sysservices.0=0x6
Код 0x06 (sysservices.0) представляет собой сумму кодов уровней модели iso, поддерживаемых системой. Для справок: 0x01 - физический уровень; 0x02 - связной уровень; 0x04 - Интернет; 0x08 - связь точка-точка; 0x40 - прикладной уровень.
Если вы хотите получить информацию о состоянии интерфейсов на одной из ЭВМ, подключенных к вашей локальной сети (команды вызова snmpi далее не повторяются; в ниже приведенных примерах в круглых скобках помещены комментарии автора), выдайте команды:
SNMPI> next iftabl (команда next в данном случае соответствует запросу get-next, здесь понятие "следующий" подразумевает порядок переменных в MIB)
snmpi> ifindex.1=1
snmpi> get ifdescr.1
snmpi> ifdescr.1="ethernet0"
snmpi> get iftype.1
snmpi> iftype.1=ethernet-csmacd(6)
snmpi> get ifmtu.1
snmpi> ifmtu.1=1500
snmpi> get ifspeed.1
snmpi> ifspeed.1=10000000 (10Мб/с ethernet)
snmpi> get ifphysaddress.1
snmpi> ifphysaddress.1=0x00:00:0c:02:3a:49 (физический адрес интерфейса)
snmpi> next ifdescr.1 iftype.1 ifmtu.1 ifspeed.1 ifphysaddress.1
snmpi> ifdescr.2="serial0"
iftype.2=proppointtopointserial(22)
ifmtu.2=1500
ifspeed.2=2048000 (2 Мбит/ c радиорелейный последовательный канал, спутниковый канал был бы охарактеризован точно также).
ifphysaddress.2=
В приведенном примере размеры пересылаемых блоков для Ethernet и радиорелейного последовательного канала идентичны и равны 1500. Помните, что SLIP-канал характеризуется как pointtopointserial, а не slip. Скорость обмена по SLIP-каналу не сообщается.
Теперь просмотрим некоторые UDP-переменные. Например:
SNMPI> next UDP
SNMPI> udpindatagrams.0=98931
SNMPI> next udpindatagrams.0 (обратите внимание на суффикс простой переменной)
SNMPI> udpnoports.0=60009
SNMPI> next udplocaladdress.0
SNMPI>udplocaladdress.193.124.137.14.7=193.124.137.14
(Идентификатор этого объекта - 1.3.6.1.2.1.7.5.1.1.193.124.137.14.7.)
SNMPI> next udplocalport
SNMPI> udplocalport.193.124.137.14.7=7
Если у вас возникла необходимость просмотреть таблицу, например, udptable, это
также можно сделать, используя snmpi:
SNMPI> next udptable
SNMPI> udplocaladdress.193.124.137.14.7=193.124.137.14
SNMPI> next udplocaladdress.193.124.137.14.7
SNMPI> udplocaladdress.193.124.224.33.67=193.124.224.33
SNMPI> next udplocaladdress.193.124.224.33.67
SNMPI> udplocaladdress.193.124.224.33.161=193.124.224.33
SNMPI> next udplocalport.193.124.224.33.67
SNMPI> udplocalport.193.124.224.33.161=161
Ниже показана методика выяснения алгоритма и параметров задания величины тайм-аута:
SNMPI> get tcprtoalgorithm.0 tcprtomin.0 tcprtomax.0 tcpmaxconn.0
SNMPI> tcprtoalgorithm.0=vanj(4) (vanj - алгоритм Ван Джакобсона для расчета времени тайм-аута)
| tcprtomin.0=300 | (минимальное значение тайм-аута = 300 мс) |
| tcprtomax.0=60000 | (максимальное - 60 сек) |
| tcpmaxconn.0=-1 | (никаких ограничений на число соединений) |
| atifindex.1.1.193.124.224.33= | 1 |
| atifindex.1.1.193.124.224.35= | 1 |
| atifindex.3.1.192.148.166.203= | 3 |
| atifindex.3.1.192.148.166.205= | 3 |
| atifindex.5.1.145.249.30.33= | 5 |
| atifindex.5.1.192.148.166.98= | 5 |
| atphysaddress.1.1.193.124.224.33= | 0x00:00:0c:02:3a:49 |
| atphysaddress.1.1.193.124.224.35= | 0x08:00:20:12:1b:b1 |
| atphysaddress.1.1.193.124.224.40= | 0x00:00:cd:f9:0d:e7 |
| atphysaddress.1.1.193.124.224.50= | 0x00:00:0c:02:fb:c5 |
| atnetaddress.1.1.193.124.224.33= | 193.124.224.33 |
| atnetaddress.1.1.193.124.224.35= | 193.124.224.35 |
| atnetaddress.1.1.193.124.224.40= | 193.124.224.40 |
| atnetaddress.1.1.193.124.224.50= | 193.124.224.50 |
| atnetaddress.1.1.193.124.224.60= | 193.124.224.60 |
Обычно элементы таблицы расположены в порядке колонка-ряд. Если вы дошли до края колонки или всей таблицы ЭВМ выдаст вам, в зависимости от реализации программы, имя и значение следующего элемента или сообщение об ошибке.
Чтобы получить полный текст адресной таблицы в рамках SNMPI достаточно выдать команду:
SNMPI> dump ipaddrtable
| snmpi> ipadentaddr.192.148.166.222= | 192.148.166.222 |
| ipadentaddr.192.168.1.1= | 192.168.1.1 |
| ipadentaddr.192.168.1.2= | 192.168.1.2 |
| ipadentaddr.193.124.224.33= | 193.124.224.33 |
| ipadentaddr.193.124.224.190= | 193.124.224.190 |
| ipadentifindex.192.148.166.222= | 3 |
| ipadentifindex.192.168.1.1= | 4 |
| ipadentifindex.192.168.1.2= | 6 |
| ipadentifindex.193.124.224.33= | 1 |
| ipadentifindex.193.124.224.190= | 5 |
| ipadentnetmask.192.148.166.222= | 255.255.255.224 |
| ipadentnetmask.192.168.1.1= | 255.255.255.0 |
| ipadentnetmask.192.168.1.2= | 255.255.255.0 |
| ipadentnetmask.193.124.224.33= | 255.255.255.224 |
| ipadentnetmask.193.124.224.190= | 255.255.255.224 |
| ipadentbcastaddr.192.168.1.1= | 1 |
| ipadentbcastaddr.192.168.1.2= | 1 |
| ipadentbcastaddr.193.124.224.33= | 1 |
| ipadentbcastaddr.193.124.224.190= | 1 |
br>
ipadentreasmmaxsize.192.148.166.222= 18024 (С точки зрения фрагментации и последующей сборки дейтограмм данные субсети эквивалентны).
| ipadentreasmmaxsize.192.168.1.1= | 18024 |
| ipadentreasmmaxsize.192.168.1.2= | 18024 |
| ipadentreasmmaxsize.193.124.224.33= | 18024 |
| ipadentreasmmaxsize.193.124.224.190= | 18024 |
sun> arp -a
itepgw.itep.ru (193.124.224.33) at 0:0:c:2:3a:49
nb.itep.ru (193.124.224.60) at 0:80:ad:2:24:b7
и дополнить полученные данные с помощью SNMPI:
SNMPI> dump ipnettomediatable
SNMPI> ipnettomediaifindex.1.193.124.224.33= 1
ipnettomediaifindex.1.193.124.224.35= 1
ipnettomediaifindex.3.192.148.166.193= 3
ipnettomediaifindex.3.192.148.166.196= 3
ipnettomediaifindex.3.193.124.226.110= 3
ipnettomediaifindex.5.145.249.30.33= 5
ipnettomediaifindex.5.192.148.166.100= 5
ipnettomediaphysaddress.1.193.124.224.33= 0x00:00:0c:02:3a:49
ipnettomediaphysaddress.3.192.148.166.196= 0xaa:00:04:00:0c:04
ipnettomediaphysaddress.3.192.148.166.198= 0xaa:00:04:00:0e:04
ipnettomediaphysaddress.3.192.148.166.203= 0x00:00:01:00:54:62
.........................................
ipnettomediaphysaddress.5.145.249.30.33= 0x00:00:0c:02:69:7d
ipnettomediaphysaddress.5.192.148.166.100= 0x00:20:af:15:c1:61
ipnettomediaphysaddress.5.192.148.166.101= 0x08:00:09:42:0d:e8
ipnettomedianetaddress.1.193.124.224.33= 193.124.224.33
ipnettomedianetaddress.1.193.124.224.35= 193.124.224.35
ipnettomedianetaddress.3.192.148.166.193= 192.148.166.193
ipnettomedianetaddress.3.193.124.226.110= 193.124.226.110
ipnettomedianetaddress.5.145.249.30.33= 145.249.30.33
ipnettomediatype.1.193.124.224.33= other(1)
ipnettomediatype.1.193.124.224.35= dynamic(3)
ipnettomediatype.1.193.124.224.37= dynamic(3)
ipnettomediatype.3.192.148.166.195= dynamic(3)
ipnettomediatype.3.192.148.166.222= other(1)
ipnettomediatype.5.193.124.224.190= other(1)
ipnettomediatype.5.193.124.225.33= other(1)
ipnettomediatype.5.193.124.225.35= dynamic(3)
Синтаксис каждого объекта описывается в рамках ASN.1 и показывает побитовое представление объекта. Кодирование объекта характеризует то, как тип объекта отображается через его синтаксис и передается по телекоммуникационным каналам. Кодирование производится в соответствии с базовыми правилами кодирования asn.1. Все описания объектов базируются на типовых шаблонах и кодах asn.1 (см. RFC-1213). Формат шаблона показан ниже:
object (Объект):
Имя типа объекта с соответствующим ему идентификатором объекта (object identifier)
syntax (Синтаксис):
asn.1 описание синтаксиса типа объекта.
definition (Определение):
Текстовое описание типа объекта.
access (доступ):
Опции доступа.
status (состояние):
Статус типа объекта.
Маршруты также являются объектами mib. Согласно требованиям к mib, каждому маршруту в этой базе соответствует запись, схема которой приведена ниже на рис. 4.4.13.1.3:

Рис. 4.4.13.1.3 Формат записи маршрутной таблицы в MIB
Поле место назначения представляет собой IP-адрес конечной точки маршрута. Поле индекс интерфейса определяет локальный интерфейс (физический порт), через который можно осуществить следующий шаг по маршруту. Следующие пять полей (метрика 1-5) характеризуют оценку маршрута. В простейшем случае, например для протокола RIP, достаточно было бы одного поля. Но для протокола OSPF необходимо 5 полей (разные TOS). Поле следующий шаг представляет собой IP-адрес следующего маршрутизатора. Поле тип маршрута имеет значение 4 для опосредованного достижения места назначения; 3 - для прямого достижения цели маршрута; 2 - для нереализуемого маршрута и 1 - для случаев отличных от вышеперечисленных.
Поле протокол маршрутизации содержит код протокола. Для RIP этот код равен 8, для OSPF - 13, для BGP - 14, для IGMP - 4, для прочих протоколов - 1. Поле возраст маршрута описывает время в секундах, прошедшее с момента последней коррекции маршрута.
Следующее поле - маска маршрута используется для выполнения логической побитовой операции И над адресом в IP-дейтограммы перед сравнением результата с кодом, хранящимся в первом поле записи (место назначения). Последнее поле маршрутная информация содержит код, зависящий от протокола маршрутизации и обеспечивающий ссылки на соответствующую информацию в базе MIB.
Новым расширением MIB является система удаленного мониторинга сетей (RMON; RFC-1513, -1271). RMON служит для мониторирования сети в целом, а не отдельных сетевых устройств. В RMON предусмотрено 9 объектных групп (см. табл. 4.4.13.1.8).
Таблица 4.4.13.1.8. Функциональные группы RMON
| Группа | Назначение |
| statistics | Таблица, которая отслеживает около 20 статистических параметров сетевого трафика, включая общее число кадров и количество ошибок |
| history | Позволяет задать частоту и интервалы для измерений трафика |
| alarm | Позволяет установить порог и критерии, при которых агенты выдают сигнал тревоги |
| host | Таблица, содержащая все узлы сети, данные по которым приводятся в сетевой статистике |
| hostTopN | Позволяет создать упорядоченные списки, которые базируются на пиковых значениях трафика группы ЭВМ |
| matrix | Две таблицы статистики трафика между парами узлов. Одна таблица базируется на адресах узлов-отправителей, другая - на адресах узлов-получателей |
| filter | Позволяет определить конкретные характеристики кадров в канале. Например, можно выделить TCP-трафик. |
| packet capture | Работает совместно с группой filter. Позволяет специфицировать объем ресурса памяти, выделяемой для запоминания кадров, которые отвечают критериям filter. |
| event | Позволяет специфицировать набор параметров или условий, которые должен контролировать агент. Когда условия выполняются, информация о событии записывается в специальный журнал |
Модель ЭВМ
Прежде чем будет сформирована сессия, ей должен быть присвоен идентификатор (DestAddress, ProtocolId [, DstPort]), который рассылается всем отправителям и получателям. Когда RSVP сессия сформировалась, в оконечных системах должны произойти следующие события.| H1 | Получатель посредством IGMP подключается к мультикаст-группе, заданной адресом DestAddress. |
| H2 | Потенциальный отправитель начинает посылать сообщения Path по адресу DestAddress. |
| H3 | Приложение получателя принимает сообщение Path. |
| H4 | Получатель начинает посылать соответствующие сообщения Resv, задавая дескрипторы нужных потоков. |
| H5 | Приложение отправителя получает сообщение Resv. |
| H6 | Отправитель начинает посылать информационные пакеты. |
Существует несколько соображений, касающихся синхронизации.
Получатель может просто игнорировать такие сообщения об ошибке или он может избежать их, ожидая сообщений, прежде чем посылать сообщения Resv. Программный интерфейс приложения (API) для RSVP в данной спецификации не определен, так как он может зависеть от ЭВМ и ОС.
Модификации существующих типов запроса
Все существующие типы запросов, которые выполняют дополнительную обработку секции a, т.е. типы запросов, относящиеся к серверу имен (ns), почтовому серверу (MX) и почтовому ящику (MB), для осуществления обработки как секции типа a, так и типа aaaa должны быть переопределены. Эти новые определения означают, что сервер имен, обрабатывая один из указанных запросов, должен добавить в соответствующую секцию запроса какие-то подходящие адреса IPv4 и какие-то адреса IPv6 доступные локально.Мульткаст-адреса
Мультикастинг-адрес IPv6 является идентификатором для группы узлов. Узел может принадлежать к любому числу мультикастинг групп. Мультикастинг-адреса имеют следующий формат (рис. 4.4.1.1.13):
Рис. 4.4.1.1.13
11111111 в начале адреса идентифицирует адрес, как мультикатинг-адрес.

Рис. 4.4.1.1.14
Старшие 3 флага зарезервированы и должны быть обнулены.
t = 0 указывает на то, что адрес является стандартным ("well-known") мультикастным, официально выделенным для глобального использования в Интернет.
T = 1 указывает, что данный мультикастинг-адрес присвоен временно ("transient").
Поле scope представляет собой 4-битовый код мультикастинга, предназначенный для определения предельной области действия мультикастинг-группы. Допустимые значения:
0 зарезервировано
1 Область действия ограничена локальным узлом
2 Область действия ограничена локальным каналом
3 (не определено)
4 (не определено)
5 Область действия ограничена локальной сетью
6 (не определено)
7 (не определено)
8 Область действия ограничена локальной организацией
9 (не определено)
A (не определено)
B (не определено)
C (не определено)
D (не определено)
E глобальные пределы (global scope)
F зарезервировано
Идентификатор группы идентифицирует мультикастинг-группы, постоянной или переходной (transient), в пределах заданных ограничений (scope).
Значение постоянно присвоенного мультикастинг-адреса не зависит от значения поля scope. Например, если "NTP servers group" присвоен постоянный мультикастинг адрес с идентификатором группы 43 (hex), тогда:
FF01:0:0:0:0:0:0:43 означает, что все ntp серверы одного и того же узла рассматриваются как отправители.
FF02:0:0:0:0:0:0:43 означает, что все NTP серверы работают с тем же каналом, что и отправитель.
FF05:0:0:0:0:0:0:43 означает, что все NTP серверы принадлежат той же сети, что и отправитель.
FF0E:0:0:0:0:0:0:43 означает, что все NTP серверы находятся в Интернет.
Непостоянно выделенные мультикаст-адреса имеют значение только в пределах данного ограничения (scope). Например, группа, определенная непостоянным локальным мультикаст-адресом FF15:0:0:0:0:0:0:43, не имеет никакого смысла для другой локальной сети или непостоянной группы, использующей тот же групповой идентификатор с другим scope, или для постоянной группы с тем же групповым ID.
Мультикастинг адреса не должны использоваться в качестве адреса отправителя в IPv6 дейтограммах или встречаться в любых заголовках маршрутизации.
Надежная доставка управляющих сообщений
L2TP обеспечивает нижний уровень надежного транспорта для всех управляющих сообщений. Поля Nr и Ns заголовка управляющего сообщения (смотри раздел 3.1) относятся к этому транспорту. Функции верхнего уровня L2TP не занимаются повторной пересылкой или упорядочением управляющих сообщений. Надежный управляющий канал обеспечивается за счет специального протокола, например, TCP, поддерживающего повторную пересылку управляющих сообщений и контроль перегрузки. Каждый партнер поддерживает независимую нумерацию сообщений для управляющего канала в туннеле.Порядковые номера сообщений Ns начинаются с 0. Каждое последующее сообщение имеет номер на 1 больше, чем предыдущее. Номер по порядку, таким образом, является простым счетчиком, работающим по модулю 65536. Порядковый номер в заголовке полученного сообщения рассматривается меньше или равным последнему полученному числу, если его значение лежит в интервале между последним полученным кодом и предыдущими 32767 включительно. Например, если последний полученный номер был равен 15, тогда сообщения с порядковыми номерами 0 - 15, а также 32784 - 65535, будут рассматриваться как сообщение с меньшим или равным номером. Такое сообщение будет рассматриваться как дубликат уже полученного и не будет обрабатываться. Однако, для того чтобы гарантировать, что все сообщения подтверждены корректно (в частности в случае потери сообщения ZLB ACK), получение сообщения-дубликата должно быть подтверждено. Это подтверждение может быть реализовано косвенно, или непосредственно через ZLB ACK.
Все управляющие сообщения в пространстве номеров занимают одну нишу, за исключением подтверждения ZLB. Таким образом, Ns не инкрементируется после посылки сообщения ZLB.
Номер последнего полученного сообщения, Nr, используется для подтверждения сообщений, принятых L2TP-партнером. Этот код должен содержать порядковый номер сообщения, которые партнер ожидает получить следующим (например, последний Ns сообщения (non-ZLB) плюс 1, по модулю 65536). В то время как Nr в полученном ZLB используется для удаления сообщений из локальной очереди сообщений, ждущих imes повторной передачи в локальной очереди (смотри ниже), Nr следующего сообщения не должен обновляться при получении Ns ZLB.
Протокол надежной доставки принимающего партнера ответственен за проверку того, что управляющие сообщения доставлены на верхний уровень в правильном порядке и без дублирования. Сообщения, пребывающие в неверном порядке, могут быть занесены в очередь для последующей корректной доставки, когда пропущенные сообщения будут получены, или они могут быть выброшены, что вынудит партнера послать их повторно. Каждый туннель поддерживает очередь управляющих сообщений, которые нужно передать его партнеру. Сообщение в начале очереди посылается с заданным значением Ns, и хранится до тех пор, пока не придет от партнера управляющее сообщение, в котором поле Nr указывает на то, что данное сообщение получено. Если в течение определенного времени (рекомендуемое значение равно 1 секунде) отклика не получено, сообщение посылается повторно. Повторно посылаемое сообщение имеет то же значение Ns, но величина Nr должна быть сделана равной номеру очередного ожидаемого сообщения.
Каждая повторная посылка сообщения должна реализовываться по истечении задержки, величина которой возрастает экспоненциально от раза к разу. Таким образом, если первая повторная передача происходит спустя 1 секунду, следующая повторная передача может производиться по истечении 2 секунд, затем 4 секунд, и т.д.. Программная реализация может установить верхний предел на время между повторными пересылками сообщения. Этот предел должен быть не меньше 8 секунд. Если после нескольких повторных посылок, не зафиксировано никакого отклика от партнера, (рекомендуемое число попыток равно 5, но должно быть настраиваемым), туннель и все сессии должны быть аннулированы.
Когда туннель закрывается не по причине обрыва соединения, состояние и механизм надежной доставки должны поддерживаться и работать в течение всего периода повторных передач.
Механизм скользящего окна используется для передачи управляющих сообщений. Рассмотрим двух партнеров A & B. Предположим A задает размер приемного окна в сообщениях SCCRQ или SCCRP равным N. B при этом позволено иметь до N ожидающих подтверждения получения сообщений.
Когда N послано, нужно ждать подтверждения, которое сдвинет окно, прежде чем посылать новое управляющее сообщение. Программная реализация может поддерживать приемное окно с размером 1 (т.e., посылать AVP размера приемного окна со значением 1), но должно воспринимать от своего партнера окна с шириной до 4 (например, имеет возможность послать 4 сообщения, прежде чем остановиться и ожидать отклика). Значение 0 для AVP размера приемного окна является недопустимым.
При повторной передаче управляющих сообщений следует использовать медленный старт и окно подавления перегрузки. Рекомендуемая процедура для этого описана в приложении A.
Партнер не должен отказываться подтверждать сообщения, в качестве меры управления потоком управляющих сообщений. Предполагается, что реализация L2TP способна работать с входными управляющими сообщениями, возможно реагируя с ошибками, отражающими невозможность выполнения запрашиваемых действий. В приложении B представлены примеры управляющих сообщений, подтверждений и повторных передач.
Не специфицированный адрес
Адрес 0:0:0:0:0:0:0:0 называется не специфицированным адресом. Он не должен присваиваться какому-либо узлу. Этот адрес указывает на отсутствие адреса. Примером использования такого адреса может служить поле адреса отправителя любой IPv6 дейтограммы, посланной инициализируемой ЭВМ до того, как она узнала свой адрес.Не специфицированный адрес не должен использоваться в качестве указателя места назначения IPv6 дейтограмм или в IPv6 заголовках маршрутизации.
Необходимые адреса узлов
ЭВМ должна распознавать следующие адреса, как обращенные к нему:Маршрутизатор должен распознавать следующие адреса (as identifying itself):
Приложение должно предопределить только следующие адресные префиксы:
Приложения должны считать все остальные адреса уникастными, если противоположное не оговорено при конфигурации (например, эникастные адреса).
Необходимые эникаст-адреса
Эникаст-адрес маршрутизатора субсети предопределен и имеет формат, отображенный на рис. 4.4.1.1.12:
Рис. 4.4.1.1.12
Префикс субсети в эникастном адресе является префиксом, который идентифицирует определенный канал. Этот эникастный адрес является синтаксически идентичным уникастному адресу для интерфейса канала с идентификатором интерфейса равным нулю.
Пакеты, посланные группе маршрутизаторов с эникастным адресом, будут доставлены всем маршрутизатам субсети. При этом все маршрутизаторы субсети должны поддерживать работу с эникастными адресами. Реальный обмен будет осуществлен лишь с тем маршрутизатором, который ответит первым.
Эникастный адрес маршрутизатора субсети предполагается использовать в приложениях, где необходимо взаимодействовать с одним из совокупности маршрутизаторов удаленной субсети. Например, когда мобильный хост хочет взаимодействовать с одним мобильным агентом в его “домашней” субсети.
New_tcp
4.4.3.3 Новый протокол TCPСеменов Ю.А. (ГНЦ ИТЭФ)
Современная версия протокола ТСР (RFC-793, -1323) имеет ряд недостатков (см. , а также RFC-2525 или [1]):
или RST, переполнение буфера SYN-запросами, прерывание сессии с помощью сообщения ICMP "адресат недоступен" и т.д.)
Попытки адаптировать действующую версию протокола имели существенный, но ограниченный успех (модели Tahoe, Reno (см. также RFC-2582), Vegas, Т/ТСР (см. RFC-1644), SACK (см. RFC-2018, -2883, -3517) и другие (см., например, RFC-2309, -3042, -3168)), а также альтернативный протокол XTP. Некоторые недостатки были частично устранены (синдром узкого окна, алгоритм Нагля).
Следует, впрочем, заметить, что радикальные изменения протокола ТСР не предпринимались неслучайно. Программные продукты, используемые на сотнях миллионов ЭВМ не поменять в одночасье. И нужно искать решение, которое позволяло бы работать со старыми версиями программного обеспечения, базирующегося на протоколе ТСР (Tahoe или Reno).
В данной статье предлагается принципиально иная модель таботы транспортного протокола ТСР (NTCP). В запросе SYN этого протокола должен присутствовать код опции NTCP (код поля опции вид может равняться, например, 20) и, если поддерживающий NTCP объект получает такой сегмент, он должен послать соответствующий отклик отправителю.
Сначала рассмотрим, что мешает традиционному ТСР работать в сверхскоростных каналах. Здесь наиважнейшими параметрами являются window > RTT×B/MSS и поле идентификатора пакета, где В - полоса пропускания канала, измеряемая в битах в сек, максимальный размер сегмента MSS здесь и далее задан в битах), а RTT-сумма времен доставки сегмента от отправителя до получателя и отклика от получателя до отправителя.
По умолчанию величина MSS равна 1460*8 = 11680бит. О проблеме работы протокола ТСР в режиме больших произведений RTT на В см. [2].
Высокопроизводительные каналы (³1 Гбит/с) уже сегодня могут исчерпать разнообразие идентификационных кодов пакетов за один сеанс связи. Появление же двух пакетов с равными идентификаторами может породить неразрешимые трудности. Для передачи мегабайтного файла по гигабитному каналу требуется около 40 мсек (при этом предполагается, что задержка в канале составляет 32 мсек (RTT=64 мсек)). Собственно передача этой информации занимает 8 мсек. Из этих цифр видно, что традиционные протоколы, размеры окон и пр. могут свести на нет преимущества скоростного, дорогостоящего канала. Пропускная способность такого канала определяется уже не его полосой, а задержкой. Понятно также, что необходимо расширить эффективное поле размера окна с 16 до 32 бит (это делается сегодня с привлечением опции ТСР). Чтобы не изменять формат TCP-сегментов, можно сделать код размера окна в программе 32-разрядным, сохранив соответствующее поле в сегменте неизменным (см. RFC-2414, -2415). Размер окна в этом случае задается как бы в формате с плавающей запятой. При установлении канала определяется масштабный коэффициент n (порядок) лежащий в интервале 0-14. Передача этого коэффициента (один байт) осуществляется сегментом SYN в поле опций. В результате размер окна оказывается равным 65535*2n. Если один из партнеров послал ненулевой масштабный коэффициент, но не получил такого коэффициента от своего партнера по каналу, то n считается равным нулю. Эта схема позволяет сосуществовать старым и новым системам. Выбор n возлагается на TCP-модуль операционной системы.
Увеличение размера окна в свою очередь приводит к проблемам, возникающим при перегрузке. Каноническое поведение протокола TCP в случае потери пакета (это может быть сегмент данных или отклик) заключается в повторной пересылке всех посланных пакетов, начиная с потерянного. Если считать, что о потере пакета отправитель узнает в среднем спустя RTT/2, то для рассмотренного выше примера за это время будет передано 2 мегабайта, которые и должны быть переданы повторно.
Для 10Гигабитного канала этот объем увеличится до 20Мбайт.
Время RTT складывается из задержки распространения электромагнитных волн по каналу и из времени пребывания пакетов в очередях и их обработки в сетевых устройствах. Вторая составляющая преобладает (если это не спутниковый канал). Время распространения волны по кабелю длиной 5000 км составляет около 25 мсек, задержка в современном маршрутизаторе варьируется от 2 до 20 мсек. Число же маршрутизаторов на пути такой длины равно 10-15. Дополнительной вклад в задержку внесут переключатели локальной сети, а также системы отправителя и получателя. Таким образом, приведенное выше значение RTT является типичным, и, следовательно, нужно искать пути выхода из тупика, сопряженного с повторной передачей больших массивов данных.
Можно рассматривать варианты, где исключается или сводится к минимуму вероятность потери пакета (тогда ничего повторно передавать не нужно). В некоторых моделях реализации ТСР предусмотрен режим “исключения перегрузки”, что подразумевает исключение потери пакетов. Но, к сожалению, полностью исключить потери пакетов невозможно, хотя бы из-за конечной вероятности их повреждения при транспортировке.
Можно задуматься о снижении величины RTT. Это делает бесперспективным использование скоростных спутниковых каналов связи, где составляющая, сопряженная с временем распространения электромагнитных волн, составляет около 400мсек. Время пребывания пакета в очереди и длительность его обработки в маршрутизаторе пока сократить нельзя. Можно ли сократить число маршрутизаторов в виртуальном соединении точка-точка?
Если следовать требованиям современного протокола ТСР, то нельзя, так как конечные точки заданы сессией (отправитель-получатель), а промежуточные узлы - топологией Интернет и протоколом маршрутизации.
Далее рассматривается принципиально новый вариант протокола ТСР, который будем называть NTCP. Все сетевые объекты, поддерживающие протокол NTCP, должны анализировать и модифицировать TCP-заголовки откликов не только адресованных им пакетов, но и всех транзитных.
Для широкомасштабной реализации протокола NTCP необходима адаптация сетевых маршрутизаторов (в настоящее время они обрабатывают только IP-заголовки) и крайне желательна переделка переключателей уровня L2.
Если исключить виртуальное соединение точка-точка и сделать так, чтобы виртуальный путь состоял из цепочки сегментов маршрута, то RTT можно сократить в разы, а для протяженных маршрутов на порядок. Традиционный виртуальный ТСР-маршрут превращается в цепь туннелей, соединяющих последовательные маршрутизаторы, поддерживающие NTCP. Здесь не имеются в виду IP-туннели с вложением IP-дейтограммы в IP-пакет. Примеры таких туннелей можно видеть на рис. 3 между узлами А и 1, а также между 3 и 4. Для каждого из туннелей RTT становится равным времени транспортировки и обработки пакета для одного шага, что может составлять 1-5 мсек (или даже меньше). 16-битного поля окна заголовка при RTT>5мсек хватит до скоростей передачи данных ~20Гбит/c. Можно предполагать, что для 100Гигабитного оборудования будут характерны меньшие значения RTT, что позволит во многих случаях исключить использование опции ширины окна. При потере пакета проблема улаживается локально в данном сегменте-туннеле, объем повторно пересылаемых данных будет минимальным. В случае минимизации RTT потребуется большая точность измерения этого времени (~10-100мксек). Сокращение среднего значения RTT пропорционально снизит требования, предъявляемые к объему буферов во всех сетевых устройствах по пути от отправителя к получателю.
В отличие от обычного протокола ТСР (рис. 1 верх) в такой схеме взаимодействует не конечный отправитель с конечным получателем, а только отправитель с ближайшим маршрутизатором (поддерживающим протокол NTCP), соседние маршрутизаторы между собой и конечный маршрутизатор с получателем (см. рис. 1, низ; случай, когда все маршрутизаторы поддерживают NTCP). Предусматривается возможность диалога с соседним маршрутизатором на предмет проверки, поддерживает ли он NTCP. Понятно, что в этом варианте маршрутизаторы должны научиться работать на уровне L4 (сейчас они работают только на уровне L3), различать сессии, установленные между одними и теми же конечными агентами (анализировать номера портов или идентификаторы сокетов).
Разбивка единого виртуального соединения отправитель- получатель на последовательность соединений соседних сетевых устройств снизит транзитный трафик, так как в случае потери пакета, повторная его транспортировка будет осуществляться лишь для одного сегмента пути (того, где произошла потеря), а не всего маршрута отправитель-получатель..

Рис. 1.

Рис. 1.а
Возможны две модели реализации протокола NTCP, ориентированного на соединение (аналог ТСР).
1. Обработка сегментов уровня L4 (TCP) осуществляется не только маршрутизаторами, но и переключателями уровня L2 (рис. 1 верх). При этом они выделяют из потока сегменты-отклики и укладывают в их поле данных свой идентификатор, полную емкость буфера и уровень его заполнения на текущий момент. Это не должно создать проблем, ведь поле данных отклика свободно и там достаточно места для практически любого объема записей, характеризующих состояние буферов. Отправитель, получив такой отклик, записывает содержащиеся в нем данные, сравнивает их с ранее полученными, методом экстраполяции вычисляет вероятность перегрузки и на основании этой оценки определяет, когда следует послать очередной пакет. Данный алгоритм исключает перегрузку в принципе, хотя вероятность потери из-за порчи пакетов все равно остается. О состоянии виртуального соединения при этом исчерпывающую информацию могут иметь все участники. Если какой-то отправитель, несмотря на неблагоприятный прогноз, осуществит передачу, этот пакет будет отвергнут ближайшим маршрутизатором и не создаст проблем для сетевых устройств, расположенных за ним. Таким образом, такое “антиобщественное” поведение не будет поощрено. Напомню, что в существующих моделях ТСР допускается “агрессивное” использование ресурсов канала в ущерб остальным участникам обменов. RTT здесь будет тем же, что и в традиционном протоколе ТСР со всеми вытекающими последствиями. Но отправитель, владея полной информацией о состоянии буферов в промежуточных узлах, может делать более точный прогноз и корректно выбрать значение окна.
С точки зрения выбора CWND этот алгоритм является идеальным, но требует использования усовершенствованного оборудования. Если некоторая часть оборудования не следует данному алгоритму, система будет работать, но станет возможной потеря из-за переполнения буферов в этом оборудовании, снижающая эффективность алгоритма.
Следует заметить, что современная технология позволяет создать переключатели уровня L2 не только способные сообщать о состоянии очередей в своих буферах, но и реализовывать приоритетное обслуживание (DiffServ), учитывающее код DSCP в заголовке IP-дейтограммы. Разработка таких переключателей даст возможность обеспечивать требуемый уровень обслуживания для локальных сетей, что принципиально поменяет характер работы многих приложений.
Структура рекорда в поле данных отклика может иметь формат, показанный на рис. 2. Число рекордов в отклике зависит от числа шагов между отправителем и получателем.

Рис. 2.
В поле идентификатор может размещаться IP-адрес сетевого объекта, а в случае прибора L2 - номер по порядку. Поля заполнение
и полный объем буфера содержат число записанных сегментов и максимально возможное число сегментов, соответственно. Необходимость отдельной записи данных о состоянии входного и выходного буферов диктуется возможностью разной загрузки этих буферов из-за различия потоков в противоположных направлениях. Можно рассмотреть вариант, где каждому из полей (кроме идентификатора) выделяется по одному байту. Проблема может существенно осложниться, если маршруты в направлении туда и обратно отличаются (хотя такая ситуация не является типичной и свидетельствует об ошибках сетевого администратора). Тогда запись состояния выходного буфера в отклик по пути следования пакета становится бессмысленной. Нужную информацию можно получить лишь при передаче кадра данных от отправителя к адресату. Сделать алгоритм универсальным можно путем расширения поля опций заголовка (или выделением специального поля в заголовке), куда производить запись состояния буферов сетевых агентов по маршруту отправитель-адресат.
Эти данные затем переносятся получателем в рекорды состояния буферов отклика. Размер MSS при этом немного сократится. Следует учитывать и возможность переполнения очередей откликами. Но так как отклики посылаются лишь на присланный сегмент, а посылка сегмента обусловлены состоянием буферов по пути следования, то правильный выбор параметров алгоритма, полностью исключит такую возможность.
2. Отклик на получение сегмента выдает ближайший маршрутизатор. В его задачу будет входить отправка сегмента очередному маршрутизатору и получение подтверждающего отклика от него. Маршрутизатор n посылает отклик подтверждения маршрутизатору n-1 немедленно, по получении сегмента.
Приняв и подтвердив получение сегмента, маршрутизатор берет на себя ответственность за последующую доставку сегмента следующему маршрутизатору, и так далее вплоть до конечного адресата (см. рис. 1а). Может возникнуть вопрос, а если в этой цепочке возникнет ситуация, когда сегмент не может быть доставлен. Что произойдет? Могут быть переполнены буферы промежуточных маршрутизаторов. Но главное, как об этом узнает исходный отправитель? Поскольку виртуальное соединение строится из цепочки туннелей, IP-адрес исходного отправителя известен всем участникам, и после нескольких неудач (максимальное число их должно быть оговорено) исходный отправитель может быть уведомлен о том, что адресат недоступен с помощью ICMP-сообщения. Если отправитель продолжает передачу, это ICMP-сообщение через некоторое время дублируется. Не переданные сегменты уничтожаются. Процедура эта может быть реализована прекращением подтверждения сегментов или посылкой ICMP-сообщения своему соседу отправителю. Одновременно с этим по цепочке маршрутизаторов будет от заблокированного устройства в направлении отправителя будет распространяться волна неподтверждений и прерываний передачи. Можно предусмотреть специальный отклик, уведомляющий соседа-отправителя о блокировке маршрута.
Алгоритм усложняется лишь в случае проблем в канале, при нормальной ситуации задержка (RTT) в цепочке отправитель-получатель минимальна.
Если пакет оказался поврежден, по истечении таймаута он будет послан повторно (RTO=RTTm +4 D, как и обычном ТСР, только RTT и его дисперсия D в несколько раз меньше; см. также RFC-2988).
Предлагаемый протокол может быть реализован по схеме точка-точка или для части виртуального пути, например, на участке опорной сети сервис-провайдера. В последнем случае туннелирование оформляется в пограничных маршрутизаторах опорной сети (примерно также, как в случае протокола MPLS).
Возможен вариант предварительного формирования цепочки туннелей, примерно так, как это делается при создании виртуального канала в ATM (см. http://book.itep.ru/4/43/atm_435.htm рис. 4.3.5.1). У такого подхода имеются привлекательные стороны, так как все участники получат исчерпывающую информацию обо всех адресах. Но и в случае разрыва связи, как в АТМ, придется формировать цепь туннелей заново. Но это неизбежная процедура в любом случае.
Здесь следует рассматривать несколько фаз работы протокола и соответствующие им угрозы.
1. Установление соединения.
2. Аутентификация
3. Работа после аутентификации
4. Завершение сессии, разрыв соединения.
Так как при внедрении нового протокола придется взаимодействовать с большим объемом оборудования и ЭВМ, которые этот протокол не поддерживают, необходимо на фазе установления соединения осуществлять контроль того, поддерживается данный протокол или нет данным сетевым объектом.
При установлении соединения могут быть использованы идеи, изложенные в RFC-1644.
Вначале процесса установления соединения отправитель (А) посылает дейтограмму по IP-адресу конечного получателя (Б). Ближайший к отправителю узел, который поддерживает протокол NTCP, перехватывает посланный пакет, заносит его в буфер, и немедленно посылает исходному отправителю подтверждение получения. Это подтверждение перехватывается ближайшим NTCP-маршрутизатором, уведомляя его о том, что посланный им сегмент благополучно доставлен. Этот процесс будет продолжаться до тех пор, пока дейтограмма не будет получена конечным адресатом.
В результате будет сформирована цепочка туннелей с номерами i=1,…,n, каждый из которых содержит от одного до k шагов (см. рис. 3). Первый шаг на рисунке соответствует туннелю A-1, содержащему К шагов.
Выигрыш в эффективности использования полосы каналов тем больше, чем больше узлов вдоль пути поддерживают NTCP (в идеале k º1). Если таких узлов вообще нет - выигрыша не будет.

Рис. 3.
Для каждого из туннелей (А-1), (1-2), (2-3), (3-4), (4-5), … и (n-1 - n) на маршруте от А до Б реализуется традиционный протокол ТСР. Если буфер в одном из промежуточных узлов оказывается близок к переполнению, он будет посылать отклики, которые уведомляют соседа-отправителя о сложившейся ситуации (это справедливо для сегментов (1-2), (2-3),. (4-5), … и (n-1 - n)). Отправитель перестанет посылать очередные пакеты. В свою очередь его сосед выше по течению (в направлении к А) может оказаться в режиме близком к переполнению и будет вынужден уведомить об этом своего предшественника. Для сегментов (А-1) и (3-4) модель работы идентична традиционному протоколу ТСР. В области узлов А и Б могут присутствовать переключатели уровня L2, не поддерживающие протокол NTCP.
Но в данной схеме, так же как и во всех моделях ТСР нет механизма подавления потери пакетов из-за их искажения. Если вероятность такого искажения существенна, нужно рассмотреть возможность оптимального определения MTU (см. например, RFC-2923). Впрочем при полной информации о состоянии буферов вдоль маршрута, отправитель может легко идентифицировать причину потери.
Не следует забывать о возможности “агрессивного” поведения одного из агентов по пути от А к Б. Имеется в виду игнорирование предупреждения о близости переполнения, ведь помимо узлов, показанных на рисунке, могут быть агенты, которые подключены к этим же узлам и осуществляют через них передачу данных.
Обе эти проблемы не могут быть решены методами управления CWND. Но ситуация, когда партнер, которому послано уведомление о предкритическом состоянии, продолжает посылать пакеты, разрешается простым игнорированием (отбрасыванием) таких пакетов.
Следует иметь в виду, что “ потеря пакета” может быть связана не только с реальной потерей кадра (из-за переполнения буфера или искажения пакета), но и с потерей подтверждения получения, вызванного теми же причинами. Отправитель может знать, что буфер получателя пуст, но не получив своевременно подтверждения на посланный ранее сегмент, будет вынужден запустить процедуру медленного старта (или повторной передачи неподтвержденного сегмента). Реально это может быть объяснено переполнением, например буфера в одном из промежуточных сетевых устройств, не поддерживающих NTCP. Если k =1, потеря пакета в такой ситуации может не сопровождаться процедурой медленного старта, так как очевидно, что переполнения буфера у получателя не произошло, а потеря носит случайный характер и достаточно ограничиться повторной передачей сегмента (значение CWND сохраняется неизменным). При k>1 такая стратегия недопустима и следует использовать одну из стандартных моделей реализации протокола ТСР. При этом необходим механизм контроля наличия буферизующих сетевых устройств между двумя узлами, поддерживающими NTCP. Иными словами нужен механизм определения, равно ли k единице.
Можно конечно предложить NTCP-отправителю посылать IP-дейтограммы с заданным значением TTL (например, 30). Тогда, если очередной узел, поддерживающий NTCP, получит пакет с TTL=29, то k=2. Каждый сетевой прибор, поддерживающий NTCP, должен присваивать перед отправкой полю TTL указанное значение.
Беда в том, что по дороге могут быть включены устройства уровня L2, не посылающие никаких откликов (что, собственно, характерно в настоящее время для всех приборов L2) и не изменяющие значение TTL. Тогда придется использовать традиционные механизмы управления перегрузкой с помощью медленного старта. Для сервис-провайдеров, которые знают структуру своих каналов (отсутствие приборов L2), можно использовать контроль по TTL. Мониторирование TTL может быть полезно и с точки зрения безопасности (выявление ложных маршрутизаторов).
Заполнение буфера получателя происходит за счет разности между входным потоком сегментов Iin и темпом обработки сегментов Iout (отправки последующим узлам).

Рис. 4.
На рисунке 4 показана временная зависимость заполнения буфера (b) сетевого устройства. Темп заполнения буфера определяется производной db/dt. Если уровень заполнения достигает Вmax, следующий пришедший сегмент будет потерян. Значение Вmax в общем случае определяется неравенством Вmax > B ×RTT/MSS. Сетевое устройство должно отслеживать уровень заполнения своего буфера. И, если после получения очередного сегмента оказывается, что
(b(t) + db/dt ×RTT + d) ³Вmax,
то всем отправителям-соседям, которые используют данное устройства для передачи данных, должен быть послан отклик с window=0 (сигнал прекращения передачи). d - конфигурационный параметр. Выполнение данного условия делает переполнение буфера практически маловероятным. Если после получения window=0 клиент все равно посылает сегмент (“агрессивное” поведение), такой сегмент отбрасывается и в буфер не попадает, даже если там имеется свободное место. Если значение db/dt=0 или отрицательно, а уровень заполнения буфера невелик, то CWND делается равным window. Window ¹0 посылается клиентам, например, при выполнении условия b(t) < (Вmax -2d). Алгоритм управления значением CWND отправителей по возможности не должен допускать такого развития событий. При получении отклика, в котором содержится уведомление, что b(t) ³ (Вmax -2d) значение CWND должно быть уменьшено на 1 (при двух таких уведомлениях подряд - на 4 и т.д.). Стратегия может варьироваться. Так как и отправитель и получатель владеют полной информацией, можно даже ввести наказание для отправителей, нарушающих принятые правила (отбрасывание пакетов в течение заданного времени или установка window=0).
В традиционной версии TCP для установления оптимального значения window предусмотрен режим медленного старта. Это делается через механизм управления CWND. Для оптимального использования канала должно выполняться очевидное условие window > RTT×B/MSS. В любой момент времени window = min(window,CWND), то есть почти всегда меньше оптимального значения.
А при медленном старте CWND варьируется от 1 до максимально возможного значения, которое может быть меньше window. Связано это с тем, что ни отправитель, ни получатель обычно не владеет информацией о заполнении буферов и поиск допустимой величины window осуществляется на ощупь.
В случае k=1 или в ситуации, когда все сетевые приборы вдоль пути следования выдают данные о заполнении своих буферов, ситуация меняется радикально.
Если буфер свободен (b=0, что нормально в начале передачи), и RTT× B/MSS < Вmax, то реализуется значение CWND=window= RTT ×B/MSS и, тем самым, исключается этап медленного старта. Значение RTT предполагается определенным на фазе установления соединения. Алгоритмы вычисления среднего значения RTT и величины RTO остаются теми же, что и в традиционном протоколе ТСР.
Проблемы безопасности
Аутентификация должна производиться в соответствии с общепринятыми способами сразу после установления соединения в процессе открытия прикладной сессии. Вообще говоря, эта процедура не должна быть частью протокола ТСР (см. также RFC-2873). На фазе аутентификации клиент и сервер обмениваются ключами, которые могут использоваться в процессе обмена в рамках протокола ТСР. Коды эти могут быть подтверждены сертификатами.
На фазе 3 в поле данных отклика (или в специально выделенное поле опций заголовка) может включаться код, присланный отправителем и закодированный (одноключевая схема шифрования) получателем, так что в случае вторжении злоумышленника в разрыв соединения он сможет прервать сессию, но подменить собой клиента или сервер ему не удастся. Атака с подбором ISN станет бессмысленной. Нельзя будет реализовать и атаку с посылкой флагов FIN, RST или ICMP в пакете, посланном не одним из партнеров соединения. Получатель принимает только ключ своего непосредственного соседа, а свой ключ посылает только соседу ”вниз по течению” (в направлении узла Б).
Ссылки
RFC0793 Transmission Control Protocol. J. Postel. Sep-01-1981.
RFC1323 TCP Extensions for High Performance. V.
Jacobson, R. Braden, D. Borman. May 1992.
RFC1644 T/TCP -- TCP Extensions for Transactions Functional Specification. R. Braden. July 1994.
RFC2018 TCP Selective Acknowledgement Options. M. Mathis, J. Mahdavi, S. Floyd, A. Romanow. October 1996.
RFC2309 Recommendations on Queue Management and Congestion Avoidance in the Internet. B. Braden, D. Clark, J. Crowcroft, B. Davie, S. Deering, D. Estrin, S. Floyd, V. Jacobson, G. Minshall, C. Partridge, L. Peterson, K. Ramakrishnan, S. Shenker, J. Wroclawski, L. Zhang. April 1998.
RFC2414 Increasing TCP's Initial Window. M. Allman, S. Floyd, C. Partridge. September 1998.
RFC2415 Simulation Studies of Increased Initial TCP Window Size. K. Poduri, K. Nichols. September 1998.
RFC2416 When TCP Starts Up With Four Packets Into Only Three Buffers. T. Shepard, C. Partridge. September 1998.
RFC2525 Known TCP Implementation Problems. V. Paxson, M. Allman, S. Dawson, W. Fenner, J. Griner, I. Heavens, K. Lahey, J. Semke, B. Volz. March 1999.
RFC2581 TCP Congestion Control. M. Allman, V. Paxson, W. Stevens. April 1999.
RFC2582 The NewReno Modification to TCP's Fast Recovery Algorithm. S. Floyd, T. Henderson. April 1999.
RFC2873 TCP Processing of the IPv4 Precedence Field. X. Xiao, A. Hannan, V. Paxson, E. Crabbe. June 2000.
RFC2883 An Extension to the Selective Acknowledgement (SACK) Option for TCP. S. Floyd, J. Mahdavi, M. Mathis, M. Podolsky. July 2000.
RFC2923 TCP Problems with Path MTU Discovery. K. Lahey. September 2000.
RFC2988 Computing TCP's Retransmission Timer. V. Paxson, M. Allman. November 2000.
RFC3042 Enhancing TCP's Loss Recovery Using Limited Transmit. M. Allman, H. Balakrishnan, S. Floyd. January 2001.
RFC3168 The Addition of Explicit Congestion Notification (ECN) to IP. K. Ramakrishnan, S. Floyd, D. Black. September 2001.
RFC3390 Increasing TCP's Initial Window. M. Allman, S. Floyd, C. Partridge.
October 2002.
RFC3448 TCP Friendly Rate Control (TFRC): Protocol Specification. M. Handley, S. Floyd, J. Padhye, J. Widmer. January 2003.
RFC3449 TCP Performance Implications of Network Path Asymmetry. H. Balakrishnan, V. Padmanabhan, G. Fairhurst, M. Sooriyabandara. December 2002.
RFC3465 TCP Congestion Control with Appropriate Byte Counting (ABC). M. Allman. February 2003
RFC3517 A Conservative Selective Acknowledgment (SACK)-based Loss Recovery Algorithm for TCP. E. Blanton, M. Allman, K. Fall, L. Wang. April 2003.
1. Ю.А.Семенов “Протоколы Интернет. Энциклопедия”, Горячая линия - Телеком, М, 2001.
2. T. V. Lakshman, Upamanyu Madhow, “The performance of TCP/IP for networks with high bandwidth-delay products and random loss” Infocom ’97, апрель, 1997, IEEE/ACM Trans. Networking, V5, N3, p.336-350, June 1997. (http://www.ece.ucsb.edu/Faculty/Madhow/publications.html/)
NIL
Специальный атом "NIL" представляет собой указание на отсутствие каких-то определенных данных типа строка или “список в скобках”. Его следует отличать от пустой строки "" или пустого “списка в скобках” ().NSAP адреса
Соответствие NSAP адреса IPv6 адресам выглядит следующим образом (рис. 4.4.1.1.7):
Рис. 4.4.1.1.7
О протоколе верхнего уровня Контрольные суммы верхнего уровня
Любой транспортный или другой протокол верхнего уровня, который включает адреса IP-заголовка в свою контрольную сумму, должен быть модифицирован, чтобы работать с 128-битовыми IPv6адресами вместо 32-битовых IPv4. В частности, ниже показаны псевдо-заголовки для TCP и UDPв IPv6 (рис. 4.4.1.1.26):
Рис. 4.4.1.1.26. Формат псевдо-заголовков для TCP и UDP
Если пакет содержит заголовок маршрутизации, в качестве адреса места назначения в псевдо-заголовке используется оконечный адрес. В исходном узле этот адрес будет последним элементом заголовка маршрутизации; для узла получателя он будет находиться в поле адрес места назначения IPv6 заголовка.
IPv6 версия ICMP-пакетов [RFC-1885] включает псевдо-заголовок в вычисление контрольной суммы; это отличается от IPv4 версии ICMP, которая не включает псевдо-заголовок в контрольную сумму. Причина изменения связана с попыткой защитить ICMP от некорректной доставки или искажений важных полей в IPv6 заголовке, который в отличие от IPv4 не защищен контрольным суммированием на интернет-уровне. Поле следующий заголовок в псевдо-заголовке для ICMP содержит код 58, который идентифицирует IPv6 версию ICMP.
О размере пакетов
Протокол IPv6 требует, чтобы каждый канал в Интернет имел MTU = 576 октетов или более. Для каждого канала, который не способен обеспечить длину пакетов в 576 октетов должна быть обеспечена фрагментация/дефрагментация на уровне ниже IPv6.Для каждого канала, с которым связан узел непосредственно, он должен быть способен принимать пакеты с размером MTU данного канала. В каналах, которые можно конфигурировать, например, PPP [RFC-1661], должно быть установлено MTU не менее 576 октетов; рекомендуется устанавливать максимально возможное MTU, чтобы позволить инкапсуляцию (туннелирование) без привлечения фрагментации.
Настоятельно рекомендуется, чтобы узлы IPv6 использовали механизм определения MTU пути [RFC-1191] для использования преимущества большого значения MTU. Однако в минимальной конфигурации IPv6 (например, в BOOT ROM) может ограничивать себя в пределах 576 октетов и не использовать path MTU discovery.
Для того чтобы послать пакет длиннее чем MTU канала, узел может использовать заголовок фрагментации IPv6. Однако использование такой фрагментации заблокировано в приложениях, где используется настройка по измеренному значению MTU пути.
Узел должен быть способен принимать фрагментированные пакеты, которые после сборки имеют размер 1500 октетов, включая IPv6 заголовок. Узлу позволено принимать пакеты, которые после сборки имеют размер более 1500 октетов. Однако узел не должен посылать фрагменты, которые после сборки образуют пакеты длиннее 1500 октетов, если он не уверен, что получатель способен их воспринять и дефрагментировать.
В ответ на IPv6 пакет, посланный IPv4 адресату (т.e., пакет, который подвергается преобразованию из IPv6 в IPv4), узел отправитель IPv6 может получить ICMP сообщение packet too big, предупреждающее о том, что MTU следующего узла меньше 576. В этом случае узел IPv6 не должен уменьшать размер пакетов до 576 октетов, он должен включить в эти пакеты заголовок фрагментации, так чтобы маршрутизатор, выполняющий трансляцию IPv6-IPv4, мог получить приемлемый код идентификации, чтобы использовать полученные IPv4 фрагменты. Заметьте, что это означает сокращение длины поля данных до 528 октетов (576 минус 40 для IPv6-заголовка и 8 для заголовка фрагментации), и меньше, если имеются другие заголовки расширения.
Замечание: Анализ MTU пути должно проводиться даже в случае, когда узел “думает”, что адресат находится на том же канале что и сам узел.
Замечание: В отличие от IPv4, в IPv6 не нужно устанавливать флаг "don't fragment" (не фрагментировать) в заголовках пакетов, для того чтобы выполнить операцию определения величины mtu канала; так как это является атрибутом любого IPv6 пакета по умолчанию. Части процедур из RFC-1191, которые включают в себя использование таблиц MTU, не применимы к IPv6, так как версия сообщения IPv6 "datagram too big" всегда указывает на точное значение MTU, которое следует использовать.
Обязательные AVP
Получение неизвестной AVP, которая имеет бит M=1, является катастрофическим для сессии или туннеля, с которым она ассоциирована. Таким образом, бит M должен быть определен только для AVP, которые критичны для нормальной работы сессии или туннеля. Далее, в случае, когда LAC или LNS получают неизвестную AVP с M-битом равным 1 и закрывают сессию или туннель, ответственность за это полностью несет партнер, пославший обязательную AVP. Прежде чем определить AVP с M=1, в особенности AVP специфичное для данного производителя, убедитесь в том, что вы именно этого хотите.Когда имеется адекватная альтернатива использованию M-бита, ей следует воспользоваться. Например, вместо того, чтобы посылать AVP с M=1 для определения существования специфического расширения, можно решить проблему путем посылки AVP в сообщении-запросе в расчете на получение соответствующего AVP в отклике.
Использование M-бита с новыми AVP (не определенными в этом документе) должно предоставить возможность сконфигурировать программу так, чтобы AVP либо не посылалась, или посылалась с M-битом равным нулю.
Области, не поддерживающие RSVP
Невозможно развернуть протокол RSVP (или любой новый протокол) во всем Интернет одновременно. Более того, RSVP вероятно никогда не будет развернут повсеместно. RSVP должен гарантировать корректную работу, когда два RSVP маршрутизатора объединены друг с другом через сетевую область, не поддерживающую этот протокол. Конечно, промежуточная сетевая область, лишенная поддержки RSVP, не способна осуществлять резервирование ресурсов. Однако, если эта область обладает достаточной емкостью, она может обеспечить необходимый уровень услуг реального времени.Протокол RSVP приспособлен для работы через такие, не поддерживающие его, сетевые области. Как поддерживающие RSVP так и не поддерживающие RSVP маршрутизаторы переадресуют сообщения Path в соответствие с адресом места назначения, используя свои локальные таблицы маршрутизации. Следовательно, на маршрутизацию сообщений Path не оказывает влияние наличие промежуточных маршрутизаторов, лишенных RSVP поддержки. Когда сообщение Path проходит через сетевую область, не поддерживающую RSVP, оно, направляясь к следующему узлу, поддерживающему RSVP, несет в себе IP-адрес последнего RSVP-маршрутизатора. Сообщение Resv тогда переадресуется непосредственно следующему RSVP-маршрутизатору на пути к отправителю.
Хотя RSVP работает корректно и через сетевые области без поддержки RSVP, узлы из этой области могут внести искажения в QoS. При встрече области без поддержки RSVP протокол устанавливает бит-флаг `NonRSVP' и передает его механизму управления трафиком. Управление трафиком комбинирует этот однобитовый флаг со своей собственной информацией об источниках и передает ее вдоль транспортного пути получателям, используя спецификацию Adspecs [RFC 2210].
При некоторых топологиях маршрутизаторов с и без поддержки RSVP возможна доставка сообщений Resv в не тот узел, или не тот интерфейс. Процесс RSVP должен быть готов обрабатывать такие ситуации. Если адрес места назначения не соответствует ни одному локальному интерфейсу, а сообщение не является Path или PathTear, тогда оно должно передаваться далее без какой-либо обработки в данном узле. Чтобы обработать случай с неправильным интерфейсом, используется дескриптор логического интерфейса LIH (Logical Interface Handle). Информация предыдущего узла, включенная в сообщение Path, содержит не только IP-адрес предшествующего узла, но также и LIH, определяющий логический выходной интерфейс; обе величины записываются в состояние прохода. Сообщение Resv, пребывающее в адресуемый узел, несет в себе IP-адрес и LIH правильного выходного интерфейса, т.е., интерфейса, который должен получить запрошенное резервирование, вне зависимости от того, на какой интерфейс оно попало.
Обозначения
Алгоритмы фильтрации и селекции NTP используют несколько переменных для хранения значений сдвига часов, RTT и дисперсии. Переменные, относящиеся к партнерам, обычно обозначаются строчными греческими буквами, а для первичного эталона времени используются прописные буквы. Эти алгоритмы базируются на параметре, называемом расстояние синхронизации(l) и вычисляемом с использованием rtt и дисперсии.
Дисперсия партнера (e) содержит вклады от ошибок измерения (r) и накопления ошибок дрейфа (skew-error).
Каждый раз, когда соответствующие переменные партнеров изменяются, значения дисперсии корректируются. Ниже приводятся основные определения переменных и формулы их вычисления:
q = peer.offset,
d = peer.delay,
e = peer.dispersion = r + jt + es,
l = e + |d|/2,
где d = rtt, q - сдвиг часов, jt - накопление сбоя, j = ntp.maxskew/ntp.maxage, t - момент времени передачи исходной временной метки (на основе t вычисляется q и d), e
s
- дисперсия фильтра. Переменные, относящиеся к партнеру i, определяются следующим образом:
q i = j i,
d i = peer.rootdelay + d i,
e i = peer.rootdispersion + e
i + j ti
(максимальная дисперсия часов партнера),
li= ei + |di|/2,
Окончательно, предполагая, что для синхронизации выбран i-ый партнер, система переменных определяется следующим образом:
q = комбинированное окончательное смещение (combined final offset),
d = di,
e = ei + ex + q,
l = li,
где ex дисперсия выбора (select dispersion).
Приводимые ниже тексты программ, реализующие вычисления переменных, записаны на условном языке, напоминающем СИ.
Обработка событий
Существенные события с точки зрения протокола NTP происходят при истечении времени таймеров партнера (peer.timer), один из которых ориентирован специально на данного партнера в активной ассоциации, а также при получении NTP-сообщения от различных партнеров. Событие может произойти как результат команды оператора или обнаруженной ошибки, такой как отказ первичного эталона.Общий формат сообщений
Сообщения ICMPv6 образуют два класса: сообщения об ошибках и информационные сообщения. Сообщения об ошибках идентифицируются по нулю в старшем бите поля тип. Таким образом, сообщения об ошибках могут иметь код поля тип от 0 до 127; информационные сообщения имеют коды поля тип от 128 до 255.В данном документе определены форматы для следующих сообщений ICMPv6:
Сообщения об ошибках ICMPv6:
1 destination unreachable (место назначения недоступно)
2 packet too big (пакет слишком велик)
3 time exceeded (время превышено)
4 parameter problem (проблема с параметрами)
Информационные сообщения ICMPv6:
128 echo request (Запрос эхо)
129 echo reply (Эхо-отклик)
130 group membership query (запрос участия в группе)
131 group membership report (отчет об участии в группе)
132 group membership reduction (сокращение числа участников в группе)
Каждое сообщение ICMPv6 начинается с заголовка IPv6, за которым следует нуль или более заголовков расширения IPv6. Заголовок ICMPv6 идентифицируется кодом следующего заголовка 58 в предыдущем заголовке. (Заметим: этот код отличается от значения, принятого для ICMP IPv4.)
Сообщения ICMPv6 имеют следующий общий формат (рис. 4.4.1.1.33):

Рис. 4.4.1.1.33. Общий формат сообщений ICMPv6
Поле тип указывает на тип сообщения. Его значение определяет формат последующих данных.
Поле код зависит от типа сообщения. Оно используется для создания дополнительного уровня структуризации сообщения. Поле контрольная сумма используется для обнаружения повреждений сообщения ICMPv6 и заголовка IPv6.
Узел отправитель сообщения ICMPv6 должен определить IPv6-адреса отправителя и получателя до вычисления контрольной суммы. Если узел имеет более одного уникастного адреса, то он должен выбрать адрес отправителя следующим образом:
Контрольная сумма является 16-битным дополнением по модулю 1 суммы всего сообщения ICMPv6, начиная с поля тип сообщения ICMPv6, дополненного полями псевдозаголовка IPv6. Код поля следующий заголовок для псевдозаголовка выбирается равным 58. (Заметим: включение псевдозаголовка в контрольную сумму ICMPv6 является изменением по отношению к протоколу IPv4; обоснование причин этого см. в [IPv6]). Перед вычислением контрольной суммы поле контрольная сумма обнуляется.
Приложения должны следовать следующим правилам при обработке сообщений ICMPv6 (из [RFC-1122]):
Если исходный пакет имеет необычно большое число заголовков расширения, возможно, что тип протокола верхнего уровня может отсутствовать в сообщении ICMPv6, из-за укорочения исходного пакета до уровня 576 октетов.
В этом случае сообщение об ошибке отбрасывается после обработки уровня IPv6.
(e.1) сообщения об ошибке ICMPv6, или
(e.2) пакета, направленного по IPv6 мультикаст-адресу (существует два исключения из этого правила: (1) сообщения packet too big - пакет слишком велик) - чтобы позволить скорректировать MTU прохода, и (2) сообщения parameter problem (проблема с параметрами), Код 2, оповещающий о нераспознанной опции), или
(e.3) мультикастинг-пакета канального уровня, (исключения пункта e.2 применимы и здесь), или
(e.4) широковещательного пакета канального уровня, (исключения пункта e.2 применимы и здесь), или
(e.5) пакета, чей адрес отправителя не однозначно определяет какой-то узел, например, не специфицированный адрес IPv6, мультикаст-адрес IPv6 или эникаст-адрес.
(f) Наконец, узел IPv6 должен ограничить частоту посылки сообщений об ошибке, если адресат на них не реагирует. Это ограничит загрузку канала.
Существует много способов ограничения частоты посылки сообщений, например:
(f.1) Таймерный метод. Передача сообщений производится не чаще, чем раз за указанное число T миллисекунд.
(f.2) Метод полосы пропускания. Сообщения об ошибке должны занимать не более определенной доли F полосы пропускания канала.
Ограничивающие параметры (например, T или F в вышеприведенных примерах) должны задаваться узлом со значениями по умолчанию (напр., T = 1 сек, и F = 2%, не 100%!).
Общий заголовок

Рис. 4.4.9.6.8. Формат общего заголовка
В общем заголовке имеются следующие поля:
Vers. 4 бита - Номер версии протокола. В данном описании = 1.
Флаги: 4 бита - 0x01-0x08. Зарезервированы.
Флаги пока не определены.
Тип Msg. Тип сообщения (8 бит).
1 = Path
2 = Resv
3 = PathErr
4 = ResvErr
5 = PathTear
6 = ResvTear
7 = ResvConf
Контрольная сумма RSVP: 16 бит
Дополнение по модулю один контрольной суммы сообщения (в процессе вычисления поле контрольной суммы считается нулевым). Если в поле записан нуль, это означает, что контрольная сумма не вычислялась.
Send_TTL: 8 бит
Значение TTL для протокола IP, с которым было послано сообщение.
Длина RSVP: 16 бит
Полная длина RSVP сообщения в байтах, включая общий заголовок и объекты переменной длины, которые за ним следуют.
Обсуждение реализации
Базовая модель надежности NTP предполагает, что не должно быть никаких других способов изменения показаний кроме предусмотренных самим протоколом NTP. Системы с часами-календарем, имеющие питание от батареи или аккумулятора, считаются надежными, но менее точными, чем использующие NTP-синхронизацию. При последовательных коррекциях, если величина поправки превышает конфигурационный параметр (напр., 1000 секунд), поправка отбрасывается и посылается сообщение об ошибке. Некоторые реализации периодически записывают содержимое регистра Skew-Compensation (компенсация дрейфа) в системный файл или в NVRAM (память, сохраняемая при отключении питания).Преобразование из формата NTP в обычный информационный формат осуществляется прикладными программами. В день накануне добавления/вычитания секунды из показаний времени значение sys.leap устанавливается на первичном сервере вручную. Следует иметь в виду, что большинство радио-часов не имеет автоматических или ручных средств добавления/вычитания секунд. Но даже в случае некорректного добавления/вычитания секунды локальные часы будут вновь синхронизованы не позднее чем через число секунд, заданное CLOCK.MINSTEP.
Обзор AVP
Имя AVP является списком, указывающим типы сообщений, которые использует каждая AVP. После каждого названия AVP следует короткое описание назначения AVP, подробности формата значения атрибута, и любая дополнительная информация, необходимая для правильного использования AVP.Одновременное исполнение нескольких команд
Клиент может послать другую команду, не дожидаясь отклика на предшествующую, сервер может начать обработку другой команды до завершения обработки текущей.Исключение может составлять случаи, когда результат выполнения одной команды зависит от выполнения других команд. Клиенты не должны посылать несколько команд, не дожидаясь результата, если возможна неопределенность из-за их взаимозависимости. Если сервер детектирует возможную неопределенность, он должен исполнить их последовательно в порядке их получения от клиента.
Наиболее очевидный пример неопределенности реализуется, например, когда последовательно выполняются команды FETCH для флагов сообщения и STORE для тех же самых флагов.
Неочевидные неопределенности возникают с командами, которые допускают немаркированный отклик EXPUNGE (команды отличные от FETCH, STORE и SEARCH), так как немаркированный отклик EXPUNGE может нарушить корректность порядковых номеров сообщений для последующих команд. Это не представляет проблем для команд FETCH, STORE или SEARCH, так как серверам запрещено посылать отклики EXPUNGE, когда исполняется одна их этих команд. Следовательно, если клиент посылает любую команду, отличную от FETCH, STORE или SEARCH, он должен ждать отклика, прежде чем посылать команду, содержащую номер сообщения. Например, следующая последовательность команд (без ожидания) является некорректной:
FETCH + NOOP + STORE
STORE + COPY + FETCH
COPY + COPY
CHECK + FETCH
Ниже представлены примеры последовательностей, не требующих ожидания завершения предшествующих инструкций:
FETCH + STORE + SEARCH + CHECK
STORE + COPY + EXPUNGE
Опции заголовка Hop-by-Hop (шаг за шагом)
Заголовок опций hop-by-hop (шаг за шагом) используется для опционной информации, которая просматривается каждым узлом по пути доставки. Заголовок опций hop-by-hop идентифицируется кодом поля следующий заголовок 0 в IPv6 заголовке и имеет формат (рис. 4.4.1.1.18):
Рис. 4.4.1.1.18. Формат заголовка опций hop-by-hop
| Следующий заголовок | 8-битовый селектор. Определяет тип заголовка, который следует непосредственно за заголовком опций hop-by-hop. Использует те же значения поля протоколов, что и IPv4 [RFC-1700] |
| HDR EXT LEN | 8-битовое число без знака. Длина заголовка поля опций hop-by-hop в октетах, исключая первые 8 октетов. |
| Опции | Поле переменной длины. Содержит один или более TLV-закодированных опций. |
В дополнение к Pad1 и Padn опциям определены следующие опции hop-by-hop:
| Опция Jumbo Payload | (необходимо выравнивание: 4n + 2) |

Рис. 4.4.1.1.19.
Опция Jumbo payload используется для посылки пакетов IPv6 с полем данных, превосходящим 65535 октетов. Длина Jumbo Payload характеризует длину пакета в октетах, исключая заголовок IPv6, но включая заголовок опций hop-by-hop; Это поле должно содержать код более чем 65535. Если получен пакет с опцией Jumbo payload, содержащей код длины меньше или равный 65535, посылается сообщение ICMP (parameter problem, код 0) с указателем на старший октет поля длины Jumbo payload.
Поле длины Payload length IPv6 заголовка должно быть равно нулю для каждого пакета с опцией Jumbo payload. Если получен пакет с корректным значением опции Jumbo Payload и ненулевым кодом длины поля данных, посылается сообщение ICMP (parameter problem код 0) с указателем на поле тип опции.
Опция Jumbo payload не может использоваться в пакетах, которые несут в себе заголовок фрагмента. Если заголовок фрагмента встретится в пакете, содержащем корректную опцию jumbo payload, посылается сообщение ICMP (parameter problem, код 0) с указателем на первый октет заголовка фрагмента.
Приложения, которые не поддерживают опцию Jumbo Payload, не могут иметь интерфейсы для каналов с MTU больше 65575 (40 октетов IPv6 заголовка плюс 65535 октетов данных).
Опции
Два из определенных в настоящее время заголовков расширения - заголовок опций hop-by-hop и заголовок опций места назначения - несут в себе переменное число TLV-кодированных (type-length-value) опций следующего формата (Рис. 4.4.1.1.16):
Рис. 4.4.1.1.16 Формат опций
| Тип опции | 8-битовый идентификатор типа опции. |
| Длина опции | 8-битовое целое число без знака. Длина поля данных опции в октетах. |
| Данные опции | Поле переменной длины. Данные зависят от типа опции. |
Последовательность опций в заголовке должна обрабатываться строго в соответствии с их порядком записи.
Идентификаторы типа опций кодируются так, что их старшие два бита характеризуют операцию, которая должна быть выполнена, если узел не узнает тип опции:
| 00 | обойти эту опцию и продолжить обработку заголовка. |
| 01 | выбросить данный пакет. |
| 10 | выбросить данный пакет и вне зависимости от того, является ли адрес назначения мультикастинговым, послать отправителю ICMP-пакет с кодом parameter problem (код=2), с указателем на не узнанный код опции. |
| 11 | выбросить данный пакет и, если адрес места назначения не мультикастинговый, послать отправителю icmpпакет с кодом parameter problem (код=2) с указателем на не узнанный код опции. |
Третий старший бит типа опции определяет, может ли информация в поле опция измениться по пути до места назначения пакета. Когда в пакете присутствует заголовок аутентификации, для любой опции, информация которой может измениться по пути, должна рассматриваться как нулевые октеты при определении значения идентификации. Значения этого бита:
0 - Данные опции не меняют маршрута
1 - Информация опции может изменить маршрут.
Отдельные опции могут требовать определенного выравнивания, с тем, чтобы обеспечить выкладку мультиоктетного значения данных поля опции. Требование выравнивания опции описывается с помощью выражения xn+y, означающего, что поле тип опции должно находиться через целое число, кратное x октетам плюс y октетов (отсчет от начала заголовка). Например:
| 2n | означает любое двухоктетное смещение от начала заголовка. |
| 8n+2 | означает любое 8-октетное смещение от начала заголовка плюс 2 октета. |
Существует две опции заполнения, которые используются, когда необходимо выровнять последующие опции и вывести границу заголовка на значение кратное 8 октетам. Эти заполняющие опции должны распознаваться всеми приложениями IPv6:
Опция Pad1 (выравнивание не требуется)
Опция Pad1 используется для введения одного октета заполнителя в зону опций заголовка. Если требуется более одного октета, используется опция Padn.
Опция padn (выравнивание не требуется)

Рис. 4.4.1.1.17
Опция Padn используется для введения двух и более октетов заполнителей в поле опций заголовка. Для n октетов заполнителя поле OPT data Len содержит значение n-2, а поле данных опции состоит из n-2 нулевых октетов
Операции клиента SNTP
Клиент SNTP может работать в мультикастном, уникастном и эникаситном режимах. В мультикастном режиме клиент не посылает никаких запросов и ждет широковещательных сообщений (режим 5) от специально выделенного мультикастного сервера. В уникастном режиме клиент посылает запросы (режим 3) специально выделенному серверу и ожидает от него откликов (режим 4). В эникастном режиме клиент посылает запросы (режим 3) по специально выделенному местному широковещательному или мультикастному адресу и ожидает откликов (режим 4) от одного или более эникастных серверов. Клиент использует первый полученный отклик и устанавливает с соответствующим сервером связь в уникастном режиме. Последующие отклики от данного, или других серверов игнорируются. Запросы номинально посылаются с интервалом от 64 до 1024 секунд, в зависимости от стабильности частоты клиента и от требуемой точности.Уникастные или эникастные клиенты используют заголовок сообщения NTP, посылают запрос серверу и считывают время дня из поля Transmit Timestamp отклика. Для этой цели все поля заголовка NTP могут быть установлены равными нулю, за исключением первого октета и (опционно) поля Transmit Timestamp. В первом октете поле LI устанавливается равным 0 (никаких предупреждений), а в поле режим заносится код 3 (клиент). Поле VN должно соответствовать номеру версии сервера NTP/SNTP; однако, серверы V.4 воспринимают и предыдущие версии. Серверы V.3 (RFC-1305) и версии 2 (RFC-1119) воспринимают предшествующие версии, включая версию 1 (RFC-1059). Версия 0 (RFC-959) в настоящее время уже не поддерживается.
Рекомендуется чтобы клиенты использовали последнюю версию, которую поддерживает выбранный сервер.
Чтобы вычислить полную циклическую задержку d и смещение локальных часов по отношению к серверу t, клиент устанавливает значение поля transmit timestamp в запросе равным времени дня согласно часам клиента и в соответствии с форматом временных меток NTP. Сервер копирует этот код в поле originate timestamp отклика и устанавливает поле receive timestamp и transmit timestamp в соответствии с показанием своих часов.
Когда будет получен отклик от сервера, клиент определяет значение переменной Destination Timestamp, как время прибытия по своим часам. В таблице 4.4.16.5. рассмотрены все 4 типа временных меток.
Таблица 4.4.16.5. Типы временных меток
| Имя временной метки | ID | Когда генерируется |
| Originate Timestamp (исходная метка) | T1 | Время отправки запроса клиента |
| [ZEBR_TAG_td style=text-align:center>T2 | Время получения запроса сервером | |
| Transmit Timestamp (метка посылки) | T3 | Время посылки отклика сервером |
| Destination Timestamp (метка назначения) | T4 | Время получения отклика клиентом |
d = (T4 - T1) - (T2 - T3) t = ((T2 - T1) + (T3 - T4)) / 2.
В таблице 4.4.16.6. собраны операции клиента в уникаст, эникаст и мультикаст режимах. Рекомендуемые проверки ошибок представлены в колонках таблицы “Отклик” и “Мультикаст”. Сообщение следует рассматривать как корректное только в случае, если все поля содержат допустимые коды. Следует ли воспринимать сообщение, если оно содержит неверные значения для поля (ей), помеченного ремаркой “Игнорируется”, зависит от конкретной реализации программы.
Таблица 4.4.16.6. Операции клиента и значения полей заголовка
| Имя поля | Уникаст/Эникаст | Мультикаст | |
| Запрос | Отклик | ||
| LI | 0 | 0-2 | 0-2 |
| VN (номер версии) | 1-4 | копируется из запроса | 1-4 |
| Режим | 3 | 4 | 5 |
| Слой | 0 | 1-14 | 1-14 |
| Запрос | 0 | Игнорируется | Игнорируется |
| Точность | 0 | Игнорируется | Игнорируется |
| Root Delay | 0 | Игнорируется | Игнорируется |
| Root Dispersion | 0 | Игнорируется | Игнорируется |
| Reference Identifier | 0 | Игнорируется | Игнорируется |
| Reference Timestamp | 0 | Игнорируется | Игнорируется |
| Originate Timestamp | 0 | (смотри текст) | Игнорируется |
| Receive Timestamp | 0 | (смотри текст) | Игнорируется |
| Transmit Timestamp | (смотри текст) | не равно нулю | не равно нулю |
| Аутентификатор | опционно | опционно | опционно |
Операции сервера SNTP
Сервер SNTP может работать в уникастном, эникастном или мультикастном режимах, а также реализовать любую из комбинаций этих режимов. В уникаст и эникаст режимах сервер получает запросы (режим 3), модифицирует определенные поля в заголовке NTP, и посылает отклик (режим 4), возможно используя тот же буфер сообщения, что и в случае запроса. В режиме эникаст сервер прослушивает определенный широковещательный или групповой мультикаст-адрес, определяемый IANA, но использует свой собственный уникастный адрес в поле адреса отправителя отклика. За исключением выбора адреса в отклике работа сервера в эникаст и уникаст режима идентична. Мультикастные сообщения обычно посылаются с интервалом от 64 до 1024 сек, в зависимости от стабильности часов клиента и требуемой точности.В эникаст и уникаст режимах поля VN и регистрация (Poll) запроса копируются без изменений в отклик. Если поле режим запроса содержит код 3 (клиент), оно делается в отклике равным 4 (сервер); в противном случае в это поле записывается 2 (симметричный пассивный), для того чтобы обеспечить соответствие со спецификацией NTP. Это позволяет клиентам, сконфигурированным для симметричного активного режима (режим 1) успешно работать, даже если конфигурация не является оптимальной. В мультикастном режиме в поле VN заносится код 4, в поле режим код 5 (широковещательный) и в поле регистрация целая часть значение логарифма по основанию 2 от длительности периода посылки запросов.
Заметим, что крайне желательно чтобы серверы, поддерживающие мультикастинг, поддерживали и уникастный режим. Это необходимо для измерения RTT клиент/сервер, прежде чем осуществлять регулярный обмен в мультикастном режиме.
В уникастном и эникастном режимах сервер может реагировать, а может и игнорировать запросы, если не синхронизован надлежащим образом с помощью радио-часов. Но предпочтительным поведением является присылка отклика в любом случае, так как позволяет убедиться в достижимости сервера. В мультикастном режиме сервер посылает широковещательные сообщения, только если он синхронизован.
Остальные поля заголовка NTP заполняются следующим образом. Если сервер синхронизован и функционирует правильно, в поле LI заносится 0, а в поле слой - 1 (первичный сервер). Если это не так, в поле слой записывается 0, а в поле LI - 3. В поле точность заносится код, характеризующий точность локальных часов. Для всех практических случаев этот код вычисляется, как отрицательное число бит справа от запятой в формате временной метки NTP. Поля Root Delay и Root Dispersion для первичного сервера делаются равными 0. Поле Root Dispersion опционно может быть сделано равным значению, соответствующему максимальной ожидаемой ошибке радио-часов. В поле Reference Identifier заносится идентификатор первичного эталона времени, как это указано в таблице 4.4.16.4.
Поля временных меток заполняются следующим образом. Если сервер не синхронизован или только что включился, все временные метки устанавливаются равными нулю. Если сервер синхронизован, в поле Reference Timestamp записывается время последней коррекции по радио-часам или модему. В уникастном и эникастном режимах в поля Receive Timestamp и Transmit Timestamp заносится время дня, когда было послано сообщение, а в поле Originate Timestamp записывается неизмененная копия поля Transmit Timestamp из запроса. В мультикастном режиме в поля Originate Timestamp и Receive Timestamp заносится 0, а в Transmit Timestamp время дня, когда послано сообщение. В таблице 4.4.16.7 представлены все перечисленные операции.
Таблица 4.4.16.7
| Имя поля | Уникаст/Эникаст | Мультикаст | |
| Запрос | Отклик | ||
| LI | игнорируется | 0 или 3 | 0 или 3 |
| VN | 1-4 | копия из запроса | 4 |
| Режим | 3 | 2 или 4 | 5 |
| Слой | игнорируется | 1 | 1 |
| Регистрация | игнорируется | копия из запроса | log2 периода запросов |
| Точность | игнорируется | -log2 числа значащих бит сервера | -log2 числа значащих бит сервера |
| Root Delay | игнорируется | 0 | 0 |
| Root Dispersion | игнорируется | 0 | 0 |
| Идентификатор эталона | игнорируется | Идентификатор эталона | Идентификатор эталона |
| Reference Timestamp | игнорируется | время последней коррекции по радио-часам | время последней коррекции по радио-часам |
| Originate Timestamp | игнорируется | копируется из поля transmit timestamp | 0 |
| Receive Timestamp | игнорируется | время дня | 0 |
| Transmit Timestamp | (см. текст) | время дня | время дня |
| Аутентификатор | опционно | опционно | опционно |
Операционные соображения Присвоение имени почтовому ящику
Интерпретация имен почтовых ящиков является независимой от конкретной программной реализации. Однако имя почтового ящика INBOX является специальным именем, зарезервированным для "первичного почтового ящика данного пользователя на данном сервере" (значение не зависит от использования строчных или прописных букв). Почтовые ящики могут образовывать иерархическую структуру. Если желательно экспортировать иерархию имен почтовых ящиков, имена почтовых ящиков должны быть упорядочены по буквам слева направо.Определение частоты
В течение многих лет наиболее важным использованием времени и частоты были всемирная навигация и космическая наука, которые зависят от наблюдений солнца, луны и звезд. За стандартную секунду (в 1957 году) принята 1/31,556,925.9747 периода вращения Земли вокруг Солнца (тропический год). Согласно этой шкалы тропический год длится 365.2421987 дней, а лунный месяц 29.53059 дней. Однако тропический год может быть определен лишь с точностью около 50 мсек.С древнейших времен человечеству были известны три осциллятора (процесса задающих временную шкалу) - вращение земли вокруг своей оси, вращение Луны вокруг Земли и вращение Земли вокруг Солнца. К сожалению, с точки требований современных технологий все эти три осциллятора не обладают достаточной стабильностью. В 1967 стандартная секунда была переопределена и теперь равняется 9,192,631,770 периодов перехода в атоме цезия-133. С 1972 стандарты времени и частоты базируются на международном атомном времени TAI (International Atomic Time). Точность таких часов составляет около микросекунды в сутки. Важно то, что новая шкала абсолютно однородна и не подвержена дрейфам.
Определение новой ресурсной записи и домена
Определен новый тип ресурсной записи для хранения IPv6-адреса ЭВМ. Если ЭВМ имеет более одного IPv6-адреса, тогда используется более одной такой ресурсной записи.Тип ресурсной записи aaaa является специфическим для класса Интернет и служит для записи одного IPv6-адреса. Код типа равен 28 (десятичное).
128-битовый IPv6-адрес записывается в информационной части ресурсной записи aaaa, придерживаясь порядка байт, используемого в сети (старший байт первый).
Запрос aaaa для конкретного имени домена в классе Интернет возвращает в качестве отклика все ресурсные записи, соответствующие ресурсной секции aaaa. Запрос типа aaaa не выполняет никакой дополнительной обработки этой секции.
Текстовое представление информационной секции ресурсной записи aaaa, используемое в файле базы данных имеет формат, описанный в [3], а также в текущем разделе.
Определен специальный домен, который предназначен для установления соответствия между именами и IPv6-адресами. Домен имеет имя ip6.int.
IPv6-адрес представляется в виде имени в домене ip6.int. Это имя выглядит как последовательность символов, разделенных точками, завершающаяся суффиксом .ip6.int. Последовательность символов записывается в обратном порядке, т.е. младший по порядку символ записывается первым и т.д... Каждый из символов представляет собой шестнадцатеричную цифру. Например, запрос, соответствующий адресу
4321:0:1:2:3:4:567:89ab
будет выглядеть как
b.a.9.8.7.6.5.0.4.0.0.0.3.0.0.0.2.0.0.0.1.0.0.0.0.0.0.0.1.2.3.4.ip6.int.
Определение времени и необходимости добавления/вычитания секунды
Международное бюро мер и стандартов IBWM (International Bureau of Weights and Measures) использует астрономические наблюдения, выполненные морской обсерваторией США и другими обсерваториями для определения UTC.Для более точной временной привязки событий после 1972 года необходимо знать, когда вставлялись или удалялись секунды коррекции (удаление пока никогда не производилось). Как определено в докладе 517 CCIR, который воспроизведен в [BLA74], дополнительные секунды вставляются после 23:59:59 в последний день июня или декабря. Неоднородность во временную шкалу (TAI) помимо добавляемых секунд вносят также 100 миллисекундные коррекции UT1, называемые DUT1, которые служат для повышения точности при навигации. Следует признать, что момент добавления секунды является началом новой (однородной) временной шкалы.
Временная шкала NTP базируется на шкале UTC, но необязательно всегда совпадает с ней. В 0 часов 1 января 1972 начинается эра UTC, часы NTP были установлены на 2,272,060,800 стандартных секунд после 0 часов 1 января 1900.
Определения
Поле данных RTP: Информация, пересылаемая в пакете RTP, например фрагменты звука или сжатые видео данные.Пакет RTP: Информационный пакет, содержащий фиксированный заголовок. Один пакет транспортного нижнего уровня, например UDP, обычно содержит один RTP-пакет, но это требование не является обязательным. Поле источников информации может быть пустым.
Пакет RTCP: Управляющий пакет, содержащий фиксированный заголовок сходный с RTP, за которым следуют структурные элементы, зависящие от типа RTCP-пакета. Обычно несколько RTCP-пакетов посылаются как составной RTCP-пакет, вложенный в дейтограмму нижележащего уровня.
Транспортный адрес: Комбинация сетевого адреса и порта, которая идентифицирует конечную точку канала (например, IP-адрес и UDP-порт). Пакеты следуют от транспортного адреса отправителя к транспортному адресу получателя.
Сессия RTP: Период с момента установления группы участников RTP-обмена до ее исчезновения. Для каждого из участников сессия определяется конкретной парой транспортных адресов (сетевой адрес и номера портов для RTP и RTCP). Транспортный адрес места назначения может быть общим для всех участников сессии. Допускается реализация нескольких сессий для каждого из участников одновременно.
Источник синхронизации (SSRC): Источник потока RTP-пакетов, определяется 32-битным числовым SSRC-идентификатором, который записывается в заголовок RTP-пакета и не зависит от сетевого адреса. Все пакеты от источника синхронизации образуют часть с идентичной временной привязкой и нумерацией. Эти данные используются принимающей стороной при воспроизведении. Источниками синхронизации могут служить источники первичного сигнала (микрофоны или видеокамеры), а также RTP-смесители. SSRC-идентификатор представляет собой случайное число, которое является уникальным для данной RTP-сессии. Участник сессии не должен использовать один и тот же SSRC-идентификатор для всех RTP-сессий мультимедийного набора. Если участник формирует несколько потоков в рамках одной RTP-сессии (например, от нескольких видеокамер), каждый участник должен быть снабжен уникальным SSRC-идентификатором.
Информационный источник CSRC (contributing source): Источник потока RTP-пакетов, который вносит вклад в общий поток, формируемый RTP-смесителем. Смеситель вставляет список SSRC-идентификаторов, которые идентифицируют парциальные источники, в заголовок RTP-пакетов. Этот список называется CSRC-списком. Примером приложения может быть аудио-конференция, где смеситель отмечает всех говорящих, чей голос порождает исходящие пакеты. Это позволяет принимающей стороне идентифицировать говорящего, хотя все пакеты имеют один и тот же SSRC-идентификатор.
Оконечная система: Приложение, которое генерирует или воспринимает данные, посылаемые в виде RTP-пакетов. Оконечная система может выступать в качестве одного или нескольких источников синхронизации для конкретной сессии.
Смеситель: Промежуточная система, которая получает RTP-пакеты от одного или нескольких источников, при необходимости меняет их формат, объединяет и пересылает их адресатам. Так как временная привязка входных пакетов может отличаться, смеситель осуществляет их синхронизацию и генерирует свой собственный поток RTP-пакетов. Таким образом все посылаемые пакеты имеют в качестве источника синхронизации смеситель.
Транслятор: Промежуточная система, которая переадресует RTP-пакеты, не изменяя их идентификаторы источника синхронизации. Такие устройства используются для преобразования системы кодирования, перехода от мультикастинг- к традиционной уникаст-адресации или при работе с Firewall.
Монитор: Приложение, которое получает RTCP-пакеты, посланные участниками RTP-сессии, в частности диагностические сообщения, производит оценку состояния связи, копит долгосрочную статистику обмена.
Все целочисленные поля передаются в соответствии c сетевым порядком, т.е. старший байт следует первым (big-endian). Порядок передачи описан подробно в работе [3]. Если не оговорено обратного все цифровые константы являются десятичными. Все поля заголовка выравниваются по их естественным границам, т.е. 16-битовые поля имеют четное смещение, а 32-битные имеют адрес, кратный 4.
Октеты-заполнители содержат нули.
Абсолютное время представляется с помощью временных меток в соответствии с форматом NTP (network time protocol), который характеризует время в секундах от начала суток (UTC) 1 января 1900 [4]. Полное разрешение временной метки NTP определяется 64-битовым числом с фиксированной запятой без знака. Целочисленная часть задается первыми 32 битами, а дробная часть последними. В некоторых полях, где допустимо более компактное представление, используются только средние 32 бита (16 бит целочисленная часть и 16 бит дробная).
Заголовок RTP-пакета имеет следующий формат (см. рис. 4.4.9.2.1).

Рис. 4.4.9.2.1. Заголовок пакета RTP
Первые 12 октетов присутствуют во всех RTP-пакетах, в то время как список CSRC-идентификаторов присутствует только, когда пакет формируется смесителем. Поля имеют следующие назначения:
v (Версия): 2 бита
Это поле идентифицирует версию протокола RTP. В настоящее время в это поле записывается код 2. Значение 1 использовалось в опытной версии RTP, а код 0 - в аудио приложении "vat".
p (Заполнитель): 1 бит
Если Р=1, пакет содержит один или более дополнительных октетов-заполнителей в конце поля данных (заполнители не являются частью поля данных). Последний октет заполнителя содержит число октетов, которые должны игнорироваться. Заполнитель нужен при использовании некоторых алгоритмов шифрования при фиксированном размере блоков или при укладке нескольких RTP-пакетов в один UDP.
x (Расширение): 1 бит
Если бит Х=1, далее следует фиксированный заголовок, за которым размещается одно расширение заголовка.
CC(CSRC count - число CSRC): 4 бита
Число CSRC содержит код количества csrc-идентификаторов, которые записаны в пакете.
M (маркер): 1 бит
Интерпретация маркера определяется профайлом. Предполагается разрешить выделять в потоке пакетов существенные события, такие как границы кадра. Профайл может определить дополнительные маркерные биты или специфицировать отсутствие маркерных битов путем изменения числа битов в поле PT.
PT(Тип данных): 7 бит
Это поле идентифицирует формат поля данных RTP-пакета и определяет интерпретацию его приложением. Могут быть определены дополнительные коды типа данных. Исходный набор кодов по умолчанию для аудио и видео задан в профайле Internet-draft draft-ietf-avt-profile, и может быть расширен в следующих редакциях стандарта assigned numbers (RFC-1700) [5].
Номер по порядку: 16 бит
Номер по порядку инкрементируется на 1 при посылке очередного RTP-пакета данных, этот код может использоваться получателем для регистрации потерь пакетов и для восстановления истинного порядка присланных фрагментов. Начальное значение кода является случайным. Алгоритм генерации таких кодов рассмотрен в [6].
Временная метка: 32 бита
Временная метка соответствует времени стробирования для первого октета в информационном RTP-пакете. Время стробирования должно быть получено от часов, показания которых увеличиваются монотонно и линейно, чтобы обеспечить синхронизацию и вычисление временного разброса. Разрешающая способность часов должна быть достаточной для обеспечения приемлемой точности синхронизации (одного тика на видео кадр обычно не достаточно). Частота часов зависит от формата данных и задается статически в профайле, в спецификации поля данных, или динамически средствами, выходящими за пределы спецификации протокола RTP. Если RTP-пакеты генерируются периодически, используется временная привязка, определенная задающим генератором стробирования, а не показаниями системных часов.
Начальное значение временной метки является случайным. Несколько последовательных RTP-пакетов могут иметь идентичные временные метки, если логически они генерируются одновременно (например, относятся к и тому же видео кадру).
SSRC: 32 бита
Поле SSRC идентифицирует источник синхронизации. Этот идентификатор выбирается случайным образом, так чтобы в пределах одной RTP-сессии не было двух равных SSRC-кодов. Все приложения должны быть способны выявлять случаи равенства SSRC-кодов. Если отправитель изменяет свой транспортный адрес, он должен также сменить и SSRC-идентификатор.
CSRC-список: от 0 до 15 элементов, по 32 бита каждый
CSRC-список идентифицирует источники информации, которые внесли свой вклад в поле данных пакета. Число идентификаторов задается полем CC. Если число источников больше 15, только 15 из них могут быть идентифицированы.
Для эффективной реализации протокола число точек мультиплексирования должно быть минимизировано. В RTP, мультиплексирование осуществляется по транспортным адресам мест назначения, которые определены RTP-сессией. Использование пакетов с различным типом поля данных но с идентичным ssrc создает определенные проблемы:
1. Если один из типов данных будет изменен в ходе сессии, нет универсальных средств для определения, какое из старых значений следует заменить на новое.
2. ssrc определено для идентификации одного пространства номеров и временных меток. Совместное использование нескольких типов данных в общем потоке может потребовать разных средств синхронизации и разной нумерации, чтобы определять, какой из типов пакетов потерян.
3. RTCP-сообщения отправителя и получателя могут описать только одно пространство номеров и временных меток для каждого SSRC и не имеют поля типа данных.
4. RTP-смеситель не сможет объединять перекрывающиеся потоки при условии их несовместимости.
5. Работа со многими средами в пределах одной RTP-сессии предполагает: использование различных сетевых путей или разного размещения сетевых ресурсов; приема только одного субнабора, например аудио, когда видео недоступно из-за недостатка широкополосности.
Использование различных ssrc для каждого вида среды, при посылке их в пределах одной RTP-сессии позволяет преодолеть первые три проблемы.
Хотя существующие RTP-заголовки позволяют решать широкий круг проблем, предусмотрена возможность их модификации с помощью профайлов. При этом сохраняется возможность контроля и мониторирования с использованием стандартных средств.
Октет, где размещаются эти поля, может быть переопределен профайлом. При любом числе маркерных битов один должен размещаться в старшем разряде октета, так как это необходимо для мониторирования потока.
В протоколе RTP предусмотрен механизм расширений заголовка, который позволяет модифицировать заголовок и экспериментировать с новыми форматами поля данных. Этот механизм устроен так, что расширения заголовка могут игнорироваться приложениями, которые не нуждаются в расширениях.
Расширения заголовка предназначены для ограниченного использования. И многие приложения лучше реализовать, используя профайл. Формат реализации расширений показан на рис. 4.4.9.2.2.

Рис. 4.4.9.2.2. Формат расширения заголовка
Если бит x в RTP-заголовке равен 1, то к заголовку добавлено расширение переменной длины, за которым может следовать список csrc. Расширение заголовка содержит 16-битовое поле длины, определяющее число 32-битных слов в расширении, исключая 4-октета заголовка расширения (т.о. значения поля длина, равное нулю вполне допустимо). Информационный заголовок RTP может иметь только одно расширение. Для того чтобы обеспечить работу различных приложений с различными расширениями заголовка или чтобы обеспечить работу с более чем одним типом расширений, первые 16 бит расширения заголовка остаются свободными для выбора идентификаторов или параметров.
Формат этих 16 бит определяется спецификацией профайла, с которым работает приложение.
Кроме оконечных систем RTP поддерживает трансляторы и смесители, которые рассматриваются как промежуточные системы на уровне RTP.
RTP транслятор/смеситель соединяет две или более области на транспортном уровне. Обычно каждая область определяется сетью и транспортным протоколом (например, ip/udp), мультикаст-адресом или парой уникаст-адресов, а также портом назначения транспортного уровня. Одна система может служить транслятором или смесителем для нескольких RTP сессий.
Для того чтобы исключить зацикливание при использовании транслятора или смесителя следует придерживаться следующих правил:
Аналогично все оконечные системы RTP, которые взаимодействуют через один или более трансляторов или смесителей, принадлежат одной и той же ssrc-области, т.е., ssrc-идентификаторы должны быть уникальными для задействованных оконечных систем. Существует большое разнообразие трансляторов и смесителей, спроектированных для решения различных задач и приложений. Некоторые служат для шифрования/дешифрования несущих дейтограмм. Различие между смесителями и трансляторами заключается в том, что последние пропускают через себя потоки данных, при необходимости их преобразуя, а смесители объединяют несколько потоков в один.
Транслятор. Переадресует RTP-пакеты, не изменяя их SSRC-идентификаторы. Это позволяет получателям идентифицировать отдельные источники, даже если пакеты от всех источников проходят через один общий транслятор и имеют сетевой адрес транслятора. Некоторые типы трансляторов передают данные без изменений, другие кодируют данные и соответственно изменяют коды типа данных и временные метки.
Приемник не может заметить присутствия транслятора.
Смеситель. Принимает потоки RTP-данных от одного или нескольких источников, может изменять формат данных, определенным образом объединяет потоки и затем формирует из них один общий поток. Так как объединяемые потоки не синхронизованы, смеситель производит синхронизацию потоков и формирует свою собственную временную шкалу для исходящего потока. Смеситель является источником синхронизации. Таким образом, все пакеты данных, переадресованные смесителем, будут помечены SSRC-идентификатором смесителя. Для того чтобы сохранить информацию об источниках исходных данных, смеситель должен внести свои SSRC-идентификаторы в список CSRC-идентификаторов, который следует за фиксированным RTP-заголовком пакета. Смеситель, который, кроме того, вносит в общий поток свою составляющую, должен включить свой собственный SSRC-идентификатор в CSRC-список для данного пакета.
Для некоторых приложений смеситель может не идентифицировать источники в CSRC-списке. Однако это создает опасность того, что петли, включающие эти источники, не смогут быть выявлены.
Преимуществом смесителя перед транслятором для аудио- приложений является то, что выходная полоса не превосходит полосы одного источника, даже когда в сессии на входе смесителя присутствуют несколько участников. Недостатком является то, что получатели с выходной стороны не имеют никаких средств для контроля того, какой из источников передает данные даже в случае наличия дистанционного управления смесителем.

Рис. 4.4.9.2.3 Пример RTP сети с оконечными системами, смесителями и трансляторами
Некоторый набор смесителей и трансляторов представлен на рис. 4.4.9.2.3. Здесь показано их влияние на SSRC и CSRC-идентификаторы. Оконечные системы обозначены символами ES и выделены желтым цветом. Трансляторы обозначены буквами TRS (на рисунке овалы голубого цвета) и смесители обозначены как MUX (прямоугольники сиреневого цвета). Запись "M1:13(1,17)" обозначает пакет отправленный смесителем MUX1, который идентифицируется случайным значением SSRC 13 и двумя CSRC-идентификаторами 1 и 17, скопированными с SSRC-идентификаторов пакетов оконечных систем ES1 и ES2.
Последовательное включение смесителей
В RTP- сессии могут быть задействованы несколько смесителей и трансляторов, как это показано на рис. 4.4.9.2.3. Если два смесителя включены последовательно, так как MUX2 и MUX3, пакеты полученные смесителем могут быть уже объединены и включать CSRC-список со многими идентификаторами. Cмеситель (MUX3) должен формировать CSRC-список для исходящих пакетов, используя CSRC-идентификаторы уже смешанных входных пакетов (выход MUX2) и SSRC-идентификаторы несмешанных входных пакетов, поступивших от ES9 (E:36). Это отмечено на рисунке для выходных пакетов смесителя MUX3 как M3:99(9,11,36). Если число идентификаторов в списке CSRC превышает 15, остальные не могут быть туда включены.
SSRC-идентификаторы в RTP-заголовках и в различных полях RTCP-пакетов являются случайными 32-битовыми числами, которые должны быть уникальными в рамках RTP-сессии. Очень важно, чтобы одни и те же числа не были использованы несколькими участниками сессии.
Недостаточно использовать в качестве идентификатора локальный сетевой адрес (такой как IPv4), так как может быть не уникальным. Так как RTP трансляторы и смесители допускают работу с сетями, использующими различные адресные пространства, это допускает их случайное совпадение с большей вероятностью, чем в случае использования случайных чисел.
Не приемлемо также получать идентификаторы SSRC путем простого обращения к функции random() без тщательной инициализации.
Так как идентификаторы выбраны случайным образом, существует малая, но конечная вероятность того, что два или более источников выберут одно и то же число. Столкновение более вероятно, если все источники стартуют одновременно. Если N число источников, а L длина идентификатора (в нашем случае, 32 бита), вероятность того, что два источника независимо выберут одно и то же значение (для больших N [8]) составляет 1 - exp(-N2 / 2(L+1)). Для N=1000, вероятность примерно равна 10-4.
Типовое значение вероятности столкновения много меньше худшего случая, рассмотренного выше.
Рассмотрим случай, когда новый источник подключается к RTP-сессии, в которой все остальные источники уже имеют уникальные идентификаторы. Если N равно числу источников, а L длина идентификатора, вероятность столкновения равна N / 2L. Для N=1000, вероятность составит около 2*10-7.
Вероятность столкновения уменьшается еще больше в случае, когда новый источник получает пакеты других участников до того, как передаст свой первый пакет. Если новый источник отслеживает идентификаторы других участников, он легко может устранить вероятность конфликта.
Преодоление столкновений и детектирование петель
Хотя вероятность столкновения идентификаторов SSRC довольно мала, все RTP реализации должны быть готовы обнаруживать столкновения и предпринимать адекватные меры для их преодоления. Если источник обнаруживает в какой-либо момент, что другой источник использует тот же идентификатор SSRC, он посылает пакет RTCP BYE для старого идентификатора и выбирает новый. Если получатель обнаруживает, что два других источника имеют равные идентификаторы (столкновение), он может воспринимать пакеты от одного и игнорировать от другого до тех пор, пока это не будет зарегистрировано отправителями или CNAME.
Так как идентификаторы уникальны, они могут использоваться для детектирования петель, которые могут создаваться смесителем или транслятором. Петля приводит к дублированию данных и управляющей информации:
Это может быть выполнено непосредственно, через смеситель или через транслятор.
Источник может обнаружить, что его собственный пакет движется по кругу, или что пакеты других источников осуществляют циклическое движение.
Оба вида петель и столкновения приводят к тому, что пакеты приходят с тем же самым SSRC-идентификатором, но с разными транспортными адресами, которые могут принадлежать оконечной или какой-то промежуточной системе. Следовательно, если источник меняет свой транспортный адрес, он должен также выбрать новый SSRC-идентификатор с тем, чтобы ситуация не была интерпретирована, как зацикливание. Петли или столкновения, происходящие на дальней стороне транслятора или смесителя, не могут быть детектированы с использованием транспортного адреса источника, если все копии пакетов идут через транслятор или смеситель. Однако, столкновения могут быть детектированы, когда фрагменты двух RTCP SDES пакетов содержат равные SSRC-идентификаторы, но разные коды CNAME (см. описание протокола ).
Для того чтобы детектировать и устранять конфликты, реализации RTP должны содержать алгоритм, аналогичный описанному ниже. Он игнорирует пакеты от нового источника, которые входят в противоречие с работающим источником. Алгоритм разрешает конфликты с SSRC-идентификаторами участников путем выбора нового идентификатора и посылки RTCP BYE для старого. Однако, когда столкновение вызвано зацикливанием собственных пакетов участников сессии, алгоритм выбирает новый идентификатор только раз и после этого игнорирует пакеты от транспортного адреса, вызвавшего зацикливание. Это требуется для того, чтобы избежать потока пакетов BYE.
Этот алгоритм зависит от равенства транспортных адресов для RTP и RTCP пакетов источника. Алгоритм требует модификации приложений, которые не отвечают этому ограничению.
Этот алгоритм требует наличия таблицы транспортных адресов источников, упорядоченных по их идентификаторам. В таблицу заносятся адреса, откуда данный идентификатор был впервые получен. Каждый SSRC или CSRC идентификатор, полученный с информационным или управляющим пакетом ищется в этой таблице, для того чтобы корректно обработать полученные данные.
Для управляющих пакетов каждый элемент с его собственным SSRC, например, фрагмент SDES, требует отдельного просмотра. SSRC в сообщениях-отчетах составляют исключение. Если SSRC или CSRC не найдены, создается новая запись в таблице. Эти записи в таблице удаляются, когда приходит пакет RTCP BYE с соответствующим кодом SSRC, или когда достаточно долго не приходит вообще никаких пакетов.
Для того чтобы отслеживать зацикливание собственных пакетов участников, необходимо также завести отдельный список транспортных адресов источников, которые считаются конфликтными. Заметим, что это должен быть короткий список, обычно пустой. Каждый элемент этого списка хранит адрес источника и время, когда был получен последний конфликтный пакет. Элемент может быть удален из списка, когда за время 10 периодов посылки RTCP сообщений-отчетов не прибыло ни одного конфликтного пакета.
Предполагается, что собственные идентификаторы и состояния участников записаны в таблицу идентификаторов источников.
IF SSRC или CSRC-идентификатор не найден в таблице идентификаторов источников:
THEN создать новую запись и внести туда транспортный адрес источника и SSRC или
CSRC вместе с кодом состояния.
CONTINUE (продолжить) обычную процедуру обработки.
Идентификатор найден в таблице
IF транспортный адрес источника из пакета совпадает с одним из записанных в таблице:
THEN CONTINUE Продолжить обычную процедуру обработки.
Обнаружено столкновение идентификаторов или зацикливание
IF идентификатор источника не совпадает с собственным идентификатором участника:
THEN IF идентификатор источника совпадает с тем, что содержится в фрагменте RTCP SDES содержащем элемент CNAME, который отличается от CNAME из рекорда таблицы:
THEN (опционно) Случилось столкновение посторонних идентификаторов.
ELSE (опционно) Случилось зацикливание.
ABORT Прервать обработку информационного или управляющего пакета.
Столкновение для идентификатора участника или зацикливание его пакетов
IF транспортный адрес найден в списке конфликтных адресов:
THEN IF идентификатор источника не найден во фрагменте RTCP SDES, содержащем CNAME, или если CNAME принадлежит участнику:
THEN (опционно) случилось зацикливание собственного трафика.
Записать текущее время в соответствующую запись таблицы конфликтных адресов.
ABORT (прервать) обработку информационного или управляющего пакета.
Зафиксировать факт столкновения.
Внести новую запись в таблицу конфликтных адресов и зафиксировать время записи.
Послать пакет RTCP BYE с идентификатором SSRC.
Выбрать новый идентификатор.
Внести новую запись в таблицу идентификаторов источников со старым SSRC, транспортным адресом источника обработанного пакета.
CONTINUE Продолжить обычную процедуру обработки.
В этом алгоритме все пакеты от вновь конфликтующих источников будут игнорироваться, а пакеты от исходного источника будут приниматься. Если в течение достаточно протяженного периода времени пакеты от исходного источника не приходят, соответствующая запись в таблице будет аннулирована.
Когда из-за столкновения выбран новый SSRC-идентификатор, кандидат-идентификатор должен быть сверен с содержимым таблицы идентификаторов. Если такой код там уже имеется, должен быть выбран другой кандидат и процедура сверки повторена.
Зацикливание информационных мультикастинг-пакетов может вызвать сильную перегрузку сети. Все смесители и трансляторы должны реализовывать алгоритм детектирования зацикливания с тем, чтобы немедленно прервать этот опасный процесс. Это должно уменьшить лишний трафик. Однако, в крайних случаях, где смеситель или транслятор не прерывают зацикливание, может быть необходимо для оконечных систем прервать передачу.
Когда необходимо шифрование RTP или RTCP, все октеты будут инкапсулированы в одну дейтограмму нижележащего уровня и зашифрованы как единое целое. Для RTCP в начало последовательности перед шифрованием добавляется 32-битное случайное число, чтобы предотвратить возможные атаки. В случае RTP никаких префиксов не требуется, так как порядковый номер и временная метка и без того являются случайными числами.
Алгоритмом шифрования по умолчанию является DES (Data Encryption Standard), работающий в режиме CBC (Cipher Block Chaining), как это описано в RFC 1423 [9], за исключением того, что используется заполнение кратное 8 октетам. Инициализационный вектор равен нулю, так как для RTP-заголовка используются случайные числа. Более подробно о векторах инициализации можно прочесть в [10]. Приложения, которые используют шифрование должны поддерживать алгоритм DES в режиме CBC. Этот метод выбран потому, что он показал на практике свою эффективность при работе с аудио и видео приложениями в Интернет. Возможно применение и других криптографических средств.
В качестве альтернативы шифрованию на уровне RTP, можно определить дополнительные типы поля данных для шифрованных полей данных в профайлах. Этот метод позволяет шифровать только данные, в то время как заголовки остаются незашифрованными. Это может оказаться полезным для реализации шифрования и дешифрования.
Для обеспечения демультиплексирования RTP полагается на нижележащий протокольный уровень. Для UDP и сходных с ним протоколов, RTP использует четные номера портов, а соответствующие RTCP-потоки используют нечетные номера портов. Если приложению предлагается использовать нечетный номер RTP-порта, этот номер должен быть заменен на ближайший четный меньше исходного.
Информационные RTP-пакеты не имеют поля длины или каких-либо других средств ограничения размеров пакета, по этой причине RTP полагается на нижележащий протокол при задании размера поля данных. Максимальная длина RTP-пакетов ограничена размером используемых транспортных пакетов (например, UDP).
Если RTP-пакеты переносятся посредством протокола, который поддерживает поточный метод передачи, должен быть определен механизм вложения. Механизм вложения должен быть детализован и в случае, когда транспортный протокол использует в поле данных заполнители.
Механизм вложения может быть определен в профайле даже в случае, когда для транспортировки RTP используется не поточный протокол, это позволяет укладывать несколько RTP-пакетов в одну дейтограмму транспортного протокола (например, UDP).
Передача нескольких RTP-пакетов в одном транспортном уменьшает издержки, связанные с заголовком и может упростить синхронизацию различных потоков.
Константы, определяющие тип данных (PT) RTP-пакета, задаются профайлом а не самим протоколом. Однако, значение октета RTP-заголовка, который содержит бит(ы) маркера не должно ни при каких обстоятельствах равняться 200 и 201 (десятичные), для того чтобы отличить RTP-пакеты от RTCP-пакетов типа SR и RR.
Использование протокола RTP в различных приложениях может предъявлять различные требования. Адаптация протокола к этим требованиям осуществляется путем выбора определенных параметров, использования различных расширений (см. рис. 4.4.9.2.2) или путем вариации формата на основе профайлов. Типовое приложение использует только один профайл. Спецификация формата поля данных определяет то, например, как, закодированный видеосигнал (H.261) должен переноситься RTP-пакетами.
В рамках RTP-стандарта определены следующие элементы поля данных (этот список не следует рассматривать, как окончательный):
Заголовок поля данных RTP. Октет RTP заголовка, содержащий маркер тип поля данных, может быть переопределен с помощью профайла (например, можно изменить число маркерных битов).
Типы поля данных. Профайл обычно определяет набор форматов поля данных (напр., типов кодирования исходных данных) и соответствие между этими форматами и кодами типа поля данных. Для каждого описанного типа поля данных должна быть определена частота временных меток.
Дополнения к заголовку RTP. К стандартному RTP-заголовку могут быть добавлены новые поля, расширяющие функциональность приложения.
Расширения заголовка RTP. Структура содержимого первых 16 бит расширения RTP-заголовка должна быть определена профайлом (см. рис. 4.4.9.2.2).
Безопасность. Профайл может специфицировать, какие услуги и алгоритмы безопасности должно обеспечить приложение.
Установка соответствия между строкой и ключом. Профайл может специфицировать, какому ключу шифрования соответствует введенный пользователем пароль.
Нижележащий протокол. Определяется нижележащий транспортный протокол, который служит для пересылки RTP-пакетов.
Транспортное соответствие. Соответствие RTP и RTCP адресам транспортного уровня, например, UDP-портам.
Инкапсуляция. Инкапсуляция RTP-пакетов может быть определена для того, чтобы позволить транспортировку нескольких RTP-пакетов в одной дейтограмме нижележащего протокола.
Не предполагается, что для каждого приложения требуется свой профайл. В пределах одного класса приложений целесообразно использовать расширения одного и того же профайла. Простое расширение, такое как введение дополнительного типа поля данных или нового типа RTCP-пакета, может быть выполнено путем регистрации их через комитет по стандартным числам Интернет и публикации их описаний в приложении к профайлу.
Алгоритмы работы отправителя и получателя RTP-пакетов описаны в RFC-1889 на примере кодов, написанных на языке СИ.
Нижеприведенные определения заимствованы целиком из RFC, ссылка на который приведена в начале данного раздела. Все цифра представлены в формате, где первым является старший октет. Предполагается, что битовые поля размещаются без заполнителей в том же порядке, что и октеты.
/*
* rtp.h -- Файл заголовка RTP (RFC 1889)
*/
#include
/*
* Нижеприведенные определения предполагают 32-битовое представление, а в случаях
* 16- или 64-битового представлений необходимы соответствующие модификации.
*/
typedef unsigned char u_int8;
typedef unsigned short u_int16;
typedef unsigned int u_int32;
typedef short int16;
/*
* Текущая версия протокола.
*/
#define RTP_VERSION 2
#define RTP_SEQ_MOD (1<<16)
#define RTP_MAX_SDES 255 /* максимальная длина текста для SDES */
typedef enum {
RTCP_SR = 200,
RTCP_RR = 201,
RTCP_SDES = 202,
RTCP_BYE = 203,
RTCP_APP = 204
} rtcp_type_t;
typedef enum {
RTCP_SDES_END = 0,
RTCP_SDES_CNAME = 1,
RTCP_SDES_NAME = 2,
RTCP_SDES_EMAIL = 3,
RTCP_SDES_PHONE = 4,
RTCP_SDES_LOC = 5,
RTCP_SDES_TOOL = 6,
RTCP_SDES_NOTE = 7,
RTCP_SDES_PRIV = 8
} rtcp_sdes_type_t;
/*
* Заголовок RTP-пакета
*/
typedef struct {
unsigned int version:2; /* версия протокола */
unsigned int p:1; /* флаг заполнителя */
unsigned int x:1; /* Флаг расширения заголовка */
unsigned int cc:4; /* число CSRC */
unsigned int m:1; /* Бит маркера */
unsigned int pt:7; /* тип поля данных */
u_int16 seq; /* номер по порядку */
u_int32 ts; /* временная метка */
u_int32 ssrc; /* источник синхронизации */
u_int32 csrc[1]; /* опционный список CSRC */
} rtp_hdr_t;
/*
* Общее слово RTCP-заголовка
*/
typedef struct {
unsigned int version:2; /* версия протокола */
unsigned int p:1; /* флаг заполнителя */
unsigned int count:5; /* варьируется в зависимости от типа пакета */
unsigned int pt:8; /* тип пакета RTCP */
u_int16 length; /* Длина пакета в словах */
} rtcp_common_t;
/*
* Маска версии, бита заполнителя и типа пакета
*/
#define RTCP_VALID_MASK (0xc000 | 0x2000 | 0xfe)
#define RTCP_VALID_VALUE ((RTP_VERSION << 14) | RTCP_SR)
/*
* Блок отчета о приеме
*/
typedef struct {
u_int32 ssrc; /* Источник, для которого составлен отчет */
unsigned int fraction:8; /* доля потерянных пакетов с момента последнего SR/RR */
int lost:24; /* полное число потерянных пакетов */
u_int32 last_seq; /* номер последнего полученного пакета */
u_int32 jitter; /* разброс времени прихода пакетов */
u_int32 lsr; /* последний SR-пакет от этого источника */
u_int32 dlsr; /* задержка с момента последнего SR пакета */
} rtcp_rr_t;
/*
* элемент SDES
*/
typedef struct {
u_int8 type; /* тип элемента (rtcp_sdes_type_t) */
u_int8 length; /* Длина элемента (в октетах) */
char data[1]; /* текст */
} rtcp_sdes_item_t;
/*
* One RTCP packet
*/
typedef struct {
rtcp_common_t common; /* общий заголовок */
union {
/* sender report (SR) */
struct {
u_int32 ssrc; /* Отправитель, генерирующий этот отчет */
u_int32 ntp_sec; /* временная метка NTP */
u_int32 ntp_frac;
u_int32 rtp_ts; /* временная метка RTP */
u_int32 psent; /* послано пакетов */
u_int32 osent; /* послано октетов */
rtcp_rr_t rr[1]; /* список переменной длины */
} sr;
/* Отчет о приеме (RR) */
struct {
u_int32 ssrc; /* приемник, формирующий данный отчет */
rtcp_rr_t rr[1]; /* список переменной длины */
} rr;
/* описание источника (SDES) */
struct rtcp_sdes {
u_int32 src; /* первый SSRC/CSRC */
rtcp_sdes_item_t item[1]; /* список элементов SDES */
} sdes;
/* BYE */
struct {
u_int32 src[1]; /* список источников */
/* can' t express trailing text for reason */
} bye;
} r;
} rtcp_t;
typedef struct rtcp_sdes rtcp_sdes_t;
/*
* Информация состояния источников
*/
typedef struct {
u_int16 max_seq; /* наибольший зарегистрированный номер */
u_int32 cycles; /* shifted count of seq. number cycles */
u_int32 base_seq; /* основной порядковый номер */
u_int32 bad_seq; /* последний 'плохой' порядковый номер + 1 */
u_int32 probation; /* sequ. packets till source is valid */
u_int32 received; /* пакетов получено */
u_int32 expected_prior; /* пакет, ожидаемый в последнем интервале */
u_int32 received_prior; /* пакет, полученный за последний интервал */
u_int32 transit; /* относительное время передачи для предыдущего пакета */
u_int32 jitter; /* оценка временного разброса */
/* ... */
} source;
Получатель RTP-пакета должен проверить корректность заголовка. Здесь следует учитывать, что пакет может быть зашифрован. Если пакет не пройдет данную проверку (например, неверно дешифрован, ошибка в адресе или обнаружен неизвестный тип поля данных), должно быть выработано соответствующее сообщение. Ограниченная проверка допустима только для нового источника:
В противном случае длина поля расширения должна быть меньше полной длины пакета минус длина стандартного заголовка вместе с заполнителем.
Последние три проверки достаточно сложны и не всегда возможны. Если SSRC-идентификатор в пакете соответствует одному из полученных ранее, тогда пакет вероятно корректен и следует проверить то, что его порядковый номер лежит в нужном диапазоне. Если SSRC-идентификатор ранее не встречался, тогда данный пакет может рассматриваться некорректным до тех пор, пока не будет получено несколько таких последовательно пронумерованных пакетов.
Программа update_seq, приведенная ниже гарантирует, что источник декларирован правильно после получения MIN_SEQUENTIAL последовательно пронумерованных пакетов. Она также проверяет номера пакетов SEQ и актуализует состояние источника пакетов в структуре, на которую указывает S.
Когда новый источник дает о себе знать впервые (т.е. его SSRC-идентификатор отсутствует в таблице), и для описания его состояния выделено место в памяти, S->probation должно быть сделано равным числу последовательных пакетов, которые должны быть зарегистрированы до того, как источник будет объявлен легальным (параметр MIN_SEQUENTIAL ), а переменной s->max_seq присваивается значение SEQ-1. s->probation помечает источник как еще нелегальный, так что описание его состояния может быть выброшено после короткой выдержки.
После того как источник признан легальным, номер по порядку считается корректным, если он не больше чем на MAX_DROPOUT впереди S->max_seq и не больше на MAX_MISORDER после.
В противном случае возвращается нуль, что означает неудачу проверки, а плохой последовательный номер запоминается. Если номер очередного полученного пакета имеет следующий номер по порядку, то он рассматривается как начало новой последовательности (возможно источник рестартовал). Так как при этом теряется много циклов, статистика потерь пакетов сбрасывается.
Приведенные типовые значения параметров базируются на максимальном времени сбоя нумерации равном 2 секундам при скорости 50 пакетов/сек и времени таймаута 1 минута. Параметр таймаута MAX_DROPOUT должен соответствовать небольшой доле от 16-битового диапазона нумерации. Таким образом, после рестарта новый номер пакета с большой вероятностью не должен попасть в допустимый диапазон.
void init_seq(source *s, u_int16 seq)
{
s->base_seq = seq - 1;
s->max_seq = seq;
s->bad_seq = RTP_SEQ_MOD + 1;
s->cycles = 0;
s->received = 0;
s->received_prior = 0;
s->expected_prior = 0;
/* other initialization */
}
int update_seq(source *s, u_int16 seq)
{
u_int16 udelta = seq - s->max_seq;
const int MAX_DROPOUT = 3000;
const int MAX_MISORDER = 100;
const int MIN_SEQUENTIAL = 2;
*
* Источник нелегален до тех пор, пока не будет получено MIN_SEQUENTIAL пакетов
* с последовательно нарастающими номерами.
*/
if (s->probation) {
/* пакет соответствует последовательности */
if (seq == s->max_seq + 1) {
s->probation--;
s->max_seq = seq;
if (s->probation == 0) {
init_seq(s, seq);
s->received++;
return 1;
}
} else {
s->probation = MIN_SEQUENTIAL - 1;
s->max_seq = seq;
}
return 0;
} else if (udelta < MAX_DROPOUT) {
/* в порядке, с допустимым зазором */
if (seq < s->max_seq) {
/*
* Порядковый номер переполнен - начинаем новый 64K цикл.
*/
s->cycles += RTP_SEQ_MOD;
}
s->max_seq = seq;
} else if (udelta <= RTP_SEQ_MOD - MAX_MISORDER) {
/* порядковый номер изменился слишком сильно */
if (seq == s->bad_seq) {
/*
* Два последовательных пакета - предполагается, что другая сторона рестартовала, не
* предупредив нас об этом. re-sync (т.е., считаем, что получили первый пакет).
*/
init_seq(s, seq);
}
else {
s->bad_seq = (seq + 1) & (RTP_SEQ_MOD-1);
return 0;
}
} else {
/* задублированные пакеты или пакеты с перепутанным порядком прихода */
}
s->received++;
return 1;
}
Проверка корректности может быть и жестче, требуя более двух пакетов с последовательными номерами подряд.
Недостатком такого подхода будут трудности, связанные с каналами, где вероятность потери пакета велика. Однако, так как проверка корректности заголовка RTCP-пакета достаточно строга, можно ограничиться требованием двух последовательных информационных пакетов. Если начальная потеря данных в течение нескольких секунд приемлема, приложение может выбрасывать все информационные пакеты до тех пор, пока не будет получен от источника корректный RTCP-пакет.
В зависимости от приложения и используемого кодирования для проверки можно использовать дополнительную информацию о структуре поля данных. Например, для типов данных, где используются временные метки, можно с некоторой точностью предсказывать очередное значение метки на основании знания предыдущей и разности номеров пакетов.
Для того чтобы посчитать частоту потерь пакетов, нужно знать ожидаемое и реально полученное число пакетов для каждого из источников. Число полученных пакетов получается простым их подсчетом с учетом возможного дублирования и запаздывания. Ожидаемое число пакетов может быть подсчитано получателем как разность между наибольшим порядковым номером пакета (s->max_seq) и номером первого пакета в последовательности (S->base_seq). При этом нужно учитывать то, что номера имеют 16 бит, и по этой причине могут переполниться (число переполнений хранится в переменной s->cycles).
extended_max = s->cycles + s->max_seq;
expected = extended_max - s->base_seq + 1;
Число потерянных пакетов определяется как разность между ожидаемым и реально полученным числом пакетов:
lost = expected - s->received;
Доля потерянных пакетов за отчетный период (с момента посылки предыдущего SR или RR пакета) вычисляется из разности ожидаемого и реально полученного числа пакетов за отчетный период, где expected_prior и received_prior представляют собой значения, записанные в момент подготовки предыдущего отчета:
expected_interval = expected - s->expected_prior;
s->expected_prior = expected;
received_interval = s->received - s->received_prior;
s->received_prior = s->received;
lost_interval = expected_interval - received_interval;
if (expected_interval == 0 lost_interval <= 0) fraction = 0;
else fraction = (lost_interval << 8) / expected_interval;
Результирующее значение доли равно 8-битовому числу с фиксированной запятой, расположенной слева.
Ошибки
Существует два типа RSVP сообщений об ошибках: ResvErr и PathErr. Сообщения PathErr очень просты, они посылаются отправителю виновнику ошибки и не изменяют состояния прохода в узлах, через которые проходят. Существует всего несколько причин ошибок прохода.Однако для синтаксически верных запросов резервирования имеется много способов быть отвергнутыми. Узел может решить аннулировать установленное резервирование из-за более приоритетных заданий. Так как неудовлетворение запроса может быть вызвано объединением нескольких запросов, ошибка резервирования должна быть ретранслирована всем получателям группы. Кроме того, объединение разнородных запросов создает потенциальную трудность, известную как проблема "резервирования килера", в которой один запрос может блокировать услуги другого. В действительности существует две такие проблемы.
Чтобы решить эту проблему сообщения ResvErr устанавливают дополнительное состояние, называемое, "состояние блокады", в каждом из узлов, через которые проходит это сообщение. Состояние блокады в узле модифицирует процедуру объединения, так чтобы игнорировать блокирующие спецификации flowspec (Q1 в вышеприведенном примере), позволяя скромным запросам проходить и осуществлять свое резервирование.
Состояние резервирования Q1 считается в данном случае заблокированным.
Запрос резервирования, не прошедший контроль допуска создает состояние блокады в соответствующем узле, но остается действующим во всех предшествующих узлах. Было предложено, чтобы эти резервирования до точки отказа были удалены. Однако, эти резервирования были сохранены по следующим причинам:
алгоритмы предложены Дикстрой) является альтернативой
4.4.11.2 Протокол OSPF (алгоритм Дикстры)Семенов Ю.А. (ГНЦ ИТЭФ)
Протокол OSPF (Open Shortest Pass First, RFC-1245-48, RFC-1583-1587, алгоритмы предложены Дикстрой) является альтернативой RIP в качестве внутреннего протокола маршрутизации. OSPF представляет собой протокол состояния маршрута (в качестве метрики используется - коэффициент качества обслуживания). Каждый маршрутизатор обладает полной информацией о состоянии всех интерфейсов всех маршрутизаторов (переключателей) автономной системы. Протокол OSPF реализован в демоне маршрутизации gated, который поддерживает также RIP и внешний протокол маршрутизации BGP.
Автономная система может быть разделена на несколько областей, куда могут входить как отдельные ЭВМ, так и целые сети. В этом случае внутренние маршрутизаторы области могут и не иметь информации о топологии остальной части AS. Сеть обычно имеет выделенный (designated) маршрутизатор, который является источником маршрутной информации для остальных маршрутизаторов AS. Каждый маршрутизатор самостоятельно решает задачу оптимизации маршрутов. Если к месту назначения ведут два или более эквивалентных маршрута, информационный поток будет поделен между ними поровну. Переходные процессы в OSPF завершаются быстрее, чем в RIP. В процессе выбора оптимального маршрута анализируется ориентированный граф сети. Ниже описан алгоритм Дикстры по выбору оптимального пути. На иллюстративном рис. 4.2.11.2.1 приведена схема узлов (A-J) со значениями метрики для каждого из отрезков пути. Анализ графа начинается с узла A (Старт). Пути с наименьшим суммарным значением метрики считаются наилучшими. Именно они оказываются выбранными в результате рассмотрения графа (“кратчайшие пути“).

Рис. 4.2.11.2.1 Иллюстрация работы алгоритма Дикстры
Ниже дается формальное описание алгоритма. Сначала вводим некоторые определения.
Пусть D(v) равно сумме весов связей для данного пути.
Пусть c(i,j) равно весу связи между узлами с номерами i и j.
Далее следует последовательность шагов, реализующих алгоритм.
D(v)=min{D(v), D(v)+c(w,v)}.
Топология маршрутов для узла a приведена на нижней части рис. 4.2.11.2.1. В скобках записаны числа, характеризующие метрику отобранного маршрута согласно критерию пункта 3.
Таблица 4.2.11.2.1. Реализация алгоритма
| Множество | Метрика связи узла a с узлами | |||||||||
| Шаг | N | B | C | D | E | F | G | H | I | J |
| 0 | {A} | 3 | - | 9 | - | - | - | - | - | - |
| 1 | {A,B} | (3) | 4 | 9 | 7 | - | 10 | - | - | - |
| 2 | {A,B,C} | 3 | (4) | 6 | 6 | 10 | 10 | 8 | - | 14 |
| 3 | {A,BC,D} | 3 | 4 | (6) | 6 | 10 | 10 | 8 | 9 | 14 |
| 4 | {A,B,C,D,E} | 3 | 4 | 6 | (6) | 10 | 10 | 8 | 9 | 14 |
| 5 | {A,B,C,D,E,H} | 3 | 4 | 6 | 6 | 10 | 10 | (8) | 9 | 14 |
| 6 | {A,B,C,D,E,H,I} | 3 | 4 | 6 | 6 | 10 | 10 | 8 | (9) | 14 |
| 7 | {A,B,C,D,E,H,I,F} | 3 | 4 | 6 | 6 | (10) | 10 | 8 | 9 | 14 |
| 8 | {A,B,C,D,E,H,I,F,G} | 3 | 4 | 6 | 6 | 10 | (10) | 8 | 9 | 14 |
| 9 | {A,B,C,D,E,H,I,F,G,J} | 3 | 4 | 6 | 6 | 10 | 10 | 8 | 9 | (14) |
Определяющими являются три характеристики: задержка, пропускная способность и надежность. Для транспортных целей OSPF использует IP непосредственно, т.е. не привлекает протоколы UDP или TCP. OSPF имеет свой код (89) в протокольном поле IP-заголовка. Код TOS (type of service) в IP-пакетах, содержащих OSPF-сообщения, равен нулю, значение TOS здесь задается в самих пакетах OSPF.
Отклик BAD
Содержимое: опционный код отклика;текст, читаемый человеком
Отклик BAD отмечает сообщение об ошибке со стороны сервера. В маркированной форме он сообщает об ошибке протокольного уровня в команде клиента; метка отмечает команду, которая вызвала ошибку. Непомеченная форма указывает на ошибку протокольного уровня, для которой нельзя указать команду, вызвавшую ошибку; это может также означать внутреннюю ошибку сервера. Текстовое сообщение описывает условия.
Пример: C: ...very long command line...
S: * BAD Command line too long
C: ...empty line...
S: * BAD Empty command line
C: A443 EXPUNGE
S: * BAD Disk crash, attempting salvage to a new disk!
S: * OK Salvage successful, no data lost
S: A443 OK Expunge completed
Отклик BYE
Содержимое: опционный код отклика;текст, читаемый человеком
Отклик BYE является всегда непомеченным, он указывает, что сервер намеривается разорвать соединение. При этом пользователю может быть послано текстовое сообщение, проясняющее статус клиента. Отклик BYE посылается при выполнении одного из четырех условий:
Отличие между откликом BYE, который является частью обычной процедуры LOGOUT (первый вариант), и BYE при отказе (остальные три варианта), заключается в том, что соединение в последнем случае разрывается немедленно.
Пример: S: * BYE Autologout; idle for too long
Отклик CAPABILITY
Содержимое: список возможностей.Отклик CAPABILITY возникает в результате исполнения одноименной команды. Список возможностей, содержащийся в перечне наименований, разделенных пробелами, характеризует функции, поддерживаемые сервером. Список возможностей должен включать в себя атом "IMAP 4.1".
Имя возможности, которое начинается с "AUTH=" указывает, что сервер поддерживает данный механизм аутентификации. Другие наименования возможностей отмечают, что сервер поддерживает расширение, модификацию или усовершенствования протокола IMAP 4.1. Отклик сервера должен соответствовать данному документу до тех пор, пока клиент использует команды, согласованные со списком возможностей.
Имена возможностей должны либо начинаться с "X", либо быть стандартными, либо соответствовать расширениям IMAP 4.1, модификациям или усовершенствованиям, зарегистрированным IANA. Сервер не должен предлагать незарегистрированные или нестандартные имена возможностей, если их имена не начинаются с символа "X".
Реализациям клиента не следует требовать каких-либо имен возможностей, отличных от "IMAP 4.1", они должны игнорировать неизвестные имена возможностей.
Пример: S: * CAPABILITY IMAP4rev1 AUTH=KERBEROS_V4 XPIG-LATIN
Отклик EXISTS
Содержимое: отсутствует.Отклик EXISTS сообщает о числе сообщений в почтовом ящике. Этот отклик является результатом команды SELECT, EXAMINE или изменения размера почтового ящика (например, получено новое почтовое сообщение). Отклик EXISTS должен регистрироваться клиентом.
Пример: S: * 23 EXISTS
Отклик EXPUNGE
Содержимое: отсутствует.Отклик EXPUNGE уведомляет, сообщение с каким порядковым номером удалено из почтового ящика. Порядковые номера последующих сообщений немедленно уменьшаются на единицу.
Как результат этого немедленного уменьшения порядковых номеров следует рассматривать то, что порядковые номера сообщений, появляющиеся при последующих командах EXPUNGE, зависят от того, в каком порядке удаляются сообщения. Например, если последние 5 сообщений в почтовом ящике с 9 сообщениями стерты, сервер, удаляющий записи "снизу-вверх" пошлет 5 немаркированных откликов EXPUNGE (с номером 5), в то время как сервер, стирающий записи "сверху вниз", пошлет немаркированные отклики с номерами 9, 8, 7, 6 и 5.
Отклик EXPUNGE не должен посылаться, когда не исполняется никакая команда, или при отклике на команды FETCH, STORE или SEARCH. Это правило необходимо, чтобы предотвратить потерю синхронизации нумерации для клиента и сервера.
Информация отклика EXPUNGE должна регистрироваться клиентом.
Пример: S: * 44 EXPUNGE
Отклик FETCH
Содержимое: текст сообщения.Отклик FETCH возвращает данные о сообщении клиенту. Данные сформированы в группы из имени элемента и его значения в скобках. Этот отклик является следствием команды FETCH или STORE, а также одностороннего решения сервера (например, об изменении флагов). В настоящее время существуют следующие информационные элементы:
BODY Форма BODYSTRUCTURE без расширения данных.
BODY[
Строка, отражающая содержимое специфицированной секции. Строка должна интерпретироваться клиентом согласно транспортной кодировке, типу и субтипу тела.
Если специфицирован начальный октет, то это субстрока полного содержимого тела, начинающаяся с заданного октета. Это означает, что BODY[ ] может быть укорочено, но BODY[ ] никогда не укорачивается.
Если идентификатор [CHARSET] является частью списка параметров тела секции, допустимы 8-битовые текстовые данные. Заметьте, что заголовки (спецификаторы частей HEADER, MIME или часть заголовка секции MESSAGE/RFC822), должны содержать только 7-битовые символы (применение 8-битовых символов в заголовке запрещено). Заметим также, что пустая строка в конце заголовка всегда включается в текст заголовка.
Не текстовые данные, такие как двоичные, должны передаваться закодированными в текстуальной форме, например BASE64. Чтобы получить исходные двоичные данные клиент должен декодировать полученную последовательность.
BODYSTRUCTURE - список, заключенный в скобки, который описывает [MIME-IMB],
структура тела сообщения.
Эта структура вычисляется сервером путем разбора полей заголовка [MIME-IMB], и подставления при необходимости значений по умолчанию.
Например, простое текстовое сообщение из 48 строк и 2279 октетов может иметь структуру тела: ("TEXT" "PLAIN" ("CHARSET" "US-ASCII") NIL NIL "7BIT" 2279 48)
Если имеется несколько частей, они выделяются вложенными скобками. Вместо типа тела в качестве первого элемента списка используется тело с иерархической структурой.
Вторым элементом списка, заключенного в скобки, является составной субтип (mixed, digest, parallel, alternative, и т.д.).
Например, сообщение из двух частей, включающее в себя текст и приложение, закодированное в BASE64, может иметь структуру тела: (("TEXT" "PLAIN" ("CHARSET" "US-ASCII") NIL NIL "7BIT" 1152 23)("TEXT" "PLAIN" ("CHARSET" "US-ASCII" "NAME" "cc.diff") "<960723163407.20117h@cac.washington.edu>" "Compiler diff" "BASE64" 4554 73) "MIXED"))
Данные расширения следуют за составным субтипом. Данные расширения никогда не присылаются при доставке тела, но могут быть доставлены с помощью BODYSTRUCTURE. Данные расширения, если они присутствуют, должны иметь следующий формат:
Список параметров тела, заключенный в скобки.
Список содержит пары атрибут/значение [например, ("foo" "bar" "baz" "rag"), где "bar" представляет собой значение "foo", а "rag" является значением "baz"] как это определено в [MIME-IMB].
Размещение тела
Список, заключенный в скобки, состоящий из строки типа размещения, за которой следует список пар атрибут/значение. Имена типов размещения и атрибутов будут определены в будущих стандартах.
Язык тела
Строка или список в скобках, определяющие язык, так как это задано в [LANGUAGE-TAGS].
Любое из последующих расширений данных в данной версии протокола не определено. Такие расширения могут состоять из нуля или более NIL-строк, чисел, или вложенных списков таких данных, заключенных в скобки. Реализации клиента, которые осуществляют доставку BODYSTRUCTURE, должны быть готовы принять такие расширения данных. Реализации сервера не должны посылать такие расширения, до тех пор, пока они не войдут в новую версию протокола. Базовые поля несоставной части тела размещаются в следующем порядке:
Тип тела
Строка, описывающая имя типа содержимого, как это определено в [MIME-IMB].
Субтип тела
Строка, описывающая имя субтипа, как это определено в [MIME-IMB].
Список параметров тела, заключенный в скобки
Список пар атрибут/значение, заключенный в скобки, [например, ("foo" "bar" "baz" "rag"), где "bar" является значением "foo", а "rag" - значением "baz"], как это описано в [MIME-IMB].
Идентификатор тела
Строка, описывающая идентификатор содержимого, как это определено в [MIME-IMB].
Описание тела
Строка, предоставляющая описание содержимого, как это задано в [MIME-IMB].
Шифрование тела
Строка, предоставляющая транспортную кодировку, как это задано в [MIME-IMB].
Размер тела
Число, указывающее размер тела в октетах. Заметьте, что этот размер характеризует размер тела с учетом транспортного кодирования. Размер исходного текста может быть иным.
Тип тела MESSAGE и субтип RFC822 сразу после базовых полей содержат структуру заголовка, структуру тела и размер вложенного сообщения в строках.
Тип тела TEXT сразу после базовых полей содержат размер тела в строках. Заметьте, что этот размер отражает размер фрагмента после выполнения транспортного кодирования.
Данные расширения следуют после базовых полей и полей, перечисленных выше и зависящих от типа. Данные расширения никогда не транспортируются при передаче тела, но могут быть пересланы при доставке BODYSTRUCTURE. Данные расширения, если они присутствуют, должны быть упорядочены.
Данные расширения для несоставной части тела располагаются в следующем порядке:
MD5 тела
Строка, содержащая значение MD5 тела, как это описано в [MD5].
Размещение тела
Список, заключенный в скобки, с тем же содержимым и функциями, что и размещение тела для составной части тела.
Язык тела
Строка или список, заключенный в скобки, определяющие язык тела, как это задано в [LANGUAGE-TAGS].
Любые последующие данные расширения пока не определены в данной версии протокола.
ENVELOPE - список, заключенный в скобки, который описывает структуру заголовка (конверта) сообщения.
Он вычисляется сервером в результате разбора заголовка [RFC-822], при необходимости некоторым полям присваиваются значения по умолчанию.
Поля структуры конверта размещаются в следующем порядке: дата, subject (предмет сообщения), from (от), отправитель, reply-to (ответ на), to, cc, bcc, in-reply-to (в ответ на), и идентификатор сообщения. Поля дата, subject, in-reply-to и идентификатор сообщения являются строками. Поля from, отправитель, reply-to, to, cc и bcc являются списками адресных структур, заключенными в скобки.
Адресная структура представляет собой список, который описывает электронный почтовый адрес. Поля адресной структуры размещаются в следующем порядке: персональное имя, [SMTP] @-домен (маршрут отправителя), имя почтового ящика и имя ЭВМ.
Синтаксис группы [RFC-822] определяется специальной формой адресной структуры, в которой поле имени ЭВМ равно NIL. Если поле имени почтового ящика также равно NIL, это является концом группового маркера (двоеточие в синтаксисе RFC 822). Если поле имени почтового ящика не равно NIL, это обозначает начало группового маркера, а поле имени почтового ящика содержит имя группы.
Любое поле в конверте или адресной структуре, которое не используется, характеризуется значением NIL. Заметим, что сервер должен заполнять по умолчанию поля reply-to и sender из поля from.
| FLAGS | Список флагов, установленных для данного сообщения, заключенный в скобки. |
| INTERNALDATE | Строка, представляющая внутреннюю дату сообщения. |
| RFC822 | Эквивалент BODY[]. |
| RFC822.HEADER | Эквивалент BODY.PEEK[HEADER]. |
| RFC822.SIZE | Число, выражающее размер сообщения [RFC-822]. |
| RFC822.TEXT | Эквивалент BODY[TEXT]. |
| UID | Число, выражающее уникальный идентификатор сообщения. |
Отклик FLAGS
Содержимое: список флагов, заключенный в скобки.Отклик FLAGS является результатом команды SELECT или EXAMINE. Список флагов, заключенный в скобки определяет флаги (системные флаги), которые могут использоваться для данного почтового ящика. Допускаются флаги, отличные от системных, это зависит от реализации сервера. Отклик FLAGS должен записываться клиентом.
Пример: S: * FLAGS (\Answered \Flagged \Deleted \Seen \Draft)
Отклик исходящего вызова OCRP (Outgoing-Call-Reply)
Сообщение Outgoing-Call-Reply (OCRP) является управляющим сообщением, посылаемым от LAC к LNS в ответ на полученное сообщение OCRQ. Оно является вторым из трех сообщений, которые используются при установлении сессии в L2TP-туннеле. OCRP используется для индикации того, что LAC может попытаться послать исходящий вызов и вернуть определенные параметры, относящиеся к попытке вызова. Следующие AVP должны присутствовать в OCRP:Тип сообщения (Message Type)
Assigned Session ID
| Следующие AVP могут присутствовать в OCRP: | Physical Channel ID |
Отклик LIST
Содержимое: атрибуты имени, иерархический разделитель, имя.Отклик LIST посылается как результат команды LIST. Он возвращает одно имя, которое соответствует спецификации LIST. Допускается несколько откликов LIST на одну команду.
Определено четыре атрибута имени:
| \Noinferiors | Дочерние уровни иерархии не могут иметь то же самое имя. Не существует дочерних уровней в настоящее время, и они не могут быть созданы в будущем. |
| \Noselect | Не допускается использование данного имени для именования почтового ящика, который может быть выбран. |
| \Marked | Почтовый ящик помечен сервером как "interesting"; почтовый ящик, вероятно, содержит сообщения, которые добавлены со времени, когда почтовый ящик последний раз был выбран. |
| \Unmarked | Почтовый ящик не содержит каких-либо дополнительных сообщений, со времени, когда почтовый ящик последний раз был выбран. |
Если сервер не может определить, является ли почтовый ящик "интересным", или, если имя имеет атрибут \Noselect, сервер не должен посылать отклики \Marked или \Unmarked. Иерархическим разделителем является символ, используемый для разграничения уровней иерархии имен почтового ящика. Клиент может использовать разделитель для формирования дочерних уровней в почтовом ящике, а также для поиска в иерархической системе имен. Все дочерние уровни верхнего уровня иерархии должны использовать один и тот же тип разделителя. Иерархический разделитель NIL означает, что никакой иерархии нет.
Имя представляет собой однозначную иерархию (слева направо) и должно быть пригодным для использования в качестве шаблона командами LIST и LSUB. Если не использован атрибут \Noselect, имя должно быть пригодно в качестве аргумента команд, типа SELECT, которые требуют ввода имени почтового ящика.
Пример: S: * LIST (\Noselect) "/" ~/Mail/foo
Отклик LSUB
Содержимое: атрибуты имени, иерархический разграничитель, имя.Отклик LSUB является результатом команды LSUB. Он возвращает одно имя, которое соответствует спецификации LSUB. Допускается несколько откликов на одну команду LSUB. Формат данных идентичен используемому в отклике LIST.
Пример: S: * LSUB () "." #news.comp.mail.misc
Отклик NO
Содержимое: опционный код отклика;текст, читаемый человеком
Отклик NO указывает на сообщение от сервера об операционной ошибке. В помеченной форме он отмечает неудачное завершение соответствующей команды. Непомеченная форма служит для индикации предупреждения, команда все еще может завершиться успешно. Текстовое сообщение описывает условия.
Пример: C: A222 COPY 1:2 owatagusiam
S: * NO Disk is 98% full, please delete unnecessary data
S: A222 OK COPY completed
C: A223 COPY 3:200 blurdybloop
S: * NO Disk is 98% full, please delete unnecessary data
S: * NO Disk is 99% full, please delete unnecessary data
S: A223 NO COPY failed: disk is full
Отклик OK
Содержимое: опционный код отклика;текст, читаемый человеком
Отклик OK индицирует информационное сообщение от сервера. Если оно маркировано, сообщение указывает на успешное завершение соответствующей команды. Пользователю может быть предложено текстовое информационное сообщение. Немаркированная форма указывает на чисто информационное сообщение; природа информации может быть указана в коде отклика.
Немаркированная форма используется также как один из трех видов оповещения об установлении начального соединения. Эта форма указывает, что еще не выполнена аутентификация и необходима команда LOGIN.
Пример: S: * OK IMAP4rev1 server ready
C: A001 LOGIN fred blurdybloop
S: * OK [ALERT] System shutdown in 10 minutes
S: A001 OK LOGIN Completed
Отклик PREAUTH
Содержимое: опционный код отклика;текст, читаемый человеком
Отклик PREAUTH является всегда непомеченным и представляет собой одну из трех возможных реакций при установлении соединения. Он указывает, что для соединения уже выполнена аутентификация, и команда LOGIN не нужна.
Пример: S: * PREAUTH IMAP4rev1 server logged in as Smith
Отклик RECENT
Содержимое: отсутствует.Отклик RECENT сообщает число сообщений с флагами \Recent. Этот отклик является результатом команды SELECT, EXAMINE или изменения размера почтового ящика (например, получено новое почтовое сообщение).
Замечание: Нельзя гарантировать, чтобы порядковые номера для последних сообщений образовывали в почтовом ящике непрерывный ряд с предыдущими. Примерами, когда складывается такая ситуация могут служить варианты: несколько клиентов, имеют один и тот же открытый почтовый ящик; или случай, когда сообщения в почтовом ящике переставлены не-IMAP приложением.
Единственным способом идентифицировать последние сообщения является рассмотрение флагов \Recent, или выполнение команды SEARCH RECENT. Информация отклика RECENT должна регистрироваться клиентом.
Пример: S: * 5 RECENT
Отклик SEARCH
Содержимое: нуль или более чисел.Отклик SEARCH является результатом команды SEARCH или UID SEARCH. Числа относятся к тем сообщениям, которые отвечают критериям отбора. Для SEARCH это порядковые номера сообщений, а для UID SEARCH - их уникальные идентификаторы. Числа отделяются друг от друга пробелами.
Пример: S: * SEARCH 2 3 6
Отклик Start-Control-Connection (SCCRP)
Start-Control-Connection-Reply (SCCRP) является управляющим сообщением, посланным в ответ на сообщение SCCRQ. SCCRP используется для индикации того, что SCCRQ было принято и установление туннеля должно быть продолжено. Следующие AVP должны присутствовать в SCCRP:Тип сообщения (Message Type)
Версия протокола (Protocol Version)
Framing Capabilities
Имя ЭВМ (Host Name)
Присвоенный туннелю ID (Assigned Tunnel ID)
Следующие AVP могут присутствовать в SCCRP:
Возможности несущего канала (Bearer Capabilities)
Фирменная версия (Firmware Revision)
Имя производителя (Vendor Name)
Размер приемного окна (Receive Window Size)
Приглашение (Challenge)
Отклик на приглашение (Challenge Response)
Отклик STATUS
Содержимое: имя, статусный список, заключенный в скобки.Отклик STATUS является результатом команды STATUS. Он возвращает имя почтового ящика, которое соответствует спецификации STATUS, и запрашиваемую статусную информацию почтового ящика.
Пример: S: * STATUS blurdybloop (MESSAGES 231 UIDNEXT 44292)
Отклик в случае, когда не исполняется никакой команды
Реализациям сервера разрешается посылать непомеченные отклики (за исключением EXPUNGE), если в это время не выполняется ни одной команды. Реализации, которые посылают такие отклики, должны учитывать соображения управления трафиком. В частности, они должны либо (1) проверить, что размер данных не превосходит транспортные возможности, или (2) использовать неблокирующую запись.Отклик входящего вызова ICRP (Incoming-Call-Reply)
Incoming-Call-Reply (ICRP) является управляющим сообщением, посылаемым LNS к LAC в ответ на полученное сообщение ICRQ. Он является вторым из трех сообщений обмена, используемых для установления сессии в пределах L2TP туннеля.ICRP используется для индикации того, что ICRQ успешен, и для LAC, чтобы ответить на вызов, если это еще не было сделано. Оно позволяет также LNS индицировать необходимые параметры для L2TP-сессии. Следующие AVP должны присутствовать в ICRP:
Тип сообщения (Message Type)
ID, присвоенный сессии (Assigned Session ID)
Отклики сервера - отклики состояния
Статусными откликами являются OK, NO, BAD, PREAUTH и BYE. OK, NO и BAD могут быть маркированными или нет. PREAUTH и BYE - всегда не маркированы.Статусные отклики могут включать опционный код отклика. Код отклика состоит из информации, заключенной в квадратные скобки, в форме атома. Далее может следовать пробел и аргументы. Код отклика содержит дополнительную информацию или статусные коды для программы клиента помимо условий OK/NO/BAD. Эти данные определяются, когда клиент может предпринять действия на основе этой дополнительной информации. В настоящее время определены следующие коды откликов:
| ALERT | Текстовое сообщение, содержащее специальное предупреждение, которое должно быть представлено пользователю в форме, привлекающей внимание. |
| NEWNAME | За этим откликом следует имя почтового ящика и новое имя. Команды SELECT или EXAMINE не пройдут, так как ящик места назначения более не существует из-за переименования. Это является указанием для клиента, попытаться повторить команду с новым именем почтового ящика. |
| PARSE | Текстовое сообщение, которое указывает на ошибку при разборе заголовка [RFC-822] или заголовка [MIME-IMB] сообщения в почтовом ящике. |
| PERMANENTFLAGS | Когда за этим кодом следует в скобках список флагов, это указывает, какие из известных флагов могут быть изменены на постоянной основе. Любые флаги, которые указаны в немаркированном отклике FLAGS, но отсутствуют в списке PERMANENTFLAGS, могут быть установлены на постоянной основе. Если клиент пытается запомнить (STORE) флаг, который отсутствует в списке PERMANENTFLAGS, сервер либо отвергнет этот запрос с помощью отклика NO или запомнит состояние только до конца текущей сессии. Список PERMANENTFLAGS может также включать специальный флаг \*, который указывает, что имеется возможность создать новые ключевые слова путем записи этих флагов в почтовом ящике. |
| READ-ONLY | Почтовый ящик выбран в режиме только для чтения или доступ к нему был сменен с read-write на read-only. |
| READ-WRITE | Почтовый ящик находится в режиме read-write, или доступ к нему был сменен с read-only на read-write. |
| TRYCREATE | Попытка выполнения APPEND или COPY оказалась неуспешной из-за того, что почтовый ящик места назначения отсутствует. Это указывает клиенту, что операция может оказаться успешной, если почтовый ящик будет сначала создан с помощью CREATE |
| UIDVALIDITY | Когда за этим кодом следует десятичное число, это указывает на значение уникального идентификатора. |
| UNSEEN | Когда за этим кодом следует десятичное число, это указывает на значение номера первого сообщения без флага \Seen. |
Дополнительные коды откликов определенные конкретным клиентом или сервером должны иметь префикс "X", если они отклоняются от рекомендаций данного документа. Реализации клиента должны игнорировать отклики, которые ими не распознаются.
Отклики сервера - размер почтового ящика
Эти отклики являются немаркированными. Они передают от сервера клиенту информацию об изменении размера почтового ящика. Число, которое следует за символом "*" определяет количество сообщений.Отклики сервера - сообщения о состоянии сервера и почтового ящика
Эти отклики всегда не маркированы. Они служат для передачи статусной информации сервера и почтового ящика клиенту. Большинство этих откликов являются результатом команд, носящих то же имя.Отклики сервера - статусное сообщение
Эти отклики являются немаркированными. Они несут информацию о том, как сообщения доставляются от сервера к клиентам, и возникают как результат работы одноименных команд. Сразу за символом "*" следует число, которое является порядковым номером сообщения.Отклики сервера - запрос продолжения команды
Отклик на запрос продолжения команды вместо метки выделяется символом "+". Эта форма отклика указывает на то, что сервер готов принять продолжение команды от клиента. Остальная часть этого отклика имеет текстовую форму.Этот отклик используется командой AUTHORIZATION, для того чтобы передать данные от сервера клиенту, и запросить дополнительные данные у клиента. Этот отклик применяется также, если аргументом какой-то команды является литерал.
Клиенту не позволено посылать литеральные октеты, если только сервер в явной форме не запросил их. Это позволяет серверу обрабатывать команды и отвергать ошибки строчка за строчкой. Остальная часть команды, включая CRLF, завершающие команду, следует за октетами литерала. Если имеются какие-либо дополнительные аргументы команды, за литеральными октетами следует пробел, после чего передаются аргументы.
Пример: C: A001 LOGIN {11}
S: + Ready for additional command text
C: FRED FOOBAR {7}
S: + Ready for additional command text
C: fat man
S: A001 OK LOGIN completed
C: A044 BLURDYBLOOP {102856}
S: A044 BAD No such command as "BLURDYBLOOP"
Отклики сервера
Существует три вида откликов сервера: отклики состояния, информация сервера и запрос продолжения команды. Информация, содержащаяся в отклике сервера, идентифицируется словом "Содержимое:".Клиент должен быть готов воспринять любой отклик в любое время. Отклики состояния могут быть маркированными или нет. Маркированные отклики состояния указывают на результат завершения команды клиента (OK, NO или BAD) и имеют метку, соответствующую команде.
Некоторые отклики состояния и любая информация сервера не маркируются. Немаркированный отклик выделяется символом "*" вместо метки. Немаркированные отклики состояния отмечают реакцию сервера, они не указывают на завершение выполнения команды (например, предупреждение о предстоящем отключении системы). По историческим причинам немаркированные информационные отклики сервера называются также "незапрашиваемыми данными".
Определенные данные от сервера должны записываться клиентом при получении. Такие данные несут критическую информацию, которая влияет на интерпретацию всех последующих команд и откликов (например, создание или уничтожение сообщений).
Прочие данные сервера следует записывать для последующих ссылок, если клиент не нуждается в записи данных или если запись данных не имеет очевидного смысла (например, отклик SEARCH, когда никакой команды SEARCH не исполняется), такая информация должна игнорироваться.
Немаркированная информация посылается сервером, когда соединение IMAP находится в состоянии "выбрано". В этом состоянии при выполнении команды сервер проверяет наличие новых сообщений в выбранном почтовом ящике. В норме, это часть процедуры выполняется любой командой, следовательно, даже команды NOOP достаточно для проверки наличия новых сообщений. Если обнаружены новые сообщения, сервер посылает немаркированные отклики EXISTS и RECENT, отражающие новые размеры почтового ящика. Реализации сервера, которые предлагают множественный одновременный доступ к одному и тому же ящику, также должны посылать соответствующие немаркированные отклики FETCH и EXPUNGE, если другие агенты изменяют состояние любого флага сообщения или удаляют любое сообщение.
Отклики запросов продолжения команды используют символ "+" вместо метки. Эти отклики посылаются сервером для индикации приема незавершенной команды клиента и готовности приема остальной части команды.
Отсутствие следующего заголовка
Код 59 в поле следующий заголовок IPv6 заголовка или любой другой заголовок расширения указывает, что за этим заголовком ничего не следует. Если поле длина данных заголовка IPv6 указывает на присутствие октетов после конца заголовка, содержащего код 59 в поле следующий заголовок, эти октеты должны быть проигнорированы и переданы без изменений при переадресации пакета.Outgoing-Call-Connected (OCCN)
Сообщение Outgoing-Call-Connected (OCCN) является управляющим сообщением, посылаемым от LAC к LNS, следом за OCRP, и после того как исходящий вызов завершен. Это завершающее сообщение из трех, используемых при установлении сессии в пределах L2TP-туннеля.OCCN используется для индикации того, что результат запрошенного исходящего вызова положителен. Оно также предоставляет LNS информацию об определенных параметрах, полученных после реализации вызова. Следующие AVP должны присутствовать в OCCN:
Тип сообщения (Message Type)
Скорость обмена ((Tx) Connect Speed)
Тип кадрового обмена (Framing Type)
Следующие AVP могут присутствовать в OCCN:
Скорость обмена (Rx Connect Speed)
Необходима нумерация (Sequencing Required)
Пакетная процедура
Пакетная процедура проверяет корректность сообщения, вычисляет задержку/смещение и вызывает другие процедуры для отбора данных и выбора источника синхронизации. Тест 1 требует, чтобы переданная временная метка отличалась от последней, полученной от того же партнера. Тест 2 требует, чтобы исходная временная метка соответствовала последней метке, посланной тому же партнеру. В случае широковещательного режима (5) rtt=0 и полная точность операции передачи времени будет недостижимой. Однако, полученная точность может быть вполне приемлемой для многих целей. Процедура вызова коррекции времени использует в качестве параметра peer.hostpoll (peer.peerpoll может быть изменено).begin packet procedure
| peer.rec | /* забрать полученную временную метку */ |
if (pkt.mode ? 5) begin
| test1 | /* Тест 1 */ |
| test2 | /* Тест 2 */ |
endif
else begin
| pkt.org | /* потеря временной метки из-за ошибки */ |
pkt.rec
| test1; | /* ложные тесты */ |
test2;
endif
| peer.org | /* актуализация исходной временной метки */ |
| peer.peerpoll | /* скорректировать период рассылки */ |
poll-update(peer.hostpoll);
Тест 3 требует, чтобы исходная и полученная временные метки не были равны нулю. Если любая из них равна нулю, ассоциация не синхронизирована или потеряла доступ в одном или обоих направлениях.
test3
rtt и временное смещение по отношению партнера вычисляется следующим образом. Пусть i четное целое число.
Тогда ti-3, ti-2, ti-1 и ti - содержимое переменных pkt.org, pkt.rec, pkt.xmt и peer.rec, соответственно. Смещение часов j, rtt=d и дисперсия e ЭВМ по отношению к партнеру равны:
d = (ti - ti-3) - (ti-1 - ti - 2),
j = ((ti - 2 - ti-3) + ( ti-1 - ti))/2,
e = (1 j (ti - ti-3),
где, как и прежде, j = ntp.maxskew/ntp.maxage. e представляет собой максимальную ошибку или дисперсию, связанную с ошибкой измерения на стороне ЭВМ, а также накопление ошибок из-за дрейфа локальных часов за время после посылки последнего сообщения, посланного партнером. Дисперсия корректируется процедурой фильтра часов (clock-filter).
Рассмотренный метод эквивалентен непрерывному стробированию, которое используется в некоторых телефонных сетях [bel86]. Преимуществом метода является полная независимость от порядка и времени прихода сообщений, а также допустимость потери некоторых пакетов. Очевидно, что достижимые точности зависят от статистических свойств каналов связи.
Тест 4 требует, чтобы вычисленная задержка лежала в допустимых пределах:
test4 d| < ntp.maxdisperse И e
Тест 5 используется, только если реализован механизм аутентификации. Он требует, чтобы либо аутентификация была явно блокирована, либо чтобы аутентификатор в точности соответствовал тому, что описано в процедуре дешифровки.
#ifdef (authentication implemented) /* Тест 5 */
test5
#endef
Тест 6 требует, чтобы часы партнера были синхронизованы, и время с момента последней коррекции было положительным и меньше чем ntp.maxage.
Тест 7 гарантирует, что ЭВМ не будет синхронизовано от партнера с большим кодом номера слоя.
Тест 8 требует, чтобы заголовок содержал соответствующие коды в полях pkt.rootdelay и pkt.rootdispersion.
| test6 2 and | /* Тест 6 */ |
| test7 | /* Тест 7 */ |
| test8 | /* Тест 8 */ |
С точки зрения последующей обработки пакеты содержат корректные данные, если успешно проходят тесты 1-4 (test1 & test2 & test3 & test4 = 1), вне зависимости от результатов других тестов. Только пакеты с корректными данными могут использоваться для вычисления смещения (offset), задержки (delay) и дисперсии. Пакеты имеют корректные заголовки, если успешно проходят тесты 5-8 (test5 & test6 & test7 & test8 = 1), вне зависимости от результатов остальных тестов. Только пакеты с корректными заголовками могут использоваться для определения того, может ли партнер быть выбран в качестве источника синхронизации. Заметим, что тесты 1-2 не используются в широковещательном режиме.
Процедура "часовой фильтр" вызывается для вычисления задержки (peer.delay), смещения (peer.offset) и дисперсии (peer.dispersion) для партнера.Спецификация алгоритма часового фильтра не является составной частью протокола NTP. По этой причине описания, приводимые ниже, следует рассматривать как рекомендательные.
if (not valid header) exit;
| peer.leap < pkt.leap; | /* Копирование переменных пакета */ |
peer.precision ;
peer.rootdelay ;
peer.rootdispersion ;
peer.refid ;
peer.reftime ;
| if (valid data) call clock-filter(q, d, e); | /* обработка данных */ |
Пакетные I/O интерфейсы RSVP
Реализация RSVP нуждается в следующей поддержке со стороны систем ввода/вывода пакетов и со стороны механизма переадресации узла.Пакеты, полученные для IP-протокола (код 46) но не адресованные узлу, должны быть переправлены программе RSVP для последующей обработки. Сообщения RSVP переправляемые таким образом включают сообщения Path, PathTear и ResvConf. Эти типы сообщений несут в себе IP-опцию оповещение маршрутизатора (Router Alert), которая может быть использована для выделения этих пакетов в высокоскоростном канале переадресации. В качестве альтернативы узел может перехватывать все пакеты с кодом протокола 46.
В маршрутизаторе или ЭВМ с несколькими сетевыми интерфейсами идентификация интерфейса (реального и виртуального), через который получено заданное сообщение, также как IP-адрес источника и TTL, с которым оно получено, должна быть также доступна для процесса RSVP.
RSVP должен уметь обеспечить посылку дейтограммы через специальный выходной интерфейс (реальный или виртуальный) в обход обычного механизма маршрутизации. Виртуальным каналом может быть, например, мультикастный туннель.
RSVP должен быть способен специфицировать IP-адрес отправителя и TTL, которые могут использоваться при посылке сообщений Path.
RSVP должен быть способен вызвать посылку сообщения Path, PathTear и ResvConf с опцией оповещения маршрутизатора (Router Alert).
Пакетные переменные
Номер версии (pkt.version) - целое число индицирующее номер версии отправителя. NTP сообщения всегда посылаются с текущим значением версии ntp.version и будут восприняты лишь при условии совпадения кодов версии (ntp.version). Исключения допускаются лишь при смене номера версии.Ниже описаны параметры для всех
Ниже описаны параметры для всех реализаций, работающих в сети Интернет. Необходимо договориться относительно значений этих параметров для того, чтобы исключить ненужную избыточность и стабилизировать ассоциации партнеров. Приведенные параметры применимы для всех ассоциаций.Номер версии (ntp.version) - текущий номер версии NTP (3).
Порт NTP (ntp.port) - стандартный номер порта (123), присвоенный протоколу NTP.
Максимальный номер слоя (ntp.maxstratum) - максимальный номер слоя, который может быть использован при кодировании пакетной переменной. Этот параметр обычно интерпретируется как определение бесконечности (недостижимости для протокола маршрутизации в субсети).
Максимальный возраст часов (ntp.maxage) - максимальный интервал в секундах, в течение которого эталонные часы будут рассматриваться корректными после последней сверки.
Максимальный сбой (ntp.maxskew) - максимальная ошибка смещения, связанная со сбоем локальных часов за время ntp.maxage, в секундах. Отношение ntp.maxskew к ntp.maxage интерпретируется как максимальный сбой, вызванный всей совокупностью факторов.
Максимальное расстояние (ntp.maxdistance) - максимально допустимое расстояние между партнерами при синхронизации с использованием алгоритма отбора.
Минимальный период рассылки (ntp.minpoll) - минимальный период рассылки, допустимый для любого из партнеров в сети Интернет. Этот период выражается в секундах и представляет собой степень 2.
Максимальный период рассылки (ntp.maxpoll) -максимальный период рассылки, допустимый для любого из партнеров в сети Интернет. Этот период выражается в секундах и представляет собой степень 2.
Минимум избранных часов (ntp.minclock) - минимальное число партнеров, необходимое для синхронизации (при использовании алгоритма отбора).
Максимум избранных часов (ntp.maxclock) - максимальное число партнеров, необходимое для организации отбора (при использовании алгоритма селекции).
Минимальная дисперсия (ntp.mindisperse) - минимальное значение приращения дисперсии для каждого из слоев в секундах (при использовании алгоритма фильтрации).
Максимальная дисперсия (ntp.maxdisperse) - максимальная дисперсия в секундах с учетом потерянных данных (при использовании алгоритма фильтрации).
Размер регистра доступности (ntp.window) - размер регистра доступности (peer.reach) в битах.
Размер фильтра (ntp.shift) - размер сдвигового регистра фильтра часов (peer.filter) в каскадах.
Вес фильтра (ntp.filter) - вес, используемый при вычислении дисперсии фильтра (применяется при работе с алгоритмом фильтрации).
Выбранный вес (ntp.select) - вес, используемый при вычислении выбранной дисперсии (применяется при работе алгоритма селекции).
Пары значений-атрибутов управляющих сообщений Формат AVP
Каждая AVP кодируется следующим образом:| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| M | H | rsvd | Длина | ID производителя | |||||||||||||||||||||||||||
| Тип атрибута | Значение атрибута | ||||||||||||||||||||||||||||||
| Продолжение поля значение атрибута до границы, заданной полем длина |
Рис. 4.
Первые 6 бит представляют собой битовую маску, характеризующую атрибуты AVP.
Два бита определены в этом документе, остальные - зарезервированы на будущее. Зарезервированные биты должны равняться нулю. AVP, полученная с зарезервированным набором бит равным 1, должна рассматриваться как не узнанная AVP.
Обязательный бит M (Mandatory) контролирует реакцию системы на получение нераспознанной AVP. Если бит M =1 для нераспознанной AVP в сообщении, ассоциированном с определенной сессией, эта сессия должна быть немедленно завершена. Если бит M =1 для нераспознанной AVP в сообщении, ассоциированном со всем туннелем, этот туннель (и все его сессии) должен быть ликвидирован. Если бит M =0, нераспознанную AVP следует игнорировать. Управляющие сообщения должны обрабатываться при этом так, как если бы AVP не было.
Бит сокрытия (H). Идентифицирует скрываемые данные в поле значения атрибута AVP. Эта возможность может использоваться, чтобы исключить передачу важных данных, например пароля пользователя, в незашифрованном тексте AVP. В разделе 4.3 описана процедура выполнения сокрытия AVP.
Длина. Число октетов (включая поля полной длины и маски) в AVP. Длина может быть вычислена как 6 + длина поля значения атрибута в октетах. Поле имеет 10 бит, позволяя закодировать до 1023 октетов в одной AVP. Минимальный код длины AVP равен 6. Если длина равна 6, поле значения атрибута отсутствует.
ID производителя (Vendor ID). IANA определила значения кодов производителей (SMI Network Management Private Enterprise Codes) [RFC1700]. Значение 0, соответствующее атрибутам, адаптированным для IETF, используется для всех AVP, определенных в данном документе. Любой производитель, желающий реализовать свое собственное расширение L2TP, может использовать свой код Vendor ID вместе с частными значениями атрибута, гарантирующие отсутствие столкновений с любыми расширениями других производителей, или будущими расширениями IETF. Заметим, что для ID-производителя выделено 16 бит, что ограничивает максимальное число производителей цифрой 65,535.
Тип атрибута: 2-октетное значение с уникальной интерпретацией для совокупности AVP данного ID-производителя.
Значение атрибута. Действительное значение атрибута для заданного Vendor ID и типа атрибута. Оно следует немедленно после поля типа атрибута, и занимает все пространство октетов, отведенное значением поля длина (т.e., длина минус 6 октетов заголовка). Это поле отсутствует, если длина равна 6.
Переадресация кадров PPP
Когда туннель сформирован, PPP-кадры от удаленной системы, получаемые LAC, освобождаются от CRC, канальных заголовков, и т.д., инкапсулированных в L2TP, и переадресуются через соответствующий туннель. LNS получает L2TP-пакет, и обрабатывает инкапсулированный PPP-кадр, как если бы он был получен через локальный интерфейс PPP.Отправитель сообщения, ассоциированный с определенной сессией и туннелем, помещает ID сессии и туннеля (специфицированные партнером) в соответствующие поля заголовка всех исходящих сообщений. Таким способом, PPP-кадры мультиплексируются и демультиплексируются через общий туннель для данной пары LNS-LAC. Для заданной пары LNS-LAC может быть реализовано несколько туннелей, а для любого туннеля несколько сессий.
Значение 0 для ID-сессии и ID-туннеля является зарезервированным и не должно использоваться в качестве ID-сессии или ID-туннеля. Для случаев, когда ID-сессии еще не присвоен партнером (т.e., в процессе установления новой сессии или туннеля), поле ID-сессии должно содержать 0, а для идентификации сессии должна использоваться AVP ID-сессии сообщения. Аналогично, для случаев, когда ID-туннеля еще не присвоен партнером, ID-туннеля должен быть присвоен 0, а для идентификации туннеля должна использоваться AVP ID-туннеля.
Переменные аутентификации
При использовании механизма аутентификации привлекаются следующие переменные состояния.Бит разрешения аутентификации (peer.authenable) - бит, указывающий, что ассоциация должна работать в режиме аутентификации.
Бит аутентификации (peer.authentic) - бит, индицирующий то, что последнее сообщение, полученное от партнера, было корректно аутентифицировано.
Идентификатор ключа (peer.hostkeyid, peer.peerkeyid, pkt.keyid) - целое число, идентифицирующее криптографический ключ, использованный при генерации аутентификационного кода сообщения.
Криптографические ключи (sys.key) - набор 64-битных ключей DES. Каждый ключ создается в соответствии с берклиевскими UNIX-распределениями, которые состоят из 8 октетов, где 7 младших бит каждого октета соответствуют битам des 1-7, а старший бит соответствует биту четности DES.
Контрольная крипто-сумма (pkt.check) - криптографическая контрольная сумма, вычисляемая процедурой шифрации.
Переменные фильтра часов
Когда используются фильтры и алгоритмы отбора, дополнительно привлекаются следующие переменные состояния.Регистр фильтра (peer.filter) - сдвиговый регистр каскадов ntp.shift, где каждый каскад запоминает значения измеренной задержки, смещения и вычисленной дисперсии, соответствующих одному наблюдению. Эти три параметра вводятся со стороны старших разрядов и сдвигаются в направлении младших разрядов (направо). При получении результатов нового наблюдения старые результаты теряются.
Счетчик корректных данных (peer.valid) - целочисленный счетчик, указывающий на корректные образцы, остающиеся в регистре фильтра. Он используется для определения состояния доступности и для управления увеличением и уменьшением периода рассылки сообщений.
Смещение (peer.offset) - число с фиксированной запятой со знаком, индицирующее значение смещение часов партнера по отношению к локальным часам в секундах.
Задержка (peer.delay) - число с фиксированной запятой со знаком, индицирующее полную циклическую задержку (RTT) часов партнера по отношению к локальным часам с учетом времени распространения сообщения и отклика в сети в секундах. Заметим, что переменная может принимать как положительное, так и отрицательное значение в зависимости от точности часов и накопившейся ошибки смещения.
Дисперсия (peer.dispersion) - число с фиксированной запятой, индицирующее максимальную ошибку часов партнера по отношению к локальным часам с учетом сетевой задержки в секундах. Допускаются только значения больше нуля.
Переменные партнера
Ниже перечислены все переменные партнера, которые используются для управления и реализации измерительных процедур.Бит конфигурации (peer.config) - бит, индицирующий, что ассоциация была сформирована на основе конфигурационной информации и не должна быть расформирована, когда партнер становится недоступен.
Временная метка актуализации (peer.update) - локальное время в формате временной метки, отмечающее момент, когда было получено последнее NTP сообщение. Переменная используется для вычисления дисперсии временного сдвига.
Регистр достижимости (peer.reach) - сдвиговый регистр битов ntp.window, используемых для определения статуса достижимости партнера. Ввод данных производится со стороны младших бит (справа). Партнер считается достижимым, если как минимум один бит этого регистра равен 1.
Таймер партнера (peer.timer) - целочисленный счетчик, используемый для управления интервалом между последовательно посылаемыми NTP-сообщениями. После установки значения счетчика его содержимое уменьшается на 1 (1сек) пока не достигнет нуля. При этом вызывается процедура передачи. Заметим, что работа этого таймера не должна зависеть от локальных часов.
Первичная частота и стандарты времени
Первичными стандартами частоты являются осцилляторы с высокой стабильностью. Такие стандарты используют межуровневые переходы в атомах водорода, цезия и рубидия. В таблице 4.4.15.12 приведены характеристики типичных стандартов времени. Локальные же часы обычно используют некомпенсированные кварцевые генераторы. Такие генераторы не только подвержены дрейфам под действием изменения параметров окружающей среды, но систематически меняют свои свойства со временем (старение).Даже если кварцевый генератор имеет температурную компенсацию, его частота должна время от времени сравниваться первичным стандартом для обеспечения высокой точности.
Сеть, в которой все часы фазированы и согласованы по частоте с единым стандартом, называется изохронной. Сети, где разные часы сфазированы с разными стандартами, но все они привязаны к одной базовой частоте называются плезиохронными. В плезиохронных системах фазы разных осцилляторов могут дрейфовать друг относительно друга, что может приводить к накоплению ошибок.
Обычно часовые осцилляторы классифицируются по трем параметрам: стабильность, разброс и блуждание. Стабильность определяется систематическими вариациями частоты со временем. Синонимом нестабильности является старение и дрейф. Разброс (называемый также временным дрожанием) характеризует кратковременные случайные вариации частоты с составляющими более 10 Гц, в то время как блуждание характеризует медленные вариации частоты с составляющими менее 10 Гц.
Таблица 4.4.15.12. Точность и стабильность часов для различных слоев
| Слой | Минимальная точность (за день) | Минимальная стабильность (за день) |
| 1 | 1 x 10-11 | Не специфицировано |
| 2 | 1.6 x 10-8 | 1 x 10-10 |
| 3 | 4.6 x 10-6 | 3.7 x 10-7 |
| 4 | 3.2 x 10-5 | Не специфицировано |
Конструкция, работа и характеристики осциллятора слоя 1 предполагаются сопоставимыми с национальными стандартами времени и часто базируются на цезиевом стандарте. Часы слоя 4 соответствуют требованиям обычных цифровых каналов и систем PBX. Слои 2-3 могут использоваться для работы с мощными синхронными каналами связи.
Подтверждение
Чтобы запросить подтверждение на свое резервирование, получатель Rj включает в сообщение Resv объект запроса подтверждения, содержащий IP-адрес Rj. В каждой точке объединения только наибольшая из спецификаций flowspec и соответствующий объект запроса подтверждения посылаются далее. Если запрос резервирования от Rj равен или меньше уже существующего резервирования, его Resv не переадресуется последующим узлам, и, если Resv включает в себя запрос подтверждения, отправителю Rj посылается сообщение ResvConf. Если запрос подтверждения переадресуется, это делается немедленно и не более одного раза на каждый запрос.Этот механизм подтверждения имеет следующую последовательность:
Политика в области трафика и узлы с не интегрированными услугами
Некоторые уровни QoS могут требовать определенной политики в управлении трафиком в некоторых или всех перечисленных ниже случаях:RSVP знает, где такие точки находятся, и должен обеспечивать этими данными механизм управления трафиком. С другой стороны, RSVP не интерпретирует информацию в flowspec и, следовательно, не знает, использованы ли рекомендации управления в каждом конкретном случае.
Процесс RSVP передает управлению трафиком специальный флаг политики для каждой из трех указанных выше ситуаций.
Этот флаг устанавливается для первого узла RSVP, который реализует управление трафиком. Например, ЭВМ-отправители должны поддерживать RSVP, но многие из них не поддерживают управление трафиком. В этом случае флаг E_Police_Flag в ЭВМ-отправителе должен быть равен нулю, флаг устанавливается равным 1, когда достигнута первая ЭВМ, поддерживающая управление трафиком. Это контролируется флагом E_Police в объектах SESSION.
Этот флаг должен быть установлен для резервирования, использующего стили WF или SE, когда объединяются потоки более чем одного отправителя.
Этот флаг должен быть установлен, когда инсталлированная flowspec меньше или сравнима с FLOWSPEC какого-либо другого интерфейса для того же самого FILTER_SPEC и SESSION.
RSVP должен также проверять наличие вдоль пути узлов, не поддерживающих RSVP, и переправлять эту информацию управлению трафиком. На основании этого флага и другой сопутствующей информации система контроля трафиком может обнаружить узлы, которые не способны обеспечить управление QoS. Эта информация передается получателям в спецификации Adspecs [RFC 2210].
При обычной IP-переадресации, RSVP может обнаружить узлы без поддержки RSVP путем сравнения значения IP TTL, с которым послано сообщение Path, с полученным TTL. Для этой цели TTL помещается в общий заголовок. Однако, TTL не всегда является надежным индикатором узлов без поддержки RSVP, и для этих целей иногда используются другие средства. Например, если маршрутный протокол использует туннели с IP-инкапсуляцией, этот протокол должен проинформировать RSVP о наличии узлов, лишенных поддержки RSVP. В отсутствии автоматических механизмов осуществляется ручная конфигурация.
Порядок заголовков расширения
Когда используется более одного заголовков расширения в одном пакете, рекомендуется помещать их в следующем порядке:IPv6 заголовок
Заголовок опций hop-by-hop
Заголовок опций места назначения (destination options header, (1) )
Заголовок маршрутизации
Заголовок фрагмента
Заголовок authentication (2)
Заголовок безопасных вложений (encapsulating security payload, (2) )
Заголовок опций места назначения (destination options header (3) )
Заголовок верхнего уровня.
(1) для опций, которые должны обрабатываться по адресу, указанному в поле IPv6 destination address и во всех узлах, перечисленных в заголовке маршрутизации.
(2) дополнительные рекомендации относительно порядка заголовков authentication и encapsulating security payload приведены в RFC-1827.
(3) для опций, которые должны обрабатываться при достижении пакетом конечной точки маршрута.
Каждый заголовок расширения должен встречаться не более одного раза, исключение представляет собой заголовок опций места назначения, который должен быть представлен дважды (один раз перед заголовком маршрутизации и второй раз перед заголовком верхнего уровня).
Если заголовок верхнего уровня представляет собой еще один IPv6 заголовок (в случае туннелирования IPv6 или инкапсуляции в IPv6), за ним может следовать его собственный заголовок расширения.
Узлы IPv6 должны принимать и пытаться обработать заголовки расширения в любом порядке, встречающиеся любое число раз в пределах одного пакета, за исключением заголовка опций типа hop-by-hop, который может появляться только непосредственно за IPv6 заголовком.
Постепенная настройка фазы
Если локальные часы нескорректированы, они продолжают работать со смещением и частотой (при отсутствии дрейфа), установленными при последней коррекции. Корректирующая информация имеет формат 48-битного целого числа со знаком. Это число характеризует целое и дробное число миллисекунд (запятая располагается после 32-го двоичного разряда). Если полученная величина превосходит максимальное значение, заданное CLOCK.MAX, необходима постепенная пошаговая коррекция. В норме величина поправки вычисляется в рамках алгоритма NTP. Однако, если код счетчика PPS больше нуля, вместо него должен использоваться регистр PPS-ADJUST. Пусть u представляет собой 32-битовый код с битами 0-31 равными разрядам 16-47 корректирующего кода. Если некоторые младшие биты корректирующего кода не используются, они устанавливаются равными биту знака. Такие операции сдвигают положение запятой влево по отношению биту 16, что уменьшает влияние ошибок округления. Пусть b число начальных нулей в коде регистра Compliance и пусть c - число начальных нулей в коде счетчика W@atchdog. Тогда b установится равным:b = b - 16 + clock.comp
b не должно быть меньше нуля (это логарифм постоянной времени обратной связи). Затем установим c равным:
c = 10 - c
Величина c представляет собой логарифм времени интегрирования со времени последней коррекции. Затем вычисляются новые значения кодов для регистров CLOCK.ADJUST и Skew-Compensation.
x = u >> b,
y = y + (u >> (b + b - c)).
В заключение вычисляем экспоненциальное среднее
z = z + (u > clock.weight,
где сдвиг влево переносит положения запятой с целью достижения большей точности.
Для каждого периода подстройки определяется корректирующий код из двух составляющих. Первая составляющая (фаза) определяется как
x >> clock.phase,
эта величина затем вычитается из предшествующего значения регистра Clock-Adjust. Результат становится новым значением кода этого регистра. Вторая компонента - (частота) определяется как
y >> clock.freq.
Совокупность фазы и частоты представляет собой окончательный корректирующий код, который затем добавляется к коду регистра (clock). В заключение, счетчик Watchdog обнуляется.
Величина b вычисленная ранее может использоваться для изменения величины системной переменной, характеризующей период запросов (коррекций) sys.poll.
sys.poll
При условии, что шум коррекций велик, частота аппаратного задающего генератора может меняться быстро из-за изменений условий окружающей среды. В этом случае период запросов укорачивается. Когда шум незначителен, задающий генератор стабилен и период запросов растет вплоть до NTP.MAXPOLL секунд.
Посылка сообщений RSVP
Сообщения RSVP посылаются от узла к узлу между RSVP-маршрутизаторами, поддерживающими этот протокол, в виде IP-дейтограмм с кодом протокола 46. IP-дейтограммы предназначены также для использования между оконечными системами и первыми/последними маршрутизаторами.Сообщения Path, PathTear и ResvConf должны посылаться с опцией Router Alert IP [RFC-2113] в их IP-заголовках.
По прибытии RSVP-сообщения M, которое меняет статус, узел должен немедленно послать сообщение о модификации состояния. Однако это не должно привести к посылке сообщения через интерфейс, откуда пришло M (что может случиться, если приложение запустит процедуру обновления состояний для текущей сессии). Это правило предотвращает лавину пакетов в сетях с широковещательной рассылкой.
Каждое RSVP-сообщение должно пересылаться только в одной IP-дейтограмме. Если оно превосходит MTU, такая дейтограмма будет фрагментирована. Восстановление сообщения будет произведено узлом-получателем. Это имеет несколько следствий:
RSVP использует свой механизм периодического обновления для предотвращения влияния случайной потери отдельных пакетов. При перегрузке сети, однако, существенные потери RSVP-сообщений могут вызвать серьезные нарушения при резервировании сетевых ресурсов. Для контроля задержек, связанных с обслуживанием очереди, и влияния потерь RSVP пакетов, маршрутизаторы должны быть сконфигурированы так, чтобы обеспечивать для данных целей приоритетное обслуживание. Если RSVP-пакеты идут через область сети, где вероятность потери значительна, следует увеличить значение таймаутов.
Некоторые мультикастные протоколы маршрутизации обеспечивают туннели, которые организуют IP-инкапсуляцию мультикастных пакетов и их транспортировку через маршрутизаторы, которые не поддерживают мультикастную маршрутизацию. RSVP может работать через такие мультикастные туннели следующим образом:
Предопределенные мультикаст-адреса
Приведенные ниже мультикаст-адреса являются зарезервированными (предопределенными):FF00:0:0:0:0:0:0:0
FF01:0:0:0:0:0:0:0
FF02:0:0:0:0:0:0:0
FF03:0:0:0:0:0:0:0
FF04:0:0:0:0:0:0:0
FF05:0:0:0:0:0:0:0
FF06:0:0:0:0:0:0:0
FF07:0:0:0:0:0:0:0
FF08:0:0:0:0:0:0:0
FF09:0:0:0:0:0:0:0
FF0A:0:0:0:0:0:0:0
FF0B:0:0:0:0:0:0:0
FF0C:0:0:0:0:0:0:0
FF0D:0:0:0:0:0:0:0
FF0E:0:0:0:0:0:0:0
FF0F:0:0:0:0:0:0:0
Перечисленные выше мультикаст-адреса зарезервированы и не будут присваиваться каким-либо мультикаст-группам.
Адреса для обращения ко всем узлам:
FF01:0:0:0:0:0:0:1
FF02:0:0:0:0:0:0:1
Приведенные выше адреса идентифицируют группу, включающую в себя все IPv6 узлы в пределах группы 1 (локальные узлы) или 2 (локально связанные узлы).
Адреса всех маршрутизаторов:
FF01:0:0:0:0:0:0:2
FF02:0:0:0:0:0:0:2
Приведенные выше мультикаст-адреса идентифицируют группу всех IPv6 маршрутизаторов в пределах области 1 (локальные узлы) или 2 (связанные локально узлы).
DHCP server/relay-agent: FF02:0:0:0:0:0:0:C
Приведенные выше мультикастинг-адреса идентифицируют группу всех IPv6 DHCP серверов и транзитных агентов в пределах области (scope) 2 (локальный канал).
Адрес активного узла (solicited-node): FF02:0:0:0:0:1:xxxx:xxxx
Приведенный выше мультикаст-адрес вычислен как функция уникастного и эникастного адресов узла. Мультикаст-адрес активного узла (solicited-node) сформирован из младших 32 бит адреса (уникастного или эникастного) добавлением 96 битного префикса FF02:0:0:0:0:1. В результате получен мультикастинг адрес, охватывающий интервал:
FF02:0:0:0:0:1:0000:0000
до
FF02:0:0:0:0:1:FFFF:FFFF
Например, код мультикаст-адреса активного узла (solicited node), соответствующий IPv6 адресу 4037::01:800:200E:8C6C, равен FF02::1:200E:8C6C. IPv6 адреса, которые отличаются только старшими разрядами, например, из-за множественных старших префиксов, соответствующих разным провайдерам, будут совпадать с адресом активного узла, что сокращает число мультикаст-групп, к которым узел должен присоединиться.
Прерывание сессии
Прерывание сессии может быть инициировано LAC или LNS и выполняется путем посылки управляющего сообщения CDN. После того как последняя сессия прервана, управляющее соединение может быть также разорвано. Ниже приводится типовой обмен управляющими сообщениями:LAC или LNS LAC или LNS
CDN ->
(Clean up)
| <- ZLB ACK | |
| (Clean up) |
к последней минуте текущего дня.
Формат NTP-сообщения, которое следует сразу после UDP-заголовка, показан на рис 4.4.15.1.Индикатор добавления (LI - leap indicator) - двухбитовое поле предупреждения о предстоящем добавлении/вычитании секунды к последней минуте текущего дня. Значения этих битов смотри в таблице 4.4.15.1.

Рис. 4.4.15.1. Формат сообщения NTP.
Номер версии (VN) - трехбитовое поле, указывающее на номер версии протокола NTP, в настоящее время (3).
Режим (Mode) - трехбитовое поле, определяющее режим, значения кодов режима приведены в таблице 4.4.15.2.
Слой (Stratum) - 8-битовое поле, определяющее код слоя, где работают локальные часы. Коды слоя представлены в таблице 4.4.15.3. Возможные значения кодов лежат в интервале от нуля до NTP.INFIN включительно.
Период запросов (poll interval) - 8-битовое поле, указывающее на максимальное значение интервала между запросами. Код, записанный в этом поле, интерпретируется как целое число со знаком и характеризует значение периода в секундах, как ближайшее к величине степени двух. Коды, которые могут быть записаны в этом поле, должны лежать в интервале между NTP.MAXPOLL и NTP.MAXPOLL включительно.
Точность (precision) - 8-битовое поле, обозначающее точность локальных часов в секундах. Код поля интерпретируется как целая степень со знаком числа 2.
Базовая задержка (Root Delay) - 32-битовое поле, характеризующее RTT до эталонного источника в секундах. Код поля интерпретируется как число с фиксированной запятой, размещенной между битами 15 и 16. Заметим, что величина этого кода может иметь и отрицательное значение (зависит от точности часов и величины дрейфа).
Базовая дисперсия (Root Dispersion) - 32-битовое поле, определяющее максимальную ошибку по отношению к эталонному источнику в секундах. Код поля интерпретируется как число с фиксированной запятой (между 15 и 16 битами). Допустимы только положительные значения.
Идентификатор эталонных часов (Reference Clock Identifier) - 32-битовое поле, идентифицирующее конкретные эталонные часы. В случае кода слоя нуль (не специфицировано) или слоя 1 (первичный эталон), это 4-октетная комбинация выравнивается по левому краю и дополняется нулями (ASCII).
Когда идентификатор в NTP не специфицирован, предлагаются ascii- идентификаторы, приведенные в таблице 4.4.15.4.
В случае слоя 2 и больше (вторичный эталон) - это 4-октетный IP-адрес ЭВМ - первичного эталона.
Эталонная временная метка (Reference Timestamp) - поле локального времени (64-битовый формат временных меток), когда часы корректировались в последний раз.
Исходная временная метка (Originate Timestamp) определяет время, когда запрос направлен серверу (стандартный 64-битовый формат временных меток).
Получаемая временная метка (Receive Timestamp) - время, когда запрос прибыл к серверу (стандартный 64-битовый формат временных меток).
Передаваемая временная метка (Transmit Timestamp) - локальное время, когда послан отклик сервером (стандартный 64-битовый формат временных меток).
Аутентификатор (authenticator) (опционно) - поле, содержащее аутентификационную информацию. Используется лишь в случае реализации NTP-аутентификации.
A Определения объектов
C-типы определены для двух семейств адресов Интернет IPv4 и IPv6. Для работы с другими адресными семействами можно легко определить новый C-тип. Все неиспользуемые поля должны заполняться нулями и игнорироваться при получении .Класс сессии
Класс сессии = 1.

Объект IPv6/UDP SESSION: Класс = 1, C-тип = 2

DestAddress
Уникастный или мультикастный IP-адрес места назначения сессии. Это поле не должно быть равно нулю.
Протокол Id
Идентификатор IP-протокола для потока данных. Это поле не должно быть равно нулю.
Флаги
0x01 = E_Police flag
Флаг E_Police используется в сообщениях Path для определения эффективного “края” сети, с целью организации управления трафиком. Если ЭВМ отправитель сама не способна осуществлять управление трафиком, она установит этот бит в сообщениях Path, которые посылает. Первый узел, где RSVP имеется возможность управления трафиком (если это требуется), установит этот флаг равным нулю.
DstPort
UDP/TCP порт места назначения сессии. Допустимо значение нуль, означающее отсутствие порта.
Класс RSVP_HOP
RSVP_HOP класс = 3.

Объект IPv4 RSVP_HOP: Класс = 3, C-Тип = 1

Объект IPv6 RSVP_HOP: Класс = 3, C-Тип = 2
Этот объект несет в себе IP-адрес интерфейса, через который последний RSVP-узел переслал это сообщение. Дескриптор логического интерфейса LIH (Logical Interface Handle) используется, для того чтобы различать логические выходные интерфейсы. Узел, получая LIH в сообщении Path, запоминает его величину и возвращает его в объектах HOP последующих сообщений Resv, посланных узлу, который сформировал LIH. LIH должен быть тождественно равен нулю, если не существует дескриптора логического интерфейса.
Класс INTEGRITY
INTEGRITY класс = 4.
Класс TIME_VALUES
TIME_VALUES класс = 5.
Период обновления
Период таймаута обновления R, использованного для генерации этого сообщения (в миллисекундах).
Класс ERROR_SPEC
ERROR_SPEC класс = 6.


Поле адрес узла, где произошла ошибка является IP-адресом (IPv4 или Ipv6).
Флаги
0x01 = InPlace
Это значение поля флаги используется только для объектов ERROR_SPEC в сообщении ResvErr. Если флаг = 1, это указывает, что в узле, где произошла ошибка, установлено резервирование.
0x02 = NotGuilty
Это значение поля флаги используется только для объекта ERROR_SPEC в сообщении ResvErr. Это значение устанавливается для интерфейса в прикладной программе получателя. Если флаг имеет такой код, спецификация FLOWSPEC, которая вызвала ошибку, больше запрошенной получателем.
Код ошибки.Одно-октетное поле кода описания ошибки.
Значение ошибки
Двухоктетное поле, содержащее дополнительную информацию об ошибке. Его содержимое зависит от типа ошибки. Значения поля код ошибки и значение ошибки приведены в приложении B (см. ниже).
Класс SCOPE = 7.

Этот объект содержит список IP-адресов, использованных для сообщений маршрутизации с произвольным выбором отправителей (wildcard) без петель. Адреса должны быть перечислены в возрастающем порядке.
Объект Ipv6 SCOPE: Класс = 7, C-тип = 2
Объект имеет ту же структуру, что и предыдущий, только для каждого адреса выделяется 16 байт.
Класс STYLE = 8.

Поле Флаги: 8 бит. (Пока не определены)
Вектор опций: 24 бита
Этот набор битовых полей определяет опции резервирования. Если в будущем будут добавлены новые опции, нужно будет ввести соответствующие поля в вектор опций со стороны младших разрядов. Если узел не распознает идентификатор стиля, он может интерпретировать ту часть вектора опций, которая ему известна, игнорируя новые незнакомые ему поля. Биты вектора опций определены (слева направо) следующим образом:
19 бит: Зарезервировано
2 бита: контроль совместного использования
00b: Зарезервировано
01b: Явное резервирование
10b: Распределенное резервирование
11b: Зарезервировано
3 бита: Управление выбором отправителя
000b: Зарезервировано
001b: Произвольный выбор (Wildcard)
010b: Прямой выбор (Explicit)
011b - 111b: Зарезервировано
Младшие биты вектора опций определяются стилем:
WF 10001b
FF 01010b
SE 10010b
Класс FLOWSPEC
Класс FLOWSPEC = 9.
Содержимое и правила кодирования этого объекта описаны в документах, подготовленных рабочей группой int-serv [RFC 2210].
Класс FILTER_SPEC = 10.

Объект IPv6 FILTER_SPEC: Класс = 10, C-тип = 2
Объект имеет ту же структуру, что и предыдущий, только для каждого адреса выделяется 16 байт.

SrcAddress. Это поле характеризует IP-адрес источника для ЭВМ отправителя. Его значение не должно быть равно нулю.
SrcPort. UDP/TCP номер порта отправителя, или нуль, указывающий на отсутствие порта.
Метка потока. 24-битовое поле метки потока, определенной в IPv6. Этот код может использоваться классификатором пакетов для эффективной идентификации кадров, принадлежащих определенному потоку данных (отправитель-> место назначения).
Класс SENDER_TEMPLATE = 11.
Определение то же, что и для объекта IPv4/UDP FILTER_SPEC.
Определение то же, что и для объекта IPv6/UDP FILTER_SPEC.
Класс SENDER_TSPEC = 12.
Содержимое и правила кодирования для этого объекта специфицированы в документах, подготовленных рабочей группой int-serv.
Класс ADSPEC = 13.
Содержимое и формат этого объекта специфицированы в документах, подготовленных рабочей группой int-serv.
Класс POLICY_DATA = 14.
Содержимое этого объекта будет определено в будущем.
Класс Resv_CONFIRM = 15.
Объект характеризует 4-байтовый IP-адрес получателя (Ipv4).
Объект характеризует 15-байтовый IP-адрес получателя (Ipv6).
a Рекомендации по формированию опций
Это приложение дает некоторые советы, как выкладывать поля, при формировании новых опций, предназначенных для использования в заголовке опций hop-by-hop или в заголовке опций места назначения. Эти рекомендации базируются на следующих предположениях:Эти предположения определяют следующий подход к выкладке полей опций: порядок опций от коротких к длинным без внутреннего заполнения. Требования выравнивания границ для всей опции определяется требованием выравнивания наиболее длинного поля (до 8 октетов). Этот подход иллюстрируется на следующих примерах:
Пример 1
Если опция x требует двух полей данных, одно длиной 8 октетов, а другое длиной 4 октета, ее формат будет иметь вид (рис. 4.4.1.1.27):

Рис. 4.4.1.1.27.
Требование выравнивания соответствует 8n+2, для того чтобы гарантировать начало 8-октетного поля со смещением, кратным 8, от начала последнего заголовка. Полный заголовок (hop-by-hop или destination options), содержащий одну из этих опций будет иметь формат (рис. 4.4.1.1.28):

Рис. 4.4.1.1.28
Пример 2
Если опция y требует трех полей данных, одно длиной 4 октета, одно - 2 октета и одно - длиной один октет, она будет уложена следующим образом (рис. 4.4.1.1.29):

Рис. 4.4.1.1.29
Требование выравнивания выглядит как 4n+3, и призвано гарантировать, что 4-октетное поле начнется со смещением кратным 4 по отношению к началу завершающего заголовка. Полный заголовок (hop-by-hop или destination options), содержащий одну из указанных опций будет иметь вид (рис. 4.4.1.1.30):

Рис. 4.4.1.1.30
Пример 3
Заголовок с опциями hop-by-hop или destination options, содержащий обе опции x и y из примеров 1 и 2, будет иметь один из приведенных ниже форматов, в зависимости от того, какая из опций встречается первой (рис. 4.4.1.1.31, 4.4.1.1.32):

Рис. 4.4.1.1.31

Рис. 4.4.1.1.32
B Коды и значения ошибки
Нижеприведенные коды ошибок могут встретиться в объектах ERROR_SPEC, и предназначены для пересылки оконечным системам. За исключением специально оговоренных случаев эти коды могут использоваться только в сообщениях ResvErr.Это код зарезервирован для использования в объекте ERROR_SPEC сообщения ResvConf. Значение ошибки также будет равно нулю.
Запрос резервирования отвергнут системой управления допуском из-за недостатка ресурсов. Для этого кода ошибки 16 бит поля значение ошибки имеют формат:
ssur cccc cccc cccc
где биты имеют следующие значения:
ss = 00: Младшие 12 бит содержат глобально-определенный субкод (значение приведены ниже).
ss = 10: Младшие 12 бит содержат организационно-специфический субкод. Предполагается, что RSVP интерпретирует этот код как обычное число.
ss = 11: Младшие 12 бит содержат субкод, зависящий от вида услуг. Предполагается, что RSVP интерпретирует этот код как обычное число.
Так как механизм управления трафиком может предлагать различные услуги, кодирование может включать в себя некоторые особенности используемой услуги.
u = 0: RSVP отвергает сообщение без модификации локального состояния
u = 1: RSVP может использовать сообщение для модификации локального состояния и для последующей пересылки. Это означает, что сообщение является информационным.
r: зарезервированный бит, должен быть равен нулю.
cccc cccc cccc: 12 битовый код.
Следующие глобально-заданные субкоды могут появиться в младших 12 битах, когда ssur = 0000:
- Субкод = 1: Предел (bound) по задержке не может быть обеспечен.
- Субкод = 2: Запрашиваемая полоса пропускания недоступна.
- Субкод = 3: MTU в flowspec больше чем MTU интерфейса.
Сообщение резервирования или path было отвергнуто по административным причинам, например, не выполнены условия аутентификации, недостаточная квота и т.д.. Этот код ошибки может появиться в сообщении PathErr или ResvErr.
Содержимое поля значение ошибки должно быть определено в будущем.
Для этого кода ошибки 16 бит поля значения ошибки имеют формат:
ssur cccc cccc cccc
Ниже приведены значения старших бит ssur, как они определены при коде ошибки 01. Глобально-заданные субкоды, которые могут появиться в младших 12 битах, когда ssur = 0000 должны быть определены в будущем.
Этот код ошибки может появиться в сообщении PathErr или ResvErr.
Для этого кода ошибки 16 бит поля значения ошибки имеют формат:
ss00 cccc cccc cccc
Ниже представлены значения старших бит ss, как это определено для кода ошибки 01.
Следующие глобально-заданные субкоды могут появляться в младших 12 битах (cccc cccc cccc), когда ss = 00:
Поле значения ошибки предоставляет информацию об ошибке с учетом конкретной реализации приложения. Предполагается, что RSVP не может интерпретировать его значение.
Вообще каждое сообщение RSVP переформируется в каждом узле, а узел, в котором генерируется RSVP сообщение, несет ответственность за его правильную структуру.
Аналогично, каждый узел должен контролировать корректность структуры полученного им сообщения. В случае, когда из-за ошибки программы будет генерировано сообщение с некорректным форматом, оконечная система не обязательно будет проинформирована об этом. Ошибка, скорее всего, будет зафиксирована локально и передана через механизмы управления сетью.
Единственными ошибками формата сообщений, которые доводятся до сведения оконечной системы, являются несоответствия версии.
Ошибки формата сообщения, которые могут быть зафиксированы локально и сообщены приложению RSVP, относятся к числу специфических для данной реализации. Наиболее типичными из них можно считать следующие:
B: Примеры управляющих сообщений B Установление туннеля Lock-step
В этом примере, LAC формирует туннель, при этом реализуется обмен сообщениями в обоих направлениях. В этом примере показано, что окончательное подтверждение посылается в сообщении ZLB ACK. Альтернативой может быть подтверждение, пришедшее в сообщении, посланном в ответ на ICRQ или OCRQ, которые направляются стороной, инициировавшей формирование туннеля.LAC или LNSLNS или LAC
SCCRQ ->
Nr: 0, Ns: 0
| Nr: 1, Ns: 0 |
SCCCN ->
Nr: 1, Ns: 1
| Nr: 2, Ns: 1 |
Б Сообщения управления NTP
В сетевой среде должны быть средства управления программами NTP, такие как установка индикатора добавления секунды (Leap-Indicator) со стороны первичного сервера, настройка различных системных параметров и процедур мониторинга. Такие операции могут быть реализованы с привлечением протокола snmp и соответствующего расширения базы данных MIB. Однако в тех случаях, когда такие средства недоступны, эти функции могут быть реализованы с помощью специальных управляющих NTP-сообщений.Управляющие сообщения NTP имеют код 6 в поле режима первого октета NTP-заголовка. Формат поля данных специфичен для каждой из команд или отклика. Однако, в большинстве случаев формат конструируется так, чтобы облегчить его непосредственное чтение. Как правило, он состоит из ASCII-строк. Если используется аутентификатор, поле данных дополняется нулями до границы, кратной целому числу 32-битных слов.
IP-ЭВМ не должны обрабатывать дейтограммы длиннее 576 октетов; однако, некоторые команды или отклики могут содержать данные, непомещающиеся в одну дейтограмму. Для решения данной проблемы все октеты сообщения нумеруются, начиная с нуля. При передаче фрагментов сообщения номер первого октета записывается в поле смещения (offset), а число октетов в поле длины. Бит (M - more) устанавливается во всех фрагментах за исключением последнего.
Большинство контрольных функций включает посылку команды и получение отклика. Отправитель выбирает ненулевой порядковый номер и устанавливает статусное поле и биты R и E равными нулю. Получатель интерпретирует код операции и дополнительную информацию, содержащуюся в поле данных, вносит изменение в поле статуса и устанавливает бит R=1, а также возвращает три 32-битного слова заголовка вместе с другой дополнительной информацией поля данных. В случае неверного формата сообщения или ошибки в поле данных получатель заносит соответствующий код в поле статуса, устанавливает биты R и E равными 1, и опционно записывает диагностическое сообщение в поле данных.
Некоторые команды осуществляют чтение или запись для системных переменных и переменных партнеров для ассоциации, идентифицированной в команде. Другие читают или записывают значения переменных, связанных с радио-часами и другими приборами, имеющими непосредственное отношение к эталонам времени. Для определения ассоциации используется ее 16-битовый идентификатор. Для системных переменных используется идентификатор нуль. Управляющий объект может затребовать текущий список идентификаторов с тем, чтобы их использовать в дальнейшем. При попытке употребить уже недействительный идентификатор будет прислан соответствующий отклик, после чего необходимо запросить список идентификаторов еще раз.
Некоторые события, такие как изменение статуса доступа к партнеру, не сопряжены с какими-либо командами и происходят асинхронно. Программа может запоминать информацию о таких событиях и пересылать ее в откликах. Текущий статус и краткая аннотация чрезвычайных событий пересылаются каждым откликом. Биты в статусном поле указывают на то, произошло ли какое-либо событие с момента предыдущего отклика и было ли их больше одного.
C UDP-инкапсуляция
Реализации RSVP обычно требуют возможности выполнять любые сетевые операции ввода/вывода, т.е., посылать и получать IP-дейтограммы, используя код протокола 46. Однако, некоторые важные классы вычислительных систем могут не поддерживать такого рода операции. Для использования RSVP, такие ЭВМ должны инкапсулировать сообщения RSVP в UDP-дейтограммы.Базовая схема UDP-инкапсуляции использует два предположения:
Пусть Hu является ЭВМ, которая нуждается в UDP-инкапсуляции, а Hr ЭВМ, способная выполнять любые сетевые операции ввода/вывода. Схема UDP-инкапсуляции должна допускать RSVP взаимодействие ЭВМ типа Hr, Hu и маршрутизаторов.
Сообщения Resv, ResvErr, ResvTear и PathErr посылаются по уникастным адресам, полученным из состояний прохода или резервирования узла. Если узел отслеживает, в каком из предыдущих узлов и в каком интерфейсе нужна UDP-инкапсуляция, эти сообщения при необходимости могут быть посланы с применением UDP инкапсуляции. С другой стороны, сообщения Path и PathTear могут посылаться адресату с применением как мультикастных, так и уникастных адресов.
В таблицах 4.4.9.6.1 и 4.4.9.6.2 приведены базовые правила UDP-инкапсуляции сообщений Path и PathTear, для уникастных и мультикастных DestAddress. Другие типы сообщений, которые работают с уникастными адресами, должны следовать правилам из табл. 4.4.9.6.1. Записи в колонке `RSVP посылает' имеют формат `mode(destaddr, destport)'.
Полезно определить две разновидности UDP-инкапсуляций, одна используется для посылки сообщений от Hu, другая от Hr и R. Это делается, для того чтобы избежать двойной обработки сообщения получателем. На практике эти два вида инкапсуляций разделяются по номерам UDP портов Pu и Pu'.
В таблицах используются следующие символы.
Таблица 4.4.9.6.1. Правила UDP- инкапсуляции для уникастных сообщений Path и Resv
(D - уникастный адрес места назначения; R - маршрутизатор; Raw - режим произвольных операций сетевого ввода/вывода.)
| Узел | RSVP посылает | RSVP получает |
| Hu | UDP(D/Ra,Pu) [1] | UDP(D,Pu) и UDP(D,Pu’) [2] |
| Hr | Raw(D) и, если (UDP), тогда UDP(D, Pu’) |
RAW() и UDP(D, Pu) [2] (игнорировать Pu’) |
| R (интерфейс а) | Raw(D) и, если (UDP), тогда UDP(D, Pu’) |
RAW() и UDP(Ra, Pu) (игнорировать Pu’) |
| [1] | Hu посылает уникастные сообщения Path либо по адресу D, если D является локальным, либо по адресу Ra маршрутизатора первого узла. Ra предполагается известным. |
| [2] | Здесь D является адресом локального интерфейса, через который приходит сообщение. |
| [3] | Это предполагает, что приложение присоединилось к группе D. |
| Узел | RSVP посылает | RSVP получает |
| Hu | UDP(G*,Pu) | UDP(D,Pu’) [3] и UDP(G*,Pu) |
| Hr | Raw(D,Tr) и, если (UDP), тогда UDP(D, Pu’) |
RAW() и UDP(G*, Pu) (игнорировать Pu’) |
| R (интерфейс а) | Raw(D,Tr) и, если (UDP), тогда UDP(D, Pu’) |
RAW() и UDP(G*, Pu) (игнорировать Pu’) |
Когда получен UDP-инкапсулированный пакет, в большинстве систем TTL не доступно для приложения.
Процесс RSVP, который получает UDP- инкапсулированное сообщение Path или PathTear должен использовать поле Send_TTL общего RSVP-заголовка для извлечения значения TTL. В тех случаях, когда это по каким-либо причинам не приемлемо, значение TTL может быть задано вручную при конфигурации.
Мы предположили, что первый маршрутизатор, поддерживающий RSVP, подключен непосредственно к локальной сети. Существует несколько подходов в случае, когда это не так.
Г Временная шкала NTP и ее хронометрия
Ниже рассматривается соответствие временной шкалы NTP и UTC (Coordinated Universal Time). Синхронизация часов предполагает их согласование по частоте и времени.Для синхронизации необходимо уметь сравнить их частоты и показания. Базовыми источниками временных стандартов традиционно являлись периоды движения Земли, Луны и других космических объектов. К сожалению, они не слишком стабильны.
В Аутентификация
Требования надежности NTP подобны аналогичным для других протоколов, работающих с большим числом партнеров и служащих для маршрутизации, управления и доступа к файлам. Система должна противостоять случайным ошибкам и злонамеренным действиям.Механизм управления доступом в NTP отвечает всем базовым требованиям. Различные проверки препятствуют большинству возможных атак, связанных с подменой временных меток.
Однако имеется возможность того, что хакер нарушит процедуру синхронизации путем модификации NTP-сообщений. Для подавления такой возможности нужно привлекать криптографические механизмы аутентификации (в частности сертификаты).
Механизм, который работает на прикладном уровне, служит для того, чтобы исключить неавторизованную модификацию потока сообщений. Это достигается с помощью контрольных крипто-сумм, вычисляемых отправителем и проверяемых получателем. Однако сам протокол NTP не имеет средств для работы с сертификатами и ключами.
Процедура вычисления контрольной крипто-суммы использует алгоритм DES (Data Encryption Standard) [NBS77].
Последующее является записью для соединения
Последующее является записью для соединения IMAP 4.1. (Данный пример и нижеприведенное описание синтаксиса практически без изменения взято из документа RFC-2060).S: * OK IMAP4rev1 Service Ready
C: a001 login mrc secret
S: a001 OK LOGIN completed
C: a002 select inbox
S: * 18 EXISTS
S: * FLAGS (\Answered \Flagged \Deleted \Seen \Draft)
S: * 2 RECENT
S: * OK [UNSEEN 17] Message 17 is the first unseen message
S: * OK [UIDVALIDITY 3857529045] UIDs valid
S: a002 OK [READ-WRITE] SELECT completed
C: a003 fetch 12 full
S: * 12 FETCH (FLAGS (\Seen) INTERNALDATE "17-Jul-1996 02:44:25 -0700"
RFC822.SIZE 4286 ENVELOPE ("Wed, 17 Jul 1996 02:23:25 -0700 (PDT)"
"IMAP4rev1 WG mtg summary and minutes"
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
((NIL NIL "imap" "cac.washington.edu"))
((NIL NIL "minutes" "CNRI.Reston.VA.US")
("John Klensin" NIL "KLENSIN" "INFOODS.MIT.EDU")) NIL NIL
"")
BODY ("TEXT" "PLAIN" ("CHARSET" "US-ASCII") NIL NIL "7BIT" 3028 92))
S: a003 OK FETCH completed
C: a004 fetch 12 body[header]
S: * 12 FETCH (BODY[HEADER] {350}
S: Date: Wed, 17 Jul 1996 02:23:25 -0700 (PDT)
S: From: Terry Gray gray@cac.washington.edu
S: Subject: IMAP4rev1 WG mtg summary and minutes
S: To: imap@cac.washington.edu
S: cc: minutes@CNRI.Reston.VA.US, John Klensin KLENSIN@INFOODS.MIT.EDU
S: Message-Id: B27397-0100000@cac.washington.edu
S: MIME-Version: 1.0
S: Content-Type: TEXT/PLAIN; CHARSET=US-ASCII
S:
S: )
S: a004 OK FETCH completed
C: a005 store 12 +flags \deleted
S: * 12 FETCH (FLAGS (\Seen \Deleted))
S: a005 OK +FLAGS completed
C: a006 logout
S: * BYE IMAP4rev1 server terminating connection
S: a006 OK LOGOUT completed
Примеры уникастных адресов
Примером уникастного адресного формата, который является стандартным для локальных сетей и других случаев, где применимы MAC адреса, может служить:
Рис. 4.4.1.1.3
Где 48-битовый идентификатор интерфейса представляет собой IEEE-802 MAC адрес. Использование IEEE 802 mac адресов в качестве идентификаторов интерфейсов будет стандартным в среде, где узлы имеют IEEE 802 MAC адреса. В других средах, где IEEE 802 MAC адреса не доступны, могут использоваться другие типы адресов связного уровня, такие как E.164 адреса, в качестве идентификаторов интерфейсов.
Включение уникального глобального идентификатора интерфейса, такого как IEEE MAC адрес, делает возможным очень простую форму авто-конфигурации адресов. Узел может узнать идентификатор субсети, получая информацию от маршрутизатора в виде сообщений оповещения, которые маршрутизатор посылает связанным с ним партнерам, и затем сформировать IPv6 адрес для себя, используя IEEE MAC адрес в качестве идентификатора интерфейса для данной субсети.
Другой формат уникастного адреса относится к случаю, когда локальная сеть или организация нуждаются в дополнительных уровнях иерархии. В этом примере идентификатор субсети делится на идентификатор области и идентификатор субсети. Формат такого адреса имеет вид:

Рис. 4.4.1.1.4
Эта схема может быть развита с тем, чтобы позволить локальной сети или организации добавлять новые уровни внутренней иерархии. Может быть, желательно использовать идентификатор интерфейса меньше чем 48-разрядный IEEE 802 MAC адрес, с тем, чтобы оставить больше места для полей, характеризующих уровни иерархии. Это могут быть идентификаторы интерфейсов, сформированные администрацией локальной сети или организации.
Приоритет
4-битовое поле приоритета в IPv6 заголовке позволяет отправителю идентифицировать относительный приоритет доставки пакетов. Значения приоритетов делятся на два диапазона. Коды от 0 до 7 используются для задания приоритета трафика, для которого отправитель осуществляет контроль перегрузки (например, снижает поток TCP в ответ на сигнал перегрузки). Значения с 8 до 15 используются для определения приоритета трафика, для которого не производится снижения потока в ответ на сигнал перегрузки, например, в случае пакетов “реального времени”, посылаемых с постоянной частотой.Для трафика, управляемого сигналами перегрузки, рекомендуются следующие значения приоритета для конкретных категорий приложений (см. таблицу 4.4.1.1.2).
Таблица 4.4.1.1.2. Значения кодов приоритета
| Код приоритета | Назначение |
| 0 | Нехарактеризованный трафик |
| 1 | Заполняющий трафик (например, сетевые новости) |
| 2 | Несущественный информационный трафик (например, электронная почта) |
| 3 | Резерв |
| 4 | Существенный трафик (напр., FTP, HTTP, NFS) |
| 5 | Резерв |
| 6 | Интерактивный трафик (напр. telnet, x) |
| 7 | Управляющий трафик Интернет (напр., маршрутные протоколы, snmp) |
Предполагается, что чем больше код, тем выше приоритет данных, тем быстрее они должны быть доставлены. Так для передачи мультимедийной информации, где управление скоростью передачи не возможно, уровень приоритета должен лежать в пределах 8-15. Практически, уровни приоритета выше или равные 8 зарезервированы для передачи данных в реальном масштабе времени.
Для трафика, не контролируемого на перегрузки, нижнее значение приоритета (8) должно использоваться для тех пакетов, которые отправитель разрешает выбросить в случае перегрузки (например, видео трафик высокого качества), а высшее значение (15) следует использовать для пакетов, которые отправитель не хотел бы потерять (напр., аудио трафик с низкой надежностью). Не существует связи между относительными приоритетами обменов с и без контроля перегрузки.
Процедура часовой фильтр (clock-filter)
Процедура часовой фильтр исполняется по прибытии сообщения NTP или другого события, в результате которого получены новые данные. Она использует аргументы (q, d, e), где q - результат измерения смещения часов, содержащийся в записи, а d и e соответственно RTT и дисперсия. Процедура определяет значение отфильтрованного смещения часов (filtered clock offset - peer.offset), RTT (peer.delay) и дисперсии (peer.dispersion). Она также корректирует дисперсию хранящихся записей и текущее показание часов (peer.update).Процедура часового фильтра использует сдвиговый регистр (peer.filter), который состоит из NTP.SHIFT каскадов, каждый каскад содержит значения qi, di и e i, которые пронумерованы, начиная с нуля, слева направо. Фильтр инициализируется процедурой очистки при этом заносятся значения [0, 0, NTP.MAXDISPERSE] во всех каскадах. Новые данные записей вдвигаются в фильтр с левого конца. Пакетная процедура выдает записи в формате (q ,d, e), когда приходят новые корректирующие данные, в то время как процедура передачи выдает записи в форме [0, 0, NTP.MAXDISPERSE], когда истекает два периода запроса без поступления свежих данных. Когда одни и те же символы (q, d, e) используютсядля аргументов, содержимого часового фильтра и переменных партнера, их значения обычно понятно из контекста. Ниже представлена псевдопрограмма, поясняющая работу данной процедуры.
begin clock-filter procedure (q, d, e)
Дисперсия ei для всех корректных записей в регистре фильтра должна корректироваться с тем, чтобы отражать накопление смещения со времени последней коррекции. Эти записи заносятся также во временный список, следуя стандартному формату записей [расстояние, индекс]. Записи в регистре сдвигаются вправо, новые записи вводятся слева, а самая правая запись теряется. Временный список сортируется по значению расстояния. Если в списке не остается записей, процедура прерывается без корректировки переменных партнера.
| for (i from ntp.size 1 to 1) begin | /* коррекция дисперсии */ |
[qi, di, ei] q{i-1}, d{i-1}, e{i-1}];
/* shift stage right */
ei = ei + ft;
add [li ? ei + {|di|}/2, i] to temporary list;
endfor;
| [q0, d0, e0] q, d, e]; | /* ввести новую запись */ |
| peer.update | /* сбросить показание часов */ |
где [distance index] представляет собой объединение полей расстояния и индекса (расстояние занимает старшую позицию). Дисперсия фильтра es вычисляется и включается в дисперсию партнера. Заметим, что временный список для этой цели уже упорядочен.
es
| for (i from ntp.shift-1 to 0) | /* вычисление дисперсии фильтра */ |
- q0 > NTP.MAXDISPERSE)
es es + NTP.MAXDISPERSE) * NTP.FILTER;
else
es es + |qi
- q0|) * NTP.FILTER;
Смещение партнера q0, задержка d0 и дисперсия e0 выбираются как величины, соответствующие записи с минимальным расстоянием; другими словами, записи, соответствующей первому элементу временного списка (в данной нотации имеет индекс 0).
| peer.offset q0; | /* корректировка переменных партнера */ |
peer.dispersion e0 + es, NTP.MAXDISPERSE);
end clock-filter procedure
Переменные peer.offset и peer.delay представляют смещение шкалы часов и RTT для локальных часов, измеренные относительно часов партнера. Обе они усредняются по большому числу измерений в течение длительного периода времени. Переменная peer.dispersion характеризует максимальную ошибку из-за неточности измерений, дрейфа и вариации записей. Все три переменные используются при выборе часов для синхронизации.
Процедура initialization-instantiation
Эта процедура является аппаратно-зависимой и служит, среди прочего, для формирования ассоциации. Адреса и режимы работы партнеров определяются в процессе чтения при перезагрузке или в результате обработки команд оператора. В случае привлечения механизма аутентификации только аутентифицированный партнер может стать источником синхронизации.begin initialization-instantiation procedure
peer.config
#ifdef (authentication implemented)
peer.authenable
peer.authentic
peer.hostkeyid
peer.peerkeyid
#endef;
| peer.peeraddr | /* копирование переменных */ |
peer.peerport
peer.hostaddr
peer.hostport
peer.mode
peer.peerpoll
peer.timer
peer.delay
peer.offset
| call clear; | /* инициализация ассоциации */ |
end initialization-instantiation procedure;
Процедура коррекции показаний часов
Процедура коррекции показания часов вызывается процедурой приема, когда процедура фильтрации определила корректные значения смещения задержки и дисперсии для данного партнера.begin clock-update procedure
| call clock-select; | /* Выбор базовых часов */ |
if (sys.peer ? peer) exit;
Может так случиться, что локальные часы оказались сброшены. В этом случае вызывается процедура очистки (clear procedure) для каждого из партнеров, чтобы возвратить в исходное состояние фильтр часов, период рассылки и, если необходимо, осуществить выбор нового источника синхронизации.
Процедура расстояния вычисляет базовую (root) задержку d, базовую дисперсию e и базовое расстояние синхронизации l. ЭВМ не будет синхронизовать выбранного партнера, если расстояние больше чем ntp.maxdistance.
| l andistance(peer); | /* обновление системных переменных */ |
if (l ? ntp.maxdistance) exit;
sys.leap
sys.stratum
sys.refid
call local-clock;
| if (local clock reset) begin | /* если сброс, очистить системные переменные */ |
sys.leap 2;
for (all peers) call clear;
endif
else begin
| sys.peer | /* если нет, то подстроить локальные часы */ |
sys.rootdelay d;
sys.rootdispersion e + max (ex
+ |t|, ntp.mindisperse);
endif
sys.reftime
end clock-update procedure;
В некоторых конфигурациях системы прецизионный источник временной информации доступен в виде последовательности синхронизующих импульсов, следующих с периодом в одну секунду. Обычно это является дополнением к базовому источнику времязадающей информации, такому как радио-часы или даже сам протокол NTP, для того чтобы обеспечить подсчет секунд, минут, часов и дней. В этих конфигурациях системные переменные устанавливаются с учетом источника, от которого поступают такие импульсы. Для конфигураций, которые поддерживают первичные эталонные источники, такие как радио-часы или калиброванные атомные часы код слоя устанавливается равным 1, поскольку именно он является действительным источником синхронизации.
Спецификация алгоритмов выбора часов и работы локальных часов не являются составной частью NTP. По этой причине описания этих алгоритмов, представленные ниже, следует рассматривать лишь как рекомендации.
Процедура очистки
Процедура очистки вызывается, когда произошло событие, которое значительно изменило достижимость или вызвало поломку локальных часов.begin clear procedure
| peer.org | /* пометка неопределенных временных меток */ |
peer.rec
peer.xmt
| peer.reach | /* сброс переменных состояния */ |
| peer.filter | /* все ступени */ |
peer.valid
peer.dispersion
| {peer.hostpoll | /* первичная установка периода рассылки */ |
call poll-update;
| call clock-select; | /* Выбор эталонных часов */ |
end clear procedure;
Процедура передачи
Процедура передачи запускается, когда таймер партнера станет равным нулю. В режиме клиента с широковещательным сервером сообщения вообще не посылаются. В режиме сервера сообщения посылаются только в качестве отклика на полученные запросы.Нижеприведенный фрагмент программы инициализирует пакетный буфер и копирует пакетные переменные.
| pkt.peeraddr | /* копирование системных и партнерских переменных */ |
pkt.peerport
pkt.hostaddr
pkt.hostport
pkt.leap
pkt.version
pkt.mode
pkt.stratum
pkt.poll
pkt.precision
pkt.rootdelay
if (sys.leap = 112 or (sys.clock - sys.reftime) > ntp.maxage)
skew
else
skew j (sys.clock - sys.reftime);
{pkt.rootdispersion
pkt.refid
pkt.reftime
Временная метка передачи pkt.xmt будет использована позднее, для того чтобы проконтролировать отклик. Таким образом, программа должна сохранить точное переданное значение. Кроме того, порядок копирования временных меток должен быть выбран так, чтобы не понизить точность.
| pkt.org | /* копирование временных меток */ |
pkt.rec
pkt.xmt
peer.xmt
Регистр доступности сдвигается на одну позицию влево, в освободившийся разряд записывается нуль. Если все биты регистра равны нулю, вызывается процедура очистки (clear procedure) для обнуления фильтра часов и выбора, если необходимо, нового источника синхронизации. Если ассоциация не была сконфигурирована при инициализации, то она ликвидируется.
| peer.reach | /* актуализация доступности */ |
if (peer.reach = 0 and peer.config =0)
begin
ликвидируем ассоциацию;
exit;
endif
Если корректные данные введены в сдвиговый регистр фильтра хотя бы раз за время предыдущих двух периодов рассылки (младший бит peer.reach равен 1), счетчик корректных данных увеличивается на 1. После восьми таких удачных периодов интервал рассылки увеличивается. Процедура выбора часов вызывается, если необходимо заменить источник синхронизации.
| if (peer.reach & 6 ? 0) | /* Проверка младших двух бит */ |
| if (peer.valid << ntp.shift) | /* получены корректные данные */ |
peer.valid <- peer.valid + 1;
else peer.hostpoll <- peer.hostpoll + 1;
else begin
| peer.valid | /* ничего не слышно */ |
peer.hostpoll
call clock-filter(0, 0, ntp.maxdisperse);
| call clock-select; | /* выбираем источник синхронизации */ |
endif
call poll-update;
end transmit procedure;
Процедура получения
Процедура получения выполняется по приходу NTP-сообщения. Она проверяет сообщения, интерпретирует различные режимы и вызывает другие процедуры для фильтрации данных и выбора источника синхронизации. Если номер версии в пакете не соответствует текущей версии, сообщение может быть отброшено. Если получено управляющее сообщение NTP и код режима пакета равен 6 (управление), вызывается процедура управляющего сообщения. IP-адреса отправителя и адресата, а также номера портов устанавливаются соответствующими заданному партнеру. Если соответствия нет, производится новая инсталляция протокольной машины и формируется новая ассоциация.begin receive procedure
if (pkt.version ? ntp.version>) exit;
#ifdef (control messages implemented)
if (pkt.mode = 6) call control-message;
#endef
| for (all associations) | /* Здесь выполняется управление доступом */ |
match addresses and ports to associations;
if (no matching association)
| call receive-instantiation procedure; | /* создаем ассоциацию */ |
Вызов процедуры дешифровки осуществляется только в случае применения аутентификации.
#ifdef (authentication implemented)
call decrypt;
#endef
Если код режима пакета не равен нулю, он определяет режим на следующем этапе; в противном случае, режим определяется по номеру порта.
| if (pkt.mode = 0) | /* для совместимости со старыми версиями */ |
mode;
else
mode
case (mode, peer.hostmode)
В случае ошибки пакет просто игнорируется, а ассоциация, если она не была предварительно сконфигурирована, ликвидируется.
error: if (peer.config = 0) demobilize association;
break;
В случае recv пакет обрабатывается, а ассоциация помечается как достижимая при условии 5-8 успешных проверок. Если и проверки с первой по 4-ую проходят успешно (данные корректны), вызывается процедура коррекции показания локальных часов. В противном случае, если ассоциация не была предварительно сконфигурирована, она ликвидируется.
| recv: call packet; | /* обработать пакет */ |
| if (valid header) begin | /* если правильный заголовок, актуализовать внутренние часы */ |
peer.reach
if (valid data) call clock-update;
endif
else
if (peer.config = 0) ликвидировать ассоциацию;
break;
В случае xmit, пакет обрабатывается и посылается промежуточный отклик. Ассоциация затем ликвидируется.
| xmit: call packet; | /* обработать пакет */ |
| peer.hostpoll | /* послать немедленно отклик */ |
call transmit;
if (peer.config = 0) ликвидировать ассоциацию;
break;
В случае pkt, пакет обрабатывается, а ассоциация помечается как достижимая при условии, что тесты 5-8 (правильный заголовок), перечисленные в пакетной процедуре, прошли успешно. Если, кроме того, прошли тесты 1-4 (корректные данные), вызывается процедура коррекции показаний локальных часов. В противном случае, если ассоциация не была предварительно сконфигурирована, она сразу после отклика ликвидируется.
| pkt: call packet; | /* обработка пакета */ |
| if (valid header) begin | /* если заголовок правилен, поправляется показание местных часов */ |
if (valid data) call clock-update;
endif
else if (peer.config = 0) begin
| peer.hostpoll | /* послать немедленно отклик */ |
call transmit;
ликвидировать ассоциацию;
endif
endcase
end receive procedure;
Процедура primary clock-instantiation
Эта процедура вызывается из процедуры инициализации для того, чтобы установить переменные состояния для первичных часов. Значение peer.precision определяется из спецификации радио-часов и аппаратного интерфейса. Значение peer.rootdispersion номинально равно удесятеренной максимальной ошибке радио-часов, например, 10 мсек для WWVB или радио-часов goes и 100 мсек для менее точных радио-часов WWV.begin clock-instantiation procedure
| peer.config | /* копирование переменных */ |
peer.peeraddr
peer.peerport
peer.hostaddr
peer.hostport
peer.leap 2;
peer.mode
peer.stratum
peer.peerpoll
peer.precision
peer.rootdelay
peer.rootdispersion
peer.refid
peer.reftime
peer.timer
peer.delay
peer.offset
| call clear; | /* инициализация ассоциации */ |
end clock-instantiation procedure;
В некоторых конфигурациях, включающих в себя атомные часы или приемники LORAN-C, первичный эталон может выдавать только секундные импульсы и не предоставлять полного временного кода (числа секунд и пр.). В этих конфигурациях нумерация секунд может быть получена из других источников, таких как радио-часы или даже другие NTP-партнеры. В этих конфигурациях переменные первичных часов должны отражать особенности первичного эталона, а не источника нумерации секунд. Однако если источник нумерации секунд отказал или работает некорректно, актуализация локальных часов от первичного эталона должна быть заблокирована.
Процедура расстояния синхронизации (synchronization distance)
Процедура расстояния вычисляет расстояние синхронизации на основе переменных партнеров.begin distance(peer) procedure;
d
e f (sys.clock - peer.update)};
le + |d|/2;
end distance procedure;
Заметим, что, в то время как d может быть в некоторых случаях отрицательной, e и l всегда положительны.
Процедура receive-instantiation
Процедура receive-instantiation вызывается процедурой приема, когда обнаруживается новый партнер. Она инициализирует переменные партнера и формирует ассоциацию. Если сообщение получено от партнера, работающего в режиме клиента (3), ЭВМ переводится в режим сервера (4); в противном случае, она устанавливается в симметрично пассивный режим (2).begin receive-instantiation procedure
#ifdef (authentication implemented)
peer.authenable
peer.authentic
peer.hostkeyid
peer.peerkeyid
#endef
| peer.config | /* Копирование переменных */ |
peer.peeraddr
peer.peerport
peer.hostaddr
peer.hostport
| if (pkt.mode = 3) | /* Определение режима */ |
peer.mode
else
peer.mode
peer.peerpoll
peer.timer
peer.delay
peer.offset
| call clear; | /* инициализация ассоциации */ |
end receive-instantiation procedure;
Процедура выбора часов
Процедура выбора часов использует переменные партнера q, d, e и t, она вызывается, когда эти переменные изменились или изменился статус доступности. Процедура включает в себя две составные части: алгоритм пересечения (intersection algorithm) и алгоритм кластеризации (clustering algorithm). Алгоритм пересечения подготавливает список кандидатов партнеров, могущих стать источниками синхронизации и вычисляет доверительный интервал для каждого из них. Алгоритм кластеризации сортирует список кандидатов по кодам слоя и расстояния синхронизации. Системная переменная sys.peer представляет собой указатель на наиболее вероятного кандидата, если таковой имеется, или на нулевую величину в противном случае.Процедура запроса-коррекции (poll-update)
Процедура запросов-коррекции вызывается, когда происходит событие, которое может вызвать изменение периода запросов (рассылки) или таймера партнера. Она проверяет значения периода запросов ЭВМ (peer.hostpoll) и партнера (peer.peerpoll), а также устанавливает их в заданных пределах.begin poll-update procedure
| temp | /* определение периода запросов ЭВМ */ |
if (peer = sys.peer)
temp
else
temp
peer.hostpoll
temp
Если интервал запросов (рассылок) не изменился, а таймер партнера на нуле, то таймер просто сбрасывается в начальное состояние. Если интервал запросов изменен, и новое значение таймера больше текущего значения, никаких дополнительных действий не требуется; в противном случае величина выдержки таймера партнера должна быть уменьшена. Когда время выдержки таймера партнера уменьшается, важно исключить тенденцию синхронизации обмена между партнерами. Благоразумной предосторожностью является рэндмизация первой передачи после уменьшения выдержки таймера.
| if (peer.timer = 0) | /* сброс таймера партнера */ |
peer.timer
else if (peer.timer >temp)
peer.timer
end poll-update procedure;
Процедуры аутентификации NTP
Когда используется аутентификация для реализации протокола NTP, привлекается две дополнительные процедуры. Одна из них формирует крипто-сумму для передаваемых сообщений, а другая дешифрует и проверяет корректность контрольной суммы получаемых сообщений. Процедуры представляют собой варианты программ, используемых для реализации алгоритма DES и описанных в [NBS80]. На самом деле процедура не связана жестко с алгоритмом DES, а лишь предполагают работу с 64-битовыми блоками данных.Процедуры инициализации
Процедура инициализации вызывается при перезагрузке системы или при повторном запуске демона NTP. Состояние локальных часов при загрузке предполагается неопределенным; однако, некоторые виды оборудования обеспечивают доступ к локальным часам, как в ходе загрузки, так и сразу после нее. Переменная точности определяется внутренней архитектурой оборудования локальных часов. Аутентификационные переменные используются лишь при реализации механизма аутентификации. Значения этих переменных определяются процедурами, выходящими за рамки протокола NTP.begin initialization procedure
#ifdef (authentication implemented)
sys.keys
#endef;
| sys.leap 2; | /* копирование переменных */ |
sys.stratum
sys.precision
sys.rootdelay
sys.rootdispersion
sys.refid
sys.reftime
sys.clock
sys.peer
sys.poll
| for (all configured peers) | /* создание конфигурированных ассоциаций */ |
call initialization-instantiation procedure;
end initialization procedure;
Прочие ссылки
T. V. Lakshman, U. Madhow, B. Suter, “Window-based error recovery and flow control with a slow acknowledgement channel: a study of TCP/IP performance”, Proceedings of IEEE Infocom 1997.
IEEE Infocom ‘93.
Протокол управляющих сообщений (ICMPv для спецификации IPv(RFC-)
Протокол IPv6 является новой версией IP. IPv6использует протокол управляющих сообщений (ICMP) так, как это определено для IPv4 [RFC-792], но с некоторым количеством изменений. Протокол подключения к группам (IGMP), специфицированный для IPv4 [RFC-1112] был также пересмотрен и включен в протокол ICMP для IPv6. Результирующий протокол называется ICMPv6, и имеет код следующего заголовка 58.Протокольная спецификация контрольного соединения
Следующие сообщения управляющего соединения используются для установления, ликвидации и поддержания L2TP-туннелей. Вся информация посылается в порядке, определенном для сети (старший октет первый). Любые "резервные" или "пустые" поля для обеспечения протокольной масштабируемости должны содержать 0.Протокольные операции контрольного соединения
Этот раздел описывает работу различных функций управляющего соединения L2TP и сообщения управляющего соединения, которые используются для их поддержания.Получение некорректного или неправильно сформатированного управляющего сообщения должно регистрироваться соответствующим образом, а управляющее соединение возвращается в исходное состояние, чтобы гарантировать восстановление заданного состояния. Управляющее соединение может затем перезапуститься инициатором операции.
Некорректное управляющее сообщение определяется как сообщение, которое содержит тип сообщения, помеченное как обязательное (смотри раздел 4.4.1) и неизвестное программе управляющее сообщение, которое получено в правильной последовательности (например, в ответ на SCCRQ послано SCCCN).
Примеры управляющих сообщений с некорректным форматом включают те, которые имеют неверное значение в своем заголовке, содержат AVP, сформированную некорректно или чье значение находится вне допустимых пределов, или сообщение, которое не имеет необходимого AVP. Управляющее сообщение с некорректным заголовком должно быть отброшено. Управляющее сообщение с некорректным AVP должно проверить M-бит для этого AVP, чтобы определить, является ли ошибка исправимой или нет.
Неверно сформатированное, но исправимое необязательное (M-бит равен нулю) AVP в управляющем сообщении должно рассматриваться, также как нераспознанное необязательное AVP. Таким образом, если получена AVP с неверным форматом и битом M=1, сессия или туннель должны быть разорваны с соответствующим кодом результата или ошибки. Если M-бит не равен 1, AVP должно игнорироваться (за исключением записи об ошибке в местном журнале).
Это не должно рассматриваться, как разрешение посылать неверно сформатированные AVP, а лишь как указание на то, как реагировать на неверно сформатированное сообщение в случае его получения. Невозможно перечислить все возможные ошибки в сообщениях и дать совет, как с ними обходиться. Примером исправимой неверно сформатированной AVP может быть случай, когда получена AVP скорости соединения Rx, атрибут 38, с полем длина 8, а не 10 и BPS с двумя, а не четырьмя октетами. Так как Rx Connect Speed не является обязательным, такое условие не может рассматриваться как катастрофическое. Как таковое, управляющее сообщение должно быть воспринято, как если бы AVP не было получено (за исключением записи в локальный журнал ошибок). В нескольких случаях в последующих таблицах, посылается протокольное сообщение, а затем случается "сброс". Заметим, что, несмотря на ликвидацию туннеля одним из партнеров, в течение определенного времени механизм надежной доставки должен быть сохранен (смотри раздел 5.8) вплоть до окончательного закрытия туннеля. Это позволяет сообщениям управления туннеля надежно доставляться партнеру.
Протокольные операции
Необходимая процедура установления PPP-сессии туннелирования L2TP включает в себя два этапа:Туннель и соответствующий управляющий канал должны быть сформированы до инициализации входящего или исходящего вызовов. L2TP-сессия должна быть реализована до того, как L2TP сможет передавать PPP-кадры через туннель. В одном туннеле могут существовать несколько сессий между одними и теми же LAC и LNS.

Рис. 18. PPP-туннелирование
Протокольный отправитель клиента и протокольный получатель сервера
Любая процедура начинается с команды клиента. Любая команда клиента начинается с префикса-идентификатора (обычно короткая буквенно-цифровая строка, например A0001, A0002 и т.д.), называемого меткой (tag). Для каждой команды клиент генерирует свою метку. Имеется два случая, когда строка, посланная клиентом, не представляет собой законченную команду. В первом - аргумент команды снабжается кодом, определяющим число октетов в строке (см. описание литеральных строк в разделе “Форматы данных”). Во втором - аргументы команды требуют отклика со стороны сервера (см. описание команды authenticate). В обоих вариантах сервер посылает запрос продолжения команды, если он готов. Такой отклик сервера начинается с символа "+".Замечание: Если, вместо этого, сервер детектирует ошибку в команде, посылается отклик завершения bad с меткой, требующей игнорирования команды и предотвращения посылки клиентом каких-либо еще запросов.
Отправитель может послать отклик завершения и в случае некоторых других команд (если одновременно исполняется несколько команд) или если данные не имеют меток. В любом случае, ожидается запрос продолжения, клиент предпринимает в ответ соответствующие действия и читает следующий отклик сервера. Во всех вариантах клиент должен завершить отправку одной команды прежде чем послать новую.
Протокольный приемник IMAP 4.1 сервера читает строку команды, пришедшей от клиента, осуществляет ее разбор, выделяет ее параметры и передает серверу данные. По завершении команды сервер посылает отклик.
Протокольный отправитель сервера и протокольный получатель клиента
Данные, передаваемые сервером клиенту, а также статусные отклики, которые не указывают на завершение выполнения команды, имеют префикс "*" и называются непомеченными откликами.Данные сервера могут быть посланы в ответ на команду клиента или отправлены сервером по своей инициативе. Формат данных не зависит от причины посылки.
Отклик указывает на успешное выполнение операции или на ее неудачу. Отклик использует ту же метку, что и команда клиента, запустившая процедуру. Таким образом, если осуществляется более чем одна команда, метка сервера указывает на команду, вызвавшую данный отклик. Имеется три вида отклика завершения сервера: ok (указывает на успешное выполнение), no (отмечает неуспех) или bad (указывает на протокольную ошибку, например, не узнана команда или зафиксирована синтаксическая ошибка).
Протокольный приемник клиента IMAP 4.1 читает строку отклика от сервера. Он должен предпринять действия, в соответствии с первым символом метки "*" или "+".
Клиент должен быть готов принять любой отклик сервера в любое время. Это касается и не запрошенных данных, присланных сервером. Данные сервера должны быть записаны так, чтобы клиент мог их непосредственно использовать, не посылая серверу уточняющих запросов.
Каждое сообщение имеет несколько связанных с ним атрибутов. Эти атрибуты могут быть определены индивидуально или совместно с другими атрибутами.
Доступ к сообщениям в IMAP 4.1 осуществляется с помощью уникального идентификатора или порядкового номера сообщения.
Провайдерские глобальные уникаст-адреса
Глобальный уникаст-адрес провайдера имеет назначение, описанное в [ALLOC]. Исходное назначение этих уникаст-адресов аналогично функции IPv4 адресов в схеме CIDR [см. CIDR]. Глобальный IPv6 уникаст-адрес провайдера имеет формат, отображенный ниже на рис. 4.4.1.1.9:
Рис. 4.4.1.1.9. Глобальный адрес провайдера
Старшая часть адреса предназначена для определения того, кто определяет часть адреса провайдера, подписчика и т.д.
Идентификатор регистрации определяет регистратора, который задает провайдерскую часть адреса. Термин "префикс регистрации" относится к старшей части адреса, включая поле идентификатор регистрации (ID).
Идентификатор провайдера задает специфического провайдера, который определяет часть адреса подписчика. Термин "префикс провайдера" относится к старшей части адреса включая идентификатора провайдера.
Идентификатор подписчика позволяет разделить подписчиков, подключенных к одному и тому же провайдеру. Термин "префикс подписчика" относится к старшей части адреса, включая идентификатор подписчика.
Часть адреса интра-подписчик определяется подписчиком и организована согласно местной топологии Интернет подписчика. Возможно, что несколько подписчиков пожелают использовать область адреса интра-подписчик для одной и той же субсети и интерфейса. В этом случае идентификатор субсети определяет специфический физический канал, а идентификатор интерфейса - определенный интерфейс субсети.
Qos_lan
4.4.3.2 Качество обслуживание (QoS) в локальных сетях и не толькоСеменов Ю.А. (ГНЦ ИТЭФ)
Существует три модели реализации QoS: наилучшая возможная; интегральная и дифференцированная. Наилучший возможный вид услуг реализуется в сети, когда делается все возможное для доставки пакета, но при этом ничего не гарантируется (например, FTP или HTTP). Интегрированный вид услуг (RFC-1633, 1994 год) разрабатывался первым и реализуется путем резервирования по схеме точка-точка (протокол RSVP; 1997; см. ). Протокол RSVP предоставляет сигнальный механизм для конфигурирования удаленных маршрутизаторов с целью получения нужного QoS. Протокол ориентирован на работу с тремя видами трафика: best efforts (обычная передача IP-данных без установления соединения), чувствительный к скорости передачи и чувствительный к задержкам. Трафик чувствительный к загрузке требует формирования канала с гарантированной пропускной способностью. Приложение при этом вынуждено мириться с определенными задержками доставки (класс услуг с гарантированной скоростью в битах в сек. Третий вид трафика (чувствительный к задержкам) гарантирует минимальную задержку и низкую дисперсию времени доставки. Пропускная способность может при этом варьироваться. Примером такого вида трафика может служить передача голоса или видео. RSVP определяет два типа услуг для этого вида трафика: сервис с контролируемыми задержками и предсказуемый сервис (для приложений реального времени (видео-конференции и телефонные переговоры)).
В рамках протокола стандартизованы схемы обработки очередей WFQ (Weighted Fair Queuing) и WRED (Weighted Random Early Detection). В CISCO IOS по умолчанию используется WFQ (для каналов Е1 = 2028 кбит/с или медленнее). Intserv предлагает на L3 тот же уровень услуг, что можно получить в АТМ на уровне L2. В АТМ определены 4 QoS класса:
Следует помнить, что в Интернет нет гарантий ни по задержке, ни вообще по доставке, что неприемлемо для передачи голоса ( пропускная способность ? 16 кбит/с, максимально допустимая задержка <100мсек), видеоконференций и приложений виртуальной реальности.
Приложение в этой модели не будет осуществлять передачу, пока не получит подтверждения резервирования. Инициатором резервирования в этой модели всегда является получатель. Получатель в рамках RSVP анализирует параметры потока отправителя (Tspec) и посылает ему запрос резервирования Resv, который должны воспринять все промежуточные узлы (если они способны это сделать). Этот запрос специфицирует желательные параметры QoS. Для поддержания резервирования вдоль всего пути это сообщение должно периодически повторяться. В протоколе RSVP всего предусмотрено семь разных типов сообщений. Вообще RSVP первоначально предназначался для организации IP-телефонии. Если с помощью RSVP произведено резервирование всей полосы канала, никакая передача прочих данных через этот канал будет невозможна, пока хотя бы часть резервирований не будет отменена. Характер резервирования определяется спецификацией потока (flow spec). Если запрашивается лишь контроль загрузки, flow spec будет тождественна Tspec. Если же требуется гарантированный вид услуг, flow spec содержит Tspec и Rspec. Надо учитывать, что RSVP не очень удобен при работе с каналами малой пропускной способности. WFQ может начать работать, когда пакеты имеют разный приоритет. Существует 8 уровней приоритета (чем больше номер, тем выше приоритет):
Не ищите разъяснения смысла этих определений, его пока не существует... Значению 000 соответствует услуга наилучших усилий (best efforts). Архитектура listserv ориентирована на получение минимального временного разброса доставки при гарантии пропускной способности не ниже требуемой. Listserv предназначен для работы с приложениями, требующими низкой полосы и малых задержек (передача голоса или видео).
Когда установлены соответствующие биты поля TOS, WFQ настраивает обработку так, чтобы очереди с более высоким приоритетом продвигались быстрее, чем менее приоритетные очереди. Порядок обслуживания очередей остается тем же, но объем данных, обрабатываемых из очереди, зависит от веса очереди. Весовой коэффициент обратно пропорционален уровню приоритета. Все это справедливо, если приложение и все участники обмена поддерживают приоритетное обслуживание с использованием TOS. Следует иметь в виду, что методы приоритетного обслуживания используются не только для получения требуемого уровня QoS, но и для подавления перегрузки канала. Смотри также .
Дифференциальный вид услуг (RFC-2474 и RFC-2475) предполагает наличие определенного набора средств классификации и механизмов организации очередей, обеспечивающих работу с приоритетами. Дифференциальный вид услуг обычно предполагает использование 6-битового поля DSCP (DiffServ Code Point) и определяет пошаговое поведение виртуального канала PHB (Per Hop Behavior). PHB задается сервис-провайдером и определяется на основе кода в поле DSCP. Запись в поле DSCP обычно осуществляется на входе сети. Поле DS (Differentiated Services), где размещается DSCP, фактически замещает поле TOS (RFC-791) в IP-заголовке. Стандартизации значений поля DS пока не произведено. Любая сеть должна поддерживать, по крайней мере, два класса PHB. Express Forwarding PHB (экспрессная переадресация) относится к наивысшему уровню услуг, возможному в модели Diffserv.
Здесь для обеспечения низких потерь, малого временного разброса и гарантированной полосы используется RSVP. Diffserv достаточно хорошо адаптируется для работы в каналах с малой пропускной способностью.
Первой попыткой ввести некоторые параметры качества обслуживания относятся к 1981 году (RFC-791). Тогда было определено поле IP-заголовка TOS (Type of service; значения бит см. в ). Позднее (в 1992 году) определение TOS было скорректировано в RFC-1349 (определено 4 бита вместо трех). Из-за неопределенности механизмов реализации ToS реально это поле не использовалось в течение 20 лет. Значения бит поля TOS из RFC-1349 описаны в таблице:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Приоритет | X | X | X | X | 0 |
1000 - Минимальная задержка
0100 - Максимальная пропускная способность
0010 - Максимальная надежность
0001 - Минимальная стоимость
0000 - Обычные (нормальные) услуги
Diffserv не определяет частоту отбрасывания пакетов, но утверждает, что класс 4 обрабатывается более приоритетно, чем класс 3 и что в пределах каждого AF (Assured Forwarding) все классы имеют преимущества перед прочими классами. В таблице ниже представлены значения приоритетов для AF.
| Класс 1 | Класс 2 | Класс 3 | Класс 4 | |
| Низкий приоритет отбрасывания | 001010 | 010010 | 011010 | 100010 |
| Средний приоритет отбрасывания | 001100 | 010100 | 011100 | 100100 |
| Высокий приоритет отбрасывания | 001110 | 010111 | 011110 | 100110 |
Компания CISCO разработала специальную технологию для обеспечения нужного уровня QoS - CISCO Content Networkig (транспортировка через сеть с учетом содержимого). В рамках этой технологии решается фундаментальная проблема - классификации транспортируемых пакетов с учетом содержимого их заголовков.
Сетевые технологии стремительно усложняются. Раньше было достаточно определить приоритет для определенного адреса или для заданного протокола, теперь этого мало. Один и тот же пользователь с фиксированным IP может в одно и то же время реализовать через сеть передачу голоса, осуществлять поиск информации в WEB-сети и т.д., причем все это делать в рамках одного и того же протокола. Понятно, что эти задачи имеют разную значимость. Все это требует классификации трафика по большему числу параметров, чем адрес и протокол. Здесь следует учитывать динамическое присвоение кодов номера порта, которое усложняет распознавание приложений.
CISCO для решения этой проблемы в IP-среде разработала специальное средство, называемое NBAR (Network Based Application Recognition - распознавание приложения по сетевым параметрам). Техника NBAR применима только к такому трафику, который может быть переадресован с помощью технологии CEF (Cisco Express Forwarding). NBAR может классифицировать HTTP-трафик не только по адресам и номерам портов, но и по информации, содержащейся в URL (до 400 байт). Реально NBAR просматривает 512 байт (сюда помимо URL входят заголовки L2, L3, L4 и HTTP). В рамках NBAR предусматривается классификация субпортов. NBAR классифицирует HTTP-трафик по mime-типу или get-запросам. Предельное число одновременно обслуживаемых URL-ЭВМ или mime-типов не должно превышать 24. Анализ NBAR 400 байт URL-заголовка способствует уменьшению вероятности злоупотреблений сетевыми ресурсами. Здесь появляется возможность выявления неавторизованной пересылки пользователями больших файлов mp3 и пр.. NBAR может классифицировать TCP и UDP-протоколы, использующие стандартизованные номера портов, а также и прочие протоколы (например, маршрутные, ICMP, IPSec, IPINIP, Kerberos, IMAP/SIMAP, HTTPS, L2TP, LDAP, NETBIOS, RSVP, SNNTP, NTP, POP3/SPOP3, SFTP, SSH, X-Windows, SOCKS и т.д.).
NBAR позволяет загружать в маршрутизатор шаблоны классификации в любой момент времени. Это осуществляется с помощью использования PDLM (Packet Description Language Module - модуль языка описания пакетов).
PDLM копируется в флэш-память с консоли маршрутизатора или каким- то другим способом. Список поддерживаемых протоколов постоянно обновляется. Следует помнить, что NBAR сам по себе не обеспечивает QoS, а лишь выделяет определенный класс трафика из общего информационного потока. Раз трафик классифицирован, могут быть применены определенные механизмы для обеспечения определенного уровня сервиса. При классификации NBAR просматривает первые 512 байт пакета (заголовки L2, L3, L4 и т.д.). NBAR может классифицировать трафик по MIME-заголовкам. В перечень услуг NBAR входят:
Использование NBAR для классификации 500 потоков потребует дополнительно 1 Мбайт памяти. В младших моделях маршрутизаторов, например 2600, применение NBAR займет до 15% мощности процессора. Это обстоятельство следует учитывать, если нужно обеспечить определенный уровень QoS, ведь это потребует дополнительной мощности процессора. Применение CEF потребует еще больше ресурсов процессора. NBAR не поддерживает трафик, отличный от IP. NBAR не может также использоваться для VLAN, многоканальных PPP (multilink PPP).
В то время как на уровне IP (L3) реализуется несколько подходов обеспечения QoS (intserv в RSVP и diffserv в MPLS; см. ), на уровне L2 ситуация пока много хуже. Следует, впрочем, признать, что решение в протоколе MPLS полностью пригодно и для L2. Требуется лишь появление на рынке сетевых приборов, поддерживающих MPLS или 802.1Q.
В стандарте 802.1Q (Virtual Bridged Local Area Network) определен тип маркированного кадра путем введения метки, содержащей следующие поля:
введении этих полей в кадр Ethernet приходится пересчитать контрольную сумму кадра (FCS). Для поддержки стандарта IEEE 802.1р канальный уровень должен работать с множественными очередями (по одной на каждый код приоритета). В настоящее время разрабатывается стандарт расширения RSVP для 802.3 (SBM -Subnet Bandwidth Manager - http://search.ietf.org/internet-drafts/draft-ietf-issll-is802-sbm-08.txt). Смотри также http://www.ietf.org/html.charters/issll-charter.html (Integrated Services over Specific Lower Layers). Этот протокол должен работать в том числе и в сетях Ethernet.
Для управления протоколом SBM используются следующие мультикаст-адреса:
224.0.0.17 - все SBM-системы должны прослушивать этот адрес.
224.0.0.16 - все кандидаты DSBM должны прослушивать этот адрес.
Обычно важно обеспечить качество обслуживания (QoS) в режиме точка-точка (см. ). На практике это удается реализовать достаточно редко, в частности потому, что многие технологии LAN не поддерживают QoS. Ниже в таблице приведены приоритеты, поддерживаемые известными технологиями LAN (L2; см. ). В локальных сетях различают приоритет доступа (access_priority) и приоритет пользователя (user_priority). Значение приоритета пользователя формируется МАС-уровнем, помещается в соответствующее поле заголовка кадра и используется для обеспечения QoS в режиме точка-точка в среде переключателей L2. Значение приоритета доступа используется переключателем LAN для передачи кадров. Приоритет пользователя может быть не равен приоритету доступа. К сожалению кадры 802.3 и 802.11 соответствующих полей приоритета в заголовке не имеют. Значение 0 соответствует наинизшему приоритету.
Коды приоритета используются переключателями при обработке очередей. Применение приоритетов регламентируется документом IEEE 802.1D (1998).
Таблица 1. Выходной приоритет доступа для разных технологий LAN
| Приоритет пользователя | Выходной приоритет для МАС-технологий | ||||||
| 802.3 | 802.4 | 802.5 | 802.6 | 802.11 | 802.12 | FDDI | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 |
| 2 | 0 | 2 | 2 | 2 | 0 | 0 | 2 |
| 3 | 0 | 3 | 3 | 3 | 0 | 0 | 3 |
| 4 | 0 | 4 | 4 | 4 | 0 | 4 | 4 |
| 5 | 0 | 5 | 5 | 5 | 0 | 4 | 5 |
| 6 | 0 | 6 | 6 | 6 | 0 | 4 | 6 |
| 7 | 0 | 7 | 7 | 7 | 0 | 4 | 6 |
| 802.3 | CSMA/CD |
| 802.4 | Token Bus |
| 802.5 | Token Ring |
| 802.6 | DQDB - Double Queue, Double Bus |
| 802.11 | Беспроводные локальные сети |
| 802.12 | 100VGAnyLAN (с приоритетным запросом) |
| FDDI | Fiber Distributed Data Interface (token ring) |
Переключатель может быть сконфигурирован так, чтобы можно было поддерживать несколько очередей. Для определения относительного приоритета очередей вводится класс трафика, так чтобы кадры с высоким классом передавались раньше. Кадр низкого класса может быть передан, если очереди более высокого класса пусты. Документ IEEE 802.1D определяет соответствие между классами трафика и приоритетами пользователя.
Ниже перечислены типы трафика, начиная с высоко приоритетного:
В случае информационной службы этот режим может использоваться для привилегированных клиентов.
Восьмой тип (1) оставлен на будущее, он имеет приоритет выше фонового, но ниже наилучших усилий. Это означает, что в каждом из выходных портов формируется до 8 очередей. Ниже в табл. 2 перечислены рекомендуемые приоритеты пользователя для указанных выше классов трафика.
Таблица 2. Рекомендуемые приоритеты пользователя для существующих классов трафика
| Приоритет пользователя | Число доступных классов трафика | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 0 по умолчанию |
0 | 0 | 0 | 1 | 1 | 1 | 1 | 2 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0 | 1 | 1 | 2 | 2 | 3 |
| 4 | 0 | 1 | 1 | 2 | 2 | 3 | 3 | 4 |
| 5 | 0 | 1 | 1 | 2 | 3 | 4 | 4 | 5 |
| 6 | 0 | 1 | 2 | 3 | 4 | 5 | 5 | 6 |
| 7 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
Таблица 3. Рекомендуемое число очередей для разных классов трафика
| Число очередей | Типы трафика | |||||||
| 1 | BE (EE,BK,Vo,CL,VI,NC) |
|||||||
| 2 | BE(EE,BK) | VO(CL,VI,NC) | ||||||
| 3 | BE(EE,BK) | CL(VI) | VO(NC) | |||||
| 4 | BK | BE(EE) | CL(VI) | VO(NC) | ||||
| 5 | BK | BE(EE) | CL | VI | VO(NC) | |||
| 6 | BK | BE | EE | CL | VI | VO(NC) | ||
| 7 | BK | BE | EE | CL | VI | VO | NC | |
| 8 | BK | - | BE | EE | CL | VI | VO | NC |
| Приоритет пользователя | 1 | 2 | 0 | 3 | 4 | 5 | 6 | 7 |
br>
Надписи полужирным шрифтом относятся к типу трафика, который определяет типы классов.
| BK | - Background (фон) |
| BE | - Best Effort (наилучшие усилия) |
| EE | - Excelrnt Effort (максимальные усилия) |
| CL | - Controlled Load (контролируемая нагрузка) |
| VI | - Video (задержка и разброс доставки |
| VO | - Voice (голос, задержка и разброс доставки |
| NC | - Network Control (управление сетью) |
В современных сетях VPN часто содержат IP (PPP или Ethernet) и АТМ участки. Соединение сетевых элементов MPLS через АТМ каналы оказывается наиболее дешево. Обычно это реализуется с помощью постоянных виртуальных путей PVC ATM. Коммутация в АТМ производится в этом случае на основе поля VPI. Поле же VPI выполняет функцию метки. VPI-соединение должно быть заказано с определенным классом АТМ-сервиса. В АТМ предусмотрены следующие стандартные классы сервиса:
Обычно для приложений MPLS используются классы ATM CBR или VBR. Выбор определяется расценками сервис-провайдеров, которые могут варьироваться в широких пределах. Протокол MPLS поддерживает следующие услуги в сфере QoS:
RSVP может запросить ресурсы, необходимые для осуществления обмена некоторым конкретным приложением в заданной сети.
По проблематике QoS смотри также:
| RFC-1633 | "Integrated Services in the Internet Architecture: An Overview" Braden R., Clark D., Shenker S., June 1994. |
| RFC-2474 | "Definition of the Differentiated Services Field (DS Field) in the IPv4 and IPv6 Headers", K. Nichols, December 1998. |
| RFC-2475 | "An Architecture for Differetiated Services", Blake S., Black D., Carlson M. Davies E., Wang Z., Weiss W., December 1998. |
| RFC-2386 | "A Framework for QoS-based Routing in the Internet", E. Crawley, August 1998 |
| RFC-2597 | "Assured Forwarding PHB Group", J. Heinanen, June 1999 |
| >RFC-2598 | "An Expedited Forwarding PHB", V. Jacobson, June 1999 |
| RFC-3387 | "Considerations from the Service Management Research Group (SMRG) on Quality of Service (QoS) in the IP Network", M. Eder, H. Chaskar, S. Nag. September 2002 |
| http://staff.washington.edu/gray/papers/eqos22.html | "Enterprise QoS Survival Guide 1999 Edition" Gray T., 1999. |
| http://www.ietf.org/internet-drafts/draft-iab-qos-00.txt | "Next Steps for IP QoS Atchitecture" Huston G., |
| "Administering CISCO QoS in IP-Networks", Michael E. Flannagen, Syngress, 2001 |
Работа первичных часов (primary-clock procedure)
Когда ЭВМ связана с первичным эталоном времени, таким как радио-часы, удобно ввести информацию об этих часах в базу данных, как если бы это был обычный партнер. В процедуре первичных часов часы запрашиваются раз в минуту или около того, полученный же временной код используется для корректировки показаний местных часов. Когда обнуляется peer.timer для первичного партнера, процедура передачи не вызывается, а посылается запрос радио-часам с использованием ASCII-последовательности, предусмотренной для этого случая. Когда получен корректный временной код от радио-часов, он преобразуется в формат временной метки NTP и корректируются соответствующие переменные партнера. Величина peer.leap устанавливается в зависимости от состояния бита оповещения временного кода, если таковой имеется, или вручную оператором. Значение для peer.peeraddr, которое становится равно sys.refid, когда вызывается процедура корректировки показаний часов, делается равным ASCII-строке, описывающей часы.begin primary-clock-update procedure
| peer.leap | /* Копирование переменных */ |
peer.peeraddr
peer.rec
peer.reach
| call clock-filter({sys.clock - peer.rec, 0, 1 | /* образец процесса */ |
| call clockupdate; | /* коррекция локальных часов */ |
end primary-clock-update procedure;
Расширение DNS для поддержки IP-версии (DNS Extensions to Support IP Version S Thomson RFC-)
Существующая поддержка записи адресов Интернет в DNS (Domain Name System) [1,2] не может быть легко расширена для поддержки IPv6-адресов [3], так как приложение предполагает, что адресный запрос вернет только 32-битовый IPv4-адрес.Для того чтобы запоминать IPv6-адреса, определены следующие расширения:
Изменения выполнены так, чтобы быть совместимыми с имеющимся программным обеспечением. Существующая поддержка IPv4-адресов сохраняется. Переходное состояние осуществования IPv4 и IPv6-адресов обсуждается в [4].
Временной код содержит информацию об UTC времени-дне-годе, а также предупреждение о добавлении/вычитании секунды в конце дня. Точность этой службы составляет 0,5 мсек.
Министерство обороны США разработало глобальную систему определения координат GPS (Global Positioning System). Эта система базируется на 24 спутниках, движущихся по орбитам с периодом 12 часов. Система GPS может обеспечить точность определения времени на уровне нескольких наносекунд [VAN84].
Американская береговая охрана в течение многих лет использует службу радионавигации LORAN-C [FRA82]. Эта служба обеспечивает временную точность менее 1 мксек.
Система радионавигации военно-морского флота США и других стран OMEGA [VAS78] состоит из 8 передатчиков, работающих на частотах от 10.2 до 13.1 КГц (УНЧ или CIR диапазон 4) и перекрывающих весь земной шар 24 часа в сутки. Точность этой системы составляет около 1 мсек. Система OMEGA обеспечивает высокую точность для частоты, но не передает временного кода. По этой причине приемник должен предварительно получить географические координаты с точностью до градуса и время UTC с точностью 5 секунд от независимых источников.
Заметим, что не все службы времени передают информацию о текущем годе и предупреждения о добавлении/вычитании секунды. Протокол NTP позволяет решить эту проблему.
Раздача времени и частоты
Для того чтобы атомное и обычное время могли быть взаимосвязаны, национальные администрации обеспечивают работу первичных стандартов времени и частоты и совместно координируют их функционирование. Большинство морских держав поддерживают широковещательные радиослужбы времени.Американский Национальный Институт Стандартов и Технологии (NIST - National Institute of Standards and Technology) поддерживает три радиослужбы для рассылки временной информации. Одна из них использует передачу (ВЧ или CCIR диапазон 7) на частотах 2.5, 5, 10, 15 и 20 Мгц. Сигнал распространяется, отражаясь от верхних слоев атмосферы, что неизбежно приводит к непредсказуемым вариациям задержки на принимающей стороне. С 60-секундным интервалом передается временной код, который транслируется на 100 килогерцной субнесущей со скоростью передачи 1 бит/с. Этот код содержит информацию об UTC времени и дате, но не включает в себя данных о текущем годе и оповещения о добавлении/вычитании секунды для последней минуты данного дня. Существуют и другие сходные службы времени (например, в Оттаве), гарантирующие точность на уровне 1-10 мсек.
Вторая служба времени NIST использует передачу (НЧ или CCIR диапазон 5) на частоте 60 КГц, она доступна на континентальной части США и вблизи берегов. Сигнал распространяется в нижней части атмосферы и по этой причине слабо подвержен вариациям времени распространения. Временной код передается с периодом в 60 секунд со скоростью 1 бит/с. Достижимая точность составляет 50 миллисекунд [BLA74]. Ряд европейских стран предлагают аналогичные службы времени (Великобритания - MSF; Германия - DCF77). Коды времени здесь включают информацию о текущем годе и предупреждение о добавляемой/вычитаемой секунде. Третья служба NIST использует передачу на частоте 468 МГц (УВЧ или CCIR диапазон 9) с геостационарных спутников GOES, три из которых перекрывают западное полушарие. Временной код перемежается с сообщениями, адресованными удаленным датчикам и состоит из 600 4-битовых слов, передаваемых с периодом в 30 секунд.
Размер почтового ящика и актуализации состояния сообщений
В любое время сервер может послать данные, которые клиент не запрашивал. Иногда, такое поведение системы является необходимым. Например, агенты, внешние по отношению к серверу, могут положить сообщения в почтовый ящик, изменить флаги сообщения в почтовом ящике (например, одновременный доступ в почтовый ящик нескольких агентов), или даже удалить сообщения из почтового ящика. Сервер должен автоматически послать уведомление об изменении размера почтового ящика, если такое изменение произошло в процессе выполнения команды. Сервер должен автоматически послать уведомление об изменении флагов сообщений, не требуя соответствующего запроса клиента. Имеются специальные правила для оповещения клиента сервером об удалении сообщений, чтобы избежать ошибок синхронизации (смотри также описание EXPUNGE). Программа клиента должна своевременно фиксировать изменения размера почтового ящика. Она не должна полагаться на то, что любая команда после начального выбора почтового ящика возвращает значение его размера.Разрыв контрольного соединения
Разрыв контрольного соединения может быть инициирован LAC или LNS и выполняется путем посылки одного управляющего сообщения StopCCN. Получатель StopCCN должен послать ZLB ACK, чтобы подтвердить получение сообщения, и поддерживает состояние управляющего соединения на уровне достаточном для корректного приема StopCCN, а также повторения цикла, если ZLB ACK потеряно. Рекомендуемое время повторения цикла равно 31 секунде (смотри раздел 5.8). Ниже приводится типовой обмен управляющими сообщениями:LAC или LNS LAC или LNS
StopCCN ->
(Clean up)
| <- ZLB ACK | |
| (Wait) | |
| (Clean up) |
Программа может ликвидировать туннель и все сессии туннеля путем посылки StopCCN. Таким образом, не нужно прерывать каждую сессию, если разорван туннель.
Реализация LP через специфическую среду
Протокол L2TP является само документируемым, работающим поверх уровня, который служит для транспортировки. Однако, необходимы некоторые детали подключения к среде, для того чтобы обеспечить совместимость различных реализаций.Реализация "пушистый шарик" (Fuzzball)
Локальные часы "пушистый шарик" представляют собой комбинация аппаратных и программных регистров, а также алгоритмов, которые осуществляют функционирование часов - работу управляемого задающего генератора, синхронизуемого от внешнего источника. Долее следует описание его компонент и способа работы. Заметим, что все числа представлены в представлении дополнений до 2, а все сдвиги являются арифметическими (заполнение знаком при сдвиге вправо и нулем при сдвиге влево).48-битовый часовой регистр (clock) и 32-битовый предварительный счетчик (prescaler) образуют управляемый задающий генератор с периодом 1 мс. Дробная часть кода времени представляет число миллисекунд с начала суток. 32-битовый регистр коррекций (Clock-Adjust) используется для подстройки фазы часов постепенными шагами, что исключает неоднородности временной шкалы. Его содержимое обозначается x. 32-битовый регистр компенсации дрейфа (Skew-Compensation) используется для подстройки частоты задающего генератора с помощью добавления небольших фазовых сдвигов (0,01%). Его содержимое обозначается символом y. 16-битовый счетчик оповещения (Watchdog) и 32-битный регистр согласования (Compliance) используются для определения корректности и служит также для задания периода рассылки запросов. Содержимое регистра согласования обозначается символом z. 32-битовый регистр настройки (PPS-Adjust) служит для подстройки точности, когда имеется точный источник сигналов с периодом в одну секунду. 2-битовый регистр флагов управляет добавлением/вычитанием секунд к показаниям часов, когда это необходимо.
Все регистры кроме предварительного счетчика обычно размещаются в памяти. В типовом интерфейсе часов, таком как DEC KWV11-C, регистр prescaler реализован в виде 16-битового буферного счетчика, управляемого кварцевым генератором с частотой, кратной 1000 Гц. Переполнение счетчика вызывает прерывание процессора, которое осуществляет приращение содержимого регистра часов.
Когда наступает момент подстройки, CLOCK.ADJ секунд вычитается из содержимого PPS-счетчика, но это CLOCK.ADJ делается лишь при условии, что там лежит число больше нуля. CLOCK.ADJ добавляется к коду счетчика Watchdog. Этот код не должен превышать значения NTP.MAXAGE, поделенного на CLOCK.ADJ. Если счетчик Watchdog достигнет этой величины, часы считаются не синхронизованными, а Leap-биты устанавливаются равными 112.
Режимы работы
За исключением широковещательного режима, NTP-ассоциация формируется, когда два партнера обмениваются сообщениями и один или оба из них создает и поддерживает протокольную машину, называемую ассоциацией. Ассоциация может работать в одном из 5 режимов, заданных переменной peer.mode: симметрично активный, симметрично пассивный, клиент, сервер и широковещательный:Симметрично активный (1). ЭВМ, работающая в этом режиме, периодически посылает сообщения вне зависимости от достижимости или слоя своего партнера. При работе в этом режиме ЭВМ оповещает о своем намерении синхронизовать и быть синхронизованной партнером.
Симметрично пассивный (2). Этот тип ассоциации первоначально создается по прибытии сообщения от партнера, работающего в симметрично активном режиме. Он сохраняется, пока партнер достижим и функционирует в слое ниже или равном данной ЭВМ. В противном случае ассоциация распадается. Однако ассоциация будет существовать до тех пор, пока, по крайней мере, одно сообщение не будет послано в качестве отклика. При работе в этом режиме ЭВМ оповещает о своем намерении синхронизовать и быть синхронизованной партнером.
Клиент (3). ЭВМ, работающая в этом режиме, периодически посылает сообщения вне зависимости от достижимости или слоя своего партнера. При работе в этом режиме ЭВМ, обычно это сетевая рабочая станция, оповещает о своем намерении быть синхронизованной партнером.
Сервер (4). Этот тип ассоциации первоначально создается по прибытии запроса клиента и существует только для отклика на этот запрос. После отклика ассоциация ликвидируется. При работе в этом режиме ЭВМ, обычно рабочая сетевая станция, оповещает о намерении синхронизовать партнера.
Широковещательный (5). ЭВМ, работающая в этом режиме, периодически посылает сообщения вне зависимости от доступности или слоя партнеров. При работе в этом режиме ЭВМ, обычно сетевой сервер времени, который работает в широковещательной среде, оповещает о намерении синхронизовать всех партнеров.
ЭВМ, работающая в режиме клиента, иногда посылает NTP-сообщение ЭВМ, работающей в режиме сервера, например, сразу после перезагрузки и периодически после этого.
Сервер откликается, меняя адреса и номера портов, занося необходимую информацию и отправляя сообщение назад клиенту. Серверы не должны хранить какую-либо статусную информацию в паузах между запросами клиента, в то время как клиенты могут варьировать интервалы между NTP сообщениями, для того чтобы удовлетворить локальным требованиям. В этих режимах протокольная машина, описанная в этой статье, может быть существенно упрощена без заметной потери точности или надежности особенно при работе в быстродействующей локальной сети.
В симметричных режимах отличие клиента от сервера практически исчезает. Симметрично пассивный режим предназначен для использования временными серверами, работающими вблизи базовых узлов (нижний слой) субсети синхронизации и со сравнительно большим числом партнеров. В этом режиме идентификации партнера не требуется заранее, так как ассоциация с ее переменными состояния создана, только когда получено NTP-сообщение. Более того, запомненное состояние может быть использовано позднее, когда партнер станет недостижим или будет работать на более высоком уровне и по этой причине будет непригоден в качестве источника синхронизации.
Симметрично активный режим предназначен для использования серверами времени, работающими вблизи оконечных узлов (наивысший слой) синхронизации. Надежный временной сервис обычно может быть реализован с помощью двух партнеров на ближайшем нижележащем слое и одном партнере в том же слое. По этой причине поток сообщений обычно невелик, даже когда связь потеряна, и на каждый запрос приходит отклик об ошибке.
В норме, один партнер работает в активном режиме (симметричный активный, клиент или широковещательный), как это сконфигурировано в стартовом файле, в то время как другие работают в пассивном режиме (симметричный пассивный или сервер), часто без предварительной конфигурации. Однако оба партнера могут быть сконфигурированы для работы в симметричном режиме. Условие ошибки возникает, когда оба партнера работают в одном и том же режиме, но не в симметричном активном.В таких случаях каждый партнер будет игнорировать сообщения, поступающие от другого, и ассоциация, если она существовала, будет ликвидирована из-за недостижимости партнера.
Широковещательный режим предназначен для работы в скоростных локальных сетях с большим числом рабочих станций, где не требуется высокая точность. При типичном сценарии один или более временных серверов LAN периодически посылают широковещательные сообщения рабочим станциям, которые затем определяют время на основе предварительно заданной задержки распространения порядка нескольких миллисекунд.
Этот протокол маршрутизации предназначен для
4.4.11.1 Внутренний протокол маршрутизации RIPСеменов Ю.А. (ГНЦ ИТЭФ)
Этот протокол маршрутизации предназначен для сравнительно небольших и относительно однородных сетей (алгоритм Белмана-Форда). Протокол разработан в университете Калифорнии (Беркли), базируется на разработках фирмы Ксерокс и реализует те же принципы, что и программа маршрутизации routed, используемая в ОC Unix (4BSD). Маршрут здесь характеризуется вектором расстояния до места назначения. Предполагается, что каждый маршрутизатор является отправной точкой нескольких маршрутов до сетей, с которыми он связан. Описания этих маршрутов хранится в специальной таблице, называемой маршрутной. Таблица маршрутизации RIP содержит по записи на каждую обслуживаемую машину (на каждый маршрут). Запись должна включать в себя:
IP-адрес места назначения.
Метрика маршрута (от 1 до 15; число шагов до места назначения).
IP-адрес ближайшего маршрутизатора (gateway) по пути к месту назначения.
Таймеры маршрута.
Первым двум полям записи мы обязаны появлению термина вектор расстояния (место назначение - направление; метрика - модуль вектора). Периодически (раз в 30 сек) каждый маршрутизатор посылает широковещательно копию своей маршрутной таблицы всем соседям-маршрутизаторам, с которыми связан непосредственно. Маршрутизатор-получатель просматривает таблицу. Если в таблице присутствует новый путь или сообщение о более коротком маршруте, или произошли изменения длин пути, эти изменения фиксируются получателем в своей маршрутной таблице. Протокол RIP должен быть способен обрабатывать три типа ошибок:
Малое предельное значение метрики улучшает сходимость, но не устраняет проблему.
Несоответствие маршрутной таблицы реальной ситуации типично не только для RIP, но характерно для всех протоколов, базирующихся на векторе расстояния, где информационные сообщения актуализации несут в себе только пары кодов: адрес места назначение и расстояние до него. Пояснение проблемы дано на рис. 4.4.1.11.1 ниже.

Рис. 4.4.11.1. Иллюстрация, поясняющее возникновение циклических маршрутов при использовании вектора расстояния.
На верхней части рисунка показана ситуация, когда маршрутизаторы указывают маршрут до сети в соответствии со стрелками. На нижней части связь на участке GW1 оборвана, а GW2 по-прежнему продолжает оповещать о ее доступности с числом шагов, равным 2. При этом GW1, восприняв эту информацию (если GW2 успел передать свою маршрутную информацию раньше GW1), может перенаправить пакеты, адресованные сети А, на GW2, а в своей маршрутной таблице будет характеризовать путь до сети А метрикой 3. При этом формируется замкнутая петля маршрутов. Последующая широковещательная передача маршрутных данных GW1 и GW2 не решит эту проблему быстро. Так после очередного обмена путь от gw2 до сети А будет характеризоваться метрикой 5. Этот процесс будет продолжаться до тех пор, пока метрика не станет равной 16, а это займет слишком много циклов обмена маршрутной информацией.
Проблема может быть решена следующим образом. Маршрутизатор запоминает, через какой интерфейс получена маршрутная информация, и через этот интерфейс эту информацию уже не передает. В рассмотренном выше примере GW2 не станет посылать информацию о пути к сети А маршрутизатору GW1, от которого он получил эти данные. В этом случае в маршрутной таблице GW1 путь до А исчезнет сразу. Остальные маршрутизаторы узнают о недостижимости сети А через несколько циклов. Существуют и другие пути преодоления медленных переходных процессов. Если производится оповещение о коротком пути, все узлы-получатели воспринимают эти данные немедленно.
Если же маршрутизатор закрывает какой- то путь, его отмена фиксируется остальными лишь по тайм-ауту. Универсальным методом исключения ошибок при маршрутизации является использование достаточно большой выдержки, перед тем как использовать информацию об изменении маршрутов. В этом случае к моменту изменения маршрута эта информация станет доступной всем участникам процесса маршрутизации. Но все перечисленные методы и некоторые другие известные алгоритмы, решая одну проблему, часто вносят другие. Многие из этих методов могут при определенных условиях вызвать лавину широковещательных сообщений, что также дезорганизует сеть. Именно малая скорость установления маршрутов в RIP (и других протоколах, ориентированных на вектор расстояния) и является причиной их постепенного вытеснения другими протоколами.
Но даже усовершенствование, изложенное выше, не всегда срабатывает. На рис. 4.4.11.1а приведен пример, когда переходной процесс, несмотря на усовершенствование будет идти долго. При обрыве связи В-Г узлы А и Б сообщают узлу В, что они потеряли связь с узлом Г. Узел В делает вывод, что Г не достижим, о чем и сообщает узлам А и Б. К сожалению А знает, что Б имеет проход к Г длиной 2, из чего он делает вывод о достижимости Г за три шага. Аналогично рассуждает Б о возможности достижимости Г через А. Далее при последующих рассылках метрика доступности Г, характеризуется все большими значениями, до тех пор пока не станет равной "бесконечности".

Рис. 4.4.11.1а. Пример топологии, где переходной процесс осуществляется медленно, даже при усовершенствовании алгоритма.
В RIP сообщения инкапсулируются в udp-дейтограммы, при этом передача осуществляется через порт 520. В качестве метрики RIP использует число шагов до цели. Если между отправителем и приемником расположено три маршрутизатора (gateway), считается, что между ними 4 шага. Такой вид метрики не учитывает различий в пропускной способности или загруженности отдельных сегментов сети. Применение вектора расстояния не может гарантировать оптимальность выбора маршрута, ведь, например, два шага по сегментам сети ethernet обеспечат большую пропускную способность, чем один шаг через последовательный канал на основе интерфейса RS-232.
Маршрут по умолчанию имеет адрес 0.0.0.0 (это верно и для других протоколов маршрутизации). Каждому маршруту ставится в соответствие таймер тайм-аута и "сборщика мусора". Тайм-аут-таймер сбрасывается каждый раз, когда маршрут инициализируется или корректируется. Если со времени последней коррекции прошло 3 минуты или получено сообщение о том, что вектор расстояния равен 16, маршрут считается закрытым. Но запись о нем не стирается, пока не истечет время "уборки мусора" (2мин). При появлении эквивалентного маршрута переключения на него не происходит, таким образом, блокируется возможность осцилляции между двумя или более равноценными маршрутами. Формат сообщения протокола RIP имеет вид, показанный на рис. 4.4.11.2. Поле команда определяет выбор согласно следующей таблице:
Таблица 4.4.11.1. Значения кодов поля команда
| Команда | Значение |
| 1 | Запрос на получение частичной или полной маршрутной информации; |
| 2 | Отклик, содержащий информацию о расстояниях из маршрутной таблицы отправителя; |
| 3 | Включение режима трассировки (устарело); |
| 4 | Выключение режима трассировки (устарело); |
| 5-6 | Зарезервированы для внутренних целей sun microsystem. |
Инициализация, определение всех "живых" интерфейсов путем посылки запросов, получение таблиц маршрутизации от других маршрутизаторов. Часто используются широковещательные запросы.
Получен запрос. В зависимости от типа запроса высылается адресату полная таблица маршрутизации, или проводится индивидуальная обработка.
Получен отклик. Проводится коррекция таблицы маршрутизации (удаление, исправление, добавление).

Рис. 4.4.11.2.
Формат сообщения RIP.
Регулярные коррекции. Каждые 30 секунд вся или часть таблицы маршрутизации посылается всем соседним маршрутизаторам. Могут посылаться и специальные запросы при локальном изменении таблицы. RIP достаточно простой протокол, но, к сожалению не лишенный недостатков:
Протокол RIP-2 (RFC-1388, 1993 год) является новой версией RIP, которая в дополнение к широковещательному режиму поддерживает мультикастинг; позволяет работать с масками субсетей. На рис. 4.4.11.3 представлен формат сообщения для протокола RIP-2. Поле маршрутный демон является идентификатором резидентной программы-маршрутизатора. Поле метка маршрута используется для поддержки внешних протоколов маршрутизации, сюда записываются коды автономных систем. При необходимости управления доступом можно использовать первые 20 байт с кодом набора протоколов сети 0xFFFF и меткой маршрута =2. Тогда в остальные 16 байт можно записать пароль.

Рис. 4.4.11.3 Формат сообщений протокола RIP-2
Проблемы аутентификации в протоколе RIP-2 c использованием дайджестов MD5 обсуждаются в документе RFC-2082
Rut_
4.4.11 Протоколы маршрутизации (обзор, таблицы маршрутизации, вектор расстояния)Семенов Ю.А. (ГНЦ ИТЭФ)
| Номер раздела | Название раздела | Объем в страницах | Объем в кбайт |
| 4.4.11.1 | 5 | 5 | |
| 4.4.11.2 | 16 | 164 | |
| 4.4.11.3 | 7 | 28 | |
| 4.4.11.4 | 10 | 89 | |
| 4.4.11.5 | 1 | 4 | |
| 4.4.11.6 | 1 | 4 | |
| 4.4.11.7 | 5 | 17 | |
| 4.4.11.8 | 46 | 196 | |
| 4.4.11.9 | 6 | 27 |

| Дорожные указатели могут превратить шоссе в лабиринт Станислав Ежи Лец, "Непричесанные мысли" |
Основная задача сетей - транспортировка информации от ЭВМ-отправителя к ЭВМ-получателю. В большинстве случаев для этого нужно совершить несколько пересылок. Проблему выбора пути решают алгоритмы маршрутизации. Если транспортировка данных осуществляется дейтограммами, для каждой из них эта задача решается независимо. При использовании виртуальных каналов выбор пути выполняется на этапе формирования этого канала. В Интернет с его IP-дейтограммами реализуется первый вариант, а в ISDN - второй.
Алгоритм маршрутизации должен обладать вполне определенными свойствами: надежностью, корректностью, стабильностью, простотой и оптимальностью. Последнее свойство не так прозрачно, как это может показаться на первый взгляд, все зависит от того, по какому или каким параметрам производится оптимизация. Эта задача иногда совсем не проста даже для сравнительно простых локальных сетей (смотри, например, рис. 4.4.11.1). Предположим, что поток данных между ЭВМ b и d, соединенных через концентратор (К) весьма высок, что окажет ощутимое влияние на скорость обмена между ЭВМ А и С. Но этот факт довольно трудно выявить, находясь в ЭВМ А или С. Внешне это проявится лишь как повышенная задержка и пониженная пропускная способность участка А-С.

Рис. 4.4.11.1
Среди параметров оптимизации может быть минимальная задержка доставки, максимальная пропускная способность, минимальная цена, максимальная надежность или минимальная вероятность ошибки.
Алгоритмы маршрутизации бывают адаптивными и неадаптивными.
Вторые, осуществляя выбор маршрута, не принимают во внимание существующую в данный момент топологию или загрузку каналов. Такие алгоритмы называются также статическими. Адаптивные же алгоритмы предполагают периодическое измерение характеристик каналов и постоянное исследование топологии маршрутов. Выбор того или иного маршрута здесь производится на основании этих измерений.
Практически все методы маршрутизации базируются на следующем утверждении (принцип оптимальности). Если маршрутизатор M находится на оптимальном пути от маршрутизатора I к маршрутизатору J, тогда оптимальный путь от М к J проходит по этому пути. Чтобы убедиться в этом обозначим маршрут I-M R1, а m-j - R2. Если существует маршрут оптимальнее, чем R2, то он должен быть объединен с R1, чтобы образовать более оптимальный путь I-J, что противоречит исходному утверждению об оптимальности пути J-J. Следствием принципа оптимальности является утверждение, что оптимальные маршруты от всех отправителей к общему месту назначения образуют дерево, лишенное циклов (см. разделы и ). Такое дерево (называется sink tree) может быть не единственным, могут существовать другие деревья с теми же длинами пути. А это, в свою очередь означает, что любой пакет будет доставлен за строго ограниченное время, пройдя однократно определенное число маршрутизаторов
Главным параметром при маршрутизации пакета в Интернет является ip-адрес его места назначения. Проблема оптимальной маршрутизации в современном Интернет, насчитывающем уже более десяти миллионов узлов, весьма сложна. Полная таблица маршрутов может содержать 107! записей (здесь ! означает знак факториала, а не выражение эмоций), что не по плечу не только сегодняшним ЭВМ.
Обычный пользователь не задумывается и не должен задумываться над проблемами маршрутизации, но даже ему иногда может оказаться полезным понимать, что возможно, а что невозможно в Интернет. Нужно только четко разделять работу протоколов маршрутизации, которые формируют маршрутные таблицы, и процесс маршрутизации пакетов, когда эти таблицы используются.
IP делит все ЭВМ на маршрутизаторы и обычные ЭВМ (host), последние, как правило, не рассылают свои маршрутные таблицы. Предполагается, что маршрутизатор владеет исчерпывающей информацией о правильных маршрутах (хотя это и не совсем так). Обычная ЭВМ имеет минимальную маршрутную информацию (например, адрес маршрутизатора локальной сети и сервера имен). Автономная система может содержать множество маршрутизаторов, но взаимодействие с другими as она осуществляет только через один маршрутизатор, называемый пограничным (border gateway, именно он дал название протоколу bgp). Пограничный маршрутизатор нужен лишь тогда, когда автономная система имеет более одного внешнего канала, в противном случае его функции выполняет порт внешнего подключения (gateway). Если адресат достижим более чем одним путем, маршрутизатор должен сделать выбор, этот выбор осуществляется на основании оценки маршрутов-кандидатов. Обычно каждому сегменту, составляющему маршрут, присваивается некоторая величина - оценка этого сегмента. Каждый протокол маршрутизации использует свою систему оценки маршрутов. Оценка сегмента маршрута называется метрикой. Здесь следует обратить внимание на то, что при выборе маршрута всем сегментам пути должны быть даны сопоставимые значения метрики. Недопустимо, чтобы одни сегменты оценивались числом шагов, а другие - по величине задержки в миллисекундах. В пределах автономной системы это обычно не создает проблем, ведь это зона ответственности одного администратора. Но в региональных сетях, где работает много администраторов, проблема выбора метрики может стать реальной трудностью. Именно по этой причине в таких сетях часто используется вектор расстояния, исключающий субъективность оценок метрики.
Помимо классической схемы маршрутизации по адресу места назначения, часто используется вариант выбора маршрута отправителем (данный вариант получил дальнейшее развитие при введении стандарта IPv6). В этом случае IP-пакет содержит соответствующий код опции и список промежуточных адресов узлов, которые он должен посетить по пути к месту назначения.
Существуют и другие схемы, например, использующие широковещательные методы адресации (flooding), где каждый приходящий пакет посылается по всем имеющимся исходящим каналам, за исключением того, по которому он получен. С тем чтобы исключить беспредельное размножение пакетов в заголовок вводится поле-счетчик числа шагов. В каждом узле содержимое поле уменьшается на единицу. Когда значение поля становится равным нулю, пакет ликвидируется. Исходное значение счетчика определяется размером субсети. Предпринимаются специальные меры против возможного зацикливания пакетов. Существует усовершенствованная версия широковещательной маршрутизации, называемая селективной широковещательной рассылкой. В этом алгоритме рассылка производится не по всем возможным направлениям, а только по тем, которые предположительно ведут в правильную сторону. Широковещательные методы не относятся к широко применимым. Но они используются там, где нужна предельно возможная надежность, например в военных приложениях, когда весьма вероятно повреждение тех или иных каналов. Данные методы могут использоваться лишь при формировании виртуального канала, ведь они всегда обеспечивают наикратчайший путь, так как перебираются все возможности. Если путь записывается в пакете, получатель может выбрать оптимальный проход и уведомить об этом отправителя.
Большинство алгоритмов учитывают топологию связей, а не их качество (пропускную способность, загрузку и пр.). Но существуют подходы к решению проблемы статической маршрутизации, учитывающие как топологию, так и загрузку (flow-based routing). В некоторых сетях потоки между узлами относительно стабильны и предсказуемы. В этом случае появляется возможность вычислить оптимальную схему маршрутов заранее. Здесь на основе теории массового обслуживания производится оценка средней задержки доставки для каждой связи. Топология маршрутов оптимизируется по значению задержки доставки пакета. Исходными данными при расчете считается описание топологии связей, матрица трафика для всех узлов Ti,j (в пакетах в секунду) и матрица пропускных способностей каналов Bi,j в битах в секунду.
Задержка t для каждой из связей оценивается по формуле
ti,j = 1/(p*bi,j - ti,j),
где 1/Р - среднее значение ширины пакета в битах, произведение p*bi,j выражается в пакетах в секунду, а t измеряется в мсек. Сформировав матрицу ti,j, можно получить граф кратчайших связей. Так как вычисления производятся не в реальном масштабе времени, особых трудностей здесь не возникает.
Статические протоколы (примером реализации статических протоколов может служить первая версия маршрутизатора Netblazer) предполагают, что любые изменения в маршрутные таблицы вносит администратор сети. Рассмотрим для примера сеть, изображенную на рис. 4.4.11.2.

Рис. 4.4.11.2 Схема для иллюстрации методики составления маршрутных таблиц.
g1, g2, g3 - Маршрутизаторы
Примитивная таблица маршрутизации для приведенного примера может иметь вид (для маршрутизатора g2):
| Сеть-адресат | Маршрут к этой сети |
| 193.0.0.0 | Прямая доставка |
| 193.148.0.0 | Прямая доставка |
| 192.0.0.0 | Через адрес 193.0.0.1 |
| 192.166.0.0 | Через адрес 193.148.0.7 |
Алгоритм выбора маршрута универсален и не зависит от протокола маршрутизации, который используется лишь для формирования маршрутной таблицы. Описание алгоритма выбора маршрута представлено ниже:
Извлечь IP-адрес (ID) места назначения из дейтограммы.
Вычислить IP-адрес сети назначения (IN)
IF INсоответствует какому-либо адресу локальной сети, послать дейтограмму по этому адресу;
else if in присутствует в маршрутной таблице, то послать дейтограмму к серверу, указанному в таблице;
else if описан маршрут по умолчанию, то послать дейтограмму к этому серверу;
else выдать сообщение об ошибке маршрутизации.
Если сеть включает в себя субсети, то для каждой записи в маршрутной таблице производится побитная операция для ID и маски субсети. Если результат этой операции совпадет с содержимым адресного поля сети, дейтограмма посылается серверу субсети. На практике при наличии субсетей в маршрутную таблицу добавляются соответствующие записи с масками и адресами сетей.
Одна из базовых идей маршрутизации заключается в том, чтобы сконцентрировать маршрутную информацию в ограниченном числе (в идеале в одном) узловых маршрутизаторов-диспетчеров. Эта замечательная идея ведет к заметному увеличению числа шагов при пересылке пакетов. Оптимизировать решение позволяет backbone (опорная сеть), к которой подключаются узловые маршрутизаторы. Любая as подключается к backbone через узловой маршрутизатор.
"Прозрачные" backbone не работают с адресами класса С (все объекты такой сети должны иметь один адрес, а для c-класса число объектов слишком ограничено). "Прозрачные" мосты трудно диагностировать, так как они не следуют протоколу ICMP (команда ping не работает, в последнее время такие объекты снабжаются snmp-поддержкой). За то они позволяют перераспределять нагрузку через несколько маршрутизаторов, что невозможно для большинства протоколов.

Рис. 4.4.11.3.
В примере, приведенном на рис. 4.4.11.3, задача маршрутизации достаточно сложна. ЭВМ1,2 и ЭВМ6,1 можно связать многими путями: ЭВМ1,2 - GW1 - ЭВМ6,1; ЭВМ1,2 - GW2 - ЭВМ6,1; ЭВМ1,2 - GW3 - ЭВМ6,1; ЭВМ1,2 - GW4 - ЭВМ6,1; ЭВМ1,2 - GW1 - GW2 - GW3 - ЭВМ6,1; и т.д.
Трафик между двумя географически близкими узлами должен направляться кратчайшим путем, вне зависимости от направления глобальных потоков. Так ЭВМ1,2 и ЭВМ1,1 должны соединяться через GW1. Маршрутизация через опорные сети (backbone) требует индивидуального подхода для каждого узла. Администраторы опорных сетей должны согласовывать свои принципы маршрутизации. Ситуация, когда узел не владеет исчерпывающей маршрутной информацией, в сочетании с использованием маршрутов по умолчанию может привести к зацикливанию пакетов. Например, если маршрут по умолчанию в GW1 указывает на GW2, а в GW2 на GW1, то пакет с несуществующим адресом будет циркулировать между gw1 и gw2 пока не истечет ttl (время жизни пакета), полностью блокируя канал. По этой причине желательно иметь полную таблицу маршрутизации, и, если не вынуждают обстоятельства, избегать использования маршрутов по умолчанию.

Рис. 4.4.11.4.
Протоколы маршрутизации отличаются друг от друга тем, где хранится и как формируется маршрутная информация. Оптимальность маршрута достижима лишь при полной информации обо всех возможных маршрутах, но такие данные потребуют слишком большого объема памяти. Полная маршрутная информация доступна для внутренних протоколов при ограниченном объеме сети. Чаще приходится иметь дело с распределенной схемой представления маршрутной информации. Маршрутизатор может быть информирован лишь о состоянии близлежащих каналов и маршрутизаторов.
Динамические протоколы (обычно используются именно они, наиболее известным разработчиком является компания CISCO):
В маршрутизаторе с динамическим протоколом (например, BGP-4) резидентно загруженная программа-драйвер изменяет таблицы маршрутизации на основе информации, полученной от соседних маршрутизаторов. В ЭВМ, работающей под UNIX и выполняющей функции маршрутизатора, эту задачу часто решает резидентная программа gated или routed (демон). Последняя - поддерживает только внутренние протоколы маршрутизации.
Применение динамической маршрутизации не изменяет алгоритм маршрутизации, осуществляемой на IP-уровне.
Программа-драйвер при поиске маршрутизатора-адресата по- прежнему просматривает таблицы. Любой маршрутизатор может использовать два протокола маршрутизации одновременно, один для внешних связей, другой - для внутренних.
Любая автономная система (AS, система маршрутизаторов, ЭВМ или сетей, имеющая единую политику маршрутизации) может выбрать свой собственный протокол маршрутизации.
Внутренний протокол маршрутизации IGP (Interior Gateway Protocol) определяет маршруты внутри автономной системы. Наиболее популярный IGP - RIP (Routing Information Protocol, RFC-1058), разработан Фордом, Фулкерсоном и Белманом (фирма XEROX). Существует более новый протокол OSPF (Open Shortest Pass First, RFC-1131, -1245, -1247, -1253). Наиболее старые системы (IGP) используют протокол HELLO. Протокол HELLO поддерживался фирмой DEC, в качестве метрики он использует время, а не число шагов до цели. Для взаимодействия маршрутизаторов используются внешние протоколы (EGP - Exterior Gateway Protocols).
Одной из разновидностей EGP является протокол BGP (Border Gateway Protocol, RFC-1268 [BGP-3], RFC-1467 [BGP-4]).
Протокол IGRP (Interior Gateway Routing Protocol) разработан компанией CISCO для больших сетей со сложной топологией и сегментами, которые обладают различной полосой пропускания и задержкой. Это внутренний протокол маршрутизации имеет некоторые черты сходства с OSPF.
IGRP использует несколько типов метрики, по одной на каждый вид QOS. Метрика характеризуется 32-разрядным числом. В однородных средах этот вид метрики вырождается в число шагов до цели. Маршрут с минимальным значением метрики является предпочтительным. Актуализация маршрутной информации для этого протокола производится каждые 90 секунд. Если какой-либо маршрут не подтверждает своей работоспособности в течение 270 сек, он считается недоступным. После семи циклов (630 сек) актуализации такой маршрут удаляется из маршрутных таблиц. IGRP аналогично OSPF производит расчет метрики для каждого вида сервиса (TOS) отдельно.
Протокол IDPR (InterDomain Policy Routing Protocol, RFC-1477, -1479) представляет собой разновидность BGP-протокола.
Протокол IS-IS ( Intermediate System to Intermediate System Protocol, RFC-1195, -1142) является еще одним внутренним протоколом, который используется для маршрутизации CLNP (Connectionless Network Protocol, RFC-1575, -1561, -1526). IS-IS имеет много общего с OSPF. Смотри также .
Сразу после включения маршрутизатор не имеет информации о возможностях соседних маршрутизаторов. Статичесикие маршрутные таблицы могут храниться в постоянной памяти или загружаться из какого-то сетевого сервера. По этой причине первейшей задачей маршрутизатора является получение маршрутной информации от соседей, а для начала выявление наличия соседей и их адресов. Для этой цели посылается специальный пакет Hello через каждый из своих внешних интерфейсов. В ответ предполагается получить отклик, содержащий идентификационную информацию соответствующего маршрутизатора. Когда два или более маршрутизаторов объединены через локальную сеть, ситуация несколько усложняется. Смотри рис. 4.4.11.5. Маршрутизаторы E, F, G и H подключены непосредственно к локальной сети, некоторые из них имеют связи с другими маршрутизаторами (сети, которые они обслуживают, на рисунке не показаны).
Одним из способов смоделировать локальную сеть - рассматривать маршрутизаторы E, F, G и H, как соединеные непосредственно, введя виртуальный узел сети L (выделен зеленым цветом). На правой части рисунка показан граф такой сети. Возможность прохода из узла F к G обозначена путем FLG. Для протоколов, учитывающих состояние канала, желательно иметь исчерпывающую информацию о нем (загрузка, задержка, пропускная способность, надежность, стоимость и т.д.). Некоторые из перечисленных параметров довольно легко измерить, например, задержку. Для этого вполне пригоден протокол ICMP. К сожалению многие из указанных параметров довольно сильно коррелированы и подвержены флуктуациям. В частности результаты измерения задержки зависят от загрузки канала (вариация времени ожидания в очереди).

Рис. 4.4.11.5. Маршрутизаторы, подключенные к локальной сети
Рассмотрим трафик на пути А-Н. Допустим на основании анализа состояния канал выбран путь через узел Е. В этом случае он может оказаться перегружен, что приведет к большим задаржкам пакетов на пути А-Н. Последующий анализ ситуации может привести к тому, что более оптимальным может оказаться маршрут через узел F. Если будет принято решение переключить трафик на маршрут ACFH, может перегрузиться участок АСF и история повторится. Данный сценарий описывает типичную ситуацию с осцилляциями маршрута. Осцилляции маршрутов не так безобидны, как это может показаться. Маршрутные таблицы в маршрутизаторах актуализуются вдоль пути с заметными задержками и отнюдь не синхронно. Такие осцилляции могут в разы понизить пропускную способность сети, что необходимо учитывать, выбирая параметры протоколов маршрутизации.
К сожалению многие современные протоколы маршрутизации не имеют встроенных средств аутентификации (контроля доступа), что делает их уязвимыми для различных злоупотреблений.
В последнее время все больше людей обзаводятся компактными переносимыми ЭВМ, которые они берут с собой в деловые поездки, и хотели бы использовать в привычном режиме для работы в Интернет. Конечно, можно заставить модем дозвониться до вашего модемного пула в офисе, но это не всегда лучшее решение как по надежности так и по цене. Пользователи с точки зрения их подвижности могут быть разделены на три группы:
Предполагается, что все эти пользователи имеют свою постоянную приписку к какой-то сети и соответствующий постоянный IP-адрес. (см. RFC-2794 "Mobile IP Network Access Identifier Extension for IPv4. P. Calhoun, C. Perkins. March 2000). На рис. 4.4.11.6 показана схема подключения подвижных пользователей к Интернет.
В этой схеме предполагается наличие в каждой области сети Интернет внешнего агента, обеспечивающего доступ к этой зоне подвижных ЭВМ (на рисунке такой агент помечен надписью "чужая LAN"). Доступ может осуществляться через мобильную телефонную сеть. Предполагается также наличие соответствующего агента в "домашней" LAN, куда стационарно приписана данная ЭВМ. Домашний агент отслеживает все перемещения своих пользователей, в том числе и тех, кто подключается к "чужим" LAN.

Рис. 4.4.11.6. Схема подключения к Интернет подвижных объектов
Когда к локальной сети подключается новый пользователь (непосредственно физически или через модем сотовой телефонной сети), он должен там зарегистрироваться. Процедура регистрации включает в себя следующие операции:
Когда пользователь покидает зону обслуживания данной LAN или MAN, регистрация должна быть анулирована, а ЭВМ должна быть автоматически зарегистрирована в новой зоне. Когда посылается пакет мобильному пользователю, "домашняя LAN", получив его, маршрутизирует пакет внешнему агенту, зарегистрировавшему данного пользователя. Этот агент переправит пакет адресату.
Процедуры переадресации выполняются с привлечением технологии IP-туннелей.
Домашний агент предлагает отправителю посылать пакеты непосредственно внешнему агенту области, где зарегистрирована подвижная ЭВМ. Существует много вариантов реализации протокола с разным распределением функций между маршрутизаторами и ЭВМ. Существуют схемы и временным выделением резервного IP-адреса подвижному пользователю. Международный стандарт для решения проблемы работы с подвижными пользователями пока не разработан.
В локальных или корпоративных сетях иной раз возникает необходимость разослать некоторую информацию всем остальным ЭВМ-пользователям сети (штормовое предупреждение, изменение курса акций и т.д.). Отправителю достаточно знать адреса всех N заинтересованных пользователей и послать им соответствующее сообщение. Данная схема крайне не эффективна, ведь обычная широковещательная адресация предлагает решение в N раз лучше с точки зрения загрузки сети (посылается одно а не N сообщений). Широковещательная адресация сработает, если в локальной сети нет маршрутизаторов, в противном случае широковещательные адреса МАС-типа заменяются на IP-адреса (что, впрочем, не слишком изящное решение) или применяется мультикастинг адресация. Маршрутизация для мультикастинга представляет собой отдельную задачу. Ведь здесь надо проложить маршрут от отправителя к большому числу получателей. Традиционные методы маршрутизации здесь применимы, но до крайности не эффективны. Здесь для целей выбора маршрута можно с успехом применить алгоритм "расширяющееся дерево" (spanning tree; не имеет циклических структур). Когда на вход маршрутизатора приходит широковещательный пакет, он проверяет, является ли интерфейс, через который он пришел, оптимальным направлением к источнику пакета. Если это так, пакет направляется через все внешние интерфейсы кроме того, через который он пришел. В противном случае пакет игнорируется (так как скорее всего это дубликат). Этот алгоритм называется Reverse Path Forwarding (переадресация в обратном направлении). Пояснение работы алгоритма представлено на рис. 4.4.11.7 (прямоугольниками на рис.
обозначены маршрутизаторы). Секция I характеризует топологию сети. Справа показано дерево маршрутов для маршрутизатора I (sink tree). Секция III демонстрирует то, как работает алгоритм Reverse Path Forwarding. Сначала I посылает пакеты маршрутизаторам B, F, H, J и L. Далее посылка пакетов определяется алгоритмом.

Рис. 4.4.11.7. Алгоритм Reverse Path Forwarding
При передаче мультимедиа информации используются принципиально другие протоколы маршрутизации. Здесь путь прокладывается от получателя к отправителю, а не наоборот. Это связано с тем, что там при доставке применяется мультикастинговый метод. Здесь, как правило, один отправитель посылает пакеты многим потребителям. При этом важно, чтобы размножение пакета происходило как можно ближе к кластеру адресатов. Такая стратегия иной раз удлинняет маршрут, но всегда снижает результирующую загрузку сети. Смотри описания протоколов и .
В последнее время конфигурирование сетевого оборудования (маршрутизаторов, DNS и почтовых серверов усложнилось нкастолько, что это стало составлять заметную часть издержек при формировании коммуникационного узла. Заметного упрощенияи удешевления маршрутизаторов можно ожидать при внедрении IPv6. Следующим шагом станет внедрение объектно-ориентированного языка описания маршрутной политики RPSL (Routing Policy Specification Language). Здесь конфигурирование маршрутизатора будет осуществляться на основе описанной маршрутной политики.
Теперь немного подробнее о наиболее популярных протоколах маршрутизации - RIP, OSPF, IGRP и BGP-4. Начнем с внутреннего протокола маршрутизации RIP.
Set-Link-Info (SLI)
Сообщение Set-Link-Info является управляющим сообщением L2TP, посланным от LNS к LAC для установления согласуемых опций PPP. Эти опции можно изменять в любое время на протяжении реализации вызова, таким образом, LAC должен быть способен обновлять свою собственную информацию вызова и поведение на протяжении активной PPP-сессии. Следующие AVP должны присутствовать в SLI:Тип сообщения (Message Type)
ACCM
Системные переменные
Следующие переменные используются операционной системой для синхронизации локальных часов.Переменная локальные часы (sys.clock) содержит показание локальных часов в формате временных меток. Локальное время получается от аппаратных часов конкретной ЭВМ и дискретно увеличивается с конструктивно заданными приращениями.
Переменная Базовые часы (sys.peer) представляет собой селектор, идентифицирующий используемый источник синхронизации. Обычно это указатель на структуру, содержащую переменные партнера. Значение нуль указывает, что в настоящее время источник синхронизации отсутствует.
Системные статусные слова
Системное статусное слово может присутствовать в статусном поле отклика. Системное статусное слово имеет следующий формат.Индикатор добавления (LI - leap indicator) - двухбитовое поле предупреждения о предстоящем добавлении/вычитании секунды к последней минуте текущего дня. Значения этих битов смотри в таблице 4.4.15.1.
Источник часов (clock source) - 6-битовое поле, указывающее на используемый в данный момент источник синхронизации. Назначение кодов этого поля описано в таблице 4.4.15.6.
Таблица 4.4.15.6. Коды источников временного эталона
| Код | Функция |
| 0 | Не специфицирован или неизвестен |
| 1 | Калиброванные атомные часы (напр., hp 5061) |
| 2 | vlf (диапазон 4) или НЧ (диапазон 5) радио (напр., omega, wwvb) |
| 3 | ВЧ (диапазон 7) радио (напр., chu, msf, wwv/h) |
| 4 | УВЧ (диапазон 9) спутник (напр., goes, gps) |
| 5 | Локальная сеть (напр., dcn, tsp, dts) |
| 6 | UDP/NTP |
| 7 | UDP/time |
| 8 | eyeball-and-wristwatch |
| 9 | Телефонный модем (напр., nist) |
| 10-63 | Зарезервировано на будущее |
Системный счетчик событий - четырех битовое целое число, обозначающее число событий, происшедших с момента последнего получения статусного слова системы. Счетчик обнуляется, когда присылается в статусном поле отклика и остается неизменным после достижения значения 15.
Код системного события - четырехбитовое число, идентифицирующее последнее системное событие, новое значение переписывает предыдущее. Коды событий перечислены в таблице 4.4.15.7.
Таблица 4.4.15.7. Коды системных событий
| Код | Функция |
| 0 | Не специфицировано |
| 1 | Рестарт системы |
| 2 | Системный или аппаратный сбой |
| 3 | Новое статусное слово системы (изменение битов добавления или синхронизации) |
| 4 | Новый источник синхронизации или слой (изменение sys.peer или sys.stratum) |
| 5 | Сброс системных часов (корректирующая добавка превысила clock.max) |
| 6 | Некорректное системное время или дата |
| 7 | system clock exception |
| 8-15 | Зарезервировано на будущее |
Слово состояния часов
Существует два способа подключить эталонные часы к NTP-серверу, как специальный прибор, поддерживаемый операционной системой или как партнера, управляемого NTP. Как и в случае команды чтения статуса идентификатор ассоциации определяет, часы какого из партнеров имеются в виду. При нулевом идентификаторе речь идет о системных часах. Протокол поддерживает только одни системные часы, число часов-партнеров практически не ограничено. Статусное слово часов системы или партнера записывается в поле статуса отклика на команды чтения или записи переменных, характеризующих часы. Это слово может рассматриваться как расширение системного статусного слова или статусного слова партнера. Формат слова описан ниже (См. также рис. 4.4.15.3).Состояние часов - 8-битовое число, характеризующее текущее состояние часов. Допустимые значения этого числа и их смысл представлены в таблице 4.4.15.11.
Таблица 4.4.15.11. Коды состояния часов
| Код | Функция |
| 0 | Работа часов в пределах нормы |
| 1 | Таймаут ответа |
| 2 | Плохой формат ответа |
| 3 | Сбой оборудования или программы |
| 4 | Потеря при передаче |
| 5 | Неверный формат или значение даты |
| 6 | Неверный формат или значение времени |
| 7-255 | Зарезервировано на будущее |
Код события для часов - 8-битовый код, идентифицирующий последнее событие для данных часов (exception). Новое значение переписывает предыдущее значение кода. Когда значение кода становится ненулевым для поля статуса радио-часов, этот код копируется в статусное поле кода события и считается, что произошло событие для системных часов или часов партнера.
Слово состояния ошибки
Статусное слово ошибки присылается в поле статуса отклика, если обнаружена ошибка в формате сообщения или в его содержимом. Его присутствие указывается равенствами E (error) и R (response) битов 1. Коды ошибки и их значения собраны в таблице 4.4.15.12.Таблица 4.4.15.12. Коды ошибки
| Код ошибки | Значение |
| 0 | Не специфицировано |
| 1 | Неудачная аутентификация |
| 2 | Неверный формат или длина сообщения |
| 3 | Неверный код операции |
| 4 | Неизвестный идентификатор ассоциации |
| 5 | Неизвестное имя переменной |
| 6 | Неверное значение переменной |
| 7 | Административно запрещено |
| 8-255 | Зарезервировано на будущее |
Соглашение о пространстве имен почтовых ящиков
В соответствии с соглашением первый иерархический элемент любого имени почтового ящика, который начинается с символа "#" указывает на “пространство имен” остальной части имени. Например, реализации, которые предлагают доступ к группам новостей USENET могут использовать пространство имен "#news", для того чтобы отделить пространство имен групп новостей от имен других почтовых ящиков. Таким образом, группа новостей comp.mail.misc будет иметь имя почтового ящика "#news.comp.mail.misc", а имя "comp.mail.misc" может относиться к другому объекту (напр., к почтовому ящику пользователя).Сокрытие значений атрибутов AVP
Бит H в заголовке каждой AVP предлагает механизм указания принимающему партнеру, представлено ли содержимое AVP скрытым или открытым текстом. Эта возможность применяется, чтобы скрыть важную информацию управляющих сообщений, такую как пароль пользователя или его ID.Бит H должен быть равен 1, если имеется общий ключ для LAC и LNS. Этот ключ является тем же ключом, который использовался для аутентификации туннеля (смотри раздел 5.1.1). Если бит H =1 в любой AVP в данном управляющем сообщении, там должен также присутствовать случайный вектор AVP и должен предшествовать первому AVP, имеющему H = 1.
Сокрытие значения AVP делается за несколько шагов. Сначала берутся поля длины и значения оригинала (открытый текст) AVP и кодируются согласно субформата скрытого AVP:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Длина значения оригинала | Значение оригинала атрибута | ||||||||||||||||||||||||||||||
| Продолжение значения оригинала атрибута | Заполнитель |
Рис 5. Субформат скрытого AVP
Исходная длина значения атрибута. Это длина кода исходного значения атрибута, которое следует закрыть, в октетах. Необходимо определить исходную длину значения атрибута, так как ее значение теряется при добавлении заполнителя.
Исходное значение атрибута. Значение атрибута, которое должно быть скрыто.
Заполнитель. Произвольные дополнительные октеты, используемые для того, чтобы скрыть длину значения атрибута, когда необходимо скрыть само значение.
Чтобы замаскировать размер скрытого поля данных, используемый субформат может быть дополнен некоторым количеством произвольных октетов. Заполнитель не меняет значения поля, но изменяет величину поля длина AVP, которое было сформировано. Например, если значение атрибута, которое необходимо скрыть, занимает 4 октета, исходная длина AVP будет равна 10 октетам (6 + длина поля значения атрибута). После операции сокрытия, длина AVP станет равной 6 + длина атрибута + размер поля длины исходного значения атрибута + длина заполнителя. Таким образом, если заполнитель имеет 12 октетов, длина AVP будет равна 6 + 4 + 2 + 12 = 24 октетам.
Далее, производится хэширование (MD5) для полученного объединения:
+ 2 октета номера атрибута AVP
+ общий секретный ключ
+ случайный вектор произвольной длины
Значение случайного вектора, используемого в этом хэше, передается в поле случайный вектор AVP. Этот случайный вектор AVP должен быть помещен в сообщение отправителем до любого скрытого AVP. Тот же самый случайный вектор может быть использован для более чем одного скрытого AVP сообщения. Если для сокрытия последующих AVP используется другой случайный вектор, тогда новый случайный вектор AVP должен быть помещен в командное сообщение до первого его использования.
Значение хэша MD5 затем объединяется с помощью операции XOR с первыми 16 октетами сегмента субформата скрытого AVP и помещается в поле значения атрибута скрытого AVP. Если субформат скрытого AVP имеет менее 16 октетов, субформат преобразуется так, как если бы поле значения атрибута было дополнено до 16 октетов перед операцией XOR, но модифицируются только действительные октеты, присутствующие в субформате, а длина AVP не изменяется.
Если субформат длиннее 16 октетов, вычисляется второй хэш MD5 для потока октетов, состоящего из общего секретного ключа, за которым следует результат первой операции XOR. Этот хэш объединяется с помощью операции XOR со вторым 16 октетным (или менее) сегментом субформата, а результат помещается в соответствующие октеты поля значения скрытого AVP.
Если необходимо, эта операция повторяется, для общего секретного ключа, используемого совместно с каждым результатом операции XOR, чтобы получить очередной хэш, для которого будет выполняться XOR с кодом следующего сегмента.
Метод сокрытия был адаптирован из RFC 2138 [RFC2138], который был взят из секции "Mixing in the Plaintext" книги "Network Security" Кауфмана, Пелмана и Спенсера [KPS]. Ниже дается детальное пояснение метода:
Берется общий секретный ключ S, случайный вектор RV и значение атрибута AV. Поле значение делится на секции по 16 октетов p1, p2 и т.д..
Последняя секция дополняется до границы в 16 октетов специальным заполнителем. Вычисляются блоки шифротекста c(1), c(2), и т.д.. Мы также определяем промежуточные значения b1, b2, и т.д.
| b1 = MD5(AV + S + RV) | c(1) = p1 xor b1 |
| b2 = MD5(S + c(1)) | c(2) = p2 xor b2 |
| . | . |
| . | . |
| . | . |
| bi = MD5(S + c(i-1)) | c(i) = pi xor bi |
По получение, случайный вектор берется из AVP, включенного в сообщение до AVP, подлежащего сокрытию. Описанный выше процесс реверсируется с целью получения исходного значения.
Соображения безопасности
Протокольные операции IMAP 4.1, включая данные электронной почты, передаются через сеть открытым текстом, если только не согласовано применение конфиденциальных методов обмена посредством команды AUTHENTICATE.Сообщения об ошибках сервера для команды AUTHENTICATE, которая не прошла из-за неверных параметров аутентификации, не должна уточнять какой из параметров содержит ошибку.
Использование команды LOGIN осуществляет передачу паролей открытым текстом. Этого можно избежать, используя для этого команду AUTHENTICATE.
Заголовок IP идентификации [RFC-1826] и безопасная IP инкапсуляция [RFC-1827] будут использоваться в IPv6, в соответствии с безопасной архитектурой протоколов Интернет [RFC-1825].
Протокол L2TP сталкивается при своей работе с несколькими проблемами безопасности. Ниже рассмотрены некоторые подходы для решения этих проблем.
Соображения IANA
Этот документ определяет ряд "магических" числе, которые определяются IANA. Эта секция объясняет критерии, которые должна использовать IANA при присвоении дополнительных чисел в каждый из этих списков. Следующие субсекции описывают политику присвоения для пространства имен, определенных в данном документе.Адрес места назначения копируется из

Рис. 4.4.1.1.34. Формат сообщения о недостижимости адресата
Поля IPv6:
Адрес места назначения копируется из поля адрес отправителя пакета, вызвавшего ошибку.
Поля ICMPv6:
Тип = 1
Код = 0 - нет маршрута до места назначения
1 - связь с адресатом административно запрещена
2 - не сосед
3 - адрес не достижим
4 - порт не достижим
Не используется. Это поле не используется при всех значениях поля код. Оно должно быть обнулено отправителем и игнорироваться получателем.
Описание
Сообщение адресат не достижим (destination unreachable) должно генерироваться маршрутизатором, или уровнем IPv6 узла-отправителя, в случае, когда пакет не может быть доставлен адресату не по причине перегрузки. (Сообщение ICMPv6 не должно посылаться при потере пакета из-за перегрузки).
Если причиной потери пакета является недостаток места в маршрутной таблице узла, поле код должно принять значение 0 (Заметим, что такая ошибка может произойти только при наличии в таблице маршрута по умолчанию).
Если причиной потери пакета является административный запрет, например, Firewall, поле код принимает значение 1.
Если причиной потери пакета является то, что следующий узел в маршрутной таблице не является соседом данного узла, то поле код принимает значение 2.
Если имеет место какая-то другая причина недоставки пакета, в поле код заносится значение 3.
Узел места назначения может посылать сообщение “адресат не достижим” с кодом 4, когда транспортный протокол пакета (напр., UDP) не имеет получателя, а другого метода, уведомить об этом отправителя нет.
Узел, получивший сообщение ICMPv6 “адресат не достижим” должен уведомить об этом протокол вышележащего уровня.

Рис. 4.4.1.1.35. Сообщение packet too big (пакет слишком велик)
Поля IPv6:
Адрес места назначения копируется из поля адрес отправителя пакета, вызвавшего ошибку.
Поля ICMPv6:
Тип 2
Код 0
mtu mtu следующего шага.
Описание
Сообщение packet too big (пакет слишком велик) должно посылаться маршрутизатором в ответ на получение пакета, который не может быть переадресован, из-за того, что он длиннее, чем MTU выходного канала.
Информация в этом сообщении используется в качестве части процесса определения MTU прохода [RFC-1191].
Пришедшее сообщение packet too big должно быть передано протоколу верхнего уровня.
Формат сообщения о превышении времени аналогичен формату сообщения о недостижимости адресата (рис. 4.4.1.1.33).
Поля ICMPv6:
Тип 3
Код 0 - при передаче превышен лимит числа шагов
1 - превышено время восстановления сообщения из фрагментов.
Не используется. Это поле не используется при всех значениях поля код. Оно должно быть обнулено отправителем и игнорироваться получателем.
Описание
Если маршрутизатор получает пакет с предельным значением числа шагов равным нулю (hop limit = 0), или маршрутизатор после декрементации получил нулевое значение поля hop limit, он должен выбросить такой пакет и послать отправителю пакета сообщение ICMPv6 о превышении времени (time exceeded) со значением поля код равным 0. Это указывает на зацикливание маршрута или на слишком малое значение поля hop limit.
Посылая сообщение ICMPv6 о превышении времени (time exceeded) со значением поля код равным нулю, маршрутизатор должен рассматривать входной интерфейс, в соответствии с правилом выбора адреса отправителя (d).
Пришедшее сообщение time exceeded должно быть передано протоколу верхнего уровня.

Рис. 4.4.1.1.36. Сообщение о конфликте параметров
Поля ICMPv6:
Тип 4
Код 0 - встретилась ошибка в поле заголовка
1 - встретился неопознанный код поля следующий заголовок
2 - встретилась неопознанная опция IPv6
Указатель. Идентифицирует смещение в октетах в пакете, вызвавшем ошибку.
Указатель отмечает позицию в пакете, если размер пакета ICMPv6 не позволяет поместить его в отклик полностью, а ошибочное поле в сообщение не поместилось.
Описание
Если узел IPv6, обрабатывающий пакет, обнаруживает какую-то проблему с одним из полей заголовка или заголовков расширения, такую, что дальнейшая обработка невозможна, он должен выбросить пакет и послать сообщение ICMPv6 parameter problem (проблема с параметрами) отправителю пакета с указанием типа и позиции ошибки.
Поле указатель идентифицирует октет заголовка исходного пакета, где обнаружена ошибка. Например, сообщение ICMPv6 с полем тип = 4, полем код = 1 и полем указатель = 40 указывает на то, что заголовок расширения IPv6, следующий за заголовком IPv6 исходного пакета содержит нераспознанный код следующего заголовка.
Сообщения об ошибках Resv
Сообщения ResvErr (reservation error) сообщают об ошибках при обработке сообщений Resv, или о спонтанном нарушении резервирования, напр., в результате административного вмешательства.Сообщения ResvErr направляются соответствующим получателям, они маршрутизируются от узла к узлу с использованием состояния резервирования. В каждом из узлов в качестве IP-адреса места назначения используется уникастный адрес следующего узла.
[