Руководство по реляционной субд DB2
А.ЗЦЕЛОСТНОСТЬ РЕЛЯЦИОННЫХ ДАННЫХ
Одно важное следствие из определений, приведенных в предыдущем разделе, заключается в том, что каждое отношение имеет первичный ключ. Поскольку отношение — это множество, а множества по определению не содержат совпадающих элементов, никакие два кортежа отношения в произвольный заданный момент времени не могут быть дубликатами друг друга. Пусть R — отношение с атрибутами A1, A2, ..., An. Говорят, что множество атрибутов К= (Ai, Aj, ..., Ak)
отношения R является возможным ключом R тогда и только тогда, когда удовлетворяются два следующих независимых от времени условия:
1. Уникальность:
В произвольный заданный момент времени никакие два различных кортежа R не имеют одного и того же значения для Ai, Aj, ..., Ak.
2. Минимальность:
Ни один из атрибутов Ai, Aj, ..., Ak не может быть исключен из К без нарушения условия уникальности.
Каждое отношение обладает по крайней мере одним возможным ключом, поскольку по меньшей мере комбинация всех его атрибутов удовлетворяет условию уникальности. Один произвольным образом выбранный возможный ключ для данного отношения принимается за его первичный ключ. Остальные возможные ключи, если они имеются, называются альтернативными
ключами.
Пример.
Предположим, что как фамилии поставщиков, так и их номера являются уникальными — никакие два поставщика не имеют одного и того же номера или одной и той же фамилии. Тогда отношение S имеет два возможных ключа — НОМЕР_ПОСТАВЩИКА и ФАМИЛИЯ. Выберем НОМЕР_ПОСТАВЩИКА в качестве первичного ключа. Тогда ФАМИЛИЯ будет альтернативным ключом. Отметим, однако, что система DB2 не располагает какими-либо знаниями ни о первичном, ни об альтернативных ключах как таковых, хотя добиться уникальности можно с помощью предложения CREATE UNIQUE INDEX (см. раздел 3.3).
Продолжая обсуждение данного примера, рассмотрим атрибут НОМЕР_ПОСТАВЩИКА отношения SP. Ясно, что появление заданного значения этого атрибута, скажем, S1, в базе данных должно допускаться, только если это же значение входит как значение первичного ключа НОМЕР_ПОСТАВЩИКА в отношение S. В противном случае нельзя считать, что база данных находится в целостном состоянии. Такой атрибут, как SР.НОМЕР_ПОСТАВЩИКА, называется внешним
ключом. В общем случае внешний ключ — это атрибут или комбинация атрибутов одного отношения R2, значение которого обязательно должно совпадать со значением первичного ключа некоторого другого отношения R1, причем не требуется, чтобы R1 и R2 были различны. Заметим, что внешний ключ и соответствующий ему первичный ключ должны быть определены на одних и тех же доменах.
Теперь мы можем сформулировать два правила целостности для реляционной модели.
Примечание. Эти правила являются общими в том смысле, что от любой базы данных, которая согласуется с этой моделью, требуется удовлетворение этих правил. Однако для любой конкретной базы данных будет иметься множество дополнительных специфических правил, которые относятся к ней одной. Например, для базы данных поставщиков и деталей может иметься специфическое правило, требующее, чтобы объемы поставок находились, к примеру, в диапазоне от 1 до 9999. Но такие специфические правила выходят за рамки самой по себе реляционной модели.
1. Целостность по сущностям.
Не допускается, чтобы какой-либо атрибут, участвующий в первичном ключе базового отношения, принимал неопределенные значения.
2. Целостность по ссылкам.
Если базовое отношение R2 включает некоторый внешний ключ FK, соответствующий первичному ключу РК какого-либо базового отношения R1, то каждое значение FK в R2 должно либо а) быть равным значению РК в некотором кортеже R1, либо б) должно быть полностью неопределенным, т. е. каждое значение атрибута, участвующее в этом значении FK, должно быть неопределенным. При этом R1 и R2 не обязательно различны.
Базовое отношение соответствует тому, что мы назвали в тексте этой книги базовой таблицей: это — независимое именованное отношение (дальнейшее обсуждение см. в главе 3). Мотивировка правила целостности по сущностям заключается в следующем:
1. Базовые отношения соответствуют сущностям в реальном мире. Например, базовое отношение S соответствует множеству поставщиков в реальном мире.
2. Сущности в реальном мире по определению отличимы, т. е. они имеют некоторого рода уникальную идентификацию.
3. В реляционной модели функцию уникальной идентификации выполняют первичные ключи.
4. Таким образом, ситуация, когда первичный ключ принимает неопределенное значение, была бы, по существу, противоречивой — это, в действительности, говорило бы о том, что имеется некоторая сущность, которая не обладает индивидуальностью, и, следовательно, не существует. Отсюда название «целостность по сущностям».
Относительно второго правила («целостность по ссылкам») ясно, что для заданного значения внешнего ключа должно иметься соответствующее значение первичного ключа в некотором кортеже отношения, на которое производится ссылка, если это значение внешнего ключа не является неопределенным. Иногда, однако, необходимо допустить, чтобы внешний ключ принимал неопределенные значения. Предположим, например, что в данной компании может иметь место ситуация, когда некоторый служащий в настоящее время не назначен вообще ни в какой отдел. Для такого служащего атрибут — номер отдела, являющийся внешним ключом, должен был бы иметь неопределенное значение в кортеже, представляющем этого служащего в рассматриваемой базе данных.
Мы должны будем еще поговорить о первичных и внешних ключах в Приложении В.
АМАНИПУЛИРОВАНИЕ РЕЛЯЦИОННЫМИ ДАННЫМИ
Манипулятивная часть реляционной модели состоит из множества операций, получивших в совокупности название реляционной алгебры, и реляционной операции присваивания, которая присваивает значение некоторого произвольного выражения этой алгебры другому отношению. Обсудим сначала реляционную алгебру.
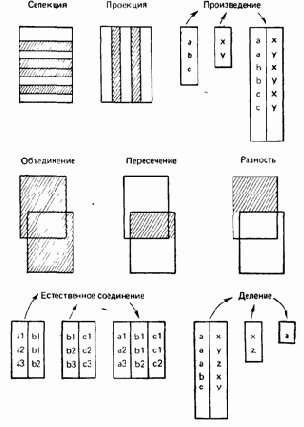
Каждая операция реляционной алгебры использует одно или два отношения в качестве ее операндов и продуцирует в результате некоторое новое отношение. Первоначально Кодд определил восемь таких операций, две группы по четыре операции в каждой: 1) традиционные теоретико-множественные операции объединения, пересечения, разности и декартова произведения, которые были несколько модифицированы с тем, чтобы принять во внимание тот факт, что их операнды являются отношениями, а не произвольными множествами и 2) специальные реляционные операции селекции, проекции, соединения и деления. Эти восемь операций символически показаны на рис. А.2. Ниже дается краткое определение каждой из них. Для простоты в этих определениях предполагается, что в отношениях принимается упорядочение атрибутов слева направо — не потому, что это необходимо сделать, а для того, чтобы упростить обсуждение.
Риc. A.2.
Реляционная алгебра
Традиционные теоретико-множественные операции
В каждой из традиционных теоретико-множественных операций используются два операнда. Для всех операций, кроме декартова произведения, эти два операнда должны быть совместимыми по объединению, т. е. они должны быть одной и той же степени, например п, и i-e их атрибуты (i = 1, 2, ...,. п) должны быть связаны с одним и тем же доменом. Они не должны, однако, иметь одинаковое имя.
— Объединение
Объединением двух (совместимых по объединению) отношений А и В называется множество всех кортежей t, принадлежащих либо А, либо В, либо им обоим.
Пример в языке SQL:
SELECT НОМЕР_ПОСТАВЩИКА FROM S
UNION
SELECT НОМЕР_ПОСТАВЩИКА FROM SP;
— Пересечение
Пересечением двух (совместимых по объединению) отношений А и В называется множество всех кортежей t, каждый из которых принадлежит как А, так и В.
Пример в языке SQL;
SELECT НОМЕР_ПОСТАВЩИКА FROM S
WHERE EXISTS
(SELECT НОМЕР_ПОСТАВЩИКА FROM SP
WHERE SP.HOMEP_ПОСТАВЩИКА =
S.НОМЕР_ПОСТАВЩИКА);
— Разность
Разностью между двумя (совместимыми по объединению) отношениями А и В называется множество всех кортежей t, каждый из которых принадлежит А и не принадлежит В.
Пример в языке SQL:
SELECT НОМЕР_ПОСТАВЩИКА FROM S
WHERE NOT EXISTS
(SELECT НОМЕР_ПОСТАВЩИКА FROM SP
WHERE SP.HOMEP_ПОСТАВЩИКА =
S. НОМЕР_ПОСТАВЩИКА);
— Декартово произведение
Декартовым произведением двух отношений А и В называется множество всех кортежей t,
таких, что t является конкатенацией некоторого кортежа а,
принадлежащего А, и какого-либо кортежа t, принадлежащего В.
Пример в языке SQL:
SELECT S.*, SP.*
FROM S, SP;
Специальные реляционные операции
— Селекция
Пусть theta представляет собой любой допустимый оператор сравнения скаляров, например =, ¬ =,
>, >= и т. д. Theta-ceлекцией отношения А по атрибутам Х и Y называется множество всех кортежей t
из А, таких, что истинен предикат «t. X theta t. Y». Атрибуты Х и Y должны быть определены на одном и том же домене, и для этого домена оператор theta должен иметь смысл. Вместо атрибута Y может быть специфицирована константа. Таким образом, оператор theta-селекции позволяет получать «горизонтальное» подмножество заданного отношения, т. е. подмножество таких кортежей заданного отношения, для которых удовлетворяется специфицированный предикат.
Примечание. «Theta-селекцию» часто для краткости называют просто «селекцией». Но нужно отметить, что «селекция» — это не то же самое, что оператор SELECT языка SQL.
Пример в языке SQL:
SELECT *
FROM S
WHERE ГОРОД ¬= 'Лондон';
—— Проекция
Операция проекции позволяет получать «вертикальное» подмножество заданного отношения, т. е. такое подмножество, которое получается выбором специфицированных атрибутов с последующим исключением, если это необходимо, избыточных дубликатов кортежей, состоящих из значений выбранных атрибутов.
Пример в языке SQL: .
SELECT DISTINCT ЦВЕТ, ГОРОД
FROM P;
— Соединение
Пусть theta
имеет тот же смысл, что и в случае селекции. Тогда theta-соединением отношения А по атрибуту Х с отношением В по атрибуту Y называется множество всех кортежей t, таких, что t является конкатенацией какого-либо кортежа а, принадлежащего А, и какого-либо кортежа Ь,
принадлежащего В, и предикат «а. Х theta b. Y» принимает значение «истина». При этом атрибуты А.Х и B.Y должны быть определены на одном и том же домене, и оператор theta должен иметь смысл для этого домена.
Пример в языке SQL:
SELECT S.*, P.*
FROM S, P
WHERE S. ГОРОД > Р. ГОРОД;
Если оператор theta — равенство, то соединение называется эквисоединением. Из этого определения следует, что результат эквисоединения должен включать два идентичных атрибута. Если один из этих двух атрибутов исключается, что можно осуществить с помощью проекции, результат называется естественным соединением. Под неуточненным термином «соединение» обычно понимается естественное соединение.
— Деление
В ее простейшей форме, и только она здесь рассматривается, операция деления делит отношение степени два (делимое) на отношение степени один (делитель) и продуцирует результирующее отношение степени один (частное). Пусть делимое А имеет атрибуты Х и Y, а делитель В — атрибут Y. Атрибуты A.Y и B.Y должны быть определены на одном и том же домене. Результатом деления А на В является отношение С с единственным атрибутом X, таким, что каждое значение х этого атрибута С.Х появляется как значение А.Х и пара значений (х,у)
входит в А для всех значений у, входящих в В.
Пример в языке SQL:
SELECT DISTINCT НОМЕР_ПОСТАВЩИКА FROM SP, SP1
WHERE NOT EXISTS
(SELECT НОМЕР_ДЕТАЛИ
FROM P
WHERE NOT EXISTS
(SELECT * FROM SP, SP2
WHERE SP2. НОМЕР_ПОСТАВЩИКА =
SP1 .НОМЕР_ПОСТАВЩИКА
AND SP2. НОМЕР_ДЕТАЛИ = Р.НОМЕР_ДЕТАЛИ));
Здесь для простоты предполагается, что: а) отношение SP имеет только два атрибута, а именно НОМЕР_ПОСТАВЩИКА и НОМЕР_ДЕТАЛИ (атрибут КОЛИЧЕСТВО игнорируется) и б) отношение Р имеет только один атрибут — НОМЕР_ДЕТАЛИ (игнорируются атрибуты НАЗВАНИЕ, ЦВЕТ, ВЕС, ГОРОД). Первое из этих двух отношений делится на второе; в результате получается отношение с одним атрибутом НОМЕР_ПОСТАВЩИКА, в котором перечисляются номера поставщиков для тех поставщиков, которые поставляют все детали.
Целесообразно упомянуть, что из восьми рассмотренных операций только пять являются примитивами, а именно: селекция, проекция, декартово произведение, объединение и разность. Другие три операции могут быть определены через первые пять. Например, естественное соединение может быть выражено как проекция селекции декартова произведения. Однако эти три другие операции, особенно соединение, оказываются настолько полезными на практике, что хорошо было бы поддерживать их непосредственно, несмотря на то, что они не являются примитивами.
Обратимся теперь к реляционной операции присваивания. Цель этой операции заключается просто в том, чтобы дать возможность сохранять значение какого-либо алгебраического выражения, например соединения, в некотором более или менее постоянном месте. Ее можно смоделировать в языке SQL с помощью операций INSERT. . .SELECT. Предположим, например, что отношение XYZ имеет два атрибута, НОМЕР_ПОСТАВЩИКА и НОМЕР-ДЕТАЛИ. Предположим также, что в настоящее время
это
отношение пусто (не содержит никаких кортежей). Тогда предложение SQL:
INSERT INTO XYZ (НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ)
SELECT S. НОМЕР_ПОСТАВЩИКА, Р. НОМЕР_ДЕТАЛИ
FROM S, P
WHERE S. ГОРОД = Р. ГОРОД;
присваивает результат входящего в него предложения SELECT, а именно проекцию соединения, отношению XYZ.
В качестве заключения на рис. А.3 приводится сводка основных компонентов реляционной модели.
Структура данных
домены (значения)
n-арные отношения (атрибуты, кортежи)
ключи (возможные, первичные, альтернативные, внешние)
Целостность данных
1. значения первичных ключей не должны быть неопределенными
2. значения внешних ключей должны соответствовать значениям первичных ключей
(или быть неопределенными)
Манипулирование данными
реляционная алгебра
объединение, пересечение, разность, декартово произведение
селекция, проекция, соединение, деление
реляционное присваивание
Рис. А.3
. Реляционная модель
АРЕЛЯЦИОННАЯ СТРУКТУРА ДАННЫХ
Наименьшей единицей данных в реляционной модели является отдельное значение данных. Такие значения рассматриваются как атомарные, т. е. они неразложимы, когда дело касается данной модели. Доменом называется множество таких значений одного и того же типа. Например, домен номеров поставщиков — это множество допустимых номеров поставщиков, домен объемов поставки — множество всех целых, больших нуля и меньших, например 10000. Таким образом, домены представляют собой пулы, значений, из которых берутся фактические значения, появляющиеся в атрибутах (столбцах). Смысл доменов заключается в следующем. Если значения двух атрибутов берутся из одного и того же .домена, то, вероятно, имеют смысл сравнения, вовлекающие эти два атрибута, а следовательно, и соединения, объединения и т. д., поскольку они сравнимы друг с другом. Если, наоборот, значения двух атрибутов берутся из различных доменов, то сравнения и т. д., вовлекающие эти два атрибута, вероятно, лишены смысла. Например, следующий запрос в языке SQL:
SELECT S.*, SP.*
FROM S, SP
WHERE S. НОМЕР_ПОСТАВЩИКА = SP.HOMEP_ПОСТАВЩИКА;
по-видимому, имеет смысл в отличие от запроса:
SELECT S.*, SP.*
FROM S, SP
WHERE S.COCТОЯHИE = SP.КОЛИЧЕСТВО;
В системе DB2, однако, понятие домена как таковое не используется. Оба приведенных предложения SELECT представляют собой допустимые запросы в DB2.
Отметим, что домены по природе своей являются в большой степени концептуальными. Они могут явным образом храниться или не храниться в базе данных как фактические множества значений. Но они должны специфицироваться как часть определения базы данных (в системе, которая вообще поддерживает эту концепцию; однако большинство систем в настоящее время не выполняет такой функции), и определение каждого атрибута должно далее включать ссылку на соответствующий домен. Заданный атрибут может иметь то же самое имя, что и у соответствующего домена, или какое-либо иное имя. Он должен, очевидно, иметь другое имя, если в противном случае возникала бы какая-либо двусмысленность. Такая ситуация имела бы место, в частности, если два атрибута одного и того же отношения основывались бы на одном и том же домене (см. ниже определение отношения и обратите внимание на фразу «не обязательно, чтобы все они были различны»).
Теперь мы в состоянии определить термин «отношение». Отношение на доменах D1, D2, ..., Dn ( не обязательно, чтобы все они были различны) состоит из заголовка
и тела. Заголовок состоит из такого фиксированного множества атрибутов Al, A2, .... An, что существует взаимно однозначное соответствие между этими атрибутами Ai и определяющими их доменами Di (i== I, 2,.. .,n). Тело состоит из меняющегося во времени множества кортежей, где каждый кортеж состоит в свою очередь из множества пар атрибут—значение (Ai:Vi), (i= I, 2,..., n), по одной такой паре для каждого атрибута Ai в заголовке. Для любой заданной пары атрибут—значение (Ai:Vi). Vi является значением из единственного домена Di, который связан с атрибутом Ai.
Рассмотрим для примера, как соответствует этому определению отношение поставщиков S (рис.
1.3). Определяющими доменами являются домен номеров поставщиков, скажем, Dl, домен фамилий поставщиков D2, домен значений состояния поставщиков D3 и домен названий городов D4. Заголовок S состоит из атрибутов НОМЕР_ПОСТАВЩИКА (определяющий домен D1), ФАМИЛИЯ (домен D2), СОСТОЯНИЕ (домен D3) и ГОРОД (домен D4). Тело S состоит из множества кортежей: пять кортежей показаны на рис. 1.3, но это множество изменяется во времени, когда осуществляются обновления данного отношения. Каждый кортеж представляет собой множество, состоящее из четырех пар атрибут—значение, по одной такой паре для каждого из четырех атрибутов в заголовке. Например, кортеж для поставщика S1 состоит из следующих пар:
(НОМЕР_ПОСТАВЩИКА : 'S1')
(ФАМИЛИЯ : 'Смит')
(СОСТОЯНИЕ : 20)
(ГОРОД : 'Лондон')
(хотя в неформальном контексте обычно можно опустить имена атрибутов). И конечно, значение каждого атрибута действительно взято из соответствующего определяющего домена. Значение 'S1', например, взято из домена номеров поставщиков D1. Таким образом, S в действительности является отношением, согласно данному определению.
Для строгости заметим, что когда мы изображаем отношение, например S, в виде таблицы, как это было сделано на рис. 1.3, мы просто используем удобный метод для представления отношения на бумаге. Таблица и отношение в действительности — это не одно и то же, хотя в большей части данной книги предполагалось, что это так. Например, ясно, что строки таблицы упорядочены (от верхней к нижней), а кортежи отношения —нет: отношение — это математическое множество, а множества в математике не обладают каким-либо упорядочением. Подобным же образом упорядочены также столбцы таблицы (слева направо), а атрибуты отношения — нет.
Обратите внимание, что от определяющих доменов отношения не требуется, чтобы все они были различны. Уже было приведено много примеров, в которых определяющие домены не были различными. Так, результирующее отношение в примере 4.3.1 (глава 4) включает два атрибута, которые определены на домене названий городов.
Значение n — число атрибутов в отношении или, что то же самое, число определяющих доменов — называется степенью отношения. Отношение степени один называется унарным,
отношение степени два — бинарным,
отношение степени три — тернарным
.... а отношение степени п — п-арным.
В базе данных поставщиков и деталей отношения S, Р и SP имеют степени 4, 5 и 3 соответственно. Число кортежей в отношении называется кардинальным числом этого отношения. Кардинальные числа отношений S, Р и sp, представленных на рис. 1.5, равны соответственно 5, 6 и 12. Кардинальное число отношения изменяется во времени в отличие от его степени[27].
АРЕЛЯЦИОННЫЕ СИСТЕМЫ
Теперь, наконец, имеется возможность точно определить, что мы понимаем под реляционной системой управления базами данных (реляционной СУБД или, для краткости, реляционной системой). Дело в том, что в настоящее время никакая система не поддерживает реляционную модель во всей ее полноте — несколько систем приблизилось к этому, но большинство из них «спотыкается» на ограничениях целостности, если не где-либо еще. С другой стороны, было бы неразумно утверждать, что некоторая система — не реляционная, если она не поддерживает эту модель вплоть до последней детали. Но дело в том, что не все аспекты реляционной модели в равной степени важны. Конечно, некоторые из них критичны, а другие могут рассматриваться только как возможности, которые было бы «приятно иметь». Поэтому будем называть систему реляционной, если она поддерживает, по крайней мере:
— реляционные базы данных, т. е. базы данных, которые могут восприниматься пользователем как таблицы, и только как таблицы;
— операции селекции, проекции и соединения реляционной алгебры, не требуя при этом, чтобы каким-либо образом были предопределены физические пути доступа для поддержки этих операций[28].
Для строгости заметим, что для квалификации системы как реляционной не требуется, чтобы она обязательно поддерживала операции селекции, проекции и соединения в явном
виде. Здесь речь идет лишь о функциональных возможностях этих операций. Например, система DB2 обеспечивает функциональные возможности всех этих трех операций и многое сверх того средствами ее собственного оператора SELECT. Более важно отметить, что в соответствии с нашим определением система, которая поддерживает реляционные базы данных, но не поддерживает эти три операции, не квалифицируется как реляционная. Подобным же образом система, которая, например, позволяет пользователю осуществлять селекцию кортежей в соответствии со значениями некоторого атрибута X, только если этот атрибут индексирован, также не относится к числу реляционных, поскольку здесь требуется предварительно определить физические пути доступа.
Мы мотивируем наше определение следующим образом:
1. Хотя селекция, проекция и соединение не образуют полной алгебры, они представляют собой чрезвычайно полезное ее подмножество. Можно насчитать сравнительно немного практических задач, которые решаются с помощью полной алгебры, но неразрешимы с помощью только селекции, проекции и соединения.
2. Система, которая поддерживает реляционную структуру данных, но не поддерживает реляционных операций, не обеспечивает продуктивности настоящих реляционных систем.
3. Хорошая реализация реляционных операций требует, чтобы система осуществляла некоторую оптимизацию. Система, которая бы только в точности исполняла запрашиваемые пользователем операции более или менее примитивным образом, почти наверняка имела бы неприемлемую производительность. Таким образом, создание системы, которая бы эффективным образом реализовала потенциал реляционной модели, — это весьма нетривиальная задача.
В соответствии с нашим определением DB2 — реляционная система, хотя она и не поддерживает некоторых аспектов реляционной модели. То же самое можно сказать и о SQL/DS. Однако в настоящее время имеется ряд коммерческих систем, которые рекламируются как «реляционные», но вместе с тем не удовлетворяют сформулированным выше критериям. Мы предполагаем, что эти критерии полезны как средство, позволяющее четко разграничить подлинно реляционные и «реляционно-подобные» системы. «Реляционно-подобные» системы в действительности не реализуют преимущества реляционной модели. Таким образом, целесообразно проводить такое различие, поскольку оно гарантирует, что этикетка «реляционная» не будет вводить в заблуждение.
AВВЕДЕНИЕ
DB2 — это реляционная СУБД (для краткости «реляционная система»). Задача данного приложения состоит в том, чтобы точно пояснить, что означает это утверждение. По существу, реляционная система — это такая система, которая строится в соответствии с реляционной моделью
данных или по крайней мере в соответствии с основными принципами этой модели, а реляционная модель — это способ видения данных, т. е. предписание, определяющее, каким образом следует представлять данные и как манипулировать этим представлением. Точнее говоря, реляционная модель имеет дело с тремя аспектами данных: со структурой
данных, с целостностью данных и с манипулированием данными. Рассмотрим поочередно каждый из них соответственно в разделах А.2, А.З и А.4, а затем обсудим вопрос о том, что в точности представляет собой реляционная система (раздел А.5).
Примечание. В этом приложении используется по большей части формальная реляционная терминология. Для удобства читателя на рис. A.1 повторяются из главы 1 основные реляционные термины и их неформальные эквиваленты.
|
|
Формальные реляционные термины
|
Неформальные эквиваленты
|
|
Отношение
кортеж
атрибут
|
таблица
запись, строка
поле, столбец
Рис. A.1. Некоторые термины
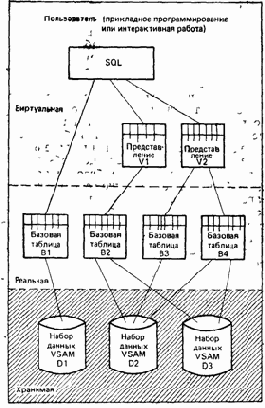
БАЗОВЫЕ ТАБЛИЦЫ
Базовая таблица — (важный) специальный случай более общего понятия «таблица». Поэтому давайте начнем с того, что несколько уточним это более общее понятие.
БАЗЫ ДАННЫХ
База данных в системе
DB2 представляет собой совокупность логически связанных объектов — хранимых таблиц, некоторым образом связанных друг с другом, вместе с относящимися к ним индексами и с множеством пространств, содержащих эти таблицы и индексы. Таким образом, база данных состоит из множества табличных пространств, каждое из которых содержит одну или несколько хранимых таблиц, а также множества индексных пространств, содержащих в точности по одному индексу. Как указывалось ранее, данная хранимая таблица и все связанные с нею индексы должны полностью содержаться в одной базе данных.
База данных представляет собой «старт-стопное устройство» в том смысле, что оператор может с консоли сделать данную базу данных доступной или недоступной для обработки с помощью соответствующих команд START и STOP. Следует отметить поэтому, что объекты группируются в одной и той же базе данных, главным образом, по причинам операционального характера. Пользователи (в нашем понимании этого термина) вообще не обязаны иметь дело с базами данных, и могут просто сосредоточиться на данных,
т. е. на таблицах — базовых таблицах и представлениях. Таблицы могут пересылаться из одной базы данных в другую, не оказывая какого-либо влияния на пользователей. И наконец, как уже указывалось в конце предыдущего раздела, база данных не является даже отдельным «физическим» объектом. В частности, она обычно не является отдельным диском или отдельным множеством дисков, а состоит, скорее, из частей многих дисков, другие части которых могут быть выделены для иных баз данных.
БУДУЩИЕ РАЗРАБОТКИ
Реляционные системы, например DB2, в значительно большей степени, чем нереляционные, подчеркнули различия между внешним и внутренним или, что равносильно, между логическим и физическим уровнями системы. На логическом уровне делается акцент на применяемость: система представляет простую структуру данных и простые операции для манипулирования этой структурой, и эта простота приводит к высокой производительности пользовательского труда, как было показано в разделе 16.2. На физическом же уровне делается акцент на свободу: разделение двух уровней означает, что на данной установке системы предоставляется свобода для осуществления нетривиальных изменений на физическом уровне таким образом, чтобы это не оказывало влияния на логический уровень, конечно, не считая производительности.
Возвращаясь теперь, в частности, к DB2, можно предположить, что в ближайшем будущем мы явимся свидетелями важных достижений, связанных с обоими уровнями. На физическом уровне должны быть, вероятно, обеспечены новые виды механизмов доступа (хеширование, цепочки указателей и т. д.) в качестве альтернативы существующему механизму индексирования. Для того чтобы учитывать эти новые структуры, должен быть также усовершенствован оптимизатор. Такие новые механизмы не должны быть, конечно, видимыми на логическом уровне. На логическом уровне должны быть, вероятно, реализованы расширения языка SQL, обеспечивающие непосредственную поддержку таких функций, как внешнее соединение. Можно ожидать также, что получит развитие поддержка целостности данных, особенно целостности по ссылкам (см. Приложения А и В).
В течение долгосрочного периода можно ожидать появления других далеко идущих разработок. Для того чтобы получить некоторое понятие о том, что они могут собой представлять, можно посмотреть, какие работы проводятся в настоящее время в некоторых университетских лабораториях и научно-исследовательских учреждениях. Фактически имеется большое число таких работ, и все они основаны на реляционной модели. К их числу относятся:
— системы распределенных баз данных
— совместно используемые машины баз данных
— семантическое моделирование
— включение новых видов данных (например, текстов, изображений)
— экспертные системы
— новые виды интерфейсов, в том числе естественный язык
— системы баз данных для инженерного дела и научных исследований и др. Некоторые из перечисленных выше разработок являются, конечно, значительно менее «долговременными», чем другие. Например, машины баз данных коммерчески доступны уже сегодня. То же можно сказать о системах, использующих естественный язык. Но дело в том, что по всем этим направлениям исследования продолжаются, и все они основаны на реляционном подходе. Кроме того, тот факт, что они строятся на реляционной основе, важен сам по себе. Многие из этих исследований едва ли были бы осуществимы на основе любого другого подхода. Таким образом, к приведенному в разделе 16.2 списку преимуществ реляционного подхода можно было бы добавить еще и расширяемость. Пользователи существующих реляционных систем находятся в лучшем положении (чем если бы они были пользователями системы некоторого иного вида) благодаря тому, что они смогут использовать достоинства новых технологий, когда они появятся.
По вопросу о распределенных системах интересно, в частности, отметить что научно-исследовательская лаборатория фирмы IBM в Сан-Хосе проводила в течение некоторого времени работу по созданию системы-прототипа под названием R* (произносится «Р-стар»). Система R* является распределенной версией более раннего прототипа, который назывался System R. В свою очередь, как уже указывалось в предисловии к этой книге, System R послужила базой для разработки программных продуктов DB2 и SQL/DS. Не исключается, таким образом, вероятность того, что технология системы R* когда-либо будет использована в распределенных версиях SQL/DS и DB2.
Тот факт, что все эти исследования основаны на реляционной модели, свидетельствует о всеобщем признании этой модели в академическом мире[26]. Совсем недавно реляционные идеи стали общепризнанными также и в коммерческих кругах. В поддержку этого утверждения можно указать на большое число объявленных в этой области новых программных продуктов, фактически почти каждый объявленный в последнее время программный продукт в области баз данных является либо «новенькой с иголочки» реляционной системой (такой, как DB2), либо «реляционным» расширением одной из более старых систем. (Здесь слово «реляционным» заключено в кавычки, поскольку всегда никоим образом неясно, что эти расширения на самом деле являются реляционными. См. обсуждение этого вопроса в Приложении А.) По заниженным оценкам в настоящее время на рынке имеется более сорока реляционных систем, в том числе большое их число для микроЭВМ, и нет сомнения, что это число, вероятно, значительно выросло за время, пока эта книга вышла из печати. И объявление системы DB2 фирмой IBM может в действительности лишь усилить влияние реляционной технологии в коммерческих кругах. Что касается управления базами данных, становится все более ясно — реляционные системы являются технологией будущего.
BВВЕДЕНИЕ
Проектирование баз данных — это крупный вопрос. Невозможно по-настоящему воздать ему должное в приложении, состоящем всего из нескольких страниц. Можно рассчитывать лишь на то, чтобы представить здесь общий подход, который был бы полезен в проектировании реляционных баз данных вообще и баз данных системы DB2 в частности. Многие конкретные вопросы останутся при этом без ответа. Мы надеемся, однако, что этот общий подход будет полезен как некоторая схема, в рамках которой пользователи могут пытаться самостоятельно отвечать на эти более конкретные вопросы.
Предполагается, что читателю хорошо знакомы и удобны такие термины, как «сущность», «связь» и «свойство». Эти термины можно неформально определить следующим образом:
— Сущность
представляет собой любой отличимый объект,
где объект, о котором идет речь, может быть настолько конкретным или абстрактным, насколько нам это нравится. Примерами сущностей могут служить люди, места, самолеты, рейсы, джаз, красный цвет и т. д. Конечно, в контексте базы данных сущности, которыми мы главным образом интересуемся,— это такие объекты, информацию о которых мы хотим хранить в базе данных.
— Связью
называется ассоциирование двух или более сущностей Примерами связей являются зачисления служащих в отделы (связь многие-к-одной) и поставка деталей поставщиками (связь многие-ко-многим).
—- Свойство —
это однозначный факт о некоторой сущности.
Примерами свойств являются зарплата служащих, вес деталей, объем поставок и т. п.
В следующем разделе будет приведена схема классификации сущностей, которая образует основу нашей методологии проектирования. После этого рассматриваются та важная роль, которую играют в проектировании баз данных первичные и внешние ключи, последовательность основных шагов, входящих в процедуру проектирования, предложения относительно способа формальной записи проектных решений, некоторые «рецепты», касающиеся отображения этих решений в формальные конструкции системы DB2. Обсуждаются также основные идеи нормализации, приводится краткий список разнообразных советов и рекомендаций.
Отметим в заключение еще один момент. Читатель, должно быть, уже понял, что термин «проектирование баз данных» используется здесь в смысле логического
проектирования. Этот факт вовсе не означает, что мы считаем физическое проектирование не настолько важным. Дело в том, что оно представляет собой самостоятельную задачу, которой можно и нужно заниматься отдельно после того, как выполнено логическое проектирование. Такая возможность строгого разделения указанным образом двух видов деятельности, связанных с логическим и физическим проектированием, является в действительности одним из основных достижений реляционной технологии.
ЧТО ТАКОЕ ТРАНЗАКЦИЯ
Транзакция в том смысле, в котором мы используем этот термин,— это логическая единица работы. Рассмотрим следующий пример (обобщенный вариант примера 6.2.4 из главы 6, представленный в форме встроенного SQL): заменить номер 'Sx' поставщика на 'Sy', где Sx и Sy — параметры. Для простоты опустим ряд проверок достоверности данных, которые обычно включаются в реальную программу. Кроме того, опустим все объявления.
TRANEX: PROC OPTIONS (MAIN); /* пример транзакции */
EXEC SQL WHENEVER SQLERROR GO TO UNDO;
GET LIST (SX, SY);
EXEC SQL UPDATE S
SET НОМЕР_ПОСТАВЩИКА = :SY
WHERE НОМЕР_ПОСТАВЩИКА = :SX;
EXEC SQL UPDATE SP
SET НОМЕР_ПОСТАВЩИКА == :SY
WHERE НОМЕР_ПОСТАВЩИКА = :SX;
EXEC SQL COMMIT;
GO TO FINISH;
UNDO: EXEC SQL ROLLBACK;
FINISH: RETURN;
END TRANEX;
Смысл данного примера заключается в том, что выражение «Заменить номер поставщика Sx на Sy», воспринимаемое конечным пользователем, вероятно, как единственная атомарная операция, требует на самом деле двух операций UPDATE над базой данных. Более того, между этими двумя операциями может даже нарушаться непротиворечивость базы данных. Например, в ней могут временно содержаться некоторые записи поставок, для которых не имеется соответствующих записей поставщиков. Заметим, что это наблюдение остается в силе, если изменить порядок исполнения двух операций UPDATE в приведенном примере. Таким образом, транзакция или логическая единица работы — не обязательно только одна операция языка SQL. В общем случае это, скорее, последовательность
нескольких таких операций, которая преобразует некоторое непротиворечивое состояние базы данных в другое непротиворечивое состояние, но не гарантирует сохранения непротиворечивости во все промежуточные моменты времени.
Ясно теперь, что в данном примере не следует допускать таких случаев, когда одна из двух операций
UPDATE исполняется, а другая — нет, поскольку при этом база данных осталась бы в состоянии, когда нарушена ее непротиворечивость. В идеальном случае нам хотелось бы, конечно, иметь твердые гарантии того, что обе операции UPDATE будут выполнены. К сожалению, обеспечить какие-либо гарантии такого рода невозможно. Всегда есть некоторый шанс, что могут возникнуть ошибки, и, более того, ошибки могут возникнуть в наихудший возможный момент. Например, аварийный отказ системы может иметь место между двумя операциями UPDATE, или сама программа может аварийно завершиться между этими двумя операциями, например в связи с ошибкой переполнения (в рассматриваемом случае такая ошибка невозможна). Однако система, которая поддерживает обработку транзакций, действительно является лучшей с точки зрения обеспечения таких гарантий. В частности, она гарантирует, что если в транзакции осуществлялись некоторые обновления и затем по какой-либо причине имела место ошибка до того, как транзакция достигла ее нормального завершения, то эти обновления будут аннулированы. Таким образом, транзакция либо полностью исполняется, либо полностью аннулируется, как будто бы она никогда не исполнялась вообще. При этом последовательность операций, не являющаяся по существу атомарной, может быть представлена таким образом, чтобы она выглядела (с точки зрения конечного пользователя) как если бы она в действительности была атомарной.
Администратор транзакций — это системный компонент, который обеспечивает такую атомарность или подобие атомарности, а операции COMMIT (фиксировать) и ROLLBACK (откат) полностью определяют способ его функционирования. Операция COMMIT сигнализирует об успешном завершении транзакции. Она сообщает администратору транзакций, что логическая единица работы была успешно завершена, что база данных снова находится (или должна находиться) в непротиворечивом состоянии, и все произведенные этой единицей работы обновления могут быть теперь «зафиксированы», т. е. приняты за свершившиеся. Напротив, команда ROLLBACK сигнализирует о неудачном завершении транзакции. Она сообщает администратору транзакций, что что-то испортилось, что непротиворечивое состояние базы данных, возможно, нарушено и что для всех произведенных до сих пор данной логической единицей работы обновлений следует сделать «откат», т. е. аннулировать их. Под «обновлением» здесь понимаются, конечно, операции INSERT и DELETE, а также сами по себе операции UPDATE.
В приведенном примере команда COMMIT издается, следовательно, в том случае, если успешно проведены обе операции UPDATE, в результате чего изменения будут фиксироваться в базе данных и принимаются за свершившиеся. Если, однако, что-нибудь испортится, т. е. для какой-либо из операций UPDATE возвращаемое значение SQLCODE будет отрицательным, то вместо этого издается ROLLBACK с тем, чтобы аннулировать сделанные до сих пор изменения. В приведенном примере операции COMMIT и ROLLBACK издаются явным образом. Однако, как указывалось в конце главы 10, для любой исполняемой в обстановке системы DB2 программы при ее нормальном завершении будет автоматически издаваться COMMIT. В противном случае для нее автоматически будет издаваться ROLLBACK, независимо от причины аварийного завершения программы. Если, в частности, программа аварийно завершается в связи со сбоем системы, ROLLBACK издается от имени этой программы при рестарте системы. Следовательно, в приведенном примере можно было бы опустить явно специфицированное предложение COMMIT, но не следует опускать явного предложения ROLLBACK.
Примечание. Читатель может заинтересоваться, каким образом возможно аннулировать обновление. Ответ заключается, конечно, в том, что система ведет журнал, в который записываются подробности всех операций обновления, в частности значения до и после обновления. (Фактически в журнал помещается регистрационная запись для каждой заданной операции обновления прежде, чем это обновление будет осуществлено над базой данных. Этот вопрос обсуждается в следующем разделе.) Поэтому, если возникает необходимость в том, чтобы аннулировать некоторое конкретное обновление, система может использовать соответствующую регистрационную запись для восстановления предыдущего значения обновленного элемента.
Отметим в заключение еще один момент. Как уже было указано в главе 1, предложения манипулирования данными языка SQL относятся к уровню множеств, и обычно операция осуществляется одновременно над множеством записей. Что же тогда произойдет, если возникнет какая-либо ошибка во время исполнения такого предложения? Возможно ли, например, чтобы вторая операция UPDATE в приведенном примере обновила бы некоторые из ее целевых записей в таблице SP, а затем неудачно завершилась, не осуществив обновления остальных записей этой таблицы? Ответ отрицателен, это невозможно. Система DB2 гарантирует, что все предложения языка SQL в отдельности являются атомарными, по крайней мере, в отношении их влияния на базу данных. Если во время исполнения такого предложения все же имела место ошибка, то база данных останется полностью неизменной.
CВВЕДЕНИЕ
В данном разделе приводится представленная в виде нормальных форм Бэкуса (Язык нормальных форм Бэкуса — формальный метаязык, используемый для описания синтаксиса различных языков программирования, языков описания данных и других искусственных языков. Впервые был предложен Д. Бэкусом для описания синтаксиса алгоритмического языка АЛГОЛ-60.— Примеч. пер.) грамматика четырех операций манипулирования данными языка SQL (SELECT, UPDATE, DELETE и INSERT), описанных в этой книге. В этой грамматике используется следующее удобное сокращение:
— Если «xyz» — какая-либо синтаксическая категория, то «список-xyz» — это синтаксическая категория, которая представляет собой список, состоящий из одной или более «xyz». При этом каждая пара смежных «xyz» в списке разделяется последовательностью литер, включающей запятую, а также, возможно, предшествующие ей и следующие за ней один или более пробелов.
Категории «идентификатор», «константа» и «целое» являются по отношению к этой грамматике терминальными.
Примечание. Не описанные в тексте этой книги аспекты четырех рассматриваемых предложений, например операторы сравнения >ANY, =ALL и др., игнорируются. Кроме того, в интересах ясности и краткости предлагаемая грамматика не отражает точно диалекта языка SQL, поддерживаемого системой DB2, и является в некоторой степени нестрогой в том смысле, что она допускает генерацию определенных конструкций, которые оказываются недопустимыми в DB2. Она позволяет, например, использовать в качестве аргумента такой функции, как AVG, ссылку на другую функцию, скажем, SUM, что не допускается в DB2.
DB РЕЛЯЦИОННАЯ СИСТЕМА
Базы данных системы DB2 являются реляционными. Реляционная база данных это такая база данных, которая воспринимается ее пользователями как совокупность таблиц (и ничего иного, кроме таблиц). Пример такой базы данных (поставщики и детали) показан на рис. 1.3.
Нетрудно видеть, что эта база данных состоит из трех таблиц, а именно: S, Р и SP.
— Таблица S представляет поставщиков. Каждый поставщик имеет номер, уникальный для этого поставщика, фамилию— не обязательно уникальную, значение рейтинга или состояния и местонахождение (город). Для целей примера предположим, что каждый поставщик находится в точности в одном городе.
— В таблице Р представлены детали (точнее, виды деталей). Каждый вид деталей имеет уникальный номер детали, название, цвет, вес и место (город), где хранятся детали этого вида. Вновь для целей примера предположим, что каждый вид деталей имеет в точности один цвет и хранится на складе только одного города.
— Таблица SP представляет поставки деталей. Она служит для того, чтобы в некотором смысле связать между собой две другие таблицы. Например, первая строка этой таблицы на рис. 1.3 связывает определенного поставщика из таблицы S (а именно, поставщика S1) с определенной деталью из таблицы Р (а именно, с деталью P1). Иными словами, она представляет поставку деталей вида Р1 поставщиком по фамилии S1 и объем поставки, равный 300 деталям. Таким образом, для каждой поставки имеется номер поставщика, номер детали, и количество деталей. Для целей примера снова предположим, что может существовать не более одной поставки в любой заданный момент времени для заданного поставщика и заданной детали. Итак, комбинация значений НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ является уникальной для заданной поставки относительно множества поставок, представленных в текущий момент времени в таблице.
|
|
S
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
ГОРОД
|
|
|
S1
S2
S3
S4
S5
|
Смит
Джонс
Блейк
Кларк
Адамс
|
20
10
30
20
30
|
Лондон
Париж
Париж
Лондон
Атенс
|
|
Р
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
ГОРОД
|
|
|
Р1
Р2
РЗ
Р4
Р5
Р6
|
гайка
болт
винт
винт
кулачок
блюм
|
красный
зеленый
голубой
красный
голубой
красный
|
12
17
17
14
12
19
|
Лондон
Париж
Рим
Лондон
Париж
Лондон
|
|
SP
|
НОМЕР_ПОСТАВЩИКА
|
НОМЕР_ДЕТАЛИ
|
КОЛИЧЕСТВО
|
|
|
S1
S1
S1
S1
S1
S1
S2
S2
S3
S4
S4
S4
|
Р1
Р2
РЗ
Р4
Р5
Р6
Р1
Р2
Р2
Р2
Р4
Р5
|
300
200
400
200
100
100
300
400
200
200
300
400
Рис. 1.3. База данных поставщиков и деталей (пример)
Конечно, этот пример чрезвычайно прост. Он значительно проще любого реального примера, с которым, вероятно, можно встретиться на практике. Тем не менее, он достаточен для того, чтобы проиллюстрировать большинство вопросов, которые нам необходимо рассмотреть в этой книге. Поэтому мы будем использовать этот пример как основу для большинства (но не всех) примеров, приводимых в последующих главах, и следует потратить немного времени, чтобы хорошо с ним здесь разобраться.
Примечание. Нет ничего плохого в использовании более описательных имен (таких, как ПОСТАВЩИКИ, ДЕТАЛИ и ПОСТАВКИ) вместо весьма кратких— S, Р и SP. В действительности, на практике вообще нужно рекомендовать описательные имена (Именно так мы поступили при переводе, заменив имена столбцов таблиц этого и других примеров, представленные в виде аббревиатур английских названий, на более понятные русскому читателю содержательные имена.— Примеч. Пер.). Но конкретно в случае базы данных поставщиков и деталей эти три таблицы упоминаются в тексте настолько часто, что представляются более желательными очень краткие имена. Часто повторяемые длинные имена стали бы надоедливыми.
Два возникающих в связи с этим примером вопроса заслуживают, чтобы сказать о них здесь явно.
— Заметим, во-первых, что все значения данных являются атомарными, т. е. в каждой таблице в каждой позиции на пересечении строки и столбца всегда имеется в точности одно значение данных и никогда не бывает множества значений. Таким образом, например, в таблице SP (если для простоты рассматривать только два первых ее столбца) имеем:
|
|
НОМЕР_ПОСТАВЩИКА
|
НОМЕР_ДЕТАЛИ
|
|
.
S2
S2
.
S4
S4
S4
.
|
.
Р1
Р2
.
Р2
Р4
Р5
.
Вместо:
|
|
НОМЕР_ПОСТАВЩИКА
|
НОМЕР_ДЕТАЛИ
|
|
.
S2
.
S4
.
.
|
.
{PI. P2)
.
(Р2, Р4, Р5}
.
.
Столбец НОМЕР_ДЕТАЛИ во втором варианте этой таблицы представляет то, что иногда называется «повторяющейся группой». Повторяющаяся группа — это столбец, который содержит множество значений данных (в различных строках могут быть различные количества значений) вместо ровно одного значения в каждой строке. Реляционные базы данных не допускают повторяющихся групп. Второй вариант приведенной выше таблицы нельзя было бы использовать в реляционной системе.
— Во-вторых, отметим, что полное информационное содержание базы данных представляется в виде явных значений данных. Такой метод представления (в виде явных значений в позициях столбцов и строк таблиц) является единственным методом, имеющимся в распоряжении в реляционной базе данных. В частности, не существует каких-либо «связей» или указателей, соединяющих одну таблицу с другой. Так, имеется связь между строкой S1 таблицы S и строкой Р1 таблицы Р (поставщик S1 поставляет деталь Р1). Но эта связь представляется не с помощью указателей, а благодаря существованию в таблице SP строки, в которой значение номера поставщика равно S1, а значение номера детали равно Р1. Напротив, в системах нереляционного типа (например, в IMS) такая информация обычно представляется с помощью некоторого рода физической связи или указателя, который является явным образом видимым для пользователя.
Читатель может здесь заинтересоваться, почему такая база данных, как приведенная на рис. 1.3, называется «реляционной», Ответ простой: «отношение» — «relation» — просто математический термин для обозначения таблицы (точнее, таблицы определенного специфического вида—подробно об этом идет речь в главе 3). Таким образом, можно, например, сказать, что база данных, приведенная на рис. 1.3, состоит из трех отношений. Фактически в значительной мере можно считать термины «отношение» и «таблица» синонимами. Реляционные системы берут свое начало в математической теории отношений. Это не означает, конечно, что необходимо быть математиком для того, чтобы использовать реляционную систему. Но это означает, что существует значительное количество теоретических результатов, которые можно применять для решения практических проблем использования баз данных, например проблемы проектирования баз данных.
Если правильно то, что отношение— это только таблица, то почему не называть его просто таблицей и не довольствоваться этим? Ответ заключается в том, что мы очень часто это делаем (и обычно так и будем делать в этой книге). Однако стоит затратить немного времени для того, чтобы понять, почему сначала был введен термин «отношение». Кратко объяснение состоит в следующем. Реляционные системы базируются на так называемой реляционной модели данных. Реляционная модель в свою очередь является абстрактной теорией данных, которая основана, в частности, на упомянутой выше математической теории. Основы реляционной модели были первоначально сформулированы доктором Э. Ф. Коддом из фирмы IBM. В конце 1968 года Кодд, математик по образованию, впервые ясно понял, что можно использовать математику для придания надежной основы и строгости области управления базами данных, которая до настоящего времени была слишком несовершенной в указанных аспектах. Идеи Кодда были впервые широко опубликованы в ставшей теперь классической работе [10]. С тех пор эти идеи (к настоящему времени принятые почти повсюду) оказали весьма широкое влияние на технологию баз данных почти во всех ее аспектах, а в действительности также и на другие области, например на область искусственного интеллекта и обработку текстов на естественных языках.
Далее, реляционная модель, первоначально предложенная Коддом, требовала очень осмотрительного использования определенных терминов, например самого термина «отношение», которые не были хорошо известными в то время в сфере обработки данных, хотя эти концепции в некоторых случаях существовали. Неприятность, однако, заключалась в том, что были очень нечеткими многие более известные термины. Им недоставало точности, необходимой для формальной теории такого рода, какая была предложена Коддом. Рассмотрим, например, термин «запись». В различных ситуациях этот термин может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т. д. Поэтому в формальной реляционной модели вообще не используется термин «запись». Вместо этого в ней используется термин «кортеж» (сокращение для «кортеж длины п»), которому было дано точное определение, когда Кодд впервые ввел его. Мы не приводим здесь это определение. Для наших целей достаточно сказать, что термин «кортеж» приблизительно соответствует понятию экземпляра плоской записи (точно так же, как термин «отношение» приблизительно соответствует понятию таблицы). Если Вы желаете изучить какие-либо более формальные публикации по реляционным системам баз данных, следует, конечно, познакомиться и с формальной терминологией. Но в этой книге мы не пытаемся быть очень формальными и будем по большей части придерживаться таких терминов, как «запись», которые являются достаточно хорошо знакомыми. На рис. 1.4 приведены термины, которые мы будем использовать наиболее часто (таблица, запись, строка, поле, столбец). Для справки в каждом случае дается также соответствующий формальный термин. Заметим, что термины «запись» и «строка»
|
|
Формальный реляционный термин
|
Неформальные эквиваленты
|
|
отношение
кортеж
атрибут
|
таблица
запись, строка
поле, столбец
Рис. 1.4. Некоторые термины
мы используем как равнозначные. Аналогично используются термины «поле» и «столбец». Заметим также, что мы, следовательно, принимаем по определению, что «запись» означает «экземпляр записи», а «поле» означает «тип поля».
DB2 можно использовать на любой
DB2 можно использовать на любой вычислительной системе, поддерживаемой операционной системой MVS Version 1 Release 3 (MVS/370) или MVS Version 2 Release 1.1 (MVS/XA). Для вычислительной системы 3033 рекомендуется использовать при этом аппаратные средства перекрестного расширения памяти. В DB2 память, прямого доступа используется для:
– наборов данных базы данных (по выбору пользователя может использоваться подсистема массовой памяти — MSS)
– наборов данных каталога наборов данных активных журналов
– наборов данных архивных журналов (по выбору пользователя может использоваться магнитная лента или MSS)
– наборов данных для копий содержимого базы данных (можно использовать по выбору магнитную ленту или MSS)
– рабочих наборов данных утилит (можно использовать по выбору магнитную ленту или MSS)
– набора данных самозагрузки.
Примечание. Набор данных самозагрузки используется при рестартах системы.
Виртуальная память: Минимальная потребность в общей области памяти (CSA) в обстановке MVS/370, примерно равна 512 K байт. Практическая минимальная потребность в приватной виртуальной памяти составляет примерно 4,5—5 мегабайт. В обстановке MVS/XA большинство требуемых для DB2 областей размещается в расширенной общей области памяти. Большинство программных модулей, управляющих блоков и буферов DB2 размещается в расширенной приватной области.
Для поддержки системы необходимы следующие средства программного обеспечения:
1. MVS/SP-JES2 или -JES3, Version 1 Release 3 или Version 2 Release 1.1 (либо последующие выпуски)
2. MVS/370 Data Facility Product Release 1 или MVS/XA Data Facility Product Release 1.1
3. MVS TSO Command Package Release 1.1 или MVS TSO Extensions (TSO/E) Release 1
4. OS/VS Sort/Merge Release 5
5. Interactive System Productivity Facility (ISPF и ISPF/Program Development Facility (ISPF/PDF
или PDF) по выбору пользователя, необязательны для работы
DB2I.
6. System Maintenance Program (SMP) Version 1 Release 4
Следующие средства используются по выбору пользователя:
1. Query Management Facility (QMF) Release 1
2. Data Extract (DXT) Release 1
3. Information Management System/Virtual Storage (IMS/VS) Version 1 Release 3
4. Customer Information Control System/OS/Virtual Storage (CICS/OS/VS) Version 1 Release 6
5. Resource Access Control Facility (RACF) Release 5
6. OS/VS COBOL Compiler and Library Release 2.3
7. TSO Assembler Prompter Release 1
8. TSO COBOL Prompter Release 1
9. OS PL/I Optimizing Compiler Release 4
10. VS FORTRAN Release 1.1
11. OS Assembler H Release 5
12. Assembler H Version 2 Release I
DТРЕБОВАНИЯ DXT
Для работы с DB2 системе DXT требуется:
1. DB2
2. ISPF/PDF Release 1.1
3. OS/VS DB/DC Data Dictionary Release 4 (по выбору пользователя)
DТРЕБОВАНИЯ QMF
Для работы с DB2 системе QMF требуется:
1. DB2
2. ISPF Release 1.1
3. Graphical Data Display Manager, Release 2
ЕДИНИЧНОЕ SELECT
Выдать состояние и город для поставщика, номер которого задается переменной включающего языка ЗАДАННЫИ_НОМЕР.
ЕХЕС SQL SELECT СОСТОЯНИЕ, ГОРОД
INTO :РАНГ, :ГОРОД
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = :ЗАДАННЫЙ_НОМЕР;
Термин «единичное
SELECT» используется здесь для обозначения предложения SELECT, которое продуцирует таблицу, содержащую не более одной строки. В данном примере, если существует в точности одна запись в таблице S, удовлетворяющая условию WHERE, то значения СОСТОЯНИЕ и ГОРОД из этой записи будут присвоены, как требовалось в запросе, переменным включающего языка РАНГ и ГОРОД, a SQLCODE будет установлено в нуль. Если же никакая запись в S не удовлетворяет условию WHERE, поле SQLCODE примет значение +100. Если, наконец, существует более одной такой записи, возникает ошибка, и значение SQLCODE будет отрицательным. В последних двух случаях значения переменных включающего языка РАНГ и ГОРОД останутся неизменными.
В связи с приведенным примером возникает другой вопрос. Что произойдет, если предложение SELECT в действительности выберет в точности одну запись, но значение поля СОСТОЯНИЕ (или поля ГОРОД) в ней окажется неопределенным? Как показано выше, в таком случае будет иметь место ошибка, и полю SQLCODE будет присвоено некоторое отрицательное значение. Если существует шанс, что выбираемое значение поля может быть неопределенным, пользователь должен предусмотреть индикаторную переменную для этого поля во фразе INTO, а также обычную целевую переменную, как показано в следующем примере:
ЕХЕС SQL SELECT СОСТОЯНИЕ, ГОРОД
INTO :РАНГ: ИНД_РАНГА, :ГОРОД: ИНД_ГОРОДА
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = :ЗАДАННЫЙ_НОМЕР;
IF ИНД_РАНГА < 0 THEN / » значение поля состояние было неопределенным */. . .;
IF ИНД_ГОРОДА < 0 THEN / * значение поля ГОРОД было неопределенным */. . .;
Если поле, выборка которого осуществляется, имеет неопределенное значение, и была специфицирована индикаторная переменная, то этой индикаторной переменной будет присвоено соответствующее отрицательное значение, а обычная целевая переменная останется неизменной. Индикаторная переменная специфицируется, как показано в приведенном примере, т. е. она следует за соответствующей обычной целевой переменной и отделяется от этой целевой переменной двоеточием. Индикаторные переменные следует объявлять как 15-битовые двоичные целые со знаком.
Примечание.
Индикаторные переменные не могут использоваться во фразе WHERE. Например, следующий фрагмент программы некорректен:
ИНД_РАНГА = -1;
ЕХЕС SQL SELECT ГОРОД
INTO :ГОРОД
FROM S
WHERE СОСТОЯНИЕ = :РАНГ : ИНД_РАНГА;
Правильный способ выборки городов при неопределенном значении поля СОСТОЯНИЕ иллюстрируется ниже:
ЕХЕС SQL SELECT ГОРОД
INTO :ГОРОД
FROM S
WHERE СОСТОЯНИЕ IS NULL;
ФУНКЦИЯ В КОРРЕЛИРОВАННОМ ПОДЗАПРОСЕ
Выдать номер поставщика, состояние и город для всех поставщиков, у которых состояние больше или равно среднему для их конкретного города.
SELECT НОМЕР—ПОСТАВЩИКА, СОСТОЯНИЕ, ГОРОД
FROM S SX
WHERE СОСТОЯНИЕ > =
(SELECT AVQ (СОСТОЯНИЕ)
FROM S SY
WHERE SY. ГОРОД = SX. ГОРОД);
Результат:
|
|
НОМЕР_ПОСТАВЩИКА
|
СОСТОЯНИЕ
|
ГОРОД
|
|
S1
|
20
|
Лондон
|
|
S3
|
30
|
Париж
|
|
S4
|
20
|
Лондон
|
|
S5
|
30
|
Атенс
Включить в результат среднее состояние для каждого города невозможно. (Почему?)
ФУНКЦИЯ В ПОДЗАПРОСЕ
Выдать номера поставщиков со значением поля СОСТОЯНИЕ меньшим, чем текущее максимальное состояние в таблице S.
SELECT НОМЕР—ПОСТАВЩИКА
FROM S
WHERE СОСТОЯНИЕ <
(SELECT MAX (СОСТОЯНИЕ)
FROM S);
Результат:
|
|
НОМЕР_ ПОСТАВЩИКА
|
|
S1
S2
S4
ФУНКЦИЯ ВО ФРАЗЕ SELECT С ПРЕДИКАТОМ
Выдать количество поставок для детали Р2.
SELECT COUNT (*)
FROM SP
WHERE НОМЕР_ДЕТАЛИ = 'Р2';
Результат:
4
Выдать общее количество поставляемых деталей Р2.
SELECT SUM (КОЛИЧЕСТВО)
FROM SP
WHERE НОМЕР_ДЕТАЛИ = 'Р2';
Результат:
1000
ФУНКЦИЯ ВО ФРАЗЕ SELECT СО СПЕЦИФИКАЦИЕЙ DISTINCT
Выдать общее количество поставщиков, поставляющих в настоящее время детали:
SELECT COUNT (DISTINCT НОМЕР—ПОСТАВЩИКА)
FROM SP;
Результат:
4
ФУНКЦИЯ ВО ФРАЗЕ SELECT
Выдать общее количество поставщиков.
SELECT COUNT (*)
FROM SP
Результат:
5
ГЕНЕРАЦИЯ ОТЧЕТОВ
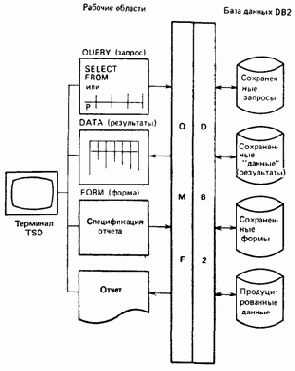
Отчет в QMF — это выводимые на экран дисплея или печатаемые результаты выполнения запроса. Каждый отчет форматируется в соответствии с множеством спецификаций, называемым формой. Когда пользователь специфицирует запрос, ему предоставляется факультативная возможность явного задания соответствующей формы. Если он не задает такой явной спецификации, QMF автоматически создает «системную» форму по умолчанию, и вывод результатов выполнения запроса будет осуществляться в соответствии с этой формой. Впоследствии пользователь может пересмотреть эту форму и снова запросить вывод результатов на экран в соответствии с пересмотренной формой. Этот цикл может повторяться необходимое количество раз до тех пор, пока пользователь не будет удовлетворен. Таким образом, типичный интерактивный сеанс работы с QMF мог бы проходить следующим образом (рис. 15.1):
Риc. 15.1. Использование QMF
1. Используя функции полноэкранного редактора QMF, пользователь с помощью SQL либо Query-By-Example формулирует запрос QMF. Этот запрос сохраняется во временной рабочей области, называемой QUERY (запрос).
2. Используя, вероятно, программируемую функциональную клавишу, пользователь выдает команду RUN QUERY (исполнить запрос) с тем, чтобы выполнить запрос из области QUERY. Peзультаты его выполнения сохраняются в другой временной рабочей области, называемой DATA (данные).
3. QMF создает «системную» форму по умолчанию для данных из области DATA и выводит эти данные в соответствии с построенной таким образом формой. Эта форма сохраняется в еще одной временной рабочей области—FORM (форма).
4. После рассмотрения полученного на предыдущем шаге отчета пользователь выдает команду DISPLAY FORM (показать форму), вероятно, снова с помощью программируемой функциональной клавиши, чтобы вывести на экран текущее содержимое области FORM.
5. Снова используя функции полноэкранного редактирования, пользователь пересматривает текущее содержимое области FORM.
6. Для формирования пересмотренного отчета, соответствующего переработанной форме, пользователь издает команду DISPLAY REPORT (показать отчет). Заметим, что при этом нет необходимости заново исполнять первоначальный запрос. Результаты этого запроса сохранены в области DATA, и при исполнении команды DISPLAY REPORT текущее содержимое FORM используется для форматизации и вывода на экран текущего содержимого DATA.
7. Шаги 4 — 6 повторяются необходимое количество раз до тех пор, пока пользователь не будет удовлетворен окончательным результатом.
8. При желании пользователь выдает команду PRINT REPORT—опять-таки, вероятно, с помощью программируемой функциональной клавиши — для получения печатной копии окончательного результата.
Рассмотрим теперь пример, показывающий, каким образом эта последовательность событий могла бы выглядеть на практике. Предположим, что первоначальный запрос имеет следующий вид:
SELECT S.ГОРОД, S.СОСТОЯНИЕ, SP.НОМЕР_ПОСТАВЩИКА,
SP.НОМЕР_ДЕТАЛИ, SP.КОЛИЧЕСТВО FROM S, SP
WHERE S.HOMEP_ПОСТАВЩИКА == SP. НОМЕР_ПОСТАВЩИКА
ORDER BY S.ГОРОД, SP.НОМЕР_ПОСТАВЩИКА,
SP.НОМЕР_ДЕТАЛИ
** * END * * *
В QMF запросы завершаются строкой * * * END * * * (КОНЕЦ), а не точкой с запятой. Пользователь не должен, однако, печатать этот признак конца, так как он является стандартным для функции показа запроса QMF. Указанный запрос исполняется QMF, и результат запоминается в области DATA. Далее создается системная форма для этого запроса, которую мы рассмотрим позднее, и полученная форма запоминается в области FORM. Наконец, QMF форматирует и выводит на экран содержимое области DATA в соответствии с формой, хранимой в FORM. Полученный и результате отчет показан на рис. 15.2.
|
|
ГОРОД
|
СОСТОЯНИЕ
|
НОМЕР_
ПОСТАВЩИКА
|
НОМЕР_
ДЕТАЛИ
|
КОЛИЧЕСТВО
|
|
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Париж
Париж
Париж
*** END***
|
20
20
20
20
20
20
20
20
20
10
10
30
|
S1
S1
S1
S1
S1
S1
S4
S4
S4
S2
S2
S3
|
P1
P2
P3
P4
P5
P6
P2
P4
P5
P1
P2
P2
|
300
200
400
200
100
100
200
300
400
300
400
200
Рис. 15.2.Отчет, содержащий результаты исполнения запроса
Автоматически сгенерированная системная форма для этого отчета, хранимая в области FORM, показана на рис. 15.3. Эта форма интерпретируется следующим образом:
1. Результат исполнения запроса, хранимый в области DATA, содержит 5 столбцов. Эти столбцы должны появиться в отчете с заголовками соответственно ГОРОД, СОСТОЯНИЕ, НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ и КОЛИЧЕСТВО.
2. Ширина этих столбцов составляет соответственно 15, 9, 10, 6 и. 11 символов, и между столбцами должны быть промежутки
Описания столбцов: Ширина страницы теперь — 61
|
|
НОМЕР
|
ЗАГОЛОВОК СТОЛБЦА
|
ИСПОЛЬЗОВАНИЕ
|
ОТСТУП
|
ШИРИНА
|
РЕДАКТИРОВАНИЕ
|
|
1
2
3
4
5
|
ГОРОД
СОСТОЯНИЕ
НОМЕР_
ПОСТАВЩИКА
НОМЕР_ ДЕТАЛИ
КОЛИЧЕСТВО
|
|
2
2
2
2
2
|
15
9
10
6
11
|
С
L
С
С
L
***
END ***
Текст при прерывании ТРЕБУЕТСЯ ЛИ ПОДАВЛЕНИЕ ДУБЛИКАТОВ?
управления: = = = >ДА
1= = => 4= = =>
2= = => 5= = =>
3= = => 6= = =>
ЗАГОЛОВОК СТРАНИЦЫ = = = >
КОНЦОВКА СТРАНИЦЫ = = = >
Рис. 15.3. Автоматически сгенерированная форма отчета
в две позиции—в
каждом случае параметр ОТСТУП составляет 2 позиции.
3. Общая ширина данного отчета—61 символ.
4. Заголовки ГОРОД, НОМЕР_ПОСТАВЩИКА и НОМЕР_ДЕТАЛИ должны быть показаны «как они есть», т. е. как простые нередактируемые строки символов (параметр РЕДАКТИРОВАНИЕ равен С), а СОСТОЯНИЕ и КОЛИЧЕСТВО—как десятичные целые (параметр РЕДАКТИРОВАНИЕ равен L).
5. Никаких прерываний управления не специфицировано (см. ниже), и поэтому не специфицирован также никакой текст, показываемый при прерывании управления. Спецификация значения «ДА» для параметра ПОДАВЛЕНИЕ ДУБЛИКАТОВ не оказывает никакого влияния при отсутствии прерываний управления.
6. Не специфицированы также никакой заголовок страницы или концовка страницы.
Предположим теперь, что эта форма выводится на экран по команде DISPLAY и редактируется следующим образом (рис. 15.4):
1 Заголовки столбцов ГОРОД, СОСТОЯНИЕ, НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ и КОЛИЧЕСТВО заменяются на ГОРОД_ПОСТАВЩИКА, СОСТОЯНИЕ, ПОСТАВЩИК, ДЕТАЛЬ и КОЛИЧЕСТВО соответственно. Для первого из них, как и для двух других в предыдущем варианте, специфицируется символ разрыва, указывающий, что два слова в заголовке должны находиться в отдельных строках отчета (слово ГОРОД должно быть над словом ПОСТАВЩИКА и должно быть отцентрировано). Для столбца СОСТОЯНИЕ не специфицируется никакого нового заголовка, поскольку предполагается, что значения СОСТОЯНИЕ не будут представлены в отчете (см. ниже п. 4).
|
|
Описания столбцов:
|
Ширина страницы теперь —56
|
|
НОМЕР
|
ЗАГОЛОВОК СТОЛБЦА
|
ИСПОЛЬЗОВАНИЕ
|
ОТСТУП
|
ШИРИНА
|
РЕДАКТИРОВАНИЕ
|
|
1
|
ГОРОД_ПОСТАВЩИКА
|
ПРЕРЫВАНИЕ!
|
3
|
10
|
|
|
2
|
СОСТОЯНИЕ
|
ОПУСТИТЬ
|
3
|
9
|
|
|
3
|
ПОСТАВЩИК
|
|
3
|
9
|
|
|
4
|
ДЕТАЛЬ
|
|
3
|
6
|
|
|
5
|
КОЛИЧЕСТВО
|
СУММИРОВАТЬ
|
3
|
10
|
* * *END * * *
ТЕKCT ПРИ ПРЕРЫВАНИИ ТРЕБУЕТСЯ ЛИ ПОДАВЛЕНИЕ ДУБЛИКАТОВ УПРАВЛЕНИЯ- = = =>ДА
1 = = = > * * * Итого для 4 = = = >
ГОРОДА &1
2= = => 5 = = =>
3 = = => б = = =>
ЗАГОЛОВОК СТРАНИЦЫ = = => ПОСТАВКИ ПО ПОСТАВЩИКАМ ГОРОДАМ
КОНЦОВКА СТРАНИЦЫ = = = > ПОДРОБНЫЙ ОТЧЕТ
Рис. 15.4. Отредактированная форма отчета
2. Ширина столбцов ГОРОД_ПОСТАВЩИКА, ПОСТАВЩИК, ДЕТААЛЬ и КОЛИЧЕСТВО изменяется соответственно на 10, 9, 6 и 10. Значение ОТСТУП в каждом случае изменяется с 2 на 3.
3. В качестве значения параметра ИСПОЛЬЗОВАНИЕ для столбца ГОРОД_ПОСТАВЩИКА принимается ПРЕРЫВАНИЕ1.
Примечание. Смысл этой спецификации в том, что для первоначального запроса ГОРОД является, вероятно, старшим полем упорядочения. ПРЕРЫВАНИЕ1 означает, что каждый раз, когда изменяется значение в столбце ГОРОД_ПОСТАВЩИКА, должно иметь место «прерывание управления». Цель спецификации прерываний управления состоит в том, чтобы дать возможность QMF вычислять и выводить на экран частичные итоги или другие промежуточные результаты при генерации отчета (см. ниже п. 5).
4. Для столбца СОСТОЯНИЕ параметр ИСПОЛЬЗОВАНИЕ принимает значение ОПУСТИТЬ. В результате никакие значения столбца СОСТОЯНИЕ не войдут в отчет.
5. В качестве значения параметра ИСПОЛЬЗОВАНИЕ для столбца КОЛИЧЕСТВО принимается СУММИРОВАТЬ. Оно указывает, что по значениям КОЛИЧЕСТВО должны формироваться итоговые суммы для каждого прерывания управления, т. е. для каждого города, а также и для отчета в целом, т. е. для всех городов. Аналогичным образом можно запросить вывод средних значений, подсчет числа записей и т. д.
ПОСТАВКИ ПО ПОСТАВЩИКАМ ГОРОДАМ
|
|
ГОРОД_ПОСТАВЩИКА
|
ПОСТАВЩИК
|
ДЕТАЛЬ
|
КОЛИЧЕСТВО
|
|
Лондон
|
S1
|
Р1
|
300
|
|
|
S1
|
Р2
|
200
|
|
|
S1
|
РЗ
|
400
|
|
|
S1
|
Р4
|
200
|
|
|
S1
|
Р5
|
100
|
|
|
S1
|
Р6
|
100
|
|
|
S4
|
Р2
|
200
|
|
|
S4
|
Р4
|
300
|
|
|
S4
|
Р5
|
400
|
|
* * * итого для города Лондон
|
2200
|
|
Париж
|
S2
|
Р1
|
300
|
|
|
S2
|
Р2
|
400
|
|
|
S3
|
Р2
|
200
|
|
* * * итого для города Париж
|
|
900
|
|
|
|
3100
|
|
83/06/29 10 : 46
|
ПОДРОБНЫЙ ОТЧЕТ
|
СТРАНИЦА 1
|
|
|
|
|
|
Рис. 15.5. Окончательный вариант отчета
6. Текст, который выводится при прерывании управления, для прерывания управления 1, единственного прерывания управления в данном примере, специфицируется следующим образом:
* * * ИТОГО ДЛЯ ГОРОДА & 1
Спецификация «& 1» обозначает текущее значение в столбце номер 1 отчета, а именно в столбце ГОРОД_ПОСТАВЩИКА. Таким образом, это — переменная,
которая позволяет QMF выводить на экран различные строки текста каждый раз, когда фактически имеет место прерывание управления. Результат этой спецификации можно видеть в приведенном окончательном варианте отчета (рис. 15.5).
7. Для параметра ПОДАВЛЕНИЕ ДУБЛИКАТОВ оставляется значение «ДА». Результат такой спецификации заключается в том, что подавляется вывод на экран идентичных значений и столбцах, для которых специфицировано прерывание управления (см. снова окончательный отчет— рис. 15.5). 8. Наконец, задается заголовок страницы:
ПОСТАВКИ ПО ПОСТАВЩИКАМ ГОРОДАМ
и концовка страницы:
ПОДРОБНЫЙ ОТЧЕТ
Сформирована, таким образом, пересмотренная форма (см. рис. 15.4). Теперь выданный по команде DISPLAY REPORT отчет представлен на рис. 15.5. Заметим, что дата, время и номера страниц включаются в этот отчет автоматически.
Приведенный выше пример дает некоторое представление о том, как легко получать с помощью QMF отчеты, имеющие привычный вид или сформированные с учетом конкретных потребностей. Он, однако, не позволяет проиллюстрировать полный диапазон возможностей генерации отчетов в QMF. Перечислим кратко некоторые дополнительные возможности:
— Предусмотрены возможности пролистывания—UP (назад), DOWN (вперед), LEFT (влево) и RIGHT (вправо) —для просмотра отчетов, а также других объектов, например форм, которые оказываются слишком большими для того, чтобы целиком поместить их на одном экране.
— Вдобавок к показанным в примере кодам редактирования С и L предусмотрены дополнительные коды, которые позволяют, например, вставлять в числовые результаты символы редактирования (например, знак доллара, десятичную точку), а также выводить на экран значения с плавающей точкой, используя их обозначения, принятые в научной литературе.
— Заголовки и концовки страниц, аналогично текстам, которые выводятся при прерываниях управления, могут включать ссылки на переменные вида «&n», что обозначает текущее значение в столбце номер n.
— Можно специфицировать несколько уровней (до 6) прерываний управления с различными итоговыми функциями и различными текстами, выводимыми на каждом уровне. Можно было бы, например, расширить рассмотренный пример и специфицировать прерывание управления по поставщикам (уровень 2) внутри городов (уровень 1). Для этого следовало бы специфицировать значение ПРЕРЫВАНИЕ2 параметра ИСПОЛЬЗОВАНИЕ для столбца ПОСТАВЩИК. В результате мы могли бы, например, получать частичные итоги по количеству поставляемых деталей по каждому поставщику, а также по каждому городу. Вывод идентичных номеров поставщиков можно было бы также подавить, предполагая, что для параметра ПОДАВЛЕНИЕ ДУБЛИКАТОВ специфицировано все еще значение «ДА».
Примечание. Когда специфицируются прерывания управления, в первоначальном запросе должна быть задана соответствующая спецификация упорядочения. В противном случае этот отчет не будет иметь смысла. В запросе, связанном с рассмотренным примером, вероятно, должна была указываться фраза ORDER BY, специфицирующая ГОРОД как старшее поле упорядочения, а НОМЕР_ПОСТАВЩИКА—как младшее поле упорядочения.
— Отчеты могут состоять только из сводной информации, т. е. только из итогов или средних, а также из сводной и подробной информации, как в приведенном примере. И опять-таки для того, чтобы отчет имел смысл, исходный запрос должен включать соответствующую спецификацию упорядочения. Сводные отчеты могут быть получены как в формате «поперек страницы», так и в более удобном формате «вдоль страницы». Мы могли бы, в частности, пересмотреть наш пример таким образом, чтобы генерировался отчет, в котором города были бы представлены вдоль страницы, а поставщики — поперек. Для каждого города имелась бы тогда строка, содержащая общее количество деталей для поставщика S1, поставщика S2, . . ., а также общее их количество для всех поставщиков в этом городе.
— Для того чтобы сохранять под выбранными пользователем именами специфицированное содержимое областей DATA, QUERY или FORM, предусмотрена команда SAVE (сохранить). В команде RUN (выполнить) можно специфицировать для выполнения указанный сохраненный запрос, а для форматирования результатов — указанную сохраненную форму. Аналогично в команде DISPLAY (показать) можно специфицировать для вывода на экран в соответствии с формой, хранимой в настоящее время в области FORM, указанной сохраненной таблицы. Указанная таблица либо может быть создана по команде SAVE DATA, либо может являться любой таблицей из базы данных. Сохраненный запрос может включать параметры. В таком случае, когда этот запрос будет вызываться для выполнения, QMF запросит у пользователя фактические значения для замены этих параметров.
Следует, наконец, упомянуть процедуры. Процедура — это последовательность команд QMF (RUN, DISPLAY, SAVE и т. д.), которая сама хранится под некоторым специфицированным именем. Она выполняется с помощью некоторого варианта команды RUN.
ГРУППЫ ПАМЯТИ
Группа памяти—это именованная совокупность томов с прямым доступом, причем все они относятся к устройствам одного и того же типа. С каждым простым табличным пространством, простым индексным пространством, сегментом сегментированного табличного пространства и сегментом сегментированного индексного пространства связана некоторая группа памяти[24]. Когда для пространства или сегмента требуется память, она берется из специфицированной группы памяти. Таким образом, группы памяти предоставляют установке системы возможности для разделения и сближения данных. Они могут, например, обеспечить хранение двух таблиц на различных томах. В то же время они дают возможность возложить на систему управление большей частью детальных аспектов размещения наборов данных, экстентов и т. д.
Пространства и сегменты в каждой группе памяти поддерживаются с использованием наборов данных
VSAM с последовательным входом. При этом одному пространству или сегменту, вообще говоря, соответствует множество наборов данных. Система DB2 использует VSAM также для управления пространствами с прямым доступом и для каталогизации наборов данных. Управление пространством внутри страниц, т. е. оперирование управляющими интервалами VSAM, осуществляется системой DB2, а не средствами VSAM, и индексирование VSAM вообще не используется. Таким образом, как уже упоминалось в главе 9, наборы данных системы DB2 не являются обычными наборами данных VSAM. Их внутренний формат не совпадает с форматом, предусмотренным для VSAM, и обращаться к этим наборам данных с использованием обычного VSAM невозможно. По тем же причинам невозможно обращаться к существующим наборам данных VSAM, используя возможности DB2, например язык SQL.
ХРАНИМЫЕ ТАБЛИЦЫ
Хранимая таблица — это хранимое представление базовой таблицы. Она состоит из множества хранимых записей, по одной для каждой строки данных в рассматриваемой базовой таблице. Каждая хранимая запись будет полностью содержаться на одной странице. Однако каждая хранимая таблица может размещаться на множестве страниц, и в простом табличном пространстве одна страница может содержать хранимые записи из многих хранимых таблиц.
Хранимая запись не идентична соответствующей записи базовой таблицы. Она состоит из строки байтов, включающей:
– префикс, содержащий управляющую информацию, например внутреннее системное имя для хранимой таблицы, частью которой является данная хранимая запись, за которым следует
– до N хранимых полей, где N — число столбцов в данной базовой таблице. Хранимых полей будет меньше, чем N, если хранимая запись имеет переменную длину, т. е. если в ней есть какие-либо поля переменной длины, и одно или несколько полей в правой части записи имеют неопределенные значения. Поля, имеющие неопределенные значения, в конце записи переменной длины физически не хранятся.
Каждое хранимое поле в свою очередь состоит из:
– префикса длины (если поле имеет переменную длину), который задает фактическую длину данных, в том числе префикса индикатора неопределенного значения, если он имеется (см. ниже);
– префикса индикатора неопределенного значения (если неопределенные значения допускаются), указывающего, должно ли значение в той части поля, которая отведена для данных: а) приниматься за действительное значение данных; б) игнорироваться, т. е. интерпретироваться как неопределенное значение;
– фактического значения данных в кодированном формате. Хранимые данные кодируются таким образом, что команда «сравнение логическое» (CLC) системы IBM/370 всегда будет давать подходящий ответ, когда она выполняется над двумя значениями данных одного и того же типа в SQL. Например, значения типа INTEGER хранятся вместе с их знаковым битом н обратном коде. Таким образом, все хранимые поля данных рассматриваются программой управления хранимыми данными просто как последовательности байтов. Любая интерпретация такой последовательности, например, как значения типа INTEGER, осуществляется указанным выше интерфейсом управления данными. Достоинство такого подхода заключается в том, что можно вводить новые типы данных, не оказывая какого-либо влияния на компоненты нижнего уровня системы. В качестве упражнения предлагаем читателю попытаться разработать подходящие способы кодирования для других типов данных SQL.
Все хранимые поля выравниваются по границе байта. Между полями не оставляется никаких промежутков. Данные переменной длины занимают ровно столько байтов, сколько это необходимо для хранения фактического их значения.
Примечание. Выше описано стандартное представление хранимых записей. Однако для любой заданной таблицы установка системы располагает факультативной возможностью предоставления «процедуры редактирования», которой будет передаваться управление каждый раз, когда осуществляется запоминание или выборка записи. При «запоминании» эта процедура редактирования может преобразовывать стандартное представление в какой-либо другой требуемый формат, и запись будет храниться именно в этом формате. При «выборке» процедура редактирования должна, конечно, выполнять обратное преобразование. Таким образом, конкретная установка системы может, например, решать, хранить ли данные в сжатом или в кодированном формате. Более того, такое решение она может принимать исходя из свойств каждой конкретной таблицы.
Для внутренней адресации записей используются идентификаторы записей (ID или RID ( Аббревиатура словосочетания «Record Identifier».—Примеч. пер. )). Например, все указатели в индексах представляют собой RID. Все RID являются уникальными в базе данных, содержащей соответствующие записи. На рис. 13.2 показано, каким образом реализованы RID. Для хранимой записи R RID состоит из двух частей: из номера Р страницы, содержащей R, и из байта смещения от конца страницы Р, указывающего участок, который в свою очередь содержит байт смещения записи R от начала страницы Р. Такой метод представляет собой хороший компромисс между быстрым доступом при прямой адресации и гибкостью косвенной адресации. Можно проводить реорганизацию записей в рамках содержащей их страницы, например ликвидировать промежуток при удалении записи или подготавливать пространство для вставки записи, не создавая необходимости изменения RID. Должны изменяться только локальные смещения, хранимые в конце данной страницы. И тем не менее доступ к записи при заданном ее RID является быстрым. Он требует доступа только к одной странице.
ИДЕНТИФИКАЦИЯ ПОЛЬЗОВАТЕЛЕЙ
Пользователи известны системе DB2 по их «идентификаторам санкционирования доступа» (для краткости, ИД санкционирования). ИД санкционирования — это то, что называлось в предшествующих главах «известным системе именем» пользователя. Если Вы — законный пользователь системы, некоторое ответственное лицо в Вашей организации, вероятно, администратор системы (см. ниже раздел 9.4), назначит для Вашего конкретного использования некоторый ИД санкционирования. На Вас возлагается обязанность идентифицировать себя с помощью этого ИД при предъявлении пароля системе. Заметим, что Вы при этом не предъявляете пароль непосредственно самой системе DB2. Пароль предъявляется соответствующей подсистеме MVS (IMS, CICS или TSO—вспомните из главы 1, что каждая прикладная задача DB2 должна исполняться под управлением в точности одной из этих трех подсистем). Эта подсистема передаст затем Ваш ИД системе DB2, когда будет передавать ей управление. Таким образом, проверка достоверности или подтверждение подлинности Вашего ИД осуществляется каждый раз соответствующей подсистемой, а не DB2. Если о каком-либо пользовательском запросе системе DB2 сообщается, что он исходит от пользователя, скажем, xyz, она предполагает, что это действительно так.
Рассмотрение подробностей процедуры предъявления пароля (а следовательно, информации о том, как в точности специфицируется ИД санкционирования) для каждого из возможных вариантов операционной обстановки выходит за рамки данной книги.
ИНДЕКСНЫЕ ПРОСТРАНСТВА
Индексное пространство играет такую же роль для индексов, как табличное пространство для таблиц. Однако в связи с тем, что соответствие между индексами и индексными пространствами всегда является взаимно однозначным (в отличие от соответствия между таблицами и табличными пространствами), нет никаких предложений определения данных для самих по себе индексных пространств. Вместо этого в предложениях определения соответствующих индексов специфицируются необходимые параметры индексных пространств. Так, например, нет предложения CREATE INDEXSPACE (создать индексное пространство), а индексное пространство создается автоматически при создании соответствующего индекса путем спецификации предложения CREATE INDEX (создать индекс). Указанное предложение может включать такие параметры, как имя связанной с этим индексом группы памяти и т. п.
Страницы в индексном пространстве всегда имеют размер 4К байт. Однако единица для целей блокирования может быть меньше, чем одна страница (это другое отличие от табличного пространства). Она может, например, составлять четверть страницы (1024 байта).
Подобно табличным пространствам индексные пространства могут реорганизовываться и восстанавливаться независимо. Индексное пространство, которое содержит требуемый индекс кластеризации для сегментированного табличного пространства, само предполагается сегментированным. Во всех других случаях индексное пространство рассматривается как простое (несегментированное). Сегмент сегментированного индексного пространства может быть реорганизован независимо. Отдельные сегменты могут быть связаны с различными группами памяти.
ИНДЕКСЫ
Подобно базовым таблицам индексы создаются и уничтожаются путем использования предложений определения данных языка SQL. Однако CREATE INDEX и DROP INDEX (а также alter INDEX и некоторые предложения управления данными) вообще являются единственными предложениями в языке SQL, в которых имеются ссылки на индексы. Другие предложения, в частности предложения манипулирования данными, такие, как SELECT, намеренно не включают каких-либо таких ссылок. Решение о том, использовать или не использовать какой-либо индекс при обработке некоторого конкретного запроса в языке SQL, принимается не пользователем, а системой DB2 (фактически оптимизатором — составной частью генератора планов прикладных задач), как указывалось в главе 2.
Предложение CREATE INDEX имеет следующий общий формат:
CREATE [UNIQUE] INDEX имя—индекса
ON имя—базовой—таблицы (имя—столбца [упорядочение]
[имя—столбца [упорядочение]] . . .)
[другие—параметры] ;
Факультативные «другие — параметры» имеют отношение к проблемам физического хранения, как и в случае предложения CREATE TABLE. Каждая спецификация «упорядочение» представляет собой либо ASC (возрастание), либо DESC (убывание). Если не специфицировано ни ASC, ни DESC, то по умолчанию предполагается ASC. Последовательность указания имен столбцов в предложении CREATE INDEX соответствует обычным образом упорядочению от старшего к младшему. Например, предложение
CREATE INDEX X ON В (Р, Q DESC, R)
создает индекс с именем Х над базовой таблицей В, в котором статьи упорядочиваются по возрастанию значений R в рамках убывающих значений Q в рамках возрастающих значений Р. Столбцы Р, Q и R не обязательно должны быть смежными. Не обязательно также, чтобы все они имели один и тот же тип данных. Наконец, не обязательно, чтобы все они были фиксированной длины.
После того как индекс создан, он автоматически поддерживается (программой управления хранимыми данными) с тем, чтобы отражать все обновления базовой таблицы, до тех пор, пока этот индекс не будет уничтожен.
Факультативный параметр
UNIQUE (уникальный) в предложении CREATE INDEX специфицирует, что никаким двум записям к индексируемой базовой таблице не позволяется принимать одно и то же значение для индексируемого поля (или комбинации полей) в одно и то же время. В случае базы данных поставщиков и деталей, например, мы специфицировали бы, вероятно, следующие индексы с параметром UNIQUE:
CREATE UNIQUE INDEX XS ON S (НОМЕР_ПОСТАВЩИКА);
CREATE UNIQUE INDEX XP ON P (НОМЕР_ДЕТАЛИ);
CREATE UNIQUE INDEX XSP ON SP (НОМЕР_ПОСТАВЩИКА,
НОМЕР_ДЕТАЛИ);
Индексы, подобно базовым таблицам, могут создаваться и уничтожаться в любое время. В приведенном примере, однако, нам хотелось бы, вероятно, создать индексы XS, XP и XSP в то же время, когда создаются сами базовые таблицы S, Р и SP. Если же эти базовые таблицы будут непустыми в то время, когда издается предложение CREATE INDEX, ограничения уникальности могут уже оказаться нарушенными. Попытка создания индекса с параметром UNIQUE над таблицей, которая в настоящее время не удовлетворяет ограничению уникальности, будет завершаться неудачно.
Примечание. Два неопределенных значения считаются равными друг другу для целей индексирования с параметром UNIQUE. Смысл этого довольно загадочного замечания состоит в том, что неопределенные значения не всегда рассматриваются как эквивалентные друг другу во всех контекстах. Обсуждение этого вопроса содержится в главе 4.
Над одной и той же базовой таблицей может быть построено любое число индексов. Например, другой индекс для таблицы S:
CREATE INDEX XSC ON S (ГОРОД);
В этом случае не было специфицировано UNIQUE, поскольку множество поставщиков может находиться в одном и том же городе.
Предложение уничтожения индекса имеет вид:
DROP INDEX имя—индекса;
в результате индекс уничтожается, т. е. его описание удаляется из каталога. Если какой-либо существующий план прикладной задачи зависит от этого уничтоженного индекса, то (как указывалось в главе 2) этот план будет помечен как недействительный супервизором стадии исполнения. Когда этот план будет в дальнейшем вызываться для исполнения, супервизор стадии исполнения автоматически вызовет генератор планов прикладных задач с тем, чтобы сгенерировать заменяющий его план, который поддерживал бы первоначальные предложения SQL, не используя исчезнувший теперь индекс. Этот процесс полностью скрыт от пользователя.
Поскольку уже говорилось о том, что система DB2 осуществляет автоматическую перегенерацию планов прикладных задач, если уничтожается существующий индекс, читатель может пожелать узнать, будет ли также выполняться автоматическая перегенерация, если создается какой-нибудь новый индекс. Ответ отрицателен, этого не делается. Причина такого положения вещей заключается в отсутствии в этом случае какой-либо гарантии относительно того, что перегенерация на самом деле будет полезной. Автоматическая перегенерация могла бы означать просто много не необходимой работы, т. к. существующие планы прикладных задач могут быть уже основанными на оптимальной стратегии. Иная ситуация с предложением DROP. Некоторый план просто не будет работать, если он предусматривает использование несуществующего индекса. И в этом случае перегенерация является необходимой. Следовательно, если создается новый индекс и имеется некоторый план, который, как Вы подозреваете, целесообразно заменить, то запрос на явную перегенерацию этого плана на Вашей ответственности. Явная перегенерация обсуждается в главе 14.
ИСЧЕРПЫВАЮЩИЙ ПРИМЕР
Эту главу мы завершим надуманным, но исчерпывающим примером (рис. 10.3), позволяющим проиллюстрировать ряд дополнительных моментов. Рассматриваемая программа получает четыре значения входных данных: номер детали (ЗАДАННАЯ_ДЕТАЛЬ), название города (ЗАДАННЫЙ_ГОРОД), прирост состояния (ЗАДАННЫЙ_ПРИРОСТ) и уровень состояния (ЗАДАННЫЙ_УРОВЕНЬ). Программа просматривает всех поставщиков детали, идентифицируемой значением ЗАДАННАЯ_ДЕТАЛЬ. Для каждого такого поставщика состояние увеличивается на заданный прирост, если он находится в городе ЗАДАННЫЙ_ГОРОД. В противном случае, если состояние поставщика меньше значения ЗАДАННЫЙ_УРОВЕНЬ, поставщик удаляется вместе со всеми его поставками. Во всех случаях информация о поставщике выводится на печать с указанием, каким образом программа поступила с этим конкретным поставщиком.
SQLEX: PROC OPTIONS (MAIN);
DCL ЗАДАННАЯ_ДЕТАЛЬ CHAR 16);
DCL ЗАДАННЫЙ_ГОРОД CHAR (16);
DCL ЗАДАННЫЙ_ПРИРОСТ FIXED BINARY (15);
DCL ЗАДАННЫЙ_УРОВЕНЬ FIXED BINARY (16);
DCL HOMEP_ ПОСТАВЩИКА CHAR (5);
DCL ФАМИЛИЯ CHAR (20);
DCL СОСТОЯНИЕ FIXED BINABY(15);
DCL ГОРОД CHAR 115);
DCL ДИСПОЗИЦИЯ CHAR (7);
DCL ДРУГИЕ_ПОСТАВЩИКИ ВIТ(1);
EXEC SQL INCLUDE SQLCA;
EXEC SQL DECLARE S TABLE
(НОМЕР_ПОСТАВЩИКА CHAR (5) NOT NULL,
ФАМИЛИЯ CHAR (20),
СОСТОЯНИЕ SMALLINT,
ГОРОД CHAR (20));
EXEC SQL DECLARE SP TABLE
(НОМЕР_ПОСТАВЩИКА CHAR (5) NOT NULL.
НОМЕР_ДЕТАЛИ CHAR (6) NOT NULL,
КОЛИЧЕСТВО INTEGER);
EXEC SQL DECLARE Z CURSOR FOR
SELECT HOMEP_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ,
ГОРОД
FROM S
WHERE EXISTS
(SELECT
FROM SP
WHERE SP. НОМЕР_ПОСТАВЩИКА=
S.HOMEP_ПОСТАВЩИКА
AND SP. НОМЕР_ДЕТАЛИ =
:ЗАДАННЫЙ_НОМЕР)
FOR update OF СОСТОЯНИЕ ;
EXEC SQL WHENEVER NOT FOUND CONTINUE;
EXEC SQL WHENEVER SQLERROR CONTINUE;
ЕХEС SQL whenever SQLWARNING CONTINUE;
ON CONDITION (DBEXCEPTION)
BEGIN:
PUT SKIP LIST (SQLCA);
EXEC SQL ROLLBACK;
GO TO QUIT;
END;
GET LIST (ЗАДАННАЯ_ДЕТАЛЬ, ЗАДАННЫЙ_ГОРОД, ЗАДАННЫЙ_ПРИРОСТ,
ЗАДАННЫЙ_УРОВЕНЬ);
EXEC SQL OPEN Z;
IF SQLCODE Ø= 0
THEN SIGNAL CONDITION (DBEXCEPTION)
ДРУГИЕ_ПОСТАВЩИКИ =‘1’ B;
DO WHILE (ДРУГИЕ_ПОСТАВЩИКИ);
EXEC SQL FETCH Z INTO
:НОМЕР_ПОСТАВЩИКА,
:ФАМИЛИЯ,
:СОСТОЯНИЕ,
:ГОРОД;
SELECT; /*SELECT языка ПЛ/1, а не SQL*/
WHEN (SQLCODE Ø= 100)
ДРУГИЕ_ПОСТАВЩИКИ = '0'B
WHEN (SQLCODE =100 & SOLCODE Ø= 0)
SIGNAL CONDITION (DBEXCEPTION);
WHEN- (SQLCODE =0)
DO;
ДИСПОЗИЦИЯ = ‘bbbbbbb ';
IF ГОРОД = ЗАДАННЫЙ_ ГОРОД
THEN
DO;
EXEC SQL UPDATE S
SET СОСТОЯНИЕ = СОСТОЯНИЕ
+ : ЗАДАННЫЙ_ПРИРОСТ
WHERE CURRENT OF Z ;
IF SQLCODE Ø=0
THEN SIGNAL CONDITION (DBEXCEPTION);
ДИСПОЗИЦИЯ = 'ОБНОВЛЕН ' ;
END;
ELSE
IF СОСТОЯНИЕ < ЗАДАННЫЙ_УРОВЕНЬ
THEN
DO;
EXEC SQL DELETE
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА =
: НОМЕР_ПОСТАВЩИКА;
IF SQLCODE Ø= 0 & SQLCODE Ø= 100
THEN SIGNAL CONDITION (DBEXCEPTION);
EXEC SQL DELETE
FROM S
WHERE CURRENT OF Z;
IF SQLCODE Ø= 0
THEN SIGNAL CONDITION (DBEXCEPTION);
ДИСПОЗИЦИЯ= ‘УДАЛЕН';
END;
PUT SKIP LIST (НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, ГОРОД,
ДИСПОЗИЦИЯ);
END; /*WHEN (SQLCODE=0) ...* /
END; /*SELECT языка ПЛ/1 */
END; /*DO WHILE* /
EXEC SQL CLOSE Z;
EXEC SOL COMMIT;
QUIT: RETURN;
END; /*SQLEX */
Рис. 10.3. Исчерпывающий пример
Возникают следующие проблемы.
1. Во-первых, всюду игнорируется возможность того, что некоторое поле, выборка которого производится, может иметь неопределенное значение. Такое упрощение введено исключительно с целью сокращения размеров примера.
2. Далее обратите внимание на два предложения DECLARE для таблиц S и SP. Эти объявления, очевидно, представляют собой не что иное, как небольшие текстуальные вариации соответствующих предложений CREATE TABLE языка SQL. Для построения таких деклараций в интересах пользователей предусматривается специальная служебная программа — генератор деклараций (DCLGEN).
Примечание.
Название DCLGEN обычно произносится «деклеген» с мягким «г».
По существу, DCLGEN использует информацию из каталога системы DB2 для построения одной или обеих следующих синтаксических конструкций:
— предложения DECLARE для данной таблицы
— соответствующей декларации в языках ПЛ/1 или Кобол для структуры того же вида, что и таблица, которая будет использоваться в качестве мишени для выборки и/или источника для обновления.
Результаты работы программы DCLGEN сохраняются в форме раздела библиотечного набора данных, имя которого специфицировано пользователем. Он может быть в дальнейшем включен в программу, записанную на включающем языке, с помощью следующего предложения:
ЕХЕС SQL INCLUDE раздел;
где «раздел» — это имя рассматриваемого раздела.
Предыдущее обсуждение показывает, что DCLGEN подобно каталогу выполняет некоторые функции, которые в более старых системах по традиции считались функциями отдельного программного продукта — словаря.
3. Как уже указывалось в разделе 10.2, каждое предложение языка SQL в принципе должно сопровождаться проверкой возвращаемого значения SQLCODE. Для того чтобы упростить этот процесс, предусмотрено предложение WHENEVER (всякий раз, когда). Это предложение имеет следующий синтаксис:
ЕХЕС SQL WHENEVER условие действие;
где «условие» может быть одним из следующих:
NOT FOUND (не найдено)
SQLWARNING (SQL-предупреждение)
SQLERROR (SQL-ошибка),
а «действие»—это либо предложение CONTINUE (продолжать), либо предложение GO TO (перейти к). Предложение WHENEVER не является исполняемым предложением. Оно представляет собой, скорее, директиву для прекомпилятора. Предложение «WHENEVER условие GO TO метка» заставляет прекомпилятор вставлять после каждого встречающегося ему исполняемого предложения языка SQL предложение вида «IF условие GO TO метка». В свою очередь предложение «WHENEVER условие CONTINUE» заставляет прекомпилятор не вставлять какие-либо такие предложения в связи с тем, что программист вставит их вручную. Указанные выше три «условия» определяются следующим образом:
NOT FOUND означает, что SQLCODE = 100
SQLWARNING означает, что SQLCODE > 0 и SQLCODE Ø= 100
SQLERROR означает, что SQLCODE < О
Каждое предложение
WHENEVER, которое встречается прекомпилятору при последовательном просмотре им текста программы (для конкретного условия), отменяет действие предыдущего найденного им такого предложения (для этого условия). Предполагается, что в начале текста программы для каждого из трех возможных условий имеется неявное предложение WHENEVER, специфицирующее в каждом случае CONTINUE.
В приведенном примере программы в учебных целях явным образом делаются все проверки на исключительную ситуацию. Если какая-либо исключительная ситуация имеет место, управление передается процедуре, которая печатает диагностическую информацию (в данном примере, область связи SQL), издает команду ROLLBACK (см. п. 4 ниже), а затем передает управление заключительному RETURN.
4. Когда программа некоторым образом обновляет базу данных, такое обновление следует рассматривать первоначально лишь как предварительное — предварительное в том смысле, что если что-либо в дальнейшем выполнится с ошибкой, это обновление может быть аннулировано самой программой или системой. Если, например, в программе встречается неожиданная ошибка, скажем, переполнение, и она аварийно завершается, то система от имени программы автоматически аннулирует все такие предварительные обновления. Обновления остаются предварительными до тех пор, пока не произойдет одно из двух: а) исполнится предложение COMMIT (фиксировать), которое все предварительные обновления сделает окончательными («зафиксированными»), или б) исполнится предложение ROLLBACK (откат), которое аннулирует все предварительные обновления. После того как обновление зафиксировано, гарантируется, что оно никогда не будет аннулировано (это определение понятия «зафиксированное обновление»).
В рассматриваемом примере программа издает COMMIT, когда она приходит к своему нормальному завершению, и издает ROLLBACK, если встречается какая-либо исключительная ситуация при исполнении предложений SQL. На самом деле, такая явная спецификация предложения COMMIT не является необходимой. Система автоматически будет издавать COMMIT от имени программы для любой программы, которая достигает нормального завершения. Она также автоматически будет издавать ROLLBACK от имени программы для любой программы, которая не достигает нормального завершения. В данном примере, однако, обязательна явная спецификация предложения ROLLBACK, поскольку программа спроектирована таким образом, чтобы осуществлять нормальное ее завершение даже в случае, если имеют место исключительные ситуации SQL.
Примечание.
Вопросы обновления рассматривались выше в предположении обстановки TSO, поскольку предложения COMMIT и ROLLBACK допустимы только в этом случае. Эффект выполнения этих предложений в обстановке IMS и CICS достигается соответствующими обращениями (с помощью CALL) к IMS и CICS. Значительно более глубокое и полное обсуждение вопроса о «зафиксированных обновлениях» и связанного с этим понятия обработки транзакций приводится в следующей главе.
ИСПОЛЬЗОВАНИЕ ФРАЗЫ GROUP BY
В примере 5.4.4 показано, как можно вычислить общий объем поставок для некоторой конкретной детали. Предположим, что теперь требуется вычислить общий объем поставок для каждой детали, т. е. для каждой поставляемой детали выдать номер этой детали и общий объем поставок.
SELECT НОМЕР—ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР—ДЕТАЛИ;
Результат:
|
|
НОМЕР_ДЕТАЛИ
|
|
|
Р1
|
600
|
|
Р2
|
1000
|
|
РЗ
|
400
|
|
Р4
|
500
|
|
Р5
|
500
|
|
Р6
|
100
Пояснение. С концептуальной точки зрения, оператор GROUP BY (группировать по) перекомпоновывает таблицу, представленную фразой FROM, в разделы или группы
таким образом, чтобы в каждой группе все строки имели одно и то же значение поля, указанного во фразе GROUP BY. Это, конечно, не означает, что таблица физически перекомпоновывается в базе данных. В рассматриваемом примере строки таблицы SP группируются таким образом, что в одной группе содержатся все строки для детали Р1, в другой—все строки для детали Р2 и т. д. Далее, к каждой группе перекомпонованной таблицы, а не к каждой строке исходной таблицы применяется фраза SELECT. Каждое выражение во фразе SELECT должно принимать единственное значение для группы, т. е. оно может быть либо самим полем, указанным во фразе GROUP BY, либо арифметическим выражением, включающим это поле, либо константой, либо такой функцией, как SUM, которая оперирует всеми значениями данного поля в группе и сводит эти значения к единственному значению.
Строки таблицы можно группировать по любой комбинации ее полей. В разделе 5.6 приведен пример, иллюстрирующий группирование более чем по одному полю. Заметим, что фраза GROUP BY не предполагает ORDER BY (упорядочить по). Чтобы гарантировать упорядочение результата этого примера по номерам деталей, следует специфицировать фразу ORDER BY НОМЕР-ДЕТАЛИ после фразы GROUP BY. Если поле, по значениям которого осуществляется группирование, содержит какие-либо неопределенные значения, то каждое из них порождает отдельную группу.
ИСПОЛЬЗОВАНИЕ ФРАЗЫ WHERE с GROUP BY
Выдать для каждой поставляемой детали ее номер и общий объем поставок, за исключением поставок поставщика S1:
SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА Ø= 'S1'
GROUP BY НОМЕР_ДЕТАЛИ;
Результат:
|
|
НОМЕР_ДЕТАЛИ
|
|
|
Р1
|
300
|
|
Р2
|
800
|
|
Р4
|
300
|
|
Р5
|
400
Строки, не удовлетворяющие фразе WHERE, исключаются до того, как будет осуществляться какое-либо группирование.
ИСПОЛЬЗОВАНИЕ HAVING
Выдать номера деталей для всех деталей, поставляемых более чем одним поставщиком (тот же пример, что и в 5.2.5).
SELECT НОМЕР_ДЕТАЛИ
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ
HAVING COUNT (*)>1;
Результат:
|
|
НОМЕР_ДЕТАЛИ
|
|
P1
Р2
Р4
Р5
Фраза HAVING играет такую же роль для групп, что и фраза WHERE для строк. (Конечно, если специфицирована фраза HAVING, то должна быть специфицирована и фраза GROUP BY.) Иными словами, HAVING используется для того, чтобы исключать группы, точно так же, как WHERE используется для исключения строк. Выражение во фразе HAVING должно принимать единственное значение для группы.
В примере 5.2.5 уже было показано, что этот запрос может быть сформулирован без GROUP BY (и без HAVING) с использованием коррелированного подзапроса. Однако пример 5.2.5 в действительности основан на несколько ином восприятии логики, связанной с определением ответа на этот вопрос. Можно также сформулировать запрос, используя по существу ту же логику, что и в варианте GROUP BY/HAVING, но без явного использования фраз GROUP BY и HAVING вообще:
SELECТ DISTINCT НОМЕР_ДЕТАЛИ
FROM SP SPX
WHERE 1 <
(SELECT COUNT (*)
FROM SP SPY
WHERE SPY.НОМЕР_ДЕТАЛИ = SPX.HOMEP_ДЕТАЛИ);
Следующий вариант, в котором вместо SPX используется таблица Р, является, вероятно, более ясным:
SELECT НОМЕР_ДЕТАЛИ
FROM Р
WHERE 1 <
(SELECT COUNT (НОМЕР_ПОСТАВЩИКА)
FROM SP
WHERE НОМЕР_ДЕТАЛИ = P. НОМЕР_ДЕТАЛИ);
Еще одна формулировка связана с использованием EXISTS:
SELECT НОМЕР_ДЕТАЛИ
FROM P
WHERE EXISTS
(SELECT *
FROM SP SPX
WHERE SPX. НОМЕР_ДЕТАЛИ = Р. НОМЕР_ДЕТАЛИ
AND EXISTS
(SELECT *
FROM SP SPY
WHERE SPY. НОМЕР_ДЕТАЛИ = Р. НОМЕР_ДЕТАЛИ
AND SPY. НОМЕР_ПОСТАВЩИК Ø= SPX. НОМЕР_
ПОСТАВЩИКА);
Все эти альтернативные варианты являются в некотором отношении более предпочтительными по сравнению с вариантом GROUP BY/HAVING в связи с тем, что они по крайней мере логически более понятны и, в частности, не требуют этих дополнительных языковых конструкций. Из первоначальной формулировки задачи на естественном языке — «Выдать номера деталей для всех деталей, поставляемых более чем одним поставщиком» — без сомнения, не ясно, что группирование само по себе—это то, что необходимо для ответа на данный вопрос, и в нем, действительно, нет необходимости. Не является также непосредственно очевидным, что необходимо условие HAVING, а не условие WHERE. Вариант GROUP-BY/HAVING более похож на процедурное предписание для решения задачи, чем просто на ясную логическую формулировку ее существа. С другой стороны, нельзя опровергнуть тот факт, что вариант GROUP-BY/HAVING наиболее лаконичен. Далее, в свою очередь имеются некоторые задачи такого же общего характера, для которых GROUP BY и HAVING просто неадекватны, в силу чего следует использовать один из альтернативных подходов. Пример такой задачи представлен в упражнении 5.24.
Наконец, конструкции
GROUP BY свойственно серьезное ограничение — она работает только на одном уровне. Невозможно разбить каждую из этих групп на группы более низкого уровня и т. д., а затем применить некоторую стандартную функцию, например SUM или AVG на каждом уровне группирования[16].
ИСПОЛЬЗОВАНИЕ INSERT..SELECT ДЛЯ ПОСТРОЕНИЯ ВНЕШНЕГО СОЕДИНЕНИЯ
Для каждого поставщика получить его номер, фамилию, состояние и город вместе с номерами всех поставляемых им деталей, Если данный поставщик не поставляет вообще никаких деталей, то выдать информацию для этого поставщика, оставляя в результате пробелы вместо номера детали.
CREATE TABLE ВНЕШ_СОЕДИНЕНИЕ
(НОМЕР_ПОСТАВЩИКА CHAR (5),
ФАМИЛИЯ CHAR (20),
СОСТОЯНИЕ SMALLINT,
ГОРОД CHAR (15)),
НОМЕР_ДЕТАЛИ CHAR (6);
INSERT
INTO ВНЕШ_СОЕДИНЕНИЕ
SELECT S.*, SP.HOMEP_ДЕТАЛИ
FROM S, SP
WHERE S. НОМЕР_ПОСТАВЩИКА=SP. НОМЕР_ПОСТАВЩИКА;
INSERT
INTO ВНЕШ_СОЕДИНЕНИЕ
SELECT S.*, 'bb'
FROM S
WHERE NOT EXISTS
(SELECT *
FROM SP
WHERE SP. НОМЕР_ПОСТАВЩИКА=
S. НОМЕР_ПОСТАВЩИКА);
Теперь таблица BHEШ_СОЕДИНЕНИЕ выглядит так:
|
|
ВНЕШ_СОЕДИНЕНИЕ
|
НОМЕР_
ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
ГОРОД
|
НОМЕР_
ДЕТАЛИ
|
|
|
S1
S1
S1
S1
S1
S1
S2
S2
S3
S4
S4
S4
S5
|
Смит
Смит
Смит
Смит
Смит
Смит
Джонс
Джонс
Блейк
Кларк
Кларк
Кларк
Адамc
|
20
20
20
20
20
20
10
10
30
20
20
20
30
|
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Париж
Париж
Париж
Лондон
Лондон
Лондон
Атенс
|
Р1
Р2
РЗ
Р4
Р5
Р6
Р1
Р2
Р2
Р2
Р4
Р5
bb
Здесь 'bb' используется для представления строки пробелов. Пояснение. Первые двенадцать строк приведенного результата, как легко видеть, соответствуют первому из двух INSERT.. .SELECT и представляют собой обычное естественное соединение таблиц S и SP по номерам поставщиков, за исключением того, что не включен столбец КОЛИЧЕСТВО. Последняя строка результата соответствует второму INSERT.. .SELECT и сохраняет информацию для поставщика S5, который не поставляет никаких деталей. Полный результат представляет собой внешнее соединение таблиц S и SP по номерам поставщиков, в котором опущен столбец КОЛИЧЕСТВО. В противоположность этому обычное соединение называется иногда внутренним
соединением.
Заметим, что нужны два отдельных INSERT.. .SELECT, поскольку подзапрос не может содержать UNION.
ЯЗЫК QUERY-BY-EXAMPLE
Как указывалось в разделе 15.1, QMF обеспечивает интерфейс Query-By-Example, а также интерфейс SQL. Query-By-Example (QBE) — реляционный язык запросов, который в некотором отношении более «дружествен для пользователей», чем SQL, по крайней мере для пользователей, не имеющих профессиональной подготовки в области обработки данных. Несомненно, справедливо, что SQL—более «дружествен для пользователей», чем более старые языки, например DL/1. Однако в нем все еще предполагается определенный опыт программирования. По существу, он является все-таки языком программирования в традиционном смысле, хотя и языком очень высокого уровня. Напротив, QBE—это язык, в котором все операции формулируются просто путем занесения данных в пустые таблицы на экране—по существу, путем заполнения форм. Такой стиль «заполнения бланков» является весьма легким для изучения и понимания и часто оказывается более привлекательным, чем стиль SQL, для пользователей с незначительной подготовкой или вообще не имеющих подготовки в области обработки данных.
С помощью интерфейса
QBE для QMF пользователь может запрашивать операции, аналогичные операциям манипулирования данными SQL - SELECT, UPDATE, DELETE и INSERT. Однако все другие операции определения данных и управления данными, например CREATE и GRANT, могут запрашиваться только через интерфейс SQL. В QBE доступны операции Р., U., D. и I., соответствующие операциям SQL - SELECT, UPDATE, DELETE и INSERT.
Примечание. «Р.» обозначает «print» (печатать), однако эта команда фактически не вызывает какой-либо печати. Для этой цели предназначена команда PRINT в QMF, как указывалось и разделе 15.2.
Основная идея, лежащая в основе QBE, очень проста и иллюстрируется следующим примером. Рассмотрим запрос «Выдать номера поставщиков, находящихся в Париже и имеющих состояние больше 20» (пример 4.2.5 из главы 4). Этот запрос может быть представлен в QBE следующим образом:
|
|
S
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
ГОРОД
|
|
|
Р.
|
|
>20
|
Париж
Пояснение.
Сначала, выдавая команду DRAW S (нарисоватьS), пользователь заставляет QMF вывести на экран пустую таблицу S, т. е. таблицу, в которой показаны только ее имя и имена столбцов без каких-либо значений данных. Затем пользователь конструирует запрос, печатая элементы трех позиций в теле этой таблицы. А именно, он печатает «Р.» в позиции НОМЕР_ПОСТАВЩИКА, чтобы указать цель запроса, в данном случае значения, которые должны быть «напечатаны» или показаны на экране. Помимо этого, он задает «>20» и «Париж» в позициях СОСТОЯНИЕ и ГОРОД, чтобы указать условия, которым должны удовлетворять эти целевые значения.
Можно специфицировать также «Р.» относительно полной строки, например, следующим образом:
|
|
S
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
ГОРОД
|
|
|
Р.
|
|
>20
|
Париж
что эквивалентно спецификации «Р.» в позиции каждого столбца таблицы:
|
|
S
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
ГОРОД
|
|
|
Р.
|
Р.
|
Р.>20
|
Р. Париж
Отметим, между прочим, что значения, являющиеся строками символов, например Париж, могут специфицироваться без заключения их в кавычки. Однако не будет ошибки, если такое значение заключается в кавычки, а иногда, например если в строке содержатся пробелы, кавычки необходимы.
В остальной части этой главы с помощью ряда дальнейших примеров иллюстрируются некоторые важные особенности интерфейса QBE. Для удобства там, где это уместно, даются ссылки на варианты этих примеров в SQL из глав 4, 5 и 6. Мы не будем, однако, настолько же вдаваться в подробности, насколько это делали в случае SQL. Прежде чем перейти к рассмотрению примеров, сделаем еще два предварительных замечания:
— В QMF имеется команда, которая дает пользователю возможность специфицировать, будут ли запросы формулироваться в SQL или в QBE. Возможно динамическое переключение этих интерфейсов в одном сеансе QMF.
— Для формирования пустых таблиц на экране путем добавления или удаления столбцов и строк, а также расширения и сужения столбцов пользователь имеет в распоряжении команды редактирования. Таким образом, таблицы могут редактироваться для того, чтобы удовлетворить требованиям любой операции, которую пытается формулировать пользователь. В частности, могут быть исключены столбцы, которые не требуются для выполнения специфицированной в запросе операции. Например, в первом из приведенных выше примеров запросов столбец ФАМИЛИЯ мог быть исключен:
|
|
S
|
НОМЕР_ПОСТАВЩИКА
|
СОСТОЯНИЕ
|
ГОРОД
|
|
|
Р.
|
>20
|
Париж
В дальнейшем мы не будем беспокоиться относительно обсуждения таких подробностей.
ЯЗЫК SQL
На рис. 1.3 представлено состояние базы данных поставщиков и деталей в некоторый конкретный момент времени. Это — фотография базы данных. В противоположность этому на рис. 1.5 показана структура
этой базы данных. Она показывает, как эта база данных определена или описана[5].
CREATE TABLE S
|
|
(НОМЕР_ПОСТАВЩИКА
|
CHAR (5),
|
|
ФАМИЛИЯ
|
CHAR (20),
|
|
СОСТОЯНИЕ
|
SMALLINT.
|
|
ГОРОД
|
CHAR (15));
CREATE TABLE P
|
|
(НОМЕР_ДЕТАЛИ
|
CHAR (5),
|
|
НАЗВАНИЕ
|
CHAR (20),
|
|
ЦВЕТ
|
CHAR (7),
|
|
ВЕС
|
SMALLINT,
|
|
ГОРОД
|
CHAR (15));
CREATE TABLE SP
|
|
(НОМЕР_ПОСТАВЩИКА
|
CHAR (5)
|
|
НОМЕР_ДЕТАЛИ
|
CHAR (6)
|
|
КОЛИЧЕСТВО
|
INTEGER);
Рис. 1.5. База данных поставщиков и деталей (определение данных)
Нетрудно видеть, что определение базы данных в рассматриваемом примере включает по одному предложению CREATE TABLE (СОЗДАТЬ ТАБЛИЦУ) для каждой из трех составляющих ее таблиц. CREATE TABLE представляет собой пример предложения определения данных языка SQL. Каждое предложение CREATE TABLE специфицирует имя таблицы, которая должна быть создана, имена ее столбцов и типы данных для этих столбцов (а также, возможно, некоторую дополнительную информацию, не иллюстрируемую данным примером).
В данный момент детальное описание предложения CREATE TABLE не является нашей задачей. Оно будет приведено позже, в главе 3. Однако с самого начала необходимо подчеркнуть, что CREATE TABLE — выполняемое предложение. (Фактически, как мы увидим позднее, каждое предложение SQL является выполняемым.) Если три представленные на рис. 1.5 предложения CREATE TABLE будут введены с терминала в точности так, как они показаны, система в действительности тотчас же построит эти три таблицы. Конечно, сначала эти таблицы будут пустыми. Каждая из них будет содержать только строку заголовков столбцов, но не будет еще содержать никаких строк с данными. Мы можем, однако, немедленно приступить к вставке таких строк данных, возможно, с помощью предложения INSERT языка SQL, которое будет обсуждаться в главе 6. Буквально за несколько минут работы мы можем получить в свое распоряжение, вероятно, небольшую, но тем не менее полезную и пригодную к использованию базу данных и можем начать делать с нею некоторые полезные вещи. Таким образом, этот простой пример сразу же показывает одно из достоинств реляционных систем вообще и системы DB2 в частности — они являются очень легкими для использования. Конечно, легкость «вступления в контакт» это лишь один аспект легкости использования вообще. В результате пользователь может работать очень продуктивно. Позже мы увидим много других достоинств.
Примечание. Хотя это в действительности и не имеет никакого отношения к теме данного параграфа (к языку SQL), целесообразно, между прочим, упомянуть, что DB2 разрабатывалась, в частности, с целью создания легко устанавливаемой системы. Это означает, что не только легко в любое время «установить» или создать новую базу данных, но прежде всего легко установить также и полную систему. Иными словами, процесс построения необходимых библиотечных наборов данных DB2, специфицирующих требуемые параметры системы, определяющих некоторые характеристики системы по умолчанию и т. п. намеренно сделан настолько простым, насколько это возможно. Для верификации корректности функционирования установки системы предоставляются контрольные примеры программ. Полная процедура установки системы обычно занимает от одного до двух рабочих дней.
Теперь вернемся к примеру. После создания трех наших таблиц и загрузки в них некоторых записей можно начать делать с ними полезную работу, используя предложения манипулирования данными языка SQL. Одна из вещей, которую мы можем делать,— это поиск данных, специфицируемый в языке SQL с помощью предложения SELECT. Пример поиска данных приведен на рис. 1.6.
SELECT ГОРОД Результат: ГОРОД
FROM S Лондон
WHERE НОМЕР-ПОСТАВЩИКА == 'S4';
а) Интерактивный (DB2I)
ЕХЕС SQL SELECT ГОРОД Результат: ХГОРОД
INTO :X ГОРОД Лондон
FROM S
WHERE НОМЕР_ПОСТАВЩИКА =='S4';
б) Встроенный в ПЛ/1 (может использоваться также КОБОЛ, ФОРТРАН или Ассемблер).
Рис. 1.6. Пример поиска данных в базе данных
Довольно важная особенность реализации языка SQL в системе DB2 (и, между прочим, в SQL/DS) заключается в том, что один и тот же язык предоставляется через два различных интерфейса, а именно через интерактивный интерфейс (DB2I в случае системы DB2) и через интерфейс прикладного программирования. На рис. 1.6,а показан пример использования интерактивного интерфейса DB2I. Пользователь вводит с терминала предложение SELECT, а система DB2 отвечает через ее компонент DB2I, показывая непосредственно на терминале результат «Лондон». На рис 1.6,б показано фактически то же самое предложение SELECT, встроенное в прикладную программу (в примере—в программу на языке ПЛ/1). В этом втором случае указанное предложение будет исполняться, когда будет исполняться программа, а результат «Лондон» будет возвращаться не на терминал, а программной переменной ХГОРОД (благодаря фразе INTO в предложении SELECT; переменная ХГОРОД представляет собой как раз область ввода в программе). Таким образом, SQL представляет собой и интерактивный язык запросов и язык программирования в обстановке базы данных. Это замечание относится ко всему языку SQL, т. е. любое предложение SQL, которое может быть введено с терминала, может быть альтернативно встроено в программу. Отметим, в частности, что приведенное замечание относится даже к таким предложениям, как CREATE TABLE. Вы можете создавать таблицы из прикладной программы, если это имеет смысл н вашей прикладной задаче и если Вы обладаете полномочиями на выполнение таких операций. Предложения языка SQL могут быть встроены в программы, записанные на любом из следующих языков: ПЛ/1, КОБОЛ, ФОРТРАН и язык ассемблера IBM/370. (Помимо этого фирма IBM объявила о своем намерении поддерживать в будущем БЭИСИК и АПЛ).
Примечание. На рис. 1.6, б префикс EXEC SQL необходим для того, чтобы отличить данное предложение SQL от предложений языка ПЛ/1, которые его окружают. Кроме того, чтобы обозначить область ввода, необходима, как мы видим, фраза INTO; указанная в этой фразе переменная должна иметь в качестве префикса двоеточие с тем, чтобы отличать ее от имени столбца в SQL. Конечно, не совсем точно, что предложение SELECT является одним и тем же для обоих интерфейсов. Но это вполне справедливо, если отвлечься от незначительных различий в деталях.
Теперь мы в состоянии понять, как выглядит система DB2 для пользователя. Под «пользователем» мы понимаем здесь либо конечного пользователя, работающего в интерактивном режиме терминала, либо прикладного программиста, пишущего программы на ПЛ/1, КОБОЛе, ФОРТРАНе или на языке ассемблера. (Заметим, между прочим, что мы будем использовать термин «пользователь» всюду в этой книге в каком-либо одном или в обоих этих смыслах). Как уже разъяснялось, каждый такой пользователь будет использовать SQL для того, чтобы оперировать таблицами (см. рис. 1.7).
Рис. 1.7. База данных системы DB2 в восприятии отдельного пользователя
Первое соображение, касающееся рис. 1.7, состоит в том, что обычно множество пользователей обоих видов будет оперировать одними и теми же данными в одно и то же время. Система DB2 будет автоматически использовать необходимые средства управления (см. главу 11) с тем, чтобы обеспечить защиту всех этих пользователей друг от друга, т. е. гарантировать, что обновления, осуществляемые одним пользователем, не могут привести к некорректному результату операций, выполняемых другим пользователем.
Отметим далее, что на рисунке также представлены таблицы двух видов, а именно: базовые таблицы, и представления. Базовая таблица это «реальная» таблица, т. е. таблица, которая существует физически в том смысле, что в одном или более наборах данных VSAM существуют физически хранимые записи и, возможно, физические индексы, которые непосредственно представляют эту таблицу в памяти. В противоположность этому представление является «виртуальной таблицей», т. е. таблицей, которая непосредственно не существует в физической памяти, но для пользователя выглядит так, как будто она существует. Представления можно считать различными способами видения «реальных» таблиц. Тривиальный пример: данный пользователь мог бы располагать представлением базовой таблицы поставщиков, в котором видимы только те поставщики, которые находятся в Лондоне. Представления определяются на основе одной или более базовых таблиц. Способ их определения рассматривается в главе 8.
Примечание.
Сказанное в предыдущем абзаце не следует интерпретировать таким образом, что базовая таблица физически хранится как таблица, т. е. как множество физически смежных хранимых записей, каждая из которых представляет собой просто непосредственную копию какой-либо строки базовой таблицы. Существуют многочисленные различия между базовой таблицей и ее представлением в среде хранения. Некоторые из них будут позднее обсуждаться. Дело в том, что пользователи всегда могут считать базовые таблицы «физически существующими», не касаясь того, каким образом эти таблицы на самом деле реализованы в памяти. Фактически проблема реляционных баз данных в полном ее объеме заключается в том, чтобы дать пользователям возможность иметь дело с данными в форме таблиц самих по себе, а не в виде представлений таких таблиц в среде хранения. Как уже говорилось в разделе 1.4, реляционная база данных—это база данных, которая воспринимается ее пользователями как
совокупность таблиц. Это совсем не база данных, в которой данные физически хранятся, как таблицы.
Представления, как и базовые таблицы, могут быть созданы в любое время. То же самое справедливо и для индексов. Уже указывалось, что предложение CREATE TABLE служит для создания «реальных» или базовых таблиц. Имеется аналогичное предложение CREATE VIEW (создать представление) для создания представлений или «виртуальных» таблиц и аналогичное предложение CREATE INDEX (создать индекс) для создания индексов. Подобным же образом базовые таблицы (а также представления и индексы) могут быть «уничтожены» (иначе говоря, разрушены) в любое время с использованием предложений DROP TABLE (уничтожить таблицу), DROP VIEW (уничтожить представление) или DROP INDEX (уничтожить индекс). Относительно индексов заметим для строгости, что хотя пользователь (т. е. некоторый пользователь, вероятно, администратор базы данных— см. главу 9) ответствен за их создание и уничтожение, он не является ответственным за их сохранность, когда эти индексы должны использоваться. Индексы никогда не упоминаются в предложениях манипулирования данными языка SQL, например в SELECT. Решение о том, использовать ли или не использовать какой-либо конкретный индекс при обработке, например, определенного предложения SELECT, принимается системой, а не пользователем. Этот вопрос более подробно обсуждается в главе 2.
Пользовательский интерфейс системы DB2 — это язык SQL. Мы уже указывали, что:
а) SQL может использоваться как в интерактивной, так и во встроенной обстановке и
б) он обеспечивает не только функции определения данных, но и функции манипулирования данными (как будет видно далее, он фактически обеспечивает также некоторые функции «управления данными»).
Выше мы уже касались главных функций определения данных:
CREATE TABLE
CREATE VIEW
CREATE INDEX
DROP TABLE
DROP VIEW
DROP INDEX
Главными функциями манипулирования данными являются (на самом деле, если на время игнорировать некоторые функции, относящиеся только к встроенному SQL, то это полный перечень таких функций):
SELECT (выбрать)
UPDATE (обновить)
DELETE (удалить)
INSERT (вставить)
Приведенные ниже примеры (рис. 1.8) предложений SELECT и UPDATE иллюстрируют важный момент, заключающийся в том, что предложения манипулирования данными языка SQL обычно оперируют одновременно полным множеством записей, а не просто одной записью. Если принять данные из примера на рис. 1.3, то предложение SELECT, приведенное на рис. 1.8 а, возвращает множество, Состоящее из четырех значений, а не из одного. В то же время, предложение UPDATE (рис. 1.8,б) изменяет две записи, а не одну. Другими словами, SQL является языком уровня множеств.
а) SELECT НОМЕР_ПОСТАВЩИКА Результат: НОМЕР_ПОСТАВЩИКА
FROM SP S1
WHERE НОМЕР_ДЕТАЛИ = 'Р2' S2
S3
S4
б) UPDATE S Результат: удвоенное состояние для
поставщиков S1 и S4
SET СОСТОЯНИЕ == 2*СОСТОЯНИЕ
WHERE ГОРОД = 'Лондон';
Рис. 1.8. Примеры манипулирования данными для языка SQL
Языки уровня множеств, такие, как SQL иногда характеризуются как «непроцедурные» на том основании, что пользователи специфицируют что, а не как (т. е. они указывают, какие данные необходимо иметь, не специфицируя процедуру для их получения). Иными словами, процесс «навигации» в физической базе данных с целью определения местонахождения требуемых данных выполняется автоматически системой, а не вручную пользователем. Однако «непроцедурный» в действительности не очень хороший термин, поскольку как процедурность, так и непроцедурность не являются абсолютными. Лучший способ выразить это — сказать, что некоторый язык А является более либо менее процедурным, чем некоторый другой язык В. Возможно, более хорошим способом выражения этого обстоятельства является утверждение о том, что некоторый язык, например SQL, находится на более высоком уровне абстракции, чем такой язык, как КОБОЛ (или DL/1). Иными словами, системе приходится в связи с языком типа SQL иметь дело с большим числом деталей, чем для языка типа КОБОЛ (или, например, DL/1). По существу, это такое повышение уровня абстракции, которое является причиной возросшей производительности, обеспечиваемой реляционными системами, такими, как DB2.
КАК ОБОЙТИСЬ БЕЗ DB
Как указывалось во введении (см. раздел 14.1), не обязательно использовать DB2I. Имеется возможность вызывать приложение DB2 в интерактивном режиме, не используя DB2I. Для этого выдается команда TSO «DSN» (вызывающая DB2), за которой должна следовать команда:
RUN PROGRAM (имя—программы) PLAN (имя—плана)
Можно также вызвать приложение DB2 в пакетном режиме с помощью предложений JCL, которые: а) специфицируют в качестве программы, подлежащей исполнению, терминальную мониторную программу TSO (TMP) и б) передают команды DSN и RUN на вход этой мониторной программе.
КАК СИСТЕМА DBРЕШАЕТ ЭТИ ТРИ ПРОБЛЕМЫ ПАРАЛЛЕЛЬНЫХ ПРОЦЕССОВ
Как уже упоминалось в начале предыдущего раздела, механизм управления параллельными процессами системы DB2, подобно предназначенным для этого механизмам большинства других доступных в настоящее время систем, основан на технике, называемой блокированием.
Главная идея блокирования проста: если транзакции нужны гарантии, что некоторый объект, в котором она заинтересована—обычно запись базы данных, не будет изменен каким-либо непредсказуемым образом в течение требуемого промежутка времени, она устанавливает блокировку этого объекта. Результат блокировки заключается в том, чтобы изолировать этот объект от других транзакций и, в частности, предотвратить его изменение средствами этих транзакций. Для первой транзакции, таким образом, имеется возможность выполнять предусмотренную в ней обработку, располагая определенными знаниями о том, что объект в запросе будет оставаться в стабильном состоянии до тех пор, пока данная транзакция этого пожелает.
Перейдем теперь к более детальному рассмотрению принципа действия блокирования конкретно для системы DB2. Начнем с некоторых упрощающих предположений.
1. Предполагается, что единственным видом объектов, подверженных действию механизма блокирования, является запись базы данных, т. е. строка базовой таблицы. Вопрос о блокировании объектов других видов отложим до раздела 11.6.
2. Будут обсуждаться только два вида блокировок, а именно — монопольные блокировки (тип X) и совместные блокировки (тип S) (Названия типов блокировок Х и S происходят от английских слов Shared (совместный) и exclusive (монопольный).—Примеч. пер.). В некоторых системах существуют другие типы блокировок. Фактически сама система DB2 внутренне поддерживает некоторые дополнительные их типы, но для пользователей в DB2 представляют интерес только блокировки типов Х и S.
3. Здесь рассматриваются только операции уровня записей (FETCH, UPDATE CURRENT и т. д.). Операции уровня множеств для целей блокирования могут рассматриваться как краткое обозначение соответствующих последовательностей операций уровня записей.
Теперь приступим к детальному рассмотрению вопроса.
1. Прежде всего если транзакция А устанавливает монопольную блокировку ( тип X) записи R, то запрос из транзакции В на любого типа блокировку записи R приведет к тому, что В перейдет в состояние ожидания. Транзакция В будет находиться в этом состоянии до тех пор, пока не будет снята блокировка, установленная транзакцией А.
2. Далее, если транзакция А устанавливает совместную блокировку (тип S) записи R, то: а) запрос из транзакции В на блокировку типа Х записи R заставит В перейти в состояние ожидания, и В будет находиться в этом состоянии до тех пор, пока не будет снята блокировка, установленная транзакцией А; б) запрос из транзакции В на блокировку типа S записи R будет удовлетворен, т. е. теперь транзакция В будет также удерживать блокировку типа S записи R.
Сказанное можно удобно резюмировать с помощью матрицы совместимости (рис. 11.5). Эта матрица интерпретируется следующим образом. Рассмотрим некоторую запись R. Предположим, что в настоящее время А удерживает блокировку R, тип которой указывается элементами в заголовках столбцов (тире обозначает отсутствие блокировки). Пусть теперь некоторая другая транзакция В издает запрос на блокировку R, тип которой указывается в левом столбце таблицы. Здесь для полноты снова включен случай «отсутствие блокировки». Тогда значение «N» на пересечении соответствующих столбца и строки матрицы указывает на конфликт—запрос транзакции В не может быть удовлетворен, и В переходит в состояние ожидания. Значение «Y» указывает совместимость — запрос В удовлетворяется. Очевидно, что приведенная матрица симметрична.
|
|
|
Х
|
S
|
—
|
|
Х
S
—
|
N
N
Y
|
N
Y
Y
|
Y
Y
Y
Рис. 11.5. Матрица совместимости типов блокировки
Продолжим наше рассмотрение.
3. Запросы транзакций на блокировку записей всегда являются неявными. Когда транзакция успешно осуществляет выборку записи (операция FETCH), она автоматически устанавливает блокировку типа S этой записи. Когда транзакция успешно обновляет запись, она автоматически устанавливает блокировку типа Х этой записи. Если же она уже удерживала блокировку типа Х для этой записи, как это будет происходить в случае последовательности операций FETCH . . . UPDATE, то операция UPDATE «повышает» блокировку типа S до уровня X.
4. Блокировки типа Х удерживаются до следующей точки синхронизации. Блокировки типа S обычно также удерживаются до этого момента времени (см. однако обсуждение вопроса об уровне изоляции в разделе 11.6).
Теперь мы имеем возможность уяснить, каким образом в системе DB2 решаются три проблемы, описанные в предыдущем разделе. Снова будем рассматривать их поочередно.
Проблема утраченного обновления
Рис. 11.6 представляет собой модифицированный вариант рис. 11.1, показывающий, что произошло бы при параллельном" исполнении приведенных на рисунке транзакций под управлением механизма блокирования, предусмотренного в системе DB2.
|
|
Транзакция А
|
Время
|
Транзакция В
|
|
—
|
|
|
—
|
|
—
|
|
|
—
|
|
FETCH R
|
t1
|
—
|
|
(установить блокировку
|
|
|
—
|
|
типа S для R)
|
|
|
—
|
|
—
|
t2
|
FETCH R
|
|
—
|
|
|
(установить блокировку
|
|
—
|
|
|
типа S для R)
|
|
—
|
|
|
—
|
|
UPDATE R
|
t3
|
—
|
|
(запрос блокировки
|
|
|
—
|
|
типа Х для R)
|
|
|
—
|
|
ждать
|
t4
|
UPDATE R
|
|
ждать
|
|
|
(запрос блокировки
|
|
ждать
|
|
|
типа Х для R)
|
|
ждать
|
|
|
ждать
|
|
ждать
|
|
|
ждать
|
|
ждать
|
|
|
ждать
|
|
|
|
|
|
|
|
|
|
|
Рис. 11.6. Не утрачиваются никакие обновления, но в момент t4 возникает тупиковая ситуация
Легко видеть, что запрос транзакции А в момент t3 на операцию UPDATЕ не принимается, поскольку это неявный запрос на блокировку типа Х для записи R, и такой запрос противоречит блокировке типа S, уже установленной транзакцией В. Поэтому А переходит в состояние ожидания. По аналогичным причинам транзакция В переходит в состояние ожидания в момент t4. Теперь обе транзакции не могут быть продолжены. Поэтому не возникает вопрос о том, что какое-либо обновление может быть утрачено. Таким образом, в системе DB2 проблема утраченного обновления решается путем сведения ее к другой проблеме, но это, по крайней мере, действительно решает первоначальную проблему! Эта новая проблема называется проблемой тупиковых ситуаций. Решение этой проблемы в системе DB2 обсуждается в разделе 11.7.
Проблема зависимости от незафиксированных обновлений
Рис. 11.7 и 11. 8 являются модифицированными вариантами рис. 11.2 и 11.3 соответственно, показывающими, что произошло бы при параллельном исполнении представленных на этих рисунках транзакций под управлением механизма блокирования, используемого в системе DB2. Нетрудно видеть, что операция транзакции А, запрашиваемая в момент t2 (FETCH—на рис. 11.7 и UPDATE—на рис. 11.8), в обоих случаях не выполняется, поскольку это неявный запрос на блокировку R, а такой запрос вступает в конфликт с уже установленной транзакцией В блокировкой типа X. Поэтому А переходит в состояние ожидания. Она остается в этом состоянии до тех пор, пока В не достигнет точки синхронизации, выполняя операцию COMMIT или ROLLBACK. При этом установленная транзакцией В блокировка снимается, и А получает возможность продолжать исполнение. В этот момент А «видит» зафиксированное значение — либо значение, предшествующее исполнению В, если В завершается операцией ROLLBACK, либо значение, соответствующее успешному завершению В, в противном случае. В любом случае А больше не зависит от незафиксированных обновлений.
|
|
|
Транзакция А
|
Время
|
Транзакция В
|
|
|
—
|
|
|
—
|
|
|
—
|
|
|
—
|
|
|
—
|
t1
|
UPDATE R
|
|
|
—
|
|
|
(запрос блокировки
|
|
|
—
|
|
|
типа Х для R)
|
|
|
FETCH R
|
t2
|
—
|
|
|
(запрос блокировки
|
|
|
—
|
|
|
типа S для R)
|
|
|
—
|
|
|
ждать
|
|
|
—
|
|
|
|
t3
|
точка синхронизации
|
|
|
ждать
|
|
|
(снять блокировку типа
|
|
|
|
|
|
Х для R)
|
|
|
ждать
|
|
|
—
|
|
|
повторно: FETCH R
|
t4
|
|
|
|
|
|
|
|
|
(установить блокировку
|
|
|
|
|
|
типа S для R)
|
|
|
|
|
|
—
|
|
|
|
|
|
|
|
|
Рис. 11.7. Предотвращается ситуация, когда транзакция А «увидела» бы в момент t2 незафиксированное изменение
|
|
Транзакция А
|
Время
|
Транзакция В
|
|
—
|
|
|
—
|
|
—
|
|
|
—
|
|
—
|
t1
|
UPDATE R
|
|
—
|
|
|
(установить блокировку
|
|
—
|
|
|
типа Х для R)
|
|
UPDATE R
|
t2
|
—
|
|
(запрос блокировки
|
|
|
—
|
|
типа Х для R)
|
|
|
—
|
|
ждать
|
|
|
—
|
|
ждать
|
t3
|
точка синхронизации
|
|
ждать
|
|
|
(снять блокировку типа
|
|
|
|
|
Х для R)
|
|
повторно: UPDATE R
|
t4
|
|
|
(установить блокировку
|
|
|
|
|
типа Х для R)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 11.8. Предотвращается ситуация, когда транзакция А обновила бы в момент t2 незафиксированное изменение
Проблема анализа на противоречивость
|
|
|
СЧЕТ 1
|
|
СЧЕТ 2
|
|
СЧЕТ 3
|
|
|
|
40
|
|
50
|
|
30
|
|
|
|
|
|
|
|
|
|
Транзакция А
|
Время
|
Транзакция В
|
|
|
|
—
|
|
|
—
|
|
|
|
—
|
|
|
—
|
|
|
|
FETCH СЧЕТ 1 (40):
|
t1
|
—
|
|
|
(установить блокировку
|
|
|
|
|
|
|
типа S для СЧЕТА 1):
|
|
|
—
|
|
|
|
сумма = 40
|
|
|
—
|
|
|
|
—
|
|
|
—
|
|
|
|
FETCH СЧЕТ 2 (50):
|
t2
|
—
|
|
|
(установить блокировку
|
|
|
|
|
|
|
типа S для СЧЕТА 2):
|
|
|
—
|
|
|
|
сумма = 90
|
t3
|
FETCH СЧЕТ 3 (30)
|
|
|
|
—
|
|
|
(установить блокировку
|
|
|
—
|
|
|
типа S для СЧЕТА 3):
|
|
|
|
—
|
|
|
—
|
|
|
|
—
|
t4
|
UPDATE СЧЕТ 3
|
|
|
|
—
|
|
|
(установить блокировку
|
|
|
—
|
|
|
типа Х для СЧЕТА З):
|
|
|
—
|
|
|
30®20
|
|
|
|
|
|
|
—
|
|
|
|
—
|
t5
|
FETCH СЧЕТ 1 (40) (
|
|
|
|
—
|
|
|
запрос блокировки)
|
|
|
|
—
|
|
|
типа S для СЧЕТА 1
|
|
|
|
—
|
|
|
ждать
|
|
|
|
—
|
t6
|
UPDATE СЧЕТ 1
|
|
|
|
—
|
|
|
(установить блокировку
|
|
|
—
|
|
|
типа Х для СЧЕТА 1)
|
|
|
|
FETCH СЧЕТ 3 (20):
|
t7
|
ждать
|
|
|
|
(запрос блокировки
|
|
|
ждать
|
|
|
|
S для СЧЕТА З):
|
|
|
ждать
|
|
|
|
Ждать
|
|
|
ждать
|
|
|
|
Ждать
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 11.9. Исключается анализ на противоречивость, но в момент t6 возникает тупиковая ситуация
Рис. 11.9—это модифицированный вариант рис. 11.4, показывающий, что произошло бы при параллельном исполнении представленных на этом рисунке транзакций под управлением механизма блокирования, который используется в системе DB2. Нетрудно видеть, что запрос транзакции В на операцию UPDATE и момент t6 не принимается, поскольку он является неявным запросом на блокировку типа Х для СЧЕТА 1, а такой запрос вступает в конфликт с блокировкой типа S, уже установленной транзакцией А. Поэтому В переходит в состояние ожидания. Подобным же образом в момент t7 не принимается также запрос транзакции А на выполнение операции FETCH, так как он является неявным запросом на установление блокировки типа S для СЧЕТА 3, а такой запрос вступает в конфликт с блокировкой типа X, уже установленной транзакцией В. По этой причине А также переходит в состояние ожидания. Итак, снова первоначальная проблема (в данном случае, проблема анализа на противоречивость) решается в системе DB2 путем форсирования возникновения тупиковой ситуации. Как уже говорилось, проблема тупиковых ситуаций обсуждается в разделе 11.7.
КОМАНДЫ ОПЕРАТОРА
Это меню позволяет пользователю вводить команды с консоли оператора, например START DATABASE, STOP DATABASE и т. п.
КОРРЕЛИРОВАННЫЙ ПОДЗАПРОС
Выдать фамилии поставщиков, которые поставляют деталь P2. Этот пример уже рассматривался в п. 5.2.1. Однако для иллюстрации проблемы, рассматриваемой в данном разделе, приведем иное решение этой задачи.
SELECT ФАМИЛИЯ
FROM S
WHERE 'P2' IN
(SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА =
S. НОМЕР_ПОСТАВЩИКА);
Пояснение. В последней строке приведенного запроса неуточненная ссылка на НОМЕР-ПОСТАВЩИКА уточняется неявным образом именем таблицы SP. Другая ссылка явно уточняется именем таблицы S. Этот пример отличается от предыдущих тем, что внутренний подзапрос не может быть обработан раз навсегда прежде, чем будет обрабатываться внешний запрос, поскольку этот внутренний подзапрос зависит от переменной, а именно от S.HOMEP_ПОСТАВЩИКА, значение которой изменяется
по мере того, как система проверяет различные строки таблицы S. Следовательно, с концептуальной точки зрения обработка осуществляется следующим образом.
а) Система проверяет первую строку таблицы S. Предположим, что это строка поставщика «S1». Тогда переменная S.НОМЕР_ПОСТАВЩИКА в данный момент имеет значение 'S1', и система обрабатывает внутренний запрос
(SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА ='S1'),
получая в результате множество ('Р1, 'P2', 'РЗ', 'Р4', 'Р5', 'Р6'). Теперь она может завершить обработку для S1. Выборка значения ФАМИЛИЯ для S1, а именно Смит, будет произведена тогда и только тогда, когда 'Р2' принадлежит этому множеству, что, очевидно, справедливо.
б) Далее система будет повторять обработку такого рода для следующего поставщика и т. д. до тех пор, пока не будут рассмотрены все строки таблицы S.
Такой подзапрос, как в этом примере, называется коррелированным. Коррелированный подзапрос — это такой подзапрос, результат которого зависит от некоторой переменной. Эта переменная принимает свое значение в некотором внешнем запросе. Обработка такого подзапроса, следовательно, должна повторяться для каждого значения переменной в запросе, а не выполняться раз навсегда. Далее будет приведен другой пример коррелированного подзапроса (см. п. 5.2.5). Несколько других примеров приведено в разделах 5.3 и 5.4.
Для того чтобы сделать более ясной связь коррелированных подзапросов с внешними запросами, некоторые пользователи любят вводить псевдонимы (если требуется освежить в памяти вопрос относительно псевдонимов, см. пример 4.3.6 из главы 4). Например:
SELECT SX.ФАМИЛИЯ
FROM S SX
WHERE 'P2' IN
(SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА=
SX.НОМЕР_ПОСТАВЩИКА);
В этом примере псевдонимом является имя SX, введенное во фразе FROM как альтернативное имя таблицы S и используемое далее в качестве явного уточнителя во фразе WHERE подзапроса, а также во фразе SELECT внешнего запроса. Действие приведенного выше полного предложения можно теперь описать более понятно и более точно следующим образом:
— SX — это переменная, областью определения которой является множество записей таблицы S, т. е. переменная, представляющая в любой заданный момент времени некоторую запись таблицы S.
— Поочередно для каждого возможного значения SX выполнить следующее:
+ вычислить подзапрос и получить множество номеров деталей, например Р;
+ добавить к результирующему множеству значение SX.ФАМИЛИЯ, если и только если P2 принадлежит множеству Р.
В предыдущем варианте этого запроса символ «S» в действительности выполнял две различные функции. Он обозначал, конечно, саму базовую таблицу, а также переменную, которая определена на множестве записей этой базовой таблицы. Как уже указывалось, многие считают более ясным использование двух различных символов для того, чтобы различать эти две различные функции.
Введение псевдонима никогда не является ошибкой, а иногда оно необходимо (см. ниже пример 5.2.5).
ЛОГИЧЕСКАЯ НЕЗАВИСИМОСТЬ ДАННЫХ
Мы еще не объяснили на самом деле, для чего нужны представления. Одна из задач, которую они позволяют решать — обеспечение того, что принято называть логической независимостью данных. Понятие физической независимости данных было введено в главе 2. Говорят, что система, подобная DB2, обеспечивает физическую независимость данных, поскольку пользователи и программы пользователей не зависят от физической структуры хранимой базы данных. Система обеспечивает логическую независимость данных, если пользователи и программы пользователей независимы также от логической структуры базы данных. Имеется два аспекта такой независимости — рост и реструктуризация.
Рост
Когда база данных растет в связи с включением новых видов информации, должно также соответственно расти ее определение.
Примечание. Вопрос о росте базы данных обсуждается здесь только для полноты. Он важен, но не имеет какого-либо отношения к самим по себе представлениям. Существуют два возможных типа роста, которые могут иметь место:
1. Расширение существующей базовой таблицы для включения в нее нового поля в соответствии с добавлением новой информации относительно некоторого существующего типа объектов, например добавление поля СКИДКА к базовой таблице поставщиков.
2. Включение новой базовой таблицы в соответствии с добавлением нового типа объектов, например при добавлении информации об изделиях в базу данных поставщиков и деталей.
Ни один из этих двух видов изменений не должен вообще оказывать какого-либо влияния на существующих пользователей, если только они не использовали предложения «SELECT *» или INSERT, в которых опущены списки имен полей. Как уже указывалось ранее в этой книге, смысл этих предложений может изменяться, если для них потребуется повторно произвести связывание, а рассматриваемая таблица была изменена (операция ALTER) в данном промежутке времени.
Реструктуризация
Иногда может стать необходимой реструктуризация базы данных. Хотя при этом общее информационное содержание остается тем же самым, размещение информации в этой базе данных изменяется, т. е. некоторым образом изменяется размещение полей в таблицах. Прежде чем продолжить обсуждение, отметим, что такая реструктуризация вообще нежелательна. Однако иногда она неизбежна. Например, может оказаться необходимым «вертикально» расщепить таблицу так, чтобы часто требующиеся столбцы могли храниться на более быстром устройстве, а реже требующиеся столбцы—на более медленном устройстве. Рассмотрим этот случай более подробно. Предположим для примера, что необходимо по некоторой причине — точная причина не является здесь важной — заменить базовую таблицу S следующими двумя базовыми таблицами:
SX (НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, ГОРОД)
SY (НОМЕР-ПОСТАВЩИКА, СОСТОЯНИЕ)
Примечание. Эта операция замены, между прочим, не совсем тривиальна. Один из способов ее осуществления состоит в следующей последовательности операций языка SQL:
CREATE TABLE SX
(НОМЕР_ПОСТАВЩИКА CHAR (5) NOT NULL,
ФАМИЛИЯ CHAR (20),
ГОРОД CHAR (15));
CREATE TABLE SY
(НОМЕР_ПОСТАВЩИКА CHAR (5) NOT NULL,
СОСТОЯНИЕ SMALLINT);
CREATE UNIQUE
CREATE UNIQUE INDEX XSX ON SX (НОМЕР_ПОСТАВЩИКА);
CREATE UNIQUE I NDEX XSY ON SY (НОМЕР_ПОСТАВЩИКА);
INSERT INTO SX (НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, ГОРОД)
SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, ГОРОД
FROM S;
INSERT INTO SY (НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ)
SELECT НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ
FROM S;
DROP TABLE S;
Важный факт, который обнаруживается в данном примере, заключается в том, что старая таблица S представляет собой соединение двух новых таблиц SX и SY по номерам поставщиков. В таблице S, например, была строка
('S1', 'Смит', 20, 'Лондон'). В таблице SX мы имеем теперь строку ('S1', 'Смит', 'Лондон'), а в SY—строку ('S1', 20). Соединение их дает, как и ранее, строку ('S1', 'Смит', 20, 'Лондон'). Поэтому создадим представление, которое является в точности этим соединением, и назовем его S:
CREATE VIEW S (НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ,
ГОРОД)
AS SELECT SX.НОМЕР_ПОСТАВЩИКА, SX.ФAMИЛИЯ,
SY СОСТОЯНИЕ, SX ГОРОД
FROM SX,SY
WHERE SX НОМЕР_ПОСТАВЩИКА =
SY.HOMEP_ПОСТАВЩИКА;
Каждая программа, которая ранее обращалась к базовой таблице S, теперь будет вместо этого обращаться к представлению S. Операции SELECT будут продолжать работать в точности как и ранее, хотя они потребуют дополнительного анализа во время процесса связывания и дополнительных накладных расходов на стадии исполнения. Однако операции обновления больше не будут работать, поскольку система DB2, как уже пояснялось в разделе 8.4, не будет допускать обновлений представления, определяемого как соединение. Иными словами, выполняющий операции обновления пользователь не обладает иммунитетом к этому типу изменений. Он должен вручную внести некоторые изменения, касающиеся предложений обновления, а затем произвести их прекомпиляцию и повторное связывание.
Таким образом показано, что система DB2 не
обеспечивает полной защиты от изменений в логической структуре базы данных. И в этом в первую очередь причина того, что проведение таких изменений вряд ли является хорошей идеей. Но дела могут быть не настолько плохими, как кажется, даже если требуются ручные изменения. Во-первых, легко обнаружить, какие программы должны быть изменены в связи с любыми такими изменениями. Эта информация может быть получена из каталога. Во-вторых, легко найти такие предложения, которые необходимо изменить в этой программе. Все они совершенно отдельны от всего другого и начинаются с префикса EXEC SQL. В-третьих, SQL — язык очень высокого уровня. Поэтому число подлежащих изменениям предложений обычно невелико, и смысл этих предложений можно легко уяснить. В результате необходимые изменения делаются, как правило, легко. Это не похоже на предложения обновления в языках сравнительно низкого уровня, таких, как PL/1 или КОБОЛ, где смысл данного предложения в большой степени зависит от динамической логики управления—от программы к предложению в запросе. Поэтому, хотя и справедливо, что должны быть сделаны некоторые поправки вручную, требуемый объем работ на практике не будет настолько большим.
Вернемся на минутку к примеру с таблицами SX и SY. Фактически представление S, определенное как соединение SX и SY, это хороший пример представления — соединения, которое теоретически обновляемо. Если предположить, что всегда существует взаимно однозначное соответствие между SX и SY таким образом, что любой поставщик, указанный в SX, должен быть указан также в SY, и наоборот, то воздействие на представление S всех возможных операций обновления понятным образом определяется в терминах SX и SY. (Упражнение. Согласны ли Вы с этим утверждением?) Таким образом, данный пример иллюстрирует, не только почему способность обновлять представления — соединения была бы полезной системной возможностью, но и случай, где такое обновление, по-видимому, является осуществимым.
МЕНЮ BIND/REBIND/FREE
Это меню позволяет пользователю выдавать команды BIND, REBIND и FREE.
1. Команда BIND создает план прикладной задачи из одного или более модулей запросов к базе данных (DBRM—см. главу 2, разделы 2.1 и 2.2). Наряду с другими могут быть специфицированы следующие параметры:
– Должен ли новый план заменить существующий.
– Уровень изоляции (RR и CS) для нового плана.
– Следует ли проверять правильность плана на стадии связывания или на стадии исполнения. Проверка правильности представляет собой процесс, позволяющий убедиться в том, что ссылки на таблицы, столбцы и т. п. являются синтаксически корректными и что пользователь, который выдает команду BIND, обладает полномочиями на исполнение данных операций SQL в связываемых модулях запросов к базе данных. Обычно проверка правильности осуществляется на стадии связывания. В некоторых случаях такая проверка может, однако, оказаться невозможной на стадии связывания. Например, план может содержать ссылки на таблицу, которая еще не существует (может быть, сам этот план создает указанную таблицу), или он может включать такие операции, на выполнение которых пользователь еще не имеет необходимых полномочий. В таких случаях следует запрашивать проверку правильности плана на стадии исполнения. Заметим, однако, что проверка правильности на стадии исполнения является сравнительно дорогой, поскольку она должна осуществляться для данного предложения каждый раз, когда оно исполняется.
2. Команда REBIND заново осуществляет связывание существующего плана. Она отличается от варианта команды BIND с заменой имеющегося плана тем, что исходными данными для нее является некоторый план, а не множество модулей запросов к базе данных. Команду REBIND обычно используют после существенного изменения физической структуры базы данных, например если были созданы какие-либо новые индексы. В результате становится целесообразной переоценка стратегии доступа для плана, указанного в запросе.
3. Команда FREE уничтожает специфицированный существующий план.
МЕНЮ DCLGEN
Меню DCLGEN позволяет пользователю вызывать программу генератора деклараций. Как уже отмечалось в главе 10, DCLGEN — это программа, которая создает предложения EXEC SQL DECLARE TABLE и декларации соответствующих структур в Коболе или ПЛ/1 из описаний таблиц в каталоге. Результаты DCLGEN сохраняются как раздел библиотечного набора данных, из которого они могут быть внесены в прикладную программу с помощью предложения EXEC SQL INCLUDE.
МЕНЮ ПОДГОТОВКИ ПРОГРАММ
Меню подготовки программ позволяет пользователю выполнять любую (или все) из указанных ниже функций:
— прекомпиляция
— компиляция или ассемблирование
— обращение к редактору связей
— обращение к генератору планов прикладных задач
— исполнение программы.
Все необходимые параметры для прекомпилятора, генератора планов и т. д. могут быть заданы с помощью меню. Заметим, что сама исходная программа должна уже к этому времени быть создана с помощью соответствующего текстового редактора, например редактора ISPF.
МЕНЮ RUN
Меню RUN, по существу, является как раз частью «исполнения» из множества всех меню, связанных с подготовкой программ. Оно позволяет пользователю исполнить предварительно подготовленную прикладную программу при условии, что эта программа, как уже упоминалось выше, является приложением TSO, а не IMS или CICS.
МЕНЮ SPUFI
SPUFI обозначает «процессор языка SQL, использующий входные данные из файла» (SQL Processor Using File Input). Как указывалось в разделе 14.1, SPUFI поддерживает интерактивное исполнение предложений SQL с терминала TSO. Основная идея заключается в том, что можно создать файл, содержащий одно или более предложений SQL, используя редактор ISPF, и затем исполнить этот файл предложений с помощью SPUFI, а далее снова использовать редактор ISPF для просмотра результатов исполнения этих предложений, которые будут записаны в другой файл. Отметим, следовательно, что SPUFI—это инструмент профессионала в области обработки данных, а не конечного пользователя. Соответствующим средством для конечного пользователя является QMF (см. главу 15). SPUFI предназначен, главным образом, для прикладных программистов, которые хотят проверить SQL-части их программ, или для администраторов, которые хотят исполнить предложения определения данных SQL, хотя QMF фактически может также использоваться для выполнения обеих этих функций.
Наряду с прочим меню SPUFI позволяет пользователю, а в некоторых случаях требует от него специфицировать:
— Файл, содержащий предложение (или предложения) SQL; этот файл должен уже существовать, хотя он может в настоящее время быть пустым.
— Указание, должен ли этот файл редактироваться с помощью редактора ISPF, прежде чем он будет готов к исполнению (обычно — ДА).
— Файл для получения результатов исполнения предложения (предложений) SQL; этот файл не обязательно должен уже существовать—если он не существует, SPUFI создаст его.
— Уровень изоляции — RR или CS (см. главу 11).
— Требуется ли «автоматическая фиксация» (обычно—ДА). Положительный ответ означает, что SPUFI будет автоматически выдавать команду COMMIT после исполнения входного файла, если не возникнут никакие ошибки, или команду ROLLBACK— в противном случае. Отрицательный ответ означает, что сам входной файл включает предложения COMMIT или, если это не так, то у пользователя после исполнения в интерактивном режиме будет запрашиваться, какую из команд—COMMIT или ROLLBACK—следует выдать.
Если входной файл содержит множество предложений SQL, SPUFI прекратит исполнение этих предложений, как только он встретит в одном из них ошибку. Выходной файл будет содержать последовательность результатов каждого из предложений, в том числе возвращаемые значения SQLCODE, с последующим резюме всего исполнения. Оно включает, в частности, указание, какая из команд—COMMIT или ROLLBACK—была выполнена. На рис. 14.4 показан пример выходного файла SPUFI.
ПРОСМОТР _ _ КДДЕЙТ. РЕЗУЛЬТАТ _ _ _ _ _ _ КОЛОНКИ 001 072
ВВОД КОМАНД = = = > ПРОСМОТР => СТРАНИЦАМИ
––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | –
SELECT * 00010000
FROM P 00020000
WHERE ВЕС
IN (12, 16, 17) 00030000
ORDER BY НОМЕР_ДЕТАЛИ; 00040000
––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | –
НOMEР_ДЕТАЛИ НАЗВАНИЕ ЦВЕТ ВЕС ГОРОД
P1 гайка красный 12 Лондон
P2 болт зеленый 17 Париж
P3 винт голубой 17 Рим
P5 кулачок голубой 12 Париж
––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | –
DSNEG10I ЧИСЛО ПОКАЗАННЫХ СТРОК 4.
DSNE616I ИСПОЛНЕНИЕ ПРЕДЛОЖЕНИЯ БЫЛО УСПЕШНЫМ,
SQLCODE 100.
––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | ––––––––– | –
DSNE617I ВЫПОЛНЕНА КОМАНДА COMMIT, SQLCODE 0.
Рис. 14.4. Пример выходного файла SPUFI
МНОГОАСПЕКТНЫЙ ПРИМЕР
Выдать номер детали, вес в граммах, цвет и максимальный объем поставки для всех красных и голубых деталей, таких, что общий объем их поставки больше, чем 350, исключая при этом из общего объема все такие поставки, для которых количество меньше или равно 200 деталей. Результат упорядочить по убыванию номеров деталей в рамках возрастающих значений этого максимального объема поставки.
SELECT Р. НОМЕР_ДЕТАЛИ, 'вес в граммах = ', Р. ВЕС*454, Р. ЦВЕТ *
'максимальный объем поставки = ',
MAX (SP. КОЛИЧЕСТВО)
FROM P, SP
WHERE Р. НОМЕР_ДЕТАЛИ = SP. НОМЕР_ДЕТАЛИ
AND P. ЦВЕТ IN ('Красный', 'Голубой')
AND SP. КОЛИЧЕСТВО > 200
GROUP BY Р. НОМЕР_ДЕТАЛИ, Р. ВЕС, Р. ЦВЕТ
HAVING SUM (КОЛИЧЕСТВО) > 350
ORDER BY 6, P. НОМЕР_ДЕТАЛИ DESC;
Результат:
|
|
НОМЕР_ДЕТАЛИ
|
|
|
ЦВЕТ
|
|
|
|
Р1
Р5
РЗ
|
вес в граммах=
вес в граммах=
вес в граммах=
|
5448
5448
7718
|
Красный
Голубой
Голубой
|
максимальный объем поставки=
максимальный объем поставки=
максимальный объем поставки=
|
300
400
400
Пояснение. Фразы предложения SELECT применяются в таком порядке, в котором они записаны, за исключением самой фразы SELECT, которая применяется между фразами HAVING и ORDER BY, если они имеются. В данном примере, следовательно, можно представить себе, что результат строится следующим образом.
1. FROM. В результате обработки фразы FROM создается новая таблица, которая является декартовым произведением таблиц Р и SP.
2. WHERE. Из результата шага 1 исключаются все строки, не удовлетворяющие фразе WHERE. В данном примере исключаются строки, не удовлетворяющие предикату:
Р.НОМЕР-ДЕТАЛИ
=SP.HOMEP_ДETAЛИ AND Р.ЦВЕТ IN ('Красный', 'Голубой') AND SP.KOAH4ECTBO>200.
3. GROUP BY. Результат шага 2 группируется по значениям поля (полей), указанного во фразе GROUP BY. В нашем примере это поля Р.НОМЕР-ДЕТАЛИ, Р.ВЕС и Р.ЦВЕТ. Замечание. Теоретически в качестве поля группирования было бы достаточно использовать только Р.НОМЕР-ДЕТАЛИ, так как Р.ВЕС и Р.ЦВЕТ однозначно определяются номером детали. Однако система DB2 не осведомлена об этом последнем факте, и если Р.ВЕС и Р.ЦВЕТ будут опущены во фразе GROUP BY, возникнет условие ошибки, поскольку они включены
во фразу SELECT. Основная проблема состоит здесь в том, что система DB2 не поддерживает первичных ключей. См. Приложение А.
4. HAVING. Группы, не удовлетворяющие условию SUM (КОЛИЧЕСТВО) > 350, исключаются из результата, полученного на шаге 3.
5. SELECT. Каждая группа, полученная на шаге, 4, следующим образом генерирует единственную строку для результата. Во-первых, из группы выделяются номер детали, вес, цвет и максимальный объем поставки. Во-вторых, вес преобразуется в граммы. В-третьих, в соответствующие места полученной строки вставляются две строковые константы 'вес в граммах=' и 'максимальный объем поставки='.
6. ORDER BY. Результат шага 5 упорядочивается в соответствии со спецификацией фразы ORDER BY для получения окончательного результата.
Конечно, приведенный выше запрос весьма сложен, но представим себе, какую он выполняет работу. Обычная программа, например, в языке КОБОЛ, которая выполняет ту же самую работу, вполне могла бы составить девять страниц по сравнению только с девятью строками, приведенными выше. При этом работа, необходимая для того, чтобы эта программа стала действующей, значительно больше, чем это необходимо для формулировки приведенного варианта запроса на языке SQL. Большинство запросов на практике будет, конечно, во всяком случае значительно проще по сравнению с ним.
ОБЪЕДИНЕНИЕ
Объединением двух множеств называется множество всех элементов, принадлежащих какому-либо одному или обоим исходным множествам. Поскольку отношение—это множество (множество строк), можно построить объединение двух отношений. Результатом будет множество, состоящее из всех строк, входящих в какое-либо одно или в оба первоначальных отношения. Если, однако, этот результат сам по себе должен быть другим отношением, а не просто разнородной смесью строк, то два исходных отношения должны быть совместимыми по объединению. Нестрого говоря, строки в обоих отношениях должны быть одной и той же «формы». Что касается SQL, то две, таблицы совместимы по объединению (и к ним может быть применен оператор UNION) тогда и только тогда, когда:
а) они имеют одинаковое число столбцов, например, m;
б) для всех i (i= 1,2,..., m) i-й столбец первой таблицы и i-й столбец второй таблицы имеют в точности одинаковый тип данных;
— если тип данных—DECIMAL (p, q), то р должно быть;
одинаковым для обоих столбцов и q должно быть одинаковым для обоих столбцов;
— если тип данных—•
CHAR (n), то n должно быть. одинаковым для обоих столбцов;
— если тип данных—VARCHAR;(n), то n должно быть одинаковым для обоих столбцов;
— если NOT NULL специфицировано для какого-либо из этих столбцов, то такая же спецификаций должна быть для другого столбца.
ОБНОВЛЕНИЕ ЕДИНСТВЕННОЙ ЗАПИСИ
Изменить цвет детали Р2 на желтый, увеличить ее вес на 5 и установить значение города «неизвестен» (NULL).
UPDATE P
SET ЦВЕТ = 'Желтый',
ВЕС = ВЕС + 5,
ГОРОД = NULL
WHERE НОМЕР_ДЕТАЛИ =
'Р2';
Для каждой записи, которая должна быть обновлена (т. е. для каждой записи, которая удовлетворяет предикату WHERE, или для всех записей, если фраза WHERE опущена), ссылки во фразе SET на поля этой записи обозначают значения этих полей перед тем, как будет выполнено какое-либо присваивание в этой фразе SET.
ОБНОВЛЕНИЕ КАТАЛОГА
Выше было показано, каким образом можно запрашивать сведения из каталога с помощью предложения
SELECT языка SQL. Однако нельзя обновлять каталог, используя предложения SQL UPDATE, DELETE и INSERT, и система DB2 будет отвергать любые попытки сделать это. Причина, конечно, заключается в том, что потенциально было бы очень опасно допустить такие операции: можно было бы слишком легко умышленно или неумышленно разрушить информацию в каталоге, так что DB2 не смогла бы больше правильно функционировать. Предположим, например, что было бы допустимо предложение:
DELETE
FROM SYSIBM. SYSCOLUMNS
WHERE TBNAME = 'S'
AND NAME = 'НОМЕР_ПОСТАВЩИКА';
Результатом его было бы удаление строки ('НОМЕР_ПОСТАВЩИКА','S','CHAR',. ..) из таблицы SYSCOLUMNS. Что касается системы, DB2, то столбец НОМЕР_ПОСТАВЩИКА в таблице S теперь больше бы не существовал, т. е. DB2 не располагала бы больше какими-либо знаниями об этом столбце. Поэтому попытки доступа к данным на основе значений в этом столбце, например:
SELECT ГОРОД
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = 'S4';
были бы безуспешными. В таких случаях система будет выдавать некоторое сообщение об ошибке, например «неопределенный столбец». К более тяжелым последствиям, а возможно, и к потере работоспособности системы, могли бы привести при этом попытки обновления записей поставщиков. Например, вставка новой записи могла бы привести к тому, что номер поставщика будет приниматься за его фамилию, фамилия поставщика — за состояние и т. д.
По причинам такого рода операции UPDATE, DELETE и INSERT для таблиц в каталоге, как уже указывалось, не допускаются. Такие обновления осуществляются с помощью предложений определения данных (CREATE TABLE, CREATE INDEX и т. д.). Например, предложение CREATE TABLE для таблицы S приводит: а) к созданию записи для S в таблице SYSTABLES и б) к созданию в таблице SYSCOLUMNS множества из четырех записей, по одной для каждого из четырех столбцов таблицы S. Оно вызывает также и ряд других действий, которые, однако, не имеют отношения к нашему обсуждению здесь. Следовательно, предложение CREATE является в некотором смысле аналогом INSERT для каталога. Таким же образом, предложение DROP — аналог DELETE, a ALTER — аналог UPDATE.
Кстати, каталог, конечно, включает также и записи для самих таблиц каталога. Однако эти записи не создаются с помощью явных операций CREATE TABLE. Они создаются автоматически самой системой DB2, как часть процедуры установки системы. Они фактически «зашиты» в систему.
Хотя, как мы только что видели, обычные предложения обновления данных SQL не могут использоваться для обновления каталога, имеется одно предложение SQL, а именно, COMMENT, которое реализует некоторого рода функцию обновления каталога. Каждая из таблиц каталога SYSTABLES и SYSCOLUMNS включает столбец, не показанный на рис. 7.1, называемый REMARKS (комментарии), который может в каждой конкретной строке рассматриваемой таблицы содержать текстовую строку, описывающую объект, идентифицируемый остальной частью этой строки. Предложение COMMENT позволяет вводить такие описания в столбец REMARKS в эти две таблицы. В следующих примерах иллюстрируются два основных формата этого предложения. Первый пример:
COMMENT ON TABLES IS
'Каждая строка представляет одного поставщика';
Специфицированная в этом примере текстовая строка запоминается в поле REMARKS таблицы SYSTABLES в строке для таблицы S, замещая значение, ранее запомненное в этой позиции. Заметим, что таблица, указываемая фразой «TABLE имя-таблицы» в предложении COMMENT, может быть либо базовой таблицей, либо представлением. Другой пример:
COMMENT ON COLUMN Р.ГОРОД IS
'Местоположение (единственного) склада, где хранится эта деталь’;
Специфицированная строка запоминается в поле REMARKS таблицы SYSCOLUMNS в строке для столбца Р.ГОРОД, замещая значение, ранее запомненное в этой позиции. Вообще говоря, специфицированный столбец может быть столбцом либо базовой таблицы, либо представления.
Выборка комментариев может осуществляться с помощью обычного предложения SELECT языка SQL.
ОБНОВЛЕНИЕ МНОЖЕСТВА ЗАПИСЕЙ
Удвоить состояние всех поставщиков, находящихся в Лондоне.
UPDATE S
SET СОСТОЯНИЕ = 2*СОСТОЯНИЕ
WHERE ГОРОД = 'Лондон';
Установить нулевой объем поставок для всех поставщиков, находящихся в Лондоне (пример 6.2.3):
|
|
SP
|
НОМЕР_
ПОСТАВЩИКА
|
КОЛИЧЕСТВО
|
|
S
|
НОМЕР_
ПОСТАВЩИКА
|
ГОРОД
|
|
|
_SX
|
U.O.
|
|
|
_SX
|
Лондон
ОБНОВЛЕНИЕ НЕСКОЛЬКИХ ТАБЛИЦ
Изменить номер поставщика S2 на S9.
UPDATE S
SET НОМЕР_ПОСТАВЩИКА = 'S9'
WHERE НОМЕР_ПОСТАВЩИКА = 'S2';
UPDATE SP
SET НОМЕР_ПОСТАВЩИКА = 'S9'
WHERE НОМЕР_ПОСТАВЩИКА = 'S2';
Невозможно обновить более одной таблицы в единственном запросе. Иными словами, в предложении UPDATE должна специфицироваться в точности одна таблица. Поэтому в данном примере мы сталкиваемся со следующей проблемой целостности (точнее, с проблемой целостности по ссылкам): база данных становится противоречивой после выполнения первого предложения UPDATE — она включает теперь некоторые поставки, для которых не имеется соответствующей записи о поставщике, и остается в таком состоянии до тех пор, пока не будет выполнено второе предложение UPDATE. Изменение порядка предложений UPDATE, конечно, не решает эту проблему. Поэтому важно обеспечить выполнение обоих
этих предложений, а не только одного. Этот вопрос о поддержании целостности в условиях, когда требуется множество обновлений, детально обсуждается в главе 11. Кроме того, проблема целостности по ссылкам, в частности, подробно описана в Приложении А, а использованный в системе DB2 подход к ее решению представлен в Приложении В.
ОБНОВЛЕНИЕ ОДНОЙ ЗАПИСИ
Изменить цвет детали Р2 на желтый, увеличить ее вес на 5, а для города установить неопределенное значение (пример 6.2.1):
|
|
Р
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
ВЕС
|
ГОРОД
|
|
|
Р2
|
|
U. желтый
|
_WT
|
U._WT+5
|
U.NULL
ОБНОВЛЕНИЕ С ПОДЗАПРОСОМ
Установить объем поставок равным нулю для всех поставщиков из Лондона.
UPDATE SP
SET КОЛИЧЕСТВО = О
WHERE 'Лондон' =
(SELECT ГОРОД FROM S
WHERE S. НОМЕР_ПОСТАВЩИКА =
SP. НОМЕР_ПОСТАВЩИКА);
ОБРАБОТКА ПРЕДЛОЖЕНИИ, ОТЛИЧНЫХ ОТ SELECT
Два основных предложения динамического SQL — PREPARE (подготовить) и EXECUTE (выполнить). Их использование проиллюстрируем следующим (правильным, но нереалистичным) примером на языке ПЛ/1:
DCL ИСХОДНЫЙ_SQL CHAR(256) VARYING;
EXEC SQL DECLARE ОБЪЕКТНЫЙ_SQL STATEMENT;
ИСХОДНЫЙ_SQL = 'DELETE FROM SP WHERE
КОЛИЧЕСТВО < 100';
EXEC SQL PREPARE ОБЪЕКТНЫЙ_SQL FROM : ИСХОДНЫЙ-SQL;
EXEC SQL EXECUTE ОБЪЕКТНЫЙ_SQL;
Пояснение. Здесь ИСХОДНЫЙ-SQL это переменная ПЛ/1 типа строки символов переменной длины, в которой программа построит некоторое предложение SQL в исходном формате, т. е. представление его в виде строки символов. Напротив, ОБЪЕКТНЫЙ_SQL это переменная SQL, а не ПЛ/1, которая будет содержать для предложения SQL, заданного в исходном формате в строке ИСХОДНЫИ_SQL, его запись в объектном формате, т. е. представление этого предложения в машинном коде. Имена ИСХОДНЫЙ_SQL и ОБЪЕКТНЫИ_SQL выбраны произвольно. Оператор присваивания «ИСХОДНЫЙ_SQL =...;» присваивает переменной ИСХОДНЫЙ_SQL запись в исходном формате предложения DELETE языка SQL. (Как уже отмечалось в разделе 12.1, на практике процесс построения такого исходного предложения является, вероятно, несколько более сложным, требует ввода нескольких команд с терминала и их анализа.) Далее предложение PREPARE осуществляет прекомпиляцию и связывание этого исходного предложения и на этой основе продуцирует некоторый вариант программы в коде машины, который она запоминает как значение переменной ОБЪЕКТНЫЙ_SQL. Наконец, предложение EXECUTE исполняет этот вариант программы и, таким образом, приводит (в данном примере) к фактическому исполнению операции DELETE. Информация обратной связи, порождаемая этой операцией, будет, как обычно, возвращаться в область связи SQLCA.
Отметим, между прочим, что поскольку имя предложения ОБЪЕКТНЫЙ_SQL обозначает переменную SQL, а не ПЛ/1, оно не
имеет префикса — двоеточия в предложениях PREPARE и EXECUTE.
Предложение PREPARE
Предложение PREPARE имеет следующий синтаксис:
EXEC SQL PREPARE имя — предложения FROM строковое — выражение;
Здесь «строковое — выражение» это выражение включающего языка, которое определяет представление некоторого предложения SQL в форме строки символов, а «имя—предложения»—имя переменной SQL, которая будет использоваться для того, чтобы содержать подготовленный операцией PREPARE, т. е. прекомпилированный и связанный вариант этого предложения языка SQL. Предложение, которое обрабатывается с помощью PREPARE, должно быть только одним из следующих:
UPDATE (включая форму CURRENT)
DELETE (включая форму CURRENT)
INSERT
SELECT
CREATE
DROP
ALTER
COMMENT
GRANT
REVOKE
COMMIT
ROLLBACK
LOCK
Исходный формат обрабатываемого PREPARE предложения не должен включать ни фразы EXEC SQL, ни признака конца предложения.
Предложение EXECUTE
Предложение EXECUTE имеет следующий синтаксис:
ЕХЕС SQL EXECUTE имя — предложения [USING аргументы];
Исполняется предложение
SQL, сформированное с помощью PREPARE в переменной SQL, которая идентифицируется «именем—предложения». Фраза USING поясняется в следующем параграфе «Аргументы и параметры».
Аргументы и параметры
Предложения SQL, которые должны обрабатываться с помощью PREPARE, не могут включать каких-либо обращений к переменным включающего языка. Они могут, однако, содержать параметры, обозначаемые в исходном формате предложения вопросительными знаками. Параметры могут использоваться всюду, где допускаются переменные включающего языка.
Например:
ИСХОДНЫЙ_SQL = 'DELETE
FROM SP
WHERE КОЛИЧЕСТВО > ?
AND КОЛИЧЕСТВО < ?';
ЕХЕС SQL PREPARE ОБЪЕКТНЫЙ _ SQL FROM :ИСХОДНЫЙ_SQL;
Аргументы для замещения параметров специфицируются с помощью фразы USING предложения EXECUTE, обеспечивающего исполнение сформированного предложения. Например:
ЕХЕС SQL EXECUTE ОБЪЕКТНЫЙ_SQL USING
: НИЖНЕЕ_ЗНАЧЕНИЕ, : ВЕРХНЕЕ_ЗНАЧЕНИЕ;
Фактически исполняемое в данном примере предложение эквивалентно обычному предложению встроенного
SQL:
ЕХЕС SQL DELETE FROM SP WHERE
КОЛИЧЕСТВО > : НИЖНЕЕ_ЗНАЧЕНИЕ
AND КОЛИЧЕСТВО < :ВЕРХНЕЕ_ЗНАЧЕНИЕ;
В общем случае фраза
USING предложения EXECUTE имеет формат:
USING аргумент [, аргумент] . . .
где каждый «аргумент» в свою очередь имеет формат:
: переменная — включающего — языка [: переменная — включающего — языка]
точно такой же, как и у ссылки на целевую переменную во фразе INTO. Необязательная вторая переменная включающего языка представляет собой индикаторную переменную неопределенного значения. При этом n-й аргумент в списке аргументов соответствует n-му параметру, т. е. n-му вопросительному знаку, в исходном формате обрабатываемого PREPARE предложения,
ОБРАБОТКА ПРЕДЛОЖЕНИЙ SELECT
Как указывалось ранее, описанная в общих чертах в разделе 12.2 процедура пригодна для динамической подготовки и исполнения всех предложений SQL (точнее, всех предложений SQL, которые могут правильно обрабатываться с помощью PREPARE), за исключением SELECT. Причина такого отличия SELECT состоит в том, что оно возвращает программе данные, в то время как другие предложения возвращают только информацию обратной связи в область связи SQLCA.
Использующей SELECT программе необходимо кое-что знать о значениях тех данных, выборка которых должна производиться, поскольку в ней должно быть специфицировано множество принимающих эти значения целевых переменных. Необходимо знать но крайней мере сколько будет значений в каждой строке результата, а также каковы типы данных и длины этих значений. Если данное предложение SELECT генерируется динамически, программе обычно невозможно заранее «знать» эту информацию. Поэтому она должна получать эту информацию динамически, используя другое предложение динамического SQL, называемое DESCRIBE (описать). Реализуемая такой программой процедура в общих чертах может быть охарактеризована следующим образом.
1. Она формирует и обрабатывает с помощью PREPARE предложение SELECT без фразы INTO. (Обрабатываемое с помощью PREPARE предложение SELECT не должно включать фразу INTO.)
2. Используя DESCRIBE, она запрашивает систему о результатах, которых можно ожидать при исполнении данного предложения SELECT. Описание этих результатов возвращается в область, называемую областью дескрипторов SQL (SQLDA).
3. Далее, в соответствии с только что полученной с помощью DESCRIBE информацией распределяется память для множества целевых переменных, предназначенных для получения результатов. Адреса этих целевых переменных также помещаются в SQLDA.
4. Наконец, с помощью курсора последовательно по одной запрашиваются строки результата. Для этого используются предложения OPEN, FETCH и CLOSE. Если это требуется, в программе можно также использовать для этих строк предложения UPDATE CURRENT (обновить текущую) и DELETE CURRENT (удалить текущую). Эти предложения однако должны, вероятно, реализовываться с помощью PREPARE и EXECUTE.
Для того чтобы описанные идеи стали несколько более конкретными, приведем простой пример, показывающий, как могла бы выглядеть в общих чертах такая программа. Этот пример написан на языке ПЛ/1. Отметим, что он должен быть написан либо на ПЛ/1, либо на языке Ассемблера, поскольку должна иметься возможность динамического распределения памяти. Поэтому интерактивное приложение, осуществляющее выборку данных, должно быть написано на одном из двух указанных языков. Вместе с тем интерактивное приложение, использующее лишь средства, описанные в разделе 12.2, может быть также написано, если это требуется, на Коболе или Фортране. Перейдем теперь к примеру.
DCL ИСХОДНЫЙ_SQL CHAR(256) VARYING;
EXEC SQL DECLARE ОБЪЕКТНЫЙ_SQL STATEMENT;
EXEC SQL DECLARE X CURSOR FOR ОБЪЕКТНЫЙ_SQL;
EXEC SQL INCLUDE SQLDA;
/* Пусть максимальное число ожидаемых значений, подлежащих выборке, равно N */
SQLSIZE = N;
ALLOCATE SQLDA;
ИСХОДНЫЙ_SQL = 'SELECT * FROM SP WHERE
КОЛИЧЕСТВО > 100';
EXEC SQL PREPARE ОБЪЕКТНЫЙ_SQL FROM :ИСХОДНЫЙ_SQL;
EXEC SQL DESCRIBE ОБЪЕКТНЫЙ_SQL INTO SQLDA;
/* Теперь наряду с прочей информацией SQLDA содержит следующее: */
/* — в SQLN — фактическое число подлежащих выборке значений */
/* — в SQLVAR(i) — тип данных и длину i-го значения. */
/* Используя возвращаемую DESCRIBE информацию, программа может */
/* теперь распределить память для каждого значения, выборка */
/* которого должна быть осуществлена, и поместить адрес i-й */
/* выделенной области в
SQLVAR(i). Тогда: */
EXEC SQL OPEN X;
DO WHILE (еще — поступают— записи);
EXEC SQL FETCH X
USING DESCRIPTOR SQLDA;
. . . .
END;
EXEC SQL CLOSE X;
Пояснение. Здесь ИСХОДНЫИ_SQL и ОБЪЕКТНЫЙ_SQL имеют в основном такой же смысл, как и ранее: ИСХОДНЫЙ_SQL будет содержать предложение SQL в исходном формате (в данном примере, конечно, предложение SELECT), а ОБЪЕКТНЫЙ_SQL — это же предложение в соответствующем объектном формате. X — курсор для этого SELECT. Обратите внимание, что он описывается предложением DECLARE CURSOR нового формата:
EXEC SQL DECLARE имя — курсора CURSOR FOR имя — предложения;
Объявление области дескрипторов SQL включается в программу с помощью предложения:
EXEC SQL INCLUDE SQLDA;
Это предложение генерирует объявление структуры SQLDA в языке ПЛ/1, а также объявление числовой переменной SQLSIZE. Программа должна установить SQLSIZE, равное N, где N — верхняя граница числа значений, которые должны быть выбраны в каждой строке предложением SELECT, выделить память для SQLDA. Объем выделяемой памяти будет функцией значения SQLSIZE.
Далее, в строке ИСХОДНЫЙ_SQL формируется требуемое предложение SELECT в исходном формате, которое затем обрабатывается с помощью PREPARE. В результате будет получен в ОБЪЕКТНЫИ_SQL соответствующий его объектный формат. После этого программа выдает команду DESCRIBE в связи с переменной ОБЪЕКТНЫИ_SQL с тем, чтобы получить описание значений, ожидаемых в каждой строке результата исполнения этого предложения SELECT. Такое описание состоит из двух частей:
а) фактическое число значений, подлежащих выборке, указывается в поле SQLN структуры SQLDA;
б) тип данных и длина каждого такого значения указываются в массиве SQLVAR структуры SQLDA.
Используя это описание, программа может теперь распределить помять для каждого из этих значений. Далее она помещает адреса выделенных областей памяти в SQLDA, а точнее — в массив SQLVAR.
Наконец, для выборки фактических данных программа использует предложения OPEN, FETCH и CLOSE в связи с курсором X. Следует обратить внимание, что при этом используется новый формат предложения FETCH. Вместо фразы INTO оно включает фразу USING DESCRIPTOR, а структура, указанная в этой фразе (обычно SQLDA), в свою очередь идентифицирует целевые переменные для подлежащих выборке значений.
С помощью PREPARE можно также обрабатывать предложения SELECT, которые содержат параметры, указываемые вопросительным знаком. Например:
ИСХОДНЫЙ_SQL = 'SELECT *
FROM SP
WHERE КОЛИЧЕСТВО > ?
AND КОЛИЧЕСТВО < ?';
ЕXEC SQL PREPARE ОБЪЕКТНЫЙ_SQL FROM :ИСХОДНЫЙ_SQL;
Аргументы специфицируются в соответствующем предложении OPEN. Например:
ЕXEC SQL OPEN X USING НИЖНЕЕ_ЗНАЧЕНИЕ, :ВЕРХНЕЕ_ЗНАЧЕНИЕ;
К SELECT не применяется предложение EXECUTE. Если выполняемое предложение—SELECT, функция EXECUTE выполняется предложением OPEN.
ОБСУЖДЕНИЕ
Возможность исполнения предложений определения данных в любое время делает систему DB2 очень гибкой. В более старых (нереляционных) системах добавление нового типа объекта, например нового типа записей, нового индекса или нового поля, представляет собой операцию, выполнить которую не так легко. Оно требует обычно приведения всей системы в состояние остановки, разгрузки базы данных, изменения и перекомпиляции определения базы данных и, наконец, перезагрузки базы данных к соответствии с этим измененным определением. В такой системе весьма желательно выполнить процесс определения данных раз и навсегда, прежде чем начать их загрузку и использование. Это означает, что: а) для того чтобы система была установлена и стала действующей, могут потребоваться в буквальном смысле месяцы или даже годы работы высококвалифицированных специалистов и б) после того как система стала функционировать, может быть трудно и дорого, а может быть и невозможно, исправить ранние ошибки проектирования.
Напротив, в DB2 можно создать и загрузить совсем немного базовых таблиц, а затем немедленно начать использовать эти данные. Позднее постепенно могут добавляться новые базовые таблицы и новые поля, не оказывая какого-либо влияния на существующих пользователей базы данных. Можно также проводить эксперименты с результатами использования или отказа от каких-либо конкретных индексов, опять-таки совсем не оказывая влияния на существующих пользователей, не считая, конечно, производительности. Более того, как будет показано в главе 8, при определенных условиях можно даже произвести реструктуризацию базы данных, например перенести некоторое поле из одной таблицы в другую, и все же не затронуть логики существующих программ. Короче говоря, нет необходимости в осуществлении полного процесса проектирования базы данных, прежде чем с помощью системы можно будет сделать какую-либо полезную работу. Нет также и необходимости в том, чтобы получать все прямо с первого раза. Система DB2 снисходительна.
Предостережение.
Не следует полагать, однако, что снисходительность системы означает отсутствие необходимости проектирования базы данных. Конечно, проектирование базы данных все же необходимо. Однако:
— не обязательно выполнять его полностью единовременно;
— не требуется, чтобы оно было совершенным с первого раза;
— можно взяться за логическое и физическое проектирование раздельно;
— если изменяются потребности, то проект может быть также изменен сравнительно безболезненно;
— в системе, подобной DB2, становятся осуществимыми многие новые приложения, типичным образцом которых являются небольшие прикладные задачи, требующие, например, базу данных сотрудников или отделов. Подобные приложения просто никогда не рассматривались в обстановке более старых (нереляционных) систем, поскольку эти системы были слишком сложны для того, чтобы такие приложения имели смысл с экономической точки зрения.
ОГРАНИЧЕННАЯ ВЫБОРКА
Выдать номера поставщиков, которые находятся в Париже и имеют состояние большее, чем 20:
SELECT НОМЕР_ПОСТАВЩИКА
FROM S
WHERE ГОРОД ='Париж
AND СОСТОЯНИЕ > 20;
Результат:
|
|
НОМЕР_ПОСТАВЩИКА
|
|
S3
Условие, или предикат,
следующий за ключевым словом WHERE, может включать операторы сравнения =, -ù = (неравно), >,ù >, > =,
<, ù
< и <=, булевские операторы AND (и), OR (или) и NOT (нет), а скобки указывают требуемый порядок вычислений. В таком предикате числа сравниваются алгебраически — отрицательные числа считаются меньшими, чем положительные, независимо от их абсолютной величины. Строки литер сравниваются в соответствии с их представлением в коде EBCDIC. Если нужно сравнить две строки литер, имеющих разные длины, более короткая строка концептуально дополняется справа пробелами для того, чтобы обе строки имели одинаковую длину перед тем, как будет осуществляться их сравнение.
ОПЕРАЦИИ, НЕ ТРЕБУЮЩИЕ ИСПОЛЬЗОВАНИЯ КУРСОРОВ
Следующие предложения манипулирования данными не требуют использования курсоров:
— «единичное SELECT»
— UPDATE, за исключением формы CURRENT (см. раздел 10.4)
— DELETE, опять-таки за исключением формы CURRENT (см. раздел 10.4)
— INSERT.
Приведем поочередно примеры каждого из этих предложений.
ОПЕРАЦИИ ОБНОВЛЕНИЯ
В главе 6 уже указывалось, что не все представления являются обновляемыми.
Теперь мы в состоянии высказать более сильное утверждение. Рассмотрим сначала два представления ХОРОШИЕ_ПОСТАВЩИКИ и ПАРЫ_ГОРОДОВ, определенные ранее в этой главе. Для удобства повторим здесь их определения:
|
|
CREATE VIEW
|
ХОРОШИЕ_
ПОСТАВЩИКИ
|
CREATE VIEW
|
ПАРЫ_ГОРОДОВ (ГОРОД_ПОСТАВЩИКА,
ГОРОД_ДЕТАЛИ)
|
|
AS SELECT
|
НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ, ГОРОД
|
AS SELECT
|
ГОРОД_ПОСТАВЩИКА, ГОРОД_ДЕТАЛИ
|
|
FROM
|
S
|
FROM
|
S, SP, Р
|
|
WHERE
|
СОСТОЯНИЕ >15;
|
WHERE
|
S НОМЕР_ПОСТАВЩИКА=SP. НОМЕР_ПОСТАВЩИКА
|
|
|
|
AND
|
SP. НОМЕР_ДЕТАЛИ = Р. НОМЕР_ДЕТАЛИ);
Из этих двух представлений ХОРОШИЕ_ПОСТАВЩИКИ обновляемо, а ПАРЫ_ГОРОДОВ нет. Поучительно рассмотреть, почему это так. В случае представления ХОРОШИЕ_ПОСТАВЩИКИ можно:
а) вставить (операция
INSERT) новую строку в представление, например строку ('S6', 40, 'Рим'), фактически вставляя соответствующую строку ('S6', NULL, 40, 'Рим') в лежащую в основе базовую таблицу;
б) удалить (операция
DELETE) существующую строку из представления, например строку ('S1', 20, 'Лондон'), фактически удаляя соответствующую строку ('S1', 'Смит', 20, 'Лондон') из лежащей в основе базовой таблицы;
в) обновить (операция
UPDATE) какое-либо поле в существующей строке представления, например изменить город (Лондон) для поставщика S1 на Рим, фактически осуществляя то же самое изменение в соответствующем поле лежащей в основе базовой таблицы.
Будем называть такое представление, как ХОРОШИЕ_ПОСТАВЩИКИ, которое продуцируется из единственной базовой таблицы путем простого исключения некоторых строк и некоторых столбцов этой базовой таблицы, представлением-подмножеством строк и столбцов.
Такие представления по своей природе обновляемы, как показывает обсуждение предшествующего примера.
Рассмотрим теперь представление ПАРЫ_ГОРОДОВ, которое, конечно, не является представлением-подмножеством строк и столбцов. Как было показано ранее, одна из строк этого представления —('Лондон', 'Лондон'). Предположим, что некоторый пользователь имел бы возможность заменить эту строку, например, на ('Рим', 'Осло'). Что означало бы такое обновление? По-видимому, некоторый поставщик — но мы не знаем, какой именно, поскольку мы отбросили эту информацию при конструировании представления — переместился из Лондона в Рим. Подобным же образом местом хранения некоторой детали — но мы не знаем, какой именно, поскольку мы опять-таки исключили эту информацию, когда конструировалось представление,— был Лондон, а стал город Осло. Поскольку неизвестно, какой поставщик и какая деталь затрагиваются, нет способа, позволяющего спуститься к лежащим в основе базовым таблицам и сделать там соответствующие изменения. Иными словами, первоначальное UPDATE является внутренне неподдерживаемой операцией. Можно привести аналогичные аргументы для того, чтобы показать, что INSERT и DELETE — также внутренне неподдерживаемые операции над этим представлением.
Мы видели, таким образом, что некоторые представления по своей природе обновляемы, в то время как другие таковыми не являются. Обратите здесь внимание на слова «по своей природе». Дело заключается не просто в том, что некоторая система не способна поддерживать определенные обновления, в то время как другие системы могут это делать. Никакая система не может непротиворечивым образом поддерживать без дополнительной помощи обновления для такого представления, как ПАРЫ_ГОРОДОВ. «Без дополнительной помощи» означает здесь «без помощи какого-либо человека — пользователя». Вследствие этого факта можно классифицировать представления в соответствии с приведенной на рис. 8.2 диаграммой Венна.
На основе этой диаграммы заметим для строгости, что все представления-подмножества строк и столбцов (например, ХОРОШИЕ_ПОСТАВЩИКИ) теоретически обновляемы, но что не все теоретически обновляемые представления — это представления-подмножества строк и столбцов. Иными словами, существуют некоторые представления, которые теоретически обновляемы, но не являются представлениями-подмножествами строк и столбцов.
Хотя нам известно, что такие представления существуют, трудность заключается в том, что точно неизвестно, какие они. Для точного установления характеристик таких представлений требуется провести исследования. Поэтому для целей этой книги важным моментом является следующее:
В системе DB2 могут обновляться только представления-подмножества строк и столбцов.
На самом деле, это утверждение несколько упрощает ситуацию. Позднее мы уточним его. Между прочим, DB2 — не единственная в этом отношении система. Насколько известно автору, в настоящее время никакая реляционная система не поддерживает операций обновления над представлениями, не являющимися подмножествами строк и столбцов.
Рис. 8.2. Классификация представлений
Тот факт, что не все представления обновляемы, часто выражается так: «нельзя обновить соединение». Однако это утверждение не только не дает точной характеристики ситуации, но и не отражает в действительности существа проблемы. Существуют некоторые представления, которые не являются соединениями, но не обновляемы. Кроме того, существуют некоторые представления, которые являются соединениями, но (теоретически) обновляемы, хотя они и не обновляемы в системе DB2. Но, без сомнения, соединение представляет собой «интересный случай» в том смысле, что было бы очень удобно иметь возможность обновлять представление, в определении которого используется соединение. Из предыдущего обсуждения должно быть ясно, что такие представления действительно могут быть обновляемыми в какой-либо будущей системе. Но здесь мы имеем дело лишь с тем, что в настоящее время допускается в системе DB2. Постараемся теперь уяснить, что это такое.
В системе DB2 представление, допускающее обновление, должно быть производным от единственной базовой таблицы. Более того:
а) Если поле данного представления продуцируется из арифметического выражения или константы, то над этим полем не допускаются операции INSERT и UPDATE. Однако операции DELETE допускаются.
б) Если какое-либо поле представления продуцируется из стандартной функции, то данное представление необновляемо.
в) Если в определении представления используется фраза GROUP BY, то данное представление необновляемо.
г) Если в определении представления используется спецификация DISTINCT, то данное представление необновляемо.
д) Если определение представления включает вложенный подзапрос и во фразе FROM подзапроса указывается базовая таблица, над которой определяется данное представление, то это представление необновляемо.
е) Если во фразе FROM в определении представления указано несколько таблиц, то это представление необновляемо. Кроме того, конечно, если данное представление определено над необновляемым представлением, то оно само также необновляемо.
Убедимся в разумности этих ограничений. Рассмотрим поочередно каждый из случаев а)—е). Для каждого из них будет приведен пример представления, иллюстрирующий соответствующее ограничение.
Случай а). Поле представления, продуцируемое с помощью арифметического выражения или константы.
CREATE VIEW ВЕС_В_ГРАММАХ (НОМЕР_ДЕТАЛИ, ВЕС)
AS SELECT НОМЕР_ДЕТАЛИ, ВЕС * 454
FROM P;
Если предположить, что таблица Р имеет вид, показанный на рис. 1.3 (глава 1), то через это представление видимо следующее множество строк:
|
|
ВЕС_В_ГРАММАХ
|
НОМЕР_ДЕТАЛИ
|
ВЕС
|
|
|
Р1
Р2
РЗ
Р4
Р5
Р6
|
5448
7718
7718
6356
5448
8626
Должно быть ясно, что ВЕС_В_ГРАММАХ не может поддерживать операции INSERT, а также операции UPDATE над полем ВЕС. Каждая из этих операций потребовала бы, чтобы система была способна преобразовывать вес в граммах обратно в фунты без каких-либо инструкций относительно того, как выполнять такое преобразование. С другой стороны, операции DELETE могут быть поддержаны, например, таким образом, что удаление строки для детали Р1 из данного представления может осуществляться путем удаления строки для детали Р1 из лежащей в основе базовой таблицы. Могут быть поддержаны также операции UPDATE над полем НОМЕР_ДЕТАЛИ. Такие операции требуют просто соответствующих операций UPDATE над полем НОМЕР_ДЕТАЛИ этой базовой таблицы. Аналогичные соображения относятся к представлению, включающему поле, которое продуцируется из константы, а не из арифметического выражения.
Случай б). Поле представления, продуцируемое с помощью стандартной функции.
CREATE VIEW TQ (ОБЩЕЕ_КОЛИЧЕСТВО)
AS SELECT SUM (КОЛИЧЕСТВО)
FROM SP;
В нашем случае имеем:
|
|
TQ
|
ОБЩЕЕ_КОЛИЧЕСТВО
|
|
|
3100
Вероятно, очевидно, что никакие операции UPDATE, INSERT, DELETE не имеют какого-либо смысла для этого представления.
Случай в).
Представление, в определении которого используется фраза GROUP BY.
CREATE VIEW P Q (НОМЕР_ДЕТАЛИ, ОБЩЕЕ_КОЛИЧЕСТВО)
AS SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ;
В данном случае имеем:
|
|
PQ
|
НОМЕР_ДЕТАЛИ
|
ОБЩЕЕ_КОЛИЧЕСТВО
|
|
|
Р1
Р2
РЗ
Р4
Р5
Р6
|
600
1000
400
500
500
100
Очевидно, что представление PQ не может поддерживать ни операций INSERT, ни операций UPDATE над полем ОБЩЕЕ_КОЛИЧЕСТВО. Операции DELETE и UPDATE над полем НОМЕР_ДЕТАЛИ можно было бы определить как удаление или обновление соответствующих строк в таблице SP. Например, операцию
DELETE
FROM PQ
WHERE НОМЕР_ДЕТАЛИ = 'Р1’;
можно было бы определить как переводимую в
DELETE
FROM SP
WHERE НОМЕР_ДЕТАЛИ = 'Р1’;
но такие операции можно было бы во всяком случае в равной степени хорошо выразить и в терминах таблицы SP. По меньшей мере, можно утверждать, что запрашивающий такие операции пользователь должен, вероятно, интересоваться, какие точно реальные записи затрагиваются этими операциями.
Случай г).
Представление, определенное со спецификацией DISTINCT:
CREATE VIEW CC
AS SELECT DISTINCT ЦВЕТ, ГОРОД
FROM P;
Имеем в этом случае (в скобках указаны соответствующие номера деталей):
|
|
CC
|
ЦВЕТ
|
ГОРОД
|
|
|
|
Красный
Зеленый
Голубой
Голубой
|
Лондон
Париж
Рим
Париж
|
(Р1, P4, P6)
(Р2)
(РЗ)
(Р5)
И снова должно быть ясно, что представление CC не может поддерживать операций INSERT. Такие операции над лежащей в основе таблицей Р требуют, чтобы пользователь специфицировал значение поля НОМЕР_ДЕТАЛИ, поскольку для него специфицировано NOT NULL. Как и в случае в), операции DELETE и UPDATE теоретически могут быть здесь определены (как удаления или обновления всех соответствующих строк в таблице Р), но замечания относительно этой возможности, высказанные для случая в), справедливы здесь, возможно, даже в большей степени.
Рассмотрим другой пример для случая г):
CREATE VIEW PC
AS SELECT DISTINCT НОМЕР_ДЕТАЛИ, ЦВЕТ
FROM P;
Имеем:
|
|
PC
|
НОМЕР_ДЕТАЛИ
|
ЦВЕТ
|
|
|
P1
Р2
РЗ
P4
Р5
P6
|
Красный
Зеленый
Голубой
Красный
Голубой
Красный
Это — пример представления, которое, очевидно, является теоретически обновляемым. Ясно, что все возможные операции INSERT, DELETE и UPDATE над этим представлением вполне определены. Фактически это представление является на самом деле представлением-подмножеством строк и столбцов. Однако система DB2 не осведомлена об этом факте. Другими словами, система DB2 не осведомлена о том, что спецификация DISTINCT является здесь фактически излишней. Вместо этого она просто предполагает, что присутствие DISTINCT означает возможность продуцирования любой заданной строки представления из множества строк базовой таблицы, как в предыдущем примере, и по этой причине не считает данное представление обновляемым.
Случай д).
Представление, в котором используется подзапрос над той же самой таблицей:
CREATE VIEW ПОСТАВЩИК_НИЖЕ_СРЕДНЕГО
AS SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ,
ГОРОД
FROM S
WHERE СОСТОЯНИЕ <
(SELECT AVG (СОСТОЯНИЕ)
FROM S);
Операции UPDATE и DELETE над представлением ПОСТАВЩИК_НИЖЕ_СРЕДНЕГО незаконны, поскольку они нарушали бы ограничения, налагаемые на такие операции, указанные в разделе 6.5. Как и операции INSERT, они могли бы в принципе поддерживаться, но давали бы непредсказуемый результат.
Случай е).
Представление, определенное на множестве таблиц.
CREATE VIEW ПАРЫ_ГОРОДОВ (ГОРОД_ПОСТАВЩИКА,
ГОРОД_ДЕТАЛИ);
AS SELECT S. ГОРОД, P. ГОРОД
FROM S. SP, P
WHERE S. НОМЕР_ПОСТАВЩИКА = SP.HOMEP_ПОСТАВЩИКА
AND SP.HOMEP_ДЕТАЛИ = Р.НОМЕР_ДЕТАЛИ;
Это представление необновляемо по тем причинам, которые уже были достаточно подробно обсуждены. Рассмотрим, однако, следующий пример:
CREATE VIEW ПОСТАВЩИКИ_Р2
AS SELECT DISTINCT S. *
FROM S, SP
WHERE S. НОМЕР_ПОСТАВЩИКА =
SP. НОМЕР_ПОСТАВЩИКА
AND SP НОМЕР_ДЕТАЛИ = 'P2';
Это представление также необновляемо в системе DB2, даже несмотря на то, что оно является фактически представлением-подмножеством строк и столбцов. Здесь снова DB2 не имеет возможности распознать этот факт. В этом примере интересно отметить, что может быть определено семантически эквивалентное обновляемое представление, а именно:
CREATE VIEW ПОСТАВЩИКИ_Р2
AS SELECT S. *
FROM S
WHERE НОМЕР_ПОСТАВЩИКА IN'
(SELECT НОМЕР_ПОСТАВЩИКА
FROM SP
WHERE НОМЕР_ДЕТАЛИ = 'P2');
В этом определении не нарушается правило «несколько таблиц во фразе FROM» (см. выше правило е).
Вернемся, наконец, снова к представлению ХОРОШИЕ_ПОСТАВЩИКИ с тем, чтобы обсудить ряд оставшихся вопросов. Напомним определение этого представления:
CREATE VIEW ХОРОШИЕ_ПОСТАВЩИКИ
AS SELECT НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ, ГОРОД
FROM S
WHERE СОСТОЯНИЕ > 15;
Это представление является представлением-подмножеством строк и столбцов и, следовательно, обновляемо. Но нужно отметить следующее:
а) Успешно выполненная операция INSERT для представления ХОРОШИЕ_ПОСТАВЩИКИ должна будет сгенерировать неопределенное значение для опущенного поля ФАМИЛИЯ, как уже указывалось в начале этого раздела. Конечно, для поля ФАМИЛИЯ не должен был специфицироваться вариант NOT NULL (При создании таблицы S.— Примеч. пер.), если требуется выполнять операцию INSERT.
б) При значениях данных, приведенных на рис. 1.3, поставщик S2 не будет видимым через представление ХОРОШИЕ_ПОСТАВЩИКИ. Но это не означает, что пользователь может вставить (операция INSERT) в это представление запись с номером поставщика S2 или обновить (операция UPDATE) какую-либо другую запись таким образом, чтобы значение ее номера поставщика стало равным S2. Такая операция должна быть отвергнута точно так же, как если бы она осуществлялась непосредственно над таблицей S.
в) Рассмотрим, наконец, следующий пример с использованием операции UPDATE:
UPDATE ХОРОШИЕ_ПОСТАВЩИКИ
SET СОСТОЯНИЕ = О
WHERE НОМЕР_ПОСТАВЩИКА ='S1';
Должна ли быть принята эта операция UPDATE? Если да, то результатом ее выполнения будет удаление поставщика S1 из данного представления, поскольку запись этого поставщика не будет больше удовлетворять предикату, определяющему представление. Подобным же образом операция INSERT:
INSERT
INTO ХОРОШИЕ_ПОСТАВЩИКИ (НОМЕР_ПОСТАВЩИКА,
СОСТОЯНИЕ, ГОРОД)
VALUE ('S8', 7, 'Стокгольм');
если она будет принята, создаст запись нового поставщика, но эта запись немедленно исчезнет из представления. Для того чтобы иметь дело с такими ситуациями, предназначена спецификация CHECK, упоминаемая в разделе 8.2. Если в определении представления включается фраза
WITH CHECK OPTION,
то все операции INSERT и UPDATE над этим представлением будут подвергаться проверке, чтобы обеспечить действительное удовлетворение предиката, определяющего представление, вновь вставляемой или обновленной записью. Если предикат не удовлетворяется, данная операция будет отвергнута.
Вариант CHECK может быть специфицирован только если данное представление обновляемо и его определение не включает вложенных подзапросов. Если данное представление таково, что обновления (операция UPDATE) допустимы только над определенными полями, а вставка (операция INSERT) не допускается вообще, то вариант CHECK относится только к этим операциям UPDATE.
ОПЕРАЦИИ, ТРЕБУЮЩИЕ ИСПОЛЬЗОВАНИЯ КУРСОРОВ
Вернемся теперь к случаю предложения SELECT, которое продуцирует целое множество записей, а не только одну запись. Как уже было объяснено в разделе 10.2, здесь необходим механизм, обеспечивающий последовательный доступ к записям в этом множестве. Такой механизм обеспечивают курсоры. В общих чертах процесс доступа иллюстрируется в примере, приведенном на рис. 10.2, в котором предусматривается выборка деталей (полей НОМЕР_ДЕТАЛИ, НАЗВАНИЕ и СОСТОЯНИЕ) для всех поставщиков, находящихся в городе, заданном переменной включающего языка Y.
ЕХЕС SQL DECLARE X CURSOR FOR / * определить курсор X * /
SELECT НОМЕР_ПОСТАВЩИКА, НАЗВАНИЕ,
СОСТОЯНИЕ
FROM S
WHERE ГОРОД = >У;
ЕХЕС SQL OPEN X; / * исполнить запрос * /
DO WHILE (пока еще есть записи);
ЕХЕС SQL FETCH X INTO :НОМЕР_
ПОСТАВЩИКА, :НАЗВАНИЕ, :СОСТОЯНИЕ;
/ * выбрать следующего поставщика * /
END;
ЕХЕС SQL CLOSE X; / * дезактивировать курсор Х * /
Рис. 10.2. Выборка множества записей
Пояснение.
Предложение DECLARE X CURSOR... определяет курсор, названный X, и ассоциированный с ним запрос, специфицированный с помощью предложения SELECT, которое образует часть этого предложения DECLARE. Указанное предложение SELECT не исполняется в данный момент, так как DECLARE CURSOR это чисто декларативное предложение. Оно исполняется, когда открывается курсор в процедурной части программы. Предложение FETCH ... INTO ... (выбрать ... в ...) используется для выборки записей результирующего множества и присваивает найденные значения переменным включающего языка в соответствии со спецификациями фразы INTO в этом предложении. Для простоты в приведенном примере переменным включающего языка даны те же самые имена, что и соответствующим полям базы данных. Заметим, что предложение SELECT в объявлении курсора не содержит фразы INTO. Поскольку в результате будет получено множество записей, предложение FETCH будет обычно входить в некоторый цикл (в языке ПЛ/1—DO... END). Этот цикл будет повторяться до тех пор, пока в этом результирующем множестве еще существуют непросмотренные записи. При выходе из цикла курсор Х закрывается (дезактивируется) с помощью соответствующего предложения CLOSE (закрыть).
2.Предложение
ЕХЕС SQL FETCH имя — курсора INTO мишень [, мишень] . . .;
где каждая «мишень» имеет формат
переменная — включающего — языка [:переменная — включающего — языка]
как в единичном SELECT, и где идентифицированный курсор должен быть открыт, продвигает этот курсор к следующей записи в активном множестве, а затем присваивает значения полей из этой записи переменным включающего языка, в соответствии с фразой INTO. Как уже указывалось, предложение FETCH обычно исполняется в программном цикле (см. рис. 102). Если при исполнении FETCH не существует следующей записи, то выборка данных не производится и SQLCODE принимает значение +100.
Отметим, между прочим, что «выбрать следующую» представляет собой единственную
операцию перемещения курсора. Невозможно переместить курсор, например, «вперед на три позиции» или «назад на две позиции» и т. п.
3. Предложение
ЕХЕС SQL CLOSE имя — курсора;
закрывает или дезактивирует специфицированный курсор, который в этот момент должен быть открыт. Теперь этот курсор не имеет соответствующего активного множества. Его можно, однако, теперь снова открыть. В этом случае с ним будет связано другое активное множество, вероятно, не в точности то же самое, что и ранее, особенно если значения переменных включающего языка, упоминаемые в предложении
SELECT, тем временем изменились. Заметим, что изменение значений этих переменных в то время, когда курсор открыт, не оказывает влияния на активное множество.
Два следующих предложения могут включать ссылки на курсоры. Имеются формы CURRENT для предложений UPDATE и DELETE. Если, например, курсор Х в настоящее время позиционирован на конкретную запись в базе данных, то можно обновить (UPDATE) или удалить (DELETE) «текущую X», т. е. запись, на которую позиционирован X. Синтаксис этих предложений таков:
ЕХЕС SQL UPDATE имя — таблицы
SET имя — поля = выражение
[, имя — поля == выражение] . . .
WHERE CURRENT OF имя — курсора;
ЕХЕС SQL DELETE
FROM имя — таблицы
WHERE CURRENT OF имя — курсора;
Пример:
ЕХЕС SQL UPDATE S
SET СОСТОЯНИЕ = СОСТОЯНИЕ + :ПРИРОСТ
WHERE CURRENT OF X;
Использование предложений UPDATE CURRENT и DELETE CURRENT не допускается, если предложение SELECT в объявлении курсора включает UNION или ORDER BY, или если это предложение SELECT определяет необновляемое представление и является частью предложения CREATE VIEW (см. раздел 8.4). Как пояснялось ранее, в случае UPDATE CURRENT предложение DECLARE должно включать фразу FOR UPDATE, идентифицирующую все поля, которые входят как мишени во фразу SET предложения UPDATE CURRENT для этого курсора.
ОПЕРАЦИИ ВЫБОРКИ
В разделе 8.1 уже было показано в общих чертах, каким образом операции выборки данных над представлением преобразуются в эквивалентные операции над лежащей в его основе базовой таблицей (или базовыми таблицами). Обычно этот процесс преобразования совершенно ясен и осуществляется вполне хорошо, без каких-либо неожиданностей для пользователя. Однако иногда такие неожиданности могут иметь место. Так, могут возникнуть проблемы, если пользователь пытается интерпретировать поле представления как обычное поле, а это поле представления продуцируется из чего-либо иного, чем простое поле лежащей в основе базовой таблицы. Например, оно может продуцироваться с помощью стандартной функции. Рассмотрим следующий пример определения представления:
CREATE VIEW PQ (НОМЕР_ДЕТАЛИ, ОБЩЕЕ_КОЛИЧЕСТВО)
AS SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ;
Это представление — «статистическая сводка» из раздела 8.2, пример 2.
Предпринятый запрос:
SELECT *
FROM PQ
WHERE ОБЩЕЕ_КОЛИЧЕСТВО > 500;
Если применить простой процесс слияния, описанный в разделе 8.1, для того, чтобы скомбинировать этот запрос с определением представления, хранимым в каталоге, мы получим нечто подобное следующему:
SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
WHERE SUM (КОЛИЧЕСТВО) > 500
GROUP BY НОМЕР_ДЕТАЛИ;
Такое предложение
SELECT недопустимо. Не разрешается, чтобы в предикате во фразе WHERE использовалась стандартная функция, например SUM. Первоначальный запрос следовало бы на самом деле преобразовать в нечто подобное следующему:
SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ
HAVING SUM (КОЛИЧЕСТВО) > 500;
Однако система DB2 не умеет выполнять такое преобразование.
Ниже приводится другой пример, в котором рассматриваемое преобразование снова не работает. В этом примере опять используется представление — статистическая сводка PQ. Предпринимаемый запрос:
SELECT AVG (ОБЩЕЕ_КОЛИЧЕСТВО)
FROM PQ;
«Преобразованная» форма:
SELECT AVG (SUM (КОЛИЧЕСТВО))
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ;
И снова это недопустимое предложение. В языке SQL не разрешается использовать вложенные таким образом стандартные функции.
Общий принцип, который нарушается в этих двух примерах, таков: преобразованная форма первоначального запроса всегда должна быть допустимым предложением SELECT языка SQL.
ОПРЕДЕЛЕНИЕ ПРЕДСТАВЛЕНИЯ
Общий синтаксис предложения CREATE VIEW (создать представление):
CREATE VIEW имя—представления
[(имя—столбца[ , имя—столбца] . . .)]
AS подзапрос
[WITH CHECK OPTION];
Как обычно, подзапрос не может включать ни оператора UNION, ни фразы ORDER BY. Однако при этих ограничениях любая таблица, выборка которой может быть осуществлена с помощью предложения SELECT, может быть, с другой стороны, определена как представление. Ниже приведено несколько примеров.
1. CREATE VIEW КРАСНЫЕ_ДЕТАЛИ (НОМЕР—ДЕТАЛИ,
НАЗВАНИЕ, ВЕС, ГОРОД)
AS SELECT НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ВЕС, ГОРОД
FROM P
WHERE ЦВЕТ = 'Красный';
Действие этого оператора заключается в том, чтобы создать новое представление, названное xyz.КРАСНЫЕ_ДЕТАЛИ, где xyz — известное системе имя пользователя, издавшего предложение CREATE VIEW. Пользователь xyz может называть это представление просто КРАСНЫЕ_ДЕТАЛИ. Другие же пользователи должны называть его xyz.КРАСНЫЕ_ДЕТАЛИ. С другой стороны, они могут, конечно, ввести для него синоним, как указывалось в главе 7. В этом представлении четыре столбца — НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ВЕС и ГОРОД, соответствующих четырем столбцам НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ВЕС и ГОРОД лежащей в основе базовой таблицы Р. Если имена столбцов явно не специфицированы в предложении CREATE VIEW, то представление очевидным образом наследует имена столбцов его источника. В приведенном примере наследуемыми именами были бы НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ВЕС и ГОРОД. Имена столбцов должны быть специфицированы явно для всех столбцов представления, если: а) какой-либо столбец этого представления продуцируется с помощью стандартной функции, арифметического выражения или константы (и не имеет, следовательно, имени, которое он мог бы наследовать) или б) два или более столбцов имели бы в противном случае одно и то же имя. Каждый из этих двух случаев иллюстрируется в следующих двух примерах.
2. CREATE VIEW PQ (НОМЕР_ДЕТАЛИ, ОБЩЕЕ_КОЛИЧЕСТВО)
AS SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ;
В этом примере нет такого имени, которое могло бы наследоваться для второго столбца, поскольку этот столбец продуцируется с помощью стандартной функции. Поэтому имена столбцов здесь должны быть специфицированы явным образом, как было показано в примере. Обратите внимание, что это представление не является просто подмножеством строк и столбцов лежащей в основе базовой таблицы (в отличие от рассмотренных выше представлений КРАСНЫЕ_ДЕТАЛИ и ХОРОШИЕ_ПОСТАВЩИКИ). Его можно было бы рассматривать как некоторого рода статистическую сводку или сжатие лежащей в основе таблицы.
3. CREATE VIEW ПАРЫ_ГОРОДОВ (ГОРОД_ПОСТАВЩИКА,
ГОРОД_ДЕТАЛИ)
AS SELECT S. ГОРОД, Р. ГОРОД
FROM S, SP, P
WHERE S. НОМЕР_ПОСТАВЩИКА =
SP. НОМЕР_ПОСТАВЩИКА
AND SP.HOMEP_ДЕТАЛИ = Р.НОМЕР_ДЕТАЛИ;
Смысл этого представления в том, что пара имен городов (х,у) будет входить в данное представление, если поставщик с местоположением в городе х поставляет какую-либо деталь, хранимую в городе у. Например, поставщик S1 поставляет деталь Р1. При этом поставщик S1 находится в Лондоне и деталь Р1 хранится тоже в Лондоне. И поэтому пара (Лондон, Лондон) входит в данное представление. Обратите внимание, что в определении этого представления используется соединение и, таким образом, оно является примером представления, продуцируемого из нескольких положенных в основу таблиц. Примечание. Мы могли бы при желании включить в определение этого представления спецификацию DISTINCT. Сравните с примером 4.3.5 в главе 4.
4. CREATE VIEW ЛОНДОНСКИЕ_КРАСНЫЕ_ДЕТАЛИ
AS SELECT НОМЕР_ДЕТАЛИ, ВЕС
FROM КРАСНЫЕ_ДЕТАЛИ
WHERE ГОРОД = 'Лондон';
Поскольку определение представления может быть любым допустимым подзапросом и поскольку подзапрос может осуществлять выборку данных как из представлений, так и из базовых таблиц, вполне возможно определять представление в терминах других представлений, как это сделано в данном примере.
5. CREATE VIEW ХОРОШИЕ_ПОСТАВЩИКИ
AS SELECT НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ, ГОРОД
FROM S
WHERE СОСТОЯНИЕ > 15
WITH CHECK OPTION;
Фраза «WITH CHECK OPTION» ( с проверкой) указывает, что для операций UPDATE и INSERT над этим представлением должна осуществляться проверка, которая обеспечивает удовлетворение определяющего представление предиката обновленной или вставляемой строкой (в данном примере СОСТОЯНИЕ>15). Вариант CHECK более подробно описан в разделе 8.4.
Предложение DROP VIEW имеет следующий синтаксис:
DROP VIEW имя — представления;
В результате исполнения этого предложения уничтожается специфицированное представление, т. е. из каталога удаляется его определение. Все представления, определенные с его использованием, также автоматически уничтожаются.
Пример рассматриваемого предложения:
DROP VIEW КРАСНЫЕ_ДЕТАЛИ;
Если уничтожается базовая таблица, то все определенные над нею (или над представлениями этой базовой таблицы и т. д.) представления также автоматически уничтожаются.
Предложения ALTER VIEW (изменить представление) в языке SQL нет. Предложение ALTER TABLE, которое добавляет новый столбец к базовой таблице, не оказывает влияния на любые существующие представления.
Определение
В реляционной системе таблица состоит из строки заголовков столбцов
и нуля или более строк значений данных
(число строк данных может быть каждый раз разным). Для заданной таблицы:
а) Строка заголовков столбцов специфицирует один или более столбцов, задавая наряду с прочим тип данных для каждого из них;
б) Каждая строка данных содержит в точности одно значение данных для каждого из столбцов, специфицированных в строке заголовков столбцов. Кроме того, все значения в заданном столбце имеют один и тот же тип, а именно: тип данных, специфицированный для этого столбца в строке заголовков столбцов.
В связи с предыдущим определением следует коснуться двух моментов.
1. Отметим, что в этом определении нет никакого упоминания об упорядочении строк.
Строго говоря, строки реляционной таблицы считаются неупорядоченными. (Отношение — это математическое множество—множество строк, а множество в математике не обладает каким-либо упорядочением.) Как мы увидим, можно, однако, задавать некоторый порядок для этих строк, когда осуществляется их выборка в ответ на запрос, но такое упорядочение следует считать не чем иным, как удобством для пользователя. Оно не существенно для понятия таблицы.
2. В отличие от строк столбцы таблицы предполагаются упорядоченными слева направо. (По крайней мере, они считаются упорядоченными таким образом в большинстве систем, в том числе в DB2). В таблице S, например (рис. 1.3), столбец НОМЕР-ПОС-ТАВЩИКА — первый столбец, ФАМИЛИЯ — второй столбец и т. д. Однако на практике существует очень немного ситуаций, когда такое упорядочение слева направо является существенным. Подобных ситуаций можно избегать при некоторой дисциплине, и это рекомендуется делать, как будет показано позднее.
Обратимся теперь, в частности, к базовым таблицам. Базовая таблица — это автономная именованная таблица. Под «автономностью» понимается то, что эта таблица существует сама по себе в отличие от представления, которое существует не само по себе, а является производным от одной или нескольких базовых таблиц. Представление служит просто альтернативным способом рассмотрения этих базовых таблиц. Под «именованной» понимается, что этой таблице с помощью соответствующего предложения CREATE явно задается некоторое имя в отличие от таблицы, которая строится как результат запроса и не имеет сама по себе какого-либо явного имени. Такая таблица существует в течение непродолжительного времени. Примерами такого рода неименованных таблиц служат две таблицы результатов, приведенные на рис. 1.1.
Предложение CREATE TABLE
Теперь мы в состоянии подробно обсудить предложение CREATE TABLE. Это предложение имеет следующий общий формат:
CREATE TABLE имя—базовой—таблицы
(определение—столбца [, определение—столбца] . . . )
[другие—параметры];
Здесь «определение—столбца» в свою очередь имеет формат:
имя—столбца тип—данных
[NOT NULL]
Факультативные «другие — параметры» имеют дело главным образом с проблемами физического хранения и кратко обсуждаются в главе 13. Примечание. В этой книге прямые скобки в синтаксических определениях используются для того, чтобы указать, что конструкции, заключенные в эти скобки, являются необязательными (т. е. могут быть опущены). Многоточие указывает, что непосредственно предшествующая ему синтаксическая единица факультативно может повторяться один или более раз. Конструкции, представленные прописными буквами, должны быть записаны в точности так, как показано. Наконец, конструкции, представленные строчными буквами, должны заменяться конкретными значениями, выбранными пользователем.
Ниже приведен пример предложения CREATE TABLE для таблицы S, теперь уже в полном виде:
CREATE TABLE S
|
|
(НОМЕР_ПОСТАВЩИКА
|
CHAR (5) NOT NULL,
|
|
ФАМИЛИЯ
|
CHAR (20),
|
|
СОСТОЯНИЕ
|
SMALLINT,
|
|
ГОРОД
|
CHAR (15));
Результат этого предложения состоит в том, что создается новая пустая базовая таблица, названная xyz.S, где xyz — имя, под которым известен системе пользователь, издающий предложение CREATE TABLE (см. главу 9). В системный каталог при этом помещается статья, описывающая эту таблицу. Пользователь xyz может обращаться к таблице по ее полному имени xyz.S или по сокращенному имени S. Другие пользователи должны обращаться к ней только по ее полному имени. Данная таблица состоит из четырех столбцов с именами xyz.S.НОМЕР_ПОСТАВЩИКА, xyz.S.ФАМИЛИЯ, хуг.S.СОСТОЯНИЕ и хуг.S.ГОРОД, имеющих указанные в определении типы данных. (Типы данных будут рассматриваться ниже). Пользователь xyz может обращаться к этим столбцам по их полным или по сокращенным именам: S.HOMEP-ПОСТАВЩИКА, S.ФАМИЛИЯ, S.СОСТОЯНИЕ и S.ГОРОД. Другие пользователи должны применять только полные имена столбцов. Заметим, однако, что независимо от того, включается ли в имя часть «xyz», часть «S» может быть опущена, если это не приводит к двусмысленности, но ее включение никогда не является ошибкой. Вообще относительно имен справедливы следующие правила. Имена пользователей, например xyz, являются уникальными во всей системе. Имена таблиц (неуточненные) уникальны для пользователя. Имена столбцов (неуточненные) уникальны для таблицы[9]. Под «таблицей» здесь понимаются как базовые таблицы, так и представления. Таким образом, представление не может иметь такое же имя, как и базовая таблица.
После того как таблица создана, в нее могут быть введены данные с помощью предложения INSERT (вставить) языка SQL, которое обсуждается в главе 6, или утилиты загрузки системы DB2, рассматриваемой в главе 14.
Типы данных
|
|
Система DB2
|
поддерживает следующие типы данных:
|
|
INTEGER
|
— двоичное целое число, занимающее полное машинное слово, 31 бит со знаком
|
|
SMALLINT
|
— двоичное целое число, занимающее полуслово, 15 бит со знаком
|
|
DECIMAL (p, q)
|
— упакованное десятичное число, включающее р цифр и знак (0 < р < 16); предполагается q цифр справа от десятичной точки (q < р; если q = 0, она может быть опущена)
|
|
FLOAT
|
— число n с плавающей точкой, занимающее двойное слово и представленное шестнадцатеричной мантиссой f с точностью до 15 знаков (—1 < f < +1) и двоичным целочисленным порядком е (—65<е < +64) таким образом, что n= = f* (16 * * е); примерный диапазон значений (По абсолютной величине — Примеч. пер.) n — от 5.4Е—79 до 7.2Е + 75; см. также ниже пояснения для констант типа FLOAT
|
|
CHAR (n)
|
— литерная строка фиксированной длины из n литер (О < n < 255)
|
|
VARCHAR (n)
|
— литерная строка переменной длины, не превышающей n литер (0 < n; максимальное значение n зависит от ряда факторов, но в общем случае должно быть меньше, чем «размер страницы» — 4К либо 32K — пространства, содержащего данную таблицу — см. главу 13)[10].
Константы
Хотя это и в некоторой степени отступление от основной темы данной главы, сейчас удобно рассмотреть различные виды констант, которые поддерживаются в DB2:
|
|
целочисленная
|
— записывается как десятичное целое число со знаком или без знака, без десятичной точки;
примеры: 4 —95 +364 О
|
|
десятичная
|
— записывается как десятичное число со знаком или без знака, с десятичной точкой;
примеры: 4,0 —95.7 +364.05 0.007
|
|
с плавающей точкой
|
— записывается как десятичная константа, за которой следует буква Е с последующей целочисленной константой;
примеры: 4ЕЗ —95.7Е46 +364Е—5 0.7Е1 (примечание:
выражение хЕу представляет значение х*(10**у))
|
|
строковая
|
— записывается либо как строка литер, заключенная в одиночные кавычки, либо как строка пар шестнадцатеричных цифр, представляющих рассматриваемые литеры в коде EBCDIC, заключенная в одиночные кавычки, которой предшествует буква X;
примеры: '123 Main St.' 'PIG'
X'F1F2F340D481899540E2A34B'
X'D7C9C7'
(первый и третий примеры представляют одно и то же значение, так же как второй и четвертый)
Неопределенное значение
Вернемся теперь к основной теме данной главы. Система DB2 поддерживает концепцию неопределенного значения данных. Фактически любой столбец может содержать неопределенное значение, если в определении этого столбца в предложении CREATE TABLE явным образом не специфицировано NOT NULL (неопределенное значение не допускается). Неопределенное значение— это специальное значение, которое используется для того, чтобы представлять «неизвестное значение» или «неприменимое значение». Это не то же самое, что пробел или ноль. Например, запись поставки может содержать неопределенное значение поля КОЛИЧЕСТВО (известно, что поставка имела место, но неизвестен объем поставки). Запись поставщика может также содержать неопределенное значение в столбце СОСТОЯНИЕ (может быть, например, что СОСТОЯНИЕ не соотносится по некоторой причине поставщикам в Сан-Хосе).
Вернемся к предложению
CREATE TABLE для базовой таблицы S. Мы специфицировали NOT NULL только для столбца НОМЕР_ПОСТАВЩИКА. Результатом этой спецификации является гарантия того, что запись каждого поставщика в базовой таблице S всегда будет содержать какой-либо реальный (отличный от неопределенного значения) номер поставщика. Напротив любое из значений ФАМИЛИЯ, СОСТОЯНИЕ и ГОРОД или все они могут быть неопределенными в той же самой записи. (Причины нашего требования о том, чтобы номера поставщиков не имели неопределенных значений, станут ясны в Приложениях А и В.)
Столбец, который может принимать неопределенные значения, физически представляется в хранимой базе данных двумя столбцами: самим столбцом данных и скрытым столбцом индикатора с длиной значений в один байт, который хранится как префикс к столбцу фактических данных. Значение X'FF' в столбце индикатора указывает, что соответствующее значение в столбце данных следует игнорировать, т. е. принять его за неопределенное значение. Значение Х'00' в столбце индикатора указывает, что в качестве соответствующего значения столбца данных следует принять его действительное значение.
Более подробно о неопределенных значениях пойдет речь в главах 4, 5, 6 и 10, а также в Приложении В.
Предложение ALTER TABLE
Точно так же, как в любое время можно с помощью предложения CREATE TABLE создать новую базовую таблицу, можно также в любое время изменить существующую базовую таблицу, добавляя к ней справа новый столбец. Для этого используется предложение ALTER TABLE:
ALTER TABLE имя—базовой— таблицы
ADD имя—столбца тип—данных;
Например:
ALTER TABLE S
ADD СКИДКА SMALLINT;
Это предложение добавляет к таблице S столбец СКИДКА. Все существующие записи таблицы S расширяются с четырех значений полей данных до пяти, и во всех случаях новое пятое поле принимает неопределенное значение. Спецификация NOT NULL в предложении ALTER TABLE не допускается. Заметим, между прочим, что только что описанное расширение существующих записей, не означает, что в это время физически обновляются записи в базе данных. Изменяется лишь хранимое в каталоге, описание таблицы. Отдельные записи физически не изменяются до тех пор, пока они в следующий раз не станут целевыми для предложения UPDATE языка SQL (см. главу 6).
Предложение DROP TABLE
Существующую базовую таблицу можно в любое время уничтожить с помощью предложения:
DROP TABLE имя—базовой—таблицы;
Специфицированная базовая таблица удаляется из системы (точнее, из каталога удаляется описание этой таблицы). Автоматически удаляются также все индексы и представления, определенные над этой базовой таблицей.
ОСНОВНЫЕ КОМПОНЕНТЫ
Внутренняя структура системы DB2 является весьма сложной, как и следует ожидать от системы, соответствующей современному уровню развития и обеспечивающей все функции, которыми обычно обладают современные СУБД (в том числе, например, управление восстановлением, параллельными процессами, санкционированием доступа и т. д.), и многое сверх того. Однако многие из этих функций не представляют непосредственного интереса для пользователя (в нашем понимании этого термина, т. е. конечного пользователя или прикладного программиста), хотя они и имеют решающее значение для общего функционирования системы. С точки зрения пользователя, систему можно фактически рассматривать как состоящую просто из четырех основных компонентов, которые называются следующим образом[6]:
Прекомпилятор (PRECOMPILER)
Генератор планов прикладных задач (BIND)
Супервизор стадии исполнения (RUNTIME SUPERVISOR)
Программа управления хранимыми данными (STORED DATA MANAGER).
Функции этих четырех компонентов в общих чертах заключаются и следующем.
Прекомпилятор
Прекомпилятор является препроцессором для языков прикладного программирования (ПЛ/1, КОБОЛ, ФОРТРАН и язык ассемблера). Его функция состоит в том, чтобы проанализировать исходный модуль на любом из этих языков, удалить из него все найденные предложения SQL, заменяя их предложениями CALL входного языка. На стадии исполнения эти предложения CALL будут передавать управление непосредственно супервизору времени исполнения. Из предложений SQL, которые ему встречаются, Прекомпилятор строит модуль запросов к. базе данных (DHRM), который используется в качестве входных данных для генератора планов прикладных задач, рассматриваемого ниже.
Рис. 2.1. Подготовка и исполнение прикладной задачи системы DB2 (общее представление)
Генератор планов прикладных задач
Функция генератора планов прикладных задач состоит в том, чтобы скомпилировать
один или более DBRM и создать тем самым план прикладной задачи. План прикладной задачи содержит необходимые команды машинного кода, реализующие первоначальные предложения SQL, из которых были построены эти DBRM. Он включает, в частности, команды обращения к программе управления хранимыми данными (см. ниже).
Супервизор стадии исполнения
При исполнении прикладной программы супервизор стадии исполнения постоянно находится в основной памяти. Его функции заключаются в том, чтобы следить за исполнением прикладной программы. Когда прикладной программе потребуется выполнить некоторую операцию, связанную с базой данных (говоря нестрого, когда будет необходимо выполнить какое-либо предложение SQL), управление передается сначала супервизору стадии исполнения, который в свою очередь передает его соответствующей части плана прикладной задачи. План прикладной задачи, наконец, передает управление программе управления хранимыми данными.
Программа управления хранимыми данными
Программу управления хранимыми данными можно рассматривать как весьма утонченный метод доступа. Она выполняет все обычные функции метода доступа, например выборку, поиск, обновление, поддержание индекса и т. д. В общих чертах программа управления хранимыми данными — это компонент, управляющий физическими базами данных. Когда во время исполнения его основной задачи необходимо выполнять более детальные функции, такие, как блокирование, запись в журнал, сортировку и т. п., он вызывает другие компоненты более низкого уровня.
На рис. 2.1 сказанное выше подытоживается в форме логической схемы. В следующем разделе основные шаги этого полного процесса будут рассмотрены более подробно.
ПОДРОБНОЕ ОБСУЖДЕНИЕ ЛОГИКИ УПРАВЛЕНИЯ
Рассмотрим сначала пример программы Р на языке ПЛ/1 (точнее, исходный модуль Р на языке ПЛ/1), которая включает плюс или более предложений SQL. Язык ПЛ/1 здесь взят для определенности. Суммарный процесс остается, по существу, неизменным и для других языков. Прежде чем программа Р может быть скомпилирована компилятором ПЛ/1, она должна быть обработана прекомпилятором (рис. 2.2). Примечание. Если Р содержит также какие-либо предложения CICS (вида ЕХЕС, СICS...;), то она должна быть также обработана препроцессором СICS. Прекомпилятор DB2 и препроцессор CICS могут исполнятся при этом в любом порядке.
Рис. 2.2. Прекомпиляция
Как указывалось в предыдущем разделе, прекомпилятор DB2 удаляет все найденные им в Р предложения SQL и заменяет[7]
их предложениями CALL языка ПЛ/1. (Эти предложения CALL осуществляют обращения к интерфейсному модулю ПЛ/1—см. ниже.) Предложения SQL он использует при этом для построения модуля запросов к базе данных
(DBRM) программы Р, который хранится вне этой программы как раздел библиотечного набора данных. В DBRM содержится копия первоначальных предложений SQL вместе с внутренней формой этих предложений в виде дерева разбора. Прекомпилятор формирует также листинг исходной программы, содержащий первоначальный исходный текст программы, диагностические сообщения, таблицы перекрестных ссылок и т. д.
Далее, модифицированный исходный модуль на языке ПЛ/1 компилируется и редактируется обычным образом за исключением того, что интерфейсный модуль языка ПЛ/1, который предоставляется системой DB2, должен быть частью входной информации для редактора связей. Условимся называть результат этого шага «загрузочным модулем Р на языке ПЛ/1».
Теперь мы подошли к шагу генератора планов прикладных задач (рис. 2.3).
В действительности, этот компонент является оптимизирующим компилятором. Он преобразует запросы высокого уровня к базе данных (на самом деле, предложения SQL) в оптимизированную машинную программу. Входной информацией для генератора служит множество, состоящее из одного или более DBRM. Таких модулей запросов будет несколько, если первоначальная программа на ПЛ/1 состоит более чем из одной внешней процедуры, т. е. включает несколько исходных модулей. Результат работы генератора, т. е. скомпилированный им код, называется планом прикладной задачи и он хранится в системной базе данных, называемой каталогом[8]
( о каталоге более подробно пойдет речь в главе 7). Таким образом, главные функции генератора типов прикладных задач состоят в следующем.
Рис. 2.3. Генератор планов прикладных задач
Выявление синтаксических ошибок
Генератор планов прикладных задач исследует предложения SQL во входных DBRM, осуществляет их синтаксический анализ и выдает сообщения обо всех синтаксических ошибках, которые он обнаружил. Такие проверки необходимы несмотря на то, что подобные проверки уже выполнялись прекомпилятором, поскольку прекомпилятор отделен от остальной части системы DB2. Его исполнение возможно, даже если DB2 недоступна. Он может даже исполняться на другой машине, и его выходные данные автоматически не защищаются. Поэтому нельзя предполагать, что входные данные генератора представляют собой достоверные результаты работы прекомпилятора — пользователь мог построить недопустимый «DBRM» с помощью некоторого другого механизма.
Оптимизация
Важной составной частью генератора планов прикладных задач является оптимизатор.
Функция оптимизатора состоит в том, чтобы выбрать для каждого обрабатываемого им манипулятивного предложения SQL оптимальную стратегию реализации этого предложения. Напомним, что предложения манипулирования данными, например SELECT, специфицируют только то, что хочет получить пользователь, а не как добраться до этих данных. Путь доступа, позволяющий добраться к этим данным, будет выбираться оптимизатором. Таким образом, программы независимы от таких путей доступа (дальнейшее обсуждение этой важной проблемы см. в заключении этого раздела).
Рассмотрим в качестве примера предложение SELECT из исходного модуля Р на языке ПЛ/1, приведенного на рис. 2.2. Даже в этом очень простом случае имеется, по крайней мере, два способа выполнения требуемого поиска: 1) путем физически последовательного просмотра (хранимой версии) таблицы S до тех пор, пока не будет найдена запись для поставщика S4; 2) если имеется индекс по столбцу НОМЕР_ПОСТАВЩИКА этой таблицы, что, вероятно, будет иметь место по причинам, которые подробно обсуждаются в Приложениях А и В, то используя этот индекс и, таким образом, непосредственно приходя к записи S4. Оптимизатору предстоит выбрать, какую из этих двух стратегий принять. Обычно оптимизатор будет делать свой выбор на основе следующих соображений: на какие таблицы ссылается данное предложение SQL (их может быть более одной), насколько велики эти таблицы, какие имеются индексы, каковы селективные их возможности, каким образом данные физически группируются на диске, какова форма фразы WHERE в запросе и т. п. Генератор планов прикладных задач будет далее генерировать машинный код, который тесно связан с
выбранной оптимизатором стратегией, т. е. в большой степени зависит от нее. Если, например, оптимизатор принимает решение использовать индекс X, то в плане прикладной задачи будут иметься команды машинного языка, которые явно обращаются к индексу X.
Генерация кода
Это процесс фактического построения плана прикладной задачи.
Проверка полномочий
Генератор планов прикладных задач осуществляет также проверку полномочий. Иными словами, он проверяет, позволяется ли лицу, выполняющему генерацию (т. е. пользователю, вызывающему генератор — см. главу 14), производить требуемые в DBRM операции, которые должны быть включены в план прикладной задачи. Вопросы санкционирования доступа будут подробно рассматриваться в главе 9.
Мы подошли, наконец, к процессу исполнения. Поскольку первоначальная программа теперь в действительности разбита на две части (загрузочный модуль и план прикладной задачи), эти две чисти должны быть на стадии исполнения каким-либо образом снова собраны вместе. Рассмотрим, как она работает (см. рис. 2.4).
Рис. 2.4. Процесс исполнения
Сначала в основную память загрузится загрузочный модуль Р на языке ПЛ/1 и он обычным образом начиняет исполняться. В конце концов, он достигает первого обращения к интерфейсному модулю языка ПЛ/1. Этот модуль получает управление и в свою очередь передает управление супервизору стадии исполнения. Далее, супервизор стадии исполнения производит поиск плана прикладной задачи в системном каталоге, загружает его в основную память и передает ему управление. План прикладной задачи в свою очередь вызывает программу управления хранимыми данными, которая выполняет необходимые операции над фактически хранимыми данными и возвращает результаты в подходящем виде программе на языке ПЛ/1.
До сих пор в нашем обсуждении умалчивался один чрезвычайно важный момент, который мы теперь поясним. Прежде всего, как уже говорилось, DB2—это компилирующая система.
В отличии от нее большинство других систем управления базами данных и, без сомнения, все системы нереляционного типа, насколько известно автору, являются, по существу, интерпретирующими.
Далее, компиляция, несомненно, имеет преимущества с точки зрения производительности. Она почти всегда будет давать лучшие характеристики времени исполнения, чем интерпретация. Однако она страдает следующим важным недостатком: возможно, что решения, принятые в процессе компиляции «компилятором» (фактически генератором планов прикладных задач), более не имеют силы на стадии исполнения. Эту проблему иллюстрирует следующий простой пример.
1. Предположим, что программа Р компилируется в понедельник, и генератор планов прикладных задач принимает решение использовать в стратегии для Р индекс, например, индекс X. Тогда план прикладной задачи для Р будет включать, как говорилось ранее, явные обращения к X.
2. В четверг некоторый обладающий полномочиями пользователь издает предложение DROP INDEX X;
3. В пятницу некоторый пользователь пытается исполнить программу Р. Что при этом происходит?
При этом происходит следующее. Когда уничтожается индекс, DB2 исследует все планы прикладных задач в каталоге с тем, чтобы установить, какие из них зависят от этого индекса, если они вообще зависят от индексов. Каждый из таких планов, который он обнаружил, помечается как «недействительный». Когда супервизор стадии исполнения осуществляет выборку такого плана для исполнения, он обнаруживает маркер «недействительный» и поэтому вызывает генератор планов прикладных задач для продуцирования нового плана, т. е. для того, чтобы выбрать какую-либо иную стратегию доступа, а затем перекомпилировать первоначальные предложения SQL, которые были сохранены в каталоге, в соответствии с этой новой стратегией. Если перекомпиляция была успешной, старый план заменяется в каталоге новым, и супервизор стадии исполнения продолжает работу уже с новым планом. Таким образом, весь процесс перегенерации (или «автоматического связывания», как его называют) является «прозрачным для пользователя». Единственный эффект, который может наблюдаться,— это незначительная задержка исполнения первого предложения SQL в программе.
Заметим, что та перекомпиляция, о которой здесь говорилось, это перекомпиляция SQL, а не ПЛ/1. Перекомпилируется не программа на языке ПЛ/1, которая стала недействительной вследствие уничтожения индекса, а лишь план прикладной задачи.
Теперь можно видеть, каким образом становится возможной независимость программ от физических путей доступа, или более определенно, каким образом возможно создавать и уничтожать такие пути доступа без необходимости в то же время изменять программы. Как указывалось ранее, предложения манипулирования данными языка SQL, например SELECT и UPDATE, никогда не включают какого-либо явного упоминания о таких путях доступа. Вместо этого в них просто указывается, в каких данных заинтересован пользователь. Выбор пути, позволяющего добраться до этих данных, а также замена его другим путем, если старый путь более не существует,— это обязанности системы, а в действительности—генератора планов прикладных задач. Будем говорить, что система типа DB2 обеспечивает высокую степень физической независимости данных: пользователь и пользовательские программы не зависят от физической структуры хранимой базы данных. Достоинство такой системы—весьма значительное достоинство—состоит в том, что можно делать изменения в физической базе данных, например по соображениям производительности, не имея необходимости делать какие-либо соответствующие изменения в прикладных программах. В системе, не обладающей такой независимостью, прикладные программисты вынуждены уделять довольно значительную часть времени—доля 50 процентов является весьма типичной—для внесения в существующие программы изменений, которые становятся необходимыми просто вследствие изменений в физической базе данных. Напротив, в системе типа DB2 эти программисты могут сосредоточиться исключительно на производстве новых прикладных задач.
Ещё один момент, касающийся предыдущего вопроса. Наш пример был связан с уничтоженным индексом и это, вероятно, наиболее частый случай на практике. Однако аналогичная последовательность событий имеет место при удалении любого объекта, а не только индекса, а также когда отменяются полномочия пользователя (см. главу 9). Поэтому, например, уничтожение какой-либо таблицы приведет к тому, что все планы, которые обращаются к этой таблице, будут помечены как недействительные. Конечно, автоматическая перегенерация будет работать лишь в том случае, если ко времени, когда ее следует выполнять, была создана другая таблица с тем же именем, что и у старой (и, вероятно, не тогда, когда имеются значительные различия между старой и новой таблицами).
В заключение данной главы отметим, что SQL всегда компилируется в DB2 и никогда не интерпретируется, даже если предложения в запросе вводятся через интерактивный интерфейс DB2I или через QMF. Иными словами, если ввести, например, предложение SELECT с терминала, то этот оператор будет компилироваться, и для него сгенерируется план прикладной задачи. Далее этот план будет исполняться. Наконец, после того как исполнение будет завершено, этот план будет удален. Практический опыт показал, что даже в интерактивном случае при компиляции почти всегда достигается лучшая общая производительность, чем при интерпретации. Достоинство компиляции состоит в том, что процесс физического доступа к требуемым данным осуществляется скомпилированной программой, т. е. программой, которая хорошо приспособлена для конкретного запроса, а не универсальной интерпретирующей программой. Недостаток состоит, конечно, в том что имеются затраты, связанные с компиляцией, т. е. с подготовкой этой хорошо приспособленной программы. Но указанное преимущество почти всегда перевешивает этот недостаток, причем иногда поразительным образом. Только в случае чрезвычайно простого запроса затраты на выполнение компиляции могут быть больше, чем потенциальная экономия. В качестве примера мог бы служить следующий простой запрос: «Осуществить выборку записи поставщика для поставщика S1». Здесь запрашивается единственная конкретная запись при заданном значении для поля, которое уникально идентифицирует эту запись. Обратим внимание, что такой запрос в действительности совсем не использует средств уровня множеств языка SQL.
ПОДЗАПРОС С НЕСКОЛЬКИМИ УРОВНЯМИ ВЛОЖЕННОСТИ
Выдать фамилии поставщиков, которые поставляют по крайней мере одну красную деталь.
SELECT ФАМИЛИЯ
FROM S
WHERE НОМЕР_ПОСТАВЩИКА IN
(SELECT НОМЕР_ПОСТАВЩИКА
FROM SP
WHERE НОМЕР_ДЕТАЛИ IN
(SELECT НОМЕР_ДЕТАЛИ
FROM P
WHERE ЦВЕТ = 'Красный'));
Результат:
ФАМИЛИЯ
Смит
Джонс
Кларк
Пояснение.
Результатом самого внутреннего подзапроса является множество ('Р1, 'Р4', 'Р6'). Подзапрос следующего уровня в свою очередь дает в результате множество ('S1', 'S2', 'S4'). Последний, самый внешний SELECT, вычисляет приведенный выше окончательный результат. Вообще допускается любая глубина вложенности подзапросов.
Для того чтобы убедиться в Вашем понимании этого примера, попытайтесь выполнить следующие упражнения:
а) Перепишите данный запрос так, чтобы все уточнения имен были указаны явным образом.
б) Напишите эквивалентную формулировку этого же запроса с использованием соединения.
ПОДЗАПРОС С ОПЕРАТОРОМ СРАВНЕНИЯ, ОТЛИЧНЫМ ОТ IN
Выдать номера поставщиков, находящихся в том же городе, что и поставщик S1.
SELECT НОМЕР_ПОСТАВЩИКА
FROM S
WHERE ГОРОД =
(SELECT ГОРОД
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = 'S1');
Результат:
|
|
НОМЕР_ПОСТАВЩИКА
|
|
S1
S4
Иногда пользователь может знать, что заданный подзапрос должен возвратить в точности одно значение, как в рассматриваемом примере. В таком случае можно использовать вместо обычного IN более простой оператор сравнения (например, =, > и т. д.). Однако, если подзапрос возвращает более одного значения и не используется оператор IN, будет возникать ошибка. Ошибка не возникнет, если подзапрос не возвратит вообще ни одного значения. При этом сравнение интерпретируется в точности так, как если бы подзапрос возвратил неопределенное значение. Иными словами, если х — переменная, то сравнение
х простой—оператор—сравнения (подзапрос),
где «подзапрос» возвращает пустое множество, имеет значение истинности не истина или ложь, а неизвестно
(см. главу 4, пример 4.2.10).
Нужно отметить, что сравнение в предыдущем примере должно быть записано именно так, как показано — подзапрос должен следовать за оператором сравнения. Иначе говоря, следующая запись запроса некорректна:
SELECT НОМЕР_ПОСТАВЩИКА
FROM S
WHERE (SELECT ГОРОД
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = 'S1') = ГОРОД;
Более того, подзапрос не может включать фраз GROUP BY или HAVING, если он используется с простым оператором сравнения, например с =, > и т. д.
ПОДЗАПРОСЫ
В этом разделе обсуждаются подзапросы или вложенные предложения SELECT. Говоря нестрого, подзапрос представляет собой выражение SELECT-FROM-WHERE, которое вложено в другое такое предложение [13]'. Обычно подзапросы используются для представления множества значений, исследование которых должно осуществляться в каком-либо предикате IN, как иллюстрируется в следующем примере.
Предлагаемая монография принадлежит перу известного
Предлагаемая монография принадлежит перу известного специалиста в области баз данных, одного из пионеров технологии реляционных баз данных— К. Дейта.
Эта работа посвящена детальному обсуждению нового программного продукта, созданного крупнейшим в мире производителем средств вычислительной техники и программного обеспечения—американской фирмой International Business Machines Corporation (IBM), в которой автор сотрудничал в течение многих лет. Речь идет о реляционной СУБД DB2, поставляемой фирмой с 1983 года. Появление на рынке программного обеспечения такого крупного программного продукта — весьма значительное событие. В немалой степени это связано и с тем, что он относится к такой сложной и перспективной области, как реляционные базы данных.
Прежде чем предоставить читателю возможность начать знакомство с системой, целесообразно кратко охарактеризовать предысторию ее создания. Это поможет лучше осознать проблемы, связанные с разработкой систем такого класса, объективно оценить научно-технический уровень системы DB2, понять, почему именно фирма IBM смогла создать такой сложный программный продукт.
Подход, основанный на реляционной модели данных, занял важное место в развитии технологии баз данных. Нет необходимости подробно обсуждать здесь его достоинства, как, впрочем, и трудности, связанные с его реализацией и использованием — они достаточно хорошо известны. Системами реляционного типа оснащены сегодня многие серийно выпускаемые модели ЭВМ, от мощных вычислительных комплексов до персональных компьютеров. Реляционный инструментарий предполагается использовать в качестве основного средства управления базами данных и базами знаний в разрабатываемых проектах ЭВМ нового поколения.
Значительный вклад в разработку теории реляционных баз данных и создание СУБД этого класса внесла фирма IBM. Еще в конце 60-х годов в ряде ее научных центров начали активно проводить теоретические исследования и экспериментальные разработки новых нетрадиционных подходов к управлению данными, базирующихся на строгом математическом понятии отношения. Необходимо было при этом решить целый ряд задач — определить целесообразную архитектуру СУБД нового типа, разработать новую модель данных, адекватные ей методы доступа и технологию обработки запросов, создать языковые средства, ориентированные на теоретико-множественный характер структур данных и операций над ними, предложить пути реализации программных систем такого типа, обеспечивающие достаточно высокую их производительность, создать прототипы будущих коммерческих СУБД, обладающих указанными возможностями, и экспериментально оценить их характеристики на ЭВМ.
Разработки, связанные с системами нового типа, получившими название «реляционных», проводились и многими другими группами специалистов. Однако именно результаты, полученные в этой области сотрудниками IBM, оказали определяющее влияние на формирование новой ветви в технологии баз данных.
В этой связи следует назвать прежде всего новаторские работы Э. Кодда, посвященные реляционной модели данных и ее математическим основам: исследования в области реляционной алгебры и реляционного исчисления, разработка алгоритма редукции (интерпретации выражений реляционного исчисления в реляционной алгебре), создание одного из первых реляционных языков, формулировка концепции реляционной полноты языка, разработка основ теории нормализации отношений. До сих пор повсеместно цитируется известная статья Кодда, опубликованная еще в 1970 году в журнале Communications of the ACM. Не здесь ли был впервые введен термин «реляционная модель данных»? Позднее, в 1979 году, Кодд опубликовал фундаментальную работу, в которой систематизируются и обобщаются результаты исследований ряда авторов, направленных на повышение семантического уровня моделей данных. В работе Кодда предлагается ввести в базовую реляционную модель новые механизмы, обеспечивающие более развитые возможности для формулировки ограничений целостности, или, иначе говоря, для выражения семантики предметной области. Тем самым были преодолены значительные трудности, связанные с использованием реляционной модели данных. Расширенная таким образом модель была названа автором RM/T.
Исследования Кодда в области реляционных баз данных получили широкое признание. В 1981 г. он был удостоен весьма престижной Тьюринговской премии, присуждаемой Ассоциацией по вычислительной технике США (ACM) за выдающийся вклад в развитие информатики.
Заслуживает внимания другой весьма интересный комплекс исследований, выполненный М. Сенко и руководимой им группой. Был предложен и конструктивно, вплоть до языковых спецификаций, проработан оригинальный подход к построению СУБД, в котором используется частный случай реляционной модели данных—модель бинарных отношений. Основная цель этого подхода, получившего название Data Independent Access Method (DIAM),—развитие концепций многоуровневой архитектуры СУБД, обеспечивающих высокую степень независимости данных. В публикациях группы Сенко, а впоследствии в большой серии принадлежащих ему лично статей и Докладов детально специфицированы все уровни архитектуры СУБД, реализующей предлагаемый подход. В частности, рассмотрены специальные методы доступа, организация среды хранения и способы представления хранимых данных, сформулированы ключевые идеи модели бинарных отношений и предложен синтаксис пользовательского языка FORAL (для версии DIAM II). Идеи СУБД с многоуровневой архитектурой были высказаны в этих работах за несколько лет до публикации известного отчета ANSI/SPARC (1975 г.), на который обычно ссылаются по этому поводу. В рамках DIAM специально изучались также возможности использования дисплея со световым пером для оперирования графическим представлением схемы базы данных. Эту работу можно рассматривать как одну из ранних попыток создания инструментария автоматизированного проектирования баз данных. К сожалению, подход DIAM не был практически реализован в какой-либо коммерческой системе. Весьма вероятно, что причиной этому явилась скоропостижная кончина М. Сенко.
Особое внимание в исследованиях IBM уделялось разработке языковых средств реляционных систем баз данных. Важное место при этом отводилось изучению психологических аспектов применения таких языков, с тем чтобы минимизировать потенциальную возможность пользовательских ошибок.
Наиболее заметными в этом направлении являются работы Д. Чемберлина, Р. Бойса и их соавторов по созданию реляционного языка, упоминаемого в литературе как SEQUEL или SQL (в процессе эволюции языка было создано несколько его версий). Благодаря большой популярности и тщательности отработки SEQUEL приобрел статус стандарта де-факто. Его описание можно найти в каждой более или менее серьезной монографии или учебном пособии по реляционным базам данных. И не случайно Комитет по разработке стандартов в области баз данных Американского национального института стандартов принял SEQUEL в качестве отправной точки в своей деятельности по созданию стандарта реляционного языка.
Наряду с SEQUEL следует указать здесь и другое направление работ IBM в области реляционных языков, связанное с именем М. Злуфа. Цель заключалась в создании более «дружественного» по сравнению с SEQUEL реляционного интерфейса, которым можно было бы воспользоваться, не обладая специальной профессиональной подготовкой в области баз данных. Исследования Злуфа увенчались созданием получившего широкую известность языка Query-By-Example (QBE). В отличие от SEQUEL, близкого по стилю к языкам программирования, QBE является «графически-ориентированным» языком и предназначен специально для интерактивной работы. Пользователь оперирует на экране дисплея формами таблиц, составляющих базу данных, и продуцируемых из них таблиц. Для спецификации запроса задаются образцы заполнения строк этих таблиц, ограничения, которым удовлетворяют их элементы, и требуемые операции над строками таблиц. В более сложных случаях применяются также другие средства языка. Интерфейс QBE поддерживается в ряде программных продуктов. Об одном из них идет речь в этой книге.
Нужно сказать, наконец, о разработках, направленных на создание собственно программного инструментария для реляционных баз данных, в основу которых были положены рассмотренные теоретические исследования. Понимая все трудности, связанные с созданием эффективной реляционной СУБД на существующем оборудовании, фирма не спешила с созданием коммерческого продукта, предназначенного для массового применения. Чтобы не дискредитировать идею с самого начала, нужна была известная осторожность.
Первым «пробным шаром» фирмы в этой области, вызвавшим большой интерес, явилась экспериментальная реляционная СУБД System R, в которой реализован язык SEQUEL. Работы над системой проводились в 1975—1979 гг. и дали возможность определить рациональные пути реализации систем подобного типа.
Развитие System R осуществлялось в двух направлениях. Одно из них — создание системы управления распределенными базами данных. Результатом этих работ стала система R*, которой посвящены многочисленные публикации. Другое направление — создание на основе System R коммерческой реляционной СУБД. Эта задача была решена к 1981 г., когда фирма начала поставку своего первого коммерческого реляционного продукта — системы SQL/DS. Спустя два года был сделан еще один шаг в этом направлении — IBM начала поставлять новую систему DB2, которой и посвящена предлагаемая монография К. Дейта.
Можно без преувеличения сказать, что система DB2 интегрирует весь арсенал современных достижений в технологии реляционных баз данных. Как видно из сказанного, ее разработке предшествовала многолетняя подготовительная работа — проведение разносторонних научных исследований, создание экспериментальных реализации и прототипов будущих программных продуктов, изучение их характеристик.
При создании системы DB2 особое внимание уделялось проблеме повышения ее производительности. В частности, DB2 реализована с этой целью по принципу компиляции запросов, тогда как в большинстве других существующих систем осуществляется их интерпретация. Связанное с этим решением определенное отступление в отношении независимости данных компенсируется в некоторой степени за счет принятия специальных мер. Тщательно продумана организация среды хранения данных, предусмотрен ряд механизмов, служащих для оптимизации обработки запросов, на самом современном уровне решены вопросы управления параллельным исполнением транзакций.
В качестве пользовательского языка в системе реализована новая версия все того же SEQUEL (называемого здесь SQL). На его основе строится как интерфейс включающего языка для прикладных программ («встроенный SQL»), так и интерактивный интерфейс для пользователя. Особый интерес представляет «динамический SQL»—интерфейс, позволяющий обрабатывать системными средствами запросы (SQL-тексты), задаваемые в прикладной программе как значения переменных типа литерной строки. Это позволяет легко создавать на основе DB2 различные интерактивные прикладные системы, причем отображение пользовательского языка в SQL осуществляется прикладной программой с помощью «динамического SQL».
Для системы DB2 предусмотрены различные варианты операционной обстановки, и пользователь может выбрать для себя наиболее подходящий. Совместно с системой могут использоваться такие полезные программные продукты, как QMF и DXT. QMF — это генератор отчетов, функционирующий по отношению к DB2 как периферийный компонент. Он позволяет специфицировать запросы не только на языке SQL, но и на QBE. В свою очередь, DXT дает возможность обрабатывать с помощью DB2 данные, хранимые в базах данных системы IMS или в наборах данных VSAM.
Совместимость системы DB2 и DXT имеет важное значение для расширения сферы ее потенциального применения. Благодаря этому новой системе открываются двери в те области, которые уже «обжиты» другой СУБД, созданной фирмой IBM,— системой IMS. За два десятилетия, прошедшие с момента начала ее поставки, система IMS получила массовое распространение — сфера ее действия стала весьма широкой. Поэтому забота о совместимости DB2 и DXT не лишена оснований.
На этом можно завершить обзор разработок фирмы IBM в области реляционных баз данных, поскольку читатель уже получил достаточно полное представление о предыстории создания системы DB2, и пора сказать несколько слов о самой книге.
Она представляет собой профессионально написанное руководство по системе DB2. В ней содержатся необходимые сведения об операционной обстановке системы, ее организации и архитектуре, принципах функционирования, порядке взаимодействия с программными продуктами QMF и DXT. Центральное место отводится детальному обсуждению функций языка SQL и особенностей его использования для всех предусмотренных пользовательских интерфейсов. В заключительной главе сжато характеризуются общие возможности системы DB2, рассматривается проблема производительности реляционных систем вообще и применительно к DB2, намечаются перспективы развития функциональных возможностей этой системы.
Читателю будет полезен и материал приложений. Здесь приведены строгие определения основных понятий реляционной модели данных, излагается точка зрения на вопрос о том, какая система имеет право называться «реляционной», рассматриваются важные методологические аспекты логического проектирования баз данных. Приводятся также требования системы DB2 и сопутствующих ей программных продуктов к операционной обстановке и оборудованию ЭВМ. Для справочных целей включена сводка синтаксических спецификаций предложений манипулирования данными языка SQL.
Новая работа К. Дейта не только будет интересна специалистам по программному обеспечению информационных систем, но и с успехом может быть использована как учебное пособие по реляционным СУБД. Для этого в книге при всей ее лаконичности имеется все необходимое — от концепций реляционной модели данных и методологии проектирования реляционных баз данных до систематического рассмотрения архитектуры, пользовательских интерфейсов и технологии функционирования самой современной СУБД такого класса, от теоретического материала до технических спецификаций и проверенных на ЭВМ многочисленных практических упражнений и ответов к ним. Книга хорошо скомпонована, написана четким и ясным языком. Умело подобран иллюстративный материал.
В заключение коротко об авторе. С начала 70-х годов К. Дейт занимается реляционными базами данных и стал одним из ведущих специалистов в этой области. В течение многих лет он тесно сотрудничал с Э. Коддом, которому в знак признательности он посвящает эту книгу. К. Дейт — один из руководителей и непосредственный участник разработки системы DB2. Знание системы «изнутри» помогло объективно показать не только ее достоинства, но и слабые места.
Можно не сомневаться в том, что советский читатель получил полезную и нужную книгу.
М. Когаловский
Предмет обсуждения этой книги, система
Предмет обсуждения этой книги, система DB2, представляет собой программный продукт фирмы IBM, функционирующий в обстановке операционной системы MVS, а точнее — реляционную систему управления базами данных для MVS. Это означает, что рассматриваемый программный продукт позволяет пользователю (как конечному пользователю, так и прикладному программисту) в такой операционной обстановке запоминать данные в базах данных и осуществлять их выборку, воспринимая при этом базу данных как совокупность отношений или таблиц. DB2 обеспечивает доступ к таким базам данных посредством реляционного языка, называемого SQL («Structured Query Language» — Структуризованный язык запросов).
Вряд ли можно сказать, что название «DB2» вносит какую-либо ясность — оно мало что говорит о природе этого программного продукта. Ненамного лучше и полное его название — «IBM Database 2» («База данных 2 фирмы IBM»). В частности, из него, не ясно, что речь идет о реляционном программном продукте, или что он поддерживает язык SQL, или, наконец, что он функционирует в обстановке MVS. Более того, такое название даже и не совсем корректно, поскольку это вовсе не база данных, а система управления базами данных. Столь неблагоприятное начало не может, однако, затушевать того факта, что DB2 является исключительно важным продуктом. Его объявление в июне 1983 г. было значительным событием: оно окончательно наложило печать одобрения IBM на то, что стало называться реляционным подходом к. управлению базами данных. Этот подход, впервые предложенный в 1969—70-х годах Э. Ф. Коддом из Научно-исследовательской лаборатории фирмы IBM в Сан-Хосе, с тех пор медленно, но уверенно получал признание в самой фирме IBM и вне ее. DB2 занимает в настоящее время ведущее место среди основных программных продуктов IBM. Все они—реляционные, поддерживают язык SQL и функционируют в обстановке одной из главных операционных систем IBM: DB2 — в обстановке MVS, SQL/DS — DOS/VSE и SQL/DS Release 2 — VM/CMS.
Как только что упоминалось, реляционный подход был впервые предложен в 1969—70-х годах. Язык SQL был разработан в 1974 году, а основная реализация — прототип этого языка под названием System R — была создана и исследована IBM в течение приблизительно пятилетнего периода — в 1975—79 годах. Разработанная в рамках этого прототипа технология была далее использована в SQL/DS", первое полностью поддерживаемом реляционном программном продукте IBM, объявленном для DOS/ VSE в 1981 году, а для VM/CMS — в 1983 году. Впоследствии. она была использована и в DB2, объявленной для MVS в 1983 году. Все эти продукты — System R, SQL/DS и DB2 — внешне очень похожи. В частности, во всех трех системах очень похож язык SQL. Поэтому, несмотря на то что данная книга посвящена системе DB2, большинство сказанного в ней относится с небольшими изменениями также к System R и SQL/DS. Однако, начиная с этого места и далее, ссылка на «язык SQL», если не оговаривается иное, должна относиться специально к диалекту этого языка, поддерживаемому DB2.
Основная задача этой книги— дать подробное описание продукта DB2, не лишенное, однако, некоторых критических замечаний: что он собой представляет и чего не представляет, для чего он предназначен и как он может быть использован. Книга ориентирована на специалистов по управлению обработкой данных, по организации работы конечных пользователей, на специалистов в области баз данных, в том числе администраторов баз данных, системных администраторов, проектировщиков баз данных и прикладных программистов, работающих в обстановке баз данных. Она рассчитана также на студентов, специализирующихся в области обработки данных, на преподавателей этих дисциплин, на конечных пользователей и профессиональных специалистов по обработке данных, желающих расширить свои знания в области баз данных путем изучения системы, воплощающей современный уровень развития технологии баз данных. На протяжении всей книги при этом основное внимание уделяется пользователю, где под «пользователем» мы понимаем, главным образом, конечного пользователя либо прикладного программиста. Дается достаточно основательная интерпретация материала, ориентированного на пользователя, например материала, связанного с языком SQL. Наоборот, подробности, представляющие интерес только для системных программистов или операторов, связанные, например, с системными командами, вообще опущены или, в лучшем случае, обсуждаются только в общих чертах. Предполагается, что читатели имеют по крайней мере некоторое представление об общей структуре, концепциях и назначении систем баз данных. Однако от них не требуется, по существу, каких-либо знаний в области реляционных систем.
Книга имеет следующую структуру. В главах 1 и 2 приводится обзор возможностей системы DB2, показывающий, каким образом она соотносится с ее обстановкой и, в общих чертах, как она функционирует. Глава 3 посвящена определению данных, а главы 4—6 — манипулированию данными. В главе 7 обсуждается системный каталог. В главе 8 описываются специальные реляционные возможности, называемые механизмом представлений. В главе 9 обсуждается подсистема безопасности данных DB2, в частности показывается, как представления, о которых идет речь в предыдущей главе, могут использоваться для обеспечения безопасности. Главы 10—12 имеют дело с прикладным программированием. Наряду с другими вопросами в них обсуждается использование языка SQL для написания прикладных программ, довольно подробно освещаются вопросы обработки транзакций, в том числе соображения, касающиеся восстановления целостности данных и параллелизма. В главе 13 рассматриваются структуры хранения данных системы DB2. В главе 14 описывается интерактивный интерфейс DB2I, а в главе 15—периферийный программный продукт QMF (Query Management Facility), позволяющий запрашивать данные из базы данных и генерировать отчеты. Наконец, в главе 16 подытоживаются достоинства системы типа DB2, обсуждаются некоторые соображения о производительности, высказываются предположения о будущем реляционных систем. В книге содержится значительное число проверенных на ЭВМ примеров и в большинстве глав — множество упражнений вместе с ответами к ним.
ПРЕДЛОЖЕНИЕ DELETE
Предложение DELETE имеет следующий общий формат:
DELETE
FROM таблица
[WHERE предикат];
Удаляются все записи в «таблице», которые удовлетворяют «предикату».
Удалить все поставки тех поставщиков, которые находятся в городе, заданном переменной включающего языка ГОРОД.
ЕХЕС SQL DELETE
FROM SP
WHERE :ГОРОД=
(SELECT ГОРОД
FROM S
WHERE S.HOMEP_ПОСТАВЩИКА =
SP.НОМЕР_ПОСТАВЩИКА);
И снова, если никакие записи не удовлетворяют условию WHERE, для поля SQLCODE будет установлено значение +100.
ПРЕДЛОЖЕНИЕ INSERT
Предложение INSERT имеет следующий общий формат:
INSERT
INTO таблица [(поле [,поле] . . .)]
VALUES (константа [,константа] . . .);
ИЛИ:
INSERT
INTO таблица [(поле [,поле] . . .)]
подзапрос;
В первом формате в «таблицу» вставляется строка, имеющая заданные значения для указанных полей, причем 1-я константа в списке констант соответствует i-му полю в списке полей. Во втором формате вычисляется «подзапрос»; копия результата, представляющего собой, вообще говоря, множество строк, вставляется в «таблицу». При этом 1-й столбец этого результата соответствует f-му полю в списке полей. В обоих случаях отсутствие списка полей эквивалентно спецификации списка всех полей в таблице (см. ниже пример 6.4.2).
Вставить в таблицу Р новую деталь. При этом номер детали, название и вес заданы соответственно переменными включающего языка НОМ_ДЕТАЛИ, НАЗВ_ДЕТАЛИ и ВЕС_ДЕТАЛИ, а цвет и город неизвестны.
ЕХЕС SQL INSERT
INTO Р (НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ВЕС)
VALUES (:HOM_ДЕТАЛИ, :НАЗВ_ДЕТАЛИ,
:ВЕС_ДЕТАЛИ);
Опять здесь можно использовать индикаторные переменные. Например, если ЦВЕТ_ДЕТАЛИ и ГОР_ДЕТАЛИ — две следующие переменные включающего языка, ИНД_ЦВЕТА и ИНД_ГОРОДА — соответствующие индикаторные переменные, то последовательность
ИНД_ЦВЕТА = -1;
ИНД_ГОРОДА = -1;
ЕХЕС SQL INSERT
INTO Р (НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС,
ГОРОД)
VALUES (:HOM_ДЕТАЛИ, :НАЗВ_ДЕТАЛИ,
:ЦВЕТ_ДЕТАЛИ: ИНД_ЦВЕТА,
:ВЕС_ДЕТАЛИ,
:ГОР_ДЕТАЛИ: ИНД_ГОРОДА);
дает тот же результат, что и приведенное выше предложение INSERT.
Для простоты в дальнейшем (в этой и двух следующих главах) будем в большинстве случаев игнорировать индикаторные переменные и возможность неопределенных значений.
ПРЕДЛОЖЕНИЕ UPDATE
Предложение UPDATE имеет следующий общий формат:
UPDATE таблица
SET поле = выражение
[,поле = выражение] . . .
[WHERE предикат];
Все записи в «таблице», которые удовлетворяют «предикату», обновляются в соответствии с присваиваниями «поле = выражение» во фразе SET (установить).
Увеличить состояние всех поставщиков из Лондона на величину, заданную переменной включающего языка ПРИРОСТ:
ЕХЕС SQL UPDATE S
SET СОСТОЯНИЕ = СОСТОЯНИЕ + :ПРИРОСТ
WHERE ГОРОД = 'Лондон';
Если записей, удовлетворяющих условию WHERE, нет, для поля SQLCODE будет установлено значение +100. Справа от знака присваивания во фразе SET может быть использована индикаторная переменная. Например, предложение:
ИНД_РАНГА = -1;
ЕХЕС SQL UPDATE S
SET СОСТОЯНИЕ = :РАНГ :ИНД_РАНГА
WHERE ГОРОД = 'Лондон';
установит состояние всех лондонских поставщиков в неопределенное значение. То же самое можно, конечно, сделать с помощью предложения:
ЕХЕС SQL UPDATE S
SET СОСТОЯНИЕ = NULL
WHERE ГОРОД = 'Лондон';
ПРЕДЛОЖЕНИЯ COMMIT И ROLLBACK
Из предыдущего раздела должно быть ясно, что COMMIT и ROLLBACK в действительности не являются такими же операциями управления базой данных, как SELECT, UPDATE и т. д. Предложения COMMIT и ROLLBACK—это вообще не команды для СУБД. Они представляют собой команды для администратора транзакций, который не является, конечно, частью СУБД. Наоборот, СУБД подчиняется администратору транзакций в том смысле, что СУБД — это только один из нескольких возможных «администраторов ресурсов», которые обеспечивают обслуживание транзакций, выполняемых под управлением этого администратора транзакций. В частности, в случае системы DB2 имеются три таких администратора транзакций — IMS, CICS и TSO, и заданная транзакция DB2 может исполняться под управлением в точности одного из них. Как уже указывалось (в несколько иных терминах) в главе 1:
— транзакция, исполняемая под управлением администратора транзакций IMS, может использовать услуги трех администраторов ресурсов — системы баз данных IMS, системы передачи данных IMS и системы DB2;
— транзакция, исполняемая под управлением администратора транзакций CICS, также может использовать услуги трех администраторов ресурсов — опять-таки системы баз данных IMS, системы передачи данных CICS и системы DB2;
— транзакция, исполняемая под управлением администратора транзакций TSO, может использовать услуги двух администраторов ресурсов — терминальной системы TSO и системы DB2.
Рассмотрим транзакцию, которая обновляет как базу данных системы IMS, так и базу данных системы DB2. Если эта транзакция завершается успешно, то все произведенные ею обновления как данных IMS, так и данных DB2, должны быть зафиксированы. Наоборот, если она завершается неудачно, то для всех
произведенных ею обновлений должен быть осуществлен откат. Не должна допускаться такая возможность, чтобы обновления для IMS были зафиксированы, а для обновлений в DB2 был осуществлен откат, и наоборот. При этом транзакция не была бы больше атомарной (все или ничего). Очевидно, таким образом, что для транзакции не имеет смысла издавать, например, COMMIT для IMS и ROLLBACK для DB2. И если даже в обоих случаях издаются одинаковые команды, в системе может все же возникнуть отказ в промежутке между ними, и результат будет неудовлетворительным. Следовательно, транзакция должна издавать единственную общесистемную команду COMMIT (или ROLLBACK), адресуя се соответствующему администратору транзакций, а этот администратор транзакций в свою очередь гарантирует, что все администраторы ресурсов в унисон будут фиксировать или осуществлять откат обновлений, за которые они ответственны. (Более того, он обеспечивает такую гарантию, даже если возникнет отказ системы в ходе этого процесса, благодаря протоколу, называемому двухфазной фиксацией. Однако подробности об этом протоколе выходят за рамки этой книги (Заинтересованный читатель может найти подробное обсуждение этого вопроса в книге Д. Ульмана «Основы систем баз данных» (М.: Финансы и статистика, 1983).— Примеч. пер.)
Именно поэтому СУБД подчиняется (подчиняются) администратору транзакций. COMMIT и ROLLBACK должны быть глобальными (общесистемными) операциями, и администратор транзакций действует как необходимый центральный пункт управления, который обеспечивает, чтобы это было так.
Из предыдущего также ясно, почему требуются различные функции «фиксации» и «отката» при трех разных вариантах операционной обстановки системы DB2. Поскольку они вообще являются не операциями DB2, а, скорее, операциями администратора транзакций, они должны запрашиваться в том стиле, который предписан для рассматриваемого администратора транзакций. В обстановке TSO они запрашиваются с помощью явных операторов языка SQL — COMMIT и ROLLBACK (подробности приведены ниже). В случае IMS и CICS они запрашиваются с помощью соответствующих обращений к IMS и CICS, подробности о которых можно найти в руководствах фирмы IBM по этим системам. В остальной части данного раздела основное внимание уделено обстановке TSO[20].
Прежде чем перейти к подробному рассмотрению предложений COMMIT и ROLLBACK как таковых, определим сначала важное понятие «точка синхронизации». Точка синхронизации представляет собой граничную точку между двумя последовательными транзакциями. Грубо говоря, она соответствует концу логической единицы работы и таким образом является точкой, в которой база данных находится в непротиворечивом состоянии. Точка синхронизации учреждается при инициации программы, издании COMMIT и ROLLBACK и только в этих случаях. Напомним, однако, что COMMIT и ROLLBACK иногда могут быть неявными.
Предложение COMMIT
Предложение COMMIT языка SQL имеет следующий формат:
COMMIT [WORK];
Это предложение сигнализирует об успешном завершении транзакции и учреждает точку синхронизации. Все обновления, сделанные данной программой со времени предыдущей точки синхронизации, фиксируются. Все открытые курсоры закрываются. Снимаются все блокировки записей. Блокировки, установленные с помощью LOCK TABLE, вероятно, не будут сняты (см. разделы 11.5 и 11.6).
Необязательный операнд
WORK (работа) является чисто вспомогательным и не оказывает какого- либо влияния на выполнение этого предложения.
Предложение ROLLBACK
Предложение ROLLBACK языка SQL имеет следующий формат:
ROLLBACK [WORK];
Это предложение сигнализирует о неудачном завершении транзакции и учреждает точку синхронизации. Все обновления, сделанные программой после учреждения последней точки синхронизации, аннулируются. Все открытые курсоры закрываются. Снимаются все блокировки записей. Однако блокировки, установленные с помощью LOCK TABLE, вероятно, не будут сняты (см. разделы 11.5 и 11.6).
Необязательный операнд
WORK является чисто вспомогательным и не оказывает какого-либо влияния на выполнение этого предложения.
Предыдущие определения порождают ряд вопросов, явно заслуживающих более серьезного обсуждения.
1. Прежде всего отметим, что каждая операция в системе DB2 исполняется в контексте некоторой транзакции. Это касается и операций SQL, которые вводятся в интерактивном режиме через интерфейс DB2I. Точки синхронизации для операций, введенных через интерфейс DB2I, учреждаются способом, который рассматривается в главе 14.
2. Из приведенных определений следует, что транзакции не могут быть вложены одна в другую, поскольку каждое из предложений COMMIT или ROLLBACK завершает одну транзакцию и инициирует другую.
3. Следствием предыдущего пункта является тот факт, что исполнение отдельной программы состоит из последовательности одной или более транзакций (часто, но совсем не обязательно, только одной). Если это только одна транзакция, часто будет возможно кодировать программу вообще без каких-либо явных предложений COMMIT или ROLLBACK.
Наконец, из всего сказанного выше следует, что транзакции являются не только единицами работы, но также и единицами восстановления. Если транзакция успешно выполнит операцию COMMIT, то администратор транзакций должен гарантировать, что сделанные ею обновления будут обязательно отражены в базе данных, даже если в следующий момент будет иметь место отказ системы. Вполне возможно, например, что отказ системы произойдет после того, как будет выполнена операция COMMIT, но прежде, чем обновления будут физически записаны в базу данных,—они могли еще оставаться в буфере в основной памяти, и поэтому утратились бы во время такого отказа системы. Даже если это случится, процедура рестарта системы все же установит эти обновления в базе данных. Она способна восстановить значения, которые должны быть записаны в базу данных благодаря анализу соответствующих записей в журнале. (Из этого следует, в частности, что запись в журнал будет физически осуществляться до того, как может завершиться обработка операции COMMIT. Это правило называется протоколом упреждающей записи в журнал.)
Таким образом, процедура рестарта будет восстанавливать любые единицы работы (транзакции), которые завершились успешно, но для которых не удалось физически записать сделанные ими обновления до того, как произойдет отказ. Следовательно, как утверждалось выше, транзакция с достаточным на то основанием может определяться и как единица восстановления.
ПРЕДЛОЖЕНИЯ GRANT И REVOKE
Рассмотренный в разделе 9.3 механизм представлений концептуально позволяет различными способами подразделить базу данных на подмножества таким образом, чтобы секретные сведения могли быть скрыты от пользователя, не обладающего правом доступа. Однако в нем не предусматривается спецификация тех операций, которые разрешается выполнять над этими подмножествами полномочному пользователю. Эту функцию выполняют предложения GRANT (предоставить) и REVOKE (отменить) языка SQL, которые обсуждаются ниже.
Прежде всего, чтобы вообще быть способным выполнить какую-либо операцию в DB2, пользователь должен обладать соответствующей привилегией (или полномочиями) на выполнение этой операции. В противном случае операция будет отвергнута с выдачей надлежащего сообщения об ошибке или кода исключительного состояния. Например, чтобы успешно выполнить предложение
SELECT *
FROM S;
пользователь должен обладать привилегией на выполнение операции
SELECT над таблицей S. В системе DB2 предусматривается широкий диапазон привилегий. Вообще говоря, каждая привилегия попадает, однако, в один из следующих классов:
а) привилегии на таблицы., связанные с такими операциями, как SELECT, которые выполняются над таблицами — как над базовыми таблицами, так и над представлениями;
б) привилегии на планы, которые имеют отношение к таким вещам, как полномочия на выполнение заданного плана прикладной задачи;
в) привилегии на базу данных, которые касаются таких операций, как создание таблицы в конкретной базе данных;
г) привилегии на использование, которые связаны с использованием определенных объектов среды хранения, а именно: с группами хранения, табличными пространствами и буферными пулами (см. главу 13);
и, наконец,
д) системные
привилегии, имеющие отношение к некоторым общесистемным операциям, таким, как операция создания новой базы данных.
Имеются также некоторые «пакетированные» привилегии, которые фактически служат кратким обозначением для совокупностей других привилегий, не всегда относящихся в точности к одному из указанных выше пяти классов. В частности, привилегия системного администрирования SYSADM является кратким обозначением для совокупности всех других привилегий в системе. Таким образом, пользователь, обладающий привилегией SYSADM, может выполнять любую операцию во всей системе при условии ее корректности. Примером операции, которая не была бы «корректной» в этом смысле, могла бы быть попытка уничтожить одну из таблиц каталога. Этого не может делать даже пользователь, обладающий привилегией SYSADM.
Итак, когда система DB2 впервые устанавливается, некоторая часть процесса установки требует назначения одного особо привилегированного пользователя системным администратором этой установленной системы. Для DB2 системный администратор идентифицируется идентификатором санкционирования доступа, точно так же, конечно, как и все другие пользователи. Этот пользователь, который автоматически получает привилегию SYSADM, становится ответственным за общее управление системой в течение всей продолжительности ее жизни. Например, в обязанности системного администратора входит текущий контроль за функционированием системы, сбор статистики о ее производительности и учетной информации. Но мы обсуждаем здесь лишь вопросы безопасности. Поэтому вернемся к главной теме обсуждения. Сначала имеется, таким образом, один пользователь, который может делать все, в частности, он или она может предоставлять привилегии другим пользователям, и никто иной не может делать вообще все.
Отметим, между прочим, что, хотя системный администратор является, конечно, обладателем привилегии SYSADM, не все обладатели привилегии SYSADM являются системными администраторами. Привилегия SYSADM может быть в дальнейшем предоставлена также другим пользователям, но эта привилегия может быть впоследствии снова отменена. Для системного администратора привилегия SYSADM никогда не может быть отменена[18].
Далее, пользователь, который создает некоторый объект, например базовую таблицу, автоматически получает полные привилегии на этот объект, включая, в частности, привилегию предоставления таких привилегий другому пользователю. Конечно, «полные привилегии» не включают здесь привилегий, которые не имеют смысла. Если, например, пользователь U обладает только привилегией на выполнение операции SELECT над базовой таблицей Т и создает некоторое представление V, которое основано на Т, то U, естественно, не получает привилегии на выполнение операции UPDATE над V. Подобным же образом, если U создает представление С, которое является соединением таблиц А и В, то U не получает привилегии на выполнение операции UPDATE над С, независимо от того, обладал ли он такими привилегиями для таблиц А и В, поскольку система DB2 не допускает каких-либо операций обновления по отношению к представлению, являющемуся соединением.
Предложение GRANT
Предоставление привилегий осуществляется с помощью предложения GRANT (предоставить). Общий формат этого предложения:
GRANT привилегии [ON тип — объектов объекты] ТО пользователи;
где «привилегии» — список, состоящий из одной или более привилегий, разделенных запятыми, либо фраза ALL PRIVILEGES (все привилегии); «пользователи» — это список, включающий один или более идентификаторов санкционирования, разделенных запятыми, либо специальное ключевое слово PUBLIC (общедоступный); «объекты» — это список имен одного или более объектов одного и того же типа, разделенных запятыми; наконец, «тип — объектов» указывает тип этого объекта или этих объектов. Фраза ON не используется, если предоставляемые привилегии являются системными.
Приведем несколько примеров.
Привилегии на таблицы
GRANT SELECT ON TABLE S TO ЧАРЛИ;
GRANT SELECT, UPDATE (СОСТОЯНИЕ, ГОРОД) ON TABLE S
TO ДЖУДИ, ДЖЕК, ДЖОН;
GRANT ALL PRIVILEGES ON TABLE S, P, SP TO УОЛТ, ТЕД;
GRANT SELECT ON TABLE P TO PUBLIC;
GRANT DELETE ON S TO ФИЛ;
Примечание. Если «тип—объектов»—TABLE (таблица), его можно опустить, как показано в последнем примере.
Привилегии на планы:
GRANT EXECUTE ON PLAN ПЛАН1 TO ДЖУДИ;
Привилегии на базу данных:
GRANT CREATETAB ON DATABASE DBX TO ШАРОН;
Пользователю Шарону разрешается создавать таблицы в базе данных DBX. Организация баз данных в системе DB2 обсуждается в главе 13.
Привилегии на использование:
GRANT USE ON TABLESPACE TSE TO КОЛИН;
Пользователю Колину разрешается использовать табличное пространство TSE для хранения любых таблиц, которые он может создавать. Более подробную информацию по этому вопросу также можно найти в главе 13.
Системные привилегии:
GRANT CREATEDBC ТО ЖАК, МАРИАН;
Пользователям Жаку и Мариан разрешается создавать новые базы данных. Если они будут это делать, то автоматически получат привилегию DBCTRL на эти базы данных (см. в конце данного раздела).
Здесь не ставилась задача в полной мере и исчерпывающим образом рассмотреть все множество привилегий, которые признает система DB2. Однако будут полностью рассмотрены привилегии на таблицы, поскольку они, вероятно, представляют наиболее широкий интерес. К таблицам (как к базовым таблицам, так и к представлениям) относятся следующие привилегии:
SELECT
UPDATE (может относиться к конкретным столбцам)
DELETE
INSERT
Две остальные привилегии относятся только к базовым таблицам:
ALTER (привилегия на исполнение предложения ALTER TABLE над данной
таблицей)
INDEX (привилегия на исполнение предложения CREATE INDEX над данной
таблицей)
Для того чтобы создать
таблицу, требуется, как уже говорилось, привилегия CREATETAB для базы данных, к которой относится эта таблица. Для создания представления требуется привилегия SELECT на каждую таблицу, упоминаемую в определении этого представления. Заметим, что привилегия SELECT, в отличие от UPDATE, не может относиться к конкретным столбцам. Причина заключается в том, что эффекта привилегии SELECT, распространяющейся на конкретные столбцы, всегда можно добиться путем предоставления привилегии SELECT, не относящейся к конкретным столбцам, на представление, состоящее как раз из рассматриваемых столбцов.
Предложение REVOKE
Если пользователь U1 предоставляет какую-либо привилегию некоторому другому пользователю U2, то пользователь U1 может впоследствии отменить эту привилегию для пользователя U2. Отмена привилегий осуществляется с помощью предложения REVOKE (отменить), общий формат которого очень похож на формат предложения GRANT:
REVOKE привилегии [ON тип — объектов объекты] FROM пользователи;
Отмена данной привилегии для данного пользователя приводит к тому, что все планы прикладных задач, связывание которых осуществлялось этим пользователем, помечаются как «недействительные» и, следовательно, автоматически приводит при следующем вызове каждого такого плана к повторному связыванию. Этот процесс, по существу, аналогичен тому, что происходит, когда уничтожается такой объект, как индекс. Ниже приводится несколько примеров предложения REVOKE:
REVOKE SELECT ON TABLE S FROM ЧАРЛИ;
REVOKE UPDATE ON TABLE S FROM ДЖОН;
REVOKE CREATETAB ON DATABASE DBX FROM НАНСИ, ДЖЕК;
REVOKE SYSADM FROM СЭМ;
Отмена привилегии
UPDATE не может относиться к конкретным столбцам.
Факультативная возможность GRANT
Если пользователь U1 имеет полномочия на предоставление привилегии Р другому пользователю U2, то пользователь U1 имеет также полномочия на предоставление привилегии Р пользователю U2 «с возможностью GRANT» (путем спецификации фразы WITH GRANT OPTION в предложении GRANT). Передача таким образом возможности GRANT от пользователя U1 пользователю U2 означает, что U2 теперь в свою очередь имеет полномочия на предоставление привилегии Р некоторому третьему пользователю U3. И, следовательно, U2, конечно, также обладает полномочиями на передачу возможности GRANT с таким же успехом пользователю U3 и т. д. Например:
Пользователь U1:
GRANT SELECT ON TABLE S TO U2 WITH GRANT OPTION;
Пользователь U2:
GRANT SELECT ON TABLE S TO U3 WITH GRANT OPTION;
Пользователь U3:
GRANT SELECT ON TABLE S TO U4 WITH GRANT OPTION;
и т. д. Если пользователь U1 издает теперь предложение:
REVOKE SELECT ON TABLE S FROM U2;
то отмена будет распространяться каскадом, т. е. будут автоматически отменены также передачи привилегий пользователем U2 пользователю U3 и пользователем U3 пользователю U4. Заметим, однако, что из этого не следует, что пользователи U2, U3 и U4 более не имеют привилегии SELECT на таблицу S—они могут помимо этого иметь такие привилегии, полученные от некоторого другого пользователя U5. Когда пользователь U1 издает предложение REVOKE, то фактически аннулируются только привилегии, которые предоставлялись этим пользователем. Рассмотрим, например, следующую последовательность событий.
Пользователь U1 в момент времени t1:
GRANT SELECT ON TABLE S TO U2 WITH GRANT OPTION;
Пользователь U5 в момент времени t2:
GRANT SELECT ON TABLE S TO U2 WITH GRANT OPTION;
Пользователь U2 в момент времени t3:
GRANT SELECT ON TABLE S TO U3;
Пользователь U1 в момент времени t4:
REVOKE SELECT ON TABLE S FROM U2;
Пусть при этом t1
Предложение REVOKE, изданное пользователем U1 в момент времени t4, фактически не лишает пользователя U2 привилегии на таблицу S, поскольку пользователь U2 получил эту привилегию также от U5 в момент времени t2. Поскольку далее предложение GRANT пользователя U2 для пользователя U3 было выполнено в момент времени t3 и t3> t2, то, возможно, что это GRANT было привилегией, которая была получена от пользователя U5, а не от U1. Поэтому пользователь U3 также не утрачивает этой привилегии. И если бы в момент t4 предложение REVOKE издал бы пользователь U5, а не U1, пользователи U2 и U3 также все еще сохранили бы эту привилегию. U2 сохранил бы привилегию, полученную от U1, и GRANT, изданный пользователем U2, мог бы, вероятно, служить для предоставления привилегии, полученной от U1, а не от U5, и пользователь U3 снова не утратил бы привилегию. Предположим, однако, что имела место другая последовательность событий.
Пользователь U1 в момент времени t1:
GRANT SELECT ON TABLE S TO U2 WITH GRANT OPTION;
Пользователь U2 в момент времени t2:
GRANT SELECT ON TABLE S TO U3 WITH GRANT OPTION;
Пользователь U5 в момент времени t 3:
GRANT SELECT ON TABLE S TO U2 WITH GRANT OPTION;
Пользователь U1 в момент времени t4:
REVOKE SELECT ON TABLE S FROM U2;
Тогда REVOKE пользователя U1 в момент времени t4 не будет лишать пользователя U3 привилегии SELECT на таблицу S, поскольку пользователь U2 получил эту привилегию также от U5 в момент t3. Однако, в противоположность предыдущему примеру, U3, утратит привилегию в этот момент времени, поскольку GRANT пользователя U2, возможно, имел дело с привилегией, полученной от пользователя U1.
Возможность GRANT нельзя отменить, не отменяя в то же время привилегии, к которой эта возможность относится.
Пакетированные (административные) привилегии
Для справочных целей завершим этот раздел кратким обзором пяти «пакетированных» привилегий, а именно: SYSADM, DBADM, DBCTRL, DBMAINT, SYSOPR.
— SYSADM
Привилегия SYSADM («системный администратор») позволяет ее обладателю выполнять любую операцию, которую поддерживает система.
— DBADM
Привилегия DBADM («администрирование базой данных»)
— относительно конкретной базы данных позволяет ее обладателю выполнять любую операцию, которую поддерживает система для этой базы данных.
— DBCTRL
Привилегия DBCTRL («управление базой данных») относительно конкретной базы данных позволяет ее обладателю выполнять любую операцию, которую поддерживает система для этой базы данных, за исключением операций доступа к значениям данных в этой базе данных, т. е. такие обслуживающие операции, как «восстановить базу данных», допускаются, а операции манипулирования данными языка SQL—нет.
— DBMAINT
Привилегия DBMAINT («ведение базы данных») относительно конкретной базы данных позволяет ее обладателю выполнять над этой базой данных обслуживающие операции, связанные только с чтением данных, например вспомогательную операцию «копировать содержимое базы данных в среде хранения».
— SYSOPR
Привилегия SYSOPR («системный оператор») позволяет ее обладателю выполнять системные функции оператора консоли, например операции начала и завершения трассировки функционирования системы.
Для конкретной базы данных привилегии категории DBADM включают DBCTRL, а привилегии DBCTRL включают DBMAINT. И конечно же, SYSADM включает привилегии всех других категорий.
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
B
B-дерево, 193
А
Автоматическая навигация, 33
Администратор базы данных, 136, 186
— системный, 136
— транзакций, 163
Алгебра реляционная, 234
Анализ на непротиворечивость, 169
Аргумент (динамический SQL), 182
Ассоциация, 241
Атомарность значений данных, 24
— операций, 164
— транзакций, 163
Атрибут, 26
Б
База данных, 186
— —по умолчанию, 195
— —
пользовательская, 186
— — реляционная, 22
— — системная, 186
Безопасность данных, 132
— представления, 133
Блок условия, 211
Блокирование, 169
Блокировка монопольная, 169
— совместная, 170
В
Вариант CHECK, 118
— GRANT, 138
Восстановление, 166
Г
Генератор деклараций DCLGEN, 155
— планов прикладных задач, 35
Генерация кода, 38
Граф ожидания, 179
Группа памяти, 188
— — по умолчанию, 196
— повторяющаяся, 25
Д
Данные скрытые, 128
Домен, 231
Е
Единица блокирования, 176
— восстановления, 166
Ж
Журнал, 163
З
Зависимость от незафиксированного обновления, 167
— функциональная, 249
Запись хранимая, 190
Значение неопределенное, 45
— — в арифметическом выражении, 55
— — в индексе с параметром UNIQUE, 47
— — в предложении SELECT DISTINCT, 60
— — в предложении UPDATE, 98
— — в сравнениях, 59
— — во встроенном языке, 149
— — во фразе GROUP BY, 86
— — во фразе ORDER BY, 60
— — при проектировании базы данных, 252
И
Идентификатор записи, 191
— санкционирования доступа, 132
Импликация, 81
Имя, 43
— представления, 116
— уточненное, 53
Индекс, 138, 187, 188, 190
— кластеризации, 190
Интерфейс интерактивный, 197
Исключение дубликатов, 54
К
Каталог, 39, 109
Квантор, 77
— общности FORALL, 79
— существования, 77
Классификация связей, 241
— сущностей, 240
Кластеризация внутритабличная, 190
— межтабличная, 190
Ключ альтернативный, 233
— внешний, 234
— возможный, 233
Команда BIND, 201
— DISPLAY FORM, 204
— DISPLAY REPORT, 205
— DRAW COND, 212
— FREE, 201
— PRINT REPORT, 205
— REBIND, 201
— RUN QUERY, 204
— DRAW, 210
Константы, 45
Кортеж, 231
Курсор, 151
—, стабильноcть его, 175
М
Макетирование, 223
Манипулирование данными, 28
Модель данных реляционная, 25
Модуль запросов к базе данных, 34
— языка программирования интерфейсный, 37
Н
Навигация, 31
— автоматическая, 221
— ручная, 221
Независимость данных, 40, 222
— логическая, 222
— физическая, 40
Нормализация, 240, 248
О
Области рабочая QUERY, 204
— дескрипторов SQLDA, 183
— рабочая FORM, 205
— рабочая временная, 204
— связи SQLCA, 183
Обновление данных, 98
— —
незафиксированное, 167
— —утраченное, 167
Обозначение, 241
Обстановка операционная системы DB2, 20
Ограничение санкционирования доступа, 132
Оператор сравнения ALL, 71
— — ANY, 71
Операция декартова произведения, 236
— деления, 237
— присваивания реляционная, 238
— проекции, 236
— разности, 236
— соединения, 237
Отношение, 232
— базовое, 234
Отношения, совместимые по объединению, 235
Отчет, 204
П
Параметр UNIQUE, 47
— динамического SQL, 182, 184
Переменная включающего языка, 146
— индикаторная, 149
— системная USER, 134
План прикладной задачи, 35, 38
Подзапрос, 72
— коррелированный, 74
Подтип сущностей, 251
Поле SQLCODE, 147
Пользователь, 28
Предикат BETWEEN, 57
— IN, 57
— — с подзапросами, 72
— LIKE, 58
Предлжение DELETE CURRENT, 153
— INSERT встроенного языка, 150
— ALTER TABLE, 46
— CLOSE, 151
— COMMENT ON, 112
— COMMIT, 155
— CREATE INDEX, 47
— CREATE SYNONYM, 113
— CREATE TABLE, 43, 46
— CREATE VIEW, 115
— DECLARE CURSOR, 151
— DECLARE TABLE, 146
— DELETE, 99
— DELETE встроенного языка, 150
— DROP INDEX, 48
— DROP SYNONYM, 113
— DROP TABLE, 46
— DROP VIEW, 118
— EXECUTE, 182
— FETCH, 151
— GRANT, 135
—INCLUDE (декларация), 155
— INCLUDE SQLCA, 147
— INCLUDE SQLDA, 183
— INSERT, 100
— LOCK TABLE, 174
— OPEN курсор, 152
— PREPARE, 181
— REVOKE, 135
— ROLLBACK, 156
— SELECT, 53
— SELECT вложенное, 72
— SELECT встроенного языка, 148
— SELECT единичное, 148
— SELECT обработка, 90
— SELECT*, 55
— UPDATE, 98
— UPDATE CURRENT, 153
— UPDATE встроенного языка, 149
— WHENEVER, 155
Представление, условие обновляемости, 121
Представления, 29
Преимущества реляционных систем, 220
Прекомпилятор, 34
Привилегия, 135
— BCTRL, 140
— DBADM, 140
— DBMAINT, 140
— SYSADM, 140
— SYSOPR, 140
— административная, 140
— требуемая пользователю, 140
Приложение интерактивное, 21
— пакетное, 21
Принцип двухрежимный, 145
Проверка полномочий, 38
—правильности плана, 201
Программа управления хранимыми данными, 36
Проектирование базы данных, 240
Производительность системы, 225
Пространство индексное, 186
— табличное, 186
— — по умолчанию, 189
— — простое, 189
— — табличное сегментированное, 190
Протокол упреждающей записи в журнал, 166
Процедура проверки достоверности, 192
— редактирования, 191
Процессор SPUFI, 199
Псевдоним, 66
ПсевдоЯОД, 245
Пул буферный, 196
Путь доступа, 38
Р
Реорганизация, 189
Реструктуризация, 126
С
Свойство, 240
Связь, 240
Сегментирование пространства, 189
Синоним, 113
Система R*, 230
— SQL/DS, 230
— реляционная, 238
Ситуация тупиковая, 176
Словарь данных (каталог), 109
Спецификация DISTINCT, 53
Средство программное DL/1 Extract, 22
— — DXT, 22
— — QMF, 22
Степень отношения, 233
Страница, 186
Супервизор стадии исполнения, 35
Сущность, 240
— ассоциативная, 240
— стержневая, 240
—
характеристическая, 240
Т
Таблица, 42
— базовая, 42
— виртуальная, 30
— каталога, 109
— хранимая, 186
Тип данных, 44
Точка синхронизации, 165
Транзакция, 162
У
Умолчание системное, 188
Управление параллельными процессами, 166
Уровень изоляции, 175
Утилита, 202
Ф
Фиксация автоматическая, 163
— двухфазная, 165
Форма отношения нормальная, 248
— отчета по умолчанию, 204
Фраза FOR UPDATE, 152
— GROUP BY, 85
— HAVING, 86
— NOT NULL, 45
— ORDER BY (определение курсора), 152
— ORDER BY (предложение SELECT), 56
— USING (предложения EXECUTE), 182
— USING (предложение FETCH), 184
Функция стандартная AVG, 83
— — COUNT (*), 83
— — MIN, 83
— — SUM, 83
— — МАХ, 83
Х
Характеристика, 241
Ц
Целостность по ссылкам, 99, 234
— — сущностям, 234
Ч
Число кардинальное отношения, 233
Чтение повторяемое, 175
Э
Эквисоединение, 62
Элемент образца, 212
Я
Язык QBE, 210
— SQL встроенный, 145
— SQL динамический, 180
— SQL интерактивный, 197
— SQL статический, 185
[1]
В этой книге мы будем использовать термин «MVS» для обозначения как стандартной операционной системы MVS (т. е. системного продукта фирмы IBM «Multiple Virtual Systems»), так и расширенной ее версии, называемой MVS/XA («MVS/Extended Architecture»). Каждая ссылка в этом тексте на MVS относится в равной степени к обеим ее версиям.
[2]
В интересах точности следует заметить, что TSO в действительности не является «подсистемой» в том специальном смысле, в котором этот термин используется в MVS Скорее она является неотъемлемой частью самой MVS. Можно приобрести систему MVS без IMS или CICS, но нельзя без TSO. Но эти различия не представляются важными для наших целей, и для простоты мы будем рассматривать в этой книге все три компонента как подсистемы.
[3]
Для читателей, хорошо знающих MVS и/или TSO, заметим, что пакетное приложение TSO есть не что иное, как обычное пакетное приложение MVS, которое исполняется под управлением телемонитора TSO (ТМР). См. раздел 14.9.
[4]
Формат хранимых данных — это, конечно, не единственное, чем отличаются эти две системы. Имеется ряд других отличий, о которых упоминается ниже. Большинство из них связано с тем фактом, что система DB2 специально разработана для обстановки больших систем (MVS). Например, объем данных в базе данных, которые могут запоминаться в интерактивном режиме в системе DB2, ограничивается только объемом памяти, доступной в таком режиме, в то время как система SQL/DS ограничивается единственной базой данных, функционирующей в интерактивном режиме, объемом 64 гигабайта (теоретический максимум; практический максимум несколько меньше). Подобным образом механизм безопасности данных системы DB2 значительно более тщательно разработан, чем в SQL/DS, отражая тог факт, что существует, вероятно, намного больше пользователей и намного больше категорий пользователей для установки DB2, чем для SQL/DS. Детальный разбор всех таких различий не является целью этой книги.
[5]
В этой книге предложения SQL, команды и т. п. для ясности записываются прописными буквами. На практике же обычно более удобно вводить такие предложения и команды строчными буквами. Система DB2 допускает то и другое.
[6]
В фирменных руководствах по системе термины «RUNTIME SUPERVISOR» или «STORED DATA MANAGER» не используются.
[7] Он оставляет также копию каждого такого предложения
SQL в модифицированом исходном модуле в форме комментария.
[8]
Точнее, план хранится в справочнике
DB2, который в действительности является расширением каталога, предназначенным только для использования самой системой. С точки зрения пользователя разница между ними состоит в том, что каталог в отличие от справочника имеет форму, позволяющую делать к нему запросы с помощью обычных предложений SQL (см. главу 7).
[9]
Кроме того, в качестве имен не могут использоваться ключевые слова языка SQL (CREATE, TABLE, SELECT и т. д.). Первая литера любого имени должна быть буквой (А—Z или одной из специальных литер ^, $, @), а остальные литеры — буквами, цифрами (0-9) или знаком подчеркивания. Имена таблиц и столбцов могут содержать максимум 18 литер, а имена пользователей—максимум 8 литер.
[10]
Если n>254, то поле является и «длинным полем», и объектом строгих ограничений. Длинные поля предназначены для того, чтобы иметь дело с данными в свободном формате, такими, как длинные текстовые строки, а не с простыми форматизированными данными, например номер поставщика или объем поставки. По существу, единственной операцией, в которой могут в качестве операндов использоваться такие поля, является операция присваивания базе данных (INSERT или UPDATE) либо из базы данных (SELECT). He допускаются какие-либо операции, которые предполагают сравнение с длинным полем Поэтому, например, длинные поля не могут быть индексированными, на них нельзя ссылаться во фразах WHERE, GROUP BY или ORDER BY и т. п. Две последние фразы рассматриваются в главах 4 и 5.
[11]
В связи с этим фактом можно сказать, что реляционные таблицы образуют замкнутую систему относительно операторов выборки данных языка, подобного SQL. Вообще говоря, замкнутая система—это совокупность (возможно, бесконечная) объектов некоторого типа, например OBJS, и соответствующая совокупность операторов, например OPS, таких, что а) операторы из OPS применяются ни к объектам из OBJS и б) результат применения любого такого оператора к любому такому объекту (любым таким объектам) является другим объектом из OBJS. Практический смысл этого соображения (в частности, для случая отношений) заключается в следующем. Поскольку результатом одной операции SELECT является другое отношение, то, по крайней мере, принципиально возможно применить другую операцию SELECT к этому результату, конечно, предусматривая, чтобы он был где-либо сохранен. Это означает, также, опять-таки принципиально, что операции SELECT могут быть вложенными друг в друга. Такая возможность иллюстрируется в разделах 5.2, 6.4 и 8.1.
[12]
Все они имеют значение истинности «неизвестно».
При наличии неопределенных значений необходимо принять трехзначную логику, значениями истинности в которой являются: истина, ложь и неизвестно.
«Неизвестно» в действительности представляет собой, по сути дела, неопределенное значение истинности. Предложение SELECT осуществляет выборку записей, для которых предикат WHERE имеет значение истина, т. е. не ложь и не неизвестно.
[13] Подзапрос может включать также фразы GROUP BY и HAVING. Однако комбинация ORDER BY и UNION недопустима.
[14] Между прочим, этот пример иллюстрирует важный момент, заключающийся в том, что порядок кванторов существен в выражениях, содержащих кванторы обоих типов Выражение FORALLx(EXISTSy (y>x)) истинно. Однако выражение EXISTSy(FORALLx(yx))—«существует действительное у такое, что для всех действительных х справедливо у больше х», т.е. «существует некоторое число, большее всех других чисел», — которое получается из предыдущего выражения просто перестановкой порядка кванторов, является ложным.
[15] EXISTS (существует) также рассматривается как стандартная функция, но она отличается от функций, обсуждаемых в данном разделе, тем, что она возвращает значение истинности, а не арифметическое или строковое значение, т. е это не числовая функция.
[16] Этого результата («группы внутри групп» и т. д.) можно достигнуть, однако, с помощью QMF. См. главу 15.
[17]
Каталог не является одинаковым в различных реализациях языка SQL, поскольку он по необходимости содержит для конкретной системы много информации, специфичной для этой системы. В частности, каталоги DB2 и SQL/DS различны.
[18]
Не следует, конечно, понимать этот абзац таким образом, что имеется фактически единственное лицо, которое на все время является системным администратором, даже если это лицо, например, покидает компанию. Имеется, скорее, один неизменный идентификатор санкционирования, который рассматривается системой как идентифицирующий системного администратора. Каждый, кто может войти в систему с этим идентификатором (и может выдержать тесты на достоверность), будет считаться системным администратором, пока он или она не выйдет из системы. Эти тесты на достоверность могут и, конечно, должны время от времени изменяться.
[19]
На самом деле, внутренняя структура этих наборов данных VSAM значительно отличается во всяком случае от структуры, которая предполагается для VSAM, поскольку управление всем их пространством осуществляется DB2, а не средствами VSAM (см главу 13). Таким образом, попытка понять их содержимое была бы нетривиальной задачей, даже если бы их можно было обработать с помощью обычных обращений к VSAM.
[20] Мы ограничимся при этом лишь обстановкой прикладного программировании. Предложения COMMIT и ROLLBACK могут быть введены и в интерактивном режиме, но делать это на практике не рекомендуется, как будет ясно позднее в этой главе, поскольку это обычно означает, что блокировки будут установлены на нежелательно долгое время.
[21]
При определенных условиях, которые здесь детально не обсуждаются, эта блокировка будет сниматься в следующей точке синхронизации, а не при завершении программы. В частности, это будет происходить в случае, если предложение LOCK TABLE вводится через DB2I (что само по себе маловероятно).
[22] Сегментированное пространство может иметь несколько групп памяти для каждого сегмента (см. раздел 13.3).
[23] Интересно отметить, что пространство памяти в 64 гигабайта со страни-1|яМ11 по 4К эквивалентно приблизительно 128 токам, т. е. 32 устройствам пря-Мпго доступа IBM 3380.
[24] Установка системы всегда располагает факультативной возможностью вообще не использовать какую-либо группу памяти для заданного пространства или его сегмента. Если это так, то для определения, расширения и удаления наборов данных необходимым образом следует использовать утилиту обслуживания методов доступа VSAM. Подробное обсуждение этих вопросов выходит за рамки данной книги.
[25]
Нельзя отрицать, что сегодня большинство систем, даже систем реляционного типа, тем не менее действительно проявляет весьма зависимое от ситуации и непредсказуемое поведение в некоторых областях. Для примера можно сослаться на обработку обновления представления в системе DB2, при которой действительно обнаруживается в некоторой степени неприятный произвол (см. раздел 8.4). Но такой произвол имеет тенденцию проявиться именно в тех вопросах, где реализация отклонилась от базовой теории. Так, важнейшим компонентом реляционной модели данных является понятие первичного ключа (см. Приложение А). Однако в системе DB2 такие ключи не поддерживаются, и это упущение является непосредственной причиной упоминаемого выше произвола. Конечно, система DB2—не единственный «правонарушитель» в этом отношении; подобная критика относится к большинству других систем, известных в момент написания этой книги, однако DB2 может служить для иллюстрации нежелательных последствий пренебрежения предписаниями модели, положенной в ее основу.
[26]
Дополнительным доказательством такого признания может служить тот факт, что Ассоциация по вычислительной технике (The Association for computing Machinery—ACM) присудила Тьюринговскую премию за 1981 год доктору Кодду, первому архитектору реляционной модели, за его работы, посвященные этой модели. Тьюринговская премия присуждается ежегодно за важнейшие работы в области информатики. По всеобщему признанию, она является наиболее престижной наградой во всей информатике.
[27]
Такая операция, как ALTER TABLE, в языке .SQL может рассматриваться не как изменение степени отношения с n на n+l, а, скорее, как создание нового отношения степени n+1 из отношения степени п.
[28]
' Под «соединением» здесь понимается либо естественное соединение, либо эквисоединение.
[29]
Это предложение включает также комментарий и ключевое слово FIELDS. Ни то ни другое не является частью реального ЯОД системы DB2.
ПРЕДСТАВЛЕНИЯ И БЕЗОПАСНОСТЬ
Чтобы проиллюстрировать использование представлений для целей безопасности, приведем ряд примеров, основанных (по большей части) опять-таки на базе данных поставщиков и деталей.
1. Пользователю разрешен доступ к полным записям поставщиков, но лишь для поставщиков, находящихся в Париже:
CREATE VIEW ПАРИЖСКИЕ_ПОСТАВЩИКИ
AS SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ,
СОСТОЯНИЕ, ГОРОД
FROM S
WHERE ГОРОД = 'Париж';
Пользователи этого представления видят «горизонтальное подмножество» (или, точнее, подмножество строк, подмножество, зависящее от значений) базовой таблицы S.
2. Пользователю разрешен доступ ко всем записям поставщиков, но не к рейтингам поставщиков (значение поля СОСТОЯНИЕ):
CREATE VIEW СКРЫТОЕ_СОСТОЯНИЕ
AS SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ,
ГОРОД
FROM S;
Пользователи этого представления видят «вертикальное подмножество» (или, точнее, подмножество столбцов, независимое от значений) подмножество базовой таблицы S.
3. Пользователю разрешен доступ к записям поставщиков только для поставщиков, находящихся в Париже, но не к рейтингам поставщиков:
CREATE VIEW ПАРИЖСКИЕ_БЕЗ_РЕЙТИНГОВ
AS SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, ГОРОД
FROM S
WHERE ГОРОД = 'Париж';
Пользователи этого представления видят подмножество строк и столбцов базовой таблицы S.
4. Пользователю разрешен доступ к записям каталога, т. е. к строкам таблицы SYSTABLES, только для таблиц, созданных этим пользователем:
CREATE VIEW МОИ_ТАБЛИЦЫ
AS SELECT *
FROM SYSIBM.SYSTABLES
WHERE CREATOR = USER;
Ключевое слово USER (пользователь) обозначает системную переменную, значение которой представляет собой ИД санкционирования. Оно может входить во фразу SELECT, во фразу WHERE, во фразу SET предложения UPDATE, либо как вставляемое значение — в предложение INSERT. Идентификатор санкционирования в запросе — это ИД санкционирования для пользователя, исполняющего фразы SELECT или WHERE (либо предложения UPDATE или INSERT), в которые он входит. В приведенном примере, следовательно, он представляет не ИД пользователя, который создает это представление, а ИД пользователя, который использует это представление. Если, например, пользователь xyz издает предложение:
SELECT *
FROM МОИ_ТАБЛИЦЫ;
то DB2, а фактически генератор планов прикладных задач, по существу, преобразует это предложение в следующее:
SELECT *
FROM SYSIBM.SYSTABLES
WHERE CREATOR = 'xyz';
Аналогично представлению из приведенного выше первого примера, это представление является «горизонтальным подмножеством» лежащей в основе базовой таблицы. Однако в данном примере различные пользователи видят здесь различные подмножества. Фактически эти подмножества не пересекаются ни для каких двух пользователей. Такие подмножества иногда называются контекстно-зависимыми.
5. Пользователю разрешен доступ к средним объемам поставок по поставщикам, но не к каким-либо индивидуальным объемам поставок:
CREATE VIEW AVG (НОМЕР_ПОСТАВЩИКА, СРЕДНИЙ_ОБЪЕМ)
AS SELECT НОМЕР_ПОСТАВЩИКА, AVG (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ПОСТАВЩИКА;
Пользователи этого представления видят статистическую сводку лежащей в основе базовой таблицы S.
Примечание.
Создатель приведенных выше представлений должен иметь по крайней мере привилегию на исполнение предложения SELECT над всеми таблицами, на которые ссылаются определения этих представлений. Привилегии доступа обсуждаются в следующем разделе.
Как показывают приведенные примеры, механизм представлений системы DB2 «задаром» обеспечивает очень важные средства безопасности — «задаром» во всяком случае потому, что механизм представлений включен в систему для иных целей, как указывалось в главе 8. Более того, многие проверки полномочий доступа, даже проверки, зависимые от значений, могут осуществляться на стадии компиляции (во время связывания), а не на стадии исполнения, что обеспечивает существенный выигрыш производительности. Однако подход к безопасности, основанный на представлениях, иногда оказывается несколько тяжеловесным, в частности, если некоторому конкретному пользователю необходимы различные привилегии доступа к различным подмножествам одной и той же таблицы в одно и то же время. Рассмотрим следующий пример. Предположим, что данному пользователю разрешена выборка (операция
SELECT) рейтингов, т. е. значений состояния, для всех поставщиков, а обновлять их (операция UPDATE) разрешается только для поставщиков из Парижа. Тогда потребуется два следующих представления:
|
|
CREATE
|
VIEW
|
ВСЕ_РЕЙТИНГИ
|
CREATE
|
VIEW
|
ПАРИЖСКИЕ_
РЕЙТИНГИ
|
|
AS
|
SELECT
|
НОМЕР_
ПОСТАВЩИКА, СОСТОЯНИЕ
|
AS
|
SELECT
|
НОМЕР_
ПОСТАВЩИКА, СОСТОЯНИЕ
|
|
|
FROM
|
S;
|
|
FROM
|
S
|
|
|
|
|
|
WHERE
|
ГОРОД=' ПАРИЖ';
При этом операции
SELECT могут быть адресованы представлению ВСЕ_РЕЙТИНГИ, а операции обновления — только представлению ПАРИЖСКИЕ_РЕЙТИНГИ. В связи с этим программирование становится довольно невразумительным. В этом можно, например, убедиться, рассматривая структуру программы, которая просматривает и печатает рейтинги всех поставщиков, а также обновляет некоторые из них (рейтинги поставщиков из Парижа), когда это требуется.
Другой недостаток связан с тем, что при вставке (операция INSERT) или обновлении (операция UPDATE) записей при помощи представления система DB2 не требует, чтобы новая или обновленная запись удовлетворяла предикату, определяющему это представление. Такое требование можно ввести с помощью спецификации CHECK, но эта возможность, как пояснялось в главе 8, не всегда может быть использована и во всяком случае это факультативная возможность — пользователь не обязан
ее специфицировать. Таким образом, приведенное выше представление ПАРИЖСКИЕ_ПОСТАВЩИКИ, например, может не дать пользователю возможности видеть поставщиков, которые находятся не в Париже, но при отсутствии спецификации CHECK оно не может помешать пользователю создать такого поставщика или переместить какого-либо существующего парижского поставщика в некоторый другой город. Такая операция, конечно, приведет к тому, что новая или обновленная запись немедленно исчезнет из этого представления, но она однако же появится в соответствующей базовой таблице.
ПРЕДВАРИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
Прежде чем мы сможем перейти к рассмотрению предложений встроенного языка SQL самих по себе, необходимо предварительно обсудить некоторые детали. Большинство из них иллюстрируется фрагментом программы, показанным на рис. 10.1. ( Здесь и далее в переводе мы отступаем от синтаксиса языка ПЛ/1, не предусматривающего использование букв русского алфавита в идентификаторах. Это же замечание относится, впрочем, и к языку SQL.— Примеч. пер.)
Рассматривая этот пример, нетрудно установить следующее:
1. Предложениям встроенного SQL всегда предшествует ЕХЕС SQL, так что их можно легко отличить от предложений включающего языка, а завершаются они следующим образом:
в ПЛ/1 — точка с запятой
в Коболе — END ЕХЕС
в Фортране — отсутствие символа продолжения в колонке 6
в языке Ассемблера — отсутствие символа продолжения в колонке 72.
2. Исполняемые
предложения SQL (далее для краткости слово «встроенный» обычно опускается) могут использоваться во всех тех случаях, когда могут использоваться исполняемые предложения включающего языка. Обратим внимание здесь на уточнитель «исполняемые». В отличие от интерактивного SQL встроенный SQL включает некоторые предложения, которые являются чисто декларативными, неисполняемыми. Например, DECLARE TABLE (объявить таблицу) не является исполняемым предложением, так же как и DECLARE CURSOR (объявить курсор),—см. раздел 10.4.
3. Предложения SQL могут содержать обращения к переменным включающего языка. Перед такими обращениями ставится двоеточие с тем, чтобы отличать их от имен полей SQL. Переменные включающего языка могут появляться в предложениях манипулирования данными языка SQL только в следующих местах:
— фраза INTO в предложении SELECT (результирующая величина, которой присваивается значение, выбираемое из базы данных)
DCL ЗАДАННЫЙ_НОМЕР CHAR (5);
DCL РАНГ FIXED BIN (15);
DCL ГОРОД CHAR (15);
DCL АЛЬФА . . . ;
DCL БЕТА . . . ;
ЕХЕС SQL DECLARE S TABLE
(НОМЕР_ПОСТАВЩИКА CHAR (5)
NOT NULL,
ФАМИЛИЯ CHAR (20),
СОСТОЯНИЕ SMALLINT,
ГОРОД CHAR (15));
ЕХЕС SQL INCLUDE SQLCA;
. . . . . . . . . . . . . . . . . . . . . . .
IF АЛЬФА > БЕТА THEN
GETSTC:
ЕХЕС SQL SELECT СОСТОЯНИЕ, ГОРОД
INTO :РАНГ,: ГОРОД
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = : ЗАДАННЫЙ_НОМЕР;
. . . . . . . . . . . . . . . . . . . . . . .
PUT SKIP LIST (РАНГ, ГОРОД);
Рис. 10.1. Фрагмент программы на языке ПЛ/1 с предложениями встроенного SQL
— фраза SELECT (значение, выборку - которого нужно произвести)
— фраза WHERE в предложениях SELECT, UPDATE, DELETE (значение, которое следует сравнивать)
— фраза SET в предложении UPDATE (источник для обновляемого значения)
— фраза VALUES в предложении INSERT (источник для вставляемого значения)
— элемент арифметического выражения во фразах SELECT, WHERE или SET, но не VALUES, где в результате вычисления этого выражения в свою очередь определяется значение, которое подлежит выборке, сравнению или обновлению. Они могут появляться также в некоторых предложениях, относящихся только к встроенному языку (подробности приведены ниже). Они не могут появиться в каких-либо других предложениях SQL.
4. Любые используемые в программе таблицы (базовые таблицы или представления) должны быть объявлены при помощи предложения ЕХЕС SQL DECLARE для того, чтобы сделать программу в большей степени самодокументируемой и дать возможность прекомпилятору выполнять некоторые синтаксические проверки манипулятивных предложений.
5. После того как было выполнено любое предложение SQL, информация обратной связи возвращается программе в область, называемую областью связи SQL (SQLCA — SQL Communication Area). В частности, в поле области SQLCA, называемое SQLCODE, возвращается числовой индикатор состояния. Нулевое значение SQLCODE означает, что данное предложение выполнено успешно. Положительное значение означает, что предложение все же выполнено, но предупреждает, что имела место некоторая исключительная ситуация. Например, значение +100 указывает, что не было найдено никаких данных, удовлетворяющих запросу. Наконец, отрицательное значение указывает, что имела место ошибка, и данное предложение не было успешно выполнено. Поэтому в принципе за каждым предложением SQL в программе должна следовать проверка значения SQLCODE и должно предприниматься соответствующее действие, если это значение оказывается не тем, которое ожидалось. Но этот шаг не показан на рис. 10.1. Как указывается в разделе 10.5, на практике такое явное тестирование значений SQLCODE, возможно, не является необходимым. Область связи SQL включается в программу с помощью предложения
ЕХЕС SQL INCLUDE SQLCA;
6. Как уже упоминалось, предложение SELECT встроенного языка должно содержать фразу INTO, специфицирующую переменные включающего языка, которым должны быть присвоены значения, найденные в базе данных. Переменные во фразе INTO могут быть скалярными переменными (элементами) или структурами. Структура рассматривается просто как краткая запись списка элементов, составляющих эту структуру. Структуры могут использоваться также во фразе VALUES предложения INSERT.
7. Переменные включающего языка должны иметь типы данных, совместимые с типами данных языка SQL тех полей, с которыми они должны сравниваться, значения которых им должны быть присвоены, или которым должны быть присвоены значения этих переменных. Совместимость типов данных определяется следующим образом:
а) литерные данные SQL совместимы с литерными данными включающего языка, независимо от их длины и независимо от того, является ли какая-либо из этих длин переменной;
б) числовые данные SQL совместимы с числовыми данными включающего языка, независимо от основания системы счисления (десятичная или двоичная), способа представления (с фиксированной или плавающей точкой) и точности (число цифр). Система DB2 выполнит все необходимые преобразования. Если при присваивании значения в программе либо в предложении языка SQL имеет место потеря значащих цифр или литер, связанная с тем, что поле, принимающее значение, слишком мало, программе возвращается информация об ошибке.
8. Отметим, что переменные включающего языка и поля базы данных могут иметь одни и те же имена. Переменная включающего языка может быть элементом структуры. Например:
DCL 1 ДАНО,
2 НОМЕР_ПОСТАВЩИКА CHAR(5),
2 . . .;
ЕХEС SQL SELECT . . .
. . . . . . .
WHERE НОМЕР_ПОСТАВЩИКА =
:ДАНО. НОМЕР_ПОСТАВЩИКА;
Заметим, что в предложениях SQL используется уточнение имен в стиле ПЛ/1, а не Кобола (:ДАНО.НОМЕР_ПОСТАВЩИКА, а не НОМЕР_ПОСТАВЩИКА OF ДАНО), даже когда включающим языком фактически является Кобол.
Это все, что касается предварительных замечаний. В остальной части данной главы мы сосредоточим внимание, главным образом, на операциях манипулирования данными SELECT, UPDATE, DELETE и INSERT. Как уже указывалось, к большинству из этих операций можно обратиться довольно простым образом, т. е. лишь с небольшими изменениями в их синтаксисе. Однако предложения SELECT требуют особого рассмотрения. Проблема заключается в том, что исполнение предложения SELECT порождает таблицу—таблицу, которая, в общем случае, содержит множество записей, а такие языки, как Кобол и ПЛ/1, просто не обладают хорошими средствами, позволяющими оперировать одновременно более чем одной записью. По этим причинам необходимо обеспечить своего рода мост между уровнем множеств языка SQL и уровнем записей включающего языка. Такой мост обеспечивают курсоры.
Курсор — это новый вид объекта языка SQL, относящийся только к встроенному SQL, поскольку интерактивный SQL, конечно же, в нем не нуждается. Курсор состоит, по существу, из некоторого рода указателя,
который может использоваться для просмотра множества записей. Поочередно указывая каждую запись в данном множестве, он обеспечивает, таким образом, возможность обращения к этим записям по одной одновременно. Отложим, однако, детальное обсуждение курсоров до раздела 10.4, а сначала рассмотрим (в разделе 10.3) те предложения, для которых они не требуются.
ПРЕИМУЩЕСТВА ПРЕДСТАВЛЕНИЙ
Завершим эту главу краткой сводкой преимуществ представлений.
— Они обеспечивают определенную степень логической независимости данных, несмотря на реструктуризацию базы данных, как было пояснено в предыдущем разделе.
— Они дают возможность различным пользователям по-разному видеть одни и те же данные, возможно, даже в одно и то же время. Это соображение, очевидно, имеет важное значение, когда имеется много различных категорий пользователей и все они взаимодействуют с единой интегрированной базой данных.
— Упрощается пользовательское восприятие. Очевидно, что механизм представлений дает возможность пользователям сосредоточить внимание именно на тех данных, которые представляют для них интерес, и игнорировать остальные данные. Вместе с тем не настолько очевидно, что по крайней мере в отношении поиска данных этот механизм может также значительно упростить пользовательские операции манипулирования данными. В частности, поскольку для пользователя может быть предусмотрено представление, в котором все лежащие в его основе таблицы соединены вместе, необходимость явных операций для перехода от одной таблицы к другой может быть значительно уменьшена. В качестве примера рассмотрим представление ПАРЫ_ГОРОДОВ и сопоставим предложение SELECT, необходимое для нахождения городов, где хранятся поставляемые из Лондона детали, и использующее это представление, с предложением SELECT, требующимся для получения того же результата непосредственно из базовых таблиц. В действительности, сложный процесс выборки был перенесен здесь из сферы манипулирования данными в сферу определения данных. (На самом деле различия между этими двумя сферами в реляционных языках, подобных SQL, далеко не ясны.)
— Для скрытых данных автоматически обеспечивается секретность. «Скрытые данные» обозначает здесь данные, невидимые через некоторое заданное представление. Ясно, что такие данные защищены от доступа через это конкретное представление. Таким образом, принуждение пользователя осуществлять доступ к базе данных через представления является простым, но эффективным механизмом для управления санкционированием доступа. Этот аспект представлений более подробно обсуждается в следующей главе.
ПРЕИМУЩЕСТВА РЕЛЯЦИОННЫХ СИСТЕМ
Если нужно выразить преимущества реляционной системы, такой, как DB2, единственным словом, то это слово — простота, где под «простотой» мы понимаем главным образом простоту для пользователя. Простота в свою очередь трансформируется в применяемость и производительность. Применяемость означает, что даже сравнительно неквалифицированные пользователи могут использовать систему для выполнения полезной работы. Иначе говоря, конечные пользователи часто могут получать от системы полезные результаты, избегая при этом необходимости преодолевать потенциально узкие места, с которыми сталкивается подразделение обработки данных. Производительность означает, что как конечные пользователи, так и профессиональные специалисты в области обработки данных могут более продуктивно выполнять свои каждодневные обязанности. В результате они могут внести значительный вклад в решение известной проблемы невыполненного заказа на разработку приложения (см. ниже параграф «Разработка приложения»). В данном разделе обсуждаются некоторые факторы, способствующие простоте такой системы, как DB2.
Теоретическая основа
Первый фактор заключается в том, что реляционные системы основаны на формальном теоретическом фундаменте — на реляционной модели, подробно обсуждаемой в Приложении А. В результате такие системы ведут себя строго определенным образом, и пользователи, возможно, не осознавая этого факта, руководствуются простой моделью их поведения, которая позволяет с уверенностью предсказывать, что будет делать система в любой заданной ситуации. Нет или не должно быть никаких неожиданностей[25]. Такая предсказуемость означает, что этому пользовательскому интерфейсу легко обучать, его легко изучить, использовать и запомнить.
В частности, отметим, между прочим, что многие критики реляционных систем в прошлом высказывали возражения именно по этому вопросу. Смысл возражений заключался, по-видимому, в том, что лишь теоретики способны понять или нуждаются в понимании чего-либо, что основано на теории. Наша точка зрения совершенно противоположна: системы, не основанные на теории, весьма трудны для понимания. Без преувеличения можно сказать, что «теоретический» вовсе не означает «не практичный». Наоборот, соображения, которые сначала отвергаются как «только теоретические» (!), имеют скверную привычку несколько лет спустя становиться чрезвычайно практичными.
Небольшое число понятий
Реляционная модель выделяется среди других моделей данных благодаря небольшому числу используемых в ней понятий. Как указывалось в главе 6, все данные в реляционной базе данных представляются одним и только одним способом, а именно как значения в столбцах и строках некоторых таблиц, и для каждой из четырех основных функций (выборка, изменение, вставка, удаление) необходим, следовательно, только один оператор. По тем же самым причинам требуется меньше операторов для всех других функций — для определения данных, обеспечения безопасности данных и санкционирования доступа, отображения в среду хранения и т. д.,—чем это необходимо в нереляционных системах. В частности, в случае санкционирования доступа простота и регулярность структуры данных дают возможность определить достаточно утонченный механизм защиты данных. При таком механизме, как отмечалось в главе 9, могут быть легко определены и удобным образом реализованы зависимые и независимые от значений данных, контекстно-зависимые и другие ограничения.
Самостоятельное значение имеет факт, связанный с указанным выше, и заключающийся в том, что в реляционной модели различные понятия четко разделены и не переплетаются сложными взаимосвязями. Напротив, конструкция связи типа владелец— член или отец — сын, встречающаяся во многих нереляционных системах, образует сложную взаимосвязь нескольких существенно различных понятий. Она одновременно является представлением связи вида один-ко-многим, путем доступа или совокупностью путей доступа, механизмом для реализации определенных ограничений целостности и т. д. В результате становится трудно установить, какой цели служит данная связь, и она может использоваться для таких целей, для которых она не была предназначена. Например, программа может воспользоваться некоторым путем доступа, появление которого в действительности является побочным эффектом того способа, который был выбран проектировщиком базы данных для представления определенного ограничения целостности. Если же потребуется изменить это ограничение, то необходимо будет произвести реструктуризацию базы данных. При этом с большой вероятностью потребуется также переписать данную программу, даже если она совершенно не заинтересована в рассматриваемом ограничении целостности как таковом.
Операции над множествами
Реляционные операции манипулирования данными, например SELECT, UPDATE и т. д., в языке SQL являются операциями над множествами. Этот факт означает, что пользователи должны просто специфицировать, что они хотят, а не как получить то, что они хотят. Например, пользователь, которому требуется узнать, какие детали поставляются поставщиком S2, просто выдает на языке SQL запрос:
SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА ='S2';
Система DB2 принимает решение, каким образом осуществить навигацию в физической структуре данных на диске для того, чтобы ответить на этот запрос. По этой причине подобные DB2 системы, как уже упоминалось в главе 1, часто характеризуются как системы с «автоматической навигацией». Напротив, системы, в которых пользователи должны сами осуществлять такую навигацию, характеризуются как системы с «ручной навигацией». Избавляя пользователя от этих забот, система DB2 позволяет ему сосредоточиться на решении настоящей задачи, т. е. в данном случае, на поиске ответа на запрос и использовании этой информации для какой-либо цели, где она необходима, во внешнем мире. В случае конечных пользователей фактически именно благодаря автоматической навигации обеспечивается возможность использования системы. Нетрудно найти такой пример запроса на языке SQL, для которого эквивалентная программа на Коболе занимала бы десять или двадцать страниц, и о написании такой программы для большинства пользователей не могло бы быть и речи, а может быть она и не стоила бы необходимых для этого усилий.
Кроме того, средствами системы для автоматической навигации могут точно так же, как конечные пользователи, воспользоваться прикладные программисты. Поэтому результативность работы прикладных программистов в реляционной системе также может быть более высокой.
Язык, используемый в двух режимах
Один и тот же язык SQL используется в системе DB2 как для программирования, так и для интерактивного доступа к базе данных. Из этого факта непосредственно следует:
1. Все пользователи различных категорий — системные администраторы и администраторы баз данных, прикладные программисты, конечные пользователи с разным уровнем подготовки — по существу, используют один и тот же язык и поэтому способны лучше общаться друг с другом. Пользователю легко также переходить из одной категории в другую — в одном случае выполнять функции администратора по определению данных, а в другом — функции конечного пользователя по спецификации специальных запросов.
2. Прикладные программисты могут отлаживать записанные на SQL части их программ через интерактивный интерфейс (SPUFI или, возможно, QMF). Этот момент несколько подробнее обсуждался в разделе 12.4.
Независимость данных
Независимость данных — это независимость пользователей, и пользовательских программ от некоторых подробностей способа хранения и доступа к данным. Она имеет важное значение по крайней мере по двум причинам:
1. Для прикладных программистов она важна, поскольку без этого изменения в структуре базы данных приводят к соответствующим изменениям в прикладных программах. При отсутствии такой независимости происходит одно из двух: либо становится почти невозможно сделать требуемые изменения в базе данных из-за капиталовложений в существующие программы, либо, что более вероятно, значительная часть усилий по прикладному программированию посвящается исключительно сопровождению, т. е. такой эксплуатационной работе, необходимость в которой была бы исключена, если бы система обеспечивала независимость данных. Оба этих фактора в значительной степени способствуют возникновению проблемы невыполненного заказа на разработку приложения, о которой упоминалось во введении к данному разделу.
2. Она важна и для конечных пользователей, поскольку без этого непосредственный доступ конечного пользователя к базе данных вообще едва ли был бы возможен. При этом независимость данных и очень высокий уровень таких языков, как SQL, дополняют друг друга.
Независимость данных не является неким абсолютом — различные системы обеспечивают ее в различной степени. (Иными словами, существуют системы, которые вообще не обеспечивают независимости данных. Это как раз и означает, что некоторые системы в большей мере зависимы от данных, чем другие.) Кроме того, термин «независимость данных» в действительности охватывает два несколько разных понятия, а именно: понятие физической независимости данных, т. е. независимости физической организации данных в среде хранения, и понятие логической независимости данных, т. е. независимости логической структуры данных как таблиц и полей. Система DB2 достаточно развита в обоих аспектах, хотя, без сомнения, еще есть поле деятельности для ее развития и в той и в другой областях. Так, например, жаль, что логическое понятие принудительной уникальности взаимосвязано с физическим понятием индекса. По существу, DB2 обеспечивает физическую независимость данных благодаря ее возможностям автоматической навигации и автоматического связывания (для того, чтобы вспомнить об автоматическом связывании, см. раздел 2.2). Подобным же образом она обеспечивает логическую независимость данных благодаря ее механизму представлений (более подробно об этом см. раздел 8.5).
Разработка приложений
Системы, подобные DB2, в целом ряде аспектов облегчают процесс разработки приложений.
1. Во-первых, возможности спецификации специализированных запросов и генерации отчетов означают, что вообще может отсутствовать необходимость разработки прикладных программ в традиционном понимании этого термина. Важность этого фактора трудно переоценить. Одна из реляционных систем (здесь нет возможности назвать ее, но это не какая-нибудь малозначащая система) обладает единственной традиционной прикладной программой. Все остальное делается с помощью препроцессорных системных средств обработки запросов и генерации отчетов.
2. Во-вторых, обеспечение высокой степени независимости данных вместе с высоким уровнем операций манипулирования данными означает, что если программу писать все-таки нужно, то писать ее легче, она требует меньше усилий для сопровождения и ее легче изменять, если в этом действительно возникает необходимость, чем это было бы в более старых нереляционных системах.
3. В-третьих, и это в большой степени является следствием указанного в предыдущем пункте, цикл разработки приложения может гораздо в большей мере, чем это обычно делается, вовлекать макетирование: первая версия может быть создана и показана предполагаемым пользователям, которые имеют далее возможность предложить некоторые улучшения для включения в следующую версию и т. д. В результате окончательный вариант приложения будет в точности соответствовать потребностям пользователя. Общий процесс разработки становится значительно менее жестким, чем обычно, и пользователи приложения могут в гораздо большей степени вовлекаться в этот процесс на пользу всем заинтересованным.
Динамическое определение данных
Преимущества динамического определения данных уже подробно обсуждались в главе 3 (см. раздел 3.4), и мы не будем здесь повторять эти аргументы. Однако отметим здесь одно дополнительное обстоятельство. Способность в любое время создавать новые определения, не требуя для этого остановки системы,— в действительности только одна из составных частей более крупной общей задачи, состоящей в том, чтобы вообще исключить необходимость каких-либо запланированных остановок системы. При этом, например, утилиты можно вызывать с работающего в интерактивном режиме терминала, и они могут исполняться параллельно с решением основных задач. Можно, например, делать копию содержимого базы данных несмотря на то, что она одновременно обновляется некоторыми транзакциями. В идеальном случае систему нужно будет стартовать только один раз, когда она впервые устанавливается, и далее она должна будет функционировать «вечно». Мы, однако, не утверждаем, что указанная задача уже решена.
Легкость установки и легкость эксплуатации
Система DB2 разрабатывалась таким образом, чтобы она была, по возможности, легкой для установки и эксплуатации. Достижению этой цели способствует ряд возможностей системы, некоторые из которых были рассмотрены выше в данном разделе. Подробное обсуждение таких возможностей, помимо тех, что уже обсуждались в предыдущих главах, выходит за рамки данной книги. Однако целесообразно явным образом указать одно весьма важное следствие, вытекающее из них, а именно: для того, чтобы предоставить услуги системы DB2 весьма большой группе пользователей (прикладных программистов и конечных пользователей), требуется лишь сравнительно маленькая группа профессиональных специалистов в области обработки данных (администраторов, системных программистов, работающих за консолью операторов). DB2—чрезвычайно экономичная система.
Проектирование баз данных
В реляционной системе проектировать базы данных легче, чем нереляционной, по ряду причин, хотя при этом в сложных ситуациях могут потребоваться некоторые трудные решения. Во-первых, разделение логического и физического уровней означает, что проблемы логического и физического проектирования можно решать по отдельности. Во-вторых, существует ряд надежных принципов, которые могут быть использованы для решения проблемы логического проектирования. В-третьих, возможности динамического определения данных и высокая степень независимости данных опять-таки означают, что нет необходимости одновременно разрабатывать весь проект, и что не настолько критична потребность в получении его прямо с первого раза. Вопрос о проектировании баз данных для системы довольно подробно обсуждается в Приложении В.
Интегрированный каталог
Как уже указывалось в главе 7, каталог в системе DB2 полностью интегрирован с остальными данными в том смысле, что он представлен точно таким же образом (в виде таблиц) и что его содержимое можно запрашивать точно таким же образом (с помощью SQL). Иными словами, нет никаких искусственных и ненужных различий между данными каталога и другими данными или между данными и «данными о данных» (или «метаданными», как их иногда называют). Такая интеграция обеспечивает ряд преимуществ, в том числе:
1. Поиск чего-либо в базе данных и поиск чего-либо в каталоге — это один и тот же процесс. Для того чтобы усмотреть здесь преимущество, рассмотрим аналогичную ситуацию — поиск чего-либо в книге и поиск чего-либо в оглавлении этой книги. Было бы очень досадно, если бы это оглавление оказалось бы где-либо в ином месте, а не в самой этой книге, и в формате, который бы требовал несколько иного способа доступа, например, если бы оглавление было бы на испанском языке и хранилось бы на карточках размером 3 на 5, в то время как сама книга была бы на английском языке. Роль каталога по отношению к базе данных совершенно аналогична роли оглавления по отношению к книге.
2. Значительно упрощается процесс создания универсальных, т. е. управляемых «метаданными», прикладных программ. Допустим, например, что требуется написать программу, которая проверяет, чтобы значение номера поставщика, появляющееся где-либо в базе данных, входило бы также в столбец НОМЕР_ПОСТАВЩИКА таблицы поставщиков S — разумное само по себе требование. Необходимо при этом, чтобы рассматриваемая программа выполняла свои функции без каких-либо предварительных предположений о структуре базы данных, т. е. в программу не должны быть встроены какие-либо знания относительно того, какие существуют таблицы и какие в них столбцы. В более общем виде предположим, что нужно написать программу, которая бы проверяла, что каждое появляющееся где-либо в базе данных значение типа Х появляется также в некотором специфицированном столбце Y некоторой специфицированной таблицы Z, где X, Y и Z — параметры. И снова здесь не принимается каких-либо предварительных предположений о структуре базы данных. В обоих этих примерах решающее значение имеет интегрированный каталог. Примечание. Такие программы были бы очень нужны на практике. См. Приложение В, раздел В.7.
ПРИМЕРЫ ЗАПРОСОВ
Начнем с простого примера — с запроса «Выдать номера и состояния для поставщиков, находящихся в Париже». Этот запрос может быть выражен в SQL следующим образом:
SELECT НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ
FROM S
WHERE ГОРОД = 'Париж';
В качестве результата получим:
|
|
НОМЕР_ПОСТАВЩИКА
|
СОСТОЯНИЕ
|
|
S2
S3
|
10
30
Этот пример иллюстрирует самую общую форму предложения SELECT в языке SQL—
"SELECT (выбрать) специфицированные поля
FROM (из) специфицированной таблицы
WHERE (где) некоторое специфицированное условие является истинным"
Заметим, что результатом запроса является другая таблица — таблица, которая некоторым образом получается из заданных в базе данных таблиц. Иными словами, в реляционной системе типа DB2 пользователь всегда действует в рамках простой табличной структуры, и это—весьма привлекательная особенность таких систем [11].
В данном случае было бы вполне возможно сформулировать запрос, используя уточненные имена полей:
SELECT S.HOMEP_ПОСТАВЩИКА, S. СОСТОЯНИЕ
FROM S
WHERE S ГОРОД = 'Париж';
Использование уточненных имен никогда не рассматривается как ошибка, и иногда это существенно, как мы увидим в разделе 4.3. Для справочных целей ниже показана общая форма предложения SELECT, в которой, однако, опущена возможность UNION, обсуждаемая в следующей главе:
SELECT [DISTINCT] элемент(ы)
FROM таблица (или таблицы)
[WHERE предикат]
[GROUP BY поле (или поля) [HAVING предикат] ]
[ORDER BY поле (или поля) ];
Перейдем теперь к иллюстрации основных особенностей этого предложения с помощью весьма продолжительной серии примеров. Примечание. Фразы GROUP BY (группировать по) и HAVING (имея) обсуждаются в главе 5. Со всеми остальными фразами читатель по крайней мере познакомится в этой главе, хотя рассмотрение более сложных их аспектов также отложено до главы 5.
Ряд других программных продуктов фирмы
Ряд других программных продуктов фирмы IBM является более или менее тесно связанным с DB2. Основные из них рассматриваются ниже.
SQL/DS (Structured Query Language/Data System)
Как уже указывалось, SQL/DS — это реляционная СУБД для операционных систем DOS/VSE и VM/CMS. Она принадлежит «семейству» DB2 в том смысле, что в обеих системах используется по существу один и тот же язык SQL. Если говорить точнее, в обеих системах — одни и те же предложения манипулирования данными и большинство предложений определения данных, которые различаются некоторыми незначительными деталями. Однако формат хранимых данных в этих системах не одинаков, но предоставляются утилиты, помогающие осуществлять передачу данных из базы данных SQL/DS в базу данных DB2 и наоборот[4].
Примечание. SQL/DS включает как части базового продукта:
а) интерактивный интерфейс запросов и генератора отчетов, называемый ISQL («Interactive SQL»); и
б) средство «DL/1 Extract» для копирования специфицированных данных из базы данных DL/1-DOS в базу данных SQL/DS, так что к ним можно осуществлять доступ через интерфейс ISQL (DL/1-DOS является по существу урезанной версией системы IMS для операционной системы DOS/VSE. DL/1—язык доступа К базам данных, используемый как в DL/1-DOS, так и в IMS).
В отношении указанных возможностей DB2 в определенной мере отличается от SQL/DS. Базовый продукт DB2 также включает интерактивный интерфейс, в некоторой степени близкий к ISQL, называемый DB2I («DB2 Interactive»). Однако DB2I в действительности предназначен для профессионалов в области обработки данных, например для прикладных программистов, а не для случайных пользователей. Настоящий интерфейс для конечных пользователей DB2 обеспечивается отдельным периферийным продуктом, называемым QMF (см. подробности ниже). Аналогично, функции «DL/1 Extract» реализуются в обстановке DB2 другим отдельным продуктом — DXT (и снова подробности см. ниже).
QMF (Query Management Facility)
QMF (Query Management Facility) — развитое периферийное средство спецификации запросов и генерации отчетов как для DB2 (под TSO), так и для SQL/DS (под DOS/VSE или VM/CMS).
Заметим, Что это отдельный программный продукт. С точки зрения DB2 это фактически не что иное, как интерактивное приложение TSO. QMF позволяет конечным пользователям вводить случайные
запросы либо на языке SQL, либо на языке QBE (Query-By-Example), и продуцировать разнообразные форматизированные отчеты из результатов обработки таких запросов. Он похож, таким образом, на встроенный интерфейс спецификации запросов/генерации отчетов ISQL, предоставляемый SQL/DS в качестве части базового продукта. Однако предоставляемый QMF диапазон возможностей значительно превосходит возможности ISQL. В частности, ISQL не поддерживает языка QBE.
Более подробная информация о QMF приводится в главе 15.
DXT (Data Extract)
DXT (Data Extract) — это универсальная программа копирования данных. Она позволяет скопировать в последовательный файл специфицированное подмножество данных заданной базы данных системы IMS либо набора данных VSAM или SAM. При этом копирование осуществляется в формате, подходящем для загрузки (с помощью соответствующей утилиты загрузки) в базу данных системы DB2 либо SQL/DS. В главе 15 содержится более подробная информация относительно DXT.
ПРОИЗВОДИТЕЛЬНОСТЬ
В последние несколько лет в области обработки данных сложился ряд ошибочных представлений, касающихся реляционных систем, большинство из которых связано с их производительностью. Очень часто можно услышать два таких мнения:
«Все реляционные системы очень хороши для обработки специальных запросов, но они никогда не достигнут уровня производительности, требуемого для производственных систем (или систем обработки транзакций или ...)».
«Для того чтобы реляционные системы были способны достигнуть приемлемой производительности, нужны новые достижения в технологии аппаратного обеспечения, например аппаратная реализация ассоциативной памяти».
Противоположное мнение, которого придерживается и автор, заключается в следующем:
«Нет никакой внутренней причины, благодаря которой производительность реляционной системы должна быть сколько-нибудь ниже — или, в действительности, сколько-нибудь выше (!) — чем у системы какого-либо иного типа».
Обсудим и попытаемся обосновать это мнение.. Отметим прежде всего, что двумя основными характеристиками производительности являются число операций ввода-вывода и продолжительность обработки (объем работы центрального процессора). Рассмотрим каждую из них поочередно.
Продолжительность обработки
DB2 — система компилирующего типа, точно так же, как и SQL/DS. Большинство других систем, реляционных или другого типа, во время написания этой книги являются системами интерпретирующего типа. Однако преимущества компиляции получили широкое признание, и известно, что в направлении подхода, основанного на компиляции, развивается несколько других реляционных систем. Преимущество компиляции заключается именно в том, что она уменьшает продолжительность обработки на стадии исполнения. При этом на стадии исполнения исключаются все перечисленные ниже операции:
— синтаксический анализ первоначального запроса
— обнаружение синтаксических ошибок и выдача сообщений о них
— отображение имен логического уровня в адреса физического уровня
— выбор стратегии доступа
— проверка полномочий доступа
— генерация машинного кода.
Наиболее важной из этих операций является, вероятно, выбор стратегии доступа, или, иными словами, оптимизация. Таким образом, в случае компиляции продолжительность обработки на стадии исполнения значительно короче, чем она была бы в иных случаях. Немаловажно также, что при компиляции машинный код генерируется для конкретного исходного запроса, и поэтому он может оказаться более эффективным, чем более универсальный код, используемый в режиме интерпретации. Более того, система достигает этого преимущества компиляции в производительности, как уже указывалось в главе 2, без какой-либо соответствующей потери гибкости в функционировании: если становится необходимой перекомпиляция, например, в случае, когда уничтожен какой-либо индекс, то система осуществляет ее автоматически («автоматическое связывание»).
Заметим, между прочим, что компиляция в том смысле, как этот термин понимается в системе DB2, т. е. оптимизированная компиляция, не была бы осуществима в системе, ориентированной на обработку записей, поскольку такая система просто неспособна подобным же образом воспринимать намерения пользователя. Понятно поэтому, что реляционная система в конечном счете может обеспечить меньшую продолжительность обработки, чем нереляционная, если, например, нереляционная система всегда должна будет осуществлять синтаксический анализ запросов на стадии исполнения.
Операции ввода-вывода
Число операций ввода-вывода, требуемых для обработки конкретного запроса, является функцией физической
структуры базы данных, а не ее логической структуры. Иными словами, оно не имеет ничего общего с тем, каким образом база данных воспринимается ее пользователями — как реляционная или как некоторая другая структура. Поэтому можно разбить вопрос о том, сколько операций ввода-вывода требуется в реляционной системе, на два составляющих вопроса:
1. Способны ли поддерживаемые данной системой физические структуры обеспечить некоторый требуемый уровень производительности операций ввода-вывода?
2. Если ответ на первый вопрос положителен, то способна ли данная система принимать реляционные запросы высокого уровня, например предложения SELECT, и преобразовывать их в операции над такими физическими структурами, настолько же эффективные, насколько написанная вручную программа, т. е. программа, которая была бы составлена квалифицированным программистом, работающим непосредственно на физическом уровне?
В связи с первым вопросом нужно отметить, что в большинстве реляционных систем в настоящее время поддерживаются индексы, имеющие структуру В-деревьев. В некоторых системах, помимо этого, поддерживается техника хеширования и т. п., однако DB2 не относится к их числу. Фактически мало сомнения в том, что если должна быть выбрана единственная структура, то, очевидно, будут выбраны организованные в виде В-деревьев индексы. Далее, индексы с такой организацией, несомненно, способны обеспечить адекватный многим приложениям уровень производительности. Это утверждение должно быть справедливым, иначе никто не использовал бы VSAM. С другой стороны, справедливо также, что имеются некоторые приложения, для удовлетворения требований которых к производительности следует просто использовать, например, хеширование. Таким образом, ответ на первый вопрос, что касается системы DB2, положителен, если индексы приемлемы для рассматриваемого приложения, и отрицателен — в противном случае. (Конечно, и в этой ситуации ответ может быть все же положительным для некоторых других реляционных систем.)
Рассмотрим теперь второй вопрос (может ли данная система продуцировать программу, которая в такой же мере эффективна, как и программа, составленная вручную?), предполагая, что ответ на первый вопрос положителен. Краткий ответ — «да, может» (во многих, но не во всех случаях). Функция оптимизатора системы DB2 заключается именно в том, чтобы преобразовывать предложения SQL в оптимизированную машинную программу, где «оптимизированная» означает, главным образом, что сгенерированная программа использует лучшую из возможных стратегий для обработки первоначального запроса. Например, если задан запрос из раздела 16.2—«Выдать номера деталей, поставляемых поставщиком S2» — то в сгенерированной программе будет использоваться индекс по номерам поставщиков для таблицы SP, а не последовательный просмотр этой таблицы, конечно, в предположении, что такой индекс существует. Разумеется, не для каждого возможного запроса оптимизатор продуцирует наилучшую возможную программу. Но с другой стороны, этого не делает и большинство программистов. Кроме того, заметим, что здесь говорится о первой версии нового программного продукта. Естественно ожидать, что в процессе эксплуатации будут продолжаться его усовершенствования в области оптимизации. В действительности область оптимизации в базах данных в настоящее время это нечто, аналогичное оптимизации в языках программирования, какой она была примерно пятнадцать лет назад. Многочисленные исследователи занимаются этой проблемой в университетах и других организациях, и плоды этой деятельности, несомненно, найдут свое место в реализованных программных продуктах. Подобные усовершенствования могут быть осуществлены при этом так, чтобы они каким-либо образом не затрагивали форму внешнего интерфейса (это приблизительно и есть то, что представляет собой независимость данных).
На самом деле, понятно, что оптимизатор мог бы продуцировать лучшую программу, чем написанная вручную. Дело заключается в том, что оптимизатору доступна информация, касающаяся, например, физической кластеризации данных, размеров таблиц, избирательности индексов и т. д., которой обычно не обладает программист, разрабатывающий программу вручную. Кроме того, эта информация со временем может изменяться. В такой ситуации может возникать необходимость в повторной оптимизации. Выполнение ее в системе, подобной DB2, имеет тривиальный характер — достаточно просто выполнить операцию REBIND. В системе с ручным программированием это было бы весьма трудно сделать.
В связи с этим отметим еще один заключительный момент, касающийся оптимизации. Имеется другая причина, в связи с которой реляционная система может в некоторых случаях превосходить нереляционную по производительности. Эта причина состоит как раз в том, что система типа DB2 является оптимизирующей. Реляционные операции высокого уровня удается оптимизировать именно благодаря их высокому уровню — они содержат много семантики, и поэтому оптимизатор способен распознать, что же пытается сделать пользователь, и способен среагировать на это оптимальным образом. В противоположность этому в нереляционной системе, в которой пользователь действует на уровне записей, а не на уровне множеств, стратегии доступа выбираются самим пользователем. Если при этом пользователь сделает ошибочный выбор, то имеется мало шансов, что система будет способна оптимизировать такую пользовательскую программу. Предположим, например, что пользователь в действительности пытается вычислить соединение двух таблиц А и В. Существуют две возможные стратегии: а) поочередно для каждой записи из А найти все соответствующие ей записи в В; б) поочередно для каждой записи из В найти все соответствующие ей записи в А. В зависимости от относительных размеров А и В и от характеристик их физической кластеризации одна из этих стратегий может, вероятно, превзойти по производительности другую на несколько порядков величины. И если, как указывалось ранее, пользователь выберет ошибочную стратегию, то в действительности пет никакого способа, позволяющего системе заменить ее на другую, поскольку выбор пользователя выражается в виде последовательности операций низкого уровня, а не единственной операции высокого уровня.
Из всего сказанного можно сделать вывод, что нет абсолютно никакой причины для того, чтобы реляционная система, которая реализована на совершенно обычном оборудовании, использующем совершенно стандартную технику программного обеспечения, не функционировала вполне приемлемым образом. И вовсе не обязательно ждать новых достижений в разработке аппаратных средств, хотя если, например, ассоциативная память большой емкости па чипах когда-либо действительно стала бы коммерческой реальностью, несомненно, ею легче было бы воспользоваться в реляционной системе, чем в нереляционной.
Предостережение.
Для строгости заметим, что все предыдущие рассуждения были очень общими. В частности, не говорилось, что DB2 способна обеспечивать такую же производительность, как и какая-либо уже давно созданная система, например IMS. Пока еще слишком рано даже давать какие-либо оценки производительности системы DB2, хотя можно заключить беспроигрышное пари по поводу того, что любые такие оценки были бы существенно менее привлекательны, чем соответствующие оценки для IMS. Не приходится сомневаться в том, что для заданного приложения, где структуры данных и образцы транзакций заблаговременно хорошо изучены, какая-либо существующая система, например IMS, может быть конфигурирована и настроена в соответствии с требованиями заказчика таким образом, что она будет обеспечивать значительно более внушительную производительность, чем может обеспечить в настоящее время система DB2. С другой стороны:
а) Система, настроенная в соответствии с требованиями заказчика, будет выглядеть не настолько внушительной, когда к ней станут добавляться другие приложения. Реализация приложения 2 в обстановке системы, которая настроена на приложение 1, подобна рубке дерева поперек волокна — мешают делу чуждые намерения.
Заметим, что речь идет здесь не только о производительности, но также и о логическом уровне системы. Имеется в виду, что приложение 2, вероятно, будет также менее удобно писать. Логические структуры данных в нереляционной системе имеют тенденцию подвергаться влиянию одних приложений вопреки другим именно в связи с тем, что они подробно отражают физическую структуру данных. Логические структуры данных в реляционных системах, напротив, более нейтральны. Специфика приложения проявляется не в логической структуре данных, а в манипулятивных операциях, которые по определению являются значительно более гибкими, чем сравнительно статичная структура данных. Эта специфика будет, конечно, проявляться и в физической структуре данных.
б) Одна из причин преимущества нереляционных систем в производительности заключается просто в том, что эти системы эксплуатируются уже в течение десяти —пятнадцати лет и на протяжении этого времени постоянно усовершенствовались и настраивались. Реляционные системы также будут усовершенствоваться в течение следующих нескольких лет. Кроме того, неясно, возможны ли дальнейшие значительные усовершенствования нереляционных систем. В то же время, как указывалось ранее, имеется широкое поле деятельности для таких усовершенствований в реляционном случае.
в) Если даже нереляционная система обеспечивает на стадии исполнения более высокую производительность, ценность такого преимущества должна быть в первую очередь сбалансирована с затратами времени, необходимыми для приведения системы в работоспособное состояние. Капиталовложения на установку будут значительно быстрее окупаться для реляционной системы, поскольку значительно скорее начнут эксплуатироваться приложения. Конечная прибыль на капиталовложения может быть также более высокой при реляционной версии, если срок жизни данного приложения меньше, чем время, необходимое для того, чтобы нереляционная версия «догнала» его, говоря экономическим языком.
Повторяем, однако, что все сказанное выше — это теоретические рассуждения. Дело в том, что в настоящее время совершенно маловероятно, чтобы система типа DB2 была способна достигнуть уровня производительности системы типа IMS. Компромисс, который следует принимать во внимание в настоящее время — это производительность против применяемости или, другими словами, производительность машины против производительности человека. Общеизвестно, что стоимость человеческого труда быстро растет, а стоимость машинного времени также быстро снижается. В результате производительность человеческого труда очень быстро становится во многих приложениях доминирующим фактором, и, в действительности, во многих случаях это уже имеет место. Очевидно, что для таких приложений идеально подходят реляционные системы даже при их существующем уровне производительности. Имеется, однако, также и ряд приложений, для которых представляет пока преобладающий интерес производительность собственно оборудования. Поэтому системы типа IMS должны будут еще играть важную роль на протяжении нескольких лет. И если даже реляционные системы в конечном счете действительно достигнут паритета в отношении производительности, огромные капиталовложения в нереляционные системы являются фактором, обеспечивающим продолжение существования этих систем в обозримом будущем. Несомненно, это одна из причин, по которой фирма IBM рассматривает DB2 как дополнение, а не замену IMS, и в связи с которой эти два продукта разрабатывались таким образом, чтобы они могли работать совместно, как указывалось в предыдущих главах.
ПРОСТАЯ ВЫБОРКА «SELECT*»
Выдать полные характеристики для всех поставщиков:
SELECT *
FROM S;
Результатом служит копия полной таблицы S.
Здесь звезда или звездочка служит кратким обозначением списка всех имен полей в таблице (таблицах), указанной(ых) во фразе FROM (из) в том порядке, в котором эти поля определяются в соответствующем (их) предложении(ях) CREATE TABLE. Таким образом, записанное выше предложение SELECT эквивалентно следующему:
SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, ГОРОД
FROM S;
Обозначение в виде звездочки удобно для интерактивных запросов, поскольку оно уменьшает число ударов по клавишам. Однако, оно таит потенциальную опасность при использовании во встроенном SQL (т. е. в предложениях SQL в прикладной программе), поскольку смысл знака «*» может измениться, если для этой программы перегенерируется план прикладной задачи, а в данном промежутке времени к рассматриваемой таблице был добавлен другой столбец. В этой книге «SELECT *» будет использоваться только в таких контекстах, где так делать безопасно (в основном только в интерактивных контекстах), и фактическим пользователям DB2 рекомендуется поступать подобным образом.
Отметим, наконец, что «*» может уточняться именем соответствующей таблицы. Допустима, например, следующая форма
SELECT S.*
FROM S;
ПРОСТАЯ ВЫБОРКА
Выдать номера для всех поставляемых деталей:
SELECT НОМЕР_ДЕТАЛИ
FROM SP;
Имеем результат:
|
|
НОМЕР_ДЕТАЛИ
|
|
Р1
Р2
РЗ
Р4
Р5
Р6
Р1
Р2
Р2
Р2
Р4
Р5
Обратим внимание на дубликаты номеров деталей в этом результате. Система DB2 не исключает дубликатов из результата предложения SELECT, если пользователь явно не потребует это сделать с помощью ключевого слова DISTINCT (различный, различные), как показано в следующем примере.
ПРОСТОЕ ЭКВИСОЕДИНЕНИЕ
Выдать все комбинации информации о таких поставщиках и деталях, которые размещены в одном и том же городе (иначе говоря, «соразмещены» — безобразный, но удобный термин):
SELECT S.*, Р.*
FROM S, P
WHERE S.ГОРОД = Р.ГОРОД;
Заметим, что здесь ссылки на поля во фразе WHERE должны уточняться именами содержащих их таблиц. В результате получим следующую ниже таблицу 1. (Во избежание двусмысленности в этой таблице два столбца ГОРОД показаны явным образом как S.ГОРОД и Р.ГОРОД.)
Таблица 1
|
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
S.ГОРОД
|
|
S1
S1
S1
S2
S2
S3
S3
S4
S4
S4
|
Смит
Смит
Смит
Джонс
Джонс
Блейк
Блейк
Кларк
Кларк
Кларк
|
20
20
20
10
10
30
30
20
20
20
|
Лондон
Лондон
Лондон
Париж
Париж
Париж
Париж
Лондон
Лондон
Лондон
Продолжение табл. 1
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
Р.ГОРОД
|
|
Р1
Р4
Р6
Р2
Р5
Р2
Р5
Р1
Р4
Р6
|
Гайка
Винт
Блюм
Болт
Кулачок
Болт
Кулачок
Гайка
Винт
Блюм
|
Красный
Красный
Красный
Зеленый
Голубой
Зеленый
Голубой
Красный
Красный
Красный
|
12
14
19
17
12
17
12
12
14
19
|
Лондон
Лондон
Лондон
Париж
Париж
Париж
Париж
Лондон
Лондон
Лондон
Пояснение. Из формулировки задачи на естественном языке ясно, что требуемые данные можно получить из двух таблиц — S и Р. Поэтому в формулировке запроса на языке SQL мы прежде всего указываем эти две таблицы во фразе FROM, а затем выражаем во фразе WHERE соединение между ними, т. е. тот факт, что значения ГОРОД должны быть равны. Для того чтобы понять, как это делается, представим себе две строки, по одной из каждой таблицы, например строки, показанные ниже:
|
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
S. ГОРОД
|
равны
|
|

|
Смит
|
20
|
Лондон
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
P. ГОРОД
|
|
Р1
|
Гайка
|
Красный
|
12
|
Лондон
Из этих двух строк можно видеть, что поставщик S1 и деталь Р1 в действительности «соразмещены». Из таких двух строк будет сформирована строка результата:
|
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
S. ГОРОД
|
|
S1
|
Смит
|
20
|
Лондон
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
P. ГОРОД
|
|
Р1
|
Гайка
|
Красный
|
12
|
Лондон
поскольку они удовлетворяют предикату во фразе WHERE (S.ГОРОД = Р.ГОРОД). Это имеет место и для всех других пар строк, содержащих соответствующие значения ГОРОД. Обратите внимание на то, что поставщик S5, размещающийся в Атенсе, не попадает в результирующую таблицу, так как нет каких-либо деталей, хранимых в этом городе. Подобным же образом результат не содержит детали РЗ, хранимой в Риме, ввиду того, что нет поставщиков, размещенных в Риме.
Результат данного запроса называется соединением таблиц S и Р по соответствию значений ГОРОД. Термин «соединение» используется также для обозначения операции конструирования такого результата. Условие S.ГОРОД = Р.ГОРОД называется условием соединения или предикатом соединения. В связи с приведенным примером нужно отметить ряд моментов. Одни из них имеют важное значение, другие не настолько существенны.
— Оба поля в предикате соединения должны быть либо числовыми, либо строками литер. Не обязательно, чтобы их типы данных были идентичны. Однако, по соображениям производительности, это было бы, вообще говоря, неплохо.
— Необязательно, чтобы поля в предикате соединения имели одинаковые имена, хотя очень часто это будет именно так.
— Нет необходимости в том, чтобы оператор сравнения в предикате соединения обязательно был равенством, хотя это будет очень часто. В дальнейшем будут приведены примеры такого рода (пример 4.3.2 и последняя часть примера 4.3.6). В случае оператора равенства соединение называют иногда эквисоединением.
— Фраза WHERE в SELECT-соединении может включать, помимо самого предиката соединения, другие условия. Эта возможность иллюстрируется ниже в примере 4.3.3.
— Можно, конечно, предусмотреть в SELECT выборку только специфицированных полей соединения, а не их всех. Эта возможность иллюстрируется ниже в примерах 4.3.4—4.3.6.
— Выражение
SELECT S.*,P.*
FROM S, P
. . . . . . ;
может быть еще более упрощено:
SELECT *
FROM S,P
. . . . . . ;
С другой стороны, оно может быть записано и в расширенном виде:
SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, S.город
НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС, Р. ГОРОД
FROM S, P
. . . . . . ;
В такой формулировке для S.ГОРОД и Р.ГОРОД во фразе SELECT следует указывать их уточненные имена, как показано в примере, поскольку неуточненное имя ГОРОД было бы двусмысленным. Если Вам нужно освежить в памяти вопросы, касающиеся уточненных имен полей, см. введение к разделу 4.2.
— По определению, эквисоединение должно продуцировать результат, содержащий два идентичных столбца. Если исключить один из этих столбцов, то оставшееся называется естественным соединением. Для того, чтобы построить естественное соединение таблиц S и Р по городам в SQL, следовало бы записать:
SELECT НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, S.ГОРОД,
НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС
FROM S, P
WHERE S.ГОРОД = Р.ГОРОД;
Естественное соединение является, вероятно, одной из наиболее полезных форм соединения — в такой степени, что мы часто используем неуточненный термин «соединение» специально для обозначения этого случая.
— Можно образовывать соединения также и трех, четырех, ... или любого числа таблиц. В примере 4.3.5, приведенном ниже, показано соединение трех таблиц.
Таблица 2
|
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
S.ГОРОД
|
|
S1
S1
S1
S1
S1
S1
S2
.
.
.
S5
|
Смит
Смит
Смит
Смит
Смит
Смит
Джонс
.
.
.
Адамc
|
20
20
20
20
20
20
10
.
.
.
30
|
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
Париж
.
.
.
Атенс
Продолжение табл. 2
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
Р.ГОРОД
|
|
Р1
Р2
РЗ
Р4
Р5
Р6
Р1
.
.
.
Р6
|
Гайка
Болт
Винт
Винт
Кулачок
Блюм
Гайка
.
.
Блюм
|
Красный
Зеленый
Голубой
Красный
Голубой
Красный
Красный
.
.
.
Красный
|
12
17
17
14
12
19
12
.
.
.
19
|
Лондон
Париж
Рим
Лондон
Париж
Лондон
Лондон
.
.
.
Лондон
— В табл. 2 рассматривается альтернативный ( и полезный) способ, позволяющий представить себе, каким образом концептуально могут конструироваться соединения. Прежде всего построим декартово произведение таблиц, перечисленных во фразе FROM. Декартово произведение множества, состоящего из n таблиц,— это таблица, содержащая всевозможные строки r, такие, что r является конкатенацией какой-либо строки из первой таблицы, строки из второй таблицы, ... и строки из n-й таблицы. Например, табл. 2 (назовем ее СР) представляет собой декартовым произведением таблиц S и Р (в указанном порядке). Полная таблица СР содержит 5х6=30 строк. Теперь исключим из этого декартова произведения все такие строки, которые не удовлетворяют предикату соединения. То, что останется, является требуемым соединением В рассматриваемом случае мы исключаем из таблицы СР все те строки, в которых S.ГОРОД не равен Р.ГОРОД. В результате получим в точности приведенное выше соединение. Между прочим, вполне возможно, хотя, может быть, и несколько необычным образом, сформулировать в языке SQL запрос, результатом которого будет декартово произведение. Например:
SELECT S S.*, P.*
FROM S, Р;
Результат. Упомянутая выше таблица СР.
ПРОСТОЙ ПОДЗАПРОС
Выдать фамилии поставщиков, которые поставляют деталь Р2.
SELECT ФАМИЛИЯ
FROM S
WHERE НОМЕР_ПОСТАВЩИКА IN
(SELECT НОМЕР_ПОСТАВЩИКА
FROM SP
WHERE НОМЕР_ДЕТАЛИ = 'P2');
Результат:
ФАМИЛИЯ
Смит
Джонс
Блейк
Кларк
Пояснение. При обработке полного запроса система обрабатывает прежде всего вложенный подзапрос. Этот подзапрос возвращает множество номеров поставщиков, которые поставляют деталь P2, а именно множество ('S1', 'S2', 'S3', 'S4'). Поэтому первоначальный запрос эквивалентен следующему простому запросу:
SELECT ФАМИЛИЯ FROM S
WHERE НОМЕР_ПОСТАВЩИКА IN ('S1'.'S2','S3','S4');
и, следовательно, получаем приведенный ранее результат.
Неявное уточнение фамилии в этом примере требует дополнительного обсуждения. Заметим, в частности, что «НОМЕР-ПОСТАВЩИКА» слева от IN неявным образом уточняется именем таблицы S, в то время как «НОМЕР-ПОСТАВЩИКА» в подзапросе неявно уточняется именем таблицы SP. Справедливо следующее общее правило: предполагается, что неуточненное имя поля должно уточняться именем таблицы (или псевдонимом таблицы — см. примеры 5.2.3–5.2.5 ниже), указанным в той фразе FROM, которая является непосредственной частью того же самого запроса или подзапроса. В случае поля НОМЕР-ПОСТАВЩИКА слева от IN этой фразой является «FROM S», а в случае поля НОМЕР-ПОСТАВЩИКА в подзапросе—это фраза «FROM SP». Для большей ясности повторим первоначальный запрос с явно указанными предполагаемыми уточнениями:
SELECT S. ФАМИЛИЯ
FROM S
WHERE S. НОМЕР_ПОСТАВЩИКА IN
(SELECT SP. НОМЕР_ПОСТАВЩИКА
FROM SP
WHERE SP. НОМЕР_ДЕТАЛИ = 'P2');
Неявные уточнения всегда можно отвергнуть путем задания явных уточнений. Это демонстрируется ниже в примерах 5.2.3–5.2.5.
Прежде чем перейти к нашему следующему примеру подзапроса, необходимо отметить еще один важный момент. Первоначальная задача — «Выдать фамилии поставщиков, которые поставляют деталь P2» — может быть эквивалентным образом выражена как запрос с использованием соединения:
SELECT S. ФАМИЛИЯ
FROM S, SP
WHERE S. НОМЕР_ПОСТАВЩИКА = SP. НОМЕР_ПОСТАВЩИКА
AND SP. НОМЕР_ДЕТАЛИ = 'P2';
Пояснение.
Соединение S и SP по номерам поставщиков представляет собой таблицу из 12 строк (по одной строке для каждой строки SP), каждая из которых состоит из соответствующей строки SP, дополненной значениями ФАМИЛИЯ, СОСТОЯНИЕ и ГОРОД для поставщика, указываемого значением НОМЕР-ПОСТАВЩИКА в этой строке. Из этих 12 строк только четыре относятся к детали P2. Окончательный результат получается, таким образом, выделением значения ФАМИЛИЯ из этих четырех строк.
Обе формулировки первоначального запроса, одна из которых использует подзапрос, а другая — соединение, в равной степени корректны. Вопрос о том, какой из этих формулировок отдать предпочтение,— исключительно дело вкуса данного пользователя.
Этим разделом завершается данная вводная
Этим разделом завершается данная вводная глава. В ней был приведен краткий обзор DB2, реляционной системы управления базами данных фирмы IBM для операционной системы MVS. Было пояснено в общих чертах, что такое реляционная система. Рассмотрена реляционная (табличная) структура данных и описаны некоторые из имеющихся в SQL операторов для работы с данными в такой табличной форме. В частности, мы коснулись вопроса о трех категориях предложений SQL (определение данных, манипулирование данными и управление данными) и привели примеры из первых двух категорий. Напоминаем читателю, что:
а) все предложения SQL являются выполняемыми; б) каждое предложение SQL, которое может быть введено с терминала, может быть также встроено в программу на языке ПЛ/1, КОБОЛ, ФОРТРАН или на языке ассемблера; в) предложения манипулирования данными SQL (SELECT, UPDATE и т. д.) оперируют над множествами. Наконец, были рассмотрены также различные варианты операционной обстановки., в которых может исполняться прикладная задача системы DB2, а именно: IMS, CICS и TSO. В следующей главе мы познакомимся с внутренней структурой и с основными компонентами DB2.
С.ЗСКАЛЯРНЫЕ ВЫРАЖЕНИЯ
скалярное — выражение
. : : скалярный—терм [арифметический—оператор скалярное — выражение]
скалярный — терм : : = [+ | –] скалярное — значение
скалярное — значение : : = имя — столбца
| ссылка — на — функцию | константа | USER
| (скалярное — выражение)
ссылка — на — функцию : : = COUNT (*)
| имя — функции (скалярное — выражение)
| имя — функции (DISTINCT имя — столбца)
имя — функции : : = COUNT | SUM|AVG | MAX | MIN
арифметический — оператор : : = + | – |*|/
СИМЕНА
имя — таблицы : : =
имя — базовой — таблицы
| имя — представления | псевдоним ) синоним
имя — базовой — таблицы : : = [имя — пользователя.] идентификатор
имя — пользователя : : = идентификатор
имя — представления : : = [имя — пользователя.] идентификатор
псевдоним : : = идентификатор
синоним : : = идентификатор
имя—столбца : := [имя—таблицы.] идентификатор
СИНОНИМЫ
Удобно завершить эту главу кратким обсуждением вопроса о синонимах, хотя он, в действительности, и не имеет отношения к каталогу как таковому, за исключением того, что синонимы записываются в каталог, как и многие другие объекты. Если говорить кратко, синоним представляет собой альтернативное имя таблицы — базовой таблицы или представления. В частности, можно определить синоним для таблицы, которая была создана каким-либо другим пользователем и для которой Вы должны были бы в противном случае использовать полностью уточненное имя. Например, пользователь АЛЬФА издает предложение:
CREATE TABLE ПРИМЕР. . .;
Пользователь БЕТА может обращаться к этой таблице, указывая АЛЬФА.ПРИМЕР:
SELECT *
FROM АЛЬФА.ПРИМЕР;
С другой стороны, пользователь БЕТА может издать предложение CREATE SYNONYM IJK FOR АЛЬФА.ПРИМЕР;
и может теперь обращаться к этой таблице, указывая просто IJK, например:
SELECT *
FROM IJK,
Имя IJK является совершенно приватным и локальным для пользователя БЕТА. Другой пользователь ГАММА также может иметь приватное и локальное имя IJK, отличное от имени, введенного пользователем БЕТА.
Другой пример:
CREATE SYNONYM ТАБЛИЦЫ FOR SYSIBM.SYSTABLES;
Имеется также предложение DROP SYNONYM (уничтожить синоним). Его синтаксис:
DROP SYNONYM синоним;
Например:
DROP SYNONYM ТАБЛИЦЫ;
СЛУЧАЙ ИСПОЛЬЗОВАНИЯ ОДНОЙ И ТОЙ ЖЕ ТАБЛИЦЫ В ПОДЗАПРОСЕ И ВНЕШНЕМ ЗАПРОСЕ
Выдать номера поставщиков, которые поставляют по крайней мере одну деталь, поставляемую поставщиком S2.
SELECT DISTINCT НОМЕР_ПОСТАВЩИКА
FROM SP
WHERE НОМЕР_ДЕТАЛИ IN
(SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА = 'S2');
Результат:
|
|
НОМЕР_ПОСТАВЩИКА
|
|
S1
S2
S3
S4
Отметим здесь, что ссылка на SP в подзапросе означает не то же самое, что ссылка на SP во внешнем запросе. В действительности, два имени SP обозначают различные переменные. Чтобы этот факт стал явным, можно использовать псевдонимы:
SELECT DISTINCT SPX. НОМЕР_ПОСТАВЩИКА
FROM SP SPX
WHERE SPX. НОМЕР_ДЕТАЛИ IN
(SELECT SPY. НОМЕР_ДЕТАЛИ
FROM SP SPY
WHERE SPY. НОМЕР_ПОСТАВЩИКА ='S2');
Эквивалентный запрос с использованием соединения имеет вид;
SELECT DISTINCT SPX. НОМЕР_ПОСТАВЩИКА
FROM SP SPX, SP SPY
WHERE SPX. НОМЕР_ДЕТАЛИ = SPY. НОМЕР_ДЕТАЛИ
AND SPY. НОМЕР_ ПОСТАВЩИКА = 'S2';
СЛУЧАЙ, КОГДА В КОРРЕЛИРОВАННОМ И ВНЕШНЕМ ЗАПРОСЕ ИСПОЛЬЗУЕТСЯ ОДНА И ТА ЖЕ ТАБЛИЦА
Выдать номера всех деталей, поставляемых более чем одним поставщиком. (Другое решение этой задачи дается позднее в примере 5.4.9):
SELECT DISTINCT SPX. НОМЕР_ДЕТАЛИ
FROM SP SPX
WHERE SPX. НОМЕР_ДЕТАЛИ IN
(SELECT SPY. НОМЕР_ДЕТАЛИ
FROM SP SPY
WHERE SPY. НОМЕР_ПОСТАВЩИКА
Ø
= SPX. НОМЕР_ПОСТАВЩИКА);
Результат:
|
|
НОМЕР_ДЕТАЛИ
|
|
P1
P2
P4
P5
Действие этого запроса можно пояснить следующим образом. «Поочередно для каждой строки таблицы SP, скажем SPX, выделить значение НОМЕР_ДЕТАЛИ, если и только если это значение входит в некоторую строку, скажем SPY, таблицы SP, значение столбца НОМЕР_ПОСТАВЩИКА в которой не является его значением в строке SPX». Заметим, что в этой формулировке должен
быть использован по крайней мере один псевдоним — либо SPX, либо SPY, но не они оба, может быть заменен просто на SP.
СОЕДИНЕНИЕ ПО УСЛОВИЮ «БОЛЬШЕ ЧЕМ»
Выдать все комбинации информации о поставщиках и деталях, таких, что город местонахождения поставщика следует за городом, где хранится деталь, в алфавитном порядке:
SELECT S.*, P.*
FROM S.P
WHERE S.ГOPOД > Р.ГОРОД;
Получим в результате следующую таблицу 3.
Таблица 3
|
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
S.ГОРОД
|
|
S2
S2
S2
S3
S3
S3
|
Джонс
Джонс
Джонс
Блейк
Блейк
Блейк
|
10
10
10
30
30
30
|
Париж
Париж
Париж
Париж
Париж
Париж
Продолжение табл. 3
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
Р.ГОРОД
|
|
P1
Р4
Р6
Р1
Р4
Р6
|
Гайка
Винт
Блюм
Гайка
Винт
Блюм
|
Красный Красный Красный Красный Красный Красный
|
12
14
19
12
14
19
|
Лондон
Лондон
Лондон
Лондон
Лондон
Лондон
СОЕДИНЕНИЕ С ДОПОЛНИТЕЛЬНЫМ УСЛОВИЕМ
Выдать все комбинации информации о поставщиках и информации о деталях, такие, что рассматриваемые поставщики и детали «соразмещены». Опустить при этом поставщиков с состоянием, равным 20:
SELECT S.*, Р.*
FROM S,P
WHERE S.ГОРОД = Р.ГОРОД
AND S.СОСТОЯНИЕ = 20;
Результат представлен в таблице 4.
Таблица 4
|
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
S.ГОРОД
|
|
S2
S2
S3
S3
|
Джонс
Джонс
Блейк
Блейк
|
10
10
30
30
|
Париж
Париж
Париж
Париж
Продолжение табл. 4
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
Р.ГОРОД
|
|
P2
Р5
Р2
Р5
|
Болт
Кулачок
Болт
Кулачок
|
Зеленый
Голубой
Зеленый
Голубой
|
17
12
17
12
|
Париж
Париж
Париж
Париж
СОЕДИНЕНИЕ ТАБЛИЦЫ С НЕЙ САМОЙ
Выдать все пары номеров поставщиков, такие, что образующие их поставщики соразмещены.
SELECT ПЕРВАЯ НОМЕР_ПОСТАВЩИКА,
ВТОРАЯ. НОМЕР_ПОСТАВЩИКА
FROM S ПЕРВАЯ, S ВТОРАЯ
WHERE ПЕРВАЯ.ГОРОД = ВТОРАЯ.ГОРОД;
Нетрудно видеть, что в этом запросе требуется соединение таблицы S с ней самой по соответствию городов. Поэтому таблица S дважды указывается во фразе FROM. Для того чтобы различать эти два ее вхождения, мы вводим в этой фразе два произвольных ее псевдонима, ПЕРВАЯ и ВТОРАЯ, и используем их как явные уточнители во фразах SELECT и WHERE. Получаем результат:
|
|
НОМЕР_ПОСТАВЩИКА
|
НОМЕР_ПОСТАВЩИКА
|
|
S1
S1
S2
S2
S3
S3
S4
S4
S5
|
S1
S4
S2
S3
S2
S3
S1
S4
S5
Мы можем привести в порядок этот результат, расширив следующим образом фразу WHERE:
SELECT ПЕРВАЯ.НОМЕР_ПОСТАВЩИКА.ВТОРАЯ.НОМЕР_ПОСТАВЩИКА
FROM S ПЕРВАЯ, S ВТОРАЯ
WHERE ПЕРВАЯ.ГОРОД = ВТОРАЯ.ГОРОД
AND ПЕРВАЯ.НОМЕР_ПОСТАВЩИКА < ВТОРАЯ. НОМЕР_ПОСТАВЩИКА
Условие ПЕРВАЯ.НОМЕР_ПОСТАВЩИКА < ВТОРАЯ.НОМЕР_ПОСТАВЩИКА дает двоякий эффект: а) оно исключает пары номеров поставщиков вида (х,х); б) оно гарантирует, что не будут появляться одновременно пары (х, у)
и (у, х).
Имеем в результате:
|
|
НОМЕР_ПОСТАВЩИКА
|
НОМЕР_ПОСТАВЩИКА
|
|
S1
S2
|
S4
S3
Это первый пример, в котором мы видели, что использование синонимов необходимо. Однако введение таких синонимов никогда не будет ошибкой, даже если их использование не необходимо, и иногда они могут помочь в том, чтобы данное предложение стало более ясным. Мы иногда будем использовать их в наших примерах в следующей главе.
Выдать все пары номеров поставщиков таких, что входящие к каждую пару поставщики соразмещены (пример 4.3.6);
|
|
S
|
НОМЕР_
ПОСТАВЩИКА
|
ГОРОД
|
|
S
|
НОМЕР_
ПОСТАВЩИКА
|
ГОРОД
|
|
|
|
|
|
|
_SX
|
_сZ
|
|
|
_SY
|
_сZ
|
|
P.
|
_SX
|
_SY
Для того чтобы специфицировать дополнительное условие SX
СОЕДИНЕНИЕ ТРЕХ ТАБЛИЦ
Выдать все пары названий городов, таких, что какой-либо поставщик, находящийся в первом из этих городов, поставляет некоторую деталь, хранимую во втором городе. Например, поставщик Sl поставляет деталь Р1. Поставщик Sl находится в Лондоне, а деталь Р1 хранится также в Лондоне. Поэтому пара городов «Лондон, Лондон» — это пара городов, которая содержится в результате.
SELECT DISTINCT S.ГOPOД, Р.ГОРОД
FROM S, SP, P
WHERE S.HOMEP_ПОСТАВЩИКА = SP.HOMEP_ПОСТАВЩИКА
AND SP.HOMEP_ДЕТАЛИ = Р.НОМЕР_ДЕТАЛИ;
Получаем результат:
|
|
S.ГOPOД
|
Р.ГОРОД
|
|
Лондон
Лондон
Лондон
Париж
Париж
|
Лондон
Париж
Рим
Лондон
Париж
В качестве упражнения читателю следует установить, какие конкретно комбинации поставщик — деталь порождают каждую из строк результата в этом примере.
СПРЕДИКАТЫ
предикат
: : = условие
|условие AND предикат
|условие OR предикат
|NOT предикат
условие
: : = условие — сравнения
| условие — between
|условие — like
|условие — in
|условие — exists
условие — сравнения
: : = скалярное — выражение оператор — сравнения скалярное — выражение
|скалярное — выражение оператор — сравнения
(выражение — селекции — для — столбца)
[скалярное—выражение IS [NOT] NULL
оператор – сравнения
: : =+| ¬=| < | ¬ < | <= | > | ¬ > | > =
выражение — селекции — для — столбца
: : = фраза — селекции — для — столбца
фраза — from
[ фраза — where]
[фраза — группирования [фраза — having]]
фраза — селекции — для — столбца
: : = SELECT [DISTINCT] скалярное — выражение
условие — between
: : = имя — столбца [NOT] BETWEEN скалярное — выражение
AND скалярное — выражение условие — like
: : = имя — столбца
[NOT] LIKE скалярное — выражение
условие — in
: : = скалярное выражение [NOT] IN (множество — скаляров)
множество — скаляров
: : = список — константа
| выражение — селекции — для — столбца
условие — exists
: := EXISTS (выражение—селекции)
СПРЕДЛОЖЕНИЯ МАНИПУЛИРОВАНИЯ ДАННЫМИ
предложение
: : = предложение — select
| предложение — update
| предложение — delete
| предложение — insert
предложение — select
: : = выражение — union [фраза — упорядочения];
выражение — union
: : = выражение — селекции [UNION выражение — union]
фраза — упорядочения
: : = ORDER BY список — элемент — упорядочения
элемент — упорядочения
: : = упорядочиваемый — столбец [ASC ] DESC]
упорядочиваемый — столбец
: : = имя — столбца | целое
предложение — update
: : = UPDATE имя — таблицы [псевдоним]
SET список — присваивание — столбцу [фраза — where];
присваивание — столбцу
: : = имя — столбца = скалярное — выражение
| имя — столбца = NULL
предложение — delete
: : = DELETE FROM имя — таблицы [псевдоним] [фраза — where]
предложение — insert
: : = INSERT INTO имя — таблицы (список — имя — столбца)
исходные — значения;
исходные — значения
: : = VALUES (список — элемент — вставки)
| выражение — селекции
элемент — вставки
: : = константа | NULL
СРЕДСТВО DATA EXTRACT (DXT)
DATA EXTRACT (извлечение данных)—DXT—не является частью ни QMF, ни DB2. Это другой, поставляемый за отдельную плату, программный продукт. Однако на практике установка, на которой DXT используется для извлечения данных, будет, вероятно, использовать также и QMF для того, чтобы запрашивать и обновлять эти извлеченные данные, а также формировать по ним отчеты. Поэтому удобно включить в данную главу краткое описание DXT.
Задача DXT заключается в том, чтобы извлечь некоторую копию специфицированных данных из базы данных, управляемой языком DL/1, или из наборов данных SAM или VSAM и построить файл, содержащий эту извлеченную копию, в формате, который требуется утилитой загрузки системы DB2. (Примечание. DXT может генерировать также файлы в формате, необходимом для SQL/DS. Однако в этой книге мы имеем дело с DB2.) Тогда эти данные могут быть загружены в какую-либо таблицу базы данных системы DB2, где они могут далее использоваться в качестве основы деятельности, связанной с запросами, обновлениями и/или генерацией отчетов, адекватной конкретному приложению. Поэтому задача состоит, по существу, в том, чтобы обеспечить в интерактивном режиме доступ средствами SQL или QBE к данным, которые первоначально хранились в некоторой нереляционной форме. Поскольку такой доступ в интерактивном режиме направлен на извлечение данных, т. е. на формирование копии, он не является помехой другому использованию этих данных. В частности, он не влияет на эффективность любых запланированных, регулярно выполняемых по расписанию работ, оперирующих этими данными.
Примечание. Для обеспечения эффективности или по другим причинам даже для базы данных системы DB2 может оказаться целесообразным осуществлять в интерактивном режиме некоторые или все работы, связанные с запросами и генерацией отчетов, над извлеченными данными, а не над самой базой данных. Однако в таком случае процесс извлечения данных может быть реализован с помощью обычных средств самой системы DB2—фактически, предложений CREATE TABLE и INSERT для множества записей; не требуется никаких средств, подобных DXT.
DXT состоит из двух основных компонентов. Один из них дает пользователю возможность создавать запросы на извлечение данных, а другой фактически выполняет эти запросы. Первый компонент, называемый the User Input Manager (средство управления пользовательским вводом), может исполняться в интерактивном режиме под управлением TSO (более простой метод) или как обычное пакетное задание MVS. При этом средство управления диалогом, которое управляет интерактивным исполнением в среде TSO, поставляется фактически как часть продукта QMF, а не самого DXT. Второй компонент, the Data Extraction Manager (средство управления извлечением данных), исполняется одним из следующих способов:
— как пакетное приложение IMS — для извлечения данных из пакетных баз данных DL/1 и, по желанию, из наборов данных SAM или VSAM
— как приложение «пакетной обработки сообщений» (BMP — batch message processing) системы IMS — для извлечения данных из баз данных DL/1, используемых в интерактивном режиме, и, по желанию, из наборов данных SAM или VSAM
— как пакетное задание
MVS — для извлечения данных из наборов данных SAM или VSAM.
Необязательный третий компонент DXT, the Dictionary Access Program (программа доступа к словарю данных) может оказывать помощь в процессе построения запросов на извлечение данных благодаря получению описаний исходных данных из словаря данных IBM DB/DC Data Dictionary, если это средство установлено.
В случае базы данных DL/1 данные можно извлекать из любого или из всех сегментов, принадлежащих одному иерархическому пути, и загружать их в одну таблицу системы DB2. При этом можно включать или исключать конкретные экземпляры сегментов в соответствии с предикатом, специфицированным в запросе на извлечение данных. Можно также по потребности включать или исключать конкретные поля сегментов.
СТАНДАРТНЫЕ ФУНКЦИИ
Хотя и весьма мощное во многих отношениях, предложение SELECT в том виде, как оно было до сих пор описано, остается все еще неадекватным для многих практических задач. Например, даже настолько простой запрос как «Сколько имеется поставщиков?» нельзя выразить, используя только введенные до сих пор конструкции. Для того чтобы усилить его основные возможности по выборке данных, в SQL предусматривается ряд специальных стандартных функций. В настоящее время доступны функции COUNT (число значений), SUM (сумма), AVG (среднее), МАХ (максимум) и MIN (минимум)[15]. Кроме специального случая «COUNT (*)» (см. ниже) каждая из этих функций оперирует совокупностью значений в одном столбце некоторой таблицы, возможно, производной,
т. е. сконструированной некоторым образом из заданных базовых таблиц, и продуцирует в качестве ее результата единственное значение, определенное следующим образом:
COUNT — число значений в столбце
SUM — сумма значений по столбцу
AVG — среднее значение в столбце
MAX — самое большое значение в столбце
MIN — самое малое значение в столбце
Для функций SUM и AVG рассматриваемый столбец должен содержать числовые значения. В общем случае аргументу функции может факультативно предшествовать ключевое слово DISTINCT (различный), указывающее, что избыточные дублирующие значения должны быть исключены перед тем, как будет применяться функция. Однако для функций МАХ и MIN ключевое слово DISTINCT не имеет отношения к делу и должно быть опущено. Для функции COUNT ключевое слово DISTINCT должно быть специфицировано. Специальная функция COUNT (*), для которой использование DISTINCT не допускается, предусмотрена для подсчета всех строк в таблице без исключения каких-либо дубликатов. Если DISTINCT специфицируется, то аргумент должен состоять только из имени столбца, например ВЕС. Если DISTINCT не специфицировано, аргумент может представлять собой арифметическое выражение, например ВЕС х 454.
В столбце-аргументе всегда перед применением функции исключаются все неопределенные значения, независимо от того, специфицировано ли DISTINCT, за исключением случая COUNT (*), при котором неопределенные значения обрабатываются точно так же, как и значения, не являющиеся неопределенными. Если оказывается, что аргумент — пустое множество, функция COUNT принимает значение нуль. Все другие функции принимают в этом случае неопределенное значение.
СВЫРАЖЕНИЯ СЕЛЕКЦИИ
выражение — селекции : : = фраза — select
фраза — from
[фраза — where]
[фраза — группирования [фраза — having]]
фраза — select : : == SELECT [DISTINCT] спецификация — селекции
спецификация — селекции : : = * | список — элемент — селекции
элемент — селекции : : = имя — таблицы.*
| скалярное выражение
фраза — from : : = FROM список — элемент — from
элемент — from : : = имя — таблицы [псевдоним]
фраза — where : : = WHERE предикат
фраза — группирования : : = GROUP BY список — имя — столбца
фраза — having : : = HAVING предикат
ТАБЛИЧНЫЕ ПРОСТРАНСТВА
Табличное пространство может рассматриваться как логическое адресное пространство во внешней памяти, используемое для размещения одной или нескольких хранимых таблиц («логическое» постольку, поскольку оно не является обычно множеством физически смежных областей). По мере того как растет объем данных в этих таблицах, для адаптации к такому росту из соответствующей группы памяти будет выделяться дополнительная память, которая добавляется к этому адресному пространству. Размер одного табличного пространства может достигать примерно 64 гигабайт, и нет никаких ограничений на число табличных пространств в базе данных, а также на количество баз данных[23]. Все страницы в заданном табличном пространстве имеют размер либо 4К, либо 32Кбайт (К=1024).
Существенно отметить, что табличное пространство является единицей памяти для целей реорганизации и восстановления. Это означает, что табличное пространство может быть восстановлено после отказов, связанных с носителями информации, или реорганизовано по команде с консоли оператора. Если, однако, табличное пространство очень велико, его реорганизация или восстановление потребовали бы очень много времени. Поэтому в DB2 предусматривается факультативная возможность сегментирования большого табличного пространства на более мелкие части. Для сегментированного табличного пространства единицей реорганизации и восстановления является отдельный его сегмент, а не полное табличное пространство.
Таким образом, различаются две разновидности табличных пространств — сегментированные и простые (несегментированные). Рассмотрим каждую из них.
Простые табличные пространства
Простое табличное пространство может содержать более одной таблицы, хотя обычный случай—это одна таблица. Возможность размещать в табличном пространстве более одной таблицы полезна тем, что хранимые записи могут группироваться в кластеры таким образом, чтобы улучшать времена доступа к логически связанным записям. Например, если таблицы S и SP хранились бы в одном и том же табличном пространстве, то было бы возможно (благодаря разумному использованию утилиты загрузки) хранить все записи поставок для поставщика S1 близко (т. е. на той же самой странице) к записи поставщика S1, все записи поставок для поставщика S2 близко к записи поставщика S2 и т. д. Тогда могут эффективно отрабатываться запросы вида «Выдать детали поставщика S1 и все соответствующие поставки», поскольку будет сокращаться число операций ввода-вывода.
3аметим, однако, что нелегко поддерживать такую кластеризацию в ситуации, когда произвольным образом осуществляются обновления. Кроме того, об этой кластеризации не имеют никакого понятия ни оптимизатор, ни утилита реорганизации. К тому же вполне возможно, что будет замедляться последовательный доступ, так как система должна будет просмотреть не только записи, относящиеся к данной таблице, но также и записи других таблиц, которые оказываются смешанными с первой таблицей. Вероятно, в большинстве ситуаций наиболее удовлетворительным является все-таки вариант организации, предусматривающей по одной таблице в каждом табличном пространстве.
Для каждой таблицы в данном табличном пространстве может иметься один или более индексов. Если таблица вообще имеет какие-либо индексы, то ровно один из них является индексом кластеризации для этой таблицы. Индексы кластеризации подробно обсуждаются в разделе 13.6. Поэтому ограничимся здесь следующим кратким пояснением. Индекс кластеризации, по существу,— это такой индекс, который используется для управления физическим размещением индексируемых записей таким образом, чтобы физическая последовательность записей в памяти была близка к логической последовательности этих записей, определяемой данным индексом. Если для таблицы имеется индекс кластеризации, то записи должны первоначально загружаться в эту таблицу в порядке кластеров с помощью утилиты загрузки. Они будут запоминаться в табличном пространстве в порядке поступления слева направо, т. е. по возрастанию последовательности адресов, с периодическими промежутками, которые позволят в будущем производить вставки. Заметим, что промежутки часто обусловливаются системой, а не пользователем. Если таблица не имеет индексов, то записи первоначально могут загружаться в произвольном порядке. И снова они будут запоминаться слева направо, но без каких-либо промежутков. Вставляемые впоследствии в эту таблицу записи будут запоминаться в каком-либо промежутке, если существует индекс кластеризации, и записи могут физически запоминаться вблизи их логических позиций. В противном случае они запоминаются в правом конце пространства.
Сегментированные табличные пространства
Сегментированное табличное пространство содержит в точности одну таблицу. Эта таблица сегментируется в соответствии с диапазоном значений поля или комбинаций полей сегментирования. Если, например, таблица поставок SP хранилась бы в сегментированном табличном пространстве, то она могла бы сегментироваться по значениям поля НОМЕР_ПОСТАВЩИКА таким образом, чтобы все поставки поставщика S1 запоминались в сегменте номер один, все поставки поставщика S2 — в сегменте номер два и т. д. Для поля или комбинации полей сегментирования нужен индекс кластеризации. Дополнительные индексы необязательны. Поле или комбинацию полей сегментирования нельзя обновлять. Записи первоначально должны загружаться в порядке кластеров с помощью утилиты загрузки. Они будут запоминаться слева направо в соответствующем сегменте с промежутками.
Как уже указывалось, отдельные сегменты сегментированного табличного пространства независимы друг от друга в том смысле, что их можно независимо восстанавливать и реорганизовывать. Они также могут быть связаны с различными группами памяти. Поэтому можно, например, хранить одни сегменты на более быстрых устройствах, а другие—на более медленных (различные группы памяти могут соответствовать различным типам устройств).
ТРИ ПРОБЛЕМЫ, СВЯЗАННЫЕ С ПАРАЛЛЕЛИЗМОМ
DB2 представляет собой совместно используемую систему, т. е. это система, позволяющая любому числу транзакций одновременно осуществлять доступ к одной и той же базе данных. Для каждой такой системы требуется некоторого рода механизм управления параллельными процессами, который бы обеспечивал, чтобы параллельно используемые транзакции не мешали действию друг друга и, конечно, система DB2 включает такой механизм (по существу, механизм блокирования). Для читателей, возможно, незнакомых с проблемами, которые могут возникнуть при отсутствии такого механизма (другими словами, с проблемами, которые способен решать такой механизм), эти проблемы в общих чертах поясняются в данном разделе. Обсуждению возможностей указанного механизма специально в системе DB2 будут посвящены разделы 11.5–11.7. Читатели, уже хорошо знакомые с основными идеями управления параллельными процессами, могут сразу же обратиться к этим разделам.
Имеется, по существу, три случая ошибочного исполнения (И соответственно три связанные с ними проблемы (см. ниже).—Примеч. пер.), т. е. три ситуации, когда транзакция, корректная сама по себе, может продуцировать тем не менее ошибочный результат из-за вмешательства со стороны некоторой другой транзакции, конечно, при отсутствии подходящего механизма управления. Заметим, между прочим, что транзакция, осуществляющая вмешательство, также может быть сама по себе корректна. Речь идет, таким образом, о чередовании операций из двух корректных транзакций, которое продуцирует в целом некорректный результат.
К указанным выше проблемам относятся:
1. Проблема утраченного обновления.
2. Проблема зависимости от незафиксированных обновлений.
3. Проблема анализа на противоречивость.
Рассмотрим поочередно каждую из них.
Проблема утраченного обновления
Рассмотрим ситуацию, показанную на рис. 11.1. Предполагается, что этот рисунок читается следующим образом: транзакция А осуществляет выборку некоторой записи R в момент времени t1.
|
|
Транзакция А
|
Время
|
Транзакция В
|
|
—
|
|
|
—
|
|
—
|
|
|
—
|
|
FETCH R
|
t1
|
—
|
|
—
|
|
|
—
|
|
—
|
t2
|
FETCH R
|
|
—
|
|
|
—
|
|
UPDATE R
|
t3
|
—
|
|
—
|
|
|
—
|
|
—
|
t4
|
UPDATE R
|
|
—
|
|
|
—
|
|
|
|
|
|
Рис. 11.1. Транзакция А утрачивает обновление в момент t4
Транзакция В осуществляет выборку той же самой записи R в момент времени t2. Транзакция А обновляет эту запись в момент t3 исходя из значений, «увиденных» в момент времени t1, а транзакция В обновляет ту же запись в момент времени t4, исходя из значений, «увиденных» в момент t2, являющихся теми же самыми, что и значения, «увиденные» в момент t1. Обновление, осуществляемое транзакцией А, утрачивается в момент t4, поскольку транзакция В перекрывает его своим обновлением, даже на него «не глядя».
Проблема зависимости от незафиксированных обновлений
Проблема зависимости от незафиксированных обновлений возникает в случае, если одной транзакции разрешается осуществлять выборку или, хуже того, обновление записи, которая уже была обновлена другой транзакцией, но это обновление еще не было зафиксировано этой другой транзакцией. Поскольку оно еще не было зафиксировано, всегда существует возможность, что оно никогда не будет зафиксировано, и вместо этого произойдет откат. В результате первая транзакция «увидит» некоторые данные, которые теперь больше не существуют, и в некотором смысле «никогда» не существовали. Рассмотрим рис. 11.2 и 11.3.
|
|
Транзакция А
|
Время
|
Транзакция В
|
|
—
|
|
|
—
|
|
—
|
|
|
—
|
|
—
|
t1
|
UPDATE R
|
|
—
|
|
|
—
|
|
FETCH R
|
t2
|
—
|
|
—
|
|
|
—
|
|
—
|
t3
|
ROLLBACK
|
|
—
|
|
|
|
|
|
|
|
|
Рис. 11.2. Транзакция А становится зависимой от незафиксированных изменений в момент t2
|
|
Транзакция А
|
Время
|
Транзакция В
|
|
—
|
|
|
—
|
|
—
|
|
|
—
|
|
—
|
t1
|
UPDATE R
|
|
—
|
|
|
—
|
|
UPDATE R
|
t2
|
—
|
|
—
|
|
|
—
|
|
—
|
t3
|
ROLLBACK
|
|
—
|
|
|
|
|
|
|
|
|
Рис. 11.3. Транзакция А обновляет незафиксированное изменение в момент t2 и утрачивает это обновление в момент t3
В первом из этих примеров (рис. 11.2) транзакция А «видит» незафиксированное обновление (или незафиксированное изменение) в момент t2. Затем это обновление в момент t3 аннулируется. Следовательно, транзакция А выполняется при ошибочном предположении, а именно при предположении, что запись R имеет значение, «увиденное» в момент t2, тогда как на самом деле она вообще имеет значение, которое имела до момента t1. В результате вполне возможно, что транзакция А будет продуцировать некорректный результат. Отметим, между прочим, что откат транзакции В (по команде ROLLBACK) может и не являться следствием каких-либо ошибок в В. Он может быть, например, результатом отказа системы. (И транзакция А уже может завершиться к этому времени. В результате отказ системы не вызовет необходимости издать команду ROLLBACK также и для А.)
Второй пример (рис. 11.3) еще хуже. Транзакция А не только становится зависимой от незафиксированного изменения данных в момент t2, но и фактически утрачивает обновление в момент t3, поскольку операция ROLLBACK в момент t3 заставляет восстановить для записи R ее значение, которое она имела в момент t1. Это другой вариант проблемы утраченного обновления.
Проблема анализа на противоречивость
Рассмотрим рис. 11.4, на котором показаны две транзакции А и В, оперирующие записями счетов. Транзакция А суммирует остатки на счетах, транзакция В переносит сумму 10 со счета 3 на счет 1. Продуцируемый А результат 110, очевидно, некорректен, и если бы А должна была записать этот результат в базу данных, она оставила бы фактически базу данных в противоречивом состоянии. Будем говорить, что А «видела» противоречивое состояние базы данных и поэтому провела анализ на противоречивость. Отметим различие между данным и предыдущим примером. Здесь нет проблемы зависимости А от незафиксированных изменений, поскольку В фиксирует все произведенные ею обновления прежде, чем А «увидит» запись СЧЕТА 3.
|
|
СЧЕТ 1
|
|
СЧЕТ 2
|
|
СЧЕТ 3
|
|
40
|
|
50
|
|
30
|
|
|
|
|
|
Транзакция А
|
Время
|
Транзакция В
|
|
—
|
|
|
—
|
|
—
|
|
|
—
|
|
FETCH СЧЕТ 1 (40):
СУММА == 40
|
t1
|
—
|
|
—
|
|
|
—
|
|
FETCH СЧЕТ 2 (50): СУММА = 90
—
|
t2
|
—
|
|
—
|
|
|
—
|
|
—
|
t3
|
FETCH СЧЕТ 3 (30)
|
|
—
|
|
|
—
|
|
—
|
t4
|
UPDATE СЧЕТ 3: 30®20
|
|
—
|
|
|
—
|
|
—
|
t5
|
FETCH СЧЕТ 1 (40)
|
|
—
|
|
|
—
|
|
—
|
t6
|
UPDATE СЧЕТ 1: 40®50
|
|
—
|
|
|
—
|
|
—
|
t7
|
COMMIT
|
|
—
|
|
|
|
|
FETCH СЧЕТ 3 (20): СУММА=110, а не 120
|
t8
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис.
11.4. Транзакция А осуществляет анализ на противоречивость
ТУПИКОВАЯ СИТУАЦИЯ
Выше было показано, каким образом блокирование может использоваться для решения трех основных проблем параллельных процессов. Однако мы видели также, что, к сожалению, блокирование порождает свои собственные проблемы, прежде всего проблему тупиковых ситуаций. В разделе 11.5 были приведены два примера тупиковых ситуаций. Ниже на рис. 11.10 показан несколько более общий случай этой проблемы.
Примечание.
Имеется в виду, что приведенные на этом рисунке операции блокировки обозначают любые операции, устанавливающие блокировки, а совсем не обязательно предложения SQL LOCK TABLE.
|
|
Транзакция А
|
Время
|
Транзакция В
|
|
—
|
|
|
—
|
|
—
|
|
|
—
|
|
LOCK R1 IN X MODE
|
t1
|
—
|
|
—
|
|
|
—
|
|
—
|
t2
|
LOCK R2 IN X MODE
|
|
—
|
|
|
—
|
|
LOCK1R2 IN X MODE
|
t3
|
—
|
|
ждать
|
|
|
—
|
|
ждать
|
t4
|
LOCK R1 IN X MODE
|
|
ждать
|
|
|
ждать
|
|
ждать
|
|
|
ждать
Рис. 11.10. Пример тупиковой ситуации
Тупиковая ситуация — это такая ситуация, при которой две или более транзакции одновременно находятся в состоянии ожидания, и каждая из них ожидает, пока одна из других транзакций снимет блокировку, прежде чем ее исполнение сможет продолжаться. На рис. 11.10 показана тупиковая ситуация, вовлекающая две транзакции, но возможны также, по крайней мере теоретически, тупиковые ситуации, вовлекающие три, четыре и более транзакций. На практике, однако, тупиковые ситуации почти никогда не вовлекают более двух транзакций.
Если возникает тупиковая ситуация, система обнаруживает и ликвидирует ее. Для того чтобы ликвидировать тупиковую ситуацию, одна из вовлеченных в нее транзакций выбирается в качестве жертвы и, в зависимости от обстановки, либо автоматически производится ее откат, либо от нее требуется произвести откат самостоятельно. Между прочим на этот запрос не может последовать отказа. В любом случае данная транзакция снимет свои блокировки и, таким образом, позволит продолжить исполнение некоторой другой транзакции. Следовательно, в общем случае любая операция, требующая блокировки, в частности любая операция манипулирования данными языка SQL, может быть отвергнута с отрицательным значением SQLCODE, указывающим, что эта транзакция только что была выбрана жертвой в тупиковой ситуации, и либо уже был произведен ее откат, либо требуется его выполнить. Тупиковые ситуации представляют собой, таким образом, важную проблему, когда речь идет о прикладном программисте, поскольку может потребоваться включить в прикладные программы явные средства, имеющие с ними дело, если они возникают. Например:
ЕХЕС SQL . . . ;
IF SQLCODE = значение, указывающее ”жертву тупиковой ситуации”
THEN DO;
ROLLBACK;
повторно инициализировать переменные с помощью
начальных входных данных;
GO TO начало программы;
END;
Здесь предполагается, что программа где-либо сохранила свои начальные входные параметры (не в базе данных! — почему?) для подготовки как раз к таким возможным случаям.
УДАЛЕНИЕ ЕДИНСТВЕННОЙ ЗАПИСИ
Удалить поставщика S1.
DELETE
FROM S
WHERE НОМЕР_ПОСТАВЩИКА = 'S1’.
И снова, если таблица
SP в настоящее время содержит какие-либо поставки для поставщика S1, это удаление нарушит непротиворечивость базы данных (сравните с примером 6.2.4; как и в случае предложения UPDATE, нет операций DELETE, воздействующих на несколько таблиц). См. главу 11, а также Приложения А и В.
УДАЛЕНИЕ МНОЖЕСТВА ЗАПИСЕЙ
Удалить всех поставщиков из Лондона.
DELETE
FROM S ,
WHERE ГОРОД = 'Лондон';
УДАЛЕНИЕ С ПОДЗАПРОСОМ
Удалить все поставки для поставщиков из Лондона.
delete
FROM SP
WHERE 'Лондон' =
(SELECT ГОРОД
FROM S
WHERE S. НОМЕР_ПОСТАВЩИКА =
SP. НОМЕР_ПОСТАВЩИКА);
В чем смысл утверждения, что
1.1. В чем смысл утверждения, что DB2 — реляционная система?
1.2. При условии, что приняты данные из примера на рис. 1.3, найдите результат
каждого из следующих предложений SQL.
а)SELECT ФАМИЛИЯ
FROM S
WHERE СОСТОЯНИЕ = 30;
б) SELECT НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ
FROM SP
WHERE КОЛИЧЕСТВО > 200;
в) UPDATE SP
SET КОЛИЧЕСТВО = КОЛИЧЕСТВО + 300
WHERE КОЛИЧЕСТВО < 300;
г) DELETE
FROM P
WHERE ЦВЕТ = 'Голубой'
OR ГОРОД = 'Париж';
д) INSERT
INTO SP (НОМЕР_ПОСТАВЩИКА, НОМЕР—ДЕТАЛИ,
КОЛИЧЕСТВО)
VALUES ('S3', 'Р1’, 500);
1.3. Постройте диаграмму, иллюстрирующую различные категории прикладных программ системы DB2 и различные варианты операционной обстановки, в которых они могут исполняться.
1.4. Что обозначают следующие акронимы:
SQL, DB2, DB2I, QMF, DXT?
1.5. Что такое повторяющаяся группа?
1.6. Определите термины отношение и реляционная база данных.
1.7. Приведите возможное предложение CREATE TABLE для таблицы ВИННЫЙ— ПОГРЕБ (рис. 1.1). Запишите встроенное предложение SQL для программы на языке ПЛ/1, которое обеспечит выборку числа бутылок цинфанделя 1977 г. из этой таблицы.
1.8. Определите термины базовая таблица и представление.
2.1. Укажите четыре основных компонента системы DB2. Начертите диаграмму, показывающую полный процесс подготовки и исполнения программы в DB2.
2.2. Перечислите четыре главных функции генератора планов прикладных задач.
2.3. Дайте определение физической независимости данных.
Объясните, как DB2 обеспечивает такую независимость. Почему желательна физическая независимость данных?
3.1. На рис. 3. 1 приведены некоторые примеры значений данных для базы данных, содержащей информацию, касающуюся поставщиков (таблица S), деталей (таблица Р) и проектируемых изделий (таблица J). Поставщики, детали и изделия уникально идентифицируются при этом соответственно номером поставщика, номером детали и номером изделия. Смысл записей таблицы SPJ состоит в том, что специфицированый поставщик поставляет специфицированную деталь для специфицированного проектируемого изделия в специфицированном количестве. Комбинация НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ и НОМЕР_ИЗДЕЛИЯ уникально идентифицирует такие записи. Напишите для этой базы данных соответствующее множество предложений CREATE TABLE.
Примечание. Эта база данных будет использоваться в ряде упражнений в последующих главах.
3.2. Запишите множество предложений CREATE INDEX для базы данных из упражнения 3.1 таким образом, чтобы привести в действие требуемые ограничения уникальности.
3.3. В чем состоят основные достоинства индексов? В чем их основные недостатки?
3.4. «Уникальность» поля или комбинации полей — логическое свойство, но оно реализуется в системе DB2 с помощью индекса, который является физической конструкцией. Выскажите Ваше мнение по этому вопросу.
Все последующие упражнения к данной главе основываются на базе данных поставщиков_деталей_изделий (см. упражнения к главе 3). В каждом из них требуется записать предложение SELECT для указанного запроса. Для удобства ниже вновь приводится структура рассматриваемой базы данных:
S(HOMEP_ ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, ГОРОД)
Р(НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС, ГОРОД)
J (НОМЕР_ИЗДЕЛИЯ, НАЗВАНИЕ, ГОРОД)
SPJ (НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ, НОМЕР_ИЗДЕЛИЯ КОЛИЧЕСТВО)
Простые запросы
4.1. Выдать полный список деталей для всех изделий.
4.2. Выдать полный список деталей для всех изделий, изготавливаемых в Лондоне.
4.3. Выдать упорядоченный список номеров поставщиков, поставляющих детали для изделия номер J1.
4.4. Выдать список всех поставок, в которых количество деталей находится в диапазоне от 300 до 750 включительно.
4.5. Выдать список всех комбинаций «цвет детали—город, где хранится деталь», исключая дубликаты пар (цвет—город).
4.6. Выдать список всех поставок, в которых количество не является неопределенным значением.
4.7. Выдать номера изделий и города, где они изготавливаются, такие, что второй буквой названия города является «О». (Англоязычные названия городов, используемых в рассматриваемой базе данных — London, Paris, Rome, Athens, Oslo.— Примеч. пер.)
Соединения
4.8. Выдать все триплеты «номер поставщика, номер детали и номер изделия», такие, что образующие каждый из них поставщик, деталь и изделие являются соразмещенными.
4.9. Выдать все триплеты «номер поставщика, номер детали и номер изделия», такие, что образующие каждый из них поставщик, деталь и изделие не являются соразмещенными
4.10. Выдать все триплеты «номер поставщика, номер детали и номер изделия», такие, что в каждом триплете указанные поставщик, деталь и изделие не являются попарно соразмещенными.
4.11. Выдать номера деталей, поставляемых каким-либо поставщиком из Лондона, для изделия, изготавливаемого также в Лондоне.
4.12. Выдать номера деталей, поставляемых каким-либо поставщиком из Лондона.
4.13. Выдать все пары названий городов, таких, что какой-либо поставщик из первого города поставляет детали для некоторого изделия, изготавливаемого во втором городе.
4.14. Выдать номера деталей, поставляемых для какого-либо изделия поставщиком, находящимся в том же городе, где изготавливается это изделие.
4.15. Выдать номера изделий, для которых детали поставляются по крайней мере одним поставщиком не из того же самого города.
4.16. Выдать все пары номеров деталей, таких, что некоторый поставщик поставляет обе указанные детали.
Как и в предыдущей главе. Все следующие упражнения основаны на базе данных поставщиков-деталей-изделий (см. упражнения в главе 3). В каждом из них требуется записать предложение
SELECT для указанного запроса, за исключением упражнений 15—18 и 26. Для удобства повторим здесь структуру рассматриваемой базы данных:
S (НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, ГОРОД)
Р (НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС, ГОРОД)
J (НОМЕР_ИЗДЕЛИЯ, НАЗВАНИЕ, ГОРОД)
SPJ (НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ, НОМЕР_ИЗДЕЛИЯ,
КОЛИЧЕСТВО)
В каждом разделе упражнения упорядочены приблизительно в порядке возрастания их сложности. Необходимо попытаться выполнить по крайней мере некоторые из легких упражнений в каждой группе. Упражнения 12—18 являются весьма трудными.
Подзапросы
5.1. Выдать названия изделий, для которых поставляются детали поставщиком S1.
5.2. Выдать цвета деталей, поставляемых поставщиком S1.
5.3. Выдать номера деталей, поставляемых для какого-либо изделия в Лондоне.
5.4. Выдать номера изделий, использующих по крайней мере одну деталь, поставляемую поставщиком S1.
5.5. Выдать номера поставщиков, поставляющих по крайней мере одну деталь, поставляемую по крайней мере одним поставщиком, который поставляет по крайней мере одну красную деталь.
5.6. Выдать номера поставщиков, имеющих состояние меньшее, чем у поставщика S1.
5.7. Выдать номера поставщиков, поставляющих детали для какого-либо изделия с деталью Р1 в количестве, большем, чем средний объем поставок детали Р1 для этого изделия. Примечание.
В этом упражнении нужно использовать стандартную функцию AVG.
Квантор EXISTS
5.8. Повторите упражнение 5.3 и используйте в Вашем решении EXISTS.
5.9. Повторите упражнение 5.4 и используйте в Вашем решении EXISTS.
5.10. Выдать номера изделий, для которых не поставляет какой-либо красной детали поставщик из Лондона.
5.11. Выдать номера изделий, для которых детали полностью поставляет поставщик S1.
5.12. Выдать номера деталей, поставляемых для всех изделий в Лондон.
Как обычно, все следующие упражнения основаны на базе данных поставщиков-деталей-изделий:
S (НОМЕР_ПОСТАВЩИКА, ФАМИЛИЯ, СОСТОЯНИЕ, ГОРОД)
Р (НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС, ГОРОД)
J (НОМЕР_ИЗДЕЛИЯ, НАЗВАНИЕ, ГОРОД)
SPJ (НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ, НОМЕР_ИЗДЕЛИЯ, КОЛИЧЕСТВО)
Запишите подходящее предложение INSERT, DELETE или UPDATE для каждой из следующих задач.
6.1. Измените цвет всех красных деталей на оранжевый.
6.2. Удалите все изделия, для которых нет поставок деталей.
6.3. Увеличьте размер поставки на 10 процентов для всех поставок тех поставщиков, которые поставляют какую-либо красную деталь.
6.4. Удалите все изделия из Рима и все соответствующие поставки.
6.5. Вставьте в таблицу S нового поставщика S10. Его фамилия и город — 'Уайт' и 'Нью-Йорк' соответственно, а состояние еще неизвестно.
6.6. Постройте таблицу, содержащую список номеров деталей, которые поставляются либо каким-нибудь поставщиком из Лондона, либо для какого-либо изделия в Лондоне.
6.7. Постройте таблицу, содержащую список номеров изделий, которые либо находятся в Лондоне, либо для них поставляются детали каким-нибудь поставщиком из Лондона.
6.8. Добавьте 10 к состоянию всех поставщиков, состояние которых в настоящее время меньше, чем состояние поставщика S4.
6.9. Постройте внешнее естественное соединение изделий и поставок по номерам изделий.
6.10. Постройте внешнее естественное соединение деталей и изделий по городам.
6.11. Постройте таблицу, содержащую полную информацию о поставщиках, деталях и изделиях, с указанием объема поставок для каждой поставки вместе с «сохраненной» информацией для каждого поставщика, детали и изделия, которые не входят в таблицу поставок (о смысле понятия «сохраненная информация» в этом контексте см. пример 6.4.5).
7.1. Сделайте набросок элементов каталога для базы данных поставщиков-деталей-изделий.
Напишите теперь предложения SELECT для следующих запросов (упражнения 7 2—7.8).
7.2. В какие таблицы входит столбец ГОРОД?
7.3. Сколько имеется столбцов в таблице поставок?
7.4. Составьте список имен всех таблиц каталога;
7.5. Составьте список фамилий всех пользователей, которыми были созданы таблицы со столбцом ГОРОД, вместе с именами этих таблиц.
7.6. Составьте список фамилий всех пользователей, которыми была создана по крайней мере одна таблица, вместе с числом таблиц, созданных каждым из них.
7.7. Составьте список всех таблиц, для которых имеется по крайней мере один индекс.
7.8. Составьте список имен всех таблиц, для которых имеется более одного индекса.
7.9. Запишите предложения для того, чтобы сделать следующее:
а) Создать подходящий комментарий для таблицы SPJ.
б) Заменить этот комментарий на «Игнорировать предыдущий комментарий».
в) Создать подходящий комментарий для столбца НОМЕР_ДЕТАЛИ в таблице SPJ.
г) Создать подходящий комментарий для индекса XS.
д) Создать подходящий синоним для таблицы SYSCOLUMNS.
е) Уничтожить этот синоним.
8.1. Определите отношение SP из базы данных поставщиков и деталей как представление отношения SPJ из базы данных поставщиков, деталей и изделий.
8.2. Создайте для базы данных поставщиков, деталей и изделий представление. состоящее из всех изделий (включающее только поля номера изделия и города), которые поставляются поставщиком S1 и используют деталь Р1.
8.3. Является ли Ваше решение упражнения 8 2 обновляемым представлением?
а) Если да, то можно ли для него специфицировать вариант CHECKS
б) Если нет, найдите обновляемую версию представления и повторите это упражнение.
8.4. Создайте представление, состоящее из номеров поставщиков и номеров деталей, для таких поставщиков и деталей, которые не «соразмещены».
8.5. Создайте представление, состоящее из записей поставщиков, только для тех поставщиков, которые находятся в Лондоне
8.6. При условии, что задано определение представления:
CREATE VIEW СВОДКА (НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ,
МАКС_КОЛИЧЕСТВО, МИН_КОЛИЧЕСТВО,
СРЕДНЕЕ_КОЛИЧЕСТВО)
AS SELECT НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ, MAX
(КОЛИЧЕСТВО), MIN (КОЛИЧЕСТВО),
AVG (КОЛИЧЕСТВО)
FROM SPJ
GROUP BY НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ
HAVING SUM (КОЛИЧЕСТВО) > 50;
установите, какие из следующих операций корректны и приведите для них полученный в результате трансляции эквивалент.
а) SELECT *
FROM СВОДКА;
б) SELECT *
FROM СВОДКА
WHERE НОМЕР_ПОСТАВЩИКА Ø= ‘S1';
в) SELECT
FROM СВОДКА
WHERE МАКС_КОЛИЧЕСТВО > 250;
г) SELECT МАКС_КОЛИЧЕСТВО - МИН_КОЛИЧЕСТВО,
НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ
FROM СВОДКА
WHERE НОМЕР_ПОСТАВЩИКА ='S1'
AND НОМЕР_ДЕТАЛИ = 'Р1';
д) SELECT НОМЕР_ПОСТАВЩИКА
FROM СВОДКА
GROUP BY НОМЕР_ПОСТАВЩИКА;
e) SELECT НОМЕР_ПОСТАВЩИКА, МАКС_КОЛИЧЕСТВО
FROM СВОДКА
GROUP BY НОМЕР_ПОСТАВЩИКА, МАКС_КОЛИЧЕСТВО;
ж) SELECT S.НОМЕР_ПОСТАВЩИКА, СВОДКА. СРЕДНЕЕ_КОЛИЧЕСТВО
FROM S,CBOДKA
WHERE S.HOMEP_ПОСТАВЩИКА = СВОДКА. НОМЕР_ПОСТАВЩИКА;
з) UPDATE СВОДКА
SET НОМЕР_ПОСТАВЩИКА = 'S2'
WHERE НОМЕР_ПОСТАВЩИКА = ‘S1';
и) UPDATE СВОДКА
SET МАКС_КОЛИЧЕСТВО = 1000
WHERE НОМЕР_ПОСТАВЩИКА = 'S1';
к)DELETE
FROM СВОДКА
WHERE НОМЕР_ПОСТАВЩИКА = 'S1';
8.7. Сформулируйте правила, касающиеся обновляемости представлений в системе DB2.
8.8. Сформулируйте правила, касающиеся спецификации CHECK.
8.9. Предположим, что база данных реструктуризуется таким образом, что таблицы А и В заменяются их естественным соединением С. В какой степени механизм представлений может скрыть эту реструктуризацию от существующих пользователей?
1.9. Как Вы понимаете термин "автоматическая навигация”?
УТИЛИТЫ
Это меню дает пользователю возможность вызывать утилиты системы DB2. В состав этих утилит наряду с другими входят следующие:
LOAD. Утилита LOAD загружает данные из набора данных SAM в одну или более таблиц DB2. Примечание.
Такой набор данных SAM может состоять из данных, разгруженных из набора данных VSAM или из базы данных системы IMS, из таблицы DB2 или SQL/DS (см. раздел 15.4).
COPY. Утилита COPY создает полную или инкрементную копию содержимого табличного пространства или сегмента. Инкрементная копия — это копия именно тех данных, которые были изменены с тех пор, когда была создана предыдущая полная или инкрементная копия.
MERGE COPY. Утилита MERGE COPY производит объединение полной копии и одной или более инкрементных копий для заданного табличного пространства или его сегмента с тем, чтобы продуцировать текущую полную копию. Она позволяет также объединять множество инкрементных копий и продуцировать текущую инкрементную копию.
RECOVER. Утилита RECOVER служит для восстановления табличного пространства или его сегмента после разрушения относящейся к ним информации на носителях. При этом используется самая поздняя полная копия, последующие инкрементные копии, а также журнал.
REORG. Утилита REORG осуществляет реорганизацию табличного пространства или его сегмента, в результате которой появляется возможность использовать ранее остававшееся бесполезным пространство. Если это необходимо, осуществляется также восстановление последовательности кластеризации.
RUNSTATS. Утилита RUNSTATS вычисляет различные статистические характеристики, касающиеся таких вещей, как число записей в каждой таблице, и записывает их в системный каталог. Эти характеристики используются генератором планов прикладных задач в осуществляемом им процессе оптимизации.
В.ЗПЕРВИЧНЫЕ И ВНЕШНИЕ КЛЮЧИ
Единственным и самым важным аспектом сущностей в реальном мире является их отличимость.
Следовательно, при рассмотрении проблемы представления сущностей в базе данных нужно ответить на единственный самый важный вопрос, каким образом представители этих сущностей отличаются друг от друга, т. е. каким образом идентифицируются сущности в базе данных.
В последующем, в процедуре проектирования, которая в общих чертах рассматривается в следующем разделе, каждый тип сущностей (поставщики, служащие, поставки, заказы на закупки и т. д.) независимо от того, являются ли они стержневыми, характеристическими или ассоциативными, будет отображаться в базовую таблицу системы DB2. Свойства типа сущностей будут отображаться в поля этой базовой таблицы. Вследствие того что функцию идентификации в реляционной модели выполняют первичные ключи (см. определение этого термина в Приложении А), каждая такая базовая таблица должна иметь первичный ключ, представляющий идентифицирующее свойство рассматриваемого типа сущностей Ниже приведены первичные ключи для базы данных поставщиков и деталей:
— таблица S : поле S НОМЕР_ПОСТАВЩИКА
— таблица Р : поле Р. НОМЕР_ДЕТАЛИ
— таблица SP : составное поле SP.(НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ)
Таким образом, для каждой базовой таблицы в проекте проектировщик базы данных должен специфицировать поле или комбинацию полей, образующих первичный ключ для этой базовой таблицы. Ниже, в разделе В.5 приводятся некоторые предложения относительно способа записи такой спецификации.
Далее, если сущности представляются базовыми таблицами, то соединения между сущностями представляются с помощью внешних ключей в этих базовых таблицах (определение этого термина см. опять таки в Приложении А). Более строго:
— Если сущности типа В обозначают сущность типа А и если эти типы сущностей представлены базовыми таблицами соответственно ТВ и ТА, то ТВ будет включать внешний ключ, соответствующий первичному ключу ТА.
— Подобным же образом, если сущности типа С являются ассоциациями между сущностями типа А и сущностями типа В, и эти типы сущностей представлены базовыми таблицами соответственно ТС, ТА и ТВ, то ТС будет включать внешний ключ, соответствующий первичному ключу ТА, и внешний ключ, соответствующий первичному ключу ТВ. Примером для этого последнего случая могут служить поставки, где внешними ключами являются SP.НОМЕР_ПОСТАВЩИКА, соответствующий первичному ключу НОМЕР_ПОСТАВЩИКА таблицы S, и SP.НОМЕР_ДЕТАЛИ, соответствующий первичному ключу НОМЕР_ДЕТАЛИ таблицы Р. Рассмотрим теперь пример, иллюстрирующий предыдущий случай. Снова предположим, что служащие обозначают отделы. Тогда таблица служащих (например, СЛУЖАЩИЕ) будет включать внешний ключ (к примеру, СЛУЖАЩИЕ.НОМЕР_ОТДЕЛА), соответствующий первичному ключу (например, НОМЕР_ОТДЕЛА) таблицы отделов (например, ОТДЕЛЫ).
Таким образом, при рассмотрении проблемы выбора способа представления ассоциаций и обозначений в базе данных основной вопрос, на который следует получить ответ: «Каковы внешние ключи?». Но на этом дело не заканчивается. Для каждого внешнего ключа необходимо решить три дальнейших вопроса:
1. Может ли данный внешний ключ принимать неопределенные значения? Иными словами, может ли существовать некоторый экземпляр сущности данного типа, для которого неизвестна целевая сущность, указываемая внешним ключом? В случае поставок это, по всей вероятности, невозможно — поставка, осуществляемая неизвестным поставщиком, или поставка неизвестной детали не имеют смысла. Но в случае со служащими такая ситуация однако могла бы иметь смысл — вполне возможно, что какой-либо служащий в данный момент не зачислен вообще ни в какой отдел. Заметим для ясности, что ответ на рассматриваемый вопрос (допускаются ли неопределенные значения для заданного внешнего ключа) зависит не от прихоти проектировщика базы данных, а от фактического образа действий, принятого в той части реального мира, которая должна быть представлена в рассматриваемой базе данных. Подобные замечания имеют, конечно, отношение и к вопросам 2 и 3, обсуждаемым ниже.
2. Что должно случиться при попытке удаления целевой сущности, на которую ссылается внешний ключ? Например, может быть предпринята попытка удаления поставщика, для которого существует по крайней мере одна соответствующая поставка. Для определенности рассмотрим этот случай подробнее. Вообще говоря, существуют три возможности:
|
|
— CASCADES (КАСКАДИРУЕТСЯ)
|
Операция удаления «каскадируется» с тем, чтобы удалить также эти соответствующие поставки..
|
|
— RESTRICTED (ОГРАНИЧИВАЕТСЯ)
|
Операция удаления «ограничивается» случаями, где нет таких соответствующих поставок. В противном случае она отвергается
|
|
— NULLIFIES (УСТАНАВЛИВАЕТСЯ НЕОПРЕДЕЛЕННОЕ ЗНАЧЕНИЕ)
|
Для всех таких соответствующих поставок внешний ключ устанавливается в неопределенное значение, а затем этот поставщик удаляется. Такая возможность, конечно, неприменима, если данный внешний ключ не должен принимать неопределенных значений.
3. Что должно происходить при попытке обновления первичного ключа целевой сущности, на которую ссылается некоторый внешний ключ? Например, может быть предпринята попытка обновить номер такого поставщика, для которого имеется по крайней мере одна соответствующая поставка. Этот случай для определенности снова рассмотрим подробнее. Имеются, вообще говоря, те же самые три возможности, как и в случае операции DELETE:
|
|
— CASCADES (КАСКАДИРУЕТСЯ)
|
Операция обновления «каскадируется» с тем, чтобы обновить также и внешний ключ в этих соответствующих поставках.
|
|
— RESTRICTED (ОГРАНИЧИВАЕТСЯ)
|
Операция обновления «ограничивается» случаями, где нет таких соответствующих поставок. В противном случае она отвергается.
|
|
— NULLIFIES (УСТАНАВЛИВАЕТСЯ НЕОПРЕДЕЛЕННОЕ ЗНАЧЕНИЕ)
|
Для всех таких соответствующих поставок внешний ключ устанавливается в неопределенное значение, а затем обновляется этот поставщик. Такая возможность, конечно, неприменима, если данный внешний ключ не может принимать неопределенных значений.
Таким образом, для каждого внешнего ключа в проекте проектировщик базы данных должен специфицировать не только поле или комбинацию полей, составляющие этот внешний ключ, и целевую таблицу, которая идентифицируется этим ключом, но также и ответы на три указанных выше вопроса, т. е. три ограничения, которые относятся к этому внешнему ключу. Некоторые предложения о способе записи таких спецификаций опять-таки можно найти ниже в разделе В.5.
Завершим этот раздел кратким замечанием относительно характеристик. По определению характеристика является обозначающей сущностью, существование которой зависит от типа сущностей, которые она обозначает. Обозначение будет, конечно, представляться внешним ключом в таблице, соответствующей этой характеристике. Но три рассмотренные выше ограничения на внешний ключ для данного случая должны
специфицироваться следующим образом:
NULLS NOT ALLOWED
DELETE (цель) CASCADES
UPDATE (первичный ключ целевой сущности) CASCADES
Указанные спецификации представляют зависимость по существованию характеристических сущностей. Здесь использован синтаксис, рассматриваемый ниже в разделе В.5.
с тремя другими подсистемами MVS
Система управления базами данных DB2 сконструирована для совместной работы с тремя другими подсистемами MVS — IMS, CICS и TSO[2]. На рис 1.2 показана эта совокупность программных компонентов.
Рис. 1.2. Варианты операционной обстановки системы DB2
Этот рисунок можно интерпретировать следующим образом:
1. Любое заданное приложение (прикладная задача) DB2, т. е. любая прикладная программа, которая осуществляет доступ к одной или более базам данных DB2, будет исполняться под управлением в точности одной из трех подсистем IMS, CICS или TSO Иначе говоря, в точности одна из трех подсистем будет ответственной за обеспечение определенных необходимых системных услуг (которые обсуждаются в главе 11). Следовательно, можно разделить приложения DB2 на три непересекающиеся категории, а именно—на приложения IMS, CICS и TSO соответственно.
2. Вообще, любое заданное приложение (DB2 или иное) может факультативно использовать средства передачи данных IMS, CICS или TSO, когда они применимы, для связи с одним или более терминалами. Если это имеет место, такое приложение называется интерактивным (работающим в режиме On-line), в противном случае—пакетным (работающим в пакетном режиме). Приложения, исполняемые под IMS или CICS, должны быть интерактивными (см. п. 4 ниже). Приложения DB2, исполняемые под TSO, могут быть либо интерактивными, либо пакетными[3].
3. Приложение DB2, исполняемое под IMS или CICS (но не TSO), может, помимо базы (баз) данных DB2, факультативно осуществлять доступ к одной или более базам данных IMS.
4. Пакетные приложения, исполняемые не под TSO, вообще не могут осуществлять доступа к базам данных DB2, как уже отмечалось выше в п. 2.
5. Приложения TSO вообще не могут осуществлять доступ к базам данных IMS, как уже отмечалось выше в п. 3.
6. Все приложения IMS, CICS и TSO могут исполняться параллельно и даже могут совместно использовать одну и ту же базу данных (одни и те же базы данных) DB2.
Читателей, не знакомых с IMS и/или с CICS и/или с TSO, мы хотим ободрить следующим: для того чтобы понимать возможности DB2, нет необходимости в знакомстве с этими подсистемами. Достаточно понимать, что программа, использующая возможности DB2, должна функционировать под управлением в точности одного из компонентов — IMS, CICS или TSO, а не их совокупности. Заметим, однако, что приложение TSO может исполняться как пакетное приложение TSO в одном случае и как интерактивное приложение TSO — в другом. Предложения ввода/ вывода в программе могут быть связаны с обычными наборами данных в одном случае и с терминалом — в другом, если, конечно, программа записана таким образом, что она готова к любой из этих возможностей.
ВНОРМАЛИЗАЦИЯ
Следуя процедуре проектирования, описанной в общих чертах в предыдущем разделе, мы всегда будем получать проект, согласующийся со следующим простым образцом:
|
|
Каждая таблица состоит из:
а) первичного ключа, представляющего уникальный идентификатор некоторого конкретного типа сущностей,
а также:
б) нуля или более дополнительных полей, представляющих дополнительные свойства типа сущностей, идентифицируемого данным первичным ключом, а не некоторым другим типом сущностей.
Такой проект является чистым
в том смысле, что каждая таблица содержит информацию об одном и только об одном типе сущностей. Проект такого рода будет легче понимать, легче использовать и, что более важно, легче расширять, когда позднее новая информация будет добавляться к этой базе данных, чем проект, в котором информация о многих типах сущностей перемешана в одной таблице. Иными словами, данный проект будет стабилен и будет хорошей основой для будущего развития.
Другой способ выражения критерия чистоты проекта таков:
«Каждый факт в одном месте».
Каждый факт, например, тот факт, что определенный поставщик имеет определенное состояние, появляется в таком проекте в точности в одном месте. Еще один, очень неформальный, способ выражения того же свойства: «Каждое поле представляет некоторый факт о ключе, полном ключе и ни о чем более, кроме ключа», где «ключ» означает «сущность, идентифицируемую первичным ключом таблицы, которую содержит рассматриваемое поле».
Создание чистых проектов является целью дисциплины, называемой нормализацией. На самом деле, методология, которая рассматривалась до сих пор в данном приложении, и дисциплина нормализации дополняют друг друга в том смысле, что, как Вы сами, вероятно, убедитесь, целесообразно применение их обеих на практике. Однако в литературе нормализация часто обсуждается таким образом, как будто она является единственным необходимым инструментом проектирования. Наше мнение, как уже указывалось, заключается, наоборот, в том, что максимальную пользу из нее можно извлечь как из завершающей проверочной стадии в рамках представленной выше методологии проектирования. Нормализация, несомненно, не панацея от всех бед. По этой причине ей посвящается лишь сравнительно небольшая часть данного приложения. Более полное обсуждение вопросов, связанных с нормализацией, можно найти в публикациях, указанных в библиографии.
Коротко, идея нормализации заключается в следующем. Как указывалось в главе 1, каждая таблица в реляционной базе данных удовлетворяет условию, в соответствии с которым в позиции на пересечении каждой строки и столбца таблицы всегда находится единственное атомарное значение, и никогда не может быть множества таких значений. Любая таблица, удовлетворяющая этому условию, называется нормализованной.
Фактически, ненормализованные таблицы, т. е. таблицы, содержащие повторяющиеся группы, даже не допускаются в реляционной базе данных. Всякая нормализованная таблица автоматически считается таблицей в первой нормальной форме, сокращенно 1НФ. Таким образом, строго говоря, «нормализованная» и «находящаяся в 1НФ» означают одно и то же. Однако на практике термин «нормализованная» часто используется в более узком смысле — «полностью нормализованная», означающем, что в проекте не нарушаются никакие принципы нормализации, обсуждаемые ниже.
Теперь в дополнение к 1НФ можно определить дальнейшие уровни нормализации —вторую нормальную форму (2НФ), третью нормальную форму (3НФ) и т. д. По существу, таблица находится в 2НФ, если она находится в 1НФ и удовлетворяет, кроме того, некоторому дополнительному условию, суть которого не имеет здесь особого значения. Таблица находится в 3НФ, если она находится в 2НФ и, помимо этого, удовлетворяет еще другому дополнительному условию и т. д. Таким образом, каждая нормальная форма является в некотором смысле более ограниченной, чем ей предшествующая. Но важнее то, что каждая нормальная форма является также и более желательной,
чем предшествующая. Это связано с тем, что «(N+1)-я нормальная форма» не обладает некоторыми непривлекательными особенностями, свойственными «N-й нормальной форме». Общий смысл дополнительного условия, налагаемого на (N+l)-ю нормальную форму по отношению к N-й нормальной форме, состоит именно в исключении этих непривлекательных особенностей. Рассмотрим, например, таблицу SPSC, приведенную ниже. Первичным ее ключом является комбинация полей (НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ). Таблица находится в первой, но не во второй, нормальной форме.
|
|
SPSC
|
НОМЕР_
ПОСТАВЩИКА
|
НОМЕР_
ДЕТАЛИ
|
КОЛИЧЕСТВО
|
ГОРОД
|
|
|
S1
S1
S2
S2
|
Р1
Р2
Р1
Р2
|
300
400
200
400
|
Лондон
Лондон
Париж
Париж
«Непривлекательная особенность» таблицы SPSC очевидна:
поле ГОРОД содержит много избыточной информации. Эта избыточность в свою очередь будет порождать проблемы, связанные с обновлением и непротиворечивостью. Например, для поставщика S1 мог бы указываться город Лондон в одной записи, а город Париж в другой, если не осуществлялись бы соответствующие проверки. Интуитивно представляется, что принято ошибочное решение относительно поля ГОРОД. Лучшим вариантом проекта был бы следующий:
|
|
sp
|
НОМЕР_
ПОСТАВЩИКА
|
НОМЕР_
ДЕТАЛИ
|
КОЛИЧЕСТВО
|
sc
|
НОМЕР_
ПОСТАВЩИКА
|
ГОРОД
|
|
|
S1
S1
S2
S2
|
Р1
Р2
Р1
Р2
|
300
400
200
400
|
|
S1
S2
|
Лондон
Париж
Эти таблицы находятся в 2НФ, а фактически также в 3НФ, в 4НФ и в 5НФ. Здесь 5НФ — это «окончательная» нормальная форма в очень специфическом смысле, обсуждение которого, к сожалению, не входит в задачу этого приложения.
Общая цель дальнейшей дисциплины нормализации заключается в исключении избыточности информации, как это было сделано в предыдущем примере. Эта дисциплина предусматривает ряд принципов, с помощью которых содержащая избыточную информацию таблица может быть разбита на меньшие таблицы, не содержащие избыточности. Окончательная цель, как уже отмечалось, сводится к получению такого проекта, в котором каждый факт появляется в одном и только в одном месте.
Принципы нормализации обсуждаются здесь лишь весьма кратко. Введем сначала понятие функциональной зависимостиОшибка! Закладка не определена. (ФЗ). Говорят, что поле В таблицы Т функционально зависит от поля А таблицы Т в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля Т.А обязательно существует только одно из различных значений поля Т.В. Например, в приведенной выше таблице SPSC поле ГОРОД функционально зависит от поля НОМЕР_ПОСТАВЩИКА, так как для каждого номера поставщика должен существовать в точности один город; если в качестве номера поставщика указывается S1, то каждый раз при этом в поле ГОРОД должно быть задано «Лондон». Отметим, что в этом определении допускается, что поля Т.А и Т.В могут быть составными. Вернемся снова к таблице SPSC. Можно обнаружить, что поле КОЛИЧЕСТВО функционально зависит от составного поля (НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ). Запишем результаты рассмотрения таблицы SPSC следующим образом:
НОМЕР_ПОСТАВЩИКА --® ГОРОД
(НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ) --® КОЛИЧЕСТВО
Мы подошли теперь к критической точке. Если проект базы данных удовлетворяет критерию «каждый факт в одном месте», единственными функциональными зависимостями в любой таблице будут зависимости вида K®F, где К — первичный ключ,, a F — некоторое другое поле.
Заметим, что это следует из определения первичного ключа таблицы, в соответствии с которым K®F всегда имеет место для всех полей данной таблицы. «Один факт в одном месте» говорит о том, что не имеют силы никакие другие функциональные зависимости. Цель дисциплины нормализации состоит именно в том, чтобы избавиться от всех этих «других» ФЗ, т. е. ФЗ, которые имеют иной вид, чем K®F.
Следует рассмотреть, по существу, два случая:
1. Таблица имеет составной первичный ключ вида, скажем, (К1,К2), и включает также поле F, которое функционально зависит от части этого ключа, например от К2, но не от полного ключа. Этот случай был проиллюстрирован выше в примере с таблицей SPSC. В этом случае принципы нормализации рекомендуют сформировать другую таблицу, содержащую К2 и F (первичный ключ— К2), и удалить F из первоначальной таблицы:
Заменить Т (К1, К2, F), первичный ключ (К1, К2), ФЗ К2 --®F
на T1 (К1, К2), первичный ключ (К1, К2),
и Т2 (К2, F), первичный ключ К2.
2. Таблица имеет первичный ключ К, поле F1, которое, конечно, функционально зависит от К, и другое ноле F2, которое функционально зависит от F1. Решение здесь, по существу, то же самое, что и прежде — формируется другая таблица, содержащая F1 и F2, с первичным ключом F1, и F2 удаляется из первоначальной таблицы:
Заменить Т (К, F1, F2) первичный ключ К, ФЗ F1 --®F2
на T1 (К, F1), первичный ключ К
и Т2 (F1, F2), первичный ключ F1.
Для любой заданной таблицы, повторяя применение двух рассмотренных правил, почти во всех практических ситуациях можно получить в конечном счете множество таблиц, которые находятся в «окончательной» нормальной форме и, таким образом, не содержат каких-либо функциональных зависимостей вида, отличного от K--®F.
Далее, дисциплина нормализации влечет за собой сведение больших таблиц к меньшим таблицам. Грубо говоря, предполагается, что в качестве входных данных уже имеется некоторое малое число больших таблиц. Манипулирование ими в соответствии с дисциплиной нормализации порождает в качестве результата большое число малых таблиц. Но эта дисциплина ничего не говорит о том, как прежде всего получить эти большие таблицы. Процедура проектирования, рассмотренная в общих чертах ранее в данном приложении, наоборот, имеет дело именно с этой проблемой. Именно поэтому мы утверждаем, что два указанных подхода дополняют друг друга. Таким образом, предлагаемая общая методология проектирования баз данных состоит из:
1. Использования процедур, рассмотренных в разделах B.1 — В.7, для генерации таблиц, представляющих стержневые, ассоциативные и т. д. сущности, а затем
2. Использования процедур, описанных в данном разделе, для проверки того, чтобы в этих таблицах не было неумышленных нарушений каких-либо принципов нормализации.
Завершая данный раздел, приведем два заключительных замечания о нормализации:
— Низшие нормальные формы, например, 2НФ, сами по себе не особенно важны. Они служат, главным образом, средством получения окончательной нормальной формы.
— Весьма маловероятно встретить на практике таблицы, которые находятся в 3НФ, но не в 4НФ или 5НФ, хотя это теоретически и возможно. Поэтому мы слышим, что люди говорят о третьей нормальной форме, а не о четвертой или пятой, как будто бы она является единственной и окончательной целью. На практике это обычно — позволительное упрощение.
ВОЗМОЖНОСТИ ЯВНОГО БЛОКИРОВАНИЯ
Помимо механизма неявного блокирования, описанного в предыдущем разделе, система DB2 обеспечивает некоторые явные возможности, о которых программист должен быть по меньшей мере осведомлен, хотя в большинстве ситуаций будет достаточно неявных возможностей. Средства явного блокирования в некоторой мере неоднородны и состоят из 1) предложения LOCK TABLE (блокировать таблицу) языка SQL, 2) факультативного параметра уровня изоляции в команде BIND и 3) параметра «единица блокирования» табличного пространства.
Предложение LOCK TABLE
Предложение LOCK TABLE языка SQL имеет следующий формат:
LOCK TABLE имя—таблицы IN режим MODE;
где «режим» может специфицироваться как SHARE (совместный) или EXCLUSIVE (монопольный), «имя—таблицы» должно обозначать базовую таблицу, а не представление. Например:
LOCK TABLE SP IN EXCLUSIVE MODE;
Это предложение устанавливает блокировку типа Х для всей базовой таблицы SP в интересах издающей его транзакции. Конечно, эта транзакция, возможно, должна будет ждать до тех пор, пока она сможет установить эту блокировку, если некоторая другая транзакция ранее уже установила блокировку, противоречащую данной. Как только указанная блокировка будет установлена, никакая другая транзакция не сможет обращаться каким-либо образом к любой части этой таблицы до тех пор, пока не будет снята первоначальная блокировка. Эта блокировка не будет снята, пока не завершится данная программа[21]
(а не транзакция).
Если вместо EXCLUSIVE специфицируется SHARE, то данная транзакция будет, конечно, устанавливать блокировку типа S, а не типа X. При этом другие транзакции не смогут установить блокировку типа Х для рассматриваемой таблицы или какой-либо се части до тех пор, пока не будет снята первоначальная блокировка. Однако до этого момента времени они смогут устанавливать блокировку типа S для данной таблицы или некоторой ее части.
Назначение предложения
LOCK TABLE состоит в следующем. Если транзакция обращается к большому числу отдельных записей и поочередно блокирует их, как было описано в предыдущем разделе, то накладные расходы на блокирование для этой транзакции могут быть весьма высокими в отношении как пространства, так и времени—пространства для удержания блокировок к основной памяти, а времени — для их установки. Рассмотрим, например, программу, которая просматривает всю таблицу поставок и печатает ее. Для такой программы, вероятно, лучше установить единственную блокировку на уровне таблицы, как в приведенном выше примере, и таким образом полностью обойтись для этой таблицы без необходимости блокировок на уровне записей. Это делается, конечно, в ущерб параллелизму, однако производительность данной отдельной транзакции будет повышаться и, возможно, в такой степени, что будет также повышаться суммарная производительность системы.
Установление блокировки типа Х на уровне таблицы действительно позволит полностью обойтись без необходимости блокировок на уровне записей для рассматриваемой таблицы, как было только что сказано. Установление же блокировки типа S на уровне таблицы избавит от блокировок типа Х на уровне записей (опять-таки для рассматриваемой таблицы). В самом деле, если программа обновляет какую-либо запись в данной таблице, ей все же потребуется установить блокировку типа Х для этой конкретной записи, благодаря чему параллельные транзакции будут лишены возможности «увидеть» незафиксированное изменение.
Примечание. Хотя операция LOCK TABLE определяется, конечно, как блокирование базовой таблицы, фактически система DB2 блокирует табличное пространство, которое содержит эту таблицу (см. главу 13).
Уровень изоляции
Уровень изоляции — это свойство плана прикладной задачи. Оно специфицируется с помощью параметра команды BIND, которая продуцирует этот план. Имеются два возможных значения этого параметра: RR («повторяемое чтение») и CS («стабильноcть курсора»), причем RR—значение, которое принимается по умолчанию.
Указанные значения параметра имеют следующий смысл:
— «Стабильность курсора» означает, что если использующая этот план транзакция:
а) получает возможность доступа к некоторой конкретной записи путем установки курсора так, чтобы он указывал эту запись, и таким образом
б) устанавливает для этой записи блокировку типа S, а затем
в) отказывается от возможности доступа к этой записи, не обновляя ее, и поэтому
г) не повышает ее блокировку типа S до уровня X, то
д) можно снять эту блокировку типа S, не обязательно дожидаясь следующей точки синхронизации.
— «Повторяемое чтение» означает, что блокировки типа S на уровне записей удерживаются до следующей точки синхронизации подобно блокировкам типа X. Уровень изоляции CS может обеспечить несколько большую степень параллелизма, чем уровень изоляции RR, но вообще это не очень хороший вариант. Именно поэтому по умолчанию принимается значение RR. Проблема, связанная со значением CS, состоит в том, что для транзакции, оперирующей на этом уровне, запись может быть изменена «у нее за спиной», как показано на рис. 11.4, и поэтому такая транзакция может продуцировать неверный ответ. Фактически, если транзакция оперирует на уровне изоляции CS, то теоретически всегда возможно определить вторую транзакцию, которая может исполняться параллельно с первой таким образом, чтобы продуцировать некорректный общий результат. Напротив, транзакция, оперирующая на уровне изоляции RR, может вести себя совершенно так, как если бы она исполнялась в системе с единственным пользователем.
Заметим, что хотя уровень изоляции специфицируется как часть команды BIND, а не как часть программы, программисту все же необходимо быть о нем осведомленным, поскольку от значения этого параметра может зависеть логика программы, иначе говоря, оно может влиять на способ, которым должна кодироваться программа.
Параметр «единица блокирования» табличного пространства
Этот вопрос здесь затрагивается только для полноты рассмотрения. Следующее описание, вероятно, не будет иметь большого смысла до тех пор, пока читатель не изучит главу 13.
Как указывалось в разделе 11.5, механизм неявного блокирования в системе DB2 определяется в терминах блокировок уровня записей. Однако это логическое
определение. Физически DB2 блокирует данные в терминах страниц или табличных пространств. Иначе говоря, когда заданная транзакция логически блокирует некоторую отдельную запись, система DB2 физически блокирует либо страницу, либо табличное пространство, которое содержит эту запись, в зависимости от того, что было специфицировано для этого табличного пространства в запросе, когда оно создавалось.
Для любого заданного табличного пространства может быть специфицирован в качестве «единицы блокирования» один из следующих вариантов: PAGE (страница), TABLESPACE (табличное пространство) или ANY (любой из предшествующих вариантов). При этом:
— ANY (вариант по умолчанию) означает, что DB2 сама будет решать вопрос о подходящей физической единице блокирования для табличного пространства каждого плана, т. е. для одного и того же табличного пространства один план может устанавливать блокировки на уровне страниц, в то время как другой устанавливает их на уровне табличного пространства.
— TABLESPACE означает, что все блокировки, устанавливаемые на данные в этом табличном пространстве, будут осуществляться на уровне табличного пространства.
— PAGE означает, что в заданном табличном пространстве блокировки данных будут всякий раз, когда это возможно, устанавливаться на уровне страниц. Однако иногда DB2 будет все же устанавливать блокировки на уровне табличного пространства. Детальное рассмотрение этого вопроса выходит за рамки данной работы.
ВПРОЦЕДУРА ПРОЕКТИРОВАНИЯ: ПОСЛЕДОВАТЕЛЬНОСТЬ ОСНОВНЫХ ШАГОВ
Теперь мы имеем возможность представить последовательность основных шагов процедуры проектирования.
Примечание. В последующем для краткости вместо «тип сущностей» будем говорить «сущность».
1. Представьте каждый стержень (независимую сущность) как базовую таблицу. Специфицируйте первичный ключ этой базовой таблицы.
2. Представьте каждую ассоциацию (связь вида «многие-ко-многим» или «многие-ко-многим-ко-многим» и т. д. между сущностями) как базовую таблицу. Используйте в этой таблице внешние ключи для идентификации участников ассоциации. Специфицируйте ограничения, связанные с каждым из этих внешних ключей. Специфицируйте первичный ключ этой таблицы, являющийся, вероятно, комбинацией всех внешних ключей, идентифицирующих участников ассоциации.
3. Представьте каждую характеристику (обозначающую сущность, существование которой зависит от соответствующей обозначаемой сущности) как базовую таблицу с внешним ключом, идентифицирующим сущность, описываемую этой характеристикой. Специфицируйте ограничения на внешний ключ, представляющие зависимость по существованию. Специфицируйте первичный ключ этой таблицы — по всей вероятности, комбинацию этого внешнего ключа и свойства, которое гарантирует «уникальность в рамках описываемой сущности».
4. Представьте каждое обозначение (связь вида «многие-к-одной» между двумя сущностями), с которыми мы еще не имели дела в п. 3, как внешний ключ в базовой таблице, представляющей обозначающую сущность. Специфицируйте связанные с каждым таким внешним ключом ограничения.
5. Представьте каждое свойство как поле в базовой таблице, представляющей сущность, которая непосредственно описывается чтим свойством.
6. Используйте для первичных и внешних ключей рецепты, приведенные ниже в разделах В.6 и В.7.
7. Для того чтобы исключить в проекте непреднамеренные нарушения каких-либо принципов нормализации, выполните процедуру, описанную в разделе В.8.
8. Повторяйте перечисленные шаги до тех пор, пока не будет завершена разработка проекта.
ВРАЗЛИЧНЫЕ СОВЕТЫ И РЕКОМЕНДАЦИИ
Завершим это довольно длинное приложение кратким перечнем различных советов и рекомендаций. Недостаток места исключает возможность слишком подробного обсуждения этих вопросов.
Составные ключи
Использование составных (состоящих из нескольких полей) первичных ключей может оказаться весьма неудобным. Если выясняется, что в Вашем проекте имеется таблица с составным первичным ключом, примите во внимание те преимущества, которые обеспечиваются введением нового, несоставного поля, которое могло бы служить первичным ключом вместо первоначально выбранного. Например, можно ввести в таблицу SP поле номера поставки НОМЕР_ПОСТАВКИ.
Подтипы сущностей
Иногда заданная сущность может быть одновременно нескольких типов. Один и тот же человек, например, может быть одновременно служащим, акционером и покупателем. Кроме того, некоторые типы сущностей являются подтипами других типов. Так, все директора являются служащими. Тип сущностей Y называется подтипом типа сущностей X, если каждый экземпляр Y обязательно является экземпляром X. Все свойства, обозначения и т. д., относящиеся к X, относятся также и к Y, но не наоборот. Например, директора имеют зарплату, поскольку зарплату имеют все служащие, но они имеют также и бюджет, которого не имеют служащие, не являющиеся директорами. Такая ситуация может быть удобно представлена следующим образом (снова с помощью псевдоЯОД):
CREATE TABLE СЛУЖАЩИЕ /* служащие (стержневые сущности)*/
PRIMARY KEY (НОМЕР_СЛУЖАЩЕГО)
FIELDS (НОМЕР_СЛУЖАЩЕГО . . ., ЗАРПЛАТА . . .);
CREATE TABLE ДИРЕКТОРА /* директора — подтип типа сущностей
СЛУЖАЩИЕ*/
PRIMARY KEY (НОМЕР_СЛУЖАЩЕГО)
FOREIGN KEY (НОМЕР_СЛУЖАЩЕГО
IDENTIFIES СЛУЖАЩИЕ и т. д.)
FIELDS (НОМЕР_СЛУЖАЩЕГО . .., БЮДЖЕТ . . .);
Одно из достоинств этого проекта по сравнению с вариантом, когда эти две таблицы скомбинированы в одну, состоит в том, что он исключает необходимость в неопределенных значениях, которые потребовались бы в противном случае для представления значений БЮДЖЕТ для служащих, которые не являются директорами.
Домены
Хотя система DB2 не поддерживает понятие домена, оно может быть все же полезно в процессе проектирования и может быть, однако, представлено средствами псевдоЯОД. Например;
CREATE DOMAIN НОМЕР_СЛУЖАЩЕГО CHAR (5); /*номера
поставщиков */
CREATE TABLE S
FIELDS (НОМЕР_СЛУЖАЩЕГО DOMAIN
(НОМЕР_СЛУЖАЩЕГО), . . .);
CREATE TABLE SP
FIELDS (НОМЕР_СЛУЖАЩЕГО DOMAIN
(НОМЕР_СЛУЖАЩЕГО), . . .);
Рекомендация.
Всегда, когда это возможно, следует давать каждому полю то же самое имя, что и у определяющего домена. Если же такой возможности нет, давайте полю имя этого домена с использованием некоторого уточнителя в качестве префикса, который обеспечивает уникальность полного имени в содержащей его таблице Так, например, можно использовать НОМЕР_ПОСТАВЩИКА, S.HOMEP_ПОСТАВЩИКА или SP.HOMEP_ПOСТАВЩИКА и т. д. в качестве имен полей, содержащих номера поставщиков. Не используйте, например, НОМЕР_ПОСТАВЩИКА в одной таблице, НОМ_ПОСТ — в другой, а НОМЕР_ПОСТ — в третьей и т. д. Одна из причин использования этого правила состоит в том, что оно облегчает жизнь пользователю— нужно запоминать меньше различных имен, допускается меньше произвола. Другая, возможно, более важная причина—это правило позволяет с помощью запроса к каталогу узнать все случаи использования данного домена. Например:
SELECT NAME, TBNAME
FROM SYSIBM. SYSCOLUMNS
WHERE NAME LIKE ' % НОМЕР_ПОСТАВЩИКА';
Неопределенные значения
Будьте очень внимательны с неопределенными значениями. В поведении неопределенных значений проявляется много произвола и противоречивости, и они могут быть в этой связи источником многих трудностей.
Например:
— два неопределенных значения считаются дубликатами друг друга в связи со спецификациями DISTINCT, UNIQUE и ORDER BY; это не относится, однако, к WHERE или GROUP BY;
— при наличии неопределенных значений для стандартных функций COUNT, SUM и AVG не гарантируется удовлетворение требования, чтобы среднее было равно сумме, деленной на количество;
— при наличии неопределенных значений не гарантируется, что выражение SUM(Fl) +SUM(F2) будет иметь то же самое значение, что и выражение SUM(F1+F2), где F1 и F2—некоторые поля.
В результате следует очень внимательно подумать, хотите ли Вы вообще допускать неопределенные значения для каких-либо полей. Вполне возможно, что Вашим намерениям будет лучше служить использование некоторого «недопустимого» значения, которое, однако, не является неопределенным, такого, как -1 для поля ОТРАБОТАННЫЕ_ЧАСЫ. Если Вы действительно выберете этот путь, то данные ранее рецепты относительно первичных и внешних ключей потребуют, конечно, некоторого пересмотра. Заметим, однако, что имеются три места, в которых понятие неопределенного значения встраивается в саму структуру языка SQL. А именно, SQL:
— предусматривает
присваивание неопределенного значения для любого поля, добавляемого к таблице с помощью предложения ALTER TABLE
— генерирует
неопределенное значение как результат применения какой-либо функции, например
AVQ, к пустому множеству
— генерирует
неопределенное значение для любого неспецифицированного поля при выполнении предложения INSERT.
Векторы
Представляйте векторы по столбцам, а не по строкам. Например, диаграмму продаж товаров х,у,... за последние годы лучше представить в виде:
|
|
ПРОДАЖИ
|
ТОВАР
|
МЕСЯЦ
|
КОЛИЧЕСТВО
|
|
|
х
х
.
х
y
y
.
y
.
|
Январь
Февраль
.
декабрь
январь
февраль
.
декабрь
.
|
100
50
.
360
75
144
.
35
.
а не так, как показано ниже:
|
|
ПРОДАЖИ
|
ТОВАР
|
КОЛИЧ_
ЯНВАРЬ
|
КОЛИЧ_
ФЕВРАЛЬ
|
. . .
|
КОЛИЧ_
ДЕКАБРЬ
|
|
|
x
y
.
|
100
75
.
|
50
144
.
|
. . .
. . .
. . .
|
360
35
.
Одна из причин такой рекомендации заключается в том, что при этом значительно проще записываются обобщенные (параметризованные) запросы. Рассмотрите, например, как выглядит сравнение сведений из диаграммы продаж для товара i
в месяце m со сведениями для товара j в месяце n, где i, j, m и n — параметры.
Смысловая перегрузка полей
Не перегружайте полей более чем одним смысловым значением. Например, ясно, что поле «размер заказа на закупку» относится только к закупаемым деталям. Но оно могло бы также использоваться для представления «количества-находящихся-в-работе» деталей, производимых на своем предприятии. Однако такой проект порождает сложности в программировании, трудности в понимании системной документации, приводит также к возникновению серьезных проблем, если когда-либо будет решено и производить на своем предприятии и закупать одну и ту же деталь.
Снова нормализация
В заключение еще несколько слов о нормализации.
— Во-первых, принципы нормализации являются только принципами. Нет никаких обязательных требований, чтобы все таблицы были, например, в третьей нормальной форме. Единственное требование состоит в том, чтобы они были по крайней мере в первой нормальной форме. Дисциплина нормализации в некотором смысле оптимизирует производительность обновления за счет производительности выборки — избыточность, которую пытается исключить нормализация, плоха для обновления, но она может быть хороша для выборки данных. Можно высказать это другим образом: «Принципы нормализации рекомендуют руководствоваться критерием «один факт в одном месте»; но иногда есть существенные причины для того, чтобы иметь два факта в одном месте или один факт в двух местах». Поэтому Вы можете иногда сделать выбор в пользу нарушения этих принципов. Но, поступая так, документируйте причины, которыми Вы руководствовались.
— Во-вторых, все наши обсуждения были связаны с базовыми таблицами. Даже если базовые таблицы находятся в 3НФ, нет никакой необходимости, чтобы этому условию удовлетворяли представления, и в действительности они чаще всего и не находятся в 3НФ. Процедура проектирования, которая была настойчиво рекомендована в этом приложении, в большой степени независима от приложений. Мы просто говорили: «Решите, в каких сущностях Вы заинтересованы; решите, какие существуют между ними связи, и т. д.», и при этом полностью игнорировали вопрос, каким образом планируется использовать эту информацию. Впоследствии можно будет в некоторой мере приспособить, реструктуризовать, скорректировать этот независимый от приложений проект с тем, чтобы удовлетворять потребности конкретных приложений с помощью механизма представлений. Однако такая деятельность по приспособлению носит в большой степени вторичный характер. Главная задача состоит прежде всего в том, чтобы получить как раз независимый проект.
ВРЕЦЕПТ, КАСАЮЩИЙСЯ ПЕРВИЧНЫХ КЛЮЧЕЙ
Как уже указывалось, ЯОД системы DB2 не поддерживает понятий первичного и внешнего ключей. Поэтому в этом и следующем разделе представлены некоторые рецепты, с помощью которых можно провести в жизнь свою собственную дисциплину использования первичных и внешних ключей. Прежде всего, о первичных ключах. Для каждого первичного ключа в Вашем проекте:
— Специфицируйте вариант NOT NULL для каждого входящего в него поля (см. раздел 3.2).
— Создайте индекс со спецификацией UNIQUE по комбинации всех входящих в него полей (см. раздел 3.3).
— Обеспечьте существование указанного индекса всякий раз, когда в эту таблицу вставляется какая-либо запись или обновляется первичный ключ какой-либо записи в этой таблице, т. е. создайте данный индекс, прежде чем первоначально будет загружаться таблица, и «никогда» его не уничтожайте.
— Сохраните спецификации PRIMARY KEY, записанные средствами псевдоЯОД, как комментарий в каталоге (см. раздел 7.3).
ВРЕЦЕПТ, КАСАЮЩИЙСЯ ВНЕШНИХ КЛЮЧЕЙ
Для каждого внешнего ключа в Вашем проекте:
— Специфицируйте вариант NOT NULL для каждого поля в этом внешнем ключе тогда и только тогда, когда для этого внешнего ключа применяется вариант NULLS NOT ALLOWED.
— Примите во внимание преимущества создания индекса (вероятно, без спецификации UNIQUE) по комбинации всех полей в данном внешнем ключе. Такой индекс обычно будет желателен по соображениям производительности — Вы сами сможете часто обнаруживать, что выполняются операции соединения по внешнему ключу и соответствующему ему первичному ключу. Однако обсуждение проблем производительности выходит за рамки этого приложения.
— Используйте механизм санкционирования доступа для запрещения в интерактивном режиме всех операций, которые могли бы нарушить ограничения, налагаемые на эти внешние ключи. Под «операциями в интерактивном режиме» здесь понимаются операции SQL, такие, как INSERT или DELETE, которые запрашиваются конечным пользователем с помощью SPUFI или QMF, а не прикладной программой. В частности, запретите в этом режиме:
— — операции DELETE над таблицей, на котирую имеются ссылки
— — операции UPDATE над первичным ключом таблицы, на которую имеются ссылки
— — операции INSERT над таблицей, на которую имеются ссылки
— — операции UPDATE над внешними ключами таблицы, на которую имеются ссылки.
Примите ограничения на внешние ключи в качестве части спецификации требований к программам ведения базы данных. Идеально было бы иметь в точности одну такую программу для каждого внешнего ключа. Это не означает, что одна программа не может иметь дела с многими внешними ключами. Но один внешний ключ не должен вестись многими программами. Используйте механизм санкционирования доступа для предотвращения исполнения всеми другими программами каких-либо операций, которые могли бы нарушить эти ограничения (см. предыдущий абзац).
Сохраните спецификации
FOREIGN KEY, записанные средствами псевдоЯОД, как комментарий в каталоге. Наконец, в качестве независимой (и консервативной) меры:
Напишите служебную программу, которую следует периодически выполнять для обнаружения любых нарушений ограничений и выдачи сообщений о них.
Ниже приведен пример предложения псевдоЯОД
Ниже приведен пример предложения псевдоЯОД для поставок, показывающий возможное множество спецификаций внешних ключей:
CREATE TABLE SP /*поставки — связывает S и Р*/
PRIMARY KEY (НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ)
FOREIGN KEY (НОМЕР_ПОСТАВЩИКА IDENTIFIES S
NULLS NOT ALLOWED
DELETE OF S.RESTRICTED
UPDATE OF S. НОМЕР_ПОСТАВЩИКА
CASCADES)
FOREIGN KEY (НОМЕР_ДЕТАЛИ IDENTIFIES P
NULLS NOT ALLOWED
DELETE OF P.RESTRICTED
UPDATE OF P.НОМЕР_ДЕТАЛИ
RESTRICTED)
FIELDS (НОМЕР_ПОСТАВЩИКА . . ., НОМЕР_ДЕТАЛИ . .
., КОЛИЧЕСТВО . . .);
Фразы PRIMARY KEY (первичный ключ) и FOREIGN KEY (внешний ключ) в псевдоЯОД имеют следующий общий синтаксис:
Фраза-PRIMARY-KEY
:: = PRIMARY KEY (первичный—ключ),
где «первичный — ключ» — это либо единственное имя-поля, например НОМЕР_ПОСТАВЩИКА, либо заключенный в круглые скобки список имен-полей, разделенных запятыми, например (НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ).
Фраза-FOREIGN-KEY
: : = FOREIGN KEY (внешний—ключ IDENTIFIES цель
NULLS [NOT] ALLOWED
DELETE OF цель эффект
UPDATE OF первичный — ключ — цели эффект),
где а) «внешний—ключ»—то же самое, что было сказано выше о «первичном-ключе», т. е. либо единственное имя-поля, либо заключенный в круглые скобки список имен-полей, разделенных запятыми; б) «цель» — имя-таблицы; в) «первичный-ключ-цели» специфицирует «первичный-ключ» для «цели» и, наконец, г) «эффект—CASCADES (каскадируется), RESTRICTED (ограничивается) или NULLIFIES (устанавливается неопределенное значение).
Примечание. Фразы PRIMARY KEY и FOREIGN KEY, подобные приведенным выше, были бы в высшей степени желательными расширениями существующего ЯОД системы DB2.
ВРЕГИСТРАЦИЯ ПРОЕКТНЫХ РЕШЕНИЙ: ПСЕВДОЯОД
Когда осуществляется процесс проектирования, необходимо, конечно, регистрировать принимаемые проектные решения, и лучше это делать некоторым более или менее формальным образом. Вопрос состоит в том, какой следует использовать для этого формализм. Есть много возможных ответов на этот вопрос, и ни один из них не является, очевидно, более предпочтительным, чем остальные. Это, до некоторой степени,— исключительно дело вкуса. Однако одним из весомых кандидатов на роль такого формализма являются предложения языка определения данных (предложения ЯОД). В конце концов, такие предложения рано или поздно должны быть сформулированы, когда проект будет трансформироваться в определение базы данных. К сожалению, одни только предложения ЯОД системы DB2 оказываются неадекватными поставленной задаче по той важной причине, что они не поддерживают некоторых понятий, в частности, первичных и внешних ключей, что чрезвычайно критично для процесса проектирования, как мы уже могли убедиться. Поэтому здесь предлагается формализм, который можно было бы назвать «псевдоЯОД». ПсевдоЯОД основан на обычном ЯОД, входящем в SQL, но включает конструкции для непосредственной поддержки необходимых отсутствующих понятий. Рассмотрим, например, тип стержневых сущностей «поставщики». Уже говорилось, что каждый тип стержневых сущностей будет отображаться в базовую таблицу системы DB2. Таким образом, можно было бы написать предложение псевдоЯОД:
CREATE TABLE S /* поставщики (стержневые сущности) * /
PRIMARY KEY (НОМЕР_ПОСТАВЩИКА)
FIELDS (НОМЕР_ПОСТАВЩИКА . . . );
для того чтобы зарегистрировать тот факт, что эта базовая таблица, названная S, существует, представляет тип стержневых сущностей «поставщики» и имеет первичный ключ НОМЕР_ПОСТАВЩИКА, который, конечно, является некоторым полем в этой таблице[29]. Позднее мы вернемся к вопросу о добавлении дальнейших спецификаций к этому предложению с тем, чтобы регистрировать другие факты об этом типе сущностей. В идеале все такие предложения псевдоЯОД следовало бы хранить форме текстового файла, и для поддержки этого файла и процессе проектирования использовать текстовой редактор. В конце концов, мы преобразуем эти предложения в подходящее множество подлинных предложений ЯОД системы DB2, которые можно использовать как исходные данные для процесса определения базы данных
ВСХЕМА КЛАССИФИКАЦИИ СУЩНОСТЕЙ
Будем различать сущности трех основных классов: стержневые, ассоциативные и характеристические. Если говорить кратко, стержневая сущность (или стержень) —это независимая сущность (ей свойственно независимое существование). Ассоциативная сущность (или ассоциация) рассматривается как связь между двумя или более другими сущностями вида "многие-ко-многим" (либо "многие-ко-многим-ко-многим" и т. п.). Наконец, характеристическая сущность (характеристика) представляет собой сущность, единственная цель которой в рамках рассматриваемой предметной области состоит в описании или уточнении некоторой другой сущности.
Примеры:
Стержни — поставщики, детали, служащие, отделы
Ассоциации — поставки
Характеристики — номенклатуры заказов (их единственная цель состоит в том, чтобы описать «старшие» сущности, а именно, заказы на закупки)
Ассоциации и характеристики не являются независимыми, поскольку они предполагают существование некоторой другой сущности или сущностей, которые будут ассоциироваться или «характеризоваться».
Основой приведенной выше классификационной схемы служит тот факт, что связи между сущностями можно естественным образом разделить на две различные категории, а именно: связи вида "многие-ко-многим", которые мы называем ассоциациями, и связи вида "многие-к-одной", которые мы называем обозначениями. Более точно:
— Ассоциация, как
уже пояснялось, это связь вида "многие-ко-многим" (-ко-многим и т. д.) между двумя или более сущностями. Ассоциации рассматриваются как полноправные сущности:
они могут обладать свойствами, могут участвовать в других ассоциациях и т. д. точно так же, как стержневые сущности. Например, поставки, являющиеся ассоциациями, имеют в качестве свойства «количество».
— Обозначение—это связь вида "многие-к-одной" между двумя сущностями. Обычно они не рассматриваются как полноправные сущности, хотя это не привело бы ни к какой ошибке. Вместо этого свойства (и т. д.) обозначения в большинстве случаев считаются свойствами (и т. д.) обозначаемой сущности. Пусть, например, служащие зачисляются в отделы. Свойство «дата зачисления» (дата зачисления служащего в отдел), которое, строго говоря, является свойством обозначения, т. е. связи служащий-отдел, вполне может с равным правом рассматриваться как свойство самого по себе служащего.
Примечание. Связь вида «одна-к-одной» рассматривается просто как специальный случай вида «многие-к-одной». В предлагаемой методологии она не получает какой-либо специальной интерпретации.
Характеристика —
это обозначающая сущность, существование которой зависит от сущности, которую она обозначает. Служащие не являются характеристиками отделов, поскольку служащие имеют независимое существование. Если удаляется отдел, то из этого не следует, что также должны быть удалены служащие этого отдела. В отличие от предыдущего примера номенклатуры заказов являются характеристиками заказов на закупки. Номенклатура заказа не может существовать в отсутствие соответствующего заказа на закупку, и если удаляется заказ на закупку, то также должна быть удалена вся номенклатура этого заказа.
Необходимость в характеристических сущностях возникает в связи с тем, что сущности реального мира имеют иногда многозначные свойства. Предположим, например, что поступают детали нескольких цветов и что имеется в распоряжении деталь Р1 красного, белого и голубого цвета. Поскольку реляционная модель не поддерживает повторяющихся групп, следующий вариант недопустим:
|
|
Р
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
. . .
|
|
|
Р1
|
Гайка
|
|
. . .
Вместо этого мы должны представить данную ситуацию следующим образом:
|
|
Р
|
НОМЕР_
ДЕТАЛИ
|
НАЗВАНИЕ
|
. . .
|
PC
|
НОМЕР_
ДЕТАЛИ
|
ЦВЕТ
|
|
|
Р1
|
Гайка
|
. . .
|
|
Р1
Р1
Р1
|
Красный
Белый
Голубой
Здесь таблица Р представляет тип стержневых сущностей (тип сущностей «деталь»), а таблица PC — тип характеристических сущностей (тип сущностей «цвет деталей»), существование которых зависит от этих стержневых сущностей. Если, например, из таблицы Р удаляется Р1, то из таблицы PC должны быть также удалены все записи, соответствующие Р1.
Поскольку характеристическая сущность представляет собой частный случай сущности, она может, конечно, иметь свойства, может участвовать в ассоциациях, обозначать другие сущности и иметь свои собственные (более низкого уровня) характеристики.
Переопределим, наконец, стрежневую сущность как сущность, которая не является ни ассоциацией, ни характеристикой. Стержневые сущности — это «все то, о чем база данных». Такие сущности имеют независимое существование, хотя они могут все-таки обозначать другие сущности, как, например, служащие обозначают отделы. Любая сущность, независимо от того, является ли она стержневой, характеристической или ассоциативной, может вместе с тем быть обозначаемой.
ВСТАВКА ЕДИНСТВЕННОЙ ЗАПИСИ С ОПУЩЕННЫМИ ИМЕНАМИ ПОЛЕЙ
Добавить деталь Р8 в таблицу Р, при этом: название—'Звездочка', цвет — 'Розовый', вес— 14, город — 'Ницца'.
INSERT
INTO P
VALUES ('Р8', 'Звездочка', 'Розовый', 14, 'Ницца');
Отсутствие списка полей эквивалентно спецификации списка всех полей в таблице в порядке слева — направо, как они были определены в предложении CREATE (или ALTER). Как и «SELECT * », такая краткая нотация может быть удобной для интерактивного SQL. Она потенциально опасна, однако, во встроенном SQL, т. е. в предложениях SQL, используемых в прикладной программе, в связи с тем, что предполагаемый список полей может изменяться, если для программы заново осуществляется связывание, а определение таблицы было в этом промежутке времени изменено.
ВСТАВКА ЕДИНСТВЕННОЙ ЗАПИСИ
Добавить в таблицу Р деталь Р7 (город 'Атенс', вес — 2, название и цвет в настоящее время неизвестны).
Insert
INTO Р (НОМЕР_ДЕТАЛИ, ГОРОД, BEC)
VALUES ('Р7', 'Атенс', 2);
Создается новая запись для детали с заданным номером, городом и весом, с неопределенными значениями для названия и цвета. Эти два последних поля не должны быть, конечно, определены как NOT NULL в предложении CREATE TABLE для таблицы Р. Порядок слева — направо, в котором поля указаны в предложении INSERT, не обязательно должен совпадать с порядком слева — направо, в котором поля были специфицированы в предложении CREATE (или ALTER).
Вставить новую поставку с номером поставщика S20, номером детали Р20 и количеством 1000.
INSERT
INTO SP (НОМЕР—ПОСТАВЩИКА, НОМЕР—ДЕТАЛИ, КОЛИЧЕСТВО)
VALUES ('S20', 'Р20', 1000);
Подобно операциям
UPDATE и DELETE операция INSERT при отсутствии соответствующего управления также может порождать проблему целостности по ссылкам (см. главу 11, а также Приложения А и В). В рассматриваемом случае система DB2 не проверяет, имеется ли поставщик S20 в таблице S и деталь Р20 в таблице Р.
ВСТАВКА МНОЖЕСТВА ЗАПИСЕЙ
Для каждой поставляемой детали получить ее номер и общий объем поставок, сохранить результат в базе данных (см. пример 5.4.7).
CREATE TABLE ВРЕМЕННАЯ
(НОМЕР_ДЕТАЛИ CHAR (6),
ОБЪЕМ_ПОСТАВКИ INTEGER);
INSERT
INTO ВРЕМЕННАЯ (НОМЕР_ДЕТАЛИ, ОБЪЕМ_ПОСТАВКИ)
SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
FROM SP
GROUP BY НОМЕР_ДЕТАЛИ;
Здесь предложение
SELECT выполняется точно так же, как обычно, но результат не возвращается пользователю, а копируется в таблицу ВРЕМЕННАЯ. Теперь с этой копией пользователь может делать все, что он пожелает — делать дальнейшие запросы, печатать и даже обновлять ее. Никакая из этих операций не будет оказывать какого-либо влияния на первоначальные данные. В конечном счете таблицу ВРЕМЕННАЯ можно будет уничтожить, когда она больше не будет нужна:
DROP TABLE ВРЕМЕННАЯ;
Предыдущий пример очень хорошо показывает, почему свойство замкнутости реляционных систем, обсуждаемое во введении к разделу 4.2, является таким важным. Приведенная полная процедура работает именно в связи с тем, что результатом предложения SELECT является другая таблица. Она не работала бы, если бы результат был чем-либо иным, кроме таблицы.
Между прочим, целевая таблица вовсе не обязательно должна быть первоначально пустой для вставки множества записей, хотя в приведенном примере это так. Если таблица не пуста, новые записи просто добавляются к тем, которые уже имеются.
Одно из важных применений INSERT.. .SELECT — построение так называемого внешнего соединения. Как указывалось в главе 4, обычное (естественное) соединение двух таблиц не включает в результате строк какой-либо из двух таблиц, для которых нет соответствующих строк в другой таблице. Например, обычное соединение таблиц S и Р по городам не включает какой-либо строки для поставщика S5 или для детали РЗ, поскольку в Атенсе не хранится никакая деталь и нет поставщиков, находящихся в Риме (см. пример 4.3.1). Следовательно, в некотором смысле можно считать, что при обычном соединении теряется информация
для таких несоответствующих строк. Однако иногда может потребоваться способность сохранять эту информацию. Рассмотрим следующий пример.
ВСТАВКА ОДНОЙ ЗАПИСИ
Добавить в таблицу Р деталь Р7 со следующими характеристиками: город «Атенс», вес 2, название и цвет в настоящее время неизвестны (пример 6.4.1):
|
|
Р
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
ГОРОД
|
|
I.
|
Р7
|
|
|
2
|
Атенс
Здесь «I.» аналогично «D.» в предыдущем примере указано под именем таблицы.
В заключение данного раздела следует заметить, что существуют некоторые запросы, которые могут быть сформулированы в SQL, но не выражаются в QBE, по крайней мере с помощью его реализации в QMF. Так, в QBE не предусмотрены какие-либо диалоги следующих конструкций SQL:
– NOT EXISTS
– стандартных функций (SUM, AVG и т. д.)
– GROUP BY и
HAVING.
Эти опущения не имеют столь важного значения: NOT EXISTS и HAVING необходимы лишь для весьма сложных запросов; а результатов, получаемых с помощью GROUP BY и стандартных функций, можно во всяком случае достигнуть более легким образом, используя возможности генерации отчетов QMF.
ВЫБОРКА ПО МНОЖЕСТВУ УСЛОВИЙ
Выдать номера деталей, вес которых находится в диапазоне от 16 до 19 включительно (пример 4.2.7):
|
|
Р
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
ВЕС
|
ГОРОД
|
|
|
Р.
|
|
|
>= 16
|
<= 19
|
Для добавления к пустой таблице второго столбца с именем ВЕС перед тем, как формулировать запрос, используются команды редактирования.
ВЫБОРКА, ПРИ КОТОРОЙ ВОВЛЕКАЕТСЯ NULL (неопределенное значение)
Допустим, например, что значением в столбце СОСТОЯНИЕ для поставщика S5 является не 30, а неопределенное значение. Выдать номера поставщиков, у которых состояние больше, чем 25:
SELECT НОМЕР_ПОСТАВЩИКА
FROM S
WHERE СОСТОЯНИЕ > 25;
В результате получим:
|
|
НОМЕР_ПОСТАВЩИКА
|
|
S3
Здесь поставщик S5 не был назван в результате. Если неопределенное значение сравнивается с некоторым другим значением при вычислении предиката, то независимо от используемого оператора сравнения результатом сравнения никогда не является истина, даже если этот другой операнд также является неопределенным значением. Иными словами, если оказывается, что СОСТОЯНИЕ имеет неопределенное значение, то ни одно из следующих сравнений не будет принимать значение истина[12]:
СОСТОЯНИЕ > 25
СОСТОЯНИЕ < = 25
СОСТОЯНИЕ = 25
СОСТОЯНИЕ Ø= 25
СОСТОЯНИЕ = NULL (Это недопустимая синтаксическая конструкция. См. ниже)
СОСТОЯНИЕ Ø= NULL (Это — тоже).
Поэтому если издать запрос:
SELECT НОМЕР_ПОСТАВЩИКА
FROM S
WHERE СОСТОЯНИЕ < = 25;
и сравнить его результат с результатом предыдущего запроса, то можно установить, что поставщик S5 не появляется ни в одном из них. Результат приведенного запроса:
|
|
НОМЕР_ПОСТАВЩИКА
|
|
S1
S2
S4
Для проверки наличия (или отсутствия) неопределенного значения предусмотрен специальный предикат вида:
имя — столбца IS [NOT] NULL
Например:
SELECT НОМЕР_ПОСТАВЩИКА
FROM S
WHERE СОСТОЯНИЕ IS NULL;
В результате имеем:
|
|
НОМЕР_ПОСТАВЩИКА
|
|
S5
Синтаксическая конструкция «СОСТОЯНИЕ = NULL» является некорректной, поскольку ничто — и даже само неопределенное значение — не считается равным неопределенному значению. (Несмотря на это, два неопределенных значения рассматриваются, однако, как дубликаты друг друга при исключении дубликатов. Предложение SELECT DISTINCT (ВЫБРАТЬ РАЗЛИЧНЫЕ) даст в результате не более одного неопределенного значения. Аналогичным образом индекс со спецификацией UNIQUE (уникальный) будет допускать в индексируемом столбце не более одного неопределенного значения. Наконец, при упорядочении ORDER BY (УПОРЯДОЧИТЬ ПО) неопределенные значения интерпретируются, как будто бы они больше или равны всем значениям, не являющимся неопределенными).
Заметим, между прочим, что использование символа NULL во фразе SELECT не допускается. Например, следующая конструкция некорректна:
SELECT НОМЕР_ДЕТАЛИ, 'ВЕС = ', NULL
FROM P
WHERE ВЕС IS NULL;
ВЫБОРКА С ИСКЛЮЧЕНИЕМ ДУБЛИКАТОВ
Выдать номера для всех поставляемых деталей, исключая избыточные дубликаты:
SELECT DISTINCT НОМЕР—ДЕТАЛИ
FROM SP;
В этом случае результат таков:
|
|
НОМЕР_ДЕТАЛИ
|
|
Р1
Р2
РЗ
Р4
Р5
Р6
ВЫБОРКА С ИСПОЛЬЗОВАНИЕМ BETWEEN (между)
Выдать сведения о деталях, вес которых находится в диапазоне от 16 до 19 включительно:
SELECT НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС, ГОРОД
FROM P
WHERE ВЕС BETWEEN 16 AND 19;
Имеем следующий результат:
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
ГОРОД
|
|
Р2
РЗ
Р6
|
Болт
Винт
Блюм
|
Зеленый
Голубой
Красный
|
17
17
19
|
Париж
Рим
Лондон
Может быть также специфицировано NOT BETWEEN (не принадлежит диапазону между), например:
SELECT НОМЕР_ДЕТАЛИ, НАЗВАНИЕ. ЦВЕТ, ВЕС, ГОРОД
FROM P
WHERE ВЕС NOT BETWEEN 16 AND 19;
Получаем тогда:
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
ГОРОД
|
|
Р1
Р4
Р5
|
Гайка
Винт
Кулачок
|
Красный
Красный
Голубой
|
12
14
12
|
Лондон
Лондон
Париж
ВЫБОРКА С ИСПОЛЬЗОВАНИЕМ IN (принадлежит)
Выдать детали, вес которых равен 12, 16 или 17:
SELECT НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС, ГОРОД
FROM P
WHERE ВЕС IN (12, 16, 17);
Результат:
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
ГОРОД
|
|
Р1
Р2
РЗ
Р5
|
Гайка
Болт
Винт
Кулачок
|
Красный
Зеленый
Голубой
Голубой
|
12
17
17
12
|
Лондон
Париж
Рим
Париж
Предикат IN является в действительности просто краткой записью предиката, представляющего собой последовательность отдельных сравнений, соединенных операторами OR (или). Предыдущее предложение SELECT эквивалентно следующему:
SELECT НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС, ГОРОД
FROM P
WHERE ВЕС = 12
OR ВЕС = 16
OR ВЕС = 17;
Имеется в распоряжении также предикат NOT IN (не принадлежит), например предложение:
SELECT НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС, ГОРОД
FROM P
WHERE ВЕС NOT IN (12, 16, 17);
дает результат:
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
ГОРОД
|
|
Р4
Р6
|
Винт
Блюм
|
Красный
Красный
|
14
19
|
Лондон
Лондон
Подобно предикату IN предикат NOT IN может рассматриваться только как сокращенная запись другого предиката, который не использует NOT IN. Упражнение.
Запишите «развернутую форму» предложения из предшествующего примера.
ВЫБОРКА С ИСПОЛЬЗОВАНИЕМ КВАНТОРОВ СУЩЕСТВОВАНИЯ
Выдать фамилии поставщиков, поставляющих деталь Р2 (пример 5.3.1):
|
|
S
|
НОМЕР_
ПОСТАВЩИКА
|
ФАМИЛИЯ
|
|
SP
|
НОМЕР_
ПОСТАВЩИКА
|
НОМЕР_
ДЕТАЛИ
|
|
|
_SX
|
Р.
|
|
|
_SX
|
Р2
Строка в таблице SP неявным образом квантифицирована квантором существования «существует». Этот запрос можно перефразировать следующим образом: «Показать на экране фамилии поставщиков SX таких, что существует какая-либо поставка детали Р2 поставщиком SX».
ВЫБОРКА С ИСПОЛЬЗОВАНИЕМ ПРЕДИКАТА LIKE (похоже на)
Выдать все детали, названия которых начинаются с буквы «С»:
SELECT НОМЕР_ДЕТАЛИ, НАЗВАНИЕ, ЦВЕТ, ВЕС, ГОРОД
FROM P
WHERE НАЗВАНИЕ LIKE 'C%';.
Получаем результат (Англоязычные названия деталей с номерами Р5 и Р6 в этом примере — Cam и Cog соответственно.— Примеч. пер.):
|
|
НОМЕР_ДЕТАЛИ
|
НАЗВАНИЕ
|
ЦВЕТ
|
ВЕС
|
ГОРОД
|
|
Р5
Р6
|
Кулачок
Блюм
|
Голубой
Красный
|
12
19
|
Париж
Лондон
Обычно предикат LIKE имеет форму:
имя—столбца LIKE литерная—строковая—константа, где «имя—столбца» должно обозначать столбец типа CHAR или VARCHAR. Этот предикат принимает для заданной записи значение истина, если значение в указанном столбце соответствует образцу, специфицируемому «литерной—строковой—константой». Литеры этой константы интерпретируются следующим образом:
— Литера «_» (разрыв или подчеркивание) обозначает любую одиночную литеру.
— Литера «%» (процент) обозначает любую последовательность из п литер (где п может быть нулем).
— Все другие литеры обозначают просто сами себя.
Следовательно, в приведенном примере предложение SELECT будет осуществлять выборку записей из таблицы P, для которых значение в столбце НАЗВАНИЕ начинается буквой «С» и содержит любую последовательность из нуля или более литер, следующую за этой буквой «С».
Ниже приведено еще несколько примеров, в которых используется LIKE:
АДРЕС LIKE '% Беркли %' будет принимать значение истина, если АДРЕС содержит где-либо внутри него строку 'Беркли'
НОМЕР_ПОСТАВЩИКА LIKE 'S_ _ ' будет принимать значение истина, если значение в столбце НОМЕР—ПОСТАВЩИКА состоит в точности из трех литер и первая из них литера «S»
НАЗВАНИЕ LIKE '% К_ _ _ ' будет принимать значение истина, если значение в столбце НАЗВАНИЕ состоит из четырех или более литер и трем последним из них предшествует литера «К»
ГОРОД NOT LIKE ' % Е %' будет принимать значение истина, если значение ГОРОД не содержит литеры «Е»
ВЫБОРКА С ИСПОЛЬЗОВАНИЕМ СОЕДИНЕНИЯ
Выдать номера деталей, которые либо весят более 16 фунтов, либо поставляются поставщиком S2, либо удовлетворяют обоим этим условиям (пример 5.5.1):
|
|
Р
|
НОМЕР_
ДЕТАЛИ
|
ВЕС
|
|
SP
|
НОМЕР_
ПОСТАВЩИКА
|
НОМЕР_ДЕТАЛИ
|
|
|
|
|
|
|
_РХ
|
> 16
|
|
|
S2
|
_PY
|
|
|
Р.
Р.
|
_РХ
_PY
Выдать номера поставщиков и состояния для поставщиков из Парижа в порядке возрастания номеров поставщиков в рамках убывания состояния. (Расширенный вариант примера 4.2.6.)
Имеем в QBE:
|
|
S
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
ГОРОД
|
|
|
Р. АО(2)
|
|
Р. DО(1)
|
Париж
Здесь «АО.» обозначает «в порядке возрастания», a «DO.» — «и порядке убывания». Целые числа в скобках указывают последовательность «от старшего к младшему» для столбцов упорядочения. В данном примере СОСТОЯНИЕ—старший столбец, а НОМЕР_ПОСТАВЩИКА—младший.
ВЫБОРКА С УПОРЯДОЧЕНИЕМ
Выдать номера и состояния поставщиков, находящихся в Париже, в порядке убывания их состояния:
SELECT НОМЕР_ПОСТАВЩИКА, СОСТОЯНИЕ
FROM S
WHERE ГОРОД = 'Париж'
ORDER BY СОСТОЯНИЕ DESC;
Результат:
|
|
НОМЕР_ПОСТАВЩИКА
|
СОСТОЯНИЕ
|
|
S3
S2
|
30
10
В общем случае не гарантируется, что результирующая таблица будет упорядочена каким-либо определенным образом. Здесь, однако, пользователь специфицировал, что результат перед тем, как он будет показан, должен быть организован в определенной последовательности. Упорядочение может быть специфицировано таким же образом, как в предложении CREATE INDEX (см. раздел 3.3):
имя—столбца [упорядочение] [,имя—столбца [упорядочение]]..., где «упорядочение», как и ранее, это ASC (возрастание) или DECS (убывание), и по умолчанию принимается ASC. Каждое «имя—столбца» должно идентифицировать некоторый столбец результирующей таблицы. Поэтому, например, следующее предложение недопустимо:
SELECT НОМЕР_ПОСТАВЩИКА
FROM S
ORDER BY ГОРОД;
Разрешается также идентифицировать столбцы во фразе ORDER BY (упорядочить по) «номерами—столбцов» вместо «имен—столбцов», где «номер—столбца» указывает порядковую позицию (слева направо) данного столбца в результирующей таблице запроса. Благодаря этому возможно упорядочение результата на основе «вычисляемых столбцов», которые не обладают именем. Например, упорядочить результат примера 4.2.3 по возрастанию номера детали в рамках возрастания веса в граммах:
SELECT НОМЕР_ДЕТАЛИ, ВЕС*454
FROM P
ORDER BY 2, НОМЕР_ДЕТАЛИ; [или ORDER BY 2,1;]
Здесь «2» ссылается на второй столбец результирующей таблицы.
Получаем:
|
|
НОМЕР_ДЕТАЛИ
|
|
|
Р1
Р5
Р4
Р2
РЗ
Р6
|
5448
5448
6356
7718
7718
8626
ВЫБОРКА СПЕЦИФИЦИРОВАННЫХ ИЗ СОЕДИНЕНИЯ
Выдать все комбинации номеров поставщиков и номеров деталей, таких, что поставщик и деталь соразмещены:
SELECT S.НОМЕР_ПОСТАВЩИКА, Р.НОМЕР_ДЕТАЛИ
FROM S, P
WHERE S.ГОРОД = Р.ГОРОД;
Имеем результат:
|
|
НОМЕР_ПОСТАВЩИКА
|
НОМЕР_ДЕТАЛИ
|
|
S1
S1
S1
S2
S2
S3
S3
S4
S4
S4
|
P1
P4
P6
P2
P5
P2
P5
P1
P4
P6
ВЫБОРКА (специфицированных полей из) СОЕДИНЕНИЯ
Выдать все комбинации «номер поставщика/номер детали» такие, что рассматриваемые поставщик и деталь «соразмещены» (пример 4.3.4):
|
|
S
|
НОМЕР_
ПОСТАВЩИКА
|
ГОРОД
|
|
Р
|
НОМЕР_
ДЕТАЛИ
|
ГОРОД
|
|
|
|
|
|
|
_SX
|
_сх
|
|
|
_РХ
|
_сх
|
|
P.
|
_SX
|
_РХ
Пояснение. Для этого запроса нужны три пустых таблицы — по одной для S и Р (показаны только столбцы, имеющие отношение к данному запросу) и одна — для результата. При этом и таблице для результата можно не специфицировать ни имени этой таблицы, ни имен столбцов. Обратите внимание, каким образом специфицированы элементы образца, которые связывают эти три таблицы. Полный запрос может быть перефразирован следующим образом: «Показать на экране пары номер поставщика/номер детали — SX/PX — такие, что SX и РХ размещены в одном и том же городе СХ».
ВЫБОРКА, ТРЕБУЮЩАЯ ИСПОЛЬЗОВАНИЯ СВЯЗКИ OR
Выдать номера поставщиков и состояния для поставщиков, которые либо находятся в Париже, либо имеют состояние более 20, либо удовлетворяют обоим этим условиям (модифицированный вариант примера 4.2.5).
Условия, специфицированные в одной строке, считаются соединенными связкой AND, как иллюстрировалось приведенными до сих пор примерами. Для того, чтобы два условия были связаны с помощью OR, они должны быть специфицированы в разных строках, как показано ниже:
|
|
S
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
ГОРОД
|
|
|
Р.
Р.
|
|
> 20
|
Париж
Замечание. Если данный поставщик удовлетворяет обоим условиям этого примера, соответствующий номер поставщика будет всеже появляться в результате только один раз.
Другой подход к этому запросу основан на использовании так называемого блока условия.
Блок условия позволяет специфицировать условия любой степени сложности. Например:
|
|
S
|
НОМЕР_ПОСТАВЩИКА
|
ФАМИЛИЯ
|
СОСТОЯНИЕ
|
ГОРОД
|
|
|
Р.
|
|
-ST
|
-SC
|
|
УСЛОВИЯ
|
|
-SC = Париж OR -ST > 20
Пояснение. Здесь -ST и -SC являются «элементами образца». Фактически они представляют собой переменные,
обозначающие состояние и город соответственно некоторого потенциального целевого поставщика. Блок условия специфицирует предикат, которому должны удовлетворять эти переменные для того, чтобы соответствующий целевой поставщик оказался среди поставщиков, подлежащих выборке. Имя элемента образца может быть произвольным с тем лишь ограничением, что оно должно начинаться с символа подчеркивания.
Другая команда редактирования DRAW COND (нарисовать блок условия) служит для того, чтобы заставить QMF показать на экране пустой блок условия. Условия в блоке условия могут включать AND, OR, NOT, IN (только в форме простого списка значений), LIKE и NULL, совсем как в SQL. (Замечание. IN, LIKE и NULL могут использоваться при заполнении пустой таблицы так же, как и блока условия.) Однако часто легче формулировать запросы без использования блока условия, и в дальнейшем возможность его использования часто будет игнорироваться.
ВЫБОРКА ВЫЧИСЛЯЕМЫХ ЗНАЧЕНИЙ И КОНСТАНТ
Выдать для всех деталей номера деталей и вес их в граммах. Вес деталей в таблице Р задан в фунтах (расширенный вариант примера 4.2.3);
|
|
Р
|
НОМЕР_ДЕТАЛИ
|
ВЕС
|
|
|
|
|
Р.
|
_PW
|
Р. 'Вес в граммах=’
|
P._ PW ´ 454
ВЫБОРКА ВЫЧИСЛЯЕМЫХ ЗНАЧЕНИЙ
Выдать номер и вес каждой детали в граммах для всех деталей, предполагая, что в таблице Р веса деталей заданы в фунтах (фунт приблизительно равен 454 грамма — Примеч. пер,)
SELECT НОМЕР_ДЕТАЛИ, ВЕС *454
FROM Р;
Получаем результат:
|
|
НОМЕР_ДЕТАЛИ
|
|
|
Р1
Р2
РЗ
Р4
Р5
Рб
|
5448
7718
7718
6356
5448
8626
Фраза SELECT (и фраза WHERE) может включать арифметические выражения, а также простые имена полей. Можно, кроме того, осуществлять выборку просто констант. Например:
SELECT НОМЕР_ДЕТАЛИ, 'Вес в граммах = ', ВЕС*454
FROM Р;
Получаем результат:
|
|
НОМЕР_ДЕТАЛИ
|
|
|
|
Р1
Р2
РЗ
Р4
Р5
Р6
|
Вес в граммах =
Вес в граммах =
Вес в граммах =
Вес в граммах =
Вес в граммах =
Вес в граммах =
|
5448
7718
7718
6356
5448
8626
Заметим, что в этом результате три столбца.
В связи с этим примером возникает следующий вопрос: что произойдет, если вес какой-либо детали имеет неопределенное значение (NULL)? Напомним, что NULL представляет неизвестное значение. Предположим, например, что вес детали Р1 задан в базе данных как неопределенное значение вместо значения 12. Каково тогда значение выражения ВЕС*454 для этой детали? Ответ состоит в том, что оно также является неопределенным значением. В общем случае фактически любое арифметическое выражение считается имеющим неопределенное значение, если какой-либо из его операндов сам имеет неопределенное значение. Иными словами, если оказывается, что вес имеет неопределенное значение, то неопределенное значение имеют и все следующие выражения:
ВЕС+454
ВЕС - 454
ВЕС*454
ВЕС/454
Неопределенные значения показываются на терминале как тире или дефис. Дальнейшее обсуждение неопределенных значений связано с примером в разделе 4.2.10.
ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
В этой главе был представлен краткий обзор объектов среды хранения, поддерживаемых системой DB2. Как уже отмечалось в разделе 13.1, мы не ставили задачи описать в этой книге во всех подробностях соответствующие предложения определения данных. Отметим, однако, следующее.
– Табличное пространство для данной таблицы специфицируется и предложении CREATE TABLE, соответствующем этой таблице.
– База данных для данного табличного пространства специфицируется в предложении CREATE TABLESPACE, соответствующем этому табличному пространству; предполагается, что база данных для заданного индексного пространства—та же, что и для таблицы, над которой определяется этот индекс — индексное пространство должно быть частью той же базы данных, в которую входит соответствующее табличное пространство.
– Детальные аспекты сегментирования (диапазоны страниц и т. п.) табличного пространства специфицируются в предложении CREATE INDEX для требуемого индекса кластеризации. Подробности сегментирования соответствующего индексного пространства специфицируются также в этом предложении CREATE INDEX.
– Группа памяти для данного пространства или сегмента специфицируется в предложении CREATE TABLESPACE или CREATE INDEX, определяющем это пространство или этот сегмент.
– Тома, составляющие данную группу памяти, специфицируются и предложении CREATE, которое создает эту группу памяти.
Помимо всего перечисленного выше, а также указанного в разделе 13.1, DB2 обеспечивает исчерпывающую систему спецификации по умолчанию, которая разработана для того, чтобы облегчить «вхождение в контакт» с системой. Полный механизм умолчаний можно представить следующим образом:
– Предложение CREATE TABLE может специфицировать базу данных, а не табличное пространство. В этом случае DB2 автоматически создает табличное пространство в этой базе данных для новой таблицы. Это табличное пространство будет автоматически уничтожаться при уничтожении данной таблицы. При этом даже нет необходимости специфицировать базу данных. Если не специфицированы ни база данных, ни табличное пространство, DB2 создаст табличное пространство для новой таблицы в базе данных по умолчанию—базе данных, определяемой для таких целей при установке системы.
– Если в предложении CREATE TABLESPACE не специфицируется база данных, то новое табличное пространство будет назначаться в базе данных по умолчанию.
— Группа памяти может быть специфицирована на любом (или на всех) из следующих уровней:
— уровень базы данных (в предложении CREATE DATABASE)
— уровень пространства (в предложениях CREATE TABLESPACE и CREATE INDEX)
— уровень сегмента (в спецификации сегмента в предложениях CREATE INDEX и CREATE TABLESPACE).
Если для заданного сегмента не специфицирована группа памяти на уровне сегмента, то имеется в виду группа памяти, которая относится к пространству, содержащему данный сегмент. Если группа памяти не специфицирована для заданного пространства на уровне пространства, то для этого пространства имеется в виду группа памяти, которая относится к содержащей это пространство базе данных. Если же не специфицирована группа памяти на уровне базы данных для заданной базы данных, то для этой базы данных будет использоваться группа памяти по умолчанию — группа памяти, которая определяется для таких целей при установке системы.
Из всего сказанного выше следует, что приведенные в главе 3 предложения определения данных действительно адекватны потребностям «легкого вхождения в контакт». Однако в большинстве реальных ситуаций на установке потребуется, вероятно, осуществлять более жесткое управление, которое возможно без использования умолчаний. Назначение умолчаний состоит, главным образом, в том, чтобы дать пользователю возможность быстро научиться использованию системы, а не в обеспечении подходящего множества спецификаций для производственной обстановки.
В заключение следует кратко упомянуть о буферных пулах. Буферы в основной памяти группируются в ряд пулов. Заданное пространство может использовать только один такой пул. Буферный пул для заданного пространства специфицируется с помощью еще одного параметра в соответствующем предложении CREATE. Если этот параметр опущен, то, как обычно, предполагается, конечно, спецификация по умолчанию. Таким образом, установка системы может в некоторой степени управлять разделением и близостью данных в основной памяти. Например, можно было бы приписать данное индексное пространство и соответствующее ему табличное пространство к различным буферным пулам, повышая, таким образом, вероятность того, что статьи индекса и записи данных могут одновременно находиться в основной памяти.
ЗАПРОС, ИСПОЛЬЗУЮЩИЙ EXISTS
Выдать фамилии поставщиков, которые поставляют деталь P2 (та же самая задача, что и в примерах 5.2.1 и 5.2.3).
SELECT ФАМИЛИЯ
FROM S
WHERE EXISTS
(SELECT *
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА=
S.НОМЕР_ПОСТАВЩИКА
AND НОМЕР_ДЕТАЛИ = 'P2');
Пояснение. EXISTS (существует) представляет здесь квантор существования — понятие, заимствованное из формальной логики. Пусть символ «х» обозначает некоторую произвольную переменную. Тогда в логике предикат с навешенным квантором существования EXISTS х (предикат—зависящий—от—х) принимает значение истина
тогда и только тогда, когда «предикат—зависящий—от—х» имеет значение истина при каком-либо значении переменной х. Предположим, например, что переменная х обозначает любое целое число в диапазоне от 1 до 10. Тогда предикат
EXISTS х (х < 5)
принимает значение истина. Напротив, предикат
EXISTS х (х < 0)
принимает значение ложь.
В языке SQL предикат с квантором существования представляется выражением вида
EXISTS (SELECT * FROM. . .).
Такое выражение считается истинным тогда и только тогда, когда результат вычисления подзапроса, представленного с помощью «SELECT* FROM.. .», является непустым множеством, иными словами, тогда и только тогда, когда существует какая-либо запись в таблице, указанной во фразе FROM подзапроса, которая удовлетворяет условию WHERE этого подзапроса. (На практике этот подзапрос всегда будет коррелированным множеством.)
Вернемся к приведенному выше примеру. Поочередно рассматриваем каждое значение столбца ФАМИЛИЯ и проверяем, является ли для него истинным условие существования. Предположим, что первое значение поля ФАМИЛИЯ — 'Смит'. Тогда соответствующее значение поля НОМЕР_ПОСТАВЩИКА—S1. Является ли пустым множество записей из SP, содержащих НОМЕР_ПОСТАВЩИКА, равный S1, и НОМЕР_ДЕТАЛИ, равный Р2? Если ответ отрицателен, то существует запись в SP с НОМЕРОМ_ПОСТАВЩИКА, равным S1, и номером детали, равным Р2, и, следовательно, 'Смит' должно быть одним из результирующих значений. Аналогично поступаем для каждого из других значений столбца ФАМИЛИЯ.
Хотя этот первый пример только показывает иной способ формулировки запроса для задачи, с которой мы уже умеем справляться в языке SQL (используя либо соединение, либо оператор IN), EXISTS представляет собой одну из наиболее важных возможностей полного языка SQL. Фактически любой запрос, который может быть выражен с использованием IN, может быть альтернативным образом сформулирован также с помощью EXISTS. Однако обратное высказывание несправедливо (см., например, п. 5.3.3 ниже).
ЗАПРОС, ИСПОЛЬЗУЮЩИЙ NOT EXISTS
Выдать фамилии поставщиков, которые не поставляют деталь Р2 (обратная задача по отношению к примеру 5.3.1).
SELECT ФАМИЛИЯ
FROM S
WHERE NOT EXIST
(SELECT *
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА=
S.НОМЕР_ПОСТАВЩИКА
AND НОМЕР_ДЕТАЛИ = 'Р2');
Результат:
фамилия
Адамc
Этот запрос можно перефразировать: «Выбрать фамилии поставщиков таких, что не существует поставки, связывающей их с деталью Р2». Заметим, что легко преобразовать решение предыдущей задачи (пример 5.3.1) в решение данной.
Между прочим, заключенный в скобки подзапрос, входящий в выражение EXISTS, вовсе не обязательно должен использовать предложение SELECT вида «SELECT *». Можно использовать, например, предложение следующего вида: «SELECT имя-поля FROM...». Однако на практике оно почти всегда будет иметь вид «SELECT *», как уже было продемонстрировано в наших примерах.
ЗАПРОС, ТРЕБУЮЩИЙ ИСПОЛЬЗОВАНИЯ UNION
Выдать номера деталей, которые имеют вес более 16 фунтов либо поставляются поставщиком S2 (либо то и другое).
SELECT НОМЕР_ДЕТАЛИ
FROM P
WHERE BEC>16
UNION
SELECT НОМЕР_ДЕТАЛИ
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА ='S2';
Результат:
P1
P2
P3
P6
Из этого простого примера следует несколько соображений:
—Избыточные дубликаты всегда исключаются, из результата UNION. Поэтому, хотя в рассматриваемом примере деталь P2 выбирается обеими из двух составляющих предложений SELECT, в окончательном результате она появляется только один раз.
—Любое число предложений SELECT может быть соединено операторами UNION. Можно расширить данный пример с тем, чтобы включить номера красных деталей, дополнив приведенный выше запрос следующей конструкцией:
UNION
SELECT НОМЕР_ДЕТАЛИ
FROM P
WHERE ЦВЕТ = 'Красный'
перед заключительной точкой с запятой. Заметим, что такого же результата можно было достигнуть, добавляя к первому из первоначальных предложений
SELECT фразу OR ЦBET= ='Красный'.
—Любая фраза ORDER BY в запросе должна входить как часть только в последнее предложение SELECT и должна указывать столбцы, по которым осуществляется упорядочение, путем указания их порядковых позиций, т. е. их номеров.
—В связи с оператором
UNION часто оказывается полезной возможность включения констант во фразу SELECT. Например, можно указать, какому из двух условий WHERE удовлетворяет каждая из отдельных деталей:
SELECT НОМЕР_ДЕТАЛИ, 'ее вес > 16 фунтов'
FROM P
WHERE ВЕС > 16
UNION
SELECT НОМЕР_ДЕТАЛИ, 'деталь поставляется S2'
FROM SP
WHERE НОМЕР_ПОСТАВЩИКА = 'S3'
ORDER BY 2, 1;
Результат:
|
|
PI
Р2
Р2
РЗ
Р6
|
деталь поставляется S2
деталь поставляется S2
ее вес > 16 фунтов
ее вес > 16 фунтов
ее вес > 16 фунтов
Когда строковая константа выступает в качестве элемента, подлежащего выборке, считается, что она имеет тип VARCHAR и длину, равную числу литер в константе, и допускаются неопределенные значения.
У читателя может возникнуть желание узнать, поддерживаются ли в языке SQL какие-либо аналоги операторов INTERSECTION (пересечение) и DIFFERENCE (разность), поскольку объединение, пересечение и разность в теоретико-множественных рассмотрениях обычно выступают совместно. Пересечение двух множеств представляет собой множество всех элементов, принадлежащих обоим исходным множествам. Разность двух множеств — это множество элементов, принадлежащих первому исходному множеству, но не принадлежащих второму. В языке SQL эти два оператора непосредственно не поддерживаются, но каждый из них может быть смоделирован с помощью функции EXISTS. Пусть, например, А и В—таблицы, состоящие из единственного столбца, а именно, столбца номеров поставщиков. Пусть А представляет «поставщиков из Лондона», а В — «поставщиков, которые поставляют деталь Р1». Тогда
SELECT НОМЕР_ПОСТАВЩИКА
FROM A
WHERE EXISTS
(SELECT НОМЕР_ПОСТАВЩИКА
FROM В
WHERE В. НОМЕР_ПОСТАВЩИКА=
А. НОМЕР_ПОСТАВЩИКА);
представляет пересечение А и В, т. е. поставщиков из Лондона, которые поставляют деталь P1, a
SELECT НОМЕР_ПОСТАВЩИКА
FROM A
WHERE NOT EXISTS
(SELECT НОМЕР_ПОСТАВЩИКА
FROM В
WHERE В.НОМЕР_ПОСТАВЩИКА=
А. НОМЕР_ПОСТАВЩИКА);
представляет разность между А и В (в указанном порядке), т. е. поставщиков из Лондона, которые не поставляют деталь Р1. Упражнение.
Что представляет собой разность между В и А (именно в этом порядке)?
ЗАПРОС, В КОТОРОМ ИСПОЛЬЗУЕТСЯ ИМПЛИКАЦИЯ
Выдать номера поставщиков, поставляющих по крайней мере все те детали, которые поставляются поставщиком S2 (тот же самый запрос, что и в предыдущем примере).
В этом примере иллюстрируется еще одно очень полезное понятие — логическая импликация.
Первоначальную задачу можно перефразировать следующим образом: «Выдать номера поставщиков, скажем, Sx, таких, что ДЛЯ ВСЕХ деталей Ру, если поставщик S2 поставляет деталь Ру, то поставщик Sx поставляет деталь Ру».
Выражение
IF p THENq (ЕСЛИ р ТО q),
где р и q — предикаты, является предикатом логической импликации. Он определяется как эквивалент предиката:
NOT (p) OR q.
Иными словами, импликация «IF p THEN q» (читается также следующим образом: «из р СЛЕДУЕТ q») принимает значение ложь
тогда и только тогда, когда q — ложь,
а р — истина, как показывает приведенная ниже таблица истинности (В таблице Т обозначает «истина» (от англ. true), a F-
«ложь» (от англ.false) .— Примеч. пер.)
|
|
Р
|
q
|
IF p THEN q
|
|
Т
|
Т
|
Т
|
|
Т
|
F
|
F
|
|
F
|
Т
|
Т
|
|
F
|
F
|
Т
Многие формулировки задач на обычном языке весьма естественным образом выражаются в терминах логической импликации. Несколько примеров можно найти в конце данной главы среди предлагаемых упражнений. Язык SQL непосредственно не поддерживает импликацию. Но предыдущее определение показывает, каким образом любой содержащий импликацию предикат может быть трансформирован в другой предикат, который ее не содержит. Пусть, например, р представляет собой предикат «Поставщик S2 поставляет деталь Ру», а q — предикат «Поставщик Sx поставляет деталь Ру». Тогда предикат
IF p THEN q
эквивалентен предикату
NOT (поставщик S2 поставляет деталь Ру)
OR (поставщик Sx поставляет деталь Ру);
или в языке SQL:
NOT EXISTS
(SELECT *
FROM SP SPY
WHERE SPY. НОМЕР_ПОСТАВЩИКА = 'S2')
OR EXISTS
(SELECT *
FROM SP SPZ
WHERE SPZ. НОМЕР_ПОСТАВЩИКА = Sx
AND SPZ. НОМЕР_ДЕТАЛИ = SPY. НОМЕР_ДЕТАЛИ)
Следовательно, предикат
FORALL Py (IF p THEN q),
который эквивалентен предикату
NOT EXISTS Py (NOT (IF p THEN q)),
т. е. предикату
NOT EXISTS Py (NOT (NOT (p) OR q)),
может быть записан, таким образом, в виде:
NOT EXISTS Py (p AND NOT (q)),
или в языке SQL:
NOT EXISTS
(SELECT *
FROM SP SPY
WHERE НОМЕР_ПОСТАВЩИКА = 'S2'
AND NOT EXISTS
(SELECT *
FROM SP SPZ
WHERE SPZ.НОМЕР_ПОСТАВЩИКА=Sx
AND SPZ.НОМЕР_ДЕТАЛИ=.SPY.НОМЕР_
ДЕТАЛИ))
Поэтому полный запрос принимает вид:
SELECT DISTINCT НОМЕР_ПОСТАВЩИКА
FROM SP SPX
WHERE NOT EXISTS
(SELECT *
FROM SP SPY
WHERE SPY.НОМЕР_ПОСТАВЩИКА = 'S2'
AND NOT EXISTS
(SELECT *
FROM SP SPZ
WHERE SPZ.НОМЕР_ПОСТАВЩИКА =
SPX. НОМЕР_ПОСТАВЩИКА
AND SPZ. НОМЕР_ДЕТАЛИ =
SPY. НОМЕР_ДЕТАЛИ));
Такой же вид имеет запрос в примере 5.3.4. Таким образом, понятие импликации обеспечивает основу для систематического подхода к определенному классу (весьма сложных) запросов и их преобразованию в эквивалентную форму в языке SQL. Попрактиковаться в таком подходе позволяют упражнения 5.12—5.18 в конце данной главы.
ЗАПРОСЫ, ИСПОЛЬЗУЮЩИЕ СОЕДИНЕНИЕ
Способность «соединять» две или более таблицы в одну представляет собой одну из наиболее мощных возможностей реляционных систем. Фактически наличие операции соединения (join) — едва ли не самое главное, что отличает реляционные системы от систем других типов (см. Приложение А). Итак, что такое соединение? Говоря нестрого, это запрос, в котором выборка данных осуществляется более чем из одной таблицы. Ниже приводится простой пример.
ЗАПРОСЫ ПО КАТАЛОГУ
Поскольку каталог состоит из таблиц, точно таких же, как обычные пользовательские таблицы, из него можно запрашивать данные с помощью предложений SELECT языка SQL так же, как из обычных таблиц. Например, чтобы узнать, какие таблицы содержат столбец НОМЕР-ПОСТАВЩИКА, можно использовать следующий запрос:
SELECT TBNAME
FROM SYSIBM.SYSCOLUMNS
WHERE NAME = 'НОМЕР_ПОСТАВЩИКА';
Результат:
TBNAME
S
SP
«Создателем» таблиц каталога считается SYSIBM. Поэтому для того, чтобы обратиться к таблице каталога, например SYSCOLUMNS, необходимо использовать SYSIBM в качестве префикса для имени таблицы, как во фразе FROM рассмотренного примера. В противном случае система DB2 будет предполагать, что Вы обращаетесь к Вашей собственной таблице, т. е. префиксом по умолчанию является Ваше собственное имя, известное системе, как пояснялось в главе 3.
Другой пример. Из каких столбцов состоит таблица S?
SELECT NAME
FROM SYSIBM. SYSCOLUMNS
WHERE TBNAME == 'S';
Результат:
|
|
NAME
|
|
НОМЕР_ПОСТАВЩИКА
ФАМИЛИЯ
СОСТОЯНИЕ
ГОРОД
И еще один пример. Сколько таблиц создал пользователь КДДЕЙТ?
SELECT COUNT(*)
FROM SYSIBM.SYSTABLES
WHERE CREATOR = 'КДДЕЙТ';
Пользователь, незнакомый со структурой базы данных, может с помощью подобного рода запросов получить информацию об этой структуре. Например, пользователь, которому требуется сформулировать запросы к базе данных, скажем, поставщиков и деталей, но который не располагает какими-либо подробными знаниями относительно того, какие в точности таблицы существуют в этой базе данных и из каких именно столбцов они состоят, может воспользоваться запросами к каталогу и сначала получить нужные знания, а затем перейти к .формулировке собственно запроса на данные. В традиционной (нереляционной) системе такие первоначальные запросы обычно должны были бы направляться к системному словарю данных, а не к базе данных (На самом деле, представление каталога (метаданных) базы данных как части самой базы данных, доступной не только СУБД, но и пользователю с помощью обычных средств манипулирования данными, не является прерогативой реляционных систем. Такой подход может быть реализован в СУБД, основанных и на других моделях данных. Обсуждение этого вопроса можно найти в работе: Когаловский М. Р., Виноградов М. М., Макальский К. И. Самоописываемые базы данных и реализация СУБД//Математические и реализационные проблемы СУБД.—М.: ЦЭМИ АН СССР, 1981—С. 31—53— Примеч. пер.) В действительности, каталог системы DB2 может рассматриваться как рудиментарный словарь — рудиментарный в том смысле, что он содержит только информацию, которая непосредственно необходима DB2, тогда как полноценный словарь данных обычно содержит много дополнительной информации, например о том, какие отчеты получают различные отделы. Важное отличие и существенное, с точки зрения легкости использования, достоинство системы DB2 заключаются в том, что запросы к каталогу и к базе данных осуществляются через один и тот же интерфейс, а именно—SQL. Напротив, в традиционных системах словарь и база данных всегда различались, и доступ к ним осуществлялся через различные интерфейсы. Интересно подумать о том, можно ли будет когда-либо расширить каталог системы DB2 с тем, чтобы он мог обеспечивать функции развитого словаря (такое расширение должно быть достаточно простым для реализации).
�