Базы данных - разработка Основы баз данных Проектирование базы данных Базы данных - Разработка Управление базой данных Базы данных - СУБД Управление базой данных Базы данных - виды Базы данных - софт для разработки Базы данных - софт Язык SQL Access FoxPro Oracle Informix Линтер Postgres СУБД DB2 InterBase |

|
Использование технологий WWW для доступа к базам данных
Администрирование Cold Fusion
Для администрирования в Cold Fusion предусмотрен специальный интерфейс администратора.Этот интерфейс позволяет изменять различные параметры настройки Cold Fusion по четырем категориям:
для использования их с Cold Fusion.
Чтобы добавить источник данных, нужно нажать на кнопку "Add...",
выбрать один из установленных в системе драйверов ODBC
и задать определенные для него настройки. Переопределить эти настройки
можно воспользовавшись кнопкой "Setup...",
предварительно выделив конкретный источник данных. Если нужно
определить способы взаимодействия Cold
Fusion с источником данных, то нужно нажать на кнопку "Preferences..."
и определить такие атрибуты как имя пользователя, пароль,
допустимые операции с базой данных и др.
для настройки логических путей до директорий в которых расположены
файлы с шаблонами Cold Fusion.
для настройки отладочных сообщений и сообщений об ошибках.
и позволяет просматривать журнал сообщений и ошибок.
Адреса
В HTML есть средство для оформления адресов (адрес будет, по возможности,выделен шрифтом). Конечно, никто не заставляет пользоваться этой возможностью, но без ее описания наша книга не была бы полной.
Адрес оформляется с помощью тега
...
Браузеры обычно выделяют его курсивом, то есть строка ул. Пирогова, д. 2 будет отображена как
ул. Пирогова, д. 2.
Аргументы командной строки
СGI-модуль в командной строке от сервера получает:для скрипта поиска, или
Ключевые слова, имена и значения полей формы передаются декодированными (из HTTP URL формата кодирования) и перекодированными в соответствии с правилами кодирования Bourne shell так, что cgi-модуль в командной строке получит информацию без необходимости осуществлять дополнительные преобразования.
Ассоциативные массивы
Ассоциативные массивы или хэши содержат пары ``ключ'' и ``значение''.Например:
\%map = ('red',0x00f,'blue',0x0f0,'green',0xf00);
Часто для удобства чтения между ``ключом'' и ``значением'' ставят оператор =>.
%map = (
'red' => 0x00f,
'blue' => 0x0f0,
'green' => )xf00
);
Библиотеки и функции на языке C
Одной из основных технологий создания CGI-модулей для реализации функций "преобразователя"и "обработчика" сценариев 1-3 является язык C. Язык C - наиболее распространенный
язык программирования. В каждом ВУЗе есть специалисты, способные использовать его для создания приложений.
При решении описанных задач язык C можно использовать для создания следующих программ:
документов (рис. );
к БД. (рис. );
рис. );
Для поддержки этих функций создано большое количество библиотек и функций языка C,
готовых приложений в исходных текстах. В главе описывается использование языка C
для создания исполняемых CGI-программ.
Бинарные операторы
Звездочка * - умножение двух чисел. Cлэш / - деление числа на число.Процент % - вычисляет модуль двух чисел, x - оператор повторения. В
скалярном контексте возвращает строку, состоящую из многократно повторенного
левого операнда, причем повторяется он то количество раз, которое стоит справа.
В списковом контексте он многократно повторяет список.
print 'a' x 80; напечатает букву a 80 раз.
@ones = (1) x 80; массив из восьмидесяти единиц.
@ones = (5) x @ones сделает все элементы равными пяти.
Бинарный плюс - операция сложения двух чисел.
Бинарный минус - операция вычитания двух чисел.
Бинарная точка - конкатенация строк.
Что такое progressive JPEGs и как ИХ делать
Существует возможность создавать GIF-файлы, которые отображаются черезстрочнымспособом. Эта возможность является очень удобной для Web-страниц.
Не все знают, что подобная возможность имеется и в формате JPEG. Метод
этот называется progressive JPEGs. Сейчас все большее количество
программных пакетов начинает его использовать. Например для Adobe Photoshop
существует подключаемый модуль, создающий progressive JPEGs. Смотрите внимательно
в меню экспорта графики Вашей любимой программы. Быть может она уже имеет
такую функцию!
Что такое transparent/interlaced GIFs и как их делать
Графический формат GIF имеет несколько интересных возможностей, делающих его особенно привлекательным для WWW. К ним относятся возможности создавать ``прозрачные'' (transparent) изображения и изображения, проявляющиеся постепенно, по мере подкачки (interlaced). Эффект постепенного проявления достигается за счет черезстрочной отрисовки изображения: сначала появляются каждые четвертые строчки растра, затем каждые четвертые строчки со сдвигом на одну строку вниз и т.д. Таким образом, картинка появляется как бы в четыре приема. Эффект прозрачности состоит в том, что один из индексов палитры объявляется прозрачным, то есть при отображении вместо соответствующего цвета будет использоваться цвет ``из-под'' изображения, например, цвет фона документа.Существует множество различных программ для большинства систем, позволяющих придать GIF-картинкам свойства прозрачности и черезстрочности. Из них
выделяются по своим возможностям и удобству использования:
Цитаты и преформатированный текст
Иногда возникает ситуация, когда необходимо вставить в документ цитату,исходный текст программы или просто текстовый документ, где формат
имеет значение и нежелательно, чтобы Web-браузер сам пытался вставлять
переводы строк там, где он хочет. Язык HTML имеет для возможности для
всех эти случаев.
Цитаты в HTML оформляются с помощью тега
Браузер выделит цитату каким-либо способом, например шрифтом и/или вставит
горизонтальные отступы справа и слева.
Чтобы вставить в документ исходный текст можно воспользоваться тегом
... Текст будет выделен шрифтом фиксированной ширины.
Случай, когда в документе необходимо присутствие текста с фиксированным
форматом особенно распространен. Часто такая возможность применяется,
например, при включении в текст содержимого электронных писем или статей из
сети Usenet. Оформляется все это с помощью тега
текст1
...
...
текстN
При этом отображен он будет, по возможности, примерно так:
текст1
...
...
текстN
Cтруктуры данных
Perl поддерживает три типа данных:Обычные массивы, как и в языке C, индексируются числами, начиная с нуля.
Ассоциативные массивы индексируются строками.
Простые скаляры (в дальнейшем мы будем также называть их переменными) всегда
начинаются со знака доллара: $, даже в том случае, когда мы обращаемся к
элементу массива.
?
$day простая переменная day
$day[28] 29 элемент массива day
$day{'Feb'} значение 'Feb' из хэша %day
$#day последний индекс массива @day
Простой массив начинается со знака @: ?
@day массив day - ($day[1],$day[2],...)
@day[3,4,5] то же, что и @day[3..5]
Ассоциативный массив (хэш) начинается со знака процент %:
%day (key1, val1, key2, val2, ...)
Каждый тип данных имеет свое именное пространство, поэтому вы можете использовать
одно и то же имя одновременно для скалярной переменной, массива или
хэша (а также для подпрограммы или метки) без опасения, что произойдет ошибка.
Perl различает большие и маленькие буквы: FOO, foo и Foo будут
рассматриваться Perl-ом как разные переменные. Имена, начинающиеся с буквы или
знака подчеркивания, могут в дальнейшем содержать в себе цифры или знаки подчеркивания.
Имена,
начинающиеся с цифры, могут в дальнейшем содержать только цифры. Имена, начинающиеся не с буквы, цифры или подчерка должны состоять только из одного символа.
Большинство таких имен зарезервировано, например $$ является
идентификатором текущего процесса.
Интерпретация команды или величины часто зависит от требований контекста.
Существует два основных контекста: скалярный и списковый. Некоторые операции
возвращают список величин если в контексте подразумевается список и одну величину,
если контекст скалярный.
Например, операция &ora_fetch в скалярном контексте возвращает количество
выбранных строк:
$nfields = &ora_fetch($csr);
В списковом контексте она возвращает массив выбранных строк:
@array = &ora_fetch($csr);
Левый аргумент определяет контекст правого аргумента.
Деструкторы
Когда удаляется последняя ссылка на объект, этот объект автоматически удаляется.Это может произойти даже после завершения программы, если ссылки на объект
содержались в глобальных переменных. Если необходимо контролировать процесс
удаления объекта, можно определить в объекте специальный метод, называемый
деструктором. Деструктор объекта (в отличие от C++) имеет
фиксированное имя DESTROY и вызывается перед удалением объекта. В нем можно
реализовать дополнительные процедуры, необходимые для корректного
завершения (например, удаление временных файлов, используемых объектом).
[]
[]
[]
Динамическое определение SQL выражения
В некоторых сложных приложениях может потребоваться, в зависимостиот значений параметров, определять не только содержание запроса,
но и его структуру. В Cold Fusion
предусмотрен тег DBSQL,
который может употребляться внутри тега DBQUERY,
доопределяя SQL - выражение,
в зависимости от значений параметров. Тег DBSQL
имеет единственный атрибут SQL,
значение которого будет добавляться к основному SQL
- выражению.
Пример
SQL="SELECT * FROM SITES
WHERE SiteType = #SiteType# ">
Динамическое создание гипертекстовых документов на основе содержимого БД
В этом варианте доступ к БД осуществляется специальной CGI-программой,запускаемой WWW-сервером в ответ на запрос WWW - клиента.
Эта программа, обрабатывая запрос, просматривает содержимое БД и создает выходной HTML-документ,
возвращаемый клиенту (см.рис.1-3).
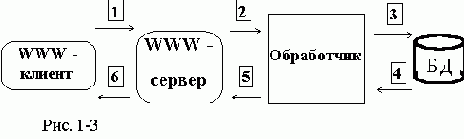
Это решение эффективно для больших баз данных со сложной структурой
и при необходимости поддержки операций поиска. Показаниями также являются частое обновление и невозможность
синхронизации преобразования БД в статические документы с обновлением
содержимого. В этом варианте возможно осуществлять изменение БД из WWW-интерфейсов.
К недостаткам этого метода можно отнести большое время обработки
запросов, необходимость постоянного доступа к основной базе данных, дополнительную
загрузку средств поддержки БД, связанную с обработкой запросов от WWW - сервера.
Для реализации такой технологии необходимо использовать взаимодействие WWW-сервера
с запускаемыми программами CGI - Common Gateway Interface. Выбор программных
средств достаточно широк - языки программирования, интегрированные средства типа генераторов отчетов. Для СУБД со внутренними языками программирования существуют
варианты использования этого языка для генерации документов.
Для метода GET
при декодировании сервером были заменены символом "+"
и все символы с десятичным кодом больше 128 преобразованы в символ
"%" и следующим за ним шестнадцатеричным кодом символа.)
для дальнейшего использования в cgi-модуле
Для метода POST
при декодировании сервером были заменены символом "+"
и все символы с десятичным кодом больше 128 преобразованы в символ
"%" и следующим за ним шестнадцатеричным кодом
символа.)
для дальнейшего использования в cgi-модуле
Очевидно, что отличие только в источнике данных. Поэтому, в принципе,
возможно создание единого модуля для методов POST и GET. Необходимо
только добавить в начало проверку значения переменной REQUEST_METHOD
для определения метода запроса. После формирования структуры "имя-значение"
можно приступить к решению задач, ради которых, собственно, создавался
cgi-модуль. Понятно, что задачи, решаемые cgi-модулем, могут быть
очень разнообразными (получение и обработка почты, доступ к базам
данных, гостевая книга и т.д.).
Следующим важным моментом является динамическое формирование cgi-модулем
HTML-документа (оформление результата работы модуля). Например,
таблицы выборки из базы данных.
Для этого cgi-модуль должен выдать в стандартный выходной поток
заголовок состоящий из строки:
Content-type: text/html и пустой строки (двух символов
CR)
После этого заголовка можно давать любой текст в формате HTML.
Дополнительные функции
Дополнительные возможности предоставляются функциями&ora_titles()
&ora_length()
&ora_types()
&ora_autocommit()
&ora_commit()
&ora_rollback()
&ora_version()
&ora_titles
@titles = &ora_titles($csr)
Программа может определить название полей, содержимое которых будет извлечено запросом, вызовом функции
&ora_title. Эта функция имеет один параметр - курсор. Заголовки обрезаются
до длины поля.
&ora_length
@length = &ora_length($csr)
Программа может определить длину каждого из полей, возвращенных запросом,
с помощью вызова функции &ora_length. Она имеет только один параметр - курсор и
возвращает массив целых чисел.
&ora_types
@types = &ora_types($csr)
Программа может определить тип каждого из полей, возвращенных запросом,
с помощью вызова функции &ora_types. Она имеет один параметр - курсор и возвращает
массив целых чисел. Эти типы определяются в документации по OCI и в файле
oraperl.ph для Oracle v6.
&ora_autocommit
&ora_autocommit($lda,$on_or_off)
Режим автоматического завершения транзакций можно установить или отменить
вызовом функции &ora_autocommit. Эта функция имеет два параметра:
идентификатор регистрации и булевскую переменную, которая указывает
действие, которое нужно выполнить. Если значение переменной ненулевое, то
режим включается, если нулевое, то отключается. По умолчанию режим не включен.
Режим включается на продолжительность пребывания в системе. Если есть
необходимость включать его только для одного оператора, то лучше делать
несколько регистраций и использовать для каждого оператора отдельный
идентификатор регистрации.
&ora_commit, &ora_rollback
&ora_commit($lda)
&ora_rollback($lda)
Изменения в базе данных могут быть сохранены или отменены вызовом этих
функций. Они имеют один параметр - идентификатор регистрации в системе.
Транзакции, результат которых уже был сохранен не могут быть отменены
&ora_rollback. Эти функции также действуют на все время пребывания в
системе, а не на отдельные операторы.
&ora_version
&ora_version()
Эта функция печатает версию и информацию об авторских правах, касающуюся
Oraperl. Она не возвращает ничего.
Дополнительные команды SQL
В теге DBOUTPUT, кроме выраженияSELECT языка SQL,
допускается использование и любых других, допустимых для конкретного
источника данных, SQL - команд,
включая:
в таблицу.
Использование непосредственно команд SQL
вместо тегов DBINSERT и
DBUPDATE в некоторых случаях
может обеспечить большую гибкость и эффективность. Например, при
модификации или создании новой записи, появляется возможность
использовать все параметры и переменные доступные в шаблоне в
том числе и результаты определенных в шаблоне запросов.
Пример использования команды UPDATE
в теге DBQUERY приведен
в
[]
[]
[]
Дополнительные замечания по созданию DBML - шаблонов
Конфигурационные файлы Режимы работы сервера
Главный файл конфигурации (ГКФ) сервера содержит все параметры,необходимые серверу для начала работы, а также пути других конфигурационных
файлов. По умолчанию, главный файл конфигурации сервера находится
в подкаталоге conf/ каталога и имеет имя httpd.conf.
При запуске серверу можно указать другой путь, используя ключ
-f.
Например:
/usr/local/sbin/httpd -f /etc/httpd.config
Ниже приведены параметры, указываемые в главном файле конфигурации
сервера, с необходимыми пояснениями. Значения параметров отделяются
от названия одним или несколькими пробелами или табуляциями. Если
одному параметру соответствуют несколько значений, они разделяются
запятыми.
Параметры запуска серверных процессов
Определяет способ запуска сервера:
ServerType inetd
серверный процесс запускается в ответ на каждое обращение клиента
через механизм inetd. После обработки запроса, сервер прекращает
свою работу.
ServerType standalone
серверный процесс запускается один раз и находится в состоянии
ожидания запросов клиентов. После обработки запроса, сервер остается
запущенным.
Определяет порт tcp, по которому сервер принимает запросы клиентов.
Этот параметр используется только для сервера типа standalone.
При механизме старта inetd порт определяется конфигурационным
файлом сервера inetd - inetd.conf.
Стандартный порт для WWW - сервера - 80.
Пример:
Port 80
Для режима standalone определяют количество процессов сервера
при многопоточной обработке. StartServers - указывает
число процессов сервера, создаваемых при запуске httpd. MaxServers
определяет максимальное число одновременно работающих процессов
сервера.
Пример:
StartServers 3
MaxServers 5
Определяет время (в секундах), которое серверный процесс, запущенный
в режиме standalone, будет
ожидать повторного обращения клиента. По умолчанию используется
1200 секунд.
Пример:
TimeOut 3600
Определяют имя пользователя и группу, права которого получает
сервер при запуске в режиме standalone. Изменение прав сервера
производится с целью предотвращения доступа WWW - клиентов к файлам
операционной системы, не являющимися общедоступными. Например:
User nobody
Group nobody
Информационные параметры для WWW - клиентов
Определяет имя сервера, которое пересылается клиенту вместе с
другими параметрами запроса. Используется в случае, если сервер
имеет несколько имен (синонимов).
Например:
ServerName Indy.cnit.nsu.ru
Определяет адрес электронной
почты администратора сервера. При возникновении каких - либо ошибок
в работе сервера, он выдает клиенту сообщение с просьбой проинформировать
о них администратора сервера по указанному Email.
Например:
ServerAdmin fancy@nsu.ru
Расположение необходимых файлов и каталогов
Определяет местоположение каталога ServerRoot. По
умолчанию, это /usr/local/etc/httpd
или измененное значение параметра HTTPD_ROOT файла src/config.h.
Например:
ServerRoot /var/httpd
Определяет местоположение файла - журнала ошибок, в который заносятся
все сообщения об ошибках, возникающих в процессе работы сервера.
Если значение не начинается со slash (/), подразумевается путь
относительно ServerRoot.
Например:
ErrorLog logs/errlog
Журналом ошибок является файл /var/httpd/logs/errlog
Определяет местоположение файла - журнала доступа, в который заносятся
данные обо всех передачах данных между WWW - клиентом и WWW -
сервером. Если значение не начинается со slash (/), подразумевается
путь относительно ServerRoot.
Например:
TransferLog logs/translog
Журналом доступа является файл /var/httpd/logs/translog
Определяет местоположение файла - журнала клиентов, в который
заносятся данные о программном обеспечении, используемом WWW клиентами
при доступе к данному серверу. Если значение не начинается со
slash (/), подразумевается путь относительно ServerRoot.
Например:
TransferLog logs/agentlog
Журналом клиентского программного обеспечения является файл /var/httpd/logs/agentlog
Определяет местоположение файла в который записываются все факты
обращений к данным сервера в виде ссылок от клиентов к данным.
Если значение не начинается со slash (/), подразумевается путь
относительно ServerRoot.
Например:
RefererLog logs/reflog
Журналом ссылок является файл /var/httpd/logs/reflog
Определяет местоположение файла, хранящего номер процесса запущенного
WWW - сервера. Используется для остановки работы сервера путем
посылки сигнала командой kill. Если значение не
начинается со slash (/), подразумевается путь относительно ServerRoot.
Например:
PidFile logs/httpd.pid
Номер процесса - сервера записывается при старте в файл /var/httpd/logs/httpd.pid
Определяет местоположение файла управления доступом. Если значение
не начинается со slash (/), подразумевается путь относительно
ServerRoot.
Например:
AccessConfig conf/access.conf
Определяет местоположение файла, содержащего список соответствий
расширений файлов ОС типам MIME. По умолчанию используется файл
conf/mime.types в каталоге, определяемом ServerRoot. Если не начинается
с backslash (/), подразумевается путь относительно ServerRoot.
Например:
TypesConfig /etc/mime.types
Определяет местоположение каталога, в который записывается файл
дампа памяти при возникновении сбоя.
Например:
CoreDirectory /tmp
Параметры протоколирования
Определяет, будут ли несколько протоколов записываться в один
файл (Combined) или каждый будет записан в свой
файл (Separate).
Например:
LogOptions Separate
Определяет имена серверов, обращения от которых не будут протоколироваться.
Например:
RefererIgnore Indy.cnit.nsu.ru
Другие режимы работы
Определяет интенсивность обращений WWW сервера к серверу имен
Интернет. Minimum означает,
что сервер будет обращаться к DNS только при необходимости проверить
ограничения доступа по домену. Standard означает,
что сервер будет обращаться к серверу имен каждый раз при обработке
запроса клиента. Maximum означает, что сервер будет
дважды обращаться к серверу имен при каждой обработке запроса.
Например:
DNSMode Standard
Процедура определения конфигурации сервера
После запуска основного серверного процесса сервер пытается открыть
главный конфигурационный файл. Этот файл ищется по умолчанию в
каталоге /usr/local/etc/http/conf с именем httpd.conf.
Умолчание можно изменить при сборке системы редактированием файла
src/config.h. За каталог отвечает параметр HTTPD_ROOT,
за имя файла - параметр SERVER_CONFIG_FILE. Изменить значения
по умолчанию можно при запуске сервера, указав ключи -h
и-f (см. выше).
Местоположение файлов конфигурации доступа, документов, типов
MIME, а также файлов журналов сервер получает из главного конфигурационного
файла. Если каких - либо параметров там нет, их значения берутся
по умолчанию (см. src/config.h).
Конфигурация ресурсов
Расположение файлов данных, их интерпретация сервером и поведение
сервера при обращении к разным типам файлов определяются параметрами
файла конфигурации ресурсов. Ниже приведен список основных параметров
с пояснениями.
Определяет каталог локальной файловой системы,
от которого начинается отсчет виртуального пути URL.
Например:
DocumentRoot /apply/www
Определяет название публичного подкаталога пользователей. ПО WWW
- сервера позволяет обеспечить внешний доступ к гипертекстовым
документам пользователей базовой операционной системы. Для этого
пользователям необходимо создать в своем домашнем каталоге подкаталог
с именем, определяемым параметром UserDir. После
этого все обращения по URL:
http://<имя_сервера>/~<имя_пользователя_ОС>
будут транслироваться в реальный путь до подкаталога, определенного
параметром UserDir в домашнем каталоге пользователя <имя_пользователя_ОС>.
Например:
UserDir public_html
при этом при обращении по URL
http://www.nsu.ru/~fancy/index.html
сервер будет искать файл Index.html в подкаталоге
public_html/ домашнего каталога пользователя fancy.
Переадресует запрос к одной иерархии в запрос к другой иерархии,
возможно расположенной на другом сервере.
Например:
Redirect /HTTPd/ http://hoohoo.ncsa.uiuc.edu/
Определяет синоним для документа или каталога на локальном сервере.
Пример:
Alias /icons /var/opt/images
Определяет синоним для каталогов, содержащих CGI - программы.
Пример:
ScriptAlias /hrv-cgi /var/opt/cgi
Определяет имена файлов, трактующихся сервером как индексные.
Их содержимое выдается сервером при обращении к данному каталогу.
Пример:
DirectoryIndex index.html index.htm index.cgi
Определяет имя файла, трактующегося сервером как файл управления
доступом (см. раздел ).
Пример:
AccessFileName .htaccess
Конструкторы и деструкторы пакетов
Существует две функции специального вида - конструкторы и деструкторы. ЭтоBEGIN и END программы в их описании необязательно использование sub. Подпрограмма
BEGIN исполняется сразу, как только это возможно, то есть в момент, когда
она полностью определена, даже перед тем как обрабатывается остаток содержащего
файла. В файле может быть несколько блоков BEGIN. Они исполняются в порядке
определения.
Подпрограмма END исполняется в самом конце. В файле может содержаться несколько
END блоков, они исполняются в обратном порядке.
Контроль работоспособности сервера
Проверка работоспособности сервера может осуществляться различнымиспособами. На Unix - платформе, в режиме standalone, можно посмотреть
список процессов, выделив среди них процессы с именем httpd:
#
ps -aef | grep httpd
root
28816 1 0 Nov 14 ? 7:42 /usr/local/sbin/httpd
nobody 28817 28816 0 Nov
14 ? 5:50 /usr/local/sbin/httpd
nobody 28818 28816 0 Nov
14 ? 5:32 /usr/local/sbin/httpd
nobody 28819 28816 0 Nov
14 ? 4:49 /usr/local/sbin/httpd
nobody 28820 28816 0 Nov
14 ? 5:24 /usr/local/sbin/httpd
nobody 28821 28816 0 Nov
14 ? 5:42 /usr/local/sbin/httpd
root 19150 19145 0 14:57:58
pts/4 0:00 grep httpd
#
Мы увидим несколько процессов, у одного из которых собственником
является root, а у других - пользователь, определенный
параметром User главного конфигурационного файла
(ГКФ). Процесс с собственником root запускается
первым. Он контролирует работу остальных процессов - серверов.
По использованному процессорному времени (колонка 8
примера) можно судить о загруженности серверов.
Если сервер работает в режиме inetd или необходимо
проверить работоспособность сервера извне, нужно выполнить команду
telnet, указав ей имя машины - сервера и номер порта.
После установления соединения наберите команду GET /.
Сервер должен выдать содержимое корневого каталога документов
или индексного файла, находящегося в этом каталоге. Номер порта
обычно равен 80. В режиме standalone он определяется параметром
Port ГКФ. Для режима inetd он определяется парой файлов - services
и inetd.conf, определяющих соответствие между входными
tcp - портами и сервисами Unix.
Например:
$ telnet www.cnit.nsu.ru
80
Trying 193.124.209.70...
Connected to Indy.
Escape character is '^]'.
GET /
. . .
Connection closed by foreign host.
$
Логическое И и логическое ИЛИ
Бинарное && - логическое И. Если левый аргумент FALSE, то правыйне проверяется.
Бинарное - логическое ИЛИ. Если левый аргумент TRUE, то правый
аргумент не проверяется.
''и && отличаются от подобных операторов в \verbC| тем, что вместо 0 или
1 они возвращают последнюю обработанную величину.
Таким образом, наиболее удобным способом определить домашний каталог
пользователя из переменной окружения HOME будет (на практике такой способ
определения домашнего каталога пользователя не рекомендуется):
$home = $ENV{'HOME'} $ENV{'LOGDIR'}
(getpwuid($<))[7] die "You're homeless!\n";
В качестве более удобной для чтения альтернативы Perl поддерживает операторы and и
or, которые будут описаны далее. Их приоритет ниже, однако их можно с
удобством использовать, не расставляя скобки,
после операторов, аргументами которых являются списки:
unlink "alpha", "beta", "gamma"
or gripe(), next LINE;
Если писать в стиле C, то это может быть записано так:
unlink("alpha", "beta", "gamma")
(gripe(), next LINE);
Логическое И, ИЛИ и Исключающее ИЛИ
and возвращает конъюнкцию двух выражений. Он эквивалентен &&, заисключением более низкого приоритета.
or возвращает дизъюнкцию аргументов. Он эквивалентен , за исключением
более низкого приоритета.
xor (eXclusive OR) - исключающее ИЛИ, возвращает истину, если истинен
ровно один из аргументов.
Логическое НЕ
Унарное NOT возвращает отрицание аргумента. Оно эквивалентно !, заисключением более низкого приоритета.
Методы HTTP запроса
Для реализации взаимодействия "клиент-сервер" важно, какой метод HTTP запроса используетклиентская часть при обращении к WWW серверу. В общем случае, запрос - это сообщение, посылаемое
клиентом серверу. Первая строка HTTP запроса(см. ) включает в себя метод, который должен быть применен к запрашиваемому ресурсу,
идентификатор ресурса(URI-Uniform Resource Identifier), и используемую версию
HTTP-протокола. В рассматриваемом нами случае, клиентская часть применяет методы запроса POST
и GET. Метод POST используется для запроса серверу, чтобы тот принял информацию, включенную в запрос, как
относящуюся к ресурсу, указанному идентификатором ресурса. Метод GET используется для получения
любой информации, идентифицированной идентификатором ресурса в HTTP запросе.
Для WWW-сервера стандарта NCSA прикладные программы или CGI-модули, обрабатывающие поток данных от клиента
или (и) формирующие обратный поток данных могут быть написаны на таких языках программирования как:
Методы
В Perl-е метод имеет синтаксис простой подпрограммы. В качестве первого аргументаметода выступает объект или пакет. Существует два типа методов: статические и
виртуальные методы.
Статические методы имеют первым аргументом имя класса. Они обеспечивают функциональность
для класса в целом, а не для отдельных объектов принадлежащих классу. Конструкторы
являются, как правило, статическими методами. Многие статические методы просто игнорируют
свой первый аргумент, так как заранее знают, какому пакету они принадлежат.
Другой способ использования статических методов состоит в том, что метод работает
с объектом, используя имя:
sub find {
my ($class, $name) = @_;
$objtable{$name};
}
Виртуальные методы имеют первым аргументом ссылку на объект. Обычно они
помещают
эту ссылку в переменную self или this и в дальнейшем используют ее как обычную
ссылку.
sub display {
my $self = shift;
my @keys = @_ ? @_ : sort keys %$self;
foreach $key (@keys) {
print "\t$key => $self ->{$key}\n";
}
}
Модули
В Perl 5 понятие пакетов расширено в понятие модулей. Модули это пакеты находящиесяв одноименном файле, включенном в библиотеку. Модули подключаются следующим образом:
use Module; или use Module LIST;
Это эквивалентно:
BEGIN { require "Module.pm"; import Module; }
Все модули имеют расширение .pm. Если именное пространство модуля пересекается
с именным пространством основной программы то всегда используется use, если не
пересекается то можно использовать require.
Стандартные модули Perl описаны в документации.
Multimedia-материалы
Все большее количество Web-страниц использует различные multimedia-материалы,как-то звуки или видеовставки. Они обычно имеют ОЧЕНЬ большой размер
и передаются по сети ОЧЕНЬ долго. Как этого избежать? Единого ответа
на этот вопрос нет. Все зависит от того что вам на самом деле нужно.
Как всегда, возникает вопрос о форматах хранения данных.
Для звука используются форматы MIDI, WAV (Windows Audio), AU (Sun Audio),
AIFF (Mac Audio).
Для видео-вставок -- AVI (Microsoft Video for Windows), MPEG (Motion
Picture Experts Group), и MOV (Apple QuickTime movies).
Рассмотрим сначала форматы хранения аудиоданных:
MIDI
- Musical Instruments Digital Interface -- формат хранения команд
для различных электронных музыкальных инструментов (например, синтезатора на
музыкальной карте компьютера). Грубо говоря, внутри файла формата MIDI
хранится нотная запись музыкального фрагмента. Это позволяет достичь
минимального размера файла при максимальной сложности мелодии. Файлы MIDI
являются оптимальными для записи мелодий, если не требуется гарантий
абсолютно идентичного звучания различных инструментов на различных системах.
WAV
- формат хранения звуков, используемый в системах семейства Windows.
Содержит запись звука в виде сигнала, то есть, гарантирует точность
воспроизведения (если, конечно, устройство вывода позволяет).
AU
- формат представления звука, используемый в системах компании
Sun Microsystems. По принципу схож с WAV. Имеет встроенную компрессию.
AIFF
- формат представления аудиоданных, используемый в системах
Apple Computer и Silicon Graphics. По принципу схож с WAV.
Имеет встроенную компрессию.
Как и в случае с изображениями, следует прежде всего избавиться от избыточной
информации. Для цифрового звука характерны два параметра, влияющие на размер
данных: частота оцифровки и разрядность уровня сигнала. Частота оцифровки
определяет, сколько раз в секунду замерялся уровень сигнала (и сколько раз в
секунду он будет меняться при нормальном воспроизведении).
Разрядность
показывает, сколько бит при этом выделялось на запись этого уровня.
Для примера: на музыкальных компакт-дисках частота дискретизации составляет
примерно 44.1 Кгерц при разрядности 16 бит. Нетрудно подсчитать, что при
такой схеме одна секунда звука будет занимать больше 88 килобайт (!)
К счастью, уровень качества звука, присущий компакт-дискам, далеко не всегда
необходим при передаче звука по сетям. Например, для корректной передачи
голоса достаточно частоты дискретизации в 8.0 Кгерц при разрядности
сигнала в 8 бит. Таким образом, в те же 88 килобайт поместится уже почти
11 секунд звучания голоса. Если при этом использовать еще и сжатие (с потерями),
то это значение можно сильно увеличить.
Таким образом, главное правило звучит так:
Для звуковых файлов выбирайте минимальную частоту дискретизации и
разрядность, при которых качество все еще остается приемлемым. Выбирайте формат
с максимальным показателем сжатия для ваших данных.
Видеовставки, пожалуй -- самый объемный элемент современных Web-страниц.
Единственный совет, который можно дать по отношению к ним: старайтесь не
вставлять их прямо в документ (inline). Лучше вставьте один из кадров
в виде статичной картинки и сделайте ссылку на весь фрагмент. Кроме того,
можно выбирать формат и способ компрессии, достигая при этом оптимального
соотношения размер / качество.
Обычно в WWW применяются следующие форматы хранения видеофрагментов:
AVI
- формат компании Microsoft, используемый в системах семейства
Windows. Построен по схеме применения так называемых ``кодеков'', то есть
модулей сжатия/распаковки. Точно такой же подход используется в формате
QuickTime фирмы Apple, только набор стандартных кодеков отличается.
QuickTime MOV
- формат, разработанный компанией Apple и ныне получивший
повсеместное распространение. Программы его воспроизведения (некоторое
множество кодеков) ныне существуют для большинства систем.
MPEG
- Формат экспертной группы по кинематографии. Очень сильно
распространен и популярен.
Написание модулей CGI
Язык Perl очень широко используется при написании исполняемых модулейCGI (Common Gateway Interface) для Web.
Это обусловлено прежде всего тем, что Perl предоставляет разработчикам
простые и удобные средства обработки текста и взаимодействия с базами
данных. Наша цель - лишь дать пример
использования Perl для написания CGI-модуля.
Рассмотрим простую подпрограмму разбора входного потока CGI-программы
(при передаче параметров используется метод POST ).
#!/usr/local/bin/perl
sub Print {
$len = 100;
$buf = "";
read(STDIN, $buf,$len);
# считываем из стандартного потока ввода
# в переменную $buf количество символов
# $len
@ar = split(/[&=]/,$buf);
# разбиваем строку в массив строк,
# разделителями служат & и =.
$output = "Content-type: text/html\n\n
# посылает тип MIME передаваемого документа
Hi there
";
$i = 0;
while ($i <= $#ar) {
$ar[$i] =~ s/\+/ /g;
# заменяем в элементах массива + на пробел
$output .= "$ar[$i]\n";
# конкатенация переменной $output с
# элементом массива
$i++; }
$output .="
";
# завершаем HTML страницу
print $output;
}
eval &Print;
# выполняем подпрограмму осуществляющую
# считывание, обработку и вывод информации
В данном примере был проиллюстрирован случай считывания параметров из входного
потока.
Если параметры передаются CGI-модулю в командной строке, то они помещаются в служебный
массив @ARGV. Например, если параметры пишуться в URL:
http://www.host.ru/cgi-bin/name.cgi?123+resource+time+12 .
Как видно из примера, написать CGI-модуль на Perl совсем не сложно. Существуют также
различные модули для облегчения написания CGI. Документацию по ним и сами модули доступны на сервере
Назначение WWW - сервера Общая схема работы Определение
WWW сервер - это такая часть глобальной или внутрикорпоративнойсети, которая дает возможность пользователям сети получать доступ
к гипертекстовым документам, расположенным на данном сервере.
Для взаимодействия с WWW сервером пользователь сети должен использовать
специализированное программное обеспечение - броузер (от англ.
browser), другое название - программа просмотра.
Схема работы
Рассмотрим более подробно, чем
в предыдущих главах, схему
работы WWW-сервера.
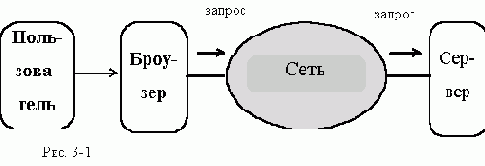
В общем виде она выглядит так:
называемый броузером,
в функции которого входит
устанавливает связь с заданным WWW - сервером и передает ему запрос
на получение заданного документа (см рис.3-1).
запрашиваемый документ и возвращает результаты броузеру
(см. рис.
3-2).
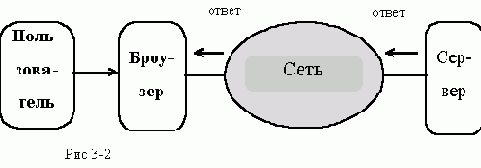
документ, отображает его пользователю
и ожидает его реакции. Возможные варианты:
операции над текущим документом
называемых связями (link) и ассоциироваными с адресом
нового документа.
В первом и третьем случае происходит обращение за новым документом.
Адрес
Как было описано в главе , адрес
документа указывается в виде специальной строки, называемой URL.
Для протокола HTTP, используемого при взаимодействии WWW клиента
и WWW сервера, URL состоит из следующих компонент:
по которому работает сервер (http).
Например:
http://www.cnit.nsu.ru:80/welcome.html
Здесь http означает протокол работы с WWW - сервером
в Internet
- сервере
Из общей схемы работы видно,
что функции WWW сервера заключаются в следующем:
В общем случае, WWW - сервером будем называть программно
- аппаратный комплекс, предназначенный для выполнения вышеперечисленных
действий.
Среда работы сервера
В настоящее время все известные WWW - серверы представляют собой
компьютер общего назначения с многозадачной операционной системой.
Один или несколько процессов такой системы отвечают за поддержку
специфических для WWW - сервера функций. Другие процессы ОС отвечают
за обеспечение других функций, не обязательно связанных с поддержкой
технологии WWW (см. рис. 3-3).
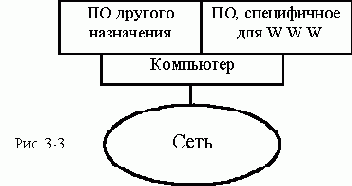
Такая структура приводит к тому, что под WWW сервером начинают подразумевать только часть программного
обеспечения, единственными функциями которой являются функции
WWW сервера, а остальную часть - компьютер, операционную систему,
другие процессы, сетевую структуру называют средой работы WWW
сервера или платформой. Ниже приведена таблица 3-1,
содержащая список наиболее распространенных платформ для
WWW - сервера.
Таблица 3-1
| Компьютер | Операционная Система |
| IBM PC |
|
| Sun SparcStation и SparcServer |
|
| Silicon Graphics серверы и рабочие станции | IRIS |
Непосредственные функции сервера Базовые определения
В простейшем случае гипертекстовый документ представляет собойсовокупность файлов. Представление этих файлов как единого документа
производится броузером. По каждому файлу документа броузер делает
запрос к WWW - серверу. Таким образом,
сервер не имеет представления о структуре и составе документов,
он отвечает только за выдачу локальных файлов по запросам.
На различных платформах, в различных операционных системах пути
файлов выглядят по разному.
Например:
D:\DOCUMENTS\HTML\INDEX.HTM - в Windows,
/u/data/www/html/index.html - в Unix - системах,
USR:WWW/HTML - в NetWare и т.д.
Путь файла, указываемый в URL, имеет стандартный вид:
/<имя_каталога>/ ... /<имя_каталога>/<имя_файла>
Таким образом, в функции WWW - сервера входит преобразование адреса
из внешнего единого формата в платформенно ориентированный внутренний
формат. Появляется ряд понятий,
специфичных для такого преобразования, необходимых для него.
Это каталог реальной файловой системы сервера, от которого идет
вычисление пути, указанного в URL.
Например, если исходным каталогом
документов является D:\Documents\HTML\,
то на запрос к этому серверу документа по URL
http://<имя_сервера>/index.htm
будет возвращен файл
D:\Documents\HTML\index.htm
В случае, когда необходимо
осуществить обращение к конкретному каталогу или файлу, находящемуся
вне иерархии Исходного каталога документов,
используется механизм синонимов. Синоним позволяет явно определить
соответствие между путем, указанным в URL, и путем локальной файловой
системы.
Например:
Синонимом для /Harvest объявляется /projects/www/harvest
или
синонимом для /test/myfile.html объявляется
C:\MYDIR\FILE.HTM
В первом случае все обращения к файлам каталога /Harvest
будут обрабатываться в каталоге /projects/www/harvest.
Второй пример показывает работу
синонима с конкретным файлом файловой системы.
Для каждого сервера определено имя так называемого индексного
файла. Обычно этот файл содержит ссылки на другие файлы данного
каталога. Содержимое индексного файла выдается сервером в случае,
если в URL указан каталог без конкретного файла.
Для многопользовательских операционных систем (таких как Unix)
ПО WWW - сервера позволяет каждому пользователю предоставлять
доступ к своему собственному набору гипертекстовых документов
вне основной иерархии (Исходного каталога документов, Синонимов
и т.д.). Этот набор документов должен находиться в собственном
(т.н. "домашнем") каталоге пользователя. Для доступа
к таким документам в URL перед путем ставится знак тильда и имя
пользователя: ~<имя_пользователя>.
Например:
На сервере Indy.cnit.nsu.ru создан пользователь
с именем fancy и "домашним" каталогом /home/fancy.
Собственные гипертекстовые документы он хранит в каталоге /home/fancy/public_html.
При обращении по URL http://Indy.cnit.nsu.ru/~fancy/start.html,
WWW - сервер будет искать документ start.html в
каталоге /home/fancy/public_html.
Объектная ориентация
Понятие объектной ориентации зиждется на трех простых определениях:ссылками.
объектную ссылку (или имя пакета для статического метода).
Объекты
В отличие от C++, Perl не имеет специального синтаксиса для описанияконструкторов. Конструктор, как уже говорилось раньше, это просто подпрограмма,
которая возвращает ссылку ассоциированную с классом (как правило с тем, где
определена подпрограмма). Например, типичный конструктор:
package Critter;
sub new { bless {} }
{} создает ссылку на анонимный хэш.
В пределах класса методы как правило работают с обычными ссылками. Конструктор
может привязать объект к другому классу, в таком случае предыдущая привязка
бывает забыта, так как объект не может принадлежать одновременно нескольким
классам.
Обработка файлов формата DBF
Для взаимодействия с файлами этого формата существует специальный модуль - Xbase.pmНа текущий момент поддерживается только возможность чтения таких файлов.
Этот модуль подключается стандартным образом: use Xbase;
Новый Xbase объект создается следующим образом:
$database = new Xbase;
Будет создан объект $database, который в дальнейшем будет использоваться для
взаимодействия со всевозможными методами, которые поддерживает модуль.
Доступ к базе данных осуществляется следующим образом:
$database->open_dbf($dbf_name,$idx_name);
Мы ассоциировали DBF-файл и необязательный индексный файл с объектом. Чтобы
определить тип (database type) можно сделать следующее:
print $database->dbf_type;
Вернется строка, которая, если Xbase файл открыт, будет содержать значение
DBF3, DBF4 или FOX.
Чтобы узнать дату последнего обновления делается следующее:
print $database->last_update;
Возвращает строку с датой.
Чтобы узнать номер последней записи можно сделать следующее:
$end=$database->lastrec;
Вернется номер последней записи в файле с базой данных.
Информацию о статусе базы данных можно посмотреть следующим образом:
$database->dbf_stat;
В стандартный выходной поток будет напечатана информация о статусе и структуре
базы данных. Этот метод работает аналогично команде display status.
Посмотреть информацию о статусе индексного файла можно используя метод idx_stat:
$database->idx_stat;
Печатает в стандартный выходной поток (STDOUT) информацию о статусе открытого
IDX-файла.
Для того чтобы перейти на начало файла есть метод go_top:
$database->go_top;
Передвигает курсор чтения на физическое начало файла,если индексы не существуют
и на первую запись, соответствующую порядку, который задается индексом, в
противоположном случае.
Для того чтобы перейти на конец файла есть метод go_bottom:
$database->go_bottom;
Передвигает курсор чтения на физический конец файла,если индексы не существуют
и на последнюю запись, соответствующую порядку, который задается индексом, в
противоположном случае.
Чтобы перейти на следующую запись есть метод go_next:
$database->go_next;
Эквивалентно команде skip 1, которая передвигает курсор на следующую запись.
Чтобы перейти на предыдущую запись есть метод go_prev:
$database->go_prev;
Эквивалентно команде skip -1, которая передвигает курсор на предыдущую запись.
Есть возможность осуществить поиск по заданному ключу:
$stat=$database->seek($keyvalue);
Эта команда устанавливает курсор на первую запись, соответствующую данному
ключу. Но в данном случае база данных должна быть открыта с соответствующим
индексом, в противоположном случае будет выдано сообщение об ошибке и исполнение
прекратиться. Возвращается значение, содержащее информацию о том, был ключ найден
или нет.
Чтобы узнать номер записи, на которой стоит курсор можно использовать следующую
команду:
$current_rec=$database->recno;
Метод bof возвращает значение true, если курсор находится в самом начале файла.
if ($database->bof) {
print " At the very top of the file \n";
}
Аналогично действует метод eof:
if ($database->eof) {
print " At the very end of the file \n";
}
Чтобы прочитать содержимое какого-либо поля записи можно поступить так:
print $database->get_field("NAME");
Возвращает строку с содержимым поля. Если данная запись помечена для удаления, то
использует псевдоимя поля _DELETED.
Чтобы прочитать значения полей записи в массив можно поступить так:
@fields = $database->get_record;
В массиве они будут располагаться в такой же последовательности, как и в базе
данных.
Для закрытия базы данных используется метод close_dbf.
$database->close_dbf;
Закрывает файл с базой данных, индексами и комментариями. В завершение приведем
небольшой пример программы, которая распечатывает статус базы данных и индексного
файла, а также дату последнего обновления и количество записей в базе данных.
#!/usr/bin/perl
use Xbase;
# подключение модуля
$database = new Xbase;
# создание объекта
$d = "/home/smit/employee.dbf";
# имя файла с базой
$i = "/home/smit/employee.cdx";
# имя индексного файла
$database->open_dbf($d,$i);
# открываем базу данных
$database->dbf_stat;
# печатаем статус и структуру
# базы данных
$database->idx_stat;
# печатаем статус и структуру
# индексов
@fields = $database->get_record;
print @fields,"\n";
# печатаем содержимое текущей записи
print $database->last_update, "\n";
# печатаем дату последнего обновления
$end = $database->lastrec;
print $end;
#печатаем номер последней записи
Полная спецификация языка Perl приводиться в Приложении к отчету.
[]
[]
[]
Обработка журналов
Время от времени возникает необходимость уменьшить размер файловстатистики путем их удаления или переноса в другое место. Если
сервер находится в режиме inetd, можно свободно удалять и переносить
файлы статистики. Они снова создадутся по указанным в ГКФ путям.
Если же сервер работает в режиме standalone, эти файлы постоянно
открыты процессами - серверами. Удаление или перенос их не освободят
место на диске и не приведут к созданию новых файлов. Для корректной
работы с журналами в этом случае, необходима остановка работы
сервера. Необходимо "убить" процессы - серверы, перенести
файлы журналов и перезапустить сервер. "Убить" процессы
- серверы можно послав команду kill процессу с номером, указанном
в файле PidFile (см. параметры ГКФ). Пример последовательности
команд для выполнения такой операции:
kill `cat /usr/local/etc/httpd/logs/httpd.pid`
mv /usr/local/etc/httpd/logs/*.log
/otherdir
/usr/local/sbin/httpd
Для анализа файлов статистики существует большое количество программного
обеспечения, делающего "вытяжку" из них в виде диаграмм,
сравнительных таблиц и т.д.
Обзор расширений
Некоторые браузеры кроме поддержки базового языка HTML обладаюттакже дополнительными возможностями.
Первым браузером, имевшим действительно значительные расширения стал
Netscape Navigator. Популярность использования расширенных возможностей
Netscape была настолько высока, что они вошли в новый проект стандарта HTML 3.2.
Его конкурент, Microsoft Internet Explorer, предоставляет разработчикам Web-страниц еще больший простор; но тот факт, что
он функционирует лишь на одной платформе, делает разработку специфичных
для него документов не очень привлекательной (если, конечно, ВСЕ
пользователи ваших страниц не работают в Microsoft Windows и Internet
Explorer).
Большинство мелких расширений представляют собой дополнительные параметры
или значения параметров различных тегов. Они обсуждались нами во время
обсуждения тегов HTML.
Самыми существенными расширениями, конечно, являются внутренние языки
браузеров: JavaScript в и VBScript в .
Обсуждение этих языков выходит за рамки данной книги, их описания могут
быть найдены на серверах их производителей.
Обзор различных программ просмотра
На сегодняшний день существует множество браузеров, как коммерческих, таки бесплатных. Все они имеют свои особенности, и очень важно их учитывать
при создании Web-страниц.
Автору известны следующие браузеры для платформ Microsoft Windows
и UNIX/XWindow:
абсолютного большинства UNIX-систем, а также для ОС VMS. Бесплатный,
поставляется в исходных текстах.
используется. Существует в версиях для MS Windows, для UNIX/XWindow/Motif поставляется
в исходных текстах. Бесплатный.
стандарта HTML 3.0. Существует для большинства UNIX-систем. Поставляется
бесплатно в исходных текстах.
HTML 3.2. Находится в очень ранней стадии разработки.
WWW. В нем впервые появились такие возможности, как фоновые цвета и
изображения, поддержка формата JPEG, и т.д. Существует для
MS Windows 3.xx, MS Windows95, Sun Solaris, SGI IRIX, BSDI, Linux, IBM
RS6000, DEC Digital UNIX, HP-UX. Почти для всех систем поддерживается
язык Java. Бесплатный для образовательных организаций, некоммерческих
пользователей и для пробы перед покупкой.
должен быть WWW браузер. Существует только для систем MS Windows95 и WindowsNT.
Подерживает язык Java, бесплатный.
На самом деле, браузеров очень и очень много. Поищите список на узле
.

Рис. П1.2.1: Netscape Navigator 3.0

Рис. П1.2.2: Microsoft Internet Explorer 3.0
Оценка трудоемкости обеспечения WWW доступа
Трудоемкость обеспечения WWW-доступа к базам данных, очевидно,складывается из трудоемкости работ при реализации одного из вышеприведенных сценариев. Реализация
первого сценария связана с последовательным преобразованием всех данных, находящихся в исходной
БД. Разработка средств вывода содержимого таблицы в формате HTML с необходимым форматированием и текстовым сопровождением будет
занимать порядка 1-3-х дней для одного разработчика. Разработка средств построения индексной структуры к выводимым
данным является более творческой работой и может занять 1-3 недели для одного разработчика.
Трудоемкость построения интерфейсов для сценариев 2, 3, в общем случае,
эквивалентна трудоемкости построения этих интерфейсов при создании исходной информационной системы (т.е.
той, для которой обеспечивается WWW-доступ) с использованием традиционных средств разработки (не-CASE). В третьем сценарии дополнительные
трудозатраты пойдут на перегрузку данных в ИХ. При перегрузке данных без изменения структуры и имен
можно исходить из оценки трудозатрат: 1-2 таблицы в 1-2 дня для одного разработчика,
в зависимости от сложности и объема таблиц, при условии отладки технологии перегрузки.
При использовании различных средств разработки интерфейсов к БД,
представленных в отчете, трудозатраты могут существенно различаться. Ранжированный
по уменьшению трудозатрат на разработку интерфейсов список будет выглядеть так:
[]
[]
Однократное или периодическое преобразование содержимого БД в статические документы
В этом варианте содержимое БД просматривает специальная программа,создающая множество файлов - связных HTML-документов (см.рис.1-2).
Полученные файлы могут быть перенесены на один или несколько WWW-серверов.
Доступ к ним будет осуществляться как к статическим гипертекстовым документам сервера.
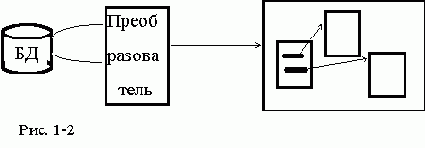
Этот вариант характеризуется минимальными начальными расходами.
Он эффективен на небольших массивах данных простой структуры и редким обновлением, а также
при пониженных требованиях к актуальности данных, предоставляемых через WWW.
Кроме этого, очевидно полное отсутствие механизма поиска, хотя возможно развитое индексирование.
В качестве преобразователя может выступать программный комплекс,
автоматически или полуавтоматически генерирующий статические документы.
Программа-преобразователь может являться самостоятельно разработанной программой либо
быть интегрированным средством класса генераторов отчетов.
Оператор чтения из файла
В Perl есть несколько операций ввода-вывода. Для вывода из файла используетсякоманда <>.
open(STDIN,"/etc/passwd");
while ($string =
{
@a = split(/[:]/,$string);
}
Внутри этих скобок стоит дескриптор файла. Считывание происходит построчно.
В конце файла
По умолчанию считывание происходит в переменную $_. Нулевой дескриптор файла
используется также как в sed и awk, то есть считывается поток из файлов перечисленных
в командной строке.
Оператор диапазона
.. - оператор диапазона. Реально это два разных оператора, в зависимостиот контекста. В списковом контексте он работает как оператор диапазона от
левого аргумента до правого.
for (1..10) {
#code
}
В скалярном контексте он возвращает булевское
значение. Если левый операнд TRUE, то .. принимает значение TRUE, если
правый операнд тоже TRUE.
if (101..200) { print 'hi;)';}
- напечатает вторую сотню строк
Оператор ``стрелка''
Также, как в С и С++ ``->'' является инфиксным оператором ссылки. Если праваячасть является [...] или {...} подпрограммой, тогда левая часть должна быть
символьной ссылкой на массив или хэш. Если правая часть - это имя метода или
скалярная переменная содержащая имя метода, то левая часть должна быть объектом
или именем класса.
Оператор замены множества символов
tr/SEARCHLIST/REPLACEMENTLIST/cds y/SEARCHLIST/REPLACEMENTLIST/cdsЗаменяет все найденные символы из множества символов SEARCHLIST на
соответствующие символы из множества символов REPLACEMENTLIST. Возвращает
число символов, которые были заменены или удалены. Если посредством операторов
=~, !~ не была указана никакая строка, то обрабатывается переменная $_.
y является синонимом tr. Если SEARCHLIST заключен в скобки,
то REPLACEMENTLIST тоже заключается в скобки, которые могут отличаться от тех,
в которые заключается шаблон, например:
tr[A-Z][a-z]
tr(+-*/)/ABCD/
Этот оператор употребляется со следующими опциями:
c заменяет символы, которые не входят во множество SEARCHLIST на
REPLACEMENTLIST, например:
tr/a-zA-Z/ /cs;
заменит неалфавитные символы.
d Стирает символы, которые ни на что не заменяются.
s Переводит последовательность символов, которые заменяются на один и тот же
символ в один символ.
Например:
$a = 'CCCCCCCCC';
$a =~ tr/C/D/s;
теперь $a = 'D'
Оператор замены строки
Оператор s/PATTERN/REPLACEMENT/egimosx производит поиск строки, соответствующейшаблону PATTERN и если строка найдена, то подстановку на ее место текста
REPLACEMENT. Возвращает количество произведенных подстановок.
Если перед этим не использовался оператор =~ или !~ для определения
переменной, которая будет обрабатываться, то будет модифицироваться переменная $_.
Этот оператор используется со следующими опциями:
e интерпретирует правую часть как выражение.
g производит подстановку на место каждой строки, соответствующей шаблону.
i производит поиск различающий большие и маленькие буквы.
m обрабатывает строку, как состоящую из нескольких строк.
o происходит подстановка только на место первой встреченной строки.
s обрабатывает строку, как состоящую только из одной строки.
x использует расширенные регулярные выражения.
Например:
$path =~ s|/usr/local/bin|/usr/bin|;
($foo = $bar) =~ s/this/that/o;
$count = ($paragraf =~ s/Mister\b/Mr./gm);
Оператор ``запятая''
, - оператор запятая или comma-оператор. В скалярном контексте онобрабатывает левый аргумент и отбрасывает его значение, потом обрабатывает
правый аргумент и возвращает его величину. В этом он подобен comma-оператору
из C. В списковом контексте он играет роль разделителя аргументов и вставляет
оба аргумента в список. => является синонимом comma-оператора.
Операторы ++ и - -
Эти операторы работают также как и в С. То есть, если они стоят передпеременной, то они увеличивают или уменьшают переменную до возвращения значения.
Если они стоят после переменной, то увеличение или уменьшение переменной
происходит после возврата значения. Если переменная содержит в себе число или
употребляется в скалярном контексте, то использование ++ дает обычное
увеличение значения. Если же переменная употреблялась только в строковом
контексте, не является пустой строкой и содержит символы a-z,A-Z,0..9, то
происходит строковое увеличение значения переменной:
print ++($foo = '99'); - напечатает 100
print ++($foo = 'a0'); - напечатает a1
print ++($foo = 'Az'); - напечатает Ba
print ++($foo = 'zz'); - напечатает aaa
Операторы эквивалентности
== возвращает TRUE, если левый аргумент численно эквивалентен правому.!= возвращает TRUE, если левый аргумент численно неэквивалентен правому.
<=> возвращает -1, 0 или 1 в зависимости от того, численно меньше,
равен или больше левый аргумент правого.
eq возвращает TRUE, если левый аргумент эквивалентен правому (в строковом контексте).
ne возвращает TRUE, если левый аргумент неэквивалентен правому (в строковом контексте).
cmp возвращает -1, 0 или 1 в зависимости от того, меньше равен или
больше левый аргумент правого (в строковом контексте).
Операторы присваивания
= - обычный оператор присваивания. Вообще операторы присваивания работаюттакже как и в C.
$a += 2; - то же самое, что и $a = $a + 2;
Можно использовать следующие сокращения:
**= += *= &= <<= &&=
-= /= |= >>= =
.= %= ^= x=
($a += 2) *= 3; - то же самое, что и :
$a = $a + 2;
$a = $a * 3;
Операторы сдвига
Двоичный сдвиг осуществляется, как и во многих других языкахпрограммирования, с помощью операторов ``<<'' и ``>>''. При применении
этих операторов значения левых аргументов сдвигаются в соответствующую
сторону на количество разрядов, указанное в правых аргументах.
Аргументы должны быть целочисленными.
Операторы сравнения
``<'' - возвращает TRUE если левый аргумент численно меньше, чем правый.``>'' - возвращает TRUE если правый аргумент численно меньше, чем левый.
``<='' - возвращает TRUE если правый аргумент численно меньше или равен левому.
``>='' - возвращает TRUE если левый аргумент численно меньше или равен правому.
``gt'' - возвращает TRUE если левый аргумент меньше (в строковом контексте), чем правый.
``lt'' - возвращает TRUE если правый аргумент меньше (в строковом контексте), чем левый.
На поведение операторов lt и gt влияют установки
системного языка, если операционная система способна работать с несколькими
языками. По этой причине операторы должны корректно работать со строками
на языках, отличных от US ASCII, что в системе UNIX задается указанием
свойств LC_COLLATE системного locale.
Операторы связки
Знак равенства с тильдой ``=~''связывает выражение слевас определенным шаблоном. Некоторые операторы обрабатывают и модифицируют
переменную $_. Эти же операции иногда желательно бывает выполнить над
другой переменной. Правый аргумент это образец поиска, подстановки или
трансляции, левый аргумент - это то, что должно быть подставлено вместо
$_. Возвращаемая величина показывает успех операции.
Бинарное ``!~'' это тоже самое, что и ``=~'', только
возвращаемая величина является отрицательной в логическом смысле.
Определение типа данных MIME для содержимого документа
Cold Fusion позволяет задаватьтип MIME для данных которые
будут отправлены пользователю из текущего шаблона
(по умолчанию используется text/html).
Для этого используется тег DBCONTENT,
имеющий единственный атрибут TYPE,
который, собственно, и задает тип данных. Например, чтобы отправить
клиенту VRML - документ может
использоваться следующий шаблон:
FROM CyberRooms WHERE
RoomNumber=#URL.RoomNumber#">
#VRML_Script#
Заметим, что Cold Fusion не
будет отправлять клиенту текст, расположенный до тега DBOUTPUT.
Оптимизация Web-страниц
По причине низкой пропускной способности каналов Internet возникаетнеобходимость в жестком слежении за размерами элементов Web-страниц,
особенно графики и multimedia-материалов. Для снижения размеров таких
ресурсов существует несколько стандартных методик, но, вообще говоря,
подход является индивидуальным. Каждое изображение или другой материал
имеет свои особенности, и на них можно выиграть драгоценное снижение
байтового размера. При разработке страницы на быстром компьютере
и с высокоскоростным каналом связи не всегда заметно то, от чего
страдают пользователи массовых модемов со скоростью 14400 бод (или даже ниже).
Поставьте себе такой модем и посмотрите на создаваемые страницы!
Если они плохо оптимизированы, то это откроет вам глаза.
В этом разделе мы рассмотрим основные приемы,
используемые при процессе оптимизации различных материалов для WWW.
Основные функции доступа
Мы приведем здесь пример программы, которая создает таблицу, помещаетв нее некоторые данные и потом производит выборку строк из этой таблицы.
#!/usr/local/bin/perl
use Oraperl;
# подключаем модуль Oraperl
$system_id = 'T:bdhost.com:Base';
$lda = &ora_login($system_id,'scott','tiger');
# вход в систему
$st = 'create table EMP (name varchar2(100),
organization varchar2(100))';
$csr = &ora_open($lda,$st) die $ora_errstr;
&ora_close($csr);
# создание таблицы в базе данных
$st = 'insert into EMP values
(\'John Smit\', \'NATO\')';
$csr = &ora_open($lda, $st);
&ora_close($csr);
# помещение строки в таблицу
В результате в базе создалась таблица из двух столбцов с одной записью:
Name | Organization |
| John Smit | NATO |
$st = 'select name from EMP
where organization = \'NATO\'';
$csr = &ora_open($lda,$st);
# выбираем из таблицы значения столбца name,
# которым сответствует значение столбца organization
# равное 'NATO'
@result = &ora_fetch($csr);
# помещаем эти значения в массив @result
&ora_close($csr);
print @result;
&ora_logoff($lda);
# выход из системы
Для взаимодействия с Oracle в Perl есть специальный модуль Oraperl.pm.
Основными функциями для доступа к базе данных являются:
&ora_login
$lda = &ora_login($system_id,$username,$password)
Для того, чтобы получить доступ к информации, хранимой в Oracle необходимо сначала
войти в систему. Это осуществляется вызовом функции &ora_login(). Эта функция
имеет три параметра: системный идентификатор базы данных, имя пользователя в базе
и пароль пользователя. Возвращается идентификатор регистрации в системе (Oracle Login Data Area).
Несколько доступов могут осуществляться одновременно. Эта функция
эквивалентна функции OCI(Oracle Call Interface) olon или orlon.
&ora_open
$csr = &ora_open($lda, $statement [,$cache])
Для определения SQL-запроса в базу данных программа должна вызывать функцию
&ora_open. Эта функция имеет как минимум два параметра: идентификатор регистрации
и SQL выражение. Необязательный третий параметр описывает размер буфера строк для
SELECT оператора. Возвращается курсор Oracle. Если третий параметр опущен,
то используется стандартный размер буфера.
$csr = &ora_open($lda,'select ename,
sal from emp order by ename',10);
Эта функция эквивалентна функции OCI oopen или oparse.
&ora_bind
&ora_bind($csr, $var, ...)
Если SQL выражение содержит обращение к переменным языка Perl, то необходимо подставить вместо имен
значения переменных. Для этого используется функция &ora_bind.
$csr = &ora_open($lda, 'insert into emp values (:1,:2)');
&ora_bind($csr,$ename,$sal);
- подставляет в SQL выражение вместо :1 и :2 значения переменных $ename
и $sal.
&ora_fetch
$nfields = &ora_fetch($csr[, trunc]);
@array = &ora_fetch($csr);
Эта функция используется с оператором SQL SELECT для
извлечения информации из базы данных и имеет только один обязательный параметр
- идентификатор курсора, полученный в результате вызова функции &ora_open. В скалярном
контексте она возвращает число выбранных строк, в списковом - массив выбранных
строк. Второй необязательный параметр содержит информацию о том, можно ли обрезать
данные типов LONG и LONG RAW или выдавать сообщение об ошибке. Если параметр
опущен, то информация берется из переменной $ora_trunc.
Если произошло обрезание данных, то переменная $ora_errno принимает значение
1406. Эта функция эквивалентна функции OCI ofetch.
&ora_close
&ora_close($csr)
Если открытый курсор не будет больше использоваться, то его нужно закрыть
вызовом функции &ora_close. Это эквивалентно функции OCI oclose.
&ora_do
&ora_do($lda,$statement)
Не все SQL-выражения возвращают данные или содержат переменные для подстановки.
В таких случаях функция &ora_do выступает в качестве альтернативы &ora_open
и &ora_close. Первым параметром является идентификатор регистрации, вторым --
SQL выражение.
&ora_do($lda,'drop table employee');
это эквивалентно:
&ora_close(&ora_open($lda, 'drop table employee'));
&ora_logoff
&ora_logoff($lda)
Для выхода из системы используется
функция &ora_logoff. Она эквивалентна функции OCI ologoff.
Основные понятия
Использование технологий WWW для обеспечения доступа к каким-либо информационным ресурсам подразумевает существование следующих компонент (см.рис.1-1):обеспечивающего предоставление гипертекстовых документов через IP - сеть в ответ на запросы WWW - клиентов.
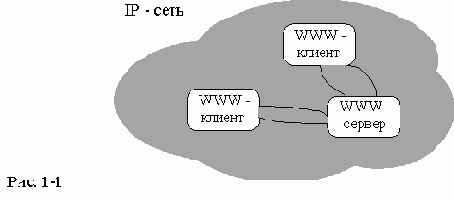
Передаваемые гипертекстовые документы оформляются в стандарте HTML - языке описания гипертекстовых документов. Эти документы могут либо храниться в статическом виде (совокупность файлов на диске), либо динамически компоноваться
в зависимости от параметров запроса специальным программным обеспечением. Для динамической компоновки HTML-документов, WWW-сервер использует специальным образом оформленные программы- CGI-программы.
Основные типы графики для WWW
Несмотря на то, что графическое оформление Web-страницы является довольно широким полем для фантазии, существует несколько типов наиболее употребимых графических вставок, как то:В Internet имеются довольно обширные коллекции бесплатных изображений такого типа. Тем не менее, иногда бывает проще нарисовать их для конкретных страниц самостоятельно.
Особенности WWW-графики
При подготовке графического материала для WWW следует учитывать некоторую специфику, связанную с тем, что графика будет передаваться по сети, а также с тем, что он будет, в основном, отображаться на компьютерных дисплеях.Еще одной особенностью является тот исторически сложившийся факт, что на графических системах с глубиной цвета 8 бит (256 цветов) используется фиксированная палитра из 216-ти цветов выбранных так, чтобы в палитре равномерно присутствовали цвета спектра.
Пакет Cold Fusion фирмы Allaire Corp
Пакет предназначен для использования под ОС Windows и позволяет обращаться к различным базам данных,поддерживающим интерфейс ODBC через WWW-интерфейсы. Пакет имеет коммерческий статус,
его "evaluation copy" является свободно-распространяемой.
Для доступа к базам данных используются конструкции языка DBML - расширения языка HTML,
дополненного средствами доступа к БД через ODBC. Документы на языке DBML обрабатываются
на серверной части, в результате чего создается HTML-документ.
Полноценная версия пакета, вместе с WWW - сервером стоит $486.
Пакет может эффективно использоваться в качестве обработчика запросов
WWW к исходным базам данных или информационному хранилищу (сценарии 2,3).
Глава отчета посвящена описанию процедуры установки и использованию пакета.
Пакет Web - Oracle - Web
Пакет WOW является свободно-распространяемым программным средством, предназначеннымдля создания интерактивных WWW-интерфейсов с СУБД Oracle. Пакет WOW был первым и наиболее простым средством,
выпущенным фирмой Oracle. В настоящее время существует набор продуктов, развивающих
функциональность WOW'а - Oracle Web Server версий 1, 2, Oracle Web Arcitecture.
Все перечисленные продукты позволяют использовать процедурное
расширение языка SQL - PL/SQL, разработанное фирмой Oracle для динамического
создания гипертекстовых документов. Высокая скорость разработки достигается за счет резкого
упрощения доступа к БД - программы на PL/SQL исполняются самим сервером Oracle.
Предлагаемый пакет WOW был переработан в Новосибирском областном центре НИТ с целью поддержки
нескольких русскоязычных кодировок.
Основной областью использования WOW является обработка запросов от WWW-сервера к SQL-серверу Oracle в среде Unix. В предложенных сценариях пакет WOW позволит
организовать эффективный WWW доступ к информационному хранилищу, построенному на базе сервера баз данных Oracle (сценарий 3). Глава
отчета посвящена описанию процедур установки и администрирования
пакета.
Пакеты
Perl поддерживает механизм альтернативного именного пространства для каждогоотдельного пакета. Обычная программа является пакетом с именем main. Можно
ссылаться на переменные или дескрипторы файлов из других пакетов посредством
использования префикса перед именем переменной, состоящего из имени пакета и
двойного двоеточия: $Package::Variable. Если имя пакета нулевое, то предполагается
использование переменной из main пакета. То есть $::sail эквивалентно
$main::sail. Пакеты могут включать в себя другие пакеты, в таком случае
чтобы обратиться к переменной нужно применить описанное обозначение рекурсивно:
$OUTER::INNER::var.
В пакете могут содержаться только переменные, чьи имена начинаются с буквы или
подчерка, остальные переменные содержатся в пакете main. Кроме того
зарезервированные переменные, как то STDIN, STDOUT, STDERR, ARGV, ARGVOUT, ENV,
INC и SIG также содержатся в главном пакете.
package mypack;
sub main::mysub {
...
}
Передача параметров в DBML-шаблон
Существует несколько способов передачи параметров между шаблонами.Можно передавать параметры непосредственно в URL,
использовать для этого форму либо cookie.
Если параметры передаются через URL,
то они добавляются к адресу вызываемого шаблона через символ "&"
(амперсант) в виде параметр
= значение. Например, гипертекстовая ссылка,
приведенная ниже, отправляет параметр с именем 'user_id'
и значением 5 в шаблон 'example.dbm':
При передаче параметров через форму используются поля формы, которые
должны иметь имена, совпадающие с именами параметров, которые
требуется передать. Ниже приведен пример передачи параметра, из
предыдущего примера используя форму:
Заметим, что при обращении к CGI
- программе DBML.EXE должен
быть определен стандартный параметр Template,
указывающий на конкретный шаблон.
Переменные, занесенные в cookie браузера
и переменные окружения CGI доступны
в любом шаблоне. Способы занесения информации в cookie
описаны в .
Переменные для подстановки
Oraperl позволяет SQL выражению содержать обращение к переменным языка Perl. Онисостоят из двоеточия и следующего за ним номера. Например:
$csr = &ora_open($lda,"insert into tel values(:1,:2)");
Эти два имени :1 и :2 называются переменными для подстановки. Функция
&ora_bind() используется для привязывания переменных к их значениям.
&ora_bind($csr, "Annette","3-222-2-22-22-22");
&ora_bind($csr,$name,$telephone);
Номера переменных должны следовать в порядке возрастания начиная с 1, так как
&ora_bind выполняет подстановку именно в таком порядке.
Переменные окружения CGI
Каждый сеанс связи вызывающий CGI- программу имеет конкретные переменные окружения. Доступ
к ним из шаблона осуществляется, также как и к другим параметрам,
только используется префикс 'CGI.',
например #CGI.REMOTE_ADDR#.
Переменные окружения
Переменные окружения условно делятся на два типа:К переменным первого типа относятся следующие переменные:
SERVER_SOFTWARE содержит информацию о WWW сервере (название/версия)
SERVER_NAME содержит информацию об имени машины, на которой запущен WWW сервер,
символическое имя или IP адрес соответствующие URL.
GATEWAY_INERFACE содержит информацию о версии CGI(CGI/версия)
Следующие переменные являются специфичными для разных типов запросов
и значения этим переменным присваиваются перед вызовом cgi-модуля.
CONTENT_LENGTH значение этой переменной соответствует длине стандартного входного
потока в символах.
CONTENT_TYPE эта переменная специфицирована для запросов содержащих дополнительную
информацию, таких как HTTP POST и PUT, и содержит тип данных этой информации.
SERVER_PROTOCOL эта переменная содержит информацию об имени и версии информационного
протокола (протокол/версия).
SERVER_PORT значение переменной содержит номер порта, на который был послан запрос.
REQUEST_METHOD метод запроса, который был использован "POST","GET","HEAD"
и т.д.
PATH_INFO значение переменной содержит полученный от клиента виртуальный путь до cgi-модуля
PATH_TRANSLATED значение переменной содержит физический путь до cgi-модуля, преобразованный из значения PATH_INFO.
SCRIPT_NAME виртуальный путь к исполняемому модулю, используемый для получения URL.
QUERY_STRING значение этой переменной соответствует строке символов следующей
за знаком "?" в URL соответствующему данному запросу. Эта информация не декодируется сервером.
REMOTE_HOST содержит символическое имя удаленной машины, с которой был произведен
запрос. В случае отсутствия данной информации сервер присваивает
пустое значение и устанавливает переменную REMOTE_ADDRESS.
REMOTE_ADDRESSсодержит IP адрес клиента
AUTH_TYPE если WWW-сервер поддерживает аутентификацию (подтверждение подлинности)
пользователей и cgi-модуль
является защищенным от постороннего доступа то, значение переменной
специфицирует метод аутотентификации.
REMOTE_USER
содержит имя пользователя в случае аутотентификации.
REMOTE_IDENT содержит имя пользователя, полученное от сервера (если сервер
поддерживает аутентификацию согласно RFC 931)
HTTP_ACCEPT список типов MIME известных клиенту. Каждый тип в списке должен
быть отделен запятой согласно спецификации HTTP (тип/подтип,тип/подтип
и т.д.)
HTTP_USER_AGENT название программы просмотра которую использует клиент при посылке
запроса.
Переменные
В модуле Oraperl.pm есть шесть специальных переменных:$ora_cache
$ora_long
$ora_trunc
$ora_errno
$ora_errstr
$ora_verno
Эти переменные
используются для определения поведения Oraperl в определенных условиях.
$ora_cache
Эта переменная определяет размер буфера для функции
&ora_open() и SELECT-выражения, если точный размер буфера не указан.
Как правило устанавливается размер буфера равный пяти. Присваивание этой
переменной значения, равного нулю, устанавливает значение этой переменной
равным первоначальному значению. Присваивание отрицательной величины
приводит к ошибке.
$ora_long
Обычно Oraperl спрашивает базу данных о длине каждого поля и соответствующим
образом распределяет буферное пространство. Это невозможно для полей типа
LONG и LONGRAW. Распределение пространства в предположении максимально
возможной длины (65535 bytes) привело бы к излишним тратам памяти. Поэтому
когда &ora_open() определяет, что поле имеет тип LONG, память распределяется
согласно значению переменной $ora_long. При инициализации она принимает
значение 80 (для совместимости с продуктами Oracle), но в программе ее
можно устанавливать произвольным образом.
$ora_trunc
Так как Oraperl не может точно определять длину значений
типа LONG, возникают ситуации, когда значение $ora_long недостаточно для
хранения полученных данных. В таком случае, если у &ora_fetch есть
необязательный второй параметр, происходит обрезание данных. Если второй
параметр опущен, то вместо него используется значение $ora_trunc.
$ora_errno
Содержит код ошибки произошедшей при последнем вызове
какой-либо функции. Есть два интересных случая, касающихся &ora_fetch().
В первом случае, если произошло обрезание данных типа LONG или LONGRAW и
обрезание было разрешено, тогда выполнение этой функции полностью успешно,
но $ora_errno принимает значение 1406, для индикации того, что произошло
обрезание. Во втором случае, если &ora_fetch() возвратила false, то
$ora_errno принимает значение 0 в случае конца данных или код ошибки,
если действительно произошла ошибка.
$ora_errstr
Содержит сообщение об ошибке, соответствующее значению
$ora_errno.
$ora_verno
Содержит версию Oraperl в формате v.ppp, где v -
основной номер версии, а ppp - patchlevel.
Перенаправление на другой URL (DBLOCATION & DBABORT)
Для перенаправления пользователя на другой URLпредназначен тег DBLOCATION. Этот
тег обычно применяется, если в шаблоне выполняется один или более
запросов, а затем нужно сразу же перейти к другому документу,
либо URL, на который нужно
отправит пользователя, зависит от параметра. Приведем пример использования
тега, иллюстрирующий его синтаксис:
В качестве значения атрибута URL
тега DBLOCATION можно
использовать параметры и переменные, допустимые в шаблоне. Например,
Для прерывания обработки шаблона в Cold
Fusion используется тег DBABORT.
Этот текст будет отправлен
клиенту
Этот текст не будет
отправлен клиенту
Обычно этот тег используется при неправильной аутентификации.
План отчета
В главах отчета будут подробно освещены различные этапы приведенныхсценариев, технологические решения, используемые для поддержки этих этапов. Взаимосвязь
глав отчета показывает схема на рис. 1-6.
Во второй главе подробно описывается язык HTML. Она необходима для понимания того,
какой вид должна иметь информация, представляемая с использованием технологий WWW.
Третья глава посвящена описанию базовых элементов WWW-технологии,
процедур установки и администрирования WWW-сервера.
Четвертая глава содержит материал по корневой технологии создания
динамических HTML-документов - интерфейсу CGI. Подробно описывается интерфейс CGI WWW-сервера
с вызываемыми программами. Именно CGI-программы (программы, удовлетворяющие спецификации CGI)
способны динамически обрабатывать WWW - запросы к базам данных.
В главах , , излагается три технологических
направления, используемых при реализации приведенных выше сценариев. Сориентировавшись на одно или несколько таких направлений,
можно реализовывать программные комплексы с функциями "Преобразователь"
и "Обработчик" сценариев 1-3.
Предлагаемые технологические решения обладают универсальностью
области применения. Одно решение может использоваться для:
БД или информационного хранилища.
Побитовое И, побитовое ИЛИ и Исключающее ИЛИ
Бинарное & возвращает объединенные побитово операнды.Бинарное | возвращает перемноженные побитово операнды.
Бинарное ^ возвращает исключенные побитово операнды.
Поддержка русскоязычных кодировок
Исторически сложилось, чтов России распространены несколько русскоязычных кодировок, в основном
ориентированных на разные платформы. Наиболее известные из них:
используемая в MS-DOS
по стандартизации
используемая в Microsoft Windows.
Специалисты утверждают что всего в России имеют хождение 11 кодировок
русского алфавита.
Если Ваш WWW сервер ориентирован на использование внутри организации
или его пользователями будет являться ограниченный круг людей
с однотипными рабочими местами, Вы можете ограничиться одной кодировкой
русскоязычной информации на сервере.
Сложности возникают, когда Вы захотите расширить круг клиентов
сервера. Вам необходимо будет организовать поддержку нескольких
кодовых страниц для русскоязычных документов. Приведенный выше
список из четырех кодировок удовлетворит более 99% всех возможных
абонентов сервера.
Вообще говоря, в составе языка HTML имеются теги, определяющие
кодировку документа и должные позволить корректно прочитать документ
в любой кодировке. Однако в связи с тем,
что эти теги не поддерживаются ни одним из известных броузеров,
надеяться на них не стоит. Возможно, в будущем эта ситуация изменится,
и проблема с кодировками будет решена.
Для поддержки нескольких кодовых страниц применяется множество
методов, которые можно разбить на две группы:
они лежат на сервере, в кодировку, поддерживаемую WWW - клиентом.
В первом случае, на сервере физически присутствуют все файлы во
всех поддерживаемых кодировках. Документы в различных кодировках
отличаются между собой по правилам образования путей и имен.
Например:
indexw.html,
indexa.html
- добавление суффиксов, определяющих
кодировку. Или
.../koi8/index.html,
.../win/index.html
- различные базовые каталоги для разных кодировок.
При этом выделяется одна мастер - кодировка,
в которой новые документы располагаются на сервере,
а все остальные варианты документов получаются после работы
специальной программы - перекодировщика.
Программа - перекодировщик может запускаться вручную -
администратором WWW сервера
или автоматически, с использованием
команд cron, at.
Во втором случае, доступ к
документам осуществляется через дополнительную программу - перекодировщик,
динамически перекодирующую документы сервера в кодировку
WWW - клиента. Эта программа может быть CGI
- программой, через которую всегда осуществляется доступ
к русскоязычной части сервера. На
вход такой программе передается реальный путь документа и кодировка
WWW - клиента,
в которую нужно перекодировать указанный документ
(см. рис.
12.1)
Программа - перекодировщик может также располагаться между WWW
- клиентом и сервером (см.рис.12.2).
В таком варианте она называется PROXY.

Однако здесь возникает проблема с перекодировкой всех данных,
включая графику, видео,
аудио и других нетекстовых материалов.
Для ее решения PROXY придается
дополнительный интеллект - определять тип передаваемых данных
по заголовку MIME и решать,
перекодировать документ или нет,
на основе его типа. Программы
- перекодировщики с различными кодировками обрабатывают обращения
к разным портам tcp сервера.
Клиенту работа с PROXY видна
в URL.
Например:
http://www.nsu.ru:80/index.html
- для кодировки КОИ-8,
http://www.nsu.ru:8000/index.html
- для кодировки ISO-8859-5
и т.д.
[]
[]
[]
Поддержка транзакций
Для объединения нескольких запросов в одну транзакцию может бытьиспользован тег DBTRANSACTION. Все
запросы, содержащиеся внутри этого тега,
будут интерпретироваться как одна транзакция. То есть все изменения
сделанные в базе данных, либо будут одновременно сохранены, либо
не будет сохранено ни одно из них.
Приведем пример, в котором денежная сумма переводится с одного
банковского счета на другой:
SQL = "UPDATE Accounts
SET Balance = Balance - #Amount#
WHERE Account_ID = #AccountFrom#
">
SQL = "UPDATE Accounts
SET Balance = Balance + #Amount#
WHERE Account_ID = #AccountTo#
">
Заметим, что не все драйверы ODBC
поддерживают транзакции. Например,
драйверы для Oracle, SQL Server
и Access поддерживают транзакции,
а драйверы для FoxPro, dBase
и Paradox - нет.
Подпрограммы
Описать и использовать подпрограмму можно несколькими способами:Вызвать подпрограмму можно тоже несколькими способами:
или включения подпрограммы из модуля.
Аргументы передаются подпрограмме в виде локального массива @_, его элементы
являются ссылками на реальные скалярные параметры. Подпрограмма возвращает
значение, полученное в результате исполнения последнего оператора подпрограммы.
Как уже говорилось, подпрограмма вызывается использованием префикса & перед
ее именем, в Perl 5 этот префикс не обязателен. Пример:
sub MAX {
my $max = pop(@_);
foreach $foo (@_) {
$max = $foo if $max < $foo;
}
$max;
}
...
$bestmark = &MAX(1,2,3,4,5);
Подпрограмма может вызываться рекурсивно. Если подпрограмма вызывается с использованием
& формы, то список аргументов необязателен.
Если вы хотите создать внутри модуля его собственную, невидимую снаружи подпрограмму,
то описание должно быть анонимным:
my $subref = sub {...}
&$subref(1,2,3);
Поля формы и параметры URL
Если в шаблон, с помощью полей формы или в URL, были переданыпараметры, то внутри любого тега DBML к этим параметрам
можно обращаться, используя следующий синтаксис:
#Form.Name#, #URL.Name#. На самом деле, префиксы 'Form.'
и 'URL.' могут опускаться,
если заранее известно, что не может быть параметров других типов
с такими же именами. Это правило относится ко всем типам параметров
и переменных.
Последовательность действий для
Исходя из разницы методов запросов GET и POST, можно определить последовательность действий для обработки входных данных cgi-модулядля разных типов запросов.
Представление цвета
Для обозначения цветов можно использовать слова вроде красный илибелый. Но человеческий глаз различает миллионы цветовых оттенков,
и не хватит слов ни одного языка, чтобы точно передать каждый из них.
По этой причине с приближением эры цветного телевидения и печати
люди стали задумываться над тем, как можно закодировать информацию
о цвете.
Всем хорошо известно, что существует чистые цвета (цвета видимого спектра,
радуги) и смешанные цвета (например, белый цвет -- смешанный).
В видимом спектре четко выделяются три основных цветовых оттенка:
красный, зеленый и синий. Было замечено, что, смешивая эти основные цвета,
можно с хорошей точностью получать почти все возможные оттенки,
наблюдаемые нами в спектре. Именно на принципе смешения красного, зеленого
и синего цветов построены электронные лучевые трубки цветных телевизоров
и мониторов.
Как известно, компьютеры работают с числами, и именно с числами им
проще всего работать. Естественно, что для обозначения яркости цветовых
компонент (так мы будем называть интенсивности основных цветов)
в цифровой технике стали применять числа. Подсчитано, что для корректного
цветовоспроизведения достаточно выделить по 256 уровней интенсивности
для каждой из компонент. За нулевой уровень принимается полное отсутствие
яркости, за 255-й -- полная яркость. Таким образом может быть отображено
цветов.
Для короткого обозначения такого представления цветов используется
аббревиатура RGB (от Red-Green-Blue, названий основных цветов на
английском языке).
Если представить себе цветовое пространство, соответствующее
RGB-модели, то оно будет представлять собой куб в системе координат, где
в качестве осей выбраны линии возрастания интенсивности компонент,
точками которого будут являться конкретные цвета.
Люди с хорошим пространственным воображением, представив себе такой куб,
могут сразу примерно прикидывать RGB-разложения конкретных цветов.
RGB-куб выглядит примерно так:
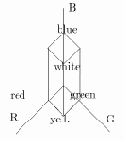
Запись RGB-описания цвета удобно производить в виде так называемого
RGB-триплета: тройки чисел в шестнадцатеричной системе счисления
(тогда все числа будут двузначными). Шестнадцатеричная система счисления
отличается от общепринятой десятичной тем, что в качестве основания
при разложении чисел используется число 16. ``Дополнительными'' цифрами
считаются шесть первых букв латинского алфавита: A, B, C, D, E, F.
Для получения RGB-триплета из имеющихся десятичных значений компонент
легко произвести с помощью научного калькулятора (если не настоящего, то
содержащегося в системе MS Windows или аналогичного).
Получить значения RGB-компонент какого-либо конкретного цвета
можно с помощью некотроых графических пакетов: диалоговые окна
выбора цветов нередко содержат подобную информацию. Хорошим примером
программы, имеющей подобные возможности, служит великолепный
пакет Paint Shop Pro компании Jasc Inc.
Если вы не хотите даже иметь дело с ``ученой цифирью'', вам
сильно поможет программа Color Manipulation Device, доступная
в Internet.
Для пользователей системы XWindow можно порекомендовать программы
XColorMix и XColorSel, также доступные в Internet.
к гл Конструкции языка HTML для построения форм
использование: предназначен для получения информации от клиента
и определяет начало и конец формы.
атрибуты:
ACTION - определяет URI (Universal Resource Identifier-адрес
или место расположения документа) CGI-скрипта
METHOD - определяет метод передачи информации скрипту.
Возможные значения GET или POST.
[ENCTYPE] - определяет тип MIME декодирования информации
(значение этого атрибута по умолчанию - "application/x-www-form-urlencoded").
[SCRIPT] - используется для передачи URI скрипта. Язык
скрипта и интерфейс пользователя при этом не являются частью
спецификации HTML 3.0
Важно: Формы не могут быть вложенными!
Для реализации формы используются следующие теги.
использование: предназначен для создания различных по своей функциональности
полей ввода.
атрибуты:
TYPE - определяет тип поля формы.
Допустимые значения:
TEXT - позволяет символьный ввод.
PASSWORD - предназначено для "скрытого" ввода
символов (вводимые символы не отображаются).
CHECKBOX - поле, позволяющее два состояния ("есть",
"нет"). Должен применяться с атрибутами NAME и VALUE
RADIO - поле, позволяющее выбор "один из всех"
SUBMIT - кнопка инициирующая передачу информации из формы
обрабатывающему скрипту, определенному в ACTION в соответствии
с методом,
определенным атрибутом METHOD.
RESET - кнопка, сбрасывающая все введенные ранее значения.
IMAGE - поле позволяющее воспроизвести событие SUBMIT при
помощи вашего изображения, при этом
возвращается два значения: name.x = координата
Х и name.y = координата Y, где Х и Y
координаты положения курсора мыши на изображении
в момент щелчка.
HIDDEN - поле создающее неотображаемое значение.
RANGE - определяет поле позволяющее ввести
цифровое значение с определенными допустимыми верхним и нижним
пределами.
Используется вместе с атрибутами MAX и
MIN определяющими область допустимых значений (например: TYPE=RANGE
MIN=1 MAX=10).
NAME - значение этого атрибута определяет
идентификатор поля.
VALUE - значение этого атрибута определяет
что будет передано в качестве значения по умолчанию для данного
поля при инициации формы.
SRC - определяет URI файла изображения.
Используется только с типом поля IMAGE.
[CHECKED] - позволяет установить начальное
значение поля типа CHECKBOX.
SIZE - определяет размер поля.
[MAXLENGTH] - определяет максимальное количество
символов, допустимое для ввода в поле.
[ALIGN] - позволяет позиционирование
Допустимые значения:
TOP - выравнивание по верху.
MIDDLE - выравнивание по середине.
BOTTOM выравнивание по низу.
Эти значения используются только с TYPE=IMAGE.
[LEFT] - выравнивание слева
[RIGHT] - выравнивание справа
[DISABLED] - определяет поле как "read
only" - только для чтения. Значение в поле не может
быть изменено пользователем.
[ERROR] - определяет сообщение об ошибке,
объясняющее, почему введенное значение в поле не верно.
использование: предназначен для определения области ввода
текста. Размер поля определяется атрибутами.
атрибуты:
NAME - значение этого атрибута определяет идентификатор
поля. Возвращается при инициации формы.
ROWS - определяет количество строк в текстовой
области.
COLS - определяет количество столбцов в текстовой
области.
[VALUE] - задает значение по умолчанию.
[DISABLED] - определяет поле как "read only"
- только для чтения. Значение в поле не может быть изменено пользователем.
[ERROR] - определяет сообщение об ошибке, объясняющее,
почему введенное значение в поле не верно.
значение1
...
значениеN
использование: предназначен для определения области выбора из
нескольких значений (меню).
Атрибуты:
NAME - значение этого атрибута определяет идентификатор
поля. Возвращается при инициации формы.
[SIZE] - определяет количество видимых возможных значений.
[MULTIPLE] - определяет возможность множественного выбора.
[DISABLED] - определяет меню как "read only"
- только для чтения. Значения в меню не может быть выбрано пользователем
и показывается серым цветом.
значение
использование: используется только с