Общение в бизнесе Общение в бизнесе Бизнес общения - виды Деловое Коммуникации Коммуникации Оратор Психология общения в бизнесе Публичное общение Бизнес общения в России Русское общение в бизнесе Язык общения в бизнесе Техника бизнес общения Разговор Речь Слово Мимика Спор в бизнесе Спор и общение в бизнесе Риторика в бизнесе Обман в бизнесе Понимание |

|
Общение
А для чего, собственно?
К blog-ам в первую очередь хотелось бы привлечь внимание тех, кто задумывается над созданием персональной веб-страницы или сайта. Как показывает опыт, после бурного творческого порыва, вызванного прочтением книжки о FrontPage, большинство новоявленных веб-зодчих угасает, так и не внеся в Сеть что-либо действительно новое и интересное. Опубликовав фотографию своей кошки и пару любимых анекдотов, владелец сайта упирается в стену творческого кризиса. Публиковать ссылки на интересные сайты? Yahoo.com и Yandex.ru все равно не переплюнешь. Публиковать анекдоты? anekdot.ru их публикует по сотне в день. Так, сайт быстро "стареет", на него не ходят даже собственные друзья владельца, потому как читать там совершенно нечего.А между тем blog идеальным образом подходит для домашних страниц. Руководствуясь принципом "что вижу, то пою", вы - как владелец сайта - никогда не испытаете "страха чистого листа". Никогда не будете грызть ногти в раздумьях "что же мне там на сайте опубликовать-то"? Ведь писать можно все, что угодно. Лучший материал - это то, что вы написали сами, лично, а не скопировали с anekdot.ru или с omen.ru. Blog-и в сети напоминают площадь в день митинга, где у каждого в руках мегафон и каждый кричит в него всё, что ему взбредет в голову. Благодарные слушатели ходят от оратора к оратору, пробегают мимо зануд и матерщинников и толпятся у трибун с интересными личностями.
На первый взгляд этот хаос и поток слов (перемежающийся с запором мыслей) кажется ужасным, но поверьте, читать ежедневные blog-и намного интереснее, чем любоваться домашней страницей двухлетней давности с подборкой засаленных рефератов и ссылкой на www.design.ru.
Благодаря blog-у, ваша персональная страница приобретает личностный оттенок, несет особую индивидуальность, и тем самым выделяется на фоне скучных аляповатых домашних страниц. По самой природе blog-а, у вас руки сами будут тянуться написать туда что-нибудь. И вы еще будете извиняться перед своими посетителями за то, что целых два дня не написали ни строчки - как будто до этого есть кому-то дело.
Что говорит наука?
Как общественный сетевой феномен, blog-и стали предметом исследования психологов. Причины популярности blog-ов кроются в природе человека. Вот некоторые из этих причин:Что такое blog?
Что такое blog? Это web-страница, содержащая личные заметки, дневник, или ленту новостей со ссылками. Название blog произошло от английского слова "weblog ", означающего дословно "web-лента записей". И вправду, любой blog представляет собой список записей-заметок, расположенных в хронологическом порядке, - этакий личный сетевой дневник.Самым-самым первым blog-ом можно считать страницу Тима Бернерса-Ли (Tim Berners-Lee), где он начиная с 1992 года публиковал новости о развитии WWW и появлении новых web-сайтов.
Первые blog-и появились в 1996 году, а к 2003 году популярность их стала настолько высока, что они объявлены даже отдельным жанром сетевой литературы и журналистики.
Ярким примером сетевых дневников является , , , . Как вариант дневниками коллективного пользования можно считать . И чем, кстати, не дневник - Тёмино ru/kovodstvo, Miu Mau или http://www.kottke.org/ - фундаментальный blog дизайнера Jason Kottke?
End of Print
Каковы бы ни были причины феномена blog-ов, мода на них еще не скоро сойдет на нет. Самое главное позитивное изменение в Web-е, вызванное благодаря blog-ами: стало меньше заброшенных уродливых страниц с фотографиями кошек и бородатыми анекдотами.И если к вам подойдет друг или подруга и спросит, что нужно сделать, чтобы опубликовать в Интернете свою домашнюю страничку, посоветуйте им blog. Сделайте доброе дело, увеличьте тем самым качество смысла, распределенное на общее количество буквенных знаков, опубликованных в Интернете.
Ну что, о-blog-имся?
Прежде чем завести свой blog, необходимо решить, хотите ли вы вести его на своем сайте, или воспользоваться услугами другого сайта. В первом случае вам придется устанавливать и настраивать blog-программу самому, но зато вы будете полным хозяином своего blog-а, его внешнего вида, его размеров и прочее. Во втором случае вы получаете все уже готовенькое (часто даже и бесплатно - http://www.blogger.com/about.pyra), только ваши манипуляции с blog-ом будут несколько ограничены (изменение внешнего вида, настройки кодировки) или будет раздражать отсутствие какой-либо нужной вам функции.Самый простой blog-ом можно сделать вручную. Всякий раз, когда вы хотите что-то написать, вы открываете страницу сайта в Блокноте или в FrontPage и добавляете в начало страницы новую запись. Затем закачиваете страницу на сервер по FTP... и так каждый день.
Но можно и автоматизировать этот процесс. Blog-программа или blog-скрипт по сути ничем не отличается от скриптов, используемых для гостевых книг и форумов. Они бывают платными и бесплатными (менее функциональны). Записи-заметки хранятся либо в текстовых файлах, либо в базе данных. Существует множество blog-программ, написанных на php, asp, jsp, perl и т.д. Любой поисковый сервер поможет вам найти скрипт, подходящий для вашего случая. Самые простые blog-и позволяют только публиковать заметки. Более продвинутые позволяют читателям оставлять свои комментарии к заметкам, разбивать заметки по категориям (http://xplane.com/xblog/).
Обычно blog обновляется через веб-интерфейс. Но есть blog-программы, которые имеют клиентскую часть, из которой вы можете сделать запись в blog-е, не утомляясь набором URL-а в броузере. Эта клиентская программа сидит тихонечко себе в system tray, и вам достаточно одного щелчка мышки, чтобы, не задерживаясь, написать только что пришедшее в голову тысяча семьсот восемьдесят пятое доказательство теоремы Ферма или очередную тайну мадридского двора.
В своем blog-е вы можете давать ссылки и на другие "дружественные" blog-и, чтобы посетитель, почитав ваши опусы, мог перейти на опусы ваших друзей.
А от них, на опусы их друзей. И так далее, пока круг не замкнется, и посетитель не вернется опять на вашу страницу с blog-а какого-нибудь вашего друга. Некоторые blog-программы (livejournal.com) позволяют генерировать объединенный blog с записями всех ваших друзей. Зайдя на такую страницу посетитель сможет увидеть все, что написали в ближайшее время все ваши друзья. Подбирая себе в коллекцию "друзей", вы как бы формируете собственную web-газету по своему вкусу. И то, какими друзьями вы "угощаете" своих посетителей, тоже говорит о многом. Воистину, "скажи мне, кто твой друг, и я скажу - кто ты".
Если вы новичок в html, воспользуйтесь blog-программой. Тогда ваш blog будет выглядеть более изящно, стильно, так как часто записи публикуются в XHTML с помощью логических тегов
и , а само оформление осуществляется с помощью стилей CSS. Поупражняться с CSS еще никому не мешало, зато каждый день вы можете менять внешний вид blog-а как душе угодно, редактируя только один css-файл. Именно с работая с blog-ами, вы почувствуете принцип "разделения содержания и оформления", о котором столько говорят веб-дизайнеры ().
Одна из примечательных функций многих blog-программ это способность генерировать rss-документ или xml-представление blog-а. В этом случае записи blog-а пересекают границы сайтов, на которых они расположены, и могут быть включены в любой веб-сайт, умеющий работать с XML-документами. Например, мой дневник , а rss представление его - вот так. Вытянув этот документ и пропустив его через парсер и xsl-преобразование, вы можете вставить список моих новостей в свой сайт. Или например (правда этот blog уже закрыт), Дениса Карницкого или blog тусовки российских дизайнеров
Журнал "Открытые системы" #08/2004
В последние два года популярным стал подсчет числа пользователей Internet в России и калькуляция их процента от общей численности населения страны, что связано с ожиданием достижения «магического» рубежа — 10%. Говорится об этом «волшебном» числе много, но первоисточник, который бы коротко, ясно и просто объяснял, почему именно 10% является таким важным рубежом, упоминается редко. А все, на самом деле, просто. Из пороговых моделей теории «внедрения достижений науки и техники в народное хозяйство» (Diffusion of innovation) следует, что когда число реальных пользователей инновации подходит к 16% от общего числа потенциальных пользователей инновации, то последующий рост числа реальных пользователей приобретает «взрывной» характер. Это означает, что с данного момента можно уже не заботиться о рекламе инновации, а просто «стричь купоны».
Модели эти в свое время были разработаны для анализа практики внедрения удобрений в сельском хозяйстве «медвежьих» углов США, но позже хорошо себя зарекомендовали для анализа внедрения любых других инноваций, в том числе и в сфере информационных технологий. Любопытно, что сам автор метода, Эверет Роджерс, оценивая Сеть, пришел к выводу [1], что «критическая» масса пользователей Internet в США, достигнутая в 1990 году, оценивалась тогда в 5 млн человек, что, понятно, не равнялось 10% населения Северо-Американских Штатов. Пока Фонд «Общественное мнение» [2] и другие исследователи, занимающиеся мониторингом числа пользователей, констатируют линейный рост числа пользователей в России, отметка в 10% (более 12 млн жителей) по их же данным уже достигнута.
В конечном счете, социологический мониторинг критической массы связан с ожиданиями коммерческого успеха Internet-начинаний, который ассоциируется с такими понятиями как «спрос» и «предложение». Число пользователей — это оценка спроса, а число зарегистрированных в национальной зоне доменов можно, видимо, считать оценкой предложения.
В конце концов, пользователи Internet «ходят» в Сеть за информацией, а она размещена, главным образом на сайтах, которые, в свою очередь, имеют доменные имена. Если верна формула «спрос рождает предложение», то кроме числа пользователей должно увеличиваться и число зарегистрированных доменов. Домен COM дает тому наглядное подтверждение (рис. 1). «Критическая» масса в зоне COM была достигнута в 1994 году, и линейный рост сменился экспоненциальным. При этом следует отметить, что основной «двигатель» коммерческого успеха Internet-технологий — World Wide Web — фактически появился позже, чем была достигнута критическая масса пользователей.
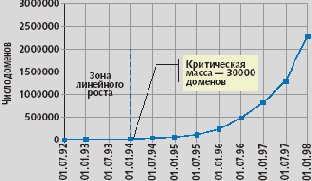
Рис.1. Рост числа регистраций в 90-е годы в зоне COM по данным zooknic.com
Интересно сравнить тенденции регистрации доменов, наблюдаемые в США с отечественными. Данные РосНИИРОС ( www.ripn.net ) и Ru-center ( www.nic.ru ) свидетельствуют о том, что намечавшийся в 1998 году показательный рост числа регистраций доменов в национальной зоне RU постепенно, после 2000 года, сменился линейным ростом (рис. 2).
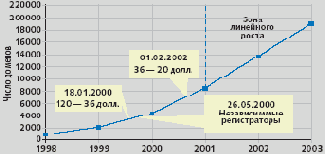
Рис.2. Рост числа регистраций в зоне RU (1998-2003) по данным РосНИИРОС и RU-Center
При этом следует обратить внимание на два принципиальных момента. Во-первых, рост числа регистраций никак не зависел от изменений тарифной политики РосНИИРОС. Во-вторых, введение института независимых регистраторов пока существенно не изменило существующей картины.
Существует твердое убеждение, что чем дешевле стоимость регистрации, тем больше будет новых доменов. Косвенным подтверждением этому служит ситуация с введением института независимых регистраторов, с которым связывают падение стоимости регистрации в домене COM с 35 долл. до 15 долл. и менее, а также «драматический» рост числа регистраций, начиная с первого квартала 2000 года и до «схлопывания Internet-пузыря» 2002 года. Осмелюсь предположить, что это не совсем так.
Заметим, что снижение цены регистрации происходило и при монополии NSI. Кроме того, в 2000-м и 2001 году любой американский «стартап» имел такие подъемные, что затраты на регистрацию домена в них можно было разглядеть только под электронным микроскопом.
А падение общего числа зарегистрированных доменов с 23 до 21 млн штук произошло уже при наличии «соревновательной» системы независимых регистраторов, которая смогла вернуться к цифрам начала 2001 года только летом 2003. Введение института независимых регистраторов в зонах ORG, NET, COM — это просто реакция на бурный рост регистраций, вызванный коммерческой привлекательностью Сети. Институт независимых регистраторов разрушил монополию NSI, позволил заработать независимым регистраторам, уменьшив, соответственно, доходы NSI, и за счет конкуренции снизил цену регистрации домена, не повлияв существенным образом на динамику роста числа регистраций.
В российском национальном домене RU мы наблюдаем аналогичную картину. Показательный рост числа регистраций начался задолго до того, как РосНИИРОС снизил цены на регистрацию под напором «Internet-общественности», однако к изменению существующей на тот момент тенденции это не привело — число зарегистрированных доменов было бы точно таким же и без снижения цены регистрации. Второе понижение цены на регистрацию, вообще никак не повлияло на темпы регистрации доменов.
В домене RU введен институт независимых регистраторов и сегодня их уже семь. Так же, как и в других доменах, существенного влияния на общее число регистраций это нововведение не оказывает. Главным отличием домена RU образца 2004 года от домена COM образца 2000 года является то, что последние два года рост регистраций носил линейный характер. Это означает, что с коммерческой привлекательностью Рунета не все так очевидно, как было в Соединенных Штатах во времена президента Клинтона. Либо у нас все еще впереди (на что очень хочется надеяться), либо, учитывая период с 1998 по 2000 год, все уже позади.
Еще одним отличием RU от COM является размер доли традиционного регистратора среди общего объема регистраций. В зоне COM сразу после введения института независимых регистраторов доля NSI в общем объеме регистраций сразу упала ниже 50%. За первый квартал 2000 года на NSI пришлось 1,5 млн регистраций, а на всех остальных регистраторов около 5 млн.
В домене RU доля компании RU-Сenter (наследник РосНИИРОС) составляет около 60% всех регистраций и продолжает расти. Видимо, мнение, что «старый конь борозды не портит» доминирует среди владельцев российских доменов.
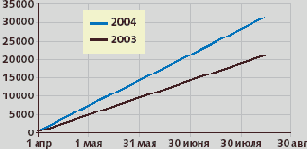
Рис.3 Рост числа регистраций в 2004 году по сравнению с тем же периодом 2003 года (по данным проекта stat.nic.ru)
Однако кое-какие положительные изменения все же происходят. Мониторинг динамики регистраций (рис. 3) показывает, что темпы регистрации доменов в 2004 году выше, чем в 2003. Характер динамики роста не изменился и остался линейным, но эта линия идет заметно круче. Период майских праздников и летних отпусков выбран не случайно. Обычно в это время темпы регистраций существенно падают, но в нашем случае эти сезонные колебания тенденции не меняют. Линейный характер роста числа зарегистрированных доменов, видимо, связан с экстенсивным расширением Рунет, т.е. по мере физического подключения новых пользователей к Сети появляются и новые домены. У большинства этих пользователей еще не наступило озарение, что кроме банального «Вася и Петя уже здесь» можно «учудить» что-нибудь более полезное. Одним словом, не все так плохо и хочется надеяться, что у Рунета все еще впереди.
Сбоку экрана (изначально справа) располагается Toolbar. В отличие от современных пиктографических палитр инструментов (вероятно, рассчитанных на неграмотных), в этом Toolbar'e перечисляются команды по функциональным группам, предоставляя тем самым способ быстрого построения кода.
Сеть разбухает с каждым днем, и наш усталый мозг давно уже не в состоянии обрабатывать входящий трафик. Но лень на то и добродетель программиста, чтобы побудить его к автоматизации собственной жизни… Интернет, скажем, автоматизировать можно по-всякому - к примеру, так...
Идея автоматизации работы в Сети не нова. Если условно считать сеть состоящей из серверов и клиентов, то код, работающий на стороне сервера, изначально создавался для работы в автоматическом режиме. В последнее время, например, большинство контента веб-страниц генерируется динамически. Так что для того, чтобы действительно "вкалывали" роботы, а не человек, осталось автоматизировать клиентскую часть. Идея проста: пускай компьютеры общаются друг с другом - а человеку останется обналичивать кэш. (Программы, работающие на стороне и/или от имени клиента, будем называть сетевыми агентами, роботами или ботами.)
Исторически сложилось два подхода к программированию сетевых агентов. Первый заключается в реализации сетевых протоколов, таких как http и ftp. Обычно это уже не нужно делать вручную, поскольку современные языки, как правило, содержат необходимые библиотеки. К наиболее известным можно отнести сетевые библиотеки perl, Delphi, Java, а теперь еще и этот новомодный.NET.
Другой подход, специфичный для нескольких протоколов, связан с автоматизацией Internet Explorer'a и реализуется обычно на Бейсике. Хотя многие программисты могут посмеяться над этой техникой, но на самом деле использовать чужой код всегда выгодно. Internet Explorer реализует массу высокоуровневых вещей, которые тот же perl не сделает никогда - или, по крайней мере, это будет лишняя и ненужная работа. К таким вещам относится поддержка куков вообще и сессий в частности, выполнение скриптов, динамическая генерация контента, обработка встроенных объектов и так далее. То есть проблема сводится к одному: некоторый контент генерируется автоматически, и не всегда легко вычислить, что там в конце концов получится.
Расскажу вам о языке программирования NQL, сочетающем в себе лучшее из обоих миров,- это значит, что он может как работать на уровне GET-POST, так и автоматизировать IE. И дело не столько в том, что NQL может это делать (при определенной сноровке такие вещи можно проделать на любом языке) - суть в том, что для NQL это основное занятие: синтаксис доступа к Сети крайне прост, встроен в язык, хорошо документирован и доступен для понимания на уровне продвинутого пользователя (бывалый кодировщик может при случае вспомнить dbase2).
В язык встроены две уникальные по своему удобству возможности, в других языках не встречающиеся. Первая - это встроенное состояние, оставляемое после последней команды. Это состояние сигнализирует о том, успешно ли была выполнена команда (или был ли получен положительный результат), и принимает значения true или false. Впоследствии это значение может быть предметом исследования - так, как бы вы выполнили if:
get URL then { ... }
Такая манера выполнения может оказаться более удобной, чем постоянный опрос функций. Второй уникальной конструкцией является стек. Собственно в самом стеке ничего уникального нет. А вот то, что он встроен на уровне языка, это, конечно, сильно. Со стеком по умолчанию работают многие функции и команды, так что код становится "интуитивным". Например:
get URL: show
показывает в окне содержимое только что получtнного htpp-документа (или что уж там было получено). Стек адресуется встроенными переменными. (точка) и.. (две точки) - для указания на первый и второй сверху элементы. Встроенные функции push и pop позволяют, соответственно, получить и вставить в стек элемент - так что стеком можно управлять как явно, так и неявно, в процессе выполнения команд.
head 'http://easypic.com/main.html?bypass' show httpHeader
После каждой HTTP-операции четыре переменные: httpAction, httpHeader, httpURL и httpData - устанавливаются в последнее полученное значение. Если нет уверенности в том, что ресурс существует, можно сделать отображение условным:
head 'http://yahoo.com' then { show httpHeader }
Отобразить собственно содержимое страницы еще проще, поскольку после загрузки по get контент находится в стеке:
get 'aaa.com' show
Если требуется передать данные по POST, то нужные параметры следует затолкать в стек и после этого вызвать команду post:
push 'Login=melkosoft&Password=guess&level=1&Domain=ukr.net' post 'http://www2.ukr.net/cgi-bin/auth' show
Последний пример может оказаться полезным для пересылки почты с ukr.net на какой-то POP3-аккаунт, поскольку POP3 на ukr.net может как работать, так и не работать. Более сложная программа может делать анонсы полученной почты за последнюю неделю, выбирать только интересные сообщения и посылать сообщение об этом на другой аккаунт. Если последний еще и связан с пейджером, то можно создать систему фильтрации входящих сообщений от спама с параллельным уведомлением на SMS. Другое применение - брутальные форсеры для онлайн-почты.
При входе в систему с паролем вам придется отслеживать сессии, записываемые в куки - возможно, вы предпочтете автоматизировать браузер в случаях, подобных показанных в следующем примере.
Хочу подчеркнуть, что это только демонстрация работающей технологии, а не дискуссия по правовым и/или моральным вопросам, таким как порно в Сети, использование "Ad Killers" и чужого контента.
// следующий фрагмент - калька с get 'http://easypic.com/main.html?bypass' // здесь get не работает - из-за перегрузки сервера страница часто // не успевает загрузиться и сеанс обрывается. for j=1,10 { openbrowser 'http://easypic.com/main.html?bypass', '', '', '', '', true every 10 // с периодичностью 10 сек { i=1 getbrowserdata if (contains (., 'EasyPicTM')) // первый параметр - вершина стека { break 4 } else { pop i=i+1 if (i>60) // если за 10 мин. не закачалось - начинаем сначала { closebrowser break 3 } } } } closebrowser
// прошу прощения у всех Василиев Пупкиных за использование их несгибаемого трейдмарка create 'C:\index.htm' write 'Too Easy Pics
' write '
To see original EasyPic with counters, banners, links to links, popups ' write 'and other useless stuff click herom
' match ('
Webcams') while (match ('size=4>{Title}')) { write '
{Title}
' write ''
// смысл следующих строк - сделать копию контента (остатка), отрезать спереди один раздел, копию // выбросить а сам раздел положить в стек, не факт что все оптимально, главное, что работает push. match '{once} size=4>' pop push once
while (match ('')) { if (!contains (Link,'traffic.cgi')&&!contains (Link,'cout.cgi')&&!contains (Link,'spotbrokers')) { write "XXX " } } pop write '
' if (Title=='Shemale') { break 2 } } write '' close
end // закомментируйте, если хотите выложить результат в Сеть,- только не пишите, что это ваше:\
ftpidentity 'tooeasy','guess' ftpopen 'ftp.narod.ru' ftpput 'C:\index.htm' ftpclose
NQL может получать доступ к БД тремя способами, или, как говорят, "методами": ODBC, ADO и OLEDB. По умолчанию стоит ODBC, и поскольку это работает нормально, нет никаких причин изменять это умолчание. Для Java-версии, соответственно, предусмотрено несколько методов с участием JDBC.
Для операций можно использовать SQL-конструкции и дополнительно - nextrecord для выбора следующей записи. Поля результирующего набора при выборе по SELECT отображаются в переменные автоматически. Nextrecod тоже автоматически, в духе NQL, устанавливает код ошибки, так что код, выполняющий запрос и обрабатывающий результат, выглядит тривиально:
opendb "phonebook" select "SELECT Contacts WHERE State='NY'"; while { show Name, Street, City, State, Zip, Phone nextrecord }
Рассмотрим практический пример - пусть наша программа получает данные из газеты объявлений и складывает их в таблицу БД. Как всегда, можно "пойти другим путем" - выкачать весь раздел или даже газету и потом в комфортной обстановке разбирать ее на молекулы. Либо же прямо в момент выкачки анализировать и выбирать нужные строки. Мы продемонстрируем второй вариант - то есть выкачаем один раздел с фильтрацией строк. Допустим, мы ищем б/у Hi-Fi технику.
Наша программа может выглядеть так:
record #avizorec=issue, rubric, rubname, pline
get 'http://www.aviso.com.ua/aviso/browse.asp' match "ads/kiv/{codename}.asp" pop
push codename match '{prefix}/' pop
get "http://www.aviso.com.ua/aviso/ads/kiv/" &codename&".asp" match "HRef=\"{pagename}.asp\">Rubric #620" pop push pagename match "{dbsec}/" pop
openbrowser "http://www.aviso.com.ua/aviso/ads/kiv/" &prefix&"/"&pagename&".asp",'','','','',True getbrowserdata
opendb 'avizo' table 'ads'
while true { match "Aviso newspaper {issue}. Rubric {rubric}.{rubname}" match "
" push. match "{lines}
" pop push lines while (match ("{pline}
")) { if contains (pline,'б/у')&&contains (pline,'удио') { addrecord #avizorec } } pop
match "- NEXT -
" else { break 2 } browse "http://www.aviso.com.ua/aviso/ads/kiv/" &prefix&"/"&dbsec&"/"&lnextp&".asp" getbrowserdata } closedb closebrowser
Как видно, здесь применяется комбинированный подход - сначала осуществляется поиск нужной страницы с помощью get (URL имеет прихотливый и непредсказуемый вид, так что приходится исследовать ссылки), а после, во избежание работы к куками, закачивается собственно информация - можете переделать этот фрагмент с использованием get и посмотреть, что получится. Результат в данном случае сохраняется в базе данных - предполагается, что вы предварительно создали ODBC-источник с именем avizo и что эта БД содержит таблицу adv. В дальнейшем нам ничего не мешает снова использовать NQL для работы с этими данными.
Пример реализации этой технологии: периодическое выкачивание предложений работы по заданному критерию (допустим, с такого мегапортала, как dice.com) и массовая рассылка резюме по найденным адресам (это вовсе не спам - там оставляют свои адреса как раз затем, чтобы им присылали резюме; да и как же иначе должен рассылать программист, если не автоматически?). Поскольку данные изменяются сравнительно медленно (скажем, раз в сутки-двое), а рассылки (гипотетически) производятся по несколько раз в день, то окажется выгодным закачивать данные один раз и хранить их в БД для последующего использования.
* * *
Всё, о чем тут шла речь, это только верхушка айсберга. Каждый из вас придумает (если уже не придумал) десятки применений своим агентам - от закачки бизнес-котировок до системы управления контентом, поиска квартирных вариантов или активной раскрутки веб-проектов. Только имейте в виду: вы в ответе за сетевых агентов, которых приручили,- и потом не говорите, что я вас не предупреждал!
Выполнение всегда происходит по одному и тому же сценарию: ваша программа в текстовом виде находится в файле или в переменной в памяти. Дополнительно есть две области для входных и выходных данных и, возможно, еще несколько параметров. Иными словами, вы имеете текст программы и передаете его интерпретатору. Такой "полностью динамический" механизм позволяет не только загружать файлы во время выполнения, но и конструировать программы прямо во время выполнения - точно так же, как это делается с командами SQL. Обратная сторона, быстродействие, в сети вряд ли будет критическим местом - запросы к сети, как правило, будут раз в 100-1000 медленнее интерпретации.
Первый способ выполнения - в среде разработки IDE. Фактически вы можете выполнять программу в трех режимах: выделенном (не рекомендую - подвешивает систему), фоновом и отладочном. В последнем случае код выполняется по одной строке, и вы по ходу дела имеете доступ к переменным, стеку данных и прочим подробностям рантайма. Как вариант - с помощью IDE создать файл бота с расширением .BOT. Это бинарная форма программы после синтаксического разбора, созданная для поставки ваших программ в "нечитабельном" виде.
Способ номер два - создать независимой приложение, выбрав в IDE Create EXE. Само приложение располагается на рабочем столе (несколько нетипичное поведение, обычно на стол выкладывается ярлык). У независимых модулей есть дополнительные возможности - выводить данные о текущем состоянии программы в специальных областях нотификации. При выполнении таких программ вы можете прикрепить к своей программе скин - bmp-образ, и таким образом сделать вашего бота ни на что не похожим.
К сожалению, эта возможность еще требует доработки.
Способ № 3 - выполнять программы NLQ из командных файлов или из командной строки с помощью программы nqlexec. Этот метод имеет ограничение - ваша программа не сможет получать или выдавать входной и выходной потоки данных.
Способ № 4 - выполнять скрипт в заданное время с помощью программы NQL Agent. Это оконная программа, доступная через меню Пуск.
Остальные способы - программные, то есть вы вызываете интерпретатор NQL из другого языка программирования, такого как C или Basic.
Для вызова из таких языков, как Basic, проще всего использовать ActiveX-компонент. Расскажу об этом подробнее, поскольку такое применение является самым вероятным, например в VBA. В вашем распоряжении только три метода: Run, RunScript и RunScriptFile - что, в общем-то, одно и то же, за исключением того, где лежит текст вашей программы. Из событий в наличии тоже три наименования: End, Notify, Show - соответствующие активным действиям вашего приложения. Несколько больше полей данных - в частности, для входных и выходных потоков, флаги обработки ошибок и нотификации.
Метод № 6, облегченный ActiveX - ATL-класс для встраивания в "легкие" контейнеры. Обычно для создания экземпляров класса в ASP-приложениях с помощью CreateObject.
Метод номер следующий - вызов скриптов через классы Java и C++, для чего нужно подключить к вашему приложению соответствующие файлы class, java, h - и так далее.
И, наконец, если вам не подходит ни один из перечисленных способов (что само по себе странно), то вы можете вызывать интерпретатор непосредственно из DLL через соответствующий API. Для этого, опять-таки, понадобится nql.h, и придется продумать еще пару трюков - то есть это не то, к чему вы должны стремиться, поскольку для интерпретатора не существует разницы между ATL/DLL.
Если вы заинтересованы в подробностях - читайте раздел Working with NQL в NQL language manual.
Теперь приведу несколько примеров в подтверждение своих слов. Скажу сразу - не всё из перечисленного будет работать :-).В частности, ftp-сервер narod.ru больше не отвечает на запросы. Так что, хотя сайт tooeasy.narod.ru и существует, реально обновить его не удастся - и, уж конечно, не с приведенным паролем. Естественно, что в реальных приложениях все окна автоматизированного браузера можно скрыть - здесь они отображаются только в целях наглядности.
Хотя этот перечень и выглядит как набор "все на свете", но реализация сделана очень прямолинейно и поэтому изящно, в духе языков "эпохи до ООП". Поскольку NQL не предназначен для создания масштабных и, тем более, универсальных приложений, то здесь не применяются классы и объекты. Это можно рассматривать и как недостаток, и как достоинство - поскольку объекты и классы часто применяются в тех случаях, где без них было бы лучше.
Увеличение пропускной способности каналов связи мотивируется по-разному. Одна из основных целей производителей аппаратуры и программного обеспечения - сделать так, чтобы пользователи могли в полной мере ощутить возможности транспортировки мультимедиаинформации, в которой доминирует видео.
Увеличение пропускной способности каналов связи мотивируется по-разному. Одна из основных целей производителей аппаратуры и программного обеспечения - сделать так, чтобы пользователи могли в полной мере ощутить возможности транспортировки мультимедиаинформации, в которой доминирует видео.
Передача мультимедиаданных по IP-сетям сегодня является настоящим двигателем индустрии, ее стимулом к развитию. Судите сами: видео и аудио автоматически подразумевают генерирование больших объемов трафика, а значит, требуется "разогнать" каналы, обзавестись разнообразнейшим мощным сетевым оборудованием, которому по силам справиться с лавиной информации, разработать и создать методы защиты этих данных и т. д.
Конечно, такое положение вещей только на руку производителям - ведь все вышеперечисленные обстоятельства подразумевают увеличение выпуска оборудования и продаж, поэтому идея мультимедиатрансляций старательно культивируется и оберегается от посягательств скептиков.
Идея комплексных услуг (когда одна розетка обеспечивает доступ в Интернет, к телефонии, телетрансляции и т. д.) уже не нова, по крайней мере, на мировом уровне. В России же этот подход внедряется достаточно вяло: причины очевидны - оказание комплексных услуг требует ощутимых инвестиций. Еще одно препятствие - нежелание застройщиков или владельцев зданий сотрудничать с операторами.
Видеотрансляция посредством IP-сети сегодня уже достаточно хорошо отработана и даже может быть разбита на несколько подвидов:
собственно IP-телевидение (Live TV) - вещание в реальном времени с использованием режима IP multicast. Есть обычное понятие ТВ-канала и, соответственно, оплаты за его просмотр; видео по запросу (Video on Demand, VoD) - предоставление видео по персональному запросу подписчика через IP в режиме unicast.
Продается обычно фильм или его часть; NVoD (Near Video on Demand) - вещание c VoD-сервера в соответствии с сеткой вещания по IP multicast. По сути, комбинация двух предыдущих технологий; видеоконференции.

Сформированный поток ТВ-каналов представляет собой поток IP-пакетов, передаваемых в сети по отдельному групповому адресу
В идеальном случае провайдеру необходимо предоставлять клиенту все три типа сервиса (и довольно много дополнительных, типа network based Personal Video Recorder, nPVR). А для этого требуется генерировать контент, инкапсулировать в IP и далее транслировать его клиенту. И все это - в реальном времени и на десятки или сотни каналов.
Одним из пионеров российского рынка TV-over-IP выступила компания CTI. В конце прошлого года CTI провела пресс-конференцию по данному вопросу, на которой менеджер проектов по направлению Video-over-IP Павел Ребров сказал: "Продавать услуги выгоднее, чем мегабайты, поэтому все больше компаний уделяет внимание технологии Video-over-IP. Ведь легче продать 1 Гбайт кино, чем просто 1 Гбайт. Следовательно, операторам надо думать о разнообразии предоставляемых сервисов. Кроме того, например, в США по данным Minerva Networks, на связь и развлечения абонент тратит в среднем $150 в месяц, в России же этот показатель можно довести до $120".
Еще один участник рынка подобных услуг, компания "КОМКОР", предоставляет комплекс услуг телевизионного видеовещания - ТВ через IP (TVoIP). Проект реализуется на базе технологии IP Multicast - передача видеотрафика по протоколу IP. На первом этапе проекта организуется многоадресная рассылка пакетов - multicast - видеовещание телевизионных каналов. В настоящее время "КОМКОР" предоставляет 30 российских и 35 развлекательных, музыкальных и познавательных зарубежных телеканалов (Discovery, CNN, BBC World, Eurosport, Hallmark, VH-1 и др.). Данной услугой могут воспользоваться все операторы и организации, имеющие интерфейс 100BaseT/1000BaseLX с сетью "КОМКОР".
Сформированный поток телевизионных каналов представляет собой поток IP-пакетов, передаваемых в сети по отдельному групповому адресу, соответствующему данному телеканалу. Таким образом, вещание нескольких каналов представляет собой формирование нескольких потоков multicast-трафика, когда каждый из каналов однозначно определяется уникальным адресом групповой рассылки. Каждый ТВ-канал занимает от 4 до 6 Мбит/с, на сеть оператора он загружается только в том случае, если абонент подписан на этот канал. Для просмотра канала клиент использует компьютер или абонентское устройство STB, которое с одной стороны подключено к сети оператора (среде вещания), а с другой - имеет соединение с телевизором. Для подключения к сети или выхода из группы рассылки используется стандартный протокол IGMP (Internet Group Membership Protocol).

IP-сети позволяют доставлять видеосигнал произвольного качества, в том числе HDTV со звуком Dolby Surround
На втором этапе внедрения видеовещания по IP-сети "КОМКОР" планирует организацию дополнительных сервисов на базе технологии TV-over-IP, к их числу относятся: видео по запросу (Video on Demand, VoD), NVoD (Near Video on Demand), персональный видеомагнитофон (Personal Video Recorder, PVR), сдвинутое во времени вещание (Time Shifted TV), сервис по заказу (Services-on-Demand, SoD).
Почему в качестве транспорта используется протокол IP, который, как мы знаем, изначально был разработан совершенно для других целей? Дело в том, что сегодня IP-технологии обладают достаточной зрелостью для решения задач передачи видеоинформации. Из основных свойств протокола отметим Multicast - использование многоадресной рассылки, что позволяет значительно сократить расходы на доставку информации до конечного подписчика. Не менее важным является качество обслуживания (Quality of Service - QoS). Сквозной QoS обеспечивает корректную приоретизацию различных видов IP-трафика и, несмотря на значительную нагрузку на IP-сеть, создаваемую интернет-пользователями, видеоинформация, равно как и VoIP, будет доставляться без задержек.
Кроме того, огромная роль отводится технологиям широкополосного доступа - ведь со старинным дозвоном с помощью модема можно забыть о трафике, создаваемом передачей видеоинформации. Но уже сейчас ADSL2 позволяет предоставить подписчику два одновременно проигрываемых ТВ-потока, несколько одновременных телефонных разговоров и высокоскоростной доступ в Интернет по телефонных проводам. Дальнейшее расширение Ethernet-сетей масштаба города (MAN) позволит увеличить возможности предоставления услуг для подписчиков.
Благодаря передаче видеосигнала при помощи IP-сетей появляется ряд очевидных преимуществ. Во-первых, ощутимая экономия средств на кабельной системе - нет необходимости строить и обслуживать дополнительную кабельную инфраструктуру. Помимо этого сегодня гораздо больше специалистов в области IP-технологий, чем специалистов в ТВ-вещании. В конце концов, имеет место более эффективное использование IP-сети, повышение ее рентабельности.
Ну и, конечно же, IP-сети в нынешней ситуации позволят интегрировать все виды приложений в единую сервис-ориентированную платформу. Технология Video-over-IP позволяет предоставить не только традиционную услугу просмотра ТВ-каналов на качественно более высоком уровне, но и внедрить совершенно новые услуги.
Для операторов становится очевидным, что в современном мире объектом продажи становится не трафик как таковой, а услуги поверх этого трафика. Как, например, для оператора более выгодной является продажа конечному абоненту 1 минуты телефонного разговора, чем 200 кбайт исходящего IP-трафика, так и видеоуслуги станут дополнительным источником дохода для оператора. Каковы сегодня наиболее применимые услуги, связанные с Video-over-IP?
Видео по запросу. Video over IP позволяет реализовать услуги "Видео по запросу" без использования каких-либо дополнительных шлюзов и сложных схем взаимодействия. Прямо с экрана телевизора подписчик сможет заказать просмотр фильма и тут же начать его смотреть. Телевизионный сервис. Традиционная услуга получает "второе дыхание" за счет возможностей создания интерактивных каналов, интеграции с интерактивной программой телепередач EPG (Electronic Program Guide).
Кроме того, IP- сети позволяют уже сейчас доставлять видеосигнал произвольного качества. Изображение HDTV со звуком Dolby Surround можно транслировать и сегодня. "Отложенный просмотр". Можно начать запись текущего ТВ-канала и, вернувшись, продолжить просмотр с того места, где пользователь вынужден был отвлечься. Личный видеомагнитофон. С помощью календаря подписчик сможет прямо на экране телевизора назначить время начала и окончания записи ТВ-канала или прямо из EPG заказать запись телепрограммы для того, чтобы просмотреть запись в удобное время. При этом никакого дополнительного оборудования не требуется. Net-surf on TV. Посредством все того же IP-подключения пользователю предоставляется доступ в Интернет с телевизора. Интерактивные сервисы. Голосования, рейтинги и обсуждения фильмов и телепередач. Электронная коммерция - "магазин на диване", для которого достаточно телевизора.
Функционально решение задачи передачи телевизионных каналов по IP-сети состоит из трех компонентов. Ключевым является IP Headend - традиционный для телевизионных операторов комплекс, обеспечивающий прием, раскодирование и демультиплексирование сигналов со спутника, прием и MPEG-кодирование материалов из аналогового источника и мультиплексирование каналов в IP Multicast-потоки. Именно этот мультиплексор или, иначе говоря, стример (streamer), становится уникальным компонентом headend для Video-over-IP. Он обеспечивает IP-вещание телевизионных каналов таким образом, что каждый канал имеет собственный уникальный адрес и порт IP Multicast. Кроме того, требуется система обеспечения условного доступа (CAS), гарантирующая защиту контента, то есть шифрующая телеканалы для того, чтобы смотреть их могли лишь авторизованные пользователи. CAS может обеспечивать авторизацию как собственными методами, так и средствами автоматизированной системы расчетов, сторонних систем или middleware ("прослойка"). В качестве средства авторизации могут использоваться смарт-карты, программные ключи (когда пользователю достаточно пароля).
Декодирование телеканалов осуществляется непосредственно на абонентском устройстве IP Set Top Box или персональном компьютере. Абонентское устройство внешне напоминает спутниковый ресивер, за тем исключением, что в качестве входного интерфейса у него используется не разъем для подключения спутниковой антенны, а стандартный сетевой интерфейс Ethernet. По сути, это небольшой компьютер со своей операционной системой, MPEG-декодером и веб-браузером - именно наличие веб-браузера и IP-канала позволяет реализовать интерактивные сервисы.
Видео по запросу можно условно разделить на два вида: "настоящий" (True VoD) и "условный" (Near VoD). Если True VoD представляет собой комплекс, обеспечивающий unicast-поток для каждого пользователя в любое время, то Near VoD - это способ экономии полосы пропускания за счет применения MultiCast. В последнем случае несколько экземпляров каждого из фильмов запускается на воспроизведение "по кругу" со смещением начала произведения во времени, и подписчик получает доступ к каналу, на котором воспроизводится конкретный фильм. Естественно, только True VoD предоставляет подписчику услуги персонального видеоплейера: "перемотка" в любые стороны, воспроизведение с произвольной позиции, постановка на "паузу" и просмотр фильма в любое удобное время.

Ключевой компонент системы TV-over-IP является IP Headend — комплекс, обеспечивающий прием, раскодирование и демультиплексирование сигналов
Для обоих видов услуги видео по запросу являются обязательными такие компоненты, как сервер VoD, Middleware и абонентское устройство. Сервер VoD - это видеосервер с дисковым массивом большой емкости для хранения видеоматериалов и специализированным программным обеспечением, обеспечивающим multicast-трансляцию видеоматериалов в режиме Near VoD или доступ к видеоматериалам по протоколу RTSP для True VoD. Обычно видеосервер может также осуществлять перехват и запись multicast-потоков, что используется для реализации услуг PVR (видеозапись).Middleware представляет собой специализированный программный комплекс, который обеспечивает управление услугами VoD, IP TV и всеми сопутствующими, такими как интерактивные сервисы, Personal Video Recorder ,и многими другими. Middleware также обеспечивает авторизацию, ведение статистики и предоставляет визуальные интерфейсы пользователям и администраторам. В качестве абонентского устройства в данном случае выступает тот же самый Set Top Box, что используется подписчиком для услуг IP TV.
Современный дом, офис и даже мобильный терминал уже немыслимы без доступа к IP-сервисам, самым распространенным и самым малоприбыльным из которых является доступ в Интернет. И нет никаких причин не повышать доходность построенных сетей за счет внедрения новых услуг, таких как Video-over-IP.
Публикуемые объекты располагаются в иерархической объектной базе данных Zope. Хотя она и напоминает по структуре обычную файловую систему, веб-сервер не может обращаться к ней непосредственно, поскольку он работает с URL, а по компонентам URL необходимо вначале перейти к объекту. Одна из задач, выполняемых ZORB-брокером, состоит в прямом и обратном переходе по иерархии объектов и преобразовании ступеней этой иерархии в компоненты URL.
ZORB-брокер выполняет также обработку данных формы, «пряников» (cookie) и параметров запроса, проводит опознавание пользователя и проверку прав доступа, автоматизирует обработку исключительных ситуаций (исключений), подготавливает заголовки HTML и обрабатывает пакеты протокола HTTP с информацией запроса и ответа.
ZORB-брокер выполняет все действия, связанные с выполнением запроса, автоматически, поэтому от прикладного программиста скрыты все технические вопросы реализации протокола веб.
Для создания динамического информационного наполнения применяется серверный интерпретируемый язык DTML на основе тегов.
Он обеспечивает доступ объекта только к атрибутам, приобретенным этим объектом. Например, если в текущей или вышележащей папке установлен метод отправки почты, объект может его приобрести и выполнять отправку почты. Но выход за пределы объектной модели сайта для объекта исключен. Это позволяет, с одной стороны, создавать исключительно надежные и безопасные сайты, а с другой стороны, если речь идет о провайдере или, точнее, хостере, — передавать управление сайтом назначенному для этого администратору без опасений нарушить защиту всего хоста.
Администратор управляет сайтом Zope по веб через специальный административный интерфейс. Он создает пользователей Zope, назначает им пароли, определяет права доступа к папкам и другим объектам. Эти пользователи существуют только в объектном пространстве Zope и не имеют никакого отношения к пользователям операционной системы. Главный администратор сайта также может смело назначать администраторов, отвечающих за определенный уголок сайта,— они не могут выйти за рамки предоставленных им полномочий и нарушить защиту всего сайта.
ZODB — очень сложная по структуре, но прозрачная для пользователя база данных, которая обладает такими развитыми возможностями, как поддержка версионирования, транзакционная обработка и отмена ошибочно внесенных изменений. Версионирование позволяет создавать версии сайта или фрагмента сайта, отлаживать их в реальной обстановке незаметно для пользователей, а затем моментально вносить. Транзакционная обработка предусматривает автоматическое оформление в виде транзакций любых действий, которые влекут за собой изменение состояния объектной базы данных, выполнение этих действий и откат в случае их неудачного завершения. Выполненные транзакции регистрируются в объектной базе данных и могут быть отменены, если предусмотренные ими изменения были внесены ошибочно.
Объекты Zope, которые могут быть представлены в ZODB, выполняют три основных функции:
хранение информационного наполнения. Такие объекты Zope, как документы, изображения и файлы, могут хранить текстовые и двоичные данные различных форматов; представление деловой логики. Zope позволяет представлять логику обработки деловой информации в виде сценариев на языках Python, Perl и SQL; презентация. Для управления отображением информации применяется интерпретируемый язык на основе тегов — DTML (Document Template Markup Language).
Разработка в среде Zope в основном состоит в проектировании иерархии объектов (в этой среде в процессе разработки иерархической структуры сайта одновременно происходит построение его информационной модели) и отображении объектной модели прикладной задачи на объекты Zope.
Это требует взаимного согласования следующих трех информационных моделей:
модель данных (как правило, данные представлены в реляционной базе данных, то есть в виде таблиц); прикладная модель (структура прикладных объектов — товаров, заказов, счетов и т. д.); презентационная модель (способ представления данных на веб-странице, организация внешнего интерфейса, ввода/вывода).
Обычно эти модели реализуются в виде так называемой трехуровневой структуры распределенной обработки данных, которая включает в себя сервер базы данных, сервер приложений и веб-сервер.
Однако в среде публикации объектов Zope применяется иной подход, в основе которого лежит метод непосредственного предоставления доступа к объектам, которые хранятся в объектной базе данных, иными словами, публикация объектов.
Публикация объектов — это применение объектно-ориентированных программных компонентов для создания динамического информационного наполнения (то есть HTML-страниц). В среде публикации объектов Zope (Z Object Publishing Environment) применяется широкий перечень таких программных компонентов, которые в основном подразделяются на два типа: лист-объекты и контейнерные объекты. Как правило, происходит публикация лист-объектов (в частности, DTML-документов или DTML-методов), но контейнерные объекты (например, папки) также могут иметь публикуемые атрибуты (свойства), такие как имя и идентификатор. Контейнерные объекты могут содержать в себе и лист-объекты, и другие контейнеры. Объекты объединены в иерархию включения (подобно каталогам файловой системы) и позволяют разработчику создавать сложные, разветвленные древовидные структуры.
Таким образом, переход к объекту в среде публикации объектов Zope происходит в направлении сверху вниз, а приобретение атрибутов — в направлении снизу вверх. Таковы же и две основные составляющие защиты Zope: при обращении пользователя к опубликованному объекту происходит проверка прав доступа пользователя на каждом уровне, и объекты, обращаться к которым пользователь не имеет права, являются для него невидимыми, а обращение объекта к своему атрибуту является невидимым, инкапсулированным внутреннее устройство атрибута.
Сайт, построенный на платформе Zope, является полиморфным, многоликим. На него может прийти и анонимный пользователь, и зарегистрированный пользователь с именем и паролем, обладающий определенными правами. Но для разных категорий пользователей он выглядит по-разному. Это значит, что он может выполнять и разные функции, в зависимости от категории пользователя. Например, для обычного пользователя «с улицы» он может показать, какие на предприятии есть товары и цены (актуальную информацию, которую не нужно постоянно обновлять вручную), для руководителя, находящегося в командировке,— товары, цены, количество и общие экономические показатели; для склада — одно, для магазина — другое...
Однако сайт на платформе Zope может не только выдавать, но и накапливать информацию, и надежно ее хранить. В принципе, он может стать не менее, а более защищенным, по сравнению со многими современными производственными локальными сетями. Интрасеть (внутренняя сеть) предприятия отличается по степени защищенности от экстрасетей (внешних сетей) или интерсетей (сетей общего доступа, интернет) лишь тем, что позволяет дополнительно предусмотреть физические меры защиты: исключить физический доступ посторонних лиц и экранировать излучение компьютеров и кабелей.
Отказавшись от такой «защиты», можно выиграть гораздо больше: сделать сосредоточением всех своих деловых операций единый, полиморфный, защищенный веб-сайт на платформе Zope. На него могут выходить и рядовые потребители, и территориально разобщенные структурные подразделения, и деловые партнеры, и заказчики, и надомные работники, и командированные сотрудники.По этому принципу работают многие деловые предприятия. Он вполне себя оправдывает. Для такого назначения и была разработана платформа Zope.
Такой мощный и перспективный программный продукт больше не может оставаться незамеченным.
Подготовка сценариев DTML, которые позволяют манипулировать с объектами Zope с помощью тегов в документах DTML. Это простейший способ программирования в среде Zope. Язык DTML не позволяет выйти за пределы объектной модели сайта, поэтому программирование на этом уровне не позволяет никоим образом нарушить защиту сайта. Это уровень массового программирования, на котором работают рядовые программисты и веб-дизайнеры.Разработка методов, позволяющих расширить объектную модель сайта, например, методов доступа к базе данных (SQL Methods) и внешних методов (External Methods). На этом уровне работают ответственные разработчики и администраторы. Высокоприоритетная разработка на основе API-интерфейса Product. Эта технология разработки дает возможность создавать объекты Zope, к которым можно обращаться через веб так же, как к обычным документам и папкам Zope. Разработка на основе этого API-интерфейса значительно сложнее по сравнению со сценариями DTML и внешними методами, но позволяет применять методы объектно-ориентированного проектирования. Для настройки среды Zope на конкретную прикладную область может применяться технология Z-классов (ZClass). Эта технология предоставляет в основном такие же функциональные возможности, как и традиционный способ разработки на основе API-интерфейса Product, но намного менее трудоемка.
Для управления средой Zope предусмотрен защищенный административный интерфейс, который позволяет администратору регистрироваться и работать с удаленного компьютера. Через этот интерфейс можно создавать и удалять пользователей, определять права доступа, настраивать параметры объектной базы данных, останавливать и запускать сервер Zope и т. д.
Предусмотрены средства экспорта/импорта любых фрагментов объектной базы данных (например, папок со всеми подпапками). Экспортированные объекты можно импортировать в эту или другую объектную базу данных, а также сохранить в качестве резервной копии.
В трехуровневой среде (веб-сервер <--> сервер приложений <--> сервер базы данных) сервер приложений выполняет в основном такие функции:
сопровождает пул устойчивых соединений с базой данных; обеспечивает создание и поддержку непрерывных соединений по протоколу HTTP (этот протокол не предусматривает хранение информации о состоянии и не способен сам поддерживать непрерывные соединения); позволяет отделить прикладную логику от логики презентации; хранит и выполняет программный код.
Zope, как платформа для размещения веб-приложений, отличается от других платформ тем, что в ней применяется не отдельная, реляционная база данных, а встроенная, объектная база данных. Наряду с этим, она позволяет использовать в качестве информационного ресурса и реляционные базы данных, предоставляя механизмы для интеграции внешних баз данных в ее объектную структуру. Для этой цели в составе программного обеспечения Zope предусмотрено несколько модулей: Oracle, Sybase, MySQL и ODBC. Коллекция этих модулей постоянно пополняется.
Новые технологии веб-хостинга позволяют коренным образом изменить организацию работы предприятия. Zope - бесплатный программный продукт с открытым исходным кодом, который может служить в качестве программной платформы для разработки и размещения веб-сайтов с динамически обновляемым информационным наполнением.
Разработка Zope выполнена на языках:
Python и C(http://www.zope.org).
Как таковой, Zope перешел в категорию бесплатных программных продуктов с открытым исходным кодом с ноября 1998 года. Все предыдущие версии этого продукта были коммерческими. Zope разработан консультационной компанией Digital Creations на основе трех программных продуктов: «Bobo», «Principia» и «Aquaduct». Передавая Zope во всеобщее пользование, компания Digital Creations стремилась сделать этот продукт стандартом в области разработок для веб и увеличить свои доходы за счет предоставления консультационной поддержки.
Zope — мультиплатформенный программный продукт. Он может применяться на многих платформах, включая Linux/Intel, Solaris (SPARC и Intel), Digital Unix, BSDI и Windows NT (а также SGI/Irix, HP-UX, Windows 95/98, Mac OS и Windows CE, хотя официальная поддержка этих платформ в настоящее время не предусмотрена). Zope может работать на таких веб-серверах, как Apache, Netscape Server и Microsoft IIS, а также на мощном веб-сервере Medusa с открытым исходным кодом, который предоставляет доступ к программной платформе Zope на основе протоколов HTTP, вебDAV и FTP.
NAME -- Имя файла, содержащего данные тела письма.
SITE -- Полный доменный адрес или псевдоним компьютера, с которого файл может быть получен по указанному протоколу.
Перед тем, как начнется считывание данных по FTP, пользователь обычно должен быть спрошен на предмет логина и пароля для машины, указанной в параметре 'site'. По причинам безопасности логин и пароль не указываются как параметры Content-Type и должны быть получены от получателя письма.
Дополнительно определены следующие необязательные параметры:
DIRECTORY -- каталог, содержащий тело письма на удаленной машине.
MODE -- Нечувствительное к регистру букв строка, указывающая режим передачи данных. Допустимые эначения для типа доступа TFTP:
NETASCII, OCTET и MAIL. Для типа доступа FTP: ASCII, EBCDIC, IMAGE и LOCALn, где n - десятичное целое число, обычно 8. Эти значения соответствуют типам представления A, E, I и Ln, определенным FTP-протоколом. Заметьте, что "BINARY" и "TENEX" не являются допустимыми значениями для параметра MODE. Вместо них должны использоваться "OCTET", "IMAGE" или "LOCAL8". Если параметр MODE отсутствует, значением по умолчанию является "NETASCII" для TFTP и "ASCII" для FTP.
NAME -- Имя файла, содержащего данные тела письма.
Следующий необязательный параметр может быть использован для локализации ссылки на файл и содержит адрес сайта или сайтов, на которых данный файл виден:
SITE -- Доменный адрес машины или машин, на которых возможен доступ к файлу данных. Допускаются маски с использованием звездочки вместо части доменного имени, например, "*.bellcore.com", для обозначения набора машин, на которых файл виден напрямую. Единственная звездочка вместо всего доменного имени может означать, что файл, где би он ни был, виден через глобальную файловую систему.
SERVER -- email-адрес mail-сервера, с которого могут быть запрошены данные тела письма.
Так как почтовые серверы предполагают множество различных синтаксисов, некоторые из них могут быть многострочными, полная команда, которую нужно послать на mail-сервер, не включается как параметр в однострочное поле 'content-type'. Вместо этого она помещается в мнимое тело, когда значением поля 'content-type' является 'message/external-body', и параметр 'access-tyoe' имеет значение 'mail-server'.
Необязательный параметр для этого способа доступа:
SUBJECT -- Subject, который будет использован в заголовке письма-запроса, которое почторый клиент получателя пошлет на указанный почтовый сервер для получения данных тела письма. Заметьте, что помещение адреса сервера в subject не рекомендуется, однако, известны mail-серверы, требующие этого.
MIME-стандарт не определяет синтаксиса обращения к почтовому серверу. Поэтому он допускает включение полной команды для mail-сервера в мнимое тело.
В отличие от других способов доступа, доступ через mail-сервер не синхронен, и данные могут быть получены в непредсказуемый момент в будущем. По этой причине важно иметь механизм, обеспечивающий вставку полученных от mail-сервера данных в исходное письмо. Mail-сервер при отправке запрошенных данных должен использовать то же самое значение поля Content-ID в заголовке письма с возвращаемыми данными, какое было в первоначальном "бестелесном" письме, чтобы облегчить работу этого механизма.
Если внешнее тела письма доступно посредством нескольких различных механизмов, отправитель может включить несколько частей типа message/external-body в письмо типа multipart/alternative.
Однако, механизм external-body не должен быть ограничен получением удаленных файлов. Например, можно представить использование видеосервера с внешними ссылками на видеофрагменты.
Если письмо / часть письма имеет тип "message/external-body", то оно / она будет содержать поля заголовка вложенного письма. Тело само по себе неходится где-либо во вне. Это значит, что если тело типа "message/external-body" содержит два последовательных конца строки (CRLF), то все, что идет далее, не является чстью сообщения и просто должно игнорироваться. Однако, этот "хвост" - удобное место для каких-либо дополнительных данных, которые не могут быть помещены в поле заголовка Content-Type. В частности, если значение "access-type" есть "mail-server", то "хвост" может содержать команды, посылаемые затем mail-серверу по адресу, на который указывает параметр SERVER.
Поля заголовка вложенного письма, которые на самом деле являются телом общего письма типа "message/external-body", должны нести информацию о типе содержимого внешнего (удаленного) тела, если оно не является простым ASCII-текстом (что подразумевается по умолчанию), поскольку эти внешние данные сами по себе не имеют заголовка, опрпеделяющего их тип. Также, необходимо указывать Content-transfer-encoding, если он имеет значение, отличное от "7-bit". Так, полное письмо типа message/external-body, ссылающееся на документ в формате PostScript, может выглядеть следующим образом:
From: Whomever To: Someone Subject: whatever MIME-Version: 1.0 Message-ID:
Content-Type: multipart/alternative; boundary=42 Content-ID:
--42 Content-Type: message/external-body; name="BodyFormats.ps"; site="thumper.bellcore.com"; access-type=ANON-FTP; directory="pub"; mode="image"; expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript Content-ID:
--42 Content-Type: message/external-body; name="/u/nsb/writing/rfcs/RFC-MIME.ps"; site="thumper.bellcore.com"; access-type=AFS expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript Content-ID:
--42 Content-Type: message/external-body; access-type=mail-server server="listserv@bogus.bitnet"; expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript Content-ID:
get RFC-MIME.DOC --42--
В приведенных примерах значение Content-transfer-encoding для внешних данных в формате postscript полагается по умолчанию как "7bit".
Заголовки общего и вложенного(их) писем (имеющих внешнее тело) должны удовлетворять тем же правилам, что и для типа message/partial во избежание путаницы.
Поскольку внешнее тело не пересылается в виде почты, то оно не обязано удовлетворять требованиям длины строк и иметь 7-битную форму, оно может быть просто бинарным файлом. Поэтому поле Content-Transfer-Encoding не является необходимым, хотя его наличие допускается.
Тело письма типа "message/external-body" обрабатывается в сответствии с основным синтаксисом стандарта RFC 822, в частности, все, что идет до первой последовательной пары концов строки (CRLF), является заголовком письма, а все, что идет после, является "мнимым" телом письма, которое игнорируется для большинства типов доступа.
Формальный синтаксис поля заголовка 'content-type' для данных типа 'message' - следующий:
message_тип := "message" "/" message_подтип message_подтип := "rfc822" / "partial" 2-3 partial_параметра / "external-body" 1 external_параметр / расширение (не предопределенный подтип) partial_параметр := (";" "id" "=" значение) / (";" "number" "=" 1*ЦИФРА) / (";" "total" "=" 1*ЦИФРА) ; id и number требуются всегда; total требуется для последнего фрагмен- ; та послания. external_параметр := (";" "access-type" "=" тип_доступа) / (";" "expiration" "=" дата-время) ; Дата-время должны быть экранированы кавычками / (";" "size" "=" 1*Цифра) / (";" "permission" "=" ("read" / "read-write")) ; Значение permission нечувствительно к регистру букв / (";" "name" "=" значение) / (";" "site" "=" значение) / (";" "dir" "=" значение) / (";" "mode" "=" значение) / (";" "server" "=" значение) / (";" "subject" "=" значение) ; access-type требуется всегда; все остальное - в зависимости от значе- ; ния access-type тип_доступа := "ftp" / "anon-ftp" / "tftp" / "local-file" / "afs" / "mail-server" / / расширение (непредопределенный параметр) ; Нечувствителен к регистру букв
Вызов серверного метода асинхронно схож с синхронным вызовом, за исключением появления дополнительных параметров при вызове:
Ссылка на callback функцию в клиентском скрипте, которая вызывается при успешном завершении работы серверного метода. Ссылка на error callback функцию, которая вызывается при возникновении ошибки Необязательные контекстные параметры. Эти данные просто вернутся обратно по окончании работы серверного метода.
Как и при синхронном вызове, асинхронный вызов создает объект call, содержащий результат работы серверного метода и дополнительную статусную информацию.
При асинхронном вызове объект call передается в callback функцию в качестве параметра. Следовательно, вы можете проверить статус вызова и получить результат работы метода.
Так как при асинхронном вызове необходимо передать ссылку на callback функцию, то используется только JavaScript.
Для вызова серверного метода асинхронно:
Если вы создали page объект, то используется следующая форма вызова.
callObject = ASPObject.methodName(p1, p2[,...], callbackFunction, errorCallbackFunction, context);
В противном случае используется RSExecute() функция:
callobject = RSExecute(url, methodName, p1, p2[,...], callbackFunction, errorCallbackFunction, context)
Где:
callobject - имя call объекта; ASPObject - объект ссылающийся на ASP страницу; url - URL ASP страницы содержащей описание серверных методов. Эта страница должна находится на том же сервере, что и страница осуществляющая вызов; methodName - имя метода, который вы хотите исполнить; p1, p2 - параметры необходимые для вызова methodName метода. Параметра передаются по значению. В качестве параметров могут быть переданы значения простых типов. callbackFunction - ссылка на JavaScript функцию в клиентском скрипте, которая будет вызвана, когда удаленный метод окончит работу.
Т. к. вы передаете ссылку, не включайте имя функции в кавычки. errorCallbackFunction - ссылка на необязательную JavaScript функцию в клиентском скрипте, которая будет вызвана, если при работе удаленного метода произойдет ошибка. Т. к. вы передаете ссылку, не включайте имя функции в кавычки. context - необязательные параметры вызова, эти данные вернутся обратно.
Например, в следующем скрипте асинхронно вызывается серверный метод square. После работы метода вызывается функция showResults(). Имя операции передается как context-параметр.
Аналогичный пример с использованием RSExecute метода:
Функция showResults, которая является callback функций в предыдущем примере, может выглядеть следующим образом:
В данном случае callback функция служит для вывода результата работы операции. Функция демонстрирует, как вы можете использовать context свойство для определения того, какая операция арифметическая применялась.
Вы можете проверить состояние работы удаленного метода. При асинхронном вызове, можно проверить состояние работы серверного метода. Для этого используется свойства status объекта call Возможные значения свойства status:
-1 - произошла ошибка 0 - работа завершена 1 - в процессе (только для асинхронного вызова)
Асинхронный вызов можно прервать, для этого используется cancel() метод объекта call.
В общем случае для корректного функционирования необходимо чтобы скриплет был загружен с того же Web сервера, что и использующая его HTML страница (как и JAVA апплеты).
Преобразуется добавлением ".bitnet" в конце: пользователь@хост.bitnet.
Не все майл-серверы понимают домен .bitnet, им надо указывать шлюз,
например, пользователь%хост.bitnet@cunyvm.cuny.edu.
Теперь разработчики могут создавать интерактивные Web приложения, в которых появляется возможность исполнять серверный скрипт без обновления страницы.
C использованием RS Web приложении может проверить корректность вводимых пользователем данных в процессе заполнения формы, избегая перезагрузки.
С появлением RS, Web приложение может использовать как клиентский, так и серверный скрипт. Клиентский скрипт часто используется для управления пользовательским интерфейсом, например, динамическое изменение содержимого Web страницы или обработка действий пользователя. Клиентский скрипт выполняется локально в браузере и обеспечивает интерактивный интерфейс.
Возможности применения серверного скрипта ограничиваются только вашей фантазией. Серверный скрипт может использоваться для доступа к базе данных или выполнения звена бизнес логики в многослойных приложения. При этом серверный скрипт исполняется на сервере с полным доступом к ресурсам сервера, а из клиентского скрипта его вызов почти ничем не отличается от вызова локальных процедур и методов.
Так как при вызове серверного скрипта текущая страница не покидается, то ее состояния сохраняется, а вместе с ней и состояние переключателей и глобальных переменных.
Что касается скриплетов, то это полноценные COM компоненты и могут использоваться для решения широкого класса задач, как то:
доступ к базам данных; реализация бизнес-логики в многослойных архитектурах; транзакционные процессы; интерактивные эффекты в Web страницах, с использованием DHTML behavior.
например, 1234,56789. В нотации Internet это выглядит
1234.56789@compuserve.com (точка вместо запятой).
Обратно письмо можно отправить по адресу
>INTERNET:пользователь@хост.домен
В скриплете есть возможность описать некоторые функции, так что они выдают себя за свойства, и при изменении свойства выполняется код реализованный в этих функциях. Таких функций всего две: put и get. При изменении значения свойства вызывается функция put, а при получении значения - get.
В этом примере в переменных property1GetCount и property1PutCount хранят количество обращений к свойству property1 и его изменений. В функции public_put_property1 после того как новое значение установлено, компонента обновляет значения. В контейнере вы можете ссылаться на property1, как если бы это было обычное свойство.
Scriplet1.property1 = 'Another'; a = Scriplet1.property1;
С помощью put_ и get_ функций можно реализовать read-only и write-only свойства. Для создания read-only свойства описывается только функция get_, т. к. функции put_ нет, то значение изменено быть не может, аналогично с write-only.
Если вы пишите на JavaScript, то имеется альтернативная возможность описания интерфейса DHTML скриплета. При определении объекта public_description в скриплете, свойства и методы этого объекта являются свойствами и методами скриплета. При таком описании интерфейса префикс public_ не используется. Удобнее описать весь интерфейс скриплета в одном месте, как это предлагается с использованием объекта public_desription, чем рассеивать описание по всему коду скрипта. В дальнейшем предполагается реализовать подобный механизм и на VBScript.
В качетстве демонстрации можно присовокупить стандартные Microsoft примеры DHTML скриплетов. Я кинул пару самых простых и наглядных, можно также посмотреть у Microsoft на www.microsoft.com/scripting/.
Формальный синтаксис дла поля 'content-type' для данных типа 'application' дается следующим образом.
application_тип := "application" "/" application_подтип application_подтип := ("octet-stream" *stream_параметр) / "postscript" / расширение (непредопределенный под- тип) stream_параметр := (";" "type" "=" значение) / (";" "padding" "=" число_дополняющих_битов) число_дополняющих_битов := "0" / "1" / "2" / "3" / "4" / "5" / "6" / / "7"
Формальный синтаксис поля Content-Type для данных типа "multipart":
multipart-тип := "multipart" "/" multipart-подтип ";" "boundary" "=" метка_границы multipart-подтип := "mixed" / "parallel" / "digest" / "alternative" / подтип-расширение
name himark lomark flags
Ниже описывается значение параметров:
name - имя группы новостей;
himark - номер самой новой статьи в данной группе новостей на локальном сервере. Это число увеличивается при получении новых статей;
lomark - номер самой старой статьи в данной группе новостей на локальном сервере. Это число изменяется в результате удаления старых статей на диске;
flags - это поле определяет один из шести возможных флагов:
y - для данной группы новостей разрешена локальная публикация;
n - для данной группы новостей не разрешена локальная публикация;
m - данная группа с ведущим (модератором) и все публикации должны быть одобрены ведущим;
j - статьи из данной группы новостей не храняться на локальном сервере (на самом деле они помещаются в группу junk, которая обязательно должна быть указана в файле active), а только передаются через него;
x - статьи не могут посылаться в данную группу новостей;
=news.group - статьи для данной группы новостей помещаются локально в группу news.group.
Основные операции, которые должен время от времени выполнять администратор включают в себя добавление новых групп, удаление ненужных групп, изменение флагов текущих групп новостей. Все эти операции должны отображать свои действия в файле active. Существует два основных подхода к выполнению указанных выше операций с группами новостей:
Первый подход - использование соответствующих подкоманд команды ctlinnd: "newgroup", "rmgroup" и "changegroup". Например, команда
ctlinnd newgroup relcom.humor y
добавляет группу новостей "relcom.humor" с флагом "y" (см.
выше), помещая соответствующие строки в файлах active и active.times. Файл active.times
содержит информацию о времени создания новой группы новостей (и о том, кто ее создал), которая используется некоторыми программами чтения новостей (Trumpet одна из них) для оповещения своих пользователей о наличии новых групп новостей.
Второй подход - непосредственное редактирование файла active, удобен для операций с большим количеством групп новостей (попробуйте удалить несколько десятков групп с помощью первого способа :-)), но имеет один недостаток: он не вносит автоматических изменений в файл active.times. Общая последовательность действий такова:
Приостановить работу демона innd (входящие соединения при этом не принимаются):
ctlinnd pause "edit active"
Отредактировать файл active. Например, при добавлении группы "relcom.humor", Вы должны добавить следующую строку в этот файл (флаг может быть и другим):
relcom.humor 0000000000 0000000001 y
Проверить корректность изменений в файле active, дав команду:
inncheck active
Считать в память новую копию файла active:
ctlinnd reload active "edit active"
Восстановить работу сервера innd:
ctlinnd go "edit active"
/remember/:время
где время - срок хранения в днях (можно указывать и дробную часть дня, наприме, /remember/:7.5
- семь с половиной дней), по истечении которого из системы удаляются идентификаторы старых статей. Последующие командные строки определяют когда нужно удалять из системы тела статей. Они имеют следующий формат:
pattern:modflag:keep:default:purge
Ниже описывается значение параметров:
pattern - образец для групп новостей в wildmat-формате, для которых применяется остаток данной строки;
modflag - флаг, используемый для дальнейшего ограничения списка групп новостей, для которых использовать данную строку. Если это поле:
М - то применять остаток данной строки только для групп с ведущим (moderated groups) из тех, которые соответствуют образцу pattern первого поля;
U - то применять остаток данной строки только для групп без ведущего (unmoderated groups) из тех, которые соответствуют образцу pattern первого поля;
A - то применять остаток данной строки для всех групп новостей, соответствущих образцу pattern
первого поля.
Следующие 3 поля определяют какое количество дней хранить тела статей на локальном сервере новостей:
keep - определяет минимальное число дней хранения тел статей на системе для определяемых групп новостей. Любая статья из этих групп не может хранится меньше указанного этим полем срока (если Expires-заголовок статьи имеет меньший срок, то будет использовано значение keep).
default - определяет число дней хранения для тех статей из определяемых групп, у которых отсутствует заголовок Expires.
purge - определяет максимальное число дней хранения тел статей на системе для определяемых групп новостей. Любая статья из этих групп не может хранится больше указанного этим полем срока (если Expires-заголовок статьи имеет больший срок, то будет использовано значение purge).
Помимо строки /remember/ Вы должны указать строку с pattern
'*' и modflag 'A'. Эта строка является строкой по умолчанию для срока хранения всех статей на системе. При этом она обязательно должна стоять раньше, чем строки с образцами для конкретных групп, поскольку этот файл проверяется программой expire до конца и последняя соответствующая группе новостей строка будет использована.
Например, мы хотим после удаления тела статьи хранить ее идентификатор в базе данных в течение 5-ти дней. Тела статей будут храниться на системе от 3-ех до 5-ти дней, за исключением локальных конференций, которые мы хотим хранить подольше (в течение 10-ти дней). Тогда наш файл будет выглядеть так:
/remember/:5 *:A:3:4:5 local*:A:10:10:10
имя: [возможны пробелы] значение
Здесь имя - имя параметра, значение
- его значение. Некоторые параметры могут быть изменены определением переменных окружения системы. Ниже описываются имена параметров и их значения:
fromhost - этот параметр используется при формировании заголовка From:, если того нет. Переменная окружения FROMHOST затирает это значение. По умолчанию, это полное доменное имя локальной машины.
moderatormailer - имя машины, содержащей псевдонимы для всех управляемых (moderated) групп. Этот параметр используется только если нужную информацию нельзя почерпнуть из файла moderators.
organization - определяет содержимое заголовка Organization:, если он пуст. Если определена переменная окружения ORGANIZATION, то она изменяет это значение.
pathhost - определяет, какое имя локального узла помещается в заголовок Path:. По умолчанию, это полное доменное имя
Адрес "поинт" выглядит примерно так: 2:5020/12.345, где
2 - зона (в данном случае - Россия);
5020 - сеть (в Москве);
12 - машина;
345 - поинт;
Адрес "нода" имеет на один пункт меньше: 1:350/12
(Северная Америка).
Послать письмо можно по адресу
Imya_Familia@p345.f12.n5020.z2.gate.phantom.msk.su
(через московский шлюз) или соответственно
Fname_Lname@f12.n350.z1.fidonet.org (через шлюз в США).
Mirza_Kurbanov@p45.f123.n5020.z314.goldnet.squeen.msk.su.
Во-первых, Вам необходимо заполучить свеженький дистрибутив INN. Обратитесь на сервер ftp.isc.org и перейдите в каталог isc/inn. Выберите необходимый архив (например, ), перекачайте, декомпрессируйте и разархивируйте его, поместив результат в выбранный Вами каталог (в дальнейшем он упоминается как $inn).
Сменив текущий каталог на $inn, Вы обнаружите два файла формата nroff, использующие макрос -ms: Install.ms.1
и Install.ms.2. Это две части оффициального руководства по инсталляции InterNetNews.
Дайте команду
make Install.ms
При этом два файла объединяются в один - Install.ms
с правами доступа 444. Приведите этот файл в более читабельный вид (в частности, для просмотра с помощью more) командой:
nroff -ms Install.ms > Install
При возникновении проблем в инсталляции пакета необходимо обращаться за помощью к этому файлу.
Следующий этап процедуры инсталляции - редактирование главного файла конфигурации сonfig.data.
В каталоге $inn/sample-configs содержатся шаблоны файла config.data для различных платформ. Вам необходимо выбрать наиболее подходящий для Вас файл и скопировать его в $inn/config/config.data, например, для FreeBSD выполните следующие команды:
cd $inn cp sample-configs/config.data-FreeBSD-2.0 config/config.data
Теперь настала пора отредактировать сам файл config.data. INN получает из этого файла информацию о своей среде (т.е. где лежат компоненты, используемые INN).; Для пользователей FreeBSD надо подкорректировать опции для LIBS:
LIBS -lutil -lcrypt
Пакет поставляется с некоторыми perl-сценариями, требующими пакет языка perl версии не ниже, чем 5.001, так что Вам, возможно, придется установить новый пакет языка perl и прописать корректный путь к команде perl:
_PATH_PERL /usr/local/bin/perl
Подробное описание содержимого файла config.data
смотрите в файле Install.
Скомпилируйте все исходники:
cd $inn make all
Перед инсталляцией компонентов пакета необходимо создать каталоги, куда они будут помещены:
mkdir /usr/news /var/news /var/news/spool
Теперь можно инсталлировать компоненты пакета INN. Если Вы ставите пакет в первый раз на эту систему, то просто дайте команду:
make install
Если же Вы заменяете уже существующую систему INN, то рекомендуется инсталлировать отдельно программы и отдельно конфигурационные файлы и сценарии. Это позволит не затирать конфигурационные файлы текущей INN системы. Итак, сначала запустите сценарий:
makedirs.sh
Он создаст все остальные каталоги (ниже созданных командой mkdir на предыдущем этапе). Заметим, что команда make install вызывает этот сценарий сама. Теперь инсталлируйте программы и руководства (man'ы):
make update
При этом сценарии и конфигурационные файлы будут скопированы из каталога $inn/samples в каталог $inn/site. Если Вы хотите сохранить настройки предыдущей версии INN, затрите файлы из каталога $inn/site такими же файлами из старого программного обеспечения, после чего:
cd $inn/site make install
Запуск сценария:
$inn/BUILD
позволит создать файлы и history. После запуска сценария, он спросит, использовать ли с-версию subst (если она существует):
-- do you want to use it [y or n]? y
Далее он спросит построили ли Вы бинарники:
Have you already built the executables [y or n]? y
Затем он спросит существуют ли каталоги spool, etc
и т.д.:
Do the spool, etc., directories exist [y or n]? y
Следующим вопросом будет: желаете ли Вы продолжить инсталляцию:
Do you want to continue with the installation [y or n]? y
И, наконец, последний ворос: запускать ли subshell для редактирования конфигурационных файлов:
Start a subshell to edit the config files [y or n]? n
После завершения работы сценария проверьте, что владельцем файла active является пользователь news, группа news, права доступа на него 644, а если это не так (а практика показывает что в сценарии действительно что-то не так :-)), то исправьте это, дав команды
chmod 644 active chown news:news active
Сделайте почтовый псевдоним для пользователя news
в файле /etc/mail/aliases:
usenet: news
Дайте знать об этом sendmail, перестроив после редактирования файла базу псевдонимов:
/usr/bin/newaliases
INN оповещает о своей работе, используя систему syslog. Проверьте конфигурационный файл демона syslogd /etc/syslog.conf. Раскомментируйте в этом файле строки, содержащие news.crit, news.err, news.notice. После этого не забудьте создать соответствующие файлы в каталоге /var/log/news
(владелец - news, группа -news, права доступа - 664).
Заметим, что, если Ваш файл newsfeeds
не содержит строк с указанием "питающихся" у Вас сторон, кроме строки ME, то демон innd при запуске выдаст ошибку: "SERVER bad_newsfeeds no feeding sites". Для того, чтобы успокоить сервер, на начальной стадии Вы можете прописать холостой поток:
dummy-feed:!*::
Добавьте в .profileпользователя root пути поиска в новых каталогах:
PATH=$PATH:/usr/news/bin:/var/news
Для чтения руководств с помощью команды man, добавьте строку в файле /etc/manpath.config:
MANDATORY_MANPATH /usr/news/man
Поместите запуск демона innd в сценарий rc.local:
/usr/news/bin/rc.news > /dev/console
Проверьте наличие строки
DOINNWATCH=true
в файле rc.news. Это позволит использовать утилиту innwatch.ctl, которая "гасит" сервер новостей, когда Ваш диск переполнился и предотвращает крушение системы.
Перезагрузите машину и проверьте, работает ли демон innd. Во-первых, должен быть соответствующий процесс, запущенный пользователем news:
ps -U news | grep inn
Во-вторых, дав команду
telnet localhost nntp
Вы должны увидеть примерно следующее:
Trying 127.0.0.1 Connected to localhost.your.domain. Escape character is '^]'. 200 news.your.domain InterNetNews server INN 1.7.2 ready
Чтобы увидеть, какие команды понимает этот news-сервер, дайте команду help. Для возврата из сеанса telnet обратно в shell, дайте команду quit.
на другую машину с Internet-почтой всегда будет просто? Ну-ну!
Прямая нотация: юзер@хост.домен.
Обратная (bang'овая) нотация:
хост1.домен1!хост2.домен2!...!хостN.доменN!юзер.
Письмо сначала зайдет на хост1, потом на хост2 и так далее,
пока не попадет юзеру на последнем хосте. Если хост указывается
без домена, то это, как правило, означает передачу по UUCP.
Аналогично юзер%хост1.домен1%хост2.домен2%...@хостN.доменN
заставит письмо придти на хостN,... и наконец попадет юзеру
на хосте1.
Это необходимо в случае, когда письма по какой-либо причине напрямую
не доходят; а в обратной нотации ведентся запись пути следования письма.
Не советую смешивать прямую и обратную нотацию - протоколы не определяют
приоритет операций.
Еще в адресе используют знаки "^", ":" и некоторые другие; когда я точно выясню, что они значат, сообщу "городу и миру". :-)
Одна из примечательных функций многих blog-программ это способность генерировать rss-документ или xml-представление blog-а. В этом случае записи blog-а пересекают границы сайтов, на которых они расположены, и могут быть включены в любой веб-сайт, умеющий работать с XML-документами. Например, мой дневник , а rss представление его - вот так. Вытянув этот документ и пропустив его через парсер и xsl-преобразование, вы можете вставить список моих новостей в свой сайт. Или например (правда этот blog уже закрыт), Дениса Карницкого или blog тусовки российских дизайнеров
Рунет: второе дыхание?
- сотрудник РНЦ "Курчатовский Институт" (Москва)Журнал "Открытые системы" #08/2004
В последние два года популярным стал подсчет числа пользователей Internet в России и калькуляция их процента от общей численности населения страны, что связано с ожиданием достижения «магического» рубежа — 10%. Говорится об этом «волшебном» числе много, но первоисточник, который бы коротко, ясно и просто объяснял, почему именно 10% является таким важным рубежом, упоминается редко. А все, на самом деле, просто. Из пороговых моделей теории «внедрения достижений науки и техники в народное хозяйство» (Diffusion of innovation) следует, что когда число реальных пользователей инновации подходит к 16% от общего числа потенциальных пользователей инновации, то последующий рост числа реальных пользователей приобретает «взрывной» характер. Это означает, что с данного момента можно уже не заботиться о рекламе инновации, а просто «стричь купоны».
Модели эти в свое время были разработаны для анализа практики внедрения удобрений в сельском хозяйстве «медвежьих» углов США, но позже хорошо себя зарекомендовали для анализа внедрения любых других инноваций, в том числе и в сфере информационных технологий. Любопытно, что сам автор метода, Эверет Роджерс, оценивая Сеть, пришел к выводу [1], что «критическая» масса пользователей Internet в США, достигнутая в 1990 году, оценивалась тогда в 5 млн человек, что, понятно, не равнялось 10% населения Северо-Американских Штатов. Пока Фонд «Общественное мнение» [2] и другие исследователи, занимающиеся мониторингом числа пользователей, констатируют линейный рост числа пользователей в России, отметка в 10% (более 12 млн жителей) по их же данным уже достигнута.
В конечном счете, социологический мониторинг критической массы связан с ожиданиями коммерческого успеха Internet-начинаний, который ассоциируется с такими понятиями как «спрос» и «предложение». Число пользователей — это оценка спроса, а число зарегистрированных в национальной зоне доменов можно, видимо, считать оценкой предложения.
В конце концов, пользователи Internet «ходят» в Сеть за информацией, а она размещена, главным образом на сайтах, которые, в свою очередь, имеют доменные имена. Если верна формула «спрос рождает предложение», то кроме числа пользователей должно увеличиваться и число зарегистрированных доменов. Домен COM дает тому наглядное подтверждение (рис. 1). «Критическая» масса в зоне COM была достигнута в 1994 году, и линейный рост сменился экспоненциальным. При этом следует отметить, что основной «двигатель» коммерческого успеха Internet-технологий — World Wide Web — фактически появился позже, чем была достигнута критическая масса пользователей.
Рис.1. Рост числа регистраций в 90-е годы в зоне COM по данным zooknic.com
Интересно сравнить тенденции регистрации доменов, наблюдаемые в США с отечественными. Данные РосНИИРОС ( www.ripn.net ) и Ru-center ( www.nic.ru ) свидетельствуют о том, что намечавшийся в 1998 году показательный рост числа регистраций доменов в национальной зоне RU постепенно, после 2000 года, сменился линейным ростом (рис. 2).
Рис.2. Рост числа регистраций в зоне RU (1998-2003) по данным РосНИИРОС и RU-Center
При этом следует обратить внимание на два принципиальных момента. Во-первых, рост числа регистраций никак не зависел от изменений тарифной политики РосНИИРОС. Во-вторых, введение института независимых регистраторов пока существенно не изменило существующей картины.
Существует твердое убеждение, что чем дешевле стоимость регистрации, тем больше будет новых доменов. Косвенным подтверждением этому служит ситуация с введением института независимых регистраторов, с которым связывают падение стоимости регистрации в домене COM с 35 долл. до 15 долл. и менее, а также «драматический» рост числа регистраций, начиная с первого квартала 2000 года и до «схлопывания Internet-пузыря» 2002 года. Осмелюсь предположить, что это не совсем так.
Заметим, что снижение цены регистрации происходило и при монополии NSI. Кроме того, в 2000-м и 2001 году любой американский «стартап» имел такие подъемные, что затраты на регистрацию домена в них можно было разглядеть только под электронным микроскопом.
А падение общего числа зарегистрированных доменов с 23 до 21 млн штук произошло уже при наличии «соревновательной» системы независимых регистраторов, которая смогла вернуться к цифрам начала 2001 года только летом 2003. Введение института независимых регистраторов в зонах ORG, NET, COM — это просто реакция на бурный рост регистраций, вызванный коммерческой привлекательностью Сети. Институт независимых регистраторов разрушил монополию NSI, позволил заработать независимым регистраторам, уменьшив, соответственно, доходы NSI, и за счет конкуренции снизил цену регистрации домена, не повлияв существенным образом на динамику роста числа регистраций.
В российском национальном домене RU мы наблюдаем аналогичную картину. Показательный рост числа регистраций начался задолго до того, как РосНИИРОС снизил цены на регистрацию под напором «Internet-общественности», однако к изменению существующей на тот момент тенденции это не привело — число зарегистрированных доменов было бы точно таким же и без снижения цены регистрации. Второе понижение цены на регистрацию, вообще никак не повлияло на темпы регистрации доменов.
В домене RU введен институт независимых регистраторов и сегодня их уже семь. Так же, как и в других доменах, существенного влияния на общее число регистраций это нововведение не оказывает. Главным отличием домена RU образца 2004 года от домена COM образца 2000 года является то, что последние два года рост регистраций носил линейный характер. Это означает, что с коммерческой привлекательностью Рунета не все так очевидно, как было в Соединенных Штатах во времена президента Клинтона. Либо у нас все еще впереди (на что очень хочется надеяться), либо, учитывая период с 1998 по 2000 год, все уже позади.
Еще одним отличием RU от COM является размер доли традиционного регистратора среди общего объема регистраций. В зоне COM сразу после введения института независимых регистраторов доля NSI в общем объеме регистраций сразу упала ниже 50%. За первый квартал 2000 года на NSI пришлось 1,5 млн регистраций, а на всех остальных регистраторов около 5 млн.
В домене RU доля компании RU-Сenter (наследник РосНИИРОС) составляет около 60% всех регистраций и продолжает расти. Видимо, мнение, что «старый конь борозды не портит» доминирует среди владельцев российских доменов.
Рис.3 Рост числа регистраций в 2004 году по сравнению с тем же периодом 2003 года (по данным проекта stat.nic.ru)
Однако кое-какие положительные изменения все же происходят. Мониторинг динамики регистраций (рис. 3) показывает, что темпы регистрации доменов в 2004 году выше, чем в 2003. Характер динамики роста не изменился и остался линейным, но эта линия идет заметно круче. Период майских праздников и летних отпусков выбран не случайно. Обычно в это время темпы регистраций существенно падают, но в нашем случае эти сезонные колебания тенденции не меняют. Линейный характер роста числа зарегистрированных доменов, видимо, связан с экстенсивным расширением Рунет, т.е. по мере физического подключения новых пользователей к Сети появляются и новые домены. У большинства этих пользователей еще не наступило озарение, что кроме банального «Вася и Петя уже здесь» можно «учудить» что-нибудь более полезное. Одним словом, не все так плохо и хочется надеяться, что у Рунета все еще впереди.
Документация
Опыт доказывает: недокументированная возможность равнозначна ее отсутствию - поэтому от документации зависит очень многое. Документация к NQL может служить примером "как это нужно делать". Есть два основных текста: обзоры по всем темам - NQL Language Manual, и отдельно - NQL Statement Reference Guide. Единственный недостаток последнего - модальное окно. То есть во время чтения справки вы не можете править программу. Кроме названных двух help'ов, во время набора текста вы получаете внизу экрана справку по введенной команде и ее параметрам - очень удобно.Сбоку экрана (изначально справа) располагается Toolbar. В отличие от современных пиктографических палитр инструментов (вероятно, рассчитанных на неграмотных), в этом Toolbar'e перечисляются команды по функциональным группам, предоставляя тем самым способ быстрого построения кода.
NQL: твои агенты в Сети
Арсений Чеботарев,Сеть разбухает с каждым днем, и наш усталый мозг давно уже не в состоянии обрабатывать входящий трафик. Но лень на то и добродетель программиста, чтобы побудить его к автоматизации собственной жизни… Интернет, скажем, автоматизировать можно по-всякому - к примеру, так...
Идея автоматизации работы в Сети не нова. Если условно считать сеть состоящей из серверов и клиентов, то код, работающий на стороне сервера, изначально создавался для работы в автоматическом режиме. В последнее время, например, большинство контента веб-страниц генерируется динамически. Так что для того, чтобы действительно "вкалывали" роботы, а не человек, осталось автоматизировать клиентскую часть. Идея проста: пускай компьютеры общаются друг с другом - а человеку останется обналичивать кэш. (Программы, работающие на стороне и/или от имени клиента, будем называть сетевыми агентами, роботами или ботами.)
Исторически сложилось два подхода к программированию сетевых агентов. Первый заключается в реализации сетевых протоколов, таких как http и ftp. Обычно это уже не нужно делать вручную, поскольку современные языки, как правило, содержат необходимые библиотеки. К наиболее известным можно отнести сетевые библиотеки perl, Delphi, Java, а теперь еще и этот новомодный.NET.
Другой подход, специфичный для нескольких протоколов, связан с автоматизацией Internet Explorer'a и реализуется обычно на Бейсике. Хотя многие программисты могут посмеяться над этой техникой, но на самом деле использовать чужой код всегда выгодно. Internet Explorer реализует массу высокоуровневых вещей, которые тот же perl не сделает никогда - или, по крайней мере, это будет лишняя и ненужная работа. К таким вещам относится поддержка куков вообще и сессий в частности, выполнение скриптов, динамическая генерация контента, обработка встроенных объектов и так далее. То есть проблема сводится к одному: некоторый контент генерируется автоматически, и не всегда легко вычислить, что там в конце концов получится.
Расскажу вам о языке программирования NQL, сочетающем в себе лучшее из обоих миров,- это значит, что он может как работать на уровне GET-POST, так и автоматизировать IE. И дело не столько в том, что NQL может это делать (при определенной сноровке такие вещи можно проделать на любом языке) - суть в том, что для NQL это основное занятие: синтаксис доступа к Сети крайне прост, встроен в язык, хорошо документирован и доступен для понимания на уровне продвинутого пользователя (бывалый кодировщик может при случае вспомнить dbase2).
Особенности NQL-синтаксиса
Что общего у синтаксиса C и Basic? Этим общим знаменателем как раз и является синтаксис NQL. Некоторые элементы позаимствованы у Basic (например, разделение команд в одной строке двоеточиями). С другой стороны - фигурные скобки и комментарии явно указывают на родство с C. Обработка ошибок поддерживается в двух формах - можно обрабатывать прерывания по ошибке в духе On Error, а можно анализировать значения возвращаемой функции.В язык встроены две уникальные по своему удобству возможности, в других языках не встречающиеся. Первая - это встроенное состояние, оставляемое после последней команды. Это состояние сигнализирует о том, успешно ли была выполнена команда (или был ли получен положительный результат), и принимает значения true или false. Впоследствии это значение может быть предметом исследования - так, как бы вы выполнили if:
get URL then { ... }
Такая манера выполнения может оказаться более удобной, чем постоянный опрос функций. Второй уникальной конструкцией является стек. Собственно в самом стеке ничего уникального нет. А вот то, что он встроен на уровне языка, это, конечно, сильно. Со стеком по умолчанию работают многие функции и команды, так что код становится "интуитивным". Например:
get URL: show
показывает в окне содержимое только что получtнного htpp-документа (или что уж там было получено). Стек адресуется встроенными переменными. (точка) и.. (две точки) - для указания на первый и второй сверху элементы. Встроенные функции push и pop позволяют, соответственно, получить и вставить в стек элемент - так что стеком можно управлять как явно, так и неявно, в процессе выполнения команд.
использование http
Часто нужно посмотреть, как сделана та или иная страничка - то есть не просто HTML-содержание, а, например, тип возвращаемого контента (некоторые мастера любят периодически толкать html, а то и exe с расширением jpeg). Кроме того, часто бывает полезным "выцепить сессию" - то есть отследить, какие куки устанавливаются в момент авторизации, чтобы потом передвигаться по сайту под своей сессией. Получить хедер ресурса не просто, а очень просто:head 'http://easypic.com/main.html?bypass' show httpHeader
После каждой HTTP-операции четыре переменные: httpAction, httpHeader, httpURL и httpData - устанавливаются в последнее полученное значение. Если нет уверенности в том, что ресурс существует, можно сделать отображение условным:
head 'http://yahoo.com' then { show httpHeader }
Отобразить собственно содержимое страницы еще проще, поскольку после загрузки по get контент находится в стеке:
get 'aaa.com' show
Если требуется передать данные по POST, то нужные параметры следует затолкать в стек и после этого вызвать команду post:
push 'Login=melkosoft&Password=guess&level=1&Domain=ukr.net' post 'http://www2.ukr.net/cgi-bin/auth' show
Последний пример может оказаться полезным для пересылки почты с ukr.net на какой-то POP3-аккаунт, поскольку POP3 на ukr.net может как работать, так и не работать. Более сложная программа может делать анонсы полученной почты за последнюю неделю, выбирать только интересные сообщения и посылать сообщение об этом на другой аккаунт. Если последний еще и связан с пейджером, то можно создать систему фильтрации входящих сообщений от спама с параллельным уведомлением на SMS. Другое применение - брутальные форсеры для онлайн-почты.
При входе в систему с паролем вам придется отслеживать сессии, записываемые в куки - возможно, вы предпочтете автоматизировать браузер в случаях, подобных показанных в следующем примере.
автоматизация IE, match, upload по ftp
Следующий пример показывает автоматизацию браузера. Происходящее можно назвать "похищением контента": из Сети закачивается веб-страничка, содержание анализируется на предмет наличия полезных линков, после чего формируется новая страничка, содержащая только интересующую нас информацию. Опционально полученная страничка "поднимается" по ftp на наш сайт.Хочу подчеркнуть, что это только демонстрация работающей технологии, а не дискуссия по правовым и/или моральным вопросам, таким как порно в Сети, использование "Ad Killers" и чужого контента.
// следующий фрагмент - калька с get 'http://easypic.com/main.html?bypass' // здесь get не работает - из-за перегрузки сервера страница часто // не успевает загрузиться и сеанс обрывается. for j=1,10 { openbrowser 'http://easypic.com/main.html?bypass', '', '', '', '', true every 10 // с периодичностью 10 сек { i=1 getbrowserdata if (contains (., 'EasyPicTM')) // первый параметр - вершина стека { break 4 } else { pop i=i+1 if (i>60) // если за 10 мин. не закачалось - начинаем сначала { closebrowser break 3 } } } } closebrowser
// прошу прощения у всех Василиев Пупкиных за использование их несгибаемого трейдмарка create 'C:\index.htm' write '
' write '
Vasiliy Pupkin presents: great EasyPic now easier than ever!
' write 'To see original EasyPic with counters, banners, links to links, popups ' write 'and other useless stuff click herom
' match ('
Webcams') while (match ('size=4>{Title}')) { write '
{Title}
' write ''
// смысл следующих строк - сделать копию контента (остатка), отрезать спереди один раздел, копию // выбросить а сам раздел положить в стек, не факт что все оптимально, главное, что работает push. match '{once} size=4>' pop push once
while (match ('')) { if (!contains (Link,'traffic.cgi')&&!contains (Link,'cout.cgi')&&!contains (Link,'spotbrokers')) { write "XXX " } } pop write '
' if (Title=='Shemale') { break 2 } } write '' close
end // закомментируйте, если хотите выложить результат в Сеть,- только не пишите, что это ваше:\
ftpidentity 'tooeasy','guess' ftpopen 'ftp.narod.ru' ftpput 'C:\index.htm' ftpclose
закачка контента в БД
Это самый типичный случай для делового приложения - закачка контента в БД. Ситуация может быть самая разбанальная - вы ищете варианты квартир или еще что-то в газетах типа "Авизо". Можно сканировать саму газету, можно листать сайт бесконечным образом, но все-таки более экономичный вариант - выкачать контент в базу данных и после программно обеспечить условия для поиска, печати или анализа информации.NQL может получать доступ к БД тремя способами, или, как говорят, "методами": ODBC, ADO и OLEDB. По умолчанию стоит ODBC, и поскольку это работает нормально, нет никаких причин изменять это умолчание. Для Java-версии, соответственно, предусмотрено несколько методов с участием JDBC.
Для операций можно использовать SQL-конструкции и дополнительно - nextrecord для выбора следующей записи. Поля результирующего набора при выборе по SELECT отображаются в переменные автоматически. Nextrecod тоже автоматически, в духе NQL, устанавливает код ошибки, так что код, выполняющий запрос и обрабатывающий результат, выглядит тривиально:
opendb "phonebook" select "SELECT Contacts WHERE State='NY'"; while { show Name, Street, City, State, Zip, Phone nextrecord }
Рассмотрим практический пример - пусть наша программа получает данные из газеты объявлений и складывает их в таблицу БД. Как всегда, можно "пойти другим путем" - выкачать весь раздел или даже газету и потом в комфортной обстановке разбирать ее на молекулы. Либо же прямо в момент выкачки анализировать и выбирать нужные строки. Мы продемонстрируем второй вариант - то есть выкачаем один раздел с фильтрацией строк. Допустим, мы ищем б/у Hi-Fi технику.
Наша программа может выглядеть так:
record #avizorec=issue, rubric, rubname, pline
get 'http://www.aviso.com.ua/aviso/browse.asp' match "ads/kiv/{codename}.asp" pop
push codename match '{prefix}/' pop
get "http://www.aviso.com.ua/aviso/ads/kiv/" &codename&".asp" match "HRef=\"{pagename}.asp\">Rubric #620" pop push pagename match "{dbsec}/" pop
openbrowser "http://www.aviso.com.ua/aviso/ads/kiv/" &prefix&"/"&pagename&".asp",'','','','',True getbrowserdata
opendb 'avizo' table 'ads'
while true { match "Aviso newspaper {issue}. Rubric {rubric}.{rubname}" match "
" push. match "{lines}
" pop push lines while (match ("{pline}
")) { if contains (pline,'б/у')&&contains (pline,'удио') { addrecord #avizorec } } pop
match "- NEXT -
" else { break 2 } browse "http://www.aviso.com.ua/aviso/ads/kiv/" &prefix&"/"&dbsec&"/"&lnextp&".asp" getbrowserdata } closedb closebrowser
Как видно, здесь применяется комбинированный подход - сначала осуществляется поиск нужной страницы с помощью get (URL имеет прихотливый и непредсказуемый вид, так что приходится исследовать ссылки), а после, во избежание работы к куками, закачивается собственно информация - можете переделать этот фрагмент с использованием get и посмотреть, что получится. Результат в данном случае сохраняется в базе данных - предполагается, что вы предварительно создали ODBC-источник с именем avizo и что эта БД содержит таблицу adv. В дальнейшем нам ничего не мешает снова использовать NQL для работы с этими данными.
Пример реализации этой технологии: периодическое выкачивание предложений работы по заданному критерию (допустим, с такого мегапортала, как dice.com) и массовая рассылка резюме по найденным адресам (это вовсе не спам - там оставляют свои адреса как раз затем, чтобы им присылали резюме; да и как же иначе должен рассылать программист, если не автоматически?). Поскольку данные изменяются сравнительно медленно (скажем, раз в сутки-двое), а рассылки (гипотетически) производятся по несколько раз в день, то окажется выгодным закачивать данные один раз и хранить их в БД для последующего использования.
* * *
Всё, о чем тут шла речь, это только верхушка айсберга. Каждый из вас придумает (если уже не придумал) десятки применений своим агентам - от закачки бизнес-котировок до системы управления контентом, поиска квартирных вариантов или активной раскрутки веб-проектов. Только имейте в виду: вы в ответе за сетевых агентов, которых приручили,- и потом не говорите, что я вас не предупреждал!
Способы запуска программ
NQL не является универсальным языком программирования, на нем нельзя написать полноценную программу с графическим интерфейсом пользователя. Поэтому фрагменты NQL-кода часто должны выполняться в каком-то другом приложении. Поговорим о том, как выполняются NQL-программы, то есть, как вы используете готовые скрипты на SQL - как из OS, так и из других программ.Выполнение всегда происходит по одному и тому же сценарию: ваша программа в текстовом виде находится в файле или в переменной в памяти. Дополнительно есть две области для входных и выходных данных и, возможно, еще несколько параметров. Иными словами, вы имеете текст программы и передаете его интерпретатору. Такой "полностью динамический" механизм позволяет не только загружать файлы во время выполнения, но и конструировать программы прямо во время выполнения - точно так же, как это делается с командами SQL. Обратная сторона, быстродействие, в сети вряд ли будет критическим местом - запросы к сети, как правило, будут раз в 100-1000 медленнее интерпретации.
Первый способ выполнения - в среде разработки IDE. Фактически вы можете выполнять программу в трех режимах: выделенном (не рекомендую - подвешивает систему), фоновом и отладочном. В последнем случае код выполняется по одной строке, и вы по ходу дела имеете доступ к переменным, стеку данных и прочим подробностям рантайма. Как вариант - с помощью IDE создать файл бота с расширением .BOT. Это бинарная форма программы после синтаксического разбора, созданная для поставки ваших программ в "нечитабельном" виде.
Способ номер два - создать независимой приложение, выбрав в IDE Create EXE. Само приложение располагается на рабочем столе (несколько нетипичное поведение, обычно на стол выкладывается ярлык). У независимых модулей есть дополнительные возможности - выводить данные о текущем состоянии программы в специальных областях нотификации. При выполнении таких программ вы можете прикрепить к своей программе скин - bmp-образ, и таким образом сделать вашего бота ни на что не похожим.
К сожалению, эта возможность еще требует доработки.
Способ № 3 - выполнять программы NLQ из командных файлов или из командной строки с помощью программы nqlexec. Этот метод имеет ограничение - ваша программа не сможет получать или выдавать входной и выходной потоки данных.
Способ № 4 - выполнять скрипт в заданное время с помощью программы NQL Agent. Это оконная программа, доступная через меню Пуск.
Остальные способы - программные, то есть вы вызываете интерпретатор NQL из другого языка программирования, такого как C или Basic.
Для вызова из таких языков, как Basic, проще всего использовать ActiveX-компонент. Расскажу об этом подробнее, поскольку такое применение является самым вероятным, например в VBA. В вашем распоряжении только три метода: Run, RunScript и RunScriptFile - что, в общем-то, одно и то же, за исключением того, где лежит текст вашей программы. Из событий в наличии тоже три наименования: End, Notify, Show - соответствующие активным действиям вашего приложения. Несколько больше полей данных - в частности, для входных и выходных потоков, флаги обработки ошибок и нотификации.
Метод № 6, облегченный ActiveX - ATL-класс для встраивания в "легкие" контейнеры. Обычно для создания экземпляров класса в ASP-приложениях с помощью CreateObject.
Метод номер следующий - вызов скриптов через классы Java и C++, для чего нужно подключить к вашему приложению соответствующие файлы class, java, h - и так далее.
И, наконец, если вам не подходит ни один из перечисленных способов (что само по себе странно), то вы можете вызывать интерпретатор непосредственно из DLL через соответствующий API. Для этого, опять-таки, понадобится nql.h, и придется продумать еще пару трюков - то есть это не то, к чему вы должны стремиться, поскольку для интерпретатора не существует разницы между ATL/DLL.
Если вы заинтересованы в подробностях - читайте раздел Working with NQL в NQL language manual.
Теперь приведу несколько примеров в подтверждение своих слов. Скажу сразу - не всё из перечисленного будет работать :-).В частности, ftp-сервер narod.ru больше не отвечает на запросы. Так что, хотя сайт tooeasy.narod.ru и существует, реально обновить его не удастся - и, уж конечно, не с приведенным паролем. Естественно, что в реальных приложениях все окна автоматизированного браузера можно скрыть - здесь они отображаются только в целях наглядности.
Встроенные возможности языка
Минималистический стиль этого описания я позаимствую из инструкции к трояну Donald Dick. Итак, в язык встроено всё: сокеты, http, ftp, почта (писать, получать, разбирать), работа с локальными файлами, базами данных через ADO/OLEDB/ODBC SQL, автоматизация браузера (полнейшая), базовая обработка графики (включая управление TWAIN-устройствами), OLE-автоматизация, разбор XML, работа под CGI, управление мобильными устройствами, финансовые и e-commerce функции (OFX), Fuzzy logic, нейронные сети, функции принятия решения, приложения теории вероятностей, воспроизведение голосовых сообщений, масса функций и возможности расширения языка.Хотя этот перечень и выглядит как набор "все на свете", но реализация сделана очень прямолинейно и поэтому изящно, в духе языков "эпохи до ООП". Поскольку NQL не предназначен для создания масштабных и, тем более, универсальных приложений, то здесь не применяются классы и объекты. Это можно рассматривать и как недостаток, и как достоинство - поскольку объекты и классы часто применяются в тех случаях, где без них было бы лучше.
Говорит и показывает Интернет
Евгений ПатийУвеличение пропускной способности каналов связи мотивируется по-разному. Одна из основных целей производителей аппаратуры и программного обеспечения - сделать так, чтобы пользователи могли в полной мере ощутить возможности транспортировки мультимедиаинформации, в которой доминирует видео.
Увеличение пропускной способности каналов связи мотивируется по-разному. Одна из основных целей производителей аппаратуры и программного обеспечения - сделать так, чтобы пользователи могли в полной мере ощутить возможности транспортировки мультимедиаинформации, в которой доминирует видео.
Передача мультимедиаданных по IP-сетям сегодня является настоящим двигателем индустрии, ее стимулом к развитию. Судите сами: видео и аудио автоматически подразумевают генерирование больших объемов трафика, а значит, требуется "разогнать" каналы, обзавестись разнообразнейшим мощным сетевым оборудованием, которому по силам справиться с лавиной информации, разработать и создать методы защиты этих данных и т. д.
Конечно, такое положение вещей только на руку производителям - ведь все вышеперечисленные обстоятельства подразумевают увеличение выпуска оборудования и продаж, поэтому идея мультимедиатрансляций старательно культивируется и оберегается от посягательств скептиков.
Идея комплексных услуг (когда одна розетка обеспечивает доступ в Интернет, к телефонии, телетрансляции и т. д.) уже не нова, по крайней мере, на мировом уровне. В России же этот подход внедряется достаточно вяло: причины очевидны - оказание комплексных услуг требует ощутимых инвестиций. Еще одно препятствие - нежелание застройщиков или владельцев зданий сотрудничать с операторами.
Видеотрансляция посредством IP-сети сегодня уже достаточно хорошо отработана и даже может быть разбита на несколько подвидов:
Продается обычно фильм или его часть;
Сформированный поток ТВ-каналов представляет собой поток IP-пакетов, передаваемых в сети по отдельному групповому адресу
В идеальном случае провайдеру необходимо предоставлять клиенту все три типа сервиса (и довольно много дополнительных, типа network based Personal Video Recorder, nPVR). А для этого требуется генерировать контент, инкапсулировать в IP и далее транслировать его клиенту. И все это - в реальном времени и на десятки или сотни каналов.
Одним из пионеров российского рынка TV-over-IP выступила компания CTI. В конце прошлого года CTI провела пресс-конференцию по данному вопросу, на которой менеджер проектов по направлению Video-over-IP Павел Ребров сказал: "Продавать услуги выгоднее, чем мегабайты, поэтому все больше компаний уделяет внимание технологии Video-over-IP. Ведь легче продать 1 Гбайт кино, чем просто 1 Гбайт. Следовательно, операторам надо думать о разнообразии предоставляемых сервисов. Кроме того, например, в США по данным Minerva Networks, на связь и развлечения абонент тратит в среднем $150 в месяц, в России же этот показатель можно довести до $120".
Еще один участник рынка подобных услуг, компания "КОМКОР", предоставляет комплекс услуг телевизионного видеовещания - ТВ через IP (TVoIP). Проект реализуется на базе технологии IP Multicast - передача видеотрафика по протоколу IP. На первом этапе проекта организуется многоадресная рассылка пакетов - multicast - видеовещание телевизионных каналов. В настоящее время "КОМКОР" предоставляет 30 российских и 35 развлекательных, музыкальных и познавательных зарубежных телеканалов (Discovery, CNN, BBC World, Eurosport, Hallmark, VH-1 и др.). Данной услугой могут воспользоваться все операторы и организации, имеющие интерфейс 100BaseT/1000BaseLX с сетью "КОМКОР".
Сформированный поток телевизионных каналов представляет собой поток IP-пакетов, передаваемых в сети по отдельному групповому адресу, соответствующему данному телеканалу. Таким образом, вещание нескольких каналов представляет собой формирование нескольких потоков multicast-трафика, когда каждый из каналов однозначно определяется уникальным адресом групповой рассылки. Каждый ТВ-канал занимает от 4 до 6 Мбит/с, на сеть оператора он загружается только в том случае, если абонент подписан на этот канал. Для просмотра канала клиент использует компьютер или абонентское устройство STB, которое с одной стороны подключено к сети оператора (среде вещания), а с другой - имеет соединение с телевизором. Для подключения к сети или выхода из группы рассылки используется стандартный протокол IGMP (Internet Group Membership Protocol).
IP-сети позволяют доставлять видеосигнал произвольного качества, в том числе HDTV со звуком Dolby Surround
На втором этапе внедрения видеовещания по IP-сети "КОМКОР" планирует организацию дополнительных сервисов на базе технологии TV-over-IP, к их числу относятся: видео по запросу (Video on Demand, VoD), NVoD (Near Video on Demand), персональный видеомагнитофон (Personal Video Recorder, PVR), сдвинутое во времени вещание (Time Shifted TV), сервис по заказу (Services-on-Demand, SoD).
Почему в качестве транспорта используется протокол IP, который, как мы знаем, изначально был разработан совершенно для других целей? Дело в том, что сегодня IP-технологии обладают достаточной зрелостью для решения задач передачи видеоинформации. Из основных свойств протокола отметим Multicast - использование многоадресной рассылки, что позволяет значительно сократить расходы на доставку информации до конечного подписчика. Не менее важным является качество обслуживания (Quality of Service - QoS). Сквозной QoS обеспечивает корректную приоретизацию различных видов IP-трафика и, несмотря на значительную нагрузку на IP-сеть, создаваемую интернет-пользователями, видеоинформация, равно как и VoIP, будет доставляться без задержек.
Кроме того, огромная роль отводится технологиям широкополосного доступа - ведь со старинным дозвоном с помощью модема можно забыть о трафике, создаваемом передачей видеоинформации. Но уже сейчас ADSL2 позволяет предоставить подписчику два одновременно проигрываемых ТВ-потока, несколько одновременных телефонных разговоров и высокоскоростной доступ в Интернет по телефонных проводам. Дальнейшее расширение Ethernet-сетей масштаба города (MAN) позволит увеличить возможности предоставления услуг для подписчиков.
Благодаря передаче видеосигнала при помощи IP-сетей появляется ряд очевидных преимуществ. Во-первых, ощутимая экономия средств на кабельной системе - нет необходимости строить и обслуживать дополнительную кабельную инфраструктуру. Помимо этого сегодня гораздо больше специалистов в области IP-технологий, чем специалистов в ТВ-вещании. В конце концов, имеет место более эффективное использование IP-сети, повышение ее рентабельности.
Ну и, конечно же, IP-сети в нынешней ситуации позволят интегрировать все виды приложений в единую сервис-ориентированную платформу. Технология Video-over-IP позволяет предоставить не только традиционную услугу просмотра ТВ-каналов на качественно более высоком уровне, но и внедрить совершенно новые услуги.
Для операторов становится очевидным, что в современном мире объектом продажи становится не трафик как таковой, а услуги поверх этого трафика. Как, например, для оператора более выгодной является продажа конечному абоненту 1 минуты телефонного разговора, чем 200 кбайт исходящего IP-трафика, так и видеоуслуги станут дополнительным источником дохода для оператора. Каковы сегодня наиболее применимые услуги, связанные с Video-over-IP?
Кроме того, IP- сети позволяют уже сейчас доставлять видеосигнал произвольного качества. Изображение HDTV со звуком Dolby Surround можно транслировать и сегодня.
Функционально решение задачи передачи телевизионных каналов по IP-сети состоит из трех компонентов. Ключевым является IP Headend - традиционный для телевизионных операторов комплекс, обеспечивающий прием, раскодирование и демультиплексирование сигналов со спутника, прием и MPEG-кодирование материалов из аналогового источника и мультиплексирование каналов в IP Multicast-потоки. Именно этот мультиплексор или, иначе говоря, стример (streamer), становится уникальным компонентом headend для Video-over-IP. Он обеспечивает IP-вещание телевизионных каналов таким образом, что каждый канал имеет собственный уникальный адрес и порт IP Multicast. Кроме того, требуется система обеспечения условного доступа (CAS), гарантирующая защиту контента, то есть шифрующая телеканалы для того, чтобы смотреть их могли лишь авторизованные пользователи. CAS может обеспечивать авторизацию как собственными методами, так и средствами автоматизированной системы расчетов, сторонних систем или middleware ("прослойка"). В качестве средства авторизации могут использоваться смарт-карты, программные ключи (когда пользователю достаточно пароля).
Декодирование телеканалов осуществляется непосредственно на абонентском устройстве IP Set Top Box или персональном компьютере. Абонентское устройство внешне напоминает спутниковый ресивер, за тем исключением, что в качестве входного интерфейса у него используется не разъем для подключения спутниковой антенны, а стандартный сетевой интерфейс Ethernet. По сути, это небольшой компьютер со своей операционной системой, MPEG-декодером и веб-браузером - именно наличие веб-браузера и IP-канала позволяет реализовать интерактивные сервисы.
Видео по запросу можно условно разделить на два вида: "настоящий" (True VoD) и "условный" (Near VoD). Если True VoD представляет собой комплекс, обеспечивающий unicast-поток для каждого пользователя в любое время, то Near VoD - это способ экономии полосы пропускания за счет применения MultiCast. В последнем случае несколько экземпляров каждого из фильмов запускается на воспроизведение "по кругу" со смещением начала произведения во времени, и подписчик получает доступ к каналу, на котором воспроизводится конкретный фильм. Естественно, только True VoD предоставляет подписчику услуги персонального видеоплейера: "перемотка" в любые стороны, воспроизведение с произвольной позиции, постановка на "паузу" и просмотр фильма в любое удобное время.
Ключевой компонент системы TV-over-IP является IP Headend — комплекс, обеспечивающий прием, раскодирование и демультиплексирование сигналов
Для обоих видов услуги видео по запросу являются обязательными такие компоненты, как сервер VoD, Middleware и абонентское устройство. Сервер VoD - это видеосервер с дисковым массивом большой емкости для хранения видеоматериалов и специализированным программным обеспечением, обеспечивающим multicast-трансляцию видеоматериалов в режиме Near VoD или доступ к видеоматериалам по протоколу RTSP для True VoD. Обычно видеосервер может также осуществлять перехват и запись multicast-потоков, что используется для реализации услуг PVR (видеозапись).Middleware представляет собой специализированный программный комплекс, который обеспечивает управление услугами VoD, IP TV и всеми сопутствующими, такими как интерактивные сервисы, Personal Video Recorder ,и многими другими. Middleware также обеспечивает авторизацию, ведение статистики и предоставляет визуальные интерфейсы пользователям и администраторам. В качестве абонентского устройства в данном случае выступает тот же самый Set Top Box, что используется подписчиком для услуг IP TV.
Современный дом, офис и даже мобильный терминал уже немыслимы без доступа к IP-сервисам, самым распространенным и самым малоприбыльным из которых является доступ в Интернет. И нет никаких причин не повышать доходность построенных сетей за счет внедрения новых услуг, таких как Video-over-IP.
Архитектура Zope
После поступления HTTP-запроса на HTTP-сервер запрос передается публикатору Zope (Zope Publisher), который, в свою очередь, передает его брокеру объектных запросов Zope (ZORB — Zope Object Request Broker). ZORB-брокер анализирует запрос и на основании полученной информации узнает, какой именно объект нужно опубликовать (это может быть объект, непосредственно указанный в URL, или объект, приобретенный от верхнего уровня иерархии). После этого ZORB-брокер вызывает объект, который выполняет предусмотренные в нем действия и в качестве результата возвращает код DTML, который называется образцом. Образец может содержать нераскрытые переменные и невыполненные вызовы других объектов. ZORB-брокер возвращает результаты вызова объекта публикатору Zope, который обрабатывает образец, передавая ZORB-брокеру требования выполнить подстановку переменных или вызвать другие объекты. Выполнив до конца всю эту работу, публикатор Zope выдает результат на браузер пользователя в виде простого HTML-кода.Публикуемые объекты располагаются в иерархической объектной базе данных Zope. Хотя она и напоминает по структуре обычную файловую систему, веб-сервер не может обращаться к ней непосредственно, поскольку он работает с URL, а по компонентам URL необходимо вначале перейти к объекту. Одна из задач, выполняемых ZORB-брокером, состоит в прямом и обратном переходе по иерархии объектов и преобразовании ступеней этой иерархии в компоненты URL.
ZORB-брокер выполняет также обработку данных формы, «пряников» (cookie) и параметров запроса, проводит опознавание пользователя и проверку прав доступа, автоматизирует обработку исключительных ситуаций (исключений), подготавливает заголовки HTML и обрабатывает пакеты протокола HTTP с информацией запроса и ответа.
ZORB-брокер выполняет все действия, связанные с выполнением запроса, автоматически, поэтому от прикладного программиста скрыты все технические вопросы реализации протокола веб.
Для создания динамического информационного наполнения применяется серверный интерпретируемый язык DTML на основе тегов.
Он обеспечивает доступ объекта только к атрибутам, приобретенным этим объектом. Например, если в текущей или вышележащей папке установлен метод отправки почты, объект может его приобрести и выполнять отправку почты. Но выход за пределы объектной модели сайта для объекта исключен. Это позволяет, с одной стороны, создавать исключительно надежные и безопасные сайты, а с другой стороны, если речь идет о провайдере или, точнее, хостере, — передавать управление сайтом назначенному для этого администратору без опасений нарушить защиту всего хоста.
Администратор управляет сайтом Zope по веб через специальный административный интерфейс. Он создает пользователей Zope, назначает им пароли, определяет права доступа к папкам и другим объектам. Эти пользователи существуют только в объектном пространстве Zope и не имеют никакого отношения к пользователям операционной системы. Главный администратор сайта также может смело назначать администраторов, отвечающих за определенный уголок сайта,— они не могут выйти за рамки предоставленных им полномочий и нарушить защиту всего сайта.
Объектная база данных
Для хранения кода и информационного наполнения веб-сайта Zope применяется объектная база данных Zope или сокращенно ZODB (Zope Object Database). Эта база данных построена так, что для конечного пользователя она выглядит как файловая система, но в действительности сама занимает один большой файл в файловой системе хоста. В ZODB хранится каждый созданный объект, каждый файл, каждый фрагмент информационного наполнения сайта. Это позволяет моделировать иерархию объектов, обеспечивать приобретение атрибутов в иерархии включения, проверять права доступа к объектам, определять контекст объекта. Формат представления данных в ZODB оптимизирован с учетом типичной модели доступа к информации в веб (большого объема вывода и малого объема ввода) и позволяет хранить всевозможную информацию, необходимую для создания динамических веб-приложений: файлы HTML, прикладной код, графику и т. д.ZODB — очень сложная по структуре, но прозрачная для пользователя база данных, которая обладает такими развитыми возможностями, как поддержка версионирования, транзакционная обработка и отмена ошибочно внесенных изменений. Версионирование позволяет создавать версии сайта или фрагмента сайта, отлаживать их в реальной обстановке незаметно для пользователей, а затем моментально вносить. Транзакционная обработка предусматривает автоматическое оформление в виде транзакций любых действий, которые влекут за собой изменение состояния объектной базы данных, выполнение этих действий и откат в случае их неудачного завершения. Выполненные транзакции регистрируются в объектной базе данных и могут быть отменены, если предусмотренные ими изменения были внесены ошибочно.
Объекты Zope, которые могут быть представлены в ZODB, выполняют три основных функции:
Разработка в среде Zope в основном состоит в проектировании иерархии объектов (в этой среде в процессе разработки иерархической структуры сайта одновременно происходит построение его информационной модели) и отображении объектной модели прикладной задачи на объекты Zope.
Объектный характер веб и публикация объектов
Веб, фактически, имеет объектную структуру, поэтому URL к веб-ресурсу — это просто путь к объекту в иерархии включения (домен -> компьютер -> объект), а протокол HTTP — лишь один из возможных способов отправки сообщений объекту и получения от него ответов. В настоящее время для создания объектов с динамически обновляемым информационным наполнением (вместо обычных веб-страниц) чаще всего применяются средства автоматической генерации кода HTML на основе содержимого базы данных.Это требует взаимного согласования следующих трех информационных моделей:
Обычно эти модели реализуются в виде так называемой трехуровневой структуры распределенной обработки данных, которая включает в себя сервер базы данных, сервер приложений и веб-сервер.
Однако в среде публикации объектов Zope применяется иной подход, в основе которого лежит метод непосредственного предоставления доступа к объектам, которые хранятся в объектной базе данных, иными словами, публикация объектов.
Публикация объектов — это применение объектно-ориентированных программных компонентов для создания динамического информационного наполнения (то есть HTML-страниц). В среде публикации объектов Zope (Z Object Publishing Environment) применяется широкий перечень таких программных компонентов, которые в основном подразделяются на два типа: лист-объекты и контейнерные объекты. Как правило, происходит публикация лист-объектов (в частности, DTML-документов или DTML-методов), но контейнерные объекты (например, папки) также могут иметь публикуемые атрибуты (свойства), такие как имя и идентификатор. Контейнерные объекты могут содержать в себе и лист-объекты, и другие контейнеры. Объекты объединены в иерархию включения (подобно каталогам файловой системы) и позволяют разработчику создавать сложные, разветвленные древовидные структуры.
Таким образом, переход к объекту в среде публикации объектов Zope происходит в направлении сверху вниз, а приобретение атрибутов — в направлении снизу вверх. Таковы же и две основные составляющие защиты Zope: при обращении пользователя к опубликованному объекту происходит проверка прав доступа пользователя на каждом уровне, и объекты, обращаться к которым пользователь не имеет права, являются для него невидимыми, а обращение объекта к своему атрибуту является невидимым, инкапсулированным внутреннее устройство атрибута.
Сайт, построенный на платформе Zope, является полиморфным, многоликим. На него может прийти и анонимный пользователь, и зарегистрированный пользователь с именем и паролем, обладающий определенными правами. Но для разных категорий пользователей он выглядит по-разному. Это значит, что он может выполнять и разные функции, в зависимости от категории пользователя. Например, для обычного пользователя «с улицы» он может показать, какие на предприятии есть товары и цены (актуальную информацию, которую не нужно постоянно обновлять вручную), для руководителя, находящегося в командировке,— товары, цены, количество и общие экономические показатели; для склада — одно, для магазина — другое...
Однако сайт на платформе Zope может не только выдавать, но и накапливать информацию, и надежно ее хранить. В принципе, он может стать не менее, а более защищенным, по сравнению со многими современными производственными локальными сетями. Интрасеть (внутренняя сеть) предприятия отличается по степени защищенности от экстрасетей (внешних сетей) или интерсетей (сетей общего доступа, интернет) лишь тем, что позволяет дополнительно предусмотреть физические меры защиты: исключить физический доступ посторонних лиц и экранировать излучение компьютеров и кабелей.
Отказавшись от такой «защиты», можно выиграть гораздо больше: сделать сосредоточением всех своих деловых операций единый, полиморфный, защищенный веб-сайт на платформе Zope. На него могут выходить и рядовые потребители, и территориально разобщенные структурные подразделения, и деловые партнеры, и заказчики, и надомные работники, и командированные сотрудники.По этому принципу работают многие деловые предприятия. Он вполне себя оправдывает. Для такого назначения и была разработана платформа Zope.
Организационная поддержка
Вокруг проекта Zope сплотилась очень большая группа инициативных разработчиков. Достаточно сказать, что только на сайте Zope () зарегистрировано около 11 тыс. программистов, которые вносят свой вклад в развитие этого проекта. Перечень продуктов, разработанных на основе Zope и предоставленных во всеобщее пользование, насчитывает сотни наименований. Существуют многочисленные дискуссионные группы и списки рассылки. Документация Zope пока оставляет желать лучшего, но положение постепенно выправляется.Такой мощный и перспективный программный продукт больше не может оставаться незамеченным.
Основные способы разработки в среде Zope
В среде Zope может применяться несколько способов разработки разной категории сложности:Подготовка сценариев DTML, которые позволяют манипулировать с объектами Zope с помощью тегов в документах DTML. Это простейший способ программирования в среде Zope. Язык DTML не позволяет выйти за пределы объектной модели сайта, поэтому программирование на этом уровне не позволяет никоим образом нарушить защиту сайта. Это уровень массового программирования, на котором работают рядовые программисты и веб-дизайнеры.
Основные средства сопровождения
При использовании в качестве веб-сервера программного продукта Medusa (который входит в стандартную поставку и также является бесплатным продуктом) прикладная платформа Zope обеспечивает доступ ко всей иерархии объектов с FTP-клиента (с учетом прав доступа). Это позволяет быстро выгружать на сайт с удаленного компьютера прикладной код и информационное наполнение, создавать и удалять каталоги и т. д.Для управления средой Zope предусмотрен защищенный административный интерфейс, который позволяет администратору регистрироваться и работать с удаленного компьютера. Через этот интерфейс можно создавать и удалять пользователей, определять права доступа, настраивать параметры объектной базы данных, останавливать и запускать сервер Zope и т. д.
Предусмотрены средства экспорта/импорта любых фрагментов объектной базы данных (например, папок со всеми подпапками). Экспортированные объекты можно импортировать в эту или другую объектную базу данных, а также сохранить в качестве резервной копии.
Сервер приложений
Как программный продукт, Zope может успешно применяться в качестве платформы для веб-приложений. К числу программных продуктов этой категории относятся также Cold Fusion, Silverstream, Netscape Application Server, Active Server Pages (Microsoft) и многие другие. Программные платформы такого типа позволяют значительно упростить разработку и сопровождение веб-сайтов за счет применения программных средств динамического обновления информационного наполнения. Программы, написанные на интерпретируемых языках (Java, JavaScript, VBScript, PHP, Perl, PL/SQL и т. д.), хранятся и выполняются на сервере приложений, а доступ к данным обеспечивает сервер базы данных.В трехуровневой среде (веб-сервер <--> сервер приложений <--> сервер базы данных) сервер приложений выполняет в основном такие функции:
Zope, как платформа для размещения веб-приложений, отличается от других платформ тем, что в ней применяется не отдельная, реляционная база данных, а встроенная, объектная база данных. Наряду с этим, она позволяет использовать в качестве информационного ресурса и реляционные базы данных, предоставляя механизмы для интеграции внешних баз данных в ее объектную структуру. Для этой цели в составе программного обеспечения Zope предусмотрено несколько модулей: Oracle, Sybase, MySQL и ODBC. Коллекция этих модулей постоянно пополняется.
Zope — платформа для веб-хостинга
,Новые технологии веб-хостинга позволяют коренным образом изменить организацию работы предприятия. Zope - бесплатный программный продукт с открытым исходным кодом, который может служить в качестве программной платформы для разработки и размещения веб-сайтов с динамически обновляемым информационным наполнением.
Разработка Zope выполнена на языках:
Python и C(http://www.zope.org).
Как таковой, Zope перешел в категорию бесплатных программных продуктов с открытым исходным кодом с ноября 1998 года. Все предыдущие версии этого продукта были коммерческими. Zope разработан консультационной компанией Digital Creations на основе трех программных продуктов: «Bobo», «Principia» и «Aquaduct». Передавая Zope во всеобщее пользование, компания Digital Creations стремилась сделать этот продукт стандартом в области разработок для веб и увеличить свои доходы за счет предоставления консультационной поддержки.
Zope — мультиплатформенный программный продукт. Он может применяться на многих платформах, включая Linux/Intel, Solaris (SPARC и Intel), Digital Unix, BSDI и Windows NT (а также SGI/Irix, HP-UX, Windows 95/98, Mac OS и Windows CE, хотя официальная поддержка этих платформ в настоящее время не предусмотрена). Zope может работать на таких веб-серверах, как Apache, Netscape Server и Microsoft IIS, а также на мощном веб-сервере Medusa с открытым исходным кодом, который предоставляет доступ к программной платформе Zope на основе протоколов HTTP, вебDAV и FTP.
Типы доступа "ftp" и "tftp"
Тип доступа по FTP или TFTP означает, что тело сообщения доступно как внешний файл по протоколу FTP [RFC-959] или TFTP [RFC-783] соответственно. Для этих типов доступа обязательны следующие дополнительные параметры:NAME -- Имя файла, содержащего данные тела письма.
SITE -- Полный доменный адрес или псевдоним компьютера, с которого файл может быть получен по указанному протоколу.
Перед тем, как начнется считывание данных по FTP, пользователь обычно должен быть спрошен на предмет логина и пароля для машины, указанной в параметре 'site'. По причинам безопасности логин и пароль не указываются как параметры Content-Type и должны быть получены от получателя письма.
Дополнительно определены следующие необязательные параметры:
DIRECTORY -- каталог, содержащий тело письма на удаленной машине.
MODE -- Нечувствительное к регистру букв строка, указывающая режим передачи данных. Допустимые эначения для типа доступа TFTP:
NETASCII, OCTET и MAIL. Для типа доступа FTP: ASCII, EBCDIC, IMAGE и LOCALn, где n - десятичное целое число, обычно 8. Эти значения соответствуют типам представления A, E, I и Ln, определенным FTP-протоколом. Заметьте, что "BINARY" и "TENEX" не являются допустимыми значениями для параметра MODE. Вместо них должны использоваться "OCTET", "IMAGE" или "LOCAL8". Если параметр MODE отсутствует, значением по умолчанию является "NETASCII" для TFTP и "ASCII" для FTP.
Способ досупа "anon-ftp"
Этот способ доступа идентичен "ftp", за исключением того, что пользователю не требуется указывать свой логин и пароль для удаленной машины. FTP-протокол будет использоваться с логином "anonymous" и email-адресом получателя вместо пароля.Способы доступа "local-file" и "afs"
Способ доступа "local-file" означает, что тело письма доступно как файл на локальной машине. "afs" означает, что тело доступно как файл через общую файловую систему AFS. В обоих случаях требуется единственный обязательный параметр:NAME -- Имя файла, содержащего данные тела письма.
Следующий необязательный параметр может быть использован для локализации ссылки на файл и содержит адрес сайта или сайтов, на которых данный файл виден:
SITE -- Доменный адрес машины или машин, на которых возможен доступ к файлу данных. Допускаются маски с использованием звездочки вместо части доменного имени, например, "*.bellcore.com", для обозначения набора машин, на которых файл виден напрямую. Единственная звездочка вместо всего доменного имени может означать, что файл, где би он ни был, виден через глобальную файловую систему.
Способ доступа "mail-server"
Применяется, когда тело письма доступно через почтовый сервер. Обязательный параметр для этого способа доступа:SERVER -- email-адрес mail-сервера, с которого могут быть запрошены данные тела письма.
Так как почтовые серверы предполагают множество различных синтаксисов, некоторые из них могут быть многострочными, полная команда, которую нужно послать на mail-сервер, не включается как параметр в однострочное поле 'content-type'. Вместо этого она помещается в мнимое тело, когда значением поля 'content-type' является 'message/external-body', и параметр 'access-tyoe' имеет значение 'mail-server'.
Необязательный параметр для этого способа доступа:
SUBJECT -- Subject, который будет использован в заголовке письма-запроса, которое почторый клиент получателя пошлет на указанный почтовый сервер для получения данных тела письма. Заметьте, что помещение адреса сервера в subject не рекомендуется, однако, известны mail-серверы, требующие этого.
MIME-стандарт не определяет синтаксиса обращения к почтовому серверу. Поэтому он допускает включение полной команды для mail-сервера в мнимое тело.
В отличие от других способов доступа, доступ через mail-сервер не синхронен, и данные могут быть получены в непредсказуемый момент в будущем. По этой причине важно иметь механизм, обеспечивающий вставку полученных от mail-сервера данных в исходное письмо. Mail-сервер при отправке запрошенных данных должен использовать то же самое значение поля Content-ID в заголовке письма с возвращаемыми данными, какое было в первоначальном "бестелесном" письме, чтобы облегчить работу этого механизма.
Примеры и дополнительные пояснения
С появлением возможности очень широких (протяженных) файловых систем стало непредсказуемым, на каком наборе машин файловой системы данный файл будет доступен напрямую, а на каком - нет. Поэтому, имеет смысл указывать как имя файла, так и сетевой адрес (адреса) машин, на которых файл доступен.Если внешнее тела письма доступно посредством нескольких различных механизмов, отправитель может включить несколько частей типа message/external-body в письмо типа multipart/alternative.
Однако, механизм external-body не должен быть ограничен получением удаленных файлов. Например, можно представить использование видеосервера с внешними ссылками на видеофрагменты.
Если письмо / часть письма имеет тип "message/external-body", то оно / она будет содержать поля заголовка вложенного письма. Тело само по себе неходится где-либо во вне. Это значит, что если тело типа "message/external-body" содержит два последовательных конца строки (CRLF), то все, что идет далее, не является чстью сообщения и просто должно игнорироваться. Однако, этот "хвост" - удобное место для каких-либо дополнительных данных, которые не могут быть помещены в поле заголовка Content-Type. В частности, если значение "access-type" есть "mail-server", то "хвост" может содержать команды, посылаемые затем mail-серверу по адресу, на который указывает параметр SERVER.
Поля заголовка вложенного письма, которые на самом деле являются телом общего письма типа "message/external-body", должны нести информацию о типе содержимого внешнего (удаленного) тела, если оно не является простым ASCII-текстом (что подразумевается по умолчанию), поскольку эти внешние данные сами по себе не имеют заголовка, опрпеделяющего их тип. Также, необходимо указывать Content-transfer-encoding, если он имеет значение, отличное от "7-bit". Так, полное письмо типа message/external-body, ссылающееся на документ в формате PostScript, может выглядеть следующим образом:
From: Whomever To: Someone Subject: whatever MIME-Version: 1.0 Message-ID:
Content-Type: multipart/alternative; boundary=42 Content-ID:
--42 Content-Type: message/external-body; name="BodyFormats.ps"; site="thumper.bellcore.com"; access-type=ANON-FTP; directory="pub"; mode="image"; expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript Content-ID:
--42 Content-Type: message/external-body; name="/u/nsb/writing/rfcs/RFC-MIME.ps"; site="thumper.bellcore.com"; access-type=AFS expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript Content-ID:
--42 Content-Type: message/external-body; access-type=mail-server server="listserv@bogus.bitnet"; expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type: application/postscript Content-ID:
get RFC-MIME.DOC --42--
В приведенных примерах значение Content-transfer-encoding для внешних данных в формате postscript полагается по умолчанию как "7bit".
Заголовки общего и вложенного(их) писем (имеющих внешнее тело) должны удовлетворять тем же правилам, что и для типа message/partial во избежание путаницы.
Поскольку внешнее тело не пересылается в виде почты, то оно не обязано удовлетворять требованиям длины строк и иметь 7-битную форму, оно может быть просто бинарным файлом. Поэтому поле Content-Transfer-Encoding не является необходимым, хотя его наличие допускается.
Тело письма типа "message/external-body" обрабатывается в сответствии с основным синтаксисом стандарта RFC 822, в частности, все, что идет до первой последовательной пары концов строки (CRLF), является заголовком письма, а все, что идет после, является "мнимым" телом письма, которое игнорируется для большинства типов доступа.
Формальный синтаксис поля заголовка 'content-type' для данных типа 'message' - следующий:
message_тип := "message" "/" message_подтип message_подтип := "rfc822" / "partial" 2-3 partial_параметра / "external-body" 1 external_параметр / расширение (не предопределенный подтип) partial_параметр := (";" "id" "=" значение) / (";" "number" "=" 1*ЦИФРА) / (";" "total" "=" 1*ЦИФРА) ; id и number требуются всегда; total требуется для последнего фрагмен- ; та послания. external_параметр := (";" "access-type" "=" тип_доступа) / (";" "expiration" "=" дата-время) ; Дата-время должны быть экранированы кавычками / (";" "size" "=" 1*Цифра) / (";" "permission" "=" ("read" / "read-write")) ; Значение permission нечувствительно к регистру букв / (";" "name" "=" значение) / (";" "site" "=" значение) / (";" "dir" "=" значение) / (";" "mode" "=" значение) / (";" "server" "=" значение) / (";" "subject" "=" значение) ; access-type требуется всегда; все остальное - в зависимости от значе- ; ния access-type тип_доступа := "ftp" / "anon-ftp" / "tftp" / "local-file" / "afs" / "mail-server" / / расширение (непредопределенный параметр) ; Нечувствителен к регистру букв
Асинхронный вызов
Можно вызывать удаленные методы асинхронно - клиентский скрипт продолжает работать пока серверный метод исполняется и следовательно страница остается доступной для пользователя.Вызов серверного метода асинхронно схож с синхронным вызовом, за исключением появления дополнительных параметров при вызове:
Как и при синхронном вызове, асинхронный вызов создает объект call, содержащий результат работы серверного метода и дополнительную статусную информацию.
Так как при асинхронном вызове необходимо передать ссылку на callback функцию, то используется только JavaScript.
Для вызова серверного метода асинхронно:
callObject = ASPObject.methodName(p1, p2[,...], callbackFunction, errorCallbackFunction, context);
callobject = RSExecute(url, methodName, p1, p2[,...], callbackFunction, errorCallbackFunction, context)
Где:
Т. к. вы передаете ссылку, не включайте имя функции в кавычки.
Например, в следующем скрипте асинхронно вызывается серверный метод square. После работы метода вызывается функция showResults(). Имя операции передается как context-параметр.
Аналогичный пример с использованием RSExecute метода:
Функция showResults, которая является callback функций в предыдущем примере, может выглядеть следующим образом:
В данном случае callback функция служит для вывода результата работы операции. Функция демонстрирует, как вы можете использовать context свойство для определения того, какая операция арифметическая применялась.
Вы можете проверить состояние работы удаленного метода. При асинхронном вызове, можно проверить состояние работы серверного метода. Для этого используется свойства status объекта call Возможные значения свойства status:
Асинхронный вызов можно прервать, для этого используется cancel() метод объекта call.
Безопасность
Скриплет также безопасен, как HTML и скрипт. К тому же, в скриплете есть возможность распознать в каком контейнере он находится и если это контейнер с повышенными требованиями безопасности (IE), то скриплет работает согласно политике безопасности этого контейнера.В общем случае для корректного функционирования необходимо чтобы скриплет был загружен с того же Web сервера, что и использующая его HTML страница (как и JAVA апплеты).
BitNet
Адрес похож на Internet'овский: пользователь@хост.Преобразуется добавлением ".bitnet" в конце: пользователь@хост.bitnet.
Не все майл-серверы понимают домен .bitnet, им надо указывать шлюз,
например, пользователь%хост.bitnet@cunyvm.cuny.edu.
Что такое RS?
Remote Scripting (RS) - это механизм, обеспечивающий вызов серверных процедур из клиентского скрипта. С помощью RS, процедуры и функции, описанные на сервере, могут вызываться из скрипта HTML страницы, исполняющегося в браузере пользователя. Вызываемые процедуры и функции будем также называть серверными методами, далее вы поймете почему. Серверные методы описываются в ASP странице и для их реализации подходит любой язык сценариев (JavaScript, VBScript). При удаленном вызове процедуры и функции исполняются на сервере с полным доступом к системным ресурсам, а результат работы возвращается в клиентский скрипт.Теперь разработчики могут создавать интерактивные Web приложения, в которых появляется возможность исполнять серверный скрипт без обновления страницы.
C использованием RS Web приложении может проверить корректность вводимых пользователем данных в процессе заполнения формы, избегая перезагрузки.
С появлением RS, Web приложение может использовать как клиентский, так и серверный скрипт. Клиентский скрипт часто используется для управления пользовательским интерфейсом, например, динамическое изменение содержимого Web страницы или обработка действий пользователя. Клиентский скрипт выполняется локально в браузере и обеспечивает интерактивный интерфейс.
Возможности применения серверного скрипта ограничиваются только вашей фантазией. Серверный скрипт может использоваться для доступа к базе данных или выполнения звена бизнес логики в многослойных приложения. При этом серверный скрипт исполняется на сервере с полным доступом к ресурсам сервера, а из клиентского скрипта его вызов почти ничем не отличается от вызова локальных процедур и методов.
Так как при вызове серверного скрипта текущая страница не покидается, то ее состояния сохраняется, а вместе с ней и состояние переключателей и глобальных переменных.
Что такое скриплет?
Скриплет является COM компонентой реализованной на XML (eXtensible Markup Language) и языке сценариев. XML используется для построения структуры скриплета (определения типа COM компоненты, ее методов, свойств, инициируемых событий, и т. д.), а код на языке сценариев обеспечивает функциональность.Что касается скриплетов, то это полноценные COM компоненты и могут использоваться для решения широкого класса задач, как то:
CompuServe
Адрес в CompuServe - два числа, разделенные запятыми,например, 1234,56789. В нотации Internet это выглядит
1234.56789@compuserve.com (точка вместо запятой).
Обратно письмо можно отправить по адресу
>INTERNET:пользователь@хост.домен
Дополнительные возможности
Рассмотрим пример, когда у скриплета есть свойство "цвет" и при изменении значения этого свойства хотелось бы, чтобы цвет компоненты тоже менялся. Безусловно, логичнее было бы реализовать метод при вызове которого цвет изменялся, но в общем случае предположим что компоненте необходимо реагировать немедленно при изменении каких-либо свойств.В скриплете есть возможность описать некоторые функции, так что они выдают себя за свойства, и при изменении свойства выполняется код реализованный в этих функциях. Таких функций всего две: put и get. При изменении значения свойства вызывается функция put, а при получении значения - get.
В этом примере в переменных property1GetCount и property1PutCount хранят количество обращений к свойству property1 и его изменений. В функции public_put_property1 после того как новое значение установлено, компонента обновляет значения. В контейнере вы можете ссылаться на property1, как если бы это было обычное свойство.
Scriplet1.property1 = 'Another'; a = Scriplet1.property1;
С помощью put_ и get_ функций можно реализовать read-only и write-only свойства. Для создания read-only свойства описывается только функция get_, т. к. функции put_ нет, то значение изменено быть не может, аналогично с write-only.
Если вы пишите на JavaScript, то имеется альтернативная возможность описания интерфейса DHTML скриплета. При определении объекта public_description в скриплете, свойства и методы этого объекта являются свойствами и методами скриплета. При таком описании интерфейса префикс public_ не используется. Удобнее описать весь интерфейс скриплета в одном месте, как это предлагается с использованием объекта public_desription, чем рассеивать описание по всему коду скрипта. В дальнейшем предполагается реализовать подобный механизм и на VBScript.
В качетстве демонстрации можно присовокупить стандартные Microsoft примеры DHTML скриплетов. Я кинул пару самых простых и наглядных, можно также посмотреть у Microsoft на www.microsoft.com/scripting/.
Другие подтипы типа Application
Ожидается, что многие подтипы типа 'Application' будут введены в будущем. MIME-совместимые почтовые программы должны интерпретировать любой незнакомый им подтип как эквивалент 'application/octet-stream'.Формальный синтаксис дла поля 'content-type' для данных типа 'application' дается следующим образом.
application_тип := "application" "/" application_подтип application_подтип := ("octet-stream" *stream_параметр) / "postscript" / расширение (непредопределенный под- тип) stream_параметр := (";" "type" "=" значение) / (";" "padding" "=" число_дополняющих_битов) число_дополняющих_битов := "0" / "1" / "2" / "3" / "4" / "5" / "6" / / "7"
Другие подтипы типа "multipart"
В будущем ожидается введение новых подтипов. Программистам рекомендуется интерпретировать незнакомые подтипы типа 'multipart' аналогично "multipart/mixed".Формальный синтаксис поля Content-Type для данных типа "multipart":
multipart-тип := "multipart" "/" multipart-подтип ";" "boundary" "=" метка_границы multipart-подтип := "mixed" / "parallel" / "digest" / "alternative" / подтип-расширение
Файл active
Этот файл содержит список групп новостей, которые принимает локальный сервер. Содержимое файла считывается демоном innd при запуске, либо при получении этим демоном соответствующего указания от программы ctlinnd. Все статьи, опубликованные в группы новостей, которые не указаны в файле active отвергаются локальным сервером новостей. Строки в этом файле имеют следующий формат:name himark lomark flags
Ниже описывается значение параметров:
Основные операции, которые должен время от времени выполнять администратор включают в себя добавление новых групп, удаление ненужных групп, изменение флагов текущих групп новостей. Все эти операции должны отображать свои действия в файле active. Существует два основных подхода к выполнению указанных выше операций с группами новостей:
ctlinnd newgroup relcom.humor y
добавляет группу новостей "relcom.humor" с флагом "y" (см.
выше), помещая соответствующие строки в файлах active и active.times. Файл active.times
содержит информацию о времени создания новой группы новостей (и о том, кто ее создал), которая используется некоторыми программами чтения новостей (Trumpet одна из них) для оповещения своих пользователей о наличии новых групп новостей.
ctlinnd pause "edit active"
relcom.humor 0000000000 0000000001 y
inncheck active
ctlinnd reload active "edit active"
ctlinnd go "edit active"
Файл expire.ctl
Этот файл считывается программой expire при запуске и определяет правила очистки дерева статей на локальном сервере (сроки хранения тел статей и их идентификаторов). В начале этого файла обязательно должна находится строка (причем, только одна), определяющая как долго хранить записи об идентификаторах статей в файле history, после того, как тело статьи удалено. Это позволяет отклонить эту статью, если поставщик новостей вновь предложит ее в определенный промежуток времени. Эта строка имеет следующий формат:/remember/:время
где время - срок хранения в днях (можно указывать и дробную часть дня, наприме, /remember/:7.5
- семь с половиной дней), по истечении которого из системы удаляются идентификаторы старых статей. Последующие командные строки определяют когда нужно удалять из системы тела статей. Они имеют следующий формат:
pattern:modflag:keep:default:purge
Ниже описывается значение параметров:
первого поля.
Следующие 3 поля определяют какое количество дней хранить тела статей на локальном сервере новостей:
Помимо строки /remember/ Вы должны указать строку с pattern
'*' и modflag 'A'. Эта строка является строкой по умолчанию для срока хранения всех статей на системе. При этом она обязательно должна стоять раньше, чем строки с образцами для конкретных групп, поскольку этот файл проверяется программой expire до конца и последняя соответствующая группе новостей строка будет использована.
Например, мы хотим после удаления тела статьи хранить ее идентификатор в базе данных в течение 5-ти дней. Тела статей будут храниться на системе от 3-ех до 5-ти дней, за исключением локальных конференций, которые мы хотим хранить подольше (в течение 10-ти дней). Тогда наш файл будет выглядеть так:
/remember/:5 *:A:3:4:5 local*:A:10:10:10
Файл inn.conf
Файл inn.conf содержит различные глобальные параметры сервера новостей (имя сервера, имя домена) и параметры, используемые при формировании заголовков статей (начавших свой путешествие по Usenet с этого сервера). Все изменения, сделанные в этом файле считываются демоном innd только после перезагрузки сервера новостей. Строки в этом файле имеют следующий формат:имя: [возможны пробелы] значение
Здесь имя - имя параметра, значение
- его значение. Некоторые параметры могут быть изменены определением переменных окружения системы. Ниже описываются имена параметров и их значения:
FidoNet
Адрес в FidoNet бывает двух типов: "поинт" и "нода".Адрес "поинт" выглядит примерно так: 2:5020/12.345, где
Адрес "нода" имеет на один пункт меньше: 1:350/12
(Северная Америка).
Послать письмо можно по адресу
Imya_Familia@p345.f12.n5020.z2.gate.phantom.msk.su
(через московский шлюз) или соответственно
Fname_Lname@f12.n350.z1.fidonet.org (через шлюз в США).
Общение
Аналогично, но через другой шлюз:Mirza_Kurbanov@p45.f123.n5020.z314.goldnet.squeen.msk.su.
Инсталляция пакета INN
Процесс инсталляции пакета INN идентичен для Unix-основанных систем, но каждая платформа имеет свои особенности инсталляции. Описанная ниже последовательность действий ориентирована на FreeBSD (пакет inn-1.7.2 ставился на FreeBSD-2.2.5).Во-первых, Вам необходимо заполучить свеженький дистрибутив INN. Обратитесь на сервер ftp.isc.org и перейдите в каталог isc/inn. Выберите необходимый архив (например, ), перекачайте, декомпрессируйте и разархивируйте его, поместив результат в выбранный Вами каталог (в дальнейшем он упоминается как $inn).
Сменив текущий каталог на $inn, Вы обнаружите два файла формата nroff, использующие макрос -ms: Install.ms.1
и Install.ms.2. Это две части оффициального руководства по инсталляции InterNetNews.
Дайте команду
make Install.ms
При этом два файла объединяются в один - Install.ms
с правами доступа 444. Приведите этот файл в более читабельный вид (в частности, для просмотра с помощью more) командой:
nroff -ms Install.ms > Install
При возникновении проблем в инсталляции пакета необходимо обращаться за помощью к этому файлу.
Следующий этап процедуры инсталляции - редактирование главного файла конфигурации сonfig.data.
В каталоге $inn/sample-configs содержатся шаблоны файла config.data для различных платформ. Вам необходимо выбрать наиболее подходящий для Вас файл и скопировать его в $inn/config/config.data, например, для FreeBSD выполните следующие команды:
cd $inn cp sample-configs/config.data-FreeBSD-2.0 config/config.data
Теперь настала пора отредактировать сам файл config.data. INN получает из этого файла информацию о своей среде (т.е. где лежат компоненты, используемые INN).; Для пользователей FreeBSD надо подкорректировать опции для LIBS:
LIBS -lutil -lcrypt
Пакет поставляется с некоторыми perl-сценариями, требующими пакет языка perl версии не ниже, чем 5.001, так что Вам, возможно, придется установить новый пакет языка perl и прописать корректный путь к команде perl:
_PATH_PERL /usr/local/bin/perl
Подробное описание содержимого файла config.data
смотрите в файле Install.
Скомпилируйте все исходники:
cd $inn make all
Перед инсталляцией компонентов пакета необходимо создать каталоги, куда они будут помещены:
mkdir /usr/news /var/news /var/news/spool
Теперь можно инсталлировать компоненты пакета INN. Если Вы ставите пакет в первый раз на эту систему, то просто дайте команду:
make install
Если же Вы заменяете уже существующую систему INN, то рекомендуется инсталлировать отдельно программы и отдельно конфигурационные файлы и сценарии. Это позволит не затирать конфигурационные файлы текущей INN системы. Итак, сначала запустите сценарий:
makedirs.sh
Он создаст все остальные каталоги (ниже созданных командой mkdir на предыдущем этапе). Заметим, что команда make install вызывает этот сценарий сама. Теперь инсталлируйте программы и руководства (man'ы):
make update
При этом сценарии и конфигурационные файлы будут скопированы из каталога $inn/samples в каталог $inn/site. Если Вы хотите сохранить настройки предыдущей версии INN, затрите файлы из каталога $inn/site такими же файлами из старого программного обеспечения, после чего:
cd $inn/site make install
Запуск сценария:
$inn/BUILD
позволит создать файлы и history. После запуска сценария, он спросит, использовать ли с-версию subst (если она существует):
-- do you want to use it [y or n]? y
Далее он спросит построили ли Вы бинарники:
Have you already built the executables [y or n]? y
Затем он спросит существуют ли каталоги spool, etc
и т.д.:
Do the spool, etc., directories exist [y or n]? y
Следующим вопросом будет: желаете ли Вы продолжить инсталляцию:
Do you want to continue with the installation [y or n]? y
И, наконец, последний ворос: запускать ли subshell для редактирования конфигурационных файлов:
Start a subshell to edit the config files [y or n]? n
После завершения работы сценария проверьте, что владельцем файла active является пользователь news, группа news, права доступа на него 644, а если это не так (а практика показывает что в сценарии действительно что-то не так :-)), то исправьте это, дав команды
chmod 644 active chown news:news active
Сделайте почтовый псевдоним для пользователя news
в файле /etc/mail/aliases:
usenet: news
Дайте знать об этом sendmail, перестроив после редактирования файла базу псевдонимов:
/usr/bin/newaliases
INN оповещает о своей работе, используя систему syslog. Проверьте конфигурационный файл демона syslogd /etc/syslog.conf. Раскомментируйте в этом файле строки, содержащие news.crit, news.err, news.notice. После этого не забудьте создать соответствующие файлы в каталоге /var/log/news
(владелец - news, группа -news, права доступа - 664).
Заметим, что, если Ваш файл newsfeeds
не содержит строк с указанием "питающихся" у Вас сторон, кроме строки ME, то демон innd при запуске выдаст ошибку: "SERVER bad_newsfeeds no feeding sites". Для того, чтобы успокоить сервер, на начальной стадии Вы можете прописать холостой поток:
dummy-feed:!*::
Добавьте в .profileпользователя root пути поиска в новых каталогах:
PATH=$PATH:/usr/news/bin:/var/news
Для чтения руководств с помощью команды man, добавьте строку в файле /etc/manpath.config:
MANDATORY_MANPATH /usr/news/man
Поместите запуск демона innd в сценарий rc.local:
/usr/news/bin/rc.news > /dev/console
Проверьте наличие строки
DOINNWATCH=true
в файле rc.news. Это позволит использовать утилиту innwatch.ctl, которая "гасит" сервер новостей, когда Ваш диск переполнился и предотвращает крушение системы.
Перезагрузите машину и проверьте, работает ли демон innd. Во-первых, должен быть соответствующий процесс, запущенный пользователем news:
ps -U news | grep inn
Во-вторых, дав команду
telnet localhost nntp
Вы должны увидеть примерно следующее:
Trying 127.0.0.1 Connected to localhost.your.domain. Escape character is '^]'. 200 news.your.domain InterNetNews server INN 1.7.2 ready
Чтобы увидеть, какие команды понимает этот news-сервер, дайте команду help. Для возврата из сеанса telnet обратно в shell, дайте команду quit.
InterNet
Вы думаете, что если у Вас Internet-почта, то послать письмона другую машину с Internet-почтой всегда будет просто? Ну-ну!
хост1.домен1!хост2.домен2!...!хостN.доменN!юзер.
Письмо сначала зайдет на хост1, потом на хост2 и так далее,
пока не попадет юзеру на последнем хосте. Если хост указывается
без домена, то это, как правило, означает передачу по UUCP.
заставит письмо придти на хостN,... и наконец попадет юзеру
на хосте1.
Это необходимо в случае, когда письма по какой-либо причине напрямую
не доходят; а в обратной нотации ведентся запись пути следования письма.
Не советую смешивать прямую и обратную нотацию - протоколы не определяют
приоритет операций.
Еще в адресе используют знаки "^", ":" и некоторые другие; когда я точно выясню, что они значат, сообщу "городу и миру". :-)