Работа с информацией Анализ информационных систем Войны в информационных системах Информационные системы - Общество Источники информации - методы Информационные системы - методы Информационные системы - Интернет Информационные системы - Искусственный интеллект Информационные системы - обработка информации Информационные системы в офисе Информационные системы - управление Управление информационными системами Экономика информационных систем Информационные системы - технологии Технологии информационных систем Информационные системы - теория Информационные системы - почта Информационные системы - пакет Outlook |

|
ПРОЕКТИРОВАНИЕ И РАЗРАБОТКА ИНФОРМАЦИОННЫХ СИСТЕМ
Агрегатные функции и результаты запросов
Агрегатные функции (в стандарте SQL/89 они называются функциями над множествами) определяются в SQL/89 следующими синтаксическими правилами:Как видно из этих правил, в стандарте SQL/89 определены пять стандартных агрегатных функций: COUNT - число строк или значений, MAX - максимальное значение, MIN - минимальное значение, SUM - суммарное значение и AVG - среднее значение.
API
(Application Program Interface) - в данном контексте это спецификация, определяющая правила обмена данными между сервером и программным модулем, который должен быть включен в состав сервера.Архитектура современных информационно-поисковых систем World Wide Web
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения, рассмотрим типовую схему такой системы (рисунок 5.7). В различных публикациях, посвященных конкретным системам, приводятся схемы, которые отличаются друг от друга только применением конкретных программных решений, но не принципом организации различных компонентов системы.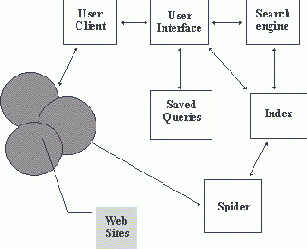
Рис. 5.7. Структура ИПС для Internet(Budi Yuwono, Dik L.Lee. Search and Ranking Algorims for Locating Resources on the World Wide Web)
На этой схеме обозначены:
ARP
Ассоциативной связи
каждый экземпляр связи (ассоциативный объект) может существовать только при условии существования определенных экземп-ляров каждой из взаимосвязанных сущностей. Ассоциативный объект - объект, являющийся одновременно сущностью и связью. Ассоциативная связь - это связь между несколькими "независимыми" сущностями и одной "зависимой" сущностью. Связь между независимыми сущ-ностями имеет атрибуты, которые определяются в зависимой сущности. Таким образом, зависимая сущность определяется в терминах атрибутов связи между остальными сущностями.В примере на рисунке 4.24 самолет выполняет посадку на взлетную полосу в заданное время при оп-ределенной скорости и направлении ветра. Поскольку эти характеристики при-менимы только к конкретной посадке, они являются атрибутами посадки, а не самолета или взлетной полосы. Пилот, выполняющий посадку, связан гораздо сильнее с конкретной посадкой, чем с самолетом или взлетной полосой.
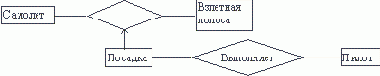
Рис. 4.24. Ассоциативная связь
Первичный ключ каждого типа сущности помечается звездочкой (*).
ER-диаграмма должна подчиняться следующим правилам:
Атрибут
- любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Атрибут представляет тип характеристик или свойств, ассоциированных со множеством реальных или абстрактных объектов (людей, мест, событий, состояний, идей, пар предметов и т.д.). Экземпляр атрибута - это определенная характеристика отдельного элемента множества. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Таким образом, экземпляр сущности должен обладать единственным определенным значением для ассоциированного атрибута.Атрибут может быть либо обязательным, либо необязательным (рисунок 4.6). Обязательность означает, что атрибут не может принимать неопределенных значений (null values). Атрибут может быть либо описательным (т.е. обычным дескриптором сущности), либо входить в состав уникального идентификатора (первичного ключа).
AT&T GIS
Решение компании направлено на решение проблем корпораций, у которых одинаково сильны потребности и в системах поддержки принятия решений, и в системах оперативной аналитической обработки данных. Предлагаемая архитектура называется Enterprise Information Factory и основывается на опыте использования системы управления базами данных Teradata и связанных с ней методах параллельной обработки.База данных World Wide Web или Website
- набор страниц базы данных World Wide Web. При более подробном рассмотрении Website - это вся совокупность данных и программного обеспечения, обеспечивающая отображение страниц информационной базы данных World Wide Web.Если страница Website представляет из себя обычный файл в стандарте HTML, то тогда говорят об элементарном или стандартном элементе хранения. В этом случае URL указывает непосредственно на этот файл и сервер просто отправляет его в ответ на запрос пользователя.
Многие страницы содержат внутри себя контейнеры-формы, которые служат для передачи информации от программы клиента программе-серверу. В рамках данного рассмотрения эти страницы выделены в особую группу страниц World Wide Web.
Базовая архитектура сервера баз данных
Типичный сервер баз данных отвечает за выполнение следующих функций:Базовые средства построения ИС в архитектуре "клиент-сервер"
Применительно к системам баз данных архитектура "клиент-сервер" интересна и актуальна главным образом потому, что обеспечивает простое и относительно дешевое решение проблемы коллективного доступа к базам данных в локальной сети. В некотором роде системы баз данных, основанные на архитектуре "клиент-сервер", являются приближением к распределенным системам баз данных, конечно, существенно упрощенным приближением, но зато не требующим решения основного набора проблем действительно распределенных баз данных.Реальное распространение архитектуры "клиент-сервер" стало возможным благодаря развитию и широкому внедрению в практику концепции открытых систем. Поэтому мы начнем с краткого введения в открытые системы.
Основным смыслом подхода открытых систем является упрощение комплексирования вычислительных систем за счет международной и национальной стандартизации аппаратных и программных интерфейсов. Главной побудительной причиной развития концепции открытых систем явились повсеместный переход к использованию локальных компьютерных сетей и необходимость решения проблем комплексирования аппаратно-программных средств, которые вызвал этот переход. В связи с бурным развитием технологий глобальных коммуникаций открытые системы приобретают еще большее значение и масштабность.
Ключевой фразой открытых систем, направленной в сторону пользователей, является независимость от конкретного поставщика. Ориентируясь на продукцию компаний, придерживающихся стандартов открытых систем, потребитель, который приобретает любой продукт такой компании, не попадает к ней в рабство. Он может продолжить наращивание мощности своей системы путем приобретения продуктов любой другой компании, соблюдающей стандарты. Причем это касается как аппаратных, так и программных средств и не является необоснованной декларацией. Реальная возможность независимости от поставщика проверена в отечественных условиях.
Практической опорой системных и прикладных программных средств открытых систем является стандартизованная операционная система.
В настоящее время такой системой является UNIX. Фирмам-поставщикам различных вариантов ОС UNIX в результате длительной работы удалось придти к соглашению об основных стандартах этой операционной системы. Сейчас все распространенные версии UNIX в основном совместимы по части интерфейсов, предоставляемых прикладным (а в большинстве случаев и системным) программистам. Как кажется, несмотря на появление претендующей на стандарт системы Windows NT, именно UNIX останется основой открытых систем в ближайшие годы.
Технологии и стандарты открытых систем обеспечивают реальную и проверенную практикой возможность производства системных и прикладных программных средств со свойствами мобильности (portability) и интероперабельности (interoperability). Свойство мобильности означает сравнительную простоту переноса программной системы в широком спектре аппаратно-программных средств, соответствующих стандартам. Интероперабельность означает возможность упрощения комплексирования новых программных систем на основе использования готовых компонентов со стандартными интерфейсами.
Использование подхода открытых систем выгодно и производителям, и пользователям. Прежде всего открытые системы обеспечивают естественное решение проблемы поколений аппаратных и программных средств. Производители таких средств не вынуждаются решать все проблемы заново; они могут, по крайней мере, временно продолжать комплексировать системы, используя существующие компоненты.
Заметим, что при этом возникает новый уровень конкуренции. Все производители обязаны обеспечить некоторую стандартную среду, но вынуждены добиваться как можно лучшей ее реализации. Конечно, через какое-то время существующие стандарты начнут играть роль сдерживания прогресса, и тогда их придется пересматривать.
Преимуществом для пользователей является то, что они могут постепенно заменять компоненты системы на более совершенные, не утрачивая работоспособности системы. В частности, в этом кроется решение проблемы постепенного наращивания вычислительных, информационных и других мощностей компьютерной системы.
Безопасность, Java и Intranet
Раз уж затронули проблему безопасности, то следует назвать безопасность программирования на Java другим важным свойством этой технологии. Речь конечно идет не о личной безопасности, а о том, что программы, написанные на Java, являются безопасными. Дело в том, что многие источники проблем безопасности системы, связанные с программированием, как то: переполнение строковых массивов, адресная арифметика, отведение и освобождение памяти и т.п. в Java контролируются системой. Нельзя использовать метод (процедуру), если параметры ее вызова не совпадают с объявленными при ее описании. При этом длина передаваемых строк будет проверяться либо при компиляции, если речь идет о константах, либо на шаге исполнения.При этом в угоду безопасности была даже урезана сетевая компонента системы. При программировании на Java можно получать данные и апплеты только с той машины, с которой был загружен выполняемый applet. Это серьезное препятствие на пути построения действительно распределенных вычислительных систем, тем более, что это ограничение обходится путем использования proxy-серверов (серверов-посредников), которые через себя способны транслировать запросы к информационным ресурсам, поддерживаемым другими серверами.
Данное ограничение обнажило действительную сферу применения Java - системы Intranet. Термин "Intranet" появился в начале 1995 года. Его появление было вызвано необходимостью обозначить сферу применения новой технологии компании Sun Microsystems - Java. Однако, часто он толкуется гораздо шире, чем область применения Java-приложений или Java-апплетов. Очень быстро об Intranet стали говорить как о применении информационных технологий Internet для создания внутрикорпоративных систем. Но это также не дает ответа на вопрос, вынесенный в заглавие раздела. Не претендуя на истину в последней инстанции, попробуем понять, что имеется в виду когда говорят об Intranet.
Введя в употребление термин "Intranet", Sun Microsystems стремилась придать своей новой технологии Java налет революционности.
В течении 1996 года Java не сходила со страниц компьютерных изданий. Но постепенно стало расти понимание того, что Intranet - это не только Java, а гораздо более емкое понятие.
В то же самое время Sun заговорила о своей системе защиты от несанкционированного доступа Sunscreen как о компоненте Intranet-технологии. Sunscreen к технологии Java никакого отношения не имеет. Общим является только то, что Java - это, в данном контексте, среда безопасного программирования, и Sunscreen средство обеспечения безопасности.
Конечно, Sunscreen не единственное средство, назначение которого - защита локальной сети от непрошенных гостей. В настоящее время, согласно данным, опубликованным Эдвином Маером (Edwin Mier) в Network World, существует около двух десятков межсетевых экранов, которые используются для защиты локальных сетей. Из них наиболее удачными являются (по данным того же автора):
К слову сказать, последние две системы сертифицированы Гостехкомиссией России и могут на законном основании применяться в наших условиях.
Но межсетевые фильтры используются не только для защиты локальной сети, но и для организации виртуальных локальных сетей поверх публичных сетей. Обычно такое решение называют Virtual Private Network.
Очень похожее решение предлагает и компания CISCO, только называется оно VirtualLocal Area Network (VLAN). Используя маршрутизаторы и/или коммутаторы этой компании можно в рамках одной организации построить на базе ее опорной сети передачи данных несколько виртуальных локальных сетей подразделений. При этом каждую из этих сетей можно защитить.
Однако, защита сетей и организация виртуальных сетей - это тоже не весь Intranet. Производители Систем Управления Базами Данных также заявили, что они производят смычку своих технологий с Intranet-технологией. Informix заявил о добавлении средств Web-bludes к своим продуктам, а Oracle просто выпустил свой собственный Web-сервер. Такая активность производителей СУБД понятна. Раз уж речь идет о корпоративной информационной системе, то такой системы не бывает без баз данных.
И при упоминании Java, и при разговоре о СУБД постоянно появляется слово "Web". Действительно, в рамках технологии Intranet все технологические решения так или иначе вращаются либо вокруг сервера протокола HTTP (HyperText Transfer Protocol), либо вокруг программы-браузера документов World Wide Web. Таким образом, технология World Wide Web занимает центральное место в Inranet.
Однако, так ли уж устойчива эта конструкция? В рамках небольших компаний у Intranet-решений, выполненных с использованием Web-технологии, есть серьезные конкуренты в лице семейства продуктов Microsoft и Lotus. Очень часто приходится слышать вопрос: "Чем же все-таки Intranet лучше существующих корпоративных информационных систем?". Ответ на этот вопрос не так уж и очевиден.
На поверхности лежит только одно преимущество - единый интерфейс ко всем информационным ресурсам. Собственно, когда Тим Бернерс-Ли (Tim Berners Lee) предлагал руководству международного центра физики высоких энергий (CERN, Швейцария) свой проект "Гипертекст для CERN", который превратился в итоге во Всемирную паутину (World Wide Web), главной задачей называлась разработка единого простого интерфейса доступа к разнообразным информационным ресурсам Центра. Фактически, это была первая Intranet-система, только в то время ее так не называли.
Таким образом, Intranet - это решение, ориентированное на пользователей информационных систем, а не на их разработчиков. Количество программ, написанных в этой технологии будет не меньше того, что пишется, скажем, в рамках технологий Microsoft.
Есть правда одно смутное предположение, что система, выполненная с опорой на Web, будет лучше переноситься с одной платформы на другую. На мой взгляд это иллюзия. Переносимость здесь такая же, как при переходе с одной реляционной СУБД на другую. Данные можно перенести без особых хлопот, а вот ПО придется переписать или, в лучшем случае, перетранслировать. Не помогут здесь и мобильные коды Java, т.к. обычно переход сопровождается изменением части базового программного обеспечения, что требует перепрограммирования сопряжений частей общей системы.
Можно сказать больше. Там где структура информационных потоков хорошо известна и для этой структуры имеются готовые решения городить огород Intranet вообще не имеет смысла. Особенно это касается сетей никак не связанных с Internet. В этом случае даже достоинство единого интерфейса не выглядит достаточно убедительным. Другое дело, когда пользователь ищет информацию не только в корпоративной базе данных, но во всем множестве ресурсов Internet. В этом случае единый интерфейс сразу показывает все свои достоинства.
Программирование в Intranet и для Intranet - это другая сторона вопроса. Какие собственно задачи должны решаться за счет создания программ Intranet. Как считают в компании Silicon Graphics, Intranet - это клей, связывающий различные технологические решения. Такая точка зрения базируется на том, что практически все элементы Web-технологии позволяют решать достаточно широкий класс задач без использования дополнительного ПО. Так, проблемы разработки интерфейса решаются средствами языка гипертекстовой разметки HTML, передача информации по сети - это забота протокола обмена гипертекстовой информацией HTTP, адрес ресурса в сети определен в спецификации CGI (Common Gateway Interface) и т. п. Разработчик системы будет писать программы, которые будут передавать данные от Web-сервера поисковой машине или серверу СУБД, или какой-либо другой внешней компоненте системы. При этом спецификации обмена данными также стандартизованы.
Это заставляет обратить внимание еще на одну группу средств, связанных с проблематикой Intranet - средства разработки. Задача этих средств - облегчить создание программного обеспечения для Intranet.
Именно к этой группе и относятся интегрированные средства разработки Java-приложений. Собственно место Java в Intranet можно схематично показать в виде связей между отдельными компонентами, составляющими Intranet систему (рисунок 5.8).
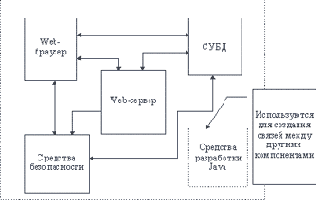
Рис. 5.8. Место Java среди компонентов Intranet
На рисунке 5.8 не отображены другие источники информации, которые обычно входят в Intranet-системы, например, системы электронной почты, средства коллективной работы и т. п. Но, во-первых, эти системы можно реализовать и в рамках Web-технологии, а во-вторых, для их создания также можно использовать Java. Однако, пока мощь Java в качестве клея еще недостаточна для серьезного обсуждения. Единственный Java-пакет (набор инструментов: описания классов и методов работы с ними), который годится на эту роль - это пакет net, но там, кроме нижнего уровня обмена данными в сетях TCP/IP и обмена по http, пока еще ничего не реализовано. Действительно неплохо выполнен в Java пакет awt, который существенно облегчает разработку интерфейса пользователя, и здесь со всей очевидностью проступает тот факт, что первоначально Java не предназначалась для работы в Internet.
Библиотеки доступа к базам данных
Библиотеки доступа к серверам приложений удобно применять для адаптации файл-серверных приложений, построенных на системах программирования типа Clipper или Clarion.Система управления записями Clarion достаточно легко связывается с сервером баз данных Btrieve через библиотеку доступа. Нужно только заметить, что Btrieve не является SQL-сервером БД, что затрудняет программирование с использованием этого средства.
Приложения, построенные на Clipper, можно адаптировать с помощью программного интерфейса с выбранным сервером БД. Для примера рассмотрим библиотеку интерфейса Clipper-Oracle.
Интерфейс реализован в виде библиотеки функций, доступных для их использования в прикладных программах, написанных на языке Clipper, и выполняющих все необходимые операции над базой данных Oracle. Функции написаны на языках Clipper и Си.
С помощью функций этой библиотеки можно выполнять следующие операции над таблицами базы данных системы Oracle:
В то же время для всех этих операций (кроме обработки транзакций) имеются соответствующие аналоги в системе Clipper, и все операции с базой данных системы Clipper могут быть реализованы с помощью функций предлагаемой библиотеки.
Кроме того, существует возможность прямого использования языка SQL, который является основным языком обработки данных не только в системе Oracle, но и в большинстве других развитых СУБД.
Версия языка SQL, реализованная в Oracle, ориентирована на стандарт этого языка и содержит ряд ограничений. Например, оператор Fetch позволяет перемещаться по результирующей таблице только в одном направлении, исключая возвраты назад.
Функции библиотеки снимают эти ограничения.
С помощью функций библиотеки можно обрабатывать таблицы Oracle всех типов, в том числе виртуальные таблицы, кластеризованные таблицы, таблицы с индексами и без индексов. При этом обеспечивается преобразование форматов данных Oracle в форматы данных Clipper и наоборот.
Единицей обмена между прикладной программой и базой данных является строка таблицы, которая с точки зрения Clipper является массивом. Каждый элемент массива соответствует одному полю таблицы. Аналогично представляются ключи и поля поиска.
В состав библиотеки входят следующие функции:
INIT () подключение к Oracle; OPEN () открытие таблицы; INSERT () добавление строки; UPDATE () корректировка строки; DELETE () удаление строки; SELECT () поиск строки; NEXT () чтение следующей строки; SET () чтение строки по относительному номеру; SKIP () пропуск строк; FILTER () выбор строк по условию; GETIND () сохранение индекса; SETIND () установка индекса; COMMIT () конец транзакции; SAVE () установка контрольной точки; ROLL () откат транзакции; LOCK () блокировка таблицы; SQL () выполнение оператора SQL; CLOSE () закрытие таблицы; STOP () отключение от Oracle.
Предлагаемые функции не препятствуют использованию собственных средств управления данными Clipper, что позволяет совместно обрабатывать разнородные базы данных. Так, в качестве центральной может использоваться база данных Oracle на большой, мини- или персональной ЭВМ, а в качестве локальной может использоваться база данных Clipper на персональном компьютере пользователя.
В состав интерфейсных средств включен специальный модуль для автономной отладки прикладных программ без системы Oracle. Этот модуль выполняет все функции интерфейса на DBF-файлах, что позволяет разрабатывать и полностью отлаживать программы, используя только систему Clipper на обычном персональном компьютере. Кроме того, эта возможность позволяет разрабатывать прикладные программы сразу в двух вариантах - сетевом и автономном.
Такой подход позволяет сохранить ранее разработанное и внедренное программное обеспечение, обеспечить преемственность при разработке новых прикладных систем, поддержать единую технологию программирования.
Более сложные элементы ER-модели
Мы остановились только на самых основных и наиболее очевидных понятиях ER-модели данных. К числу более сложных элементов модели относятся следующие:Эти и другие более сложные элементы модели данных "Сущность-Связи" делают ее существенно более мощной, но одновременно несколько усложняют ее использование. Конечно, при реальном использовании ER-диаграмм для проектирования баз данных необходимо ознакомиться со всеми возможностями.
В нашей лекции мы немного подробнее разберем только один из упомянутых элементов - подтип сущности.
Сущность может быть расщеплена на два или более взаимно исключающих подтипа, каждый из которых включает общие атрибуты и/или связи. Эти общие атрибуты и/или связи явно определяются один раз на более высоком уровне. В подтипах могут определяться собственные атрибуты и/или связи. В принципе подтипизация может продолжаться на более низких уровнях, но опыт показывает, что в большинстве случаев оказывается достаточно двух-трех уровней.
Сущность, на основе которой определяются подтипы, называется супертипом. Подтипы должны образовывать полное множество, т.е. любой экземпляр супертипа должен относиться к некоторому подтипу. Иногда для полноты приходится определять дополнительный подтип ПРОЧИЕ.
Пример: Супертип ЛЕТАТЕЛЬНЫЙ АППАРАТ
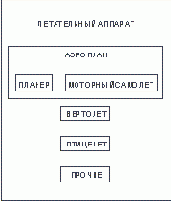
Как полагается это читать? От супертипа: ЛЕТАТЕЛЬНЫЙ АППАРАТ, который должен быть АЭРОПЛАНОМ, ВЕРТОЛЕТОМ, ПТИЦЕЛЕТОМ или ДРУГИМ ЛЕТАТЕЛЬНЫМ АППАРАТОМ. От подтипа: ВЕРТОЛЕТ, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА. От подтипа, который является одновременно супертипа: АЭРОПЛАН, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА и должен быть ПЛАНЕРОМ или МОТОРНЫМ САМОЛЕТОМ.
Иногда удобно иметь два или более разных разбиения сущности на подтипы. Например, сущность ЧЕЛОВЕК может быть разбита на подтипы по профессиональному признаку (ПРОГРАММИСТ, ДОЯРКА и т.д.), а может - по половому признаку (МУЖЧИНА, ЖЕНЩИНА).
BPM - Business Process Modeler
) позволяет моделировать функционирование обследуемой организации или создаваемой информационной системы. В модуле BPM обеспечена возможность работы с моделями большой сложности: автоматическая перенумерация, работа с деревом процессов (включая визуальное перетаскивание ветвей), отсоединение и присоединение частей модели для коллективной разработки. Диаграммы могут изображаться в нескольких предопределенных нотациях, включая Yourdon/DeMarco и Gane/Sarson. Имеется также возможность создавать собственные нотации, в том числе добавлять в число изображаемых на схеме дескрипторов определенные пользователем поля.Модуль концептуального моделирования данных (
BPwin
- средство функционального моделирования, реализующее методологию IDEF0.Возможные конфигурации и ориентировочная стоимость средств (без технической поддержки) приведены в таблице.
CASE.Аналитик
1.1 является практически единственным в настоящее время конкурентоспособным отечественным CASE-средством функционального моделирования и реализует построение диаграмм потоков данных. Его основные функции:Среда функционирования: процессор - 386 и выше, основная память - 4 Мб, дисковая память - 5 Мб, MS Windows 3.x или Windows 95.
Ориентировочная стоимость:
База данных проекта реализована в формате СУБД Paradox и является открытой для доступа.
С помощью отдельного программного продукта (Catherine) выполняется обмен данными с CASE-средством ERwin. При этом из проекта, выполненного в CASE.Аналитике, экспортируется описание структур данных и накопителей данных, которое по определенным правилам формирует описание сущностей и их атрибутов.
Case-метод Баркера
Нотация ER-диаграммы была впервые введена П. Ченом (Chen) и получила дальнейшее развитие в работах Баркера. Метод Баркера будет излагаться на примере предметной области компании по торговле автомобилями. Ниже приведены выдержки из интервью, проведенного с персоналом компании.Главный менеджер: одна из основных обязанностей - содержание автомобильного имущества. Он должен знать, сколько заплачено за машины и каковы накладные расходы. Обладая этой информацией, он может установить нижнюю цену, за которую мог бы продать данный экземпляр. Кроме того, он несет ответственность за продавцов и ему нужно знать, кто что продает и сколько машин продал каждый из них.
Продавец: ему нужно знать, какую цену запрашивать и какова нижняя цена, за которую можно совершить сделку. Кроме того, ему нужна основная информация о машинах: год выпуска, марка, модель и т.п.
Администратор: его задача сводится к составлению контрактов, для чего нужна информация о покупателе, автомашине и продавце, поскольку именно контракты приносят продавцам вознаграждения за продажи.
Первый шаг моделирования - извлечение информации из интервью и выделение сущностей.
CASE-системы для проектирования информационных систем
Современные CASE-средства охватывают обширную область поддержки многочисленных технологий проектирования информационных систем: от простых средств анализа и документирования до полномасштабных средств автоматизации, покрывающих весь жизненный цикл программного обеспечения.Наиболее трудоемкими этапами разработки информационных систем являются этапы анализа и проектирования, в процессе которых CASE-средства обеспечивают качество прини-маемых технических решений и подготовку проектной документации. При этом большую роль играют методы визуального представления информации. Это предполагает построение структурных или иных диа-грамм в реальном масштабе времени, использование многообразной цветовой палитры, сквозную проверку синтаксических правил. Графические средства моделирования предметной области позволяют разработчикам в наглядном виде изучать существующую информационную систему, перестраивать ее в соответствии с поставленными целями и имеющимися ограничениями.
Назад | Содержание | Вперед
CCI
(Common Client Interface) - спецификация обмена данными меду прикладной программой и браузером Mosaic. В случае применения программного обеспечения, выполненного согласно CCI, браузер превращается в сервер-посредник для программного обеспечения пользователя.CGI
(Common Gateway Interface) - спецификация на формат обмена данными между сервером протокола HTTP и прикладной программой.Часть Глобально распределенные информационные системы
В мире существует громадное количество готовых к использованию информационно-вычислительных ресурсов. Они создавались в разное время, для их разработки использовались разные подходы. Почти всегда при разработке новой информационной системы можно найти подходящие по своим функциям уже работающие готовые компоненты. Проблема состоит в том, что при их создании не учитывались требования интероперабельности. Эти компоненты не понимают один другого, они не могут работать совместно. Желательно иметь механизм или набор механизмов, которые позволят сделать такие независимо разработанные информационно-вычислительные ресурсы интероперабельными.Первым шагом на пути решения проблемы интеграции информационных ресурсов была попытка создать средства, позволяющие интегрировать набор разнородных баз данных (иерархических, сетевых, реляционных и т.д.). Такие средства должны были обеспечить возможность работы с неоднородными базами данных в единой концептуальной модели данных. Известные нам подходы основывались на использовании в качестве единой модели реляционной модели данных. (Заметим, что такие решения коренным образом отличаются от решения склада данных. Здесь речь идет об интегрированной распределенной базе данных, которая состоит из разнородных автономно обслуживаемых компонентов.)
Нужно отметить, что несмотря на высокий уровень проработки системы управления интегрированными распределенными неоднородными базами данных так и не вышли за пределы академических экспериментов. Видимо, это связано с целым рядом причин, основной из которых, по нашему мнению, является то, что реляционная модель данных слишком ограничена, чтобы ее можно было использовать в качестве единой концептуальной модели.
Тем не менее, проблема интеграции остается очень актуальной, и в последние годы все большее число специалистов соглашаются с тем, что ее можно и нужно решать на основе объектно-ориентированного подхода.
Часть Информационные приложения, основанные на использовании "складов данных" (DataWarehousing)
В этой части мы рассмотрим вопросы организации специального класса информационных приложений, ориентированных не на оперативную обработку транзакций (On-Line Transaction Processing - OLTP), а на оперативную аналитическую обработку (On-Line Analitical Processing - OLAP). У этих двух разновидностей систем принципиально разные задачи. Корпоративные информационные OLTP-системы создаются для того, чтобы способствовать повседневной деятельности корпорации, и опираются на актуальные для текущего момента данные. OLAP-системы служат для анализа деятельности корпорации или ее компонентов и прогнозирования будущего состояния. Для этого требуется использовать многочисленные накопленные данные о деятельности корпорации в прошлом, а также внешние источники данных, формирующие контекст, в котором работала корпорация.Система оперативной аналитической обработки данных отличается от статической системы поддержки принятия решений (Decision Support System - DSS) тем, что OLAP-система позволяет аналитику динамически формировать класс вопросов, который требуется для решаемой им текущей аналитической задачи. DSS обеспечивает выдачу отчетов в соответствии с заранее сформулированными правилами. Для удовлетворения нового запроса нужно формально его описать, запрограммировать и только потом выполнить.
Тематика OLAP-систем очень широка и специальна. Мы не будем обсуждать соответствующие вопросы на глубоком уровне, а в основном (и тоже не очень глубоко) сосредоточимся на проблемах обеспечения OLAP-системы данными. Мы будем говорить о складах данных (Datawarehouse).
Эта часть курса главным образом основана на статьях А. Сахарова, опубликованных в журнале "СУБД" (номера 3 и 4 за 1996 г.), а также на книге Harjinder Gill и Prakash Rao "The Official Guide to Data Warehousing" (Que Corporation, 1996 г.).
Часть Общая классификация архитектур информационных приложений
В первой части курса мы кратко рассмотрели основные требования, которым должна удовлетворять информационная система, и задачи, которые должны решаться такой системой. При этом мы постоянно подчеркивали, что строгость соблюдения требований и фиксированность набора решаемых задач во многом являются условными в зависимости от конкретных целей, для достижения которых разрабатывается прикладная информационная система. Соответственно, проектирование и разработка информационной системы может базироваться на разных архитектурных решениях.В этой части курса приводится классификация возможных архитектур информационных систем. Мы начинаем с традиционных архитектурных решений, основанных на использовании выделенных файл-серверов или серверов баз данных. Затем рассматриваются варианты архитектур корпоративных информационных систем, базирующихся на технологии Internet (Intranet-приложения). Следующая разновидность архитектуры информационной системы основывается на концепции "склада данных" (DataWarehouse) - интегрированной информационной среды, включающей разнородные информационные ресурсы. Наконец, последняя выделяемая нами архитектура предназначена для построения глобальных распределенных информационных приложений с интеграцией информационно-вычислительных компонентов на основе объектно-ориентированного подхода.
Замечание по поводу терминологии. С терминологией в области информационных систем вообще, а русскоязычной терминологией в особенности дела обстоят неважно. Область информационных систем очень быстро развивается. Практически каждый год возникают новые технологии и архитектурные решения, для которых в маркетинговых целях придумываются оригинальные, привлекающие внимание названия, далеко не всегда точно отражающие смысл технологии и/или архитектуры. На самом деле, все подходы к организации информационных систем, рассматриваемые в этом курсе базируются на общей архитектуре "клиент-сервер". Различие состоит только в том, что делают клиенты и серверы. Тем не менее, чтобы не запутать читателя, далее мы вынуждены применять русскоязычные эквиваленты соответствующих англоязычных терминов.
Следует заметить, что как и любая классификация, наша классификация архитектур информационных систем не является абсолютно жесткой. В архитектуре любой конкретной информационной системы часто можно найти влияния нескольких общих архитектурных решений. Тем не менее, при архитектурном проектировании системы кажется полезным иметь хотя бы частично ортогонализированный архитектурный базис. В следующих частях курса мы подробно рассмотрим особенности каждой архитектуры и остановимся на методологиях и инструментально-технологических средствах, поддерживающих проектирование и разработку информационных систем в соответствующей архитектуре.
Часть Общее представление об информационной системе
В уже достаточно долгой истории компьютерной индустрии (скоро будем отмечать 50-летний юбилей) всегда можно было выделить два основных направления: вычисления, а также накопление и обработка информации. Как известно, возникновение компьютеров главным образом стимулировалось необходимостью проведения массивных расчетов для создания ядерного оружия и ракетной техники. Объемы требуемых вычислений просто не позволяли произвести их в приемлемое время традиционным коллективом расчетчиков. Итак, первыми пользователями компьютеров и разработчиками компьютерных программ стали вычислительные математики. До сих пор многие представители старшего поколения программистов предпочитают называть себя математиками, даже если в последние 20-30 лет им не приходилось написать хотя бы одну вычислительную программу, не говоря уже о разработке методов и алгоритмов компьютерных вычислений.Однако, почти сразу на появление компьютеров обратили внимание бизнесмены. Как правило, в гражданском бизнесе не требуются массивные расчеты за исключением таких отраслей как, например, авиа- или автомобилестроение. В более распространенных видах гражданского бизнеса (банковское дело, биржевые операции, системы резервирования билетов или мест в гостиницах) основной проблемой всегда являлись объемы информации, которую необходимо собирать, надежно хранить и оперативно обрабатывать. Появление информационных систем, основным назначением которых является решение отмеченной проблемы, явилось ответом компьютерной индустрии на требования мира бизнеса.
В этой вводной части курса будет введено общее представление о сути понятия "информационная система". Основной целью является формулировка понятийной основы, на которой будет базироваться более конкретный материал следующих частей. Часть состоит из четырех разделов. В первом разделе определяются общие специфические черты класса программных систем, которые можно отнести к информационным системам. Второй раздел посвящен рассмотрению типовых задач, для решения которых используются информационные системы. В третьем разделе обсуждаются типичные проблемы, с которыми приходится сталкиваться при проектировании, разработке и сопровождении информационных систем. Наконец, в четвертом разделе анализируются требования к техническим средствам, на основе которых разумно строить информационную систему.
Часть Прогнозы на будущее (вместо заключения)
В начале курса мы уже говорили о том, что используемая в нем классификация подходов к разработке информационных систем является весьма условной. В любой сложной информационной системе на самом деле применяется некоторая смесь технологий.Видимо, в будущем эта тенденция не только сохранится, но и будет усиливаться. Можно ожидать появления инструментальных средств и методологий, которые будут явно поддерживать такой смешанный стиль разработки.
Конечно, будут появляться и принципиально новые технологии (хотя обычно в компьютерном мире все новое оказывается хорошо забытым старым). Какими будут эти новые технологии - покажет будущее.
Назад | Содержание
Часть Средства и методологии проектирования,разработки и сопровождения файл-серверных приложений
Как мы уже отмечали, по поводу файл-серверных приложений имеется значительная путаница в терминологии. В этом курсе мы будем называть файл-серверной информационной системой систему, которая в основном базируется на персональных компьютерах, используя в качестве внешней поддержки один или несколько файловых серверов, обеспечивающих значительные возможности управления внешней памятью, но не обладающих "интеллектом", поддерживая в основном только управление файлами. Практически во всех файл-серверных средствах и методологиях имеется тенденция к переходу к технологии "клиент-сервер". Выражая только свое личное мнение, заметим, что файл-серверные архитектуры являются в большой степени облегченными вариантами клиент-серверных архитектур "для бедных", хотя во многих случаях предлагаемые решения являются достаточными для небольшого по объему класса информационных систем.Как мы отмечали в разделе 2.3, Intranet-приложение - это корпоративная система, для организации которой используются механизмы Internet. Intranet-система может основываться на локальной сети компьютеров, собственной корпоративной глобальной сети или виртуальной корпоративной подсети Internet. Различают несколько типов Intranet-систем, для реализации каждого из которых, вообще говоря, применяются разные средства:
Конечно, в общем случае информационная Intranet-система может включать свойства каждого из перечисленных типов, и в этом случае при ее разработке придется учитывать все требования.
Естественно, эта часть курса не может заменить развернутого изложения принципов построения, администрирования и сопровождения Intranet-систем. Эта тема очень широка, и мы только бегло рассмотрим некоторые ее аспекты.
51
Четвертая нормальная форма
Рассмотрим пример следующей схемы отношения:ПРОЕКТЫ (ПРО_НОМЕР,ПРО_СОТР, ПРО_ЗАДАН)
Отношение ПРОЕКТЫ содержит номера проектов, для каждого проекта список сотрудников, которые могут выполнять проект, и список заданий, предусматриваемых проектом. Сотрудники могут участвовать в нескольких проектах, и разные проекты могут включать одинаковые задания.
Каждый кортеж отношения связывает некоторый проект с сотрудником, участвующим в этом проекте, и заданием, который сотрудник выполняет в рамках данного проекта (мы предполагаем, что любой сотрудник, участвующий в проекте, выполняет все задания, предусмотренные этим проектом). По причине сформулированных выше условий единственным возможным ключом отношения является составной атрибут ПРО_НОМЕР, ПРО_СОТР, ПРО_ЗАДАН, и нет никаких других детерминантов. Следовательно, отношение ПРОЕКТЫ находится в BCNF. Но при этом оно обладает недостатками: если, например, некоторый сотрудник присоединяется к данному проекту, необходимо вставить в отношение ПРОЕКТЫ столько кортежей, сколько заданий в нем предусмотрено.
Content-Length
. Поле Content-Length указывает размер (количество байтов) передаваемого ресурса. Это поле указывается как клиентом при работе по методу POST, так и сервером при ответе на запросы клиентов. При этом в ранних версиях программ-серверов может порождаться ошибка, вызванная возможностью вставки сервером некоторой информации в текст ресурса. Например, сервер NCSA (1.3) позволяет вставлять в текст HTML-документов фрагменты текста из других файлов при помощи выражения типа:[an error occurred while processing this directive]
В данном случае речь идет об общей заставке для всех документов некоторого раздела. На сервере в директории документов хранится файл одного размера, но после выполнения подстановки размер файла увеличивается, однако, сервер сообщает клиенту старый размер файла. Новые программы-клиенты (Netscape, Mosaic) неправильно обрабатывают такой ответ и информация не отображается.
Поле Content-Type определяет тип информации, передаваемой сервером. Наиболее часто используются типы text/play - простой тест и text/html - документ в формате HTML. Для сокращения трафика по сети существует несколько полей, связанных со временем передачи информации и периодичностью ее изменения на серверах. Поле Date определяет время отправки сообщения. Информация из данного поля сохраняется в файле статистики сервера и может быть использована для анализа доступа к ресурсам сервера из сети.
Поле Expires определяет время годности ресурса для использования. Если время использования вышло, то ресурс не должен передаваться. Точнее, его не следует передавать и принимать. О поле if-Modified-Sience уже упоминалось. Оно предназначено для того, чтобы не передавать имеющиеся у клиента копии ресурса, если не были произведены его изменения. Поле Pragma используется при передаче сообщений с сервера на сервер. Реально известно только одно значение данного поля: no-cache, которое запрещает запоминать в буфере данные для последующего использования.
Поле Referer используется для того, чтобы указать, из какого ресурса была осуществлена ссылка на ресурс. Данное поле - это мечта любого администратора базы данных сети. При помощи информации из этого поля можно определить, в каких WWW-страницах прописан конкретный сервер. От этого зависит количество обращений к серверу, "качество" пользователей, время отклика на информацию, размещаемую на сервере. При необходимости можно связаться с администратором этого сервера и уведомить его об изменениях на вашем сервере.
Денормализация для оптимизации
В этом подразделе мы только наметим тему обсуждения. Если еще раз внимательно посмотреть на шаги процесса построения хорошей нормализованной схемы реляционной базы данных, то можно заметить, что на каждом шаге нормализации порождаются потенциальные соединения отношений. Для некоторых приложений это несущественно, для других - критично. Известно, что если для выполнения запроса к базе данных требуется выполнить десять соединений, то ни один из современных серверов баз данных не обеспечивает умеренное время ответа.Поэтому иногда приходится жертвовать идеями и работать с недостаточно нормализованной схемой БД. Конечно, при работе с такой схемой могут возникать аномалии изменений, но с ними можно бороться другими способами, например, с помощью триггеров.
Назад | Содержание | Вперед
Designer/ + Developer/
CASE-средство Designer/2000 2.0 фирмы ORACLE является интегрированным CASE-средством, обеспечивающим в совокупности со средствами разработки приложений Developer/2000 поддержку полного жизненного цикла программного обеспечения для систем, использующих СУБД ORACLE.Структура и функции
Designer/2000 представляет собой семейство методологий и поддержи-вающих их программных продуктов. Базовая методология Designer/2000 (CASE*Method) - структурная методология проектирования систем, полностью охватывающая все этапы жизненного цикла информационной систем. В соответствии с этой методологией на этапе планирования определяются цели создания системы, приоритеты и ограничения, разрабатывается системная архитектура и план разработки информационной системы. В процессе анализа строятся модель информационных потребностей (диаграмма "сущность-связь"), диаграмма функциональной иерархии (на основе функциональной декомпозиции информационной системы), матрица перекрестных ссылок и диаграмма потоков данных.
На этапе проектирования разрабатывается подробная архитектура информационной системы, проектируется схема реляционной БД и программные модули, устанавливаются перекрестные ссылки между компонентами информационной системы для анализа их взаимного влияния и контроля за изменениями.
На этапе реализации создается БД, строятся прикладные системы, производится их тестирование, проверка качества и соответствия требованиям пользователей. Создается системная документация, материалы для обучения и ру-ководства пользователей. На этапах эксплуатации и сопровождения анализируются производи-тельность и целостность системы, выполняется поддержка и, при необходимости, модификация информационной системы.
Designer/2000 обеспечивает графический интерфейс при разработке различных моделей (диаграмм) предметной области. В процессе построения моделей информация о них заносится в репозиторий. В состав Designer/2000 входят следующие компоненты:
Помимо продуктов ORACLE, генерация и реинжиниринг БД может выполняться для СУБД Informix, DB/2, Microsoft SQL Server, Sybase, а также для стандарта ANSI SQL DDL и баз данных, доступ к которым реализуется посредством ODBC;
Репозиторий Designer/2000 представляет собой хранилище всех проектных данных и может работать в многопользовательском режиме, обеспечивая па-раллельное обновление информации несколькими раз-работчиками. В процессе проектирования автоматически поддерживаются пере-крестные ссылки между объектами словаря и могут генерироваться более 70 стандартных отчетов о моделируемой предметной области. Физическая среда хранения репозитория - база данных ORACLE.
Генерация приложений, помимо продуктов ORACLE, выполняется также для Visual Basic.
Взаимодействие с другими средствами
Designer/2000 можно интегрировать с другими средствами, используя открытый интерфейс приложений API (Application Programming Interface). Кроме того, можно использовать средство ORACLE CASE Exchange для экспорта/импорта объектов репозитория с целью обмена информацией с другими CASE-средствами.
Developer/2000 обеспечивает разработку переносимых приложений, работающих в графической среде Windows, Macintosh или Motif. В среде Windows интеграция приложений Developer/2000 с другими средствами реализуется через механизм OLE и управляющие элементы VBX. Взаимодействие приложений с другими СУБД (DB/2, DB2/400, Rdb) реализуется с помощью средств ORACLE Client Adapter для ODBC, ORACLE Open Gateway и API.
Среда функционирования
Среда функ-ционирования Designer/2000 и Developer/2000 - Windows 3.x, Windows 95, Windows NT.
Диаграммное представление
Далее мы кратко рассмотрим некоторые черты одной из наиболее популярных семантических моделей данных - модель "Сущность-Связи" (часто ее называют кратко ER-моделью).На использовании разновидностей ER-модели основано большинство современных подходов к проектированию баз данных (главным образом, реляционных). Модель была предложена Ченом (Chen) в 1976 г. Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов. В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных баз данных. Среди множества разновидностей ER-моделей одна из наиболее развитых применяется в системе CASE фирмы ORACLE. Ее мы и рассмотрим. Более точно, мы сосредоточимся на структурной части этой модели.
Динамический SQL в стандарте SQL/
Описанный в стандарте SQL/89 набор операторов SQL предназначен для встраивания в программу на обычном языке программирования. Поэтому в этом наборе перемешаны операторы "истинного" реляционного языка запросов (например, оператор удаления из таблицы части строк, удовлетворяющих заданному значению) и операторы работы с курсорами, позволяющими обеспечить построчный доступ к таблице-результату запроса.Понятно, что в диалоговом режиме набор операторов SQL и их синтаксис должен быть несколько другим. Весь вопрос состоит в том, как реализовывать такую диалоговую программу. Правила встраивания стандартного SQL в программу на обычном языке программирования предусматривают, что вся информация, касающаяся операторов SQL, известна в статике (за исключением значений переменных, используемых в качестве констант в операторах SQL). Не предусмотрены стандартные средства компиляции с последующим выполнением операторов, которые становятся известными только во время выполнения (например, вводятся с терминала). Поэтому, опираясь только на стандарт SQL/89, невозможно реализовать диалоговый монитор взаимодействия с БД на языке SQL или другую прикладную программу, в которой текст операторов SQL возникает во время выполнения, т.е. фактически так или иначе стандарт необходимо расширять.
Один из возможных путей расширения состоит в использовании специальной группы операторов, обеспечивающих динамическую компиляцию (во время выполнения прикладной программы) базового подмножества операторов SQL и поддерживающих их корректное выполнение. Некоторый набор таких операторов входил в диалект SQL, реализованный в System R, а в новом стандарте SQL/92 появилась стандартная версия динамического SQL.
ERwin
- средство концептуального моделирования БД, использующее методологию IDEF1X. ERwin реализует проектирование схемы БД, генерацию ее описания на языке целевой СУБД (ORACLE, Informix, Ingres, Sybase, DB/2, Microsoft SQL Server, Progress и др.) и реинжиниринг существующей БД. ERwin выпускается в нескольких различных конфигурациях, ориентированных на наиболее распространенные средства разработки приложений 4GL. Версия ERwin/OPEN полностью совместима со средствами разработки приложений PowerBuilder и SQLWindows и позволяет экспортировать описание спроектированной БД непосредственно в репозитории данных средств.Для ряда средств разработки приложений (PowerBuilder, SQLWindows, Delphi, Visual Basic) выполняется генерация форм и прототипов приложений.
Сетевая версия Erwin ModelMart обеспечивает согласованное проектирование БД и приложений в рамках рабочей группы.
ERX - Entity-Relationship eXpert
) обеспечивает построение моделей данных "сущность-связь", не привязанных к конкретной реализации. Этот модуль имеет встроенную экспертную систему, позволяющую создать корректную нормализованную модель данных посредством ответов на содержательные вопросы о взаимосвязи данных. Возможно автоматическое построение модели данных из описаний структур данных. Анализ функциональных зависимостей атрибутов дает возможность проверить соответствие модели требованиям третьей нормальной формы и обеспечить их выполнение. Проверенная модель передается в модуль RDM.Модуль реляционного моделирования (
Файл-серверные приложения
По всей видимости, организация информационных систем на основе использования выделенных файл-серверов все еще является наиболее распространенной в связи с наличием большого количества персональных компьютеров разного уровня развитости и сравнительной дешевизны связывания PC в локальные сети. Чем привлекает такая организация не очень опытных в области системного программирования разработчиков информационных систем? Скорее всего, тем, что при опоре на файл-серверные архитектуры сохраняется автономность прикладного (и большей части системного) программного обеспечения, работающего на каждой PC сети. Фактически, компоненты информационной системы, выполняемые на разных PC, взаимодействуют только за счет наличия общего хранилища файлов, которое хранится на файл-сервере. В классическом случае в каждой PC дублируются не только прикладные программы, но и средства управления базами данных. Файл-сервер представляет собой разделяемое всеми PC комплекса расширение дисковой памяти (рисунок 2.1).Не останавливаясь подробно на имеющихся на сегодняшнем рынке перспективных инструментальных средствах разработки файл-серверных приложений и не приводя анализа тенденций развития соответствующих технологий (этому посвящается третья часть курса), мы кратко перечислим основные достоинства и недостатки файл-серверных архитектур.
Конечно, основным достоинством является простота организации. Проектировщики и разработчики информационной системы находятся в привычных и комфортных условиях IBM PC в среде MS-DOS, Windows или какого-либо облегченного варианта Windows NT. Имеются удобные и развитые средства разработки графического пользовательского интерфейса, простые в использовании средства разработки систем баз данных и/или СУБД. Но во многом эта простота является кажущейся. (Как гласит русская пословица, "Простота хуже воровства", а здесь мы, как правило, имеем простоту на основе воровства программных продуктов для PC.)
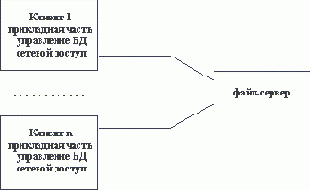
Рис. 2.1. Классическое представление информационной системы в архитектуре "файл-сервер"
Во-первых, информационной системе предстоит работать с базой данных. Следовательно, эта база данных должна быть спроектирована. Почему-то часто разработчики файл-серверных приложений считают, что по причине простоты средств управления базами данных проблемой проектирования базы данных можно пренебречь. Конечно, это неправильно. База данных есть база данных. Чем качественнее она спроектирована, тем больше шансов впоследствии эффективно использовать информационную систему. Естественно, сложность проектирования базы данных определяется объективной сложностью моделируемой предметной области. Но, собственно, из чего должно следовать, что файл-серверные приложения пригодны только в простых предметных областях?
Во-вторых, как мы неоднократно подчеркивали в первой части курса, необходимыми требованиями к базе данных информационной системы являются поддержание ее целостного состояния и гарантированная надежность хранения информации. Минимальными условиями, при соблюдении которых можно удовлетворить эти требования, являются:
В принципе, файл-серверная организация, как она показана на рисунке 2.1, не противоречит соблюдению отмеченных условий. В качестве примера системы, соблюдающей выполнение этих условий, но основанной на файл-серверной архитектуре, можно привести популярный в прошлом "сервер баз данных" Informix SE.
Длинноезамечание:
Для сохранения четкости дальнейшего изложения нам необходимо несколько уточнить терминологию. Мы недаром написали "сервер баз данных" в кавычках применительно к СУБД Informix SE. При использовании этой системы копия программного обеспечения СУБД поддерживалась для каждого инициированного пользователем сеанса работы с СУБД. Грубо говоря, для каждого пользовательского процесса, взаимодействующего с базой данных создавался служебный процесс СУБД, который выполнялся на том же процессоре, что и пользовательский процесс (т.е.
на стороне клиента). Каждый из этих служебных процессов вел себя фактически так, как если бы был единственным представителем СУБД. Вся синхронизация возможной параллельной работы с базой данных производилась на уровне файлов внешней памяти, содержащих базу данных. Условимся впредь называть такие СУБД не серверами баз данных, а системами управления базами данных, основанными на файл-серверной архитектуре (СУБД-ФС).
Под истинным сервером баз данных мы будем понимать программное образование, привязанное к соответствующей базе (базам) данных, существующее, вообще говоря, независимо от существования пользовательских (клиентских) процессов и выполняемое, вообще говоря (хотя и не обязательно) на выделенной аппаратуре (мы намеренно используем не очень конкретные термины "программное образование" и "выделенная аппаратура", потому что их конкретное воплощение различается в разных серверах баз данных).
Истинные серверы баз данных существенно сложнее по организации, чем СУБД-ФС, на зато обеспечивают более тонкое и эффективное управление базами данных. Везде далее в этом курсе при употреблении термина "сервер баз данных" мы будем иметь в виду истинные серверы баз данных.
Но с другой стороны, в большинстве персональных СУБД эти условия не выполняются даже с помощью грубых приемов. В лучшем случае удается частично восполнить недостатки на уровне прикладных программ.
В третьих, интерфейс развитых серверов баз данных основан на использовании высокоуровневого языка баз данных SQL, что позволяет использовать сетевой трафик между клиентом и сервером баз данных только в полезных целях (от клиента к серверу в основном пересылаются операторы языка SQL, от сервера к клиенту - результаты выполнения операторов). В файл-серверной организации клиент работает с удаленными файлами, что вызывает существенную перегрузку трафика (поскольку СУБД-ФС работает на стороне клиента, то для выборки полезных данных в общем случае необходимо просмотреть на стороне клиента весь соответствующий файл целиком).
В целом, в файл-серверной архитектуре мы имеем "толстого" клиента и очень "тонкий" сервер в том смысле, что почти вся работа выполняется на стороне клиента, а от сервера требуется только достаточная емкость дисковой памяти (рисунок 2.2).

Рис. 2.2. "Толстый" клиент и "тонкий" сервер в файл-серверной архитектуре
Краткие выводы. Простое, работающее с небольшими объемами информации и рассчитанное на применение в однопользовательском режиме, файл-серверное приложение можно спроектировать, разработать и отладить очень быстро. Очень часто для небольшой компании для ведения, например, кадрового учета достаточно иметь изолированную систему, работающую на отдельно стоящем PC. Конечно, и в этом случае требуется большая аккуратность конечных пользователей (или администраторов, наличие которых в этом случае сомнительно) для надежного хранения и поддержания целостного состояния данных. Однако, в уже ненамного более сложных случаях (например, при организации информационной системы поддержки проекта, выполняемого группой) файл-серверные архитектуры становятся недостаточными.
Физическое проектирование баз данных
Как мы отмечали в разделе 4.4, основная часть проблем физического проектирования баз данных в большой степени зависит от особенностей используемого сервера баз данных. В частности, это относится к планированию размещения в дисковой памяти различных частей базы данных: таблиц, индексов, BLOB'ов, журналов и т.д. Соответствующие рекомендации обычно содержатся в руководстве администратора используемой системы.Но можно, тем не менее, выделить некоторые общие соображения, которые осмысленны вне зависимости от деталей реализации сервера. Прежде всего это касается индексов. Понятно, что чем больше индексов существует над таблицами базы данных, тем более вероятным будет выполнение запросов по выборке данных и тем медленнее будут выполняться операции модификации базы данных.
В большинстве систем индекс создается автоматически для каждого определенного в таблице первичного, возможного и внешнего ключа. Здесь никуда не денешься: потребность в определении ключей следует из семантики предметной области, а для поддержания и использования ключей СУБД нуждается в соответствующих индексах. Но вот что касается дополнительных индексов, вводимых для целей более эффективного выполнения запросов, то с ними нужно быть очень аккуратным. Требуется тщательный предварительный анализ наиболее важного набора запросов (к сожалению далеко не всегда это возможно). Нужно также отдавать себе отчет в том, что создание нового индекса для большой заполненной таблицы - это серьезная дорогостоящая операция (как правило, СУБД выполняет сортировку строк таблицы в соответствии со значением ключевого атрибута).
Далее, хотя в языке SQL и в большинстве его реализаций допускается динамическое изменение реляционной схемы базы данных, не все такие изменения выполняются дешево и безопасно. Дешево и безопасно можно создать новую таблицу с набором индексов и добавить столбец к существующей заполненной таблице. Дорого и опасно уничтожается большая заполненная таблица или ее отдельный столбец. (Опасно в том смысле, что, как правило, соответствующие операции не журнализуются.)
Форма запроса клиента
Программа-клиент посылает после установления соединения запрос серверу. Этот запрос может быть в двух формах: в форме полного запроса и в форме простого запроса. Простой запрос содержит метод доступа и запрос ресурса. Например:GET http://polyn.net.kiae.su/
В этой записи слово GET обозначает метод доступа GET, а http://polyn.net.kiae.su/ - это запрос ресурса. Клиенты, которые способны поддерживать версии протокола выше 0.9 должны пользоваться полной формой запроса. При использовании полной формы в запросе указываются строка запроса, несколько заголовков (заголовок запроса или общий заголовок) и, возможно, тело обозначения ресурса. В форме Бекуса-Наура общий вид полного запроса выглядит так:
<Полный запрос> := <Строка Запроса> (<Общий заголовок> <Заголовок запроса> <Заголовок обозначения ресурса>)<символ новой строки>[<тело ресурса>]
Квадратные скобки здесь обозначают необязательные элементы заголовка. Строка запроса - это, практически, простой запрос ресурса. Отличие состоит в том, что в строке запроса можно указывать различные методы доступа и за запросом ресурса следует указывать версию протокола. Например, для вызова внешней программы можно использовать следующую строку запроса:
POST http://polyn.net.kiae.su/cgi-bin/test HTTP/1.0
В данном случае используется метод POST и протокол версии 1.0.
Формы
впервые были подробно описаны в инструкциях по использованию сервера NCSA. До введения форм в WWW был только один механизм передачи параметров - поле ключевых слов. WWW была информационно-справочной системой и только. Формы произвели революцию в технологии WWW и превратили ее в технологию открытой системы. Посредством форм стала возможна передача параметров внешним программам, которые вызываются сервером, что сделало WWW универсальным интерфейсом ко всем ресурсам сети.Формы реализуются с помощью элемента FORM и ряда вложенных в него элементов:
FTP-серверы
FTP-архивы являются одним из основных информационных ресурсов Internet. Фактически, это распределенный депозитарий текстов, программ, фильмов, фотографий, аудио записей и прочей информации, хранящейся в виде файлов на различных компьютерах во всем мире.FTP
Функциональные и прочие зависимости
В этом разделе рассматривается классический подход, при котором весь процесс проектирования производится в терминах реляционной модели данных методом последовательных приближений к удовлетворительному набору схем отношений. Исходной точкой является представление предметной области в виде одного или нескольких отношений, и на каждом шаге проектирования производится некоторый набор схем отношений, обладающих лучшими свойствами. Процесс проектирования представляет собой процесс нормализации схем отношений причем каждая следующая нормальная форма обладает свойствами лучшими, чем предыдущая.Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной форме, если удовлетворяет свойственному ей набору ограничений. Примером набора ограничений является ограничение первой нормальной формы - значения всех атрибутов отношения атомарны. Поскольку требование первой нормальной формы является базовым требованием классической реляционной модели данных, мы будем считать, что исходный набор отношений уже соответствует этому требованию.
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм: первая нормальная форма (1NF); вторая нормальная форма (2NF); третья нормальная форма (3NF); нормальная форма Бойса-Кодда (BCNF); четвертая нормальная форма (4NF); пятая нормальная форма, или нормальная форма проекции-соединения (5NF или PJ/NF).
Основные свойства нормальных форм:
В основе процесса проектирования лежит метод нормализации, декомпозиция отношения, находящегося в предыдущей нормальной форме, в два или более отношения, удовлетворяющих требованиям следующей нормальной формы.
Наиболее важные на практике нормальные формы отношений основываются на фундаментальном в теории реляционных баз данных понятии функциональной зависимости. Для дальнейшего изложения нам потребуются несколько определений. (Заметим, что везде ниже под термином "атрибут X (Y, Z, ...)", вообще говоря, понимается некоторое подмножество атрибутов отношения, или "составной" атрибут.)
ПРОЕКТИРОВАНИЕ И РАЗРАБОТКА ИНФОРМАЦИОННЫХ СИСТЕМ
- метод, позволяющий получить данные, заданные в форме URI в запросе ресурса. Если ссылаются на программу, то возвращается результат выполнения этой программы, но не текст программы. Дополнительные данные, которые надо передать для обработки, кодируются в запрос ресурса. Имеется разновидность метода GET - условный GET. При использовании этого метода сервер ответит на запрос только в том случае, если будут выполнены условия передачи. Это позволяет разгрузить сеть, избавив ее от передачи ненужной информации. Условие указывается в полеHEAD
- метод, аналогичный GET, но не возвращает тела ресурса. Используется для получения информации о ресурсе. Условного HEAD не существует. Данный метод используется для тестирования гипертекстовых ссылок.Help
. Автоматическая идентификация пользователей осуществляется при помощи файла /etc/passwd. Пароль пользователя не должен быть пустым.Существует специальный файл, в котором содержатся запрещенные пользователи, т.е. те, кому обслуживание по протоколу FTP запрещено. Возможен вход в архив по идентификатору пользователя anonymous или ftp. В этом случае сервер принимает меры по ограничению доступа к ресурсам компьютера для данного пользователя. Обычно для таких пользователей создается специальная директория ftp, в которой размещают каталоги bin, etc и pub. В каталоге bin размещаются команды, разрешенные для использования, а в каталоге pub собственно сами файлы. Каталог etc закрыт для просмотра пользователем и в нем размещены файлы идентификации пользователей.
В ряде случаев в директории pub создают каталог incoming. Этот каталог предназначен для того, чтобы пользователь мог записать в этот каталог свои программы или любые другие файлы. Однако, это довольно небезобидная, с точки зрения безопасности, операция.
В директорию bin обычно записывается только одна команда ls. Данная команда позволяет выполнять просмотр текущей директории. Согласно правилам, анонимный пользователь должен иметь возможность выполнять только те команды, которые размещены в этой директории. Однако, в большинстве систем анонимный пользователь выполняет гораздо больший набор команд, при этом эти команды берутся из стандартных директорий системы. Способность этого пользователя создавать директории, удалять файлы и т.п. будет зависеть от прав, которые установлены администратором для той ветви, файловой системы, в которой располагается файловый архив FTP. Так, например, в Windows NT можно так назначить права, что при входе пользователя с консоли он сможет получить доступ к системе, а при доступе к своему архиву FTP пользователь таких прав не получает, точнее пользователь нормально идентифицируется и проходит аутентификацию, но после этого получает сообщение, что не обладает нужными правами для доступа к своей домашней директории.
При этом данная проблема в рамках программ настроек Internet Information Services не решается. Приходится использовать стандартные средства Windows, определяющие эти права.
Другую опасность для системы представляют ссылки. Многие администраторы полагают, что взлом системы - это ситуация, когда злоумышленник проник в систему, однако это не так. Например, в классификации CERT тяжелый взлом - это, в том числе и выявление структуры файловой системы. В этом случае атакующий получает информацию о предмете атаки и может сосредоточить свои усилия на каком-то отдельном фрагменте системы.
Если в директорию etc не скопировать файл passwd, то никто не сможет получить доступ к данным FTP-архива. Однако, часто копируют настоящий файл паролей. Этого делать не следует. Во всяком случае следует убедиться в том, что поле паролей в записях описания пользователей должно быть пустым. Клиент FTP только проверяет наличие пользователя и наличие у него пароля, а идентификация проводится стандартным для системы способом через программу
Hewlett Packard
Работы, связанные со складами данных, выполняются в рамках программы OpenWarehouse. Выполнение этой программы должно обеспечить возможность построения складов данных на основе мощных компьютеров HP, аппаратуры других производителей и программных компонентов. Основой подхода HP являются Unix-платформы и программный продукт Intelligent Warehouse, который предназначен для управления складами данных. Основа построения складов данных, предлагаемая HP, оставляет свободу выбора реляционной СУБД, средств реинжиниринга и т.д.HTML
(HyperText Markup Language) - язык гипертекстовой разметки документов. Специальная форма подготовки документов для их опубликования в World Wide Web.Любимыми примерами специалистов по гипертексту являются энциклопедии, Библия, системы типа "Help".
Простой, на первый взгляд, механизм построения ссылок оказывается довольно сложной задачей, т.к. можно построить статические ссылки, динамические ссылки, ассоциированные с документом в целом или только с отдельными его частями, т.е. контекстные ссылки. Дальнейшее развитие этого подхода приводит к расширению понятия гипертекста за счет других информационных ресурсов, включая графику, аудио- и видео-информацию, до понятия гипермедиа. Тем, кто интересуется более подробно различными схемами и способами разработки гипертекстовых систем, стоит обратиться к специальной литературе.
При разработке HTML была поставлена задача решить две основных проблемы:
Первая задача была решена за счет выбора таговой модели описания документа. Такая модель широко применяется в системах подготовки документов для печати. Примером такой системы является хорошо известный язык разметки научных документов TeX, предложенный Американским Математическим Обществом, и программы его интерпретации.
К моменту создания HTML существовал стандарт языка разметки печатных документов - Standard Generalised Markup Language, который и был взят в качестве основы HTML. Предполагалось, что такое решение поможет использовать существующее программное обеспечение для интерпретации нового языка. Однако, будучи доступным широкому кругу пользователей Internet, HTML зажил своей собственной жизнью. Вероятно, многие администраторы баз данных WWW и разработчики программного обеспечения для этой системы имеют довольно смутное представление о стандартном языке разметки SGML.
Вторым важным моментом, повлиявшим на судьбу HTML, стал выбор в качестве элемента гипертекстовой базы данных обычного текстового файла, который хранится средствами файловой системы операционной среды компьютера.
Такой выбор был сделан под влиянием следующих факторов:
Таким образом, гипертекстовая база данных в концепции WWW - это набор текстовых файлов, написанных на языке HTML, который определяет форму представления информации (разметка) и структуру связей этих файлов (гипертекстовые ссылки). Но это только концепция, в реальной жизни все оказалось гораздо сложнее. В ряде случаев реальная страница Website собирается из различных файлов, записей баз данных и результатов выполнения скриптов, но в любом случае браузер получает правильно размеченный на HTML текст.
Такой подход предполагает наличие еще одной компоненты технологии - интерпретатора языка. В World Wide Web функции интерпретатора разделены между сервером гипертекстовой базы данных и интерфейсом пользователя.
Сервер, кроме доступа к документам и обработки гипертекстовых ссылок, осуществляет также предпроцессорную обработку документов, в то время как интерфейс пользователя осуществляет интерпретацию конструкций языка, связанных с представлением информации.
К настоящему времени известна уже третья версия языка - HTML 3.2, которая находится в стадии развития. Если первая версия языка (HTML 1.0) была направлена на представление языка как такового, где описание его возможностей носило скорее рекомендательный характер, вторая версия языка (HTML 2.0) фиксировала практику использования конструкций языка, версия ++ (HTML++) представляла новые возможности, расширяя набор элементов HTML в сторону отображения научной информации и таблиц, а также улучшения стиля компоновки изображений и текста, то версия 3.2 призвана упорядочить все нововведения и согласовать их с существующей практикой.Кроме этого, в версии 3.2 снова делается попытка формализации интерфейса пользователя гипертекстовой распределенной системы. Однако, коммерческое использование World Wide Web постепенно вытесняет или сильно замедляет использование научных расширений языка. Так математическую разметку документа поддерживает только один браузер Arena.
Главным следствием влияния программного обеспечения на развитие языка, является включение в HTML механизма форм заполнения (FILL-OUT FORMS).
HTTP
(HyperText Transfer Protocol) - протокол обмена гипертекстовой информацией;HTTP - это протокол прикладного уровня, разработанный для обмена гипертекстовой информацией в сети Internet. Протокол используется одной из популярнейших систем Сети - Word Wide Web - с 1990 года.
Реальная информационная система требует гораздо большего количества функций, чем просто поиск. HTTP позволяет реализовать в рамках обмена данными набор методов доступа, базирующихся на спецификации универсального идентификатора ресурсов (Universal Resource Identifier), применяемого в форме универсального локатора ресурсов (Universe Resource Locator) или универсального имени ресурса (Universal Resource Name). Сообщения по сети при использовании протокола HTTP передаются в формате, схожим с форматом почтового сообщения Internet (RFC-822) или с форматом сообщений MIME (Multiperposal Internet Mail Exchange). HTTP используется для взаимодействия программ-клиентов с программами-шлюзами, разрешающими доступ к ресурсам электронной почты Internet (SMTP), спискам новостей (NNTP), файловым архивам (FTP), системам Gopher и WAIS. Протокол разработан для доступа к этим ресурсам посредством промежуточных программ-серверов (proxy), которые позволяют передавать информацию между различными информационными службами без потерь. Протокол реализует принцип "запрос/ответ". Запрашивающая программа - клиент - инициирует взаимодействие с отвечающей программой - сервером, и посылает запрос, включающий в себя метод доступа, адрес URI, версию протокола, похожее по форме на MIME-сообщение с модификаторами типа передаваемой информации, информацию клиента, и, возможно, тело сообщения клиента. Сервер отвечает строкой состояния, включающей версию протокола и код возврата, за которой следует сообщение в форме, похожей на MIME. Данное сообщение содержит информацию сервера, метаинформацию и тело сообщения. Понятно, что в принципе, одна и та же программа может выступать и в роли сервера и в роли клиента (так собственно и происходит при использовании proxy-серверов).
При работе в Internet для обслуживания HTTP-запросов используется 80 порт TCP/IP. Практика использования протокола такова, что клиент устанавливает соединение и ждет ответа сервера. После отправки ответа сервер инициирует разрыв соединения. Таким образом, при передаче сложных гипертекстовых страниц соединение может устанавливаться несколько раз. Остановимся более подробно на механизме взаимодействия и форме передаваемой информации.
ICMP
"If-Modified-Since"
заголовка запроса. При использовании метода GET в поле тела ресурса возвращается собственно затребованная информация (текст HTML-документа, например).поисковой системы. Он служит для
- индекс - это основной массив данных информационно- поисковой системы. Он служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.индексировщик служит для сканирования Internet
- робот- индексировщик служит для сканирования Internet и поддержки базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.Информационные ресурсы и их представление в информационно-поисковой системе
Как видно из схемы (рисунок 5.7) документальным массивом ИПС Internet является все множество документов шести основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet, статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных. Здесь есть и текстовая информация, и графическая информация, и аудио информация и вообще все, что есть в указанных выше хранилищах. Естественно встает вопрос, как информационно-поисковая система должна со всем этим работать. В традиционных системах есть понятие поискового образа документа - ПОД'а. ПОД (Поисковый Образ Документа)- это нечто, что заменяет собой документ и используется при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель, в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор, размерность которого равна числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия термина в ПОД'е документа или его отсутствия. В более сложных моделях термины взвешиваются, т.е. элемент вектора равен не 1 или 0, а некоторому числу, которое отражает соответствие данного термина документу. Именно последняя модель наиболее популярна в информационно-поисковых системах Internet. Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска, и модель поиска в нечетких множествах. Анализ преимуществ и недостатков применения этих моделей при реализации информационно-поисковых систем в Internet - это тема специального исследования. Здесь имеет смысл обратить внимание читателя только на то, что пока именно линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText, AliWeb и ряде других.Исследования по применению других моделей также ведутся, например, в рамках проекта AltaVista или научными группами. Таким образом, первая задача, которою должна решить информационно-поисковая система - это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов, в которых он встречается. Такая процедура является только частным случаем, а точнее техническим аспектом создания поискового аппарата информационно-поисковой системы.
Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы. Таким образом, все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако, на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе возможность такой процедуры в анархичном Internet, где ресурсы появляются и исчезают ежедневно. При создании программы Veronica для GopherSpace предполагалось, что все серверы должны быть зарегистрированы и таким образом велся учет наличия или отсутствия ресурса.
Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД'ов документов Gopher. В World Wide Web ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики. Разработка роботов - это довольно нетривиальная задача, т.к. существует опасность зацикливания робота или попадания на виртуальные страницы. Все системы имеют своего робота. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, какие термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. В настоящее время различные роботы используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки (title), заглавия (H1, H2 и т.п.), аннотации, списки ключевых слов и полные тексты документов, сообщения администраторов о своих Web-страницах. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков - поля Subject и Keywords. Наибольший простор для построения ПОД'ов дают HTML-документы. Однако не следует думать, что все термины из перечисленных выше элементов документов попадают в их поисковые образы. Очень активно используются списки запрещенных слов (stop-words), которые не могут быть использованы для индексирования, общих слов (предлоги, союзы и т.п.), а также часто производится нормализация лексики. Таким образом, даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с целым набором различных словарей, после которого термин попадает в поисковый образ документа, а потом и в индекс системы. Для того, чтобы не раздувать словарей и индексов, а индекс Lycos, например, равен 4TB, применяется такое понятие как "вес" термина. В документе обычно индексируется 40 - 100 наиболее "тяжелых" терминов.
После того, как ресурсы заиндексированы, т.е. система составила массив поисковых образов документов, начинается построение поискового аппарата системы. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД'ов займет много времени, что абсолютно не приемлемо для интерактивной системы, которой является Web. Для того, чтобы можно было быстро находить информацию в базе данных ПОД'ов строится индекс. Индекс в большинстве систем - система связанных между собой файлов, которая нацелена на быстрый поиск данных по запросу пользователя. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов. К этим факторам можно отнести и размер массива поисковых образов, и информационно-поисковый язык системы, и размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы. Этот проект выбран потому, что он позволяет реализовывать не только примитивный булевый поиск, но и контекстный поиск, взвешенный поиск и ряд других возможностей, которые отсутствуют во многих поисковых системах, например, Yahoo.
Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного списка (IL) и прямого списка (FL).
Page-ID отображает идентификаторы станиц в URL этих страниц, Keyword-ID отображает каждое ключевое слово в уникальный идентификатор этого слова, таблица заголовков отображает идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок отображает идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову список пар (номер документа, идентификатор страницы, позиция слова в странице), а прямой список - это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них, безусловно, является файл инвертированного списка. Результат поиска в этом файле - это объединение и/или пересечение списков идентификаторов страниц.
Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками, возвращается пользователю в его программу просмотра Web. Для того, чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, с этих пар начинающихся, а также применяется механизм прямого доступа к данным - хеширование.
Для обновления индекса применяется комбинация двух подходов. Первый можно назвать коррекцией индекса "на ходу". Для этого служит таблица модификации страниц. Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса, т.е. его перезагрузка.
Успех информационно-поисковой системы с точки зрения скорости поиска, определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является "секретом фирмы" и гордостью компании.
Informix Software
Стратегия компании в отношение складов данных направлена на расширение рынка для ее продукта On-Line Dinamic Parallel Server. Предлагаемая архитектура склада данных базируется на четырех технологиях: реляционные базы данных, программном обеспечении для управления складом данных, средствах доступа к данным и платформе открытых систем. Три последние компонента разрабатываются партнерами компании. После выхода Универсального Сервера, основанного на объектно-реляционном подходе, можно ожидать, что и он будет использоваться для построения складов данных.Интегрированные распределенные приложения
Нет никаких проблем, если с самого начала информационное приложение проектируется и разрабатывается в духе подхода открытых систем: все компоненты являются мобильными и интероперабельными, общее функционирование системы не зависит от конкретного местоположения компонентов, система обладает хорошими возможностями сопровождаемости и развития. К сожалению, на практике этот идеал является трудно достижимым. По разным причинам (мы перечислим некоторые из них ниже) возникают потребности в интеграции независимо и по-разному организованных информационно-вычислительных ресурсов. Видимо, ни в одной действительно серьезной распределенной информационной системе не удастся обойтись без применения некоторой технологии интеграции. К счастью, теперь существует путь решения этой проблемы, который сам лежит в русле открытых систем, - подход, предложенный крупнейшим международным консорциумом OMG (Object Management Group).Остановимся на некоторых факторах, стимулирующих использование методов интеграции разнородных информационных ресурсов (здесь используются материалы статьи Л.А.Калиниченко и др. из журнала "СУБД" N 4, 1995 г.).
При строгой интеграции неоднородных БД локальные системы БД утрачивают свою автономность. После включения локальной БД в федеративную систему все дальнейшие действия с ней, включая администрирование, должны вестись на глобальном уровне. Поскольку пользователи часто не соглашаются утрачивать локальную автономность, желая тем не менее иметь возможность работать со всеми локальными СУБД на одном языке и формулировать запросы с одновременным указанием разных локальных БД, развивается направление мульти-БД. В системах мульти-БД не поддерживается глобальная схема интегрированной БД и применяются специальные способы именования для доступа к объектам локальных БД. Как правило, в таких системах на глобальном уровне допускается только выборка данных. Это позволяет сохранить автономность локальных БД.
Как правило, интегрировать приходится неоднородные БД, распределенные в вычислительной сети. Это в значительной степени усложняет реализацию. Дополнительно к собственным проблемам интеграции приходится решать все проблемы, присущие распределенным СУБД: управление глобальными транзакциями, сетевую оптимизацию запросов и т.д. Очень трудно добиться эффективности. Как правило, для внешнего представления интегрированных и мульти-БД используется (иногда расширенная) реляционная модель данных. В последнее время все чаще предлагается использовать объектно-ориентированные модели, но на практике пока основой является реляционная модель. Поэтому, в частности, включение в интегрированную систему локальной реляционной СУБД существенно проще и эффективнее, чем включение СУБД, основанной на другой модели данных. Основным недостатком систем интеграции неоднородных баз данных является то, что при этом не учитываются "поведенческие" аспекты компонентов прикладной системы. Легко заметить, что даже при наличии развитой интеграционной системы, большинство из указанных выше проблем не решается. Естественным развитием взглядов на информационные ресурсы является их представление в виде набора типизированных объектов, сочетающих возможности сохранения информации (своего состояния) и обработки этой информации (за счет наличия хорошо определенного множества методов, применимых к объекту).
Наиболее существенный вклад в создание соответствующей технологии внес международный консорциум OMG, выпустивший ряд документов, в которых специфицируются архитектура и инструментальные средства поддержки распределенных информационных систем, интегрированных на основе общего объектно-ориентированного подхода.
В базовом документе специфицируется эталонная модель архитектуры (OMA - Object Management Architecture) распределенной информационной системы (рисунок 2.11).
Рис. 2.11. Эталонная модель OMA
Согласованная с архитектурой OMA прикладная информационная система представляется как совокупность классов и экземпляров объектов, которые взаимодействуют при поддержке брокера объектных заявок (ORB - Object Request Broker). ORB, общие средства (Common Facilities) и объектные службы (Object Services) относятся к категории промежуточного программного обеспечения (middleware) и должны поставляться вместе. Объектные службы представляют собой набор услуг (интерфейсов и объектов), которые обеспечивают выполнение базовых функций, требуемых для реализации прикладных объектов и объектов категории "общие средства" (например, специфицированы служба именования объектов, служба долговременного хранения объектов, служба управления транзакциями и т.д.). Общие средства содержат набор классов и экземпляров объектов, поддерживающих функции, полезные в разных прикладных областях (например, средства поддержки пользовательского интерфейса, средства управления информацией и т.д.).
В основе OMA лежит базовая объектная модель COM (Core Object Model), в которой специфицированы такие понятия, как объект, операция, тип, подтипизация, наследование, интерфейс. Определены также способы согласованного расширения COM в разных объектных службах.
Интерфейсы объекта-клиента и объекта-сервера должны быть определены на специальном языке IDL (Interface Definition Language), который очень напоминает компонент спецификации класса (без реализации) языка Си++. Обращения к ORB могут быть сгенерированы статически при компиляции спецификаций IDL или выполнены динамически с использованием специфицированного в документах OMG API брокера объектных заявок.
Правила построения и использования ORB определены в документе OMG CORBA (Common Object Request Broker Architecture).
В седьмой части курса мы рассмотрим более подробно все понятия, введенные в этом разделе.
Основным выводом из материала данного раздела является то, что проблемы интеграции неоднородных информационных ресурсов являются актуальными для корпораций и существуют технологии, позволяющие решать эти проблемы.
В заключение второй части курса повторим, что приведенная классификация методов и технологий не является ортогональной. В реальной жизни требуется использовать разумные сочетания технологических и архитектурных решений. Цель курса не состоит в том, чтобы выдать готовые рецепты построения информационной системы. Мы стремимся погрузить слушателей в мир информационных технологий с тем, чтобы впоследствии было проще ориентироваться в этом мире и понимать значение его сущностей.
Назад | Содержание | Вперед
Intranet-приложения
Возникновение и внедрение в широкую практику высокоуровневых служб Всемирной Сети Сетей Internet (e-mail, ftp, telnet, Gopher, WWW и т.д.) естественным образом повлияли на технологию создания корпоративных информационных систем, породив направление, известное теперь под названием Intranet. По сути дела, информационная Intranet-система - это корпоративная система, в которой используются методы и средства Internet. Такая система может быть локальной, изолированной от остального мира Internet, или опираться на виртуальную корпоративную подсеть Internet. В последнем случае особенно важны средства защиты информации от несанкционированного доступа. Возможности и проблемы безопасных информационных Intranet-систем мы рассмотрим в пятой части курса.Хотя в общем случае в Intranet-системе могут использоваться все возможные службы Internet, наибольшее внимание привлекает гипермедийная служба WWW (World Wide Web - Всемирная Паутина). Видимо, для этого имеются две основные причины. Во-первых, с использованием языка гипермедийной разметки документов HTML можно сравнительно просто разработать удобную для использования информационную структуру, которая в дальнейшем будет обслуживаться одним из готовых Web-серверов. Во-вторых, наличие нескольких готовых к использованию клиентских частей - браузеров, или "обходчиков" избавляет от необходимости создавать собственные интерфейсы с пользователями, предоставляя им удобные и развитые механизмы доступа к информации. В ряде случаев такая организация корпоративной информационной системы (рисунок 2.6) оказывается достаточной для удовлетворения потребностей компании.
Рис. 2.6. Простая организация Intranet-системы с использованием средств WWW
Однако, при всех своих преимуществах (простота организации, удобство использования, стандартность интерфейсов и т.д.) эта схема обладает сильными ограничениями. Прежде всего, как видно из рисунка 2.6, в информационной системе отсутствует прикладная обработка данных. Все, что может пользователь, это только просмотреть информацию, поддерживаемую Web-сервером.
Далее, гипертекстовые структуры трудно модифицируются. Для того, чтобы изменить наполнение Web-сервера, необходимо приостановить работу системы, внести изменения в HTML-описания и только затем продолжить нормальное функционирование. Наконец, далеко не всегда достаточен поиск информации в стиле просмотра гипертекста. Базы данных и соответствующие средства выборки данных по-прежнему часто необходимы.
На самом деле, все перечисленные трудности могут быть разрешены с использованием более развитых механизмов Web-технологии. Эти механизмы непрерывно совершенствуются, что одновременно и хорошо и плохо. Хорошо, потому что появляются новые возможности. Плохо, потому что отсутствует стандартизация.
Что касается логики приложения, то при применении Web-технологии существует возможность ее реализации на стороне Web-сервера. Для этого могут использоваться два подхода - CGI (Common Gateway Interface) и API (Application Programming Interface). Оба подхода основываются на наличии в языке HTML специальных конструкций, информирующих клиента-браузера, что ему следует послать Web-серверу специальное сообщение, при получении которого сервер должен вызвать соответствующую внешнюю процедуру, получить ее результаты и вернуть их клиенту в стандартном формате HTTP (рисунок 2.7).
Рис. 2.7. Вызов внешней процедуры Web-сервера
Более подробно различия между подходами CGI и API мы рассмотрим в пятой части курса, а пока лишь заметим, что подход CGI является более надежным (внешняя программа выполняется в отдельном адресном пространстве), но менее эффективным, чем подход API (в этом случае внешние процедуры компонуются совместно со стандартной частью Web-сервера).
Аналогичная техника широко используется для обеспечения унифицированного доступа к базам данных в Intranet-системах. Язык HTML позволяет вставлять в гипертекстовые документы формы. Когда браузер натыкается на форму, он предлагает пользователю заполнить ее, а затем посылает серверу сообщение, содержащее введенные параметры. Как правило, к форме приписывается некоторая внешняя процедура сервера.
При получении сообщения от клиента сервер вызывает эту внешнюю процедуру с передачей параметров пользователя. Понятно, что такая внешняя процедура может, в частности, играть роль шлюза между Web-сервером и сервером баз данных. В этом случае параметры должны специфицировать запрос пользователя к базе данных. В результате получается конфигурация информационной системы, схематически изображенная на рисунке 2.8.
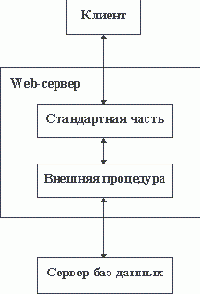
Рис. 2.8. Доступ к базе данных в Intranet-системе
Конечно, мы привели только грубую схему организации доступа к базам данных. Более детальное обсуждение содержится в пятой части курса.
На принципах использования внешних процедур основывается также возможность модификации документов, поддерживаемых Web-сервером, а также создание временных "виртуальных" HTML-страниц.
Даже начальное введение в Intranet было бы неполным, если не упомянуть про возможности языка Java. Java - это интерпретируемый объектно-ориентированный язык программирования, созданный на основе языка Си++ с удалением из него таких "опасных" средств как адресная арифметика. Мобильные коды (апплеты), полученные в результате компиляции Java-программы, могут быть привязаны в HTML-документу. В этом случае они поступают на сторону клиента вместе с документом и выполняются либо автоматически, либо по явному указанию. Апплет может быть, в частности, специализирован как шлюз к серверу баз данных (или к какому-либо другому серверу). При применении подобной техники доступа к базам данных схема организации Intranet-системы становится такой как на рисунке 2.9.
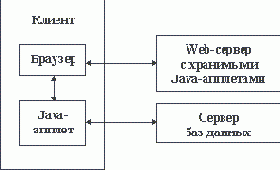
Рис. 2.9. Доступ к базе данных на стороне клиента Intranet-системы
На наш взгляд, Intranet является удобным и мощным средством разработки и использования информационных систем. Как мы уже отмечали, единственным относительным недостатком подхода можно считать постоянное изменение механизмов и естественное отсутствие стандартов. С другой стороны, если информационная система будет создана с использованием текущего уровня технологии и окажется удовлетворяющей потребностям корпорации, то никто не будет обязан что-либо менять в системе по причине появления более совершенных механизмов.
История и серверные продукты компании Informix
24 сентября 1996 г. компания Informix отметила десятилетие своей официальной деятельности. За эти годы компания увеличила объем своих доходов в 33 раза и уверенно занимает второе место на мировом рынке продуктов, связанных с управлением реляционными базами данных. С самого начала своего существования компания ориентировалась на создание серверов баз данных и сопутствующих программных продуктов, функционирующих в среде ОС Unix. В число основных стратегических партнеров Informix входят компании Sequent, Hewlett Parkard, Sun Microsystems, IBM, Siemens Nixdorf, NCR, для продуктов которых в первую очередь обеспечивается работоспособный вариант систем Informix. Помимо Unix-платформ продукты компании Informix могут работать в операционных средах DOS, NetWare, Windows и Windows NT.Характерной особенностью компании Informix является то, что она поддерживает, развивает и поставляет на рынок целое семейство серверов, отличающихся возможностями, эффективностью и, естественно, ценой. Все разновидности серверных продуктов Informix базируются на архитектуре "клиент-сервер" (мы приведем краткий обзор наиболее ярких представителей семейства).
Самым простым серверным продуктом является сервер баз данных Informix-SE. Он предназначен для использования в информационных системах со средним (или малым) объемом хранимой информации. Хранение данных поддерживается на уровне файловой системы, и на этом же уровне осуществляется синхронизация доступа со стороны параллельно выполняемых транзакций. На самом деле, в Informix-SE для каждой пользовательской транзакции образуется отдельный серверный процесс, и эти процессы взаимодействуют только при доступе к общим файлам базы данных. (Заметим, что это сильно напоминает организацию систем управления базами данных в файл-серверных архитектурах.)
Клиент и сервер могут располагаться в одном компьютере, но могут быть и разнесены на разные компьютеры, связанные сетью. Естественно, что при наличии выделенной аппаратуры, поддерживающей деятельность сервера, общая эффективность системы возрастает.
Связь между клиентами и серверами поддерживается специальным модулем Informix-NET.
Базовым продуктом компании Informix является система Informix-OnLine, выпускаемая ныне в двух основных модификациях - Informix-OnLine Dynamic Server и Informix-OnLine Extended Parallel Server. Эти серверы работают напрямую с дисковой памятью, обеспечивают выполнение транзакций в распределенной среде баз данных, поддерживают возможности хранения неструктурированных полей таблиц сверхбольшого размера BLOBs - Binary Large Objects и т.д.
Informix-OnLine Dynamic Server ориентирован на применение симметричных мультипроцессорных компьютеров и опирается на параллельное использование процессоров с общей основной памятью. Поэтому в этом сервере широко используются приемы программирования, основанные на использовании параллельных потоков управления, или нитей.
Informix-OnLine Extended Parallel Server может работать как в симметричных, так в несимметричных (sharing nothing) компьютерных архитектурах. При этом обещается наличие почти линейной масштабируемости при использовании несимметричных архитектур.
Видимо, наиболее существенным событием в жизни компании Informix в последние годы явилось приобретение компании Illustra и ее объектно-реляционной СУБД. (Бывший глава компании Illustra, бывший руководитель проектов Ingres и Postgres, профессор знаменитого Калифорнийского университета в г. Беркли Майкл Стоунбрейкер теперь является техническим директором Informix.) В течение последнего года компании удалось связать воедино технологии Informix и Illustra и выпустить серверный продукт, называемый Универсальным сервером (Universal Server). Он был объявлен в начале декабря 1996 г. В универсальном сервере компании Informix собраны вместе наиболее развитые средства Informix, Ingres и Postgres. Особенный интерес потенциальных пользователей универсального сервера вызывает возможность его развития за счет создания отдельно определяемых и реализуемых модулей, получивших название "datablades". В этих модулях содержится определение дополнительных типов данных, обеспечивающих, в частности, хранение произвольно сложной мультимедийной информации.Уже в течение 1996 г. было реализовано более 25 таких модулей. Как и в случае восьмой версии сервера компании Oracle, универсальный сервер компании Informix является существенным продвижением к реализации объектно-реляционного стандарта языка SQL-3.
Informix утверждает, что особенностью стратегии компании является полное отсутствие конкуренции с любым из своих потенциальных партнеров. В отличие от Oracle, Informix производит только базовые продукты, не навязывая своей технологии разработки информационных приложений (это мнение компании Informix, а не автора данного курса).
История и серверные продукты компании Oracle
Первая доступная заказчикам версия СУБД Oracle (Oracle V.2) была выпущена компанией Relational Software Inc. в 1979 г. Эта версия была ориентирована на использование в среде ОС RSX-11 для семейства миникомпьютеров PDP-11. Система была написана большей частью на языке ассемблера PDP-11, но включала также тексты на новом для того времени языке Си. СУБД могла функционировать не только в среде ОС RSX-11, но и в других операционных средах, поддерживаемых на PDP-11: IAS, RSTS и Unix. Тогда же было принято решение о переносе Oracle в 32-разрядную операционную среду VAX VMS, что на долгие годы определило судьбу СУБД Oracle как ведущей системы управления базами данных на миникомпьютерах.Наиболее сильное впечатление на пользователей Oracle производила возможность манипулирования базами данных на основе непроцедурного реляционного языка SQL, для которого в то время существовал только фирменный стандарт компании IBM. СУБД Oracle V.2 обладала ограниченными возможностями; в частности, в системе отсутствовали средства управления транзакциями, что заставляло пользователей постоянно прибегать к использованию утомительной процедуры резервного копирования.
СУБД Oracle V.3 была выпущена в свет в 1983 г. Она была полностью переписана на языке программирования Си, что в дальнейшем позволило решить проблему переноса системы на большое число аппаратно-программных платформ. Функции, доступные через SQL-интерфейс, были расширены. В обиход пользователей системы было введено понятие транзакции. В это же время компания Relational Software Inc. была переименована в Oracle Corp.
В 1985 г. на рынке появилась СУБД Oracle V.5. В этой системе использовалась архитектура "клиент-сервер" и впервые появилась возможность одновременного использования баз данных, расположенных в разных узлах сети.
Шестая версия системы представляла из себя инструмент построения корпоративных информационных приложений, выполняющихся в режиме OLTP. В системе были реализованы: система блокировок на уровне записей, а также механизм непротиворечивых чтений из базы данных без потребности блокировок.
СУБД Oracle V. 6 была перенесена на ряд новых платформ, в том числе, OS/2 и Macintosh.
Важными нововведениями шестой версии были появление процедурного языка программирования PL/SQL, который можно было использовать как для определения процедур, хранимых на сервере баз данных, так и для разработки приложений в составе языка четвертого поколения SQL*Forms. Кроме того, в реализованном варианте языка SQL появились средства определения ссылочной целостности (reference integrity), одного из наиболее фундаментальных механизмов поддержания целостности в реляционных базах данных.
Седьмой выпуск СУБД Oracle появился на рынке в середине 1994 г. Это один из наиболее серьезных серверных продуктов, предназначенных для управления реляционными базами данных. В Oracle V.7 используется ряд новых архитектурных решений, направленных для повышения эффективности сервера, в том числе буферизация откомпилированных SQL-операторов на сервере баз данных, использование общего пула серверных процессов и нитей для выполнения операторов SQL, поступающих от разных транзакций, использование разнообразной статистической информации для оптимизации запросов и т.д.
Существенно расширены возможности использования языка PL/SQL. В Oracle V.7 этот язык можно использовать для определения триггеров, хранимых процедур, вызываемых сервером автоматически при возникновении специфицированных событий (например, выполнении операций модификации таблицы в целом или обновлении конкретной строки таблицы). Функции PL/SQL могут вызываться как обычные встроенные функции в операторах SQL. Заметим, что относительным, но существенным недостатком языка PL/SQL является то, что он не входит в состав международного стандарта SQL, хотя, возможно это изменится в стандарте SQL-3.
В распределенном варианте Oracle V.7 поддерживаются возможности репликации данных и имеется возможность асинхронного вызова удаленных процедур.
В настоящее время ожидается выпуск восьмой версии системы, которая должна обладать целым рядом новых возможностей: встроенными средствами для использования в Internet/Intranet, поддержкой хранения мультимедийной информации, приближением реализованного варианта языка SQL к разрабатываемому стандарту языка SQL-3 и т.д.
История языка баз данных SQL
Язык для взаимодействия с БД SQL появился в середине 70-х и был разработан в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка SEQUEL (Structured English Query Language) только частично отражает суть этого языка. Конечно, язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционной БД, но на самом деле являлся полным языком БД, содержащим помимо операторов формулирования запросов и манипулирования БД средства определения и манипулирования схемой БД; определения ограничений целостности и триггеров; представлений БД; структур физического уровня, поддерживающих эффективное выполнение запросов; авторизации доступа к отношениям и их полям; точек сохранения транзакции и откатов. В языке отсутствовали средства синхронизации доступа к объектам БД со стороны параллельно выполняемых транзакций: с самого начала предполагалось, что необходимую синхронизацию неявно выполняет СУБД.В настоящее время SQL реализован практически во всех коммерческих реляционных СУБД, все фирмы провозглашают соответствие своей реализации стандарту SQL, и на самом деле реализованные диалекты SQL очень близки. Это произошло не сразу и не просто.
Наиболее близкими к System R являлись две системы фирмы IBM - SQL/DS и DB2. Как кажется (документальных подтверждений этому автор не имеет), обе эти системы прямо использовали реализацию System R. Отсюда предельная близость реализованных диалектов SQ к SQL System R. Из SQL System R были удалены только те части, которые были недостаточно проработаны (например, точки сохранения) или реализация которых вызывала слишком большие технические трудности (например, ограничения целостности и триггеры). Можно назвать этот путь к коммерческой реализации SQL движением сверху вниз.
Другой подход применялся в таких системах, как Oracle и Informix. Несмотря на различие в способе разработки этих систем, реализация SQL происходила "снизу вверх". В первых выпущенных на рынок реализациях SQL в этих системах использовалось минимальное и очень ограниченное подмножество SQL System R.
В частности, в первой известной автору реализации SQL в СУБД Oracle в операторах выборки не допускалось использование вложенных подзапросов.
Тем не менее, несмотря на эти ограничения и на очень слабую на первых порах эффективность, ориентация фирм на поддержание разных аппаратных платформ и заинтересованность пользователей в переходе к реляционным системам позволили фирмам добиться коммерческого успеха и приступить к совершенствованию своих реализаций. В текущих версиях Oracle и Informix поддерживаются достаточно мощные диалекты SQL, хотя реализация иногда вызывает сомнения.
Особенностью большинства современных коммерческих СУБД, затрудняющей анализ существующих диалектов SQL, является отсутствие полного описания языка. Обычно описание разбросано по разным руководствам и перемешано с описанием специфических для данной системы языковых средств, не имеющих отношения к SQL. Тем не менее можно сказать, что базовый набор операторов SQL, включающий операторы определения схемы БД, выборки и манипулирования данными, авторизации доступа к данным, поддержки встраивания SQL в языки программирования и операторы динамического SQL, в коммерческих реализациях относительно устоялся и более или менее соответствует стандарту.
JAM
Средство разработки приложений JAM (JYACC's Application Manager) - продукт фирмы JYACC (США). В настоящее время поставляется версия JAM 7 и готовится к выходу JAM 8.Основной чертой JAM является его соответствие методологии RAD, поскольку он позволяет достаточно быстро реализовать цикл разработки приложения, заключающийся в формировании очередной версии прототипа приложения с учетом требований, выявленных на предыдущем шаге, и предъявить его пользователю.
Структура и функции
JAM имеет модульную структуру и состоит из следующих компонент:
Ядро системы (собственно, сам JAM) является законченным продуктом и может самостоятельно использоваться для разработки приложений. Все остальные модули являются дополнительными и самостоятельно использоваться не могут.
Ядро системы включает в себя следующие основные компоненты:
При использовании JAM разработка внешнего интерфейса приложения представляет собой визуальное проектирование и сводится к созданию экранных форм путем размещения на них интерфейсных конструкций и определению экранных полей ввода/вывода информации. Проектирование интерфейса в JAM осуществляется с помощью редактора экранов. Приложения, разработанные в JAM, имеют многооконный интерфейс. Разработка отдельного экрана заключается в размещении на нем интерфейсных элементов, возможной (но не обязательной) их группировке и конкретизации различных их свойств, включающих визуальные характеристики (позиция, размер, цвет, шрифт и т.п.), поведенческие характеристики (многообразные фильтры, форматы, защита от ввода и т.п.) и ряд свойств, ориентированных на работу с БД.
Редактор меню позволяет разрабатывать и отлаживать системы меню. Реализована возможность построения пиктографических меню (так называемые toolbar). Назначение каждого конкретного меню тому или иному объекту приложения осуществляется в редакторе экранов.
В ядро JAM встроена однопользовательская реляционная СУБД JDB. Основным назначением JDB является прототипирование приложений в тех случаях, когда работа со штатной СУБД невозможна или нецелесообразна. В JDB реализован необходимый минимум возможностей реляционных СУБД за исключением индексов, хранимых процедур, триггеров и представлений (view). С помощью JDB можно построить БД, идентичную целевой БД (с точностью до отсутствующих в JDB возможностей) и разработать значительную часть приложения.
Отладчик позволяет проводить комплексную отладку разрабатываемого приложения. Осуществляется трассировка всех событий, возникающих в процессе исполнения приложения.
Утилиты JAM включают три группы:
Одним из дополнительных модулей JAM является генератор отчетов. Компоновка отчета осуществляется в редакторе экранов JAM. Описание работы отчета осуществляется с помощью специального языка. Генератор отчетов позволяет определить данные, выводимые в отчет, группировку выводимой информации, форматирование вывода и др.
Приложения, разработанные с использованием JAM, не требуют так называемых исполнительных (run-time) систем и могут быть изготовлены в виде исполняемых модулей.
Для этого разработчик должен иметь компилятор Си и редактор связей. Для изготовления промышленной версии в состав JAM входит файл сборки (makefile), исходные тексты (на языке C) ряда модулей приложения и необходимые библиотеки.
JAM содержит встроенный язык программирования JPL (JAM Procedural Language), с помощью которого в случае необходимости можно написать модули, реализующие специфические действия. Данный язык является интерпретируемым, что упрощает отладку. Существует возможность обмена информацией между средой визуально построенного приложения и такими модулями. Кроме того, в JAM реализована возможность подключения внешних модулей, написанных на каком-либо языке, совместимым по вызовам функций с языком C.
С точки зрения реализации логики приложения JAM является событийно-ориентированной системой. В JAM определен набор событий, включающий открытие и закрытие окон, нажатие клавиши клавиатуры, срабатывание системного таймера, получение и передача управления каждым элементом экрана. Разработчик реализует логику приложения путем определения обработчика каждого события. Например, обработчик события "нажатие кнопки на экране" (мышью или с помощью клавиатуры) может открыть следующее экранное окно. Обработчиками событий в JAM могут быть как встроенные функции JAM, так и функции, написанные разработчиком на Си или JPL. Набор встроенных функций включает в себя более 200 функций различного назначения. Встроенные функции доступны для вызовов из функций, написанных как на JPL, так и на C.
Промышленная версия приложения, разработанного с помощью JAM, включает в себя следующие компоненты:
Взаимодействие с другими средствами
Непосредственное взаимодействие с СУБД реализуют модули JAM/DBi (Data Base interface). Способы реализации взаимодействия в JAM разделяются на два класса: ручные и автоматические. При ручном способе разработчик приложения самостоятельно пишет запросы на SQL, в которых как источниками, так и адресатами приема результатов выполнения запроса могут быть как интерфейсные элементы визуально спроектированного внешнего уровня, так и внутренние, невидимые для конечного пользователя переменные. Автоматический режим, реализуемый менеджером транзакций JAM, осуществим для типовых и наиболее распространенных видов операций с БД, так называемых QBE (Query By Example - запросы по образцу), с учетом достаточно сложных взаимосвязей между таблицами БД и автоматическим управлением атрибутами экранных полей ввода/вывода в зависимости от вида транзакции (чтение, запись и т.д.), в которой участвует сгенерированный запрос.
JAM позволяет строить приложения для работы более чем с 20 СУБД: ORACLE, Informix, Sybase, Ingres, InterBase, NetWare SQL Server, Rdb, DB2, ODBC-совместимые СУБД и др.
Отличительной чертой JAM является высокий уровень переносимости приложений между различными платформами (MS DOS/MS Windows, SunOS, Solaris (i80x86, SPARC), HP-UX, AIX, VMS/Open VMS и др.). Может потребоваться лишь "перерисовать" статические текстовые поля на экранах с русским текстом при переносе между средами DOS-Windows-UNIX. Кроме того, переносимость облегчается тем, что в JAM приложения разрабатываются для виртуальных устройств ввода/вывода, а не для физических. Таким образом при переносе приложения с платформы на платформу, как правило, требуется лишь определить соответствие между физическими устройствами ввода/вывода и их логическими представлениями для приложения.
Использование SQL в качестве средства взаимодействия с СУБД также создает предпосылки для обеспечения переносимости между СУБД. При условии переноса структуры самой БД в ряде случаев приложения могут не требовать никакой модификации, за исключением инициализации сеанса работы.
Такая ситуация может сложиться в том случае, если в приложении не использовались специфические для той или иной СУБД расширения SQL.
При росте нагрузки на систему и сложности решаемых задач (распределенность и гетерогенность используемых ресурсов, количество одновременно подключенных пользователей, сложность логики приложения) применяется трехзвенная модель архитектуры "клиент-сервер" с использованием менеджеров транзакций. Компоненты JAM/TPi-Client и JAM/TPi-Server позволяют достаточно просто перейти на трехзвенную модель. При этом ключевую роль играет модуль JAM/TPi-Server, так как основная трудность внедрения трехзвенной модели заключается в реализации логики приложения в сервисах менеджеров транзакций.
Интерфейс JAM/CASEi подобен интерфейсу к СУБД и позволяет осуществить обмен информацией между репозиторием объектов JAM и репозиторием CASE-средства аналогично тому, как структура БД импортируется в репозиторий JAM непосредственно из БД. Отличие заключается в том, что в случае интерфейса к CASE этот обмен является двунаправленным. Кроме модулей JAM/CASEi, существует также модуль JAM/CASEi Developer's Kit. С помощью этого модуля можно самостоятельно разработать интерфейс (т.е. специализированный модуль JAM/CASEi) для конкретного CASE-средства, если готового модуля JAM/CASEi для него не существует.
Мост (интерфейс) Silverrun-RDM <-> JAM реализует взаимодействие между CASE-средством Silverrun и JAM (перенос схемы базы данных и экранных форм приложения между CASE-средством Silverrun-RDM и JAM версии 7.0). Данный программный продукт имеет 2 режима работы:
Методика построения моделей данных интерфейса в Silverrun-RDM предполагает применение механизма подсхем для прототипирования экранов приложения. По описанию каждой из подсхем RDM мост генерирует экранную форму JAM;
Режим реинжиниринга позволяет переносить модификации всех свойств экранов JAM, импортированных ранее из RDM, в схему Silverrun. На этом этапе для контроля целостности базы данных не допускаются изменения схемы в виде добавления или удаления таблиц и полей таблиц.
Групповая работа
Ядро JAM имеет встроенный интерфейс к средствам конфигурационного управления (PVCS на платформе Windows и SCCS на платформе UNIX). Под управлением этих систем передаются библиотеки экранов и/или репозитории. При отсутствии таких систем JAM самостоятельно реализует часть функций поддержки групповой разработки.
Использование PVCS является более предпочтительным по сравнению с SCCS, так как позволяет организовать единый архив модулей проекта для всех платформ. Так как JAM на платформе UNIX не имеет прямого интерфейса к архивам PVCS, то выборка модулей из архива и возврат их в архив производятся с использованием PVCS Version Manager. На платформе MS-Windows JAM имеет встроенный интерфейс к PVCS и действия по выборке/возврату производятся непосредственно из среды JAM.
Среда функционирования
JAM, как среда разработки, и приложения, построенные с его использованием, не являются ресурсоемкими системами. Например, на платформе MS-Windows достаточно иметь 8MB оперативной памяти и 50 MB дискового пространства для среды разработки. На UNIX-платформах требования к аппаратуре определяются самой операционной системой.
Java
- объектно-ориентированный язык программирования, разработанный компанией Sun Microsystems и используемый в качестве основного средства мобильного программирования.Javaapplets
- мобильные (независимые от архитектуры "железа") программные коды, написанные на языке программирования Java.Явные внешние ключи
| Преимущества | |
| Нужно только два столбца | Условия соединения - явные |
| Недостатки | |
| Оба дополнительных атрибута должны использоваться в соединениях | Слишком много столбцов |
Альтернативные модели сущностей:
Вариант 1 (плохой)

Вариант 2 (существенно лучше, если подтипы действительно существуют)
Вариант 3 (годится при наличии осмысленного супертипа D).

Язык модулей или встроенный SQL?
В стандарте SQL/89 определены два способа взаимодействия с БД из прикладной программы, написанной на традиционном языке программирования (как мы уже упоминали, SQL/89 ориентирован на использование совместно с языками Кобол, Фортран, Паскаль и ПЛ/1, но в реализациях обычно поддерживается и язык Си).Язык модулей
Структура модуля SQL в стандарте SQL/89 определяется следующими синтаксическими правилами:Существенно, что каждый модуль SQL ориентирован на использование в программах, написанных на конкретном языке программирования. Если в модуле присутствуют процедуры работы с курсорами, то все курсоры должны быть специфицированы в начале модуля. Заметим, что объявление курсора не погружается в какую-либо процедуру, поскольку это описательный, а не выполняемый оператор SQL.
Язык программирования Java
Весь 1996 год прошел под знаком внедрения в World Wide Web технологии Java. Однако реальные проекты, выполненные в этой технологии появились только к концу года. При обсуждении Java-технологии, как правило речь идет о ее безопасности, мобильности, и, как следствие, уменьшении размеров программного кода, выполняемого на машинах-клиентах.Не смотря на то, что этот раздел называется "Язык программирования Java", в нем приходится говорить о гораздо более обширном понятии, которое принято обозначать термином "Java-технология". Если обратиться к публикациям о новых концепциях разработки программного обеспечения, то Java-язык и Java-технологии ценятся не только и не столько за то, что они дали возможность "оживить" Web, как часто можно прочитать в рекламных проспектах, а за то, что давняя идея мобильного программирования для различных аппаратных платформ наконец-то стала реальностью.
При этом все прекрасно понимают, что сама по себе Java-технология еще чрезвычайно сыра и использовать ее в нынешнем виде для серьезных проектов могут только самые отчаянные смельчаки, тем не менее многие из свойств Java чрезвычайно интересны и полезны.
Язык SQL - базовый интерфейс SQL-сервера
Одним из основных преимуществ реляционного подхода к организации баз данных (БД) является то, что пользователи реляционных БД получают возможность эффективной работы в терминах простых и наглядных понятий таблиц, их строк и столбцов без потребности знания реальной организации данных во внешней памяти.Реляционная модель данных, содержащая набор четких предписаний к базовой организации любой реляционной системы управления базами данных (СУБД), позволяет пользователям работать в ненавигационной манере, т.е. для выборки информации из БД человек должен всего лишь указать список интересующих его таблиц и те условия, которым должны удовлетворять выбираемые данные. СУБД скрывает от пользователя выполняемые ей последовательные просмотры таблиц, выполняя их наиболее эффективным образом. Очень важная особенность реляционных систем состоит в том, что результатом выполнения любого запроса к таблицам БД является также таблица, которую можно сохранить в БД и/или по отношению к которой можно выполнять новые запросы.
Базовым требованием к реляционным СУБД является наличие мощного и в тоже время простого языка, позволяющего выполнять все необходимые пользователям операции. В последние годы таким повсеместно принятым языком стал язык реляционных БД SQL - Structured Query Language (теперь все чаще название языка понимается как Standard Query Language).
До появления SQL в СУБД (независимо от того, на какой модели они основывались) приходилось поддерживать по крайней мере три языка, которые обычно имели мало общего: язык определения данных (ЯОД), служащий для спецификации структур БД (обычно общую структуру БД называют схемой БД); язык манипулирования данными (ЯМД), позволяющий создавать прикладные программы, взаимодействующие с БД; и язык администрирования БД (ЯАДБ), с помощью которого можно было выполнять служебные действия (например, изменять структуру БД или производить ее настройку с целью повышения эффективности). Кроме того, если требовалось предоставить пользователям СУБД интерактивный доступ к БД, приходилось вводить еще один язык, операторы которого выполняются в диалоговом режиме. Язык SQL позволяет решать все эти задачи.
Языки БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL - Sсhema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные.В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured или Standard Query Language). В нескольких разделах этого курса язык SQL будет рассматриваться достаточно подробно, а пока мы перечислим основные функции реляционной СУБД, поддерживаемые на "языковом" уровне (т.е. функции, поддерживаемые при реализации интерфейса SQL).
Прежде всего, язык SQL сочетает средства SDL и DML, т.е. позволяет определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД - именование таблиц и их столбцов) поддерживается на языковом уровне в то смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов.
Язык SQL содержит специальные средства определения ограничений целостности БД. Опять же, ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности БД производится на языковом уровне, т.е. при компиляции операторов модификации БД компилятор SQL на основании имеющихся в БД ограничений целостности генерирует соответствующий программный код.
Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне.
Наконец, авторизация доступа к объектам БД производится также на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В число этих полномочий входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне.
Языки и протоколы
К 1989 году гипертекст представлял новую, многообещающую технологию, которая имела относительно большое число реализаций с одной стороны, а с другой стороны делались попытки построить формальные модели гипертекстовых систем, которые носили скорее описательный характер и были навеяны успехом реляционного подхода описания данных. Идея Т.Бернерс-Ли заключалась в том, чтобы применить гипертекстовую модель к информационным ресурсам, распределенным в сети, и сделать это максимально простым способом. Он заложил три краеугольных камня системы, разработав: язык гипертекстовой разметки документов HTML (HyperText Markup Language), универсальный способ адресации ресурсов в сети URL (Universal Resource Locator), протокол обмена гипертекстовой информацией HTTP (HyperText Transfer Protocol). Позже команда NCSA (National Center of Supercomputer Applications) добавила к этим трем компонентам четвертый - универсальный интерфейс шлюзов CGI (Common Gateway Interface). Усовершенствования на этом не остановились. В 1995 году Netscape Communication предлагает включить в текст HTML-страниц программы на новом языке Liveware. Позже это название было изменено на JavaScript. Таким образом технология World Wide Web была дополнена еще одним компонентом - языком программирования просмотра гипертекстовых страниц JavaScript.Исходя из важности технологии WWW для построения корпоративных Intranet-систем, мы для начала коротко рассмотрим два базовых компонента этой технологии - язык гипертекстовой разметки документов HTML и протокол обмена гипертекстовой информацией HTTP.
Классический подход к проектированию реляционных баз данных
При проектировании базы данных решаются две основных проблемы:В случае реляционных баз данных трудно представить какие-либо общие рецепты по части физического проектирования. Здесь слишком много зависит от используемой СУБД. Например, при работе с СУБД Ingres можно выбирать один из предлагаемых способов физической организации отношений, при работе с System R следовало бы прежде всего подумать о кластеризации отношений и требуемом наборе индексов и т.д. Поэтому в этом разделе мы ограничимся вопросами логического проектирования реляционных баз данных, которые существенны при использовании любой реляционной СУБД.
Более того, мы не будем касаться очень важного аспекта проектирования - определения ограничений целостности (за исключением ограничения первичного ключа). Дело в том, что при использовании СУБД с развитыми механизмами ограничений целостности (например, SQL-ориентированных систем) трудно предложить какой-либо общий подход к определению ограничений целостности. Эти ограничения могут иметь очень общий вид, и их формулировка пока относится скорее к области искусства, чем инженерного мастерства. Самое большее, что предлагается по этому поводу в литературе, это автоматическая проверка непротиворечивости набора ограничений целостности.
Так что будем считать, что классическая проблема проектирования реляционной базы данных состоит в обоснованном принятии решений о том, из каких отношений должна состоять БД и какие атрибуты должны быть у этих отношений.
Клиент-серверные приложения
Под клиент-серверным приложением мы будем понимать информационную систему, основанную на использовании серверов баз данных (см. длинное замечание в конце раздела 2.1). Общее представление информационной системы в архитектуре "клиент-сервер" показано на рисунке 2.3.(Здесь опять проявляются недостатки в терминологии. Обычно, когда компания объявляет о выпуске очередного сервера баз данных, то неявно понимается, что имеется и клиентская составляющая этого продукта. Сочетание "клиентская часть сервера баз данных" кажется несколько странным, но нам придется пользоваться именно этим термином.)
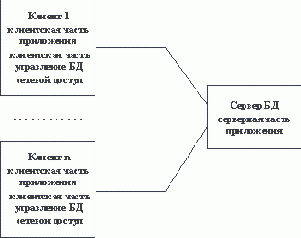
Рис. 2.3. Общее представление информационной системы в архитектуре "клиент-сервер"
Заметим, что интерфейс между клиентской частью приложения и клиентской частью сервера баз данных, как правило, основан на использовании языка SQL. Поэтому такие функции, как, например, предварительная обработка форм, предназначенных для запросов к базе данных, или формирование результирующих отчетов выполняются в коде приложения.
Наконец, клиентская часть сервера баз данных, используя средства сетевого доступа, обращается к серверу баз данных, передавая ему текст оператора языка SQL.
Здесь необходимо сделать еще два замечания.
Поэтому при организации сетевых взаимодействий между клиентской и серверной частями СУБД часто используются не стандартные средства высокого уровня (например, механизмы программных гнезд или вызовов удаленных процедур), а собственные функционально подобные средства, менее зависящие от особенностей сетевых транспортных протоколов.
Мы остановимся на этих вопросах более подробно в четвертой части курса.
Посмотрим теперь, что же происходит на стороне сервера баз данных. В продуктах практически всех компаний сервер получает от клиента текст оператора на языке SQL.
Ограничения целостности обычно сохраняются в метабазе данных прямо в текстовом представлении. Для действий, определенных в триггерах, и хранимых процедур вырабатывается и сохраняется в таблицах-каталогах процедурный выполняемый код. Заметим, что ограничения целостности, триггеры и хранимые процедуры являются, в некотором смысле, представителями приложения в поддерживаемой сервером базе данных; они составляют основу серверной части приложения (см. ниже).
Если хранимая процедура определяется с помощью достаточно развитого языка, включающего и непроцедурные операторы SQL, и чисто процедурные конструкции (например, языка PL/SQL компании Oracle), то в такую процедуру можно поместить серьезную часть приложения, которое при выполнении оператора вызова процедуры будет выполняться на стороне сервера, а не на стороне клиента.
Как видно, в клиент-серверной организации клиенты могут являться достаточно "тонкими", а сервер должен быть "толстым" настолько, чтобы быть в состоянии удовлетворить потребности всех клиентов (рисунок 2.4).
Рис. 2.4. "Тонкий" клиент и "толстый" сервер в клиент-серверной архитектуре
С другой стороны, разработчики и пользователи информационных систем, основанных на архитектуре "клиент-сервер", часто бывают неудовлетворены постоянно существующими сетевыми накладными расходами, которые следуют из потребности обращаться от клиента к серверу с каждым очередным запросом. На практике распространена ситуация, когда для эффективной работы отдельной клиентской составляющей информационной системы в действительности требуется только небольшая часть общей базы данных. Это приводит к идее поддержки локального кэша общей базы данных на стороне каждого клиента.
Фактически, концепция локального кэширования базы данных является частным случаем концепции реплицированных (или, как иногда их называют в русскоязычной литературе, тиражированных) баз данных. Как и в общем случае, для поддержки локального кэша базы данных программное обеспечение рабочих станций должно содержать компонент управления базами данных - упрощенный вариант сервера баз данных, который, например, может не обеспечивать многопользовательский режим доступа.
Отдельной проблемой является обеспечение согласованности (когерентности) кэшей и общей базы данных. Здесь возможны различные решения - от автоматической поддержки согласованности за счет средств базового программного обеспечения управления базами данных до полного перекладывания этой задачи на прикладной уровень. В любом случае, клиенты становятся более толстыми при том, что сервер тоньше не делается (рисунок 2.5).

Рис. 2.5. "Потолстевший" клиент и "толстый" сервер в клиент-серверной архитектуре с поддержкой локального кэша на стороне клиентов
Сформулируем некоторые предварительные выводы. Архитектура "клиент-сервер" на первый взгляд кажется гораздо более дорогой, чем архитектура "файл-сервер". Требуется более мощная аппаратура (по крайней мере, для сервера) и существенно более развитые средства управления базами данных. Однако, это верно лишь частично. Громадным преимуществом клиент-серверной архитектуры является ее масштабируемость и вообще способность к развитию.
При проектировании информационной системы, основанной на этой архитектуре, большее внимание следует обращать на грамотность общих решений. Технические средства пилотной версии могут быть минимальными (например, в качестве аппаратной основы сервера баз данных может использоваться одна из рабочих станций). После создания пилотной версии нужно провести дополнительную исследовательскую работу, чтобы выяснить узкие места системы. Только после этого необходимо принимать решение о выборе аппаратуры сервера, которая будет использоваться на практике.
Увеличение масштабов информационной системы не порождает принципиальных проблем. Обычным решением является замена аппаратуры сервера (и, может быть, аппаратуры рабочих станций, если требуется переход к локальному кэшированию баз данных). В любом случае практически не затрагивается прикладная часть информационной системы. В идеале, которого, конечно же не бывает, информационная система продолжает нормально функционировать после смены аппаратуры.
Компания IBM
Решение компании IBM называется A Data Warehouse Plus. Целью компании является обеспечение интегрированного набора программных продуктов и сервисов, основанных на единой архитектуре. Основой складов данных является семейство СУБД DB2. Преимуществом IBM является то, что данные, которые нужно извлечь из оперативной базы данных и поместить в склад данных, находятся в системах IBM. Поэтому естественная тесная интеграция программных продуктов.Предлагаются три решения для складов данных:
Концептуальные модели и схемы баз данных
Широкое распространение реляционных СУБД и их использование в самых разнообразных приложениях показывает, что реляционная модель данных достаточна для моделирования предметных областей. Однако проектирование реляционной базы данных в терминах отношений на основе кратко рассмотренного нами механизма нормализации часто представляет собой очень сложный и неудобный для проектировщика процесс.При этом проявляется ограниченность реляционной модели данных в следующих аспектах:
Потребности проектировщиков баз данных в более удобных и мощных средствах моделирования предметной области вызвали к жизни направление семантических моделей данных. При том, что любая развитая семантическая модель данных, как и реляционная модель, включает структурную, манипуляционную и целостную части, главным назначением семантических моделей является обеспечение возможности выражения семантики данных.
Прежде, чем мы коротко рассмотрим особенности одной из распространенных семантических моделей, остановимся на их возможных применениях.
Наиболее часто на практике семантическое моделирование используется на первой стадии проектирования базы данных. При этом в терминах семантической модели производится концептуальная схема базы данных, которая затем вручную преобразуется к реляционной (или какой-либо другой) схеме. Этот процесс выполняется под управлением методик, в которых достаточно четко оговорены все этапы такого преобразования.
Менее часто реализуется автоматизированная компиляция концептуальной схемы в реляционную. При этом известны два подхода: на основе явного представления концептуальной схемы как исходной информации для компилятора и построения интегрированных систем проектирования с автоматизированным созданием концептуальной схемы на основе интервью с экспертами предметной области. И в том, и в другом случае в результате производится реляционная схема базы данных в третьей нормальной форме (более точно следовало бы сказать, что автору неизвестны системы, обеспечивающие более высокий уровень нормализации).
Наконец, третья возможность, которая еще не вышла (или только выходит) за пределы исследовательских и экспериментальных проектов, - это работа с базой данных в семантической модели, т.е. СУБД, основанные на семантических моделях данных. При этом снова рассматриваются два варианта: обеспечение пользовательского интерфейса на основе семантической модели данных с автоматическим отображением конструкций в реляционную модель данных (это задача примерно такого же уровня сложности, как автоматическая компиляция концептуальной схемы базы данных в реляционную схему) и прямая реализация СУБД, основанная на какой-либо семантической модели данных. Наиболее близко ко второму подходу находятся современные объектно-ориентированные СУБД, модели данных которых по многим параметрам близки к семантическим моделям (хотя в некоторых аспектах они более мощны, а в некоторых - более слабы).
Линия серверных продуктов CA-OpenIngres компании Computer Associates
Проект и экспериментальный вариант СУБД Ingres были разработаны в университете Беркли под руководством одного из наиболее известных в мире ученых и специалистов в области баз данных Майкла Стоунбрейкера (Michael Stonebraker). С самого начала СУБД Ingres разрабатывалась как мобильная система, функционирующая в среде ОС UNIX. Первая версия Ingres была рассчитана на 16-разрядные компьютеры и работала главным образом на машинах серии PDP. Это была первая СУБД, распространяемая бесплатно для использования в университетах. Впоследствии группа Стоунбрейкера перенесла Ingres в среду ОС UNIX BSD, которая также была разработана в университете Беркли. Семейство СУБД Ingres из университета Беркли принято называть "университетской Ingres" (соответствующие программные продукты вместе с исходными текстами и документацией до сих пор доступны в секторе public domain Internet).В начале 80-х была образована компания RTI (Relational Technology Inc.) для доводки университетских прототипов до уровня коммерческих продуктов. С этого момента стали различать университетскую и коммерческую СУБД Ingres. В настоящее время коммерческая Ingres поддерживается, развивается и продается компанией Computer Associates. Сейчас это одна из развитых коммерческих реляционных СУБД.
Мы коснемся, главным образом, особенностей базового серверного продукта компании Computer Associates линии CA-OpenIngres - CA-OpenIngres/Server. Сервер базируется на следующих пяти ключевых архитектурных принципах компании Computer Associates:
Архитектура CA- OpenIngres Server поддерживает совместное использование многочисленных серверов баз данных на основе поддержки совместного буферного кэша, в котором хранятся данные, объекты, откомпилированные запросы, хранимые процедуры и информация, характеризующая состояние транзакций. Средства администрирования и управления позволяют выделить некоторые серверы для целей оперативного управления транзакциями, в то время как другие будут использоваться для генерации отчетов с более низким приоритетом.
В соответствии с начальным подходом Стоунбрейкера, в сервере поддерживается широкий набор допустимых способов хранения данных: куча (heap), B-деревья, таблицы хэширования и т.д. Допускается поддержание индексов с избыточными столбцами данных для эффективного выполнения особо критичных запросов. Применяются способы сжатия таблиц и индексов.
При оптимизации запросов учитываются разнообразные допустимые формы хранения. Используются истинные распределения данных за счет динамического построения гистограмм распределений значений. Для особо критических запросов поддерживаются административные способы оптимизации.
В соответствии с традициями Ingres в CA-OpenIngres поддерживается встроенная система правил (расширенный вариант более или менее известного механизма триггеров). Расширенные языковые возможности определения правил позволяют решать на основе этого механизма не только задачи поддержания целостности баз данных, но и полностью разрешать производственные задачи.
В CA-OpenIngres поддерживаются стандарты SQL-89 и ядерный уровень языка SQL-92. (Обратите внимание, что никто из ведущих производителей не гарантирует полной совместимости с SQL-92. Это очень плохо, поскольку уже на протяжении более чем 4 лет, ни одна компания не может или не хочет произвести продукт, полностью соответствующий требованиям хорошего международного стандарта. Правда, и стандарт несколько сложноват.)
Очень интересным направлением развития линии CA-OpenIngres явилось приобретение японской объектно-ориентированной СУБД Jasmin.
Это оригинальная объектно- ориентированная система, модель данных которой основывается одновременно на идеях Smalltalk и Си++. Компания Computer Associates считает, что в принципе невозможно сочетать в одной системе объектно-ориентированный и реляционный подходы (в частности, отметим по-прежнему существующую проблему потери соответствия объектных и реляционных операций [impedance mismatch], присущую объектно-реляционным системам).
Поэтому в ближайших планах компании содержатся намерения одновременного поддержания объектно-ориентированного и реляционного интерфейсов доступа к базам данных, среда хранения которых будет поддерживаться OpenIngres. Сама же СУБД OpenIngres поддерживает возможности шлюзования для доступа к унаследованным системам баз данных (в частности, IDMS), что обеспечивает полную преемственность по отношению к ранее разработанным и накопленным хранилищам данных. К сожалению, в текстах, распространяемых компанией CA, содержится слишком мало технической информации относительно Jasmin. Однако достоверно известно, что объектно-ориентированные возможности управления данными широко используются в новом продукте компании, предназначенном для управления и администрирования глобально распределенных корпоративных приложений и называемом TNG (The Next Generation of UniCenter).
Login
.Ниже приведена структура корня FTP-архива (рисунок 5.5).
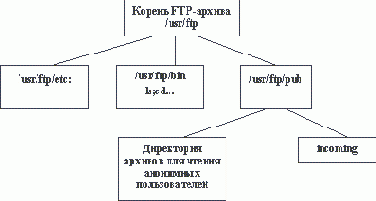
Рис. 5.5. Структура ftp-архива
Many-to-many
). Поэтому часто ограничения общего вида не выводятся автоматически из концептуальной схемы базы данных и их приходится добавлять к реляционной схеме вручную. Для того, чтобы понять, какие ограничения общего вида должны быть включены в реляционные схемы разделов, приходится возвращаться к документу, содержащему анализ требований корпорации. Задача проектировщика состоит в том, чтобы, с одной стороны, выявить все необходимые ограничения целостности и, с другой стороны, не перегрузить базу данных необязательными ограничениями (любое дополнительное ограничение целостности вызывает дополнительные проверки на стороне сервера при выполнении операций изменения базы данных; проверки для ограничений общего вида могут быть весьма громоздкими). Конечно, если предполагается использование распределенной базы данных, то опять придется учитывать возможности сервера по части ссылок на объекты "чужих" разделов. Это может повлиять на выбор ограничений целостности и/или повлечь создание новой декомпозиции общей базы данных на разделы.Триггер - это, фактически, хранимая процедура без параметров, содержащая оператор(ы) изменения базы данных и вызываемая сервером баз данных автоматически при совершении некоторого события (обычно под событием понимается выполнение определенного рода операторов изменения базы данных). Более точно, при определении триггера указывается вид события, возбуждающего триггер, условие его срабатывания и набор операторов, которые должны быть выполнены при выполнении условия. Имеется несколько практических областей применения механизма триггеров. Во-первых, триггеры позволяют поддерживать логическую целостность базы данных в тех случаях, когда пользовательская транзакция не может не нарушить эту целостность. Простой пример: информационная система отдела кадров. База данных состоит из двух таблиц:
СОТРУДНИКИ(НОМЕР_ПРОПУСКА, ФИО, НОМЕР_ОТДЕЛА, ЗАРПЛАТА)
ОТДЕЛЫ (НОМЕР_ОТДЕЛА, НОМЕР_ПРОПУСКА_НАЧАЛЬНИКА, ЧИСЛО_СОТРУДНИКОВ, ФОНД_ЗАРПЛАТЫ)
Естественные ограничения целостности могут быть выражены следующим образом:
SELECT ЧИСЛО_СОТРУДНИКОВ FROM ОТДЕЛЫ = SELECT COUNT (*) FROM СОТРУДНИКИ WHERE НОМЕР_ОТДЕЛА = ОТДЕЛЫ.НОМЕР_ОТДЕЛА
SELECT ФОНД_ЗАРПЛАТЫ FROM ОТДЕЛЫ <= SELECT SUM (ЗАРПЛАТА) FROM СОТРУДНИКИ WHERE НОМЕР_ОТДЕЛА = ОТДЕЛЫ.НОМЕР_ОТДЕЛА
Предположим, что в отделе кадров работает всего два человека: начальник отдела кадров, который, естественно, имеет доступ к обеим таблицам и, в частности, является ответственным за выполнение операций смены начальника отдела или изменения фонда заработной платы. Второй человек - рядовой клерк, который по указанию начальника выполняет рутинную работу оформления новых сотрудников или увольнения ранее работавших. Естественно, что для выполнения его операций достаточно иметь доступ только к таблице СОТРУДНИКИ. Но тогда при выполнении любой из двух операций он просто не может не нарушить, по крайней мере, первое из упомянутых выше ограничений целостности. Конечно, можно внести соответствующие корректирующие действия в код прикладной программы, соответствующей операциям клерка, но тогда он неявно получит доступ по изменению ответственной таблицы ОТДЕЛЫ. Поэтому лучше определить триггеры вида
ON INSERT TO СОТРУДНИКИ UPDATE ОТДЕЛЫ SET NEW (ЧИСЛО_СОТРУДНИКОВ) = OLD (ЧИСЛО_СОТРУДНИКОВ) + 1 WHERE НОМЕР_ОТДЕЛА = СОТРУДНИКИ.НОМЕР_ОТДЕЛА
ON DELETE FROM СОТРУДНИКИ UPDATE ОТДЕЛЫ SET NEW (ЧИСЛО_СОТРУДНИКОВ) = OLD (ЧИСЛО_СОТРУДНИКОВ) - 1 WHERE НОМЕР_ОТДЕЛА = СОТРУДНИКИ.НОМЕР_ОТДЕЛА
Эти триггеры будут автоматически вызываться на стороне сервера баз данных и незаметно для клерка поддерживать логическую целостность базы данных. Вторая область применения триггеров - автоматический мониторинг действий конечных пользователей. Снова приведем очень простой пример. Начальник отдела кадров хочет знать, сколько операций в день выполняет его клерк. Тогда он должен сказать об этом на стадии анализа требований, и в результате, например, будет создана таблица
СТАТИСТИКА (ТЕКУЩАЯ_ДАТА, ЧИСЛО_ОПЕРАЦИЙ)
и триггер вида
ON INSERT, DELETE FROM СОТРУДНИКИ IF EXISTS (SELECT * FROM СТАТИСТИКА WHERE ТЕКУЩАЯ_ДАТА = TODAY) UPDATE СТАТИСТИКА SET NEW (ЧИСЛО_ОПЕРАЦИЙ) = OLD (ЧИСЛО_ОПЕРАЦИЙ) + 1 WHERE ТЕКУЩАЯ_ДАТА = TODAY ELSE INSERT INTO СТАТИСТИКА (TODAY, 1)
Два замечания. Во-первых, в распространенном на сегодня стандарте SQL-92 механизм триггеров не специфицирован. В СУБД, которые поддерживают этот механизм, соответствующие языковые средства и их семантика различаются. Например, в Oracle V.7 для определения триггеров можно использовать процедурное расширение языка SQL PL/SQL в то время, как другие системы позволяют использовать только "чистые" конструкции SQL. Поэтому на текущий момент использование механизма триггеров неявно влечет сильную привязку к конкретному производителю. Во-вторых, как и в случае определения представлений и ограничений целостности, при определении триггеров необходимо учитывать распределенный характер базы данных и возможности сервера ссылаться на "чужие" таблицы.
Наконец, в базе данных могут храниться хранимые процедуры. Интересно, что в стандарте SQL-92 вообще не встречается термин "хранимая процедура". В стандарте специфицированы два способа взаимодействия прикладной программы с сервером баз данных. Первый, наиболее часто используемый способ состоит в встраивании операторов языка SQL в программу, написанную на одном из традиционных языков программирования. В самом стандарте определены правила встраивания SQL в программы, которые написаны на языках Си, Паскаль, Фортран, Ада и т.д. Второй способ основан на специфицированном в стандарте "языке модулей SQL". С использованием этого языка можно определить модуль, содержащий несколько процедур, каждая из которых соответствует некоторому параметризованному оператору SQL. В прикладной программе содержатся не операторы SQL, а лишь вызовы процедур (с указанием фактических параметров) из модуля SQL, с которым эта прикладная программа связана (правила связывания в стандарте не определены). Заметим, что стандарт не обязывает следовать каким-то конкретным правилам при реализации встроенного SQL или языка модулей. Посмотрим, что же делается в реализациях.
Что касается встроенного SQL, то во всех реализациях прикладная программа, содержащая операторы SQL, подвергается прекомпиляции с помощью соответствующего программного продукта, который входит в состав программного обеспечения сервера баз данных.
В результате прекомпиляции всегда формируется текст прикладной программы на используемом языке программирования, уже не содержащий напрямую текста на языке SQL. Каждое вхождение оператора SQL в исходный текст программы заменяется на вызов некоторой процедуры или функции в синтаксисе включающего языка программирования. Основная разница между разными реализациями состоит в том, что из себя представляет эта процедура или функция. В большинстве систем (Oracle, Informix, Sybase, CA-OpenIngres) такая процедура представляет собой обращение к клиентской части СУБД с передачей в качестве параметра текста оператора на языке SQL. Вся обработка оператора, включая его грамматический разбор и выработку процедурного плана производится сервером во время выполнения прикладной программы (конечно, при повторном выполнении оператора сервер использует уже подготовленный план). Однако имеется и другой подход, исторически используемый компанией IBM в ее серии продуктов DB2. В DB2 прекомпилятор, выбрав текст очередного оператора SQL, сам обращается к серверу с запросом на компиляцию оператора. Сервер выполняет грамматический разбор и строит процедурный план выполнения оператора, сохраняя этот план в базе данных и привязывая к соответствующей прикладной программе. В качестве ответа от сервера прекомпилятор получает идентификатор, указание которого серверу повлечет выполнение соответствующего плана (грубо говоря, имя удаленной процедуры). Тогда в тексте прикладной программы появится вызов процедуры-переходника (stub), которая жестко привязана к соответствующей удаленной процедуре. Другими словами, более распространен метод динамической компиляции встроенного SQL (при выполнении прикладной программы), но имеются примеры реализаций со статической компиляцией встроенных операторов SQL (при прекомпиляции текста прикладной программы со встроенным SQL) (таблица 1.1.). В этом курсе мы не будем рассматривать сравнительные преимущества и недостатки динамического и статического подходов.
Таблица 1.1.Характеристики динамической и статической схем обработки встроенного SQL
и позволяет построить модель данных,
Метод IDEF1, разработанный Т.Рэмей (T.Ramey), также основан на подходе П.Чена и позволяет построить модель данных, эквивалентную реляционной модели в третьей нормальной форме. В настоящее время на основе совершенствования методологии IDEF1 создана ее новая версия - методология IDEF1X. IDEF1X разработана с учетом таких требований, как простота изучения и возможность автоматизации. IDEF1X-диаграммы используются рядом распространенных CASE-средств (в частности, ERwin, Design/IDEF).Сущность в методологии IDEF1X является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности (рисунок 4.13).
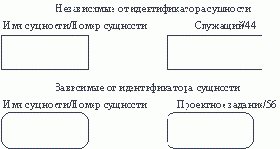
Рис. 4.13. Сущности
Каждой сущности присваивается уникальное имя и номер, разделяемые косой чертой "/" и помещаемые над блоком.
Связь может дополнительно определяться с помощью указания степени или мощности (количества экземпляров сущности-потомка, которое может существовать для каждого экземпляра сущности-родителя). В IDEF1X могут быть выражены следующие мощности связей:
Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то связь называется идентифицирующей, в противном случае - неидентифицирующей.
Связь изображается линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка.
Мощность связи обозначается как показано на рисунке 4.14 (мощность по умолчанию - N).

Рис.4.14. Мощность связи
Идентифицирующая связь между сущностью-родителем и сущностью-потомком изображается сплошной линией (рисунок 4.15). Сущность-потомок в идентифицирующей связи является зависимой от идентификатора сущностью. Сущность-родитель в идентифицирующей связи может быть как независимой, так и зависимой от идентификатора сущностью (это определяется ее связями с другими сущностями).
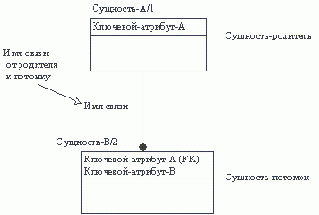
Рис. 4.15. Идентифицирующая связь
Пунктирная линия изображает неидентифицирующую связь (рисунок 4.16). Сущность-потомок в неидентифицирующей связи будет независимой от идентификатора, если она не является также сущностью-потомком в какой-либо идентифицирующей связи.
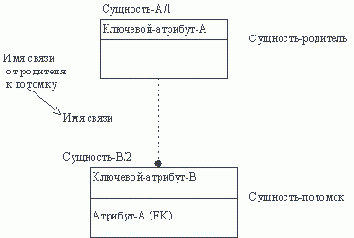
Рис. 4.16. Неидентифицирующая связь
Атрибуты изображаются в виде списка имен внутри блока сущности. Атрибуты, определяющие первичный ключ, размещаются наверху списка и отделяются от других атрибутов горизонтальной чертой (рисунок 4.17).

Рис. 4.17. Атрибуты и первичные ключи
Сущности могут иметь также внешние ключи (Foreign Key), которые могут использоваться в качестве части или целого первичного ключа или неключевого атрибута. Внешний ключ изображается с помощью помещения внутрь блока сущности имен атрибутов, после которых следуют буквы FK в скобках (рисунок 4.18).

Рис. 4.18. Примеры внешних ключей
Методы доступа
В настоящее время в практике World Wide Web реально используются только три метода доступа: POST, GET, HEAD.Миграция от средства программирования
Ломая копья вокруг предназначения и места Java в Internet вообще и в Web в частности, полезно обратить внимание на историю развития технологии. А история Java поучительна. Самое интересное ее изложение приведено в эпилоге книги Патрика Нотона "Java. Справочное руководство", одного из руководителей "Зеленого проекта" Sun, одним из результатов которого собственно и стал Java. С самого начала никакого Java не было. Был Oak (Дуб), да и весь проект никакого отношения к сетям вообще и к Internet в частности не имел. Собственно речь шла о технологии программирования электронных устройств широкого потребления. Одним из ключевых моментов этой технологии являлся язык программирования интерфейсов. Предполагалось, что все бытовые приборы (но не только они) будут иметь панель управления некоторым универсальным устройством, которое и будет уже управлять всем прибором в целом. Для программирования этого устройства, а точнее его панели управления и предназначался Oak. Из затеи создать устройство управления приборами ничего не вышло: уж больно дорогим оно получалось. Применить данную технологию к интерактивному телевидению также не удалось. В итоге, Нотон осознал, что устройство собственно уже есть - это персональный компьютер, который может управлять сразу всеми приборами, а его операционной системой является продукция Microsoft. Однако, в это время уже появились Web и Netscape. Развлечения ради написали свой собственный браузер на Oak, который в последствии получил название HotJava. Браузер умел делать то, что не умели другие программы этого класса - интерпретировать мобильные коды нового языка. При этом в качестве демонстрации возможностей использовался смешной человечек "Дюк", который махал рукой и прыгал по экрану. Вот когда это все заработало, тогда собственно и появилась Java.Но к этому моменту, реально, до уровня стандартных инструментов были проработаны только элементы интерфейса пользователя, все остальное развивалось в рамках HotJava, а это не самый удачный браузер сети. Поэтому сейчас язык Java добирает то, в чем ему было отказано при рождении - возможность работать с сетью.
Но это только полбеды. Другим серьезным препятствием на пути новой технологии является отсутствие средств разработки прикладных программ для взаимодействия с СУБД. И здесь активность разработчиков этих средств просто поражает. Практически все производители СУБД лицензировали Java и начали разработку продуктов этого класса. К сожалению, пока о каких-либо стандартных решениях здесь говорить не приходится, хотя и есть определенные сдвиги.
MIME
(Multipurpose Internet Mail Exchange) - формат почтового сообщения Internet. В данном контексте стандарт MIME используется для установления соответствия между типом информационного файла, именем этого файла и программой просмотра этого файла.Мобильность Java
Первым из свойств языка Java разберем мобильность. Суть мобильности заключается в том, что написанный на Java код может исполняться на любой компьютерной платформе. Под платформой в данном случае подразумевается программно-аппаратный комплекс, а проще собственно компьютер и операционная система, которая на нем работает. Однако, мобильность Java следует отличать от простого портирования кода с одной платформы на другую. При портировании передается исходный текст, который после этого компилируется и только затем выполняется. В Java передаются так называемые байт-коды. Байт-код - это универсальный формат программы, единый для всех аппаратных платформ. Байт-код един и для рабочих станций, и для больших универсальных ЭВМ, и для персональных компьютеров. Собственно, большинство из тех, кто работал с СУБД на персональных компьютерах с разновидностями байт-кодов наверняка встречался. Это, например, коды, которые выполняет FoxBASE. Конечно коды FoxBASE и Java - это абсолютно разные коды, но идея в общем - та же.Надо сказать, что коды Java - это не единственные мобильные коды, которые предполагалось использовать в Internet, но благодаря большим усилиям со стороны Sun Microsystems именно они стали наиболее известными и, на сегодняшний день используемыми, хотя до сих пор подходят на эту роль слабо.
Сравнение с FoxBase было не случайным. Дело в том, что байт-код Java исполняется интерпретатором, а не является откомпилированной на данной платформе программой. Многие преимущества и недостатки Java проистекают именно из-за этого. Первый и очевидный недостаток - это скорость выполнения кода. Совершенно очевидно, что интерпретатор работает гораздо медленнее откомпилированного кода. И здесь не помогут никакие Java-процессоры. Вся элементная база все равно остается двоичной, а это значит, что программы оптимизированные для работы с этим типом вычислений будут работать все равно быстрее, чем какие-либо другие коды. Здесь можно говорить, только о сравнении Java-процессоров с универсальными процессорами при выполнении Java-кода.
Собственно, и другие свойства технологии ( объектная ориентируемость, использование многопоточности, отсутствие адресной арифметики и т.п.) в большинстве случаев при стандартной комплектации оборудования, только тормозят выполнение программы.
Второй недостаток не столь очевиден, да и собственно для большинства современных разработчиков таковым не является - объектный подход к программированию. Что собственно имеется в виду, когда об объектном программировании говорится как о недостатке в данном контексте. Главным в Java-технологии являются небольшие программки-апплеты, которые передаются по сети. Размер такого апплета очень мал (до сотни строк текста). При этом разработчик должен весь вывод собрать в одну процедуру, перехват особых ситуаций в другую, порождение потоков в третью, и т. д. При этом некоторые из этих процедур будут вообще состоять из четырех - пяти строк. Это конечно дисциплинирует и ведет к построению стройных кодов, но при этом прокрутка текста на экране превращается в программу с порождением нового потока, что вместо сокращения издержек на ее выполнение приводит только к их увеличению. Одним словом, "Hello Java" также нудно писать, как и "Hello Windows".
Однако, мобильность Java имеет еще одно измерение. Апплеты передаются по сети в тот момент, когда их нужно выполнять. При этом они могут загружаться из разных мест и после загрузки взаимодействовать друг с другом. Девиз Sun "Сеть - это компьютер" здесь работает на все сто процентов. Действительно, если всю совокупность апплетов рассматривать как одну программу, состоящую из множества подгружаемых по мере необходимости модулей, то весь Internet становится одним большим компьютером, а точнее хранилищем данных и программ, т.к. все-таки программа выполняется на локальном процессоре. Хотя, и последнее не совсем точно. Java-апплеты могут обмениваться данными между собой по сети, что заставляет говорить о распределенных вычислениях, и в этом случае программа будет исполняться на многих компьютерах в сети.
До Java можно было говорить о распределенных вычислениях только после трансляции кодов для каждой из машин и отладки всего комплекса в целом. Теперь отладиться можно и на локальном компьютере, а реально считать на разных.
Основной протокол обмена апплетами - HTTP. Это значит, что они передаются по сети точно также, как и другие ресурсы Website, и приобретают свое особое значение только в момент получения их браузером. Учитывая неэффективность реализации HTTP поверх TCP, можно сказать, что и обмен апплетами тоже неэффективен, если для каждого обмена устанавливается свое TCP-соединение. Пока сравнение скорости выполнения Java-апплетов и скриптов JavaScript не в пользу первых, т.е. интерпретация скриптов в Netscape Navigator реализована эффективнее. В любом случае загрузка страниц с Java происходит гораздо медленнее, чем без Java.
Часто можно слышать, что использование Java должно снизить затраты на обмен информацией по сети. Аргумент здесь следующий: для отображения информации в виде графиков и гистограмм, и даже трехмерных объектов не надо передавать по сети изображения этих объектов, а можно передать, только числовые характеристики. Это приводит к существенному сокращению трафика, и сокращению числа ошибок при передаче. Это справедливо в том случае, если апплеты Java не перегружаются часто. Пользователь загрузил группу страниц и все апплеты на них и только стартует или останавливает выполнение программ. В случае специализированных корпоративных вычислений может быть это и так, но если брать обычного пользователя, то он практически всегда, переходя на новую страницу, загружает новые апплеты, а вот это уже не сокращает трафик, а только увеличивает.
Мобильность имеет и свою обратную сторону. Некоторые авторы прежде, чем пустить пользователя на свои страницы с Java предупреждают: Are your going to be infected? Суть предупреждения в том, что, фактически, пользователь разрешает выполняться на своем компьютере программе, о свойствах которой он ничего не знает. При этом ссылки на безопасность Java не вполне корректны.Программа может вообще никак себя внешне не проявлять, но при этом выполнять массу нежелательных, с точки зрения пользователей, действий. Например, анализировать кэш браузера, идентифицировать компьютер пользователя и многое другое.
Набор операторов манипулирования данными
В стандарте SQL/89 определен очень ограниченный набор операторов манипулирования данными. Их можно классифицировать на группы операторов, связанных с курсором; одиночных операторов манипулирования данными; и операторов завершения транзакции. Все эти операторы можно использовать как в модулях SQL, так и во встроенном SQL. Заметим, что в SQL/89 не определен набор операторов интерактивного SQL.Назначение и разновидности CASE-систем
В разряд CASE-средств попадают как относительно дешевые системы для персо-нальных компьютеров с весьма ограни-ченными возможностями, так и дорогостоящие системы для неоднородных вычислительных платформ и опера-ционных сред. Так, современный рынок программных средств насчи-тывает около 300 различных CASE-средств, наиболее мощные из которых так или иначе используются практически всеми ведущими западными фирмами.Обычно к CASE-средствам относят любое программное средство, автоматизирующее ту или иную совокупность процессов жизненного цикла программного обеспечения и обладающее следующими основными характерными особенностями:
Интегрированное CASE-средство (или комплекс средств, поддерживающих полный жизненный цикл программного обеспечения) содержит следующие компоненты;
Все современные CASE-средства могут быть классифицированы в основном по типам и категориям. Классификация по типам отражает функциональную ориентацию CASE-средств на те или иные процессы жизненного цикла.
Классификация по категориям определяет степень интегрированности по выполняемым функциям и включает отдельные локальные средства, решающие небольшие автономные задачи (tools), набор частично интегрированных средств, охватывающих большинство этапов жизненного цикла информационных систем (toolkit) и полностью интегрированные средства, поддерживающие весь жизненный цикл информационных систем и связанные общим репозиторием. Помимо этого, CASE-средства можно классифицировать по сле-дующим признакам:
Классификация по типам в основном совпадает с компонентным составом CASE-средств и включает следующие основные типы:
Средства анализа схем БД и формирования ER-диаграмм входят в состав Vantage Team Builder, PRO-IV, Silverrun, Designer/2000, ERwin и S-Designor. В области анализа программных кодов наибольшее распространение получают объектно-ориентированные CASE-средства, обеспечивающие реинжиниринг программ на языке Си++ (Rational Rose (Rational Software), Object Team (Cayenne)).
Вспомогательные типы включают:
На сегодняшний день Российский рынок программного обеспечения рас-полагает следующими наиболее развитыми CASE-средствами:
Кроме того, на рынке постоянно появляются как новые для отечественных пользователей системы (например, CASE /4/0, PRO-IV, System Architect, Visible Analyst Workbench, EasyCASE), так и новые версии и модификации перечисленных систем.
Назначение
| INPUT | поля ввода информации имеют множество типов |
| TEXTAREA | поле ввода многострочного текста |
| SELECT | описание меню |
| OPTION | описание элемента меню |
Все эти элементы имеют довольно большое количество атрибутов, которые далеко не все реализованы в большинстве интерфейсов.
Вторым краеугольным камнем WWW стала универсальная форма адресации информационных ресурсов. Universal Resource Identification (URI) представляет собой довольно стройную систему, учитывающую опыт адресации и идентификации e-mail, Gopher, WAIS, telnet, ftp и т. п. Но реально из всего, что описано в URI, для организации баз данных в WWW требуется только Universal Resource Locator (URL). Без наличия этой спецификации вся мощь HTML оказалась бы бесполезной. URL используется в гипертекстовых ссылках и обеспечивает доступ к распределенным ресурсам сети. В URL можно адресовать как другие гипертекстовые документы формата HTML, так и ресурсы e-mail, telnet, ftp, Gopher, WAIS. Различные интерфейсные программы по-разному осуществляют доступ к этим ресурсам. Одни, как, например, Netscape, сами способны поддерживать взаимодействие по протоколам, отличным от протокола HTTP, базового для WWW, другие, как например Chimera, вызывают для этой цели внешние программы. Однако, даже в первом случае, базовой формой представления отображаемой информации является HTML, а ссылки на другие ресурсы имеют форму URL. Следует отметить, что программы обработки электронной почты в формате MIME также имеют возможность отображать документы, представленные в формате HTML. Для этой цели в MIME зарезервирован тип "text/html".
Одной из проблем реализации языка
Одной из проблем реализации языка SQL всегда являлась проблема распознавания "изменяемости" соединений. Как известно, если представление включает соединение общего вида, то теоретически невозможно определить, можно ли однозначно интерпретировать операции обновления такого представления. Однако существует несколько важных классов соединений, которые заведомо являются изменяемыми. В SQL-3 предполагается выделить эти классы с помощью специальных синтаксических конструкций.Наконец-то появляется возможность определения триггеров как комбинации спецификаций события и действия. Действие определяется как SQL-процедура, в которой могут использоваться как операторы SQL, так и ряд управляющих конструкций. На самом деле, этот механизм очень близок к тому, который реализован в Oracle V.7.
Что касается управления транзакциями, то происходит возврат к старой идее System R о возможности установки внутри транзакции точек сохранения (savepoints). В операторе ROLLBACK можно указать идентификатор ранее установленной точки сохранения, и тогда будет произведен откат транзакции не к ее началу, а к этой точке сохранения.
Как видно, можно ожидать наличия в SQL-3 многих интересных и полезных возможностей. Однако даже промежуточные проекты стандарта включают почти в два раза больше страниц, чем стандарт SQL/92. Поэтому трудно ожидать быстрой реализации этого стандарта после его принятия (а многие вообще сомневаются, что этот стандарт будет когда-либо реализован).
Назад | Содержание | Вперед
Необязательной связи
(рисунок 4.20) могут участвовать не все экземпляры сущности.
Рис. 4.20. Необязательная связь
В отличие от необязательной связи в
Неперемещаемые (non-transferable) связи:
экземпляр сущности не может быть перенесен из одного экземпляра связи в другой (рисунок 4.12).
Рис. 4.11. Рекурсивная связь
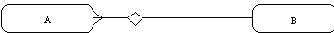
Рис. 4.12. Неперемещаемая связь
Непосредственное управление данными во внешней памяти
Эта функция включает обеспечение необходимых структур внешней памяти как для хранения непосредственных данных, входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях серверов баз данных активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.Нормальная форма Бойса-Кодда
Рассмотрим следующий пример схемы отношения:СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, СОТР_ИМЯ, ПРО_НОМЕР, СОТР_ЗАДАН)
Возможные ключи:
СОТР_НОМЕР, ПРО_НОМЕР СОТР_ИМЯ, ПРО_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР --> CОТР_ИМЯ СОТР_НОМЕР --> ПРО_НОМЕР СОТР_ИМЯ --> CОТР_НОМЕР СОТР_ИМЯ --> ПРО_НОМЕР СОТР_НОМЕР, ПРО_НОМЕР --> CОТР_ЗАДАН СОТР_ИМЯ, ПРО_НОМЕР --> CОТР_ЗАДАН
В этом примере мы предполагаем, что личность сотрудника полностью определяется как его номером, так и именем (это снова не очень жизненное предположение, но достаточное для примера).
В соответствии с определением 7~ отношение СОТРУДНИКИ-ПРОЕКТЫ находится в 3NF. Однако тот факт, что имеются функциональные зависимости атрибутов отношения от атрибута, являющегося частью первичного ключа, приводит к аномалиям. Например, для того, чтобы изменить имя сотрудника с данным номером согласованным образом, нам потребуется модифицировать все кортежи, включающие его номер.
Нормальные формы ER-схем
Как и в реляционных схемах баз данных, в ER-схемах вводится понятие нормальных форм, причем их смысл очень близко соответствует смыслу реляционных нормальных форм. Заметим, что формулировки нормальных форм ER-схем делают более понятным смысл нормализации реляционных схем. Мы приведем только очень краткие и неформальные определения трех первых нормальных форм.В первой нормальной форме ER-схемы устраняются повторяющиеся атрибуты или группы атрибутов, т.е. производится выявление неявных сущностей, "замаскированных" под атрибуты.
Во второй нормальной форме устраняются атрибуты, зависящие только от части уникального идентификатора. Эта часть уникального идентификатора определяет отдельную сущность.
В третьей нормальной форме устраняются атрибуты, зависящие от атрибутов, не входящих в уникальный идентификатор. Эти атрибуты являются основой отдельной сущности.
Новые средства разработки файл-серверных приложений
Чем дальше, тем больше файл-серверные приложения сближаются с более развитыми технологиями клиент-серверных приложений. В последнее время появилась целая серия программных продуктов, позиционируемая одновременно как средства "легкой" разработки приложений для персональных компьютеров, так и более "тяжеловесной" разработки приложений в технологии "клиент-сервер". Это и хорошо, поскольку позволяет плавно изменять технологию.Объектный подход
Для того, чтобы можно было правильно понять материал следующих разделов этой части, кратко обсудим основные понятия объектно-ориентированного подхода.Основным является понятие объекта - неразрывной совокупности данных (состояния объекта) и набора видимых за пределами объекта процедур, осуществляющих доступ к этим данным (методов объекта). Очень важно то, что после своего создания объект получает генерируемый соответствующей программной системой уникальный идентификатор, который не изменяется за все время существования объекта. В классическом объектно-ориентированном подходе объекты инкапсулированы, т.е. доступ к состоянию объекта возможен только через его методы.
Каждый объект относится к некоторому объектному типу (классу), в котором определены как внутренняя структура данных любого объекта этого типа, так и программный код методов такого объекта. Поддерживается понятие наследования объектных типов. Это означает, что при разработке нового типа можно объявить его наследником уже существующего объектного типа, и тогда в новом типе будут считаться определенными структура данных типа-предка и его набор методов. В типе-наследнике можно переопределить структуру данных и код методов типа-предка, а также добавить новые переменные состояния и методы. Наследование может быть одиночным (у каждого типа-наследника может быть только один предок) или множественным (при порождении нового типа разрешается использовать в качестве предков произвольное количество существующих объектных типов). В результате набор объектных типов образует ориентированный ациклический граф (как правило, дерево) в соответствии с отношением наследования.
Считается, что объект, относящийся к объектному типу потомка, одновременно является объектом типа любого из предков этого потомка. Другими словами, если используется объект некоторого объектного типа, у которого есть типы-наследники, то до момента реального выполнения метода реально неизвестен программный код этого метода. Поэтому в объектно-ориентированных программных системах обычно используется позднее (отложенное) связывание с используемыми объектами. С этим же связано понятие объектного полиморфизма. Когда в программе вызывается метод объекта некоторого типа, вызывающий объект на самом деле не знает, какую процедуру он вызывает. Все зависит от способа определения типов-наследников.
Перечисленные свойства делают объектно-ориентированный подход пригодным и выигрышным для использования во многих областях: операционных системах, системах управления базами данных, системах программирования, системах проектирования и т.д. В том числе, как мы уже упоминали выше, объектно-ориентированный подход все чаще применяется для интеграции разнородных информационно-вычислительных ресурсов. Далее мы главным образом будем рассматривать именно этот аспект.
Обязательная (mandatory) связь
описывает связь между "независимой" и "зависимой" сущностями. Все экземпляры зависимой ("обязательной") сущности могут существовать только при наличии экземпляров независимой ("необязательной") сущности, т.е. экземпляр "обязательной" сущности может существовать только при условии существования определенного экземпляра "необязательной" сущности.В примере (рисунок 4.21) подразумевается, что каждый автомобиль имеет по крайней мере одного водителя, но не каждый служащий управляет машиной.

Рис. 4.21. Обязательная связь
В
Общая характеристика современных средств
В индустрии СУБД для персональных компьютеров отразились тенденции нормализации систем (Rightsizing). В последнее время в этой области происходили два встречных процесса: (1) разукрупнение серверов БД - появление новых версий серверов БД Informix, Oracle и т.д. сначала в варианте для рабочих групп, а потом облегченные версии для одиночных персональных компьютеров; (2) укрупнение СУБД для персональных компьютеров - новые "персональные" СУБД и связанные с ними инструментальные средства развивались в сторону "истинно реляционных" СУБД, т.е. серверов БД, приложений клиент-сервер и инструментальных средств программирования 4GL и быстрой разработки RAD.Новые СУБД для персональных компьютеров и соответствующие инструментальные средства разработки файл-серверных приложений обладают перечисленными ниже общими чертами.
Рассмотрим подробнее несколько примеров сравнительно новых инструментальных средств: MS Access 2.0, Visual FoxPro и CA-VisualObjects.
Одиночные операторы манипулирования данными
Каждый из операторов этой группы является абсолютно независимым от какого бы то ни было другого оператора.Ограничение по ссылкам
Ограничение по ссылкам от заданного набора столбцов CT таблицы T на заданный набор столбцов CT1 некоторой определенной к этому моменту таблицы T1 определяет условие на содержимое обеих этих таблиц, при котором ссылки можно считать корректными.Если список столбцов CT1 явно специфицирован в определении ограничения по ссылкам, то требуется, чтобы этот список явно входил в какое-либо определение уникальности таблицы T1. Если же список CT1 не специфицирован явно в определении ограничения по ссылкам таблицы T, то требуется, чтобы в определении таблицы T1 присутствовало определение первичного ключа, и список CT1 неявно полагается совпадающим со списком имен столбцов из определения первичного ключа таблицы T1. Имена столбцов списков CT и CT1 должны именовать столбцы таблиц T и T1 соответственно и не должны появляться в списках более одного раза. Списки столбцов CT и CT1 должны содержать одинаковое число элементов, и столбец таблицы T, идентифицируемый i-ым элементом списка CT должен иметь тот же тип, что столбец таблицы T1, идентифицируемый i-ым элементом списка CT1.
По определению, таблицы T и T1 удовлетворяют заданному ограничению по ссылкам, если для каждой строки s таблицы T такой, что все значения столбцов s, идентифицируемых списком CT, не являются неопределенными, существует строка s1 таблицы T1 такая, что значения столбцов s1, идентифицируемых списком CT1, позиционно равны значениям столбцов s, идентифицируемых списком CT. По человечески это можно сформулировать так: ограничение по ссылкам удовлетворяется, если для каждой корректной ссылки существует объект, на который она ссылается. В привычной программистам терминологии, ограничение по ссылкам не позволяет производить "висячие" ссылки, не ведущие ни к какому объекту.
Ограничение уникальности
Каждое имя столбца в списке уникальности должно именовать столбец T и не должно входить в этот список более одного раза. При определении столбца, входящего в список уникальности, должно быть указано ограничение столбца NO NULL. Среди ограничений уникальности T не должно быть более одного определения первичного ключа (ограничения уникальности с ключевым словом RIMARY KEY).Действие ограничения уникальности состоит в том, что в таблице T не допускается появление двух или более строк, значения столбцов уникальности которых совпадают.
Оператор чтения очередной строки курсора
Синтаксис оператора чтения следующий:В операторе чтения указывается имя курсора и обязательный раздел INTO, содержащий список спецификаций назначения (список имен переменных основной программы в случае встроенного SQL или имен "выходных" параметров в случае модуля SQL). Число и типы данных в списке назначений должны совпадать с числом и типами данных списка выборки спецификации курсора.
Любой открытый курсор всегда имеет позицию: он может быть установлен перед некоторой строкой результирующей таблицы (перед первой строкой сразу после открытия курсора), на некоторую строку результата или за последней строкой результата.
Если таблица, на которую указывает курсор, является пустой, или курсор позиционирован на последнюю строку или за ней, то при выполнении оператора чтения курсор устанавливается в позицию после последней строки, параметру SQLCODE присваивается значение 100, никакие значения не присваиваются целям, идентифицированным в разделе INTO.
Если курсор установлен в позицию перед строкой, то он устанавливается на эту строку, и значения этой строки присваиваются соответствующим целям.
Если курсор установлен на строку r, отличную от последней строки, то курсор устанавливается на строку, непосредственно следующую за строкой r, и значения из этой следующей строки присваиваются соответствующим целям.
Возникает естественный вопрос, каким образом можно параметризовать курсор неопределенным значением или узнать, что выбранное из очередной строки значение является неопределенным. В SQL/89 это достигается за счет использования, так называемых, индикаторных параметров и переменных. Если известно, что значение, передаваемое из основной программы СУБД или принимаемое основной программой от СУБД, может быть неопределенным, и этот факт интересует прикладного программиста, то спецификация параметра или переменной в операторе SQL имеет вид:
Оператор чтения строки по курсору, связанному с динамически подготовленным оператором выборки
По сути, оператор чтения по курсору, связанному с динамически подготовленным оператором SQL, отличается от статического случая только возможным наличием раздела using, в котором задается размещение значений текущей строки результирующей таблицы. Кроме того, имя курсора может задаваться через переменную.
Оператор объявления курсора над динамически подготовленным оператором выборки
Как определяется в новом стандарте, для всех операторов DECLARE CURSOR, курсоры фактически создаются при начале транзакции и уничтожаются при ее завершении. Заметим, что в этом операторе
Оператор объявления курсора
Для удобства мы повторим здесь синтаксические правила объявления курсора, приводившиеся раньше:{
В объявлении курсора могут задаваться запросы наиболее общего вида с возможностью выполнения операции UNION и сортировкой конечного результата. Этот оператор не является выполняемым, он только связывает имя курсора со спецификацией курсора.
Оператор определения курсора над динамически подготовленным оператором выборки
Курсоры, определяемые с помощью оператора ALLOCATE CURSOR, фактически создаются при выполнении такого оператора и уничтожаются при выполнении оператора DEALLOCATE PREPARE или при конце транзакции. В этом операторе имена курсора и подготовленного оператора SQL могут задаваться не только в литеральной форме, но и через переменные.
Оператор определения схемы
В соответствии с правилами SQL/89 каждая таблица данной БД имеет простое и квалифицированное имена. В качестве квалификатора имени выступает "идентификатор полномочий" таблицы, который обычно в реализациях совпадает с именем некоторого пользователя, квалифицированное имя таблицы имеет вид:<идентификатор полномочий>.<простое имя>
Подход к определению схемы в SQL/89 состоит в том, что все таблицы с одним идентификатором полномочий создаются (определяются) путем выполнения одного оператора определения схемы. При этом в стандарте не определяется способ выполнения оператора определения схемы: должен ли он выполняться только в интерактивном режиме или может быть встроен в программу, написанную на традиционном языке программирования.
В операторе определения схемы содержится идентификатор полномочий и список элементов схемы, каждый из которых может быть определением таблицы, определением представления (view) или определением привилегий. Каждое из этих определений представляется отдельным оператором SQL/89, но все они, как уже говорилось, должны быть встроены в оператор определения схемы.
Для этих операторов мы приведем синтаксис, поскольку это позволит более четко описать их особенности.
Оператор освобождения памяти из-под дескриптора
Выполнение этого оператора приводит к освобождению памяти из-под ранее выделенного дескриптора. После этого использование имени дескриптора незаконно в любом операторе, кроме ALLOCATE DESCRIPTOR.
Оператор отказа от подготовленного оператора
Выполнение этого оператора приводит к тому, что ранее подготовленный оператор SQL, связанный с указанным именем оператора, ликвидируется, и соответственно, имя оператора становится неопределенным. Если подготовленный оператор являлся оператором выборки, и к моменту выполнения оператора DEALLOCATE существовал открытый курсор, связанный с именем подготовленного оператора, то оператор DEALLOCATE возвращает код ошибки. Если же для подготовленного оператора выборки существовал неоткрытый курсор, образованный с помощью оператора ALLOCATE CURSOR, то этот курсор ликвидируется. Если курсор объявлялся оператором DECLARE CURSOR, то такой курсор переходит в состояние, существовавшее до выполнения оператора PREPARE. Если с курсором был связан подготовленный оператор (динамический DELETE или UPDATE), то для этих операторов выполняется неявный оператор DEALLOCATE.
Оператор открытия курсора, связанного с динамически подготовленным оператором выборки
По сути, оператор открытия курсора, связанного с динамически подготовленным оператором SQL, отличается от статического случая только возможным наличием раздела using, в котором задаются фактические параметры оператора выборки. Кроме того, имя курсора может задаваться через переменную.
Оператор открытия курсора
Оператор описывается следующим синтаксическим правилом:В реализациях встроенного SQL обычно требуется, чтобы объявление курсора текстуально предшествовало оператору открытия курсора. Оператор открытия курсора должен быть первым в серии выполняемых операторов, связанных с заданным курсором. При выполнении этого оператора производится подготовка курсора к работе над ним. В частности, в этот момент производится связывание спецификации курсора со значениями переменных основного языка в случае встроенного SQL или параметров в случае модуля.
В большинстве реализаций в случае встроенного SQL именно выполнение оператора открытия курсора приводит к компиляции спецификации курсора.
Следующие операторы можно выполнять над открытым курсором в произвольном порядке.
Оператор подготовки с немедленным выполнением
При выполнении оператора EXECUTE IMMEDIATE производится подготовка и немедленное выполнение заданного в текстовой форме оператора SQL. При этом подготавливаемый оператор не должен быть оператором выборки, не должен содержать формальных параметров и комментариев.