
C++ Программирование в среде С++ Builder 5
Часть I. Язык С
Основные принципы и понятия
Знакомство с C++Builder
Обзор языка С
Препроцессор и особенности компилятора
Отладка программ
Первые главы этого части диска носят ознакомительный и довольно элементарный характер. Во-первых, мы расскажем об основных принципах работы компьютера и о процессе создания новой программы. Во-вторых, покажем, как упомянутый процесс реализуется при работе с C++Builder.
После этого мы перейдем к описанию языка С, послужившего основой для разработки C++. Знание непосредственного предшественника языка, изучению которого посвящена книга, представляется необходимым. Освоение С, а затем C++ — естественный путь обучения, хотя, конечно, возможны и другие подходы к этому вопросу. Например, можно было бы начать сразу с классов и объектов, но такая методика потребовала бы как от автора, так и от читателя (который, как предполагается, имеет некоторое представление о традиционном программировании) изменения “интуитивного подхода к окружающему миру”, если выражаться несколько высокопарно. Короче, переход на объектно-ориентированную технологию программирования — процесс непростой, и мы решили пойти традиционным путем, представив сначала краткий курс по языку С; и только потом, в части II, мы займемся собственно программированием на C++.
Естественно, тем читателям, кто хорошо знает С, достаточно будет только просмотреть эти главы книги, хотя совсем игнорировать их мы не рекомендуем.
Основные принципы и понятия
Поскольку книга, как предполагается, адресована широкому кругу читателей, в том числе и новичкам, мы начнем с самых элементарных вещей. И прежде всего с того, как вообще организованы вычисления (в широком смысле слова) на компьютере.
Немного теории и терминологии
Что собой представляет персональный компьютер? Если говорить о его устройстве, то в нем имеется центральное процессорное устройство (CPU), процессор плавающей арифметики, оперативная память (RAM), кэш-память, постоянная память (ROM) с зашитыми в ней подпрограммами BIOS, контроллеры внешних устройств (дисков, клавиатуры, дисплея и т.д.)... В общем, это весьма сложная система, которая, по-видимому, должна производить обработку данных.
С точки зрения программиста все выглядит несколько проще. Программисту нет дела, например, до кэш-памяти — это “прозрачный” буфер между процессором и основной памятью. Процессорное устройство — это просто набор регистров, содержимое которых интерпретируется и изменяется (в частности, вследствие обмена данными с памятью) на каждом шаге того процесса, который называют исполнением программы. Отдельный шаг — это исполнение машинной инструкции. Инструкции по очереди извлекаются из памяти машины.

Может быть, не все знают, что современные компьютеры, если рассматривать их абстрактно, являются так называемыми машинами фон Неймана. Это означает, что программа, т.е. машинные инструкции, и данные, которые машина должна обрабатывать (числа, текст и т.п.), физически никак не отличаются друг от друга и хранятся в одной и той же оперативной памяти. В каком качестве — инструкций или данных — будет интерпретироваться та или иная информация, зависит от контекста, наличного в данный момент времени. Пока программа обрабатывается компилятором, сохраняется на диске или загружается операционной системой в память, она — “данные”. Только когда программа загружена и операционная система передает управление на ее входную точку, она начинает интерпретироваться как собственно программа, состоящая из инструкций.
В качестве текущей инструкции берется содержимое той ячейки памяти, адрес которой содержится в регистре — указателе инструкций(ip). После исполнения инструкции этот регистр либо получит приращение и будет указывать на следующую по порядку инструкцию, либо будет загружен новым значением, не связанным с предыдущим, что приведет к передаче управления в другую часть программы (это происходит чаще всего при вызове процедуры). При вызовах процедур и функций очень важен еще один регистр — указатель стека (SP). О нем нам еще придется говорить в дальнейшем.
Нам, как программистам, пишущим на C++, нужно очень хорошо представлять себе логическую организацию памяти компьютера, поскольку в этом языке чрезвычайно большую роль играют указатели и ссылки, а также динамическое распределение памяти. Логически память представляет собой непрерывную последовательность 8-битных байтов, идентифицируемых своими адресами. Если некоторый объект (в широком смысле слова — число, строка, структура и т.д.) занимает несколько байтов, то его адресом будет являться адрес его младшего (начального) байта. Адрес на машинах класса Pentium — это, по существу, 32-битное целое число без знака. Указатель (или ссылка) фактически является переменной, которая содержит целое число, представляющее адрес другого объекта.
Важнейшей технической характеристикой компьютера является его разрядность. Разрядность определяется размером регистров процессора; это — размер порции данных, которую процессор способен обработать за один раз, при исполнении одиночной инструкции. Мы с вами будем говорить о программировании 32-битных машин семейства Pentium в той мере, в какой это, будет относиться к конкретным программам, создаваемым с помощью C++Builder; что касается стандартов языка C++, не имеет значения, на какой машине вы работаете.
На практике прикладному программисту не приходится иметь дела с машинными инструкциями и прочими “низменными материями” — он пишет программу на языке высокого уровня, таком, как C++ или Pascal. Заботу об управлении внешними устройствами берет на себя операционная система, оснащенная соответствующими драйверами, в нашем случае — 32-битная система Windows (NT, 95, 98, 2000). Любое устройство графического отображения информации (например, дисплей) представляется контекстом устройства (DC) системы Windows. Действия пользователя (нажатие клавиш, манипуляции мышью) преобразуются системой в события, или сообщения, получаемые прикладной программой. Кстати, Windows и называется системой, управляемой событиями.
Ну вот, мы, кажется, закончили с изложением необходимых сведений об организации персонального компьютера. Этот коротенький параграф может вызвать у читателя недоумение. Мы ввели ряд терминов, по существу никак их не определяя. Честно говоря, все написанное выше предназначено только для того, чтобы просто ввести в обиход некоторые важные слова; что они означают, будет выясняться впоследствии. А теперь мы поговорим о том, как происходит преобразование кода на языке высокого уровня, написанного прикладным программистом, в инструкции процессора, в машинный код, сохраняемый в ехе-файлах системы Windows.
О библиотеках
Выше мы уже упоминали о библиотеках, не объясняя, впрочем, что они собой представляют. Конкретнее, мы имели в виду библиотеки объектных модулей; такая библиотека является просто собранием модулей объектного кода, скомпонованных в одном файле с расширением lib, своего рода архивом. На рис. 1.1 показана гипотетическая библиотека пользователя Addon.lib. Она могла бы быть создана из нескольких объектных модулей путем обработки их библиотекарем tlib32.exe.
На рисунке показаны также код запуска и исполнительная библиотека языка C/C++. Это необходимые элементы компоновки любой программы на С. Код запуска исполняется перед тем, как управление будет передано на входную точку вашей программы (функцию main, WinMain и т. п.). Среди задач, им выполняемых, можно указать следующие:
инициализация исполнительной библиотеки
конструирование глобальных объектов C++
завершение программы при отсутствии необходимых ресурсов.
Исполнительная библиотека содержит разнообразные процедуры общего назначения, которые вы можете вызывать в своей программе. В частности, библиотека обеспечивает:
управление файлами
управление памятью
преобразование данных и многое другое.
Что касается динамически присоединяемых библиотек — DLL, — то во многих случаях они, с точки зрения программиста, мало чем отличаются от обычных, статически компонуемых библиотек объектных модулей. Функция, которая находится в DLL, вызывается так же, как и всякая другая функция. Правда, “снаружи” динамическая библиотека выглядит скорее как исполняемый файл; эти библиотеки создаются не библиотекарем, а компоновщиком. Вообще-то вопросы разработки и использования DLL выходят за рамки этой книги, но в следующей главе мы приведем пример простейшей DLL, чтобы читатель получил представление о том, как это делается в C++Builder.
Каждая библиотека, как правило, сопровождается своим заголовочным файлом (их может быть и несколько), который определяет интерфейс ее функций и других элементов. Исходный код библиотеки может быть и недоступен для программиста. Но в ее заголовочном файле (или файлах) имеется все необходимое для использования библиотеки в прикладной программе.
Заключение
В этой очень короткой главе мы попытались обрисовать “классический” процесс создания прикладной программы на языке C/C++. По сути наше изложение было ориентировано на то, чтобы дать читателю представление о терминологии, которую мы будем постоянно применять, и создать тем самым некоторый первоначальный контекст, для дальнейшего обсуждения. То, что осталось непонятным, будет проясняться в дальнейшем.
Проблема раздельной компиляции
Когда-то давно программа для машины вроде БЭСМ-4, написанная на языке Алгол-60 или FORTRAN, состояла из одного-единственного файла, а точнее, являлась просто одной “колодой” перфокарт. Также и первые версии языка Pascal для PC (например, Turbo Pascal 2) допускали, по существу, компиляцию только программ, состоящих из единственного исходного файла. Компилятор “видел” сразу весь текст программы и мог непосредственно проконтролировать, например, количество и тип фактических параметров в вызове процедуры, — соответствуют ли они тем, что указаны в заголовке ее определения (формальным параметрам). Компилятор транслировал программу сразу в машинный код (исполняемый файл).
С ростом сложности и объема программ пришлось разбивать их на несколько файлов исходного кода. Соответственно трансляция программы распалась на два этапа — компиляции, на котором каждый из исходных файлов транслируется в файл объектного кода, и компоновки, в результате которой из нескольких объектных файлов получается конечный исполняемый файл. При этом необходимо произвести, как говорят, разрешение адресных ссылок, когда, например, основной файл программы обращается к вспомогательной процедуре, находящейся в другом файле.
Компилятор C/C++ генерирует стандартные объектные файлы с расширением .obj. (Их формат определен фирмой Intel и не зависит от конкретной операционной системы.) Файлы эти содержат машинный код, который снабжен дополнительной информацией, позволяющий компоновщику разрешать ссылки между объектными модулями. Так, в начале файла формируются две таблицы: таблица глобальных символов (это имена объектов, определяемых в данном файле, на которые могут ссылаться другие модули программы) и таблица внешних ссылок (имена объектов в других файлах, к которым обращается данный модуль). Пользуясь информацией этих таблиц, компоновщик модифицирует код, подставляя в него соответствующие адреса.
Проблема состоит в том, что в объектном файле отсутствует информация, которая позволяла бы проверить корректность вызова процедуры (т.е. количество и тип ее параметров), находящейся в другом файле. Ведь компилятор обрабатывает файлы исходного кода по отдельности.
В языке Turbo Pascal (и позднее — в Delphi) эта проблема была решена благодаря определению специального формата промежуточных файлов. Эти “объектные” файлы (в Delphi они имеют расширение ,dcu) содержат, помимо всего прочего, информацию о параметрах процедур и функций, об определяемых в модуле типах данных (классах) и т.д.
C/C++ был задуман как максимально универсальный язык, и потому он не может использовать нестандартный формат объектных файлов. Это сделало бы невозможным, например, создание файлов подпрограмм, которые могли бы включаться в программы, написанные на других языках. Возможность раздельной компиляции обеспечивается в C/C++ применением заголовочных файлов, присоединяемых к компилируемым исходным файлам на этапе препроцессорной обработки. Заголовки содержат прототипы функций, объявления типов и другую информацию, необходимую для раздельной компиляции исходных модулей программы.
Заголовочные файлы (они имеют расширение .h или .hpp) подключаются к компилируемому файлу исходного кода (.с или .срр) с помощью директивы препроцессора #include, за которой следует имя заголовочного файла в кавычках или угловых скобках, например:
#include <stdlib.h>
#include "myfile.h"
Препроцессор заменяет директиву #include содержимым указанного файла; после завершения препроцессорной обработки полученный текст передается компилятору, который транслирует его в объектный код.
Во многих системах программирования на C/C++ препроцессор составляет единое целое с компилятором (это верно и для C++Builder). Тем самым ускоряется компиляция исходных файлов, и нет необходимости создавать промежуточный файл, содержащий обработанный препроцессором код. Однако в C++Builder имеется отдельный препроцессор срр32.ехе, запускаемый из командной строки. Вы можете им воспользоваться, если нужно просмотреть текст, получаемый в результате препроцессорной обработки; это может быть полезно, например, при отладке макросов препроцессора. Директивы препроцессора будут подробно рассматриваться в 4-й главе.
Один и тот же заголовок можно подключать ко многим исходным файлам. Таким образом, отдельно компилируемые модули получают доступ к необходимой информации о процедурах и прочих элементах программы, определяемых в других модулях. Кроме того, это гарантирует, что размещенное в заголовочном файле объявление типа или функции будет одним и тем же во всех компилируемых файлах, и любые внесенные в него изменения будут автоматически воздействовать на все модули программы.
Процесс построения программы
В этом разделе мы опишем “классический” процесс подготовки и трансляции программы на языке высокого уровня (в нашем случае это C++') в исполняемый файл, содержащий машинные инструкции и все остальное, что необходимо для работающей программы системы Windows. В C++Builder, как мы увидим в дальнейшем, детали этого процесса в основном скрыты от программиста и, кроме того, имеются дополнительные моменты, обусловленные спецификой визуального подхода к программированию. Создание программы на языке C++ выглядит примерно так. Прежде всего, программист с помощью того или иного текстового редактора готовит файлы исходного кода на C/C++. После этого происходит построение программы, в котором можно выделить такие этапы:
Компиляцию исходных файлов в файлы объектного кода (с расширением .obj).
Компоновку объектных файлов с присоединением необходимых библиотек (в том числе, возможно, динамических), в результате чего получается уже машинный код.
Компоновку ресурсов (ресурсы включают в себя битовые матрицы, курсоры, строковые таблицы, пиктограммы и т.п.). Это завершающий этап, на котором формируется конечный ехе-файл, запускаемый на выполнение. Этот процесс иллюстрируется рис. 1.1.
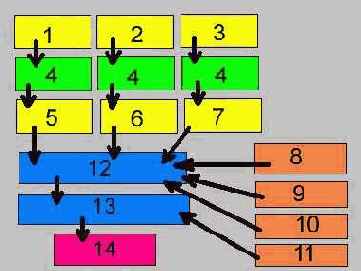
Рис. 1.1 Упрощенная схема построения программы
1. Source1.cpp
2. Source2.cpp
3. Source3.cpp
4. Компилятор
5. Source1.obj
6. Source2.obj
7. Source3.obj
8. Addon.lib
9. Код запуска
10. Исполнительная библиотека
11. Ресурсы App.res
12. Компоновщик
13. Компоновщик ресурсов
14. Приложение App.exe
Некоторые системы (и в том числе C++Builder) сразу выполняют компоновку объектных файлов с ресурсами, совмещая два последних этапа. Что касается первого шага — компиляции — то здесь возникает одна проблема, которую стоит обсудить.
Знакомство с C++Builder
В этой главе мы познакомимся с интегрированной средой разработки C++Builder и посмотрим, как с ее помощью выполняются некоторые простейшие задачи.
Hello World
По традиции изучение любого языка программирования начинается с того, что новичку предлагают написать программу, которая выводит на экран слова “Hello World”. Мы не будем отступать от этой традиции и покажем, как реализовать такую программу в C++Builder. Мы составим даже две программы; одну — с выводом на консоль, а другую — с графическим интерфейсом пользователя (GUI), т. е. настоящее приложение Windows.
Hello World — консольное приложение
Консольное приложение Windows похоже на программу DOS, но только внешне. Оно работает в “окне MS-DOS”, которое на самом деле в 32-битных системах Windows таковым не является. Консольное приложение — 32-битное, и запустить его в обычной 16-битной DOS невозможно. Однако, подобно примитивной программе DOS, оно ориентировано на символьный ввод-вывод, что делает консольные приложения полезными при изучении стандартных функций ввода-вывода языка С и классов стандартных потоков C++.
Чтобы создать в C++Builder консольное приложение, выполните следующие действия:
Выберите в главном меню File | New...; появится многостраничная диалоговая панель New Items (рис. 2.4). Этот диалог является интерфейсом так называемого хранилища объектов C++Builder (Object Repository). Помимо уже имеющихся объектов вы можете сохранять в нем свои собственные формы, диалоговые панели и прочие элементы, пригодные для повторного использования в новых программах.
На странице New выберите Console Wizard и нажмите кнопку ОК. Если у вас 4-я версия компилятора, в появившейся панели “консольного мастера” оставьте установки по умолчанию и нажмите кнопку Finish. Если же вы работаете с C++Builder 5, установите состояние флажков в соответствии с рис. 2.8 (внизу). C++Builder создаст проект консольного приложения и откроет окно редактора кода с файлом Project1.cpp или Unit1.cpp (Unit1.c) в зависимости от версии.
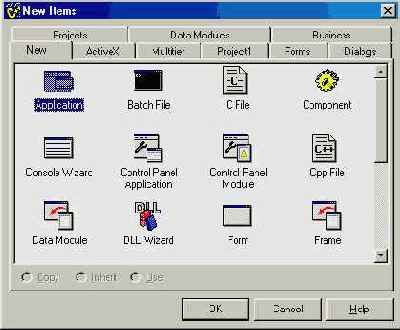
Рис. 2.4 Диалог New Items
Выберите в главном меню File | Save Project as... и сохраните файлы проекта в отдельном каталоге (папке). Назовите проект и модуль, например, HWConsole — необходимые расширения файлов C++Builder добавит автоматически. Сейчас ваш исходный файл имеет такой вид:
#pragma hdrstop
#include <condefs.h>
//--------------------------
#pragma argsused
int main(int argc, char* argv[ ])
{
return 0;
}
Строчку #include <condefs.h> вставляет только C++Builder 4-й версии. Для C++Builder 5 она не нужна. В дальнейшем не обращайте на нее внимания, если она будет попадаться в листингах. Модифицируйте код файла HWConsole. срр так, чтобы он выглядел следующим образом (строчки, которые требуется ввести, выделены жирным шрифтом):
#pragma hdrstop
#include <stdio.h>
#include <conio.h>
#include <condefs.h>
//------------------------------------------
#pragma argsused int main(int argc, char* argv[])
{
printf("Hello World from Console!\n"), printf("Press any key...");
getch() ;
return 0;
}
Сохраните файл (File Save в главном меню) и нажмите кнопку Run на инструментальной панели (кнопка с зеленой стрелкой). C++Builder компилирует исходный файл, произведет компоновку исполняемого файла и запустит программу. На экране должно появиться окно MS-DOS, показанное на рис. 2.5. Если вы нажмете любую клавишу на клавиатуре, программа завершится и ее окно закроется.
Закройте проект (File | Close All в главном меню).
Вот и все — консольное приложение готово и работает. Для этого вам потребовалось ввести вручную пять строк кода на С. Первые две из них — директивы ^include, включающие в исходный код два заголовочных файла стандартной библиотеки. Файл stdio.h содержит прототипы общеупотребительных функций буферизованного ввода-вывода (мы здесь использовали функцию prinf() — форматируемый вывод на консоль). Файл соnio.h необходим потому, что для ожидания нажатия клавиши мы применили низкоуровневую функцию ввода символа getch() ; символ, возвращаемый функцией, мы игнорировали.
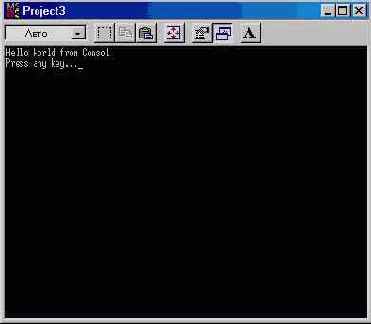
Рис. 2.5 Окно программы HWConsole.exe
Функция main () присутствует (иногда неявно) в каждой программе C/C++ и является ее входной точкой. Именно этой функции передается управление после загрузки и инициализации программы.
Директивы препроцессора #pragma мы будем обсуждать в 4-й главе. Пока скажем, что они здесь не имеют принципиального значения и их можно было бы удалить. Но это привело бы к выдаче предупреждений при компиляции, а в некоторых случаях замедлило ее.
Строки, начинающиеся с двойной дробной черты, содержат комментарии и не принимаются во внимание при компиляции файла.

Написанная программа является по сути программой на языке С. В 5-й версии компилятора, если вы хотите написать “честную” программу на С и компилировать ее как такую, проблем никаких — исходный язык задается прямо в панели консольного мастера. В 4-й версии дела обстоят несколько сложнее. Дело в том, что в C++Builder 4 главный исходный файл консольного приложения должен обязательно быть срр-файлом и определять функцию main. Если же вы хотите использовать в качестве главного файла программы именно с-файл, придется пойти на некоторые ухищрения. Сделайте следующее:
Создайте с помощью Console Wizard новый проект.
Удалите из исходного файла функцию main() и добавьте директиву ^define main, чтобы файл принял такой вид:
#pragma hdrstop
#include <condefs.h>
#define main
Выберите в главном меню File [ New... (или нажмите кнопку New — чистый листок — на инструментальной панели); появится диалог New Items.
Выберите на странице New значок Unit; к проекту будет добавлен новый модуль исходного кода с именем Unit1 .cpp. (Вы можете открыть менеджер проекта, чтобы видеть все изменения в составе исходных файлов, — для этого нужно выбрать в меню View | Project Manager.) Удалите из файла все, кроме директивы hdrstop, и введите код программы:
//---------------------------------
#pragma hdrstop
#include <stdio.h>
#include <c6nio.h>
//----------------------------
main ()
{
printf("Hello World - С main file.\n");
getch();
return 0;
}
Сохраните файл под каким-нибудь другим именем, явно указав расширение .с в диалоге Save As...
Компилируйте и запустите программу, нажав на кнопку Run инструментальной панели.
Еще раз подчеркнем, что сказанное относится только к 4-й версии. C++Builder 5 проделывает практически то же самое, но автоматически.
Теперь мы покажем, как вывести на экран сакраментальное “Hello World”, используя графический интерфейс системы Windows. Другими словами, мы применим технологию визуального программирования, реализованную в C++Builder.
Hello World — приложение GUI
Процедура создания приложения с графическим интерфейсом пользователя даже проще, чем в случае консольного приложения, поскольку C++Builder предназначен именно для этого. Выполните такие действия:
Создайте новый проект, выбрав в меню File | New Application (это эквивалентно выбору значка Application в диалоге New Items). При этом будет открыт конструктор форм с новой, пустой формой (см. рис. 2.1). Инспектор объектов будет показывать ее свойства.
Выберите в левой колонке страницы Properties свойство Caption. Замените его значение (в правой колонке) на “Hello World”. Обратите внимание, что этот текст сразу же появляется в строке заголовка формы.
Теперь разместите на форме необходимые компоненты — две командных кнопки и метку, в которой будет отображаться требуемый текст.
Откройте в палитре компонентов главного окна C++Builder страницу Standard (она открыта по умолчанию) и выберите в ней компонент Button (значок, изображающий командную кнопку). После этого щелкните кнопкой мыши в том месте формы, где должен находиться верхний левый угол компонента. Кнопка будет помещена на форму; вокруг нее будут находиться черные маркеры, которые позволяют изменять размер кнопки с помощью мыши и, кроме того, служат признаком активного (выбранного) компонента формы. Перемещать компонент по форме можно, поместив курсор внутрь компонента.
Вы наверняка заметили, что при перемещении компонента или изменении размеров положение его фиксируется узлами сетки, показанной на форме маленькими точками. Шаг сетки можно изменять или вообще отменить .привязку к сетке.
В инспекторе объектов измените свойство Caption кнопки на “Message”, аналогично тому, как это было сделано для самой формы. Введенный текст задает надпись на кнопке. (По умолчанию это Buttonl.)
Разместите на форме вторую кнопку с надписью “Exit”. (Руководствуйтесь рис. 2.6.)
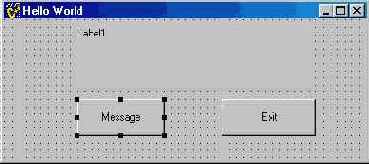
Рис. 2.6 Форма программы в процессе проектирования
Выберите в палитре компонентов значок Label (буква А) и поместите компонент метки на форму ниже командных кнопок. Выберите в инспекторе объектов свойство Font. Если нажать маленькую кнопку с многоточием в правой колонке инспектора, появится обычный диалог выбора шрифта, в котором можно задать желаемую гарнитуру и размер текста (рис. 2.6). Кнопка с многоточием в колонке значений — обычный признак того, что для свойства предусмотрен специализированный редактор.
Удалите из свойства Caption весь текст (“ Label 1”).
К данному моменту мы практически завершили то, что называют этапом визуального проектирования программы. Теперь нужно написать программный код, который будет решать требуемую задачу, в данном случае — вывод (по команде) на экран строки текста “Hello World”.
Выберите на форме первую из кнопок и перейдите в инспекторе объектов на страницу событий (Events).
Дважды нажмите кнопку мыши на событии OnClick; C++Builder создаст заготовку процедуры обработки ButtonlClick() и установит курсор редактора кода внутри нее. Введите строку кода, чтобы функция выглядела так:
void _fastcall TFormI::ButtonlClick(TObject *Sender) {
Labell->Caption = "Hello World from GUI!";
}
Точно так же создайте процедуру обработки события для второй командной кнопки:
void _fastcall TFormI::Button2Click(TObject *Sender) {
Forml->Close () ;
}
При желании измените размер формы (как это делается с обычным окном) и сохраните файлы проекта, дав исходному модулю имя, например, HWGuiU, а исходному файлу проекта — HWGui.
Осталось только компилировать и запустить программу. Нажмите на инструментальной панели C++Builder кнопку с зеленой стрелкой (Run). Если при компиляции возникают ошибки, значит вы, скорее всего, сделали где-то опечатку; другие проблемы маловероятны.
Вот и все. Нажмите кнопку Message. Будет выведена строка сообщения. Кнопка Exit завершает работу программы, закрывая ее главное окно (его можно закрыть и системной кнопкой в правом верхнем углу — это то же самое). Ниже показана запущенная программа.
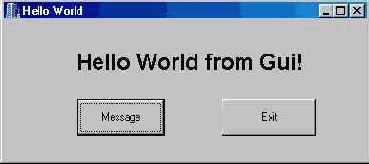
Рис. 2.7 Работающая программа
Как видите, процесс визуального проектирования пользовательского интерфейса идейно очень прост. Вы берете из палитры очередной компонент, размещаете его на форме, подгоняете положение, размер, устанавливаете различные свойства с помощью инспектора объектов. После размещения всех необходимых компонентов следует этап собственно программирования, т. е. написания кода на C++ для различных событий. Обратите внимание — в визуально спроектированном приложении C++Builder любой написанный вами код так или иначе вызывается из некоторой процедуры обработки события.
Те строки кода, что мы ввели в функции OnClick () для обеих командных кнопок, достаточно понятны. Первая из них присваивает свойству Caption расположенной на форме метки требуемую символьную строку. Вторая просто вызывает функцию закрытия формы Close (). Детали синтаксиса этого кода будут проясняться по ходу изучения языка.
Мы реализовали приложение с графическим интерфейсом пользователя, применив визуальные возможности C++Builder; однако можно построить и стандартное оконное приложение, так сказать, на пустом месте, ориентированное на интерфейс прикладного программирования (API) Windows. Для этого нужно воспользоваться тем же мастером Console Wizard, с помощью которого мы создавали заготовку консольного приложения:
Выберите File | New... и запустите Console Wizard. Если у вас C++Builder 4, вы берите радиокнопку Window (GUI) и нажмите кнопку Finish (рис. 2.8, вверху) Если вы работаете с 5-й версией, сбросьте все флажки в правой части панели консольного мастера, показанной на рис. 2.8 внизу.
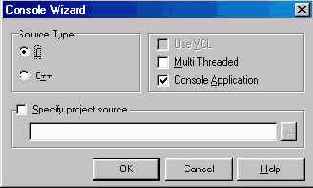
Рис. 2.8 Console Wizard 4-й версии с установками для оконного приложения и 5-й версии для консольного приложения на С
В открывшемся окне редактора кода введите единственный оператор (он рас положен в листинге на двух строчках), чтобы файл принял следующий вид:
#include <windows.h>
#pragma hdrstop
#include <condefs.h>
//--------------------------------
#pragma argsused
WINAPI WinMain(HINSTANCE, HINSTANCE, LPSTR, int) {
MessageBox(NULL, "Hello World from Windows!",
"Simple Greeting", MB_OK | MB_ICONEXCLAMATION);
return 0;
}
Сохраните проект, дав ему какое-нибудь новое имя, затем компилируйте и запустите программу, нажав кнопку Run инструментальной панели. На экране появится стандартная панель сообщения (рис. 2.9).
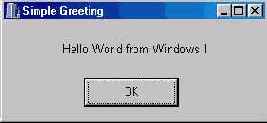
Рис. 2.9 Панель сообщения, выведенная функцией MessageBox
Эта панель отображается функцией API MessageBox (), аргументы которой задают текст сообщения, заголовок панели и ее вид (тип кнопок и значок). Главной функцией программы Windows является, как видите, не main (), а WinMain () .
Приведенные примеры показывают, каким образом в C++Builder можно экспериментировать с различными языковыми конструкциями, которые мы будем изучать. Можно написать “честное” (консольное) приложение C/C++, пользуясь в качестве интерактивных средств функциями ввода с клавиатуры и символьного вывода в окно MS-DOS. Либо с тем же (и даже большим) успехом можно воспользоваться методикой визуального программирования и общаться с тестовым приложением в рамках GUI Windows. Правда, получаемые таким способом программы не являются в строгом смысле программами на C++, поскольку язык визуально-компонентной модели содержит некоторые расширения; однако в плане изучения стандартных элементов языка это несущественно. Существенно то, что стандарт ANSI C++ поддерживается в полном объеме.
Напоследок мы продемонстрируем пример группы проектов C++Builder, т. е. совместного создания нескольких целевых модулей. Мы построим простейшую DLL и тестирующее ее приложение.
Интегрированная среда разработки C++Builder
На рис. 2.1 показан C++Builder сразу после запуска. То, что вы видите — это интегрированная среда разработки (IDE), включающая в себя четыре основных элемента. Наверху находится главное окно. Оно содержит обычную линейку меню, инструментальную панель (слева) и палитру компонентов (многостраничная панель справа).
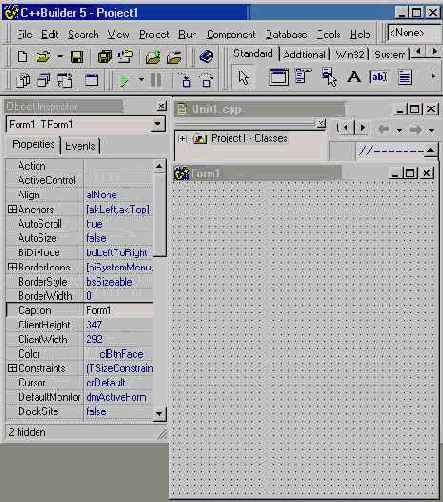
Рис. 2.1 C++Builder 5 с пустой формой
Правее инспектора объектов располагается конструктор форм. При запуске C++Builder конструктор отображает пустую форму. Форма — это центральный элемент визуального программирования. Она может представлять главное окно программы, дочернее окно, диалоговую панель. На ней вы размещаете различные элементы управления (типичный и самый распространенный — командная кнопка), называемые визуальными компонентами. Существуют также и невизуальные компоненты, например, таймеры и компоненты связи с базами данных. В инспекторе объектов вы сопоставляете событиям компонентов написанные вами процедуры обработки. Это, по существу, и есть визуальное программирование, базирующееся на компонентной модели. Подробнее мы расскажем о нем в части III этой книги.
Наконец, под конструктором форм находится окно редактора кода (на рисунке оно почти полностью закрыто формой). О нем мы поговорим отдельно.
Пример DLL
В следующем примере мы покажем, как присоединить к программе функцию из библиотеки. Причем библиотека эта будет не простая, а динамическая. Наиболее существенной особенностью динамических библиотек (DLL) является то, что содержащиеся в них процедуры, функции и ресурсы могут совместно использоваться несколькими приложениями. Это экономит, во-первых, место на диске (поскольку исключается дублирование кода), а во-вторых, оперативную память, когда в нее одновременно загружено несколько программ (по той же самой причине).
Последовательность действий в этом примере будет несколько сложнее, чем в предыдущих, так как мы здесь будем создавать сразу два программных модуля, связанных друг с другом: библиотеку и исполняемый модуль, который ее вызывает. Предлагаю вам проделать следующее:
Откройте новый проект приложения (File New Application в главном меню). Сохраните его, дав исходному модулю имя HWD11U, а исходному файлу проекта — HWD11.
Как я уже, кажется, говорил, желательно сохранять файлы каждого проекта в отдельном пустом каталоге.
Поместите на форму две командных кнопки, назвав первую Call DLL, a вторую — Exit.
Создайте (с помощью инспектора объектов) процедуру обработки события OnClick для первой кнопки и введите в нее строку: SayHelloO ;
Вторая кнопка должна закрывать программу; проделайте для нее все то же самое, что и в примере предыдущего раздела.
В верхней части файла, после всех директив #include, добавьте такую строчку: void export SayHello(void);
Файл теперь должен иметь такой вид:
#include <vcl.h> ftpragma hdrstop
#include "HWDllU.h"
void export SayHello(void);
//--------------------------------
#pragma package(smart_init) #pragma resource "*.dfm" TFormI *Forml;
//---------------------------------------
_fastcall TFormI::TFormI(TComponent* Owner)
: TForm(Owner) {
}
//------------------------------------
void_fastcall TFormI::ButtonlClick(TObject *Sender) {
SayHello() ;
} //------------------------------------
void_fastcall TFormI::Button2Click(TObject *Sender)
forml->Close() ;
}
С нашей главной программой пока все. Теперь откройте менеджер проектов (View | Project Manager). Наверху показан узел группы проектов с именем по умолчанию ProjectGroupl. Эта группа включает в себя пока всего один проект (HWDU.exe). Щелкните правой кнопкой мыши на узле группы и в контекстном меню выберите Add New Project...
Появится знакомый вам диалог New Items; выберите в нем значок DLL (4-я версия) или DLL Wizard (версия 5). В группе проектов появится новый узел, и для него будет открыто новое окно в редакторе кода. Введите код функции SayHelloO и добавьте в верхней части директиву f include, чтобы файл принял следующий вид (комментарии я удалил):
#include <vcl.h>
#include <windows.h>
#pragma hdrstop //----------------------------------
void _export SayHello(void)
{
MessageBox(NULL, "Hello World from DLL!",
"Simple Greeting", MB__OK | MB_ICONEXCLAMATION);
}
Lnt WINAPI DilEntryPoint(HINSTANCE hinst,
unsigned long reason, void*) {
return 1;
}
Сохраните проект DLL под именем SHello и постройте библиотеку, для чего вызовите для узла SHello. dll контекстное меню и выберите в нем Make. C++Builder компилирует исходный файл и создаст файл DLL; при этом он также генерирует (по умолчанию) библиотеку импорта SHello lib, которая требуется для компоновки исполняемого файла нашей программы.
Рядом с пунктом контекстного меню Make (собрать) имеется пункт Build (построить). Если вы откроете Project в главном меню, то увидите там эквивалентные пункты Make SHello и Build SHello. Обе команды выполняют построение текущего проекта (его целевого файла). Разница в том, что Build компилирует и компонует заново все входящие в проект файлы, в то время как Make производит те или иные действия лишь при необходимости, например, при модификации кода в одном исходном файле будет компилироваться только этот файл, после чего будет выполнена компоновка программы.
Теперь мы вернемся к проекту главной программы. (В верхней части менеджера проектов имеется выпадающий список; выберите в нем HWDlI.exe.) К нему следует присоединить библиотеку импорта уже построенной DLL, чтобы компоновщик мог разрешить ссылку на функцию SayHelLo () , вызываемую из главной программы (HWDlI.exe), но физически находящуюся в отдельно загружаемом файле (SHello.dll). Для этого вызовите контекстное меню ехе-узла и выберите в нем пункт Add. Появится стандартный диалог открытия файла.
В выпадающем списке типов файлов выберите Library file (.lib). Вы должны увидеть библиотеку SHello.lib; выберите ее и закройте диалог. Библиотека будет присоединена к проекту HWDll.exe (рис. 2.10). Со храните группу проектов, выбрав в ее контекстном меню Save Project Group As...
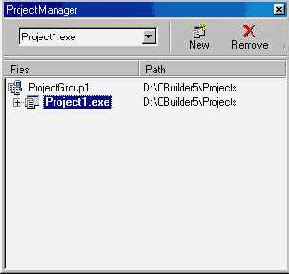
Рис. 2.10 Менеджер проектов, показывающий Структуру группы
Теперь осталось только компилировать и запустить наше главное приложение. Для этого просто нажмите кнопку Run инструментальной панели. Когда появится окно программы, нажмите кнопку Call DLL. Будет вызвана функция из DLL SayHello(), которая отобразит панель сообщения (рис. 2.11).
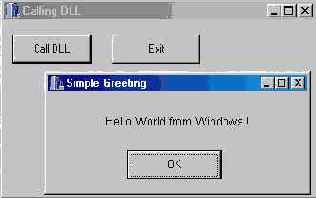
Рис. 2.11 Вызов функции DLL
То, что мы сейчас проделали, называется статической загрузкой динамической библиотеки. Суть ее в том, что DLL (если она еще не загружена) автоматически загружается в память при запуске главной программы. Библиотека импорта необходима именно для статической загрузки, при которой все ссылки на DLL разрешаются еще на этапе компоновки.
Возможна и динамическая загрузка DLL, которая, однако, выполняется вручную, т. е. специально написанным для этого программным кодом; достоинство ее в том, что она может производиться лишь при необходимости. При этом разрешение ссылок на DLL происходит уже во время выполнения, — другими словами, программе приходится “на ходу” как-то искать нужную функцию в DLL (например, по имени).
Вот, собственно, и все о DLL. Хотя динамические библиотеки (да и всякие другие) выходят за рамки тематики этой книги и в дальнейшем изложении нам встречаться больше не будут, нам показалось полезным дать читателю некоторое представление о том, как создание и использование этих библиотек выглядит в C++Builder.
Заключение
В этой главе мы показали типичные действия, выполняемые при разработке приложений в интегрированной среде C++Builder. Конечно, представленные здесь программы совершенно ничтожны, однако они работают, а заставить что-то заработать в Windows — это не шутка. В следующих главах мы переходим уже собственно к вопросам программирования и изучению различных конструкций языка C/C++.
Редактор кода
Окно редактора кода, показанное на рис. 2.2, является основным рабочим инструментом программиста. Его функции не ограничиваются редактированием исходного текста программы.
Нужно сказать, что почти все инструментальные окна C++Builder являются стыкуемыми окнами. Вы, наверное, не раз встречались в различных программах со стыкуемыми инструментальными панелями. Их масса в Microsoft Word, в котором я пишу этот текст. Такая панель может быть плавающей, а может быть состыкована с главным окном программы. В этом случае она становится обычной инструментальной линейкой.
При первоначальном запуске C++Builder к левой стороне редактора кода пристыковано окно обозревателя классов. Это не просто инструмент просмотра структуры классов. При некотором навыке можно использовать его с большой выгодой, поскольку он позволяет автоматически вводить в описание класса новые элементы (функции, данные и свойства).
Рис. 2.2 Окно редактора кода с обозревателем классов
Инструментальное окно C++Builder может быть состыковано с другим окном в одном из пяти его портов стыковки: либо вдоль какой-либо стороны окна, либо по центру. Если стыковка производится вдоль стороны окна, получается что-нибудь подобное показанному на рис. 2.2. В случае стыковки по центру окно становится многостраничным, с закладками, позволяющими переключаться между страницами.
Советую вам поэкспериментировать со стыковкой окон. Сделайте, например, такое упражнение:
Выберите в меню View Project Manager. Появится окно менеджера проектов, который служит в основном для управления исходными файлами разрабатываемых приложений. Вызовите контекстное меню окна (щелкнув правой кнопкой мыши) и убедитесь, что его пункт Dockable помечен.
Захватите мышью заголовок менеджера проектов и передвиньте курсор на окно обозревателя классов (которое само состыковано с редактором кода). При перемещении окно будет показано серым контуром. Когда курсор окажется в центре окна обозревателя классов, серый контур будет “захвачен” в центральном порте стыковки, не касаясь сторон окна. (Когда курсор пересекает границу окна, серый контур будет захватываться в порте стыковки вдоль этой границы).
Отпустите кнопку мыши. Окно обозревателя классов станет двухстраничным окном с закладками Project Manager и Class Explorer.
Поместите курсор на захват (двойную полоску в верхней части окна) и “вытащите” инструментальное окно из окна редактора. В результате у вас получится плавающее двухстраничное окно, в котором совмещаются менеджер проектов и обозреватель классов.
Снова состыкуйте комбинированное окно с окном редактора кода вдоль левой стороны последнего.
В редакторе можно открывать сразу несколько файлов исходного кода. При этом он также становится многостраничным окном с закладками. Надписи на закладках отражают имена файлов.
Рис. 2.3 показывает окно редактора кода с двумя открытыми файлами и пятью пристыкованными инструментальными окнами.
Может показаться, что все эти экзерсисы со стыковкой не более чем игра. Отнюдь нет. В процессе работы над программой, особенно во время отладки, вам понадобятся три-четыре вспомогательных окна, а может быть, и больше. Это небольшие окна, и они легко могут потеряться за более крупными. Если же все необходимые окна будут сосредоточены в одном месте, получить доступ к нужному инструменту очень просто. Любой из них находится, как говорят, “на расстоянии двух щелчков мыши” от вас.
В C++Builder, как и во многих других современных программах, многие операции реализуются через контекстные меню, которые вызываются нажатием правой кнопки в том или ином окне.
Поэкспериментируйте с различными контекстными меню; посмотрите, какие имеются пункты в контекстном меню редактора. Многое понятно и без всяких объяснений, а если непонятно, вы можете при открытом меню нажать F1 для вызова справки C++Builder. Может быть, станет понятнее.
Рис. 2.3 Редактор кода с пристыкованными окнами различных инструментов
Ну а теперь лучше всего перейти, наконец, прямо к делу и написать пару работающих программ на С.
Блоки и локальные переменные
Поскольку при описании управляющих конструкций мы попутно ввели понятие блока, нужно сделать одно уточнение касательно объявлений и области действия локальных переменных. На самом деле локальные переменные могут объявляться не только в начале тела функции, но и в любом другом блоке (if, while и т. д.). Областью действия переменной является блок, в котором она объявлена; она скрывает любую переменную с тем же именем, объявленную вне данного блока. За пределами блока переменная недоступна.
Циклы
В языке С структуры многократного повторения реализуются тремя разновидностями операторов цикла. Это циклы while, do... while и for.
Цикл while
Синтаксис оператора while выглядит так:
while (условие продолжения) оператор
Сначала оценивается условие_продолжения. Если оно истинно, выполняется оператор, после чего управление возвращается заголовку цикла, и все повторяется снова. Когда условие оказывается ложным, управление передается следующему после цикла оператору.
Как обычно, одиночный оператор тела цикла можно заменить блоком, заключенным в фигурные скобки:
whi1е (условие_продолжения)
{
операторы_тела цикла
}
Используя этот оператор, можно было бы переписать предыдущий пример (со структурой switch) следующим образом:
int main(int argc, char* argv[ ])
{
int key, done = 0;
while (!done) {
printf("\nEnter command (F, M or Q): ");
key = getche(); // Прочитать клавишу.
switch (key) ( // Определение команды... case 'f':
case 'F':
printf("\n\"File\" command selected.\n");
break;
case 'm':
case 'M':
printf("\n\"Message\" command selected.\n");
break;
case 'q':
case 'Q':
printf("\n\"Quit\" command selected.\n");
done = 1; // Завершить цикл.
break; default:
printf("\nlnvalid command!\n") ;
}
} printf("\nPress a key to Exit...");
getch() ;
return 0; // Возврат в Windows.
}
Это более “грамотная” версия цикла обработки команд. Пока done равняется нулю, цикл продолжает выполняться. Когда нажимают клавишу 'q', done присваивается единица и при очередной оценке условия оно оказывается ложным; цикл завершается.
Обратите внимание, что в цикле while проверка условия делается перед выполнением тела цикла. Если условие изначально ложно, то тело цикла не исполняется вообще, ни одного раза.
Цикл do—while
Этот цикл имеет такой вид:
do оператор while (условие продолжения);
Здесь сначала выполняется оператор, а затем производится проверка условия_продолжения. Если условие истинно, управление возвращается в начало цикла; если ложно, цикл завершается и управление переходит к оператору, следующему за циклом.
Отличие от предыдущей конструкции очевидно — тело цикла do... while исполняется хотя бы один раз вне зависимости от каких-либо условий, в то время как в цикле while при ложном условии тело не исполняется вообще. Хотя конкретную программную задачу можно решить, применив любую из этих конструкций, чаще всего одно из двух решений оказывается более экономным.
Цикл for
Цикл for, наиболее универсальный из всех циклов языка С, выглядит так:
for ([инициализация]; [условие]; [модификация]) оператор
Прежде всего выполняется инициализация цикла; секция инициализации может содержать любое выражение. Инициализация производится только один раз перед началом работы цикла.
Оценивается выражение условия. Если оно истинно, выполняется оператор тела цикла; если условие ложно, происходит выход из цикла и управление передается следующему оператору.
После исполнения тела цикла производится модификация, после чего управление возвращается заголовку цикла и все повторяется снова. Секция модификации может содержать любое выражение; обычно в ней изменяют значения управляющих переменных цикла.
Как видно из синтаксического описания, любую секцию заголовка цикла for можно опустить, но разделители — точки с запятой — все равно должны присутствовать. Если опущено условие, цикл будет выполняться бесконечно.
Простейшей и самой популярной конструкцией на основе цикла for является цикл с управляющей переменнои-счетчиком:
int i;
for (i =0; i < REPEAT; i++)
DoSomething (i);
Счетчик инициализируется значением 0. В начале каждого прохода цикла проверяется, не достиг ли он значения REPEAT. Как только i станет равным REPEAT, тело цикла пропускается и управление передается следующему оператору. В конце каждого прохода i увеличивается на единицу. Как нетрудно подсчитать, тело цикла выполняется для значений i от О до REPEAT-1, т. е. REPEAT раз.

Любую конкретную структуру повторения, требуемую для решения некоторой задачи, можно реализовать на основе любого из циклов С, однако всегда какой-то из них подходит к данному случаю наилучшим образом, позволяя написать более ясный и компактный код. Так, если необходимое число итераций цикла известно заранее (как при обработке массива), проще всего применить цикл for. Если же число итераций заранее определить нельзя, как в нашем примере обработки команд (момент завершения цикла определяется пользователем) или при операциях поиска в списке, применяют цикл while или do. . .while.
У структур повторения в ряде ситуаций есть альтернатива. Это рекурсия, заключающаяся в том, что функция вызывает саму себя. Естественно, такой вызов должен быть условным, т. е. обязательно должен наступить такой момент, когда на очередном шаге рекурсивного вызова не происходит. Есть классический пример рекурсии — вычисление факториала:
unsigned Fac(unsigned n)
{
if (n)
return n * Fac(n - 1);
else
return 1;
}
Когда аргумент в очередном вызове оказывается равен 0, рекурсия завершается — функция возвращает 1. До этого момента не происходило, по существу, реальных вычислений (умножений). На стеке накапливались вызовы Fac () с последовательно уменьшающимися аргументами. Теперь стек начинает “разматываться”, и возвращаемые на каждом шаге значения умножаются на последовательно увеличивающиеся n. Глубина рекурсии ограничивается только размером стека программы.
Факториал, конечно, вообще никто никогда не вычисляет, во всяком случае, подобным образом. Однако существуют задачи, для которых метод рекурсии оказывается естественным решением и реализуется намного проще, чем это можно
было бы сделать с помощью циклов. Таковы, прежде всего/ различные операции над древовидными структурами данных.
Не все языки программирования допускают рекурсию. Мы напомнили о ней просто для того, чтобы подчеркнуть, что С — один из тех языков, в которых рекурсия возможна.
Директивы #include
Директива # include заменяется препроцессором на содержимое указанного в ней файла. Обычно это заголовочные файлы с расширением .h. Они содержат информацию, обеспечивающую раздельную компиляцию файлов исходного кода и корректное подключение различных библиотек. Имя файла может быть заключено либо в угловые скобки (о, меньше—больше), либо в обычные двойные кавычки (""). Эти случаи различаются порядком поиска включаемых файлов; если использованы угловые скобки, поиск будет сначала производиться в стандартных каталогах C++Builder, если кавычки — в текущем каталоге.
Директивы # pragma
Строки исходного кода, начинающиеся со знака #, являются, как правило, директивами препроцессора, т. е. управляют обработкой текста программы еще до его передачи собственно компилятору (сюда относятся текстовые подстановки, вставка содержимого других файлов и некоторые специальные операции). Директивы #pragma в этом смысле являются исключением, поскольку они адресованы непосредственно компилятору и служат для передачи ему различных указаний. Например, #pragma argsused говорит компилятору, что следует подавить выдачу предупреждающего сообщения о том, что параметры функции main () никак в ней не используются.
Часто директивы tpragma эквивалентны некоторым установкам компилятора, задаваемым в диалоге Project Options. Например, упомянутые выше сообщения о неиспользуемых параметрах можно было бы запретить, открыв этот диалог (Project | Options... в главном меню) на странице Compiler и нажав кнопку Warnings..., после чего будет открыто окно со списком всех возможных предупреждений; в нем следует сбросить флажок напротив сообщения “Parameter 'parameter' is never used (-wpar)”.
Правда, тем самым в проекте будут запрещены все такие предупреждения, в то время как директива argsused позволяет управлять ими для каждой из функций в отдельности.
Подробнее о #pragma и других директивах мы поговорим в следующей главе.
Функции
Функция, как уже говорилось, является основным структурным элементом языка С. Выше мы уже показывали синтаксис определения функции:
возвращаемый_тип имя_функции(список_параметров)
{
тело_функции
} . .
Мы уже не раз пользовались подобной формой описания синтаксиса. Это нечто вроде метаязыка (первый из них назывался формой Бэкуса-Наура), которые широко используются для формального определения языков программирования. Надеемся, что смысл написанного достаточно ясен. Курсивом_без_ пробелов обозначаются синтаксические элементы, имеющие самостоятельное значение. Например, список_параметров является отдельной синтаксической единицей, хотя он обладает собственной внутренней структурой. Можно было бы раскрыть его определение примерно так:
Список__параметров:
Void
объявление_параметра[, объявление_параметра...]
Далее требовалось бы раскрыть смысл элемента объявление_параметра и т. д. (Несколько строк под определяемым понятием показывают различные варианты его раскрытия.)
Необязательные элементы помещаются в квадратные скобки. Взаимоисключающие варианты отделяются друг от друга вертикальной чертой (например, [+ | -] означает: “здесь может стоять либо плюс, либо минус, либо вообще ничего"). Многоточие показывает, что последний синтаксический элемент может повторяться произвольное число раз.
Хотя такая форма описания синтаксиса не вполне корректна, она, как нам кажется, интуитивно ясна и будет в некоторых случаях довольно полезной.
Тело функции состоит из операторов, каждый из которых завершается точкой с запятой. (В отличие, скажем, от языка Pascal точка с запятой является в С элементом оператора, а не разделителем.) Заметьте, что сам заголовок функции (его иногда называют сигнатурой) не содержит точки с запятой.
Оператор в С не обязан располагаться в одной строке. Он может занимать и несколько строк; переход на следующую строку с точки зрения компилятора эквивалентен простому пробелу. Говоря точнее, перевод строки является одним из пробельных символов (whitespace), таких, как пробел, табуляция и переход на новую страницу. Пробельный символ может быть вставлен между любыми соседними лексическими элементами С.
Помимо определения для функции обычно пишется также ее объявление, или прототип, который размещается в заголовочном файле с расширением .h и служит для проверки корректности обращений к функции при раздельной компиляции исходных файлов. Об этом мы уже рассказывали в 1-й главе. Прототип идентичен заголовку функции, но заканчивается точкой с запятой. Тело функции отсутствует:
возвращаемый тип имя функции(список параметров);
Функции пишутся для того, чтобы можно было их вызывать в различных местах программы. Вызов функции является выражением и принадлежит к типу, указанному в ее определении; он имеет вид
имя_функции(параметры)
параметры:
пусто
параметр[, параметр...]
Параметры, используемые при вызове функции, часто называют аргументами.
Значение, возвращаемое функцией, можно игнорировать, т. е. использовать функцию в качестве процедуры:
DoSomething(argi, arg2);
Мы так и поступали, когда выводили на экран сообщения функцией
printf().
Функции, “возвращающие значение” типа void, могут вызываться только таким образом. С другой стороны, возвращаемое функцией значение можно использовать в выражениях наряду с переменными и константами:
aResult = 1. - cos(arg);
Функция в С может иметь переменное или, точнее, неопределенное число параметров. В этом случае за последним обязательным параметром в заголовке функции следует многоточие (...). Подобным образом объявляется функция printf:
int printf(const char *format, ...);
Неопределенное число параметров означает, что количество и тип действительных аргументов в вызове должно так или иначе ей сообщаться, как это и происходит в случае printf () — там число аргументов определяется по числу спецификаторов в строке формата (см. следующий параграф). Тело функции с переменным числом параметров должно быть реализовано на языке ассемблера или, возможно, при помощи каких-то не вполне “законных” ухищрений.
Пока мы имели дело всего с тремя функциями: main (), printf () и getch () . Давайте поближе познакомимся с printf () и другими функциями ввода-вывода стандартной библиотеки С.
Функция main()
После всех директив в программе расположено определение функции па in () . Как уже говорилось, в строгом смысле любая программа на С содержит эту функцию, которая является ее входной точкой. Однако в среде Windows вместо main () часто используется WinMain () .
Функция main () — это, конечно, частный случай функции вообще. Функции являются основными “строительными блоками” программы, или подпрограммами. Они, в свою очередь, строятся из операторов, составляющих тело функции. Каждый оператор оканчивается точкой с запятой (;). В общем виде функция определяется таким образом:
Возвращаемый_ тип_ имя функции(список_ параметров)
{
// В фигурных скобках заключено тело функции,
// составленное из отдельных операторов.
тело_функции
}
Функции — единственный тип подпрограмм С, в отличие, например, от языка Pascal, который различает функции и процедуры. Под процедурой обычно понимают подпрограмму, не возвращающую никакого значения. В С формально любая функция возвращает какой-либо тип, хотя в ANSI С этот тип может быть пустым (void). В первоначальном варианте языка (Керниган & Ричи) функция, для которой возвращаемый тип не определялся, считалась возвращающей int (целое значение). Мы иногда будем называть функции С процедурами, хотя это, строго говоря, и неправильно.
В нашем случае тело функции состоит из четырех операторов, первые три из которых являются, в свою очередь, вызовами функций. Значения, возвращаемые функциями, здесь игнорируются, т. е. функции вызываются аналогично процедурам языка Pascal. Применяемые здесь функции содержатся в стандартной (исполнительной) библиотеке С.
Параметры функции main()
Параметры функции main () служат для передачи программе аргументов командной строки, т. е. имен файлов, ключей, опций и вообще всего, что вы вводите с клавиатуры после подсказки DOS, запуская программу. Конечно, программа не обязана воспринимать какие-либо команды, указываемые в строке запуска, однако в любом случае функции main () передаются два параметра — число аргументов/включая имя, под которым запущена программа (argc), и массив указателей (argv) на отдельные аргументы (выделенные элементы командной строки). Забегая вперед, приведем пример, который распечатывает по отдельности все “аргументы” строки, введенной пользователем при запуске:
#include <stdio.h>
int main(int argc, char *argv[])
{
int i;
for (i=0; i<argc; i++)
printf ( "%s\n", argv[i]);
return 0;
}
Вы сможете вернуться к этому примеру, когда мы изучим массивы, строки и циклы. Теперь мы займемся более последовательным изучением основ языка С.
Элементы простой программы
Давайте немного поближе познакомимся со строением консольной программы Hello World, написанной в предыдущей главе:
#pragma hdrstop
#include <stdio.h>
#include <conio.h>
#include <condefs.h>
//---------------------------------------------
#pragma argsused
int main(int argc, char* argv[ ])
{
printf("Hello World from Console!\n");
printf("Press any key...");
getch() ;
return 0;
}
и введен только для того,
Строка нашей программы, начинающаяся с двух знаков дроби (//), является комментарием. В данном случае этот “комментарий” ничего не сообщает и введен только для того, чтобы визуально отметить начало определения функции. По идее комментарии служат для вставки в текст программы пояснений, позволяющих другим программистам разобраться в назначении и работе тех или иных фрагментов кода; ну и для того, чтобы помочь самому программисту вспомнить, что же он написал полгода или месяц назад.
Комментарии совершенно игнорируются при компиляции программы, поэтому они могут содержать что угодно.
Вышеприведенная строка — комментарий в стиле C++. Стандартные компиляторы С таких комментариев не допускают. В языке С комментарий начинается с комбинации дробной черты и звездочки (/*) и заканчивается теми же символами в обратном порядке (*/). Он может занимать несколько строк, а может быть вставлен в середину строки (такие случаи бывают). Комментарий в стиле C++ начинается, как уже говорилось, с двои ной дробной черты и продолжается до конца текущей строки. Язык C++ поддерживает оба типа комментариев.
Вот пример комментария в стиле С, который можно было бы поместить в самое начало исходного файла:
/ *
** Простейшая консольная программа C++Builder.
** Выводит на экран "Hello World" и ждет, пока
** пользователь не нажмет какую-нибудь клавишу.
*/
Он занимает, как видите, пять строк. А вот комментарий в стиле C++:
getch(); // Ожидание нажатия клавиши.
В данном случае комментарий размещен в конце строки и поясняет смысл расположенного в ней оператора.
Литералы
Прежде всего, данные могут присутствовать непосредственно в тексте программы. В этом случае они представляются в виде литеральных констант. Эти литералы могут быть числовыми, символьными и строковыми. В программе Hello World мы пользовались строковыми литералами. Это — последовательность символов, заключенная в двойные кавычки.
Символьный литерал служит для представления одиночного знака. Это символ, заключенный в одиночные кавычки (апострофы).
Числовые литералы могут быть вещественными (с плавающей точкой) и целыми. В случае целого литерала он может быть записан в десятичной, восьмеричной или шестнадцатеричной нотации (системе счисления). Вещественный литерал записывается либо в обычной десятичной, либо в экспоненциальной нотации.
В таблице 3.1 перечислены все упомянутые выше виды литеральных констант и даны соответствующие примеры.
Таблица 3.1. Литеральные константы
| Литерал |
Описание |
Примеры |
|||
| Символьный | Одиночный символ, заключенный в апострофы | 'W', '&', 'Ф' | |||
| Строковый | Последовательность символов, заключенная в обычные (двойные) кавычки | "Это строка \n" | |||
| Целый | Десятичный — последовательность цифр, не начинающаяся с нуля | 123, 1999 | |||
| Восьмеричный — последовательность цифр от нуля до семерки, начинающаяся с нуля | 011, 0177 | ||||
| Шестнадцатеричный — последовательность шестнадцатеричных цифр (0 - 9 и А - F), перед которой стоит 0X или Оx | ОХ9А, Oxffff | ||||
| Вещественный | Десятичный — [цифры].[цифры] | 123., 3.14, .99 | |||
| Экспоненциальный — [цифры]Е|е[+|-] цифры | Зе-10, 1.17е6 |
Можно дать литеральной константе некоторое имя, определив ее в качестве макроса препроцессора. После этого можно вместо литерала использовать имя. Это особенно удобно в том случае, когда одна и та же константа встречается в различных частях программы; используя имя вместо литералов, вы гарантированы от опечаток и, кроме того, гораздо проще вносить в код изменения, если значение константы нужно модифицировать. Макросы определяются директивой препроцессора #define:
#define PI 3.14159265
#define TRUE 1
#define FALSE 0
При обработке исходного кода препроцессором выполняется просто текстовая подстановка: каждое вхождение имени макроса заменяется соответствующим ему литералом. Макросы называют также символическими константами (не путайте с символьными).
Массивы
Массив по существу является совокупностью однотипных переменных (элементов массива), объединенных под одним именем и различающихся своими индексами. Массив объявляется подобно простой переменной, но после имени массива указывается число его элементов в квадратных скобках:
int myArray[8];
Массив, как и переменную, можно инициализировать при объявлении. Значения для последовательных элементов массива отделяются друг от друга запятыми и заключаются в фигурные скобки:
int iArray[8] = {7, 4, 3, 5, 0, 1, 2, 6);
Обращение к отдельным элементам массива производится путем указания индекса элемента в квадратных скобках, например:
myArray[3] = 11;
myArray[i] = iArray[7-i];
Индекс должен быть целым выражением, значение которого не выходит за пределы допустимого диапазона. Поскольку индексация массивов начинается в С всегда с нуля (т. е. первый элемент имеет индекс 0), то, если массив состоит из N элементов, индекс может принимать значения от О до N-1.
В языке С не предусмотрена автоматическая проверка допустимости значений индекса времени выполнения, поэтому при индексации массивов нужно быть внимательным. Выход индекса за границы массива может приводить к совершенно непредсказуемым результатам.
Массивы естественным образом сочетаются с циклами for. Мы приведем пример программы, работающей с массивом целых чисел. Она выполняет так называемую “пузырьковую сортировку” введенных пользователем чисел в порядке возрастания. Работу программы иллюстрирует рис. 3.4.
Листинг 3.4. Программа пузырьковой сортировки
/*
** Loop.с: Программа пузырьковой сортировки.
*/
#pragma hdrstop
#include <stdio.h>
#include <stdlib.h>
#include <conio.h>
/********************************************************
** Процедура сортировки
*/
void DoSort(int array[ ], int n)
{
int i, j, temp;
for (i = n-1; i > 0; i--)
for (j = 0; j < i; j++)
if (array[j] > array[j+l]) {
temp = array[j];
array[j] = array[j+l];
array [j+1] = temp;
}
} /* Конец DoSortO */
#pragma argsused
int main(int argc, char* argv[])
{
const int N = 8;
int i, iArray[8];
char s[80], *endPtr;
printf("Enter %d integers separated by spaces:\n", N);
gets(s); // Прочитать строку пользователя.
endPtr = s; // Инициализировать указатель строки.
for (i =0; i < N; i++) // Преобразование чисел.
iArray[i] = strto1(endPtr, &endPtr, 10);
DoSort(iArray, N); // Вызов программы сортировки.
printf("Sorted array:\n");
for (i =0; i < N; i++)
// Вывод отсортированного
// массива. printf("%8d ", iArray[i]);
printf("\n\nPress a key...");
getch() ;
return 0;
}
Как видите, функция DoSort (), выполняющая сортировку массива из целых чисел, содержит двойной вложенный цикл for. Операторы внутри цикла обменивают значения двух соседних элементов массива, если первый из них больше второго. В главной функции циклы for использованы для чтения и вывода элементов массива iArray.
Строка, содержащая все введенные пользователем числа, считывается целиком в символьный массив s. После этого для преобразования символьного представления чисел в данные целого типа в цикле вызывается функция strtol (). Ее прототип (в stdlib.h) имеет вид
long strtol(const char *str, char **endptr, int radix);
Эта функция действует подобно atol (), преобразуя строку str в значение типа long, однако обладает более широкими возможностями. Параметр radix задает основание системы счисления (8, 10 или 16). В параметре endptr функция возвращает указатель на непреобразованную часть строки str (т. е. на строку, оставшуюся после исключения из нее первого из чисел). Таким образом, в цикле мы последовательно вычленяем из строки все восемь чисел и записываем их в элементы целого массива.
Функция позволяет довольно просто контролировать корректность ввода. Если при ее вызове происходит ошибка, например, строка содержит меньше чисел, чем их должно быть, возвращаемый в endptr указатель будет совпадать с аргументом str.
Ключевое слово const в объявлении первого параметра говорит компилятору, что функция не должна изменять элементы строки, на которую указывает str. Попытка модифицировать строку в теле функции вызовет ошибку при ее компиляции.
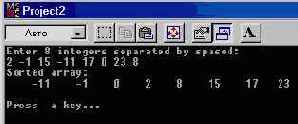
Рис. 3.4 Робота программы сортировки
Массивы и указатели
Массивы и указатели довольно тесно связаны между собой. Имя массива можно разыменовывать, как указатель. В свою очередь, указатель можно индексировать, как массив, если это имеет смысл. Поэтому мы рассматриваем массивы и указатели в одном разделе.
Объединения
Объединения, определяемые с помощью ключевого слова union, похожи по своему виду на структуры:
union этикетка {список_элементов] [переменные];
Отличие состоит в том, что все элементы объединения занимают одно и то же место в памяти, они перекрываются. Компилятор отводит под объединение память, достаточную для размещения наибольшего элемента.
Объединения полезны, когда требуется обеспечить своего рода “полиморфное поведение” некоторого объекта. Например, вы хотите определить тип, реализующий представление различных геометрических фигур — прямоугольников, окружностей, линий, многоугольников. В зависимости от того, чем конкретно является данная фигура, для ее описания необходимы различные наборы значений. Круг описывается иначе, чем многоугольник и т. п. И вот из структур, описывающих различные фигуры, можно в свою очередь составить обобщенный тип-объединение, который будет обрабатываться различно в зависимости от значения специального поля, определяющего род фигуры. В то же время на все фигуры можно будет ссылаться через указатели одного и того же типа, что, в частности, позволит составлять динамические связанные списки из любых фигур.
Доступ к элементам объединения (их иногда называют разделами) осуществляется так же, как и в структурах, — посредством точки или стрелки, за которыми следует имя раздела.
В заключение разговора о типах, определяемых пользователем, приведем пример законченной программы. В ней определяется тип структуры, способной хранить данные различных “графических объектов”. В программе реализованы всего два их вида — прямоугольник и текстовая метка.
Листинг 3.5. Демонстрация работы со структурами
/*
** Struct.с: Структуры и объединения.
*/
#pragma hdrstop
#include <stdio.h>
#include <conio.h>
#include <string.h>
/* Тип для определения вида объекта */
typedef enum {Rect=l, Labi) Type;
/***********************************************************
** Структура для хранения прямоугольников и текстовых меток.
*/ typedef struct _GForm { Type type;
struct _GForm *next;
/* Указатель для связанного списка. */
union {
/* Анонимное объединение. */
struct {
/* Прямоугольник. */
int left, top;
int right, bottom;
} rect;
struct {
/* Текстовая метка. */
int x, у;
char text [20];
} labi;
}
} Gform;
/****************************************
** Функция вывода данных объекта.
*/ void ShowForm(GForm *f)
{
switch (f->type) {
case Rect:
/* Прямоугольник. */
printf("Rectangle: (%d, %d) (%d, %d)\n",
f->data.rect.left, f->data.rect.top,
f->data.rect.right, f->data.rect.bottom);
break;
case Labi: /* Метка. */
printfC'Text label: (%d, %d) \"%s\"\n",
f->data.labl.x, f->data.labi.y, f->data.labi.text);
}
int main(void)
{
GForm formi, form2;
/* Инициализация первого объекта. */
forml.type = Rect;
forml.data.rect.left = 50;
forml.data.rect.top = 25;
forml.data.rect.right = 100;
forml.data.rect.bottom = 75;
/* Инициализация второго объекта. */
form2.type = Labi;
form2.data.labi.x = 60;
form2.data.labl.у = 40;
strcpy(form2.data.labi.text, "This is a Label!");
/* Распечатка... */ ShowForm(&formi);
ShowForm(&form2);
printf("\nPress any key...");
getch() ;
return 0;
}
Работу программы иллюстрирует рис. 3.5.
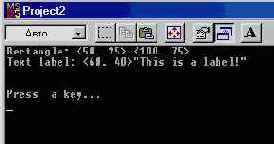
Рис. 3.5 Программа Struct.c (Project2)
Обратите внимание, что перечисления, структуры и объединения могут быть анонимными, т. е. не иметь имен-этикеток.
Внимательно рассмотрите определение типа Gform:
typedef struct _GForm { Type type;
struct GForm *next;
/* Указатель для связанного списка. */
union {
/* Анонимное объединение. */
struct {
/* Прямоугольник. */
int left, top;
int right, bottom;
} rect;
struct {
/* Текстовая метка. */
int x, у;
char text[20] ;
} labl;
} data;
} GForm;
Структура _Gform имеет, как таковая, три элемента: type, next (не используется) и data. Последний является анонимным объединением разделов rect и labl, каждый из которых, в свою очередь, является анонимной структурой. Элементы первой хранят значения координат верхнего левого и правого нижнего углов прямоугольника; элементами второй являются координаты, задающие положение текста, и сама текстовая строка. Получаются довольно длинные выражения для доступа к элементам данных (forml.data.rect.bottom).
Заключение
В этой весьма объемистой главе мы рассмотрели чуть ли не весь стандартный ANSI С, если не считать препроцессора. Препроцессором мы займемся в следующей главе.
Кроме того, вам предстоит еще познакомиться с расширениями С, поддерживаемыми C++Builder, но выходящими за рамки стандарта ANSI. Такие расширения, связанные в основном с особенностями процессора и операционной системы, почти всегда имеются в любой реализации языка.
О них также будет говориться в следующей главе.
Область действия переменных и связанные с ней понятия
Теперь, когда мы более-менее разобрались с принципами функциональной организации программы, следует обсудить некоторые весьма важные вопросы относительно переменных.
Переменные в С могут быть локальными и глобальными, статическими и автоматическими, регистровыми, внешними и даже нестабильными. Они различаются своей областью действия, видимостью и временем жизни. Попробуем как-то сориентироваться во всем этом многообразии.
Область действия
Область действия — это та часть программы, где переменная в принципе доступна для программного кйда (что означает это “в принципе”, выяснится чуть позже). По своей области действия переменные делятся на локальные и глобальные.
Локальные переменные объявляются внутри функции и вне ее тела недоступны. Вернитесь к последнему примеру. Там программа состоит из двух функций. В main () объявляются переменные number, s и name (две последних — не простые переменные, а массивы, но это несущественно). В функции Convert объявлены grp1, grp2 и grp3.
Все эти переменные являются локальными. К каждой из них можно обращаться только в пределах объявляющей ее функции. Поэтому, кстати, имена локальных переменных не обязаны быть уникальными. Если две функции описывают переменную с одним и тем же именем, то это две совершенно различные переменные и никакой неоднозначности не возникает.
Параметры в определении функции (формальные параметры) можно рассматривать как локальные переменные, инициализируемые значениями аргументов при ее вызове.
В противоположность локальным глобальные переменные не относятся ни к какой функции и объявляются совершенно независимо. В пределах текущего модуля имя глобальной переменной, естественно, должно быть уникальным. Областью действия глобальных переменных является по умолчанию вся программа.
Довольно интересная проблема возникает, казалось бы, когда имя локальной переменной функции совпадает с именем некоторой глобальной переменной. Это вполне допустимая ситуация, и одноименные переменные здесь на самом деле различны. Если мы входим внутрь определения функции, то оказываемся в области действия сразу двух переменных. Однако локальная переменная в этом случае скрывает, как говорят, глобальную переменную с тем же именем. Тут речь идет о их области видимости, которая не совпадает с областью действия. Эти два понятия часто путают. Вот пример кода, иллюстрирующий вышесказанное.
/***************************************************
** Область действия и видимость переменных.
*/
#include <stdio.h>
int iVar = 111; // Глобальная переменная.
void Funci(void)
{
int iVar = 222; // Локальная переменная Funci().
/* Локальная переменная скрывает глобальную. */
printf("Значение iVar в Func1() равно %d.\n", iVar);
}
void Func2(void)
{
/* Глобальная переменная доступна. */
printf("Значение iVar в Func2 () равно %d.\n", iVar) ;
iVar = 333; // Изменяет глобальную переменную.
}
int main(void)
(
printf ("Начальное значение iVar: %d.\n", -iVar) ;
// Печатает 111. Funci (); // Печатает 222, но не изменяет
// глобальную iVar.
printf("После вызова Func1(): %d.\n", iVar) ;
Func2 (); // Печатает 111 и изменяет iVar на 333.
printf ("После вызова F'unc2(): %d.\n", iVar) ;
return 0;
}
Время жизни
Время жизни переменной в известной мере определяется ее областью действия. Память под глобальную переменную отводится, можно сказать, еще на этапе компиляции программы; во всяком случае, переменная существует все время, пока программа выполняется.
Локальная переменная создается при входе в функцию и уничтожается при возврате из нее. Она является автоматической переменной. Поэтому никак нельзя ожидать, например, что локальная переменная будет сохранять свое значение в промежутках между вызовами объявляющей ее функции. Память под переменную выделяется на стеке программы.
Если же вы хотите, чтобы локальная переменная сохраняла значение между вызовами функции, ее следует объявить с модификатором static, как в следующем:
int AFunc(void)
{
/* Так можно организовать счетчик вызовов функции. */
static int callCount = 0;
// Здесь что-то делается...
return ++callCount;
}
На тот случай, если у кого-то этот код вызвал сомнения, скажу, что инициализация локальной статической переменной производится всего один раз — при запуске программы, а не при каждом входе в функцию.
Такая переменная будет существовать все время, пока программа выполняется. Память под статическую переменную отводится в той же области, где располагаются глобальные переменные. Таким образом, статическая локальная переменная очень похожа на глобальную, за исключением того, что ее областью действия является все-таки объявляющая функция; вне ее переменная недоступна.
Модификаторы переменных
Помимо static, в С имеются и другие модификаторы, применяемые к объявлениям переменных. Опишем их вкратце.
static. Его воздействие на локальную переменную описано выше. Примененный к глобальной переменной, он ограничивает область ее действия текущим файлом (модулем компиляции).
auto. Специфицирует локальную переменную как создаваемую автоматически и подразумевается по умолчанию. Зачем он вообще нужен? Наверное, на всякий случай — для реализации языка, в которых все переменные по умолчанию статические. Никогда не видел, чтобы его кто-то применял.
register. Этот модификатор рекомендует компилятору разместить локальную переменную в регистре процессора, если это возможно.
extern. Модификатор говорит компилятору, что переменная является внешней, т. е. объявлена в другом файле.
Модификатор volatile
Об этом модификаторе следует сказать отдельно. Он применяется для объявления переменных, которые можно назвать нестабильными. Модификатор volatile сообщает компилятору, что значение переменной может изменяться как бы само по себе, например, некоторым фоновым процессом или аппаратно. Поэтому компилятор не должен пытаться как-либо оптимизировать выражения, в которые входит переменная, — предполагая, например, что ее значение не менялось с предыдущего раза и потому выражение не нужно заново пересчитывать.
Есть и другой момент. В программе могут быть так называемые критические участки кода, во время исполнения которых изменение значения нестабильной переменной приведет к абсурдным результатам. (Возьмите случай оценки “А или не-А”, если А нестабильно!) Для таких критических участков компилятор должен создавать копию, например, в регистре, и пользоваться этой копией, а не самой переменной.
Можно написать такое объявление:
volatile const int vciVar = 10;
Другими словами, “нестабильная константа” типа int. В этом нет никакого противоречия — компилятор не позволит вашей программе изменять переменную, но и не будет предполагать ее значение известным априори, так как оно может меняться в силу внешних причин.
Обзор языка С
Как уже говорилось, хорошее понимание языка С представляется необходимым для успешного программирования на C++. C++Builder в полной мере поддерживает стандарт ANSI С и, кроме того, некоторые другие версии языка (Керниган & Ричи, Unix V). Мы в основном будем ориентироваться на стандарт ANSI, который, кстати, является в какой-то мере результатом “обратного воздействия” языка C++.
В этой главе мы, опираясь на короткие примеры, расскажем об элементах программы на С и синтаксисе различных его конструкций.
Операции и выражения
Как все знают, из переменных, функций и констант в алгебре можно составлять формулы. Точно так же и в языке C++ следующим уровнем представления данных после одиночных переменных и констант являются своего рода формулы, называемые выражениями.
Единственное отличие выражений C++ от конвенциональных формул заключается в том, что набор операций, соединяющих члены выражения, отличается от применяемого, скажем, в алгебре. Вот один пример выражения:
aResult = (first - second * RATE) <<3
Операции характеризуются своим приоритетом, определяющим порядок, в котором производится оценка выражения, и правилом ассоциации, задающим направление последовательных оценок идущих друг за другом операций одного приоритета.
Как и в обычных формулах, для изменения порядка оценки выражения могут применяться круглые скобки (кстати, в приведенном выражении они излишни и введены только для наглядности). Знак равенства здесь также является операцией присваивания, которая сама (и, соответственно, все выражение в целом) возвращает значение. В этом отличие С от других языков, в частности Pascal, где присваивание является оператором а не операцией. Оператором выражение станет, если поставить после него точку с запятой.
В следующей таблице дана сводка всех операций языка С в порядке убывания приоритета.
Таблица 3.3. Операции языка С
| Операция |
Описание |
Приоритет |
Ассоциация |
||||
|
Первичные и постфиксные операции |
|||||||
| [] | индексация массива | 16 | слева направо | ||||
| () | вызов функции | 16 | слева направо | ||||
| . | элемент структуры | 16 | слева направо | ||||
| -> | элемент указателя | 16 | слева направо | ||||
| ++ | постфиксный инкремент | 15 | слева направо | ||||
| -- | постфиксный декремент | 15 | слева направо | ||||
|
Одноместные операции |
|||||||
| ++ | префиксный инкремент | 14 | справа налево | ||||
| -- | префиксный декремент | 14 | справа налево | ||||
| sizeof | размер в байтах | 14 | справа налево | ||||
| (тип) | приведение типа | 14 | справа налево | ||||
| ~ | поразрядное NOT | 14 | справа налево | ||||
| ! | логическое NOT | 14 | справа налево | ||||
| - | унарный минус | 14 | справа налево | ||||
| & | взятие адреса | 14 | справа налево | ||||
| * | разыменование указателя | 14 | справа налево | ||||
|
Двухместные и трехместные операции |
|||||||
|
Мультипликативные |
|||||||
| * | умножение | 13 | слева направо | ||||
| / | деление | 13 | слева направо | ||||
| % | взятие по модулю | 13 | слева направо | ||||
|
Аддитивные |
|||||||
| + | сложение | 12 | слева направо | ||||
| - | вычитание | 12 | слева направо | ||||
|
Поразрядного сдвига |
|||||||
| << | сдвиг влево | 11 | слева направо | ||||
| >> | сдвиг вправо | 11 | слева направо | ||||
|
Отношения |
|||||||
| < | меньше | 10 | слева направо | ||||
| <= | меньше или равно | 10 | слева направо | ||||
| > | больше | 10 | слева направо | ||||
| >= | больше или равно | 10 | слева направо | ||||
| == | равно | 9 | слева направо |
| Операция |
Описание |
Приоритет |
Ассоциация |
| ! = | не равно | 9 | слева направо |
|
Поразрядные |
|||
| & | поразрядное AND | 8 | слева направо |
| ^ | поразрядное XOR | 7 | слева направо |
| | | поразрядное OR | 6 | слева направо |
|
Логические |
|||
| && | логическое AND | 5 | слева направо |
| || | логическое OR | 4 | слева направо |
|
Условные |
|||
| ? : | условная операция | 3 | справа налево |
|
Присваивания |
|||
| = | присваивание | 2 | справа налево |
| *= | присвоение произведения | 2 | справа налево |
| /= | присвоение частного | 2 | справа налево |
| %= | присвоение модуля | 2 | справа налево |
| += | присвоение суммы | 2 | справа налево |
| -= | присвоение разности | 2 | справа налево |
| <<= | присвоение левого сдвига | 2 | справа налево |
| >>= | присвоение правого сдвига | 2 | справа налево |
| &= | присвоение AND | 2 | справа налево |
| ^= | присвоение XOR | 2 | справа налево |
| |= | присвоение OR | 2 | справа налево |
| , | запятая | 1 | слева направо |
Оператор выбора switch
Часто возникают ситуации, когда некоторая переменная может принимать несколько возможных значений-вариантов, и для каждого варианта требуется выполнить какие-то свои действия. Например, пользователю может быть предложено меню, когда нажатие различных клавиш инициирует соответствующие команды. Управляющая конструкция, реализующая такую логику, может использовать “последовательно вложенные” операторы if...else if...:
int key;
printf("\nSelect command (F, M or Q): ");
// Вывести подсказку. key = getch();
// Прочитать символ. key = toupper(key);
// Преобразовать в верхний регистр. if (key == 'F')
// Определение команды...
printf("\n\"F\" selected - means File.\n");
else if (key == 'M')
printf("\n\"M\" selected - means Message.\n");
else if (key == 'Q')
printf("\n\"Q\" selected - means Quit.\n");
else
printf("\nlnvalid key!");
Здесь мы применили функцию преобразования символа в верхний регистр toupper (), чтобы можно было вводить букву команды в обоих регистрах (например, F или f).
Условия операторов if содержат проверку кода нажатой клавиши на равенство одному из допустимых символов. Если код клавиши не соответствует никакой команде, выводится сообщение об ошибке.
Для подобных случаев в С существует специальная конструкция выбора switch. Выглядит она так:
switch (выражение)
{
case константное_выражение: группа_операторов case константное_выражение: группа_операторов
[default: группа операторов] }
Сначала производится оценка выражения в операторе switch; полученное значение последовательно сравнивается с каждым из константных_выражений, и при совпадении значений управление передается на соответствующую группу_операторов. Если значение выражения не подходит ни под один из вариантов, управление передается на группу операторов с меткой default или на следующий после блока switch оператор, если группа default отсутствует.
Под группой _операторов подразумевается просто один или несколько произвольных операторов. Группа здесь вовсе не обязана быть блоком, т. е. заключать ее в операторные скобки не требуется.
И еще одна особенность, о которой следует помнить при написании структур switch. Если найдена метка case, совпадающая со значением проверяемого выражения, то выполняется группа_операторов данного case. Однако дело на этом не заканчивается, поскольку, если не принять никаких дополнительных мер, управление “провалится” ниже, на следующую по порядку метку case и т. д., и в результате будут выполнены все операторы до самого конца блока switch. Если это нежелательно (как чаще всего и бывает), в конце группы_операторов case нужно поставить оператор break. Он прерывает выполнение блока switch и передает управление оператору, непосредственно следующему за блоком.
Для иллюстрации мы перепишем предыдущий пример “меню”, оформив его в виде законченной программы, и продемонстрируем попутно еще один управляющий оператор С.
Листинг 3.3. Демонстрация структуры switch
/*
** Switch.с: Оператор выбора.
*/
#pragma hdrstop
#include <stdio.h>
#include <conio.h>
#pragma argsused
int rriain(int argc, char* argv[])
{
int key;
loop:
printf("\nEnter command (F, M or Q): ");
key = getche(); // Прочитать клавишу.
switch (key) ( // Определение команды... case 'f':
case 'F":
printf("\n\"File\" command selected.\n");
break;
case 'm':
case 'M':
printf ("\n\"Mess.age\" command selected.\n");
break;
case 'q':
case 'Q':
printf("\n\"Quit\" command selected.\n");
printf("\nPress a key to Exit...");
getch() ;
return 0; // Возврат в Windows. default:
printf("\nlnvalid command!\n") ;
}
goto loop; // Следующая команда.
}
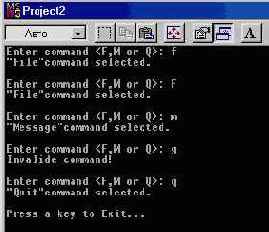
Рис. 3.3 Программа Switch
Мы организовали в программе простейший “бесконечный” цикл, который все время просит пользователя ввести команду — до тех пор, пока не будет нажата клавиша “Q”. В этом случае происходит возврат в операционную систему.
Чтение команды производится функцией getche(). Она, как и getch (), возвращает код нажатой клавиши, однако в отличие от getch () отображает введенный символ на экране.
Для реализации цикла мы использовали архаический оператор goto, исполнение которого приводит к передаче управления на метку, указанную в операторе. В примере метка с именем loop стоит в самом начале программы. Таким образом, дойдя до конца функции main (), управление возвращается к ее началу и все повторяется снова.
Как я сказал, оператор goto весьма архаичен, и он, конечно, никак не укладывается в концепцию структурированного потока управления. Единственным случаем, когда его использование в программе на С может быть оправдано, является обработка некоторых аварийных ситуаций. Если имеется очень сложная система вложенных друг в друга управляющих структур и ошибка происходит где-то глубоко внутри, то проще и надежнее всего передать управление на процедуру обработки ошибок с помощью goto.
Операторы прерывания блока
Часто бывает необходимо “досрочно” выйти из некоторого цикла, до того, как будет удовлетворено условие его завершения (говоря точнее, до того, как условие продолжения станет ложным). Например, вы просматриваете массив на предмет поиска заданного значения. Как только нужный элемент массива найден, выполнять цикл далее нет необходимости. Для досрочного завершения циклов в С применяются операторы break, return и continue. С оператором break вы уже встречались — помимо циклов, он используется в блоках switch.
Оператор break вызывает прерывание ближайшего (самого внутреннего) заключающего его блока switch, while, do... while или for. Управление немедленно передается следующему за блоком оператору.
Оператор continue воздействует только на блоки циклов. Он передает управление в конец тела цикла, пропуская, таким образом, все следующие за ним операторы блока. Здесь досрочно завершается не сам цикл, а его текущая итерация.
Разумеется, операторы прерывания циклов должны выполняться условно, т. е. должны входить в блок if или else некоторого условного оператора и исполняться только при наступлении условий досрочного завершения цикла.
Эти два оператора эквивалентны следующим конструкциям с goto:
// Эквивалент break:
while (...) {
…
goto brkLabel;
…
} // Закрывающая скобка блока. brkLabel:
// Метка следующего за блоком оператора.
// Эквивалент continue:
while (...) (
…
goto cntLabel;
…
CntLabel:; // Пустой помеченный оператор.
} // Закрывающая скобка блока.
Использование break и continue для прерывания циклов, вообще говоря, нежелательно — по тем же причинам, что и использование goto (от операторов break в структуре выбора switch никуда не уйти). Они нарушают структурную организацию потока управления и затрудняют чтение текста программы.
Оператор return прерывает выполнение текущей функции и возвращает ее значение в вызывающую программу. Он имеет вид:
return [выражение];
Если функция “возвращает” тип void, выражение опускается. Если код функции при ее вызове не исполняет ни одного оператора return, подразумевается, что return присутствует в качестве последнего оператора тела функции. Возвращаемое значение при этом не определено.
Не следует ставить операторы return где попало. Вернитесь и посмотрите на листинг 3.3. Это пример того, как не надо программировать. По правилам “хорошего тона” оператор возврата должен быть только один (от силы два) и он должен располагаться в конце тела функции.
Перечислимые типы
Ключевое слово enum позволяет описать перечислимый тип, представляющий переменные, которые могут принимать значения из заданного набора целых именованных констант. Определение перечислимого типа выглядит так:
enum имя-этикетка {имя_константы [= значение], ...};
Значение равно по умолчанию нулю для первого из перечислителей (так обычно называют определяемые в enum константы). Любая другая константа, для которой значение не указано, принимается равной значению предыдущей константы плюс единица.
Например:
enum Status
{
Success = 1,
Wait, Proceed,
Error = -1
};
В операторе enum после закрывающей фигурной скобки можно сразу объявить несколько переменных данного типа:
enum этикетка {список_констант} переменная[, ...];
Нужно иметь в виду, что имя-этикетка не является настоящим именем типа. Именем типа будет в вышеприведенном примере enum Status. Соответственно переменные должны объявляться как
enum Status ProclStatus, Proc2Status;
Однако всегда можно воспользоваться ключевым словом typedef и ввести для перечисления подлинное новое имя. Обычно это делается сразу:
typedef enum этикетка {список_констант) имя_типа;
Предыдущее объявление можно переписать так:
typedef enum _Status {
Success = 1,
Wait, Proceed,
Error = -1 } Status;
Тогда Status будет полноценным именем перечислимого типа. (Обратите внимание, что для этикетки мы указали имя _Status. Это обычная практика.)
Переименование типов
Любому типу в С можно присвоить простое имя или переименовать его. Это делается с помощью ключевого слова typedef:
typedef тип новое_имя_типа;
или
typedef тип новое_имя_типа [размер_массива][...];
для типов-массивов. (Квадратные скобки здесь означают не необязательность синтаксического элемента, а “настоящие” скобки.) Кроме того, мож-
но вводить имена для типов указателей на функцию и т. п. Формально описать все возможные typedef довольно сложно, поэтому мы этого делать не будем. Вообще следует руководствоваться таким правилом: если вы объявляете объект как принадлежащий к определенному в typedef типу, имя объекта нужно подставить вместо нового_имени_типа. Убрав typedef, вы получите эквивалентное объявление объекта. Вот примеры:
typedef short Arrlndex;
// Псевдоним для short.
typedef char MessageStr[80];
// Имя типа для массивов
// char[80].
typedef int *IPtrFunc(void);
// Функция, возвращающая
// указатель на int.
typedef int (*IFuncPtr)(void);
// Указатель на функцию,
// возвращающую int.
В общем, typedef является просто средством упрощения записи операторов объявления переменных.
Переменные
Итак, отдельная единица данных должна обязательно иметь определенный тип. Для ее хранения во время работы программы мы должны, во-первых, отвести соответствующее место в памяти, а во-вторых, идентифицировать ее, присвоив некоторое имя. Именованная единица памяти для-хранения данных называется переменной.
Переменные создаются с помощью оператора объявления переменных, в котором указывается тип, имена переменных и (при необходимости) начальные значения, которыми переменные инициализируются. Вот несколько примеров:
short i;
// Объявление короткой целой
// переменной.
char quit = 'Q';
// Инициализация символьной
// переменной.
float fl, factor = 3.0, f2;
// Три переменных типа float,
// одна из которых
// инициализируется.
Синтаксис оператора объявления можно описать примерно так:
тип имя_переменной [= инициализирующее_значение][, ...];
Как и любой другой оператор С, он оканчивается точкой с запятой.
Имена в С могут состоять из букв латинского алфавита, цифр и символов подчеркивания, причем первый символ имени не может быть цифрой. Следует помнить, что компилятор С различает регистр (прописные и строчные буквы). Таким образом, имена aVariable и AVariable считаются различными.
Инициализирующее значение должно быть литеральной (или символической) константой либо выражением, в которое входят только константы. Инициализация происходит при создании переменной, один раз за все время ее существования (об этом мы будем говорить ниже).
Объявление переменной должно предшествовать ее использованию в программе. Обычно все объявления размещают в начале тела функции или блока, до всех исполняемых операторов.
Представление данных в С
Любая программа так или иначе обрабатывает данные. Наша маленькая программа обрабатывает свои данные — строку сообщения “Hello World”, выводя ее на экран. Рассмотрим, какие возможны варианты представления информации в С.
Пример функции
Теперь мы напишем небольшую программу, которая проиллюстрирует все существенные моменты создания функции; в программе применяются некоторые из функций для работы со строками, описанных выше.
Пользователю предлагается ввести имя (в произвольной форме — только имя, имя и фамилию и т. п.), а затем номер телефона, просто как 7-значное число без пробелов или дефисов. После этого программа распечатывает полученные данные, выводя номер телефона в более привычном формате (рис. 3.2).
Листинг 3.2. Пример создания функции
/*
** Convert.с: Пример функции, преобразующей число
** в строку специального вида.
*/
#pragma hdrstop
#include <stdio.h>
#include <stdlib.h>
#include <conio.h>
/* Прототип функции */
void Convert(char *buffer, long num);
//-----------------------------------------
#pragma argsused
int main(int argc, char* argv[])
{
long number;
char s[80], name[80] ;
printf("Enter name: ");
gets(name) ;
printf("Enter phone number: ");
gets (s) ;
number = atol(s);
/* Преобразовать номер в обычную форму. */
Convert(s, number);
/* Вывести результат. */
printf("\n%-30s %10s\n", name, s);
getch () ;
return 0;
}
/* Определение функции */
void Convert(char *buffer, long num)
{
int grp1, grp2, grp3;
grp3 = num % 100; // Две последние цифры.
num /= 100;
grp2 = num % 100; // Две средние цифры
grp1 = num / 100; // Три старшие цифры /* Преобразовать в строку. */ sprintf (buffer, "%03d-%02d-%02d", grp1, grp2, grp3) ;
}
Функция Convert () описана как void и не возвращает значения, вследствие чего в ее теле можно опустить оператор return. (Я, кажется, еще не говорил, что именно этот оператор служит для возврата значения функции в вызывающую программу.) Она преобразует переданный ей телефонный номер (второй параметр) и записывает его в указанный строковый буфер (первый параметр). Центральный момент преобразования — разбиение номера на группы — является довольно характерным примером применения операций деления с остатком.
Рис. 3.2. Программа Convert
Для преобразования полученных групп в строку вызывается функция sprintf () . Она совершенно аналогична функции printf () за исключением того, что вместо вывода на консоль записывает результат в строковый буфер, указанный первым параметром.
В основной программе, т. е. в функции main (), использована функция ato1 (), преобразующая строку в длинное целое.
В верхней части файла мы поместили прототип функции Convert () Определение функции мы поместили после main(), поэтому прототип в данном случае необходим — без него компилятор не сможет корректно генерировать вызов Convert () .
Подытожим некоторые правила относительно прототипов и определений функций:
Функция может возвращать значение практически любого типа (включая определяемые пользователем) или не возвращать его вообще. В последнем случае функция описывается как void.
Функция может не иметь параметров. В этом случае на месте списка параметров в прототипе или определении также ставится ключевое слово void или список оставляют пустым; в вызове функции на месте списка аргументов также ничего не пишется (однако скобки необходимы).
В прототипе, в отличие от определения, нет необходимости указывать имена параметров; список параметров может состоять из перечисления только их типов, разделенных запятыми, например: void Convert(char*, long);
Прототип не обязателен, если определение функции расположено в тексте программы выше того места, где она вызывается (точнее говоря, в этом случае прототипом служит само определение функции).
Семантика операций
Несколько слов об операциях, перечисленных в таблице (всего их получилось что-то около пятидесяти). Смысл некоторых из них будет проясняться в дальнейшем при изучении массивов, структур и указателей; здесь же мы вкратце расскажем об операциях, относящихся в основном к арифметике.
Арифметические операции
К арифметическим мы отнесем те операции, которые перечислены в таблице под рубриками “Мультипликативные” и “Аддитивные”. Нужно сказать, что только эти операции (да и то за исключением взятия по модулю) имеет смысл применять к вещественным операндам (типам float, double и long double). Для таких операндов все обстоит вполне понятным и конвенциональным образом; это обычные умножение, деление, сложение и вычитание.
Операция взятия по модулю применяется только к целочисленным операндам (char, short, int. long) и дает остаток от деления первого операнда на второй. Специальной операции деления нацело в С нет — для него применяется обычная операция деления (/). Если оба операнда ее являются целыми, то результат этой операции также будет целым, равным частному от деления с остатком первого операнда на второй.
В качестве предостережения заметим, что это свойство деления в С часто бывает источником ошибок даже у довольно опытных программистов. Предположим, некто хочет вычислить объем шара и, не долго думая, пишет, переводя известную формулу на язык С:
volume = 4/3 * Pi * r*r*r;
Все операции в выражении правой части имеют одинаковый приоритет, и оценка выражения производится в последовательности слева направо. На первом шаге производится деление 4/3, но это будет делением нацело с результатом, равным 1. Эта единица преобразуется далее в вещественное 1.0 (возведение типа, описанное ниже), а дальше все идет как положено. Коэффициент в формуле, таким образом, получается равным 1.0 вместо ожидаемого 1.333...
Операции присваивания
Операция присваивания (=) не представляет особых трудностей. При ее выполнении значением переменной в левой части становится результат оценки выражения справа. Как уже говорилось, эта операция сама возвращает значение, что позволяет, например, написать:
а = b = с = someExpression;
После исполнения такого оператора все три переменных а, b, с получат значение, равное someExpression. Что касается остальных десяти операций присваивания, перечисленных в таблице, то они просто служат для сокращенной нотации присваивании определенного вида. Например,
s += i;
эквивалентно
s = s + i;
Другими словами, оператор вроде
х *= 10;
означает “присвоить переменной х ее текущее значение, умноженное на 10”.
Присваивание — единственная операция, меняющая содержимое одного из своих операндов (если не считать специальные операции инкремента и декремента, описанные ниже).
Приведение типа
Если в операторе присваивания тип результата, полученного при оценке выражения в правой части, отличен от типа переменной слева, компилятор выполнит автоматическое приведение типа (по-английски typecast или просто cast) результата к типу переменной. Например, если оценка выражения дает вещественный результат, который присваивается целой переменной, то дробная часть результата будет отброшена, после чего будет выполнено присваивание. Ниже показан и обратный случай приведения:
int p;
double pReal = 2.718281828;
p = pReal; // p получает значение 2
pReal = p; // pReal теперь равно 2.0
Возможно и принудительное приведение типа, которое выполняется посредством операции приведения и может применяться к любому операнду в выражении, например:
р = рО + (int)(pReal + 0.5); // Округление pReal
Следует иметь в виду, что операция приведения типа может работать двояким образом. Во-первых, она может производить дейсгвительное преобразование данных, как это происходит при приведении целого типа к вещественному и наоборот. Получаются совершенно новые данные, физически отличные от исходных. Во-вторых, операция может никак не воздействовать на имеющиеся данные, а только изменять их интерпретацию. Например, если переменную типа short со значением -1 привести к типу unsigned short, то данные останутся теми же самыми, но будут интерпретироваться по-другому (как целое без знака), в результате чего будет получено значение 65535.
Смешанные выражения
В арифметическом выражении могут присутствовать операнды различных типов — как целые, так и вещественные, а кроме того, и те и другие могут иметь различную длину (short, long и т. д.), в то время как оба операнда любой арифметической операции должны иметь один и тот же тип. В процессе оценки таких выражений компилятор следует алгоритму т. н. возведения типов, который заключается в следующем.
На каждом шаге оценки выражения выполняется одна операция и имеются два операнда. Если их тип различен, операнд меньшего “ранга экстенсивности” приводится к типу более “экстенсивного”. Под экстенсивностью понимается диапазон значений, который поддерживается данным типом. По возрастанию экстенсивности типы следуют в очевидном порядке:
char short
int, long
float
double
long double
Кроме того, если в операции участвуют знаковый и без знаковый целочисленные типы, то знаковый операнд приводится к без знаковому типу. Результат тоже будет без знаковым. Во избежание ошибок нужно точно представлять себе, что при этом происходит, и при необходимости применять операцию приведения, явно преобразующую тот или иной операнд.
Некоторые считают (я даже встречал это в книгах), что в выражении все операнды заранее приводятся к наиболее экстенсивному типу, а уж потом производится оценка. Это, конечно, не так. Возведение типов выполняется последовательно для каждой текущей пары операндов. (См. пример в замечании к параграфу “Арифметические операции”.)
Логические операции и операции отношения
В языке С нет специального логического или булева типа данных. Для представления логических значений используются целочисленные типы. Нулевое значение считается ложным (false), любое ненулевое — истинным (true).
Операции отношения служат для сравнения (больше — меньше) или проверки на равенство двух числовых операндов. Операции возвращают “логическое” значение, т. е. ненулевое целое в случае, если условие отношения удовлетворяется, и нулевое в противном случае.
Логические операции и отношения мы рассмотрим подробнее, когда будем обсуждать управляющие структуры С.
Поразрядные операции и сдвиги
Эти операции применяются к целочисленным данным. Последние рассматриваются просто как набор отдельных битов.
При поразрядных операциях каждый бит одного операнда комбинируется (в зависимости от операции) с одноименным битом другого, давая бит результата. При единственной одноместной поразрядной операции — отрицании (~) — биты результата являются инверсией соответствующих битов ее операнда.
При сдвиге влево биты первого операнда перемещаются влево (в сторону старших битов) на заданное вторым операндом число позиций. Старшие биты, оказавшиеся за пределами разрядной сетки, теряются; справа результат дополняется нулями.
Результат сдвига вправо зависит от того, является ли операнд знаковым или без знаковым. Биты операнда перемещаются вправо на заданное число позиций. Младшие биты теряются. Если операнд — целое со знаком, производится расширение знакового бита (старшего), т. е. освободившиеся позиции принимают значение 0 в случае положительного числа и 1 — в случае отрицательного. При без знаковом операнде старшие биты заполняются нулями.
Сдвиг влево эквивалентен умножению на соответствующую степень двойки, сдвиг вправо — делению. Например,
aNumber = aNumber <<4;
умножает aNumber на 16.
Инкремент и декремент
Операции инкремента (++) и декремента (--) соответственно увеличивают или уменьшают свой операнд (обязательно переменную) на единицу. Они изменяют значение самой переменной, т. е. являются скрытыми присваиваниями. Иногда эти операции применяют в качестве самостоятельного оператора:
i++; или ++i;
И то и другое эквивалентно
i = i + 1;
Но эти операции могут использоваться и в выражениях:
sum - sum + х * --i;
Инкремент и декремент реализуются в двух формах: префиксной (++i) и постфиксной (i--). Префиксные операции выполняются перед тем, как будет производиться оценка всего выражения. Все постфиксные операции выполняются уже после оценки выражения, в которое они входят.
Условная операция
Условная операция (? :) позволяет составить условное выражение, т. е. выражение, принимающее различные значения в зависимости от некоторого условия. Эта операция является трехместной. Если ее условие (первый операнд) истинно, оценкой выражения будет второй операнд; если ложно — третий. Классический пример:
max_ab = b > b? а : b;
Запятая
Помимо того, что запятая в С служит разделителем различных списков (как в списке параметров функции), она может использоваться и как операция. Запятая в этом качестве также является разделителем, но обладает некоторыми дополнительными свойствами.
Везде, где предполагается выражение, может использоваться список выражений, возможно, заключенный в скобки (так как операция-запятая имеет наинизший приоритет). Другими словами,
Выражение1, выражение2[, ...]
также будет выражением, оценкой которого является значение последнего элемента списка. При этом операция-запятая гарантирует, что оценка выражений в списке будет производиться по порядку слева направо. Вот два примера с операцией-запятой:
i++, j++;
// Значение выражения
// игнорируется.
res = (j = 4, j += n, j++);
// res присваивается n + 4.
// j равно n + 5.
Операция-запятая применяется довольно редко, обычно только в управляющих выражениях циклов.
Структуры
Массивы позволяют обращаться с набором логически связанных однотипных элементов как с единым целым. Если же требуется хранить набор разнородных, но логически связанных данных, описывающих, например, состояние некоторого объекта реального мира, используются структуры. Синтаксис структуры имеет такой вид:
struct этикетка [список элементов] [переменные];
Список_элементов состоит из объявлений, аналогичных объявлениям переменных. Объявления элементов оканчиваются точкой с запятой. Вот простой пример структуры, предназначенной для хранения основных сведений о человеке:
struct Person (
char lastName[32]; // Фамилия.
char firstName[32]; // Имя.
Sex sex;
// Пол: перечислимый тип
// (male, female}.
short age; // Возраст.
long phoneNum; // Телефон как длинное целое.
}
aPerson; // Объявляет переменную типа
// struct Person.
Как видите, все довольно просто. Структура группирует различные данные, относящиеся к конкретному человеку. Как и в случае перечислений, в определении структуры можно сразу объявить переменные структурного типа, указав их имена после закрывающей фигурной скобки. Аналогично именем типа является struct этикетка, и его можно сразу переопределить с помощью ключевого слова typedef.
Для доступа к отдельным элементам структуры имеются две операции: точка и стрелка, за которыми следует имя элемента. Какую из них следует применять, зависит от того, имеете ли вы дело с самой переменной-структурой или у вас есть только указатель на нее, как это имеет место в случае динамических объектов. С именем переменной применяется точка, с указателем — стрелка. Имея в виду предыдущее определение, можно было бы написать:
struct Person *pPerson - SaPerson;
// Указатель на
// структуру.
aPerson.age = atol(ageStr);
// Записать в структуру
// возраст aPerson.sex - male;
// и т.д.
pPerson->phoneNum = atol(phoneStr); //
/* Напечатать имя и фамилию (предполагается, что они уже инициализированы).*/
printf("%s %s\n", pPerson->firstName, pPerson->lastName);
Битовые поля
В качестве элементов структуры можно определять битовые поля. Для них задается ширина поля в битах, и компилятор отводит под элемент ровно столько бит, сколько указано. Несколько битовых полей может быть таким образом упаковано в одном слове. Синтаксис битового поля:
тип [имя поля]: ширина поля;
Тип поля может быть int или unsigned int. Доступ к битовым полям осуществляется так же, как и к регулярным элементам структуры. Если имя_поля отсутствует, место под поле отводится, но оно остается недоступным. Это будут просто “заполняющие” биты.
Битовые поля применяются либо там, где необходима плотная упаковка информации (как это бывает при передаче функции некоторого набора логических флагов), либо, например, для отображения регистров внешнего устройства, которые часто бывают организованы как совокупность небольших полей и отдельных битов.
Типизированные константы
Разновидностью переменных являются типизированные константы. Это переменные, значение которых (заданное при инициализации) нельзя изменить. Создание типизированной константы ничем не отличается от инициализации переменной, за исключением того, что перед оператором объявления ставится ключевое слово const:
const тип имя_константы = значение [, ...];
Например:
const double Pi = 3.14159265;
Ранее мы демонстрировали определение символической константы:
#define PI 3.14159265
Чем этот макрос отличается от показанной выше типизированной константы? Здесь следует иметь в виду два момента. Во-первых, типизированная константа по своему смыслу относится к конкретному типу данных, поэтому компилятор генерирует совершенно определенное представление для ее значения. Представление символической константы не определено.
Во-вторых, имя символической константы значимо только на этапе препроцессор ной обработки исходного кода, поэтому компилятор не включает ею в отладочную информацию объектного модуля. Вы не можете использовать это имя в выражениях при отладке. Напротив, типизированные константы являются по существу переменными, и их имена доступны отладчику. В силу этих причин предпочтительнее применять для представления постоянных величин типизированные константы, а не макросы #define.
Типы, определяемые пользователем
Встроенные типы данных, указатели и массивы образуют основу для представления и обработки информации на языке С. Подлинная же сила языка состоит в том, что он позволяет пользователю (под “пользователем” в подобного рода выражениях понимается программист) самому определять наиболее подходящие для конкретной задачи типы, способные адекватно представлять сложно структурированные данные реального мира. Эти средства С мы начнем изучать со сравнительно простого вспомогательного оператора typedef.
Указатели
Указатель — это переменная, которая содержит адрес другого объекта. Этим объектом может быть некоторая переменная, динамический объект или функция. Говорят, что указатель ссылается на соответствующий объект. Хотя адрес, по существу — 32-битное целое число, определяющее положение объекта в виртуальной памяти программы, указатель является не просто целым числом, а специальным типом данных. Он “помнит”, на какого рода данные ссылается. Объявление указателя выглядит так:
тип_указываемого_объекта *имя_указателя [= значение];
Вот примеры объявлений:
int *pIntVar; // Указатель на целое.
double *pDouble = SdoubleVar; // Инициализация указателя
// на double.
char *arrStr[16]; // Массив указателей на char.
char (*arrStr) [16][16]; // Указатель на матрицу char.
Последний пример довольно специфичен. Подобные конструкции применяются в объявлении параметров функций, передающих многомерные массивы неопределенного размера.
Чтобы получить доступ к объекту, на который указатель ссылается. последний разыменовывают, применяя операцию-звездочку. Например. *pDouble будет представлять значение переменной, на которую ссылается
pDouble:
double doubleVar = 3.14159265;
double *pDouble = SdoubleVar;
printf("Значение самого указателя (адрес): %р", pDoubie) ;
printf("Число, на которое он ссылается: %f", *pDouble);
Как мы уже говорили в предыдущих разделах, указатели используются при обработке строк, а также для передачи функциям параметров, зна-
чения которых могут ими изменяться (передача по ссылке). Но главная “прелесть” указателей в том, что они позволяют создавать и обрабатывать динамические структуры данных. В языке С можно выделить память под некоторый объект не только с помощью оператора объявления, но и динамически, во время исполнения программы. Объект создается в свободной области виртуальной памяти функцией та 11 о с (). Вот пример (предполагается, что переменные объявлены так, как выше):
pDouble = malice(sizeof(double)); // Динамическое выделение
// памяти. *pDouble = doubleVar; // Присвоение значения
// динамическому объекту.
printf("Значение динамического объекта: %f", *pDouble) ;
free(pDouble); // Освобождение памяти.
Аргументом malloc () является размер области памяти, которую нужно выделить; для этого можно применить операцию sizeof, которая возвращает размер (в байтах) переменной или типа, указанного в качестве операнда.
Функция malloc () возвращает значение типа void* — “пустой указатель”. Это указатель, который может указывать на данные любого типа. Такой указатель нельзя разыменовывать, поскольку неизвестно, на что он указывает — сколько байтов занимает его объект и как их нужно интерпретировать. В данном случае операция присваивания автоматически приводит значение malloc () к типу double*. Можно было бы написать в явном виде
pDouble = (double*)malloc(sizeof(double));
Если выделение памяти по какой-то причине невозможно, malloc () возвращает NULL, нулевой указатель. На самом деле эта константа определяется в stdlib.h как целое — “длинный нуль”:
#define NULL OL
Хорошо ли вы поняли смысл различия двух последних примеров? В первом из них указателю pDouble присваивается адрес переменной doubleVar. Во втором указателю присваивается адрес динамически созданного объекта типа double;
после этого объекту, на который ссылается pDouble, присваивается значение переменной doubleVar. Создается динамическая копия значения переменной.
Память, выделенную malloc (), следует освободить функцией free () , если динамический объект вам больше не нужен. Возьмите это себе за правило и не полагайтесь на то, что система Windows автоматически уничтожает все динамические объекты программы по ее завершении.
Перед тем, как разыменовывать указатель, его нужно обязательно инициализировать, либо при объявлении, либо путем присвоения ему адреса какого-либо объекта, возможно, динамического — как в последнем примере. Аналогично, если к указателю применяется функция free(), он становится недействительным и не ссылается больше ни на какие осмысленные данные. Чтобы использовать его повторно, необходимо снова присвоить ему адрес некоторого объекта.
Разыменование нулевого указателя также приводит к ошибке. Поэтому при работе с объектами, создаваемыми с помощью malloc (), обычно всегда проверяют, не возвратила ли эта функция нулевое значение.
Указатель на функцию
Можно объявить, инициализировать и использовать указатель на функцию. В вызовах API Windows часто применяют, например, “возвратно-вызываемые функции”. В вызове API в качестве аргумента в этом случае употребляется указатель на соответствующую функцию.
Вот пример, из которого все станет ясно.
/**********************************************
** Некоторая функция:
*/
void ShowString(char *s)
{
printf (s);
}
/***********************************************
** Главная функция:
*/
int main(void) {
void (*pFunc)(char*); // Объявление указателя на функцию.
pFunc = ShowString; // Инициализация указателя адресом
// функции. (*pFunc)("Calling a pointer to function!\n");
return 0;
}
Вы, возможно, обратили внимание, что в примере указателю присваивается значение, представленное просто именем функции без скобок со списком параметров. То есть “значение”, представленное именем функции, имеет тот же тип, что и объявленный здесь указатель. Поэтому и вызвать функцию через указатель можно было бы проще:
pFunc("Calling a pointer to function!\n");
Соотношение между указателями и функциями примерно такое же, как между указателями и массивами, о чем говорится в следующем разделе.
Указатели и массивы
Между указателями и массивами в С существует тесная связь. Имя массива без индекса эквивалентно указателю на его первый элемент. Поэтому можно написать:
int iArray[4] ;
int *piArr;
piArr = iArray; // piArr указывает на начальный элемент // iArray.
Последнее эквивалентно
piArr = &iArray[0];
И наоборот, указатель можно использовать подобно имени массива, г. е. индексировать его. Например, piArr [3] представляет четвертый элемент массива iArray [ ] .
К указателю можно прибавлять или отнимать от него целочисленные выражения, применять операции инкремента и декремента. При этом значение указателя изменяется в соответствии с размером объектов, на которые он указывает. Так, (piArr + 2) указывает на третий элемент массива. Это то же самое, что и & iArray [ 2 ]. Когда мы прибавляем к указателю единицу (piArr++) , адрес, который в нем содержится, в действительности увеличивается на 4 — размер типа int.
Короче говоря, в выражениях с указателями и массивами можно обращаться одинаково. Следует только помнить, что объявление массива выделяет память под соответствующее число элементов, а объявление указателя никакой памяти не выделяет, вернее, выделяет память для хранения значения указателя — некоторого адреса. Компилятор по-разному рассматривает указатели и массивы, хотя внешне они могут выглядеть очень похоже.
Однако возможности, которые раскрываются перед программистом благодаря указателям, выявляются в полной мере лишь при работе с динамическими структурами данных, о которых мы поговорим в следующем разделе.
Управляющие конструкции С
Программа, операторы которой исполняются строго последовательно — так, как они записаны, — обладает весьма скромными возможностями. Именно такими и были приводимые нами до сих пор примеры. Настоящая программа должна уметь “принимать решения”, т. е. изменять последовательность исполнения своих операторов в зависимости от текущей ситуации — входных данных, результатов вычислений, сообщений Windows и т. д. Простейшим примером может служить выполнение каких-то операторов, если некоторое условие истинно, и пропуск их в противном случае.
С и Pascal называют языками структурного программирования', не столько потому, что в этих языках имеется понятие “структуры данных”, но в основном благодаря структурированному потоку управления. Что имеется в виду? Существуют всего три основных структуры потока управления (поток управления можно определить как алгоритм перехода от текущего оператора к следующему):
Последовательная структура — следующим исполняется оператор, расположенный непосредственно после текущего.
Структура выбора — имеется несколько операторов; в зависимости от оценки некоторого выражения для исполнения выбирается только один из них, остальные игнорируются.
Структура повторения — текущий оператор исполняется снова и снова до тех пор, пока не будет удовлетворено некоторое условие завершения.
Из этих трех структур можно строить сколь угодно сложные управляющие конструкции, поскольку они подчиняются правилу суперпозиции, на место любого оператора некоторой структуры можно в свою очередь подставить любую структуру. При этом иногда последнюю требуется заключить в операторные скобки — в С это фигурные.скобки {} — подобно тому, как в арифметических выражениях используются обычные скобки. Любая последовательность операторов, заключенная в фигурные скобки, с точки зрения потока управления считается единым оператором.
Условный оператор if... else
Условный оператор реализует структуру выбора. Он имеет такой вид:
if (условие) оператор1 else оператор 2
Если условие оценивается как истинное (ненулевое), выполняется onepamop1, если как ложное (нулевое), выполняется onepamop2. Простейший пример:
if (а > b)
max_ab = a;
else
max_ab = b;
Как было сказано чуть выше, вместо одиночного оператора всегда можно подставить блок из нескольких операторов, заключенный в фигурные скобки. Другими словами, возможна следующая синтаксическая форма:
if (условие)
{опера торы_блока_if)
else
(опера торы_блока_еlsе}
В случае, когда при ложности условия не нужно выполнять никаких действий, а требуется только пропустить операторы блока if, ключевое слово else и соответствующий ему оператор (блок) могут отсутствовать, как в следующем примере:
if (а > b) { // Если а > b, поменять их местами;
temp = а; // в противном случае оставить все, как есть.
а = b;
b = temp;
}
//...Продолжение программы...
В соответствии с правилом суперпозиции можно строить вложенные структуры if...else, например:
if (a > b)
if (a > с)
max_abc = а;
else
max abc = с;
else
if (b > с)
max_abc = b;
else
max_abc = с ;
Эта конструкция всего-навсего определяет наибольшее из трех чисел, но разобраться в ее логике не так-то просто. Кроме того, следует помнить, что если во вложенных условных структурах используются как полные, так и неполные операторы if (без else), то могут возникать неоднозначности. Попробуем, например, переписать предыдущий фрагмент чуть более экономно, заранее присвоив максимуму значение с:
Max_abc = с;
if (a > b)
if (a > c)
max_abc == a;
else
if (b > C) max_abc = b;
К которому из двух первых if относится это else? По задуманной нами логике — к первому, однако компилятор считает по-другому; он разрешает подобные неоднозначности, ставя спорное else в соответствие ближайшему if, т. е. в данном случае второму. В результате все работает неправильно. Чтобы устранить неоднозначность, нужно применить операторные скобки:
max_abc = с;
if (а > b) {
if (а > с)
max_abc = а;
else if (b > с)
max abc = b;
Об условиях в операторе if
Условие оператора if может быть сколь угодно сложным выражением. Можно было бы сказать, что это выражение должно быть “логическим”, но в С нет логического типа данных. Как уже говорилось, выражение считается ложным, если его значением является нуль, и истинным, если значение ненулевое.
Вот несколько примеров условий оператора if:
if (x) DoSomething();
// Если х не равно
// нулю.
if (!x) DoAnotherThing();
// Если х равно нулю.
if (b == с) DoAnotherThing();
// Если b равно с.
if (b != с) DoSomething();
// Если b не равно с.
if ((key = getch()) == 'q') DoQuitO;
// Сохранить код
// клавиши в key
// и проверить, равен
// ли он ' q ' .
#define ERR_FLAG 0х80
// Если бит ERR_FLAG
if (flags & ERR_FLAG) ReportError();
// переменной flags
// установлен.
if (a >= b && a <= c) DoSomething();
// Если а лежит между
// b и с.
Операции отношения (==, !=, <, >= и т. д.) возвращают ненулевой целый результат, если значения операндов удовлетворяют отношению. В большинстве реализации С это 1, но полагаться на это не стоит. Если отношение не удовлетворяется, результатом операции будет нуль.
Обратите внимание на три последних примера. В пятом примере вы можете видеть разницу между присваиванием (=) и отношением равенства (= =). Не забывайте, что в С присваивание является операцией, возвращающей значение.
В шестом примере вы видите поразрядную операцию AND, с помощью которой проверяется состояние отдельного бита переменной flags. В седьмом примере применена логическая операция AND, которая логически перемножает значения двух отношений.
Кстати о флагах и поразрядных операциях. Битовые флаги — довольно распространенный и очень эффективный прием хранения и передачи информации о состоянии какого-то объекта или процесса, хотя и не очень безопасный. Вот примеры манипуляций с флагами:
flags | = ERR_FLAG; // Установка флага операцией OR.
flags &= ~ERR_FLAG; // Сброс флага операцией AND.
flags "= ERR_FLAG; // Переключение флага операцией XOR.
Встроенные типы данных
Однако данные могут не только вписываться в текст программы, но и храниться в памяти во время ее выполнения. С физической точки зрения любая информация в памяти машины выглядит одинаково — это просто последовательности нулей и единиц, сгруппированных в байты. Поэтому наличные в памяти данные должны как-то интерпретироваться процессором; этой интерпретацией управляет, естественно, компилятор С. Любая информация рассматривается компилятором как принадлежащая к некоторому типу данных. В языке имеется несколько встроенных, или простых, типов (возможны и другие типы данных, например, определяемые пользователем). Простые типы перечислены в следующей таблице.
Таблица 3.2. Встроенные типы данных
| Тип данных |
Размер (бит) |
Диапазон |
|||
| char | 8 | -128 - 127 | |||
| signed char | 8 | -128 - 127 | |||
| unsigned char | 8 | 0 - 255 | |||
| short | 16 | -32768 - 32767 | |||
| unsigned short | 16 | 0 - 65535 | |||
| int | 32 | -2147483648 - 2147483647 | |||
| unsigned int | 32 | 0 - 4294967295 . | |||
| long | 32 | -2147483648 - 2147483647 | |||
| unsigned long | 32 | 0 - 4294967295 | |||
| float | 32 | 3.410-38 - 3.41038 | |||
| double | 64 | 1.71010-308 - 1.710308 | |||
| long double | 80 | 3.410-4932 - 3.4104932 |
Может быть, стоит напомнить, что отрицательные целые числа представляются в машине в форме дополнения до двух. Чтобы изменить знак числа на противоположный, нужно инвертировать все его разряды (0 заменить на 1 и наоборот и прибавить к полученному числу единицу. Например, взяв +1 типа char (00000001), инвертировав все биты (11111110) и прибавив 1, мы получим -1 (11 111 111).
Ключевые слова short, long и unsigned являются, строго говоря, модификаторами для типа int. Однако допускается сокращенная запись. Так, unsigned short — на самом деле сокращение для unsigned short int.
Следует, вероятно, повторить, что мы говорим здесь о C++Builder 5, т. е. 32-разрядном компиляторе. Размер и допустимый диапазон значений приведены именно для данного случая. Поэтому, например, тип int имеет размер 32 бита (4 байта) и эквивалентен типу long; на 16-разрядной машине int имел бы размер 2 байта, как short. О таких вещах не следует забывать, особенно если вы занимаетесь переносом программ на машину с другой разрядностью.
Ввод и вывод в С
printf () является функцией стандартной библиотеки с переменным числом аргументов. Она всегда имеет по крайней мере один аргумент — строку формата, чаще всего строковый литерал. Строка может содержать спецификаторы преобразования. Функция сканирует строку и передает ее символы на стандартный вывод программы, по умолчанию консоль, пока не встретит спецификатор преобразования. В этом случае printf () ищет дополнительный аргумент, который форматируется и выводится в соответствии со спецификацией. Таким образом, вызов printf () должен содержать столько дополнительных аргументов, сколько спецификаторов преобразования имеется в строке формата.
Спецификация преобразования
Синтаксис спецификатора преобразования имеет такой вид:
%[флаги] [поле][.точность][размер]символ типа
Как видите, обязательными элементами спецификатора являются только начальный знак процента и символ, задающий тип преобразования. Следующая таблица перечисляет возможные варианты различных элементов спецификации.
Таблица 3.4. Элементы спецификатора преобразования
| Элемент |
Символ |
Аргумент |
Описание |
||||
| флаг | - | Выровнять вывод по левому краю поля. | |||||
| 0 | Заполнить свободные позиции нулями вместо пробелов. | ||||||
| + | Всегда выводить знак числа. | ||||||
| пробел | Вывести пробел на месте знака, если число положительное. | ||||||
| # | Вывести 0 перед восьмеричным или Ох перед шестнадцатеричным значением. | ||||||
| поле | число | Минимальная ширина поля вывода. | |||||
| точность | число | Для строк — максимальное число выводимых символов; для целых — минимальное число выводимых цифр; для вещественных — число цифр дробной части. | |||||
| размер | h | Аргумент -- короткое целое. | |||||
| 1 | Аргумент — длинное целое. | ||||||
| L | Аргумент имеет тип long double. | ||||||
| Элемент |
Символ |
Аргумент |
Описание |
||||
| символ типа | d | целое | Форматировать как десятичное целое со знаком. | ||||
| i | целое | То же, что и d. | |||||
| о | целое | Форматировать как восьмеричное без знака. | |||||
| U | целое | Форматировать как десятичное без знака. | |||||
| х | целое | Форматировать как шестнадцатеричное в нижнем регистре. | |||||
| Х | целое | Форматировать как шестнадцатеричное в верхнем регистре. | |||||
| f | вещественное | Вещественное в форме [-]dddd.dddd. | |||||
| е | вещественное | Вещественное в форме [-]d.dddde[+|-]dd. | |||||
| Е | вещественное | То же, что и е, с заменой е на Е. | |||||
| ё | вещественное | Использовать форму f или е в зависимости от величины числа и ширины поля. | |||||
| G | вещественное | То же, что и g — но форма f или Е. | |||||
| с, | символ | Вывести одиночный символ. | |||||
| s | строка | Вывести строку. | |||||
| п | указатель | Аргумент — указатель на переменную типа int. В нее записывается количество выведенных к данному моменту символов. | |||||
| р | указатель | Вывести указатель в виде шестнадцатеричного числа ХХХХХХХХ. |
Как видите, флаги задают “стиль” представления чисел на выводе, поле и точность определяют характеристики поля, отведенного под вывод аргумента, размер уточняет тип аргумента и символ_типа задает собственно тип преобразования. Следующий пример показывает возможности форматирования функции printf () . Советую не полениться и поэкспериментировать с этим кодом, меняя флаги и параметры поля вывода.
Листинг 3.1. Возможности функции printf ()
/*
** Printf.с: Демонстрация форматирования вывода на консоль
** функцией printf().
* /
#pragma hdrstop
#include <stdio.h>
#include <conio.h>
#pragma argsused
int main(int argc, char *argv[])
{
double p = 27182.81828;
int j = 255;
char s[] = "Press any key...";
/* Вывести 4 цифры; вывести обязательный знак: */
printf("Test integer formatting: %13.4d %4-8d\n", j, j);
/* Вывести по левому краю со знаком; заполнить нулями: */ printf("More integer formatting: %-+13d % 08d\n", j, j);
printf("Test octal and hex: %#13o %#8.6x\n", j, j);
printf("\nTest e and f conversion: %13.7e %8.2f\n", p, p) ;
printf("\n%s", s); /* Вывести строку подсказки. */
getch () ;
return 0;
}
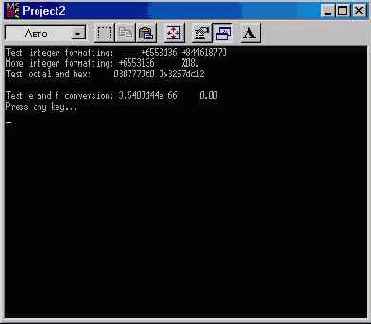
Рис. 3.1 Тестирование функции printf()
Прием, позволяющий компилировать программу с главным файлом .с (а не .срр), описан в предыдущей главе в замечании к разделу о консольных приложениях. Конечно, показанная программа будет компилироваться и в режиме C++.
Escape-последовательности
В строках языка С для представления специальных (например, непечатаемых) символов используются escape-последователъности, состоящие из обратной дробной черты, за которой следует один или несколько символов. (Название появилось по аналогии с командами управления терминалом или принтером, которые действительно представляли собой последовательности переменной длины, начинающиеся с кода ESC.) В приведенных примерах функции printf () вы уже встречались с одной такой последовательностью — \n. Сама обратная косая черта называется escape-символом..
В таблице 3.5 перечислены возможные esc-последовательности.
Таблица 3.5. Escape-последовательности языка С
| Последовательность |
Название |
Описание |
| \а | Звонок | Подает звуковой сигнал. |
| \b | Возврат на шаг | Возврат курсора на одну позицию назад. |
| \f | Перевод страницы | Начинает новую страницу. |
| \n | Перевод строки | Начинает новую строку. |
| \r | Возврат каретки | Возврат курсора к началу текущей строки. |
| \t | Табуляция | Переход к следующей позиции табуляции. |
| \v | Вертикальная табуляция | Переход на несколько строк вниз. |
| \\ | Выводит обратную дробную черту. | |
| \' | Выводит апостроф (одинарную кавычку). | |
| \" | Выводит кавычку (двойную). |
| \000 | От одной до трех восьмеричных цифр после esc-символа. |
| \хНН или \ХНН | Одна или две шестнадцатеричных цифры после esc-символа. |
В языке С для ввода имеется “зеркальный двойник” printf() — функция scant (). Функция читает данные со стандартного ввода, по умолчанию — клавиатуры. Она так же, как и printf () , принимает строку формата с несколькими спецификаторами преобразования и несколько дополнительных параметров, которые должны быть адресами переменных, куда будут записаны введенные значения.
В языке С функция не может изменять значение передаваемых ей аргументов, поскольку ей передается только временная копия содержимого соответствующей переменной. Это называется передачей параметра.по значению. В языке Pascal возможна также передача по ссылке, позволяющая функции изменить саму переменную-аргумент. Параметр, передаваемый по ссылке, объявляется с ключевым словом var. В С нет автоматического механизма передачи по ссылке. Чтобы передать из функции некоторое значение через параметр, ее вызывают с указателем на переменную (грубо говоря, ее адресом), подлежащую модификации. Функция не может изменить переданный ей аргумент, т. е. сам адрес, но она может записать информацию в память по этому адресу. Адрес получают с помощью операции &, например, SaVar. Подробнее мы обсудим это, когда будем говорить об указателях.
Примером вызова scanf () может служить следующий фрагмент кода:
int age;
printf("Enter your age: "); //' Запросить ввод возраста
// пользователя. scanf ("%d", &age); // Прочитать введенное число.
Функция возвращает число успешно сканированных полей, которое в приведенном фрагменте игнорируется. При необходимости вы можете найти полную информацию по scanf () в оперативной справке C++Builder. Однако следует сказать, что программисты не любят эту функцию и пользуются ей очень редко. Причина в том, что опечатка при вводе (скажем, наличие буквы в поле, предполагающем ввод числа и т. п.) может привести к непредсказуемым результатам. Контролировать корректность ввода и обеспечить адекватную реакцию программы на ошибку при работе со scanf () довольно сложно. Поэтому часто предпочитают прочитать целиком всю строку, введенную пользователем, в некоторый буфер, а затем самостоятельно декодировать ее, выделяя отдельные лексемы и преобразуя их в соответствующие значения. В этом случае можно контролировать каждый отдельный шаг процесса преобразования.
Ввод строки с клавиатуры производится функцией gets ():
char s[80] ;
gets (s) ;
gets(&s[0]);
// Аргумент - указатель на начальный элемент
// массива s.
Для преобразования строк, содержащих цифровое представление чисел, в численные типы данных могут применяться функции atoi(), ato1 () и atof (). Они преобразуют строки соответственно в целые, длинные целые и вещественные числа (типы int, long и double). Входная строка может содержать начальные пробелы; первый встреченный символ, который не может входить в число, завершает преобразование. Прототипы этих функций находятся в файле stdlib.h.